Generative AI: novità e riflessioni - #3 / 2026
Dai modelli ai sistemi che agiscono: agenti, world model, robotica e AI integrata nel lavoro e nella scienza. GPT-5.4, Gemini 3.1 Flash-Lite, Copilot Cowork, Workspace, Shopify agentic commerce e WebMCP: segnali chiave di un’AI sempre più operativa.

Buon aggiornamento, e buone riflessioni..
Ascolta l'audio overview che sintetizza le novità
Il podcast è stato generato attraverso NotebookLM.
Rivoluzione Artificiale
Nella puntata del 22 marzo di Presa Diretta (Rai 3) dal titolo "Rivoluzione Artificiale" si è parlato di AI: la "più grande trasformazione tecnologica del nostro tempo".
Rivoluzione Artificiale - Presa Diretta (Rai 3)
Il video della puntata completa su Rai Play:

"..nell'equazione che stiamo disegnando manca una variabile importante: le istituzioni".
La velocità del cambiamento non aspetta i tempi lenti della politica e della cultura. Rimandare significa esporsi a shock sociali sempre più violenti.
La vera incognita, infatti, non è la tecnologia, ma come la società sarà in grado di gestire l'urto di un impatto a lungo termine ancora (probabilmente) sottostimato.
Cosa significa "black box" in ambito AI?
C'è ancora confusione su cosa significhi davvero "black box" nell'AI.
"Black box" non significa che non si comprende il funzionamento. Questo è ben documentato: leggere i paper tecnici rilasciati insieme a molti modelli aiuta a capirlo.
"Black box" significa un'altra cosa: le reti neurali alla base dei modelli moderni sono così vaste e complesse che non è possibile ricostruire in modo comprensibile come si forma una “decisione” al loro interno.

Non è solo una questione di "perché questo output?", ma di "come si è costruito, passo dopo passo, attraverso milioni di trasformazioni".
Un esempio semplice:
una rete neurale può stabilire, in base a dei dati in input, se una transazione è fraudolenta (e con altissima probabilità la decisione è corretta). Ma non possiamo interpretare, in modo comprensibile per un umano, come tutte le informazioni vengano trasformate e combinate nei vari livelli della rete fino a quella decisione.
Ecco perché si sta lavorando a processi che mirano alla "spiegabilità" (XAI) dei modelli, che in alcuni settori sono fondamentali.
Sono passati 10 anni dalla famosa "mossa 37"
Nel 2016 AlphaGo di DeepMind sconfisse il campione mondiale Lee Sae Dol nel gioco del Go, uno dei giochi più complessi mai creati. Durante la seconda partita arrivò quella che sarebbe diventata una delle mosse più famose nella storia dell'AI: la mossa 37.
All'inizio i commentatori pensarono fosse un errore. In realtà era una scelta incredibilmente creativa, qualcosa che nessun giocatore umano aveva mai considerato seriamente. Cento mosse dopo, quella pietra era esattamente nel punto giusto per vincere la partita.
Con la "mossa 37" AlphaGo sconfisse Lee Sae Dol: il campione mondiale di Go
Quell'evento segnò l'inizio della moderna era dell'AI. AlphaGo combinava reti neurali profonde, ricerca nello spazio delle possibili mosse e reinforcement learning: prima imparava osservando partite umane, poi migliorava giocando centinaia di migliaia di partite contro sé stesso.
Da lì sono nati sistemi sempre più generali. AlphaGo Zero ha imparato a giocare partendo solo dalle regole del gioco. AlphaZero ha esteso lo stesso approccio a scacchi e shogi, raggiungendo livelli sovrumani in poche ore di auto-apprendimento.
Quelle stesse idee oggi vengono
applicate ben oltre i giochi.
AlphaFold ha risolto il problema del folding delle proteine, predicendo la struttura di oltre 200 milioni di proteine e diventando uno strumento usato da milioni di ricercatori nel mondo. Sistemi come AlphaProof e AlphaGeometry stanno affrontando problemi matematici avanzati. AlphaEvolve esplora lo spazio del codice per scoprire nuovi algoritmi.
Le tecniche di pianificazione, ricerca e apprendimento viste per la prima volta con AlphaGo stanno convergendo con modelli multimodali come Gemini, capaci di lavorare con testo, immagini, audio, video e codice.
Dieci anni dopo, quella mossa su una scacchiera 19×19 è diventata uno dei primi segnali concreti di come l'intelligenza artificiale possa contribuire alla scoperta scientifica.
GigaTIME di Microsoft
Microsoft Research ha presentato GigaTIME, un modello di AI multimodale progettato per studiare il microambiente tumorale su scala che finora era semplicemente irraggiungibile.
Sono questi gli ambiti in cui vorrei vedere esprimersi la massima competitività tra i colossi tecnologici.
Perché l'obiettivo, in fondo, è comune.
GigaTIME di Microsoft
Per capire come un tumore interagisce con il sistema immunitario servono tecniche molto avanzate, come la multiplex immunofluorescence (mIF), che permettono di osservare contemporaneamente molte proteine e la loro posizione nello spazio all'interno del tessuto. Sono strumenti fondamentali per capire se un tumore risponderà o meno a immunoterapie, ma hanno un limite importante: sono costosi, complessi e difficili da applicare su grandi quantità di campioni.
Qui entra in gioco l'AI
GigaTIME è stato addestrato su 40 milioni di cellule per imparare a tradurre le comuni immagini patologiche H&E, economiche e diffuse nella pratica clinica, in immagini virtuali mIF con informazioni proteiche ad alta risoluzione.
In questo modo i ricercatori possono trasformare enormi archivi di immagini patologiche già esistenti in una nuova fonte di dati biologici.
Applicando il modello a oltre 14k pazienti provenienti da 51 ospedali e più di 1k cliniche, è stata generata una popolazione virtuale di circa 300k immagini mIF, distribuite su 24 tipi di tumore e 306 sottotipi.
L'analisi di questa popolazione ha rivelato oltre 1.200 associazioni statisticamente significative tra stati cellulari immunitari, biomarcatori tumorali, stadio della malattia e sopravvivenza dei pazienti. Molte confermano conoscenze già note, altre suggeriscono nuove relazioni biologiche ancora poco esplorate.
Il punto più interessante è forse questo: trasformando dati relativamente semplici in segnali biologici complessi, l'AI permette di studiare il microambiente tumorale su scala di popolazione, qualcosa che fino a poco tempo fa era praticamente impossibile.
Un passo concreto verso un'idea che fino a pochi anni fa sembrava fantascienza: costruire "pazienti virtuali", gemelli digitali capaci di aiutare a comprendere la progressione della malattia e a migliorare la medicina di precisione.
AI e creatività
Quando si parla di AI e creatività, la cultura aziendale conta più della tecnologia.
Gli strumenti di AI generativa stanno entrando nei flussi di lavoro quotidiani: aiutano a fare brainstorming, esplorare alternative, sintetizzare informazioni e accelerare i progetti.
Molte organizzazioni si aspettano che questo porti automaticamente più creatività. La realtà è più complessa.

- Le ricerche mostrano che l'AI aumenta la creatività soprattutto per chi ha meno esperienza o meno fiducia nelle proprie capacità creative. In questi casi funziona come un acceleratore di idee, riducendo il blocco creativo e offrendo nuovi spunti da cui partire.
- Per i profili più esperti o già molto creativi, invece, il beneficio può essere minore. Se usata passivamente, l'AI rischia di uniformare le idee o di diventare una scorciatoia che riduce l'esplorazione autonoma.
- La differenza la fa il contesto organizzativo.
- Nelle aziende dove l'AI viene presentata come uno strumento di esplorazione e confronto, tende ad amplificare il pensiero creativo. Dove viene introdotta solo per aumentare efficienza e velocità, il suo impatto sulla creatività rimane limitato.
La tecnologia può generare idee. La cultura decide se quelle idee possono davvero evolvere.
Shopify: un layer tra l'e-commerce e gli agenti AI
Shopify ha annunciato una mossa chiara: si propone come layer tra l'e-commerce e gli agenti AI.
In pratica, con Agentic Storefronts i merchant Shopify possono distribuire prodotti e vendite su canali come ChatGPT, Copilot, AI Mode in Google Search e Gemini.
E con Agentic plan anche i brand che non usano Shopify come piattaforma e-commerce possono usare Shopify come layer di catalogo e commercio per questi canali.
Non stiamo parlando solo di visibilità nei risultati AI, ma di un modello in cui l'AI può diventare un vero canale di vendita.
Però non si tratta di un rollout uniforme per tutti i merchant, tutti i prodotti e tutti i paesi.
Quali sono gli scenari per gli e-commerce italiani?
Con Shopify
- Mercato italiano: oggi si può lavorare su discoverability e preparazione del catalogo, ma non sul vero canale transazionale.
- Mercato europeo: scenario simile. La presenza commerciale in Europa non basta, da sola, per attivare i canali agentic Shopify in modo pieno.
- Mercato USA: se un merchant italiano vende anche a clienti USA e i prodotti sono idonei, può puntare in particolare a ChatGPT. Per Google/Gemini/Copilot, invece, Shopify oggi richiede condizioni più strette e un'impostazione fortemente US-based.
Senza Shopify
- Mercato italiano: niente vero canale agentic Shopify, ma resta la discoverability su Google e sul web aperto.
- Mercato europeo: stessa logica dell'Italia; si può lavorare su feed, dati prodotto, SEO e merchant data, ma non si entra automaticamente nel commercio agentic di Shopify.
- Mercato USA: con Agentic plan, Shopify può diventare il layer che collega catalogo, prodotti e canali AI. Anche qui, però, l'accesso reale dipende da shipping, idoneità prodotto e requisiti specifici del canale.
La sintesi è semplice: per un e-commerce italiano, oggi l'agentic commerce è soprattutto una partita di preparazione e discoverability; diventa una partita di vendita quando entra in gioco il mercato USA.
Un test di WebMCP su un e-commerce
Quello che si vede nel video è l'agente che interagisce direttamente con il protocollo per eseguire la richiesta che ho fatto attraverso un prompt.
Un test di WebMCP su un e-commerce
Google continua a spingere sul progetto, pubblicando diverse demo di implementazione di WebMCP che si possono testare su pagine reali.
Come si può provare il sistema?
- Abilitare "WebMCP for testing" nelle impostazioni di Chrome.
- Installare l'estensione "WebMCP - Model Context Tool Inspector", che simula l'agente AI nel sito web.
- L'estensione mostra le capability della pagina esposte via WebMCP.
- Con un prompt in linguaggio naturale si possono dare le istruzioni all'agente.
Di certo, questa modalità rende solida l'interazione degli agenti AI con le pagine web, perché le operazioni avvengono via API e non attraverso la visione artificiale.
Veo 3.1 Avatar: esempi di utilizzo
Su Google Vids è arrivata la nuova funzionalità di generazione di avatar realistici. L'ho provata, e credo che i video che ho ottenuto si commentino da soli.
In questo test, ho creato due scene, e in ognuna ho usato un avatar tra quelli a disposizione.
- Ho fornito il testo in input, quindi gli avatar stanno pronunciando esattamente il mio contenuto con lip sync.
- Le slide sono generate con Nano Banana 2 Pro in base al contenuto pronunciato dell'avatar, e montate all'interno dell'editor.
- Le scene sono separate da due frame con un titolo.
Gli avatar realistici di Google Vids creati con Veo 3.1
Con Vids, Google sta riuscendo a rendere semplice l'editing video, almeno per gli aspetti di base.
È la facilità di Google Slides portata in un editor video.
E con l'aggiunta di Nano Banana 2, Veo 3.1 e gli Avatar realistici diventa una risorsa incredibilmente potente.
In questo secondo esempio, ho provato a creare una semplice guida in italiano attraverso un personaggio illustrato. Le slide sono sempre generate con Nano Banana 2, partendo dalle schermate del sito web.
Veo 3.1 Avatar: un esempio di utilizzo
Tempo effettivo: 15 minuti. Ma, una volta creato il template, si possono aggiungere nuove scene in pochissimo tempo.
I progressi di LTX 2.3
Fino a poco tempo fa, 30k dollari erano il minimo per un video musicale: decine di persone coinvolte, giorni di riprese e settimane di post-produzione.
Questo è stato realizzato da Alex Patrascu in 8 ore, a casa, con LTX 2.3 (open source) su hardware consumer.
Video musicale realizzato con LTX 2.3 su hardware consumer
Nella produzione tradizionale, tra musica, pre-produzione, riprese e post, si arriva facilmente a una forbice compresa tra i 18k e oltre 50k dollari, con troupe complete, attrezzature cinematografiche e workflow complessi.
