Feed, contenuti, intelligenza: il nuovo motore della discovery
Una condivisione dei 3 studi più interessanti che mi hanno accompagnato nel 2025. Un viaggio tra dati, AI e automazioni che stanno ridefinendo il motore della discovery.


Vorrei portarvi in un viaggio in 3 tappe: tre “studi e sperimentazioni” che oggi sono diventati progetti reali, e che nel 2025 mi hanno accompagnato (e, soprattutto, entusiasmato) più di altri.
Le tre tappe hanno nomi molto semplici:
Reranker → Contenuti → Feed
Per ognuna di queste tappe andremo a mettere a fuoco il pensiero, a capire il progetto (cioè come diventa operativo), e a descrivere i takeaway da portare a casa.
Feed, contenuti, intelligenza: il nuovo motore della discovery
1 - Reranker: la rilevanza contestuale come “metrica” operativa
Partiamo dalla prima tappa: Reranker.
Un reranker è un modello in grado di valutare la rilevanza contestuale di un contenuto rispetto a una query: in altre parole, misura la forza con cui quel contenuto riesce davvero a rispondere alla domanda.
E qui la domanda diventa inevitabile: perché è interessante considerare questa tipologia di modelli?
Il flusso "reale" dei sistemi di ricerca moderni
Se guardiamo quello che Google definisce nella documentazione come “Typical search and retrieval flow”, vediamo un pattern molto chiaro.
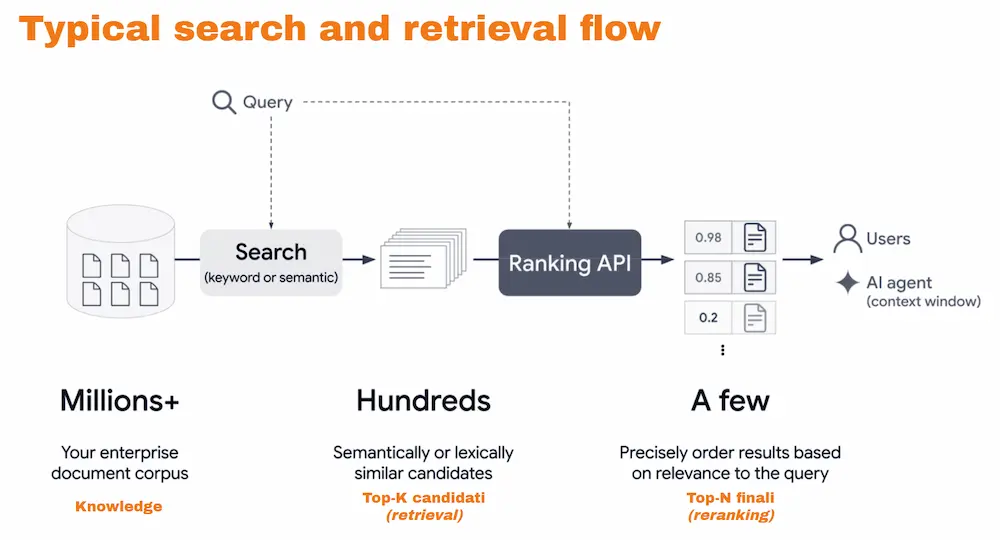
Il flusso, semplificando, è il seguente:
- si parte da milioni di documenti in un archivio;
- viene posta una query di ricerca;
- il sistema effettua un retrieval, cioè “screma” i contenuti estraendo quelli più pertinenti;
- interviene un reranker, che ordina i contenuti estratti nella fase precedente in base alla rilevanza;
- a quel punto i più rilevanti diventano la lista dei risultati, oppure il contesto elaborato da un AI Agent per generare una risposta.
Come funzionano le due fasi cruciali nel flusso (ovvero retrieval e reranking)?
Retrieval: pertinenza semantica (bi-encoder)
La prima fase, il retrieval, si basa sulla pertinenza semantica.
Query e documenti vengono codificati in embeddings, e attraverso un calcolo di similarità vengono estratte le parti dei documenti più "vicine" semanticamente alla query.
Questa architettura è il classico bi-encoder.
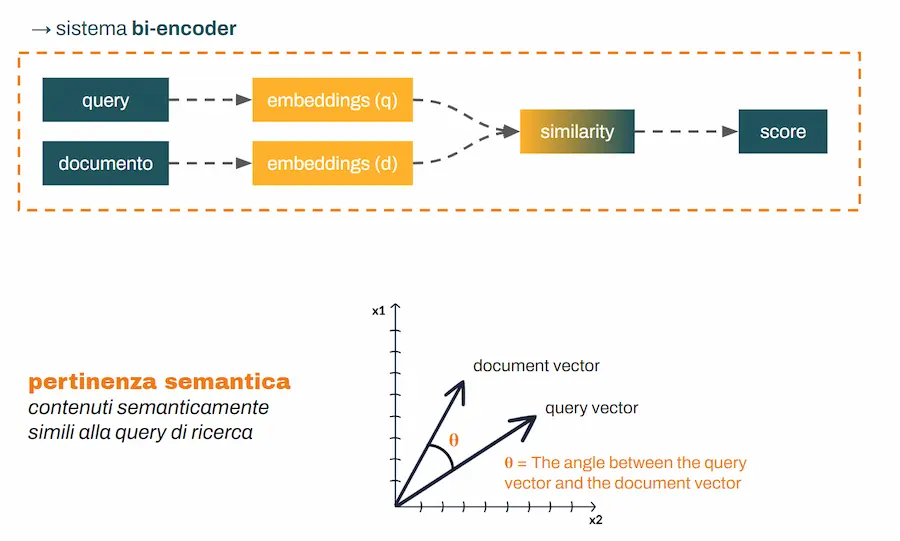
- La query viene codificata in embedding;
- ogni documento viene codificato in embedding;
- viene calcolata la similarità tra gli embeddings e si ottiene uno score di pertinenza.
