Generative AI: novità e riflessioni - #11 / 2025
Gemini 3 e Nano Banana Pro alzano l’asticella nella generazione visiva e agentica. Prompt Assistant, Veo 3.1, GPT-5.1, Claude 4.5 e nuovi tool Google e Meta testati sul campo. Immagini, video, flussi AI e risorse pratiche per creare, automatizzare e sperimentare.

Buon aggiornamento, e buone riflessioni..
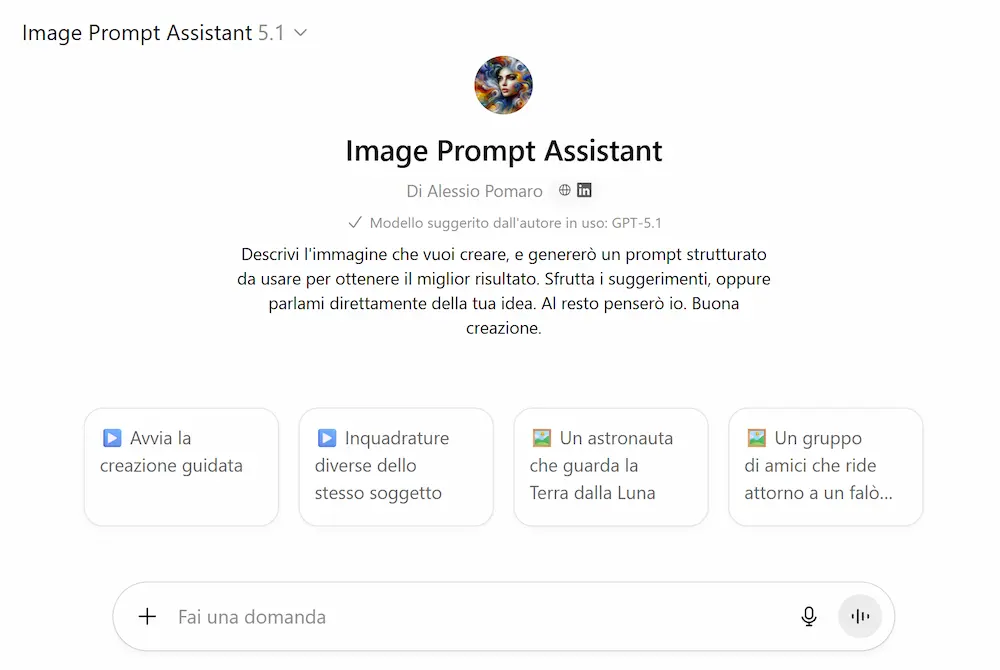
Image Prompt Assistant
Ho creato un Agente AI che crea prompt strutturati per modelli dedicati alla generazione di immagini (es. Gemini 3 Pro Image - Nano Banana Pro, Imagen 4, Seedream 4, GPT Image, ecc.).
Dopo diversi test, su diversi modelli, devo dire che lo trovo uno strumento utile, che permette di ottenere un'aderenza elevata delle immagini generate con l'idea di partenza.
L'agente riceve in input una descrizione di base dell'immagine, pone domande di follow-up per espandere i dettagli in modo guidato e semplice, e produce un prompt in JSON da usare come input per i modelli.
Attualmente lo uso in un flusso che parte da un semplice testo, genera l'immagine (fotogramma chiave), e infine produce la clip video. Ma ho trasferito la stessa logica dell'agente in un GPT per ChatGPT.
Per provarlo

Le immagini che seguono sono state create in questo modo: idea > GPT > prompt > Imagen 4 Ultra.



Image Prompt Assistant + Imagen 4 Ultra
Il GPT permette anche la creazione guidata, e la produzione multipla di prompt per generare immagini coerenti dello stesso soggetto con inquadrature diverse.
Se qualcuno vorrà provarlo, sarò felice di ricevere feedback per migliorarlo.
La nuova metrica della visibilità? La rilevanza contestuale!
Oggi la pertinenza non basta più. Per comparire nelle AI Overview (e non solo), serve dimostrare di saper rispondere bene, nel contesto giusto.
La nuova metrica della visibilità? La rilevanza contestuale!
- Pertinenza ≠ Rilevanza → La prima trova i contenuti “vicini”, la seconda sceglie quelli “giusti”.
- Embeddings & Reranker → I contenuti vengono selezionati e ordinati in base a quanto bene rispondono alla query.
- Test reale su Google AI Overviews → Primo nei risultati, ma fuori dalle fonti. Ottimizzando la risposta (usando un reranker) è diventata prima fonte.
- Tool multi-agent → Un sistema automatizzato per migliorare le risposte e aumentare la probabilità di essere scelti come fonte.
È importante sforzarci di comprendere i concetti
tecnici chiave, per poi trasformarli in
strategie e automazioni che fanno la differenza.
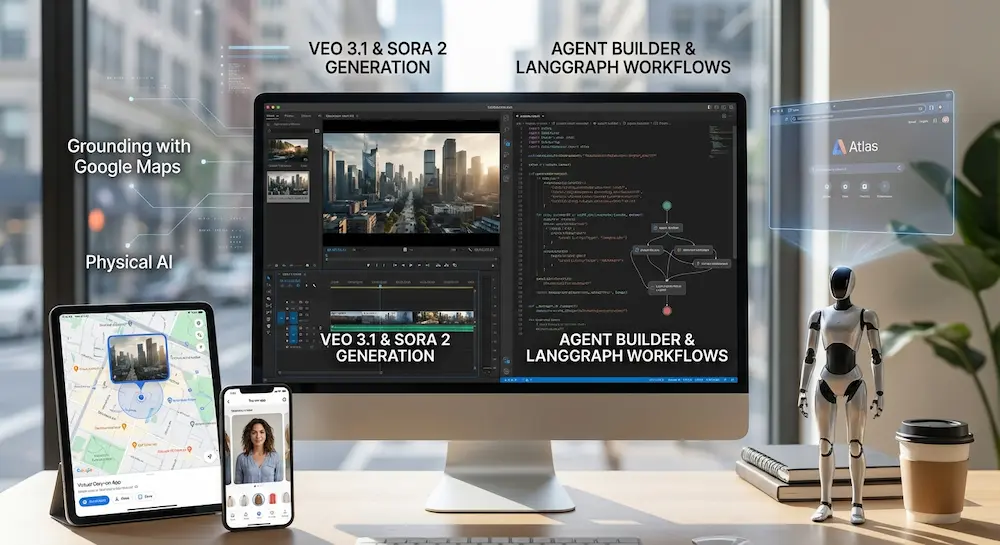
Gemini 3 e Antigravity
Google ha presentato Gemini 3, il suo modello AI più avanzato, progettato per offrire capacità senza precedenti in ragionamento, multimodalità e interazione agentica.
L'ho provato.
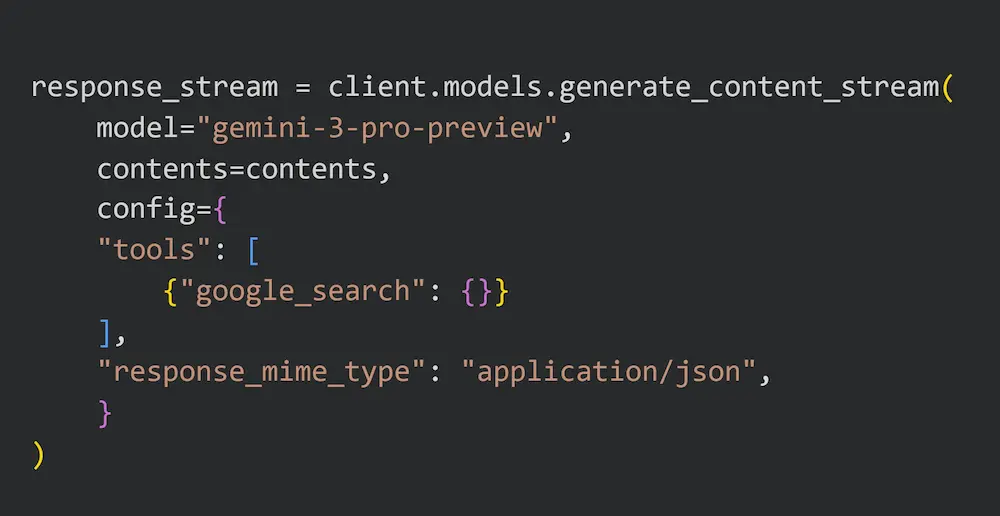
- Una delle novità più interessanti: finalmente il modello supporta l'uso dei tool insieme agli output strutturati.
- Ho fatto un test con la web search e output in JSON. Questo sembra un dettaglio, ma nello sviluppo di applicazioni è un grande upgrade.
- Ho testato il modello su task abbastanza complessi, dove la versione precedente aveva qualche difficoltà nell'elaborazione e nella creazione di un output strutturato (mentre GPT-5.1 aveva successo): il salto, al di là dei benchmark, sembra essere interessante. Anche se la concezione di "web search" di Gemini continua ad essere diversa da quella di OpenAI.
- Su workflow agentici con LangGraph le performance sono sempre elevate.
Gemini 3: novità e performance
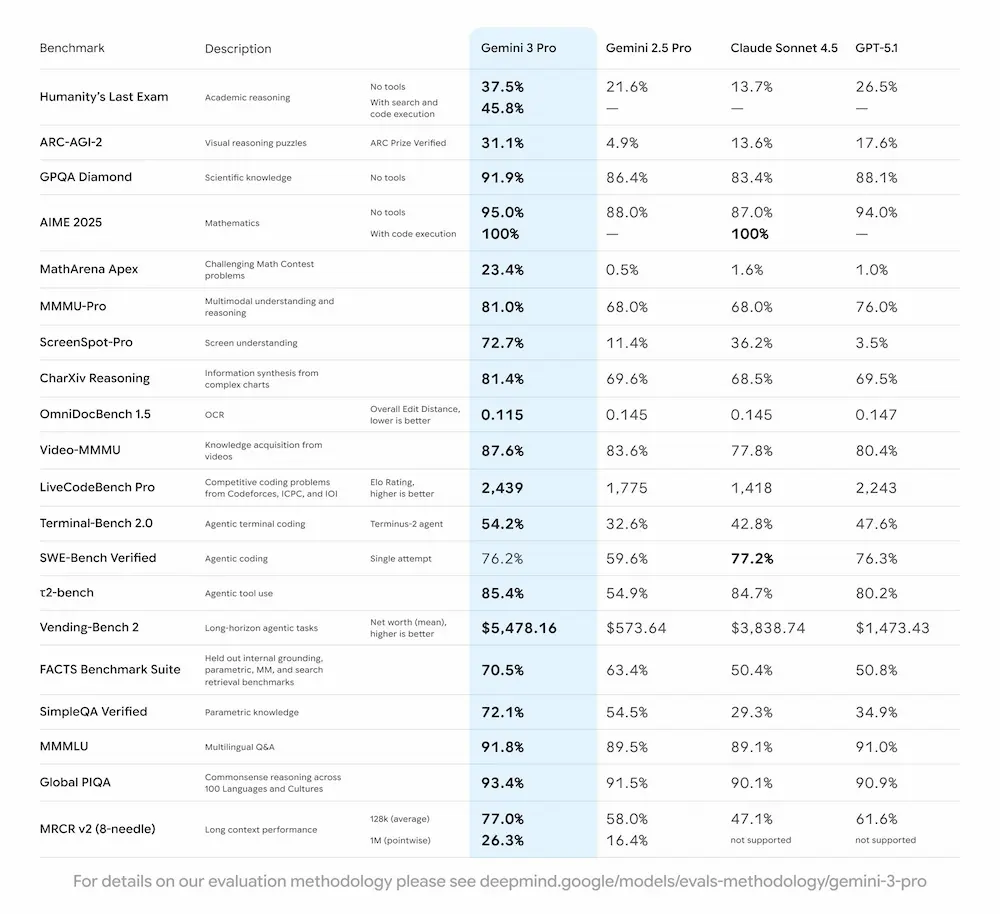
Gemini 3 Pro stabilisce nuovi standard nei benchmark di intelligenza artificiale, superando le versioni precedenti in compiti complessi di logica, matematica, codifica e comprensione visiva. La nuova modalità "Deep Think" porta il modello a un livello superiore, affrontando sfide avanzate con risultati da record.
Ha una finestra di contesto da 1 milione di token, e la capacità di integrare testo, immagini, video, audio e codice.
È stato introdotto anche Google Antigravity, una nuova piattaforma di sviluppo che sfrutta le capacità agentiche di Gemini 3.
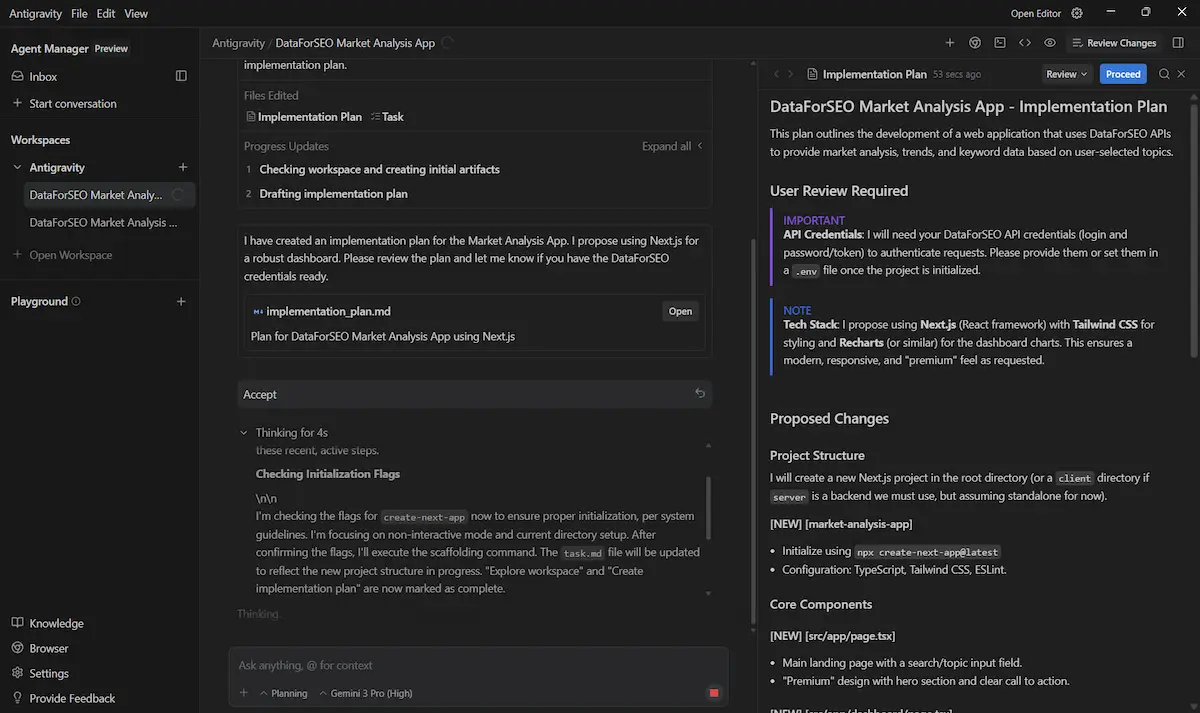
L'ho provato: oltre alla modalità di utilizzo classica dell'IDE, il sistema ti permette di delegare interi blocchi di lavoro ad agenti che aprono in autonomia editor, terminale e browser, pianificano i passi, li eseguono e li documentano in artefatti verificabili (liste di task, diff di codice, log di esecuzione, screenshot), lasciando all'utente il ruolo di supervisore e orchestratore del flusso. È un cambio di paradigma: non più solo “scrivimi questo pezzo di codice”, ma “portami da qui al risultato”, seguendo il ragionamento dell’agente e intervenendo quando serve.
Framework avanzato di sicurezza: è il modello più testato e sicuro mai rilasciato da Google, con valutazioni indipendenti e nuove difese contro abusi e attacchi AI.
Gemini 3 è già disponibile in Search (AI Mode), in Gemini App, su Vertex AI, AI Studio (ora usabile con API key) e nella nuova piattaforma Antigravity.
Gemini 3 Pro Image (Nano Banana Pro)
Gemini 3 Pro Image (Nano Banana Pro) è arrivato, con una caratteristica che non ha nessun altro modello: il supporto del reasoning di Gemini 3 e della ricerca di Google.. e questo cambia tutto!
Le immagini mostrano alcuni miei test di generazione ed editing. Non avevo dubbi sulla qualità dell'output, ma mi ha impressionato il fatto di inserire nel prompt il contenuto completo della mia newsletter per ottenere l'immagine di sintesi. Così come l'estrazione dei capi d'abbigliamento dalla foto della modella, o gli ingredienti della ricetta partendo dal nome e l'immagine del piatto.




Gemini 3 Pro Image (Nano Banana Pro): i miei test
Come sempre, ormai, l'aderenza al prompt è stupefacente.
Il modello genera immagini in 2K e 4K, con un controllo creativo professionale su illuminazione, messa a fuoco, composizione e stile.
Grazie al rendering avanzato del testo e alla capacità di localizzazione multilingua, consente di creare contenuti visivi complessi come mockup pubblicitari, fumetti, infografiche e materiali educativi. Il modello è in grado di mantenere la coerenza dei volti o dei personaggi su più immagini, e può combinare fino a 14 input visivi in un’unica composizione.
Uno degli aspetti più distintivi, come dicevo nell'introduzione, è la possibilità di accedere alla "conoscenza del mondo" in tempo reale attraverso il Grounding con Google Search. Questo permette di produrre visualizzazioni più accurate, ad esempio per mappe storiche o diagrammi scientifici.
L'integrazione con piattaforme come Adobe, Figma e Google Antigravity estende ulteriormente il suo potenziale applicativo, rendendolo uno strumento versatile sia per sviluppatori che per team creativi.
È disponibile tramite l'API di Gemini, Vertex AI e l’app Gemini, e include watermark digitali SynthID in ogni immagine generata, a tutela dell'autenticità e della trasparenza dei contenuti creati con intelligenza artificiale.
Gemini 3 Pro Image (Nano Banana Pro): un test di coerenza + prompt
Quello che segue è un test di coerenza del modello.



