Generative AI: novità e riflessioni - #4 / 2025
Da GPT-4.1, o3 e Codex CLI di OpenAI, a Veo 2, Ironwood e il protocollo A2A Di Google. Paper di DeepMind sull’AI esperienziale, guida di Stanford sull'Agentic AI, 3 guide pratiche di OpenAI e i 30 paper scelti da Sutskever. Test su Codex CLI, Gemini e NotebookLM.

Buon aggiornamento, e buone riflessioni..
TEDx Bergamo: POTERE
Il 25 maggio avrò l'onore di essere sul palco di TEDx Bergamo 2025, e il tema centrale sarà "POTERE".

"POTERE" è la capacità di generare cambiamento. Attraverso l’AI, possiamo affrontare sfide globali e aprire strade inedite. Ma c’è un potere ancora più intimo e umano: quello di comprendere la trasformazione per decidere come viverla e in quale direzione guidarla.
- Alessio Pomaro
Welcome to the Era of Experience
Un paper (da leggere) in cui i ricercatori di Google DeepMind invitano a ripensare l'AI:
non come una copia dell’intelligenza umana, ma come un sistema autonomo che impara, pianifica e agisce nel mondo reale.
L'era dell'esperienza permetterà di superare i limiti dell’imitazione e raggiungere capacità realmente superumane?
Secondo Silver e Sutton, la dipendenza dai dati umani (supervisionati o preferenziali) sta mostrando i suoi limiti. L’AI ha bisogno di nuovi stimoli, non più statici, ma dinamici, generati attraverso l’interazione continua con ambienti reali o simulati.
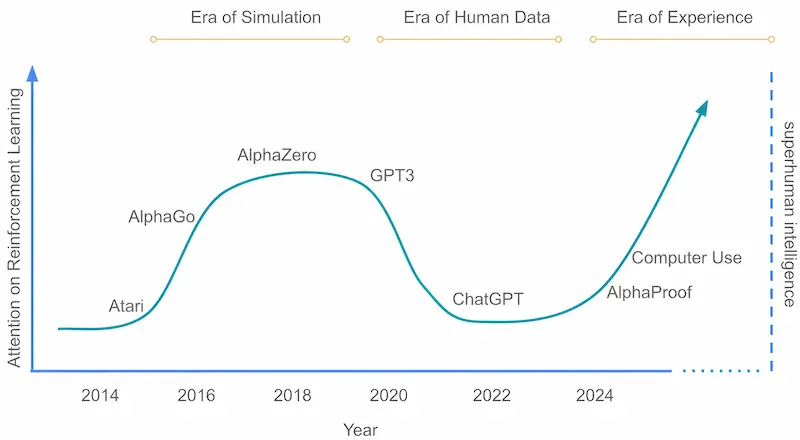
Gli agenti del futuro non vivranno più in episodi brevi e scollegati, ma in "stream" di esperienza continua, adattandosi nel tempo e perseguendo obiettivi di lungo termine. Le ricompense non arriveranno da valutazioni umane, ma da segnali concreti e misurabili dell’ambiente: salute, apprendimento, scoperta scientifica.
Non si tratta solo di efficienza, ma di visione. Uscire dal recinto del pensiero umano, imparare dal mondo, e scoprire strategie o conoscenze che ancora non esistono.
Un salto evolutivo, non solo tecnologico.
La spiegabilità dei modelli di AI
Com'è noto, Anthropic sta facendo un grande lavoro sulla spiegabilità dei modelli di AI, condividendo paper e promuovendo delle riflessioni fondamentali.
Il post pubblicato da Dario Amodei richiama con urgenza l'importanza di capire il funzionamento interno dei modelli prima che diventino troppo potenti. Un invito ad agire per chiunque lavori sull'AI o abbia a cuore il futuro della tecnologia, toccando anche argomenti delicati che riguardano la geopolitica ("I believe that democratic countries must remain ahead of autocracies in AI").
Anche se sembra una mossa ovvia da parte di chi possiede più esperienza di tutti in quest'ambito (e non possiede il modello più potente), ritengo sia un documento molto interessante per avere consapevolezza sull'argomento.

Ho provato a sintetizzare i punti principali.
- Amodei racconta come, in dieci anni di lavoro sull'AI, il settore sia passato da un ambito accademico a una delle questioni più decisive per il futuro dell'umanità. Anche se l’avanzamento è inarrestabile, possiamo influenzarne la direzione. Oggi, la vera sfida è l'interpretabilità: capire come funzionano internamente i sistemi prima che diventino troppo ampi per essere controllati.
- L'AI generativa prende decisioni che non sappiamo spiegare: a differenza del software tradizionale, i suoi meccanismi interni emergono spontaneamente, rendendo difficile prevedere o correggere i comportamenti indesiderati.
- Questa opacità alimenta rischi concreti, come comportamenti ingannevoli o usi pericolosi. Inoltre, senza spiegazioni comprensibili, l'AI non può essere applicata in settori critici come finanza o medicina. Se riuscissimo a "guardare dentro" ai modelli, potremmo prevenire errori e abusi.
- Negli ultimi anni è nata l'interpretabilità meccanicistica, grazie a pionieri come Chris Olah. Dai primi studi sui modelli visivi si è passati a quelli linguistici, scoprendo milioni di concetti nascosti, anche se sovrapposti e complessi. Tecniche come gli autoencoder sparsi stanno aiutando a mappare e manipolare questi concetti, rendendo visibili anche i "ragionamenti" attraverso circuiti interni.
- Nonostante i progressi, resta la sfida pratica: applicare l'interpretabilità per individuare e correggere "difetti" reali nei modelli. Esperimenti interni mostrano che è possibile.
- Amodei conclude affermando che siamo in una corsa tra l'avanzamento dell'AI e la nostra capacità di interpretarla. Per vincere, serve: investire nella ricerca, promuovere la trasparenza, adottare misure geopolitiche.
Capire i nostri modelli prima che trasformino il mondo è una responsabilità che non possiamo rimandare.
Agentic AI: un webinar di Stanford
Stanford ha pubblicato un'interessante lezione che riepiloga il funzionamento dei LLM e arriva fino agli AI Agent.
Agentic AI: un webinar di Stanford
I punti salienti..
- LLM Base: modelli che predicono i token successivi. Addestrati su enormi testi (pre-training), poi affinati (fine-tuning con SFT/RLHF) per seguire istruzioni e preferenze umane.
- Limiti dei LLM: possono "allucinare" (dare informazioni errate), hanno conoscenza limitata nel tempo (knowledge cutoff), non citano fonti, non accedono a dati privati/real-time e hanno un contesto limitato.
- RAG: fornisce contesto esterno rilevante (da documenti/DB) al LLM per risposte più accurate e aggiornate.
- Tool Usage: permette ai LLM di usare API esterne o eseguire codice per accedere a dati real-time o fare calcoli.
- Agentic AI: l'evoluzione dei LLM. Non solo testo, ma sistemi che: ragionano e pianificano (scompongono compiti), agiscono (usano RAG e Tools per interagire con l'ambiente), osservano (ricevono feedback dalle loro azioni) iterano (si adattano in un ciclo azione-osservazione-pianificazione).
- Pattern Agentici, per costruire agenti efficaci: pianificazione, riflessione (auto-correzione), utilizzo di strumenti e collaborazione multi-agente (più agenti specializzati).
In breve, l'Agentic AI combina il ragionamento dei LLM con l'azione nel mondo esterno, permettendo di affrontare compiti molto più complessi e interattivi.
"Stop & Think" di Anthropic su un Agent di OpenAI con o3
In questo esempio ho implementato la dinamica di "Stop & Think" definita da Anthropic su un Agent di OpenAI, basato su o3.
In pratica, il sistema è configurato per eseguire un task estraendo i dati necessari attraverso "function calling". Una volta ottenuti i dati, prima di restituire l'output, usa una funzione di "reasoning", la quale sfrutta il modello per mettere in atto delle catene di pensiero che verificano i dati, creano il miglior piano d'azione per procedere, e controllano la conformità in base alle richieste. Se è tutto conforme, procede con l'output, altrimenti ripete le operazioni, finché il controllo sarà positivo (o fino al raggiungimento del numero massimo delle interazioni consentite).
Una dinamica davvero interessante per migliorare la qualità dell'output.
"Stop & Think" di Anthropic su un Agent di OpenAI con o3
Il porting del codice di Anthropic per usare i modelli di OpenAI sul mio esempio è stato generato interamente con Gemini 2.5 Pro. Il modello ha prodotto tutto il codice partendo dall'esempio fornito da Anthropic + il prompt che usavo in precedenza nel mio progetto, che eseguiva l'operazione in un'unica azione.
OpenAI Academy
OpenAI ha lanciato ufficialmente l'AI Academy: una piattaforma formativa gratuita pensata per chi vuole portare l’AI dal laboratorio alla realtà operativa.
I contenuti sono pensati per l’uso pratico: automazioni, agenti AI, pipeline con GraphRAG, Q&A su documenti, integrazioni reali con diversi modelli.
Tra i punti forti
- Live coding sessions
- Prompt engineering, fine-tuning, RAG, multimodalità
- Esempi di codice commentato per API, automazioni e gestione dati
- Percorsi ideali per chi è agli inizi o ha esperienza intermedia
Le novità di NotebookLM di Google
Google introduce due novità molto interessanti su NotebookLM.
1) Ricerca online
Ora è possibile descrivere un argomento e ottenere una selezione di fonti rilevanti dal web, già riassunte dall'IA e integrabili con un clic al notebook.
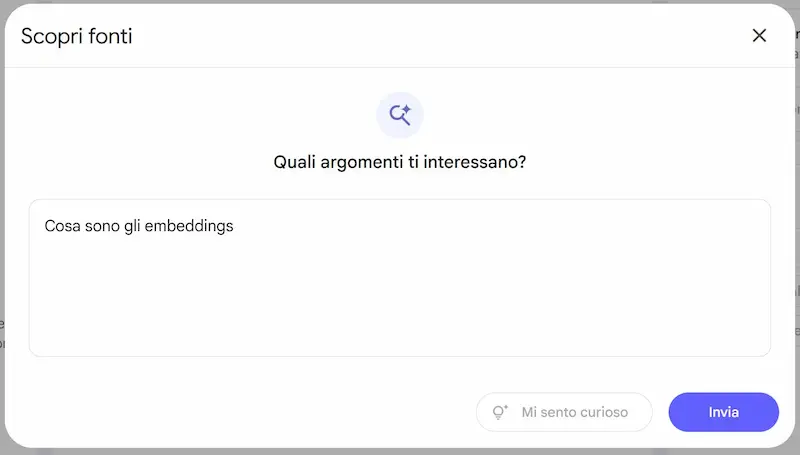
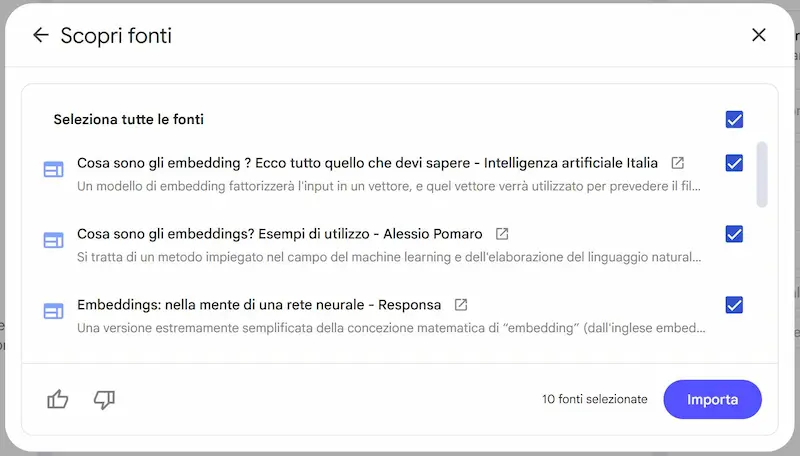
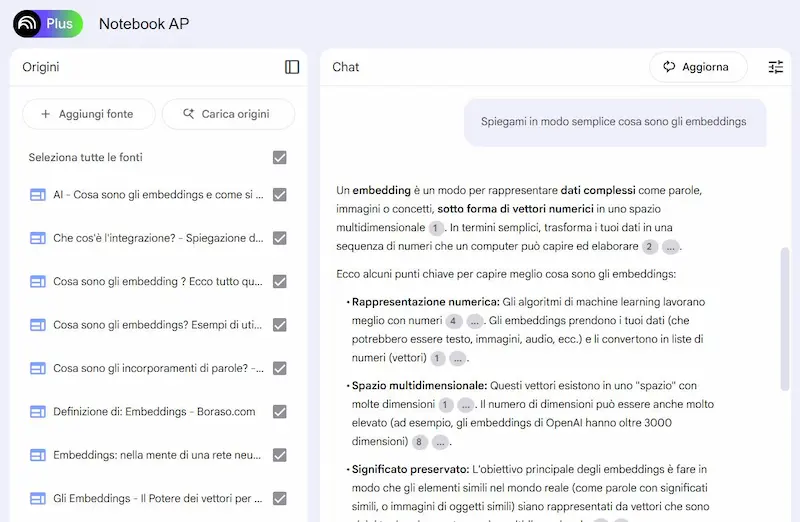
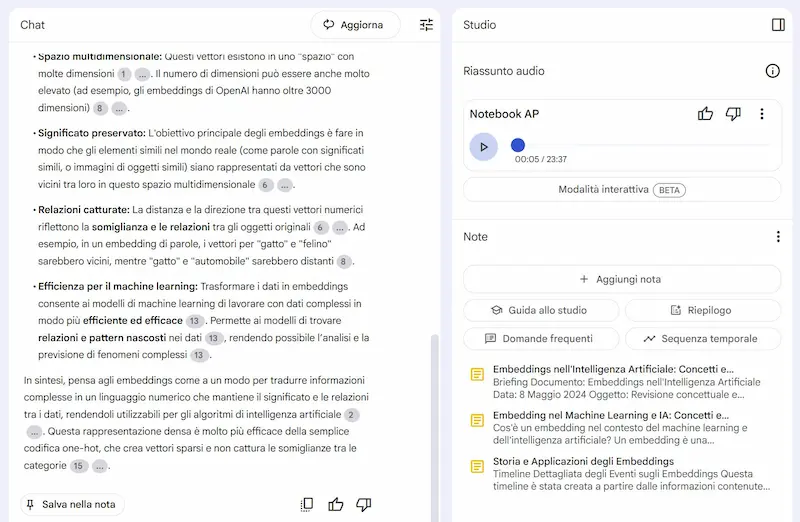
La ricerca online su NotebookLM di Google
La nuova funzione "Carica Origini", alimentata da Gemini, permette di approfondire rapidamente qualsiasi tema e integrarlo con strumenti come briefing, FAQ e Audio Overviews.