Ed è esattamente per questo che viene definito bi-encoder: due encoding separati, per poi procedere al confronto.
Questo processo ha le seguenti caratteristiche:
✅ veloce
✅ scalabile
❌ poco preciso
Questa fase è perfetta per “ridurre” la knowledge di riferimento per ottenere una risposta: considera un archivio enorme per portarlo a un set di candidati "gestibile".
Reranking: rilevanza contestuale (cross-encoder)
La seconda fase, il reranking, funziona in modo diverso.
Qui entra in gioco il reranker, che riceve in input query + contenuto e calcola uno score di rilevanza. E cambia anche l’architettura: stavolta è cross-encoder.
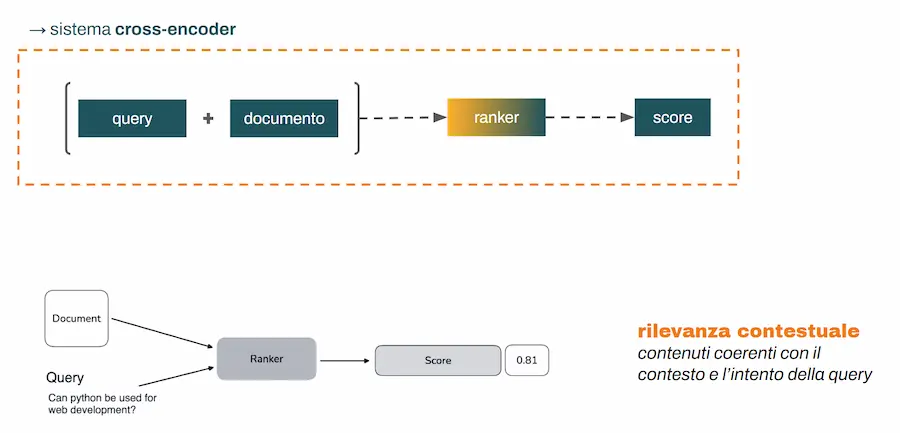
In questo caso, query e contenuto vengono concatenati, entrano insieme nel reranker (modello transformer) e il modello usa il noto meccanismo dell’attenzione per cogliere ogni minima sfumatura e correlazione tra concetti. Questo processo (cross-encoder) ha caratteristiche complementari rispetto all'architettura bi-encoder:
❌ lento
❌ costoso
✅ molto preciso
Pipeline ibrida: bi-encoder per recall prima + cross-encoder per precision
I moderni sistemi di ricerca, quindi, sono una pipeline ibrida:
- bi-encoder (veloce, meno preciso) per scremare la knowledge;
- cross-encoder (lento, preciso) per affinare e ordinare.
Questo non è solo un dettaglio tecnico: è un modo di ragionare che poi diventa operativo.
Come possiamo usare queste conoscenze nei nostri workflow operativi?
Un’idea molto concreta è usare i reranker per misurare quanto i nostri contenuti sono rilevanti rispetto alle query di interesse. E, ovviamente, possiamo anche confrontare la rilevanza dei nostri contenuti rispetto ad altri contenuti già presenti online.
Emerge, però, un altro punto, spesso sottovalutato: reranker diversi producono ranking diversi.