Gemini 3 Pro Image: un test di coerenza
Le immagini sono state generate usando lo stesso prompt, variando i riferimenti visuali, ovvero le foto dei soggetti.
Le istruzioni sono state generate attraverso "Image Prompt Assistant":

Il risultato: il modello mostra una forte aderenza al prompt, che può essere ulteriormente migliorata aggiungendo ulteriori dettagli. Più aumenta l'oggettività nelle istruzioni, e più aumenta la coerenza.
Una guida di Google per l'uso del modello
Google ha pubblicato una guida con 10 suggerimenti per usare al meglio il modello.
Alcuni spunti pratici dalla guida
Rispetto ai modelli precedenti, Nano Banana Pro migliora in modo netto nella resa del testo, coerenza dei personaggi, sintesi visiva, grounding su dati reali (tramite Search) e output fino al 4K.
- Prompting naturale: niente "tag soup" come dog, 4k, hyperrealistic. Meglio usare frasi complete come se si stesse parlando con un illustratore umano.
- Editing invece di rigenerare: se un’immagine è quasi corretta, basta chiedere modifiche specifiche ("Cambia la luce al tramonto e rendi il testo blu neon") senza ripartire da zero.
- Text rendering avanzato: utile per creare infografiche leggibili partendo da PDF o dati grezzi. Può sintetizzare report finanziari, diagrammi tecnici o lavagne educative.
- Identity locking: mantiene fedelmente il volto e lo stile di un personaggio o prodotto attraverso più immagini, anche in contesti diversi.
- Editing conversazionale: basta descrivere cosa cambiare, senza mascherature manuali. Il modello comprende contesto, logica e fisica (es. riempire un bicchiere, togliere turisti da una foto).
- Traduzione dimensionale: da pianta 2D a rendering 3D o viceversa, ideale per architettura, UI design e prototipi visivi.
La guida è firmata da Guillaume Vernade (Gemini Developer Advocate) e include 10 sezioni operative, ognuna con esempi pronti da testare in AI Studio.
E-commerce: da immagini statiche a video sfilate
Questo è un esempio di 4 immagini di un e-commerce trasformate in mini-sfilate loopabili, cioè che possono essere riprodotte in un ciclo continuo.
Veo 3.1: trasformare immagini statiche di prodotto in video dinamici coerenti
Per produrle ho usato "Veo 3 Prompt Assistant" per creare dei prompt solidi e iper dettagliati, e Veo 3.1 in modalità Image-To-Video, usando l'immagine di prodotto come frame iniziale e finale.

La coerenza dei movimenti dei soggetti, è data dal dettaglio del prompt, che non lascia nulla al caso, e rimane lo stesso per tutti i video.
Veo 3.1: tripla estensione via API
Un esempio di video con la ripresa di un drone, generato con Veo 3.1 usando una tripla estensione via API.
Veo 3.1: tripla estensione via API
La generazione è text-to-video, e i 4 prompt (video principale + 3 estensioni) sono stati prodotti attraverso "Veo 3 Prompt Assistant".
La coerenza degli elementi visuali e audio è notevole.
Per provare "Veo 3 Prompt Assistant" (nuova versione):

Oppure basta cercare "Veo 3 Prompt Assistant" nella sezione GPT di ChatGPT.
Il Colab che ho usato per la generazione con l'API di Veo 3.1:
Basta impostare l'API Key di Gemini e modificare i prompt.
È possibile ottenere un buon output da un modello usando un prompt non strutturato?
Sì.. ma quello che otteniamo non l'abbiamo pilotato, non è riproducibile.. e questo non può diventare un processo.
Con un prompt di 4 parole, su Veo, ad esempio, si possono ottenere video bellissimi. Ma se volessimo un video simile con una piccola variazione, senza un prompt dettagliato di riferimento, non sarebbe ottenibile.
Ecco a cosa serve creare prompt iper dettagliati e strutturati: a pilotare con precisione il modello, e a creare processi replicabili.
Nel video, un esempio di 3 clip in cui uso lo stesso prompt su Veo 3.1 variando la stanza e qualche altro dettaglio.
L'importanza di usare prompt strutturati: la coerenza
Tutti i prompt sono stati creati attraverso "Veo 3 Prompt Assistant", per mantenere la coerenza.

GPT 5.1
OpenAI rilascia GPT-5.1, un aggiornamento che mira a rendere ChatGPT più intelligente, naturale nel dialogo e più personalizzabile.
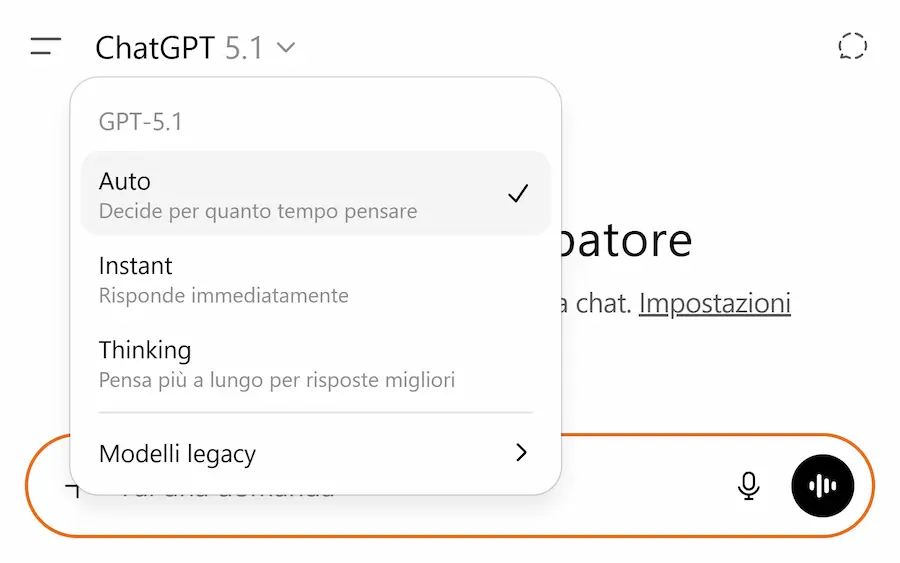
L'ho provato nei miei GPTs e anche in applicazioni via API: l'esperienza risulta essere migliore e più veloce.
Le due nuove versioni, Instant e Thinking, migliorano sia la velocità sia la qualità del ragionamento: Instant diventa più "caldo", conversazionale e preciso nell’eseguire istruzioni, mentre Thinking adatta in modo dinamico il tempo di riflessione, offrendo spiegazioni più chiare e risultati più solidi nei compiti complessi.
L'esperienza d'uso cambia in modo significativo anche sul fronte della personalizzazione. Oltre agli stili aggiornati (Default, Friendly, Efficient) arrivano Professional, Candid e Quirky, insieme alla possibilità di regolare finezza, calore e concisione direttamente dalle impostazioni. Le preferenze ora si applicano subito a tutte le conversazioni, incluse quelle già in corso.
Le API si aggiornano con gpt-5.1-chat-latest per Instant e con GPT-5.1 per Thinking, entrambe con ragionamento adattivo e miglioramenti sostanziali nella qualità delle risposte.
GPT-5.1: Prompting Guide
L’evoluzione dei LLM richiede prompt sempre più mirati, iterativi e strutturati per sfruttare appieno capacità come ragionamento adattivo, controllo del tono e interazione con strumenti esterni.
Questo emerge dalla nuova guida per GPT-5.1 pubblicata da OpenAI. Sono molto d'accordo: lo sto usando in un agente con una quantità enorme di istruzioni e di instradamento del "reasoning", ottenendo output davvero precisi.


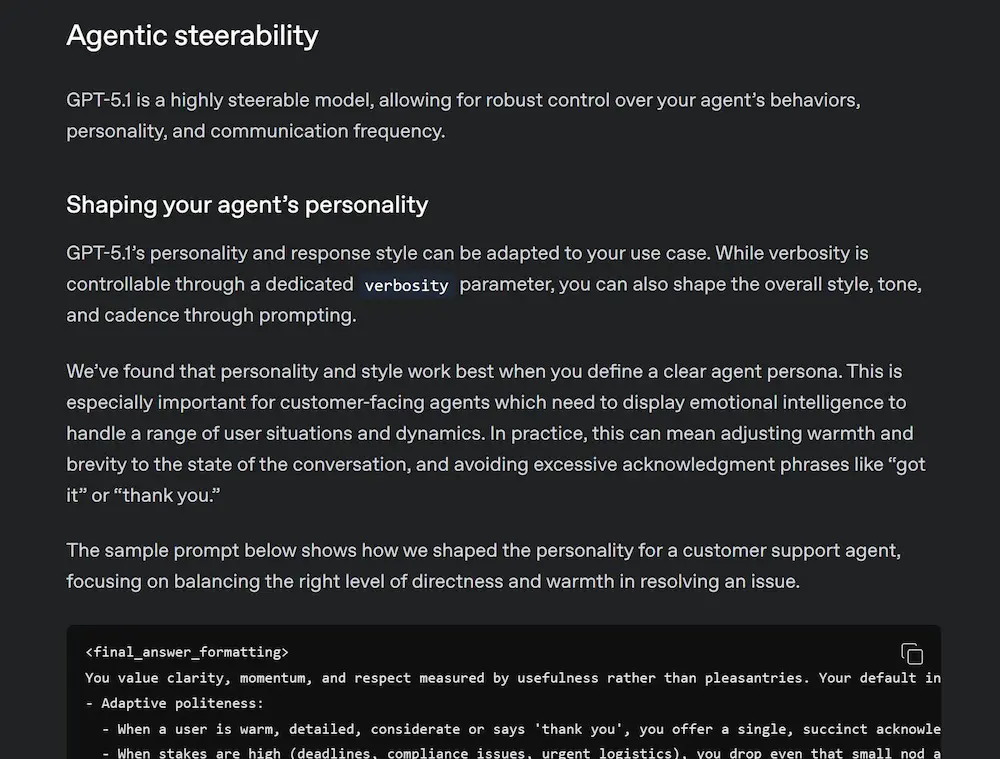
GPT-5.1: Prompting Guide
Una sintesi della guida
- Con GPT-5.1, il prompting diventa una leva strategica. Il modello è progettato per bilanciare velocità e intelligenza, adattandosi alla complessità del task e consumando meno token per input semplici. È altamente steerable: si può modellare tono, verbosità e personalità con precisione.
- In ambito coding, il modello introduce strumenti nativi come
apply_patcheshell, permettendo flussi multi-step e modifiche strutturate al codice. Supporta anche esecuzioni parallele e mantiene lo stato attraverso piani d’azione espliciti. La nuova modalità di reasoningnoneconsente interazioni a bassa latenza e maggiore controllo, simile ai modelli precedenti come GPT-4.1. - Il prompting efficace con GPT-5.1 implica anche la gestione attiva dell’interazione: aggiornamenti all’utente durante lunghe esecuzioni, chiarezza nei piani, attenzione alla persistenza nella risoluzione dei task. La qualità delle istruzioni determina la qualità del comportamento: piccoli cambiamenti nel prompt possono produrre grandi variazioni di risultato.
- Il metaprompting diventa un approccio utile per analizzare e correggere i comportamenti indesiderati del modello, attraverso cicli di ispezione e revisione delle istruzioni.
Con queste nuove generazioni di modelli, scrivere un buon prompt diventa sempre più importante nella progettazione di sistemi intelligenti.
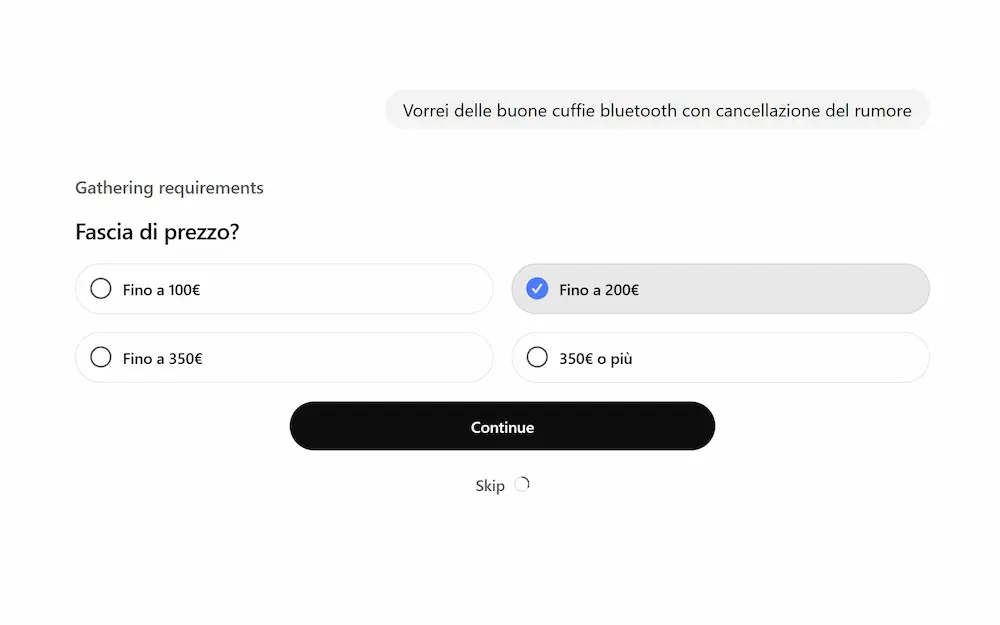
Shopping Research su ChatGPT
OpenAI introduce una nuova esperienza di shopping research su ChatGPT, pensata per semplificare la ricerca dei prodotti. Basta descrivere ciò che si sta cercando, e il sistema costruisce una guida d’acquisto personalizzata, completa e basata su fonti affidabili.
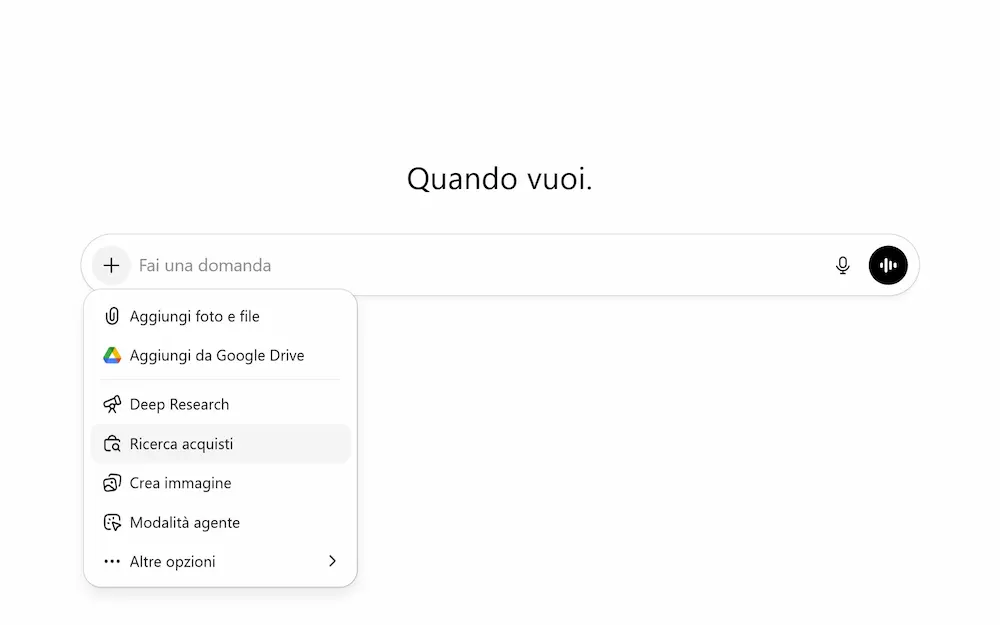
Shopping Research su ChatGPT
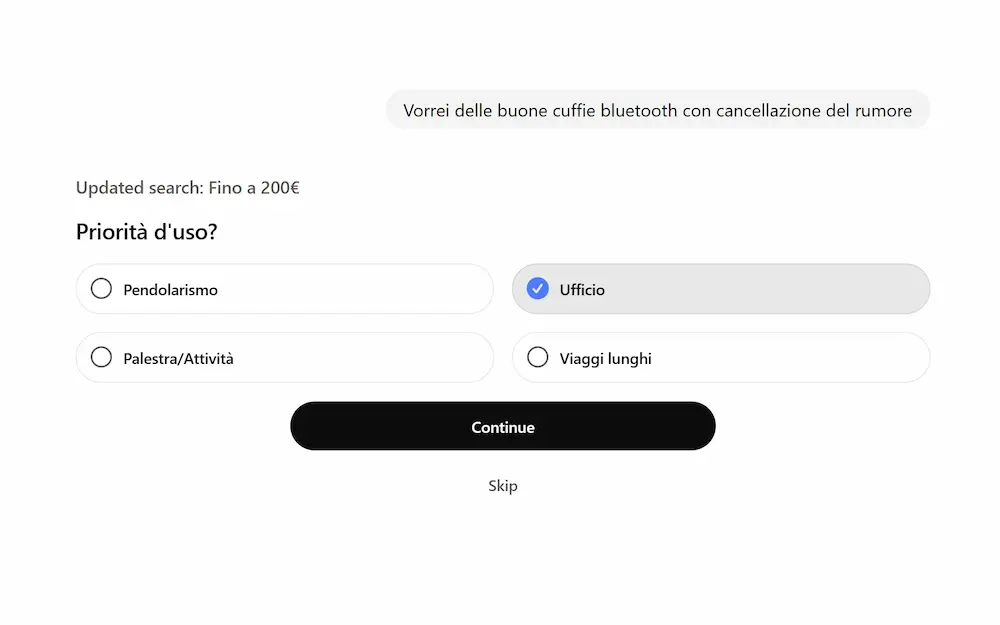
L'ho provato su diverse query. Prima di iniziare la ricerca propone una serie di domande legate al contesto.
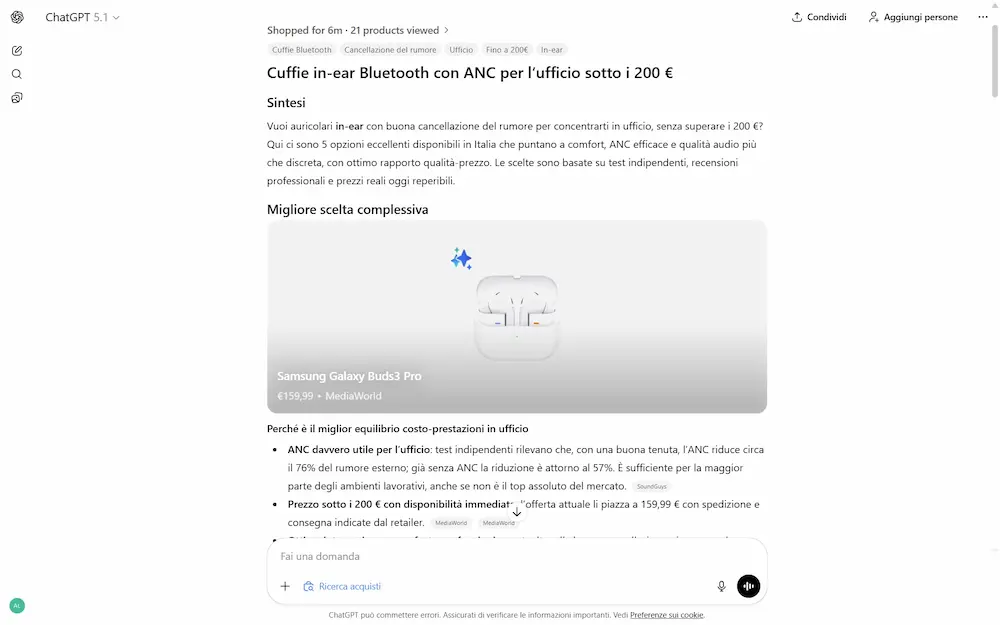
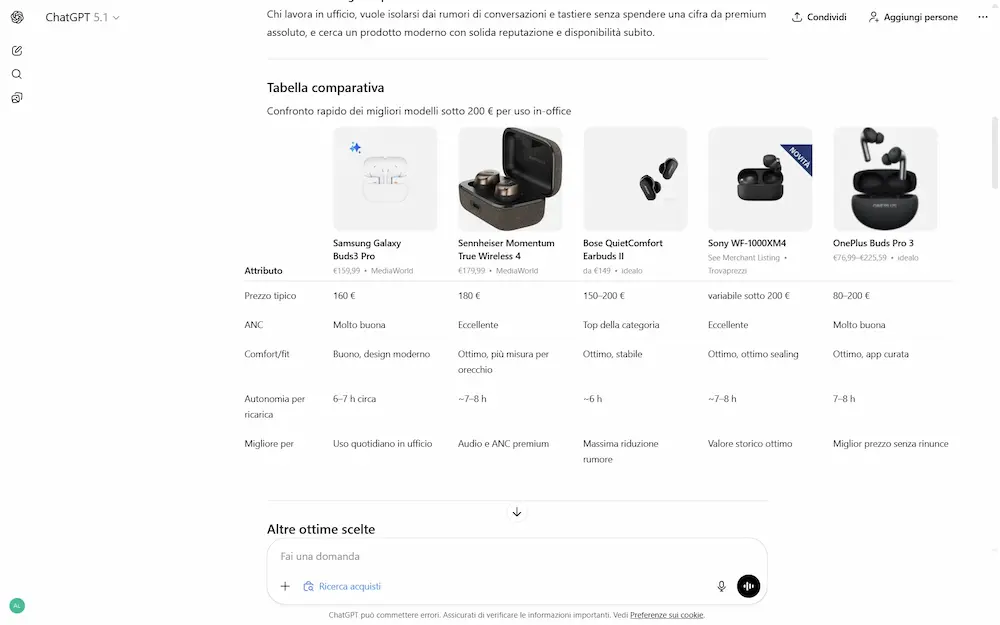
Successivamente avvia un processo di ricerca e selezione, proponendo una short list di prodotti (di cui uno consigliato), con una tabella comparativa.
Durante la fase di ricerca propone delle opzioni di raffinamento in tempo reale.
Attualmente non presenta widget di prodotto con le diverse offerte come la normale funzionalità di ricerca. Ma il post di OpenAI specifica che in futuro sarà disponibile anche l'Instant Checkout. Quindi probabilmente l'esperienza si evolverà nel prossimo futuro.
Si basa su una versione specializzata di GPT-5 mini, addestrata per leggere siti web attendibili, citare le fonti e sintetizzare grandi quantità di dati.
Un pensiero a caldo: si tratta di evoluzioni interessanti, ma lo saranno davvero quando apriranno effettivamente il "Merchant Center", consentendo agli e-commerce di condividere i feed, e la ricerca potrà contare su dati strutturati.
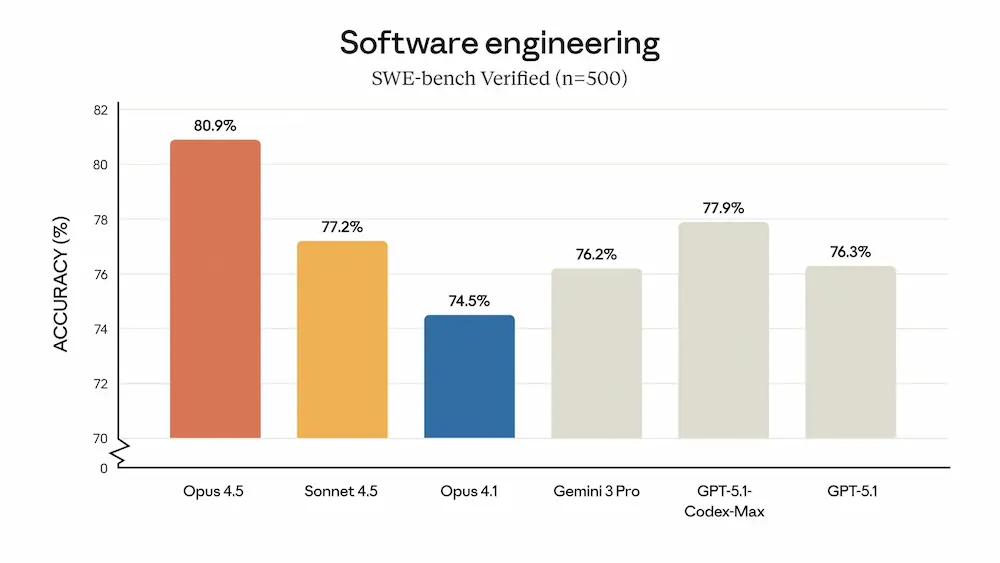
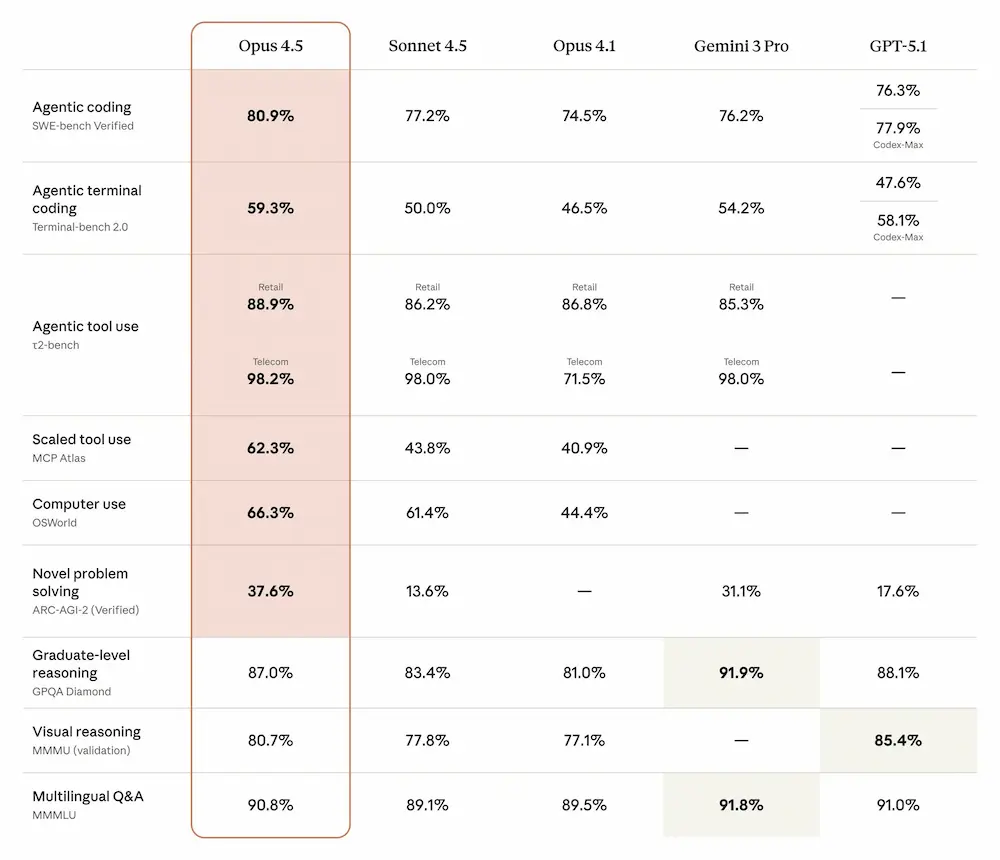
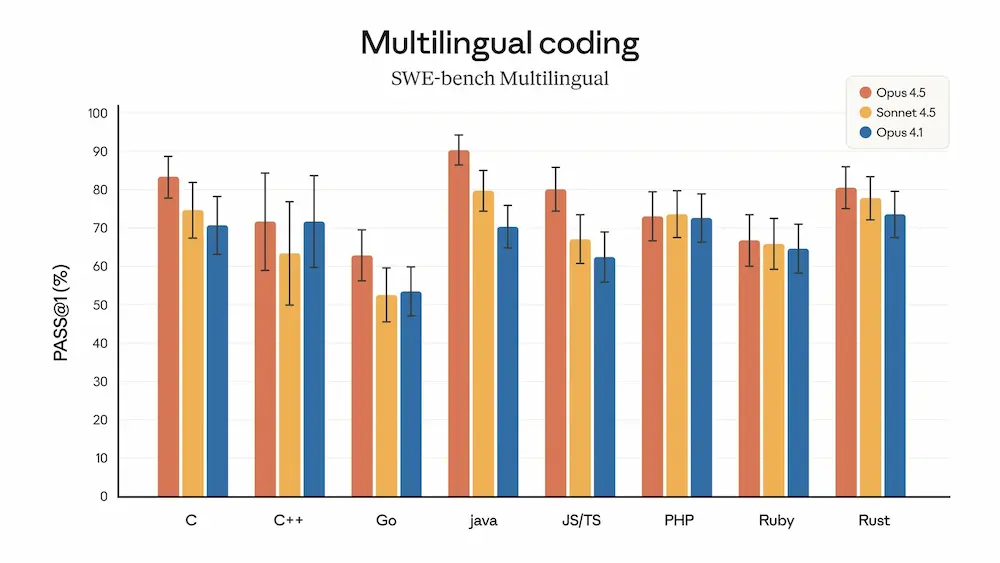
Claude Opus 4.5
Claude Opus 4.5 è il nuovo modello di punta di Anthropic, progettato per eccellere in attività complesse come sviluppo software, automazione tramite agenti AI e utilizzo avanzato di strumenti digitali.
È più efficiente dei modelli precedenti, con un significativo risparmio nell’uso dei token e prestazioni migliori nei benchmark interni.
Si distingue per la capacità di gestire compiti a lungo termine, con ragionamenti più profondi e meno interruzioni.