In questo caso, tutto è stato realizzato in locale: niente studio, niente cloud, niente intermediari. Solo software open-source, una macchina personale e tempo.
Non è un confronto perfetto: l'AI richiede competenze, tempo e non offre la stessa flessibilità di una produzione reale. Ma rende possibile creare contenuti visivi complessi senza budget elevati né strutture dedicate.
La qualità non è identica a una produzione tradizionale, ma è abbastanza vicina per contenuti social, mood reel e materiali di presentazione.
La soglia dell'"abbastanza buono" si sta spostando rapidamente, con un impatto diretto sulla fascia intermedia della produzione creativa.
Un assaggio di LTX Dubbing
La funzionalità è disponibile su LTX Studio per gli utenti Enterprise, e permette il doppiaggio con lip sync in 175 lingue.
La qualità che sta mettendo in campo LTX è impressionante, e LTX 2.3 è probabilmente il modello open source di generazione video più potente a disposizione.
Le novità tecniche di LTX 2.3
Dal punto di vista tecnico, uno dei cambiamenti principali riguarda la ricostruzione del latent space e dell'architettura VAE, addestrata con dati di qualità più alta. In pratica questo significa che il modello riesce a mantenere texture e dettagli più nitidi: capelli, bordi e piccoli elementi risultano più definiti anche a risoluzioni più basse, riducendo la necessità di correzioni in post-produzione.
È stata migliorata anche la componente che collega il testo al modello generativo, chiamata text connector. Aumentandone la capacità e ottimizzandone l'architettura, il sistema interpreta meglio prompt complessi, con più soggetti o istruzioni stilistiche specifiche. In altre parole, è meno necessario semplificare le richieste per ottenere risultati coerenti.
Un'altra area critica era l'image-to-video. In molte generazioni il video tendeva a restare quasi fermo o a produrre movimenti minimi simili a uno zoom lento. Con LTX-2.3 il training è stato rivisto per generare movimenti più naturali e continui, riducendo freeze, tagli improvvisi e incoerenze rispetto al frame iniziale.
Anche l'audio è stato migliorato grazie a un dataset filtrato da rumori e silenzi inutili e a un nuovo vocoder, che riduce artefatti e suoni casuali nelle generazioni video.
Generazione di video in real-time
Runway annuncia un importante passo avanti nella generazione video in tempo reale.
Come anteprima di ricerca sviluppata insieme a NVIDIA, hanno addestrato un nuovo modello video che gira su Vera Rubin (un supercomputer).
I video in HD vengono generati istantaneamente, con un tempo di visualizzazione del primo frame inferiore ai 100 ms.
Generazione di video in real-time: Runway e NVIDIA
Un risultato che apre un paradigma creativo completamente nuovo e rafforza le basi del General World Model, GWM-1 Runway.
La generazione in tempo reale introduce uno spazio di progettazione radicalmente diverso per i modelli video e la "simulazione del mondo".
AutoGaze: il miglioramento della comprensione dei video
AutoGaze, sviluppato da NVIDIA insieme a UC Berkeley, MIT e Clarifai, introduce un approccio più efficiente alla comprensione video ispirato al comportamento umano.
Invece di analizzare ogni pixel, il modello seleziona solo le regioni realmente informative, riducendo drasticamente la ridondanza.
Nel video che segue è possibile comprendere l'enorme potenziale di queste evoluzioni: mostra come il sistema riesca a ricostruire un video considerando solo una minima percentuale di informazioni.
AutoGaze: il miglioramento della comprensione dei video
Questo modulo leggero, infatti, è basato su un processo autoregressivo, e sceglie un insieme minimo di patch in grado di ricostruire il contenuto visivo mantenendo alta qualità. Il risultato è una riduzione dei token fino a 100× e un'accelerazione significativa dei modelli Vision Transformer e multimodali.
L'efficienza ottenuta consente di scalare l'analisi di video lunghi e ad alta risoluzione (fino a 1000 frame in 4K), superando i limiti computazionali che finora ne impedivano l'adozione su larga scala.
Il sistema dimostra anche miglioramenti concreti nei benchmark, incluso HLVid, un nuovo dataset per video lunghi e ad alta definizione, evidenziando come la selezione intelligente dell'informazione possa essere più efficace del processamento completo.
GPT 5.4 di OpenAI
GPT-5.4 è stato rilasciato come nuovo modello di frontiera progettato per il lavoro professionale. È disponibile in ChatGPT (modalità Thinking), API e Codex, con una versione GPT-5.4 Pro pensata per attività particolarmente complesse.
I miei primi test su diversi task? Convincente. Codex è impressionante.
Il modello integra i progressi recenti in ragionamento, coding e workflow agentici in un'unica architettura. L'obiettivo è migliorare la capacità dell'AI di completare attività reali, come documenti, presentazioni, fogli di calcolo e analisi, con meno iterazioni e maggiore precisione.
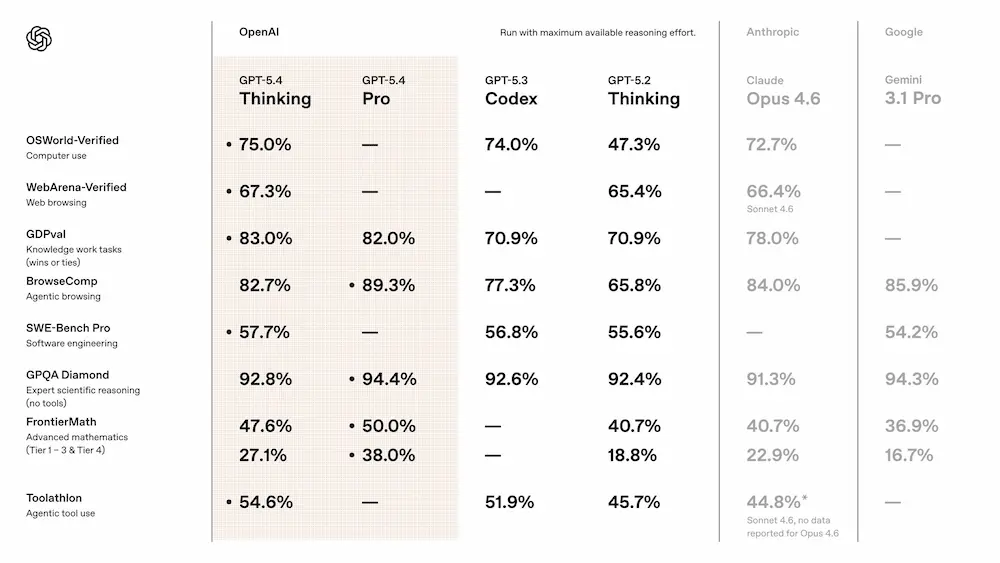
Nei benchmark dedicati al lavoro professionale (GDPval), GPT-5.4 raggiunge l'83% di performance rispetto al 70.9% della generazione precedente.
Nei task di modellazione su spreadsheet ottiene un punteggio medio dell'87.3%, e le presentazioni generate vengono preferite nel 68% dei casi rispetto a quelle di GPT-5.2. Il modello riduce anche gli errori fattuali: le affermazioni false risultano il 33% meno frequenti e le risposte complessivamente errate diminuiscono del 18%.
Una delle novità principali è l'introduzione di capacità native di "computer use". GPT-5.4 può interagire con software e siti web attraverso screenshot, mouse e tastiera, automatizzando workflow complessi tra diverse applicazioni.
Nei benchmark di navigazione desktop (OSWorld-Verified) raggiunge un tasso di successo del 75%, superando anche la performance umana riportata nel test.
Sono stati migliorati anche la visione artificiale e la comprensione di documenti e immagini ad alta risoluzione. Il modello supporta input visivi fino a oltre 10 megapixel, aumentando precisione nella localizzazione degli elementi e nell'interazione con le interfacce.
Sul fronte sviluppo software, GPT-5.4 combina le capacità di GPT-5.3-Codex con nuove funzioni per iterazione, debugging e test automatici. È stato introdotto anche un sistema di "tool search" che permette agli agenti di scegliere strumenti esterni in modo più efficiente quando operano in ecosistemi con molte integrazioni.
Il modello supporta contesti fino a 1 milione di token e utilizza meno token per il ragionamento rispetto alle versioni precedenti, con miglioramenti in velocità e costi di esecuzione.
Gemini 3.1 Flash-Lite
Google ha presentato Gemini 3.1 Flash-Lite, il modello più veloce ed economico della serie Gemini 3, progettato per gestire carichi di lavoro ad alto volume su larga scala.
L'ho provato: velocità impressionante e qualità dell'output elevata.
Gemini 3.1 Flash-Lite
È disponibile in preview tramite Gemini API in AI Studio e Vertex AI, e offre costi competitivi: $0,25 per milione di token in input e $1,50 per milione di token in output.
Rispetto a Gemini 2.5 Flash è 2,5 volte più rapido nella generazione del primo token e aumenta del 45% la velocità di output, mantenendo qualità pari o superiore nei benchmark.
Ha ottenuto un punteggio Elo di 1432 su Arena.ai, con risultati rilevanti anche su GPQA Diamond (86,9%) e MMMU Pro (76,8%), superando in alcuni casi modelli più grandi delle generazioni precedenti.
Tra i punti chiave: bassa latenza, efficienza nei costi e "thinking levels" regolabili, che permettono di bilanciare velocità e profondità di ragionamento.
È pensato per traduzioni su larga scala, moderazione dei contenuti, analisi di immagini, generazione di interfacce e dashboard, simulazioni e gestione di istruzioni complesse.
L'aggiornamento di AI Studio di Google
Google ha introdotto un importante aggiornamento di AI Studio con una nuova esperienza di "vibe coding", pensata per trasformare semplici prompt in applicazioni complete e pronte per la produzione.
L'ho provato, e sono impressionato.
In 15 minuti mi sono creato 2 tool per operazioni rapide che mi servono spesso, sostituendo una serie di applicazioni.
Si tratta di funzionalità molto semplici, ma costruite esattamente sui miei processi: è questa la potenza.