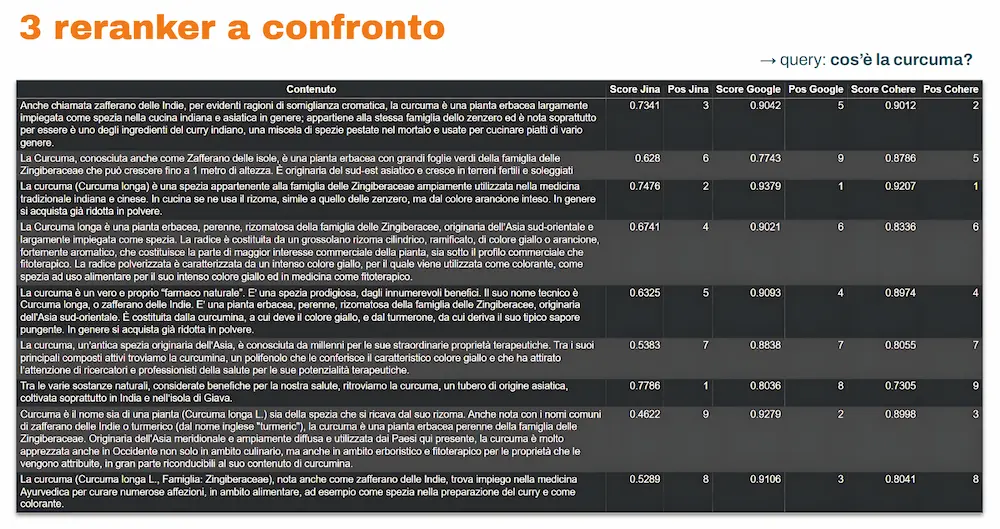
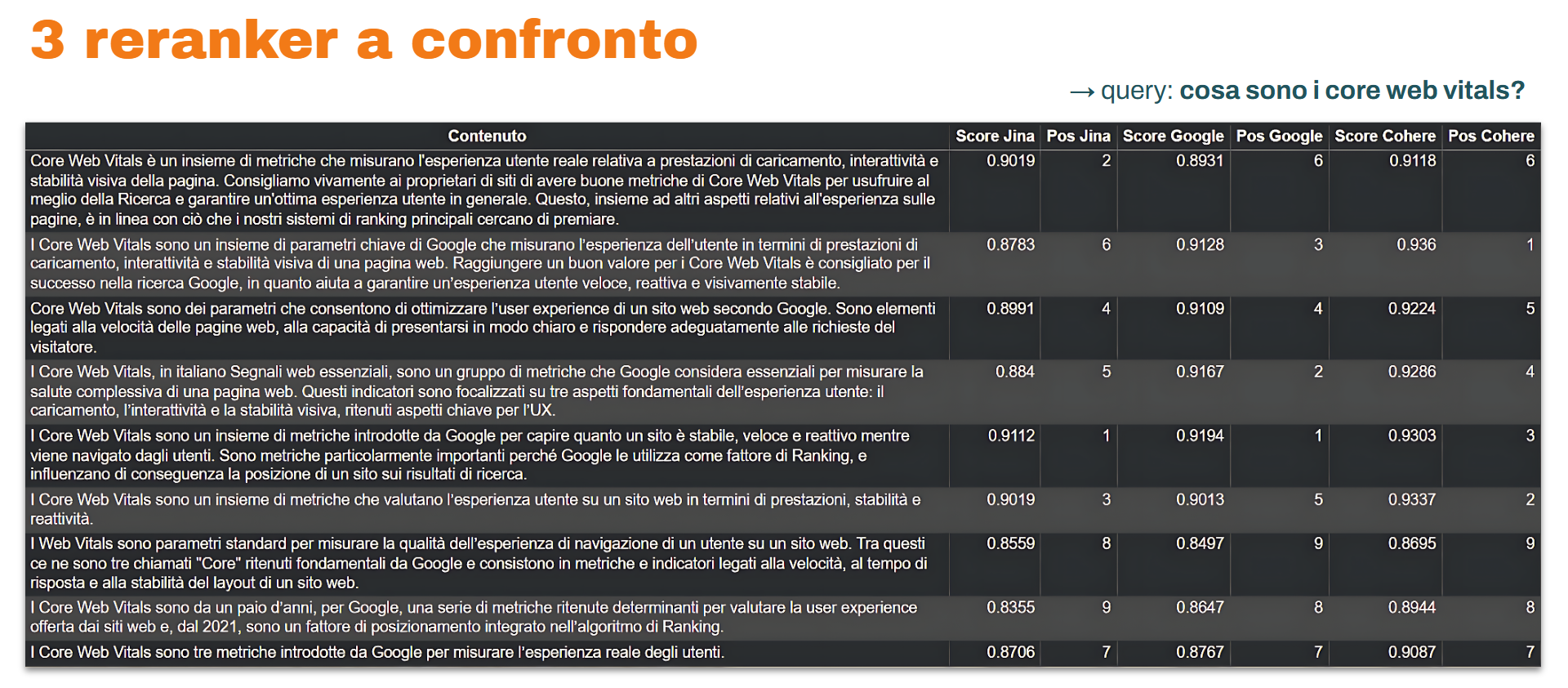
3 reranker a confronto: Jina, Google, Cohere
Nelle immagini si può vedere un confronto tra 3 reranker (Jina, Google, Cohere) sulle query “cos’è la curcuma?” e “cosa sono i core web vitals?” per diversi contenuti estratti da pagine web attualmente online. Come si nota, i modelli attribuiscono score di rilevanza diversi.
Qual è il dato corretto?
Non esiste un dato “giusto” o “sbagliato”, perché la misurazione dipende dai dati e dalle procedure messe in atto durante la fase di training dei modelli. È un po’ come chiedere a esperti estremamente competenti, ma con esperienze differenti, di valutare gli stessi testi: tenderanno a convergere, ma non saranno identici.
Reranker come ricerca personalizzabile: boost e penalizzazioni
C’è un ulteriore step di conoscenza da apprendere sui reranker: non si tratta solo di “modelli di scoring”, ma di vere e proprie piattaforme di ricerca personalizzabile.
Attraverso azioni di boost o penalizzazione, infatti, possiamo influenzare la valutazione del modello: dare più peso a certe caratteristiche, e penalizzarne altre.