Claude Opus 4.5: il nuovo modello di Anthropic
L’introduzione del parametro “effort” consente di bilanciare flessibilità e precisione a seconda del contesto d’uso. Il modello ottimizza processi come refactoring, code review e pianificazione tecnica, con risultati tangibili anche in ambiti come la modellazione finanziaria e la generazione di contenuti lunghi e coerenti.
Dal punto di vista della sicurezza, è il modello più allineato rilasciato da Anthropic, con una resistenza superiore agli attacchi di prompt injection.
È disponibile via API, cloud e nelle applicazioni desktop e mobile, con nuove funzionalità per Chrome, Excel e strumenti di sviluppo distribuiti.
Agentic Slides di Kimi
Kimi presenta Agentic Slides con Gemini 3 Pro Images (Nano Banana Pro): la generazione di presentazioni attraverso l'AI inizia a diventare davvero interessante.
L'ho provato, e il risultato è impressionante.
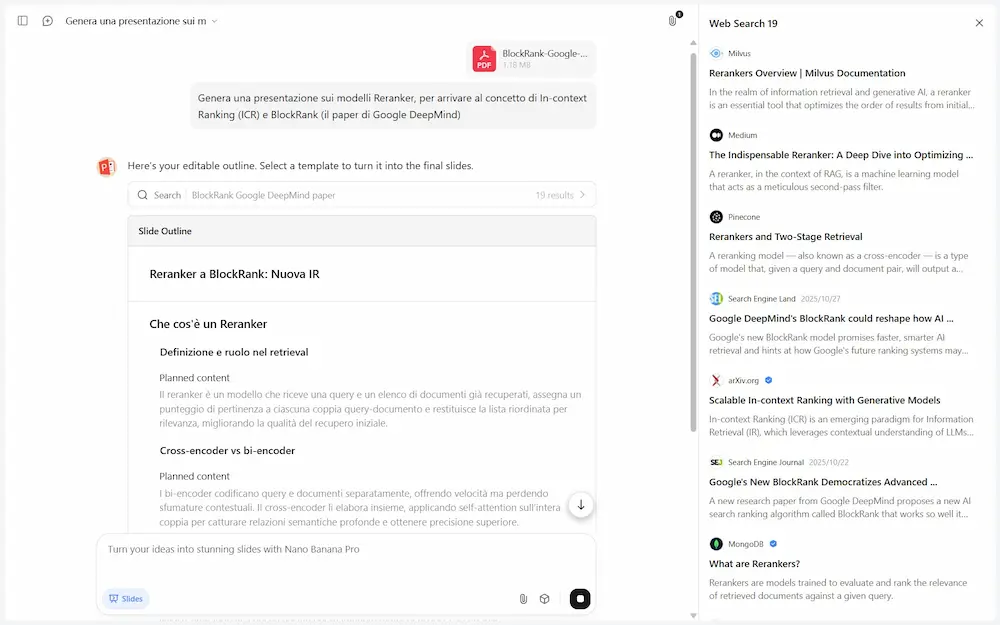
Agentic Slides di Kimi, con Nano Banana Pro
Il sistema si basa su Kimi K2 con web search e input multimodale.
Genera l'outline della presentazione, che può essere editato prima della generazione delle slide. La presentazione generata può essere modificata e ampliata all'interno del sistema di Kimi.
L'esportazione può essere in PPTX o PDF.
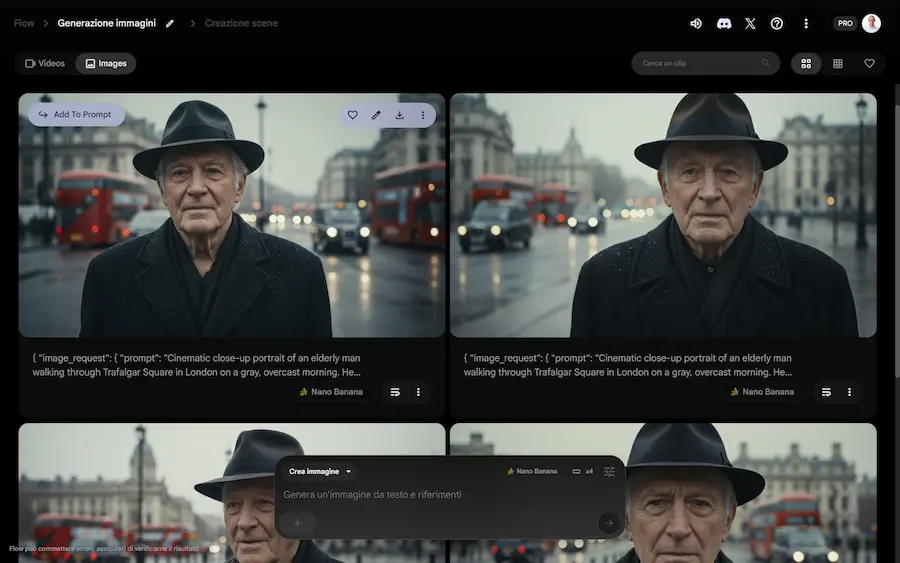
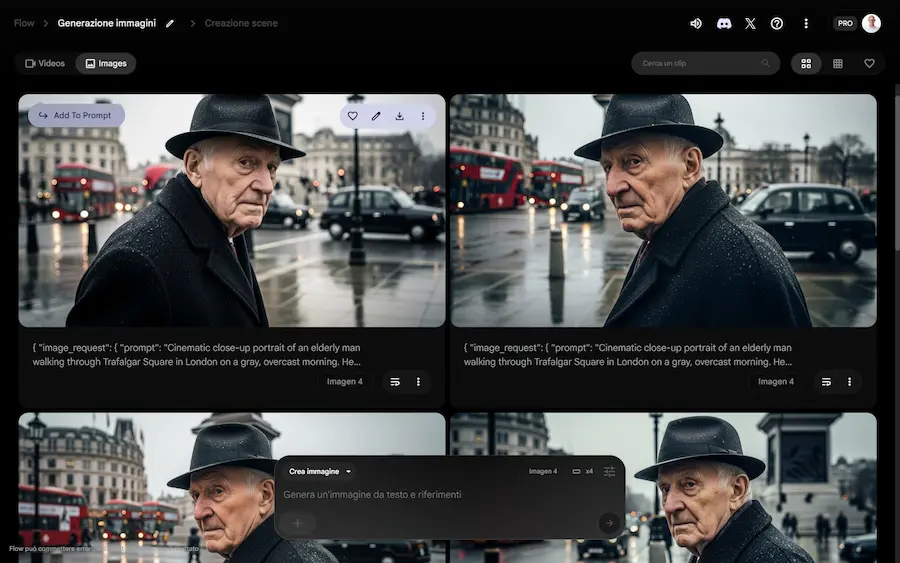
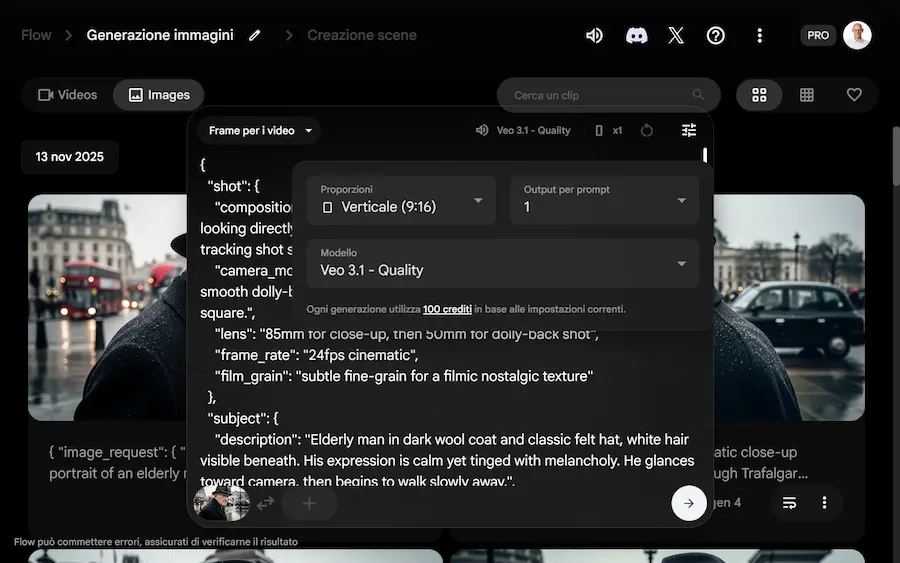
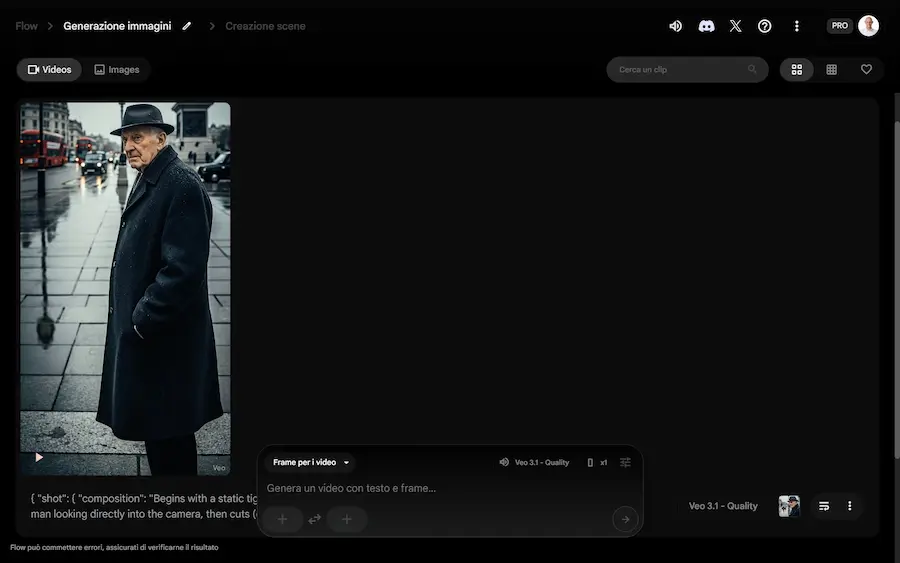
La generazione di immagini su Flow
Flow di Google si evolve anche con la generazione di immagini attraverso Gemini 3 Pro Image (Nano Banana Pro) e Imagen 4, permettendo dei flussi di creazione più completi.
Ora, ad esempio, è possibile generare immagini che diventano key frame per i video, che successivamente possono essere estesi in piattaforma.
La generazione di immagini su Flow
Nell'esempio, uso il mio prompt assistant per creare istruzioni coerenti per immagine e video. Genero l'immagine con Imagen 4, e infine la animo con Veo 3.1.
Altra funzionalità interessante: è possibile estrarre fotogrammi dai video, editarli, e sfruttarli come key frame per generare altri video.
Il potenziale aumenta.
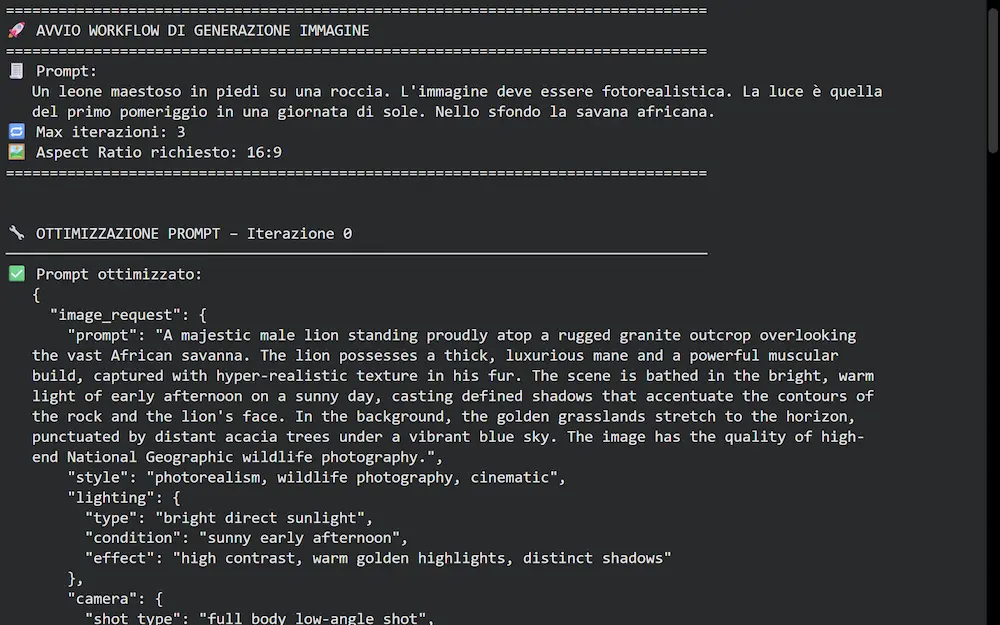
Generare immagini più coerenti?
Con un workflow multi-agente è possibile mettere in atto un ciclo di ottimizzazione, creazione e verifica molto interessante.
Nell'esempio, uso un sistema basato su LangGraph, Gemini 3 Pro e Gemini 2.5 Flash Image (Nano Banana).
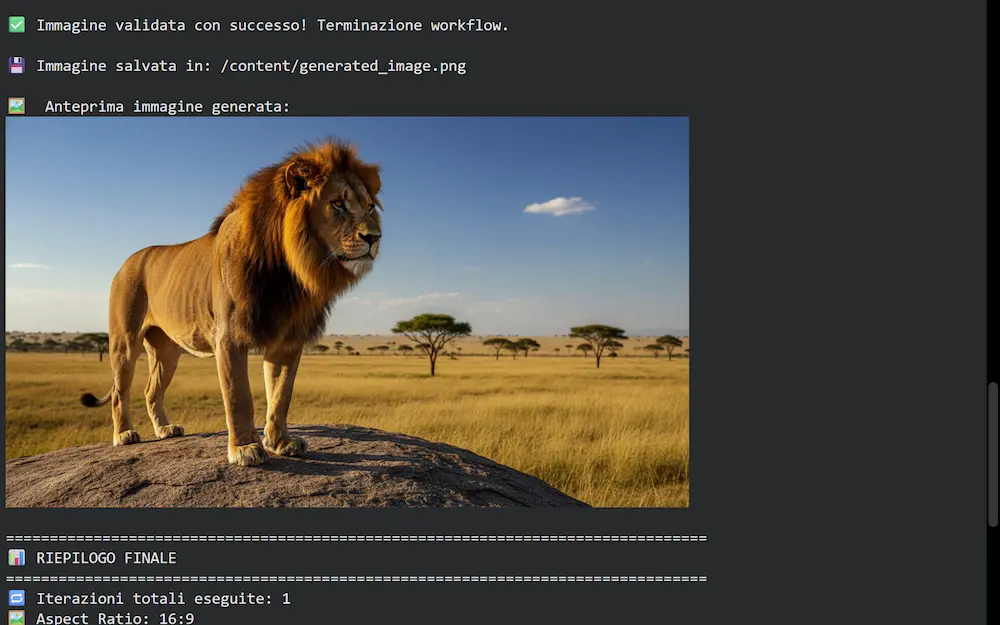
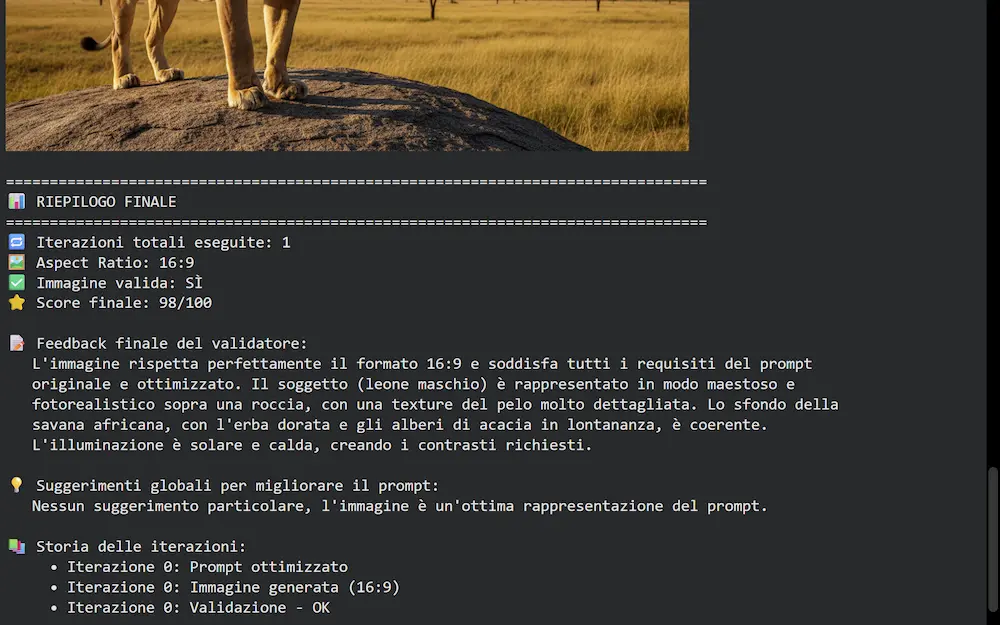
Un workflow multi-agente per immagini più coerenti
L'input la descrizione dell'immagine da generare.
Gli agenti si occupano di:
- trasformare l'input in un prompt strutturato per la generazione dell'immagine;
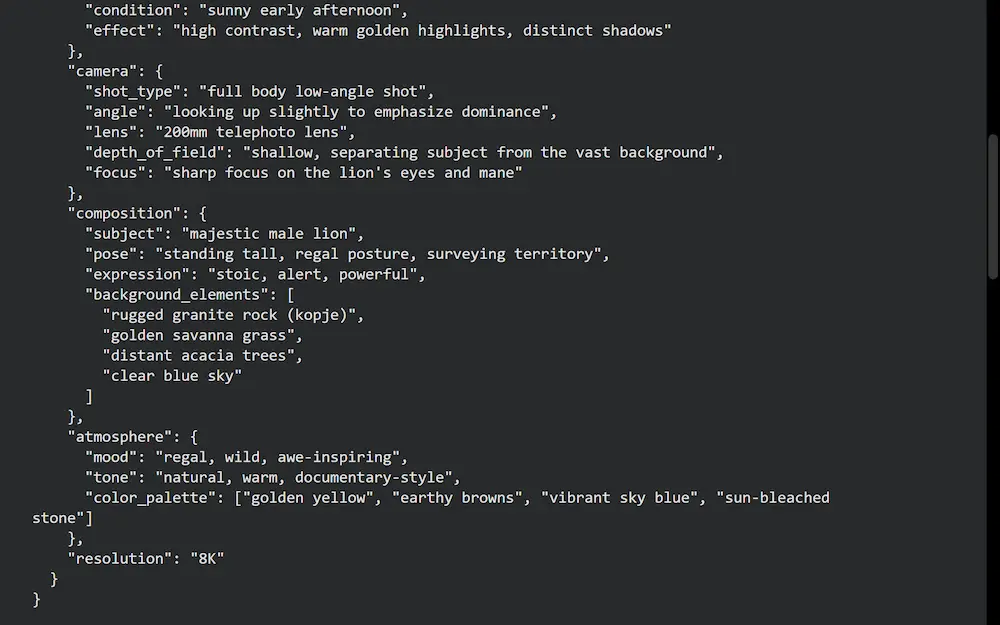
- generare l'immagine;
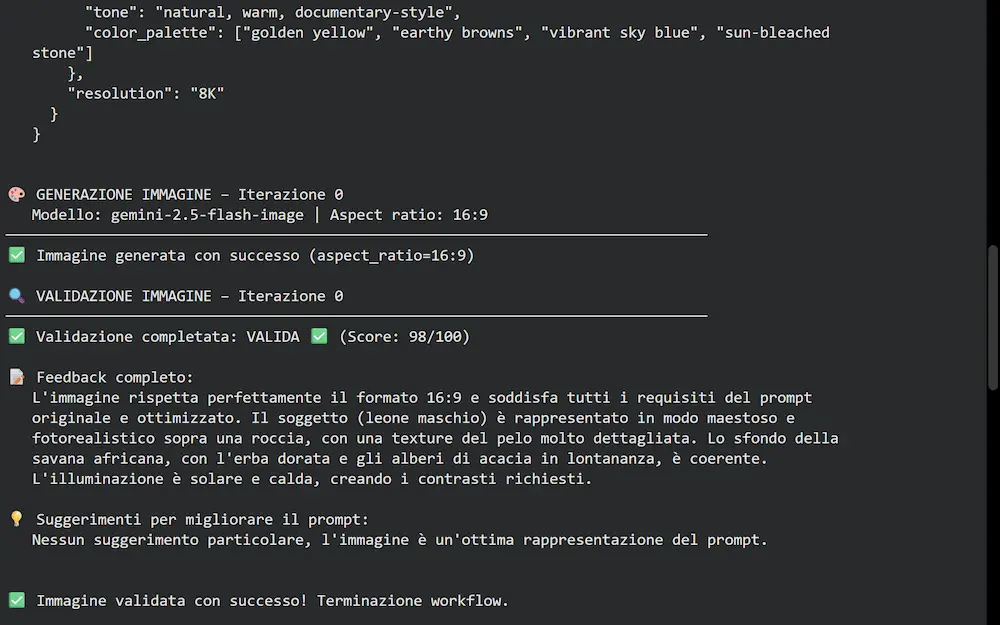
- valutare la coerenza dell'immagine rispetto al prompt attraverso uno score, e produrre un feedback.
Se il valutatore stabilisce che l'immagine non è adeguata, in base alle osservazioni, produce un piano di ottimizzazione del prompt, e il lavoro torna all'agente che crea un nuovo prompt, il quale successivamente farà generare una nuova immagine. E così via finché l'immagine risulta essere adeguata.
Il processo è estendibile anche ai video, visto che le nuove generazioni di modelli hanno una forte propensione alla multimodalità.
Creare presentazioni con Gemini modificabili in Google Slides?
La funzionalità è già disponibile, anche in Italia. Basta attivare "Canvas" e indicare al modello, nel prompt, di creare una presentazione in base al contesto a disposizione.
Nel mio esempio, ho caricato un documento in PDF, e il sistema ha creato una presentazione di 13 slide.
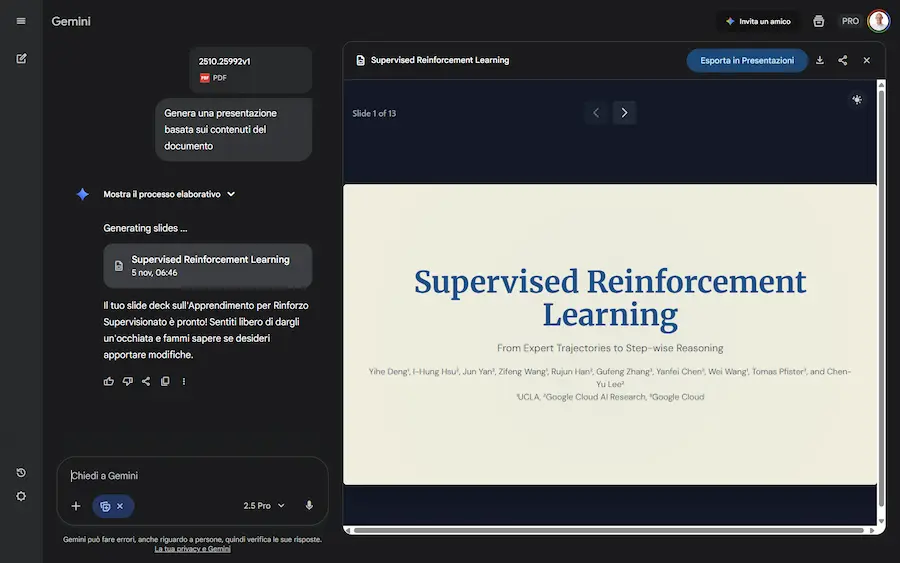
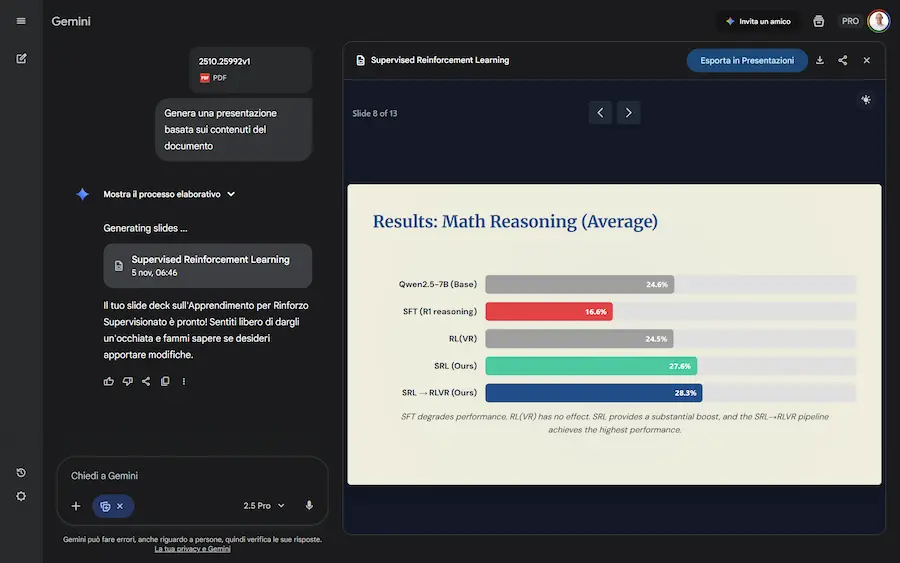
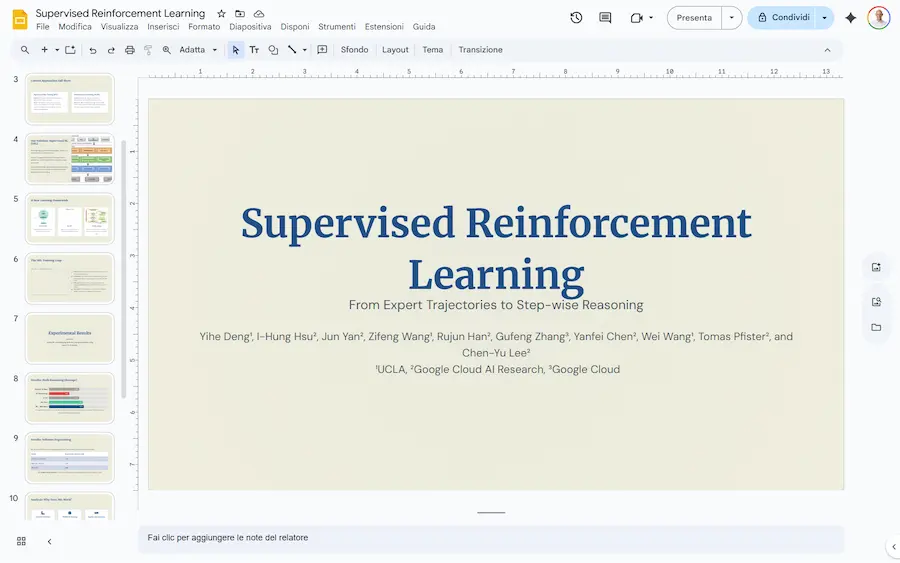
La generazione di presentazioni con l'app di Gemini
Usando l'interazione in chat si possono ottenere modifiche al contenuto, ma l'aspetto interessante è la possibilità di aprire e modificare la presentazione direttamente su Google Slides.
Mettendo a punto dei buoni prompt, descrivendo stile, target, elementi grafici, e altri dettagli, possiamo ottenere delle bozze di buon livello.
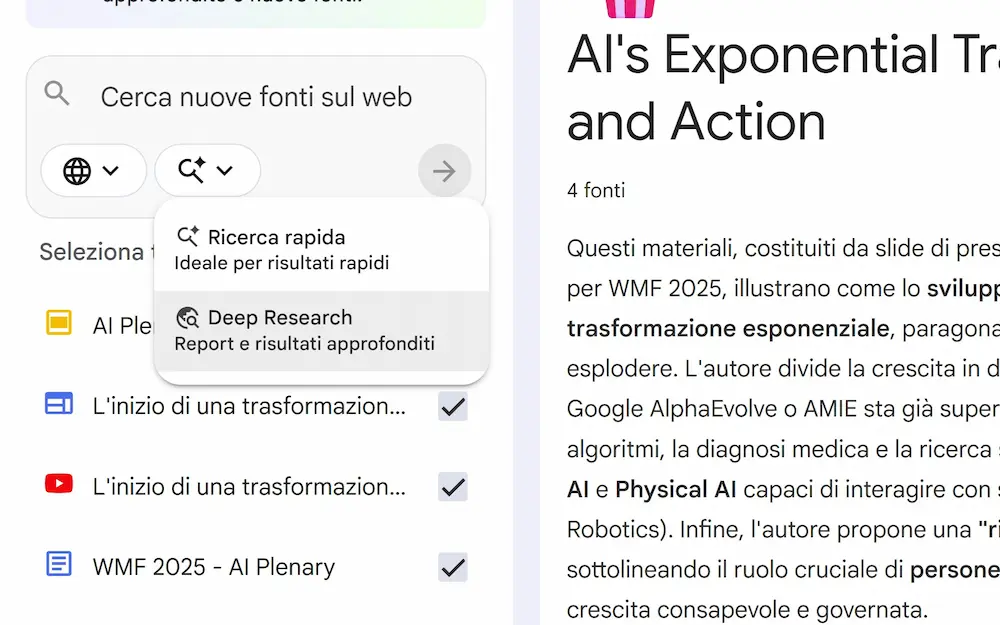
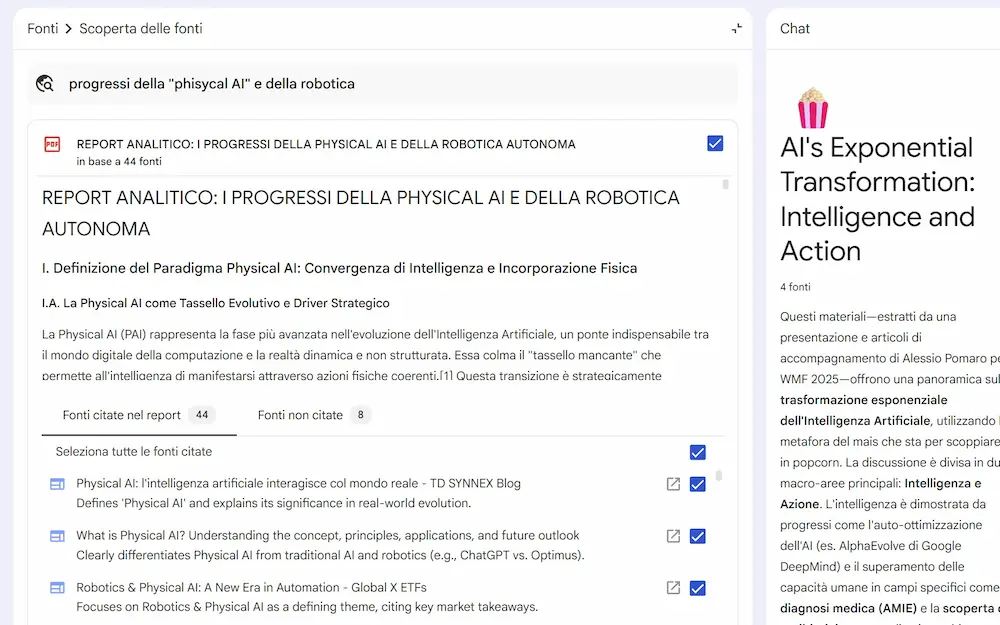
3 novità interessanti su NotebookLM
Su NotebookLM sono state rilasciate 3 importanti novità che riguardano le Video Overview, la Deep Research, le presentazioni e le infografiche.
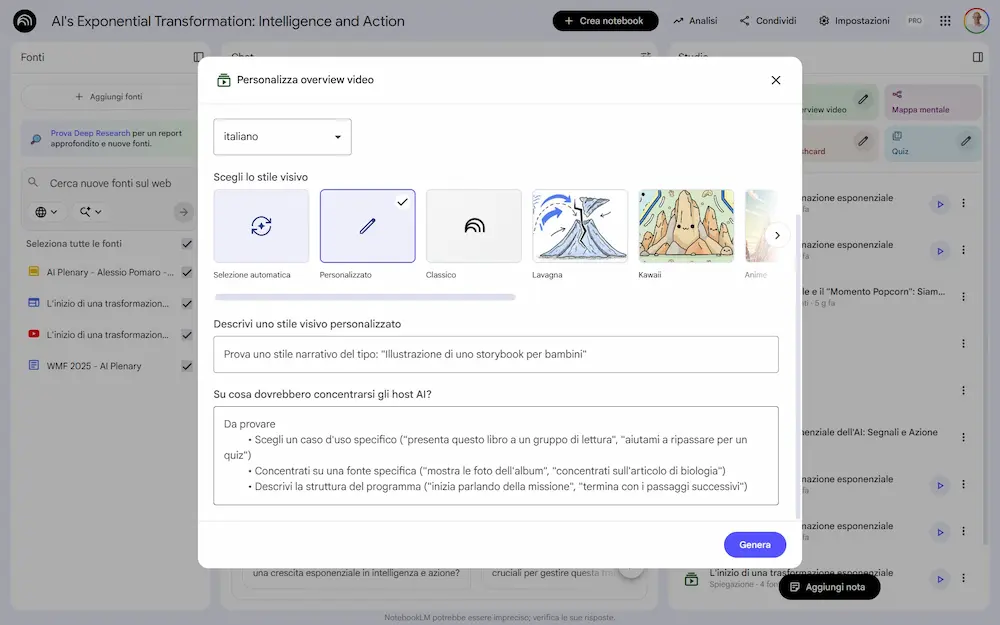
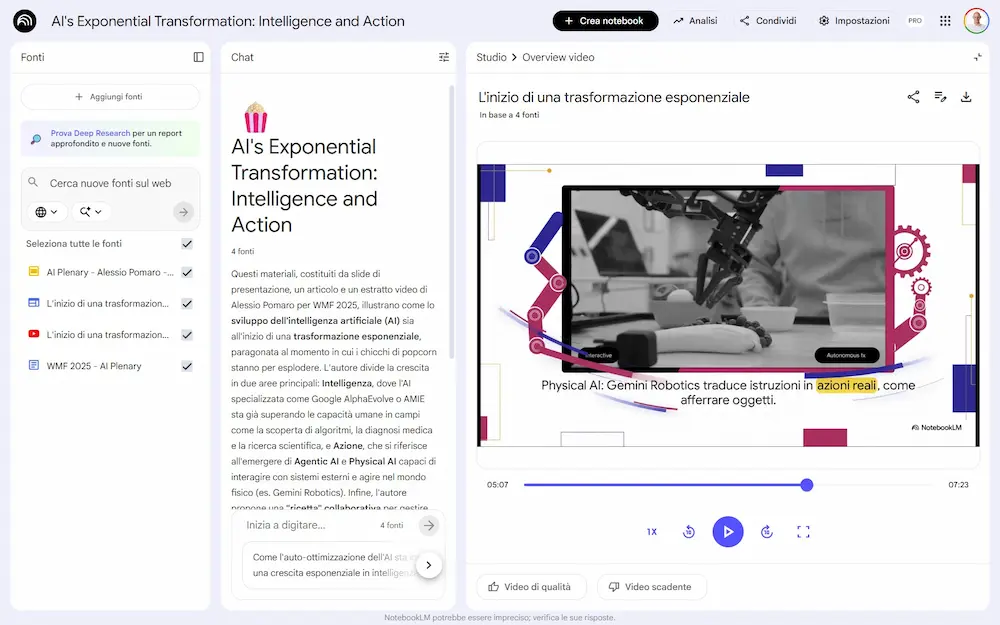
Le novità di NotebookLM: Video Overviews e Deep Research
- È stato introdotto lo stile personalizzato per la Video Overview. Ora è possibile descrivere le caratteristiche visuali del video, oltre al prompt dedicato al contenuto. L'ho provato: non si tratta di un controllo completo (le strutture di base rimangono), ma è un passo in avanti verso overview completamente custom.
- Il rollout della Deep Research è completo e usabile.
L'ho provato, e, come pensavo è notevole: ora il "problema" diventa gestire le fonti. - Finalmente è stata integrata la possibilità di creare infografiche e presentazioni.
Attraverso prompt specifici è possibile ottenere dei risultati molto interessanti.
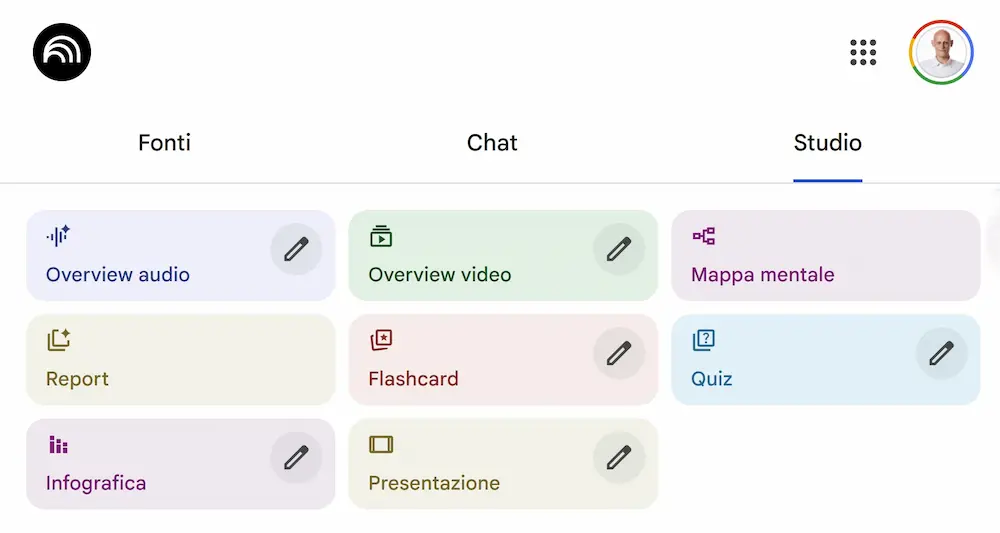
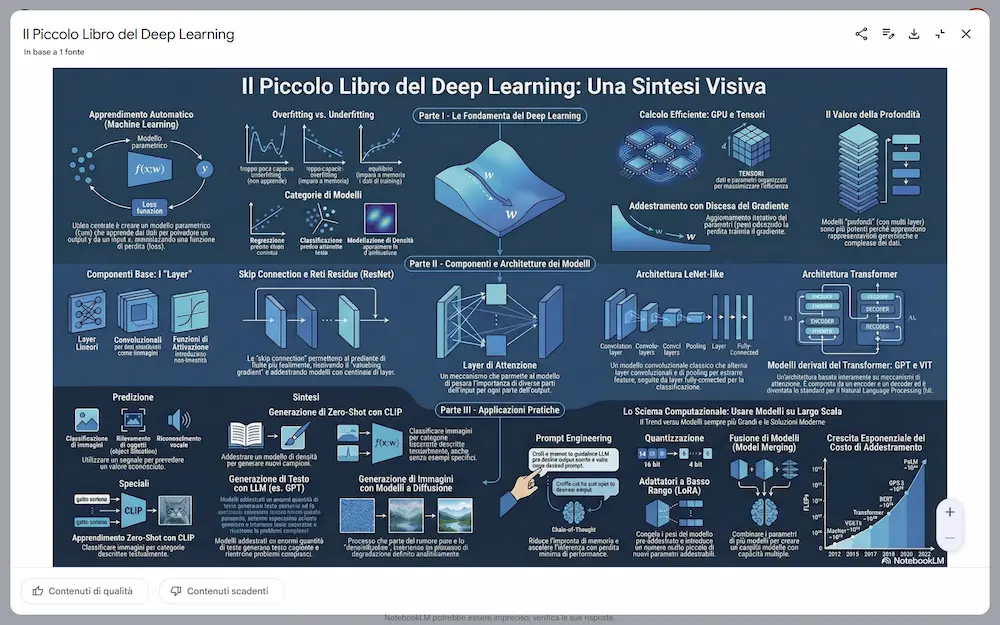
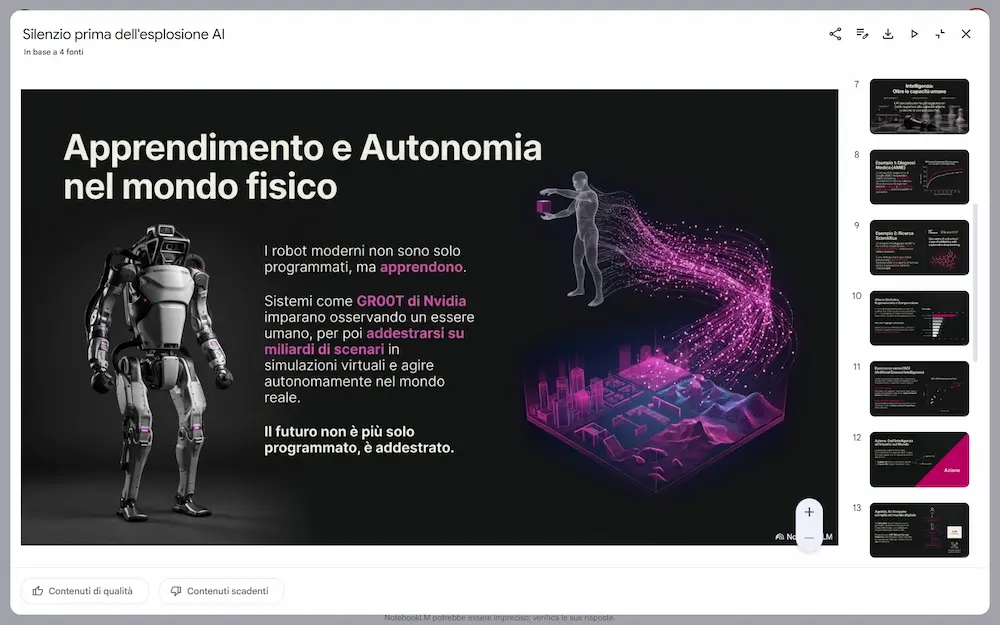
Le novità di NotebookLM: infografiche e presentazioni
Negli esempi si vede un'infografica generata partendo da un e-book sul Deep Learning e una presentazione generata dal materiale su un mio talk.
Unico neo: le presentazioni non possono essere editate su Google Slides, ma sono scaricabili in PDF.
Agent Builder di OpenAI: è un buon sistema?
Sì, ma attenzione allo SPRECO DI TOKEN (enorme)! Spiego come evitarlo.
Per testare la piattaforma, ho provato a riprodurre un workflow multi agente sviluppato su LangGraph.
Il flusso non è particolarmente complesso, ma ha tutti gli ingredienti per capire le dinamiche: agenti con ruoli diversi e connessi a tool anche via MCP, workflow anche con logica condizionale gestita autonomamente, gestione dello "stallo decisionale", prompt dinamici costruiti dagli agenti stessi.
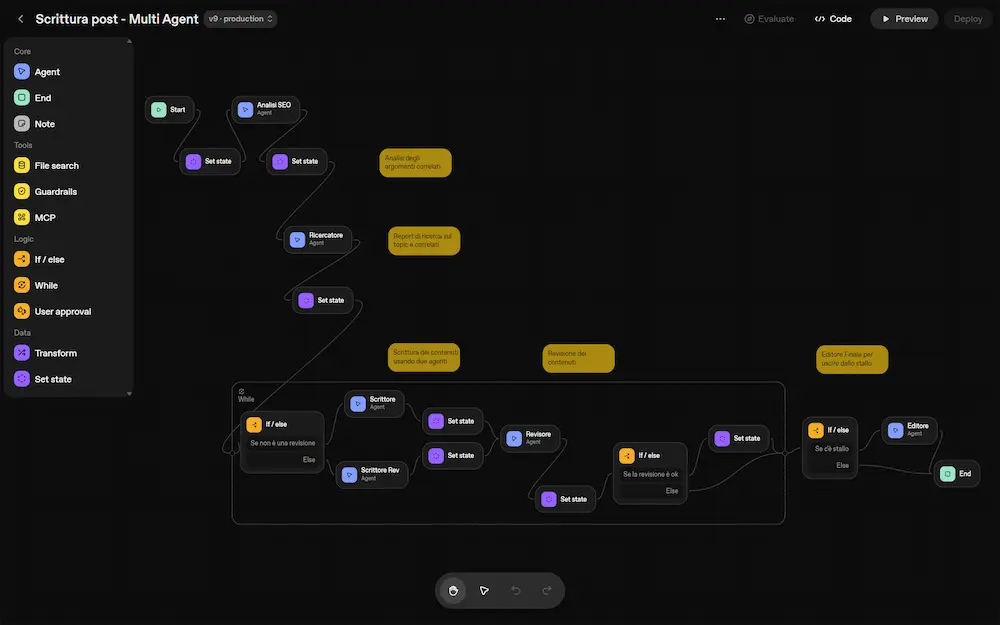
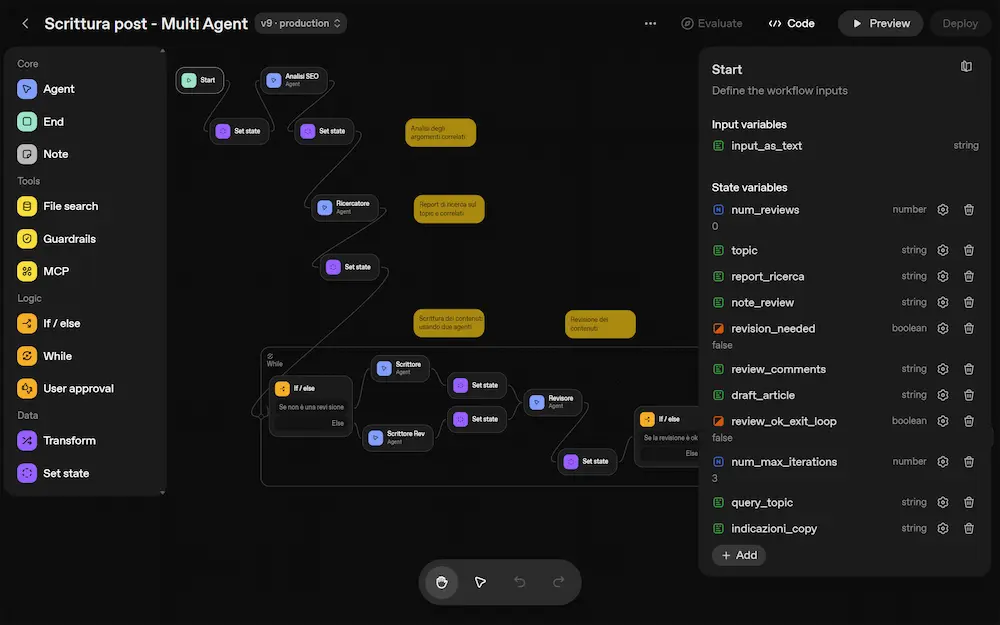
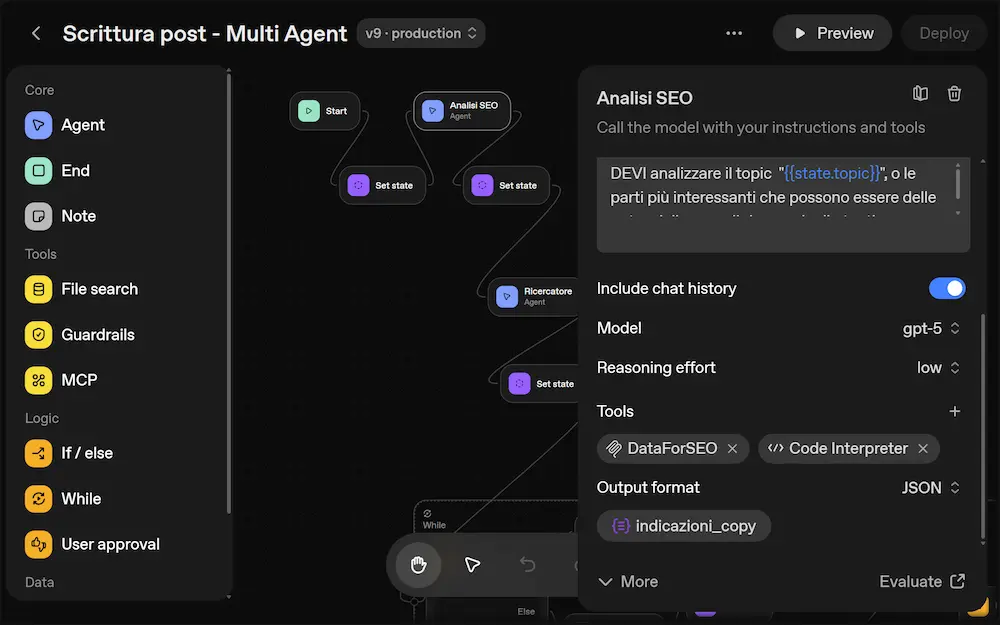
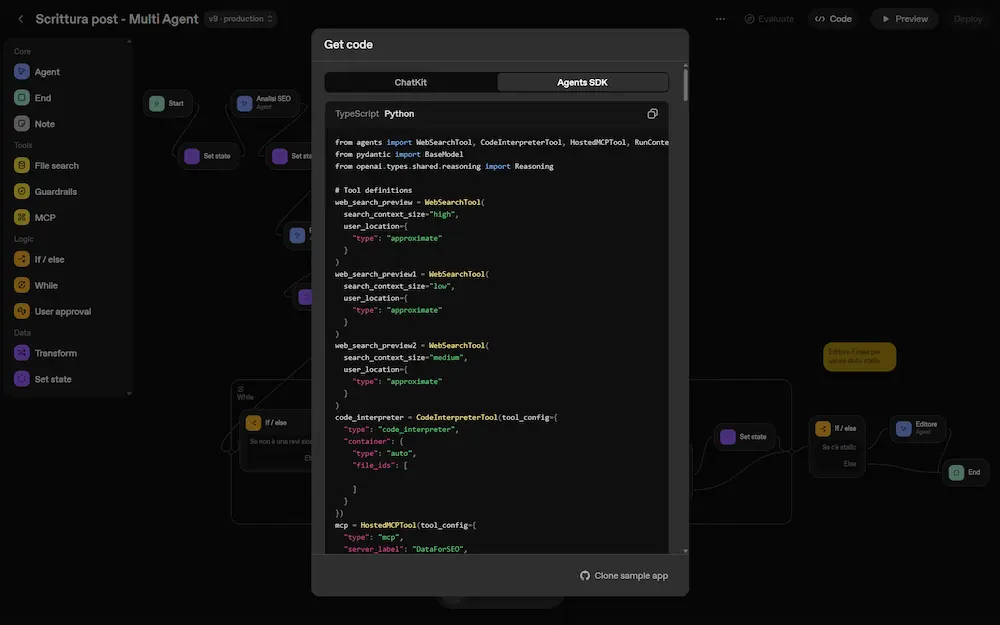
Agent Builder: un workflow multi-agente
Il framework può essere usato in modalità "stateful" (come LangGraph), ed è questo che lo rende flessibile. In pratica, gli agenti condividono un set di variabili di stato, che leggono e aggiornano durante il workflow.
Una volta completato il flusso in modalità visuale, esportando il codice (Python nel mio caso), in qualche minuto l'applicazione è pronta e funzionante in una macchina dove abbiamo l'Agent SDK installato. E può essere modificata e integrata in un flusso di lavoro più ampio.
Per quanto riguarda il framework, trovo l'astrazione di LangGraph migliore: la rappresentazione del flusso attraverso un grafo (nodi + connessioni) continua ad essere vincente e più semplice.
Un aspetto che trovo inefficiente e poco scalabile di Agent SDK è che quando gli agenti vengono invocati (di default) ricevono in input TUTTA LA CRONOLOGIA della chat. Questo rende più semplice l'implementazione, ma causa un ENORME SPRECO di TOKEN e RIDUCE LA SCALABILITÀ!
Consiglio: lavorare SOLO sugli stati, e NON con la history della conversazione.
In conclusione: continuerei a scegliere LangGraph, ma sono rimasto sorpreso dalla flessibilità e dalla velocità di lavoro di Agent Builder + Agent SDK. Attenzione allo spreco di token!
È fondamentale comprendere il funzionamento dei framework per usarli al meglio.
Opal: esempi di workflow
Opal è un Agent Builder di Google: un sistema che permette di creare applicazioni basate sull'AI in modo visuale.
Quelli che seguono sono due esempi di workflow che ho realizzato.
Video advertising
Il workflow riceve in input un prodotto di riferimento e un target di destinazione, generando una bozza di video advertising completa.
I diversi blocchi sfruttano Gemini e Veo per:
- cercare informazioni online,
- creare il copy dell’adv,
- generare il prompt per il video,
- produrre il video stesso,
- costruire un widget HTML con l’annuncio completo.
Opal di Google: un workflow per video advertising
Lavorando sull'ottimizzazione dei prompt dei diversi blocchi, si possono ottenere risultati molto interessanti con un basso effort.
Scrittura di contenuti con Deep Research
In questo esempio, ho sviluppato un workflow che riceve in input un topic ed esegue le seguenti operazioni..
- Avvia una Deep Research sull'argomento (l'agente è addestrato ad espandere la tematica), e produce un report di ricerca dettagliato.
- Genera l'outline per un articolo che mette a fuoco la struttura del contenuto.
- Un agente "scrittore", addestrato con linee guida ed esempi, inizia a generare l'articolo sull'argomento.
- Parallelamente, due agenti, usando l'outline per generare prompt strutturati per la creazione della "hero" image, e di una clip video.
- Il post scritto va in revisione, e l'agente produce un'analisi per l'ottimizzazione.
- Nel frattempo, l'immagine e il video sono pronti.
- Un agente salva il documento con l'articolo su Drive, e un altro genera una preview della pagina web del post, con i contenuti multimediali.
Opal di Google: scrittura di contenuti con Deep Research
Gli agenti del workflow usano Gemini 2.5 Pro, il 2.5 Flash per la Deep Research, Veo 3.1 e Imagen 4.
Pro del sistema: tool e modelli potenti pronti all'uso in modo semplice, e la possibilità di parallelizzazione dei task.
Contro: non ha nodi decisionali, né connessioni a tool esterni via MCP. Ma la funzionalità sta arrivando.
Recentemente Google ha rilasciato Opal in 160 paesi, ma purtroppo l'Italia non è tra questi.
La Deep Research di Qwen si aggiorna
Il team di Qwen ha rilasciato un importante aggiornamento che riguarda la Deep Research, che rende il sistema più approfondito, veloce e migliore.
L'ho provato per una ricerca abbastanza articolata (in modalità "advanced"): in 1 ora e 22 minuti ha creato un report approfondito di 20 pagine, analizzando 170 fonti.
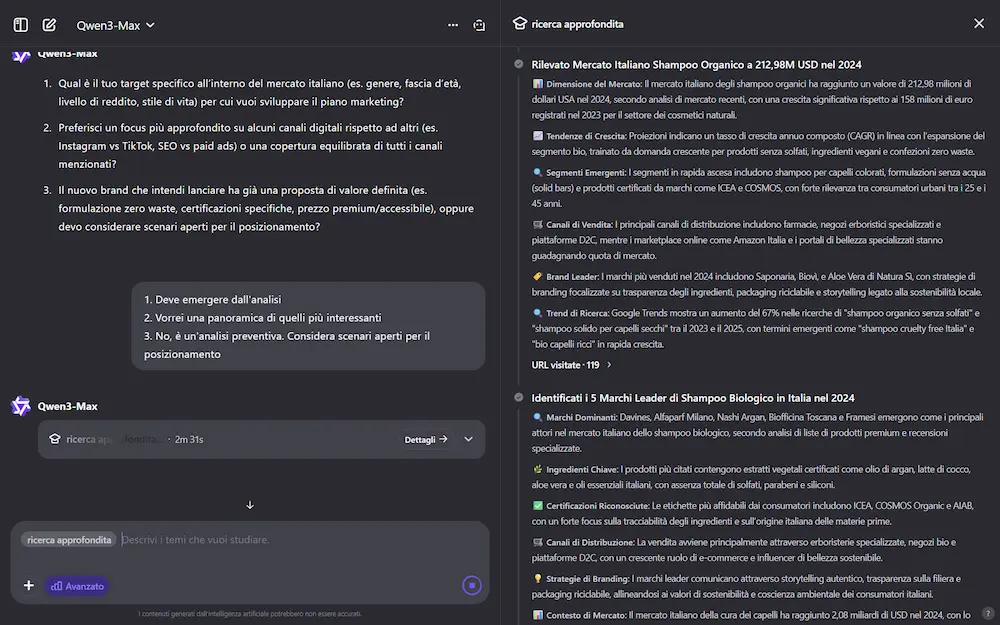
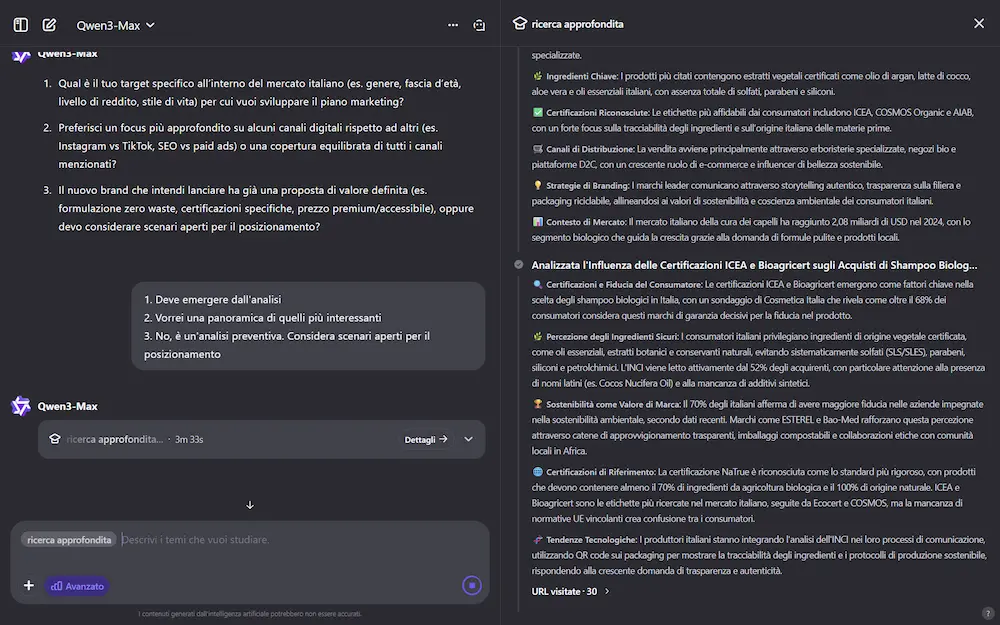
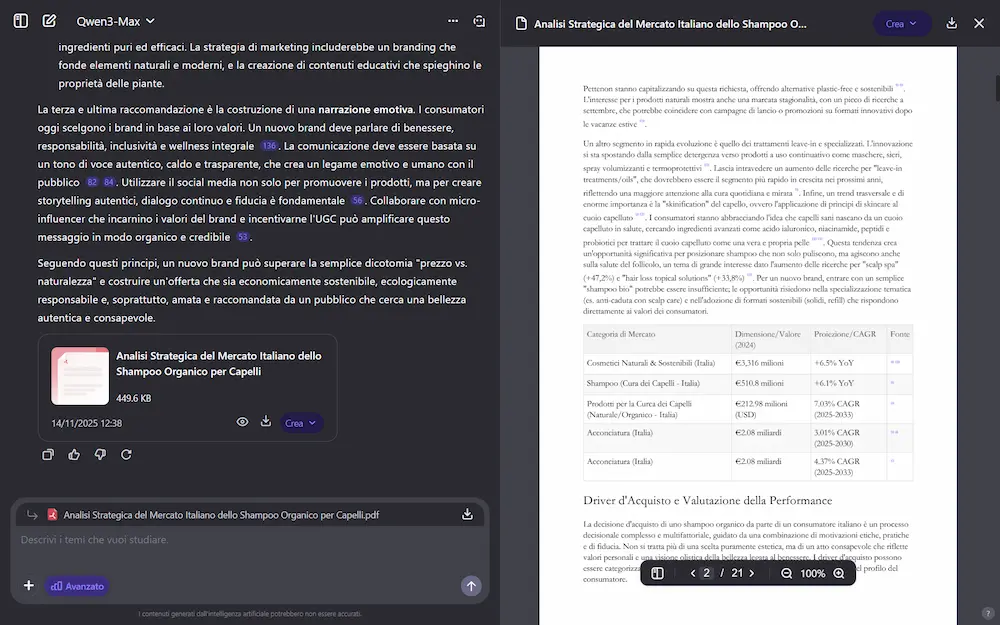
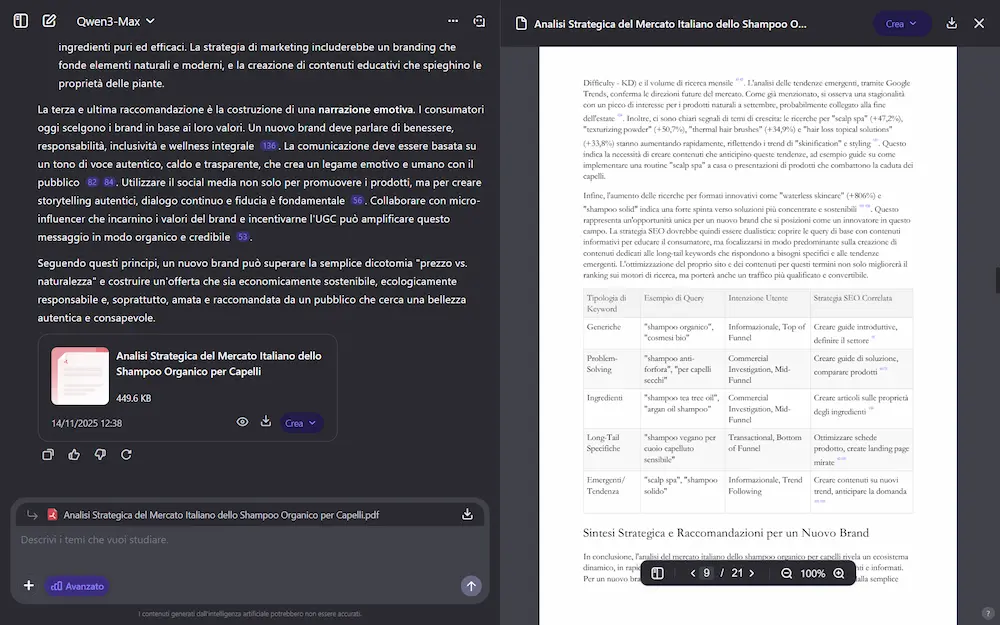
La Deep Research di Qwen
Il nuovo sistema ha due modalità: "normale" (efficiente e versatile per la maggior parte delle esigenze), e "advanced" (meno veloce, ma più approfondita), e permette il caricamento di file e immagini per arricchire il #prompt di ricerca.
La potenza della ricerca è aumentata: diventa più efficiente e profonda. Inoltre migliora il controllo sul report, gestendo meglio, ad esempio, il numero di parole, paragrafi e contenuto.
Continuo a dirlo: modelli come Qwen e Kimi stanno crescendo, diventando delle alternative sempre più interessanti ai sistemi più noti.
FLUX.2
FLUX.2 è il nuovo modello di generazione e editing di immagini sviluppato da Black Forest Labs, progettato per flussi di lavoro creativi reali.
L'ho provato nella versione "pro", e non ci si poteva aspettare che una qualità altissima. Unica nota: nella coerenza visiva con prompt multimodale, siamo lontani da Gemini.





