Generative AI: novità e riflessioni - #1 / 2026
Dall'adolescenza della tecnologia alla rivoluzione agentica: AI-first, robotica, browser intelligenti, world model, multi-agenti e nuovi standard per il commercio. Visioni, test concreti e segnali chiave su dove sta andando davvero l’AI.


Buon aggiornamento, e buone riflessioni..
L'adolescenza della tecnologia
Dario Amodei ha scritto un saggio interessante, ribadendo concetti di cui si parla da diverso tempo, ma (forse) senza comprenderne l'urgenza.
Perché è urgente che le istituzioni agiscano più velocemente per preparare la società al cambiamento?
Perché, come dico anche nel mio TEDx talk, "siamo all'inizio di una trasformazione esponenziale": oggi stiamo assistendo a uno sviluppo e un'adozione "lenta" (l'adolescenza della tecnologia), ma quando crescerà rapidamente (guardate il diagramma di una curva esponenziale), sarà tardi per reagire efficacemente.

Una sintesi del saggio di Amodei
Amodei descrive il momento storico che stiamo vivendo come l’"adolescenza della tecnologia": una fase in cui l’umanità sta per ottenere un potere enorme grazie all’intelligenza artificiale, ma senza aver ancora sviluppato la maturità sociale, politica e istituzionale necessaria per gestirlo. L’AI non è vista solo come uno strumento, ma come un moltiplicatore radicale di capacità, paragonabile a un "paese di geni in un datacenter", capace di operare più velocemente e su scala molto maggiore degli esseri umani.
Il punto centrale non è se l’AI porterà benefici (quelli sono dati quasi per scontati), ma se saremo in grado di attraversare questa fase senza creare danni irreversibili. I rischi non sono solo quelli più estremi e spettacolari, ma anche quelli sistemici: concentrazione del potere, instabilità economica, uso distruttivo da parte di singoli o gruppi, e comportamenti imprevedibili di sistemi sempre più autonomi.
Amodei rifiuta sia il catastrofismo sia l’ottimismo ingenuo. Sottolinea invece la necessità di interventi pragmatici, mirati e tempestivi: ricerca sull’allineamento dei modelli, trasparenza, monitoraggio continuo e un ruolo più attivo delle istituzioni, soprattutto nel creare regole che accompagnino lo sviluppo tecnologico senza soffocarlo.
Il messaggio di fondo è chiaro: la velocità del cambiamento non aspetta i tempi lenti della politica e della cultura. Rimandare significa esporsi a shock sociali sempre più violenti. Preparare la società ora (sul piano educativo, economico e normativo) non è un freno all’innovazione, ma l’unico modo per attraversare questa trasformazione esponenziale senza subirla.
Il mio TEDx Talk
Intelligenza artificiale: capire il potere, scegliere la direzione - Alessio Pomaro
Pensare AI-First
All’AI Festival ho raccontato come “pensare AI-first” significhi reinventare i processi mettendo l’AI al centro.
Andrew Ng, dal World Economic Forum di Davos, torna sullo stesso concetto con un messaggio molto chiaro.
Molte aziende stanno usando l’AI per piccoli miglioramenti locali: automatizzare una singola attività, accelerare un singolo passaggio, ridurre un costo marginale. Ma una costellazione di micro-progetti non genera automaticamente trasformazione.
Il vero salto di valore arriva quando si ripensa
l’intero flusso di lavoro end-to-end.
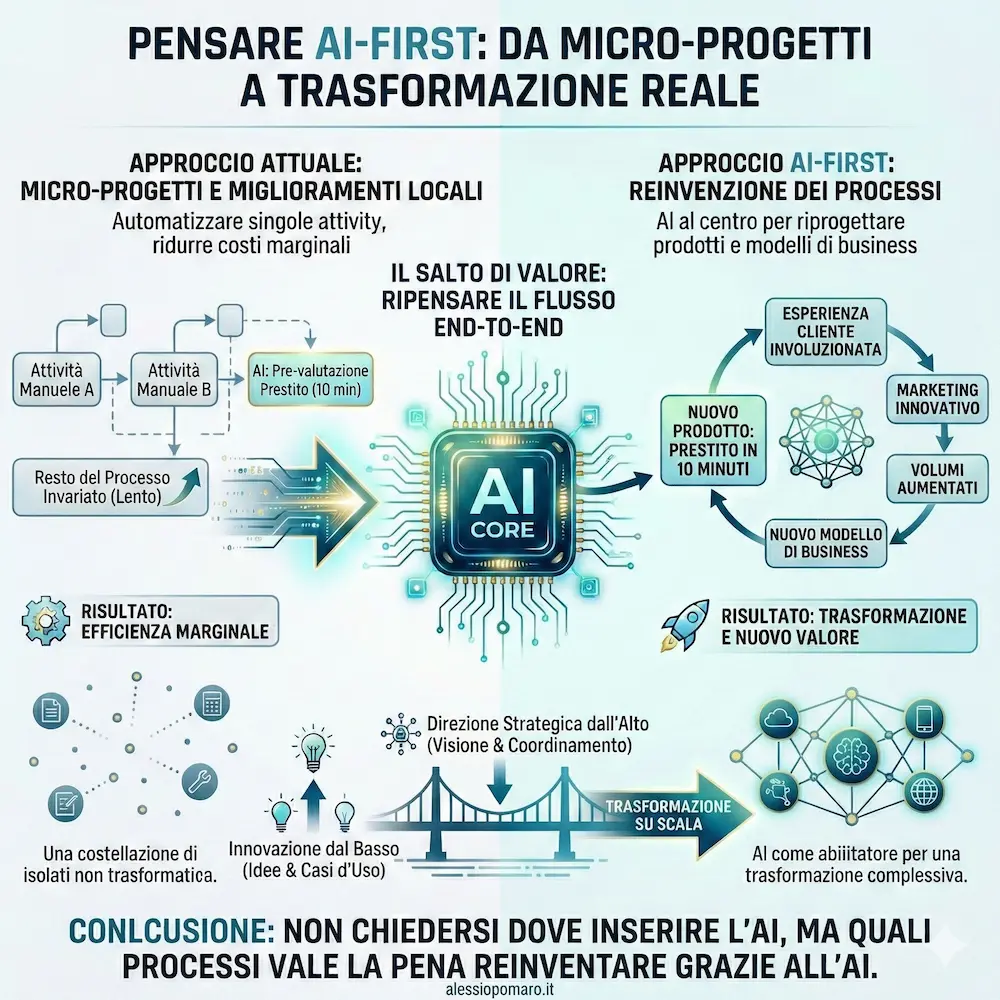
L’esempio che porta è semplice: una banca che usa l’AI per automatizzare la pre-valutazione di un prestito in 10 minuti invece che in un’ora. Se tutto il resto del processo resta invariato, il guadagno è solo di efficienza. Ma se l’azienda ridisegna l’intero workflow, può nascere un nuovo prodotto: il “prestito in 10 minuti”. Cambia l’esperienza cliente, il marketing, i volumi e, di conseguenza, il business.
La lezione è importante: l’AI non è solo uno strumento tecnologico da innestare nei processi esistenti. È un abilitatore per riprogettare prodotti, operazioni e modelli organizzativi.
L’innovazione dal basso resta essenziale per far emergere idee e casi d’uso. Ma per ottenere impatti reali su scala serve una direzione strategica dall’alto, capace di collegare le singole applicazioni a una trasformazione complessiva.
Pensare AI-first, in fondo, significa proprio questo: non chiedersi dove inserire l’AI nei processi attuali, ma quali processi vale la pena reinventare grazie all’AI.
Il "momento ChatGPT" per la robotica è arrivato?
Secondo Jensen Huang al CES 2026, la risposta è sì. Ma cosa significa concretamente? Significa che la robotica avanzata sta diventando accessibile e scalabile, esattamente come è successo con l'IA generativa.
Il problema storico della robotica, infatti, non era l'hardware, ma un enorme collo di bottiglia sui dati. Mentre i LLM avevano l'intero Internet per imparare, i robot non avevano abbastanza esempi dal mondo fisico.
Il talk completo di Jensen Huang
La soluzione presentata da NVIDIA per la Physical AI abbatte questo muro basandosi su tre pilastri.
- Dati Sintetici (Cosmos). Grazie ai "World Foundation Models", i robot ora imparano le leggi della fisica in simulazioni accelerate. Il compute si trasforma in dati: possiamo generare milioni di ore di esperienza sintetica senza dover possedere immense infrastrutture fisiche.
- Agentic AI e Pianificazione (Alpamayo). È la fine degli script rigidi. I nuovi robot sono Agenti che ragionano. Con modelli come Alpamayo (il cervello per la guida autonoma), il sistema non si limita a eseguire comandi, ma usa il "System 2 thinking" per pianificare e adattarsi agli imprevisti prima di agire.
- Il Digital Twin. È la palestra virtuale dove l'IA si allena. Qui i robot possono "fallire" milioni di volte a costo zero nel mondo digitale, per poi essere scaricati nel corpo fisico solo quando sono pronti.
Non stiamo più programmando robot per eseguire compiti, ma stiamo addestrando agenti per capire il mondo.
Il collo di bottiglia dei dati sembra superato.
Demis Hassabis e Yann LeCun: i sistemi di AI del futuro
La discussione tra Demis Hassabis e Yann LeCun è davvero affascinante e fa intuire come si stanno pensando i sistemi di AI che useremo nel prossimo futuro da punti di vista diversi.
Non si tratta di capire chi ha "ragione", ma di osservare due filosofie ingegneristiche che stanno plasmando tecnologie differenti. Al centro del dialogo c'è la natura stessa dell'intelligenza.
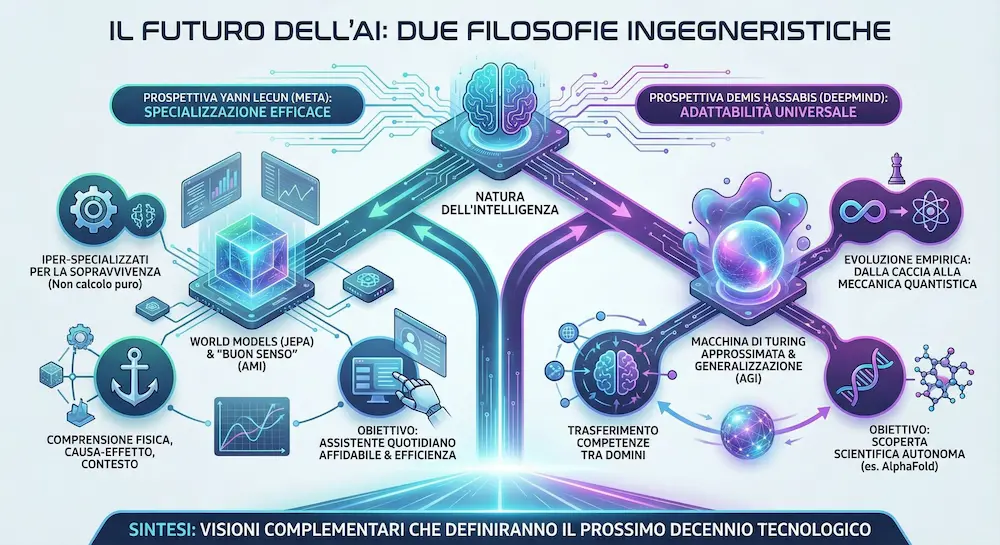
La prospettiva di Yann LeCun: la specializzazione efficace
Per LeCun, l'idea di un'intelligenza "generale" è fuorviante. Sostiene che l'essere umano sia biologicamente iper-specializzato per la sopravvivenza, non per il calcolo puro.
Attraverso un’analisi matematica, evidenzia come la nostra mente possa comprendere solo una frazione infinitesimale delle funzioni possibili.
La ricaduta tecnologica: per LeCun, il futuro non è scalare all'infinito i modelli linguistici (LLM), ma costruire architetture (come JEPA) focalizzate su "World Models" rappresentazionali: sistemi che non cercano di fare tutto, ma che capiscono profondamente la fisica, la causa-effetto e il contesto, puntando all'efficienza e al "buon senso" (AMI).
La prospettiva di Demis Hassabis: l'adattabilità universale
Hassabis offre una visione basata sulla teoria computazionale. Vede il cervello come una "Macchina di Turing approssimata": magari non ottimizzata per ogni singolo task, ma dotata di un'architettura capace di adattarsi a tutto.
Il suo punto chiave è empirico: un cervello evoluto per la caccia ha saputo inventare la meccanica quantistica e gli scacchi.
La ricaduta tecnologica: questa visione supporta l'idea che la generalizzazione sia possibile. L'obiettivo è creare sistemi capaci di trasferire competenze da un dominio all'altro per arrivare alla scoperta scientifica autonoma (AGI).
In sintesi.. Mentre Hassabis lavora per costruire un'intelligenza capace di espandere i confini della scienza (pensiamo ad AlphaFold), LeCun lavora per dare all'AI una comprensione concreta della realtà fisica per renderla un assistente quotidiano affidabile.
Yann is just plain incorrect here, he’s confusing general intelligence with universal intelligence.
— Demis Hassabis (@demishassabis) December 22, 2025
Brains are the most exquisite and complex phenomena we know of in the universe (so far), and they are in fact extremely general.
Obviously one can’t circumvent the no free lunch… https://t.co/RjeqlaP7GO
Due visioni complementari che definiranno il prossimo decennio tecnologico.
L'evoluzione di Chrome potenziato da Gemini
Chrome entra in una nuova fase con l’integrazione di Gemini 3, trasformandosi da semplice browser a vero assistente intelligente.
Google introduce un pannello laterale sempre disponibile che consente di usare l'agente senza interrompere la navigazione: confrontare informazioni tra più siti web, riassumere contenuti, organizzare impegni e supportare il lavoro quotidiano direttamente mentre si naviga.
