Generative AI: novità e riflessioni - #4 / 2026
Dai nuovi modelli agli agenti operativi: GPT-5.5, Claude Opus 4.7, Mythos, Gemma 4, DeepSeek V4, Kimi K2.6 e Gemini Agent spingono autonomia, coding, cybersecurity, video, robotica e scienza verso sistemi AI sempre più integrati nei workflow reali.

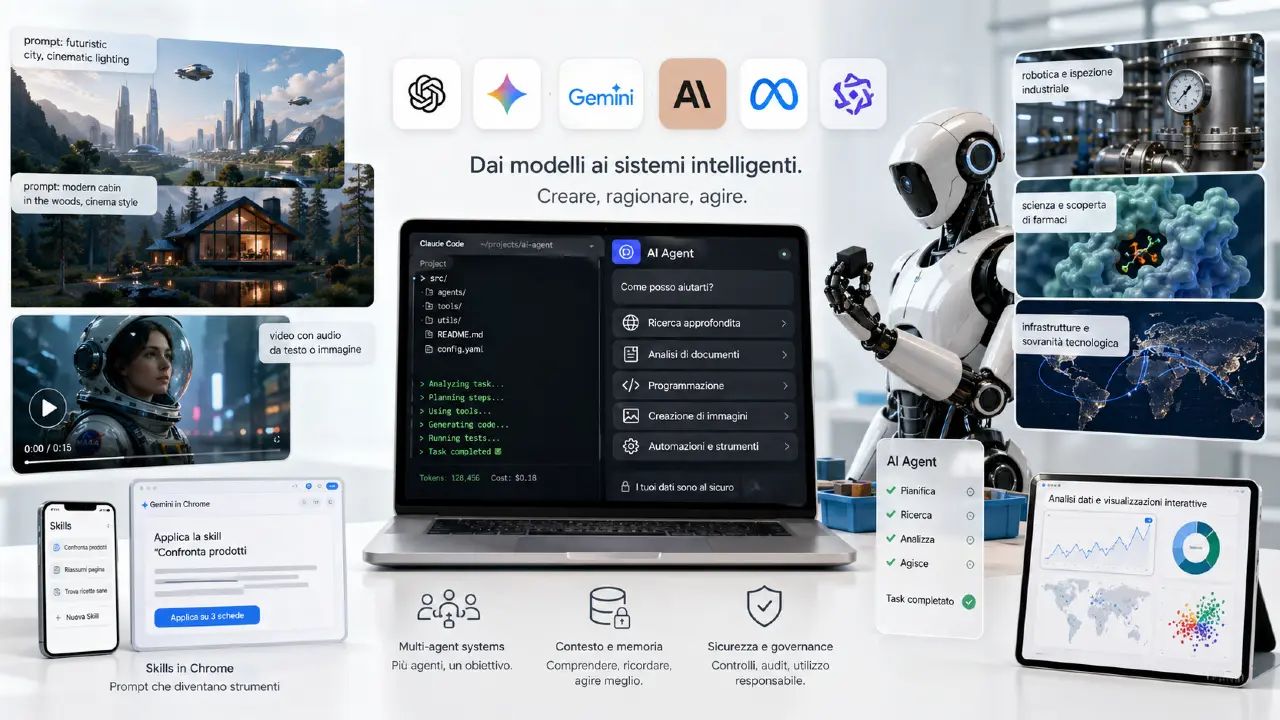
Buon aggiornamento, e buone riflessioni..
Ascolta l'audio overview che sintetizza le novità
Il podcast è stato generato attraverso NotebookLM.
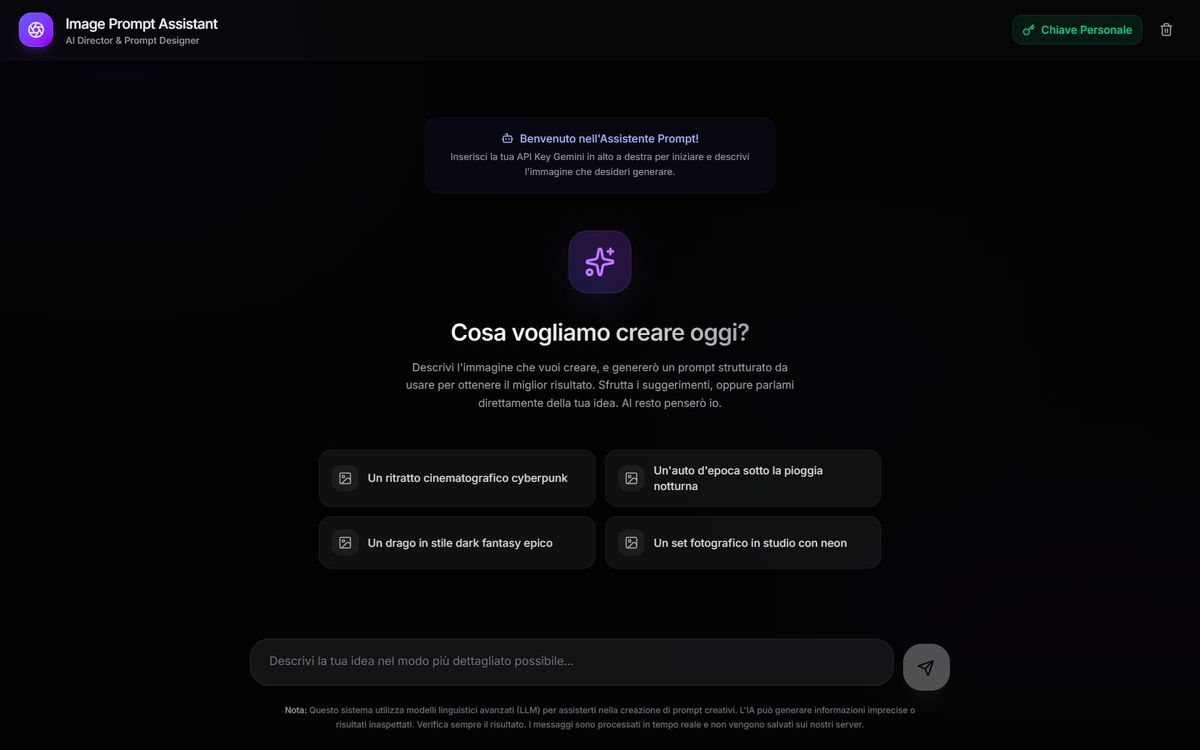
Prompt engineering: due nuovi tool
Ho sviluppato due nuovi tool (in beta) per l'ottimizzazione dei prompt per la generazione di immagini e video. Li sto usando per ogni contenuto visivo che genero su diversi modelli.