Ho provato lo strumento, e credo sia una funzionalità fantastica per esplorare gli argomenti. Ho inserito il topic, selezionato le fonti tra quelle suggerite, fatto richieste, generato note, creato un podcast interattivo.
Ho detto spesso che l'integrazione dell'AI nel suo ecosistema è la vera forza di Google. Verissimo, ma ora hanno anche il modello più performante.
2) Audio Overviews anche in italiano
Audio Overviews diventa disponibile in più di 50 lingue.
L'italiano è tra queste, e l'ho provato su un notebook che ha come fonte l'ultimo post di Dario Amodei sull'importanza dell'interpretabilità dell'AI.
Il prompt che ho usato è specifico, indicando l'ambito sul quale concentrarsi maggiormente.
Audio Overviews in italiano: un test
Il risultato? Per me è incredibile. Una risorsa davvero interessante.
Immaginiamo solo la potenzialità per l'aggiornamento personale nelle connessioni dei concetti su larga scala.
Non può esistere la figura del Prompt Engineer
Il WSJ ha condiviso dei dati su un concetto che ho sempre sostenuto: non può esistere la figura del "prompt engineer". E non si tratta di obsolescenza di una professione, ma di consapevolezza di un miraggio.

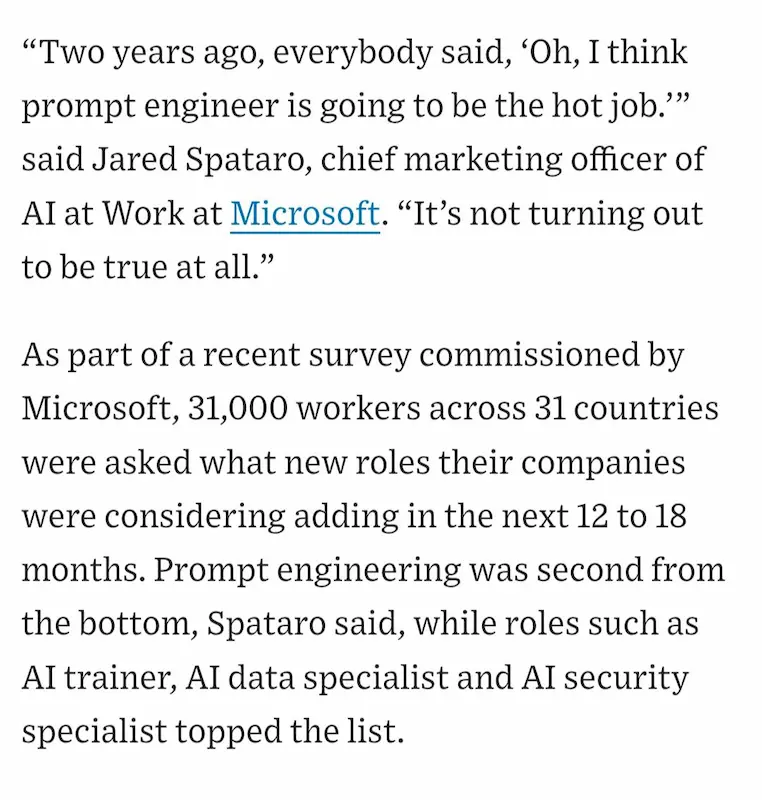
Il WSJ sulla figura del prompt engineer
La motivazione che danno nell'articolo, però, è solo parzialmente centrata. Non è solo questione di avanzamento dei LLM nella comprensione delle richieste in linguaggio naturale.
Il fatto è che la capacità di ottenere l'output desiderato da un agente basato sull'AI è una competenza trasversale che potenzia delle hard skill. Se non si possiedono quelle hard skill, nessun "mago del prompt" potrà ottenere risultati avanzati necessari in ambito professionale.
Prompt Engineering: il paper di Google
Google ha pubblicato un interessante documento sul "Prompt Engineering": una guida sulla creazione di prompt efficaci.


Prompt Engineering: il paper di Google
Non ci sono novità eclatanti, ma di certo un percorso chiaro e ordinato.
Le parti più interessanti riguardano gli approcci Chain of Thought (CoT) e ReAct.
- CoT è utile per migliorare l'accuratezza facendo sviluppare al LLM un "ragionamento" logico.
- ReAct è utile per applicazioni che richiedono interazione con fonti esterne o task complessi.
OpenAI: 3 guide pratiche dedicate all'AI



1- A Practical Guide to Building Agents
È pensata per chi vuole costruire agenti AI in grado di svolgere task multi-step in autonomia. Descrive come scegliere i modelli, integrare strumenti e impostare istruzioni chiare. Spiega modelli di orchestrazione come il "manager agent" o sistemi decentralizzati, e introduce i "guardrail" per garantire sicurezza, privacy e intervento umano nei casi critici.
2- Identifying and Scaling AI Use Cases
Offre un metodo per scoprire e scalare casi d’uso ad alto impatto. Si parte da sfide comuni come attività ripetitive, colli di bottiglia di competenze e ambiguità decisionali, e si esplorano sei "primitivi" come content creation, automazioni e analisi dati. Esempi come Promega, Tinder e BBVA mostrano come anche attività complesse possano essere trasformate in flussi AI scalabili.
3- AI in the Enterprise
Raccoglie sette lezioni chiave per adottare l’AI su larga scala. Vengono presentati esempi concreti come Morgan Stanley, che ha migliorato l’efficienza dei suoi advisor grazie a valutazioni sistematiche (evals), e Indeed, che ha potenziato il job matching con GPT-4o mini. Klarna ha implementato un assistente AI per il customer service, riducendo i tempi di risposta da 11 a 2 minuti. La guida sottolinea l’importanza di investire presto, personalizzare i modelli, e mettere l’AI nelle mani degli esperti aziendali.
I 30 paper di Ilya Sutskever
"If you really learn all of these, you’ll know 90% of what matters today".
Con queste parole, Ilya Sutskever (co-founder di OpenAI) condivide quelli che ritiene i migliori 30 paper che riguardano l'AI.
Molti mi hanno chiesto suggerimenti per affrontare questi documenti, non semplici da consultare.
Un buon aiuto per iniziare potrebbe essere l'utilizzo di NotebookLM di Google.
Nelle immagini si può vedere il mio notebook. Una volta inseriti tutti i documenti e le pagine web, è possibile creare la mappa mentale interattiva: cliccando le voci il sistema usa Gemini per estrarre tutte le informazioni utili.
Il mio notebook con i 30 paper di Ilya Sutskever
Altra idea: attraverso un prompt, ho fatto sviluppare al LLM un corso con una serie di lezioni che esplorano tutti i concetti in modo sequenziale e connesso (con riferimenti alle fonti).
Mi piacerebbe condividerlo, ma NotebookLM non permette di farlo attraverso un link, e ha politiche molto restrittive per gli utenti. Tuttavia è realizzabile in modo semplice.
Shopping su ChatGPT?
OpenAI migliora l'esperienza di shopping su ChatGPT, con risultati migliorati, dettagli dei prodotti, prezzi e recensioni, con i link diretti per l'acquisto.
La funzionalità è in fase di rilascio.
Shopping su ChatGPT
Un upgrade interessante, anche se l'esperienza di Google Shopping (soprattutto negli USA) è difficilmente eguagliabile.
Tenendo conto anche del fatto che questi dati non sono interfacciati con i feed degli e-commerce. Nella documentazione parlano di "structured metadata from third-party providers", ma non è ben chiaro il processo: di certo non potrà essere strutturato come quello di Google.
Nuovi modelli per OpenAI
GPT-4.1
Il nuovo modello (senza "reasoning") più potente, veloce ed economico, ideale per coding, gestione dei contesti lunghi (1M di token) e per l'aderenza a precise istruzioni. E, come previsto, GPT-4.5 verrà dismesso a luglio.
L'ho provato su diversi task (le immagini riportano qualche esempio): logica, matematica, coding, elaborazione di file lunghi, generazione di dati strutturati da contenuti non strutturati, analisi del testo, generazione di testo con precise istruzioni.
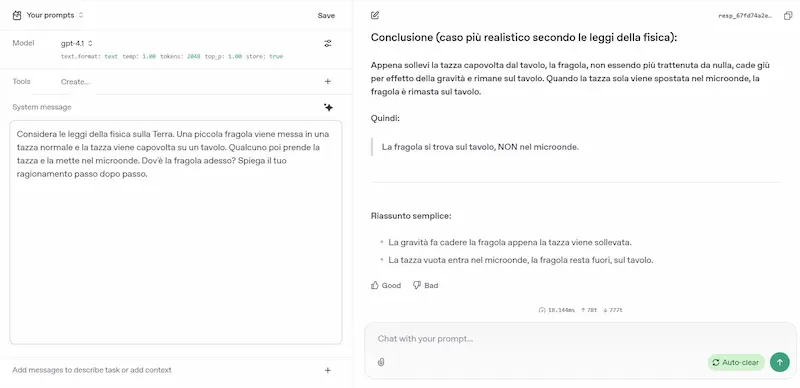
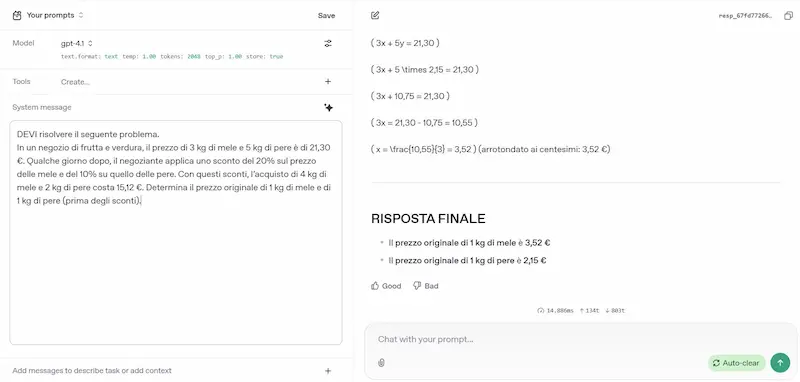
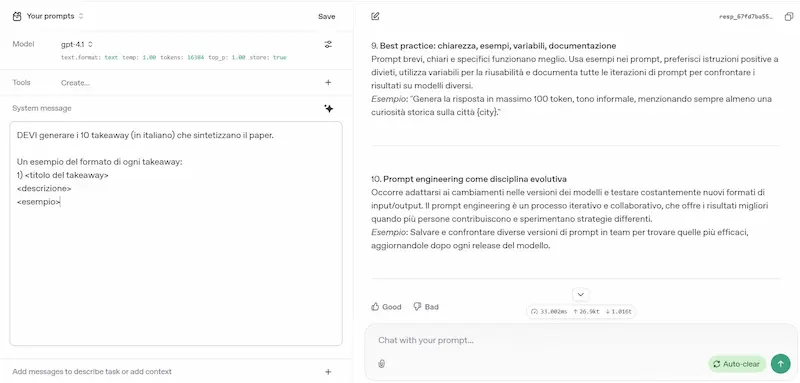
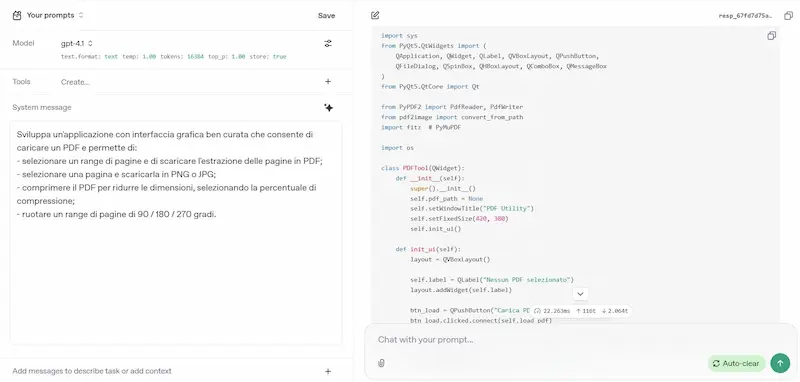
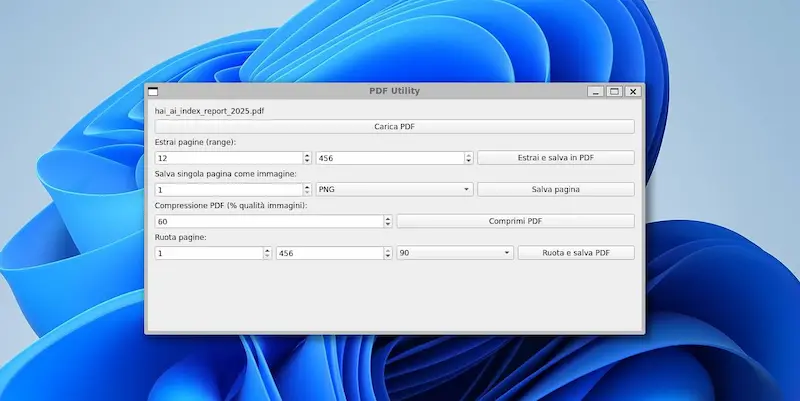
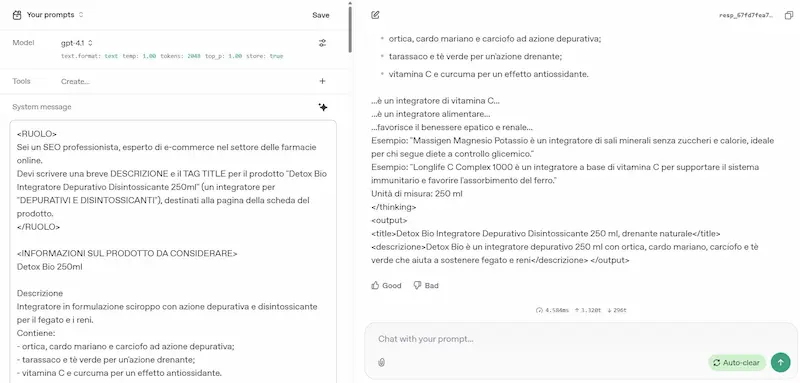
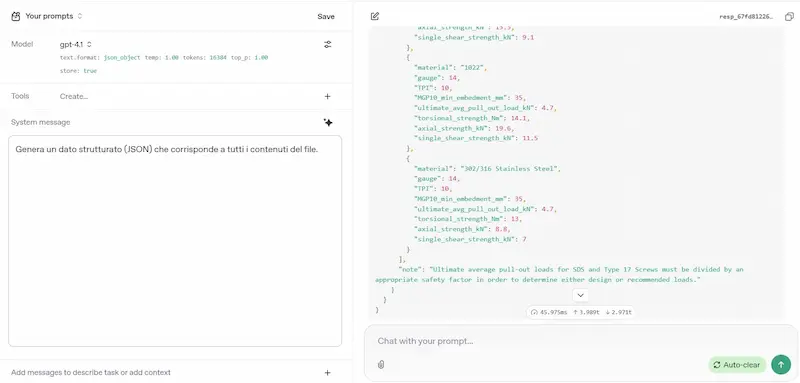
GPT-4.1 di OpenAI: test
Le impressioni sono ottime. Due note.