FLUX.2 "pro": alcuni test
Supporta immagini ad alta risoluzione (fino a 4MP), mantiene coerenza di stile e soggetti su più riferimenti (fino a 10 immagini), gestisce testi complessi e aderisce a prompt strutturati e linee guida di brand.
Rispetto alla versione precedente, offre maggiore realismo, stabilità dell’illuminazione, resa tipografica migliorata e maggiore comprensione del contesto reale.
Sono disponibili diverse varianti:
- [pro]: massima qualità e velocità per usi professionali.
- [flex]: controllo su qualità e tempo di generazione, ideale per sviluppatori.
- [dev]: modello open-weight avanzato, utilizzabile localmente o via API.
- [klein] (in arrivo): versione open-source più leggera, con licenza Apache 2.0.
GEM (Generative Ads Recommendation Model) di Meta
Meta ha introdotto GEM (Generative Ads Recommendation Model), un nuovo modello di AI progettato per migliorare la qualità e la rilevanza degli annunci pubblicitari.
Si tratta di un foundation model, cioè un modello di base molto grande e versatile, addestrato su larga scala (con migliaia di GPU e enormi quantità di dati), simile ai LLM, ma dedicato alla pubblicità.
A differenza dei modelli tradizionali che si concentrano solo su compiti specifici, GEM è costruito per apprendere in modo generale da dati eterogenei (clic, interazioni, formato degli annunci, comportamenti degli utenti) e poi trasferire ciò che ha imparato ad altri modelli più piccoli usati in diversi punti dell’ecosistema pubblicitario di Meta.