Image Prompt Assistant
Video Prompt Assistant
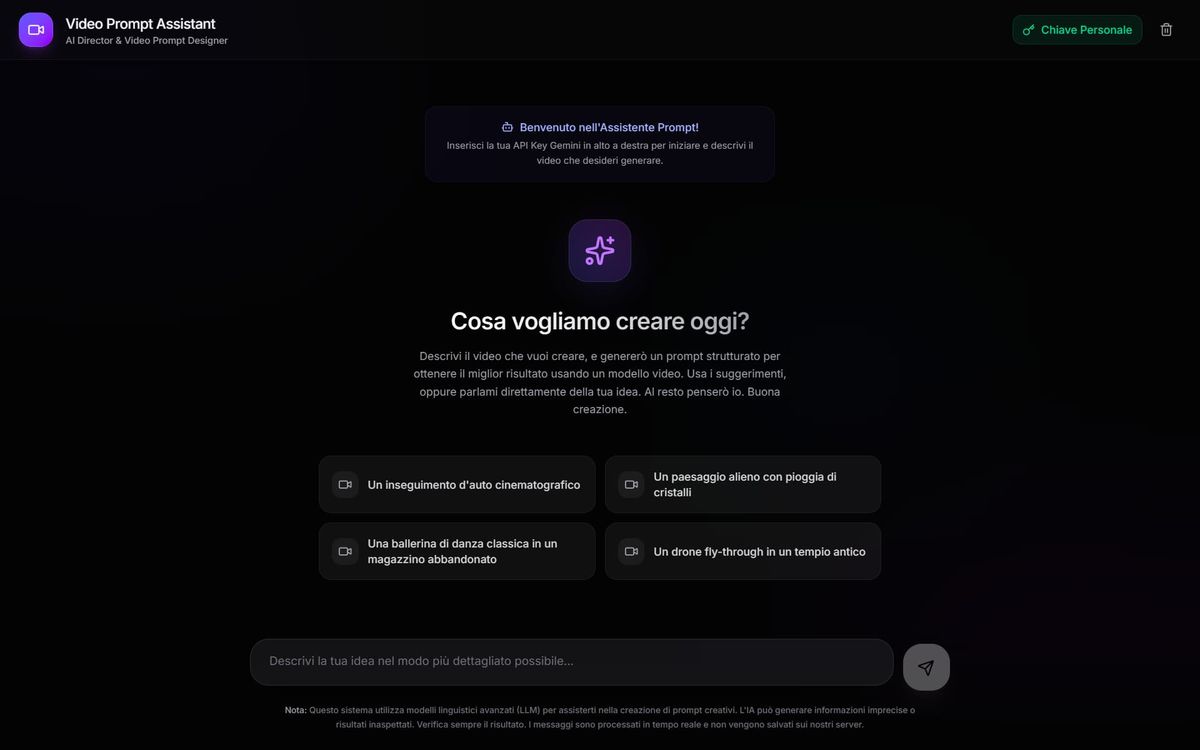
Descrivendo l'idea di immagine o video nel box è possibile generare un prompt professionale e dettagliato pronto da usare su qualsiasi modello generativo.
GPT Image 2 di OpenAI
OpenAI ha finalmente rilasciato l'atteso GPT Image 2, il nuovo modello di generazione immagini, che promette un miglioramento importante.
L'ho provato a confronto con Nano Banana Pro (nelle immagini si vedono alcuni esempi). Ho usato lo stesso prompt per entrambi i modelli. Direi che il miglioramento è netto, con un avvicinamento chiaro al modello di Google (che probabilmente, però, a breve verrà aggiornato).


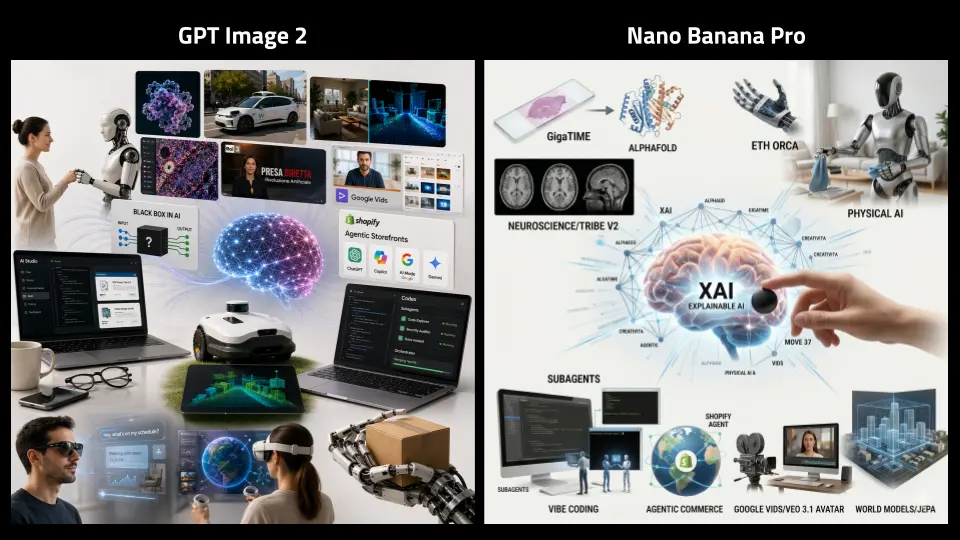


GPT Image 2: un test a confronto con Nano Banana Pro
La mia app per l'ottimizzazione dei prompt per le immagini (nuova versione):
Uno dei miglioramenti più evidenti riguarda il controllo e la fedeltà. GPT Image 2 riesce a mantenere dettagli specifici, piccoli testi, icone e interfacce, e a rispettare vincoli stilistici anche complessi, arrivando fino a risoluzioni elevate (fino a 2K via API). Il risultato è un’immagine che corrisponde davvero all’intento iniziale.
Importante anche il salto nella comprensione multilingua: il modello gestisce molto meglio lingue non latine come giapponese, coreano, cinese, hindi e bengalese, generando testi coerenti e integrati nel design, non semplici traduzioni isolate.
Dal punto di vista stilistico, la qualità è più consistente: fotografie più realistiche (con imperfezioni credibili), ma anche stili come manga, pixel art o cinematico vengono riprodotti con maggiore accuratezza in termini di luce, texture e composizione.
La flessibilità aumenta anche nei formati, con il supporto a diversi aspect ratio (da 3:1 a 1:3), rendendo il modello adatto a banner, poster, contenuti social, slide e mobile.
Un’altra novità chiave è l’integrazione con modelli "thinking": GPT Image 2 può cercare informazioni aggiornate sul web, generare più immagini coerenti da un singolo prompt e verificare i propri output. Questo lo trasforma in un vero partner creativo, capace di accompagnare un progetto dall’idea iniziale fino al risultato finale.
Inoltre, può produrre fino a otto immagini correlate in una sola richiesta, mantenendo continuità tra personaggi, oggetti e stile: utile per storyboard, serie di contenuti social, concept creativi o sequenze narrative.
Il modello è già disponibile per tutti gli utenti ChatGPT, Codex e via API (gpt-image-2), con funzionalità avanzate per utenti Plus, Pro e Business.
Nonostante i progressi, restano alcune limitazioni: difficoltà con rappresentazioni fisiche complesse (come origami o puzzle), dettagli estremamente densi e alcune imprecisioni in diagrammi o etichette molto tecniche.
GPT-5.5 di OpenAI
OpenAI presenta GPT-5.5, il modello più avanzato e "intuitivo".
Lo sto testando. Direi che ormai è diventato inutile commentare le performance. La velocità su task complessi è nettamente maggiore rispetto al modello precedente.
Secondo la presentazione, il modello comprende più rapidamente l’intento dell’utente e riesce a portare avanti attività complesse in autonomia: scrittura e debugging del codice, ricerca online, analisi dei dati, creazione di documenti e gestione di strumenti fino al completamento del task.