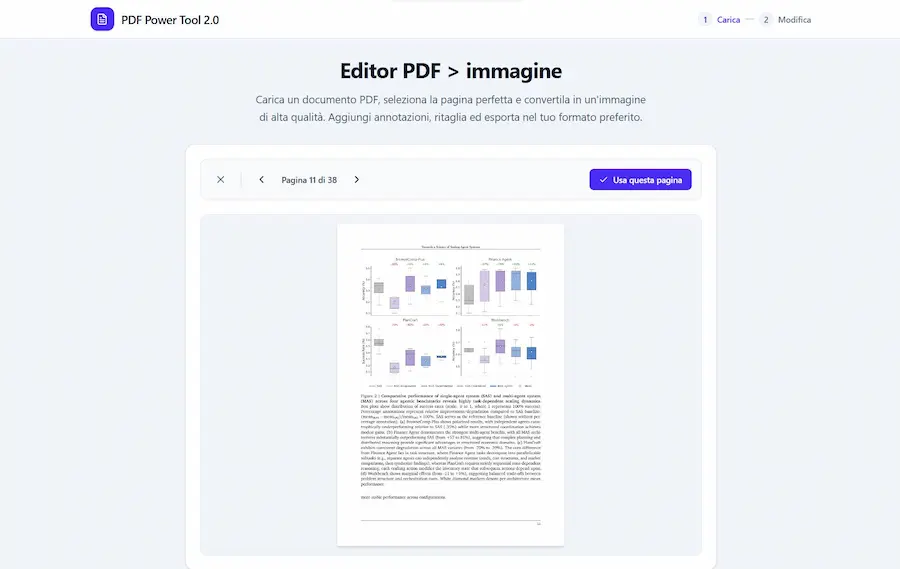
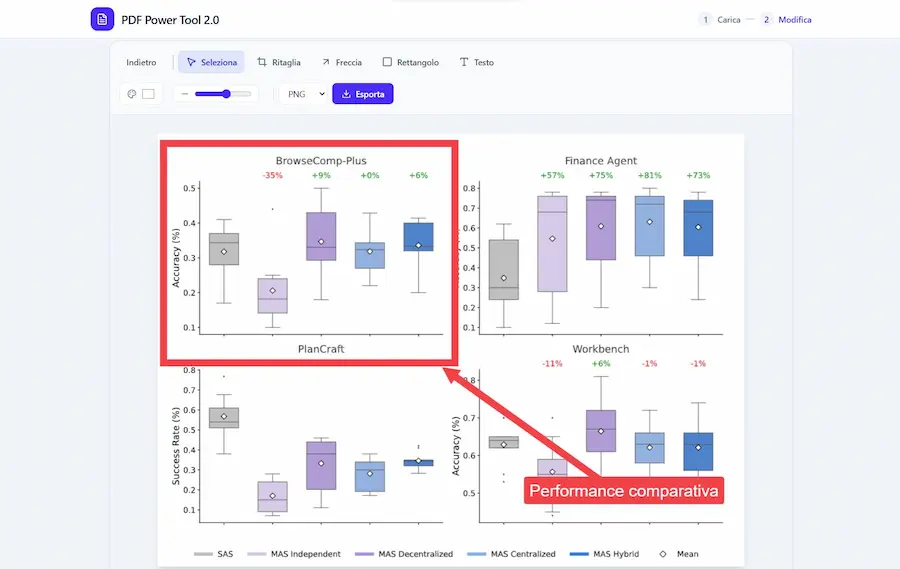
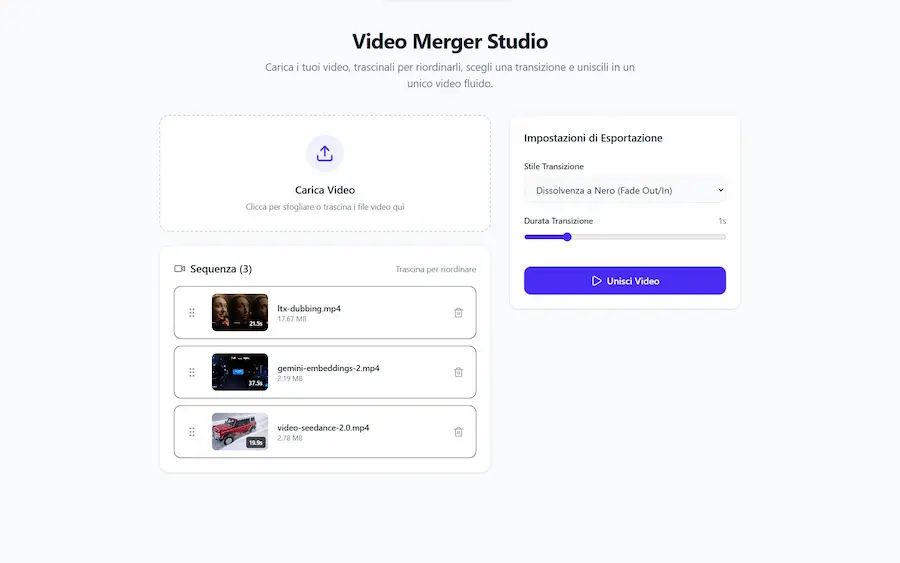
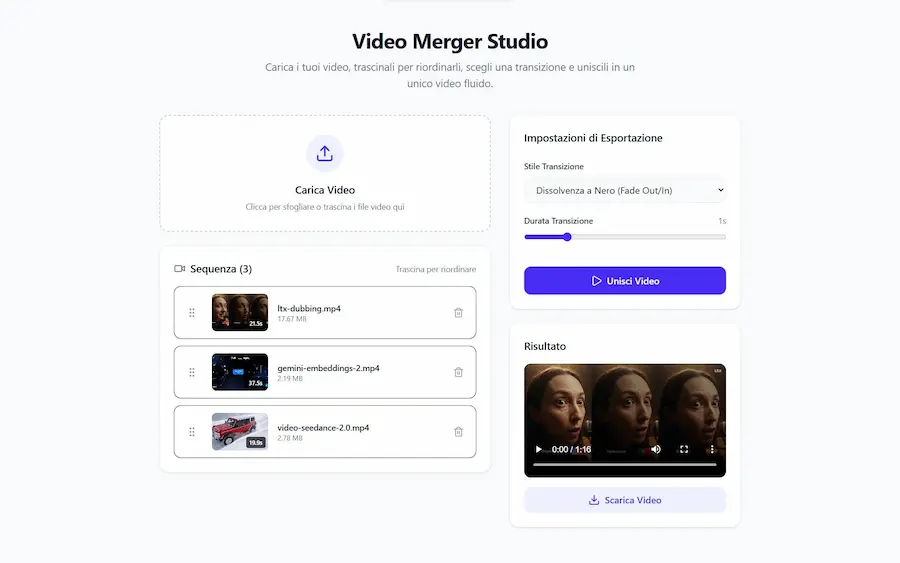
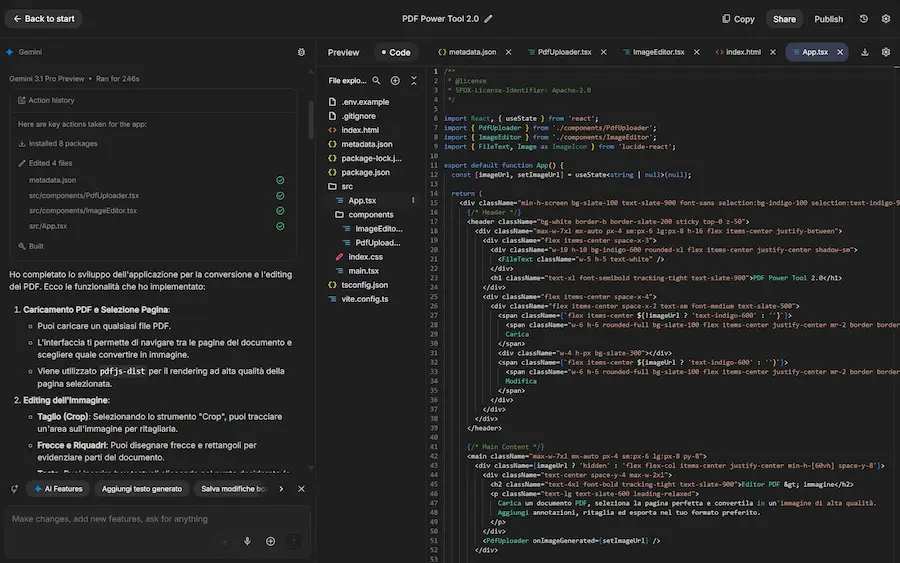
L'aggiornamento di AI Studio di Google: esempi
Le condivido per chi vuole usarle e magari modificarle.
- PDF Power Tool 2.0: permette di caricare un PDF, scegliere una pagina, editarla con crop ed elementi grafici, per poi esportare la selezione in immagine.
- Video Merger Studio: permette di caricare una serie di video, ordinarli a piacere, unirli gestendo la transizione, e scaricare il video complessivo.
Al centro c'è il nuovo agente di sviluppo Antigravity, progettato per comprendere il contesto dell'intero progetto, la cronologia delle modifiche e la struttura del codice, permettendo iterazioni più rapide e interventi più precisi anche su applicazioni complesse.
La piattaforma consente di costruire app reali senza uscire dall'ambiente di sviluppo: è possibile creare esperienze multiplayer in tempo reale, integrare database e sistemi di autenticazione tramite Firebase, e collegare servizi esterni come API, strumenti di pagamento o servizi Google. La gestione delle credenziali avviene in modo sicuro grazie a un sistema dedicato di storage delle API Key.
AI Studio supporta i principali framework moderni (React, Angular e Next.js) e utilizza automaticamente librerie e strumenti del web contemporaneo per migliorare interfacce e funzionalità, come sistemi di animazione o componenti UI avanzati.
Il sistema è in grado di riconoscere autonomamente quando un'app necessita di funzionalità aggiuntive, suggerendo e configurando integrazioni come database o login. Inoltre, i progetti vengono salvati e sincronizzati, permettendo di riprendere il lavoro in qualsiasi momento e da qualsiasi dispositivo.
Questo aggiornamento segna un ulteriore passo verso un modello di sviluppo in cui l'AI non si limita ad assistere, ma partecipa attivamente alla costruzione di prodotti completi, riducendo drasticamente la distanza tra idea, prototipo e applicazione funzionante.
Le novità dell'API di Gemini
Alcune novità interessanti per le API di Gemini che puntano a semplificare l'implementazione di workflow agentici.
Anche se OpenAI è più avanti su questo aspetto.
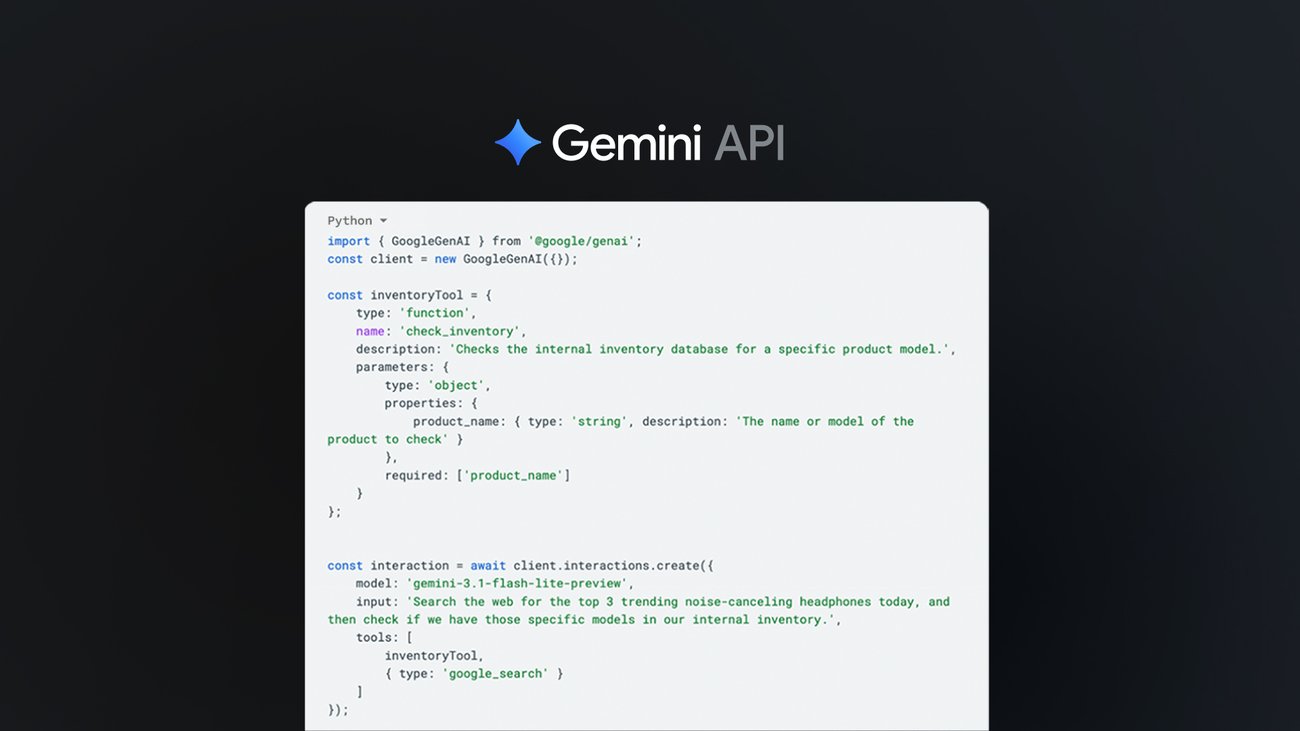
La novità più rilevante è la possibilità di combinare tool nativi (come Google Search e Google Maps) e funzioni custom all'interno della stessa richiesta.
Questo significa meno orchestrazione manuale e flussi molto più fluidi, in cui il modello può passare in autonomia da dati pubblici a logiche backend.
Altro punto chiave: la condivisione del contesto tra tool. Ogni chiamata e risposta viene mantenuta nel contesto, permettendo al modello di costruire ragionamenti multi-step più solidi e coerenti.
Arrivano anche gli ID univoci per le tool call, che migliorano il debugging e la gestione di esecuzioni parallele.
Infine, il grounding con Google Maps viene esteso alla famiglia Gemini 3, aprendo la porta a use case molto più ricchi basati su contesto geografico e dati aggiornati sui luoghi.
Perché dico che OpenAI è più avanti? Perché da Playground posso creare agenti che usano la web search, file search, server MCP remoti, funzioni custom.. Infine, posso esportare il codice per farlo funzionare ovunque via Agents SDK.
Questo non è ancora fattibile su AI Studio, e non riesco a spiegarmi il motivo.