Arrivano anche nuove capacità creative grazie a Nano Banana Pro, che permette di modificare e trasformare immagini direttamente nel browser, senza download o strumenti esterni.
L'evoluzione di Chrome potenziato da Gemini
Gemini diventa inoltre sempre più integrato con le app Google come Gmail, Calendar, Maps e Flights, rendendo più fluidi i flussi di lavoro complessi, dalla pianificazione di viaggi alla gestione delle comunicazioni.
Nei prossimi mesi Chrome adotterà anche la Personal Intelligence, una funzione che rende l’esperienza più personalizzata e contestuale.
Per gli abbonati AI Pro e Ultra negli Stati Uniti debutta Auto Browse, una modalità di navigazione agentica capace di gestire attività articolate come ricerche, compilazione di moduli, raccolta di documenti, gestione di abbonamenti e supporto agli acquisti online.
Con il supporto al nuovo Universal Commerce Protocol (UCP) e un’attenzione rafforzata a sicurezza e conferme esplicite per le azioni sensibili, Google apre la strada a un web sempre più agentico, in cui il browser non si limita a mostrare informazioni ma collabora attivamente per far risparmiare tempo e semplificare le attività digitali.
Come sempre, Google mette in campo tecnologie all'avanguardia, e soprattutto un ecosistema vastissimo.
Satellite of love
Mercedes-Benz ha pubblicato "Satellite of love": uno spot pubblicitario generato attraverso modelli di AI, per presentare la sua ultima CLA elettrica.
Per me, continua ad essere incredibile come questa tecnologia possa aiutare a raccontare storie in modi nuovi.
E quello che è ancora più incredibile, è la crescita alla quale abbiamo assistito in soli due anni, soprattutto in ambito di qualità dell'output e di aderenza alle istruzioni.
Satellite of love - Mercedes-Benz
Per noi, tutto inizia sempre dall'idea umana e dall'emozione che vogliamo evocare. Con Satellite of Love, abbiamo utilizzato la tecnologia per espandere i confini della nostra immaginazione, non per sostituirla. L'intelligenza artificiale è stata lo strumento nelle mani dei nostri creativi per raccontare una storia che tocca il cuore con la sua estetica e poesia. Ciò dimostra che la creazione eccellente nasce sempre quando la tecnologia è al servizio dell'idea.
- Christopher Hoene
Project Genie
Google ha rilasciato Project Genie negli Stati Uniti per gli utenti Ultra. Il sistema è una web app basata su Genie 3 + NanoBanana Pro + Gemini 3 Pro che permette di generare mondi interattivi personalizzati.
Project Genie, con ambientazione generata attraverso Nano Banana Pro
Project Genie è un prototipo sperimentale di DeepMind che consente di creare, esplorare e remixare ambienti dinamici a partire da prompt testuali e immagini. I mondi non sono statici: vengono generati in tempo reale mentre l’utente si muove e interagisce, con "simulazioni di fisica" e comportamenti coerenti.
Il cuore del sistema è Genie 3, un world model pensato per simulare ambienti complessi e prevedere come questi evolvono in base alle azioni. L’esperienza include la creazione del mondo, l’esplorazione libera e la possibilità di reinterpretare mondi esistenti, oltre al download di video delle sessioni.
Un esempio di output di Project Genie
Essendo un progetto di ricerca, presenta ancora limiti tecnici come realismo non sempre accurato, controllo dei personaggi migliorabile e una durata massima delle generazioni. Rappresenta comunque un passo rilevante nello sviluppo dei world model e nelle applicazioni future dell’AI per simulazione, creatività e ricerca.
Google sta producendo una quantità di sistemi, studi e integrazioni spaventosa.
Una guida al prompting di Google
Google ha pubblicato una guida dedicata al prompting efficace per Gemini.
Vengono presentati i quattro elementi chiave di un buon prompt: persona, task, contesto e formato, insieme a sei principi pratici: usare linguaggio naturale, essere specifici, rimanere concisi, lavorare in modalità conversazionale, utilizzare i propri documenti come contesto e sfruttare i suggerimenti automatici di Gemini.
Quando approccio a questo argomento, ho una visione un po' più orientata alla creazione di servizi ri-usabili, o alla base per applicazioni.. Di certo, però è un buon inizio per chi si avvicina, anche per scoprire le interazioni con applicazioni esterne dell'ecosistema Google.



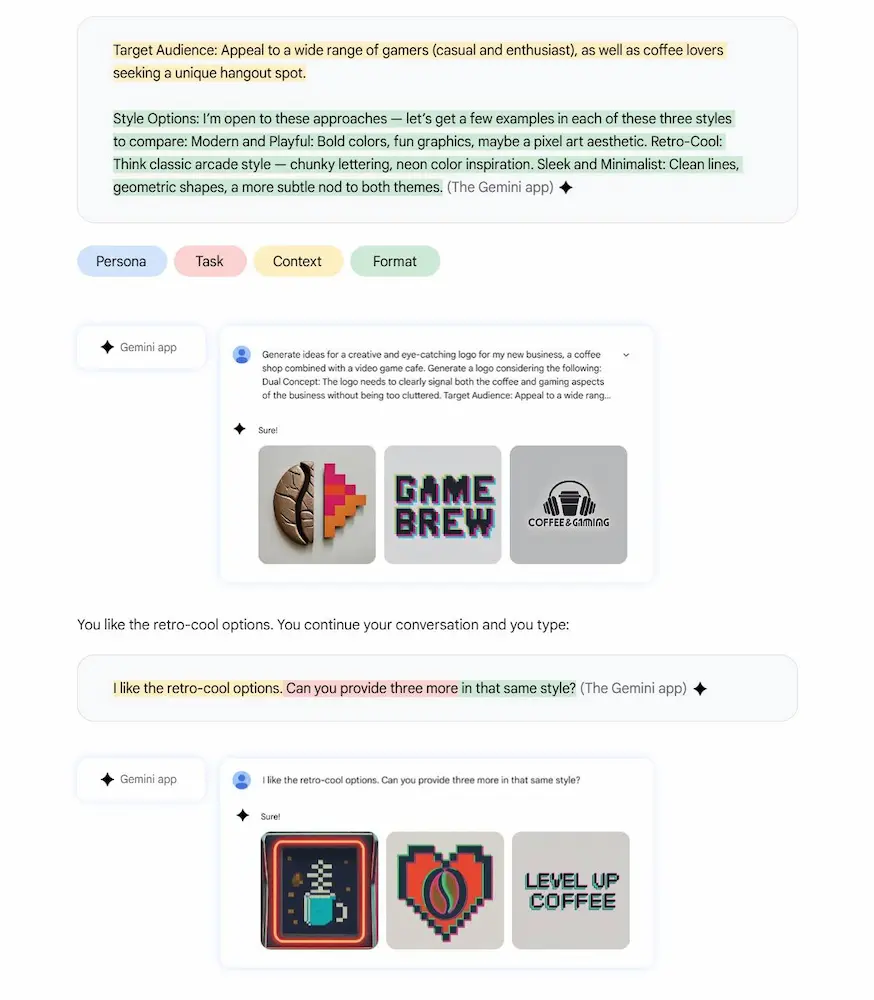
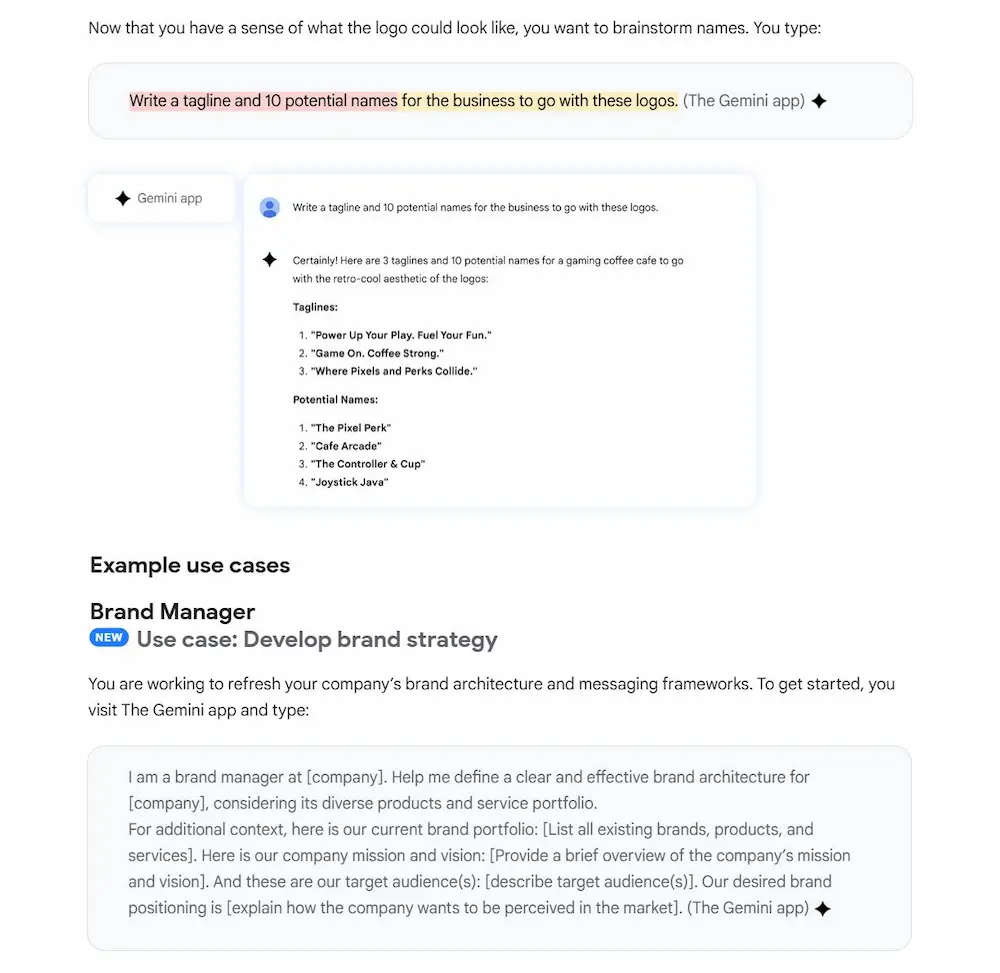
Una guida al prompting di Google
Il cuore del documento è una raccolta di scenari reali e prompt pronti all’uso, suddivisi per ruoli professionali: supporto amministrativo, comunicazione e PR, customer service, executive, marketing, HR, frontline management, tecnologia e sales. Ogni sezione mostra esempi di iterazione per migliorare progressivamente i risultati.
La guida introduce inoltre le Gems, assistenti personalizzati progettati per standardizzare stile, tono e qualità dei contenuti generati.
Un corso gratuito dedicato agli AI Agent
Google ha pubblicato un corso gratuito dedicato agli AI Agent in collaborazione con Kaggle.
Il programma è strutturato in 5 giorni, e guida sviluppatori e tecnici attraverso le basi e le applicazioni pratiche degli agenti AI, fino alla messa in produzione.
Ogni modulo unisce teoria, esercitazioni e tool reali
- Introduzione agli agenti e architetture agentiche. Cosa distingue un agente AI da un classico LLM e come progettare sistemi autonomi.
- Utilizzo di strumenti esterni tramite il Model Context Protocol (MCP). Connettere gli agenti a funzioni esterne e API per ampliare le loro capacità operative.
- Gestione di contesto e memoria per esperienze personalizzate. Costruire agenti in grado di ricordare interazioni e mantenere coerenza nei dialoghi.
- Valutazione e osservabilità per garantire affidabilità e qualità. Monitorare, tracciare e migliorare il comportamento degli agenti con log, metriche e feedback.
- Deployment in produzione su Google Cloud con protocollo Agent2Agent (A2A). Portare i tuoi agenti in ambienti reali e falli collaborare in sistemi multi-agente distribuiti.
Un percorso interessante per passare da prototipi di applicazioni basate su LLM a sistemi agentici scalabili e realmente operativi.
Agentic Vision: Gemini 3 Flash
Agentic Vision è la nuova capacità introdotta in Gemini 3 Flash che cambia radicalmente il modo in cui l’AI interpreta le immagini.
L'ho provato su AI Studio, testando l'individuazione e l'annotazione di elementi, e sulla trasformazione di tabelle dense in diagrammi. La precisione è notevole.