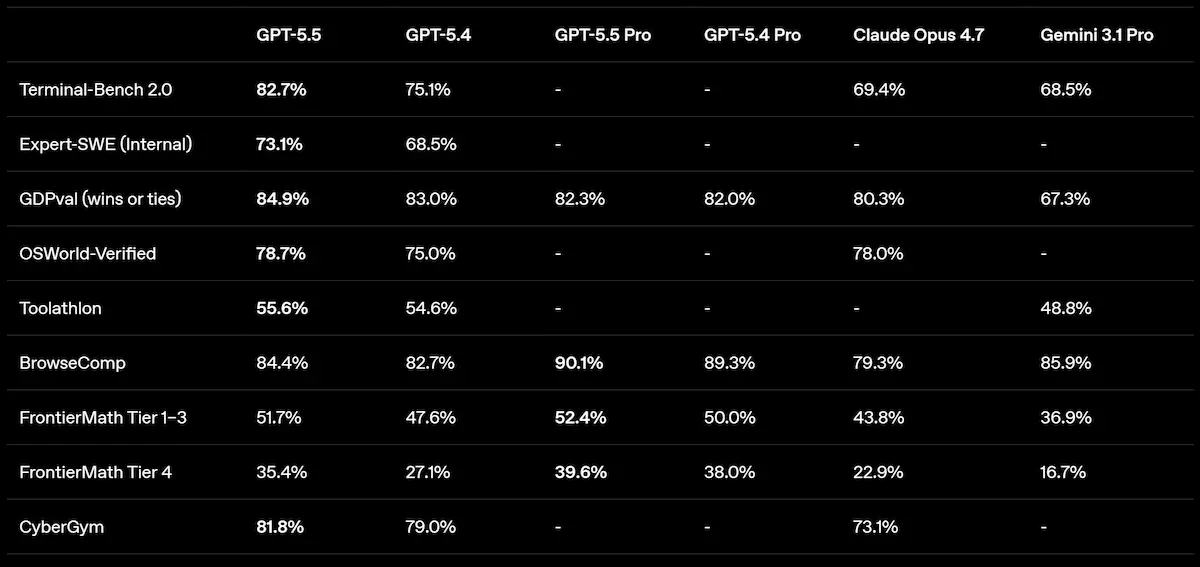
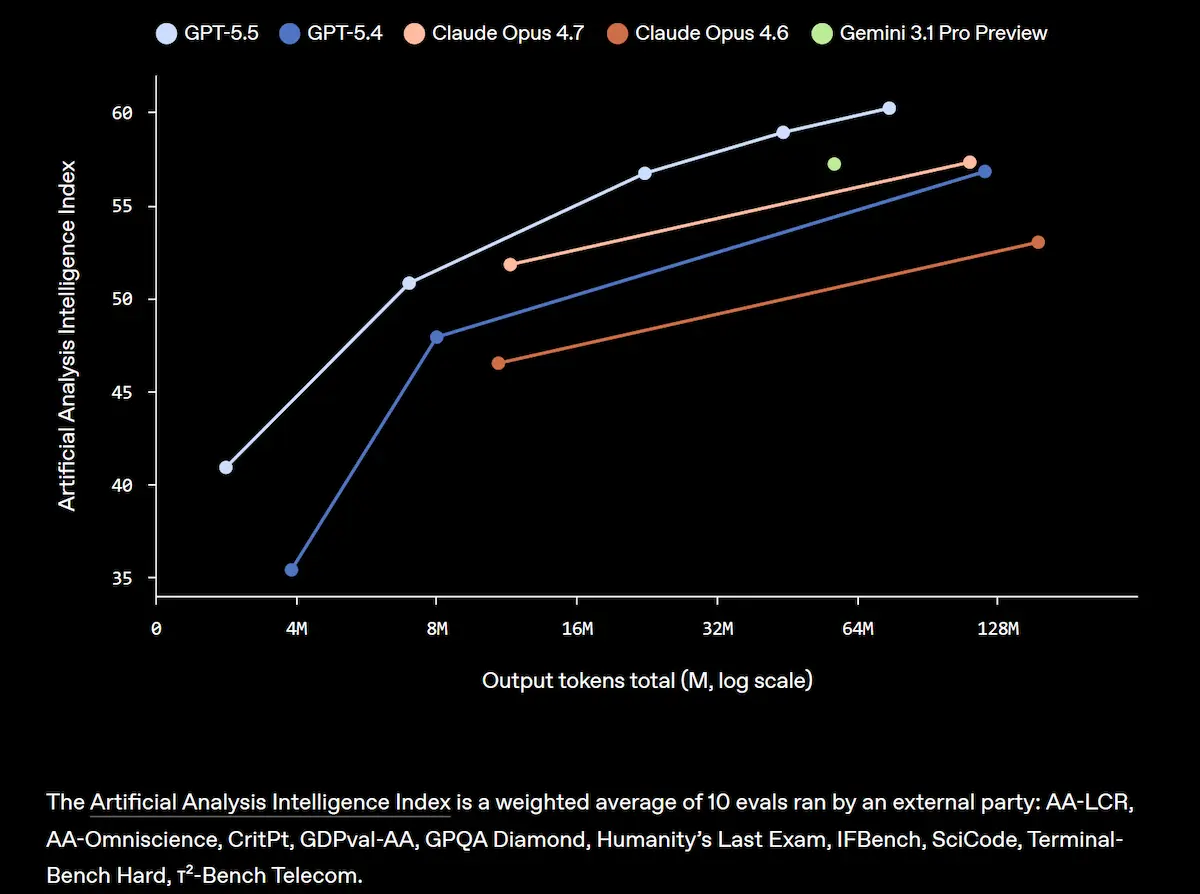
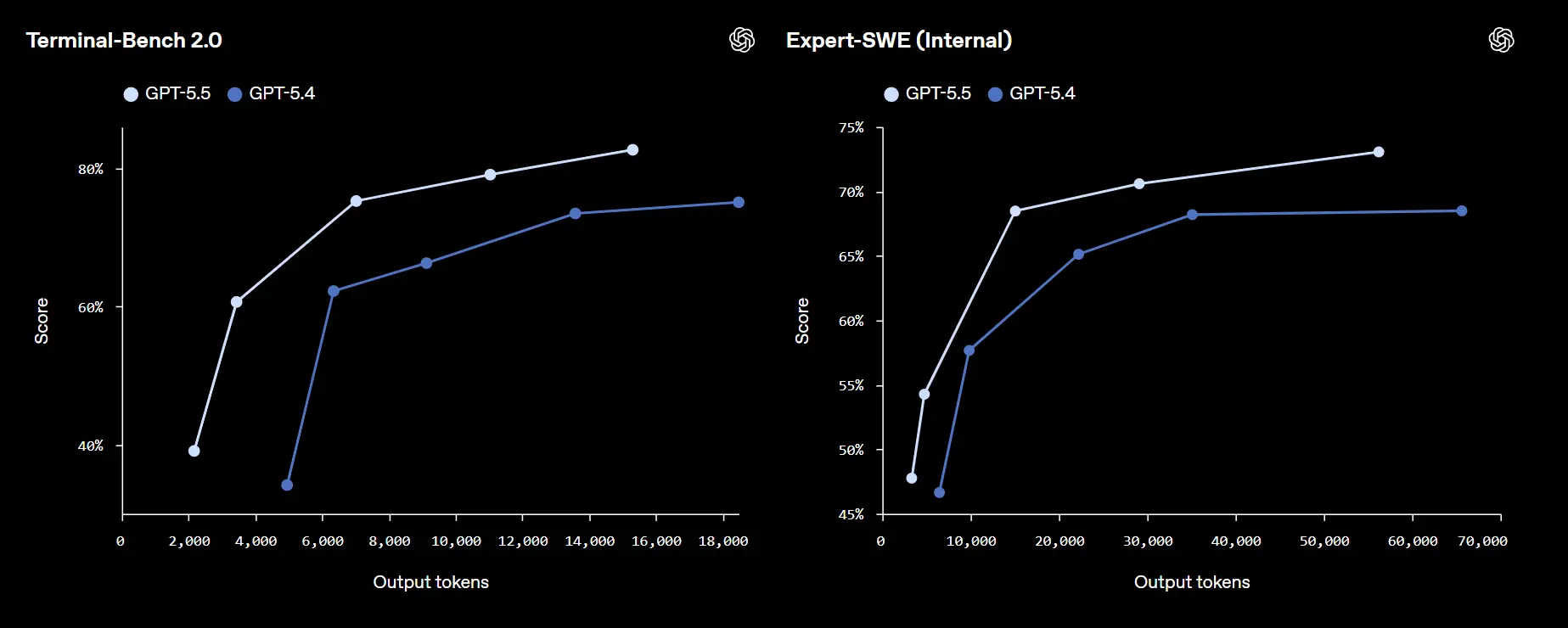
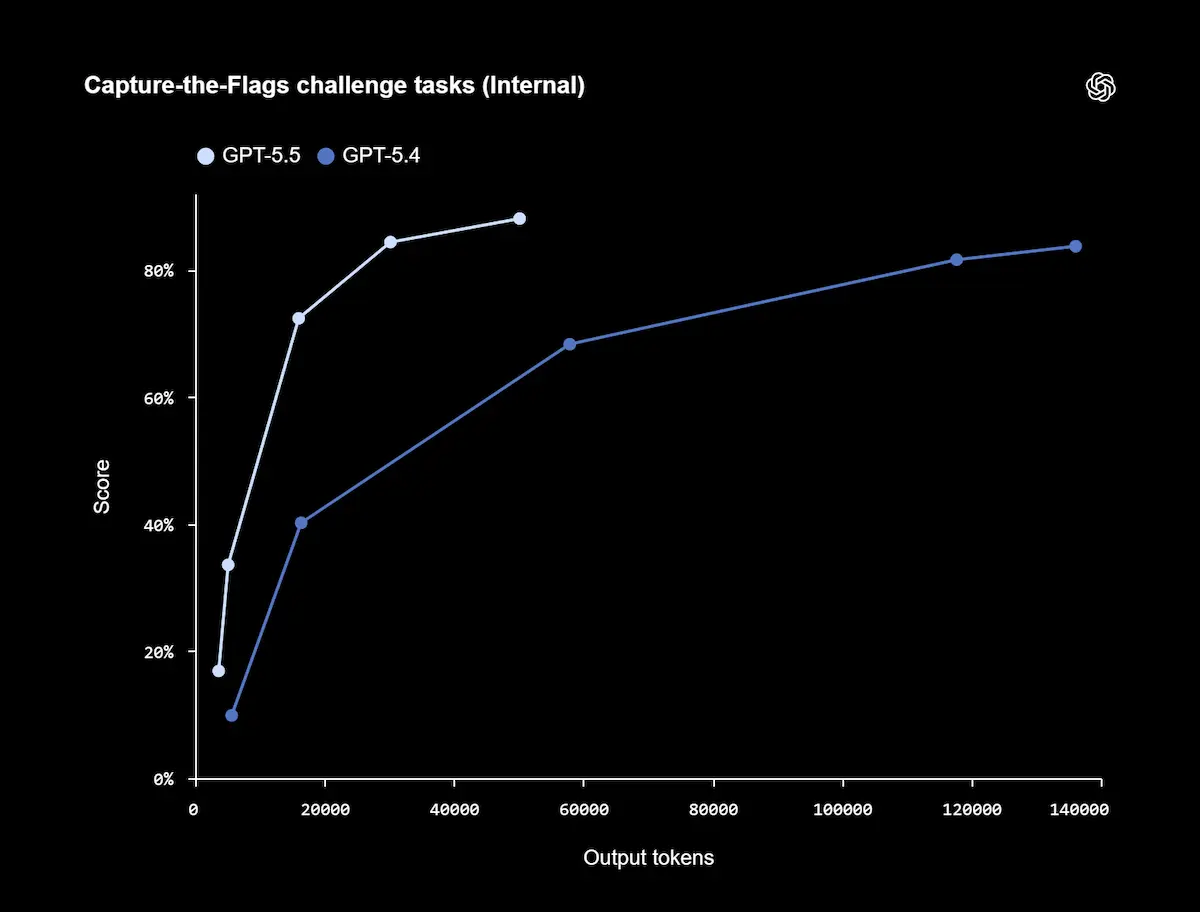
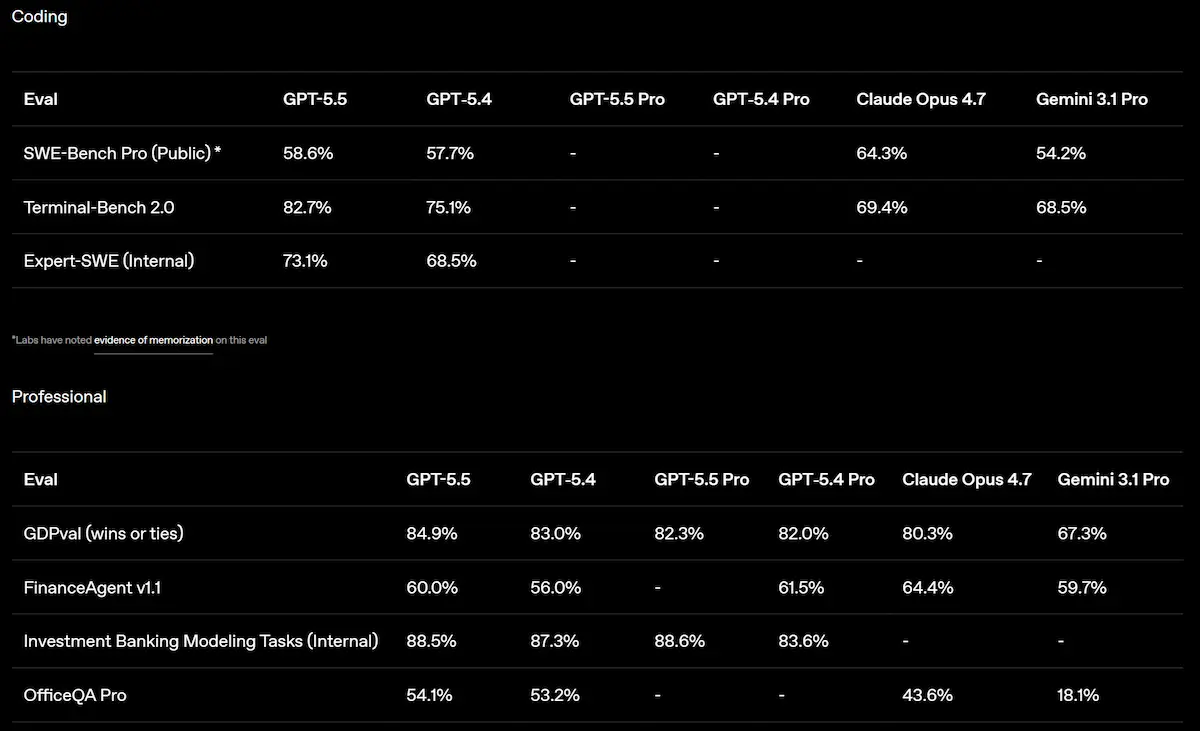
GPT-5.5 di OpenAI: performance
Anche richieste articolate e poco strutturate vengono pianificate, eseguite e verificate direttamente dal modello.
I miglioramenti sono particolarmente evidenti nel coding agentico, nell’uso del computer e nei flussi di lavoro basati sulla conoscenza, dove è fondamentale ragionare su più livelli e mantenere continuità nel tempo.
Nonostante l’aumento di capacità, GPT-5.5 mantiene la stessa latenza di GPT-5.4, risultando allo stesso tempo più veloce, più efficiente e meno costoso in termini di token.
Sul piano delle performance, il modello raggiunge risultati state-of-the-art in diversi benchmark chiave, con progressi significativi nella risoluzione di task complessi, nell’autonomia operativa e nella capacità di lavorare su sistemi estesi e ambigui. Nei contesti reali di sviluppo software, si distingue per la capacità di mantenere il contesto, anticipare problemi, verificare ipotesi e portare modifiche coerenti lungo tutto il codice.
Queste capacità si estendono anche al lavoro quotidiano: GPT-5.5 è in grado di gestire l’intero ciclo delle attività cognitive, dalla raccolta delle informazioni alla produzione di output strutturati. In ambienti come ChatGPT e Codex, può generare documenti, fogli di calcolo e presentazioni, interagendo direttamente con strumenti e interfacce.