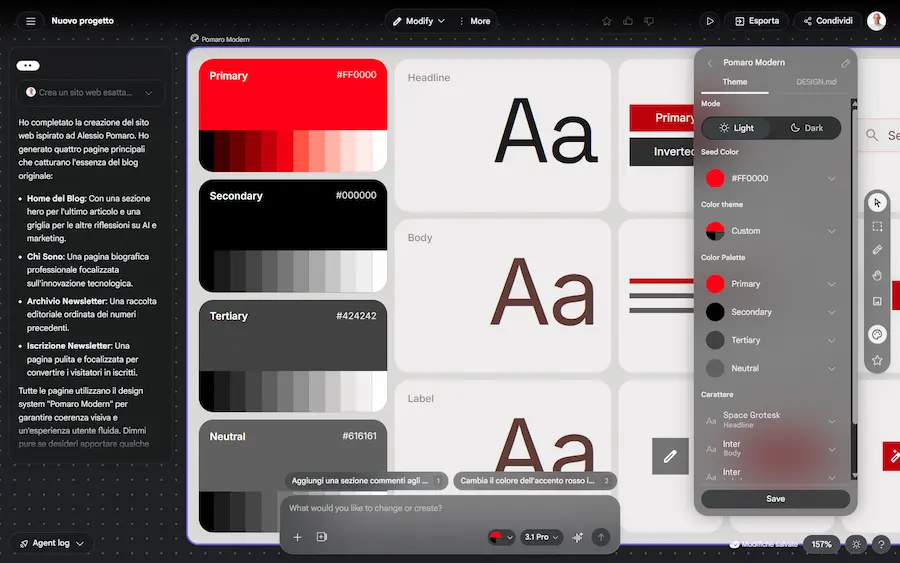
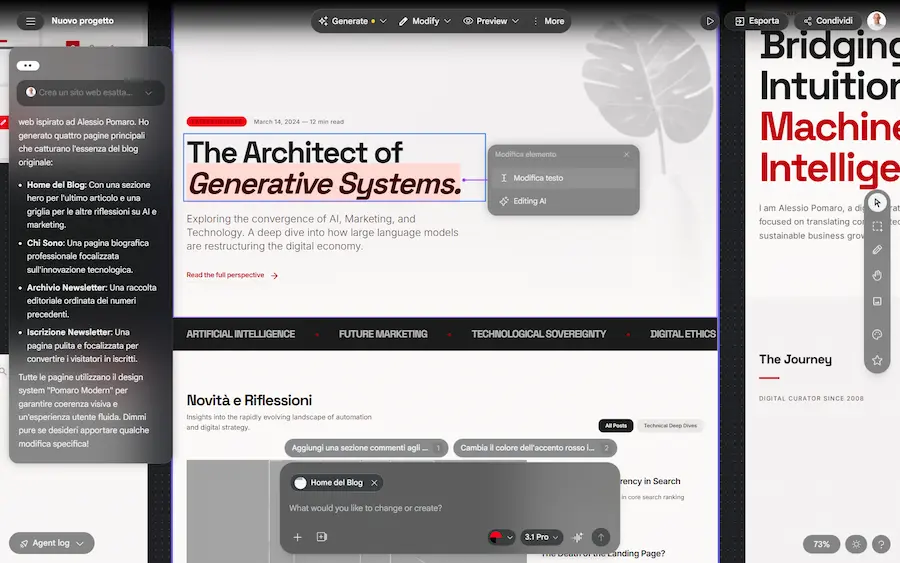
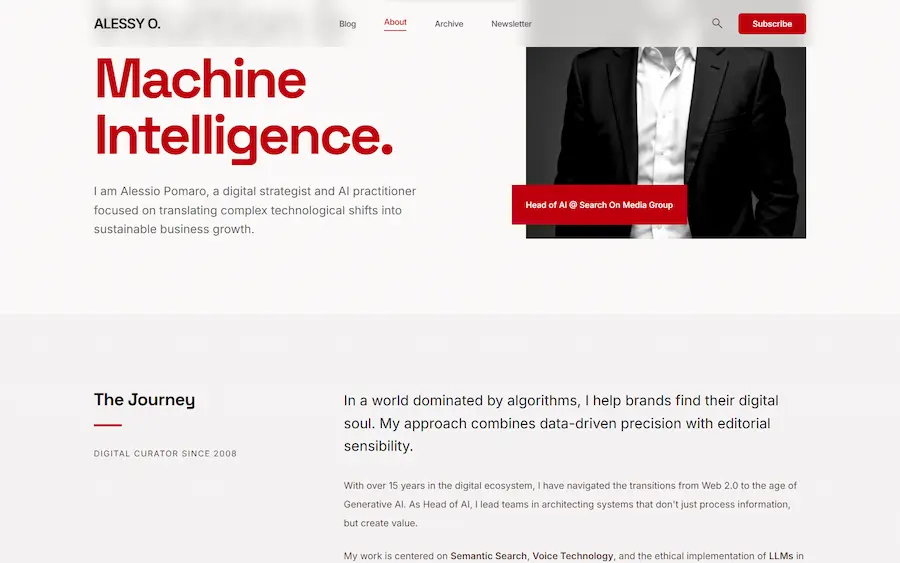
Stitch di Google: un test
Ho provato Stitch di Google: uno strumento dal potenziale enorme per la progettazione di interfacce visuali.
Nei test ho dato come input l'URL di alcune pagine del mio sito web, e l'ho fatto riprodurre dal sistema.
I template possono essere modificati via prompt o attraverso l'interfaccia. Il tutto con live preview, scaricabile in HTML o esportabile in Figma.
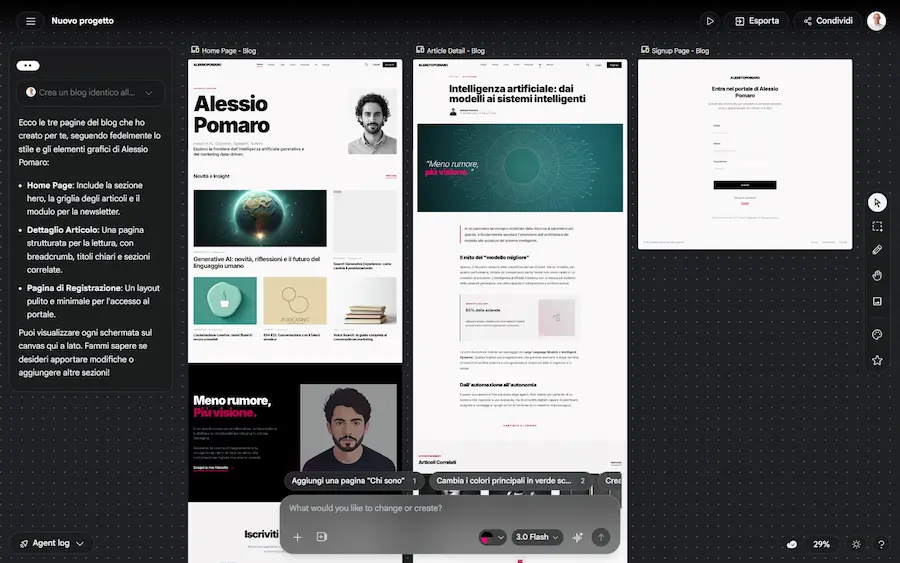
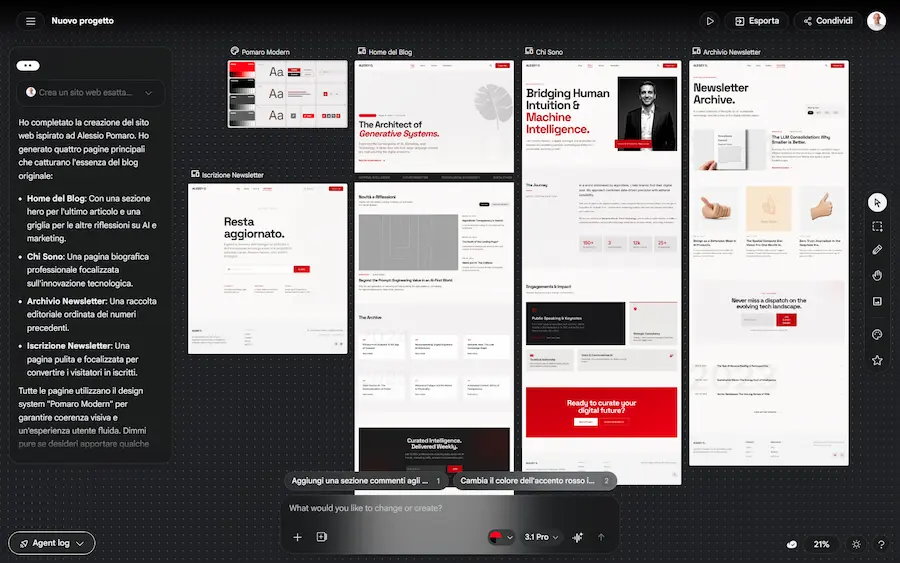
Stitch di Google: un test
Non si parte da wireframe statici, ma da descrizioni, obiettivi e "sensazioni" che si vogliono trasmettere.
L'AI genera rapidamente più varianti e permette di iterare in tempo reale, mantenendo il flusso creativo sempre attivo.
Il canvas è pensato come uno spazio infinito e multimodale: è possibile lavorare partendo da testo, immagini, codice o URL, costruendo interfacce web e mobile con un livello di dettaglio già molto vicino al prodotto finale. In questo senso, Stitch riduce drasticamente la distanza tra idea e prototipo.
Utile anche la possibilità di trasformare subito i layout in prototipi navigabili, con collegamenti automatici tra schermate e suggerimenti sui flussi utente.
In pratica, si passa dall'idea a qualcosa di testabile in pochi minuti, iterando anche interi user journey con un singolo intervento.
Interessante la gestione del design system: è possibile estrarre regole da altri progetti o da URL e riutilizzarle, mantenendo coerenza visiva senza ripartire da zero. Il formato DESIGN.md rende queste regole trasportabili anche verso altri strumenti.
Sul fronte più tecnico, Stitch introduce integrazioni tramite MCP (Model Context Protocol) e SDK: questo permette di collegare il design direttamente ad ambienti di sviluppo e tool esterni, creando un flusso continuo tra generazione dell'interfaccia e implementazione. In pratica, non è solo un tool di design, ma un ponte operativo tra designer, AI e sviluppo.
Nel complesso, dà l'impressione di essere uno strumento che sposta il focus dal "disegnare schermate" al "definire esperienze", lasciando all'AI il compito di esplorare rapidamente lo spazio delle soluzioni.
Le novità di NotebookLM
NotebookLM ha rilasciato la possibilità di gestire le infografiche attraverso stili personalizzati.
Se ne possono scegliere 10 diversi, con un prompt testuale a supporto.


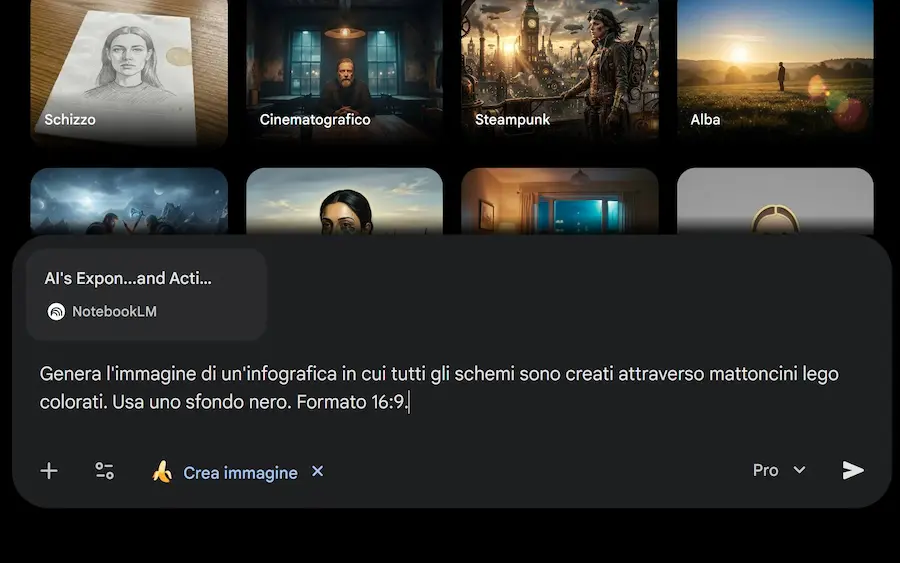

Le infografiche personalizzate di NotebookLM
Sinceramente preferisco l'uso di Gemini App con NotebookLM come fonte, perché permette di mantenere il contesto della conversazione e di ottimizzare l'output attraverso interazioni successive.
Al netto di questo, NotebookLM continua a confermarsi un "coltellino svizzero" sempre più interessante.
Il percorso verso i video personalizzati, inoltre, continua.
Per gli utenti Ultra sono già disponibili le Cinematic Video Overviews.
Cinematic Video Overviews - NotebookLM
A differenza dei modelli standard, sono alimentate da una nuova combinazione di modelli più avanzati per creare video personalizzati e immersivi a partire dalle fonti.
Gemini Embedding 2
Google ha annunciato Gemini Embedding 2, il primo modello di embedding nativamente multimodale basato sull’architettura Gemini.