- Con un singolo prompt (senza interazioni successive) ho realizzato un piccolo software con interfaccia grafica che raccoglie una serie di utility per i PDF (estrazione di pagine, compressione, conversione in immagini, rotazione, unione).
- Da diversi test svolti nei mesi scorsi, su prompt con tantissime istruzioni, avevo sempre trovato GPT-4 migliore rispetto alla versione "o". Finalmente il 4.1 supera quel limite.
Qualche dettaglio sul modello..
La nuova famiglia GPT-4.1 include tre versioni: Standard, Mini e Nano.
Il modello non solo supera GPT-4o nei benchmark più rilevanti, ma in molti casi va oltre anche GPT-4.5, motivo per cui quest’ultimo verrà ritirato. È più preciso nei compiti multi-turno, più affidabile nei formati richiesti, e significativamente più performante nello sviluppo software (con +21% su SWE-bench).
È pensato esclusivamente per l’uso via API: in ChatGPT, molte delle sue migliorie sono già confluite in GPT-4o e continueranno a essere integrate.
Grazie a ottimizzazioni nel sistema di inferenza, GPT-4.1 è anche più economico del 26% rispetto a GPT-4o, mentre Nano è il modello più economico e rapido mai rilasciato.
Anche OpenAI, come Google, dimostra l'avanzamento in termini di efficienza, dopo il passo falso della versione 4.5.
o3 e o4-mini + Codex CLI
OpenAI ha presentato i nuovi modelli o3 e o4-mini (con avanzamenti della fase di reasoning), e ha lanciato Codex CLI (un AI Agent open-source).
Ho provato o3 in diversi task: coding, generazione di testo, analisi dei dati, ricerca online, logica, matematica, istruzioni complesse, analisi delle immagini, e in un sistema multi-agent via API.
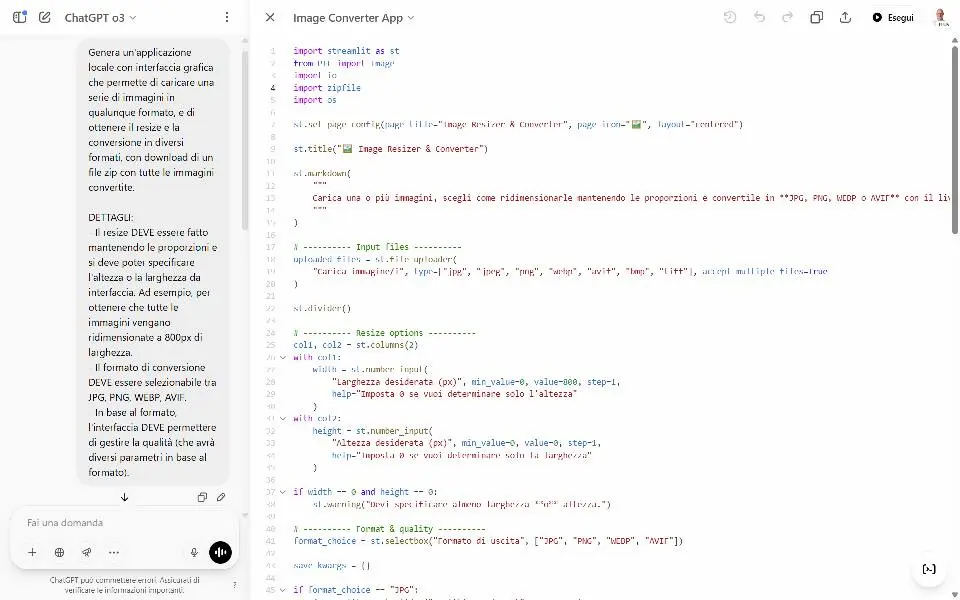
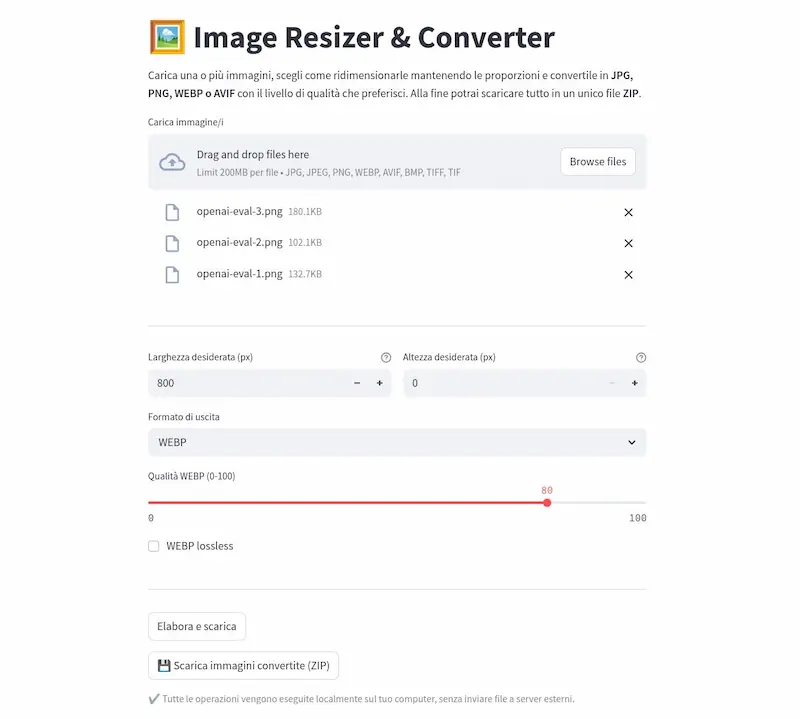

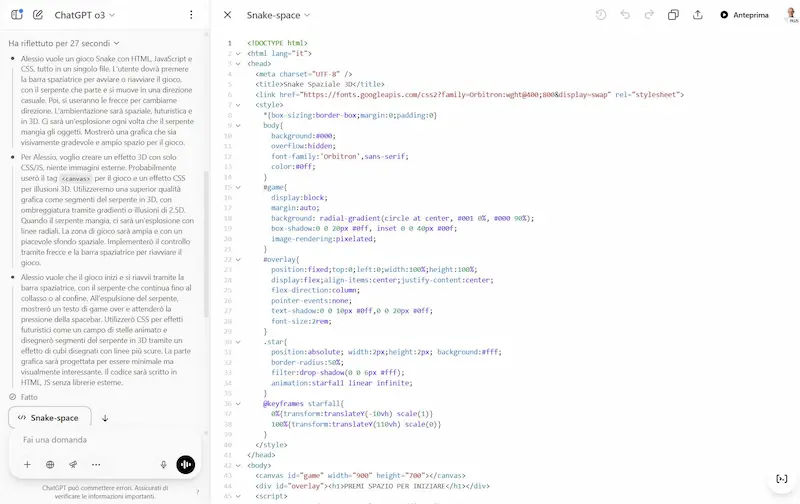
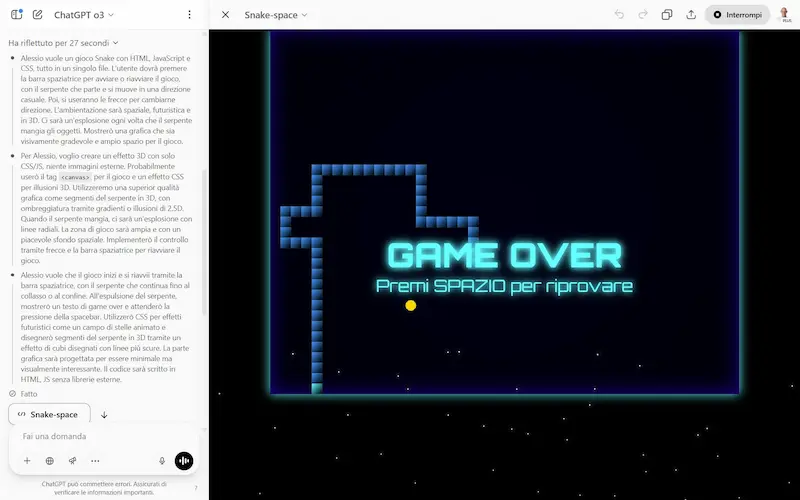
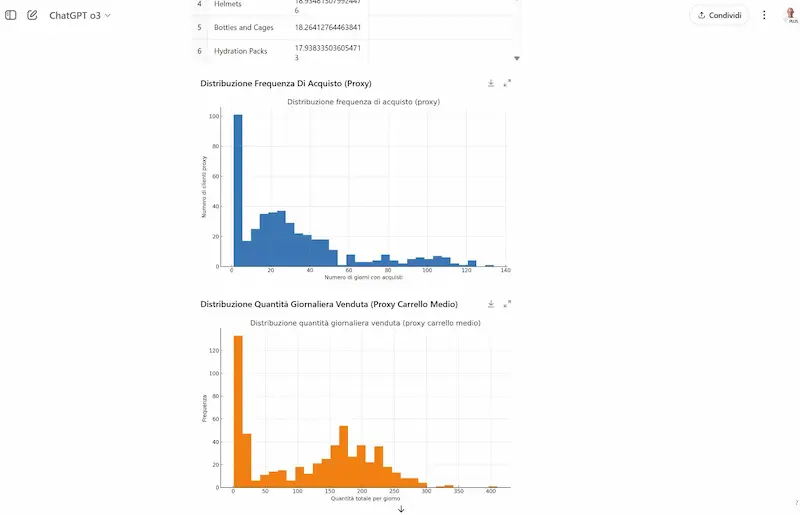
o3 e o4-mini + Codex CLI: test
- Sul coding, è molto performante: ho realizzato un'applicazione locale (Python) con interfaccia grafica che converte un gruppo di immagini in tutti i formati, con resize e gestione della qualità, funzionante alla prima esecuzione.
- Fantastici la ricerca online e code interpreter in fase di reasoning, perché sono dinamici in base al flusso di ragionamento.
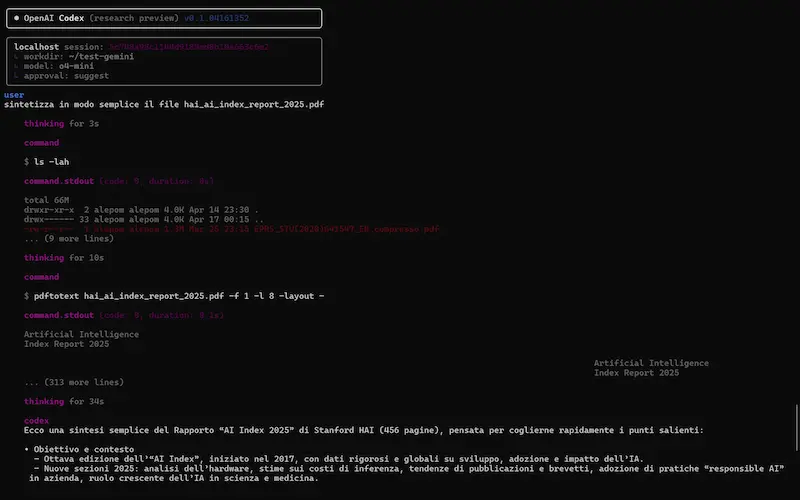
- Ho provato anche Codex CLI, un agente AI per il terminale che consente di scrivere codice, navigare file, interpretare immagini e interagire con il computer in modo multimodale e controllato. Nel test, entro in una directory e faccio sintetizzare al modello un PDF locale. Una funzionalità davvero interessante.
o3 è il modello più potente, dedicato a compiti complessi come coding, matematica, e ragionamento visivo. o4-mini, invece, offre prestazioni sorprendentemente elevate in rapporto a dimensioni e costi, risultando ideale per usi ad alto volume di richieste.