Nella ricerca scientifica emergono progressi rilevanti: il modello è in grado di esplorare ipotesi, analizzare dati complessi e contribuire alla produzione di risultati, fino alla scoperta di nuove dimostrazioni matematiche e all’analisi avanzata in ambito biologico e bioinformatico.
GPT-5.5 introduce inoltre un livello di sicurezza ancora più avanzato, con sistemi progettati per ridurre i rischi di utilizzo improprio senza limitare gli impieghi benefici. Il modello è stato testato con framework interni ed esterni, red teaming e validazioni su casi d’uso reali prima del rilascio.
AI Index Report 2026
Stanford ha pubblicato il consueto AI Index Report 2026, che provo a sintetizzare in modo semplice.
Il quadro che emerge è quello di una tecnologia che accelera ancora, sia nelle capacità sia nella diffusione. I modelli di frontiera continuano a migliorare su coding, ragionamento, matematica e scienza, mentre cresce l’adozione da parte di aziende, studenti e consumatori.

E proprio qui si ridimensiona anche il tema del possibile plateau: più che un rallentamento, il report racconta una fase in cui contano sempre di più efficienza, qualità dei dati, pruning, curation e tecniche di post-training, cioè tutto ciò che rende i modelli migliori non solo perché più grandi, ma perché meglio costruiti.