L'ho provato attraverso uno script python che codifica in embeddings un contenuto testuale, un audio (mp3), un'immagine e un PDF con contenuti in diverse lingue. Misura la similarità con l'embedding di una query di ricerca e genera una dashboard che illustra i risultati.
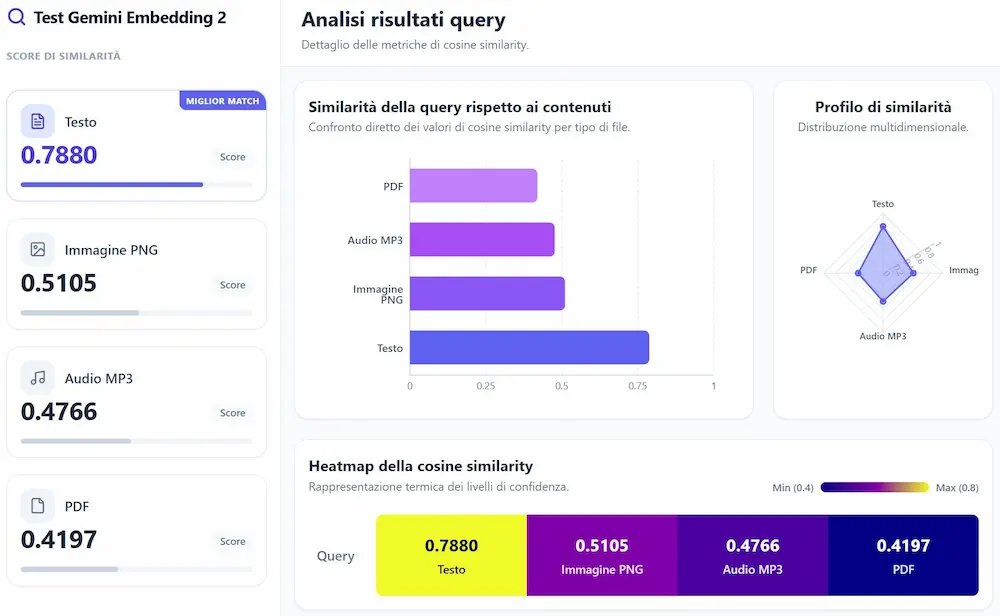
L'implementazione è diventata molto più semplice, e le correlazioni più ampie.
Il modello è progettato per trasformare testo, immagini, video, audio e documenti nello stesso spazio vettoriale, permettendo di confrontare e recuperare informazioni tra media diversi con maggiore precisione.
Tra le caratteristiche principali:
- supporto a oltre 100 lingue;
- testo fino a 8192 token;
- fino a 6 immagini per richiesta (png, jpeg);
- video fino a 120 secondi (mp4, mov);
- audio integrato senza necessità di trascrizione;
- PDF fino a 6 pagine.
Supporta anche input multimodali combinati, ad esempio immagine e testo nella stessa richiesta, permettendo di catturare relazioni semantiche più complesse tra diversi tipi di contenuto.
Gemini Embedding 2 utilizza Matryoshka Representation Learning, una tecnica che consente di ridurre dinamicamente la dimensionalità degli embedding (da 3072 fino a dimensioni inferiori) mantenendo un buon livello di qualità, permettendo di bilanciare performance e costi di storage.
È disponibile in public preview tramite Gemini API e VertexAI ed è integrabile con diversi strumenti dell’ecosistema AI come LangChain, LlamaIndex, Haystack, Weaviate, Qdrant e ChromaDB.
Questa evoluzione rende più semplice costruire sistemi basati su semantic search, RAG, classificazione e clustering che lavorano su dati multimodali.
Copilot Cowork di Microsoft
Microsoft fa valere la forza dell'ecosistema nell'integrazione dell'AI.
Con Copilot Cowork, la nuova evoluzione di Microsoft 365 Copilot, l'intelligenza artificiale non si limita più a rispondere o generare contenuti: passa all'azione. L'obiettivo è trasformare l'intento in lavoro reale, coordinando attività e flussi tra Outlook, Teams, Excel, documenti e dati aziendali.
Quando un utente delega un'attività, Cowork costruisce un piano operativo e lo esegue in background, mantenendo sempre l'utente nel controllo: suggerisce azioni, chiede conferme, gestisce passaggi intermedi e aggiorna lo stato delle attività.
Copilot Cowork di Microsoft
Tra gli scenari di utilizzo:
- riorganizzare automaticamente il calendario e proteggere il tempo di focus;
- preparare meeting con documenti, analisi e presentazioni pronte per il team;
- svolgere ricerche aziendali raccogliendo fonti finanziarie e report;
- costruire piani di lancio prodotto con analisi competitive e materiali di vendita.
Il punto chiave è l'integrazione con il contesto di lavoro: email, meeting, file e dati diventano segnali che permettono all'AI di comprendere davvero cosa sta succedendo nel flusso operativo quotidiano.
Un altro elemento interessante è l'approccio multi-model: Microsoft integra diverse tecnologie AI, tra cui quella alla base di Claude di Anthropic, per scegliere di volta in volta il modello più adatto al compito.
Il risultato è un'evoluzione dell'AI da assistente conversazionale a sistema capace di coordinare attività e processi all'interno dell'ambiente di lavoro digitale.
Gemini nel Workspace di Google
Google non lascia nemmeno il tempo a Microsoft di presentare Copilot Cowork, ed esce con l'integrazione profonda di Gemini in Workspace.
Gemini nel Workspace di Google: un esempio
- Nei Google Docs, la nuova funzione Help me create permette di descrivere ciò che si vuole realizzare e ottenere una bozza completa già strutturata, generata combinando informazioni da Drive, Gmail, Chat e dal web. È possibile poi migliorare singole sezioni, uniformare il tono del documento e adattare automaticamente la formattazione allo stile di altri file.
- In Google Sheets, Gemini può creare o modificare interi fogli di calcolo usando linguaggio naturale. Può costruire tabelle, grafici e modelli finanziari, compilare automaticamente dati e risolvere problemi di ottimizzazione complessi come pianificazione delle risorse o analisi di budget.
- In Google Slides, l'AI aiuta a costruire slide con layout e messaggi già strutturati, trasformando appunti, tabelle o idee in grafici e presentazioni visivamente coerenti. A breve sarà possibile generare un'intera presentazione partendo solo da una descrizione.
- Anche Google Drive cambia ruolo: da archivio di file diventa una vera base di conoscenza. Con le nuove AI Overviews e la funzione Ask Gemini è possibile cercare informazioni nei documenti, ricevere riassunti automatici e ottenere risposte basate sui contenuti presenti in file, email e chat.
L'obiettivo è rendere l'AI un collaboratore continuo durante tutto il processo di lavoro: dalla prima idea alla scrittura, dall'analisi dei dati fino alla presentazione finale.
Per quanto OpenAI e Anthropic tentino di creare add-on per entrare nei software esterni, non è possibile competere con un ecosistema come quello di Google, soprattutto in un momento in cui non esiste un vantaggio evidente tra i modelli di AI di pari classe.
Anthropic: Building Effective AI Agents
Un nuovo paper di Anthropic dal titolo "Building Effective AI Agents: Architecture Patterns and Implementation Frameworks" analizza come progettare agenti AI efficaci nelle organizzazioni.
La distinzione chiave è semplice: i modelli generativi rispondono alle domande, mentre gli AI agents risolvono problemi. Non si limitano a generare testo, ma pianificano azioni, utilizzano strumenti, analizzano risultati e iterano finché non raggiungono l'obiettivo.

Il paper mostra come diverse aziende stiano già ottenendo risultati concreti con architetture agentiche: automazione del customer support su larga scala, analisi dati conversazionale, sviluppo software accelerato, marketing automation e sistemi antifrode nel settore finanziario.
Uno degli aspetti più rilevanti riguarda l'architettura degli agenti. Il documento descrive diversi modelli progettuali.
- Single agent systems, dove un unico agente gestisce l'intero task con accesso a strumenti e conoscenze specializzate.
- Multi-agent systems, in cui più agenti specializzati collaborano per risolvere problemi complessi.
- Workflow sequenziali, che organizzano agenti in pipeline strutturate per processi prevedibili.
- Workflow paralleli, che permettono analisi simultanee da prospettive diverse.
- Evaluator-optimizer loops, cicli iterativi in cui un agente genera output e un altro lo valuta e lo migliora.
Il paper evidenzia anche alcune linee guida di progettazione: partire da sistemi semplici, costruire architetture modulari, scegliere il modello giusto per il task e garantire osservabilità per comprendere il comportamento degli agenti.
Un punto chiave riguarda il compromesso tra complessità e valore. I sistemi multi-agent possono offrire prestazioni molto superiori su problemi complessi, ma comportano costi operativi e architetturali più elevati. Per questo motivo il documento suggerisce un'evoluzione progressiva: iniziare con un singolo agente e aggiungere livelli di specializzazione solo quando necessario.
Nel complesso, il paper propone una visione pragmatica dello sviluppo di AI agents: non inseguire l'architettura più sofisticata, ma costruire sistemi modulari che possano evolvere nel tempo insieme ai modelli AI.
Context Hub
Gli agenti di coding basati su LLM hanno due problemi ricorrenti: spesso inventano API (o parametri) che non esistono oppure dimenticano ciò che hanno imparato tra una sessione e l'altra.
Il progetto open source Context Hub, pubblicato da Andrew Ng, prova a risolvere entrambi con una proposta davvero interessante.
L'idea è fornire agli agenti documentazione curata e versionata delle API, organizzata in modo leggibile per un LLM. Invece di cercare informazioni sul web o leggere pagine HTML piene di elementi inutili, l'agente può interrogare una CLI dedicata e recuperare direttamente documentazione strutturata.
Il flusso è semplice. L'agente cerca una libreria o un'API tramite la CLI, scarica la documentazione corretta per il linguaggio che sta utilizzando e poi usa quelle informazioni per scrivere il codice.
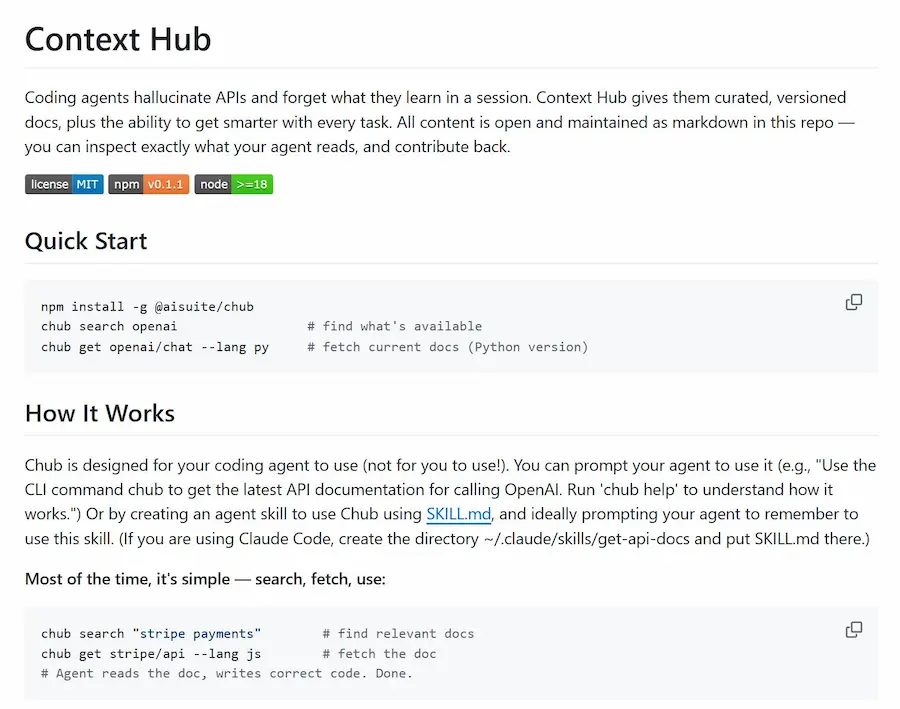
La documentazione non viene recuperata in tempo reale dai siti web ufficiali. È salvata nel repository sotto forma di file Markdown versionati, organizzati per API e linguaggio come Python o JavaScript. Questo riduce il rumore, rende i contenuti più stabili e facilita l'uso da parte degli agenti.
Un elemento interessante è la memoria incrementale. Gli agenti possono aggiungere annotazioni locali quando scoprono workaround o dettagli mancanti nella documentazione. Queste annotazioni vengono poi mostrate automaticamente nelle sessioni successive, permettendo all'agente di ricordare ciò che ha imparato in passato.
Esiste anche un sistema di feedback globale. Gli agenti possono votare la qualità della documentazione e questi segnali aiutano i maintainer a capire quali parti funzionano davvero quando vengono usate in produzione.
