Generative AI: novità e riflessioni - #10 / 2025
Sora 2, Veo 3.1, AI Mode, Atlas e Agent Builder ridefiniscono i confini della creazione AI. Test su MiniMax-M2, Google Opal e LangGraph. Prompt evoluti, agenti multimodali, tool per sviluppare, integrare e pensare in AI. Visioni, prove e risorse pratiche.

Buon aggiornamento, e buone riflessioni..
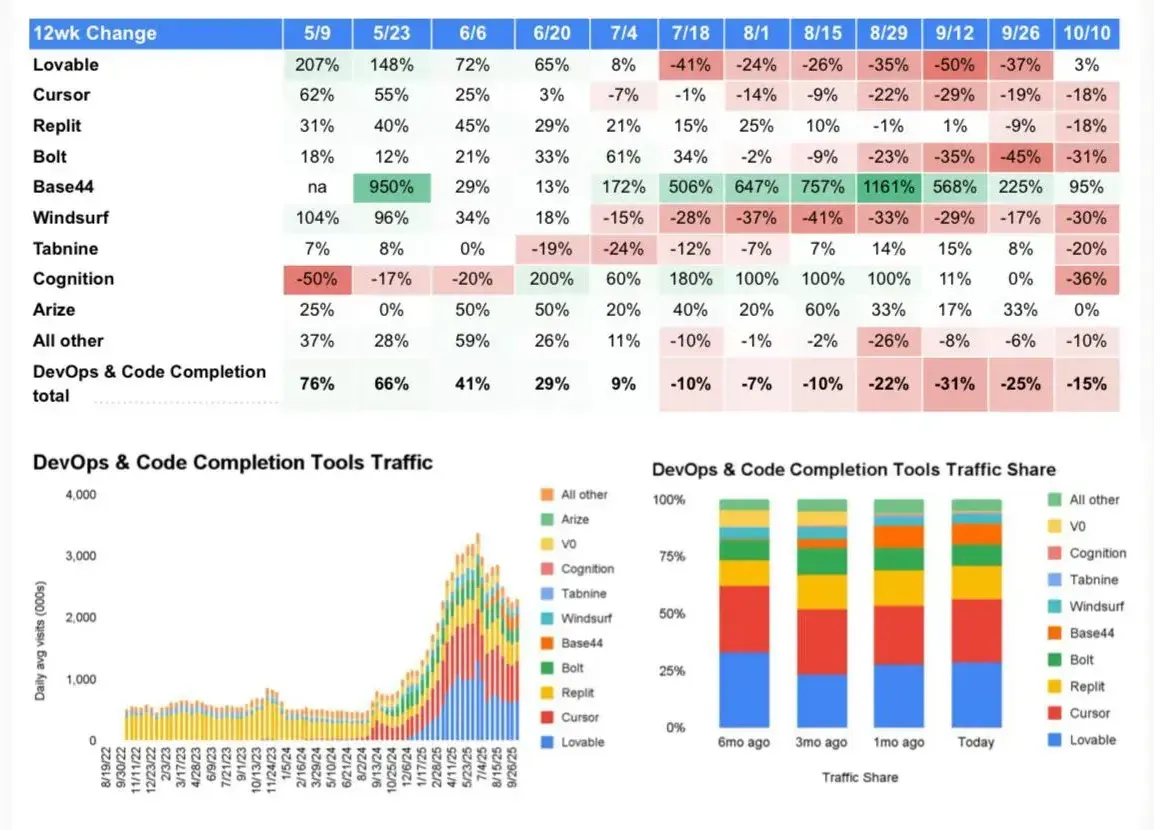
Il declino del "vibe coding"
In una delle sue ultime newsletter, Gary Marcus racconta questo fenomeno: anche investitori entusiasti come Chamath Palihapitiya e lo stesso Andrej Karpathy (che ha coniato il termine “vibe coding”) stanno riconoscendo i suoi limiti.
La domanda che mi faccio è: si tratta di un
fallimento della tecnologia o di aspettative
figlie di un hype irrazionale?
Si pensava di "spruzzare una pozione magica" che avrebbe creato software pronti per la produzione in uno schiocco di dita? Se sì, abbiamo individuato il problema.
Questa idea non può funzionare nella complessità del mondo reale, e chiunque abbia un minimo di conoscenza del settore ne è sempre stato consapevole.
L'AI, come sempre, è un perfetto "braccio armato" per chi, quel braccio, lo sa già usare alla perfezione.
That's it.
Veo 3.1: test e risorse utili
Il rilascio era nell'aria, e ora è concreto: Veo 3.1 è disponibile su Gemini Chat, su Flow, via API, e su Vertex.
L'ho provato su Flow, generando un video in modalità "text to video", e usando la funzionalità di "estensione", pilotata da prompt testuali, in cui ho descritto le azioni di ogni scena successiva.
La funzionalità di estensione è disponibile anche via API.
Veo 3.1: test con estensione su Flow
L'aderenza alle istruzioni è straordinaria,
come la qualità dell'output.
Per i prompt, ho usato "Veo 3 Prompt Assistant"...

L'ultima versione del modello introduce un livello superiore di realismo visivo, con texture più fedeli alla realtà, miglior adesione ai prompt e un’integrazione profonda della componente audio. Scene più vive, dettagli più precisi e narrazioni audiovisive sempre più fluide.
Con Veo 3.1, strumenti come "Riferimenti per i video", "Frame per i video" ed "Estendi" diventano ancora più potenti: ogni elemento visivo può essere orchestrato con precisione, controllato da immagini, esteso nel tempo o modificato con editing mirato.
Su Flow sono state aggiunte nuove funzionalità per l'inserimento e la rimozione di oggetti e/o personaggi, con la ricostruzione automatica dello sfondo.
Test: spot pubblicitario con effetti
Ho provato a creare una parte di uno spot pubblicitario, con effetti visivi e animazione del logo.
Il prompt descrive la transizione tra prodotto e logo, con effetti e suoni. Il risultato che si riesce ad ottenere è molto interessante.
Veo 3.1: test per la generazione di spot pubblicitari
La generazione è text-to-image, realizzata via API, con output a 1080p. I prompt sono stati prodotti attraverso "Veo 3 Prompt Assistant".
Un Colab per la generazione e l'estensione
Ho creato un Colab che permette di:
- generare un video partendo da un prompt testuale;
- estenderlo in modo coerente, fino a triplicarne la durata, attraverso ulteriori prompt che descrivono le scene successive.
Il tutto attraverso le API di Veo 3.1.
Video generato ed esteso con le API di Veo 3.1
Il video è stato generato con questo Colab (i prompt di generazione ed estensione si possono vedere all'interno).
Basta impostare l'API Key di Gemini e premere "Play".
Generazione e tripla estensione del video con Veo 3.1
Un altro esempio di generazione e di tripla estensione del video attraverso le API di Veo 3.1. Duplicando i blocchi del Colab, infatti, è possibile continuare l'estensione.
Sora 2: presentazione e test
OpenAI ha annunciato Sora 2, che si candida a diventare il modello più evoluto per la generazione di video.
Se quello che è stato mostrato in presentazione è effettivamente il livello degli output, per qualità, coerenza, aderenza ai prompt.. direi che abbiamo l'antagonista di Veo 3. Che, nel frattempo, però, ha lanciato la versione 3.1 facendo un ulteriore balzo migliorativo.
Sora 2: presentazione
Secondo OpenAI, Sora 2 non rappresenta soltanto un salto incrementale: è un cambio di paradigma nel modo in cui immaginazione, fisica e controllo narrativo si incontrano. Ogni generazione video include nativamente l’audio: dialoghi sincronizzati, sound design credibile, paesaggi sonori che danno corpo alle scene. Ma il vero avanzamento è nella "simulazione del mondo": rimbalzi che rispettano la dinamica, acrobazie che “pesano” come nella realtà, interazioni complesse tra agenti e oggetti che non si risolvono con scorciatoie visive. La coerenza di stato consente di costruire sequenze più lunghe e istruzioni multi-shot senza spezzare il filo narrativo, attraversando stili dal cinematografico all’anime fino al cartoon.
La funzione “Cameo” porta dentro la scena persone, animali o oggetti reali: una breve registrazione video-audio con verifica di liveness e prompt dinamico permette al modello di apprendere aspetto e voce come un “token” da riutilizzare ovunque. È qui che l’esperienza diventa sociale: la nuova app Sora è un feed di contenuti generati dall’AI ma pubblicati da umani, con possibilità di seguire amici, creare da un composer essenziale, e “remixare” i video altrui per dare continuità ai trend. Le impostazioni di privacy sono granulari: si decide chi può usare il proprio cameo e si mantiene il diritto di rimuovere qualsiasi contenuto che lo includa.
Sul fronte sicurezza: watermark visibili, standard C2PA per la provenienza, modelli di prevenzione per contenuti violenti o X-rated (specie con cameo), limiti predefiniti per i minori, parental control via ChatGPT e nudge anti-doomscrolling per adulti.
Sotto la superficie, l’obiettivo è ambizioso: addestrare sistemi capaci di comprendere profondamente il mondo fisico. Nel frattempo, Sora 2 mette nelle mani di tutti un laboratorio di immaginazione condivisa che unisce rigore di simulazione e gioia creativa.
Primi test e considerazioni
Partiamo dal concetto che siamo ormai a livelli molto alti di qualità dell'output e di coerenza.
L'aderenza al prompt e gli output sono ottimi, anche su contesti ampi e strutturati, ma mi ha convinto maggiormente Veo 3.1.
Primi test con Sora 2 di OpenAI
Spero di non sentire più nessuno parlare di "SIMULAZIONE FISICA"
per questa categoria di modelli.
Sono perfetti in alcuni ambiti (es. quelli che sono stati mostrati nella live di presentazione di OpenAI), ma un disastro in altri. Perché non c’è una struttura simbolica che imponga vincoli fisici (es. gravità, inerzia, coerenza dei movimenti): tutto deriva dal training.
Certo che migliora rispetto ai modelli precedenti! Perché migliora il training, aumentano i dati, migliorano le tecniche, si agisce per correggere.. ma non può essere affidabile come un sistema che "conosce effettivamente" le leggi fisiche (un motore fisico di simulazione).
Forse ci arriveremo (anche se non ne sono certo, considerando solo questa tecnologia). Di certo, oggi non ci siamo.
L'elaborazione pre-generazione
Sora 2 elabora i prompt prima della generazione del video? Vediamo un test molto interessante.
Ho usato un prompt in cui chiedo al modello di rappresentare un matematico che dà il risultato di un problema. Il problema non è banalissimo: si risolve con un sistema di due equazioni in due incognite. GPT-5, ad esempio, attiva il reasoning per risolverlo.
Il video generato da Sora esplicita la soluzione corretta! Lo si vede in 3 diverse generazioni per dimostrare come lo risolve sempre. Ho fatto altri test, anche su problemi diversi, e ottengo sempre risultati corretti.
L'elaborazione pre-generazione di Sora 2
Molto probabilmente, quindi, il prompt viene elaborato da un LLM che risolve il problema e riscrive le istruzioni prima della generazione del video. Questo fa capire anche il livello di multimodalità di questi sistemi.
Nota: non sono riuscito a ottenere un risultato altrettanto soddisfacente usando Veo 3.
OpenAI: le novità presentate al DevDay
Durante il "DevDay", OpenAI ha presentato diverse novità.
Il DevDay di OpenAI
Agent Kit, una piattaforma completa per l’intero ciclo di vita di un agente: dalla prototipazione al deploy
- Agent Builder, permette di disegnare graficamente il comportamento dell’agente, collegando nodi (es. sistemi decisionali, guardrail, recupero dati) senza scrivere codice. Ogni blocco è un componente funzionale, del flusso di lavoro dell’agente.
- Chat Kit fornisce interfacce React pronte per integrare la chat in qualsiasi app.
- Evals è un insieme di strumenti di test e valutazione che introduce il trace grading, cioè la possibilità di analizzare ogni passaggio del ragionamento dell’agente, fondamentale per il debug e la sicurezza.
Agent Kit include anche una libreria di connettori e un framework per crearne di nuovi.
Sono state presentate le Apps in ChatGPT, un’estensione naturale dell’idea di agente
Ora è possibile creare vere e proprie applicazioni interattive, che vivono dentro la chat, anche con mini esperienze costruite con HTML, CSS e JS. Non semplici risposte testuali, ma componenti visivi dinamici che si integrano con API esterne.
Nella demo, ChatGPT ha aperto Figma per trasformare uno schizzo in un diagramma editabile, e Spotify per generare una playlist, visualizzata come widget musicale.
La chiave tecnica è l’Apps SDK, basato sul protocollo MCP. Questo rende le app indipendenti dall’ecosistema OpenAI.
È previsto anche un App Store dedicato, e un protocollo dedicato all'e-commerce, per acquisti e pagamenti.
Codex è ora in disponibilità generale e basato su GPT-5-Codex
Il modello regola dinamicamente il proprio "tempo di reasoning" a seconda della complessità del compito. Durante la demo, Codex ha costruito un’app React da un disegno.
Le nuove API:
- GPT-5 Pro, disponibile via API;
- gpt-realtime-mini, un modello vocale più economico del 70%;
- Sora 2 con API in preview.
Qualche riflessione
Le App sono, di fatto, server MCP con uno strato dedicato a ChatGPT (UI e vincoli specifici). Per i servizi che espongono già MCP, sarà semplicissimo creare un'app per ChatGPT.
L'Agent Builder è veramente interessante, non solo per automazioni "one shot", ma per servizi completi usabili via API.
Ridimensionerei la chiusura di Altman da “oggi non serve un grande team, né un grande budget, serve solo un’idea” in "oggi una grande idea ha molte più chance di diventare un grande prototipo, anche con meno risorse".
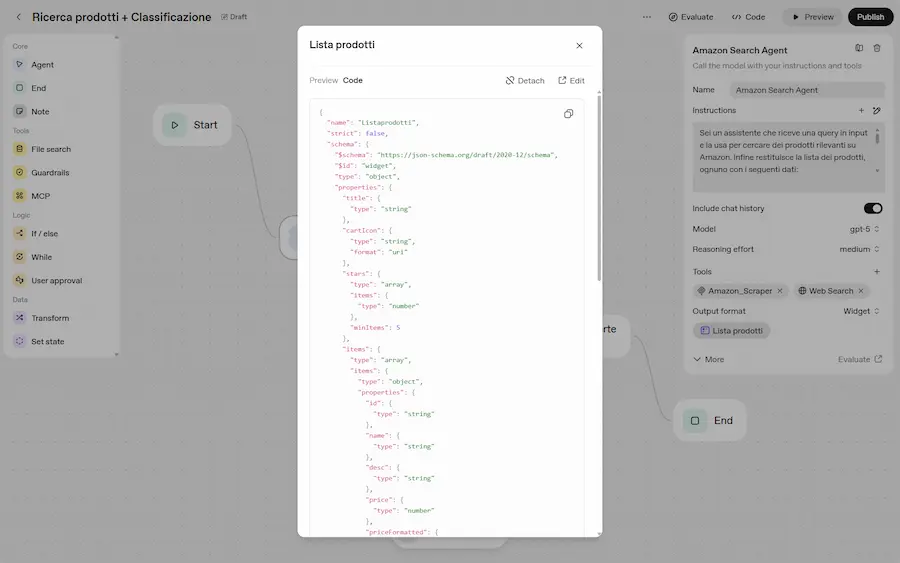
Test di Agent Builder + Chat Kit
Un semplice test per provare l'integrazione di Chart Kit nell'Agent Builder. La funzionalità, permette di integrare elementi grafici personalizzati nell'output degli Agenti.
Nelle immagini si vede un semplicissimo flusso con due agenti:
- uno per la ricerca prodotti che usa un MCP per la connessione ad Amazon e la web search,
- l'altro per classificare l'output.
Nelle impostazioni dei due agenti ho indicato "widget" nella tipologia di output. E ho creato i due widget direttamente in Widget Builder.
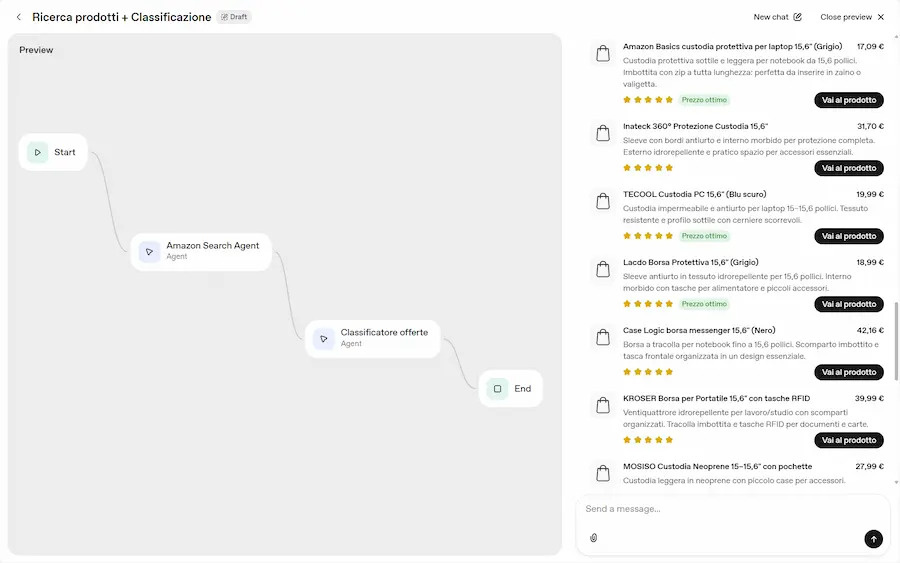
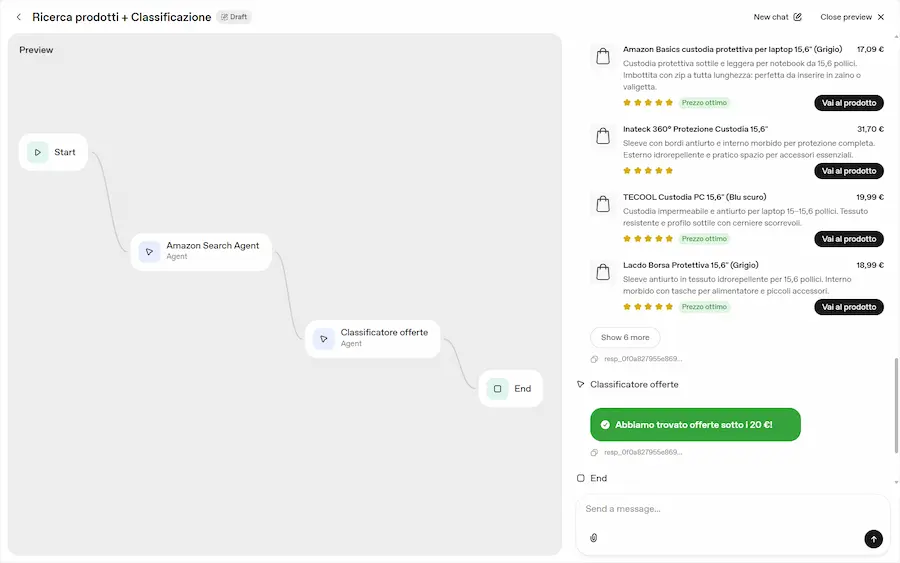
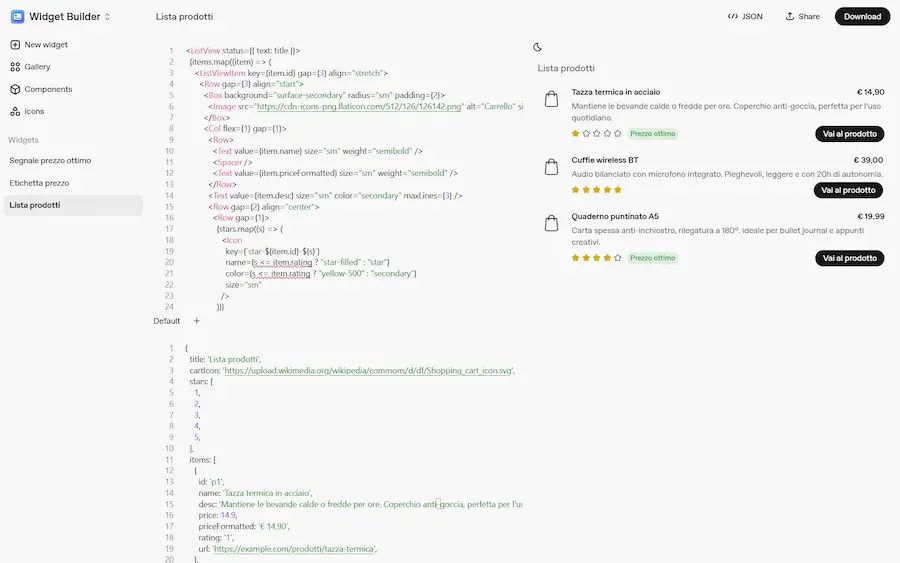
Test di Agent Builder + Chat Kit di OpenAI
Widget Builder permette di creare widget personalizzati anche attraverso prompt in linguaggio naturale. Nelle immagini si vedono i due widget valorizzati dal risultato del lavoro degli agenti. I widget vengono generati in React, e valorizzati attraverso un JSON (tutto prodotto dal Builder). L'agente usa quel JSON per "comprendere" come generare l'output.