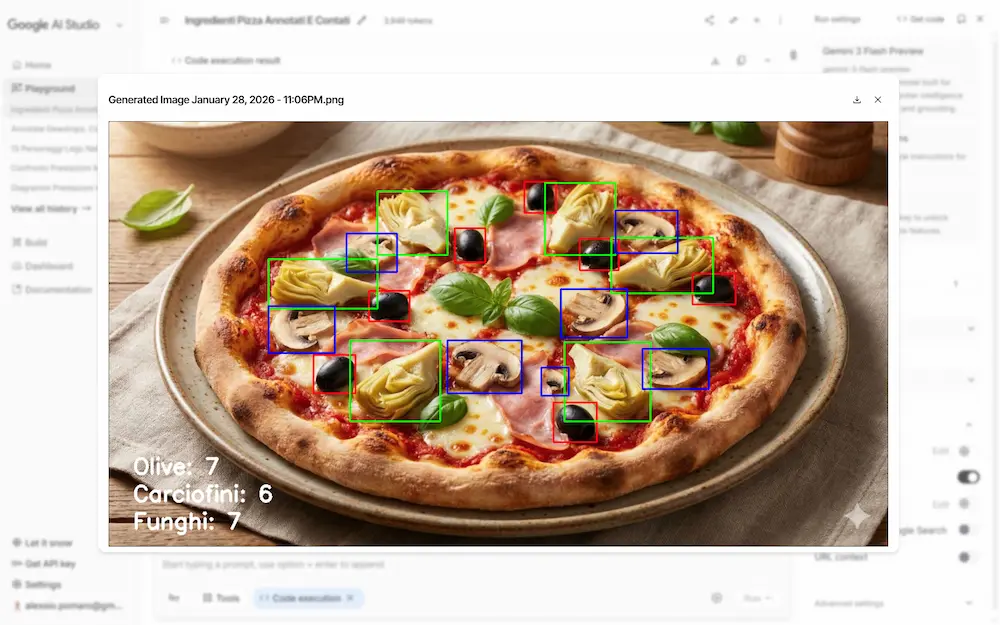
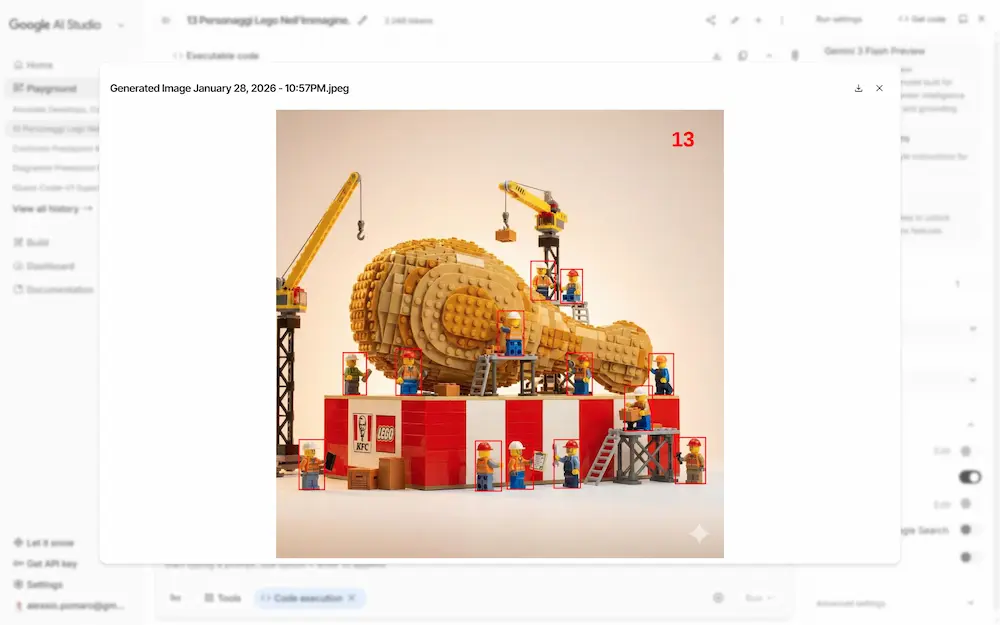
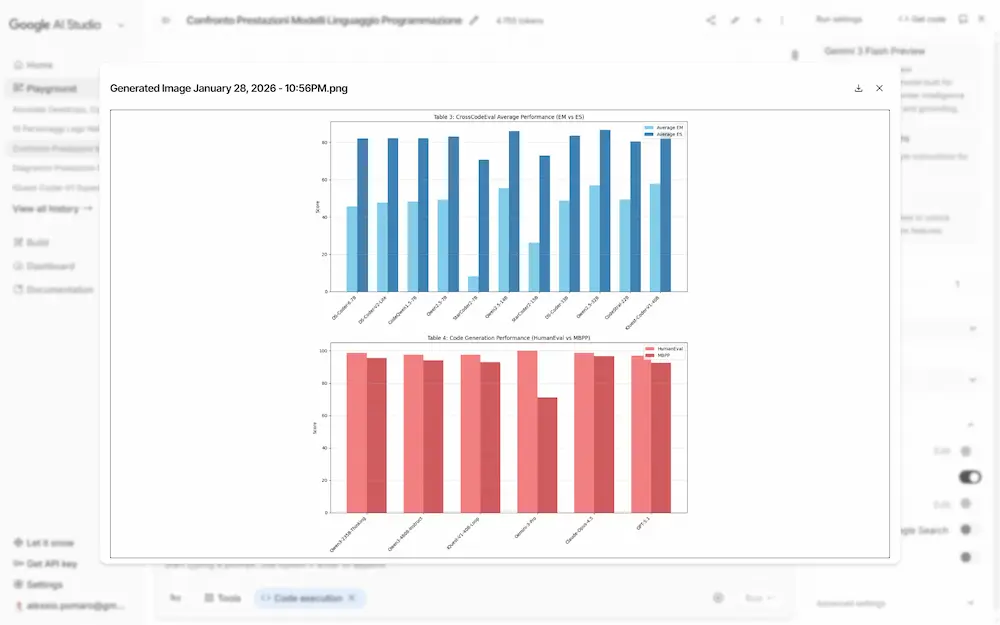
Agentic Vision su Gemini 3 Flash: un test
La comprensione visiva non è più un’analisi statica, ma un processo attivo e iterativo, simile a un’indagine.
Grazie alla combinazione di ragionamento visivo ed esecuzione di codice, il modello può pianificare azioni, zoomare sui dettagli, ritagliare immagini, annotarle ed eseguire calcoli passo dopo passo, basando le risposte su evidenze visive concrete. Questo approccio riduce errori e allucinazioni, migliorando la qualità dei risultati fino al 5–10% sui principali benchmark di visione.
Il funzionamento si basa su un ciclo Think - Act - Observe: il modello analizza la richiesta, agisce sull’immagine tramite codice Python e osserva il risultato aggiornato prima di rispondere. In pratica, l’AI “lavora” sull’immagine invece di limitarsi a descriverla.
Le applicazioni sono già concrete: ispezione di dettagli complessi in immagini ad alta risoluzione, annotazioni visive per supportare il ragionamento, lettura di tabelle dense, calcoli matematici e generazione di grafici verificabili. In ambito professionale, questo significa maggiore affidabilità in scenari come la validazione di progetti, l’analisi tecnica e la visualizzazione dei dati.
Agentic Vision è già disponibile tramite Gemini API in Google AI Studio e Vertex AI, e sarà presto nell’app Gemini, segnando un passo importante verso modelli visivi sempre più autonomi, precisi e orientati all’evidenza.
MCP Apps: di cosa si tratta?
MCP Apps è ora un’estensione ufficiale del Model Context Protocol e introduce un cambiamento importante: gli strumenti MCP possono restituire interfacce utente interattive direttamente, non solo testo.
Questo si sposa perfettamente con il concetto che OpenAI ha mostrato attraverso le sue app e in AgentKit. E infatti supporterà MCP Apps a breve.
Si tratta di un ulteriore passo verso la standardizzazione delle interfacce che i brand potranno usare per esporre funzionalità (oltre a feed di dati) da portare nelle piattaforme digitali.
Dashboard, moduli, visualizzazioni, workflow multi-step e monitoraggi in tempo reale diventano parte naturale dell’esperienza dell’utente.
MCP Apps: di cosa si tratta?
L’idea è colmare il divario tra ciò che i tool sanno fare e ciò che le persone vogliono realmente vedere e manipolare. Invece di richiedere continui prompt per filtrare dati, esplorare record o aggiornare viste, l’interazione avviene tramite UI ricche, persistenti e aggiornate in tempo reale, con il modello che rimane sempre nel loop.
Dal punto di vista tecnico, MCP Apps si basa su tool che dichiarano risorse UI e su componenti frontend eseguiti in iframe sandboxed, con comunicazione bidirezionale via JSON-RPC. Gli sviluppatori possono usare l’SDK @modelcontextprotocol/ext-apps per creare esperienze interattive che funzionano allo stesso modo su più client, senza codice specifico per ciascuno.
La sicurezza è integrata nel design: isolamento tramite sandbox, messaggi verificabili, template dichiarati e consenso dell’utente per le azioni sensibili. Oltre a ChatGPT, anche Claude, Goose e Visual Studio Code integreranno MCP Apps, segnando un passo concreto verso agenti che comprendono interfacce, contesto e azioni in un’unica esperienza coerente.
AlphaGenome di Google
AlphaGenome è il nuovo modello di AI di Google DeepMind pensato per migliorare la comprensione del genoma umano. È in grado di analizzare sequenze di DNA lunghissime, fino a un milione di basi, e prevedere con grande precisione come singole varianti genetiche influenzino i processi che regolano l’attività dei geni.
AlphaGenome di Google
Il modello unifica in un’unica architettura la predizione di migliaia di proprietà molecolari: dall’espressione genica allo splicing dell’RNA, dall’accessibilità del DNA alle interazioni tridimensionali tra regioni genomiche, su molti tipi di cellule e tessuti. Un aspetto chiave è la capacità di valutare rapidamente l’impatto delle mutazioni, confrontando sequenze normali e mutate.
AlphaGenome rappresenta un passo avanti soprattutto nello studio delle regioni non codificanti del genoma, che costituiscono circa il 98% del DNA e giocano un ruolo cruciale nella regolazione genica e nelle malattie. Rispetto ai modelli precedenti, riesce a combinare contesto a lungo raggio e risoluzione a livello della singola base, superando limiti storici della genomica computazionale.
Le potenziali applicazioni includono una migliore interpretazione delle varianti associate a malattie rare e tumori, il supporto alla biologia sintetica e l’accelerazione della ricerca di base sul funzionamento del genoma.
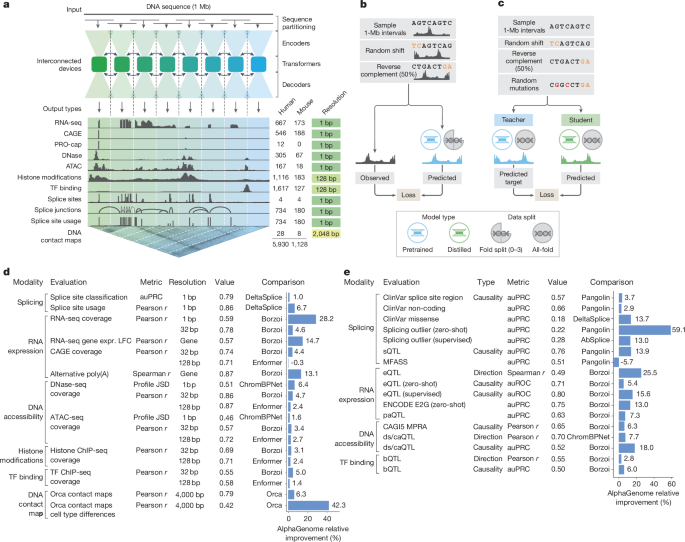
Il modello è disponibile tramite API per uso di ricerca non commerciale ed è stato pubblicato su Nature, segnando un importante traguardo per l’uso dell’IA nello studio della biologia.
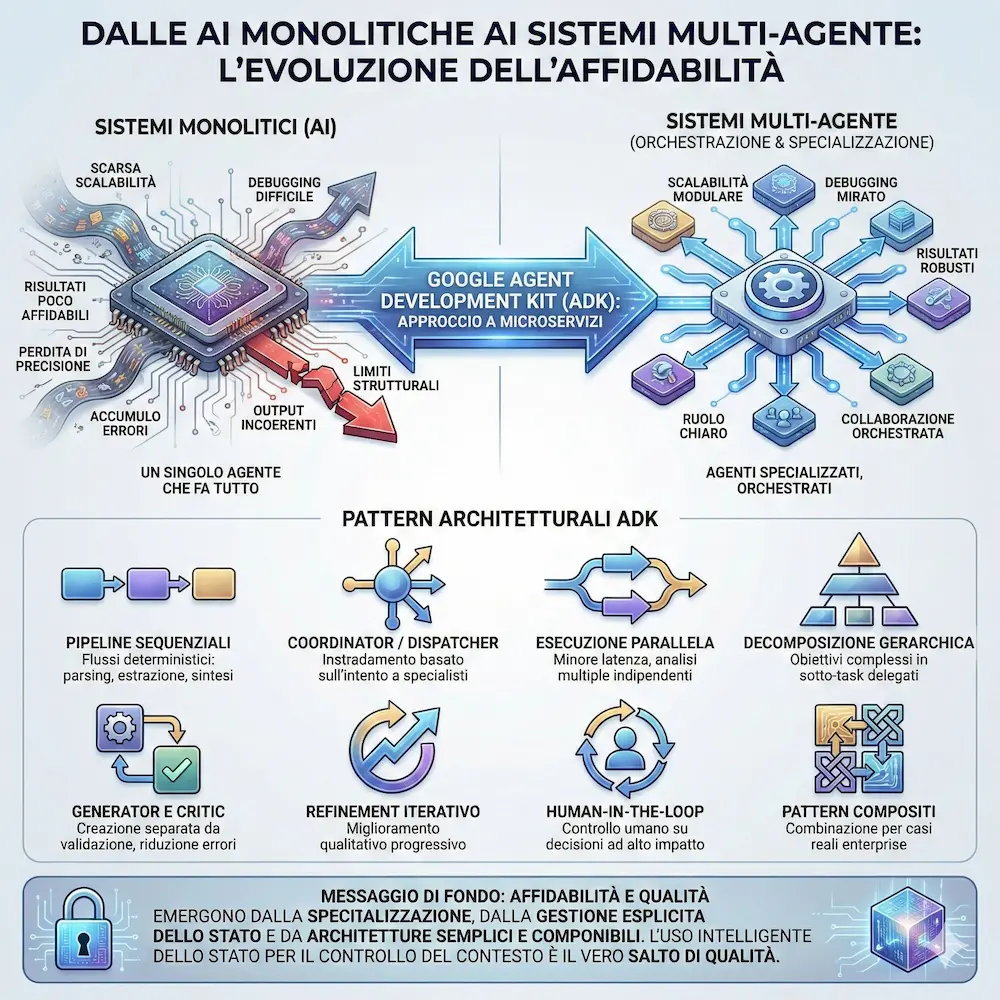
Sistemi multi-agente = microservizi
Le applicazioni AI complesse soffrono degli stessi limiti dei sistemi monolitici: scarsa scalabilità, debugging difficile e risultati poco affidabili.
