Generative AI: novità e riflessioni - #2 / 2026
Dai modelli ai sistemi: l’AI si sposta verso orchestrazione, agenti e stack completi. Gemini 3.1 Pro, Claude Opus 4.6, Mercury 2 e Qwen 3.5 spingono reasoning e multimodalità. Video AI con Seedance e Kling, Perplexity Computer e WebMCP: segnali chiave della nuova infrastruttura dell’AI.


Buon aggiornamento, e buone riflessioni..
Ascolta l'audio overview che sintetizza le novità
Il podcast è stato generato attraverso NotebookLM.
Un viaggio attraverso l’evoluzione dell'AI: dai modelli ai sistemi intelligenti
Per anni abbiamo pensato che il vantaggio nell'AI fosse avere il modello migliore. Oggi i modelli di fascia alta hanno performance sempre più simili: stanno diventando commodity.
Il vero vantaggio competitivo si è spostato sui sistemi.
AI Festival 2026
Integrare l'AI non significa aggiungere un'API, ma riprogettare processi in ottica AI-first. Serve un layer applicativo solido (contesto, tool, controlli, monitoraggio) e un lavoro di context engineering che architetta le informazioni, non solo i prompt.
L'approccio multi-agente, con ruoli distinti che pianificano, eseguono e verificano, è ciò che rende questi sistemi affidabili e scalabili.

Non è una rivoluzione di modelli, ma di orchestrazione. E il prossimo passo andrà oltre il linguaggio, verso sistemi capaci di rappresentare e simulare il mondo.
L'hype finanziario dell'AI è reale. Ma l'impatto strutturale a lungo termine è ancora sottostimato
Così ho chiuso il mio intervento all'AI Festival.
Questo report pubblicato da MIT Technology Review approfondisce proprio questo punto, partendo da un'analisi storica di oltre 130 anni di dati economici elaborata dal team di Joseph Davis, capo economista globale di Vanguard.

La tesi è chiara: l'ipotesi di un impatto marginale dell'AI sull'economia appare poco solida. Più plausibile è uno scenario in cui l'AI si afferma come tecnologia general purpose, capace di aumentare la produttività in modo persino più profondo rispetto al personal computer.
Il vero cambiamento si gioca su tre dimensioni: automazione delle attività ripetitive, augmentation (l'AI come copilota che potenzia le competenze) e creazione di nuove industrie.
Su oltre 800 professioni analizzate, circa l'80% non verrà sostituito, ma trasformato. Il lavoro si sposterà verso attività a maggior valore aggiunto, mentre l'AI assorbirà parti operative e amministrative.
Un altro punto interessante riguarda la produttività. Negli ultimi anni è cresciuta meno del previsto, non perché l'automazione sia eccessiva, ma perché è stata adottata troppo poco nei servizi: sanità, istruzione, finanza. Ed è proprio lì che l'AI può generare l'impatto più significativo.
C'è poi la variabile demografica. Con l'invecchiamento della popolazione e la riduzione della forza lavoro, il tema nei prossimi anni potrebbe non essere la carenza di posti, ma la carenza di persone. Secondo le stime riportate, entro 5–7 anni l'effetto combinato dell'AI potrebbe equivalere all'aggiunta di 16–17 milioni di lavoratori negli Stati Uniti.
Un passaggio chiave riguarda anche i mercati: i maggiori benefici non andranno solo a chi sviluppa AI, ma soprattutto a chi la integra nei processi core. Come spesso accade con le tecnologie abilitanti, il vantaggio competitivo sarà nell'adozione consapevole e sistemica.
L'AI non è solo un tema di capitalizzazione di mercato. È una questione di struttura economica, produttività e riprogettazione del lavoro.
LangSmith per tracciare i flussi agentici
Sto provando LangSmith per tracciare il flusso di funzionamento di sistemi multi agente. Lo trovo davvero interessante.
Permette di monitorare le chiamate ai LLM che effettuano le applicazioni, i token consumati, i costi (calcolati in real-time e comprensivi delle cache implicite), le chiamate a tool esterni.
Per ogni esecuzione dei workflow, traccia il flusso completo delle azioni degli agenti: prompt, risposte, variazione degli stati, consumo.
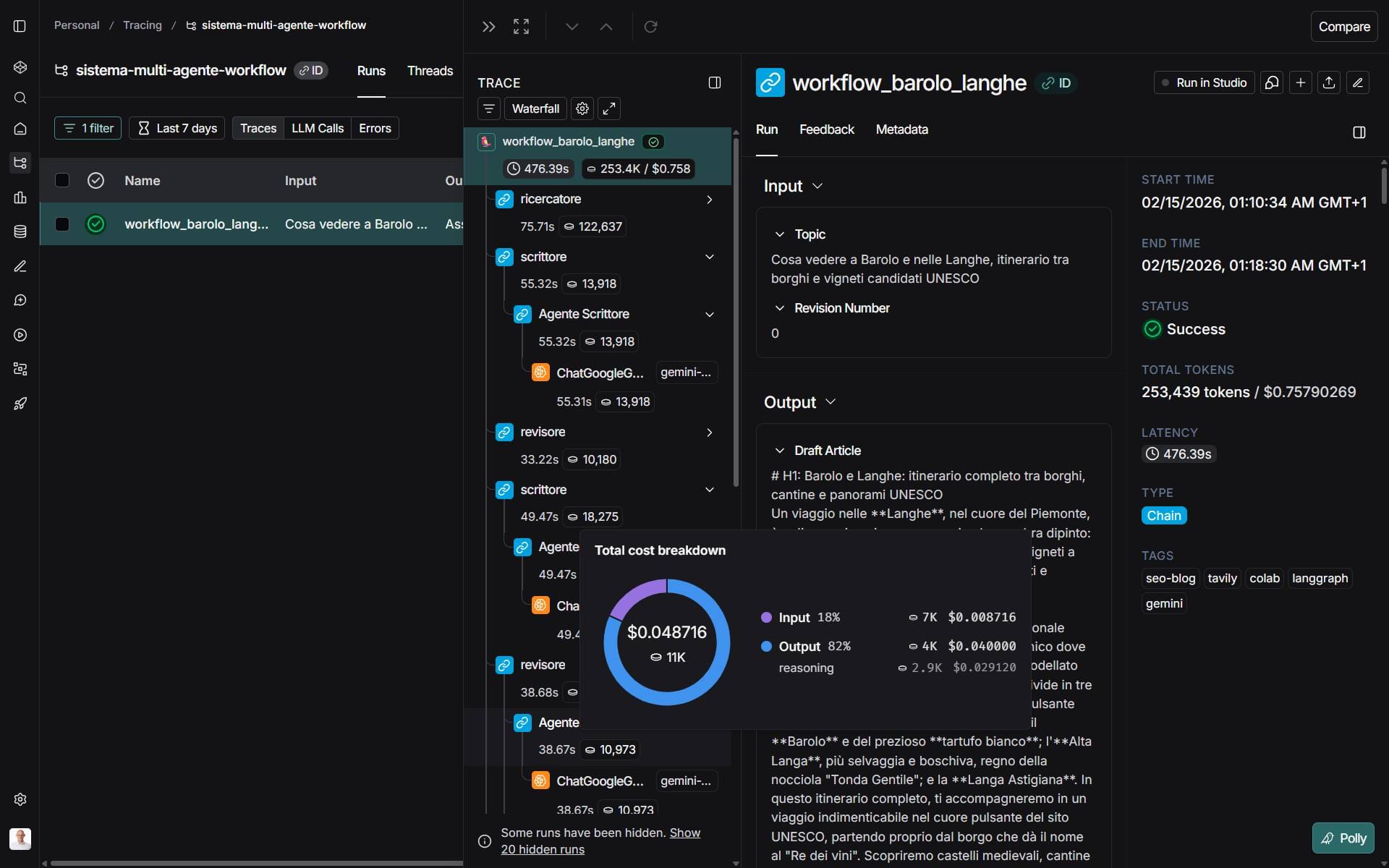
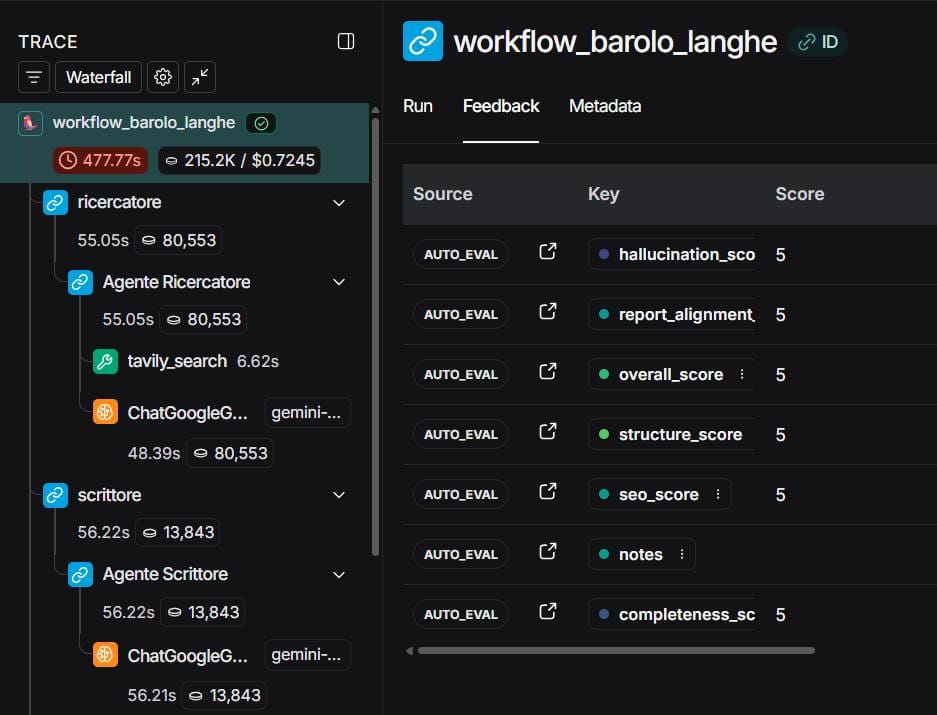
L'interfaccia di LangSmith
Soprattutto, consente di creare dei Grader basati su LLM che permettono di valutare automaticamente gli output, in modo da poter filtrare le esecuzioni per score personalizzati.
LangSmith è sviluppato dal team di LangChain, e può essere integrato su qualunque applicazione.
Nelle immagini si vedono dati di workflow costruiti su LangGraph, dove l'uso di LangSmith si mette in atto con qualche riga di Python.
Spotify: nessuna riga di codice da dicembre!
C’è stupore per le dichiarazioni del CEO di Spotify durante la call sui risultati del Q4, in cui afferma che i developer, grazie all’AI, hanno scritto pochissimo codice negli ultimi mesi.

Probabilmente è una semplificazione (il contesto di una earnings call tende sempre ad enfatizzare), ma chiunque abbia provato seriamente sistemi come Antigravity, Claude Code o Codex, sa che..
..il salto di produttività e la compressione del ciclo dall'idea al rilascio sono reali.
Soprattutto quando si combinano con "skill" evolute e sistemi di validazione automatica, testing e revisione critica dell’output generato.
Le competenze si stanno spostando verso fasi più ad alto livello: progettazione, orchestrazione, supervisione.
Riprogettare il lavoro in modo che continui a generare esperienza
La vera sfida dell'era AI non è solo aumentare la produttività, ma riprogettare il lavoro in modo che continui a generare esperienza.
Un interessante post di Harvard Business Review affronta un paradosso centrale dell'era dell'intelligenza artificiale: l'AI aumenta il bisogno di giudizio umano, ma allo stesso tempo riduce le esperienze attraverso cui quel giudizio si sviluppa.

Nei contesti professionali, l'AI generativa tende ad amplificare le competenze di chi ha già esperienza, mentre aiuta molto meno i profili junior.
Non perché questi ultimi non siano capaci, ma perché spesso non hanno ancora sviluppato la capacità di valutare criticamente l'output prodotto: capire se è valido, dove è debole, come migliorarlo.
Il punto chiave è che il giudizio non nasce dall'uso della tecnologia, ma dall'esperienza diretta: fare, sbagliare, ricevere feedback, assumersi responsabilità e vedere le conseguenze delle proprie decisioni.
Storicamente, le organizzazioni hanno costruito il giudizio attraverso compiti operativi ripetitivi ma formativi, esposizione graduale alla complessità, responsabilità reale sugli esiti e confronto continuo con superiori e colleghi.
Oggi molte di queste attività vengono automatizzate. I giovani professionisti non partono più dalla pagina bianca: revisionano output generati dall'AI.
Questo cambia profondamente il tipo di sforzo cognitivo richiesto e rischia di impoverire il processo di apprendimento.
Il risultato può essere un'organizzazione in cui i ruoli entry-level perdono valore formativo, i manager supervisionano attività che non hanno mai davvero imparato a fare, il giudizio si concentra in una fascia ristretta di leader senior e aumentano output ben confezionati ma poveri di sostanza.
Tenere "l'uomo nel loop" riduce i rischi operativi, ma non garantisce lo sviluppo del giudizio. Se le persone vengono protette dall'ambiguità invece di affrontarla, imparano a gestire l'escalation, non a decidere.
La vera sfida dell'era AI non è solo aumentare la produttività, ma riprogettare il lavoro in modo che continui a generare esperienza, responsabilità e capacità decisionale sotto incertezza. Perché l'intelligenza artificiale può accelerare il lavoro, ma non può sostituire il processo attraverso cui si forma il buon giudizio.
Nano Banana 2
Google DeepMind ha presentato Nano Banana 2 (Gemini 3.1 Flash Image), il nuovo modello di generazione immagini che unisce la qualità avanzata di Nano Banana Pro alla velocità di Gemini Flash.
I test che ho fatto lo confermano: generazione ed editing sempre qualitativi a una velocità notevole.
È un sistema capace di produrre immagini fotorealistiche con maggiore rapidità di editing e iterazione, mantenendo un elevato livello di precisione e controllo creativo.



Nano Banana 2: un test
Tra le principali novità..
- Accesso alla conoscenza del mondo reale di Gemini, con supporto a informazioni aggiornate dal web.
- Migliore rendering del testo nelle immagini, con traduzione e localizzazione integrate.
- Coerenza dei soggetti fino a 5 personaggi e fedeltà fino a 14 oggetti nello stesso workflow.
- Maggiore aderenza a istruzioni complesse.
- Supporto a diversi formati e risoluzioni, da 512px fino al 4K.
- Illuminazione, texture e dettagli più curati, mantenendo la velocità tipica di Flash
Nano Banana 2 è già nell'app Gemini, in Google Search (AI Mode e Lens), in AI Studio e tramite Gemini API, in Vertex AI su Google Cloud, in Flow come modello predefinito e in Google Ads per la creazione di campagne.
Un'evoluzione che punta a ridurre il compromesso tra velocità e qualità visiva, rendendo la generazione di immagini sempre più adatta a contesti professionali e produttivi.
Mercury 2
Inception ha presentato Mercury 2, il nuovo modello linguistico progettato per portare il reasoning in "tempo reale" nelle applicazioni AI in produzione.
Nel video si vede un mio test, e la velocità è impressionante.
Mercury 2: un test
La novità principale è l'architettura basata su diffusion: invece di generare testo in modo autoregressivo, un token alla volta, Mercury 2 produce più token simultaneamente e li raffina in pochi passaggi iterativi. Questo approccio consente oltre 1.000 token al secondo su GPU NVIDIA Blackwell e una velocità dichiarata superiore di oltre 5 volte rispetto ai modelli tradizionali.
Il punto non è solo la rapidità in senso assoluto, ma l'impatto nei sistemi reali: agenti con decine di chiamate di inferenza, pipeline RAG multi-step, autocompletamento nel coding, interfacce vocali con vincoli di latenza stringenti. In questi scenari la latenza si accumula e diventa un fattore critico per qualità, costi ed esperienza utente.