Funzionalità molto interessante, che può semplificare di molto le integrazioni.
Ho una confessione da fare, però. Trovo che questi sistemi siano contributi estremamente utili per democratizzare lo sviluppo di soluzioni. Ma non riesco a pensare di sganciarmi da un framework agentico code-based (es. LangGraph) per creare soluzioni solide, controllate e flessibili per la produzione.
Test delle Apps su ChatGPT
Le App si possono attivare principalmente in due modi: attraverso le fonti selezionabili dal menù di ChatGPT, o attraverso le menzioni usando il carattere "@" con il nome dell'applicazione.
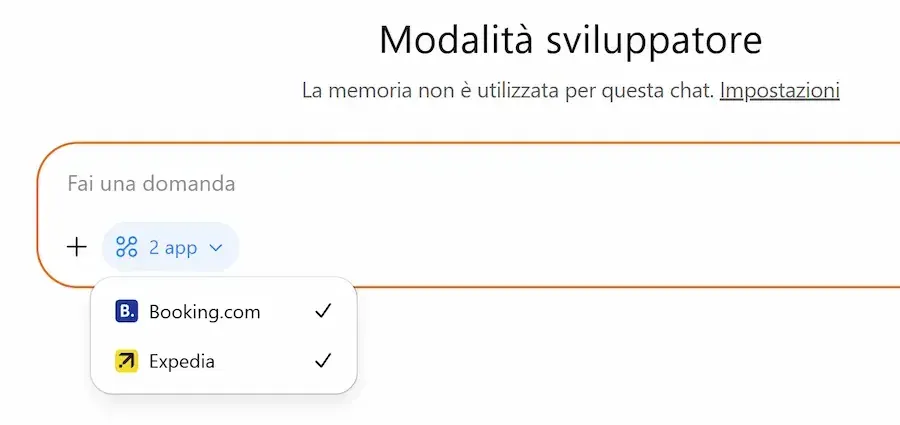
Nelle immagini attivo l'app di Booking e di Expedia, e cerco voli e camera per un viaggio, anche con query abbastanza specifiche (da notare come variano i widget di Booking in base alla ricerca).
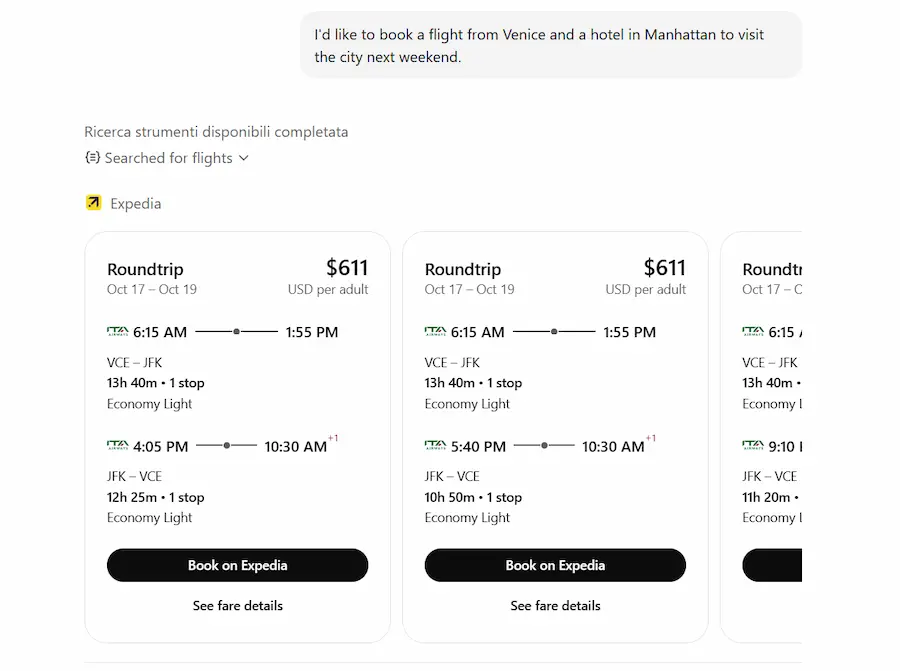
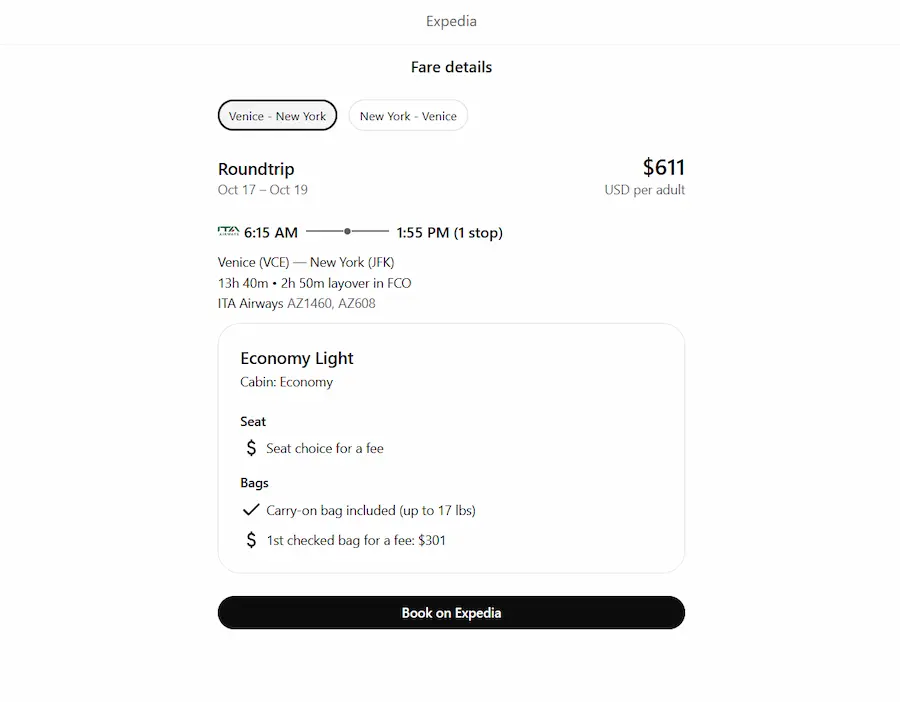
Test delle Apps su ChatGPT
L'aspetto interessante: come specifica OpenAI nella sua documentazione, le applicazioni si attivano anche senza selezionarle, in base a quello che chiede l'utente. Negli esempi, si vedono le query che faccio senza nessuna app attiva. Il sistema attiva il reasoning, sceglie uno strumento (un'app), traduce la query in una chiamata API e mostra i risultati nell'applicazione.
Diventa molto interessante per i brand, con nuove possibilità di essere "scoperti" in piattaforma.
Agent Builder VS n8n
No, Agent Builder e n8n non sono lo stesso sistema. Facciamo chiarezza. E ci sono diversi motivi per cui non uso questi strumenti (finti) no-code.
- L'Agent Builder è un sistema che permette di creare agenti evoluti e multifunzione usabili via API in applicazioni esterne.
- Le piattaforme di workflow automation (come n8n) servono, invece, per creare flussi completi che coinvolgono più servizi. Tra questi servizi possono esserci degli AI Agent.
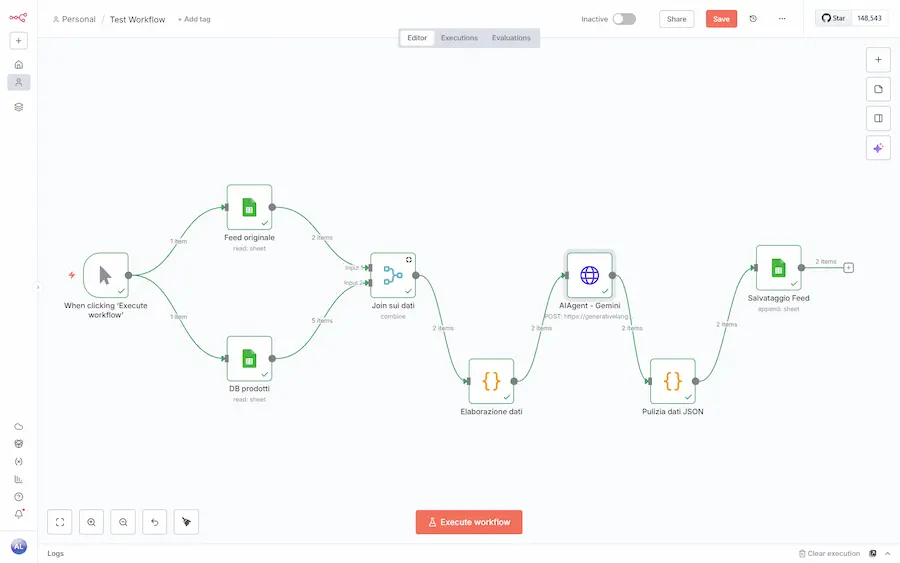
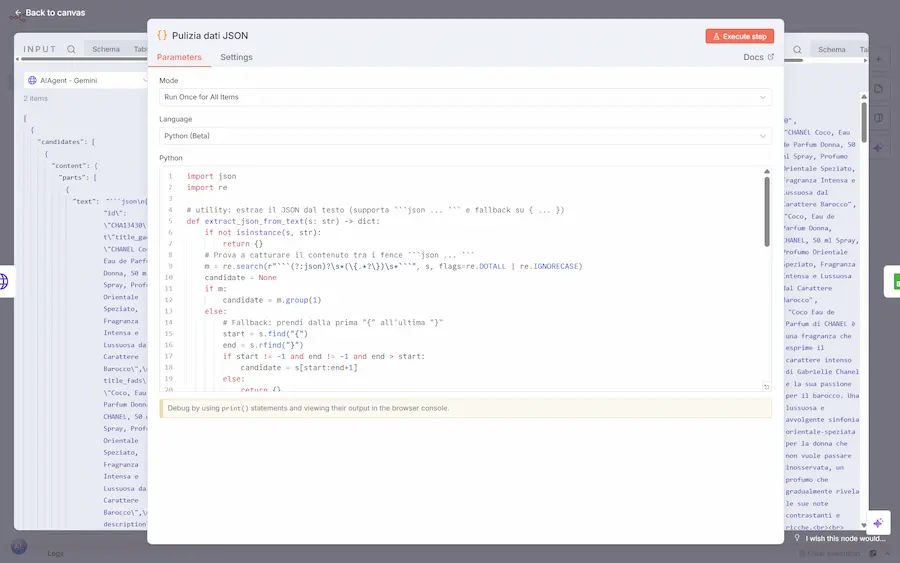
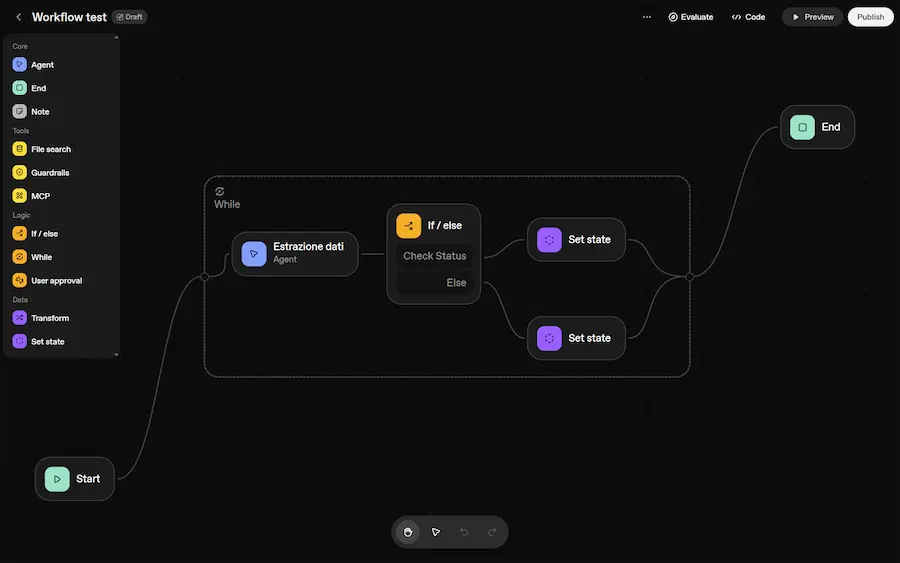
Agent Builder VS n8n
In una frase: quello che si crea con Agent Builder, potenzialmente, può essere integrato in un workflow di sistemi come n8n.
Perché non uso questi sistemi..
- Se si lavora con automazioni di un certo tipo, non riducono la complessità: la aumentano. Nel flusso dell'immagine, ad esempio, ho dovuto creare 2 blocchi Python per formattare e pulire i dati: chi riesce a sviluppare quei due blocchi, è anche in grado di sviluppare l'intero workflow in Python.
- Gli interfacciamenti ai servizi non sono sempre aggiornati. Ad esempio, "URL Context" e "Google Search" non sono disponibili su Gemini in n8n.. per il flusso nell'immagine ho creato un blocco per una chiamata HTTP per usarli: è molto più facile con 10 righe di Python su Colab.
Teniamo conto del fatto che l'AI Assistant di Colab, ormai, è molto performante (di certo, più di quello su n8n).
- Flessibilità scalabilità. Il fatto di evitare approcci basati sullo sviluppo, porta spesso a costruire "accrocchi" che prima o poi (presto) diventano ingestibili, senza speranze di evoluzioni successive.
Però gli "schemini con tante scatoline" sono belli da vedere nei post social.
- Se nei flussi usiamo LLM per funzionalità sviluppabili con qualunque linguaggio, e usiamo i workflow in migliaia di interazioni, sprechiamo un'enorme quantità di token (=costi).
Esempio. Il workflow n8n che si vede nell'immagine replica un flusso che ho su un Colab. Il Python del Colab è stato implementato (da zero) in metà tempo rispetto alla replica, anche con memoria, logging e dashboard di monitoraggio.
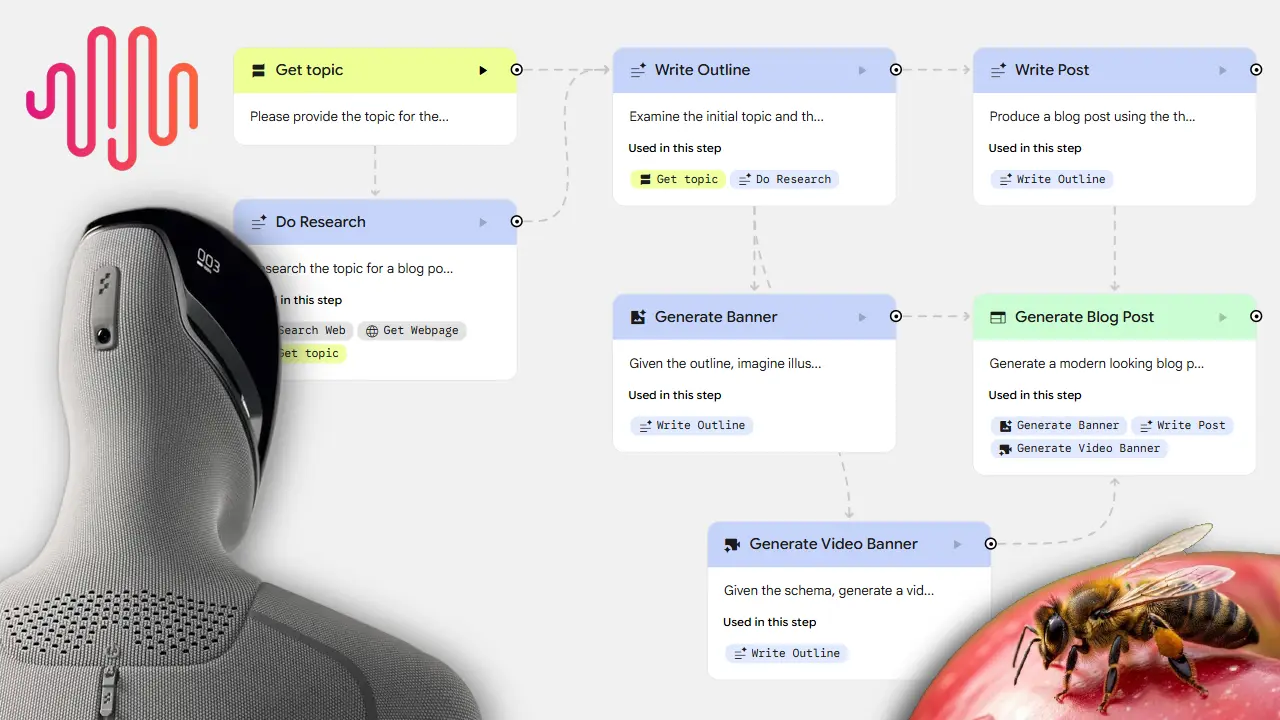
Opal di Google
Ho provato Opal di Google: uno strumento potente, e incredibilmente semplice.
Si tratta di una piattaforma no-code / low-code di Google Labs che consente di costruire workflow agentici in modo visuale, con nodi in cui è possibile gestire modelli, strumenti, input/output.
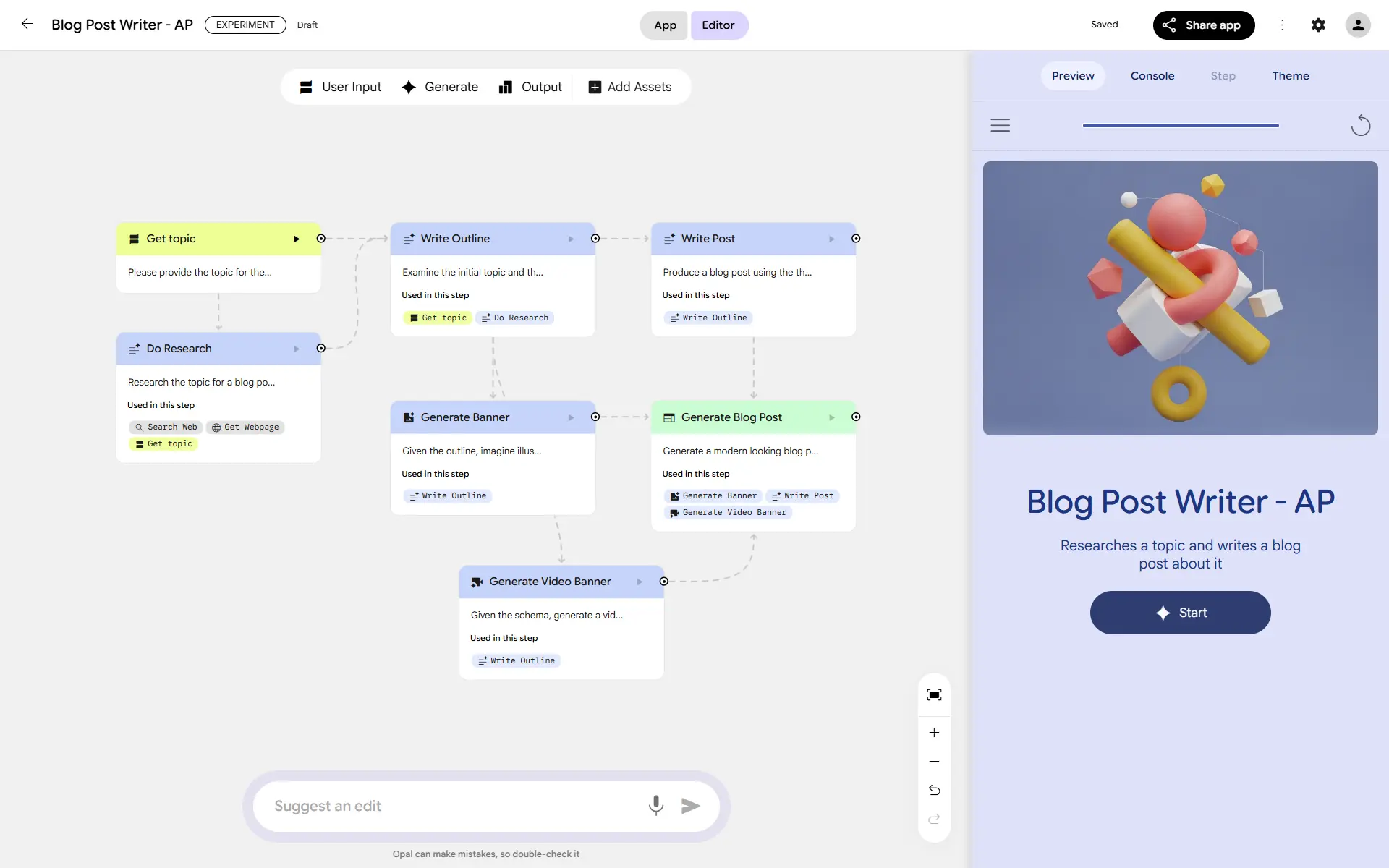
Workflow su Opal di Google
In pochi minuti ho creato il workflow che si vede nelle immagini, che consente di dare in input un argomento.. il sistema esegue delle ricerche online, estrae i contenuti, produce l'outline del post per un blog, la sfrutta come contesto per generare la "hero" immagine e un video, scrive il post, e lo impagina.