Entrambi possono usare l’intera suite di strumenti di ChatGPT: ricerca web, code interpreter, generazione e modifica immagini, function calling e tool personalizzati. Per la prima volta, ragionano anche sulle immagini: le usano come parte integrante della catena di pensiero, sbloccando nuove modalità di problem solving.
Le performance: o4-mini raggiunge il 93,4% di accuratezza su AIME 2024 e 2719 ELO su Codeforces. o3 ottiene 83,3% su GPQA (domande da PhD), 86,8% su MathVista, 78,6% su CharXiv, e domina nei task di software engineering, superando ampiamente i predecessori.
La sicurezza è stata potenziata con nuovi sistemi di rifiuto delle richieste, rilevamento di prompt rischiosi e test rigorosi: entrambi i modelli restano sotto le soglie critiche su tutti i fronti (biochimica, cybersecurity, auto-miglioramento AI).
Un test di Codex CLI
Codex CLI di OpenAI: l'ho provato con o3, ed è una bomba!
Il dettaglio dei test che si vedono nel video..
- Entro nella directory di un'applicazione, avvio Codex e mi faccio spiegare la codebase. Successivamente, chiedo all'agente di modificare l'app e inserire il bottone per la "dark mode". Il sistema edita direttamente i file, ed esegue tutto perfettamente (nel video si vede anche l'app modificata). Può gestire anche l'interazione con GitHub autonomamente.
- Entro in una directory dov'è presente un dataset in CSV. Attraverso un prompt dettagliato, chiedo all'agente di analizzare i dati, pulirli, e produrre una pagina web con un report. Non solo lo crea, ma fornisce anche il Python per aggiornare il report nel caso il dataset cambi.
Un test di Codex CLI di OpenAI
Cos'è Codex CLI? Si tratta di un AI Agent open source che funziona in locale, sfruttando qualunque modello di OpenAI. Consente di scrivere codice, navigare file, interpretare immagini e interagire con il computer in modo multimodale e controllato.
Disponibilità generale per Veo 2 di Google
È già usabile via API, e chiaramente su AI Studio.
Veo 2: un test su AI Studio
Nel video si vedono due esempi di "image to video" e uno di "text to video".
Nei due esempi di "image to video", le immagini sono state generate con il modello di OpenAI, in modo da essere coerenti. Usando Veo per animarle, si possono creare due clip da montare per un unico video.
Test: un'applicazione con Gemini 2.5 Pro
Un esempio di generazione di un'applicazione da prompt testuale con Gemini 2.5 Pro: semplice, ma funzionante alla prima esecuzione!
Ho chiesto al modello di creare un'applicazione che permette di caricare un file audio o video, e che produce la trascrizione con separazione degli speaker usando le API di Gemini (con download del TXT completo alla fine del processo).
Il sistema ha prodotto un'applicazione basata su Flask, con la struttura delle directory, HTML, Python, requirements e il file "env" per le API key.
Dopo aver avviato il server Flask, l'applicazione funziona via browser.
Test: un'applicazione con Gemini 2.5 Pro
È semplice, ma ho impiegato più tempo a produrre il video rispetto a un sistema utile e funzionante, senza errori da gestire.
Le novità nel Workspace di Google
Con uno dei migliori modelli di AI a disposizione, e un ecosistema che fa già parte della quotidianità di un'enorme insieme di utenti, Google rilascia le nuove funzionalità per Workspace.
La nuova ondata di strumenti basati su Gemini mira a migliorare concretamente l’efficienza aziendale: automazioni avanzate con Workspace Flows, assistenti intelligenti nei documenti, analisi dei dati semplificata e la possibilità di generare contenuti audio e video direttamente dalle app Workspace.
- Workspace Flows usa agenti AI personalizzati (Gems) per gestire processi multi-step con logica e contesto, senza bisogno di codice. In pratica, si potranno creare flussi e automazioni che coinvolgono azioni di ogni software di Workspace.
Google Workspace Flows
- Docs introduce la lettura audio dei testi e la funzione "Help me refine" per migliorare la scrittura in modo evoluto. Il Canvas di ChatGPT direttamente su Google Docs.
- Sheets include "Help me analyze", un analista AI sempre disponibile per scoprire insight nascosti nei dati. I più attenti avranno notato che è già disponibile su Colab.
- Google Vids si potenzia con Veo2, generando video realistici direttamente dall'app.
- Google Meet e Chat diventano ancora più smart con riepiloghi, note automatiche e suggerimenti in tempo reale.
L'integrazione e l'accelerazione di Google.. si prepara a diventare irraggiungibile?
Un Agent Builder per Postman
Postman ha presentato il suo AI Agent builder.
Un sistema che permette di creare agenti basati su LLM, che possono usare una rete di oltre 100k API pubbliche.
Il tutto attraverso un'interfaccia drag & drop.
Un Agent Builder per Postman
La prototipazione di applicazioni diventa sempre più agile.
Grok Studio
xAI ha rilasciato Grok Studio, con la possibilità di eseguire il codice generato e il supporto a Google Drive.
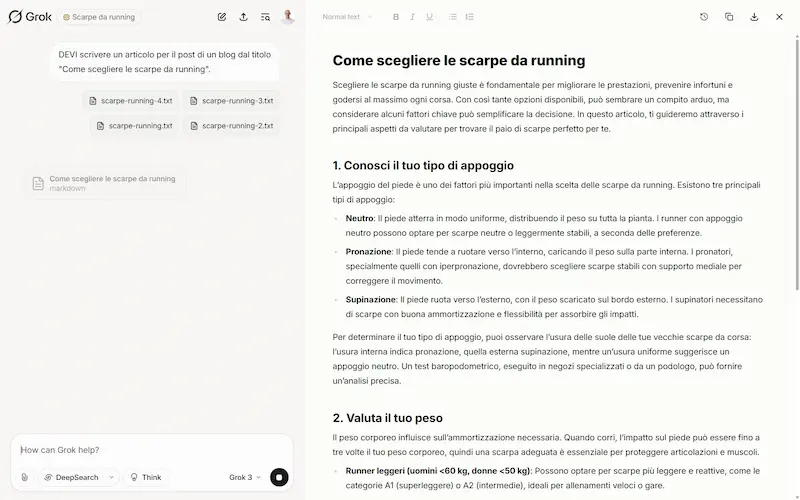
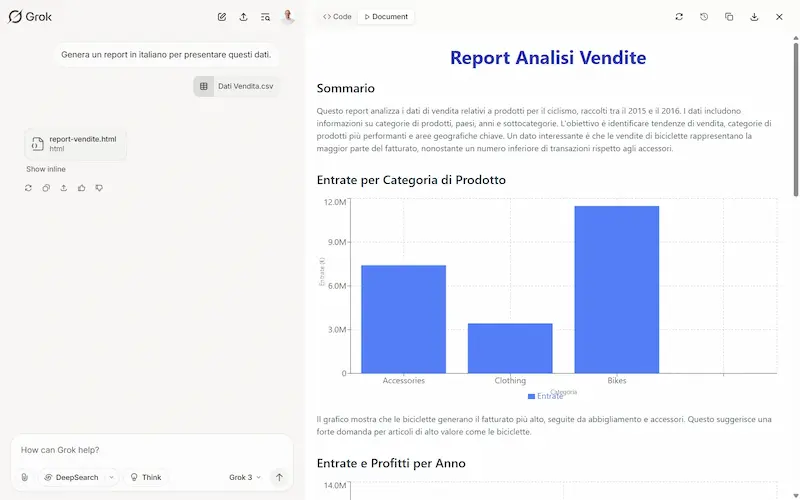
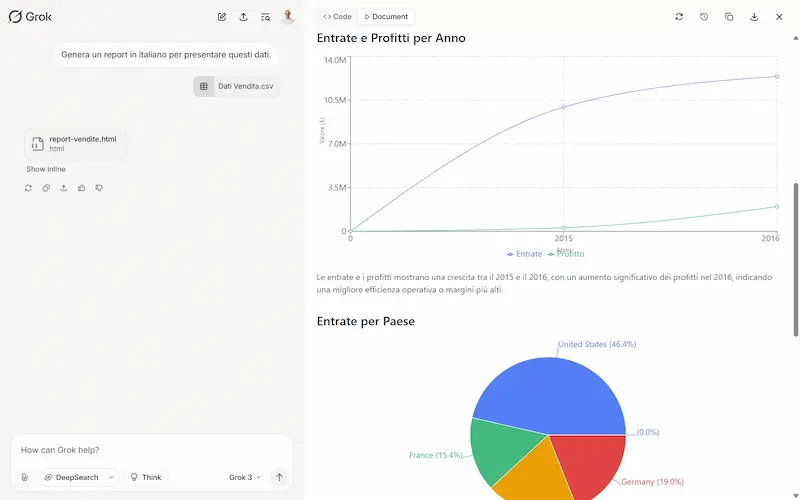
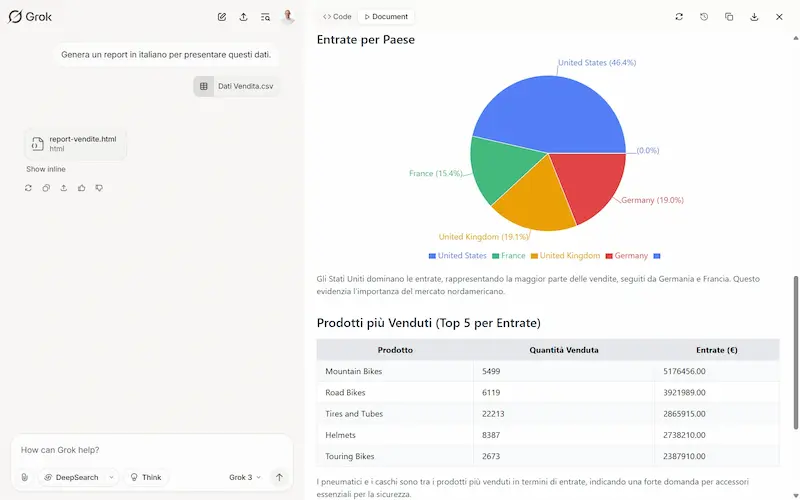
Grok Studio: un test
È molto simile a Canvas su ChatGPT, ma la funzionalità di generazione report da un foglio dati è fantastica.
La connessione a Google Drive è comoda, e permette di creare dei Workspace importando direttamente i file.
L'editor di ChatGPT è migliore, ma la generazione dei report è vincente.
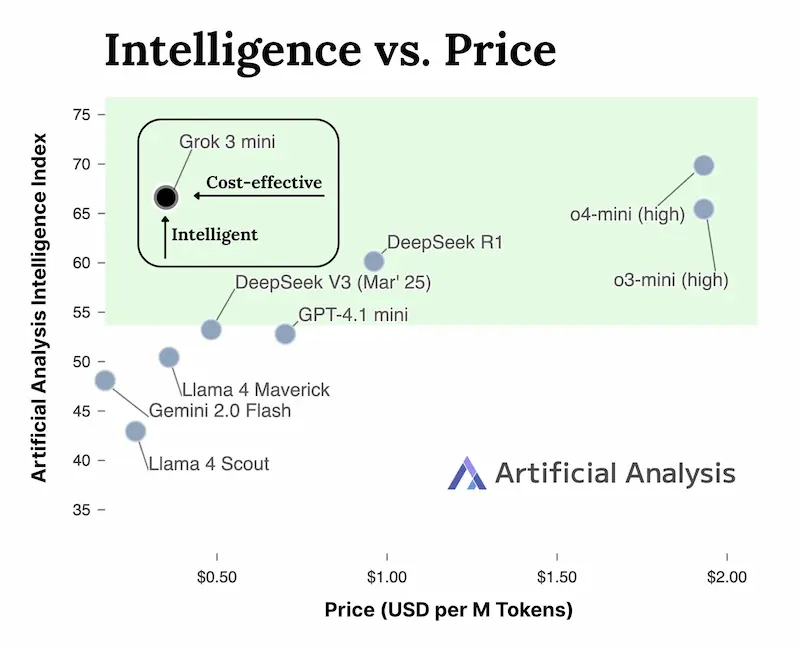
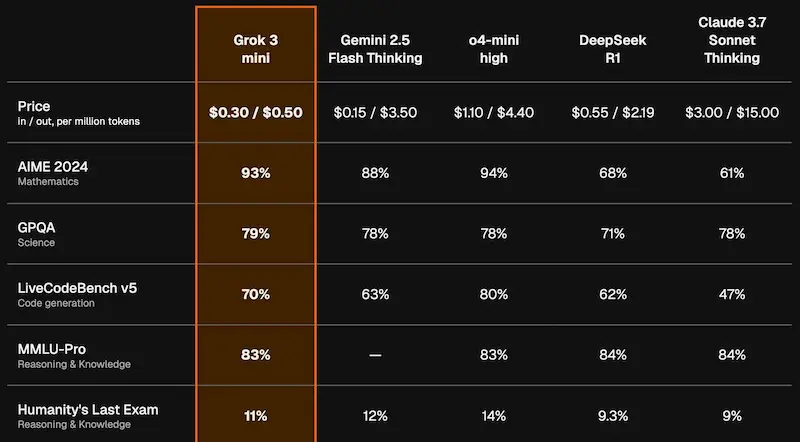
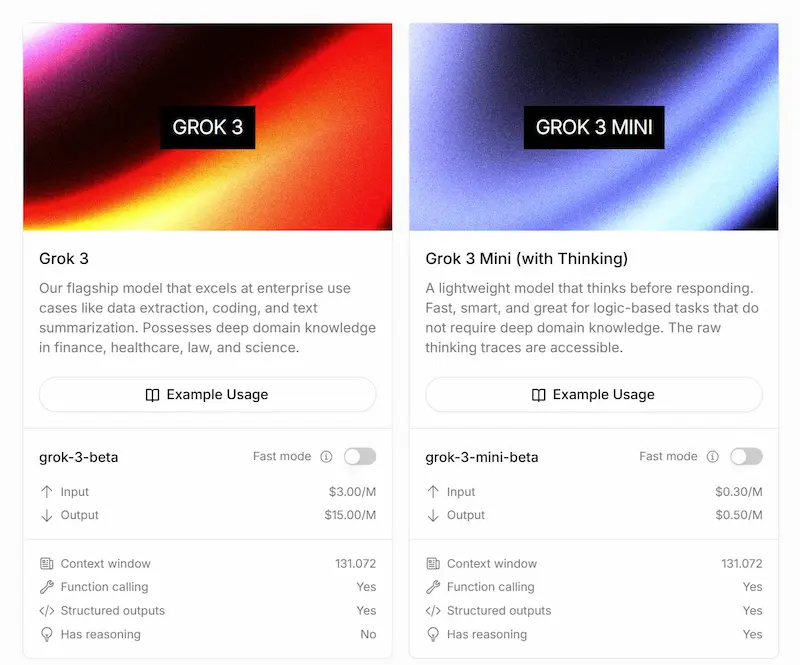
Le API di Grok 3
La "guerra dei prezzi" delle API dei LLM continua: xAI rilascia le API di Grok3 mini.