Un singolo agente che fa tutto tende a perdere precisione, accumulare errori e generare output incoerenti.
I sistemi multi-agente affrontano il problema con un approccio simile ai microservizi: agenti specializzati, ciascuno con un ruolo chiaro, che collaborano in modo orchestrato. Con l’Agent Development Kit (ADK), Google propone una serie di pattern architetturali pensati per costruire agenti più robusti, modulari e manutenibili.
Tra i principali pattern..
- Pipeline sequenziali, ideali per flussi deterministici come parsing, estrazione e sintesi dei dati.
- Coordinator / Dispatcher, dove un agente centrale instrada le richieste verso specialisti in base all’intento.
- Esecuzione parallela, utile per ridurre la latenza e ottenere analisi multiple indipendenti.
- Decomposizione gerarchica, che spezza obiettivi complessi in sotto-task delegati.
- Generator e Critic, per separare creazione e validazione e ridurre errori formali.
- Refinement iterativo, focalizzato sul miglioramento qualitativo progressivo.
- Human-in-the-loop, che mantiene il controllo umano sulle decisioni ad alto impatto.
- Pattern compositi, combinazione dei precedenti per casi reali enterprise
Il messaggio di fondo è chiaro: affidabilità e qualità emergono dalla specializzazione, da una gestione esplicita dello stato e da architetture semplici che crescono per composizione. I sistemi multi-agente non sono un esercizio teorico, ma una base concreta per portare l’AI in produzione in modo sostenibile.
Per me, il salto di qualità è stato proprio l'uso intelligente dello stato, che permette il controllo completo del contesto, evitando di basare l'esecuzione sulla conversation history.
Aggiungere più agenti migliora davvero le performance?
Non sempre. Un nuovo studio di Google Research mette in discussione l’idea diffusa che “più agenti = risultati migliori”.
Analizzando 180 configurazioni di sistemi agentici, la ricerca mostra che i sistemi multi-agente funzionano bene solo quando il tipo di task è allineato all’architettura.
- Nei compiti parallelizzabili (come l’analisi finanziaria), la collaborazione tra agenti porta miglioramenti significativi: con un coordinamento centralizzato le prestazioni aumentano anche di oltre l’80%. Qui la scomposizione del problema è la chiave.
- Nei compiti sequenziali, invece, accade l’opposto. Pianificazione passo-passo e ragionamento lineare soffrono il costo del coordinamento: comunicazione, sincronizzazione e perdita di contesto frammentano il processo cognitivo, con cali di performance fino al 70%.
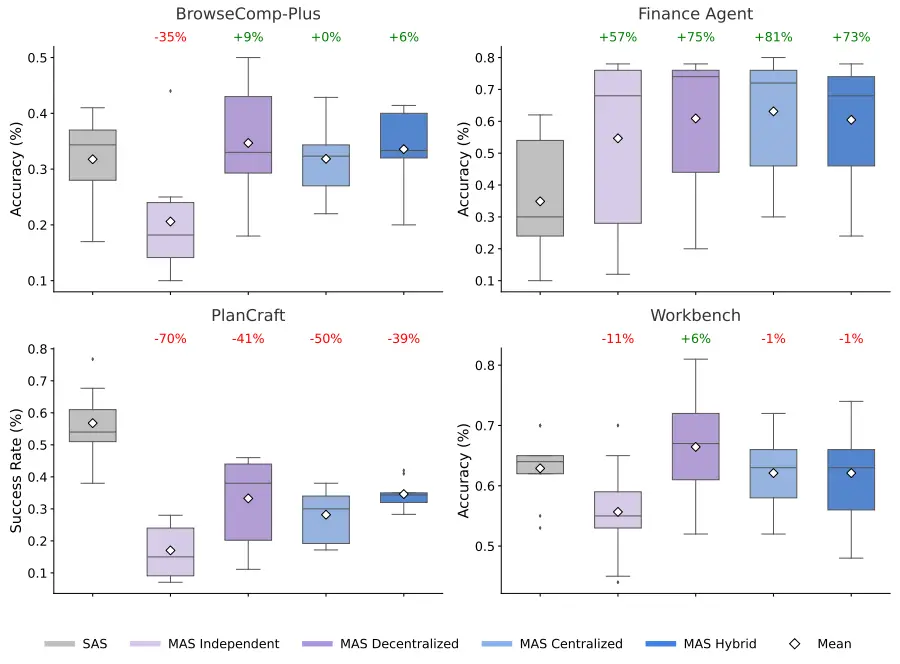
Un altro aspetto critico è l’uso degli strumenti. All’aumentare dei tool disponibili, il “costo di coordinamento” tra agenti cresce rapidamente, rendendo in molti casi un singolo agente più efficace di un team.
Dal punto di vista dell’affidabilità,
l’architettura conta quanto il modello.
Sistemi multi-agente senza coordinamento amplificano gli errori in modo drastico, mentre un orchestratore centrale riduce la propagazione degli errori e migliora la stabilità complessiva.
La conclusione è chiara: non esiste una soluzione universale. Scalare un sistema agentico non significa aggiungere agenti, ma progettare l’architettura giusta in base alla natura del compito. Meno euristiche, più principi misurabili.
DeepSeek: mHC (Manifold-Constrained Hyper-Connections)
Tutto il mondo sta parlando del nuovo paper di DeepSeek… perché? Lo vediamo in modo semplice.
DeepSeek ha proposto un miglioramento architetturale per i Transformer chiamato mHC (Manifold-Constrained Hyper-Connections).
In un Transformer classico ogni blocco ha un percorso principale (self-attention o feed-forward) e una residual connection che somma l’input all’output. Questa scorciatoia è uno dei motivi del successo dei Transformer: permette all’informazione di attraversare molti strati senza degradarsi.
Le Hyper-Connections (HC) modificano proprio la residual: invece di un solo flusso, il modello mantiene più flussi paralleli. A ogni strato, piccole matrici apprese decidono come mescolarli prima e dopo il blocco.

Se il Transformer standard ha una sola “corsia” residua, le HC ne introducono n in parallelo. Ogni strato può instradare l’informazione tra le corsie, rendendo il flusso molto più flessibile.
Il problema: se questi mescolamenti sono completamente liberi, impilando molti strati il segnale può esplodere o scomparire, causando instabilità nel training dei modelli grandi.
Qui entra in gioco mHC: mantiene le Hyper-Connections ma impone un vincolo chiave. Ogni mescolamento deve comportarsi come una media “sicura”, senza amplificare o attenuare il segnale in modo incontrollato.
Risultato: training stabile fino a 27 miliardi di parametri e performance superiori sia al baseline sia alle HC non vincolate. Dove HC può amplificare il residuo fino a circa 3000 volte, mHC lo mantiene intorno a 1,6 volte.
Non è più dati o più parametri: è una modifica strutturale che rende il flusso dell’informazione più disciplinato man mano che i modelli scalano.
Personal Intelligence di Google
Google ha introdotto Personal Intelligence nell’app Gemini, una funzione che consente di collegare in modo sicuro Gmail, Google Foto, YouTube e Search per offrire un’assistenza AI più contestuale e personalizzata.
Personal Intelligence di Google
L'aspetto più interessante? Verrà estesa anche ad AI Mode.
Una volta attivata, Gemini è in grado di incrociare dati da diverse fonti per rispondere a richieste complesse: recupera dettagli da email, trova informazioni all’interno delle foto, suggerisce contenuti e opzioni basandosi sulle abitudini e preferenze dell’utente.
Ad esempio, può suggerire pneumatici adatti all’auto analizzando email e foto di viaggi precedenti, recuperare il numero di targa da un’immagine in Google Foto o identificare il modello del veicolo da una conversazione email, tutto in tempo reale. È utile anche per organizzare viaggi, proporre libri o attività in linea con gli interessi personali.
La funzione è disattivata per impostazione predefinita: l’utente decide se e quali app collegare e può modificare le impostazioni in qualsiasi momento. I dati personali non vengono utilizzati per addestrare il modello AI; vengono solo consultati per fornire risposte mirate, con trasparenza sulla loro origine.
Universal Commerce Protocol (UCP)
Google, con Universal Commerce Protocol (UCP), assesta un ulteriore colpo a OpenAI facendo valere, ancora una volta, il suo ecosistema.
Si tratta di un nuovo standard aperto progettato per abilitare il commercio agentico su larga scala. UCP consente agli agenti AI di interagire con retailer, sistemi di pagamento e piattaforme in modo unificato, semplificando le integrazioni e garantendo esperienze d'acquisto fluide e personalizzate.
Universal Commerce Protocol (UCP)
È co-sviluppato con Shopify, Etsy, Wayfair, Target e Walmart, è supportato da oltre 20 aziende dell’ecosistema (tra cui Visa, Mastercard, Stripe, The Home Depot, Zalando), e copre l’intero percorso di acquisto: dalla scoperta al pagamento, fino al supporto post-vendita.
UCP definisce schemi standard per prodotti, offerte, carrelli, checkout e post-acquisto. È compatibile con protocolli esistenti come Agent2Agent, Agent Payments Protocol e Model Context Protocol (MCP). Gli agenti possono così richiedere offerte, creare carrelli e completare acquisti tramite Google Pay, senza redirezioni e mantenendo il retailer come merchant of record.
Il protocollo sarà attivo sui sistemi AI di Google, inclusi AI Mode in Search e l'app Gemini, permettendo il checkout diretto da parte degli utenti durante la navigazione. Funzionalità come suggerimenti di prodotti correlati, premi fedeltà e offerte personalizzate saranno integrate in questa nuova esperienza d’acquisto.
A complemento del protocollo, Google introduce anche nuovi strumenti.
- Business Agent: un assistente AI brandizzato attivabile su Google Search, che consente ai clienti di conversare direttamente con i brand per ricevere supporto e consigli in tempo reale.
- Nuovi attributi nel Merchant Center: per migliorare la visibilità nei risultati conversazionali, con dati come accessori compatibili, alternative suggerite e risposte frequenti.
- Direct Offers in AI Mode: annunci con sconti esclusivi mostrati in tempo reale a utenti ad alta intenzione d’acquisto.
Queste iniziative rispondono a un’accelerazione significativa nell’adozione dell’AI nel retail: i retailer oggi elaborano oltre 90 trilioni di token al mese su Vertex AI, una crescita di oltre 11 volte in un solo anno.
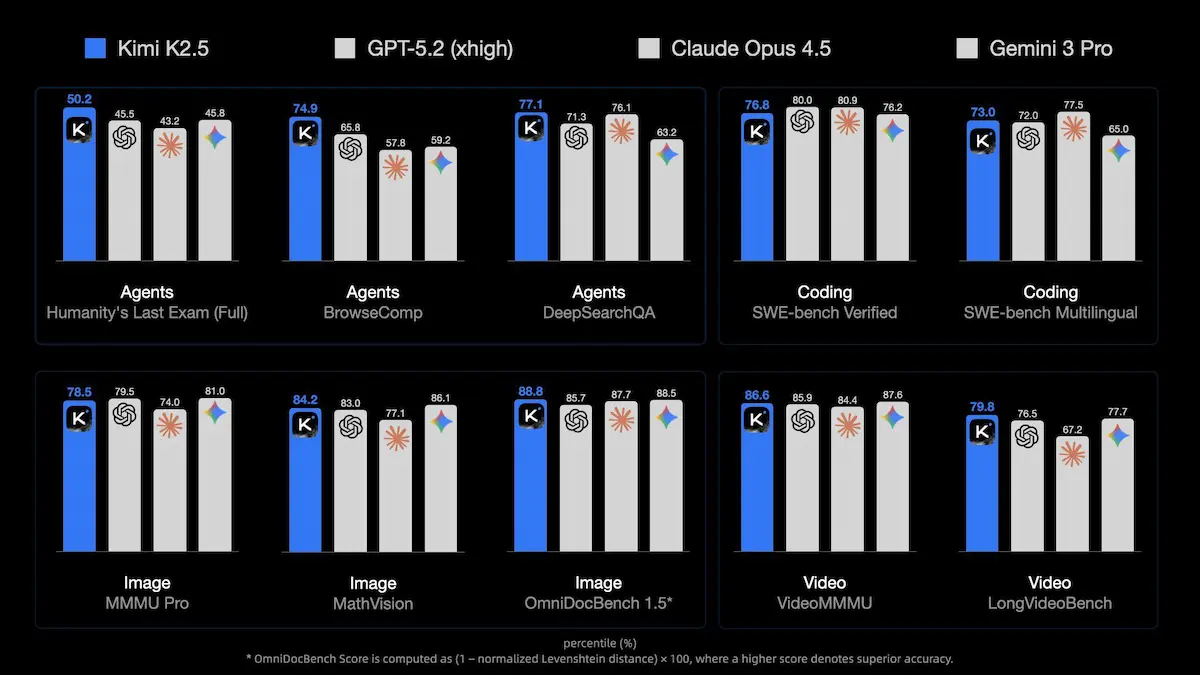
Kimi K2.5
Kimi K2.5 è il nuovo modello open-source di Moonshot AI e rappresenta un’evoluzione concreta dell’AI agentica e multimodale. Addestrato su circa 15 trilioni di token tra testo e contenuti visivi, nasce come modello nativamente multimodale, con capacità avanzate su immagini, video e codice.
Uno dei suoi punti di forza è il coding con visione: Kimi K2.5 è in grado di generare interfacce front-end complete, animazioni e layout interattivi partendo da descrizioni testuali, immagini o persino video. Può ricostruire siti web, fare debugging visivo e risolvere problemi algoritmici analizzando direttamente input grafici.
La novità più rilevante è l’introduzione dell’Agent Swarm, un paradigma che supera il modello a singolo agente.