Allo stesso tempo, però, questa crescita non è lineare. I sistemi possono raggiungere risultati straordinari in compiti molto avanzati e poi fallire su attività che, per un essere umano, sembrano elementari.
È la conferma di una frontiera ancora irregolare: grandi picchi di performance convivono con limiti molto evidenti.
E ancora una volta si arriva a una conclusione ricorrente: le performance più solide emergono quando i sistemi sono specializzati, mentre il tentativo di generalizzazione continua a mostrare fragilità, soprattutto dove servono robustezza e capacità simbolica.
Intorno a tutto questo si sta ridisegnando anche l’equilibrio competitivo globale. Il divario tra Stati Uniti e Cina si è ristretto, la competizione si gioca sempre più su infrastrutture, chip, data center ed energia, e il tema della sovranità tecnologica è ormai centrale nelle strategie nazionali.
Ma questa corsa ha anche un costo crescente: aumenta l’impatto ambientale, cresce la dipendenza da pochi attori chiave della filiera e si rafforza la concentrazione industriale.
Sul piano economico, l’AI sta già producendo valore e guadagni di produttività, soprattutto nei contesti più standardizzabili. Ma è negli stessi ambiti che iniziano a comparire segnali di tensione sul lavoro entry level.
In parallelo, governance, scuola e sistemi di sicurezza restano indietro rispetto alla velocità della tecnologia.
Demis Hassabis: i progressi nella salute umana
Demis Hassabis: se conosci la struttura di una proteina, la vera domanda diventa: dove si legherà il tuo farmaco e cosa farà realmente?
È qui che entra la prossima ondata dell’intelligenza artificiale. Non più solo previsione delle strutture, ma modellazione delle interazioni, degli esiti e dell’impatto biologico reale.
Demis Hassabis: la prossima ondata dell’intelligenza artificiale
È un cambiamento radicale nel modo in cui si costruisce la medicina. Invece di lunghi e costosi tentativi, l’AI permette di testare migliaia di ipotesi in silico, con un’efficienza centinaia o migliaia di volte superiore. Il laboratorio diventa sempre più il luogo della validazione, non più solo dell’esplorazione.
La scoperta dei farmaci sta diventando un problema computazionale: cicli più rapidi, previsioni più intelligenti e il potenziale per accelerare in modo significativo i progressi nella salute umana.
TRIBE v2 di Meta: una demo
Una demo di TRIBE v2 di Meta: mostra come il modello riesca a predire l’attività cerebrale umana in risposta a contenuti video, a confronto con dati reali.
TRIBE v2 di Meta: una demo
L'obiettivo del progetto è studiare come modelli di intelligenza artificiale possano diventare una piattaforma unificante per comprendere il cervello, aprendo la strada a una neuroscienza più integrata, scalabile e predittiva.
Ma immagino anche scenari in cui tecnologie di questo tipo possano essere usate nella creazione di contenuti digitali: affascinante dal punto di vista ingegneristico, ma con implicazioni importanti su privacy neurale e sistemi di persuasione.
TRIBE v2 è un modello multimodale (video, audio e linguaggio), addestrato su oltre 1000 ore di dati fMRI provenienti da 720 soggetti, capace di prevedere le risposte cerebrali con prestazioni significativamente superiori ai modelli tradizionali, anche su nuovi soggetti ed esperimenti.
Dario Amodei: le dinamiche cruciali dell'AI per i prossimi anni
In una recente e interessante intervista, Dario Amodei ha raccontato la sua visione sulle dinamiche cruciali dell'AI per i prossimi anni.
Il progresso dell'intelligenza artificiale sta seguendo una traiettoria esponenziale, ancora poco compresa dal pubblico, guidata dalla scalabilità della potenza di calcolo, dall’enorme quantità di dati e dall’apprendimento per rinforzo.
Dario Amodei: le dinamiche cruciali dell'AI per i prossimi anni
Questa curva ci sta portando rapidamente verso quello che viene definito "un paese di geni in un data center", una forma di superintelligenza potenzialmente raggiungibile entro tre anni.
Tuttavia, lo sviluppo tecnologico non si tradurrà subito in cambiamenti globali per via della "diffusione economica". L’adozione reale sarà rallentata da ostacoli strutturali come approvazioni normative e cliniche, oltre alle lentezze di integrazione e burocrazia aziendale.
Questo sfasamento tra capacità tecnologica e assorbimento del mercato genera un paradosso e un rischio finanziario rilevante. I laboratori di IA devono investire enormi capitali in anticipo per restare competitivi, ma un errore anche minimo sulla domanda futura può esporli a seri rischi.
La gestione di questa accelerazione è anche una sfida geopolitica. Se regimi autoritari acquisissero un vantaggio, potrebbero emergere sistemi di controllo difficili da contrastare. È quindi cruciale che le democrazie mantengano la leadership e definiscano le regole dell’era post-AI.
Questo si riflette anche nell’approccio "Constitutional AI", che punta ad allineare i modelli tramite principi solidi piuttosto che regole rigide.
Infine, sostenere una trasformazione così profonda richiede organizzazioni coese. Trasparenza radicale e comunicazione continua diventano essenziali per mantenere allineate migliaia di persone davanti a un cambiamento storico imminente.
Seedance 2.0 di ByteDance
Primi test di Seedance 2.0.
Come sempre, ormai, è inutile dire che il livello generale si è alzato enormemente.
Il grado di aderenza al prompt è altissimo, e ci si può spingere nei dettagli.
Seedance 2.0 di ByteDance: un test
La coerenza con gli elementi di "reference" è sempre più affidabile.
Come ho realizzato il video?
Ho generato il prompt per il video con il mio "Video Prompt Assistant".
Ogni dettaglio della scena viene descritto dal prompt, anche attraverso una timeline precisa dei 15 secondi.
Un test di coerenza con i riferimenti visuali
In questo esempio ho usato la mia immagine di profilo come referenza. Il resto della scena viene descritto dal prompt testuale.
Seedance 2.0: la coerenza con i riferimenti visuali
Il risultato sembra abbastanza coerente.
Mythos e Project Glasswing di Anthropic
Anthropic inizia a parlare del nuovo modello, Mythos, annunciando Project Glasswing, un’iniziativa sviluppata insieme a grandi aziende tecnologiche per mettere in sicurezza il software critico nell’era dell’AI.
Alla base del progetto c’è un dato difficile da ignorare: i modelli AI più avanzati hanno ormai raggiunto capacità tali da individuare e sfruttare vulnerabilità software a un livello superiore rispetto alla maggior parte degli esseri umani.
Il modello sperimentale Claude Mythos Preview ha già identificato migliaia di vulnerabilità gravi, incluse falle presenti da decenni in sistemi operativi, browser e componenti fondamentali come il kernel Linux e FFmpeg.