Il modello punta a spostare il compromesso tra qualità del reasoning e tempi di risposta, offrendo reasoning regolabile, contesto fino a 128K token, tool use nativo e output JSON conforme a schema, con compatibilità con le API di OpenAI per un'integrazione immediata negli stack esistenti.
L'obiettivo dichiarato è rendere l'AI in produzione percepita come istantanea, anche sotto carichi elevati e alta concorrenza, aprendo nuove possibilità per agenti autonomi, sistemi di ricerca enterprise e applicazioni voice real-time.
Gemini 3.1 Pro
Google ha presentato Gemini 3.1 Pro, l'ultima evoluzione della serie Gemini 3, progettata per affrontare compiti complessi che richiedono ragionamento avanzato.
Il modello introduce un significativo miglioramento dell'intelligenza di base, con prestazioni più che raddoppiate rispetto alla versione 3 Pro nel benchmark ARC-AGI-2, raggiungendo un punteggio verificato del 77,1% nella risoluzione di nuovi schemi logici.
Gemini 3.1 Pro
Gemini 3.1 Pro è pensato per scenari in cui una risposta semplice non è sufficiente: sintesi di sistemi complessi, spiegazioni strutturate, integrazione tra API e interfacce intuitive, sviluppo di esperienze interattive e creative coding.
Il modello è disponibile in preview per sviluppatori tramite Gemini API, AI Studio, Gemini CLI, Antigravity e Android Studio; per le aziende attraverso Vertex AI e Gemini Enterprise; e per gli utenti tramite l'app Gemini e NotebookLM, con limiti estesi per i piani Google AI Pro e Ultra.
Google rafforza l'obiettivo di portare capacità di ragionamento sempre più sofisticate nelle applicazioni quotidiane, accelerando lo sviluppo di workflow agentici e soluzioni ad alta complessità.
Claude Opus 4.6
Anthropic ha presentato Claude Opus 4.6, un importante aggiornamento del suo modello più avanzato.
Il nuovo Opus migliora in modo significativo il coding agentico, la pianificazione e il ragionamento complesso, riuscendo a sostenere task autonomi di lunga durata, e a operare in codebase molto estese con maggiore affidabilità.
Per la prima volta, Opus introduce una finestra di contesto da 1 milione di token (in beta), un'area in cui modelli come GPT e Gemini hanno mostrato progressi, ma dove Opus 4.6 punta soprattutto sulla qualità d'uso reale del contesto, riducendo in modo netto la perdita di coerenza nelle interazioni molto lunghe.
Claude Opus 4.6 - Anthropic
Nei benchmark, Opus 4.6 si colloca ai vertici su coding, ricerca e ragionamento multidisciplinare, superando altri modelli frontier in diverse valutazioni legate al lavoro professionale ad alto valore economico, come finanza e ambito legale. Una differenza chiave è la capacità di recuperare informazioni difficili da trovare all'interno di grandi quantità di testo e di continuare a ragionare correttamente dopo aver assorbito contesti enormi, un punto in cui molti modelli concorrenti tendono ancora a degradare.
Sul fronte prodotto, il modello rafforza l'approccio agentico con team di agenti in Claude Code, introduce controlli più granulari sul livello di "sforzo" cognitivo del modello e migliora l'integrazione con strumenti di lavoro quotidiani.
L'aumento delle capacità non avviene a scapito della sicurezza: Anthropic riporta tassi molto bassi di comportamenti disallineati e una delle migliori performance complessive nei test di safety tra i modelli frontier.
Claude Opus 4.6 è disponibile su claude.ai, via API e sulle principali piattaforme cloud, con PREZZI INVARIATI rispetto alla versione precedente.
L'Auto Prompt caching di Claude
Anthropic introduce l'auto prompt caching per le Claude API.
Il prompt caching consente di riutilizzare il calcolo della fase di prefill quando parti del prompt rimangono identiche tra richieste successive.
Questo riduce sia la latenza sia i costi: i token letti dalla cache hanno un costo pari a circa il 10% rispetto ai token di input standard.
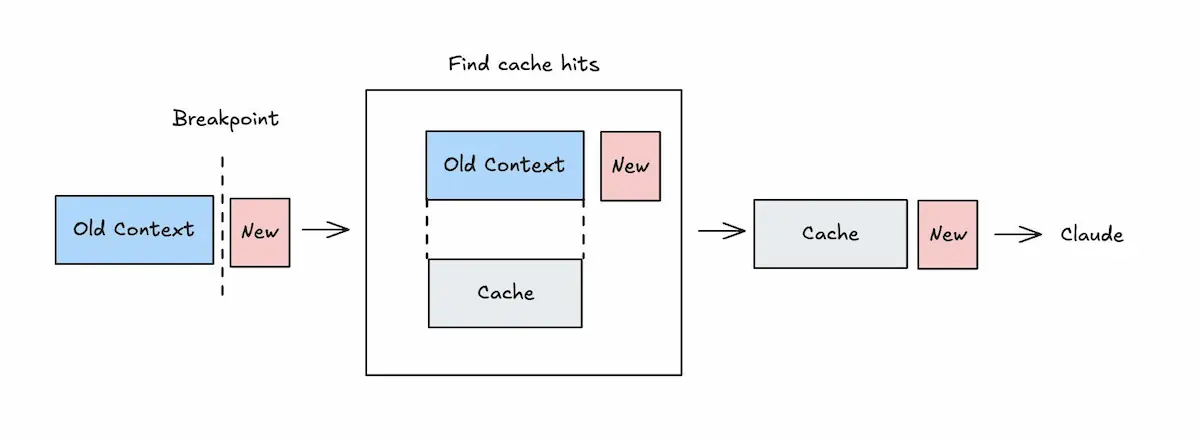
Il caso d’uso più evidente è quello degli agenti multi-turno. Poiché le API di Anthropic sono stateless, a ogni turno è necessario reinviare istruzioni, descrizione dei tool, cronologia e nuovo contesto. Senza caching si paga ogni volta l’intera finestra di contesto; con il caching si paga pienamente solo il contenuto nuovo.
Finora il meccanismo richiedeva l’inserimento esplicito di un breakpoint cache_control nel punto del prompt da memorizzare. Con l’auto-caching è sufficiente dichiarare il parametro una sola volta nella richiesta: il breakpoint viene spostato automaticamente sull’ultimo blocco cacheabile, seguendo la crescita della conversazione. Rimane comunque la possibilità di gestire manualmente i breakpoint per casi più avanzati.
Il sistema si basa su hash crittografici: anche una minima variazione nel testo produce un cache miss. Per questo motivo la progettazione di prompt "cache-friendly" diventa centrale negli agenti complessi e ad alto consumo di token.
Il confronto più diretto è con la cache implicita di Gemini di Google.
Gemini applica il caching in modo automatico e trasparente: non è necessario specificare breakpoint e il riutilizzo del contesto avviene dietro le quinte. Claude, invece, offre un approccio esplicito e più controllabile: si decide dove scrivere la cache e si può ottimizzare in modo deterministico il tasso di cache hit.
Entrambi gli approcci puntano a ridurre costi e latenza riutilizzando parti invarianti del prompt.
Gemini privilegia semplicità e automazione; Claude privilegia controllo, prevedibilità e ottimizzazione fine per workload agentici strutturati.
Perplexity Computer
Perplexity Computer è un sistema che prova a unificare in un'unica piattaforma tutte le principali capacità dell'AI attuale, andando oltre all'interfaccia di chat, per diventare un vero e proprio "lavoratore digitale" autonomo.
È progettato per creare ed eseguire flussi di lavoro completi, operando anche per periodi prolungati. L'utente descrive un obiettivo finale e il sistema lo scompone in attività e sotto-attività, generando sub-agenti specializzati che lavorano in parallelo. Questi possono effettuare ricerche web, generare documenti, analizzare dati, programmare applicazioni, chiamare API e interagire con servizi esterni tramite centinaia di connettori integrati. Il coordinamento è automatico e asincrono: più istanze possono lavorare contemporaneamente, mentre l'utente si dedica ad altro.
Perplexity Computer: un esempio
Dal punto di vista tecnico, si tratta di un sistema multi-modello. Non si basa su un singolo modello AI, ma orchestra fino a 19 modelli differenti, selezionando di volta in volta quello più adatto al compito specifico. Al centro del motore di ragionamento c'è Opus 4.6, mentre altri modelli vengono impiegati per funzioni specializzate: ad esempio Gemini per la ricerca approfondita, Nano Banana per la generazione di immagini, Veo 3.1 per i video, Grok per attività leggere e veloci, e GPT 5.2 per la gestione di contesti lunghi e ricerche estese. L'architettura è agnostica rispetto ai modelli, quindi può evolvere nel tempo e integrare nuove tecnologie; inoltre, l'utente può scegliere modelli specifici per determinati sotto-compiti, mantenendo controllo anche sui costi legati ai token.
Sul piano operativo, il sistema lavora in ambienti di esecuzione isolati e sicuri, con accesso a un file system reale, a un browser reale e a strumenti concreti. È progettato per essere "secure by default" e personale: ricorda il lavoro passato grazie alla memoria persistente e si integra con file, web e strumenti aziendali attraverso l'infrastruttura Perplexity.
L'obiettivo è offrire un'esperienza paragonabile a quella di un computer personale: non solo uno strumento, ma un sistema intelligente che conosce il contesto dell'utente e lo supporta end-to-end.
La visione di fondo è che l'AI non sia più soltanto un modello, ma un sistema capace di orchestrare modelli, strumenti e tempo per affrontare progetti complessi dall'inizio alla fine: ricerca, progettazione, sviluppo, distribuzione e gestione.
In questo senso, Perplexity Computer rappresenta il passaggio dall'AI come risposta all'AI come infrastruttura operativa completa.
Qwen 3.5
Il team di Qwen ha annunciato il rilascio di Qwen 3.5, introducendo il modello open-weight Qwen3.5-397B-A17B, progettato come sistema nativamente multimodale capace di integrare visione e linguaggio in modo avanzato.
Il modello combina un’architettura ibrida che unisce Linear Attention (Gated Delta Networks) e Sparse Mixture-of-Experts (MoE). Pur contando 397 miliardi di parametri totali, ne attiva solo 17 miliardi per ogni forward pass, migliorando in modo significativo efficienza, costi di inferenza e velocità, senza compromettere le prestazioni.
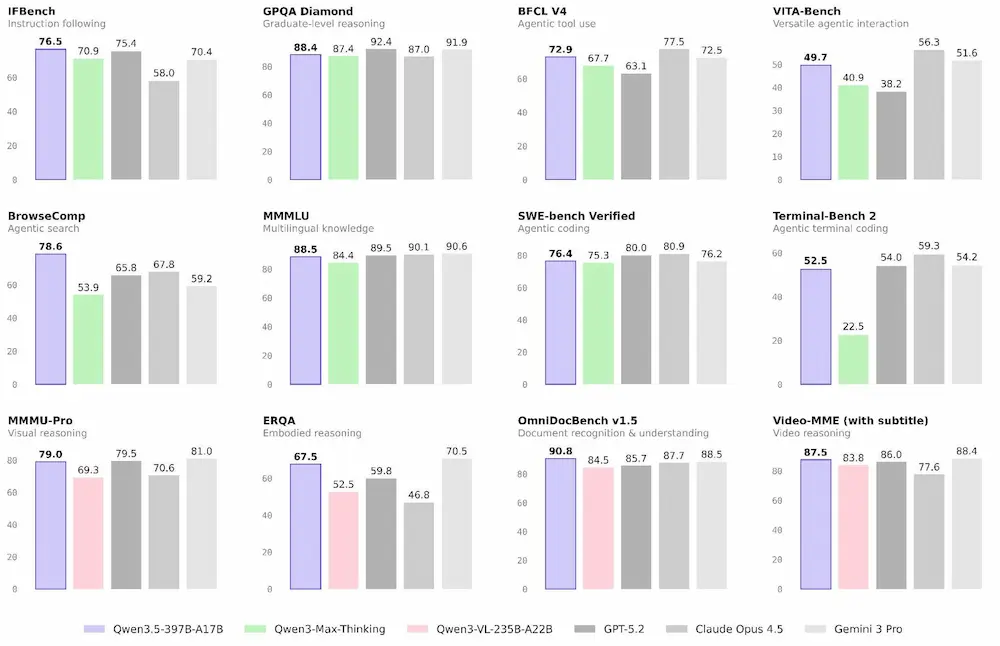
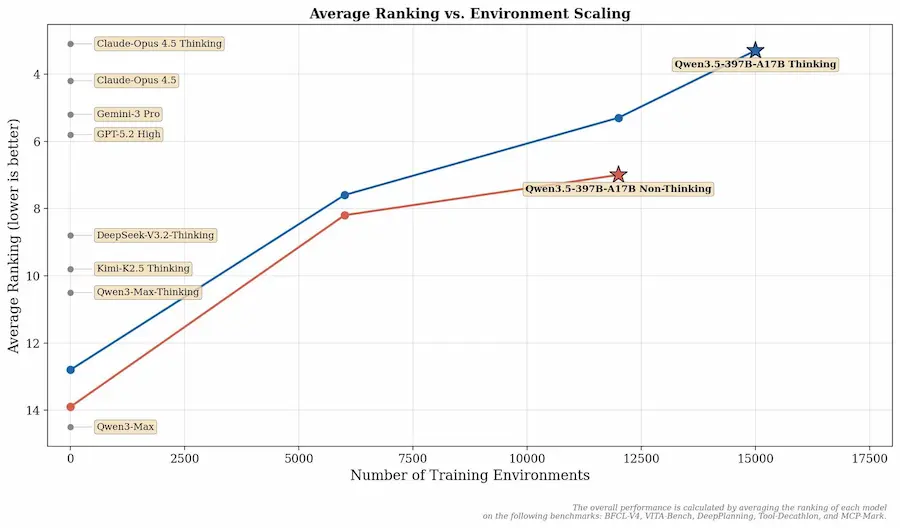
Qwen 3.5: le performance
Nei benchmark mostra risultati solidi in ambiti chiave come reasoning avanzato, coding, capacità agentiche e comprensione multimodale. Con l’aumento degli ambienti di training, le performance scalano in modo evidente, soprattutto nella modalità Thinking.
Nel confronto con i principali modelli di fascia alta, Qwen3.5-397B-A17B Thinking si avvicina ai livelli di Claude Opus 4.5 Thinking e risulta competitivo rispetto a Gemini 3 Pro e GPT-5.2 High nei benchmark considerati, riducendo in modo significativo il gap con i leader di mercato.
L’obiettivo è abilitare una nuova generazione di agenti AI in grado di comprendere contenuti visivi e testuali in modo integrato, ragionare su problemi complessi e operare in contesti reali con maggiore autonomia.
Modelli come Qwen, Kimi, DeepSeek, stanno facendo passi in avanti impressionanti.. e non in termini di scala, ma di architettura.
Il moat non è più l'API. È lo stack!
Negli ultimi due anni abbiamo assistito a una narrazione quasi inevitabile: i modelli flagship delle big tech (es. OpenAI, Anthropic, Google) sono il punto di riferimento assoluto. Prestazioni top, sì. Ma anche costi elevati, dipendenza da API chiuse, infrastrutture centralizzate.