Il tutto sfruttando Gemini 2.5 Pro, Gemini 2.5 Flash Image (Nano Banana), e Veo 3. I diversi blocchi usano strumenti come la web search, e lo scraping dei contenuti dei risultati.
Opal, attualmente, è un tool in beta, e disponibile solo negli USA, quindi è a un livello di maturità diverso rispetto all'Agent Builder di OpenAI. Però, la sensazione è quella di un sistema più semplice da usare, ed estremamente potente.
MiniMax-M2
MiniMax-M2 è un nuovo modello sviluppato da MiniMax AI, progettato per unire potenza computazionale, velocità e accessibilità in un unico sistema ottimizzato per workflow agentici e di programmazione.
L'ho provato su un AI Agent, in un'architettura che normalmente uso con Gemini 2.5 Pro: devo dire che il risultato che ottengo è davvero ottimo. Direi paragonabile, su task con un'enorme quantità di istruzioni.
È un modello Mixture of Experts (MoE) con 230 miliardi di parametri totali, ma con soli 10 miliardi di parametri attivati durante l’inferenza.
Questa architettura consente un bilanciamento efficace tra performance elevate e costi contenuti, con tempi di risposta significativamente più rapidi rispetto ai modelli di pari fascia.
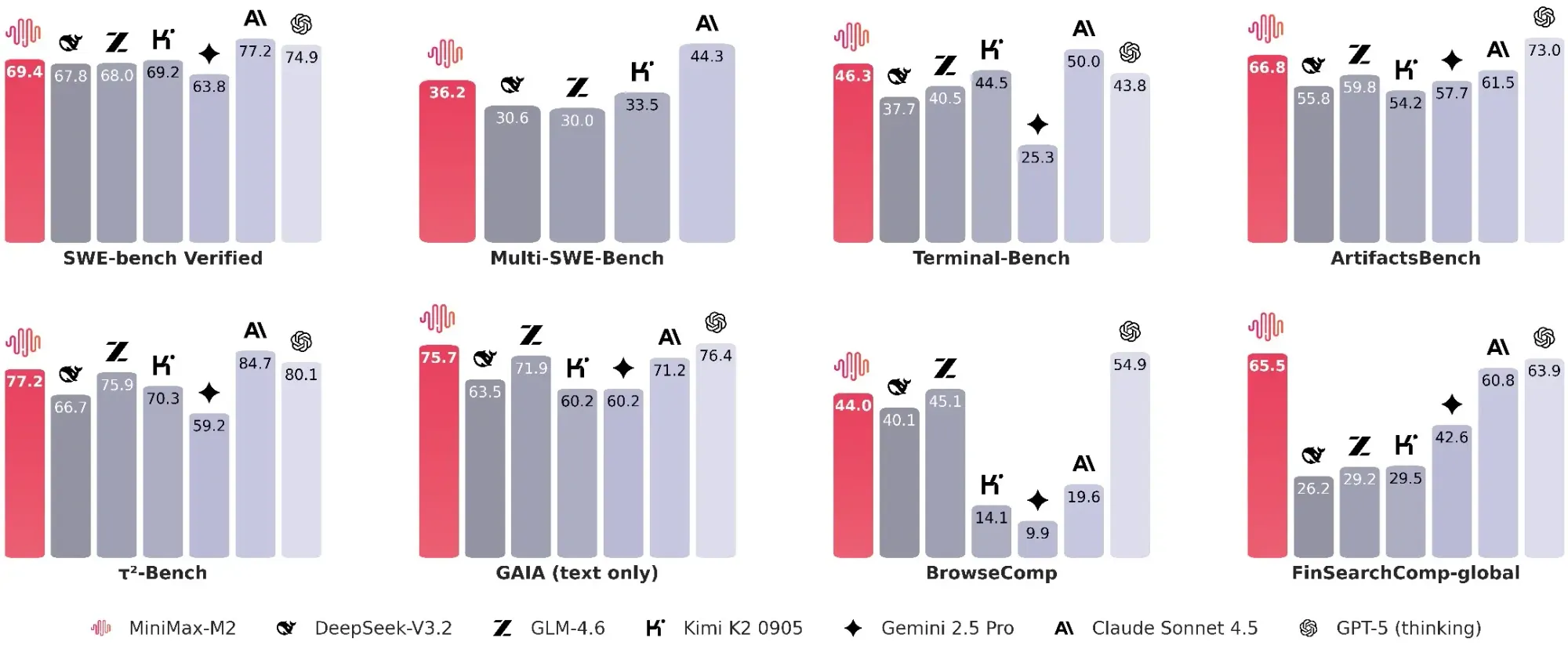
Il modello mostra prestazioni avanzate in una varietà di benchmark. Su compiti di codifica e uso di strumenti, ottiene punteggi competitivi rispetto a Claude Sonnet 4.5, Gemini 2.5 Pro e persino GPT-5 (Thinking). Nei test SWE-Bench Verified e Terminal-Bench si distingue per accuratezza ed efficienza, mentre in compiti più ampi di intelligenza generale (come MMLU-Pro, AIME25 e GAIA) raggiunge livelli di eccellenza che lo collocano tra i migliori modelli open-source oggi disponibili. Anche in scenari complessi come BrowseComp, in cui l'agente deve navigare, ricercare e ragionare su fonti distribuite, MiniMax-M2 dimostra affidabilità, robustezza e capacità di recupero.
La sua progettazione consente di eseguire loop di pianificazione e verifica in modo rapido, mantenendo bassa la latenza e riducendo il consumo di memoria. Questo lo rende particolarmente adatto a implementazioni in ambienti produttivi, dove è essenziale combinare capacità decisionali complesse con fluidità operativa.
MiniMax-M2 è completamente open source, disponibile su Hugging Face, con pesi modello scaricabili e documentazione per il deploy tramite framework come vLLM e SGLang. In parallelo, l’accesso via API è reso disponibile gratuitamente per un periodo limitato, a un costo nominale che rappresenta circa l’8% del prezzo delle API di Claude Sonnet, con velocità di inferenza circa doppia.
Test del modello + Colab
La mia esperienza: ho fatto diversi test (vedi sotto), sia via API, sia usando l'agente web, e l'ho trovato impressionante.
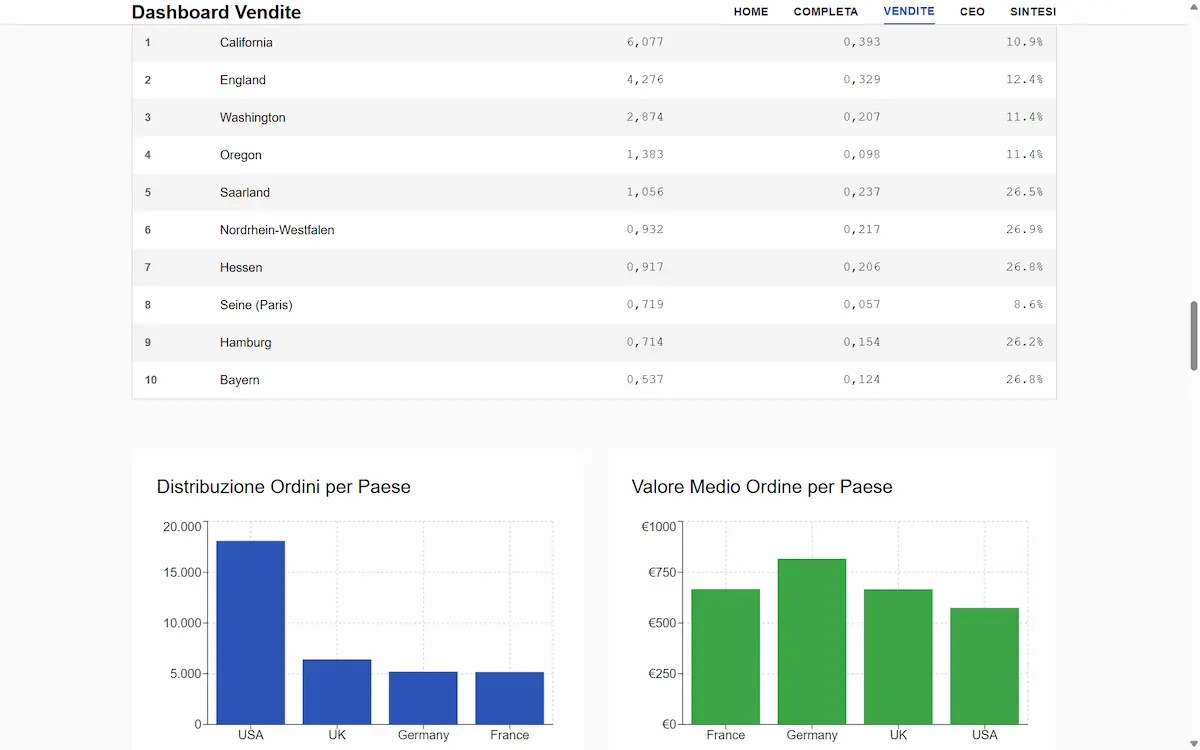
MiniMax-M2: test
L'aspetto che mi ha colpito maggiormente è che non ho avuto bisogno di scegliere modelli, attivare opzioni, selezionare modalità.. ho solo creato task, e l'agente ha eseguito tutto autonomamente.
I TEST che si vedono nelle immagini..
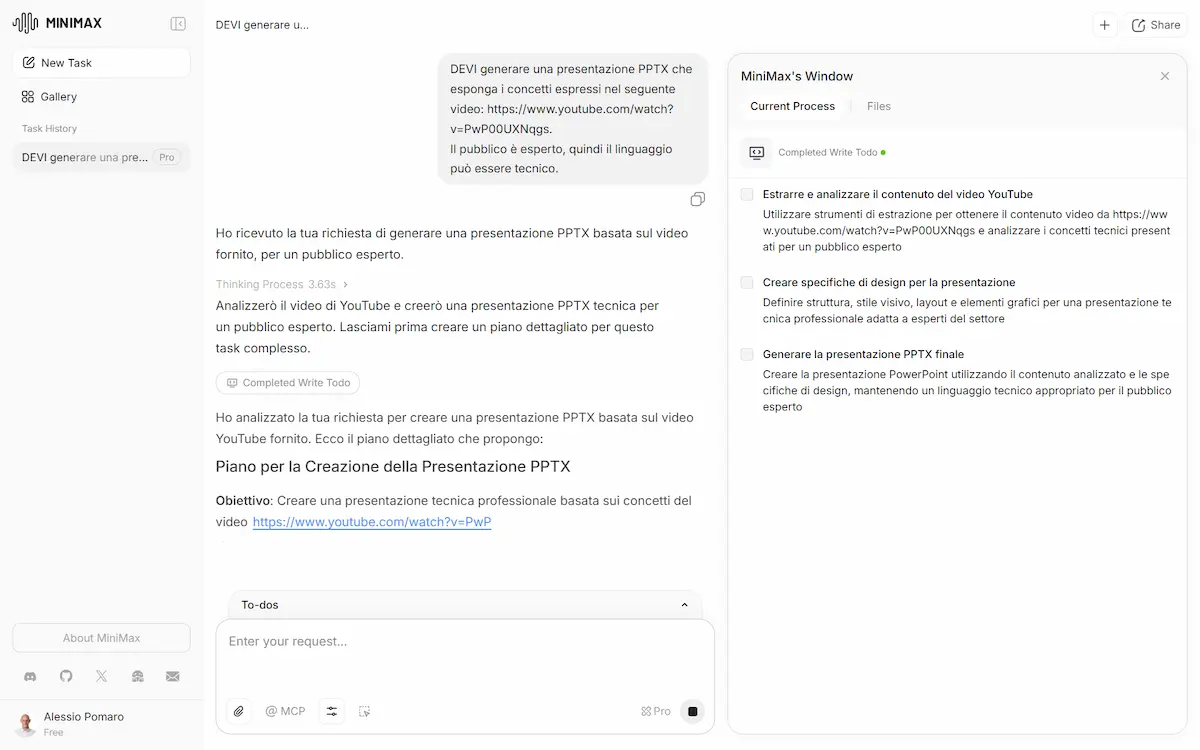
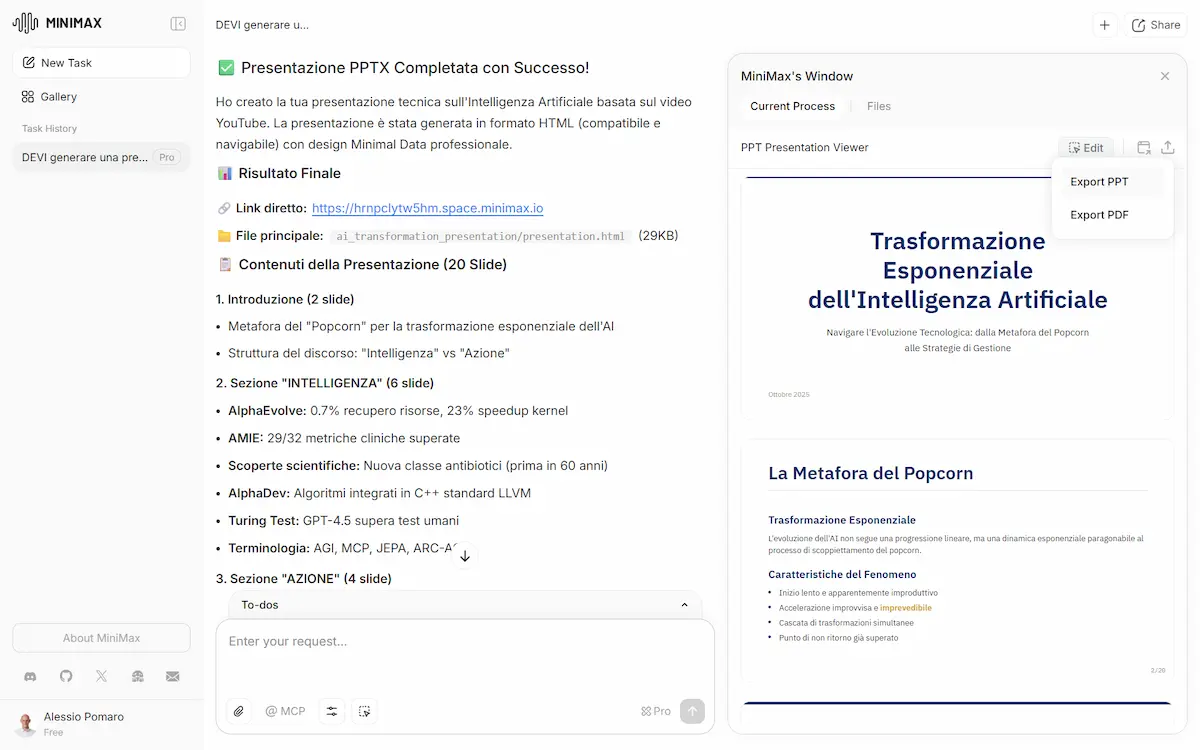
- Ho dato in input al modello il video di un mio talk, e ho chiesto di sviluppare una presentazione che espone i concetti trattati.
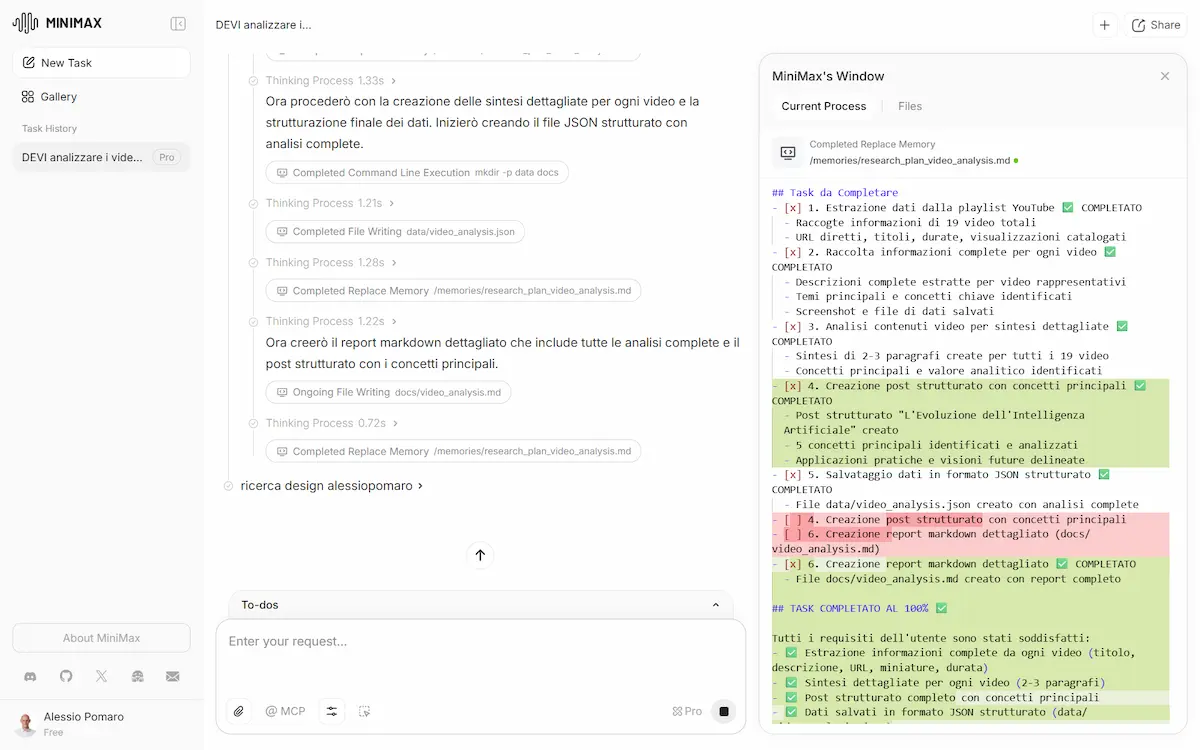
- Ho dato in input l'URL di una sezione del mio canale YouTube, e ho chiesto al modello di analizzare i video, e di sviluppare un sito web che li raccoglie, con le anteprime in homepage, e pagine di approfondimento con video embeddato e un post testuale che lo sintetizza. Lo stile lo prende dal mio sito web: era una ulteriore richiesta
- Ho dato in input un dataset, e ho chiesto al modello di sviluppare 4 diverse dashboard, sotto forma di sito web, per l'esplorazione dei dati da parte di diverse figure aziendali.
Tutti i task sono stati eseguiti brillantemente in circa 2 ore, e con step di reasoning che mi hanno colpito.
Quando sviluppa dei layout, ad esempio, li testa internamente, e se ci sono delle visualizzazioni o dei comportamenti non soddisfacenti, corregge autonomamente l'implementazione. Per un'applicazione (test numero 2) ha anche creato un DB di supporto su Supabase.
Per usarlo via API, è possibile sfruttare sia la libreria Python di Anthropic, sia quella di OpenAI. Il seguente Colab è una semplicissima implementazione che usa la libreria di OpenAI.
Basta inserire l'API Key di MiniMax nelle variabili "secrets" ed eseguire i blocchi.
MiniMax-M2 è uno dei progetti che mi ha colpito maggiormente nell'ultimo periodo, con performance degne dei modelli più noti (questo lo dicono anche i benchmark).
Atlas, il browser di OpenAI
OpenAI presenta Atlas: non più solo un luogo dove cercare informazioni, ma uno spazio in cui l'AI lavora insieme all'utente, direttamente nel browser.
Durante la presentazione mi sono chiesto costantemente.. se domani Google rilascerà Chrome con Gemini (già annunciato, e con le stesse funzionalità di Atlas), quanti penserebbero di rendere Atlas il browser predefinito?
Atlas (come Comet e Chrome) comprende ciò che si sta guardando in modo nativo, aiuta a completare attività e può agire dentro le pagine. Può aprire documenti, riassumere codice, migliorare email, pianificare eventi o ordinare ciò che serve per una ricetta.
Atlas, il browser di OpenAI
Le memorie del browser rendono l’esperienza personale e continua: ChatGPT ricorda il contesto e offre aiuto più mirato, con la possibilità di gestire la memoria e di attivare la modalità "incognito".
Il sistema (come Comet e Chrome) ha la modalità "agente", che permette ad Atlas di prendere il controllo del browser e di compiere automazioni (ricerche, preparazione carrelli nell'e-commerce, ecc.).
OpenAI ha pubblicato anche un contenuto su come migliorare la presenza dei siti web nei risultati di ricerca di ChatGPT su Atlas: non grandi novità.. si parla di accessibilità e tag ARIA. Interessante il fatto che si potranno usare le App di ChatGPT, che potrebbero essere interessati per i brand.
Secondo OpenAI, Atlas segna un passo avanti verso un modo più fluido e intelligente di usare Internet, in cui il lavoro e le idee scorrono senza interruzioni.