Kimi K2.5 può creare e coordinare autonomamente fino a 100 sub-agenti che lavorano in parallelo, eseguendo centinaia di operazioni e chiamate a strumenti in modo orchestrato. Questo approccio consente una riduzione del tempo di esecuzione fino a 4,5 volte rispetto a flussi sequenziali tradizionali.
L’addestramento avviene tramite Parallel-Agent Reinforcement Learning, una tecnica che incentiva il parallelismo reale e misura le prestazioni in termini di latenza effettiva, non solo di numero di passaggi. Il risultato è una maggiore efficienza su task complessi e di lunga durata.
Kimi K2.5 porta l’intelligenza agentica anche nel lavoro professionale quotidiano: può creare e modificare documenti, fogli di calcolo, PDF e presentazioni, costruire modelli finanziari avanzati e gestire workflow articolati end-to-end. Nei benchmark interni mostra miglioramenti significativi rispetto alla versione precedente, soprattutto sulla qualità dell’output finale.
Sul fronte delle prestazioni, il modello si dimostra competitivo nei benchmark di ragionamento, visione, coding, long context e agentic search, confrontandosi con modelli proprietari di fascia alta pur rimanendo open-source.
Con Kimi Code, l’esperienza viene estesa agli sviluppatori: integrazione con terminale e IDE, supporto a input visivi e capacità di iterazione autonoma sul codice.
Nel complesso, Kimi K2.5 segna un passo concreto verso un’AI più autonoma, scalabile e orientata a casi d’uso reali.
Un utilizzo di Codex di OpenAI che mi ha impressionato
Ho fatto alcuni esperimenti su Colab per testare alcune nuove features sperimentali, che si sono dimostrate molto interessanti.
Per portarle in produzione, ho creato un nuovo branch di un progetto del nostro team su Github, l'ho connesso a Codex e ho creato un prompt descrivendo come integrare le features.
Dopo 30 minuti di reasoning, il sistema ha prodotto il "diff" con le modifiche da apportare a tutti i file di progetto per ottenere l'integrazione completa (non si trattava di un'integrazione banale).
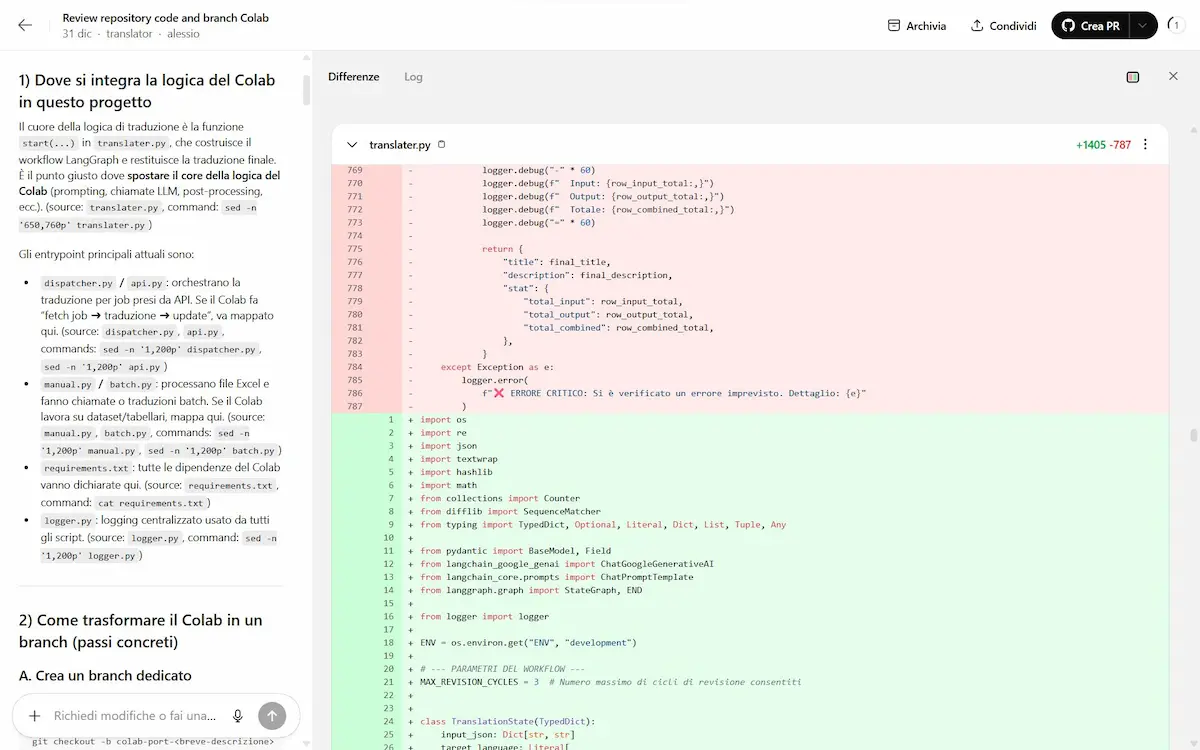
L'ho testato in locale e apportato alcune rifiniture e correzioni di flusso (sintatticamente era già perfetto), per poi eseguire il push del branch del progetto aggiornato.
Di certo, la condizione fondamentale, come sempre, è conoscere esattamente il progetto.. ma la riduzione di effort operativo è stata notevole (a dire la verità, molto più che notevole).
L'esempio, inoltre, fa intuire come si sposta il focus dallo sviluppo diretto verso la creazione di istruzioni perfette per il modello di AI come base di partenza. Il prompt che ho scritto è preciso e dettagliato, e ne ho usati altri di rifinitura.
Cos'è MCP-cli?
MCP-cli è un sistema che consente agli agenti AI di interagire in modo efficiente con server MCP (Model Context Protocol), riducendo drasticamente il consumo di token grazie alla scoperta dinamica dei tool.
Invece di caricare in anticipo tutte le definizioni degli strumenti (con un alto costo in termini di token), MCP-cli consente agli agenti di accedere solo alle informazioni necessarie, nel momento in cui servono. Questo approccio consente una riduzione importante del contesto usato, migliorando le prestazioni e riducendo i costi API.
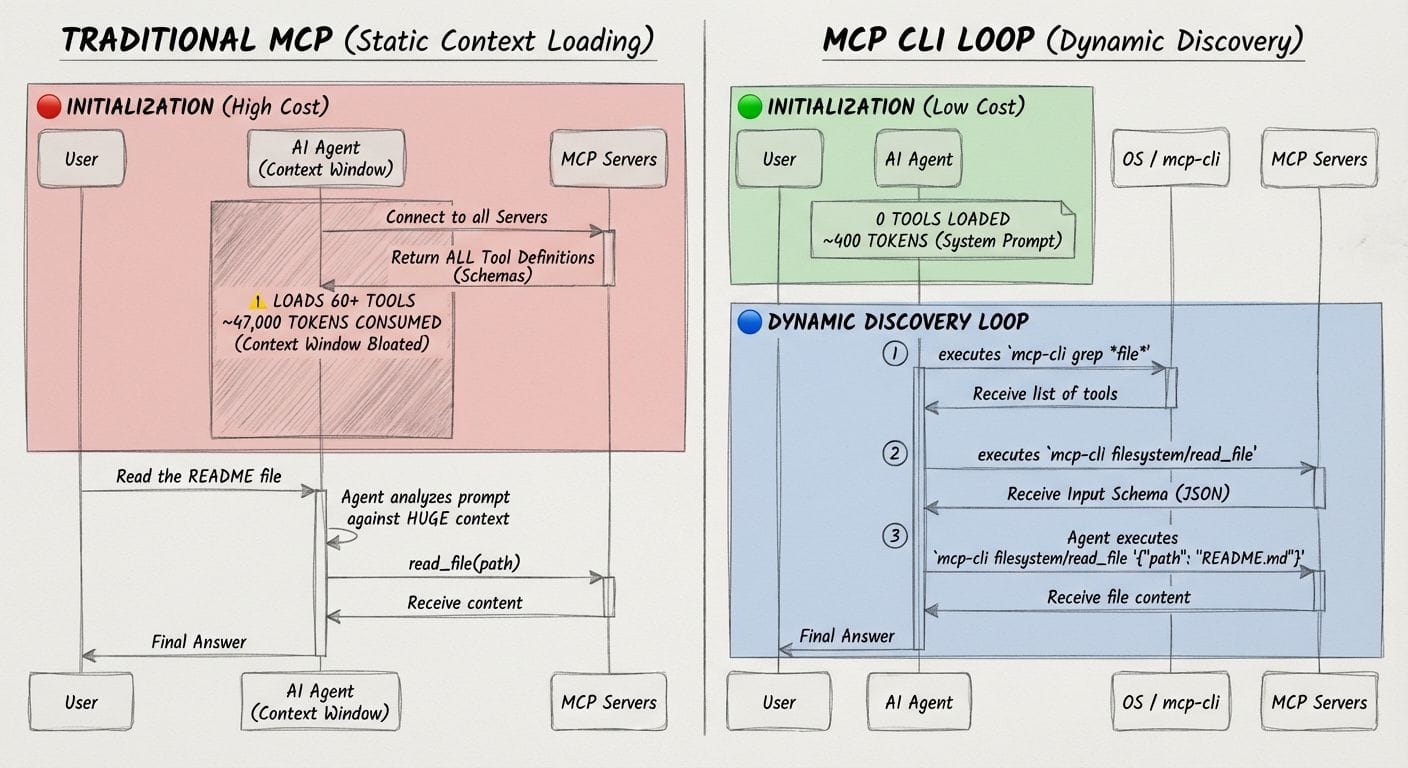
Funziona sia con server locali che remoti. Include supporto per ricerche con pattern, esecuzione di comandi complessi, output strutturati in JSON e integrazione nativa con agenti AI e skill personalizzati.
Uno strumento interessante a supporto del Context Engineering.
Runway Gen 4.5 Image-To-Video
Runway ha presentato la modalità Image-To-Video per la versione Gen 4.5: quello che (loro stessi) definiscono il miglior modello video al mondo.
Runway Gen 4.5 Image-To-Video
È progettato per creare storie più lunghe, con controlli precisi delle telecamere.
E ovviamente, con una coerenza perfetta. Nel video si vedono alcuni esempi di output.
La qualità, ormai è data per scontata. Sono la capacità di pilotare il modello e la coerenza visiva che fanno la differenza.
Engram di DeepSeek
DeepSeek continua a produrre paper in cui vengono condivisi ragionamenti di ottimizzazione delle performance "semplici", ma efficaci.
L’ultimo lavoro introduce un’idea molto intuitiva: i modelli linguistici oggi spendono molta potenza di calcolo per ricostruire informazioni statiche che potrebbero semplicemente ricordare. Nomi propri, espressioni frequenti, pattern linguistici comuni vengono ogni volta “rianalizzati” strato dopo strato, consumando capacità che potrebbe essere usata per il ragionamento.
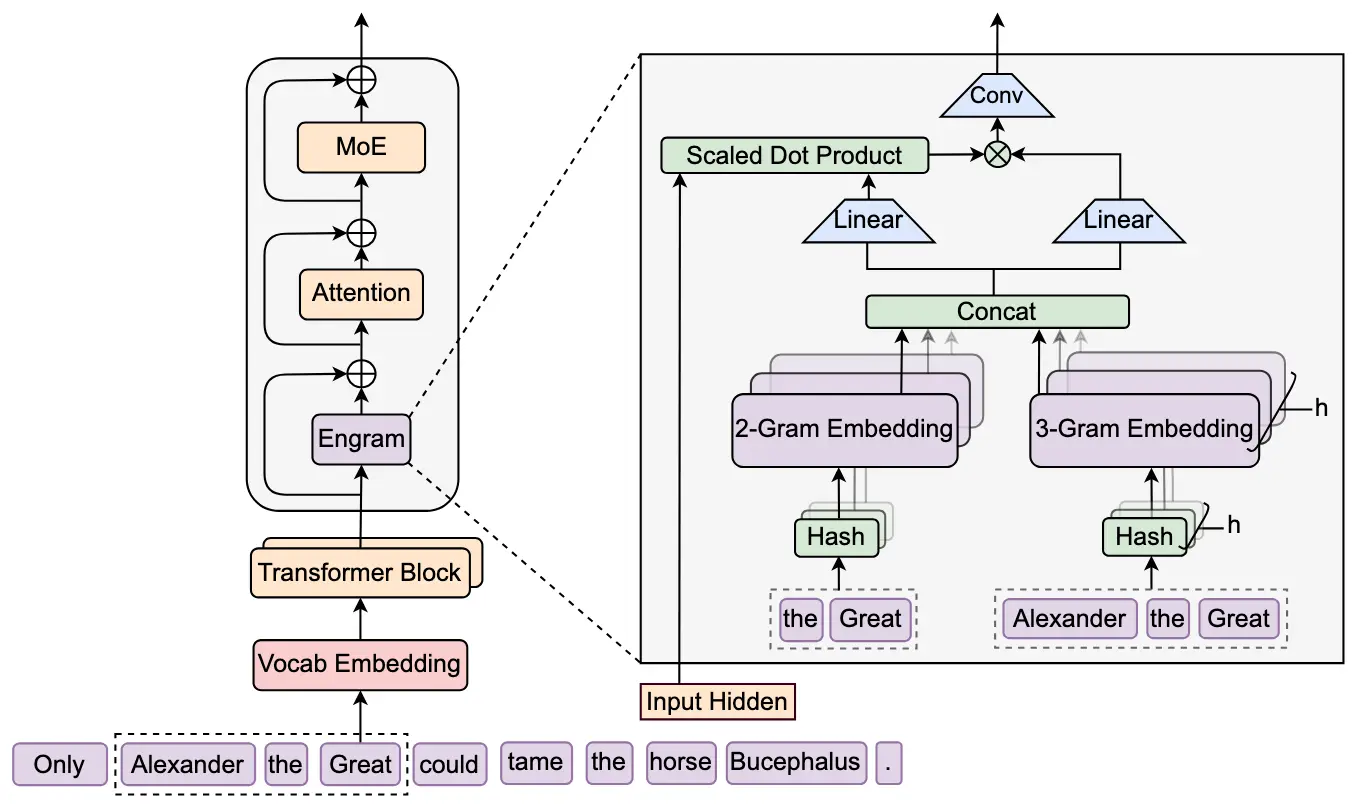
Engram aggiunge al Transformer una memoria esterna a lookup immediato, basata su N-grammi. Quando il modello riconosce sequenze di parole frequenti, recupera direttamente un vettore di memoria invece di ricostruire quel significato via attenzione e FFN. Il risultato è che gli strati iniziali vengono alleggeriti dal lavoro di riconoscimento locale, lasciando più profondità effettiva disponibile per il ragionamento.