Negli esempi influenzo il reranker di Google per dare boost ai contenuti in cui la fonte ha un popularity score maggiore, i contenuti più recenti, e quelli in cui l’autore è più autorevole, e penalizzo quelli di scarsa qualità.
Ecco come un motore di ricerca può valutare parametri esterni che vanno oltre il contenuto che scriviamo.
Un sistema multi-agente per l'ottimizzazione dei contenuti per AI Overviews
Facendo tesoro di questi concetti, internamente, con il mio team, abbiamo sviluppato un sistema multi-agente che:
- analizza l’AI Overview e i contenuti della SERP,
- sfrutta il reranker di Google (opportunamente configurato),
- crea risposte più rilevanti e contenuti strutturati meglio per concorrere nei sistemi di ricerca ibridi (come le AI Overview di Google).
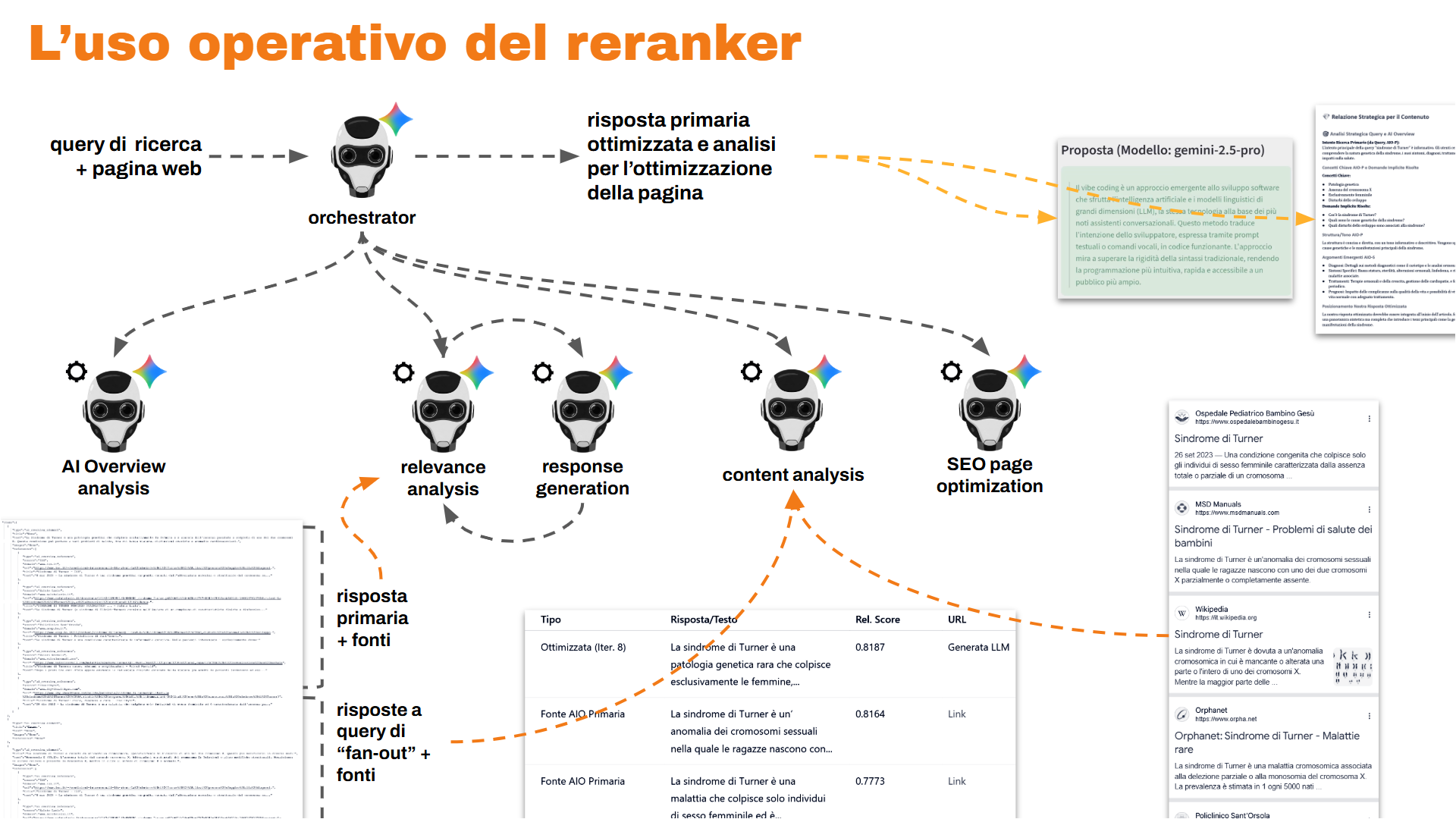
Nel seguente video è possibile vedere l'applicazione in azione all'interno della nostra piattaforma dedicata alle applicazioni AI che abbiamo sviluppato.
Un esempio dell'applicazione in azione
Attraverso il seguente post, è possibile approfondire il funzionamento del sistema.
Oltre i reranker: In-context Ranking (ICR) e BlockRank
Direzione successiva: come si supera la precisione dei reranker?
Un metodo è l’In-context Ranking (ICR): usare un LLM per processare non query e contenuti a coppie, ma query e tutti i contenuti pertinenti insieme.