Il mantenimento dei contenuti segue un modello aperto. I maintainer gestiscono la struttura del progetto, la community può proporre modifiche tramite pull request e in futuro anche i provider delle API potrebbero mantenere direttamente la documentazione delle proprie librerie.
L'obiettivo è costruire una base di conoscenza condivisa pensata non per sviluppatori umani, ma per agenti AI che scrivono codice. Una forma di infrastruttura della documentazione progettata per ridurre gli errori degli LLM e migliorare l'affidabilità del coding assistito.
Nemotron 3 di NVIDIA
NVIDIA ha presentato Nemotron 3 Super, un modello open progettato per sistemi di AI agentica, in grado di gestire task complessi multi-step come sviluppo software e cybersecurity.
La caratteristica centrale è l'architettura ibrida che combina Mamba, Transformer e Mixture-of-Experts: i primi garantiscono efficienza su contesti lunghi (fino a 1 milione di token), i secondi precisione nel recupero delle informazioni, mentre il MoE attiva solo una parte del modello per ridurre i costi computazionali.
Nemotron 3 di NVIDIA: un test
Tra le innovazioni più rilevanti..
- Latent MoE, che comprime i token e consente di usare fino a 4× in più di esperti allo stesso costo.
- Multi-Token Prediction, che genera più token per volta migliorando velocità e coerenza del ragionamento.
- Addestramento nativo in NVFP4 (4-bit), con forte riduzione di memoria e aumento delle performance.
- Reinforcement learning su 21 ambienti, con oltre 1,2 milioni di simulazioni per addestrare comportamenti agentici reali.
Il modello conta 120 miliardi di parametri totali, ma ne attiva solo 12B per inferenza, ottenendo un equilibrio tra capacità ed efficienza. Offre inoltre oltre 5× throughput rispetto alla generazione precedente.
NVIDIA propone anche un approccio combinato: Nemotron 3 Nano per task semplici e Nemotron 3 Super per pianificazione e ragionamento complesso, ottimizzando così costi e prestazioni nei sistemi multi-agente.
L'intero ecosistema è open, inclusi pesi, dataset e pipeline di training, con l'obiettivo di rendere riproducibile e personalizzabile lo sviluppo di modelli orientati all'azione e non solo alla generazione di testo.
Manus "My Computer"
Un primo sguardo verso le integrazioni che vedremo nei sistemi operativi del prossimo futuro?
Manus introduce "My Computer", una funzionalità che porta l'AI fuori dal cloud e direttamente sul desktop. Non si limita più a rispondere, ma può eseguire azioni concrete sui file locali, controllare applicazioni e automatizzare attività tramite linea di comando.
Manus "My Computer"
Questo permette di gestire operazioni ripetitive in modo rapido, come organizzare grandi quantità di file o rinominare documenti in blocco, ma anche di spingersi oltre: sviluppo di applicazioni complete, debugging e gestione dell'intero flusso di lavoro senza intervento manuale diretto.
L'integrazione tra ambiente locale e servizi cloud consente scenari più fluidi, come recuperare file dal proprio computer e inviarli automaticamente tramite e-mail, oppure eseguire attività da remoto sfruttando le risorse della propria macchina.
Allo stesso tempo, il controllo resta all'utente: ogni comando richiede autorizzazione, con la possibilità di approvare singole operazioni o automatizzare solo quelle fidate.
Il risultato è un'evoluzione dell'AI da semplice assistente conversazionale a sistema operativo capace di agire, orchestrando strumenti, dati e infrastruttura in un unico flusso.
TRIBE v2 di Meta AI
Un nuovo paper di Meta AI (FAIR) propone un cambio di paradigma nella neuroscienza: passare da modelli frammentati a un unico modello fondazionale del cervello.
Il lavoro introduce TRIBE v2, un modello multimodale (video, audio e linguaggio) addestrato su oltre 1000 ore di dati fMRI provenienti da 720 soggetti.
L'obiettivo è predire direttamente l'attività cerebrale a partire dagli stimoli, utilizzando rappresentazioni apprese da modelli di intelligenza artificiale.
TRIBE v2 di Meta AI
Il risultato è un sistema capace di prevedere con alta accuratezza le risposte cerebrali in diversi contesti, superando i modelli lineari tradizionali e mantenendo prestazioni solide anche su nuovi soggetti e nuovi esperimenti.
Uno degli aspetti più rilevanti è la capacità di fare "esperimenti in silico": il modello riesce a replicare risultati classici della neuroscienza, come l'attivazione selettiva per volti, luoghi o linguaggio, senza raccogliere nuovi dati sperimentali.
Le rappresentazioni interne del modello risultano interpretabili e allineate a reti funzionali note del cervello, mentre l'integrazione multimodale mostra come visione, udito e linguaggio contribuiscano in modo complementare alla codifica neurale.
Questo approccio suggerisce che modelli di intelligenza artificiale possano diventare una piattaforma unificante per studiare il cervello umano, aprendo la strada a una neuroscienza più integrata, scalabile e predittiva.
La robotica diventa sempre più accessibile
La robotica sta evolvendo rapidamente, con sistemi accessibili, replicabili e diffusi oltre i contesti altamente specializzati.
Questa mano robotica può essere stampata in 3D da chiunque e assemblata in meno di 8 ore.
Orca: una mano robotica completamente open-source
I ricercatori di ETH Zurich hanno sviluppato Orca, una mano completamente open-source con ossa e tendini artificiali, progettata per essere semplice, replicabile e altamente performante.
Per capire l’impatto: le mani robotiche avanzate possono superare i 100k dollari e richiedono manutenzione continua. Orca costa meno di 2k: circa 50 volte meno.
Uno dei punti chiave è il sistema di auto-calibrazione: ogni motore viene mappato automaticamente sui giunti, eliminando la necessità di regolazioni manuali tipiche delle mani ai tendini.
Ogni dito integra sensori tattili coperti da una "pelle" in silicone. La mano è quindi in grado di percepire il contatto, adattando la presa per evitare di schiacciare o far scivolare gli oggetti.
Può sollevare oltre 10 kg, apprendere osservando dimostrazioni umane e trasferire competenze dalla simulazione al mondo reale senza riaddestramento.
Il team ha dimostrato la sua affidabilità facendole eseguire oltre 2.000 cicli di presa per più di 7 ore consecutive senza intervento umano.
Tutti i file di progettazione e il codice sono open source. Questo significa che qualsiasi laboratorio (o maker) nel mondo può iniziare a costruirla oggi.
Helix 02 di Figure
Molto spesso, confrontandomi con diverse persone sul tema della Physical AI, sento opinioni della serie "le attuali dimostrazioni sono tutte pilotate, lo stato dell'arte non è quello che sembra". Nel frattempo le dimostrazioni aumentano, e aumenta la complessità dei task.
La Physical AI sarà ciò che permetterà a chiunque (anche a chi non sa nemmeno cosa sia ChatGPT) di toccare con mano l'accelerazione che stiamo vivendo.
L'ultimo esempio arriva da Figure con Helix 02, un sistema neurale unico che controlla un robot umanoide end-to-end direttamente dalla percezione visiva, coordinando locomozione, manipolazione e pianificazione.
La nuova dimostrazione riguarda il riordino di un soggiorno: uno scenario apparentemente semplice per un umano, ma estremamente complesso per un robot.
Un soggiorno è un ambiente non strutturato: oggetti sparsi in modo imprevedibile, percorsi stretti tra i mobili, oggetti rigidi e morbidi, azioni che richiedono due mani, altre che richiedono di liberarne una durante l'esecuzione. E quasi ogni azione richiede di muoversi nello spazio mentre si manipola qualcosa.
Un esempio di Helix 02 mentre riordina il soggiorno
Nella dimostrazione Helix 02 esegue una sequenza continua di comportamenti coordinati:
- usa uno spray e poi un panno per pulire una superficie;
- manipola oggetti flessibili come asciugamani;
- raccoglie oggetti con manipolazione bimanuale e li ripone in un contenitore;
- blocca un contenitore sotto il braccio per liberare entrambe le mani;
- lancia un cuscino sul divano con un movimento rapido e controllato;
- riorienta un telecomando in mano per premere il pulsante corretto;
- ripone temporaneamente strumenti mentre passa da un task all'altro;
- si muove in spazi stretti tra tavolino e divano continuando a manipolare oggetti.
L'aspetto interessante è che queste capacità non derivano da controller specifici per ogni singola azione. Il sistema utilizza la stessa architettura generale e apprende nuovi comportamenti semplicemente aggiungendo dati.
Questo tipo di approccio punta a un obiettivo molto chiaro: robot umanoidi generalisti, capaci di ampliare progressivamente il proprio repertorio di attività domestiche e lavorative attraverso l'apprendimento.
Dimostrazioni come questa non significano che il problema sia risolto. Ma indicano che la traiettoria tecnologica sta andando verso sistemi sempre più integrati, in cui percezione, movimento e manipolazione vengono appresi come parte dello stesso modello.
Come fanno a "vedere" le auto a guida autonoma e i moderni robot?
Oltre alle telecamere usano diversi sensori (es. radar e ultrasuoni), tra cui la tecnologia LiDAR.
I sensori LiDAR delle auto autonome Waymo, ad esempio, sono ben visibili.
Si tratta di un sistema che emette impulsi laser e misura il tempo che impiegano a tornare indietro dopo aver colpito gli oggetti: in questo modo calcola le distanze e costruisce in tempo reale una mappa 3D estremamente precisa dell'ambiente.
Ormai questi sistemi stanno entrando in dispositivi anche molto più semplici. Le immagini mostrano un esempio di mappa 3D generata dal LiDAR del mio robottino tagliaerba.



Un esempio di mappa 3D generata da un LiDAR
Attraverso mappe di questo tipo, telecamere e sensori, l'AI riesce a riconoscere ostacoli, identificare oggetti e prendere decisioni in tempo reale, permettendo a robot evoluti e veicoli di muoversi in modo autonomo e sicuro.
3D Scenes di Freepik
Freepik ha rilasciato "3D Scenes", un tool AI sperimentale che punta a trasformare un'immagine in un ambiente 3D completo e navigabile.
3D Scenes di Freepik
Quali sono le principali funzionalità?
- Generazione di ambienti completi e navigabili a partire da un'immagine, con possibilità di inserire oggetti e muovere la camera come in uno shooting reale.
- Esplorazione libera della scena: rotazione, zoom e cambio di prospettiva mantenendo coerenza visiva.
- Integrazione di location reali da Google Maps, per posizionare i prodotti in contesti autentici senza stock o compositing.
- Modalità "Shoot" con controlli da set fotografico (direzione e intensità della luce, angolo e distanza della camera, profondità di campo).
VisionClaw
Forse la demo può sembrare solo un esperimento, ma mostra l'avanzamento verso interazioni uomo-macchina sempre più continue, multimodali e agentiche.
VisionClaw: un progetto open-source
La domanda è: fino ad oggi è stata solo la tecnologia il limite a questo tipo di esperienza? La risposta è sempre più vicina.
VisionClaw è un progetto open-source che trasforma un paio di Meta Ray-Ban (o semplicemente uno smartphone) in un assistente che vede, ascolta e agisce in tempo reale.
La camera invia continuamente ciò che si sta vedendo, mentre l'audio viaggia in entrambe le direzioni senza usare trascrizioni.
Il sistema si basa su Gemini Live API per l'interazione, e su OpenClaw per l'azione. Si tratta di un gateway locale che collega l'AI a oltre 50 tool e app.
È un esempio concreto di assistente "always-on", che unisce visione, voce e capacità operative in un unico flusso continuo.
Codex introduce i subagents
I subagents in Codex introducono un modo più strutturato di lavorare con l'AI: invece di un singolo agente generalista, il sistema può avviare più agenti specializzati in parallelo, ciascuno con un compito preciso.
Nell'esempio, ho creato 3 agenti con compiti e ruoli specifici. Successivamente li eseguo da Codex con un prompt (nel mio caso per l'analisi delle repository). Gli agenti lavorano parallelamente, e l'orchestratore mette insieme le informazioni e genera un report finale.
Subagents in Codex: un test
Ogni subagent, infatti, opera con istruzioni, modello e permessi propri, mentre Codex si occupa dell'orchestrazione: distribuisce il lavoro, raccoglie i risultati e restituisce una risposta unificata.
Questo approccio è particolarmente efficace per task complessi come code review, debugging o analisi su larga scala.
È possibile definire agenti personalizzati tramite file di configurazione (toml), assegnando loro ruoli chiari (es. esplorazione del codice, verifica della sicurezza, consultazione della documentazione).
Il risultato è una struttura modulare che riduce il rumore nel contesto e migliora la qualità delle azioni.