L’aspetto interessante è che questa memoria è sparsa e scalabile: si possono aggiungere miliardi di parametri di memoria senza aumentare i FLOPs per token. In combinazione con architetture Mixture-of-Experts, nasce una doppia sparsità:
- MoE = sparsità di calcolo
- Engram = sparsità di memoria
I risultati mostrano miglioramenti non solo su task di conoscenza, ma soprattutto su ragionamento, matematica, codice e long-context retrieval, a parità di costo computazionale rispetto ai MoE standard.
Ancora una volta, niente magia esotica: una buona intuizione architetturale, ben ingegnerizzata, che sfrutta meglio dove servono memoria e dove servono calcolo.
Come funziona una rete neurale artificiale?
Quella che si vede nel video è una rappresentazione di ciò che accade "sotto il cofano" quando un algoritmo cerca di interpretare la scrittura umana.
Tutto inizia con una griglia di pixel che funge da occhio digitale. Ogni volta che disegno un tratto, si attivano dei neuroni di input che trasmettono segnali attraverso una fitta rete di connessioni.
Come funziona una rete neurale artificiale?
Le linee che si vedono rappresentano i "pesi" sinaptici. Le linee verdi trasportano segnali positivi che rafforzano un'ipotesi, mentre quelle rosse agiscono come inibitori. È un complesso sistema di filtraggio a strati che cerca di estrarre un significato logico da un insieme di punti disordinati.
Il passaggio cruciale avviene quando disegno un "7" volontariamente ambiguo, così dritto da poter essere scambiato per un "1". Qui si osserva la differenza tra una rete "giovane" e una "esperta".
Quando riduco i dati di training al minimo, il sistema è incerto. Le probabilità oscillano perché la rete non ha visto abbastanza esempi per capire se quel piccolo accenno orizzontale in cima sia rilevante o meno. È un'indecisione puramente statistica.
Tuttavia, nel momento in cui aumento il training set al massimo, simulando l'apprendimento su milioni di immagini, la percezione cambia drasticamente. La rete ora possiede l'"esperienza" necessaria per dare il giusto peso a quel dettaglio: l'incertezza svanisce e il riconoscimento del "7" diventa assoluto, al 100%.
Una volta stabilito questo livello di precisione, anche un numero complesso come il "3", disegnato successivamente, viene identificato istantaneamente attivando i percorsi neurali corretti.
Questa visualizzazione dimostra che l'intelligenza artificiale non è magia, ma una struttura matematica che affina la propria precisione attraverso la quantità e la qualità dei dati che ha "visto" in precedenza, imparando a distinguere le sfumature lì dove l'occhio inesperto vedrebbe solo ambiguità.
Un aggiornamento per Veo 3.1
Veo 3.1 si evolve, con un nuovo aggiornamento che amplia le possibilità creative nella generazione di video partendo da immagini di riferimento.
Nel video, una mia sperimentazione con prompt strutturati + diverse immagini di riferimento (modella e outfit).
Veo 3.1 aggiornato + prompt strutturati
Per i prompt, ho usato "Veo 3 Prompt Assistant"

Il modello ora consente di produrre video verticali in formato 9:16, ideali per piattaforme mobile-first come YouTube Shorts, senza sacrificare qualità o composizione. Grazie all’upscaling fino a 1080p e 4K, è possibile ottenere risultati nitidi e dettagliati, adatti sia alla condivisione veloce che a produzioni professionali.
Tra le novità principali, spiccano una maggiore coerenza visiva tra personaggi, sfondi e oggetti, permettendo di mantenere l’identità dei protagonisti anche su scene diverse, e un miglior controllo sugli elementi grafici, utili per narrazioni fluide e strutturate.
I contenuti generati sono inoltre dotati di watermark digitale SynthID per garantirne la tracciabilità e la trasparenza.
Nano Banana Pro + Veo 3 per la scomposizione piatti
Gemini 3 Pro Image (Nano Banana Pro) + Veo 3 per creare animazioni per la scomposizione dei piatti.
Con un prompt dettagliato per Nano Banana ho creato le immagini della scomposizione. Con un altro prompt per Veo 3, le istruzioni per l'animazione.
Con questo metodo si possono creare nuove esperienze per l'esplorazione dei prodotti.
Nano Banana Pro + Veo 3 per la scomposizione piatti
Ho creato il prompt per l'immagine usando "Image Prompt Assistant":

Il prompt per il video, invece, con "Veo 3 Prompt Assistant":

WonderZoom di Stanford AI Lab
Stanford AI Lab ha rilasciato WonderZoom, un nuovo sistema che permette di generare mondi 3D multi-scala partendo da una singola immagine.
Non si limita a ricostruire una scena: consente di esplorarla in 3D, zoomare progressivamente in qualsiasi regione e generare nuovi dettagli coerenti a ogni livello di ingrandimento.
WonderZoom di Stanford AI Lab
A differenza dei modelli 3D esistenti, che operano a una sola scala, WonderZoom crea contenuti che vanno dal panorama fino ai dettagli microscopici.
Zoomando su una finestra può apparire un uccello, poi l’occhio dell’uccello, poi la trama delle piume: dettagli che non erano presenti nell’immagine originale ma vengono sintetizzati in modo coerente.
Il cuore del sistema è una nuova rappresentazione 3D chiamata scale-adaptive Gaussian surfels, che permette di aggiungere nuovi livelli di dettaglio senza ri-ottimizzare la scena già creata, mantenendo il rendering in tempo reale. Un secondo modulo, il progressive detail synthesizer, genera immagini, profondità e viste ausiliarie guidate da prompt testuali, assicurando coerenza geometrica e semantica tra le scale.
Nei test comparativi, WonderZoom supera i migliori modelli 3D e video generativi in qualità visiva, stabilità durante lo zoom e allineamento ai prompt. Il risultato è un nuovo paradigma: lo zoom non rivela dettagli preesistenti, li crea dinamicamente, aprendo la strada a mondi virtuali esplorabili all’infinito partendo da una sola immagine.
D4RT di Google
Ricostruire il mondo 3D da un video è difficile. Ricostruire scene 3D dove "tutto si muove", ancora di più.
D4RT è un nuovo modello di DeepMind che affronta questo problema in modo sorprendentemente semplice: invece di ricostruire tutta la scena frame per frame, codifica l’intero video una sola volta e poi risponde a “query” puntuali del tipo:
dove si trova nel 3D questo pixel, in questo momento, visto da questa camera?
Il progetto D4RT di Google
Da questa singola interfaccia emergono depth map, point cloud complete, traiettorie 3D dei punti nel tempo e parametri delle camere. Tutto in un unico modello feed-forward, senza pipeline separate, senza ottimizzazioni iterative a test-time, senza decoder specializzati per ogni compito.
Il decoder lavora su punti indipendenti, rendendo l’inferenza altamente parallela ed estremamente veloce. Questo permette di tracciare densamente tutti i pixel di un video in 3D, incluse parti dinamiche della scena, superando i limiti dei metodi precedenti che o ignoravano il movimento o lasciavano buchi nelle ricostruzioni.
Nei benchmark, D4RT risulta più accurato su depth, tracking 3D e stima della posa della camera, ma soprattutto molto più efficiente: fino a centinaia di volte più veloce nel produrre traiettorie 3D dense.
Un passo importante verso modelli che comprendono spazio e tempo insieme, costruendo rappresentazioni 4D coerenti del mondo direttamente dai video.
ChatGPT Salute
ChatGPT Salute introduce un cambiamento importante nel modo in cui i sistemi digitali possono entrare in relazione con la salute delle persone.
Non si tratta solo di risposte a domande isolate, ma della possibilità (su consenso esplicito) di integrare cartelle cliniche, dati da app di benessere e informazioni contestuali di vita, creando una visione più continua e coerente dello stato di salute nel tempo.
Questo comporta un aumento significativo della profondità e sensibilità dei dati coinvolti. Il sistema non conosce semplicemente "un valore" o "un sintomo", ma può comprendere andamenti, abitudini, cambiamenti e fragilità. I dati sanitari sono tra i più delicati in assoluto: incidono su identità, scelte di vita, lavoro, assicurazioni e percezione sociale. La loro gestione alza inevitabilmente la posta in gioco.
Dal punto di vista tecnico e progettuale, la scelta di creare uno spazio separato, con memorie isolate, crittografia dedicata e l’esclusione dall’addestramento dei modelli di base riduce il rischio sistemico rispetto a un assistente generalista. È un approccio più prudente rispetto a molte soluzioni digitali che già oggi raccolgono dati sanitari in modo meno trasparente.
Resta però un elemento strutturale: la centralizzazione. Riunire informazioni prima frammentate aumenta la comodità e il controllo per l’utente, ma concentra anche fiducia e responsabilità in un unico ecosistema. A questo si aggiunge un aspetto meno visibile ma cruciale: quando un sistema si presenta come spazio di cura, le persone tendono a condividere di più, con maggiore sincerità, affidando non solo dati ma parti della propria narrazione personale.
Il bilanciamento sta qui. Da un lato, strumenti come questo possono migliorare l’alfabetizzazione sanitaria, rendere i pazienti più consapevoli e favorire un dialogo migliore con i medici. Dall’altro, richiedono una fiducia continua, nel tempo, non solo nella tecnologia ma nelle scelte di governance, nelle policy future e nella reale reversibilità del controllo sui dati.
Non è una questione di "quanto il sistema sa", ma di come, perché e per quanto tempo siamo disposti ad affidargli ciò che sappiamo di noi.
L'advertising su ChatGPT
OpenAI introduce un nuovo piano a basso costo e l'advertising.
Gli obiettivi della manovra dichiarati: sostenere l’accesso gratuito, mantenere bassi i costi per ampliare l'accesso all'AI, e favorire anche piccole imprese e nuovi brand.
Il piano ChatGPT Go viene esteso a livello globale a 8 dollari al mese, offrendo più funzionalità come immagini, caricamento file e memoria conversazionale.
Parallelamente, verrà avviata negli Stati Uniti una fase di test della pubblicità per gli utenti Free e Go, mentre gli abbonamenti Pro, Business ed Enterprise resteranno senza annunci.

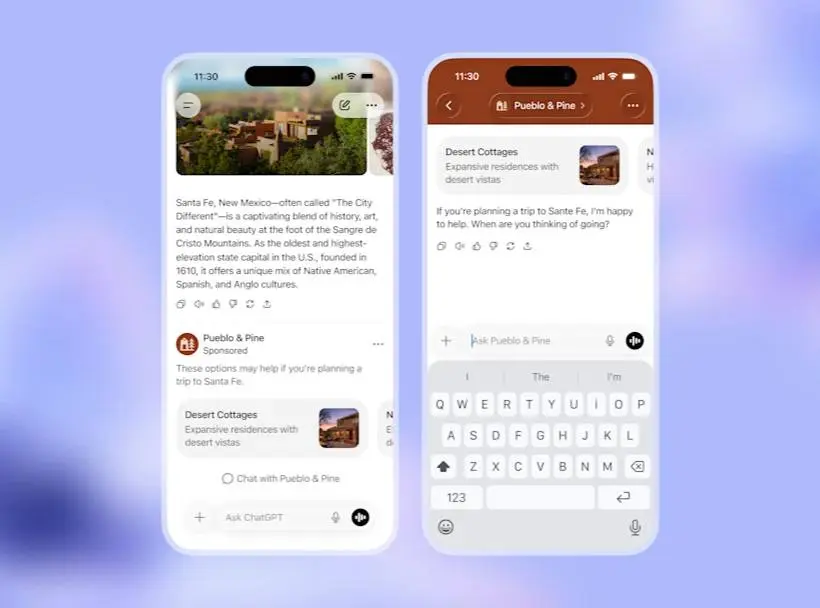
L'advertising su ChatGPT
La pubblicità, secondo l’azienda, non influenzerà le risposte dell’AI. Le conversazioni non saranno vendute né condivise con gli inserzionisti, e gli utenti potranno disattivare la personalizzazione o cancellare i dati utilizzati per gli annunci. Gli annunci saranno separati dalle risposte, non appariranno per i minori né accanto a temi sensibili come salute o politica.
L’idea è integrare messaggi sponsorizzati utili e contestuali, con la possibilità in futuro di interagire direttamente con essi in modalità conversazionale.
SEAL (Self-Adapting Language Models)
Si parla sempre più spesso di continual learning. Questo paper descrive SEAL (Self-Adapting Language Models), un framework che prova a superare la natura "statica" dei LLM, permettendo loro di auto-adattarsi quando incontrano nuovi dati o nuovi task.
L’idea centrale è che il modello non riceva solo esempi da cui imparare, ma impari anche come allenarsi da solo, generando dati sintetici e istruzioni di aggiornamento dei propri pesi.