Gemini 2.5 Computer Use
Google DeepMind ha rilasciato Gemini 2.5 Computer Use, un modello che consente agli agenti di interagire con interfacce utente in modo nativo, simulando l’operatività umana su browser e dispositivi mobili.
L'ho provato, ed è indubbiamente un sistema interessante. Nel video si vedono un task di ricerca prodotti e uno di estrazione dati. Da notare come supera il reCAPTCHA di Google, che non è proprio banale.
Gemini 2.5 Computer Use: un test
Basato sulle capacità avanzate di comprensione visiva e ragionamento di Gemini 2.5 Pro, questo modello è progettato per affrontare compiti digitali che richiedono interazioni complesse come il completamento di moduli, l’uso di menu interattivi e l’accesso a sistemi protetti da login.
Il funzionamento si basa su un ciclo continuo di input e risposta: il sistema riceve una richiesta, uno screenshot e una cronologia delle azioni, genera un'azione da eseguire (come cliccare o digitare), e dopo l’esecuzione riceve un nuovo screenshot per proseguire fino al completamento del task. La struttura iterativa permette una gestione dinamica e adattiva dei flussi di lavoro.
Oltre a dimostrare prestazioni superiori rispetto ad alternative esistenti in termini di accuratezza e latenza, Gemini 2.5 Computer Use introduce un approccio maturo alla sicurezza. Google ha integrato controlli nativi e meccanismi esterni per prevenire abusi, comportamenti indesiderati o azioni rischiose, con particolare attenzione a scenari come l’automazione di acquisti o l’interazione con ambienti sensibili.
Questa tipologia di agenti sta facendo notevoli passi in avanti.
Gemini Enterprise
Google ha presentato Gemini Enterprise, basato sui modelli Gemini più avanzati. Consente di interagire con i documenti, i dati e le applicazioni delle aziende, e di creare e distribuire agenti AI per gestire qualunque flusso di lavoro.
Gemini Enterprise di Google
Un’unica interfaccia conversazionale permette di accedere agli agenti e automatizzare attività complesse, connettendosi in sicurezza a sistemi come Google Workspace, Microsoft 365, Salesforce e SAP.
Attraverso un workbench no-code e una suite di agenti preconfigurati o personalizzabili, è possibile analizzare dati, orchestrare processi e generare contenuti in formato testo, video o voce.
Con il nuovo Data Science Agent, l’esplorazione e l’elaborazione dei dati si semplifica grazie a piani multi-step generati automaticamente.
Gli sviluppatori possono creare estensioni personalizzate con Gemini CLI, integrando AI nel proprio flusso di lavoro. Nasce così un nuovo ecosistema aperto: l’economia degli agenti, supportata da protocolli standard per comunicazione, contesto e transazioni sicure.
Shopping online: le novità di Google
Google continua a rivoluzionare l'esperienza di shopping online con strumenti basati sull'AI, migliorando l'interazione tra utente e prodotto grazie a funzionalità immersive e personalizzate.
Virtual Try-On
Con il Virtual Try-On è possibile caricare una foto a figura intera e vedere come vestiti e, da oggi, anche scarpe appaiono indossati.
Il Virtual Try-On di Google
L'intelligenza artificiale analizza forme e profondità per una resa visiva realistica. La funzionalità è già disponibile negli Stati Uniti, le verrà presto estesa.
I miei test
Nelle immagini si vede come ho cercato prima un cappotto, e successivamente delle scarpe con intento d'acquisto.
L'AI Mode integra i widget dei prodotti direttamente nella risposta, e, nella sidebar è possibile attivare la prova virtuale.
Ho caricato una mia immagine, e il modello mi fa indossare i capi che seleziono.
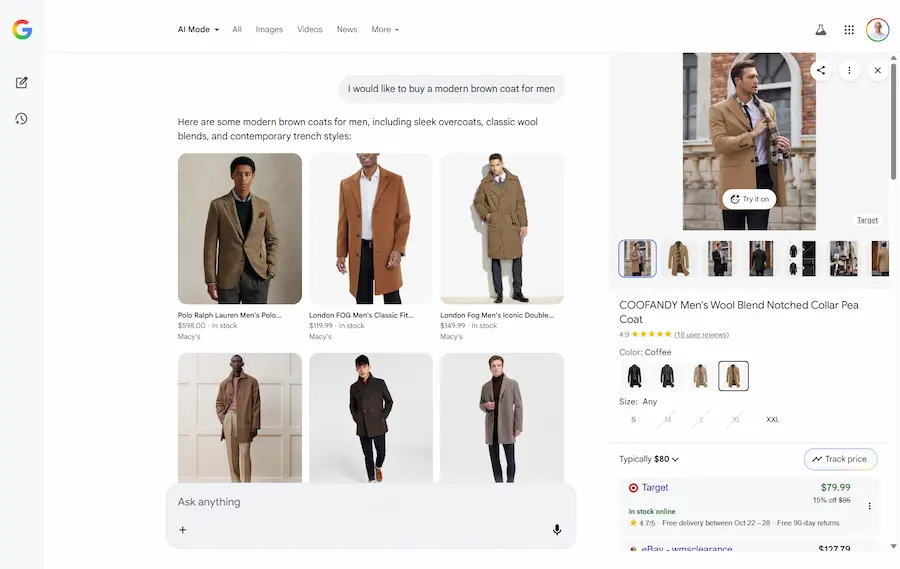
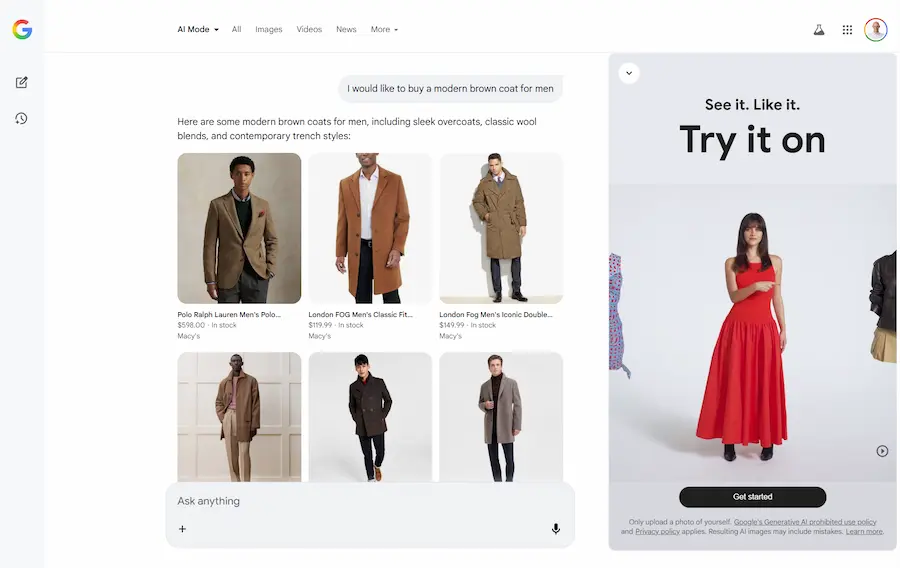
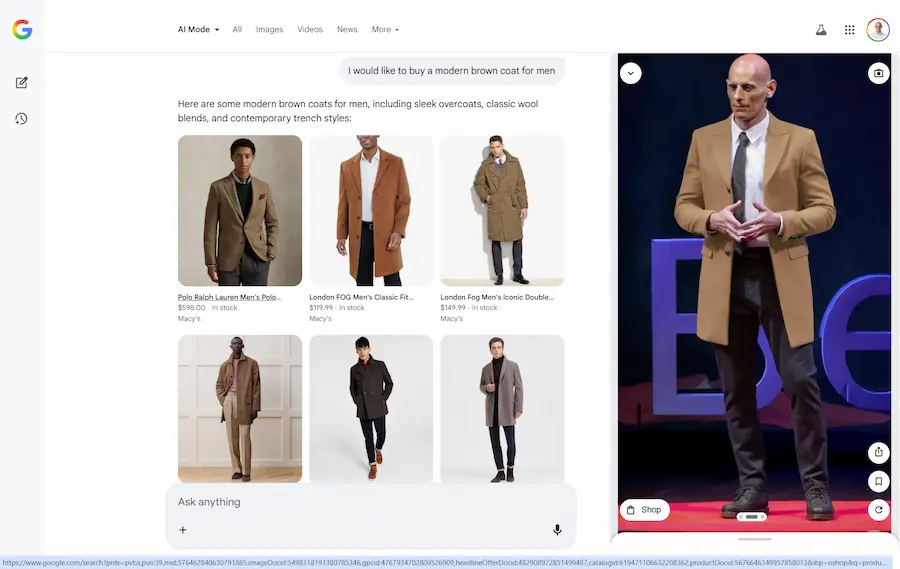
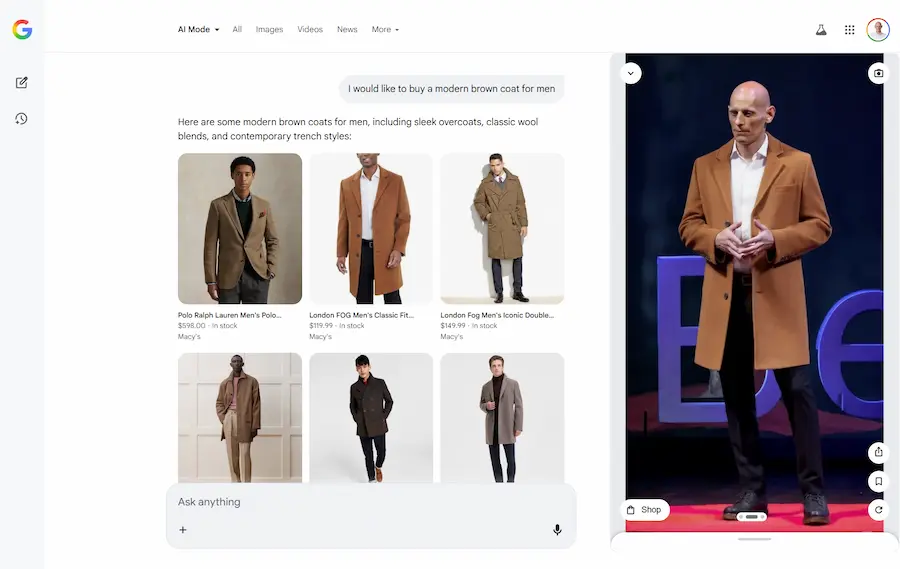
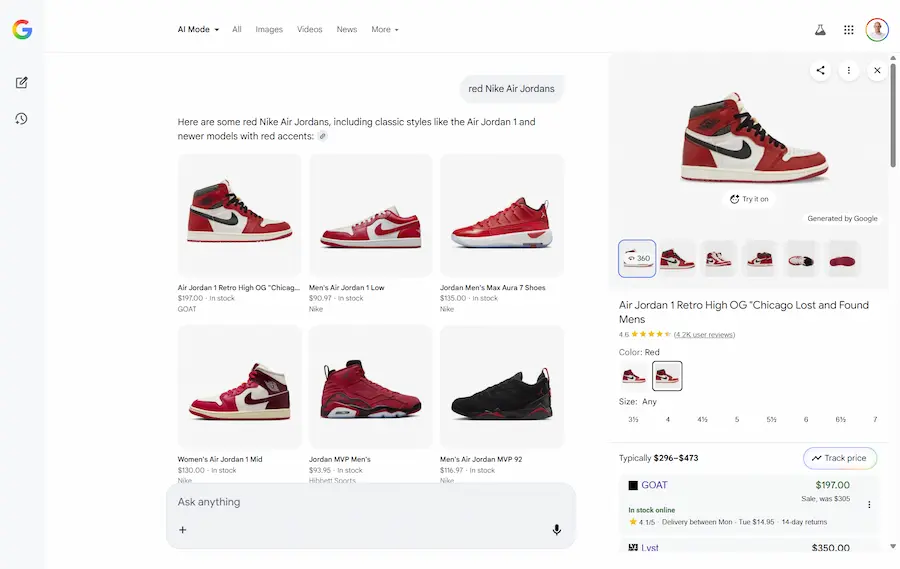
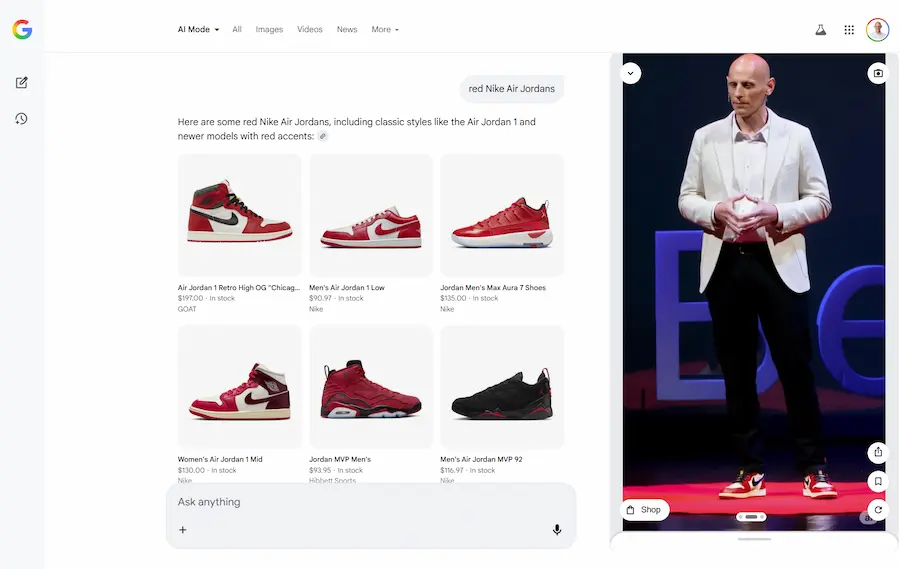
Il Virtual Try-On nell'AI Mode di Google
La mia immagine rimane a disposizione durante la sessione, quindi, se si cambia prodotto, si può vederlo direttamente indossato.
Un'interfaccia unica e risultati personalizzati. Questa è la direzione della ricerca potenziata dall'AI.
Le altre novità
Google aggiorna anche gli avvisi di prezzo: è ora possibile impostare preferenze su taglia, colore e budget desiderato. L’utente riceverà notifiche automatiche appena un prodotto corrisponde ai propri criteri.
In arrivo, inoltre, una nuova modalità che suggerisce outfit e idee per l'arredamento partendo da una semplice descrizione. L'AI genererà abbinamenti visivi con prodotti acquistabili selezionati tra miliardi di articoli nel catalogo Google.
Gemini: grounding with Google Maps
Una nuova funzionalità nell'API di Gemini: il Grounding with Google Maps.
Per me, uno dei rilasci più interessanti dell'anno.
L'applicazione nelle immagini è un esempio di utilizzo: l'ho creata su AI Studio, partendo dall'esempio nella documentazione. È un assistente (rudimentale ) per la visita delle città.
Oltre al server MCP, quindi, ora è possibile usare direttamente il tool nelle chiamate a Gemini.
Il Grounding with Google Maps permette di creare Agenti AI e applicazioni arricchite con dati geospaziali aggiornati, collegando Gemini con le informazioni di oltre 250 milioni di luoghi.
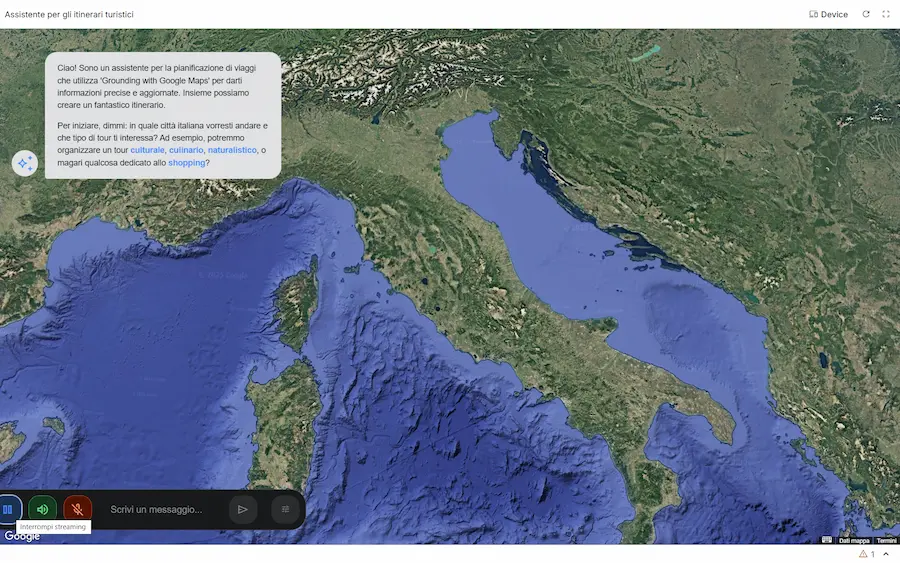
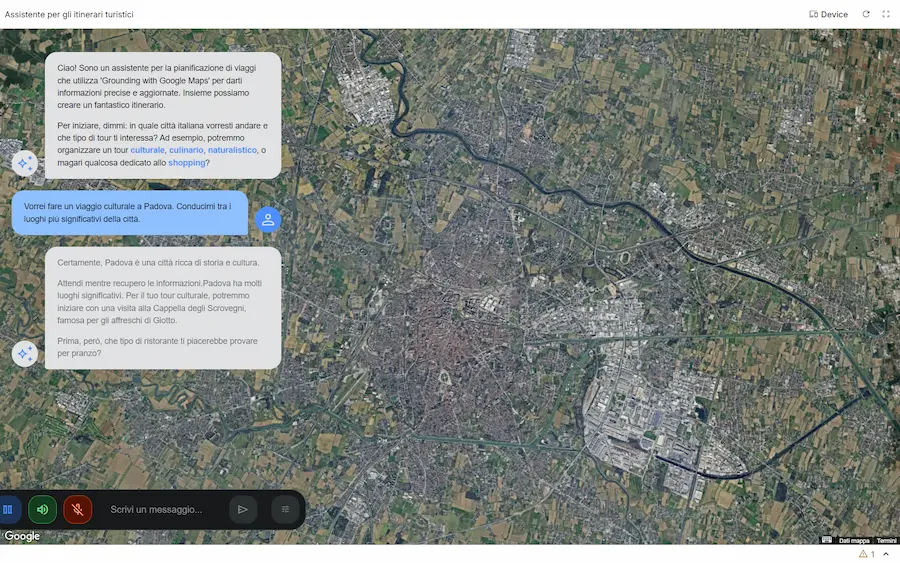
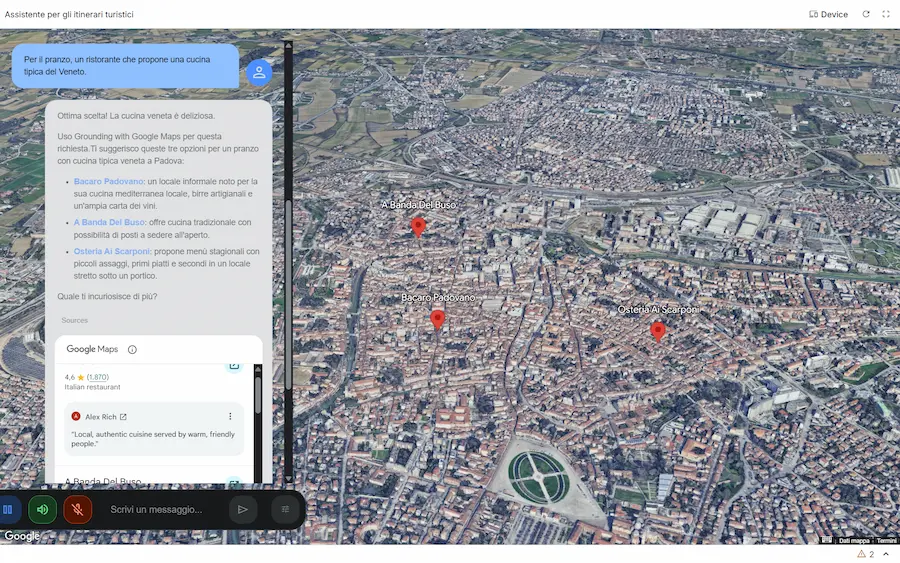
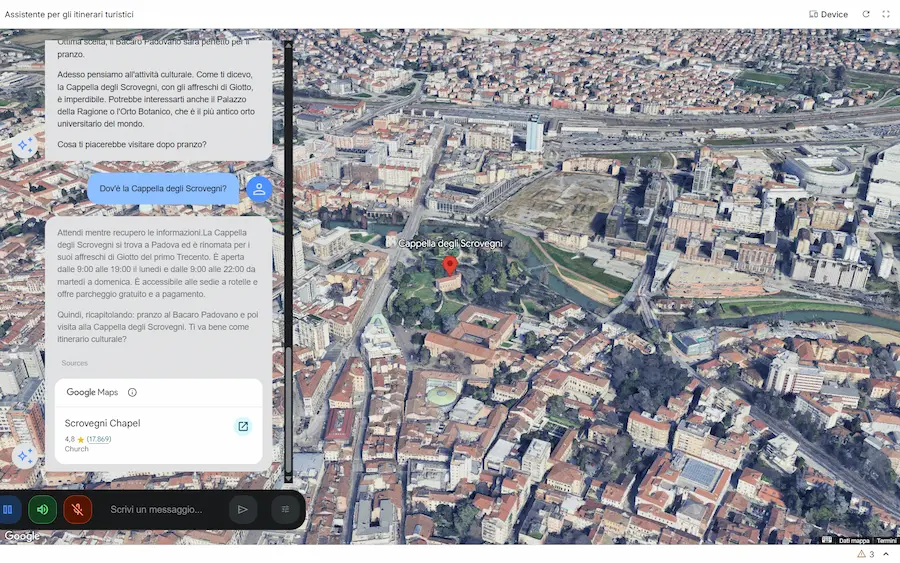
Un'applicazione che sfrutta il Grounding with Google Maps
La novità consente all'AI di generare risposte contestuali legate a una posizione geografica, utilizzando anche recensioni, orari di apertura, coordinate e dettagli visuali tramite widget interattivi.