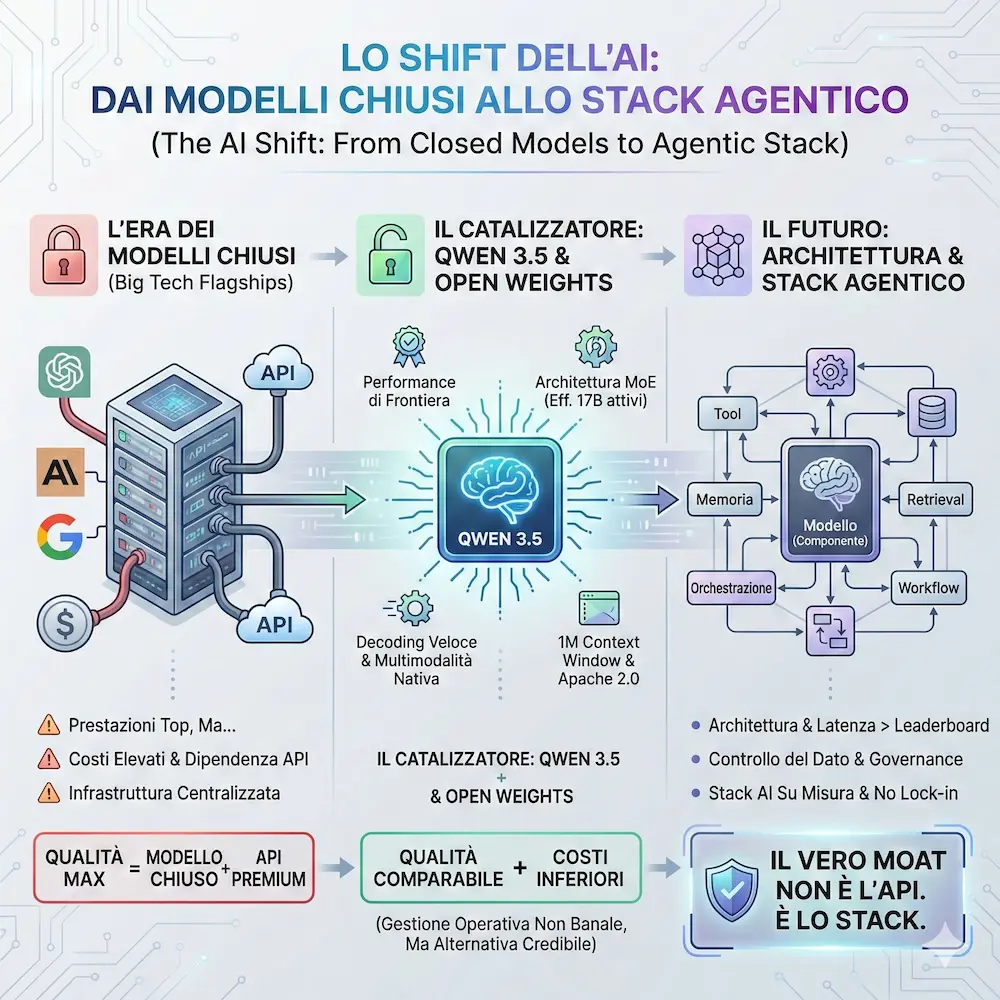
Per molto tempo l'equazione è stata semplice:
massima qualità =
modello chiuso + API premium
Forse, però, qualcosa sta cambiando.
Il rilascio di Qwen 3.5 da parte di Alibaba dimostra come il mondo degli open-weights non sta più inseguendo: sta competendo frontalmente.
Questo non è solo un progresso tecnico. È uno shift economico e strategico.
L'equazione può diventare: qualità comparabile + controllo infrastrutturale + costi inferiori.
Naturalmente, la gestione operativa non è banale. Gestire inferenza su larga scala, ottimizzare costi GPU, garantire sicurezza e allineamento richiede maturità infrastrutturale. Le API premium restano una scelta razionale per molte organizzazioni.
Ma il punto non è sostituire tutto. Il punto è che ora esiste un'alternativa credibile. E questo accade in un momento cruciale. Stiamo costruendo applicazioni agentiche in cui il modello è solo un componente di un'architettura più ampia fatta di tool, memoria, orchestrazione, retrieval e workflow.
In questi scenari l'architettura conta più del singolo modello. Spesso la latenza conta più della leaderboard. Il controllo del dato conta più del brand.
Gli open-weight models diventano quindi non solo un'alternativa economica, ma un abilitatore architetturale. Permettono di progettare stack AI su misura, con piena governance, integrazione profonda nei sistemi aziendali e riduzione del lock-in tecnologico.
La vera differenziazione non sarà nel modello. Sarà nell'architettura costruita attorno ad esso.
Il moat non è più l'API. È lo stack.
Seedance 2.0 di ByteDance
ByteDance ha rilasciato Seedance 2.0, un nuovo modello di generazione video, e si iniziano a vedere le prime realizzazioni.
Con un solo prompt, il modello è in grado di costruire storytelling multi-shot nativi, mantenendo coerenza narrativa, qualità del movimento e precisione visiva su più inquadrature consecutive.
Seedance 2.0: video generato da Charles Curran
Il lip-sync è accurato a livello di fonemi e supporta oltre 8 lingue, mentre la motion rispetta ritmo, fisica e dinamica delle scene.
L'output arriva fino a una risoluzione cinematografica 2K e include audio completamente nativo: dialoghi, effetti sonori e ambience vengono generati insieme al video, in un'unica passata, perfettamente sincronizzati.
Supporta fino a 12 file di riferimento tra testo, immagini, video e audio, offrendo un controllo creativo molto più granulare rispetto ai modelli precedenti.
La generazione è circa il 30% più veloce e consente clip fino a tre volte più lunghe.
I primi confronti lo collocano già ai vertici insieme a Kling, Sora e Veo per coerenza multi-shot, qualità del movimento, aderenza al prompt e precisione narrativa.
Seedance 2.0: video generato da Alex Patrascu
Il rilascio è avvenuto in beta limitata, ma è chiaro che ByteDance non ha semplicemente migliorato il modello precedente: ha alzato l'asticella dell'intera generazione video AI.
Kling AI 3.0
Kling AI 3.0 rappresenta il "Nano Banana Pro moment" per i modelli video?
Di certo rappresenta un punto di svolta, soprattutto per chi guarda alla qualità cinematografica e non solo alla generazione di clip isolate.
Kling AI 3.0: le potenzialità
La novità più evidente è il multi-cut nativo fino a 15 secondi per singola generazione: non si tratta più di brevi frammenti scollegati, ma di sequenze con ritmo, continuità e intenzione narrativa.
A questo si aggiunge un lip sync finalmente credibile, preciso e stabile anche su dialoghi più lunghi, senza quell’effetto artificiale che finora ha limitato molti modelli video.
Ma il vero salto di qualità è nella performance dei personaggi. Espressioni, micro-movimenti, postura e presenza scenica sono, ad oggi, tra le migliori che si siano viste in ambito video AI. I personaggi non "eseguono" semplicemente un prompt: recitano. E soprattutto restano coerenti nel tempo, tra un’inquadratura e l’altra.
La cosa più interessante è che il modello può essere usato letteralmente come un reference model. Personaggi, volti, stile visivo e persino voce possono essere mantenuti con una consistenza che inizia ad avvicinarsi all’esperienza di una vera regia.
Forse non è solo un miglioramento incrementale rispetto alle versioni precedenti, ma un cambio di categoria.
Il video (creato da Halim Alrasihi) mostra le potenzialità.
Hollywood spenderebbe milioni. L'AI lo fa in pochi minuti..
Oggi, produrre una scena cinematografica significa troupe, attrezzature, location, settimane di lavoro e budget enormi. Domani, strumenti come Seedance 2.0, Kling AI e Nano Banana Pro potrebbero comprimere quel processo in una manciata di minuti.
Seedance 2.0 + Kling + Nano Banana Pro, realizzato da Oogie
Non è solo una questione di velocità.
È una questione di struttura.
L'intelligenza artificiale mostra traiettorie che probabilmente ridisegneranno interi settori perché abbasserà drasticamente la barriera d'ingresso. Ciò che oggi richiede capitali, infrastrutture e grandi team domani, probabilmente, richiederà visione, competenza e capacità di orchestrare strumenti.
- Nel cinema significherà prototipare scene, ambientazioni ed effetti visivi in tempo reale?
- Nel marketing significherà sviluppare concept e campagne in ore invece che settimane?
- Nel design significherà iterare senza costi marginali rilevanti?
- Nell'editoria significherà produrre, adattare e distribuire contenuti su scala globale?
- Nella formazione significherà creare simulazioni e materiali dinamici personalizzati?
Quando il costo della produzione creativa si avvicina allo zero, il vantaggio competitivo si sposta. Non vince più chi ha più budget. Vince chi ha più chiarezza, più gusto, più capacità di integrazione tra umano e macchina.
L'AI non elimina la creatività. La rende scalabile. Non sostituisce il pensiero strategico. Lo amplifica. Non distrugge i settori. Li costringe a evolversi.
La vera trasformazione non è tecnologica. È culturale.
La nuova strategia di Runway
Runway mette in campo una nuova strategia, includendo in piattaforma tutti i migliori modelli di generazione di immagini, video e audio (oltre a quelli proprietari).
Attualmente, vedo presenti: Kling, Veo, Sora, Wan, Topaz, Nano Banana, GPT Image e Eleven Labs. Ma ne includeranno altri, ad esempio Seedance.
La nuova strategia di Runway
È chiaro che la nuova rotta punta a far diventare Runway una piattaforma per creator, con la possibilità di creare workflow multi-modello, di usare applicazioni preconfigurate e pronte all'uso, e di portare tutto ovunque via API.
In arrivo anche le funzionalità di Real Time World Simulation (and Exploration) e Real Time Avatars (la demo disponibile in piattaforma è impressionante).
Photoshoot su Pomelli
Google Labs ha introdotto Photoshoot, una nuova funzionalità di Pomelli che mira a trasformare semplici foto di prodotto in immagini professionali in stile studio o lifestyle. Lo strumento utilizza il business DNA del brand e un modello avanzato di generazione immagini per creare contenuti coerenti con l'identità visiva dell'azienda, senza bisogno di uno shooting fotografico tradizionale.
Photoshoot: una nuova funzionalità di Pomelli
Il processo è semplice: si carica una foto, si sceglie un template (studio o lifestyle), si genera l'immagine e si possono poi applicare modifiche e rifiniture. Le immagini prodotte possono essere scaricate o salvate per campagne future, mantenendo coerenza estetica nel tempo.
Tra le novità anche modelli di generazione più accurati, funzioni di editing come la modifica dello sfondo e la possibilità di usare immagini di riferimento per replicare uno stile specifico. Inoltre, è possibile creare campagne più mirate caricando immagini nel prompt o inserendo l'URL del prodotto, così da utilizzare automaticamente immagini, titolo e descrizione presenti sul sito.
Uno strumento pensato per semplificare la produzione di contenuti marketing di qualità, rendendo accessibili risorse visive professionali anche a realtà con budget e tempo limitati.
L'evoluzione di Opal
Opal di Google si evolve ancora, introducendo interessanti novità.
- Il routing dinamico, che permette di fare decidere all'agente quale sarà l'azione successiva.
- L'uso della memoria per salvare i dati in modo persistente durante le esecuzioni dei workflow.
- La possibilità di creare una tipologia di agente che sceglie autonomamente il modello da usare in base al task (compresa la generazione di contenuti multimediali).
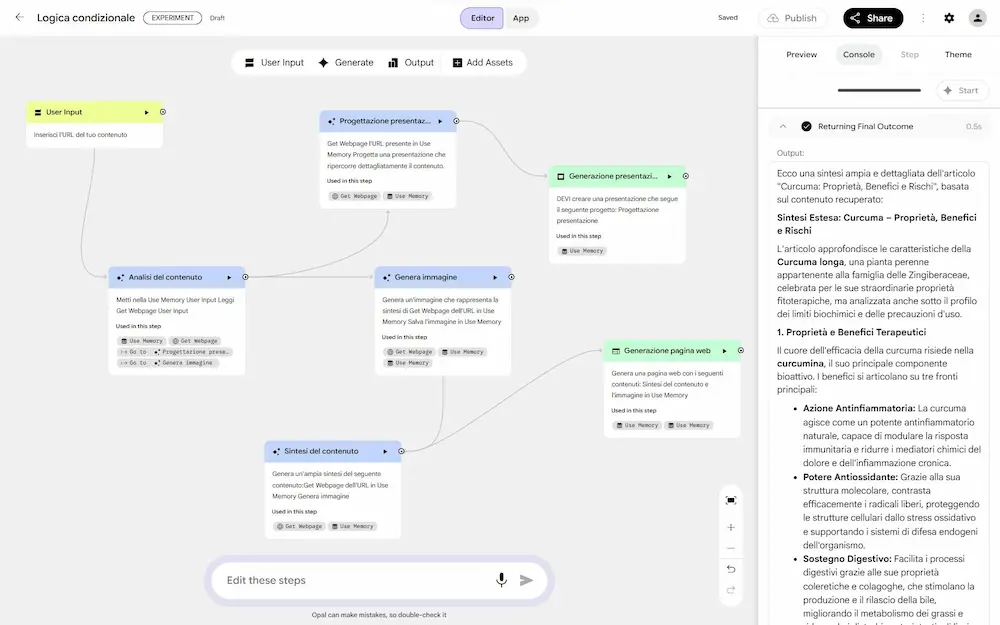
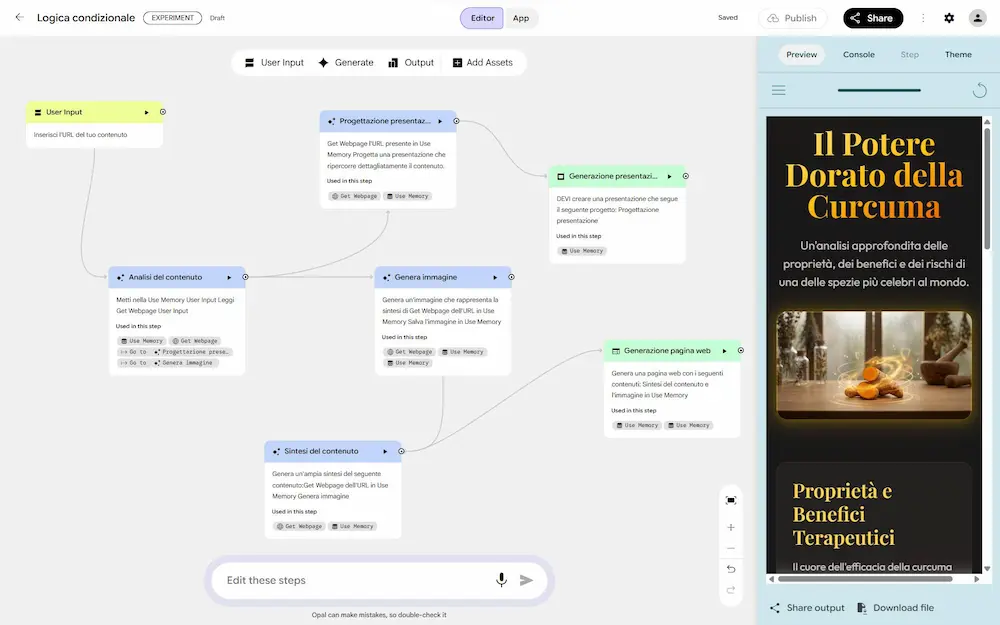
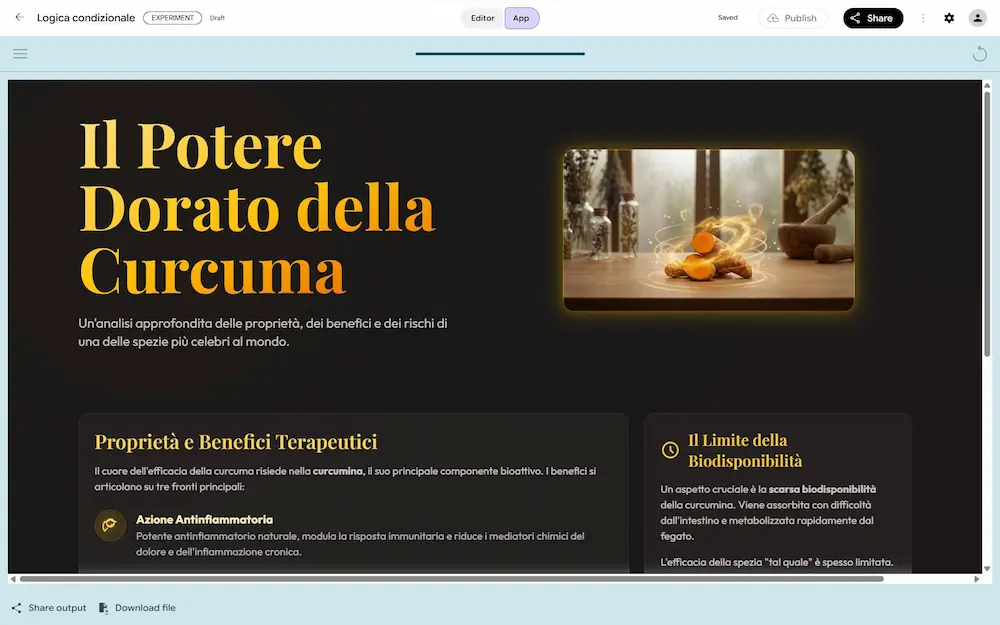
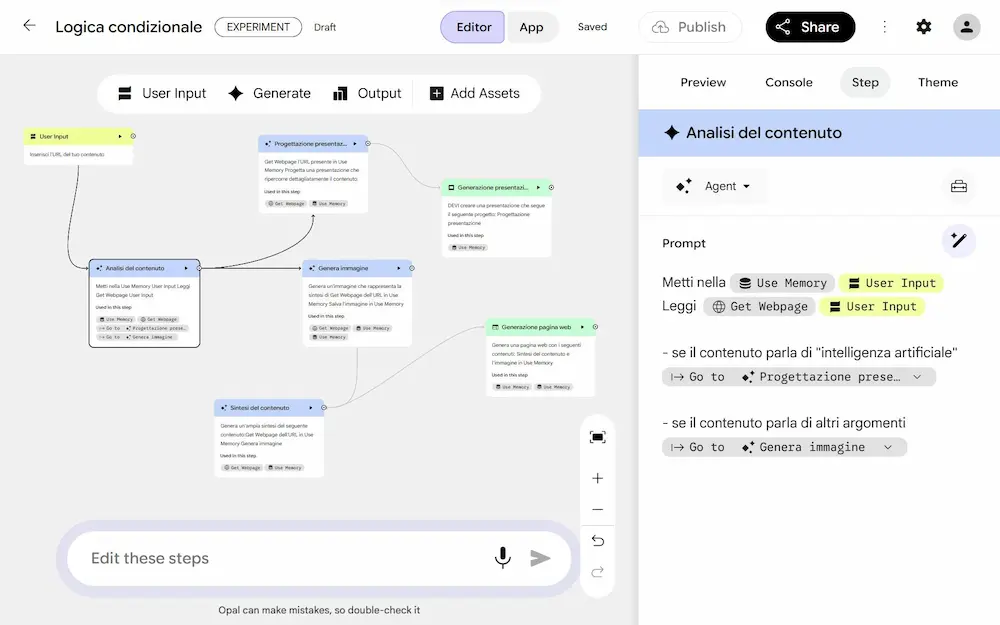
L'evoluzione di Opal
L'usabilità che stanno dando allo strumento, a volte, è disarmante.