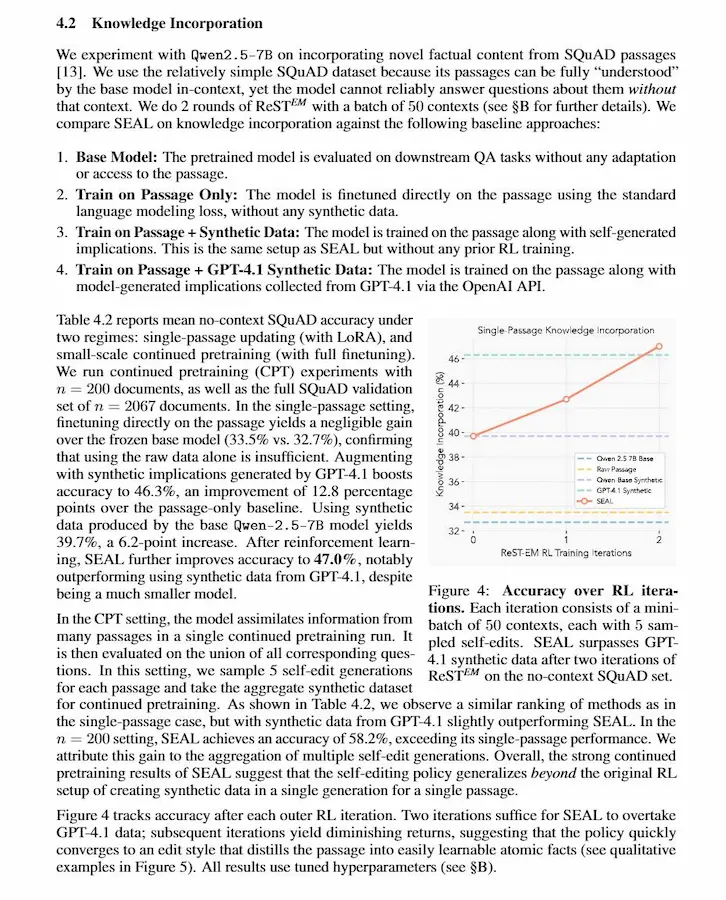
SEAL (Self-Adapting Language Models)
Nel dettaglio, SEAL introduce un doppio loop: un inner loop, in cui il modello si aggiorna tramite fine-tuning su "self-edit" auto-generati (riscritture, implicazioni, configurazioni di training), e un outer loop di reinforcement learning, che premia quei self-edit che portano a reali miglioramenti sulle prestazioni finali. Gli esperimenti mostrano risultati interessanti sia nell’integrazione di nuova conoscenza (es. SQuAD senza contesto) sia nel few-shot reasoning (ARC), dove SEAL impara automaticamente quali strategie di adattamento funzionano meglio.
Tuttavia, il paper evidenzia anche limiti importanti: costi computazionali elevati, dipendenza da segnali di valutazione espliciti e, soprattutto, catastrophic forgetting quando gli aggiornamenti diventano sequenziali e continui.
Proprio questi limiti mi fanno pensare a una direzione alternativa: un approccio ibrido. Invece di usare l’auto-adattamento per aggiornare la conoscenza fattuale (che può rimanere nel contesto, via RAG o long-context), ha più senso usare meccanismi come SEAL per migliorare il reasoning: strategie di decomposizione, generalizzazione, uso degli strumenti, test-time training. I fatti restano esterni e aggiornabili; le abilità cognitive, che generalizzano e si riusano, vengono consolidate nei pesi.
In questa lettura, SEAL non è tanto un sistema di "memoria", quanto un meta-learner che ottimizza come un modello pensa e impara.
Perché i LLM migliorano attraverso il reasoning?
I LLM più avanzati non migliorano nel ragionamento solo perché "pensano più a lungo". Secondo una nuova ricerca di Google, il salto di qualità nasce quando il pensiero viene organizzato come un dialogo interno tra più prospettive.
Nei modelli ottimizzati per il reasoning emergono comportamenti simili a una conversazione: domande e risposte interne, cambi di punto di vista, conflitti tra ipotesi, verifiche e riconciliazioni. Non è un semplice monologo esteso, ma una simulazione di confronto tra voci diverse.

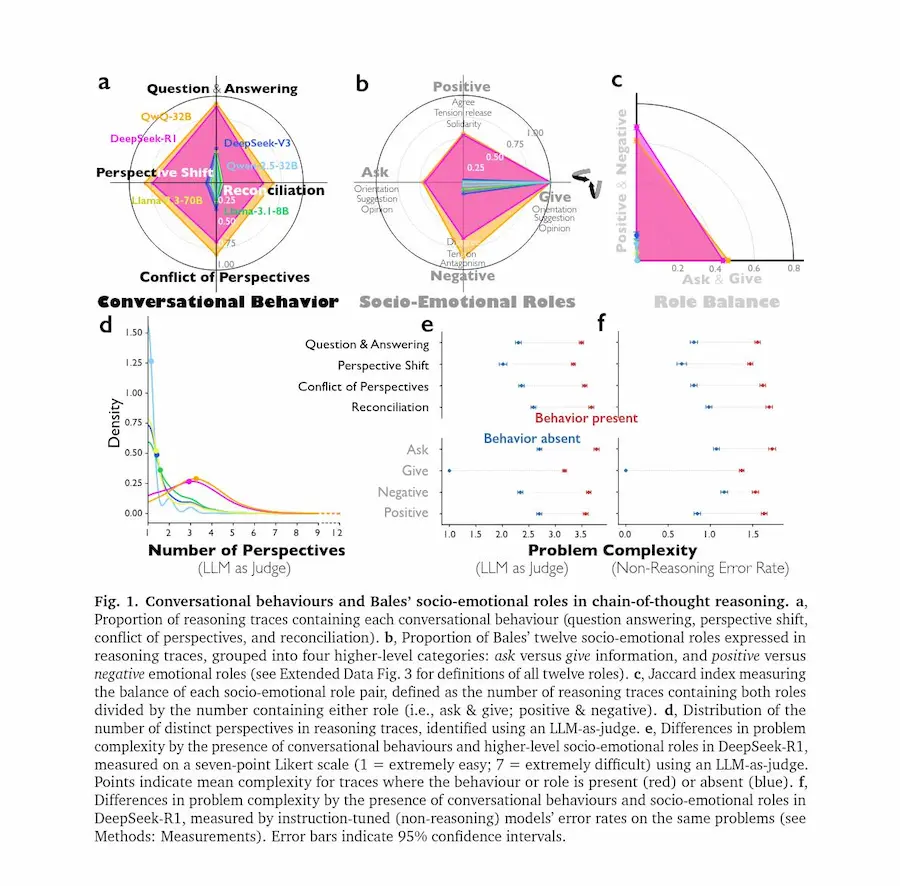
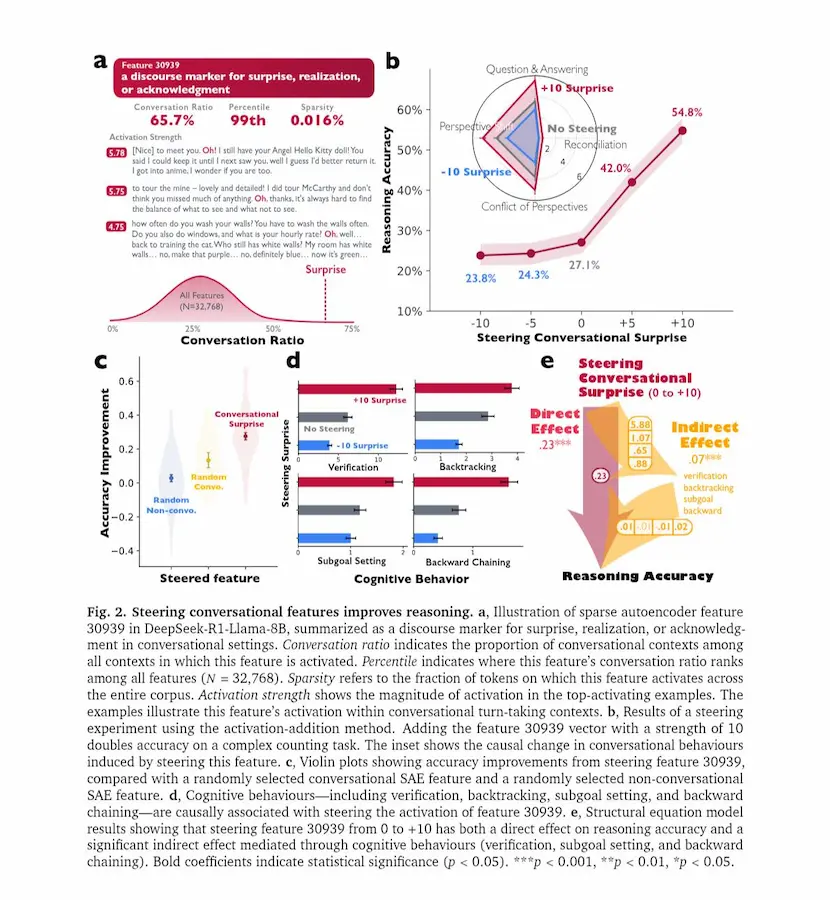
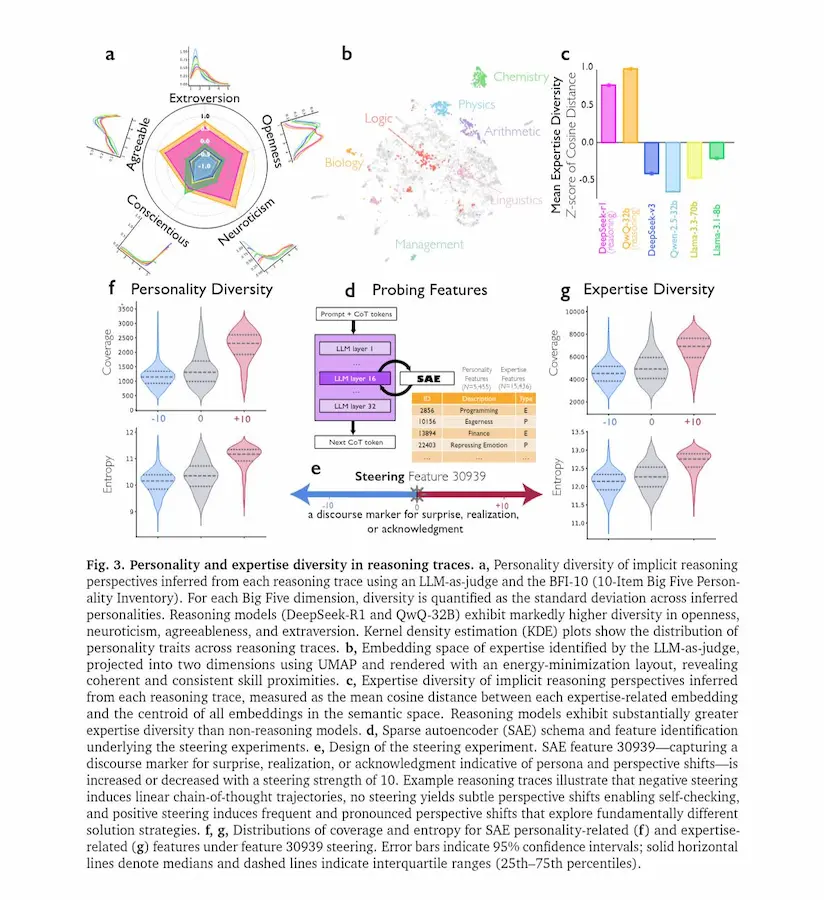
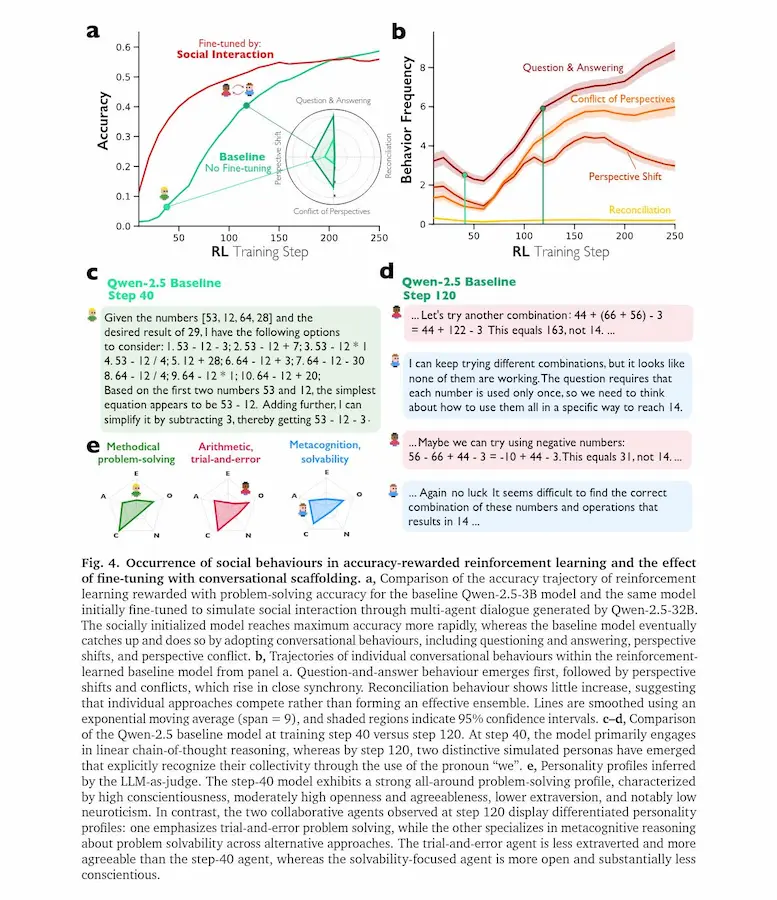
Reasoning Models Generate Societies of Thought
Analisi interpretative mostrano che queste voci differiscono per tratti “personologici” e ambiti di competenza.
Alcune parti del modello propongono soluzioni, altre le criticano, altre ancora verificano i passaggi. Questa diversità interna ricorda il modo in cui i gruppi umani risolvono problemi complessi attraverso discussione e dissenso costruttivo.