Risultato: precisione altissima e comprensione dell’intero contesto.
Contro: estremamente lento e oneroso.
Per rendere l’ICR scalabile entra in scena BlockRank: un approccio pubblicato da Google che punta a risolvere i contro dell’ICR. Per approfondire:

Takeaway della prima tappa
Quali sono i takeaway che ci portiamo a casa dalla prima tappa?
- L’evoluzione di queste tecnologie ci fa capire quanto migliorerà la ricerca nei prossimi anni, con modelli in grado di comprendere ogni sfumatura del linguaggio.
- Oggi abbiamo strumenti e documentazione per comprendere meglio la ricerca, anche tecnicamente. Sforziamoci di approfondire questi aspetti, perché possono regalarci intuizioni, e le intuizioni diventano strategie e tool da mettere in campo nei nostri flussi di lavoro.
2 - Contenuti: l’AI cambia lo scenario, ma porta anche nuovi strumenti
Seconda tappa: Contenuti.
Quante volte abbiamo sentito questa frase nell'ultimo periodo?
“Con le AI Overview è tutto finito
per i progetti editoriali…”
È vero? Ognuno tragga le proprie conclusioni. Ma un fatto è chiaro: l’AI sta cambiando lo scenario, ma, nello stesso momento, ci mette a disposizione strumenti nuovi.
Una redazione ibrida: Crea, Aggiorna, Massimizza
Nel nostro team abbiamo realizzato una redazione ibrida a supporto dell’editoria, basata su LangGraph e Gemini, che lavora su tre funzioni:
CREA → AGGIORNA → MASSIMIZZA
CREA: catturare trend, trasformarli in piano editoriale
Domanda iniziale:
quali sono i contenuti che in questo momento stanno vivendo una crescita di interesse per gli utenti?
Un Agente AI lo verifica costantemente, attingendo a più fonti:
- feed internazionali di riferimento per il settore,
- Google News su diversi mercati,
- Google Trends,
- social media,
- Google Discover.
Processa questi dati e produce un piano editoriale sul trend, pensato per "catturare" i trend "istantanei", cioè quello che è interessante per gli utenti nel momento in cui si esegue l'osservazione.
L’editore riceve il piano nel suo CMS e può approvarlo (anche parzialmente).
I contenuti approvati vengono processati da un agente specializzato che: usa tool esterni via MCP (Model Context Protocol), coopera con il sistema dedicato alla rilevanza (quello visto nella prima tappa), produce la scrittura completa di una bozza di altissima qualità, e la salva direttamente nel CMS.
Infine l’editore arricchisce, modifica, aggiunge elementi multimediali e pubblica.
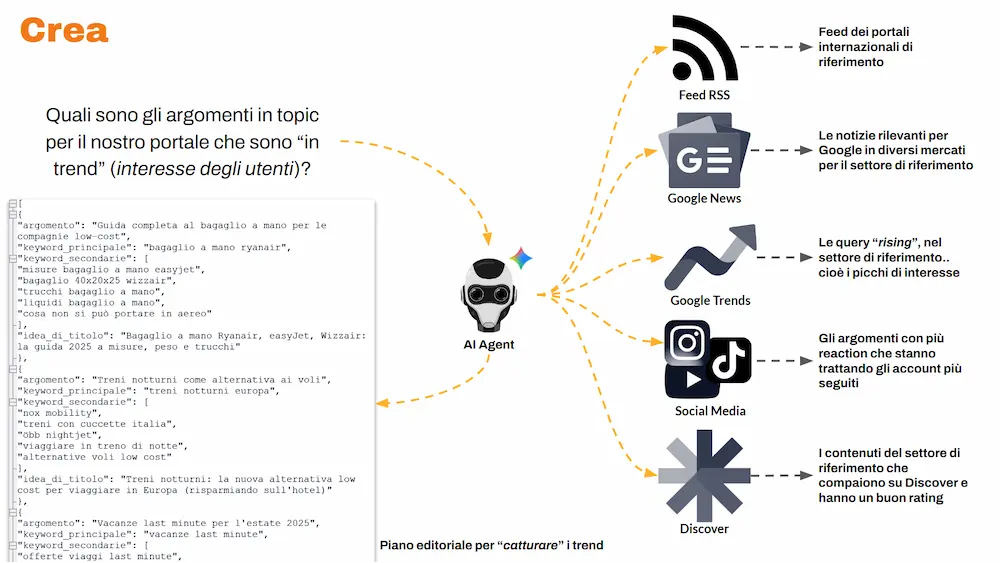
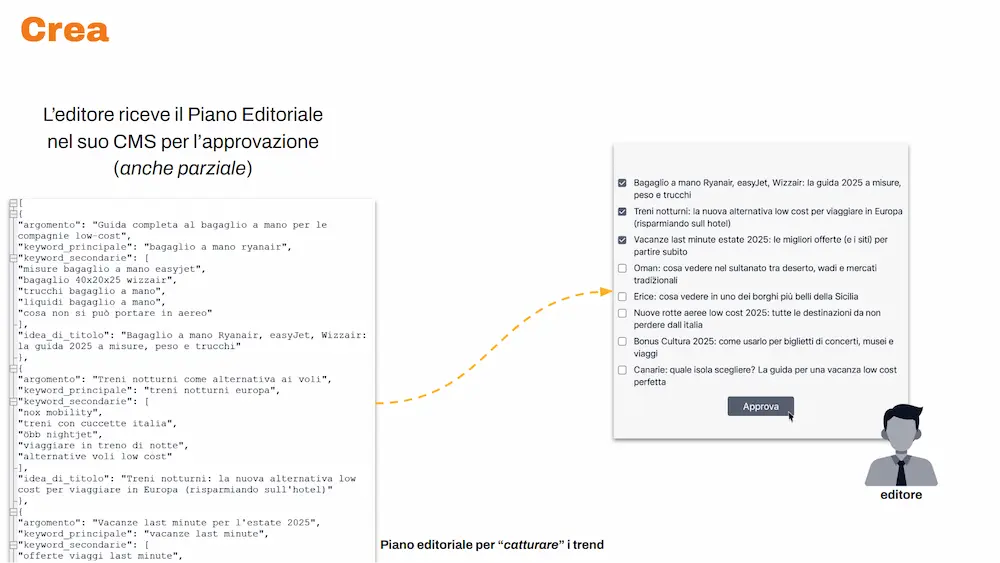
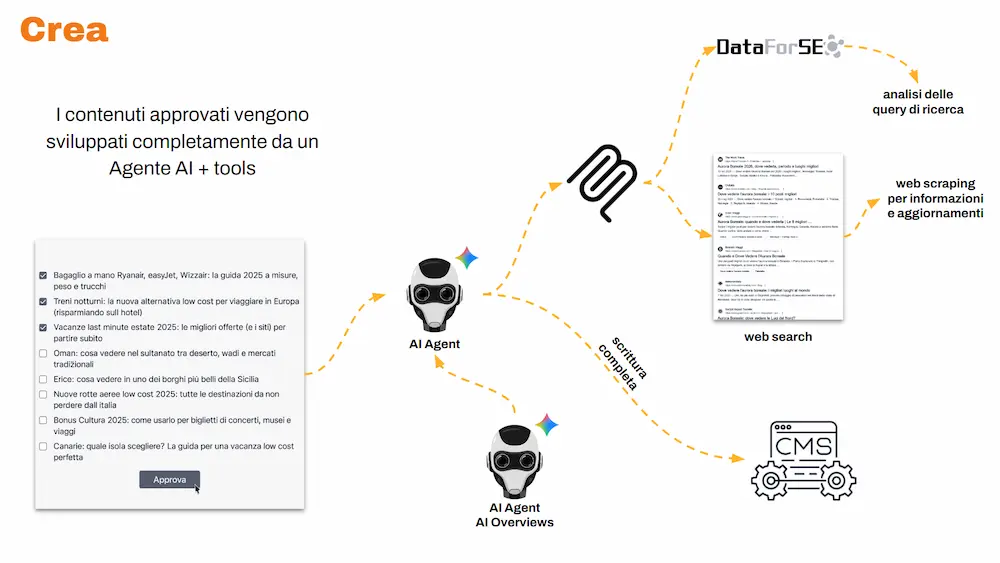
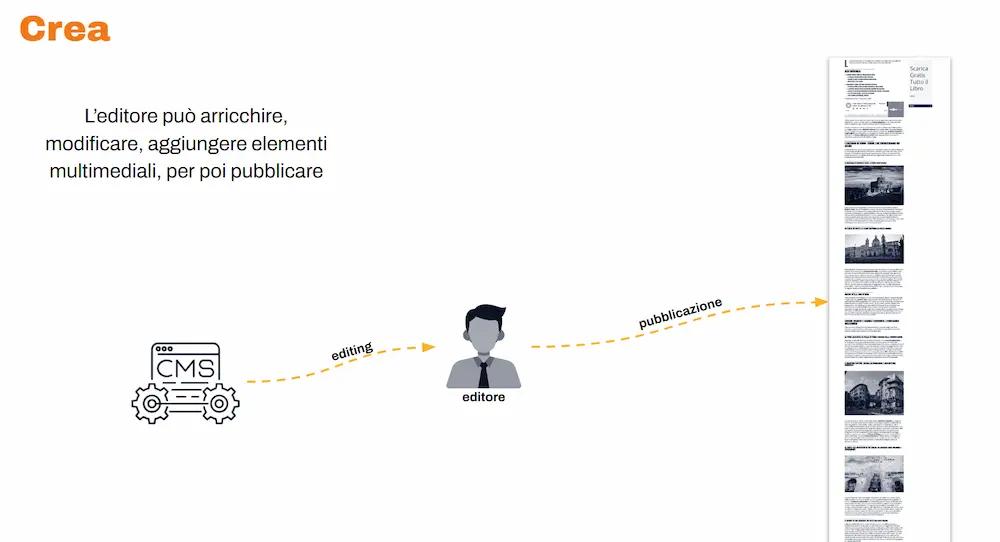
Uno schema di funzionamento della creazione dei contenuti
Questa parte, per come la vedo, è già un cambio di paradigma: non è “scrittura automatica”, è..
orchestrazione di un flusso, dove l’AI fa il lavoro pesante e ripetitivo e l’umano si mette nella posizione giusta: quella in cui può davvero alzare la qualità.