Questa integrazione apre nuove possibilità per settori come travel, real estate, logistica e retail, permettendo la creazione di itinerari personalizzati, raccomandazioni localizzate e risposte ultra-specifiche basate su dati reali e aggiornati. È anche possibile combinare i dati di Maps con quelli di Google Search per risposte ancora più precise e pertinenti.
La forza dell'ecosistema Google si concretizza sempre maggiormente: quale altro player avrebbe questa possibilità?
Nano Banana VS Imagen 4
Ultimamente si parla solo di Gemini 2.5 Flash Image (Nano Banana), ma Google ha anche Imagen 4. Qual è la differenza?
Imagen 4 è il modello text-to-image più avanzato, progettato per generare immagini di qualità fotografica e testo perfettamente leggibile all’interno delle scene. È disponibile in più varianti (Fast, Standard e Ultra) e punta tutto su fedeltà visiva, resa dei dettagli e tipografia impeccabile.
Rispetto a Flash Image, che nasce per la velocità e per l’editing interattivo (come aggiungere o rimuovere oggetti, fondere immagini o mantenere coerenza di personaggi), Imagen 4 è dedicato alla generazione pura: poster, visual pubblicitari, concept di prodotto, design e illustrazioni ad altissima definizione.




Immagine generate usando Imagen 4 Ultra
Ho generato le immagini usando Imagen 4 Ultra, con output a 2K. Direi che la qualità è l'aderenza ai prompt sono a livelli molto elevati.
In sintesi, Gemini Flash Image è lo strumento per iterare e modificare velocemente; Imagen 4 Ultra è quello da usare quando conta la perfezione visiva.
NotebookLM: l'evoluzione delle video overviews
NotebookLM introduce una nuova evoluzione nelle Video Overview: grazie a Gemini 2.5 Flash Image (Nano Banana), i video diventano non solo informativi ma anche visivamente più coinvolgenti.
L'ho provato. Ho generato questa video overview partendo da un libro sul Deep Learning, richiedendo al modello un output per bambini delle scuole medie. Non è perfetto, ma la qualità aumenta.
Un esempio di Video Overview su NotebookLM
Ora è possibile scegliere tra sei stili grafici, tra cui watercolor, papercraft e anime, per personalizzare le presentazioni, rendendo più chiari e memorabili anche i contenuti.
È stato anche aggiunto un nuovo formato: accanto ai video "Explainer", pensati per un'analisi completa, arriva "Brief", una versione breve e immediata per cogliere i concetti chiave in pochi istanti.
In arrivo anche la funzionalità dedicata a generare le infografiche.
AI Mode: nuove funzionalità
Ogni volta che apro l'AI Mode di Google negli USA trovo nuove funzionalità, arricchite dall'AI Generativa.
- Ora permette l'upload di documenti, che il sistema elabora, e integra con la ricerca per dare delle risposte alle query.
- È stato integrato Gemini 2.5 Flash Image (Nano Banana) per l'editing e la generazione di immagini.
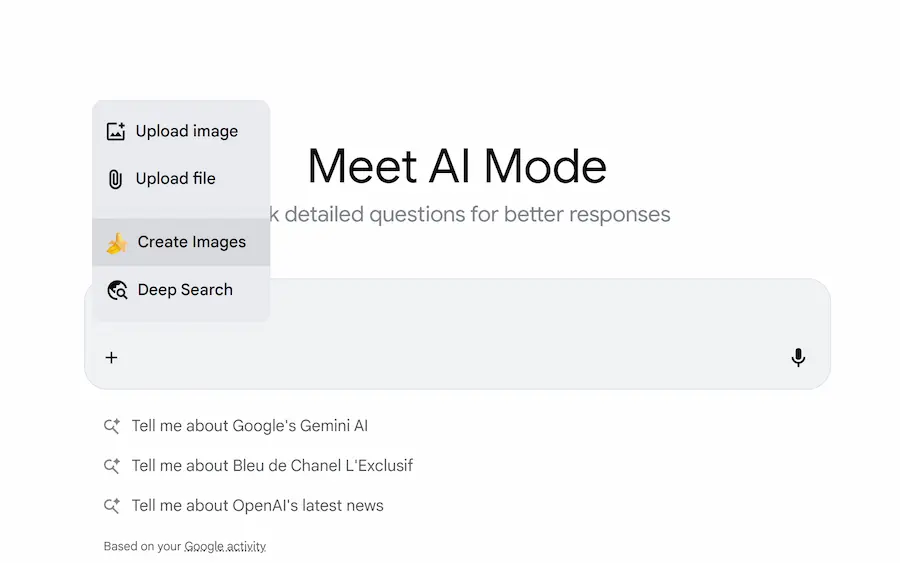
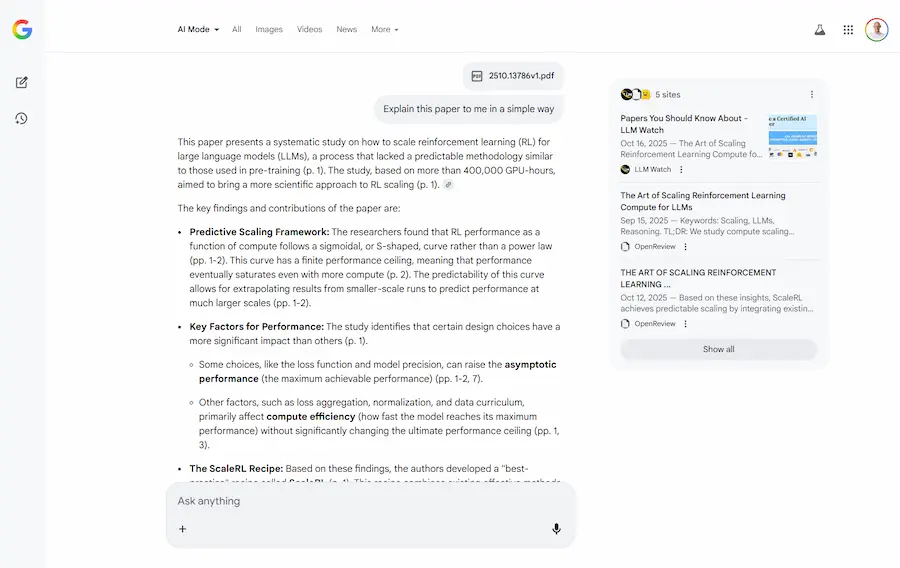
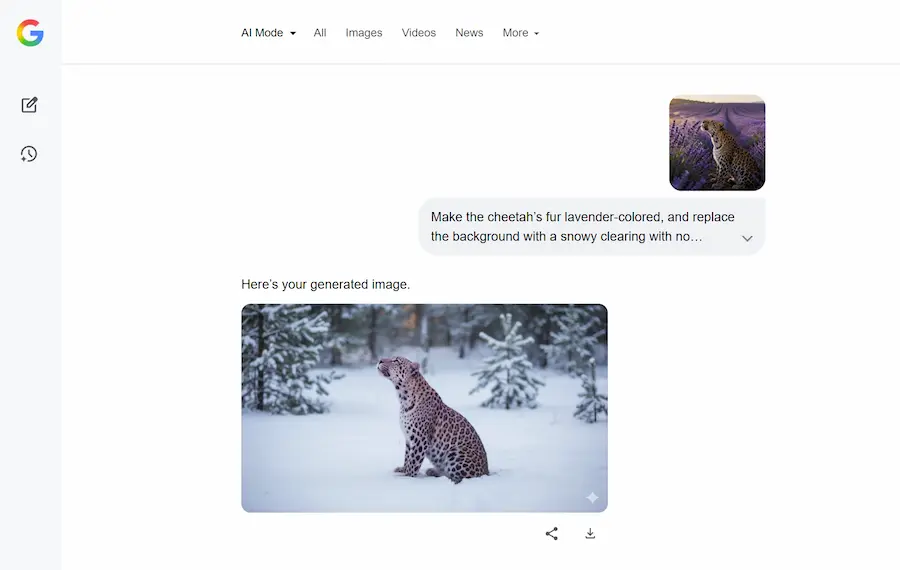
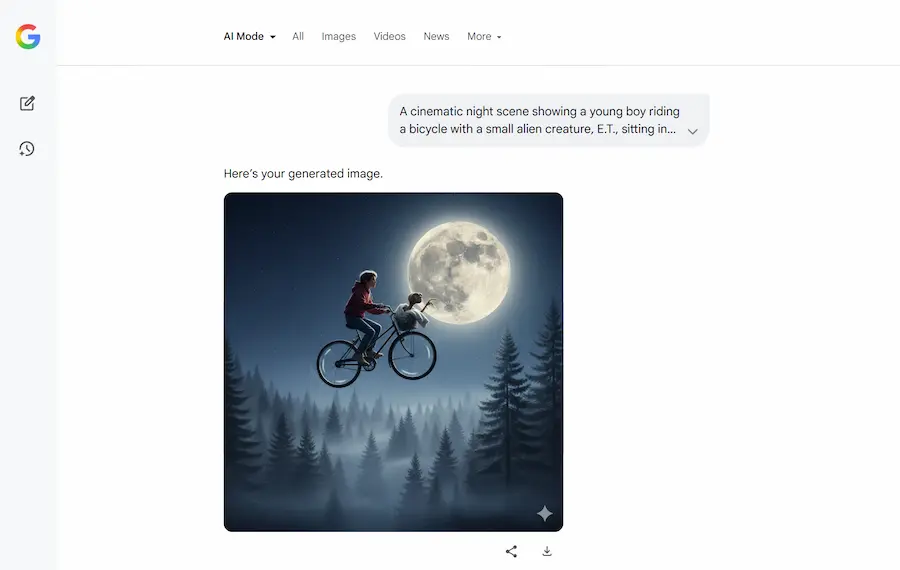
AI Mode: nuove funzionalità
Per un attimo ho dimenticato di aver iniziato l'esperienza dal "campo di ricerca" di Google.
Quando ha senso usare workflow multi-agente?
Quando un task non è una semplice esecuzione, ma richiede fasi di valutazione, decisione e auto-correzione.
In pratica, quando abbiamo bisogno che l'AI non si limiti a "fare", ma anche a "pensare" come un team.
Con LangGraph, uno dei framework più potenti per questo scopo, costruiamo questi flussi di lavoro come un grafo:
- i nodi sono gli agenti specializzati (un ricercatore, un copywriter, un revisore);
- le connessioni tra i nodi (edges) definiscono come collaborano gli agenti.
Il sistema è "stateful": tutti gli agenti lavorano su uno "stato" condiviso (AgentState), una sorta di lavagna di progetto che viene aggiornata a ogni passaggio.
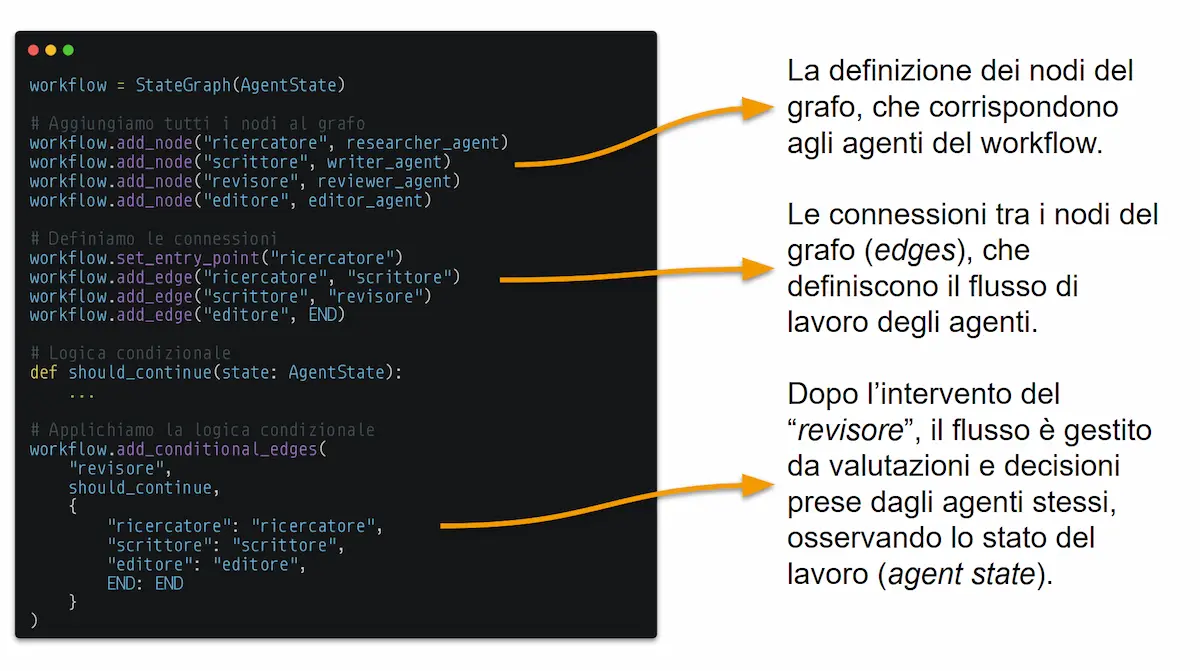
L'esempio nell'immagine mostra un flusso di revisione intelligente:
- Il Ricercatore raccoglie le informazioni.
- Lo Scrittore crea una bozza basandosi su quelle informazioni.
- Il Revisore valuta il lavoro. Se non è perfetto, può decidere autonomamente se rimandare il compito allo Scrittore (per problemi di forma) o addirittura al Ricercatore (per lacune informative), generando un piano d'azione specifico per ciascuno.
- Se il team entra in un loop, un Editore finale interviene per finalizzare il lavoro.
Il risultato? Un processo dinamico e resiliente, in cui l'AI gestisce la complessità in autonomia.
BlockRank di Google DeepMind
Google torna a spingere sull'evoluzione del ranking semantico, sfruttando la potenza dei LLM.
Search Engine Journal ha commentato il nuovo paper di Google DeepMind, "Scalable In-context Ranking with Generative Models", in cui viene presentato BlockRank: un metodo pensato per rendere il reranking semantico dei LLM più efficiente.

Il lavoro affronta un limite noto: usare i LLM per leggere e ordinare molti documenti insieme (il cosiddetto in-context ranking) è potente, ma estremamente costoso. BlockRank risolve il problema imponendo una struttura di attenzione "a blocchi": ogni documento "guarda" solo sé stesso e le istruzioni, mentre la query può "vedere" tutto. In più, una loss contrastiva insegna al modello a concentrare l’attenzione sui documenti davvero rilevanti.
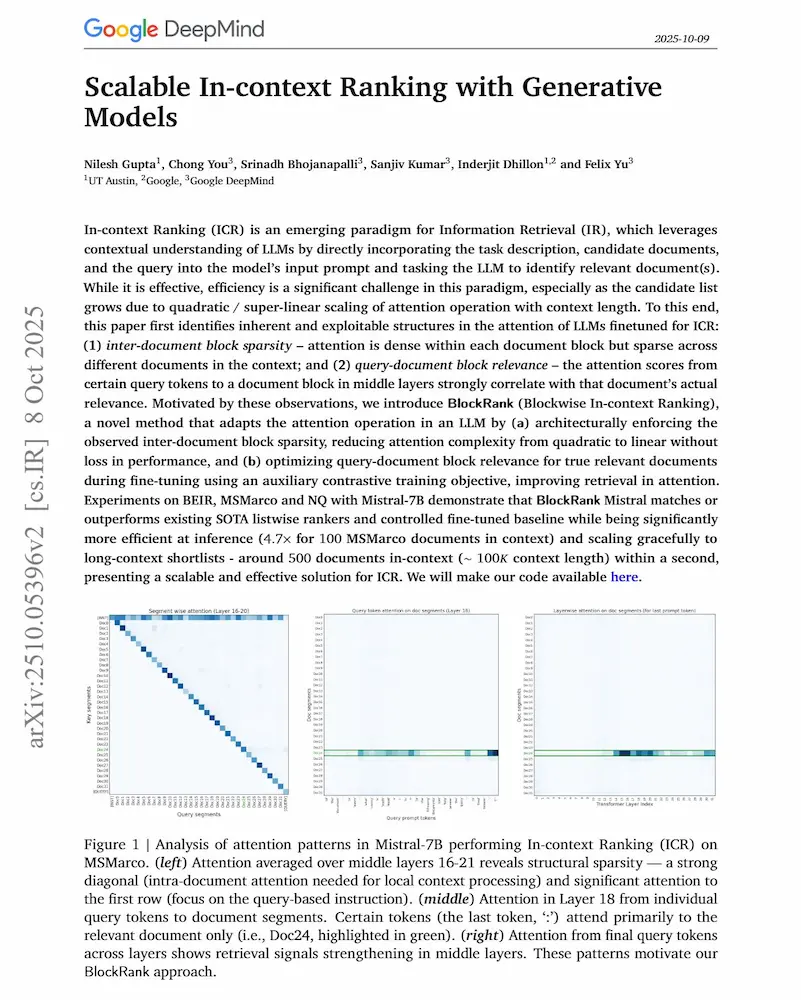
Il risultato è notevole: prestazioni allo stato dell’arte su benchmark come BEIR e MS MARCO, con una riduzione dei tempi di inferenza fino a 4,7 volte e scalabilità lineare fino a 500 documenti nel contesto.
SEJ descrive BlockRank come un passo avanti nel rendere il ranking semantico più accessibile ed efficiente, aprendo la strada a un’integrazione più profonda dei LLM nei sistemi di ricerca.
Ma attenzione: i reranker semantici sono già parte dei motori di ricerca moderni. Nel nostro laboratorio sperimentiamo con questi modelli (es. Semantic-ranker di Google) da diversi mesi, con risultati molto interessanti.
La novità di BlockRank non è tanto cosa fa, quanto come lo fa, spostando il concetto di reranker dentro l’architettura stessa del modello linguistico.
Un passo verso un futuro in cui capire e ordinare l’informazione diventeranno due facce della stessa operazione cognitiva.
AI Studio e il Vibe Coding
La nuova esperienza di "Vibe Coding" di AI Studio è molto interessante.
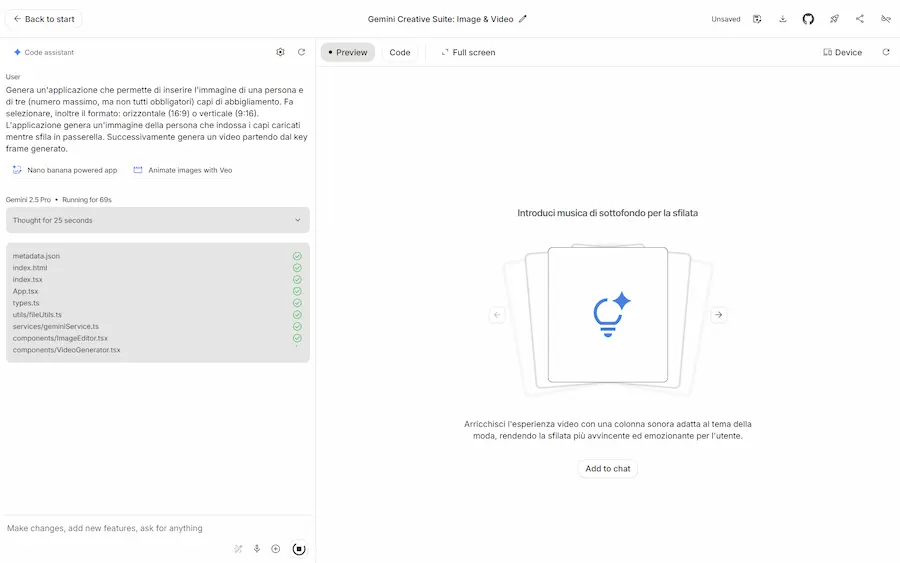
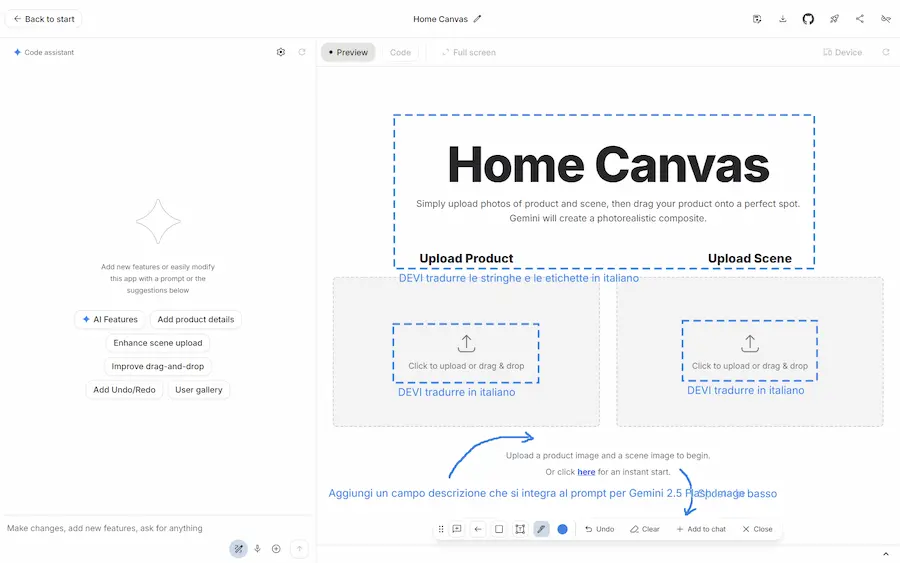
AI Studio e il "Vibe Coding"
- Permette di aggiungere funzionalità all'applicazione attraverso blocchi preimpostati che arricchiscono il prompt.