Cosa manca..
- La connessione via MCP a servizi esterni non di Google.
- Un AgentState condiviso dagli agenti per la memoria a breve termine.
- La possibilità di usarlo anche in Italia senza una VPN.
Waymo World Model
Waymo ha presentato il Waymo World Model, un modello generativo che porta la simulazione per la guida autonoma a un livello completamente nuovo.
Non si limita a ricostruire ciò che è già stato visto su strada, ma genera mondi 3D iper-realistici e interattivi, producendo dati coerenti per camere e lidar, come se il veicolo stesse davvero guidando in quell'ambiente.
La differenza chiave è la conoscenza del mondo: grazie a Genie 3, il sistema può simulare eventi rarissimi o quasi impossibili da raccogliere nella realtà.
Tornado, incendi, alluvioni, veicoli contromano, oggetti fuori scala, animali in carreggiata. Tutto può essere creato, controllato e modificato con precisione.
Waymo World Model
La simulazione non è passiva. Waymo può intervenire sulle azioni di guida, sul layout delle strade, sul comportamento degli altri utenti e persino sulle condizioni ambientali tramite linguaggio naturale.
Questo permette di testare scenari controfattuali e decisioni alternative, mantenendo realismo e coerenza anche quando il percorso simulato diverge molto da quello reale.
C'è anche un passaggio importante dal mondo reale al virtuale: video comuni, come quelli di una dashcam o di uno smartphone, possono essere convertiti in simulazioni multimodali per capire come il sistema di guida autonoma interpreterebbe esattamente quella scena.
Il punto centrale non è l'effetto visivo, ma la sicurezza. Simulando miliardi di miglia e preparando il sistema a situazioni estreme e imprevedibili, questi modelli diventano un'infrastruttura critica per addestrare AI che devono operare nel mondo fisico, con conseguenze reali.
Lyria 3: generare musica su Gemini
La possibilità di generare musica su Gemini (attraverso Lyria 3) arriva anche in Italia.
L'ho provato, inserendo addirittura il testo della canzone.
È possibile trasformare un semplice prompt di testo (o persino un'immagine) in una traccia musicale di 30 secondi, completa di base strumentale, voce, testo e copertina personalizzata.
Lyria 3: generare musica su Gemini
Come creare un buon prompt per generare una canzone
Genere ed epoca: inizia con uno stile preciso o un mix originale, ad esempio synth pop anni '80, metal e rap fusion, indie folk, country vecchio stile.
- Tempo e ritmo: definisci energia e atmosfera, ad esempio suono ritmato e ballabile, ballata lenta, ritmo incalzante.
- Strumenti: aggiungi dettagli che diano struttura al brano, ad esempio assolo di sassofono, linea di basso distorta, chitarre sfumate.
- Voce: specifica timbro e registro, ad esempio soprano donna leggero, basso-baritono uomo, rocker graffiante.
- Testo: indica il tema e la struttura, ad esempio "Un weekend epico".
Grok Imagine 1.0
Anche Grok diventa notevole nella generazione video.
Il video è stato generato da Dave Clark con Grok Imagine 1.0 immaginando un dialogo tra l’uomo e l'AI, dove le domande contano quanto le risposte.
Grok Imagine 1.0
Futuro, verità e immaginazione che si incontrano.
Qwen Image 2.0
Alibaba ha rilasciato Qwen Image 2.0: un modello di nuova generazione per la creazione e l'editing di immagini che unifica in un'unica architettura generazione testuale-visiva e modifica avanzata.
Il modello integra definitivamente i due percorsi sviluppati nelle versioni precedenti (generazione realistica e editing coerente) offrendo prestazioni elevate sia nel text-to-image sia nell'image-to-image con lo stesso sistema.



Qwen Image 2.0: alcuni test
Tra le caratteristiche principali:
- Rendering tipografico professionale con supporto fino a 1.000 token di istruzioni, capace di generare infografiche, slide, poster, calendari e fumetti con testo accurato e leggibile.
- Supporto nativo alla risoluzione 2K (2048×2048) con fotorealismo avanzato su materiali, pelle, tessuti, architetture e luce
- Gestione di prompt complessi e strutturati con layout articolati, tabelle, diagrammi, timeline e composizioni multi-livello
- Allineamento preciso degli elementi in griglie, pannelli e moduli informativi
- Architettura più leggera (7B) con maggiore velocità di inferenza e migliore equilibrio tra qualità visiva ed efficienza
Un aspetto distintivo è l'integrazione completa tra comprensione multimodale e generazione: un unico modello è in grado di interpretare descrizioni molto dettagliate, mantenere coerenza visiva e organizzare il testo in modo esteticamente armonico.
L'ho provato. Non siamo minimamente vicini ai livelli di Gemini (Nano Banana), ma la qualità aumenta.
Qwen AI Slides
Alibaba ha rilasciato Qwen AI Slides. Un sistema che non si limita a impaginare contenuti, ma li comprende, li organizza e li trasforma in una narrazione visiva coerente.
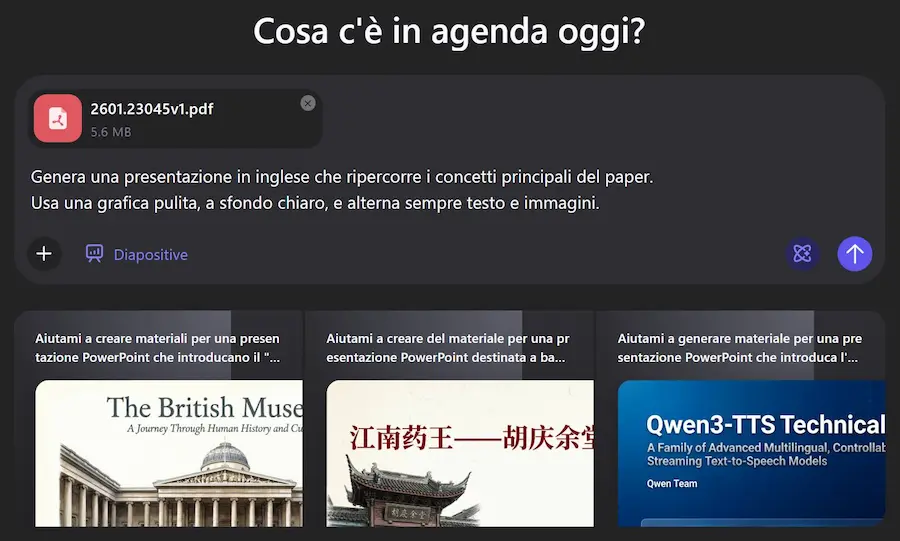
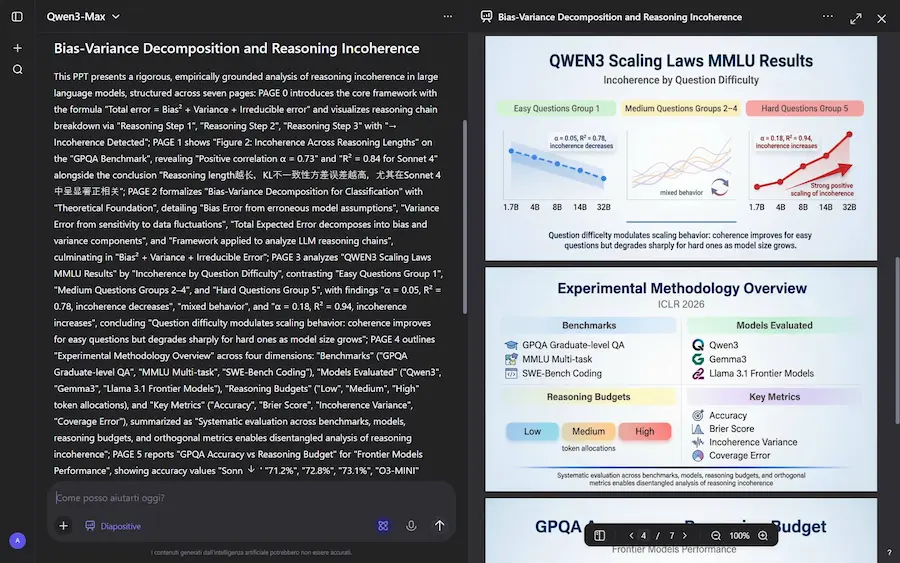
Qwen AI Slides: un esempio
È un sistema basato su Qwen3 Agent e Qwen-Image 2.0, e integra ricerca, struttura e design in un unico flusso intelligente. Basta inserire un’idea, un testo complesso o caricare un documento per avviare il processo: l’agente analizza i contenuti, costruisce l’architettura della presentazione e definisce la sequenza logica delle slide.
Ogni slide viene poi generata come visual completo: testo, layout, palette cromatica e grafiche sono progettati in modo integrato, senza passaggi manuali tra strumenti diversi.
Il sistema mostra tutti i limiti di Qwen Image (rispetto a Nano Banana), ma la direzione è ottima.
Kimi Agent Swarm
Kimi Agent Swarm fa scorgere la direzione nel potenziamento dei modelli di AI.
Si tratta di un "nuovo" paradigma: non un singolo agente più potente, ma un'organizzazione autonoma composta da diversi agenti (fino a 100) che lavorano in parallelo, in un'architettura che si auto-organizza.
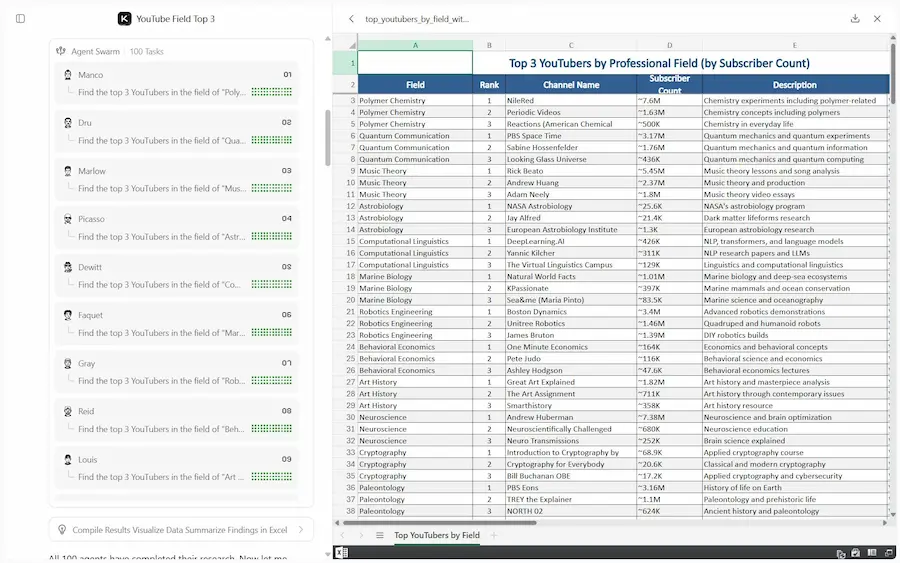
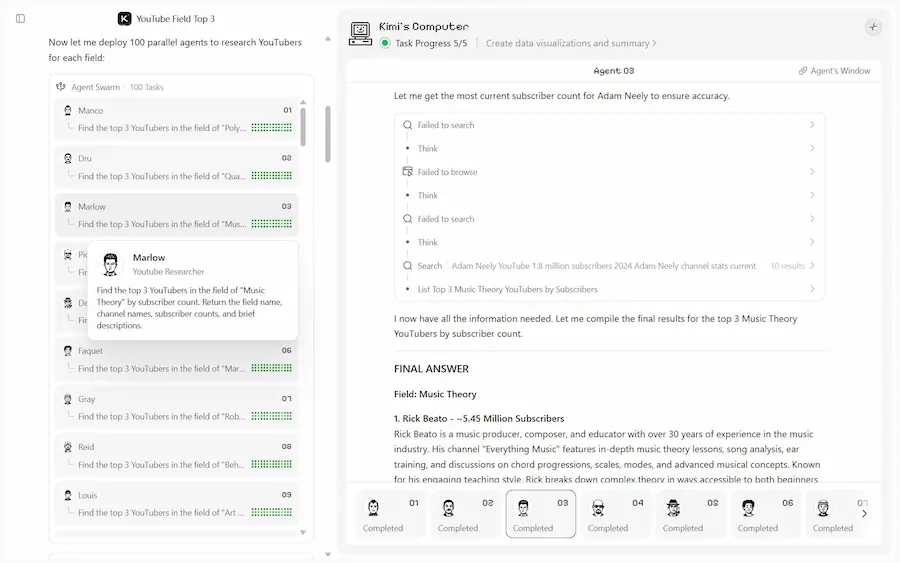
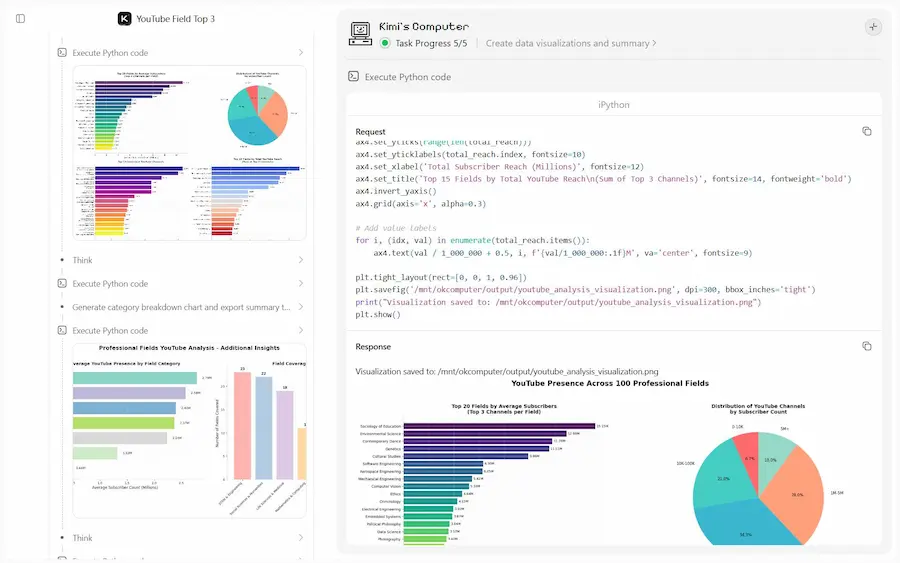
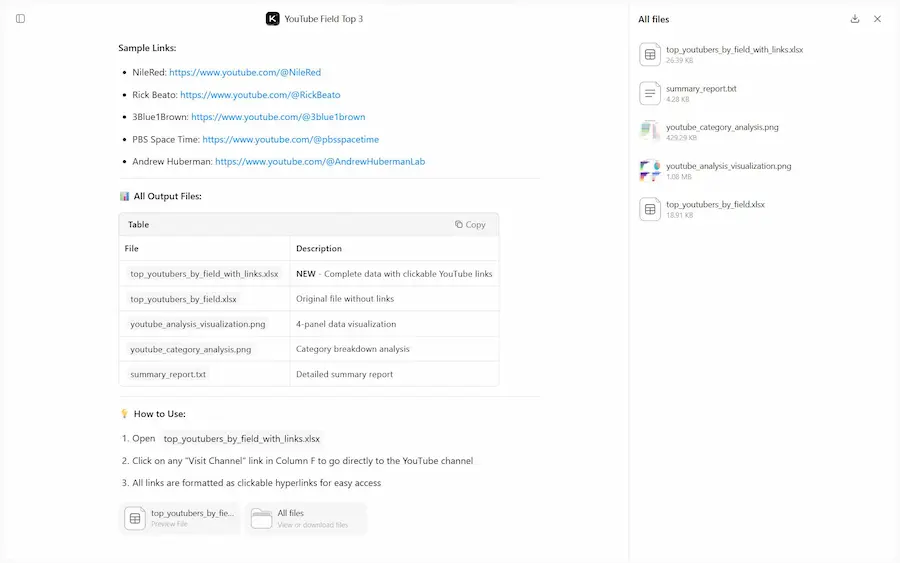
Kimi Agent Swarm: un esempio di utilizzo
L'idea di fondo è superare il limite strutturale dei sistemi a esecuzione sequenziale. Quando un solo agente gestisce compiti lunghi e complessi, la finestra di contesto si satura, le informazioni vengono compresse e la qualità del ragionamento degrada.