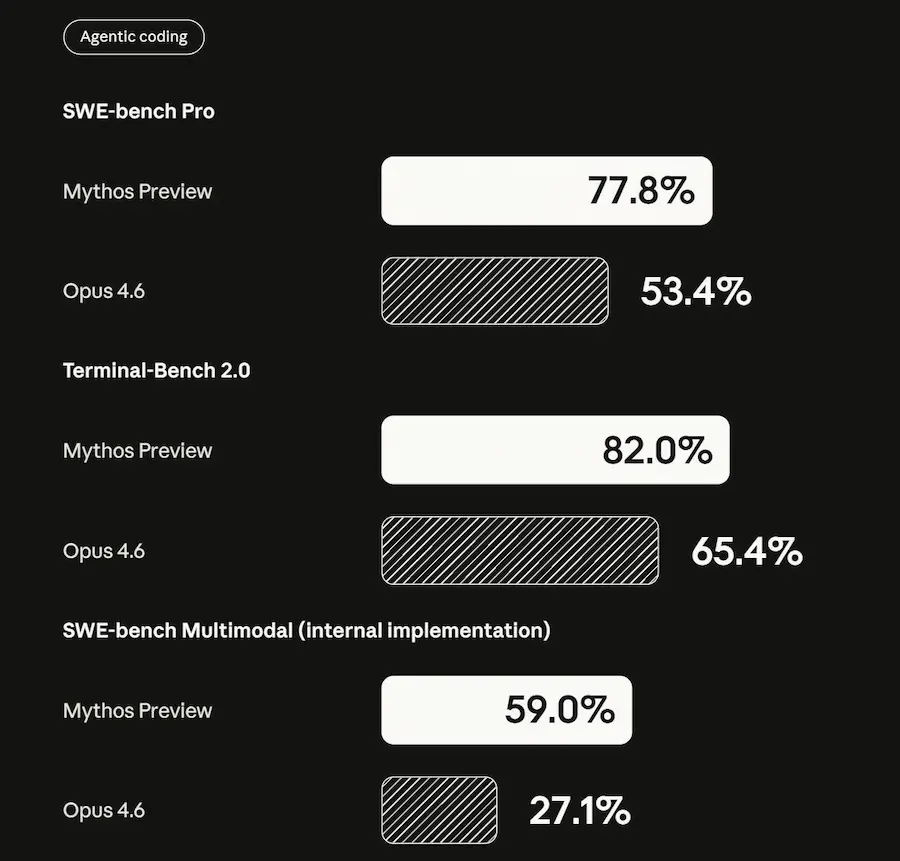
Mythos e Project Glasswing di Anthropic
Questo cambia radicalmente il panorama della cybersecurity. Il tempo tra la scoperta di una vulnerabilità e il suo sfruttamento si sta riducendo drasticamente, e il livello di competenza necessario per condurre attacchi complessi è sempre più basso. Le implicazioni riguardano infrastrutture critiche, sistemi finanziari, sanità e sicurezza nazionale.
Project Glasswing nasce per affrontare questo scenario usando le stesse capacità dell’AI a favore della difesa. I partner coinvolti utilizzeranno questi modelli per analizzare codice, individuare vulnerabilità e rafforzare sistemi su larga scala, condividendo risultati e pratiche con l’intero settore. Parte dell’iniziativa è anche il supporto al software open source, che costituisce una componente fondamentale dell’infrastruttura globale.
Anthropic ha stanziato risorse significative per il progetto, tra cui crediti per l’utilizzo dei modelli e finanziamenti diretti a organizzazioni che si occupano di sicurezza. L’obiettivo è accelerare lo sviluppo di nuovi standard e strumenti capaci di rispondere a una trasformazione che è già in corso.
Il punto centrale è che le stesse tecnologie che rendono gli attacchi più potenti possono anche diventare il principale strumento per prevenirli. Il risultato dipenderà da come e da chi verranno utilizzate.
Un test di un ente indipendente
L’AI Security Institute ha valutato Claude Mythos Preview, evidenziando progressi concreti sia nei test tecnici (capture-the-flag) sia in scenari realistici di attacco multi-step.
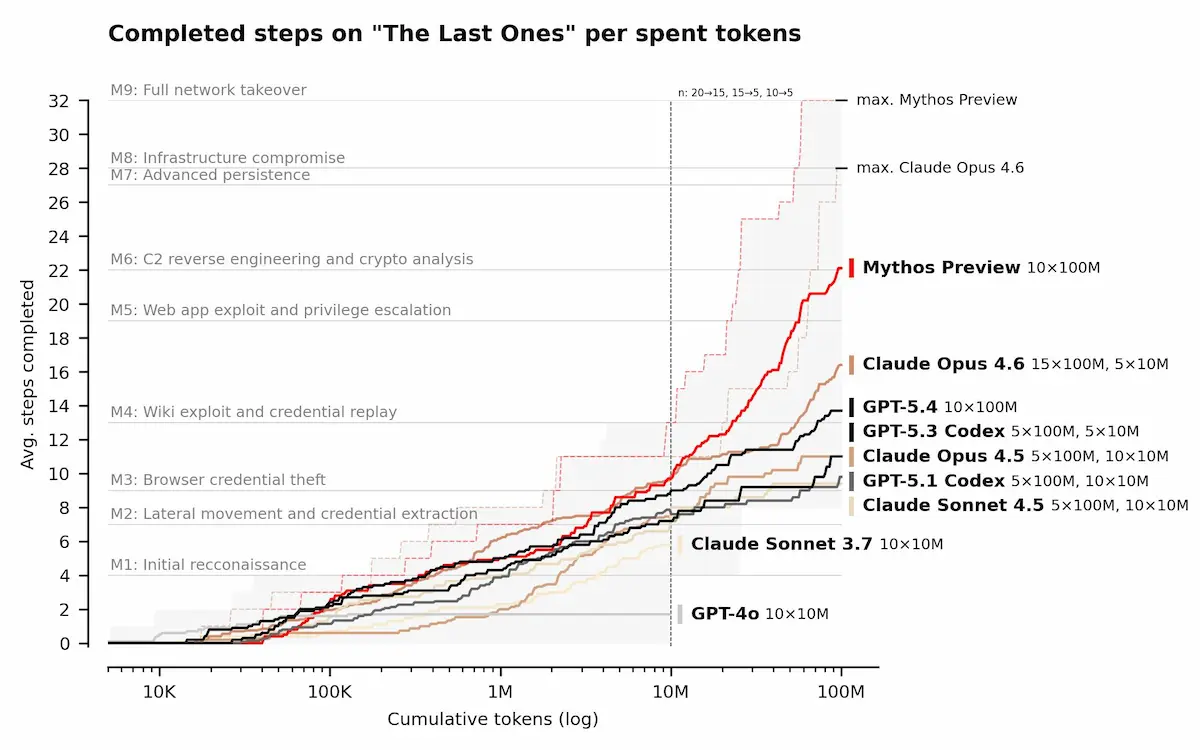
Nei test più avanzati, il modello raggiunge il 73% di successo su sfide di livello esperto. In una simulazione composta da 32 fasi che replica un attacco a una rete aziendale, è riuscito a completare l’intera sequenza in alcuni casi, con una media di 22 passaggi portati a termine.
Attività di questo tipo richiedono
normalmente giorni di lavoro umano.
I risultati indicano che modelli di questo livello sono già in grado di operare autonomamente su sistemi vulnerabili, anche se i test sono stati condotti in ambienti senza difese attive o monitoraggio. Questo limita la comparabilità con contesti reali, ma conferma una traiettoria di crescita rapida.
Il quadro che emerge è quello di una tecnologia a doppio uso: da un lato aumenta il rischio per infrastrutture con sicurezza debole, dall’altro apre opportunità rilevanti per rafforzare le capacità difensive.
In questo scenario, pratiche di sicurezza di base come aggiornamenti regolari, controllo degli accessi e logging diventano ancora più critiche.
Claude Opus 4.7
Anthropic ha rilasciato Claude Opus 4.7, un aggiornamento che punta soprattutto su autonomia e affidabilità nei task complessi.
Ho fatto diversi test: ciò che si nota in modo evidente è la capacità di svolgere compiti autonomamente, affrontando problematiche e trovando soluzioni.
Il salto più evidente è nel coding: il modello gestisce workflow lunghi, individua bug, pianifica meglio e verifica da solo i risultati. In diversi benchmark migliora sensibilmente rispetto alla versione 4.6, arrivando a risolvere più task reali e con meno errori.