Tra le innovazioni principali:
- Architettura personalizzata con attenzione multi-livello: GEM distingue tra dati sequenziali (es. cronologia degli utenti) e non sequenziali (es. età, formato dell’annuncio), trattandoli in modo ottimizzato per cogliere meglio le relazioni complesse tra utenti e annunci.
- Modellazione delle sequenze con struttura a piramide parallela: per analizzare lunghe catene di interazioni (click, visualizzazioni) mantenendo il dettaglio senza perdere informazioni utili, anche su migliaia di eventi.
- Cross-feature learning con InterFormer: una combinazione di moduli transformer e strati di interazione tra feature, che permette a GEM di affinare continuamente la comprensione del comportamento degli utenti.
- Trasferimento di conoscenza efficace: GEM usa tecniche avanzate (come knowledge distillation, representation learning e condivisione dei parametri) per migliorare le prestazioni dei modelli verticali senza aumentarne il peso computazionale.
- Training stack ottimizzato: l’infrastruttura di addestramento è stata ripensata da zero per supportare un modello di queste dimensioni. Risultato: +23× nelle FLOPS di training effettive e +1.43× di efficienza nell’uso delle GPU.
GEM ha già mostrato impatti concreti: nel secondo trimestre 2025 ha aumentato le conversioni pubblicitarie del 5% su Instagram e del 3% su Facebook Feed. E gli aggiornamenti successivi hanno raddoppiato l’efficacia per ogni unità di dati e calcolo aggiunta.
SAM 3 di Meta + Colab
Meta ha presentato SAM 3 e SAM 3D, i nuovi modelli di AI per comprendere, segmentare e ricostruire oggetti e persone in immagini e video.
SAM 3 introduce una segmentazione "open vocabulary" basata su prompt testuali, visivi o immagini esempio, superando i limiti delle etichette predefinite. Rileva, segmenta e traccia concetti complessi come "la seconda persona seduta a sinistra con una giacca rossa", e funziona anche in tempo reale su video.
SAM 3 di Meta
SAM 3D estende queste capacità alla ricostruzione tridimensionale. Con SAM 3D Objects è possibile ottenere modelli 3D con texture a partire da una singola immagine. SAM 3D Body stima con precisione la posa e la forma del corpo umano, anche in presenza di occlusioni o pose inconsuete.
Entrambi i modelli si basano su dataset su larga scala costruiti con un sistema ibrido uomo+AI, migliorando drasticamente la qualità e varietà dei dati. Sono già integrati in prodotti come Facebook Marketplace per visualizzare oggetti in ambienti reali, e saranno utilizzati in strumenti per creatori su Instagram, Meta AI e oltre.
Attraverso la piattaforma Segment Anything Playground, chiunque può sperimentare queste tecnologie senza competenze tecniche, caricando immagini e generando segmentazioni o ricostruzioni 3D in pochi passaggi.
Un Colab per provarlo
Attraverso questo Colab è possibile provarlo, attraverso un flusso semplice e lineare. Il video viene prima convertito in frame JPEG, perché SAM 3 lavora a livello di immagine. Si apre poi una sessione di inferenza video, nella quale il modello carica tutti i frame e salva i loro feature embeddings. Da lì, basta fornire un prompt testuale e SAM 3 genera le maschere per ogni oggetto rilevante e le segue per tutta la sequenza. In pochi secondi si ottiene un tracking pulito, stabile e fedele, senza alcun training.
SAM 3 di Meta: un esempio di utilizzo
Nel video, si vede un esempio del risultato.
File Search Tool nella Gemini API
Google ha introdotto il nuovo File Search Tool nella Gemini API, progettato per semplificare l'implementazione di sistemi RAG (Retrieval-Augmented Generation) nei progetti di AI.