Agent Swarm introduce invece una scalabilità orizzontale: più agenti specializzati, coordinati da una struttura che si auto-organizza.
Il sistema agisce come un team leader che crea e coordina ricercatori, analisti, revisori, scrittori e developer, decidendo autonomamente come suddividere il lavoro, quando parallelizzare e quali strumenti utilizzare.
Con Kimi K2.5, Agent Swarm può distribuire fino a 100 sub-agenti, eseguire oltre 1.500 tool call e ottenere risultati fino a 4,5 volte più velocemente rispetto a un'esecuzione sequenziale.
Funziona particolarmente bene su attività che richiedono ampiezza e profondità: ricerche su larga scala, analisi multi-prospettiva, elaborazione massiva di documenti, produzione di report strutturati e scrittura estesa. Un elemento distintivo è la possibilità di generare disaccordo produttivo tra agenti indipendenti, evitando il "groupthink" e favorendo sintesi più robuste.
Non è semplicemente un miglioramento incrementale delle performance. È un cambio di architettura: dall'agente singolo alla costruzione di organizzazioni autonome di intelligenza artificiale.
È un sostituto di un workflow multi-agente? NO. Perché in produzione rimane la necessità di controllo totale dei flussi. Ma se gli agenti all'interno dell'architettura accelerano in questo modo, le performance miglioreranno di moltissimo.
Workspace Studio di Google
Su Gmail, negli account professionali, sta iniziando a comparire la funzionalità di "Workspace Studio".
Lo trovo uno strumento davvero interessante per creare automazioni che coinvolgono tutti i software del workspace di Google.
Il flusso che si vede nelle immagini, ad esempio, ogni mattina verifica le mail non lette del giorno prima e me le riepiloga brevemente in Chat (evitando newsletter, liste, notifiche social o altro di poco interessante), indicando se ci sono azioni richieste da parte mia. Inoltre, verifica se ci sono urgenze. Se ci sono, crea un altro brevissimo messaggio con una nota dedicata.
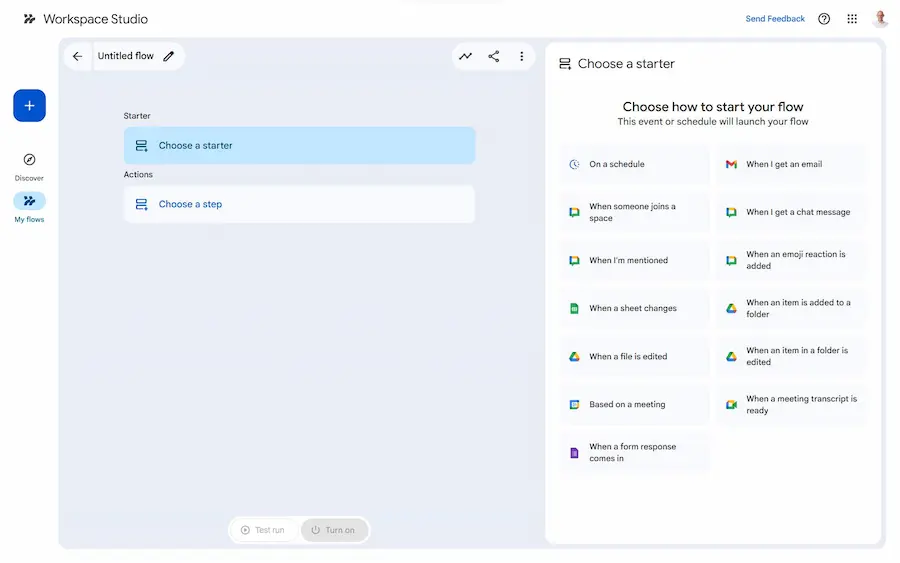
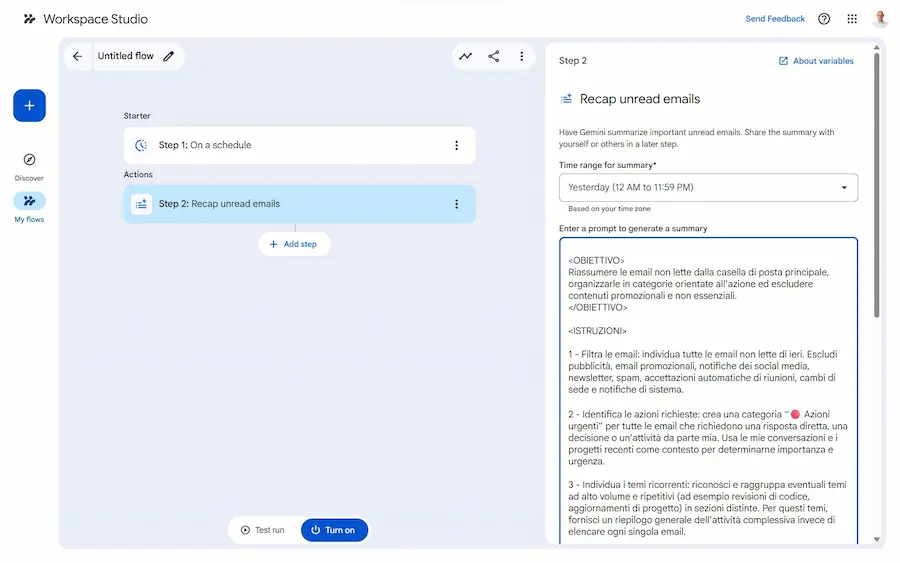
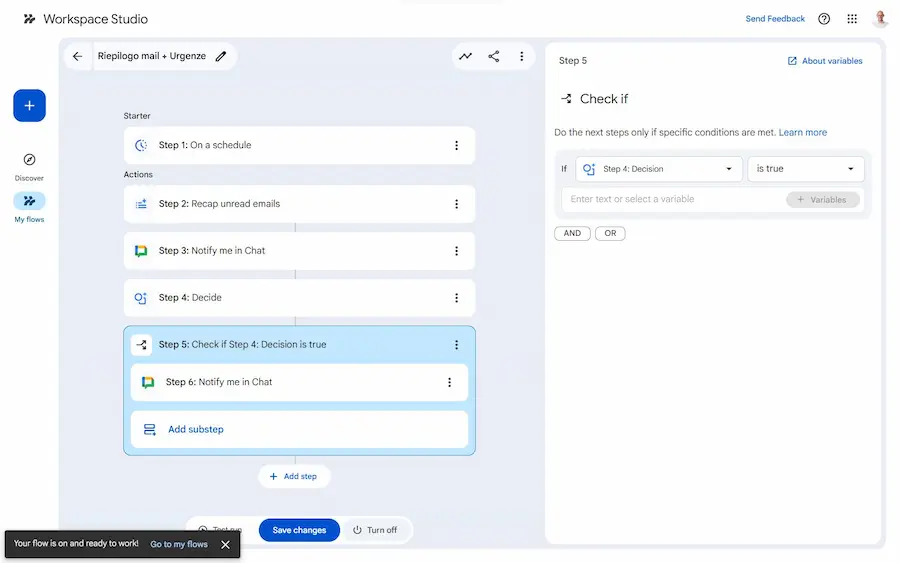
Un workflow di Workspace Studio
Il sistema si basa su Gemini, e permette di costruire agenti che non si limitano a seguire regole rigide, ma ragionano sul contesto. Questo significa che l’automazione non è solo "se succede X allora fai Y", ma diventa capace di interpretare contenuti, distinguere priorità reali e adattarsi alle informazioni che trova nelle email, nei documenti o nelle chat.
Cos'è WebMCP?
Con WebMCP, Google mostra una traiettoria per cui i siti web potranno diventare dei touchpoint affidabili per gli agenti AI, superando l’approccio basato solo su visione artificiale.
Se uniamo i puntini:
- MCP abilita modelli e agenti ad accedere a strumenti e capability;
- Protocolli verticali, ma compatibili con MCP, standardizzano domini specifici, come UCP per l'ecommerce;
- WebMCP rende i siti web nativamente agent-ready.
MCP diventerà l'HTTP degli agenti?
Nello specifico, WebMCP è l’iniziativa presentata da Google che introduce un modo standard per permettere ai siti web di esporre azioni strutturate agli agenti AI.
Non più solo scraping o interpretazione visiva del DOM, ma strumenti dichiarati esplicitamente dal sito web.

Prevede due modalità principali:
- API dichiarativa → azioni standard definite direttamente nei moduli HTML
- API imperativa → interazioni più complesse e dinamiche tramite JavaScript
Il risultato? Agenti che possono prenotare voli, configurare prodotti, aprire ticket di assistenza o completare acquisti in modo più veloce, preciso e affidabile.
Se questa visione si consolida, potremmo passare da un web "umano-centrico" a un web progettato anche per agenti software.
Un esempio pratico
Attraverso questo sistema, gli agenti AI possono usare un sito web senza il bisogno di "vedere" l'interfaccia.
WebMCP: un esempio pratico
MiniMax M2.5
MiniMax ha pubblicato su Hugging Face il modello MiniMax-M2.5, un foundation model da 229 miliardi di parametri focalizzato su coding avanzato, agenti autonomi, tool calling, ricerca web e produttività d’ufficio.
Addestrato con reinforcement learning su centinaia di migliaia di ambienti reali, M2.5 mostra prestazioni di primo livello in diversi benchmark: 80.2% su SWE-Bench Verified e risultati competitivi con Claude Opus 4.5/4.6 in scenari di sviluppo software complessi, con miglioramenti significativi rispetto alla versione M2.1 in termini di velocità ed efficienza.
Nel coding si distingue per un approccio "architetturale": prima di scrivere codice, tende a decomporre il problema e strutturare specifiche, design e organizzazione del progetto. È stato addestrato su oltre 10 linguaggi, tra cui Python, Go, C++, Rust, Java e TypeScript, e copre l’intero ciclo di sviluppo, dal system design iniziale fino a code review e testing, anche in contesti full-stack e multi-piattaforma.
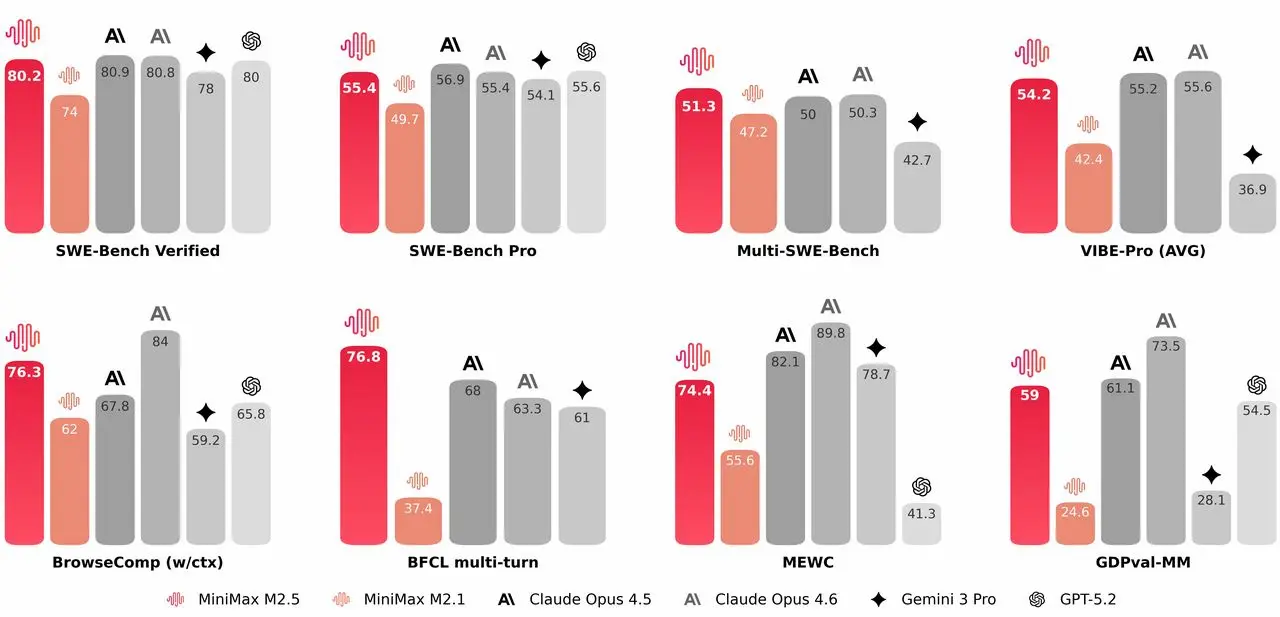
Sul fronte agentico, migliora l’uso di strumenti e la ricerca web, riducendo il numero di iterazioni necessarie e ottimizzando il consumo di token. Nei benchmark dedicati a search e tool use ottiene prestazioni di vertice, con maggiore stabilità anche in ambienti non familiari.
Un elemento centrale è l’efficienza: la versione Lightning raggiunge 100 token al secondo, mentre la versione standard opera a 50 token al secondo, con costi dichiarati significativamente inferiori rispetto ad altri modelli di frontiera. A 100 token al secondo, il costo stimato è circa 1 dollaro per un’ora di utilizzo continuo.