In base ai dati diffusi, sembra che il modello superi diversi modelli di reasoning in diversi benchmark, con un prezzo di 5 volte inferiore.
Le API di Grok 3
Alcuni dettagli
- Grok 3 Mini guida le classifiche su test STEM avanzati, matematica e coding, superando modelli flagship 20 volte più costosi.
- È 5 volte più economico di qualsiasi altro modello di reasoning sul mercato.
- Ogni risposta API include l’intero "reasoning trace", grezzo e non filtrato.
AI Index Report 2025
Stanford ha pubblicato l'AI Index Report 2025.

L’intelligenza artificiale evolve rapidamente, trasformando società ed economia, tra progressi straordinari, investimenti globali e sfide ancora aperte.
Una sintesi dei take away del report
- Le prestazioni dell’AI migliorano rapidamente nei benchmark avanzati.
I modelli AI hanno fatto grandi progressi su nuovi benchmark complessi come MMMU, GPQA e SWE-bench, superando anche le performance umane in alcuni compiti di programmazione. - L’AI è sempre più presente nella vita quotidiana.
L’intelligenza artificiale è ormai diffusa in settori come la sanità e i trasporti, con dispositivi medici approvati e robotaxi operativi su larga scala. - Le aziende puntano tutto sull’AI, trainando investimenti record.
Gli investimenti privati negli Stati Uniti hanno raggiunto 109 miliardi di dollari nel 2024, con una crescita d’uso nelle aziende e prove sempre più solide del suo impatto positivo sulla produttività. - Gli Stati Uniti guidano, ma la Cina riduce il divario qualitativo.
Gli USA producono più modelli AI di punta, ma la Cina li sta rapidamente raggiungendo in termini di qualità, mantenendo il primato per pubblicazioni e brevetti. - L’ecosistema dell’AI responsabile si evolve, ma in modo disomogeneo.
Aumentano gli incidenti legati all’AI, mentre le valutazioni standardizzate sono ancora rare. I governi mostrano maggiore impegno con nuove linee guida sulla trasparenza e sicurezza. - L’ottimismo globale verso l’AI cresce, ma con forti differenze regionali.
Paesi asiatici mostrano un forte ottimismo verso l’AI, mentre Stati Uniti, Canada ed Europa restano più scettici, sebbene con segnali di miglioramento. - L’AI diventa più efficiente, economica e accessibile.
I costi per far girare modelli potenti sono crollati, mentre l’efficienza energetica è aumentata. I modelli open-source stanno colmando rapidamente il divario con quelli chiusi. - I governi aumentano regolamentazione e investimenti sull’AI.
Nel 2024 le normative sull’AI sono raddoppiate negli USA e cresciute a livello globale, accompagnate da investimenti miliardari in vari paesi per sostenere l’innovazione. - L’educazione all’AI cresce, ma persistono disuguaglianze.
Sempre più paesi offrono educazione informatica K-12, ma permangono barriere infrastrutturali, soprattutto in Africa, e molti insegnanti non si sentono pronti a insegnare l’AI. - L’industria domina lo sviluppo AI, ma la competizione si intensifica.
La quasi totalità dei modelli più avanzati proviene dall’industria. Tuttavia, la differenza di prestazioni tra i migliori modelli si sta riducendo, segno di una frontiera sempre più affollata. - L’AI riceve riconoscimenti scientifici di massimo livello.
Nel 2024 l’AI è stata protagonista di premi Nobel e del Turing Award, evidenziando il suo impatto decisivo nella scienza, dalla fisica al ripiegamento proteico. - Il ragionamento complesso resta una sfida.
Nonostante i successi in compiti avanzati, i modelli AI faticano ancora con il ragionamento logico e la risoluzione di problemi complessi in contesti critici.
Work Trend Index 2025 di Microsoft
L'AI sta ridefinendo il lavoro nelle aziende, e Microsoft ne traccia i contorni nel suo Work Trend Index 2025.

Il rapporto evidenzia come le organizzazioni che adottano l’AI in modo strutturale — definite "Frontier Firms" — registrano benefici tangibili: il 71% dei dipendenti afferma che la propria azienda sta prosperando, e l’83% dei leader riconosce che l’AI contribuisce a una maggiore adozione di compiti strategici.
In parallelo, Microsoft ha presentato importanti evoluzioni per Copilot, puntando su un’integrazione sempre più pervasiva dell’AI nei flussi operativi.
Copilot Studio è una nuova piattaforma low-code che consente alle imprese di costruire agenti intelligenti personalizzati, con memoria, capacità di pianificazione e integrazione via OpenAPI.
Questi agenti possono operare all’interno delle app Microsoft 365 e connettersi a sistemi esterni come Jira, Miro o Monday.
Sono stati inoltre lanciati due nuovi agenti nativi — Copilot Researcher e Copilot Analyst — pensati per attività di ricerca e analisi su larga scala, capaci di interagire con Word, Excel, Outlook e Teams grazie ai dati real-time di Microsoft Graph. Il tutto è orchestrato con modelli GPT-4-turbo, in grado di mantenere il contesto e generare output coerenti e document-aware.
Open Manus: un test
Ho provato Open Manus, il progetto open source che mira a replicare le capacità dell'Agente Manus AI.
Nel video si vedono diversi task che l'agent (nel mio caso basato su GPT-4o) svolge in modo autonomo, sfruttando l'automazione del browser, e anche del computer locale.
Open Manus: un test
Le mie considerazioni: questo tipo di agenti sono davvero molto interessanti, ma acerbi per essere "liberati" a compiere operazioni autonome online senza riferimenti specifici.
Ma di certo miglioreranno, e saranno direttamente nel browser, e successivamente nei sistemi operativi.
Firebase Studio di Google: un test
Google lancia Firebase Studio, un nuovo IDE open source basato sull’AI che unisce Project IDX, Genkit e i modelli Gemini in un’unica piattaforma per creare app full-stack.
L'ho provato: con un prompt testuale ho creato un'applicazione che trasforma un contenuto in una mappa mentale modificabile. Con altri prompt successivi l'ho rifinita per ottenere il risultato che avevo in mente.
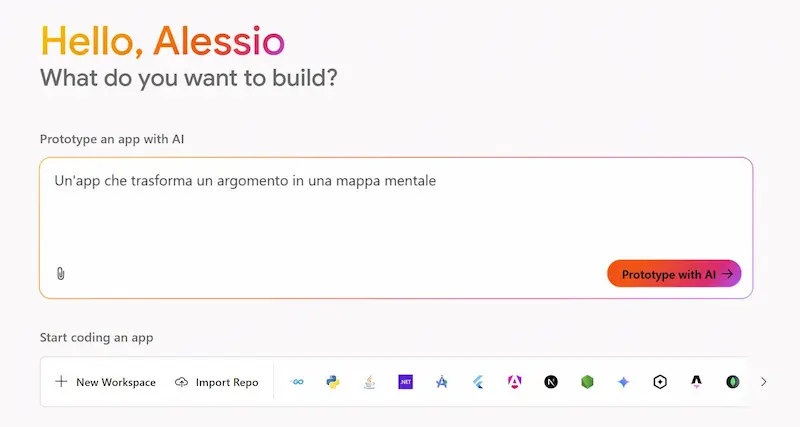
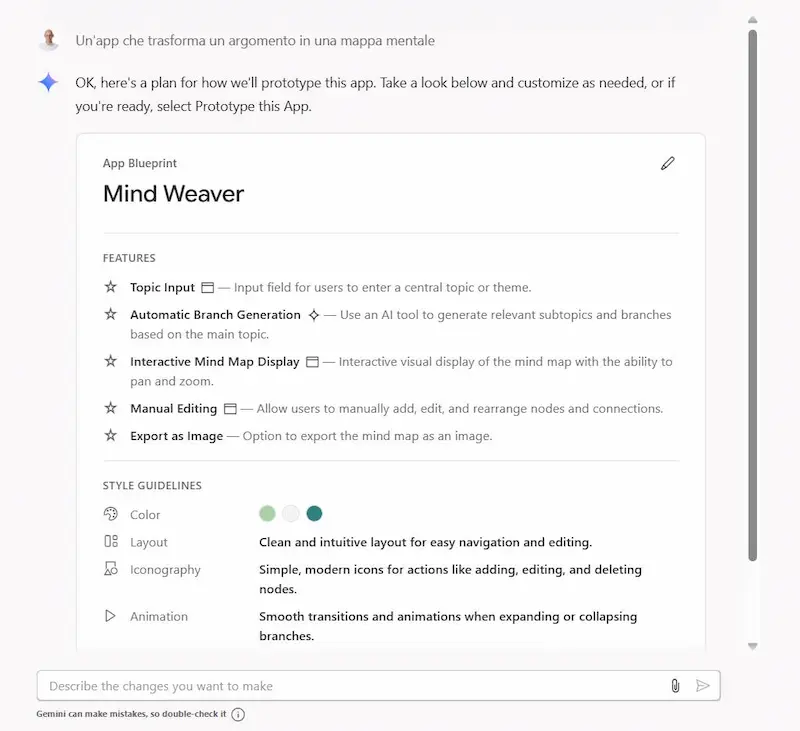
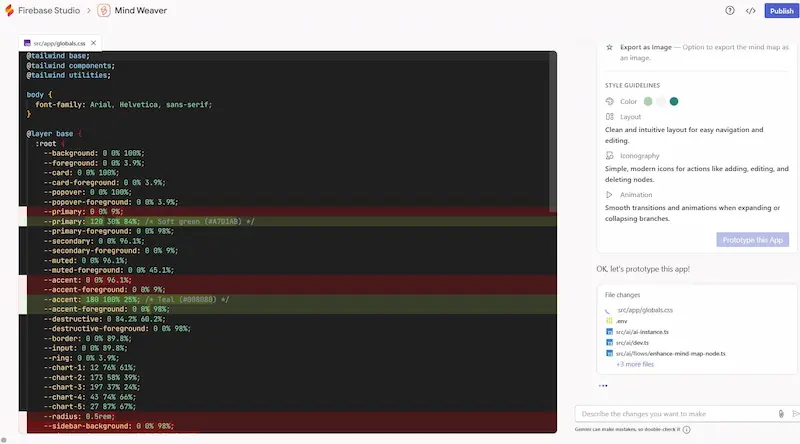
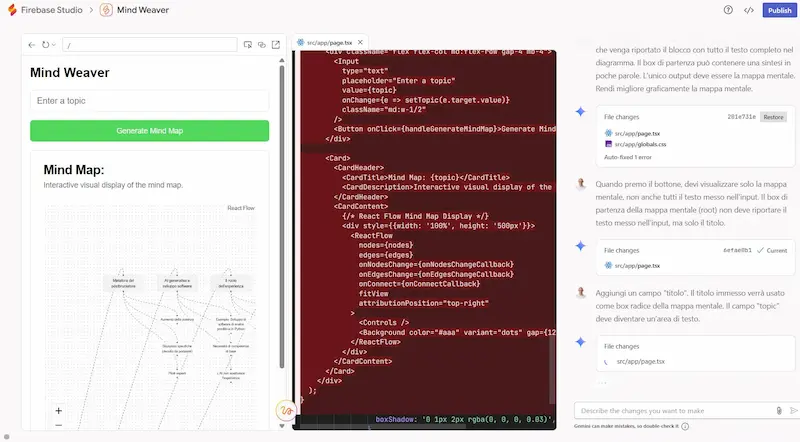
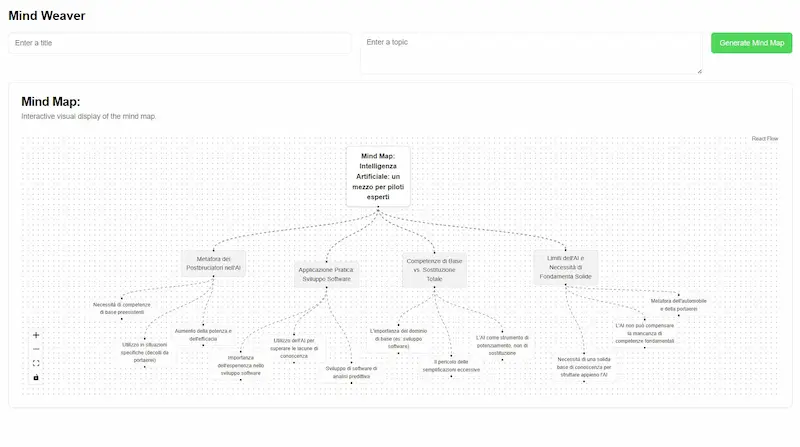
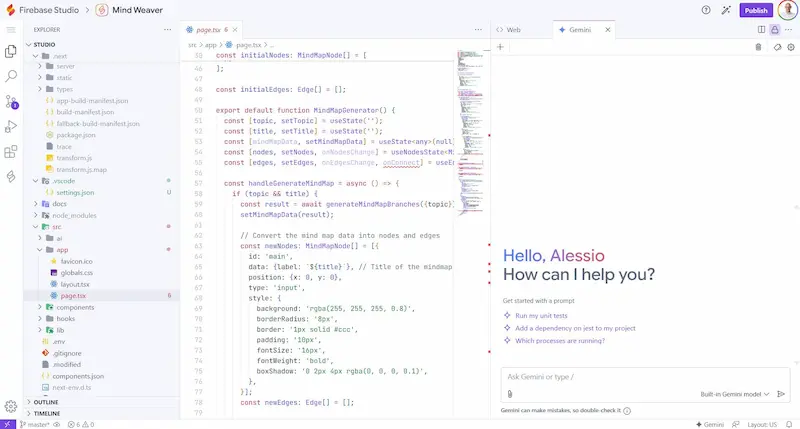
Firebase Studio di Google: un test
Il cuore del progetto è l’agente di prototipazione, capace di generare app Next.js complete in pochi secondi non solo da prompt testuali, ma anche da immagini, annotazioni visuali e schemi. L’ambiente crea UI, backend e integrazione AI in automatico, con anteprima nel browser, test mobile via QR code e codice pronto da modificare.