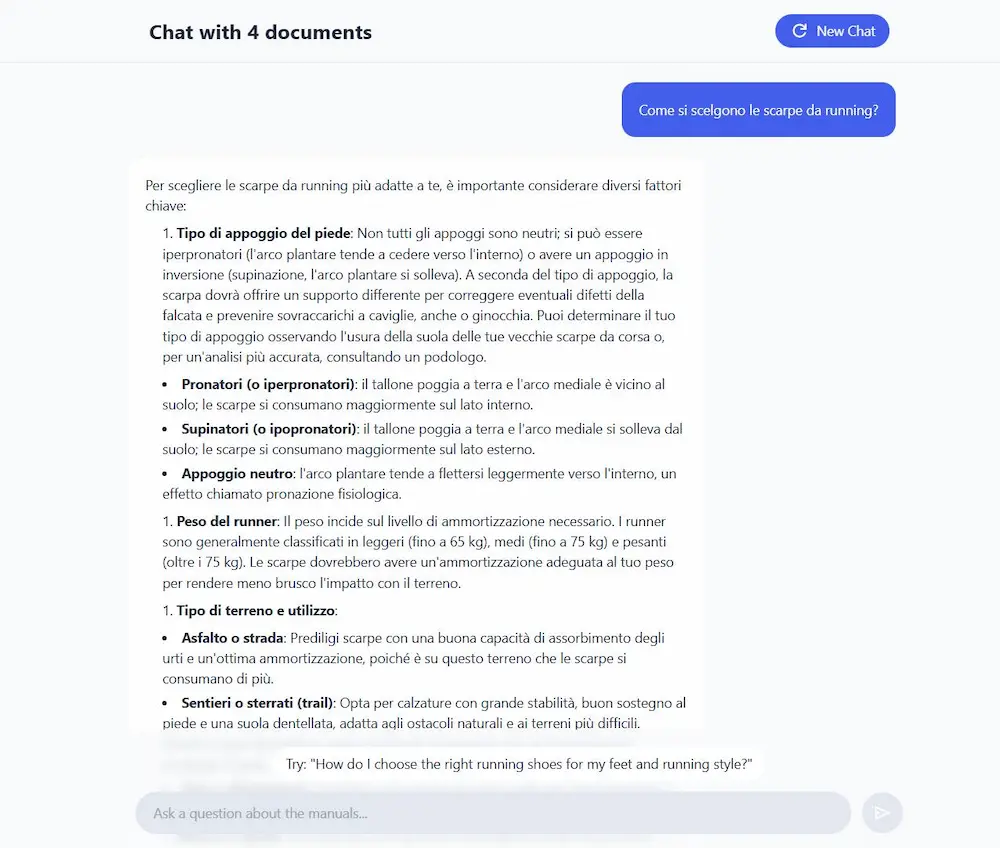
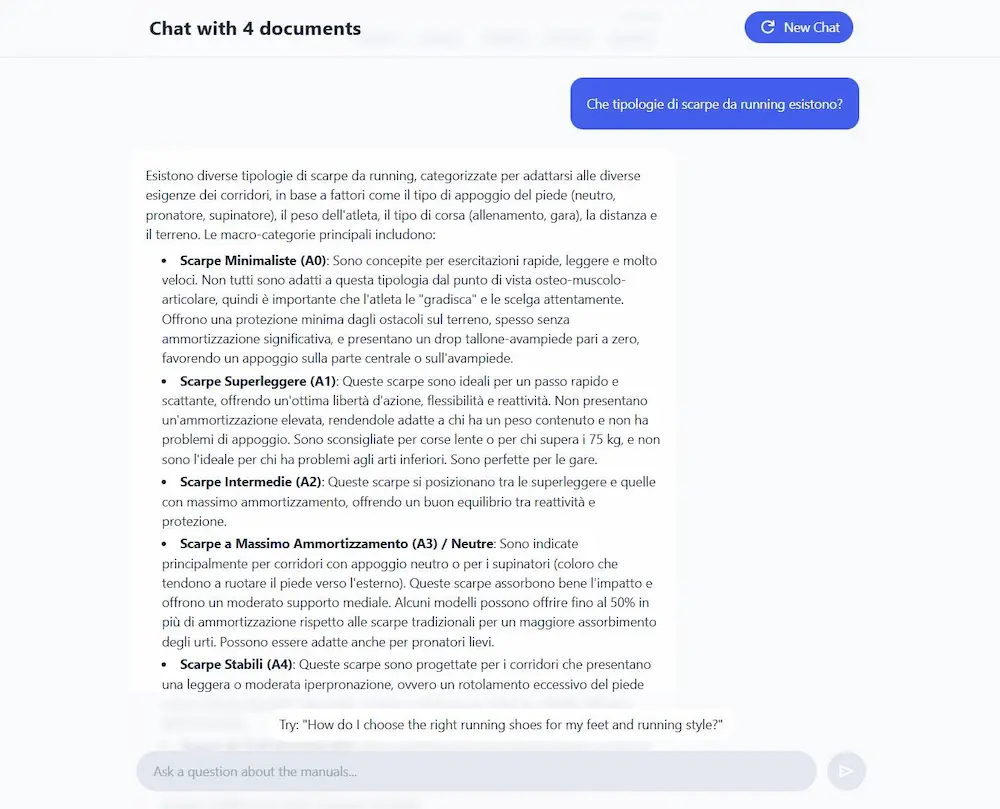
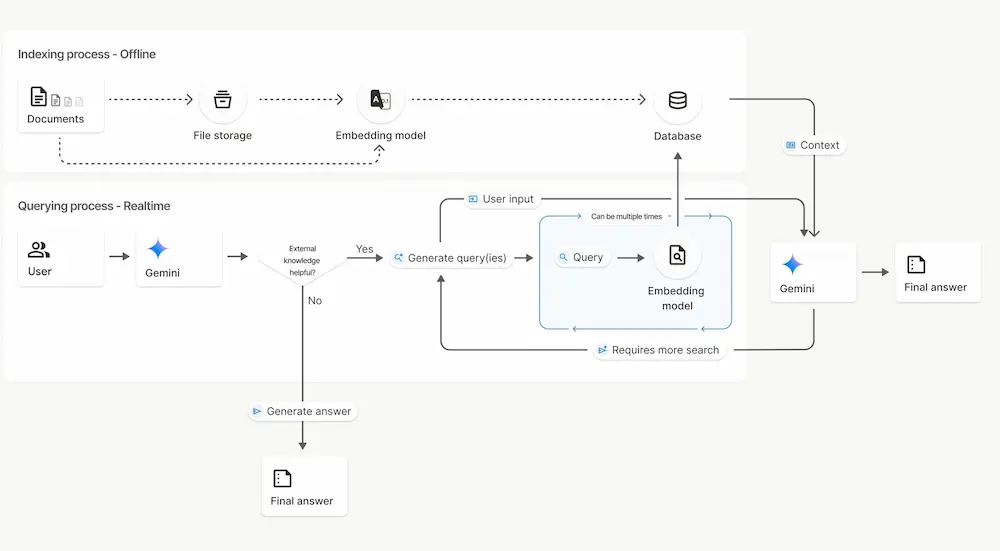
File Search Tool nella Gemini API
Il sistema è completamente gestito e integrato nell’API, permettendo agli sviluppatori di concentrare gli sforzi sulla costruzione delle applicazioni, senza occuparsi della complessità del recupero dei dati.
File Search gestisce in modo automatico lo storage dei file, le strategie di suddivisione in chunk, la generazione degli embeddings e l’iniezione del contesto nei prompt, il tutto tramite un’esperienza unificata nell’API generateContent.
Utilizza un motore di ricerca vettoriale basato sul modello gemini-embedding-001, in grado di comprendere il significato delle query e restituire risultati pertinenti anche in assenza di corrispondenze testuali esatte.
I risultati generati includono citazioni automatiche che indicano con precisione le fonti utilizzate, rendendo più semplice la verifica delle risposte. Il tool è compatibile con numerosi formati, tra cui PDF, DOCX, TXT, JSON e file di codice.
Per rendere lo strumento accessibile, Google ha introdotto un modello di pricing che prevede la gratuità per la ricerca e la generazione di embeddings al momento della query. Si paga solo per l’indicizzazione iniziale dei file, al costo fisso di 0,15 $ per 1 milione di token.
Kimi K2 Thinking
Kimi K2 Thinking è il nuovo modello open-source di agentic thinking sviluppato da Moonshot AI.
Si tratta di un agente in grado di ragionare in modo autonomo, passo dopo passo, mentre utilizza strumenti esterni come browser, motori di calcolo o ambienti di programmazione. È capace di eseguire da 200 a 300 chiamate sequenziali a tool senza alcun intervento umano, mantenendo coerenza e obiettivi lungo tutto il processo.