Esperimenti causali indicano che amplificare segnali neurali associati a marcatori conversazionali aumenta l’accuratezza su compiti logici e matematici, mentre sopprimerli la riduce.
Inoltre, quando un modello viene addestrato premiando solo la correttezza delle risposte, tende spontaneamente a sviluppare dialoghi interni tra “agenti” virtuali. Se viene inizialmente esposto a esempi di ragionamento multi-agente, apprende strategie di reasoning più rapidamente e le trasferisce meglio su nuovi domini.
Il risultato suggerisce che il ragionamento efficace nei sistemi di AI nasce da una vera e propria “società di pensiero”..
un’organizzazione interna che mette in competizione e in cooperazione prospettive differenti per esplorare meglio lo spazio delle soluzioni.
Un'infografica dalle video recensioni
La multifunzionalità di Gemini con il potenziale di Nano Banana Pro.
Ho generato questa infografica dando in input al modello le tre video recensioni degli smartphone.
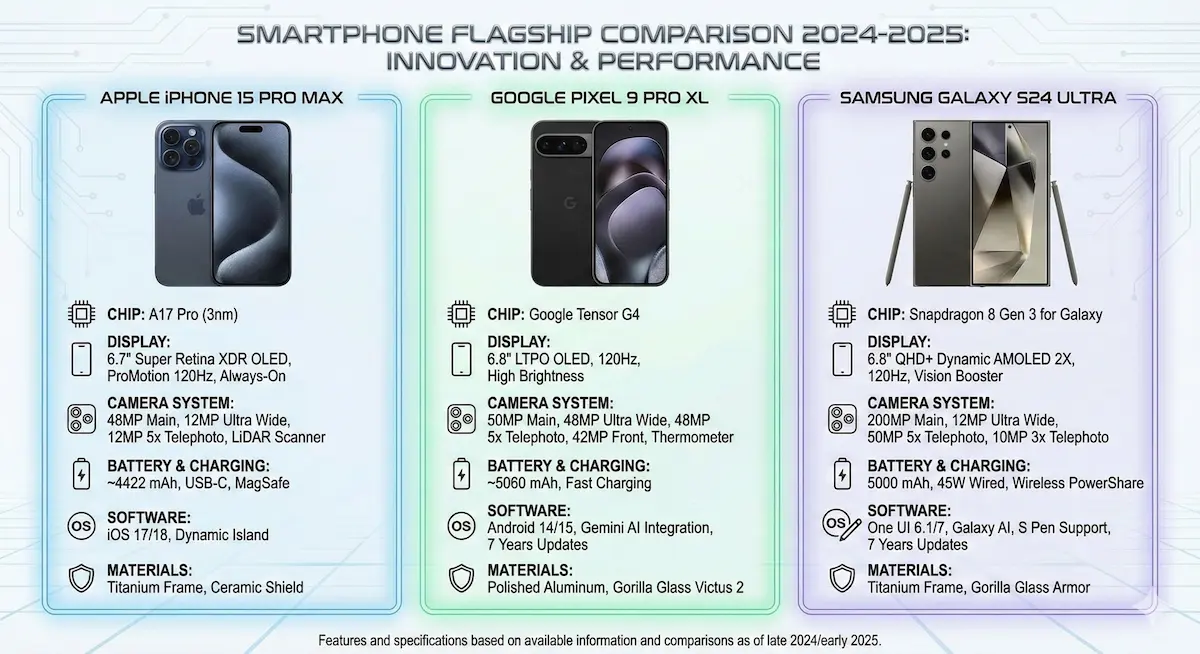
Tra le istruzioni sono presenti anche le caratteristiche grafiche dell'infografica.
L'aderenza alle istruzioni e al contesto continuano a stupire.
PersonaPlex di NVIDIA
PersonaPlex è il nuovo modello di NVIDIA che porta le conversazioni vocali AI più vicine al modo in cui parlano le persone reali.
Non usa più la classica pipeline ASR → LLM → TTS con turni rigidi, ma un’architettura full-duplex end-to-end: il modello ascolta e parla contemporaneamente, generando testo e audio in parallelo. Questo permette backchannel immediati, interruzioni naturali e un ritmo conversazionale fluido.
La novità chiave è l’Hybrid System Prompt, che combina un prompt testuale per definire il ruolo dell’agente e un breve campione audio per definire la voce. Il risultato è controllo zero-shot sia del comportamento sia della voce: basta descrivere il ruolo e fornire un esempio vocale per ottenere un assistente personalizzato, senza addestramento aggiuntivo.
PersonaPlex di NVIDIA
PersonaPlex è addestrato su migliaia di ore di dialoghi sintetici multi-ruolo e su dati conversazionali reali, con scenari customer-service e question answering.
Nei benchmark full-duplex supera i precedenti modelli open su naturalezza, gestione dei turni, interruzioni e aderenza al ruolo, avvicinandosi alle soluzioni proprietarie commerciali.
È il primo modello open-source che unisce full-duplex reale, voice cloning zero-shot e role conditioning avanzato, con pesi pubblici e licenza MIT. Un passo concreto verso assistenti vocali a bassa latenza, agenti conversazionali personalizzati e sistemi di supporto clienti più naturali.
VibeVoice di Microsoft + Colab
Il miglioramento dei sistemi TTS continua, e ora è possibile generare parlato di qualità in tempo reale.
Microsoft ha reso open-source VibeVoice, un sistema di text-to-speech in tempo reale, con una latenza di circa 300 ms per il primo audio e supporto all’input testuale in streaming. È progettato per sostenere conversazioni lunghe senza perdita di coerenza.
Il modello genera parlato multi-speaker di lunga durata: fino a 90 minuti di audio continuo, fino a 4 voci distinte e gestione stabile dei turni di parola anche in sessioni prolungate.
VibeVoice di Microsoft
La tecnologia alla base riduce la risoluzione temporale del segnale.
L’audio viene compresso in token semantici e acustici che operano a 7,5 Hz invece del frame-level tradizionale. Un modello linguistico predice la struttura e il flusso del dialogo, mentre un modulo di diffusione ricostruisce i dettagli acustici ad alta fedeltà.
La variante real-time consente generazione vocale con streaming incrementale del testo, primo output vocale in circa 300 ms.
Il codice è distribuito con licenza MIT, destinato alla ricerca.
VoxCPM: clonazione della voce in tempo reale
VoxCPM è un nuovo progetto open source che permette la clonazione della voce in tempo reale.
Sviluppato da OpenBMB, elimina del tutto la tokenizzazione dai modelli TTS tradizionali, generando direttamente voce continua da testo, con risultati più naturali e realistici.
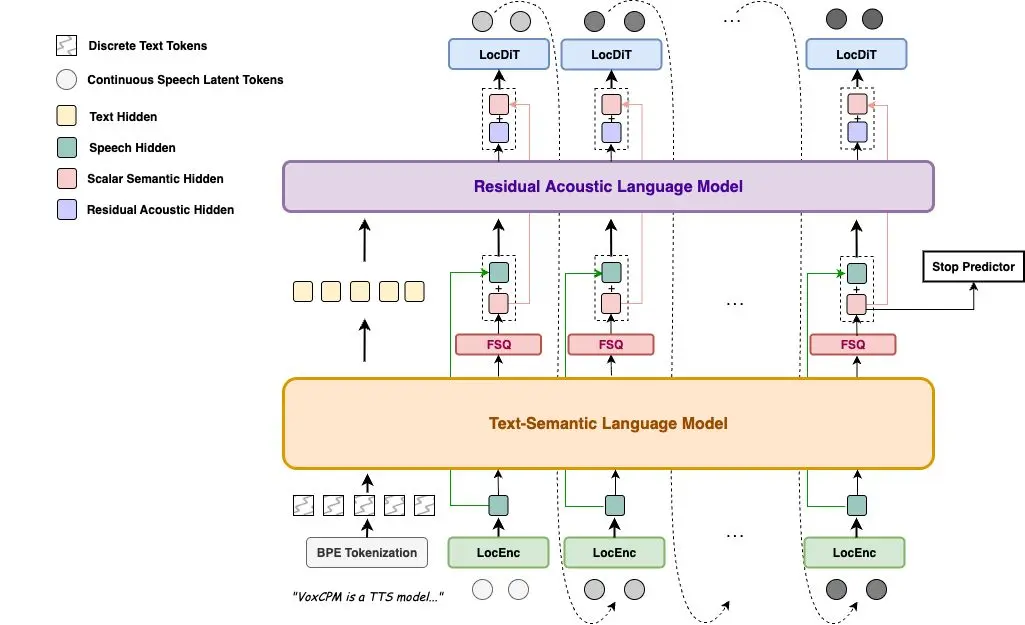
Caratteristiche principali
- Clonazione vocale zero-shot da pochi secondi di audio
- Streaming in tempo reale con latenza sotto il secondo
- Supporto al fine-tuning con LoRA per adattare le voci senza riaddestrare l’intero modello
- Architettura autoregressiva con diffusione, senza fonemi né codec discreti
- Funziona a ~0.15 Real-Time Factor su una RTX 4090
Il risultato? Una sintesi vocale che conserva intonazione, ritmo, emozione e accento, senza artefatti dovuti alla discretizzazione.
Rendere i modelli più sicuri senza raddoppiare i costi di calcolo
Un nuovo paper di Google DeepMind mostra come rendere i modelli linguistici più sicuri senza raddoppiare i costi di calcolo (un sistema già funzionante in produzione).
I ricercatori affrontano un problema concreto: i modelli come Gemini possono essere interrogati per ottenere istruzioni su attacchi informatici. Serve quindi un sistema che riconosca richieste pericolose prima che il modello risponda.
La soluzione proposta non usa un secondo modello linguistico per controllare ogni richiesta (troppo costoso) ma piccole reti chiamate activation probes, che osservano gli stati interni del modello mentre elabora il testo.
Il problema: queste "probe" funzionavano bene su testi brevi, ma fallivano su prompt lunghi o conversazioni articolate, tipiche dell’uso reale.
Il paper introduce nuove architetture di "probe" che riescono a trovare porzioni sospette anche in contesti lunghissimi, senza dover addestrarsi direttamente su testi enormi.
In parallelo, gli autori usano AlphaEvolve per far "evolvere" nuove "probe" da sole, selezionando quelle che funzionano meglio.
Infine combinano probe economiche con un LLM più potente solo quando serve: la probe decide da sola nei casi chiari, e chiede aiuto al modello grande solo se è incerta.
Risultato: quasi la stessa accuratezza di un LLM sempre attivo, ma a meno del 10% del costo.
I test su dataset realistici (inclusi attacchi informatici, conversazioni multi-turn, prompt lunghissimi e jailbreak) mostrano che queste nuove probe raggiungono prestazioni simili ai classificatori basati su LLM, con costi migliaia di volte inferiori.
Resta però una sfida aperta: attacchi adattivi e jailbreak avanzati riescono ancora a superare tutti i sistemi testati. La sicurezza perfetta non è ancora risolta.
L'autocritica iterativa nei LLM
I LLM non sono solo generatori di testo: possono imparare a pianificare meglio correggendo sé stessi.
Un recente lavoro di Google DeepMind mostra che un LLM può migliorare le proprie soluzioni di planning attraverso un processo di autocritica iterativa, senza supervisori esterni né verificatori simbolici.
Il modello genera un piano, lo controlla passo per passo usando la definizione formale del dominio, verificando precondizioni ed effetti delle azioni. Se individua errori, integra il feedback nel prompt e riprova. Il ciclo continua finché il piano viene giudicato corretto dal modello stesso.



L'autocritica iterativa nei LLM: il paper
Nelle applicazioni agentiche che sviluppiamo, usiamo la stessa tecnica.
Il risultato è un netto salto di prestazioni su benchmark classici di AI planning. Nel dominio Blocksworld con 3-5 blocchi l’accuratezza passa dal 49.8% all’89.3%. In Logistics dal 60.7% al 93.2%. In MiniGrid dal 57.7% al 75.2%. In Blocksworld con 3-7 blocchi dal 57.2% al 79.5%.
Con una tecnica aggiuntiva di self-consistency, basata su più valutazioni parallele votate, l’autovalutazione del modello si avvicina molto a quella di un verificatore perfetto. I falsi negativi diventano rari, mentre i falsi positivi si riducono sensibilmente grazie al voto multiplo.
Il metodo funziona su diversi modelli, tra cui Gemini, GPT-4o e Claude, non richiede training aggiuntivo ed è applicabile a nuovi domini semplicemente fornendo la definizione formale del problema. Inoltre mantiene buone prestazioni anche in versioni offuscate dei domini, dove i predicati non hanno significato intuitivo, segno che il modello segue realmente le regole formali.
In prospettiva, questo approccio apre una strada concreta per integrare modelli linguistici con tecniche di ricerca simbolica e planning classico, avvicinando il ragionamento linguistico a capacità decisionali più affidabili e verificabili.
Le novità di Cursor
Con la versione 2.4 di Cursor arrivano i Subagents, agenti indipendenti che lavorano in parallelo su parti specifiche di un task, con contesto e configurazioni dedicate. Il risultato è un’esecuzione più veloce, conversazioni più pulite e maggiore specializzazione sul codice.
Le novità di Cursor
Debuttano anche le Skills, definite tramite file SKILL.md, che permettono agli agenti di applicare conoscenze di dominio e workflow solo quando servono, mantenendo il contesto focalizzato e flessibile, sia nell’editor che nella CLI.
Nuova anche la generazione di immagini direttamente dall’agente: descrizione testuale o reference visiva, preview inline e salvataggio automatico negli asset del progetto. Utile per mockup UI, asset di prodotto e diagrammi architetturali.
Infine, gli agenti possono ora fare domande di chiarimento in qualsiasi conversazione, continuando a lavorare in background mentre attendono la risposta, migliorando fluidità ed efficacia nei task complessi.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