L'approccio multi-agente aumenta il consumo di risorse, ma permette di costruire veri e propri workflow paralleli, avvicinando l'AI a un modello operativo simile a un team di lavoro distribuito.
Vibe Coding XR
Con Vibe Coding XR, Google combina Gemini e il framework open-source XR Blocks per trasformare prompt in linguaggio naturale in applicazioni XR interattive, complete di fisica, interazioni e logica spaziale. Il tutto in meno di un minuto.
Il processo elimina gran parte della complessità tipica dello sviluppo XR: non è più necessario gestire manualmente motori grafici, pipeline di percezione o integrazioni hardware.
Vibe Coding XR - Google
L'AI si occupa di progettare la scena, generare il codice e rendere l'esperienza immediatamente testabile, sia su desktop (in simulazione) sia su visori Android XR.
Le applicazioni generate spaziano da ambienti educativi immersivi a simulazioni scientifiche, fino a giochi e interazioni fisiche in tempo reale.
Questo approccio accelera drasticamente la fase di prototipazione, permettendo di validare idee in pochi minuti invece che in giorni.
L'aspetto più rilevante è il cambio di paradigma: lo sviluppo di esperienze XR si sposta dalla scrittura del codice alla definizione dell'intento.
La barriera tecnica si abbassa, mentre aumenta il peso della progettazione e della creatività.
Resta aperta la sfida dell'affidabilità su casi complessi, ma la direzione è chiara: rendere lo spatial computing accessibile a chiunque sia in grado di immaginare un'esperienza.
Dai video naturali all’intuizione fisica
I modelli di AI oggi eccellono in linguaggio, codice e matematica, ma spesso falliscono in qualcosa che per gli esseri umani è banale: capire come funziona il mondo fisico.
Questo paper di Meta AI (FAIR), firmato tra gli altri da Yann LeCun, affronta direttamente questo problema e mostra un risultato sorprendente.
Gli autori studiano i cosiddetti world models, cioè modelli che cercano di costruire una rappresentazione interna del mondo imparando a prevederne l'evoluzione. In particolare utilizzano V-JEPA (Video Joint Embedding Predictive Architecture), una variante delle Joint Embedding Predictive Architectures (JEPA).

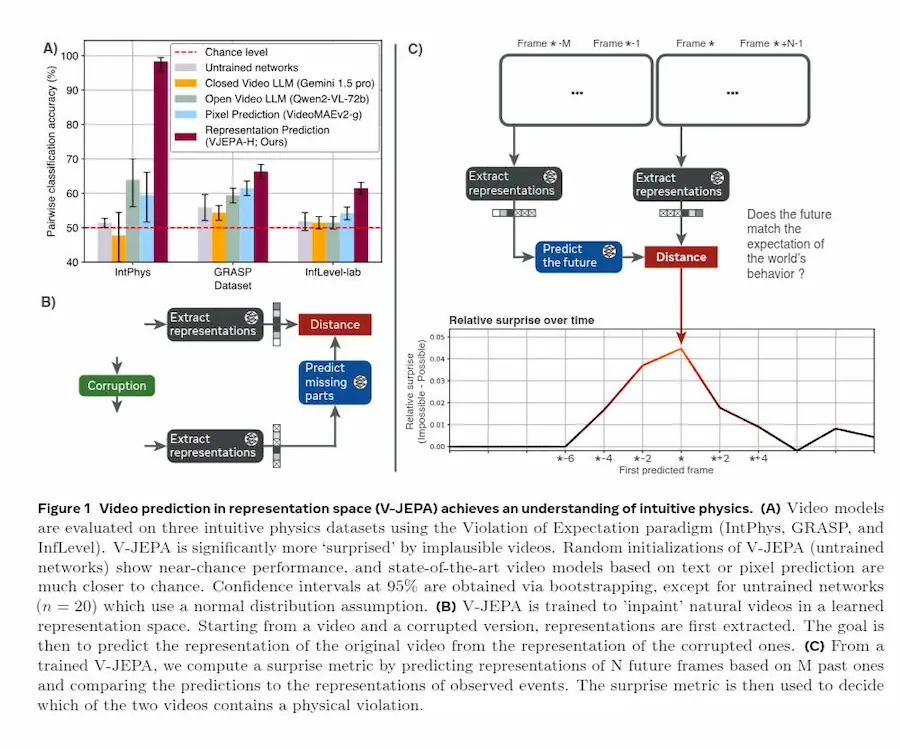
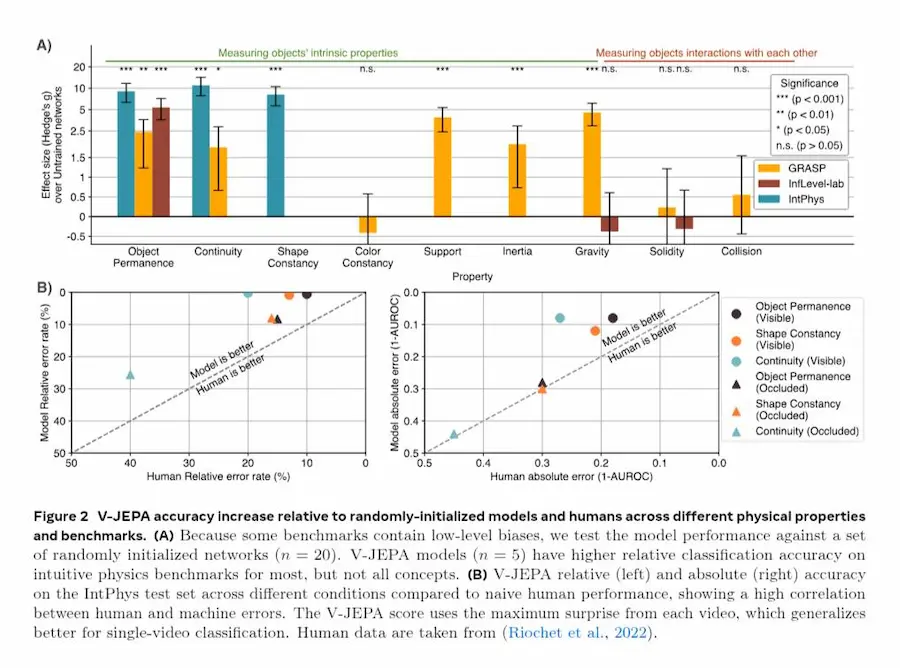
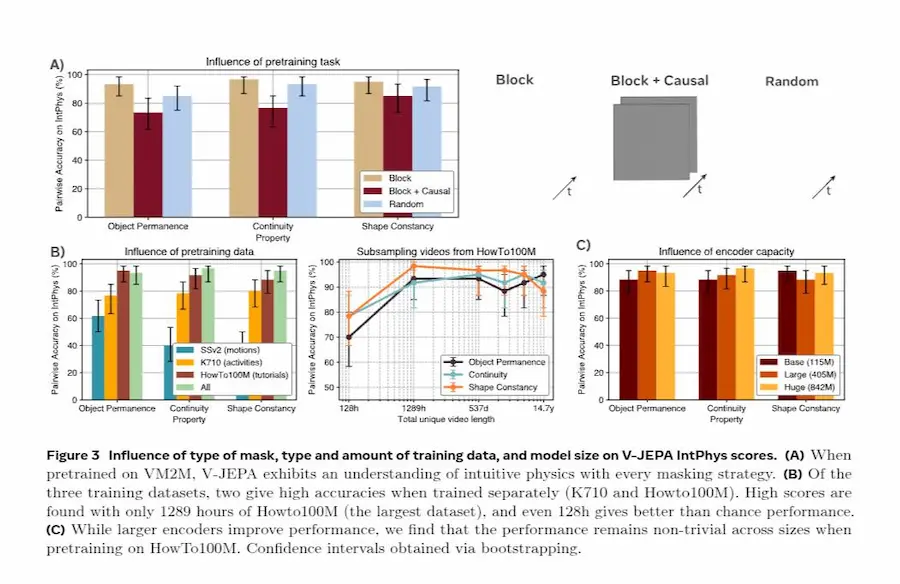
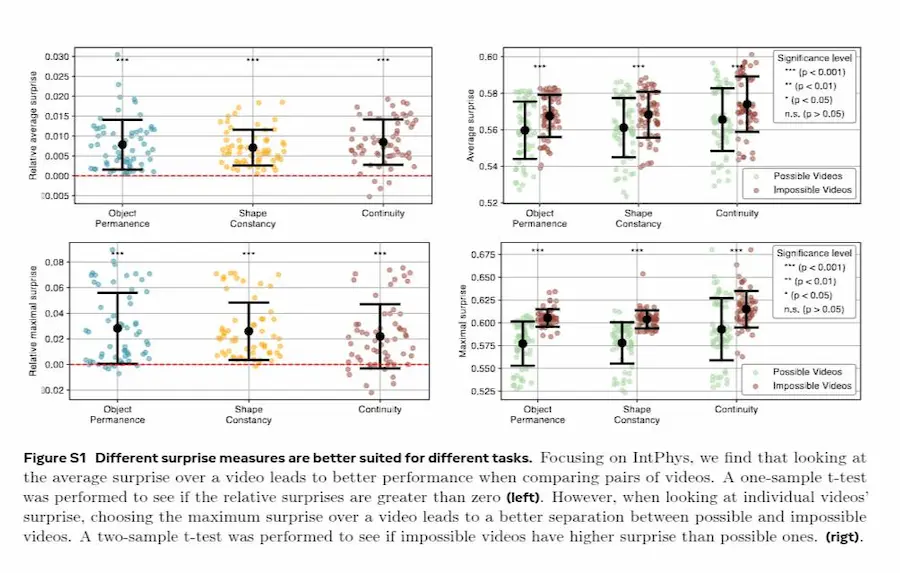
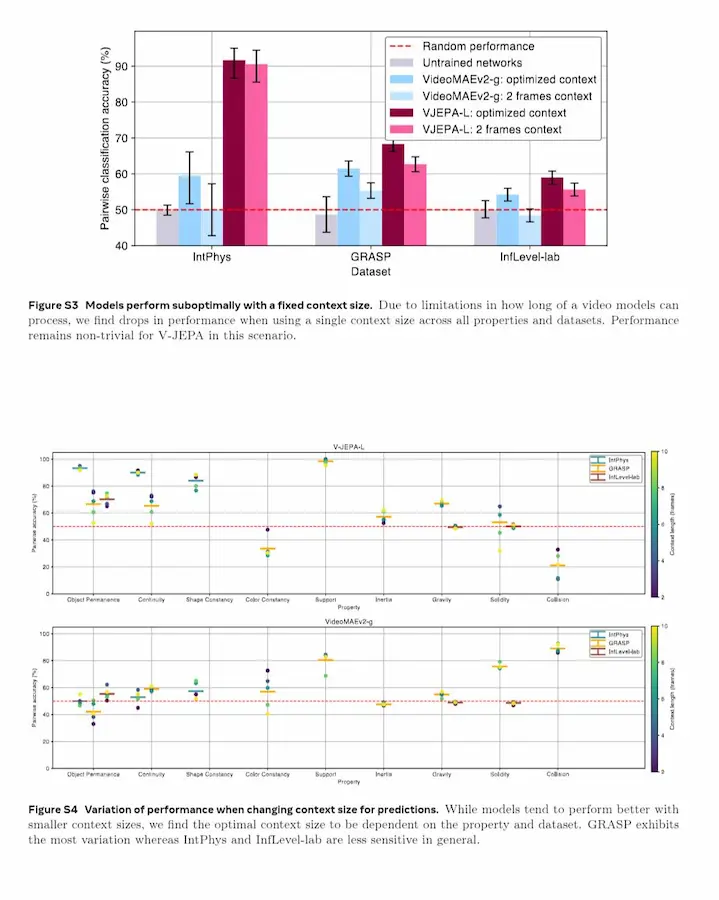
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
A differenza dei modelli tradizionali, i modelli pixel-based cercano di prevedere direttamente i pixel futuri, mentre i multimodal LLM ragionano principalmente attraverso il linguaggio.
V-JEPA invece impara a prevedere il futuro in uno spazio di rappresentazione astratto, cioè latente.
In pratica il modello guarda video e impara a "immaginare" cosa succederà dopo. Quando qualcosa viola le leggi fisiche, come un oggetto che scompare o attraversa un muro, la sua previsione fallisce e genera un segnale di "sorpresa".
Per valutare questa capacità, il paper usa il paradigma della violation of expectation: al modello vengono mostrati due video quasi identici, uno realistico e uno impossibile, e deve identificare quello incoerente con la fisica.