AGGIORNA: mantenere i contenuti vivi (e competitivi)
Un agente osserva in modo costante i dati di Search Console ed estrae i contenuti che stanno performando meno (in termini di clic, impressioni e posizionamento), e che non vengono aggiornati da diverso tempo.
Un altro agente processa questi contenuti, usa tool esterni via MCP, e si occupa di aggiornarli e ottimizzarli, salvando l’elaborato direttamente nel CMS.
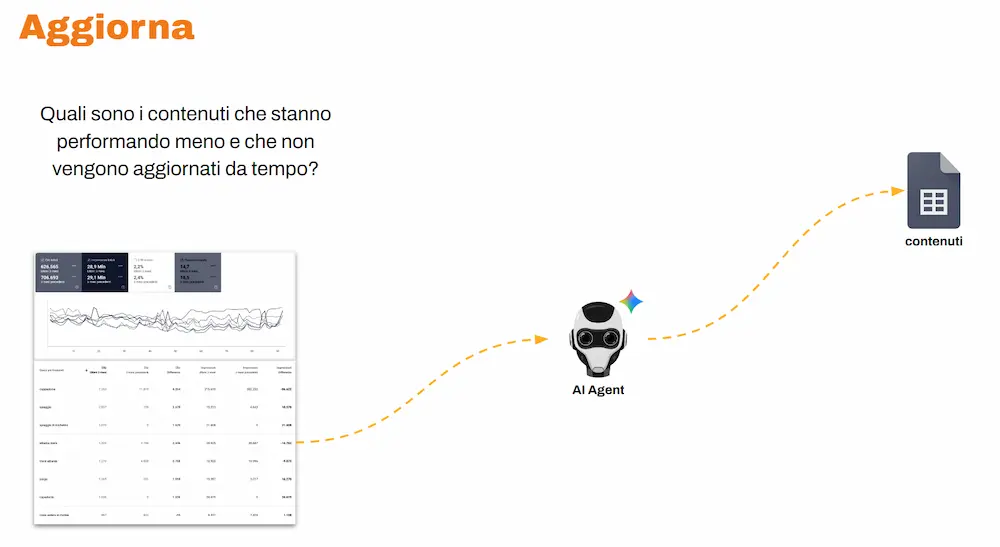
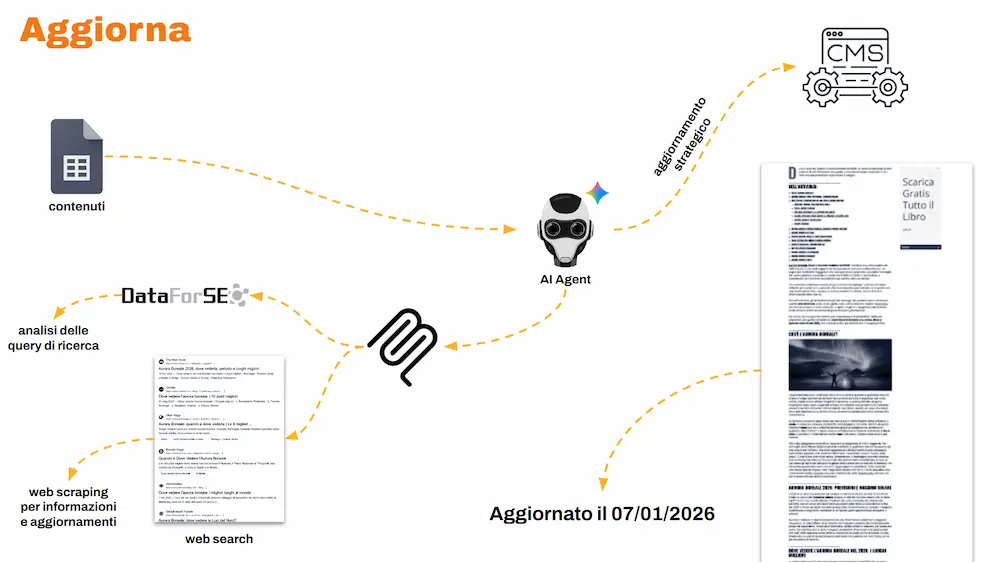
Uno schema di funzionamento dell'aggiornamento dei contenuti
Risultato: un sistema che mantiene tutti i contenuti costantemente aggiornati e ottimizzati. Questo sta contribuendo a una crescita generale di clic e impressioni, e soprattutto a una presenza costante su Google Discover, con picchi che corrispondono a diversi milioni di impressioni.
MASSIMIZZA: contenuti, affiliazione e sostituzione intelligente
Spesso i progetti editoriali lavorano con l’affiliazione. Abbiamo creato degli agenti che verificano costantemente se, nei contenuti:
- sono presenti prodotti consigliati non più disponibili nel marketplace di riferimento,
- oppure prodotti che non stanno performando, ovvero che non stanno producendo clic.

Gli agenti usano strumenti esterni via MCP per trovare prodotti simili da sostituire e producono descrizioni testuali che vengono integrate in modo armonioso nel contenuto, rispettando il contesto in cui avviene l'inserimento.