L’IDE web-based, costruito su CodeOSS, offre funzionalità avanzate come modifica e debug nel browser, terminale integrato, suggerimenti di codice con Gemini e documentazione automatica. Il tutto gira su una VM configurabile con Nix, con supporto a oltre 60 modelli ufficiali e l’importazione da GitHub, GitLab e Bitbucket.
Test su AI Overviews di Google
In questo test, in una SERP di Google in cui compare AI Overviews, ho considerato i contenuti nelle prime 12 posizioni e ho creato un piccolo RAG usando LangChain, Chroma DB e GPT-4o.
Inviandolo la query al RAG, ottengo una risposta simile a quella proposta da AI Overviews.
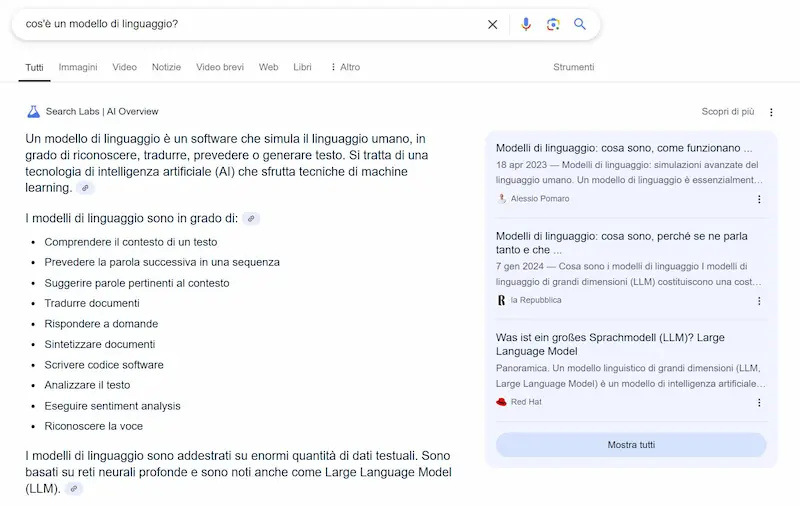
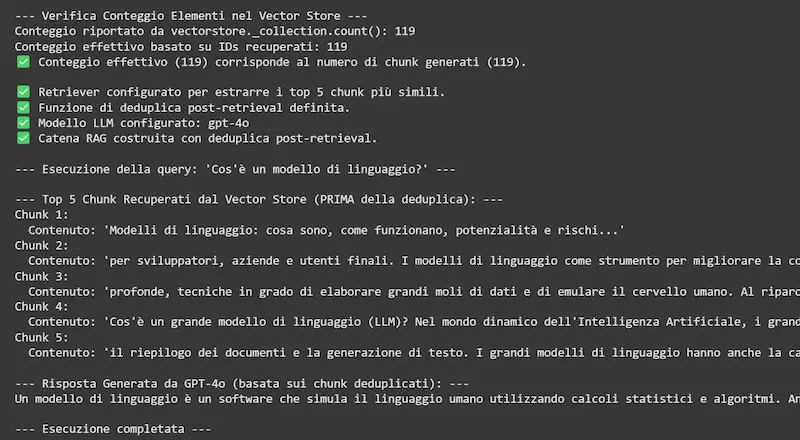
Test su AI Overviews di Google: RAG
Chiaramente Google usa anche query correlate ("fan-out") e il Knowledge Graph per espandere i risultati.
Quindi, il funzionamento l'abbiamo intuito, e possiamo anche pensare di usare dei modelli per misurare la pertinenza dei contenuti alle query per ragionare sul "posizionamento" su AI Overviews.
Chiaramente, il primo step rimane l'essere tra i risultati rilevanti, che rappresentano la knowledge a disposizione del "RAG".
Come essere presenti su AI Overviews
Per essere presenti nelle fonti delle risposte di AI Overviews (ma in generale nei sistemi ibridi come ChatGPT, Perplexity, ecc.), vanno considerati due aspetti.
- Essere tra i risultati che il sistema prende in considerazione per la query principale (quella che scriviamo nel campo): tendenzialmente le prime due pagine dei risultati, compresi PAA e SERP snippet.
- Intercettare risposte pertinenti (semanticamente vicine) alla query principale o a quelle secondarie che il motore genera per quel contesto ("fan-out").
È come ragionare su un sistema RAG, in cui ogni documento è di un'azienda diversa.
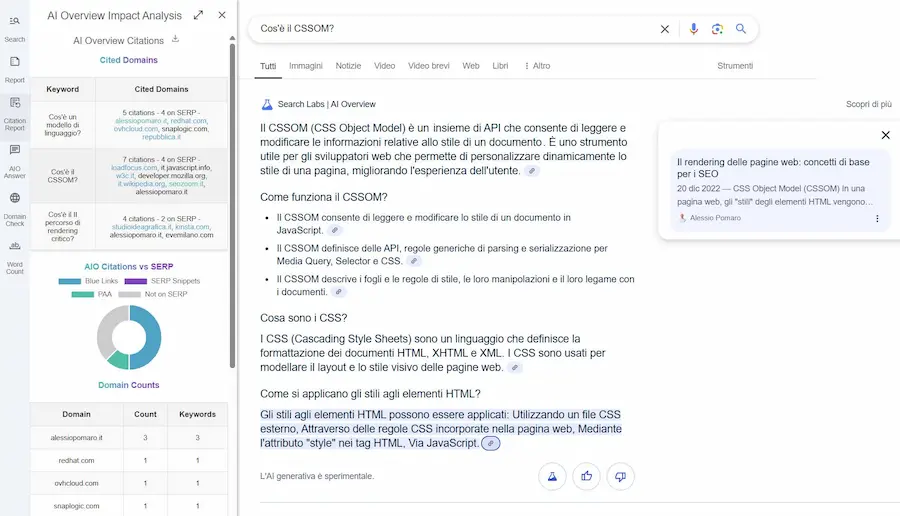
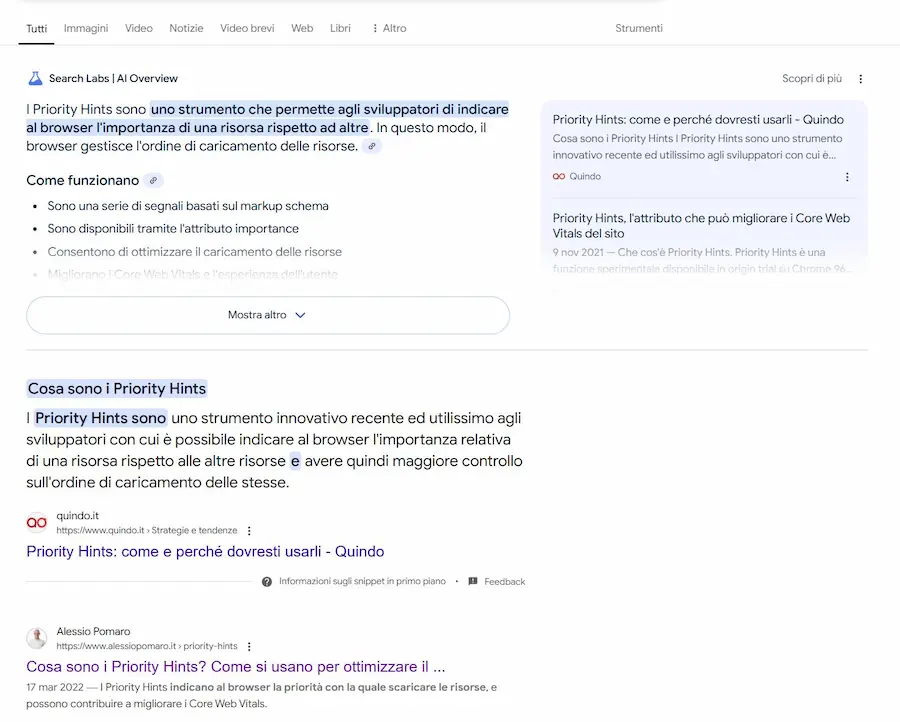
Test su AI Overviews di Google: query
Per la query "cos'è il CSSOM", ad esempio, il mio contenuto è in seconda pagina della SERP (è tra i risultati presi in considerazione), e intercetta la risposta ad una query secondaria ("come si applicano gli stili agli elementi HTML").
Ma se si cerca direttamente la query secondaria, il mio contenuto non è tra le fonti di AI Overviews, perché il contesto cambia, ed esistono molte fonti più rilevanti per questa query.
Per la query "cosa sono i priority hints", il mio risultato è primo su Google, ma non compare tra le fonti di AI Overviews. Misurando la pertinenza semantica del mio contenuto con un algoritmo, infatti, risulta inferiore a quella dei risultati che invece compaiono.
Si tratta di un sottile equilibrio, non semplice da gestire e da controllare.
Agent2Agent (A2A) e Agent Development Kit (ADK) di Google
Google presenta Agent2Agent (A2A), un protocollo aperto per l'interoperabilità tra agenti AI, sviluppato in collaborazione con oltre 50 aziende (es. Atlassian, MongoDB, PayPal, Salesforce, SAP, Langchain).
A2A consente agli agenti AI, anche se costruiti con tecnologie o da fornitori diversi, di comunicare, coordinarsi e scambiarsi informazioni in modo sicuro.
È pensato per scenari enterprise complessi: dalla gestione della supply chain alla selezione del personale, fino all'automazione dei flussi di lavoro interni.
Un esempio concreto: la ricerca dei candidati
Basato su standard diffusi (HTTP, JSON-RPC, SSE), A2A supporta task rapidi o di lunga durata, anche multimodali (testo, audio, video). Ogni agente può esporre le proprie capacità tramite una “Agent Card” e collaborare con altri per completare compiti condivisi, producendo artefatti come risultati finali.
Complementare al Model Context Protocol (MCP) di Anthropic, A2A punta a rendere gli agenti realmente interoperabili, scalabili e integrabili in ambienti già esistenti.
Un passo chiave per costruire un ecosistema in cui gli agenti AI non siano strumenti isolati, ma veri colleghi digitali capaci di collaborare in tempo reale.
A supporto dello sviluppo di AI agent interoperabili, Google ha rilasciato anche l’Agent Development Kit (ADK), un toolkit open-source in Python per costruire, testare e distribuire agenti complessi, modulari e orchestrabili. Con ADK, gli sviluppatori possono definire logiche, strumenti e workflow direttamente da codice, integrandoli con Google Cloud, Vertex AI o ambienti locali.
PySpur: AI Agent Workflow
PySpur è una nuova libreria open source che consente di creare workflow di AI Agent attraverso un'interfaccia drag & drop.
PySpur: AI Agent Workflow
Semplifica la creazione, il test e il deploy di agenti, riducendo i tempi di sviluppo. Si installa in pochi secondi con pip, permette l’aggiunta di tool personalizzati e l’esportazione degli agenti in JSON.
Google Ironwood
Google ha presentato Ironwood, la sua settima generazione di TPU (Tensor Processing Unit), progettata specificamente per l’inferenza nell’era dell’AI generativa. Ironwood è pensata per gestire modelli di "reasoning", come i LLM e le Mixture of Experts (MoE), offrendo prestazioni senza precedenti.
Tra le caratteristiche principali..
- Fino a 9.216 chip per pod, raggiungendo 42,5 Exaflops, più di 24 volte la potenza del supercomputer El Capitan.
- Miglioramenti significativi in memoria (192 GB HBM per chip) e velocità di interconnessione tra chip (1,2 Tbps).
- 2x più efficiente dal punto di vista energetico rispetto alla generazione precedente (Trillium).
- Supporta carichi di lavoro AI intensivi con alta efficienza e scalabilità.
- Utilizza la piattaforma software Pathways per facilitare l’elaborazione distribuita su larga scala.
Google Ironwood
Ironwood si inserisce nell’architettura AI Hypercomputer di Google Cloud, diventando la base per nuovi progressi nel campo dell’AI, tra cui modelli come Gemini 2.5 e AlphaFold.
L'infrastruttura hardware sarà il fattore differenziante nel prossimo futuro?