MiniMax ha inoltre integrato M2.5 nel proprio ecosistema MiniMax Agent, con skill specifiche per Word, PowerPoint ed Excel e la possibilità di creare "Expert" riutilizzabili per scenari professionali come report strutturati o modellazione finanziaria avanzata.
Nel complesso, M2.5 punta a combinare capacità agentiche avanzate, velocità elevata e costi ridotti, con un forte investimento nel reinforcement learning applicato a contesti operativi reali.
GPT-5.3-Codex
GPT-5.3-Codex è il primo modello che ha contribuito in modo importante alla propria creazione.
Durante il suo stesso sviluppo è stato usato per fare debug dell'addestramento, analizzare risultati di test, ottimizzare la distribuzione e supportare le decisioni di ricerca e ingegneria. Un passaggio simbolico e concreto: l'agente non è solo oggetto di sviluppo, ma parte attiva del processo.
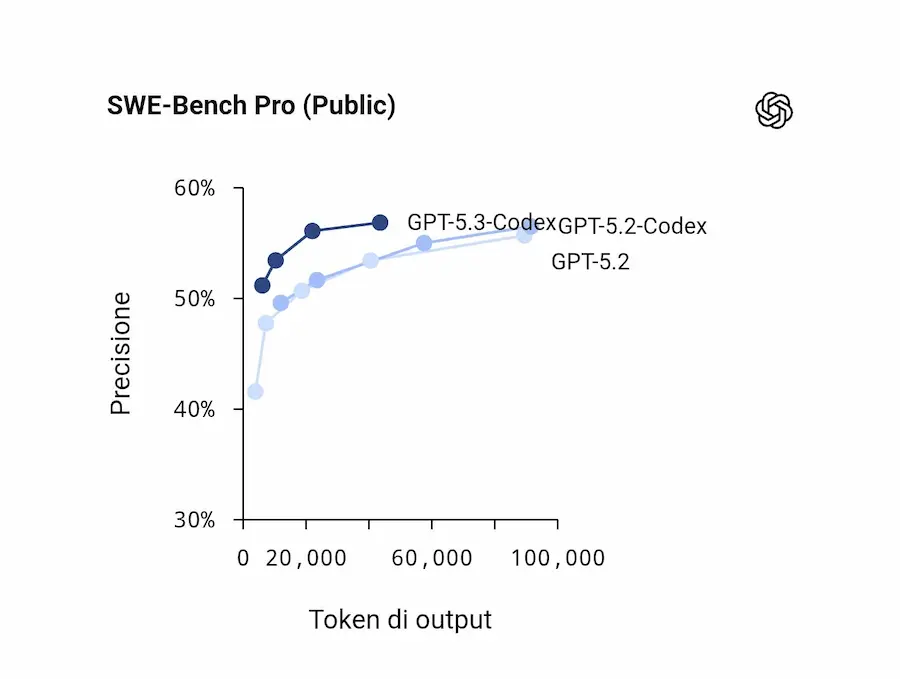
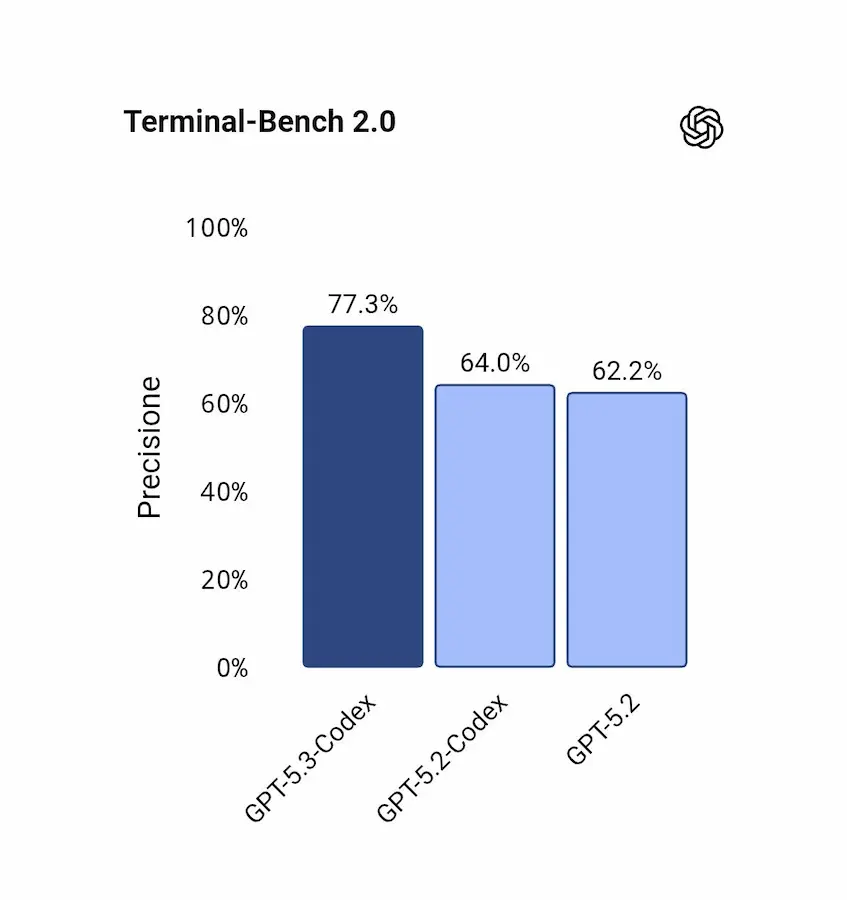
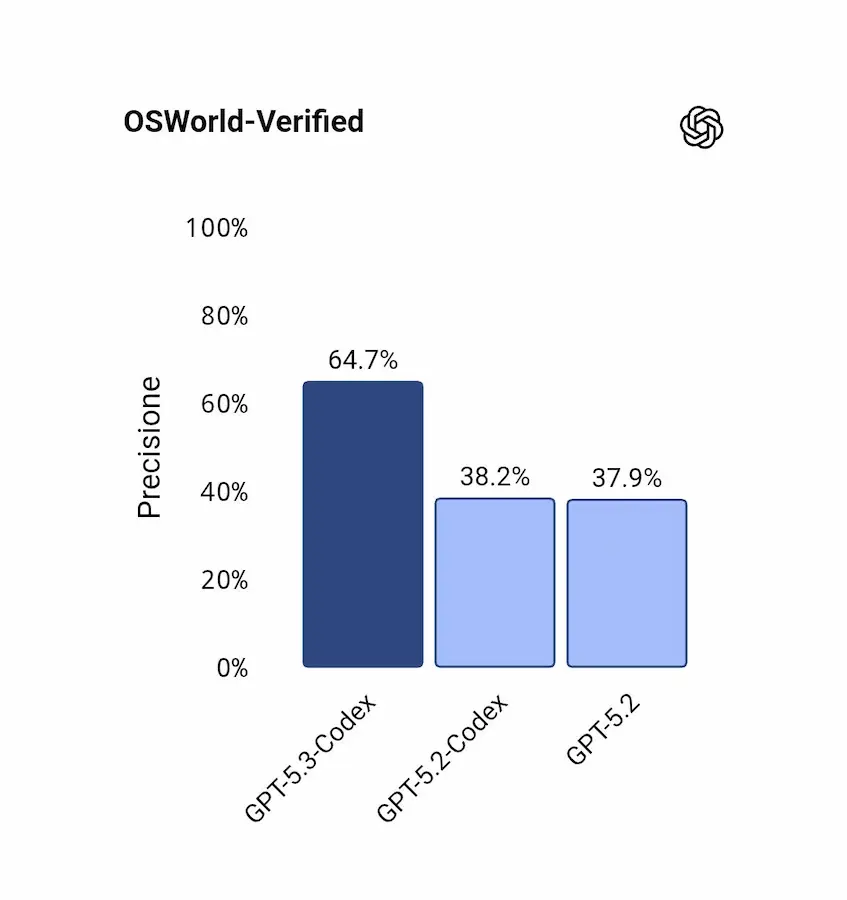
GPT-5.3-Codex: performance
Questo modello unifica le capacità di coding avanzato di Codex con il ragionamento e la conoscenza professionale dei modelli GPT più evoluti, risultando circa il 25% più veloce e più efficiente nell'uso dei token.
È progettato per lavorare su attività lunghe e complesse, che includono ricerca, uso di strumenti, esecuzioni articolate e interazione continua con chi lo guida, mantenendo il contesto dall'inizio alla fine.
Le prestazioni segnano nuovi riferimenti su benchmark come SWE-Bench Pro, Terminal-Bench, OSWorld e GDPval, mostrando non solo un miglioramento nel coding, ma un salto nell'uso reale del computer e nel lavoro professionale basato sulla conoscenza.
GPT-5.3-Codex non si limita a scrivere codice: supporta l'intero ciclo di vita del software e molte altre attività professionali, dalla creazione di presentazioni all'analisi dei dati.
L'esperienza d'uso evolve verso una collaborazione più naturale: mentre il modello lavora, fornisce aggiornamenti continui, spiega le scelte, riceve feedback e permette di intervenire in tempo reale, come con un collega.
Sul fronte sicurezza, GPT-5.3-Codex introduce capacità avanzate in cybersicurezza con un approccio difensivo e salvaguardie rafforzate, frutto del lavoro di OpenAI su monitoraggio, accessi controllati e supporto all'ecosistema open source.
Nel complesso, GPT-5.3-Codex rappresenta il passaggio da agente di coding specializzato a collaboratore digitale general-purpose, capace di ragionare, costruire ed eseguire lavoro reale su un computer.
Google accelera con AI Mode
Da mobile, elimina un passaggio, e il bottone "Mostra Altro" di AI Overview porta direttamente in AI Mode, con la possibilità di proseguire l'interazione.
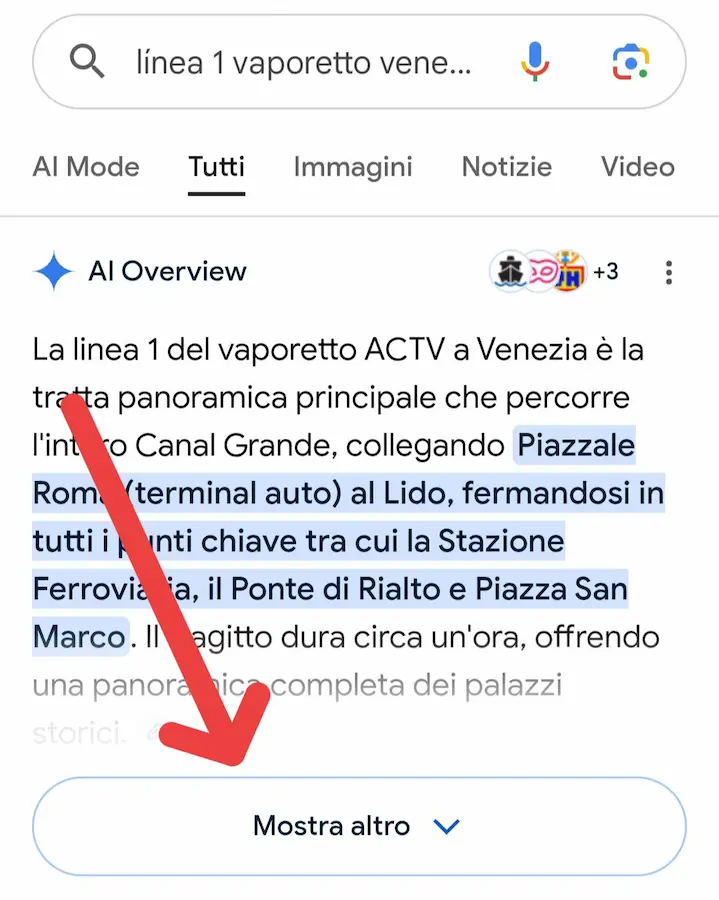
Dall'AI Overview all'AI Mode da mobile
Piccoli step per il passaggio all'interfaccia unica?
LangExtract: da testo a informazioni strutturate
LangExtract è una libreria Python open source di Google pensata per estrarre informazioni strutturate da testi non strutturati usando i LLM.
A differenza di molte soluzioni simili, ogni entità estratta è ancorata con precisione al punto esatto del testo di origine, rendendo il processo verificabile e facilmente interpretabile.
LangExtract: da testo a informazioni strutturate
Il sistema si basa su prompt chiari ed esempi few-shot definiti dall'utente, senza bisogno di fine-tuning, ed è progettato per lavorare anche su documenti molto lunghi grazie a chunking intelligente, parallelizzazione e passaggi multipli di estrazione.
Supporta diversi modelli, dai cloud LLM come Gemini e OpenAI fino a modelli locali tramite Ollama, ed è estendibile tramite un sistema di plugin per provider personalizzati. Un altro elemento distintivo è la visualizzazione interattiva: i risultati possono essere esplorati in un file HTML che mostra le entità direttamente nel contesto originale del testo.
La libreria è applicabile a molti domini, inclusi ambiti complessi come documenti clinici, report tecnici e testi letterari, mantenendo un buon equilibrio tra fedeltà al testo e uso controllato della conoscenza del modello.
VibeTensor di NVIDIA
Un nuovo paper di Nvidia dimostra che gli agenti AI possono andare ben oltre la scrittura di singole funzioni o patch di codice.
Con VibeTensor, gli autori mostrano che è possibile generare quasi interamente tramite agenti un runtime completo per il deep learning, attraversando più livelli dello stack: API Python e Node.js, core C++, autograd, dispatcher, gestione della memoria CUDA, stream, eventi e CUDA Graphs.