- Mentre il modello genera il codice, fornisce suggerimenti di integrazione, che si trasformano in istruzioni con un clic.
- Grazie all'Annotation Mode è possibile indicare le modifiche all'agente attraverso annotazioni direttamente nella preview.
Piccoli cambiamenti per grandi semplificazioni.
Quando l'AI impara a migliorarsi da sola: Google presenta VISTA
Ho sviluppato un sistema multi-agent che lavora con la stessa logica, ma l'ho abbandonato per l'elevato consumo di token. Infatti, nel paper, di Google è uno dei limiti che viene messo in evidenza.
I modelli di generazione video stanno diventando sempre più potenti, ma restano fragili: basta variare il prompt per ottenere risultati completamente diversi.
Il team di Google e della National University of Singapore ha presentato VISTA (Video Iterative Self-Improvement Test-time Agent), un sistema che ottimizza autonomamente i video generati da modelli text-to-video come Veo 3, senza bisogno di riaddestramento.

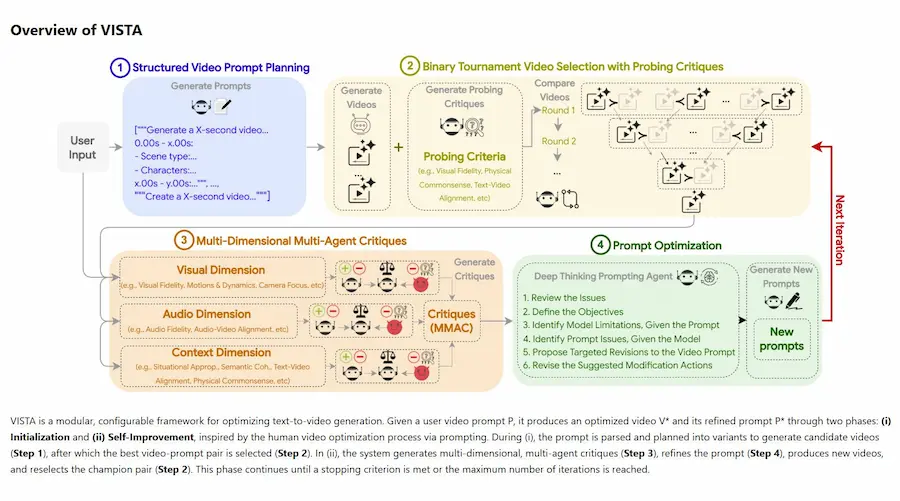

VISTA (Video Iterative Self-Improvement Test-time Agent)
Il sistema funziona come una piccola squadra di agenti intelligenti che collaborano tra loro:
- un pianificatore che scompone il prompt in scene e dettagli visivi, audio e contestuali;
- un sistema di giudici che valuta i video generati e seleziona il migliore in tornei a confronto diretto;
- una triade di critici (visivo, audio, contesto) che analizza punti di forza e debolezza;
- un agente che riscrive il prompt in modo mirato, migliorando il risultato a ogni ciclo.
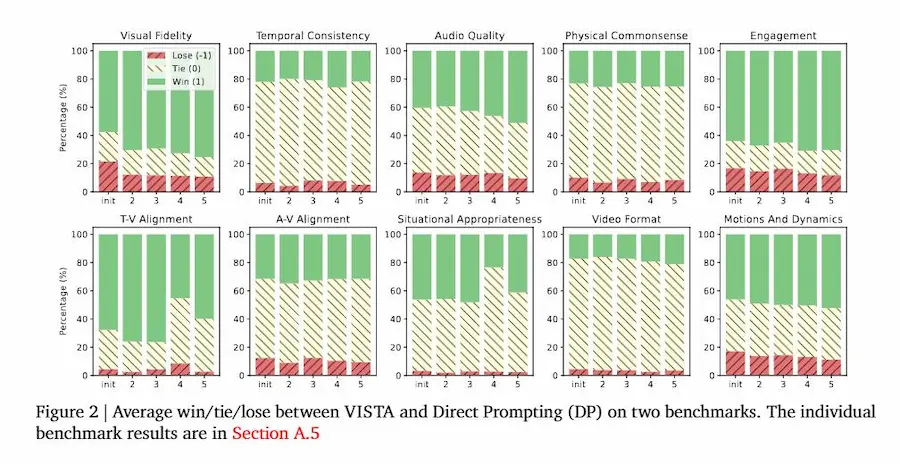
Il risultato? Video più coerenti, realistici e fedeli alle intenzioni dell’utente. Nei test, VISTA ha superato i metodi precedenti fino al 60% di win rate, con una preferenza umana del 66% sui video generati.
Un passo deciso verso un’AI capace di autovalutarsi e crescere con ogni tentativo.
Claude Skills
Claude Skills è una nuova funzionalità introdotta da Anthropic per rendere l'AI altamente personalizzabile in contesti professionali specifici.
Le Skills sono strutture modulari che includono istruzioni, codice e risorse. Quando vengono attivate, consentono a Claude di operare come uno specialista, eseguendo compiti complessi secondo procedure ben definite.
A differenza di semplici prompt, le Skills si comportano come pacchetti di competenze che Claude può attivare solo quando necessario. Questo le rende efficienti e scalabili: si costruiscono una volta sola e si riutilizzano in ambienti diversi. Dalle app Claude, all’ambiente Claude Code, fino alle integrazioni via API.
Le Skill di Claude
La forza di questo approccio risiede nella sua modularità. Claude può selezionare e combinare autonomamente più Skills per affrontare attività articolate, come l’analisi avanzata di fogli di calcolo, la generazione di documenti aderenti a brand guideline aziendali o l’esecuzione di codice specifico in un ambiente sicuro. Non si tratta quindi solo di automazione, ma di trasferimento di conoscenza operativa in un formato strutturato.
La creazione delle Skills è supportata da strumenti integrati. Non è necessario intervenire manualmente nei file di configurazione: basta descrivere un flusso di lavoro, e Claude genera automaticamente la struttura corretta. Questo rende accessibile la creazione anche a chi non ha un profilo tecnico avanzato.
Gemini CLI punta a diventare il terminale di riferimento
L'obiettivo? Trasformare Gemini nel terminale di riferimento, e non in un software che si apre da terminale.
L'ultima evoluzione di Gemini CLI, infatti, segna un passo significativo verso un’esperienza da terminale totalmente integrata, con la possibilità di eseguire comandi interattivi complessi tipici del terminale restando all’interno del contesto della CLI.
Gemini CLI: terminale di riferimento
Questo cambiamento non riguarda solo la comodità, ma una trasformazione architetturale: Gemini CLI ora gestisce una sessione di terminale virtuale in background, usando un sistema di serializzazione che cattura e restituisce lo stato del terminale in tempo reale, incluso testo, colori e movimenti del cursore.
Il risultato è una comunicazione bidirezionale completa con l’ambiente terminale. L’utente può digitare, ricevere output ricco, ridimensionare la finestra, e continuare a lavorare come se fosse in un terminale nativo, ma con tutti i vantaggi dell’ambiente contestuale di Gemini.
Come usare un server MCP in un Agente AI remoto, senza dover acquistare o configurare un server?
Vediamo una soluzione semplicissima.
Solitamente, i servizi che rilasciano un Server MCP, lo fanno attraverso una libreria da installare in locale. Una volta avviato, quel server MCP è usabile da agenti locali (es. Gemini CLI, Claude Desktop, Codex CLI) o IDE (es. Cursor).
Per usarlo su Agenti AI remoti, si dovrebbe installare il server MCP in una macchina remota, renderlo disponibile attraverso un endpoint (un URL che lo richiama). Ad esempio, potremmo ospitarlo su Cloudflare Workers per renderlo accessibile via URL pubblico.
In fase di prototipazione, o per utilizzi rapidi, invece, sto usando ngrok: si tratta di un servizio che permette di rendere raggiungibile il server MCP locale da un endpoint remoto. E questo ci permette di usarlo, ad esempio, come server MCP su Agent Builder di OpenAI, e in qualunque agente remoto che si interfacci con il protocollo MCP.
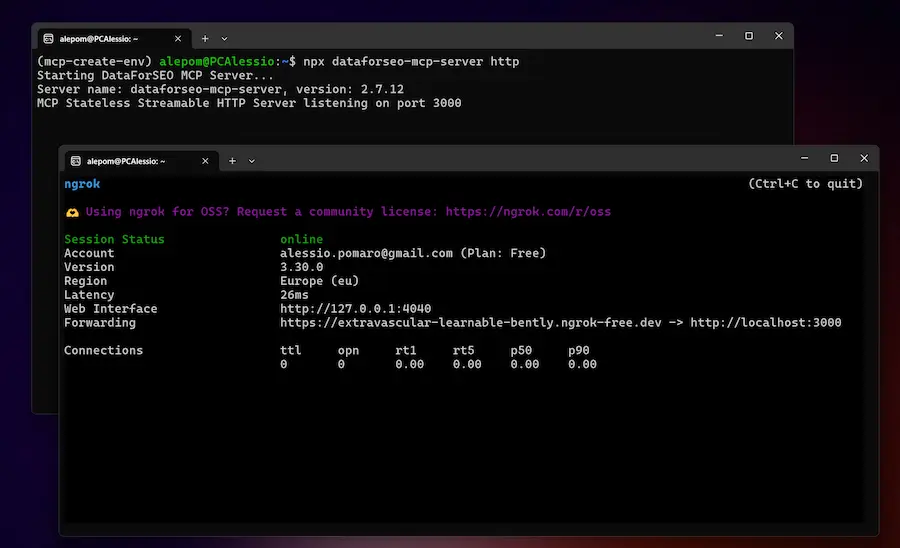
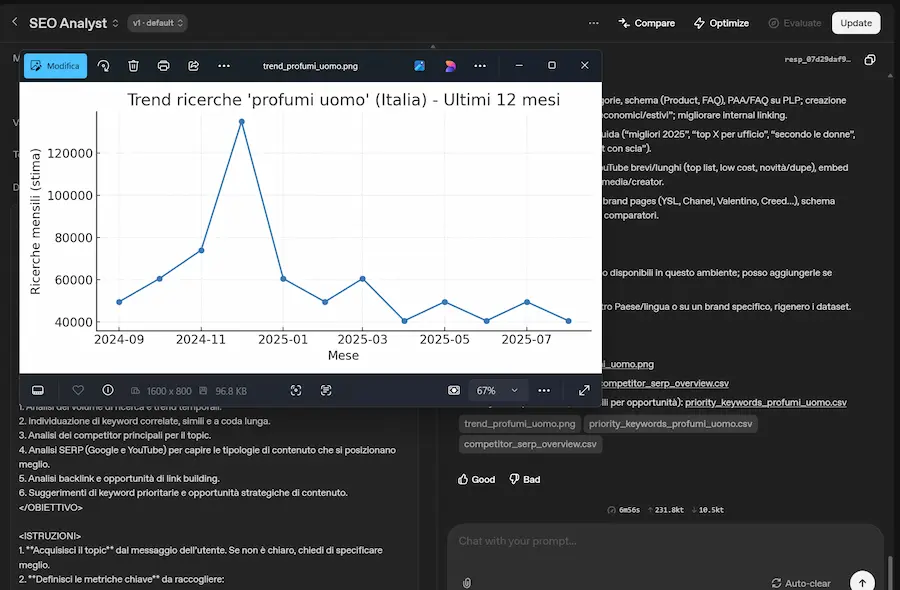
Un esempio dei un server MCP locale usato da remoto
Nelle immagini si vede come faccio funzionare il server MCP di DataForSEO in locale, con ngrok genero un endpoint raggiungibile dall'esterno, e poi uso l'MCP nel Playground di OpenAI, in un Agente che lo usa per estrarre dati per un'analisi di mercato.
- Pro del sistema: è semplicissimo da usare (un comando da console), e l'utilizzo free è più che sufficiente per prototipare o per usarlo in Agenti che usiamo in attività personali.
- Contro del sistema: l'endpoint non è fisso, ma varia ad ogni avvio del servizio.
In sintesi: con ngrok possiamo sperimentare con server MCP in modo immediato, senza infrastrutture dedicate.
MCP e scoperta dinamica dei tool
Una delle caratteristiche più interessanti dell'uso di server MCP (Model Context Protocol) è la cosiddetta "scoperta dinamica degli strumenti".
In pratica, l'agente AI può interrogare il server per scoprire quali tool (funzioni) ha a disposizione e come utilizzarli.
Quando il server MCP si connette all'agente, espone automaticamente la lista dei tool disponibili (si vede nell'immagine), ognuno corredato da una descrizione, la firma dei parametri di input e le informazioni su come viene prodotto l'output.
Quando l’utente, o un altro sistema, invia una richiesta all'agente, il LLM seleziona in modo autonomo i tool necessari basandosi sulle descrizioni fornite, genera gli input corretti e integra le risposte ottenute direttamente nel proprio contesto. Questo processo può avvenire non solo in risposta a una richiesta esterna, ma anche durante la fase di "reasoning" del modello, in modo completamente dinamico.
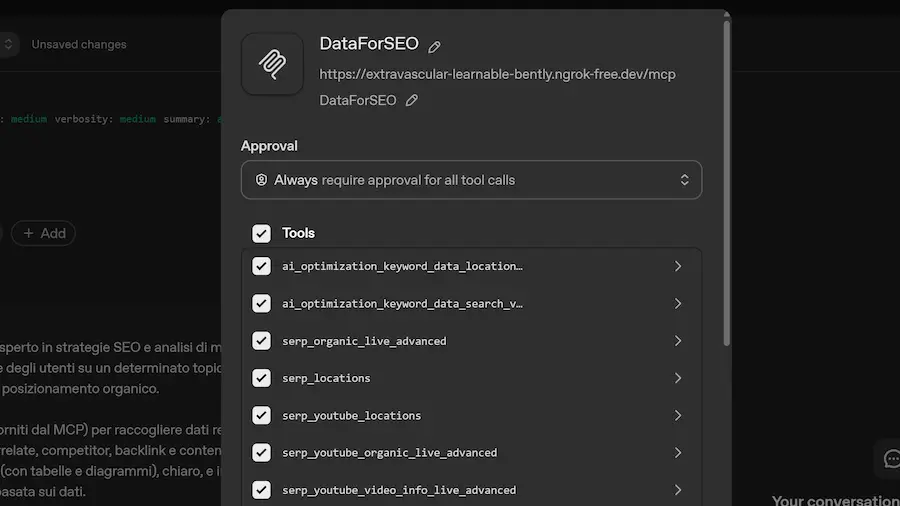
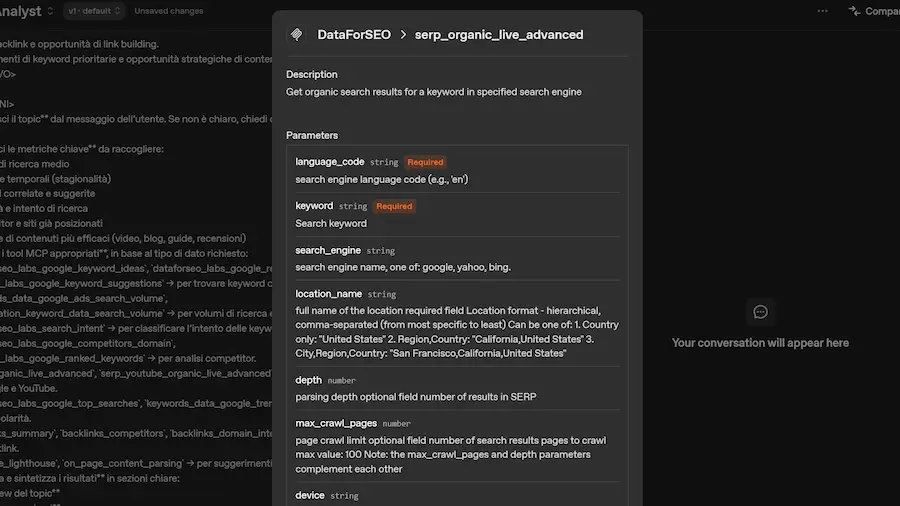
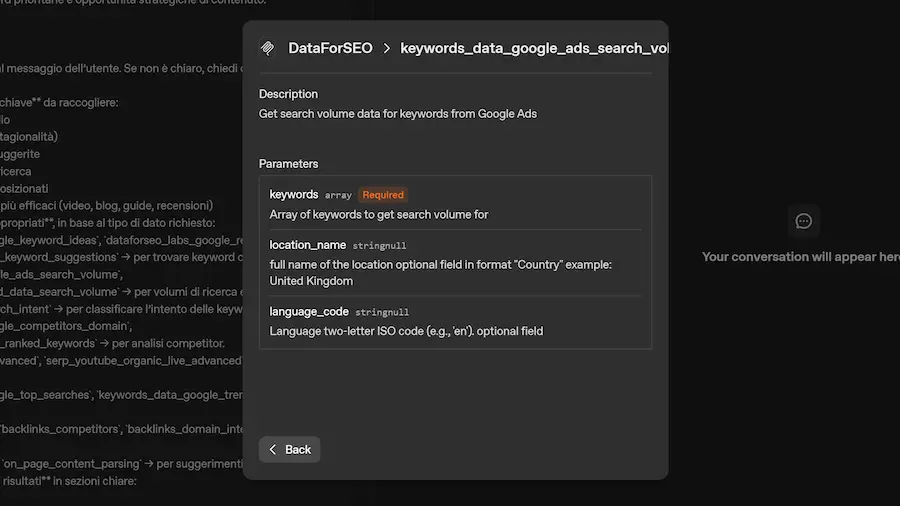
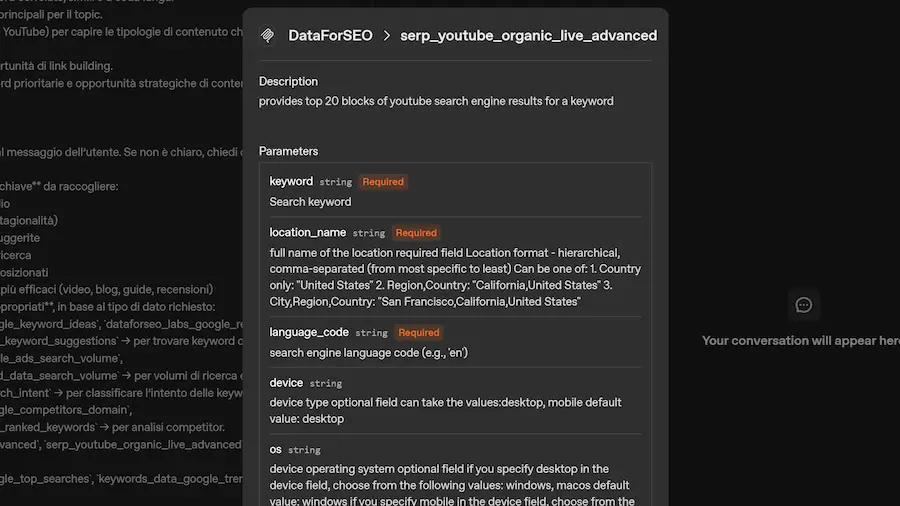
MCP e scoperta dinamica dei tool
Tutto ciò apre possibilità molto interessanti: l'agente può scoprire e combinare nuove modalità d'uso dei servizi, andando oltre i flussi predefiniti.
Nell'esempio mostrato, il server MCP collegato espone 67 tool, ognuno corrispondente a una funzionalità API del servizio, costantemente aggiornate e ampliate.
Ecco perché l’accoppiata Agent + MCP rappresenta un approccio estremamente potente.