OpenAI presenta le "Evals" API
Permettono di definire dei test, e di valutare rapidamente i prompt automatizzando le esecuzioni.
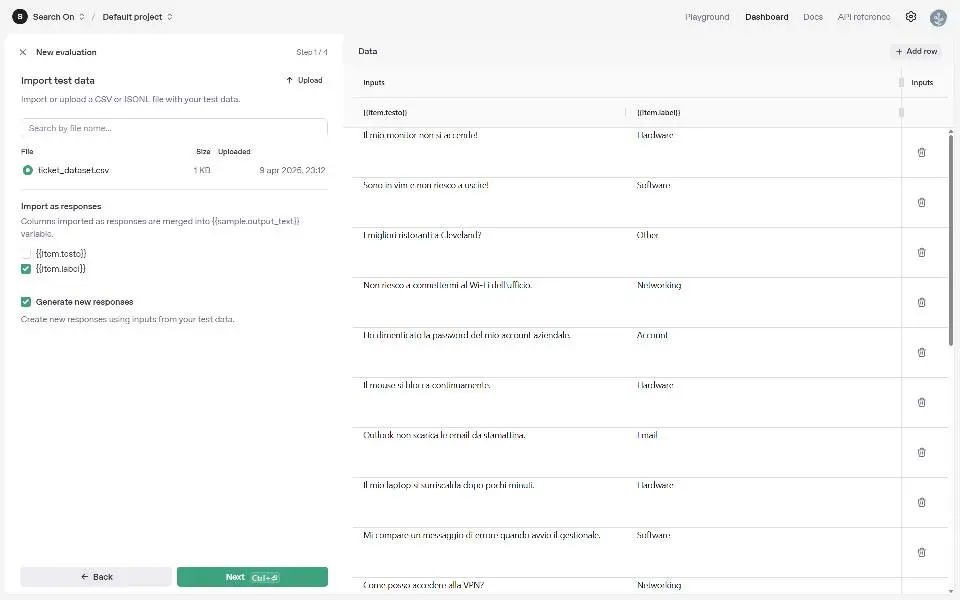
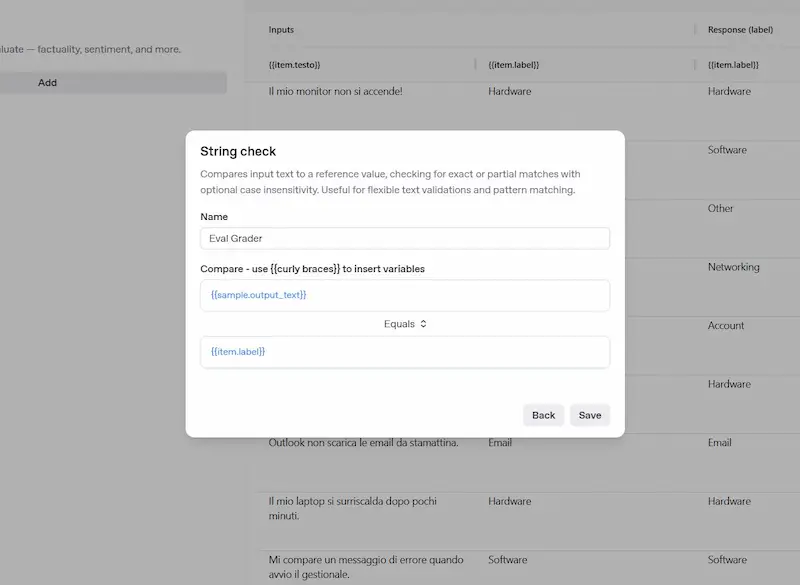
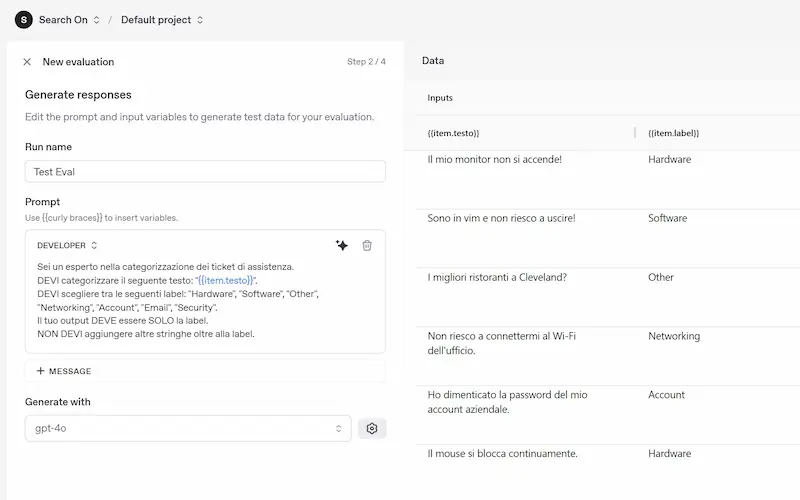
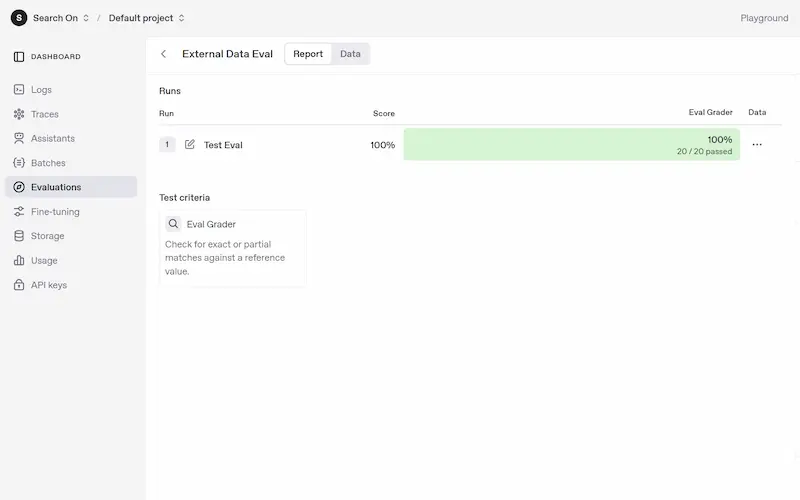
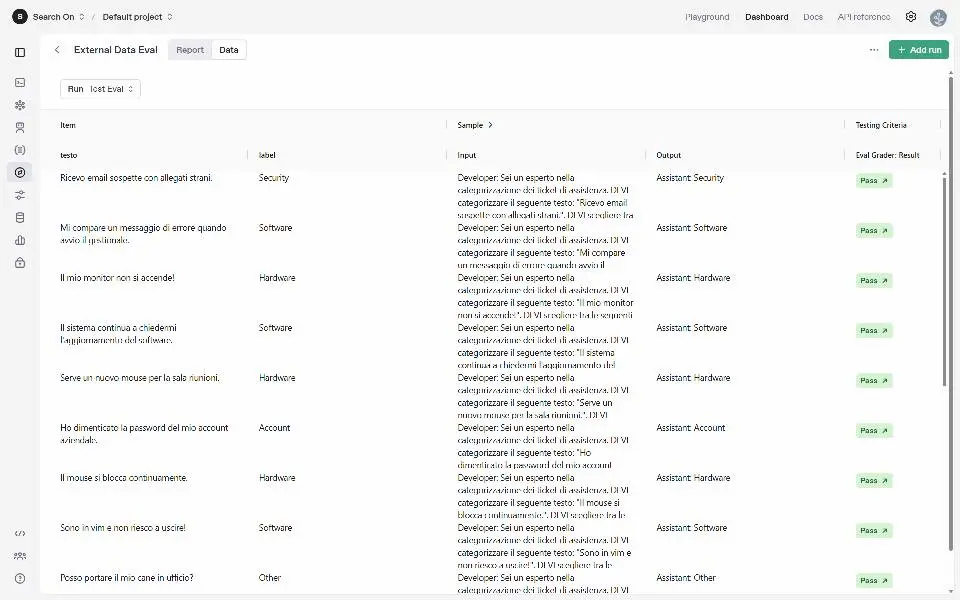
OpenAI presenta le "Evals" API: un test
Nell'esempio ho caricato nel Playground un CSV contenente stringhe e label. Successivamente ho configurato il test, creando un prompt dinamico che si valorizza attraverso i dati del CSV. L'ultimo ingrediente è un "grader" per valutare le risposte del modello in base a un criterio che possiamo definire.
Il sistema esegue automaticamente tutti i prompt e possiamo valutare il risultato del test.
Il tutto, completamente realizzabile via API: questo permette di creare procedure di test per diverse versioni di prompt.
Copilot Search
Bing lancia la risposta a AI Mode di Google: Copilot Search.
Il funzionamento è molto simile: l'utente può porre una domanda, il sistema usa il reasoning per espandere la ricerca, estrae le fonti, e compone una risposta usando un LLM.
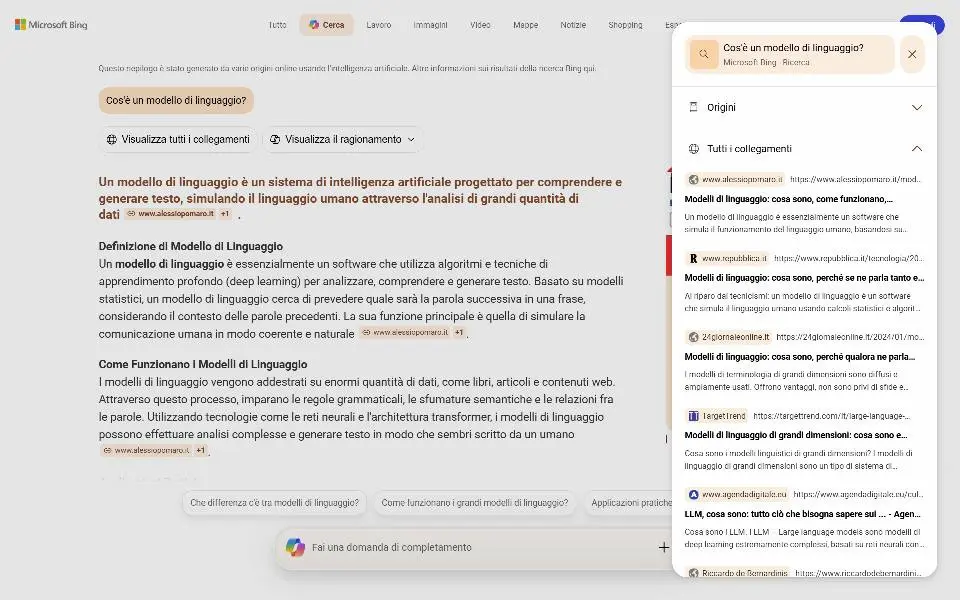
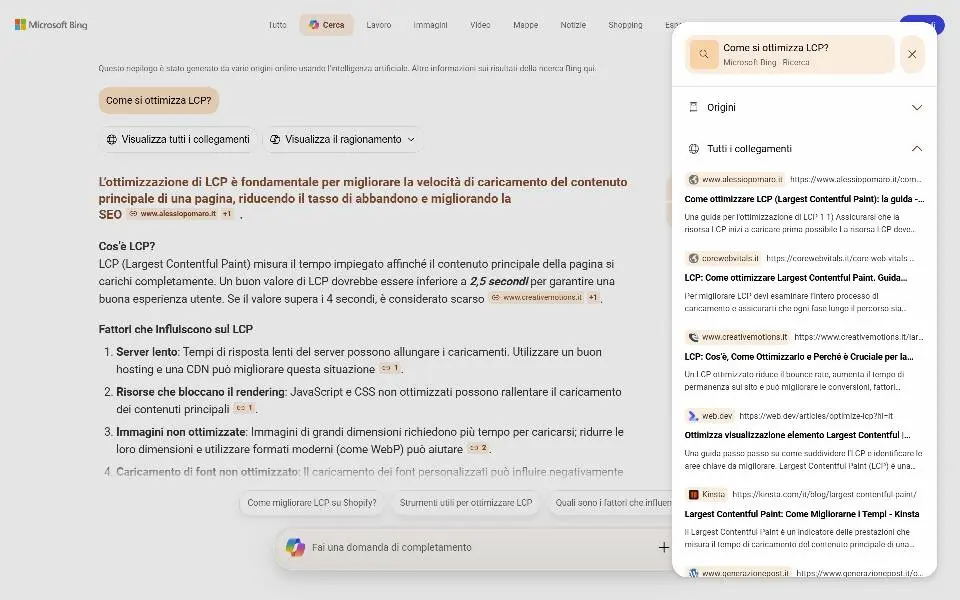
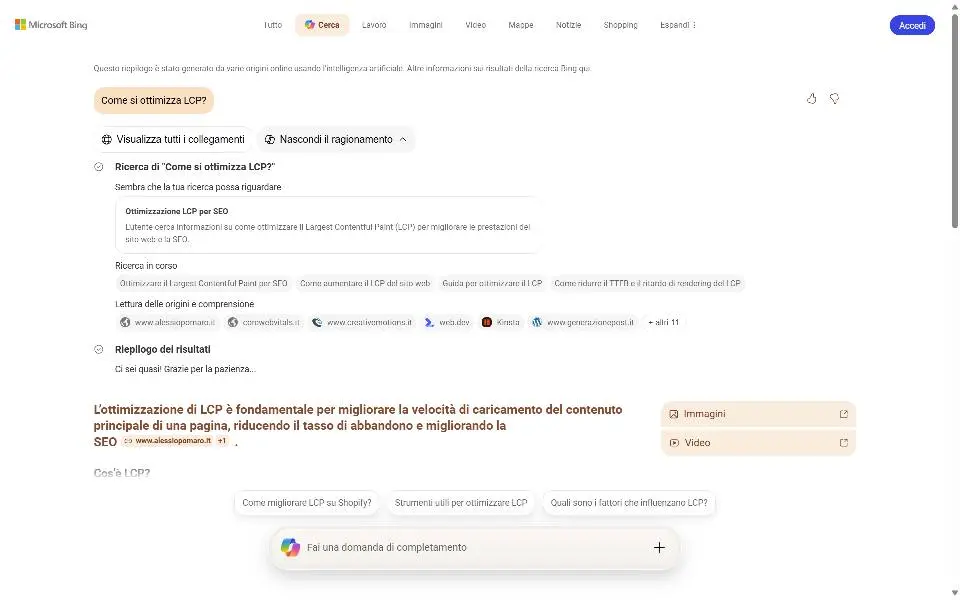
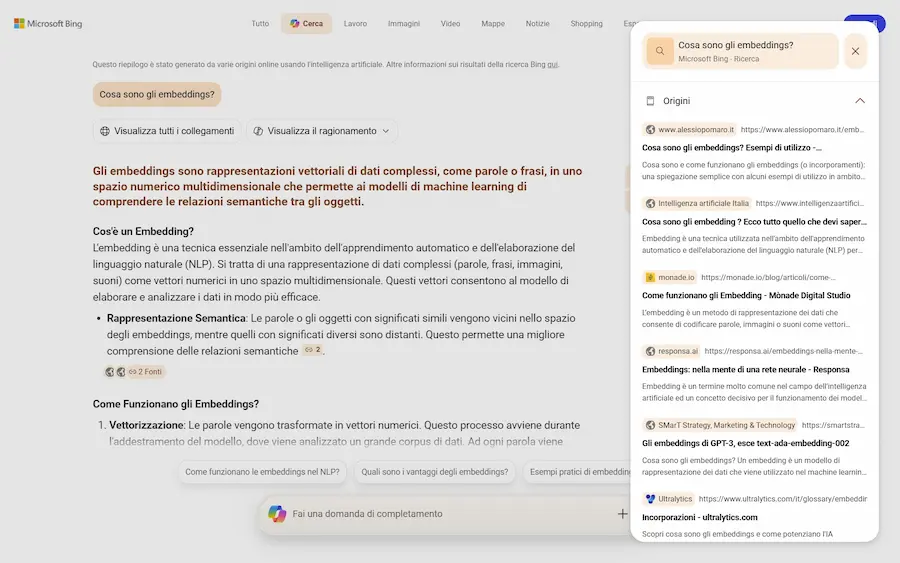
Copilot Search di Bing
È possibile visualizzare il "ragionamento" e le query correlate. Tutte le fonti sono consultabili. Successivamente permette delle ricerche di follow-up.