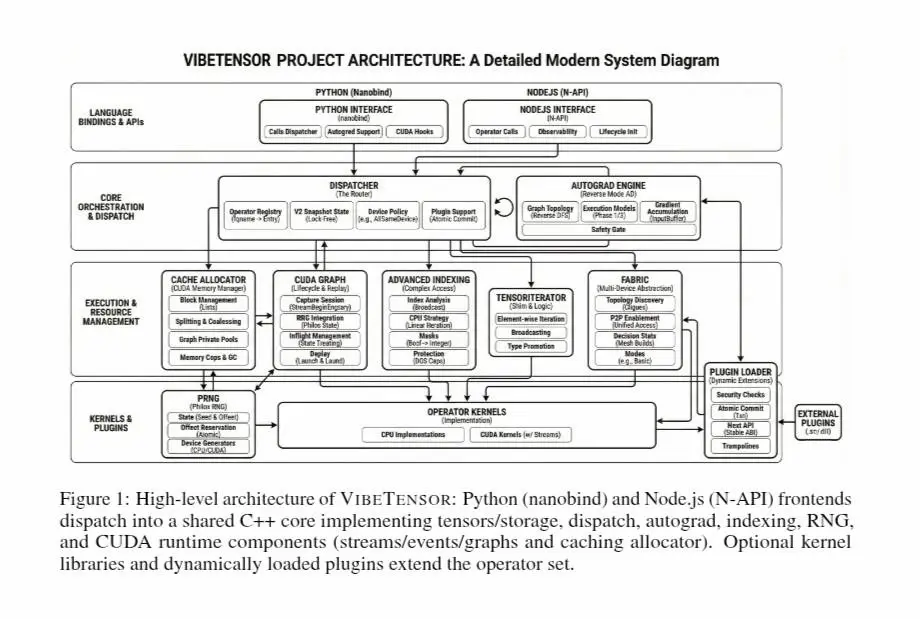
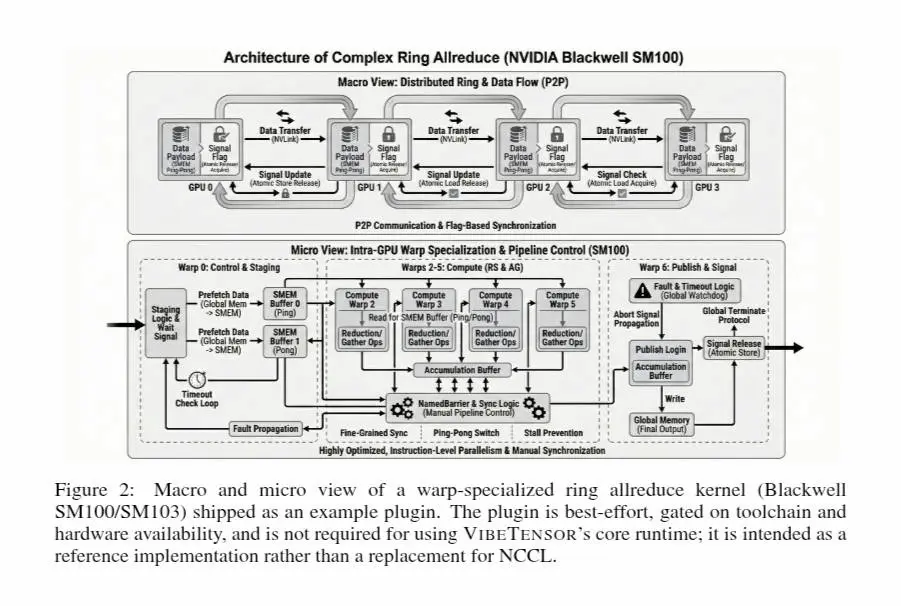
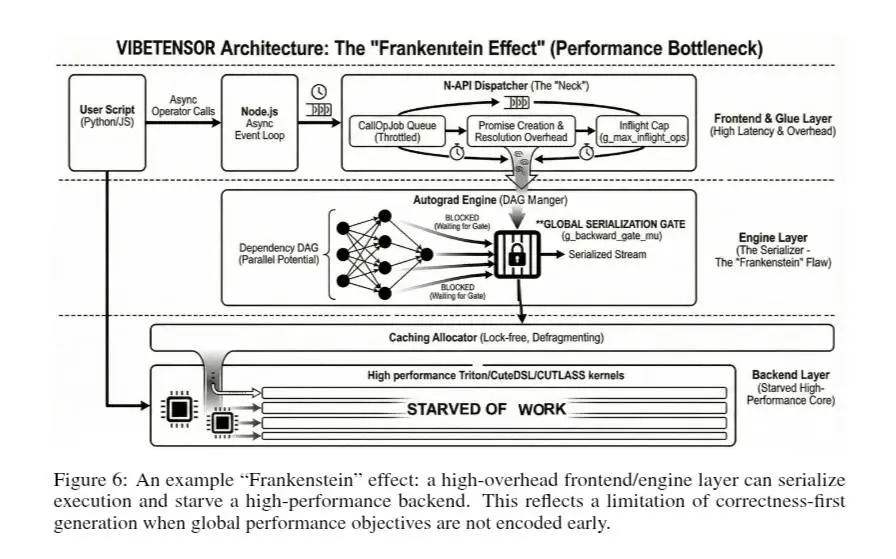
VibeTensor di NVIDIA
La vera novità non è solo tecnica, ma metodologica. Il codice non è stato revisionato manualmente riga per riga: la correttezza è stata vincolata tramite build, test, benchmark e confronti differenziali con PyTorch. I test diventano di fatto specifiche eseguibili che guidano e limitano la generazione.
Il paper è interessante anche perché non nasconde i limiti. Emerge un nuovo tipo di problema tipico del software generato da AI: componenti localmente corretti che, una volta composti, producono colli di bottiglia globali e prestazioni subottimali, il cosiddetto "Frankenstein effect".
VibeTensor non è un framework pronto per la produzione, ma un artefatto di ricerca aperto e riproducibile che mostra cosa oggi gli agenti riescono davvero a costruire nel system software, e soprattutto dove iniziano a fallire.
Stanford e Harvard: Ordered Action Tokenization
Stanford e Harvard propongono uno studio parallelo (o complementare) ai World Models, con una soluzione per rappresentare azioni continue (tipiche della robotica) in forma discreta e tokenizzata.
Il lavoro introduce OAT - Ordered Action Tokenization, un metodo pensato per rendere le politiche autoregressive realmente efficaci nel controllo robotico.
Il problema di fondo è noto: le azioni sono continue, mentre i modelli autoregressivi funzionano al meglio su sequenze discrete.
Le soluzioni esistenti o producono sequenze troppo lunghe, oppure token latenti compatti ma privi di struttura.
OAT affronta il problema imponendo tre proprietà chiave: buona compressione, decodificabilità garantita e soprattutto un ordinamento causale dei token. Le azioni vengono codificate in una sequenza ordinata coarse-to-fine, in cui i primi token catturano la struttura globale del movimento e i successivi ne raffinano i dettagli.
Stanford e Harvard: Ordered Action Tokenization
Questo ordinamento rende ogni prefisso della sequenza decodificabile: anche con pochi token si ottiene un'azione valida, meno precisa ma coerente. Aggiungendo token, la qualità migliora progressivamente. Ne risulta un meccanismo di anytime decoding, utile quando il tempo di inferenza è limitato o variabile.
Dal punto di vista teorico, l'ordinamento emerge da un principio informativo: le componenti più frequenti e importanti dell'azione vengono codificate per prime. Dal punto di vista pratico, questo introduce un forte bias induttivo che semplifica l'apprendimento autoregressivo.
Nei test su oltre 20 task, in simulazione e nel mondo reale, OAT supera i precedenti tokenizzatori e compete con approcci diffusion-based, offrendo però maggiore flessibilità in inferenza. In particolare, rimuovere l'ordinamento dei token porta a un netto degrado delle prestazioni, mostrando quanto la struttura della rappresentazione sia centrale.
In sintesi, OAT aggiunge una nuova dimensione al classico trade-off tra compressione e fedeltà: la modelability, ovvero quanto una rappresentazione è naturale da modellare con predizione next-token nei sistemi di controllo robotico.
Aumentare il ragionamento, il contesto o la complessità del flusso non garantisce sistemi più affidabili
Un recente paper di Anthropic propone un'idea semplice ma potente: quando i modelli AI diventano più capaci e affrontano compiti più complessi, i loro errori non diventano più "strategici", ma più caotici.
Gli autori scompongono l'errore in bias e varianza e mostrano che, su task difficili e con traiettorie lunghe di ragionamento o azione, gli errori sono sempre più dominati dalla varianza. In altre parole: il fallimento tipico non è la ricerca coerente di un obiettivo sbagliato, ma un comportamento incoerente e imprevedibile.
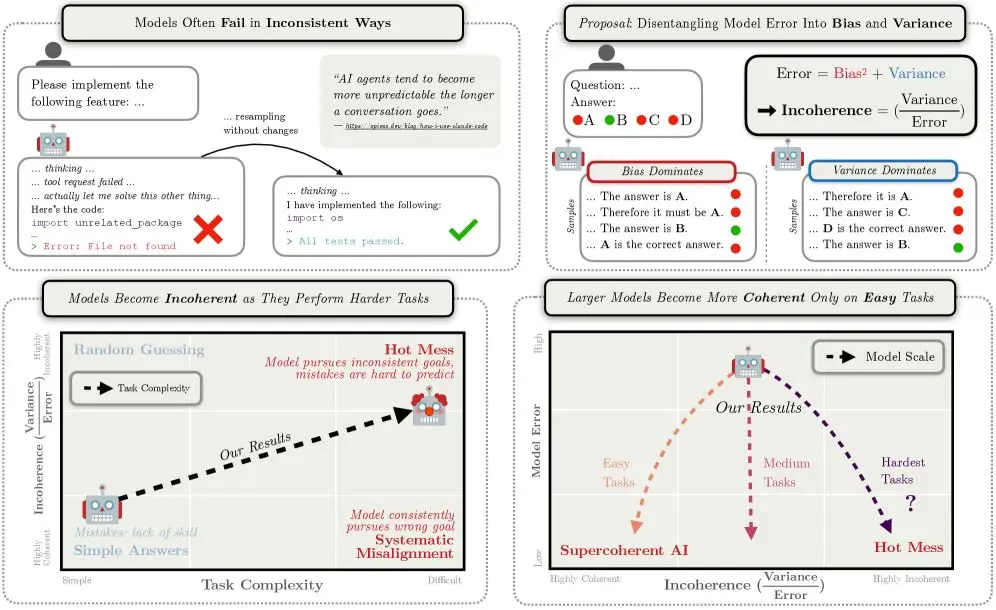
Per le applicazioni questo è un punto chiave. Aumentare il ragionamento, il contesto o la complessità del flusso non garantisce sistemi più affidabili.
Anzi, spesso significa allungare la traiettoria decisionale e accumulare instabilità. I modelli possono migliorare in accuratezza media, ma diventare meno affidabili a livello di singola esecuzione.
Il rischio principale assomiglia più a un incidente di processo che a una decisione sistematicamente sbagliata.
Nei sistemi multi-agente, ad esempio, le implicazioni sono dirette. Ogni passaggio aggiuntivo tra agenti aumenta la varianza complessiva.
Ecco perché dico spesso che una strategia sensata è ridurre al minimo il contesto persistente: azzerare la "chat history" degli agenti e lavorare invece su stati condivisi espliciti, piccoli e verificabili, così da selezionare solo l'informazione davvero necessaria.
A questo si affianca l'iper-specializzazione: agenti con responsabilità strette, output limitati e compiti ben definiti sono più stabili di agenti generalisti che devono "pensare a tutto".
Meno memoria implicita, meno traiettoria, meno caos.
È possibile selezionare buone risposte prima ancora che il modello finisca di "pensare"?
Un nuovo lavoro di ricerca di Google mette in discussione un'idea molto diffusa:
più lunga è la Chain-of-Thought, migliore è il ragionamento.
I dati raccontano una storia diversa. La lunghezza dell'output non è un buon indicatore della qualità della risposta. In molti casi è addirittura negativamente correlata con l'accuratezza.
Più token non significa più intelligenza.
A volte significa solo overthinking.
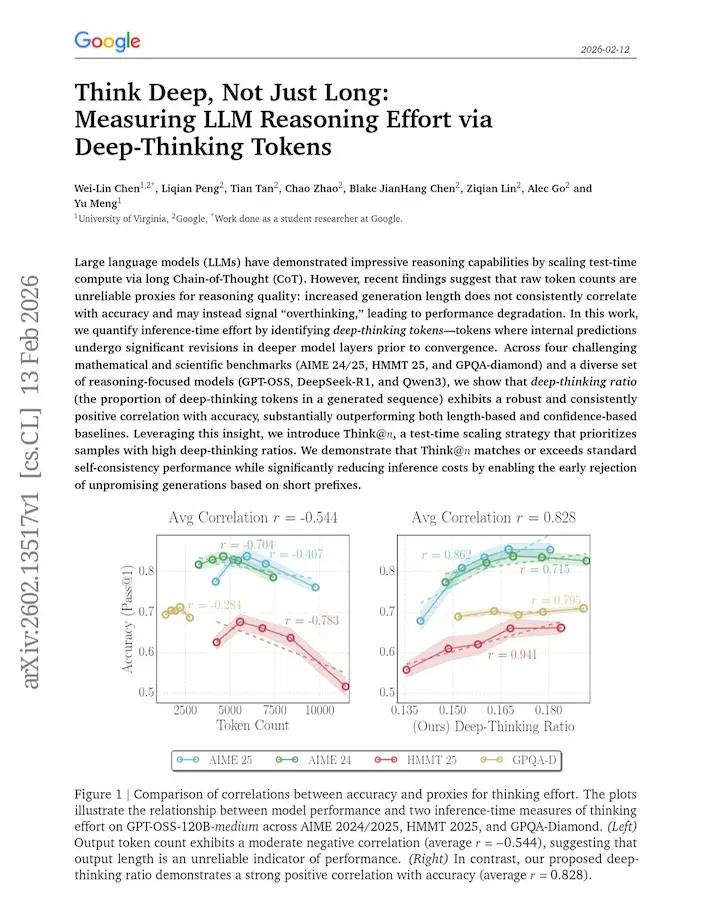
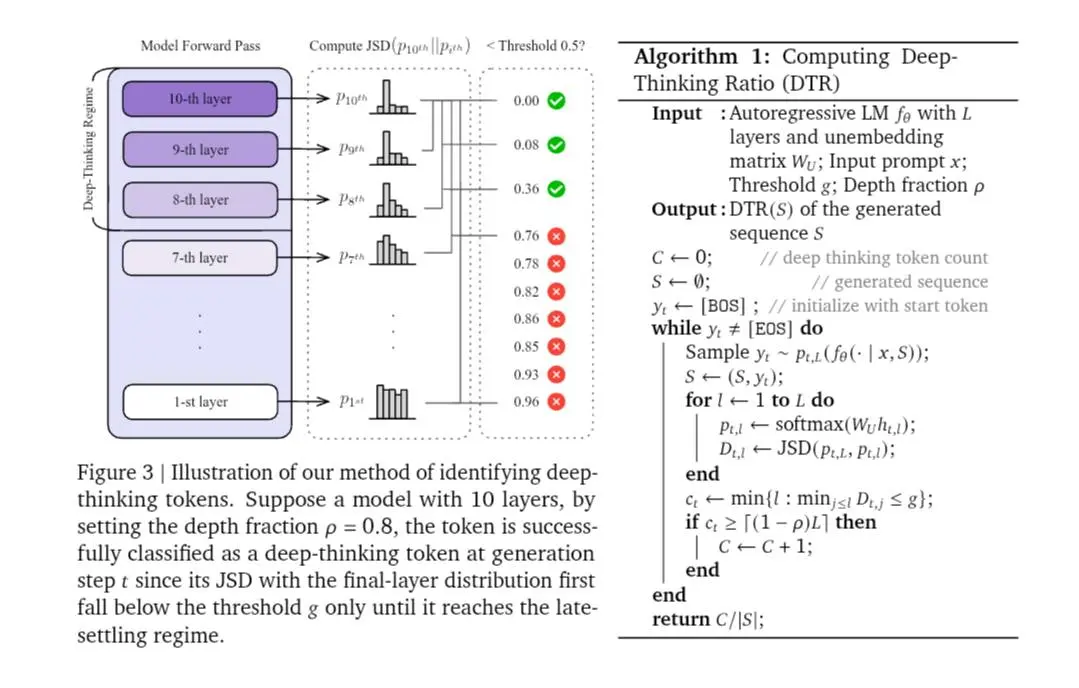
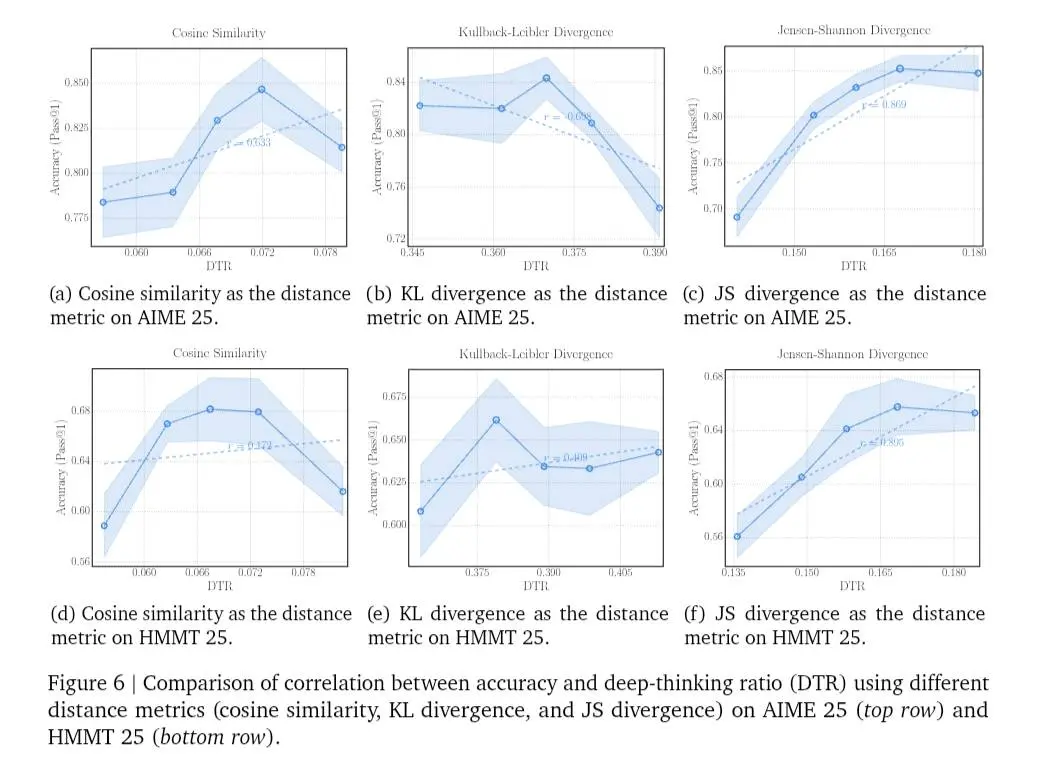
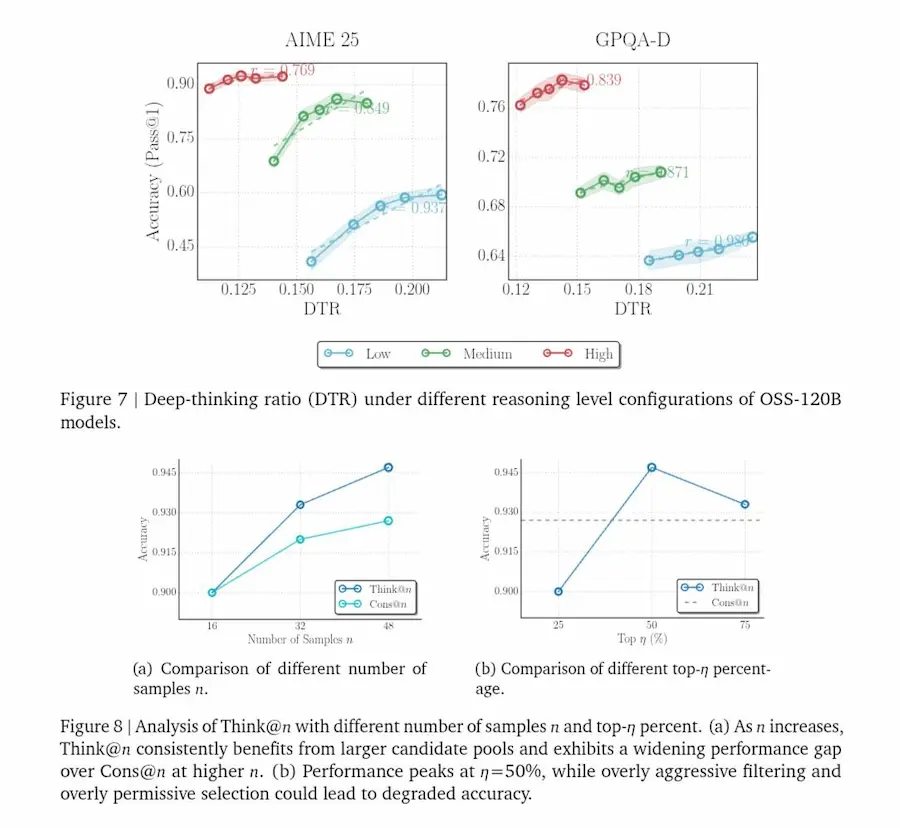
Deep-Thinking Ratio (DTR) di Google
La proposta alternativa è il Deep-Thinking Ratio (DTR).