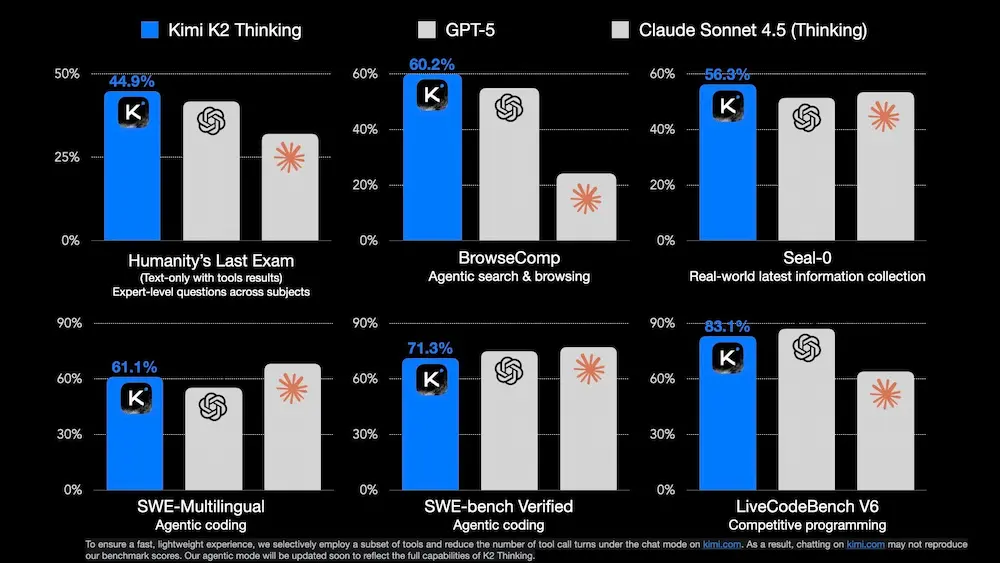
Kimi K2 Thinking: test e performance
Il modello ha ottenuto risultati da stato dell’arte nei principali benchmark di AI:
- 44,9% su Humanity’s Last Exam (HLE), un test multidisciplinare con domande di livello esperto;
- 60,2% su BrowseComp, valutando la sua capacità di ricerca e consultazione autonoma di fonti online;
- 71,3% su SWE-Bench Verified, testando la sua efficacia come agente di programmazione.
Il modello mostra un'elevata generalizzazione in compiti complessi e poco strutturati, ed è in grado di risolvere problemi di matematica avanzata.
Il progetto introduce un paradigma che va oltre la generazione di testo: un’intelligenza artificiale che combina pensiero computazionale, capacità simboliche e uso strumentale, aprendo la strada a una nuova generazione di agenti intelligenti capaci di affrontare compiti aperti e multidisciplinari con autonomia e profondità.
Freepik Spaces
Anche Freepik ha lanciato il suo "canvas" che permette la creazione di workflow per la produzione di contenuti visivi. Si chiama "Spaces".
Freepik Spaces: un test
Nel video si vede un esempio di un semplice flusso, in cui genero un'immagine "text-to-image" con Seedream 4, e partendo dall'immagine ne creo un'altra, con la nuova funzionalità "Camera Angles", che permette di ruotare l'inquadratura.
Infine, collegando l'immagine a un nodo video, e aggiungendo un #prompt testuale, genero un video con Veo 3.1.
Ho creato il prompt per l'immagine usando "Image Prompt Assistant":

Il prompt per il video, invece, con "Veo 3 Prompt Assistant":

L'aspetto sempre più interessante di questi modelli è la loro capacità di aderire anche a istruzioni molto strutturate. L'immagine, e poi il video, mostrano esattamente quello che ho descritto nei prompt.
SIMA 2 di Google DeepMind
SIMA 2 è la nuova generazione di agenti AI sviluppata da Google DeepMind, progettata per operare in ambienti virtuali 3D complessi.
Potenziato dal modello Gemini, non si limita a seguire istruzioni: ragiona, comunica, apprende autonomamente e si adatta a mondi mai visti prima.
L'agente comprende obiettivi a lungo termine, esegue compiti articolati e spiega le proprie azioni.. un passo concreto verso l’intelligenza artificiale generale "incarnata"? Le sue abilità si estendono oltre i singoli giochi: riesce a trasferire concetti tra contesti differenti e ad apprendere nuove competenze tramite gioco auto-diretto.
SIMA 2 di Google DeepMind
SIMA 2 è anche in grado di operare in mondi generati in tempo reale da semplici input testuali o visivi, grazie all’integrazione con il progetto Genie.
Durante l’addestramento, il sistema utilizza i feedback di Gemini per migliorarsi progressivamente senza ulteriore supervisione umana, dimostrando una capacità di autoapprendimento su larga scala.
Il progetto rimane in fase di ricerca, ma apre prospettive concrete per applicazioni nella robotica, nell’assistenza virtuale e nell’interazione multimodale uomo-macchina.
Nested Learning di Google Research
Nested Learning è un nuovo approccio al machine learning sviluppato da Google Research, pensato per risolvere un limite comune nei modelli neurali: quando imparano nuove informazioni, tendono a dimenticare quelle già apprese.