MCP (Model Context Protocol): un test
Un test in cui un Agente basato su o3 di OpenAI accede a file in locale attraverso il protocollo MCP (Model Context Protocol).
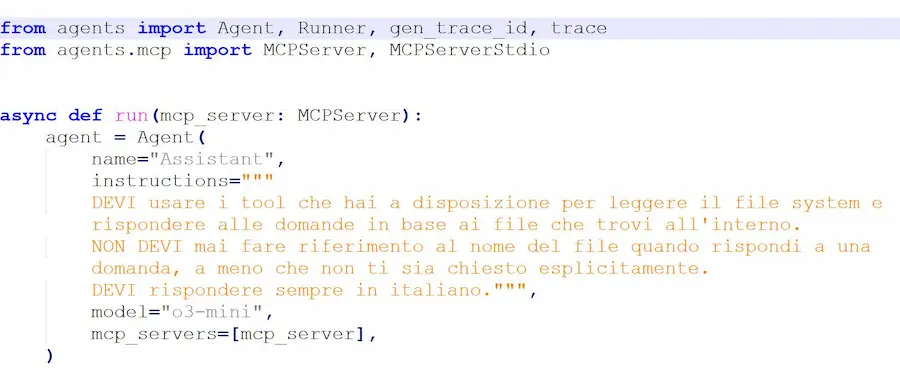

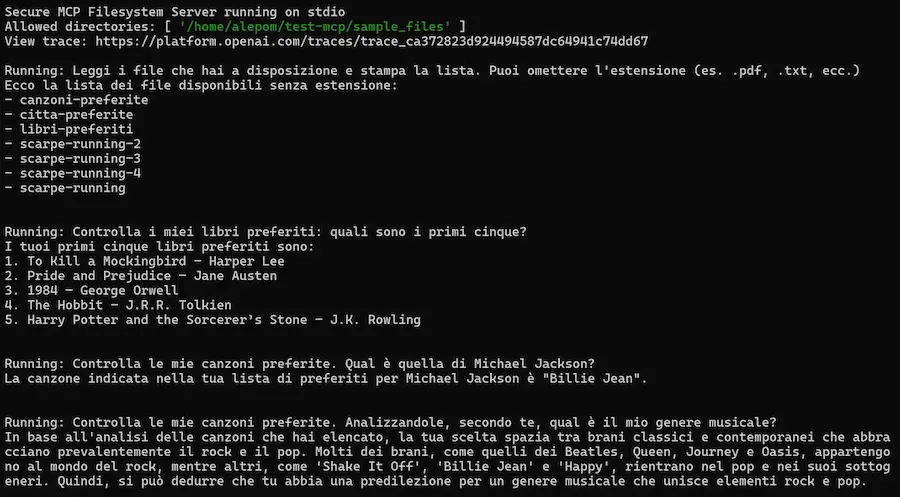
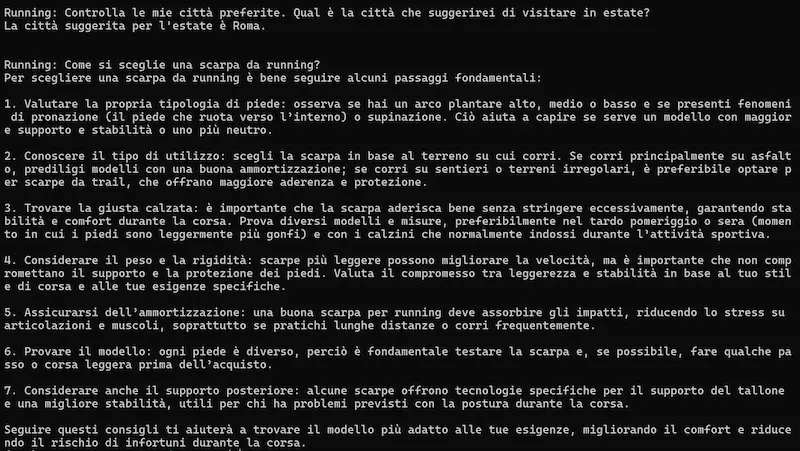
MCP (Model Context Protocol): un test
Come funziona?
Ho implementato un server MCP che può effettuare diverse operazioni sul filesystem locale del mio laptop, e l'agente è connesso a quel server.
Quando faccio richieste all'agente (che usa o3-mini via API), il sistema accede ai file in locale e cerca le informazioni necessarie per rispondere. Infine restituisce la risposta.
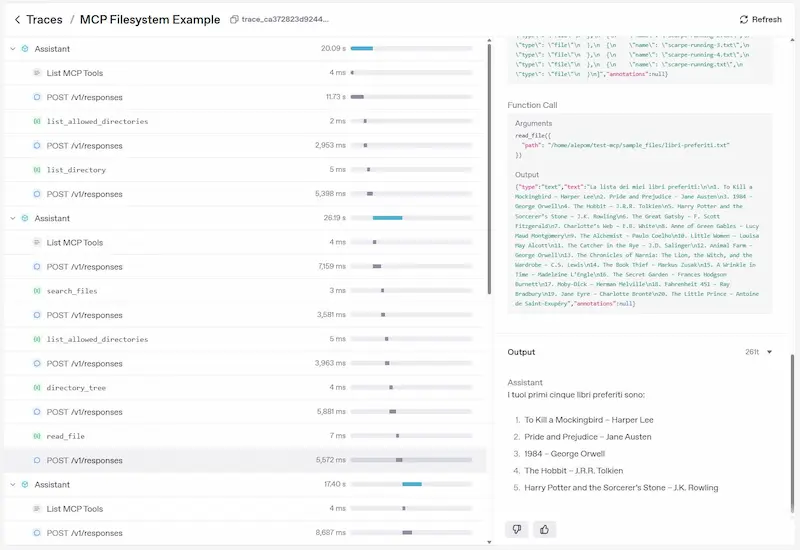
Nell'area di tracciamento del Playground di OpenAI è possibile monitorare tutte le operazioni compiute dall'agente.
MCP permette di creare applicazioni basate sui LLM che accedono a dati, software esterni e potenzialmente qualunque sistema. Questo apre la strada ad automazioni davvero interessanti.
Gemini Live: condivisione schermo e videocamera
Su Gemini Live è disponibile anche in Italia la funzionalità di condivisione in real time dello schermo e della videocamera.
Nel video, condivido lo schermo del mio dispositivo con l'assistente e interagisco attraverso la voce chiedendo informazioni su ciò che sto vedendo.
Gemini Live: condivisione schermo
Queste funzionalità fanno comprendere il grande potenziale di interazione di questi sistemi con il mondo reale.
Claude for Education
Claude for Education è il nuovo progetto di Anthropic pensato per rivoluzionare il mondo universitario con l’AI. Grazie alla modalità Learning Mode, Claude stimola il pensiero critico degli studenti invece di fornire risposte pronte, utilizzando domande socratiche e strumenti strutturati per lo studio.
Partnership con università come Northeastern, LSE e Champlain College portano l'intelligenza artificiale in aula e negli uffici amministrativi, aiutando studenti, docenti e staff a lavorare in modo più efficace e intelligente.
Con programmi dedicati agli studenti, API gratuite per progetti innovativi e integrazione nei principali sistemi educativi come Canvas LMS, Claude si afferma come un alleato concreto per un'educazione del futuro, costruita su responsabilità, accessibilità e innovazione.
Runway Gen-4
Runway ha presentato Gen-4, il nuovo modello dedicato ai contenuti visivi.
Consente la generazione di immagini e video mantenendo coerenza tra personaggi, oggetti e ambientazioni anche in scenari complessi.
Utilizza riferimenti visivi e istruzioni testuali per produrre contenuti uniformi in termini di stile, composizione e prospettiva, senza necessità di ulteriori addestramenti.
Runway Gen-4: presentazione
Tutti i brand che sviluppano modelli stanno creando piattaforme in grado di generare sia immagini che video, in modo da dare un'unica soluzione agli utenti.
Nella presentazione parlano anche di "simulazione fisica".. su questo non sono molto convinto, ma di certo i miglioramenti sono incredibili.
Flora: diversi modelli in un unico ambiente
Flora è un esempio di strumento che riunisce diversi modelli visuali in un unico ambiente consentendo sperimentazione e prototipazione rapida.
Un esempio di utilizzo di Flora
Nell'esempio si vede un progetto che parte da un'immagine generata da prompt testuale usando Flux Pro. Vengono create diverse inquadrature con prompt multimodale con Gemini 2.0 Flash. Infine le clip video usando Ray2 di Luma: da prompt + immagine, ma anche con prompt + due frame.
Tra i vari modelli sono a disposizione anche Flux Dev, Ideogram, Stable Diffusion, Photon di Luma, Kling e Runway.
Un tool davvero interessante, e la coerenza delle immagini è notevole.
Seaweed: un modello da 7B di parametri che compete con i giganti
Seaweed 7B è un nuovo modello da 7 miliardi di parametri capace di competere con giganti del settore, ma con una frazione delle risorse.
Seaweed: un nuovo modello di generazione video
Addestrato con "sole" 665.000 ore di GPU H100, raggiunge livelli di qualità visiva, fedeltà al prompt e coerenza narrativa che lo pongono tra i migliori sistemi di generazione video.
Con il supporto a testo, immagini e audio, Seaweed-7B genera video realistici, coerenti e controllabili fino a 720p in tempo reale. Il suo design include un VAE 3D causale e un Diffusion Transformer ottimizzato per performance e scalabilità, riducendo drasticamente i costi computazionali.
Come abbiamo detto più volte, la scala non può essere l'unica leva per migliorare le performance dei modelli. Ora serve evoluzione architetturale, e questo è un esempio.
UI-TARS-1.5 di ByteDance
ByteDance ha rilasciato UI-TARS-1.5, un agente multimodale basato su Qwen2.5-VL-7B che unisce visione e linguaggio con "reasoning".
Il modello valuta prima di agire, migliorando l’esecuzione dei task in ambienti complessi. Brilla nei benchmark GUI, superando modelli come Claude 3.7 e OpenAI CUA in compiti su desktop e browser. Ottimi risultati anche in giochi web, grazie a una forte capacità di pianificazione a lungo termine.
Si distingue nella navigazione web con performance superiori in SimpleQA e BrowseComp, gestendo con precisione interazioni real-time su interfacce grafiche.
In ambienti 3D come Minecraft, batte agenti top usando input visivi e controlli nativi, migliorando le decisioni grazie al suo modulo di “pensiero prima dell’azione”.
Midjourney V7
Midjourney mancava da tempo in ambito di rilasci, ma ora annuncia la versione V7 del suo modello, attualmente in fase Alpha. Più intelligente nell’interpretazione dei prompt testuali, offre una qualità visiva superiore e migliora drasticamente la coerenza nei dettagli di corpi, mani e oggetti.
V7 introduce per la prima volta la personalizzazione del modello attiva di default, che si sblocca in circa 5 minuti. Questa funzione mira a interpretare meglio ciò che l’utente desidera e trova visivamente affascinante.
Grande novità è anche il Draft Mode, che consente rendering 10 volte più veloci al 50% del costo. È pensato per esplorare idee in modo rapido: le immagini sono a qualità ridotta, ma esteticamente coerenti. È disponibile anche una modalità vocale per iterare i prompt in modo conversazionale.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