Nota: è però fondamentale mantenere un controllo accurato sulle azioni dell'agente, per ottimizzare il suo comportamento e trovare il giusto equilibrio tra autonomia e affidabilità.
La Deep Research di Qwen si evolve
Con la nuova versione, oltre al report, permette di generare una pagina web organizzata con le informazioni raccolte, e un podcast a due voci.
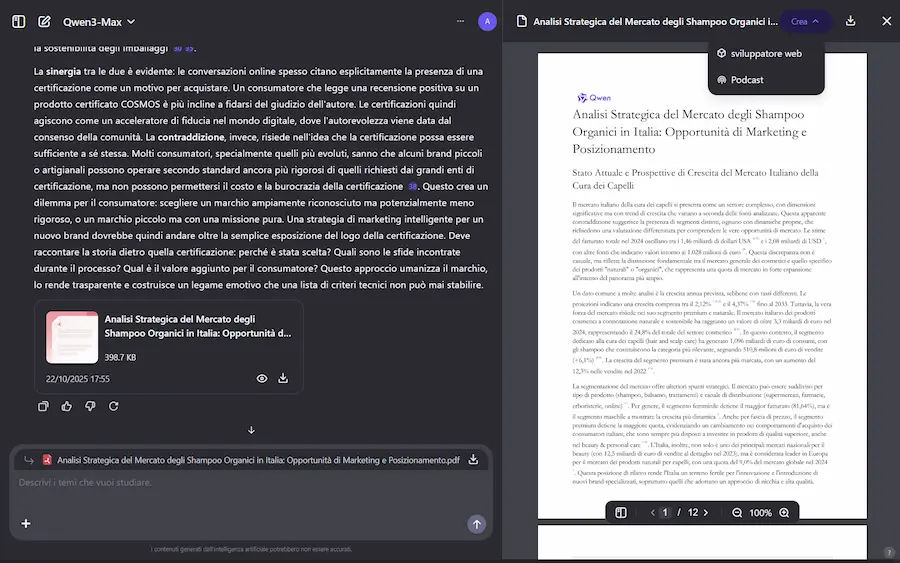
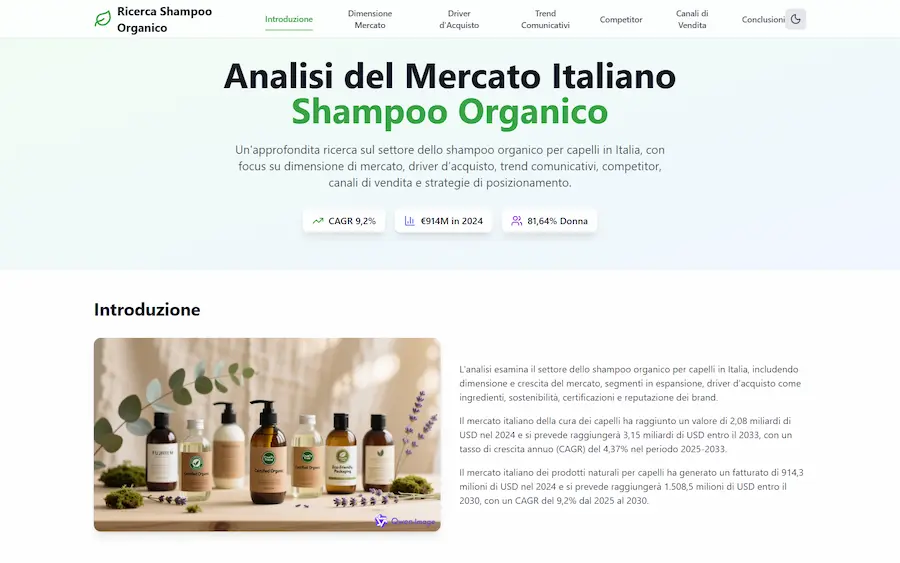
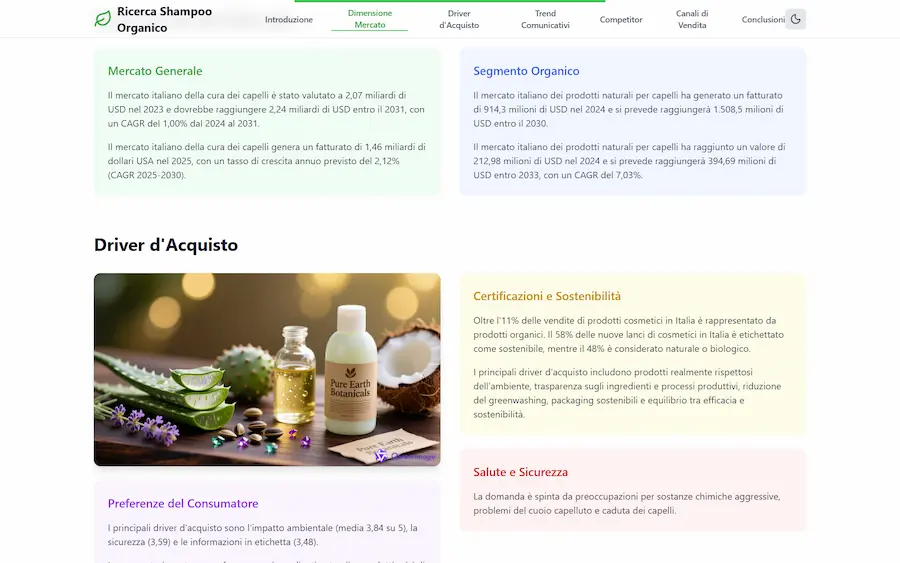
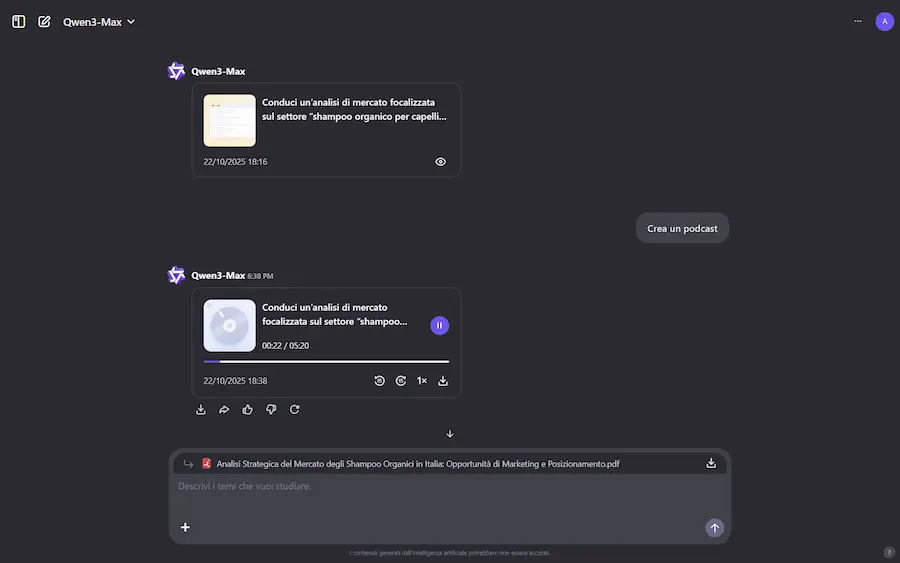
La Deep Research di Qwen
Il tutto, sfruttando Qwen3-Coder, Qwen-Image e Qwen3-TTS.
Sistemi come Qwen e Kimi, secondo me, stanno crescendo in maniera straordinaria, offrendo sistemi gratuiti ad elevato potenziale.
Figure 03
I progressi della Physical AI rappresentano un
segnale che rende immediatamente comprensibile la trasformazione che stiamo vivendo.
Figure03 è la terza generazione di robot umanoidi progettata da Figure, ed è il primo modello nato non come prototipo ma come prodotto scalabile, pensato per apprendere, adattarsi e operare nel mondo reale. Alla base c’è Helix, un sistema AI integrato visione-linguaggio-azione, attorno al quale è stato ridisegnato ogni aspetto hardware e software del robot.
La presentazione di Figure 03
Il nuovo sistema visivo permette una percezione densa e stabile dello spazio, anche in ambienti complessi come le abitazioni. Le mani, dotate di sensori tattili sviluppati internamente, riescono a cogliere variazioni minime di forza e pressione, consentendo una manipolazione fine di oggetti delicati o irregolari. L’intero sistema è progettato per apprendere in modo continuo attraverso il trasferimento ad alta velocità di grandi volumi di dati.
Nel contesto domestico, Figure 03 introduce miglioramenti significativi in termini di sicurezza, autonomia e usabilità. Le superfici morbide, i tessuti lavabili, la riduzione del peso e la ricarica wireless integrata ne fanno un dispositivo pensato per coesistere con le persone. Anche il sistema audio è stato riprogettato per favorire interazioni vocali più naturali, grazie a speaker più potenti e microfoni ottimizzati.
A differenza delle generazioni precedenti, è stato concepito fin dall’inizio per la produzione di massa. L’intero design è stato adattato a processi industriali come lo stampaggio e la pressofusione, con un drastico calo nei costi e nei tempi di assemblaggio. La nascita di una nuova filiera produttiva, insieme alla creazione dello stabilimento BotQ, rende possibile una scala di produzione mai raggiunta prima in ambito umanoide.
Figure 03 non è un semplice avanzamento ingegneristico. È una piattaforma progettata per operare nel mondo così com’è, aprendo una nuova fase nella coesistenza tra intelligenza artificiale, forma fisica e realtà quotidiana.
Cognee: memoria strutturata per Agenti AI
Quanto meglio risponderebbe un sistema RAG se lo potenziassimo con un knowledge graph? Molto!
Ho fatto qualche test con Cognee: una libreria open-source che costruisce grafi semantici da documenti testuali e li rende interrogabili come memoria strutturata per agenti AI.
Cognee non è solo una libreria di vector search: è un'alternativa strutturata al RAG tradizionale, basata su grafo + embedding, con il supporto opzionale di ontologie RDF/XML per dare forma e significato al contenuto.
Funziona in locale, si integra in 6 righe di codice, ed è pensata per diventare il layer di memoria degli agenti intelligenti.
Cognee: memoria strutturata per Agenti AI
Nell'esempio, si vede:
- come la libreria crea il knowledge graph partendo dal file dell'ontologia che gli ho messo a disposizione;
- un esempio del knowledge graph che riesce a ricavare direttamente dal contenuto testuale (meno preciso);
- un esempio delle risposte che riesco a ottenere sfruttando l'ontologia, poi senza ontologia e con il grafo generato a partire dal testo, e, infine, con un RAG tradizionale, che usa soltanto il testo nella knowledge..

Le risposte ottenute con l’ontologia sono semanticamente più ricche, meglio strutturate e più pertinenti, soprattutto per domande complesse.
Cognee ha anche un’interfaccia CLI, una UI hosted opzionale (Cogwit), e può connettersi a oltre 30 fonti dati.
DeepSeek-OCR
DeepSeek-OCR introduce un nuovo paradigma per la compressione del contesto nei LLM: la compressione ottica.
Il modello utilizza la modalità visiva come mezzo efficiente per rappresentare lunghi testi, riducendo il numero di token necessari fino a venti volte.
Composto da DeepEncoder e da un decoder Mixture-of-Experts, DeepSeek-OCR è in grado di trasformare pagine di testo in un piccolo insieme di token visivi mantenendo un’elevata precisione di decodifica: circa 97% di accuratezza con una compressione di 10× e 60% con una compressione di 20×.
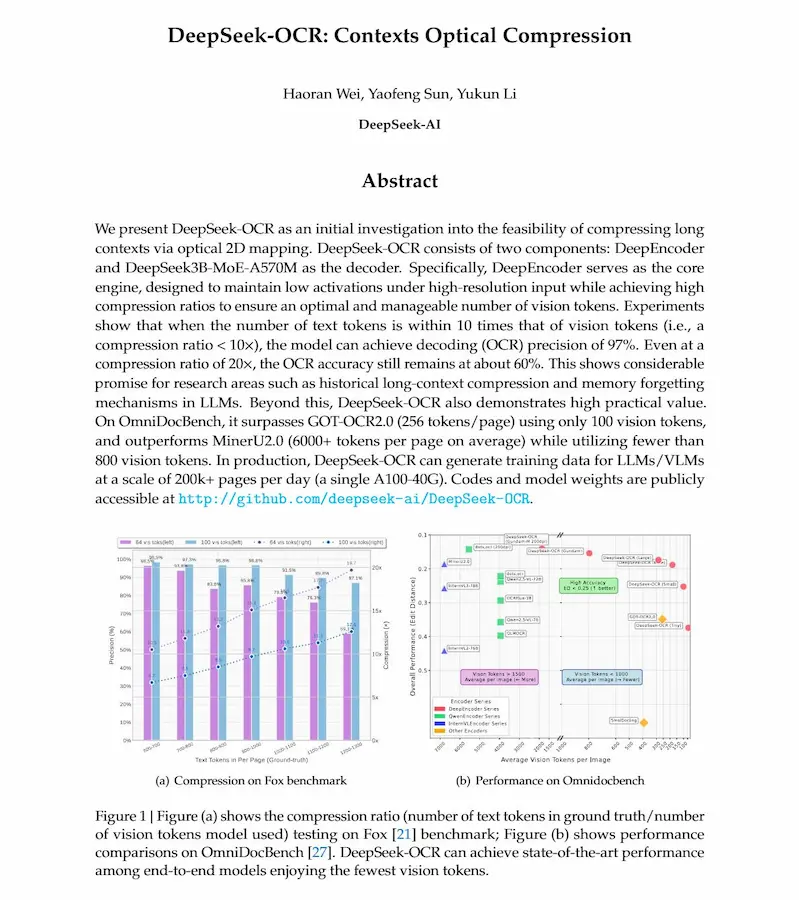
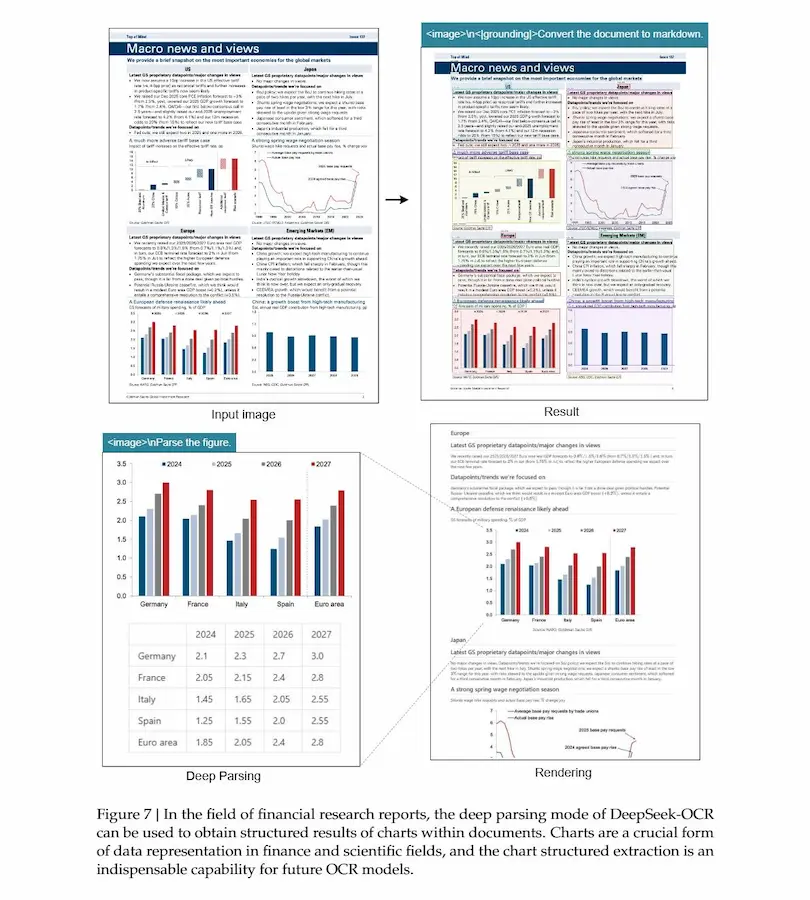


DeepSeek-OCR: il paper
Nei benchmark, supera modelli come GOT-OCR2.0 e MinerU2.0 pur utilizzando una frazione dei token visivi. Oltre all’OCR tradizionale, gestisce parsing di grafici, formule chimiche, figure geometriche e riconoscimento multilingue in quasi cento lingue.
L'approccio apre prospettive per la gestione di contesti lunghi nei LLM, consentendo di archiviare e comprimere otticamente il testo in forma visiva, simulando anche meccanismi di memoria e dimenticanza.
DeepSeek-OCR dimostra che la rappresentazione visiva può diventare un canale efficiente per l’elaborazione testuale su larga scala.
DeepSeek Sparse Attention (DSA)
Mentre annuncia l'arrivo dalle versione V4, DeepSeek rilascia la V3.2-Exp.
Si tratta di un modello sperimentale che nasce da V3.1-Terminus, ma introduce un’innovazione tecnica cruciale: la DeepSeek Sparse Attention (DSA).

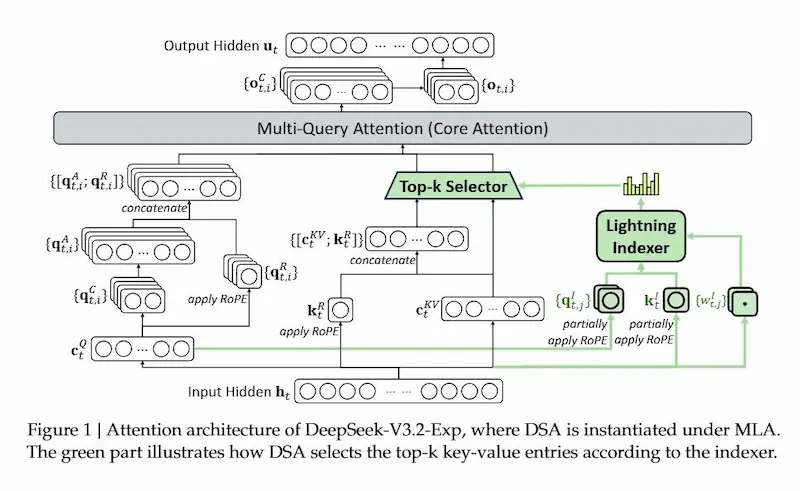
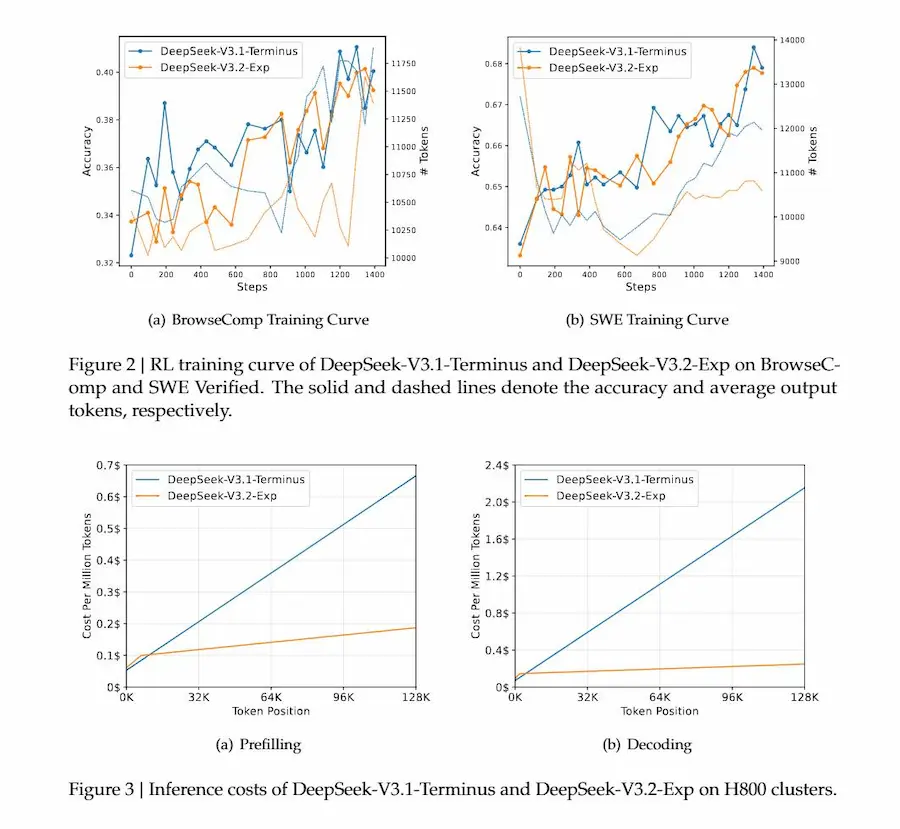
DeepSeek Sparse Attention (DSA)
Con DSA il modello non deve più confrontare ogni token con tutti gli altri, ma grazie a un lightning indexer riesce a selezionare solo le parti del contesto davvero rilevanti. È un cambio di paradigma nell’uso delle risorse: la complessità dell’attenzione scende da O(L²) a O(Lk), mantenendo quasi intatta la qualità delle risposte.