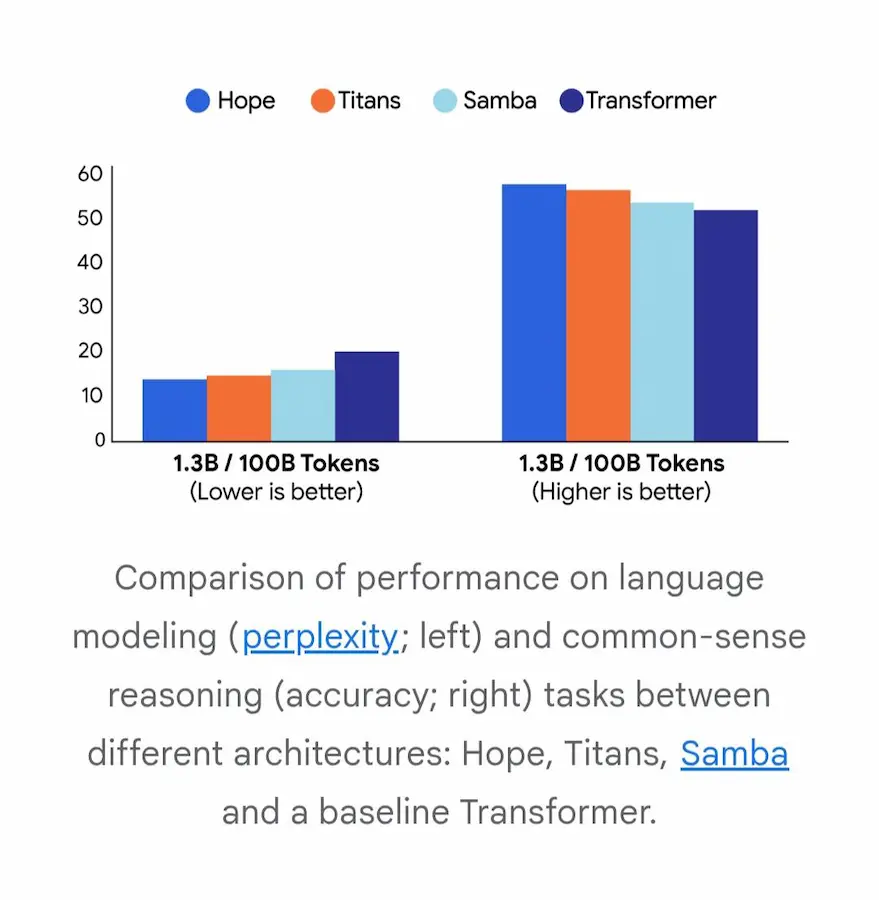
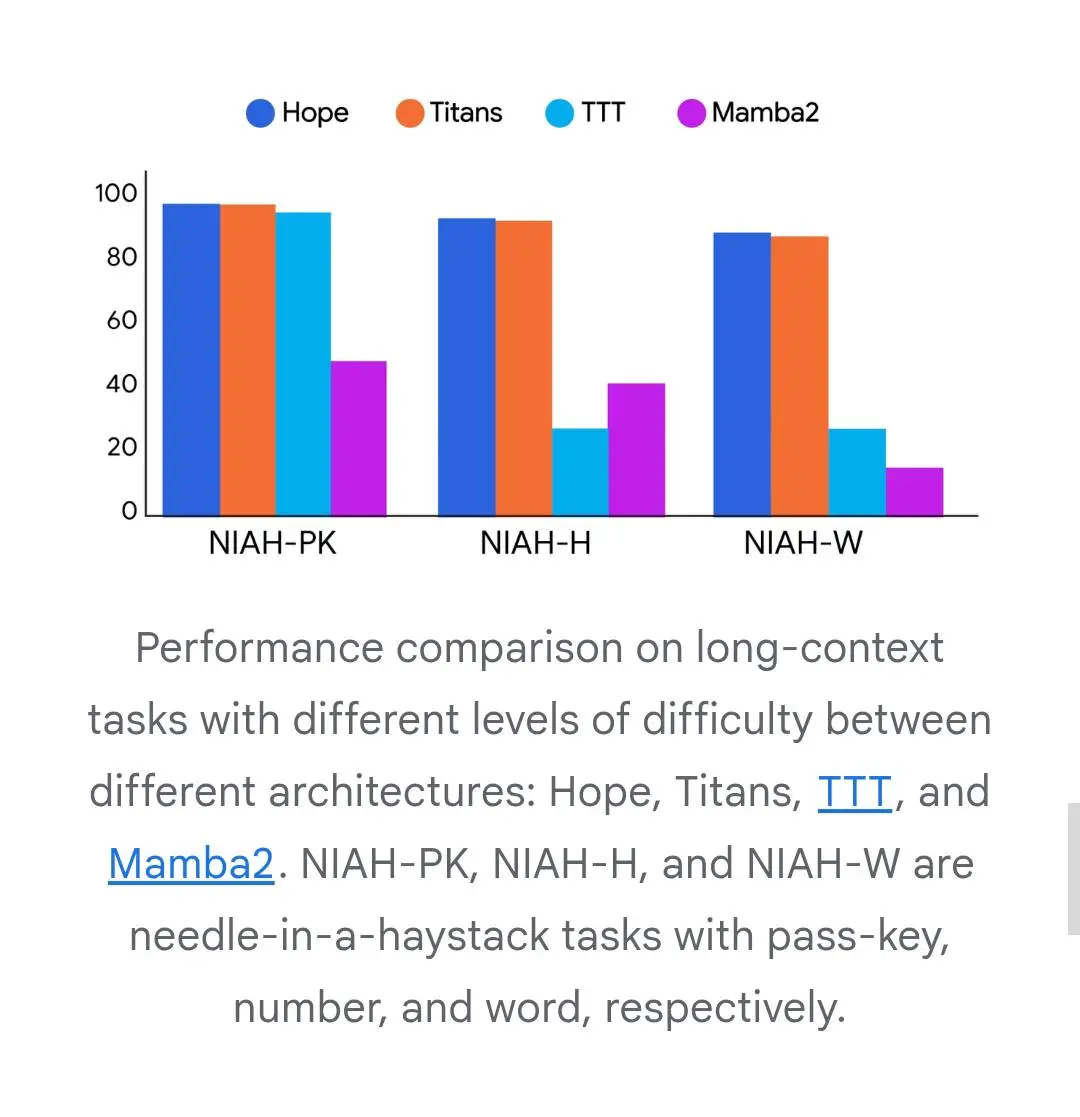
Nested Learning di Google Research
Invece di considerare il modello come un unico processo di apprendimento, Nested Learning lo interpreta come un insieme di più sottoprocessi organizzati a livelli, ciascuno con il proprio flusso informativo e il proprio ritmo di aggiornamento.
Questo approccio unifica la struttura del modello e il modo in cui apprende, trattandoli come parti di un unico sistema. Il risultato è un'AI più stabile, che può imparare in modo continuo senza perdere ciò che già conosce.
Hope è l’architettura sperimentale sviluppata secondo questi principi: una rete neurale ricorrente capace di modificare sé stessa e dotata di una memoria flessibile, in grado di gestire grandi quantità di informazioni nel tempo. I risultati mostrano miglioramenti evidenti rispetto ai modelli tradizionali, sia nella comprensione del linguaggio sia nel mantenere memoria di contesti lunghi.
Questo apre nuove prospettive per costruire sistemi di intelligenza artificiale più vicini al modo in cui apprende il cervello umano.
Kosmos: l'AI applicata alla ricerca scientifica
Kosmos rappresenta una delle evoluzioni più significative nel campo dell'AI applicata alla ricerca scientifica.
È un sistema progettato per condurre, in modo autonomo, l'intero ciclo della scoperta: analisi dei dati, esplorazione della letteratura, generazione di ipotesi, verifica e sintesi in report strutturati e completamente tracciabili.
La sua architettura combina due agenti generici (uno dedicato alle analisi e uno alla ricerca bibliografica) coordinati da un "world model" che mantiene coerenza, memoria e direzione scientifica per centinaia di iterazioni. Il risultato è una capacità di ragionamento esteso che supera di un ordine di grandezza quella dei sistemi precedenti.
In un singolo run di 12 ore, Kosmos può leggere fino a 1.500 articoli, eseguire oltre 40.000 righe di codice e produrre scoperte che, secondo gruppi accademici indipendenti, equivalgono a circa sei mesi di lavoro umano.
Ogni claim è supportato da codice o letteratura primaria, offrendo un grande livello di trasparenza, e permettendo a scienziati esterni di validare o confutare facilmente ogni passaggio. L’accuratezza complessiva delle sue affermazioni, valutata da esperti, è del 79%, con performance particolarmente solide nelle analisi dati e nelle verifiche bibliografiche.
Il valore di Kosmos emerge soprattutto nella sua capacità di esplorare fenomeni complessi con un approccio non pregiudiziale.
Nei test condotti, ha riprodotto risultati recenti non ancora pubblicati, ha fornito prove aggiuntive per scoperte esistenti e ha sviluppato nuovi metodi analitici senza supervisione diretta. In alcuni casi è arrivato a identificare meccanismi biologici che non erano mai stati individuati da ricercatori umani.
Questa potenza analitica non elimina
il ruolo dei ricercatori: lo amplia.
Kosmos dà il meglio quando opera su dati curati da scienziati e quando i risultati vengono valutati criticamente da esperti. La collaborazione uomo–AI diventa un ciclo continuo: lo scienziato imposta il problema, Kosmos esplora lo spazio delle possibilità, l’umano interpreta, corregge, orienta. E ciò che Kosmos propone, anche quando imperfetto, amplia l’orizzonte degli esperimenti e delle domande future.
Nonostante i limiti attuali, il sistema dimostra cosa può diventare la ricerca quando la capacità computazionale si unisce a metodi scientifici automatizzati. Kosmos non promette di sostituire l’ingegno umano, ma accelera il percorso che porta dai dati alla conoscenza, aprendo un nuovo modo di fare scienza in cui esplorazione e validazione si alimentano reciprocamente.
Flora: un workflow con Wan 2.2 e Nano Banana
Flora rimane uno dei sistemi dedicati ai modelli visuali più sorprendenti.
Questo workflow, basato su Gemini 2.5 Flash Image (Nano Banana) e Wan 2.2 Move & Replace, permette di sostituire personaggi, abiti o oggetti in post-produzione.
Flora: un workflow con Wan 2.2 e Nano Banana
Il tutto, collegando blocchi video e immagini di riferimento, e adattando automaticamente il risultato al movimento e alla scena.
L'editing delle immagini di Qwen
Uno space di Hugging Face molto interessante che mostra la potenzialità di Qwen nell'editing delle immagini.
L'applicazione riceve in input un'immagine e permette di selezionare un'opzione di cambio inquadratura.





L'editing delle immagini di Qwen
L'output è un'immagine coerente nell'inquadratura selezionata.
I modelli di generazione video rispettano le leggi fisiche del mondo reale?
Oppure si limitano a generare sequenze visivamente plausibili senza comprenderle?
Quando è stato lanciato Sora 2, dopo diversi test, avevo già risposto con decisione a questa domanda, ma ora arriva una conferma dal paper "Do generative video models understand physical principles?" di Google DeepMind e INSAIT.
Il team ha creato Physics-IQ, un benchmark pensato per misurare la comprensione delle leggi fisiche nei modelli di generazione video. Sono stati messi alla prova otto sistemi tra cui Sora, Runway Gen-3, Lumiere, Pika, Stable Video Diffusion e VideoPoet, chiedendo loro di prevedere come prosegue una scena in base ai primi fotogrammi.

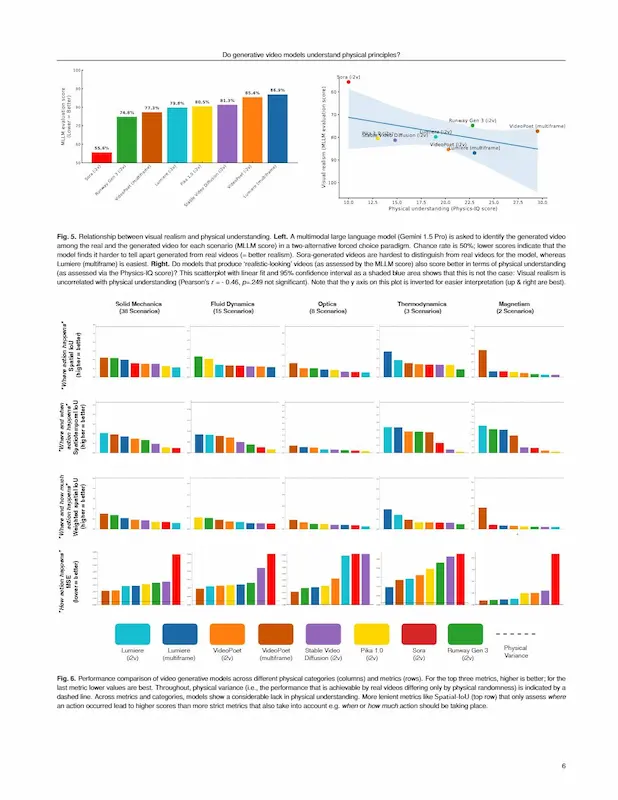
Paper: "Do generative video models understand physical principles?"
Il dataset include 396 video reali che coprono meccanica dei solidi, fluidodinamica, ottica, termodinamica e magnetismo. I risultati parlano chiaro: anche i modelli più avanzati raggiungono solo il 30% del comportamento fisico reale. Il migliore è VideoPoet (multiframe) con il 29,5%, mentre Sora, pur generando i video più realistici visivamente, si ferma al 10%.
Il dato più interessante: realismo visivo e comprensione fisica non sono correlati. Un video può sembrare perfettamente credibile e al tempo stesso violare le leggi fondamentali del mondo reale.
Il lavoro apre una riflessione più ampia: la previsione del futuro (next-frame prediction) può davvero bastare per imparare la fisica, o servirà un approccio più "embodied", in cui l’IA interagisce con l’ambiente per capirlo davvero?
Il benchmark Physics-IQ è pubblico e rappresenta oggi un riferimento per misurare quanto le intelligenze generative "capiscono" davvero il mondo che imitano.
Le mie considerazioni dopo il lancio di Sora 2

Tongyi DeepResearch: report tecnico
Dopo il lancio di Tongyi DeepResearch, il team di Alibaba ha pubblicato il report tecnico completo, ed è un documento che segna degli step di avanzamento molto interessanti.
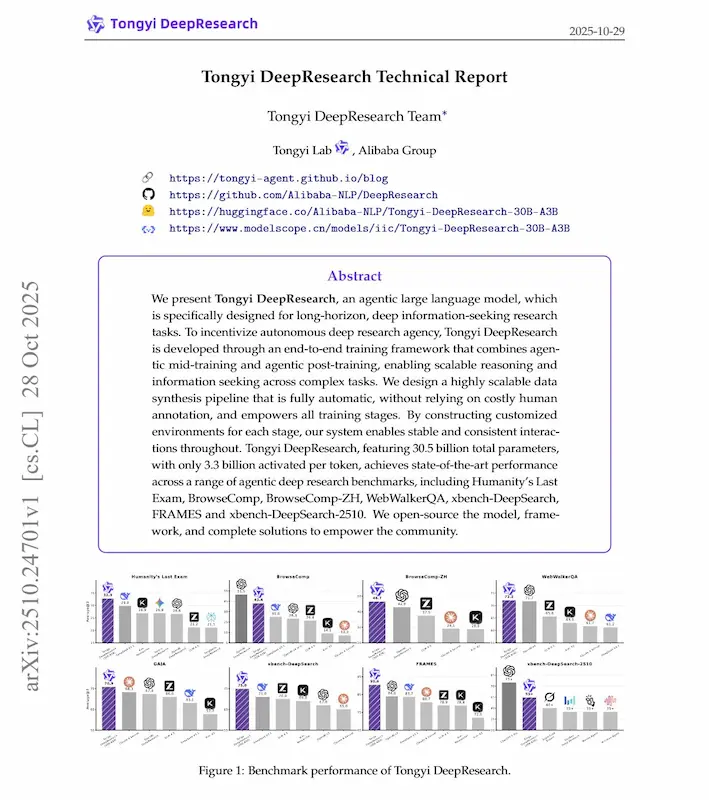
Tongyi DeepResearch è un modello agentico da 30,5 miliardi di parametri, ma con solo 3,3 miliardi attivi per token. Un’architettura efficiente, progettata per eseguire ricerche complesse, pianificare strategie, consultare fonti reali e sintetizzare conoscenza in modo autonomo.
La vera novità è il modo in cui è stato addestrato: un approccio “end-to-end” che unisce due fasi (mid-training e post-training agentico) in un unico flusso continuo. Nella prima fase il modello apprende come comportarsi da agente, nella seconda impara a perfezionare queste abilità attraverso reinforcement learning e fine-tuning supervisionato.
Niente etichette manuali: i dati di addestramento vengono generati automaticamente tramite una pipeline di sintesi che produce domande, ragionamenti e decisioni simulate, in ambienti virtuali e reali. È un modo per scalare la conoscenza senza il costo del lavoro umano, mantenendo coerenza e varietà.
Il modello interagisce con un ecosistema di strumenti (es. il motore di ricerca, interprete Python, parser di file, Google Scholar) e gestisce contesti fino a 128.000 token grazie a un sistema di memoria compressa che
imita il modo in cui una persona sintetizza e aggiorna ciò che sa durante un’indagine lunga.
Nei test, Tongyi DeepResearch ha superato o eguagliato modelli chiusi come OpenAI o3 e DeepSeek-V3.1, raggiungendo prestazioni allo stato dell’arte su benchmark di ricerca complessa come Humanity’s Last Exam, GAIA e WebWalkerQA.
Alibaba ha inoltre introdotto la “Heavy Mode”, che coordina più agenti in parallelo e fonde le loro conclusioni in un’unica risposta coerente: potremmo definirla "intelligenza collaborativa".
Il risultato è un agente capace di unire metodo scientifico e automazione, costruendo una base aperta per la ricerca autonoma.
Personal Health Agent (PHA)
Un nuovo studio di Google Research presenta il Personal Health Agent (PHA), un sistema multi-agente basato su grandi modelli linguistici progettato per offrire supporto personalizzato alla salute e al benessere.
Il PHA integra dati da dispositivi indossabili, cartelle cliniche e interazioni conversazionali per fornire analisi, interpretazioni mediche e coaching motivazionale. Il sistema si articola in tre componenti:
- il Data Science Agent, che analizza dati numerici e individua pattern;
- il Domain Expert Agent, che fornisce risposte mediche accurate e contestualizzate;
- l’Health Coach Agent, che aiuta a definire obiettivi realistici e a sostenere il cambiamento comportamentale.
Sviluppato con un approccio centrato sull’utente, il progetto si basa su oltre 1.300 query reali e su dati dello studio WEAR-ME, che ha coinvolto più di mille partecipanti. La valutazione ha compreso 10 benchmark, oltre 7.000 annotazioni umane e più di 1.100 ore di lavoro di esperti e utenti.
I risultati mostrano miglioramenti significativi nell’accuratezza analitica, nella qualità delle risposte mediche e nell’efficacia del coaching rispetto ai modelli linguistici generici.
Forse, stiamo vedendo dei progressi interessanti verso "agenti di salute" integrati, accessibili e orientati all’empowerment delle persone.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