I risultati sono notevoli. V-JEPA raggiunge fino al 98% di accuratezza su benchmark come IntPhys e ottiene performance significativamente superiori al caso anche su altri dataset come GRASP e InfLevel. Al contrario, modelli avanzati come VideoMAE (pixel prediction) e grandi multimodal LLM come Gemini o Qwen-VL restano vicini al livello casuale.
Ancora più interessante, questo comportamento emerge senza training supervisionato sulla fisica, funziona anche con modelli relativamente piccoli e richiede quantità limitate di dati, anche solo circa una settimana di video unici.
Questo è qualcosa di straordinario perché suggerisce che una forma di intuizione fisica può emergere spontaneamente da un principio molto generale: imparare a prevedere il mondo. Non è necessario codificare esplicitamente regole fisiche né introdurre strutture innate.
Il lavoro mette quindi in discussione l'idea della core knowledge innata e rafforza una visione alternativa: l'intelligenza può emergere da meccanismi di apprendimento predittivo su dati sensoriali.
Allo stesso tempo evidenzia un limite importante degli attuali sistemi basati su linguaggio:
senza un forte legame con la percezione e la previsione del mondo fisico, anche modelli molto potenti restano deboli nel senso comune fisico.
LeWorldModel
I world model si candidano a diventare rapidamente uno dei pilastri della nuova AI, e questo lavoro su LeWorldModel chiarisce bene in che direzione si sta andando.
L'idea di fondo viene dalla linea di ricerca di Yann LeCun: JEPA (Joint Embedding Predictive Architectures).
Invece di generare pixel o ricostruire immagini, questi modelli imparano a rappresentare il mondo in uno spazio latente compatto, e a prevedere come evolve nel tempo. Non interessa riprodurre tutto nei dettagli, ma catturare ciò che è utile per agire.

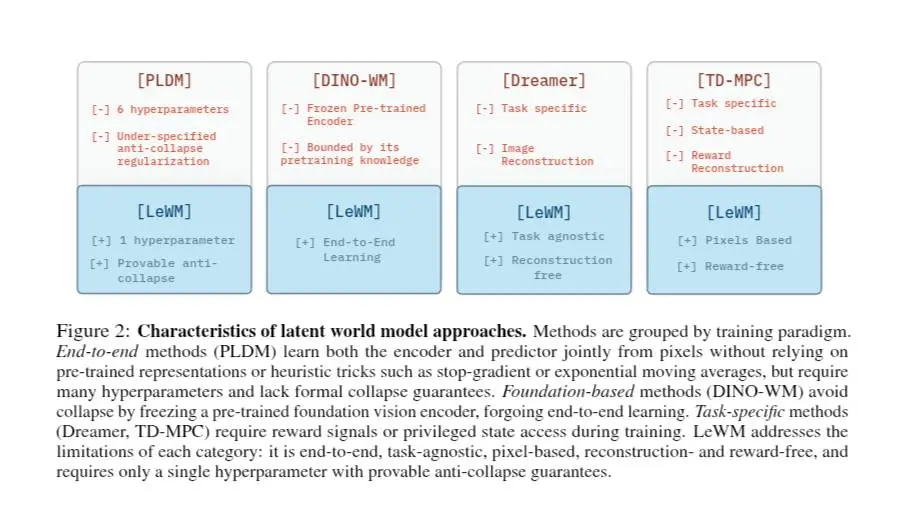
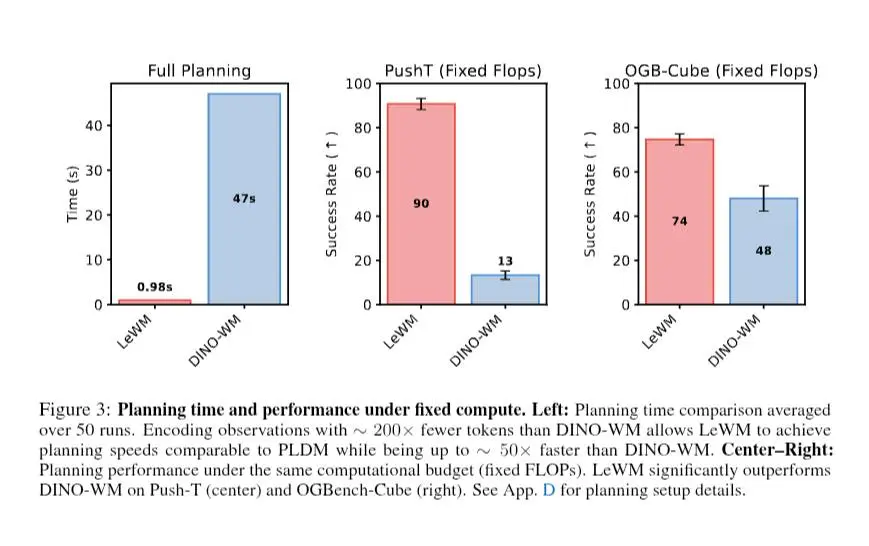
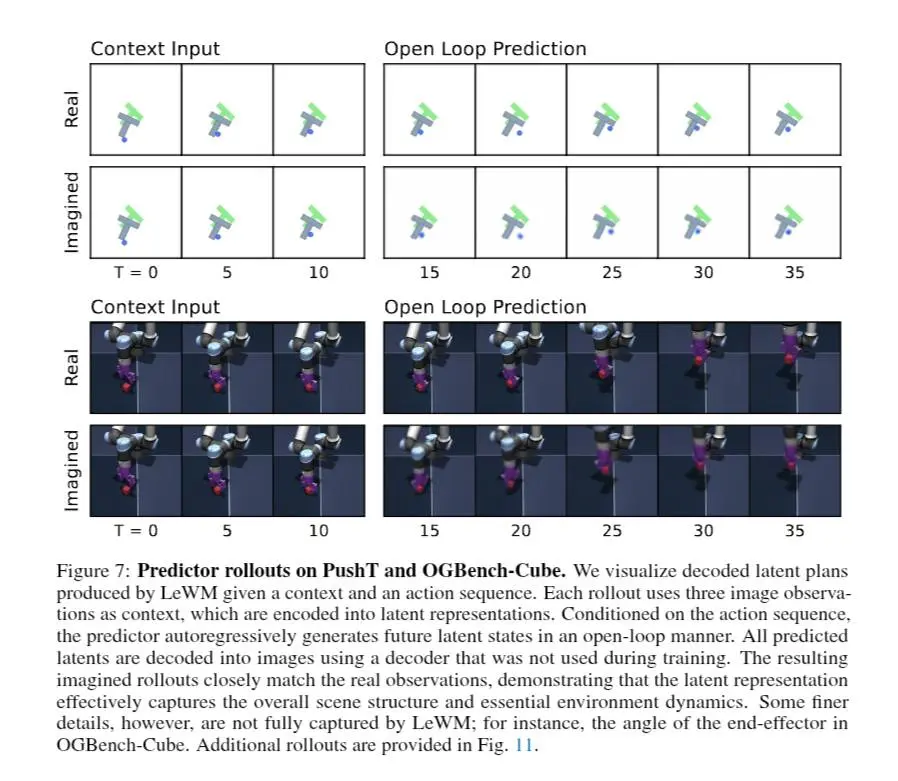
LeWorldModel: il paper
LeWorldModel porta questa visione a una forma molto più semplice e stabile. Il contributo principale non è una nuova architettura complessa, ma una drastica semplificazione dell'addestramento:
- niente encoder pre-addestrati;
- niente combinazioni complicate di loss;
- niente trucchi come stop-gradient o EMA;
- solo due obiettivi: prevedere il futuro e mantenere le rappresentazioni ben distribuite.
Il punto chiave è proprio qui: evitare il "collapse" (quando il modello rappresenta tutto allo stesso modo) senza introdurre complessità. La soluzione è forzare lo spazio latente a seguire una distribuzione gaussiana. È una scelta semplice, ma con conseguenze profonde: mantiene diversità nelle rappresentazioni e rende l'addestramento stabile end-to-end da pixel.
Questo segna un cambio di paradigma rispetto a molti approcci recenti:
- meno focus sulla ricostruzione visiva;
- meno dipendenza da foundation models congelati;
- più enfasi su predizione, struttura e dinamica.
Il risultato è un sistema che:
- impara direttamente da sequenze di immagini e azioni;
- costruisce una rappresentazione interna coerente della fisica;
- può pianificare azioni "immaginando" il futuro in spazio latente, molto più velocemente.
La direzione è chiara: modelli che non generano solo contenuti, ma costruiscono modelli interni del mondo, su cui poi ragionano e pianificano.
Le architetture JEPA sono tra i candidati più concreti per arrivarci, e questo lavoro mostra che possono essere anche semplici e scalabili, non solo teoricamente eleganti.
Recoding-Decoding (RD)
La maggior parte di LLM eccelle nel dare risposte corrette, ma fatica quando serve esplorare: idee nuove, alternative lontane, possibilità che non sappiamo ancora di cercare.
Il paper "Inducing Sustained Creativity and Diversity in Large Language Models", sviluppato da ricercatori di Harvard, introduce un concetto chiave: molte ricerche reali non sono domande con una risposta, ma percorsi di scoperta ("search quest"), in cui l'obiettivo emerge mentre esploriamo.
Il problema è che i modelli tendono a convergere verso soluzioni convenzionali. Non perché non conoscano alternative, ma perché il modo in cui generano testo privilegia ciò che è più probabile. Il risultato è una creatività apparente, ma uno spazio di idee in realtà molto ristretto.

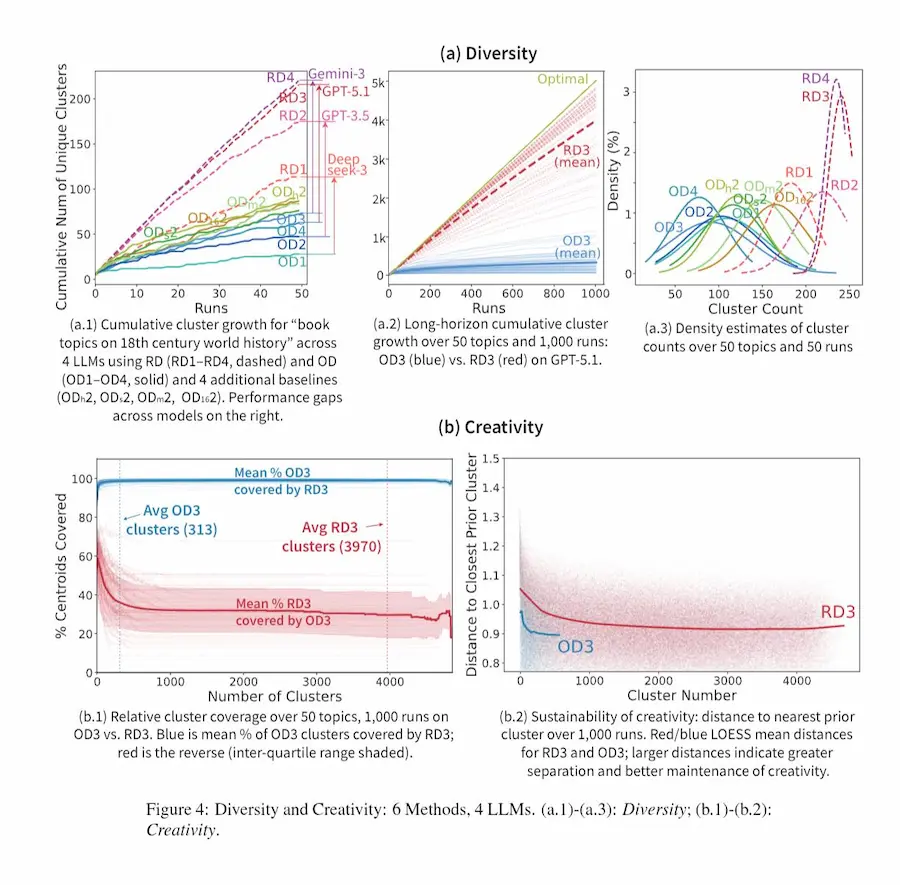

Recoding-Decoding (RD) - Harvard
La proposta del paper è il Recoding-Decoding (RD): invece di cambiare il modello, cambia il processo di generazione. Inserendo piccole deviazioni casuali nel contesto (parole guida, frammenti iniziali), il modello viene spinto fuori dai percorsi più battuti e portato a esplorare regioni meno frequenti ma ancora rilevanti del suo spazio di conoscenza.
I risultati mostrano che, rispetto ai metodi standard, RD produce molte più idee uniche, più distanti tra loro e continua a generare novità anche dopo molte iterazioni, senza collassare nella ripetizione. La rilevanza resta alta, ma lo spazio esplorato si amplia drasticamente.
Il punto più interessante è che non serve un modello migliore per ottenere più creatività.
Serve un modo diverso di interrogarlo.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