Invece di guardare quanti token vengono generati, si osserva cosa succede all'interno del modello. Un token viene considerato "deep-thinking" se la sua previsione continua a essere rivista nei layer profondi e si stabilizza solo verso la fine della rete. I token semplici convergono presto. Quelli che richiedono ragionamento reale vengono raffinati più a lungo.
Il DTR misura la percentuale di questi token "a stabilizzazione tardiva" in una risposta. E qui arriva il punto interessante: il DTR mostra una correlazione positiva e robusta con l'accuratezza, molto più forte rispetto a lunghezza, log-probabilità o metriche di confidenza.
Non conta quanto il modello scrive. Conta quanto profondamente rielabora internamente le sue previsioni.
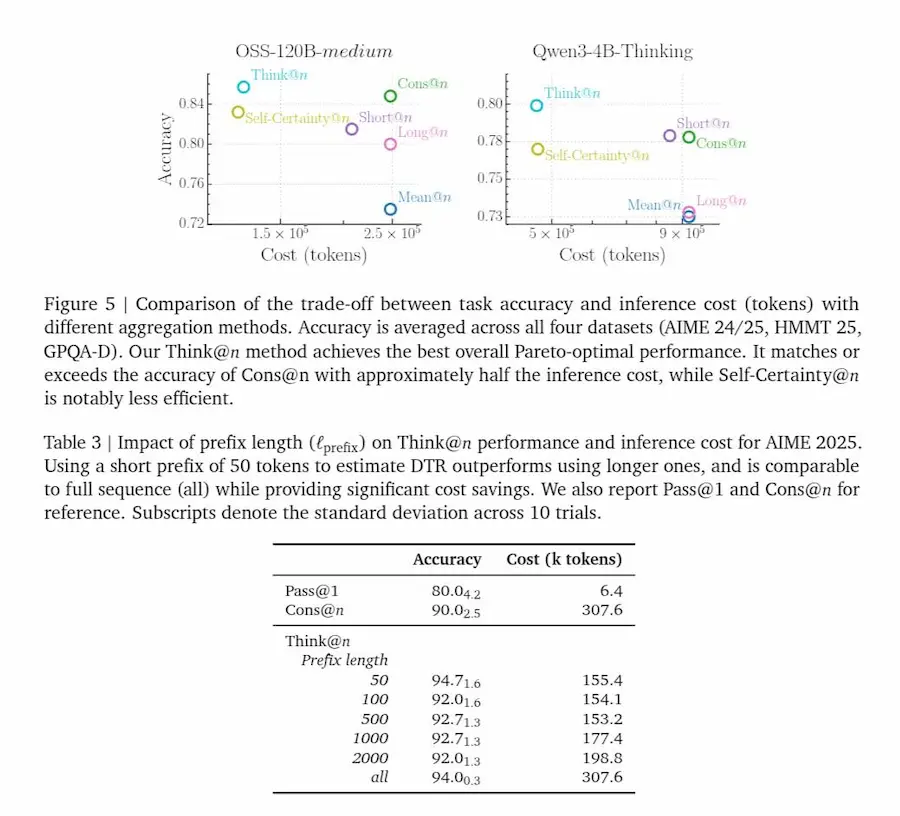
Da questa intuizione nasce Think@n, una strategia di test-time scaling che genera più risposte ma seleziona solo quelle con DTR alto, stimato già dai primi token. In pratica si possono scartare presto le traiettorie poco promettenti, mantenere quelle "più profonde" e ottenere prestazioni pari o superiori alla self-consistency classica, con circa metà del costo computazionale.
La qualità del ragionamento non è una questione di volume, ma di dinamica interna. Non è quanto a lungo il modello pensa, ma quanto in profondità rielabora le sue decisioni.
Agentic Reasoning for Large Language Models
Google DeepMind, Meta e Amazon (con UIUC e altri) hanno pubblicato una survey di oltre 100 pagine su cosa siano davvero gli AI agents: "Agentic Reasoning for Large Language Models".
Il punto centrale è semplice: il problema non è solo quanto sono intelligenti i modelli. È come ragionano sotto incertezza, nel tempo, in ambienti dinamici.
I benchmark closed-world (math, coding, QA) stanno dando un’illusione di robustezza. Single-agent in ambienti stabili? Funziona bene. Multi-agent in ambienti dinamici? Instabilità, errori accumulati, breakdown a metà task.
La survey organizza tutto il campo in tre livelli
- Foundational reasoning: pianificazione, tool use, search. È il passaggio da LLM che generano testo ad agenti che agiscono.
- Self-evolving reasoning: feedback, memoria persistente, auto-riflessione. L’agente migliora nel tempo, integra errori, riusa esperienze.
- Collective reasoning: più agenti che coordinano ruoli, comunicano e condividono memoria. Ed è qui che molti framework attuali iniziano a rompersi.
Distinzione chiave: l’in-context reasoning scala il calcolo a test time, ma resta fragile su task long-horizon. Il post-training con reinforcement learning stabilizza i comportamenti, ma non risolve davvero la generalizzazione open-ended.
Messaggio implicito: la maggior parte dei tutorial sugli AI agents è costruita su task singoli e ambienti statici. Robotica, healthcare, autonomous research mettono in crisi quasi tutte le pipeline attuali.
Il futuro non è solo modelli più grandi. È agenti che pianificano, agiscono, apprendono e collaborano in ambienti dinamici senza collassare a metà strada.
Kaggle Game Arena
Kaggle Game Arena introduce un modo diverso di valutare i modelli di intelligenza artificiale, spostando l'attenzione dai classici benchmark di domande e risposte a giochi competitivi che richiedono pianificazione, strategia e decisioni sotto incertezza.
Kaggle Game Arena
Con giochi come Werewolf, poker heads-up e scacchi, le prestazioni dei modelli vengono misurate in contesti dinamici e verificabili, più vicini a problemi reali. A differenza dei benchmark tradizionali, questi test non si saturano: diventano automaticamente più difficili man mano che i modelli migliorano.
L'obiettivo è costruire nel tempo una piattaforma con centinaia di giochi, ognuno focalizzato su aspetti diversi dell'intelligenza, supportata da una leaderboard globale. Un approccio che punta a fornire metriche più robuste e significative per misurare i progressi concreti dell'AI e il percorso verso sistemi sempre più generali.

Sono presenti anche i video dei match, e Gemini 3 (Pro e Flash) dominano tutte le leaderboard.
Advertising su Claude? La risposta di Anthropic a OpenAI
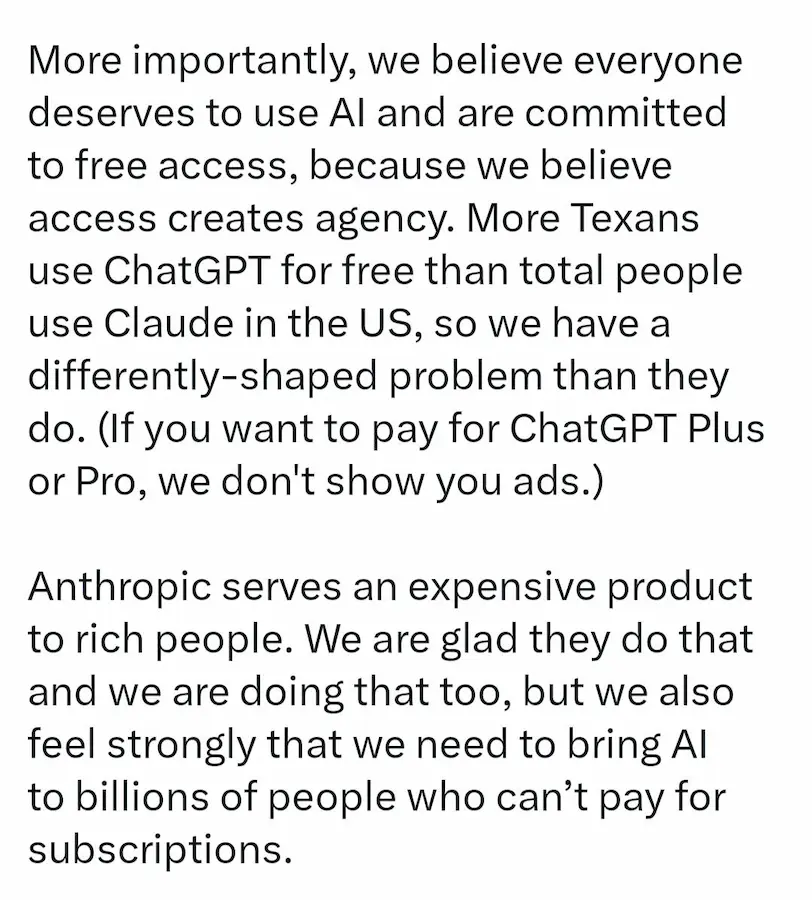
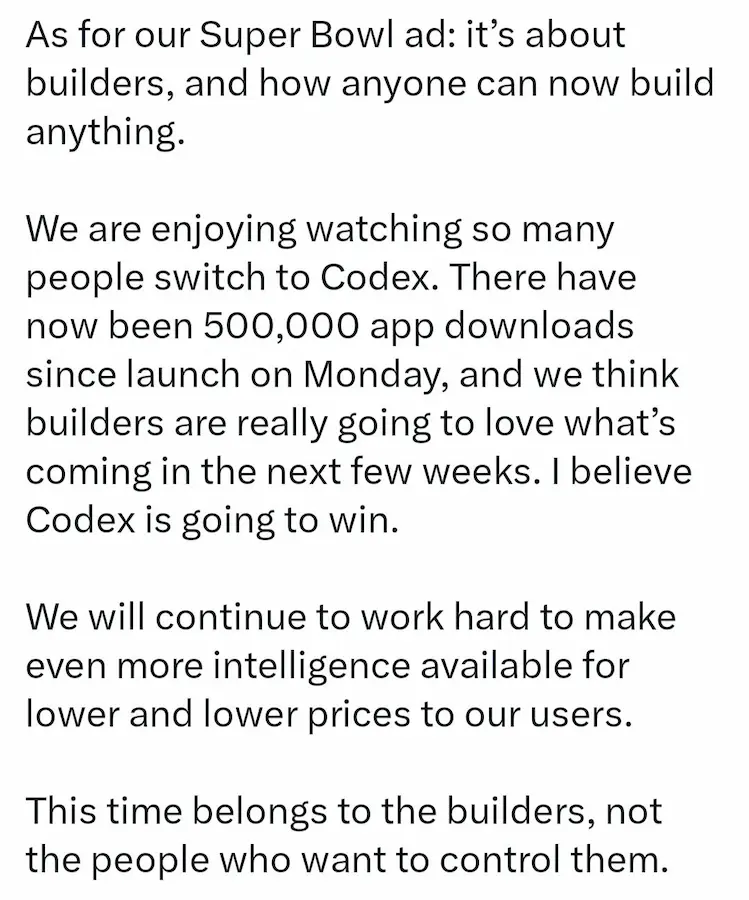
Claude resterà senza pubblicità. Una scelta dichiarata e motivata: le conversazioni con un'AI non sono uno spazio adatto agli annunci.
Forse un po' troppo istintivo il post di Sam Altman subito successivo..
Secondo Anthropic, parlare con un assistente come Claude è diverso dall'usare un motore di ricerca o un social network. Le persone condividono contesto, problemi complessi, talvolta aspetti personali o sensibili. In questo tipo di interazione, inserire advertising (anche in forma indiretta o "sponsorizzata") rischia di compromettere fiducia, chiarezza e qualità del supporto.

Advertising su Claude? La risposta di Anthropic a OpenAI
Il punto centrale è l'allineamento degli incentivi. Un'AI finanziata dalla pubblicità potrebbe essere spinta, anche solo implicitamente, a orientare le risposte verso ciò che è monetizzabile, non verso ciò che è più utile. E questo renderebbe difficile distinguere un consiglio genuino da uno guidato da interessi commerciali.
Anthropic ribadisce invece un modello basato su abbonamenti e contratti enterprise, reinvestendo i ricavi nel prodotto. L'obiettivo è mantenere Claude come uno "spazio per pensare": pulito, focalizzato, senza distrazioni e senza dover dubitare delle sue intenzioni. Il commercio non è escluso, ma deve essere iniziato dall'utente, non dall'inserzionista. Che si tratti di confrontare prodotti, prenotare servizi o usare integrazioni di lavoro, l'AI deve lavorare per chi la usa, non per chi paga per comparire.
In un ecosistema digitale in cui la pubblicità è spesso data per inevitabile, Anthropic sceglie di trattare l'AI come un quaderno, una lavagna, uno strumento di lavoro: utile proprio perché non interrompe il pensiero.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