Il training ha seguito una strategia in due tempi. Prima una fase di warm-up denso per insegnare all’indicizzatore a imitare l’attenzione tradizionale, poi una lunga fase di addestramento con pattern sparsi. Successivamente, il modello è stato rifinito con distillazione da specialisti in vari domini (matematica, programmazione, ragionamento, ricerca) e un’unica fase di reinforcement learning che integra ragionamento, capacità agentiche e allineamento con preferenze umane.
Il risultato è un modello che mantiene prestazioni molto vicine a V3.1-Terminus nei benchmark, con solo lievi cali su compiti di reasoning complesso, compensati da un guadagno enorme in efficienza: costi di inferenza ridotti e maggiore rapidità soprattutto nei contesti lunghi (fino a 128K token).
Accanto al modello, DeepSeek ha pubblicato un paper dettagliato che spiega i meccanismi tecnici della Sparse Attention, insieme al codice e ai kernel ottimizzati in CUDA e TileLang.
Un rilascio che non si limita a proporre un’ottimizzazione pratica, ma che contribuisce anche alla discussione scientifica su come rendere i grandi modelli più scalabili ed economici.
Evoluzioni tecnologiche e i limiti dei LLM
In una recente intervista di Alex Kantrowitz a Dario Amodei, CEO di Anthropic, vengono raccontate alcune evoluzioni tecnologiche e i limiti che accompagnano la crescita dei grandi modelli linguistici.
Intervista di Alex Kantrowitz a Dario Amodei
Riporto alcuni passaggi e riflessioni interessanti.
I LLM imparano nel contesto, non nei pesi. Quando li esponiamo a esempi dentro un prompt, riescono a cogliere schemi, correggere errori, imitare stili. Ma una volta chiusa la sessione, tutto svanisce. I pesi che custodiscono la loro conoscenza restano invariati. È come uno studente che risolve brillantemente un esercizio ma non può conservare l’intuizione per la volta successiva.
Per questo si parla sempre più di un passaggio da “più grande è meglio” a “più strutturato è meglio”.
Aumentare i parametri non basta più: la vera sfida è costruire sistemi che sappiano ragionare, ricordare e adattarsi, mantenendo coerenza e controllo.
Amodei sottolinea che anche senza una memoria permanente il potenziale resta enorme. Le finestre di contesto si allungano e, in teoria, potrebbero arrivare a contenere tutto ciò che un essere umano ascolta in una vita intera. Il limite non è concettuale ma computazionale: quanto costa farlo, e quanto è sostenibile.
Nel frattempo, l’evoluzione si gioca nel modo in cui il modello "pensa" durante l’inferenza: reinforcement learning, ragionamento esplicito, test-time compute, ovvero concedere più cicli di “riflessione” quando serve. È un cambiamento silenzioso ma radicale:
dall’espansione delle reti alla progettazione
di un "processo cognitivo" interno.
L’apprendimento nel contesto dimostra che l’intelligenza artificiale può adattarsi senza cambiare sé stessa. Ma ci ricorda anche che l’adattamento non è ancora apprendimento. La prossima soglia tecnica sarà forse proprio questa: trasformare la memoria temporanea in conoscenza stabile, senza sacrificare sicurezza e trasparenza.
In fondo, la storia dei modelli linguistici è la storia di una mente che sta imparando a ricordare, per ora solo per qualche pagina, domani forse per sempre.
La memoria come strumento di evoluzione
Il paper "ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory" di Google introduce un concetto chiave per lo sviluppo di Agenti AI: la memoria come strumento di evoluzione, non come archivio.
Gli agenti non devono limitarsi a ricordare ciò che hanno fatto, ma a comprendere perché qualcosa ha funzionato o fallito.

ReasoningBank trasforma ogni esperienza in una unità di conoscenza strutturata, una strategia di ragionamento riutilizzabile.
Invece di conservare semplici tracce operative, distilla principi di azione: apprende dalle vittorie e soprattutto dagli errori, affinando progressivamente il proprio modo di pensare.
Questo processo di memoria attiva si combina con il test-time scaling, dove un agente dedica più tempo e risorse a esplorare un compito, traendo segnali contrastivi dalle proprie alternative di ragionamento.
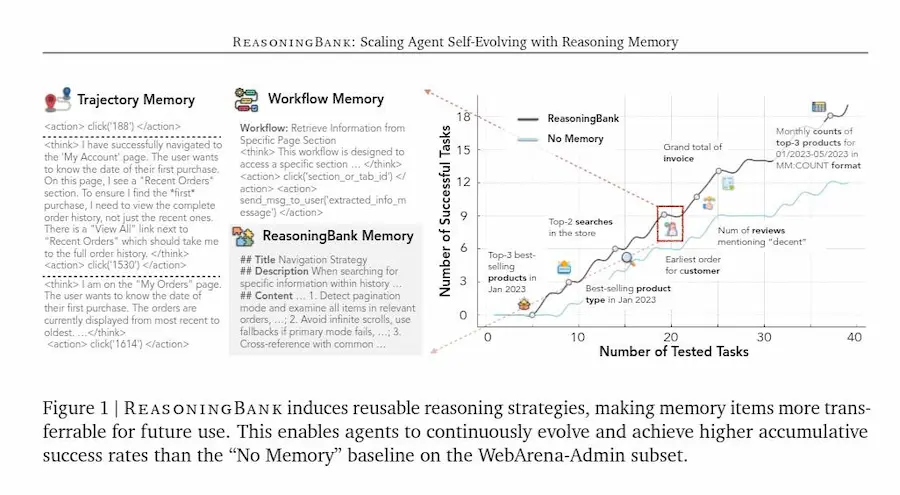
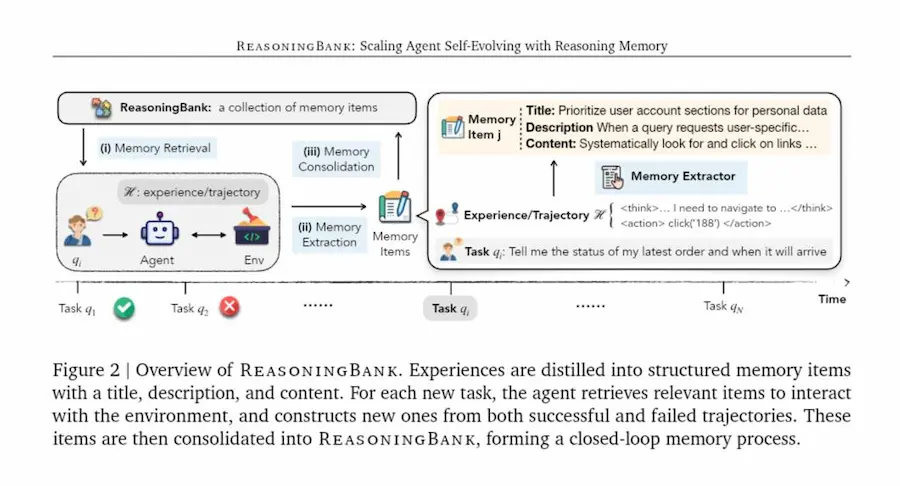
ReasoningBank di Google
La sinergia tra memoria e scaling dà vita a un ciclo virtuoso: esperienze migliori generano memorie più solide, e memorie migliori guidano esplorazioni più efficaci.
Il risultato non è solo un incremento di performance, ma un comportamento emergente che evolve con l’esperienza.
L’agente smette di essere un esecutore di istruzioni e diventa un soggetto che riflette, corregge e affina le proprie strategie.
Una forma embrionale di apprendimento continuo, che avvicina le macchine al ritmo naturale con cui gli esseri umani imparano dal tempo e dall’errore.
Agentic Context Engineering
Il paper "Agentic Context Engineering", guidato da un team di Stanford in collaborazione con SambaNova Systems e UC Berkeley, propone un paradigma in cui il prompt, la memoria e le istruzioni non sono solo un testo statico, ma un playbook che cresce e si affina nel tempo.
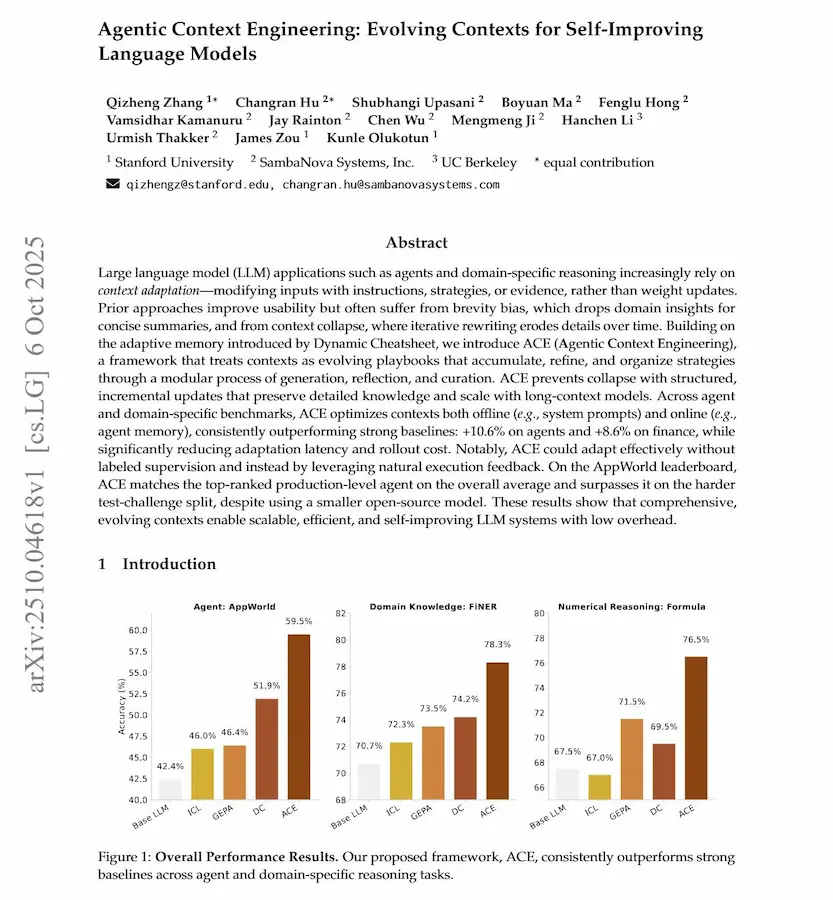
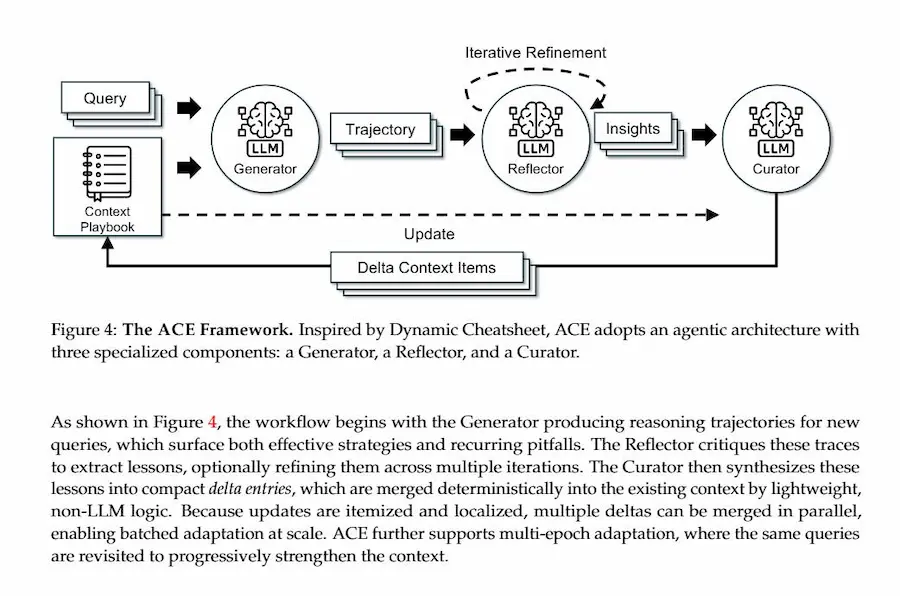
Agentic Context Engineering: il paper
Invece di comprimere l’esperienza in poche frasi sintetiche, come fanno molti ottimizzatori di prompt, il modello accumula conoscenze, strategie e intuizioni specifiche di dominio.
Questo processo avviene attraverso tre ruoli distinti: un generatore che agisce, un valutatore e un curatore che integra.
L’apprendimento avviene senza modificare i parametri, ma attraverso aggiornamenti incrementali e strutturati del contesto: piccole “differenze” che evitano la perdita di informazioni e rendono l’adattamento più efficiente.
I risultati sono notevoli: agenti e modelli di ragionamento specialistico migliorano sensibilmente la loro accuratezza, riducendo tempi e costi di adattamento.
Ma la vera novità è concettuale: il contesto diventa un organismo che si auto-organizza, preserva memoria e apprende dalle proprie azioni.
Uso una tecnica simile (ma più rudimentale) in un agente in produzione, in cui, dopo ogni interazione, un processo va ad aggiornare e a ottimizzare il prompt per le azioni successive.
ACE mostra che l’intelligenza dei modelli può progredire non solo grazie a più dati o più parametri, ma grazie a una migliore ingegneria delle loro esperienze.
Nuovo modello e Agent SDK per Anthropic
È stato rilasciato Claude Sonnet 4.5, un aggiornamento che porta significativi miglioramenti in ambiti chiave come la programmazione, l’uso del computer, il ragionamento e la matematica.
Anthropic: Claude Sonnet 4.5 e Agent SDK
Il modello è già disponibile tramite API e app, mantenendo lo stesso prezzo della versione precedente.
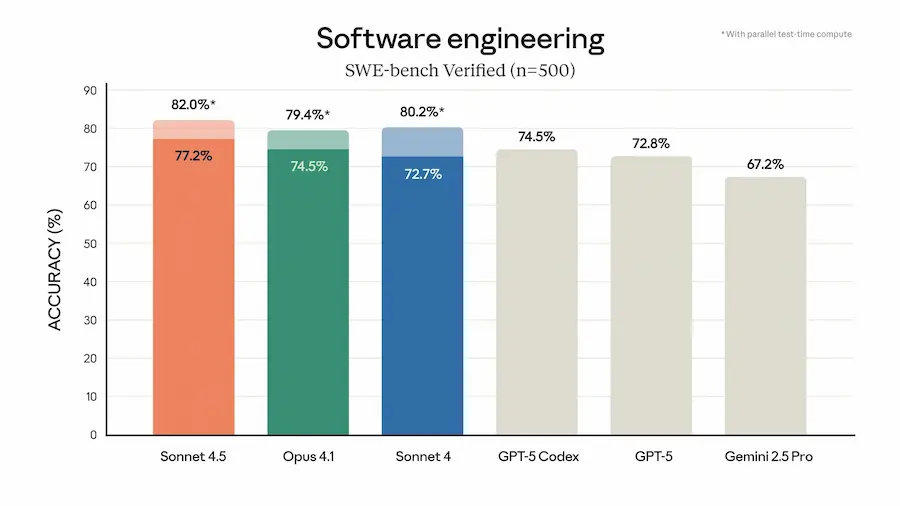
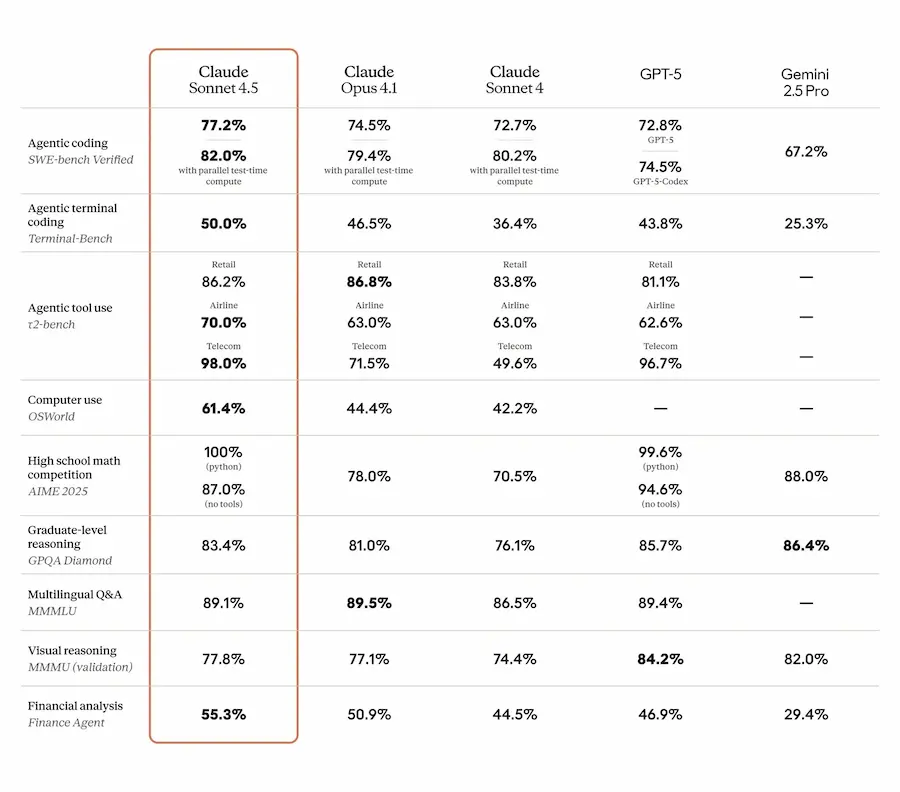
Claude 4.5 si distingue per le sue prestazioni:
- Primo al mondo su SWE-bench Verified, benchmark per capacità di codifica realistica.
- Top performer su OSWorld, che valuta l’uso dell’AI in task da computer reale.
- Capacità estese nel mantenere concentrazione su task multi-step per oltre 30 ore.
- Miglioramenti concreti in ambiti verticali: finanza, medicina, diritto, ingegneria.
Nelle Claude apps arrivano nuove funzionalità come l’esecuzione diretta di codice, la creazione di file (documenti, fogli, slide) e l’estensione per Chrome. Per gli sviluppatori, Claude Code integra ora checkpoint, editing contestuale, strumenti di memoria e un’estensione per VS Code.
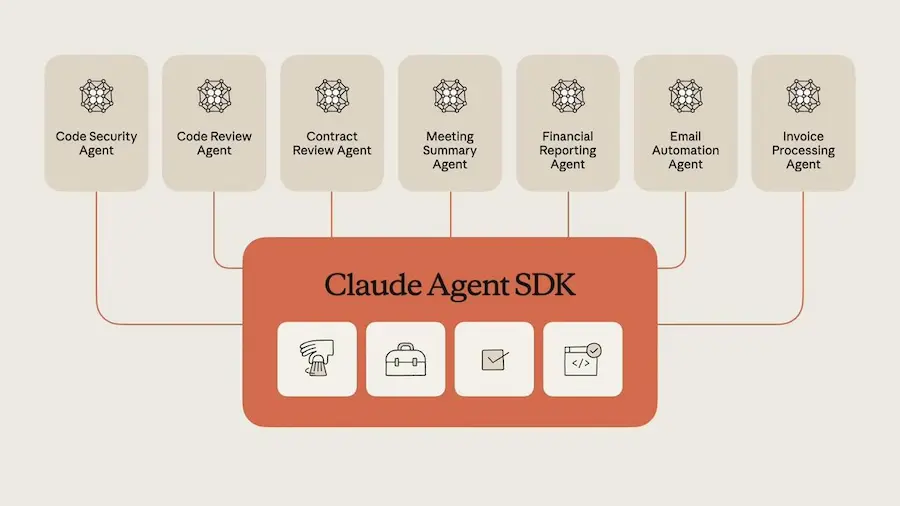
Rilasciato anche il Claude Agent SDK, l’infrastruttura che alimenta i prodotti Claude, ora disponibile per chiunque voglia costruire agenti AI in autonomia. Include soluzioni avanzate per la gestione della memoria, sistemi di permessi e coordinamento di sub-agenti.
Sul fronte della sicurezza, Claude 4.5 è il modello più allineato rilasciato da Anthropic. Riduce comportamenti problematici come piaggeria e inganno, migliora la protezione contro attacchi via prompt injection, ed è distribuito con protezioni AI Safety Level 3.
Incluso anche un esperimento temporaneo, “Imagine with Claude”, che permette di generare software in tempo reale.
Runway Apps e Workflow
Non poteva mancare Runway in questa evoluzione dei modelli di generazione video.
Infatti, hanno lanciato "Apps", una raccolta di workflow specifici per diversi casi d'uso. Alcuni esempi: reshooting dei prodotti, rimozione di elementi dai video, da immagine a video con i dialoghi, upscale fino a 4k, restyling di video e immagini.
Runway Apps
Hanno presentato, inoltre, un nuovo strumento in grado di sviluppare dei workflow per l'elaborazione degli elementi visuali.
Permette di creare flussi di lavoro personalizzati basati su nodi, concatenando più modelli, modalità e passaggi intermedi per avere controllo sulle elaborazioni.
Runway Workflow
Un approccio vincente, secondo me, perché l'obiettivo è quello di avere una continua produzione di workflow, in base anche alle esigenze della community.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