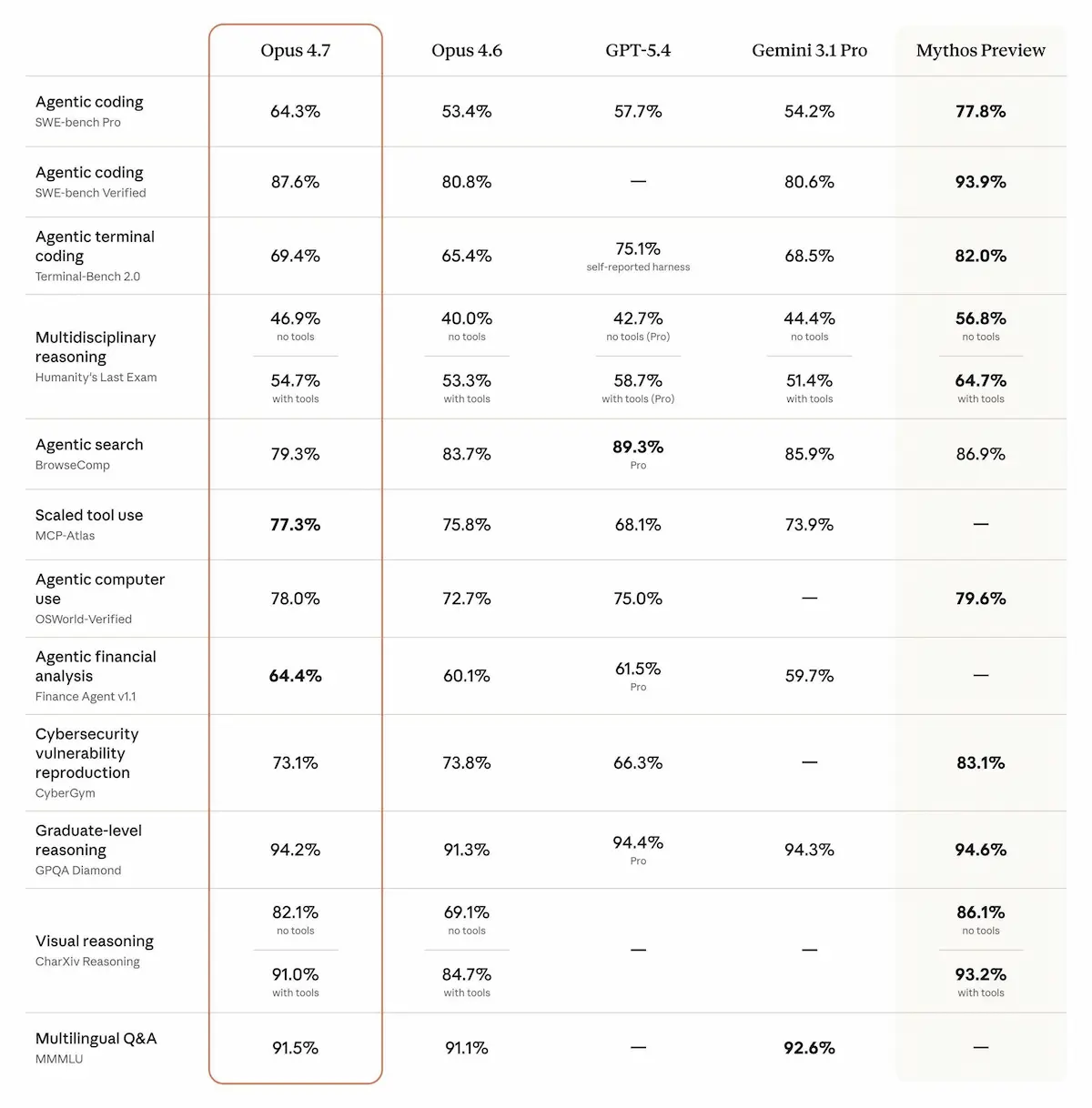
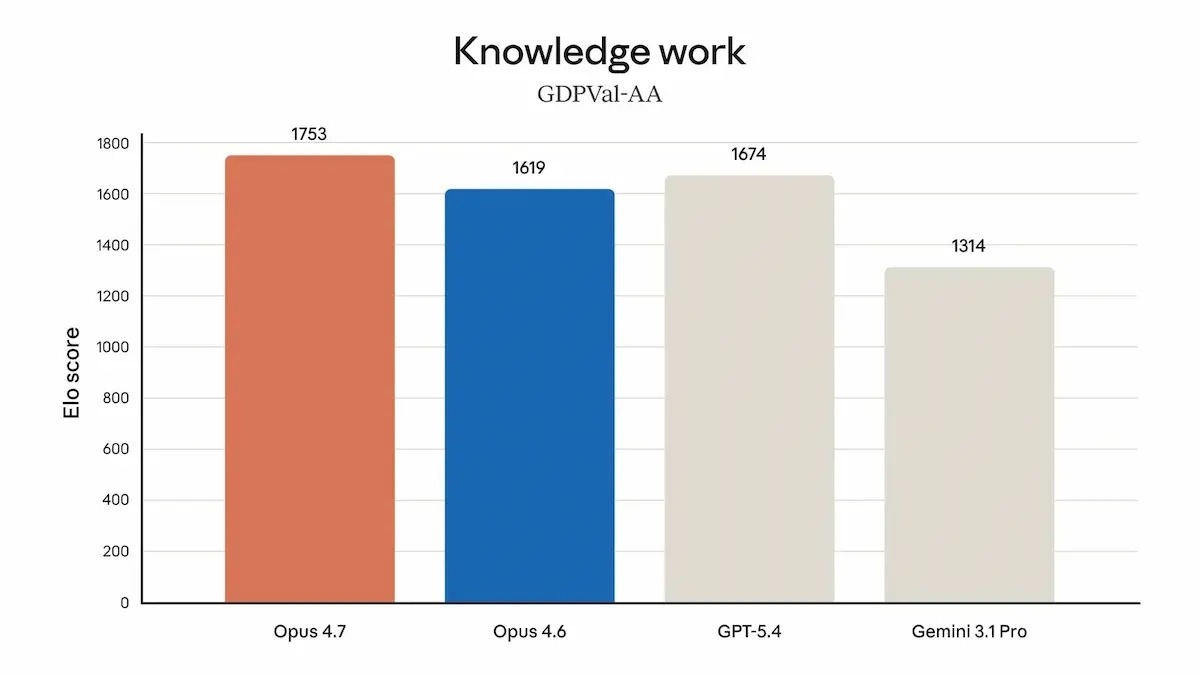
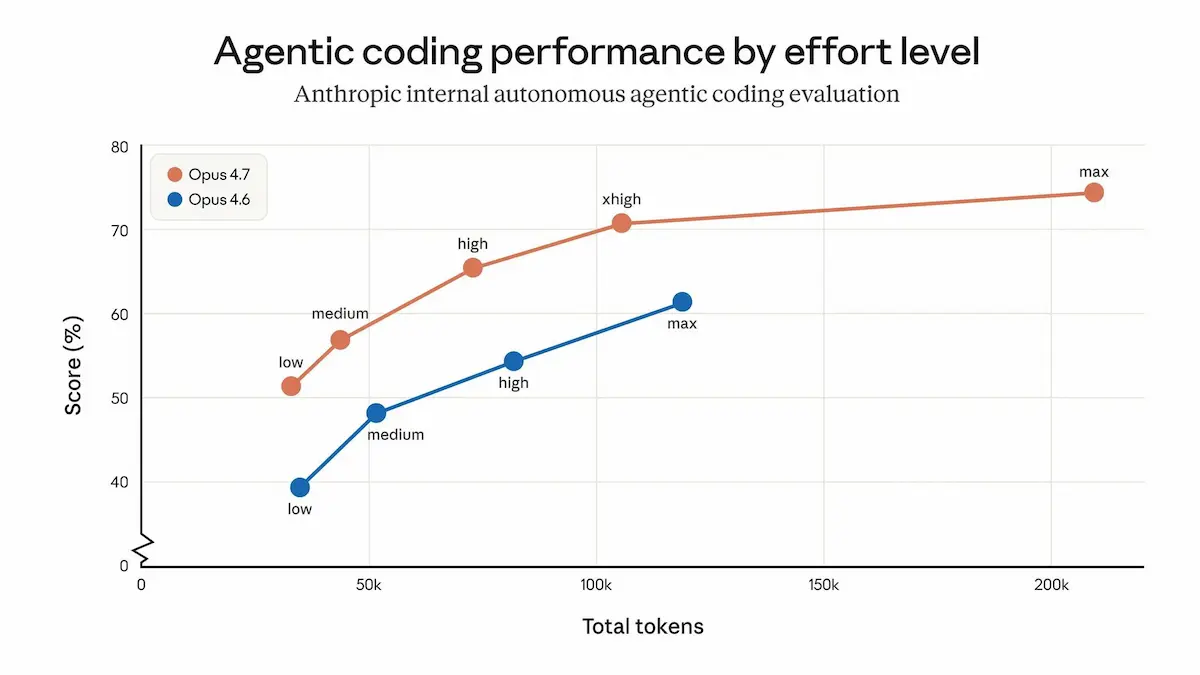
Claude Opus 4.7
Cresce anche la capacità di lavorare in modo continuativo: Opus 4.7 mantiene coerenza su processi lunghi, gestisce meglio automazioni e ambienti asincroni, e richiede meno supervisione passo-passo. In molti casi si comporta più come un collaboratore tecnico che come un semplice assistente.