Takeaway della seconda tappa
I takeaway della seconda tappa sono molto concreti.
- Un team ibrido ben strutturato può garantire output di altissima qualità: l’AI svolge i compiti più onerosi e ripetitivi, l’essere umano supervisiona e si concentra sulla qualità.
- Il flusso di lavoro cambia completamente, e cambiano le mansioni delle persone quando l’AI è davvero al centro della strategia.
- L’AI abilita un'azione su larga scala che permette di agire sulla frequenza di pubblicazione e sulla qualità generale del progetto. Operazioni di questo tipo sarebbero irrealizzabili senza automazioni come quella descritta nella tappa del viaggio.
- Si può intravvedere un pattern chiaro: trend di interesse + alta frequenza + qualità globale aumentano la capacità di entrare in Discover in modo costante.
3 - Feed: da “file tecnico” a centro della strategia
Quante volte abbiamo sentito una frase come quella che segue, soprattutto nel mondo e-commerce?
“Sì, l’e-commerce genera automaticamente il feed, poi lo ottimizziamo con XYZ Feed Manager…”
Spesso, però, per “ottimizzazione” si intende la creazione di pattern che mettono in sequenza i dati prodotto presenti nel database dell'e-commerce, oppure un timido utilizzo dell’AI per farlo in modo un po’ meno schematico.
L’approccio che, con il mio team, abbiamo messo in campo è diverso: usare un sistema multi-agente per un’ottimizzazione su larga scala.
Un sistema multi-agente per ottimizzare il feed su larga scala
Il sistema riceve in input il feed dell'e-commerce.
Un agente lo elabora analizzando anche la pagina prodotto, le immagini, i dati strutturati, e connettendosi a fonti esterne: Search Console, web search, scraping di dati online e altre fonti specifiche.
Un altro agente si occupa dell’arricchimento: aggiunge dati potenzialmente rilevanti assenti nel feed.
Infine, un agente revisore monitora la correttezza dei dati anche con verifiche incrociate.
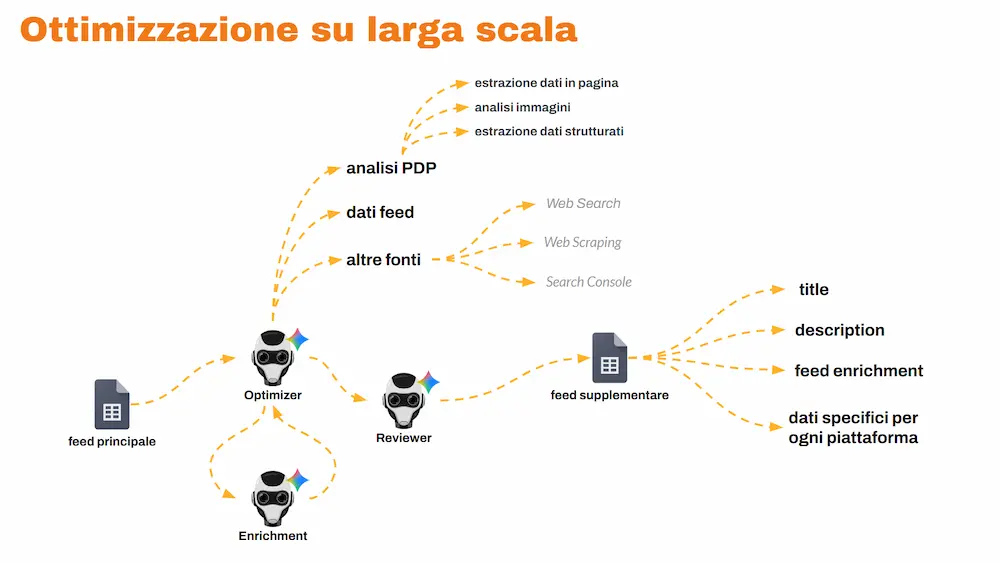
In output otteniamo un feed supplementare con title e description ottimizzati e dati di enrichment, personalizzabile per qualunque piattaforma.
Dopo aver inserito in piattaforma il feed ottimizzato su alcuni progetti, stiamo registrando (su Google Merchant Center) un aumento dei clic sui prodotti e del CTR (Click-Through Rate) degli annunci di advertising
Azione successiva: portare i dati ottimizzati del feed anche nell'e-commerce, usandoli per l’ottimizzazione delle pagine prodotto e categoria, e l'integrazione dei dati strutturati. Questo permette di ottenere la coerenza delle informazioni.
Takeaway della terza tappa
Il feed non è (solo) un “file tecnico” che l’e-commerce deve produrre. È il centro della strategia: la chiave per portare le nostre entità su tutte le piattaforme digitali. E il sito web è solo una di queste piattaforme.
Per il futuro, due direzioni diventano obbligate:
- essere sempre più abili nel curare i dati delle nostre entità;
- essere sempre più agili nel portarle ottimizzate su ogni piattaforma.
Si chiude il viaggio, si apre la strategia
Arrivati qui, il punto non è aver visto tre argomenti separati.
Il punto è capire che..
feed, contenuti e intelligenza sono parti dello stesso motore: il motore della discovery.
E oggi abbiamo tante opportunità per rendere questo motore più potente.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