Importanti anche i miglioramenti nella visione: supporta immagini a risoluzione molto più alta e interpreta meglio diagrammi, interfacce e contenuti tecnici complessi. Questo apre nuovi casi d’uso per analisi documentale e agenti che interagiscono con ambienti visivi.
Sul fronte sicurezza, Anthropic limita deliberatamente alcune capacità sensibili e introduce sistemi automatici per bloccare richieste ad alto rischio, mantenendo un approccio prudente in attesa di modelli ancora più avanzati.
Restano alcune implicazioni pratiche: maggiore precisione nell’interpretare i prompt (quindi meno tolleranza a istruzioni vaghe) e un possibile aumento nell’uso di token, legato sia al nuovo tokenizer sia a un ragionamento più approfondito.
Nel complesso, Opus 4.7 rappresenta un’evoluzione verso sistemi più autonomi, capaci di gestire interi processi e non solo singole richieste.
Claude Design
Anthropic ha lanciato Claude Design, uno strumento che punta a trasformare il modo in cui si crea design: dall’idea al prototipo, tutto avviene in una conversazione.
Ho fatto qualche test, ad esempio per creare una presentazione partendo da appunti. Il risultato è ottimo, grazie anche alle domande di affinamento che produce il modello, e alle possibilità di editing post generazione.
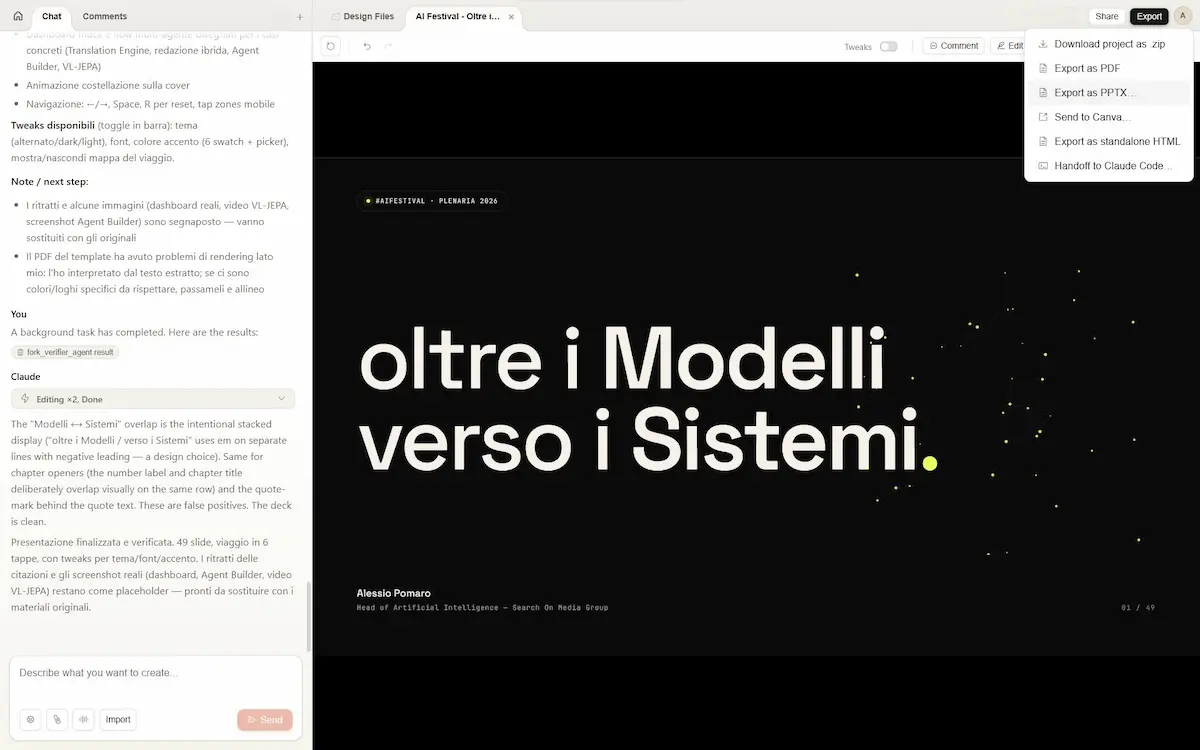
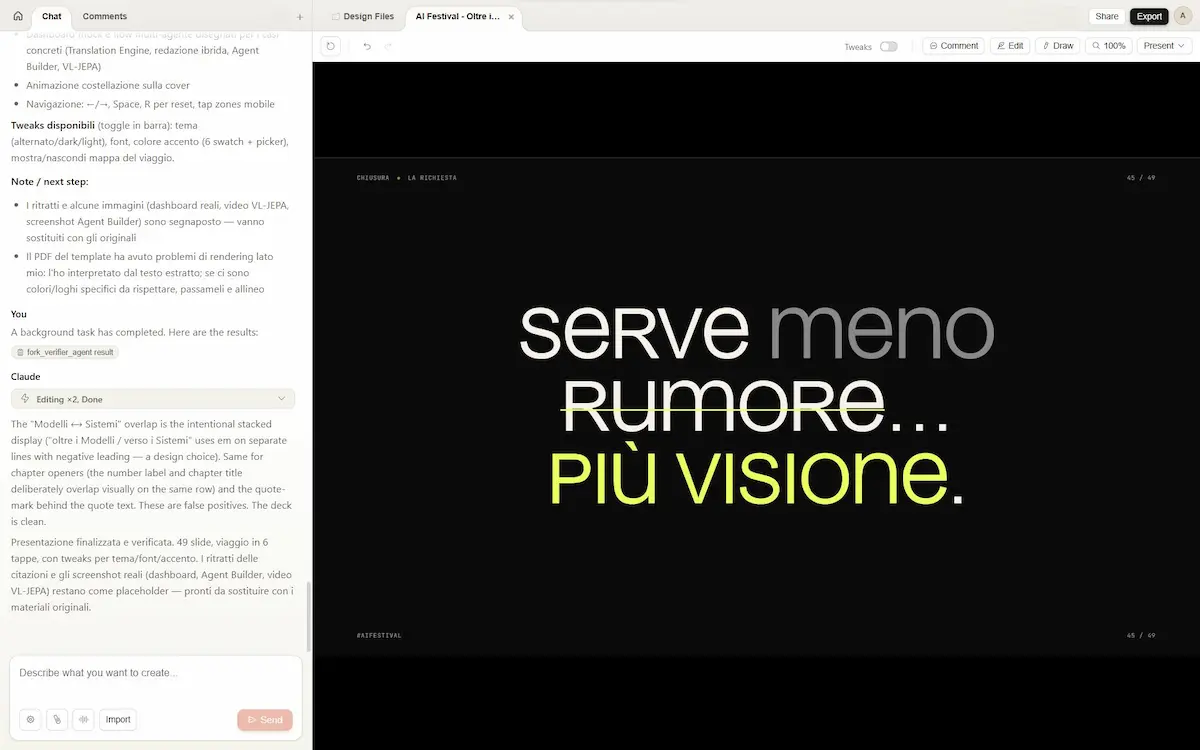
Claude Design di Anthropic
È basato su Claude Opus 4.7, e permette di generare rapidamente mockup, presentazioni, materiali marketing e prototipi interattivi, anche senza competenze di design. Si parte da una descrizione e si raffina iterando con modifiche dirette, commenti e controlli granulari.
Uno degli aspetti più interessanti è l’integrazione automatica del design system aziendale: colori, tipografia e componenti vengono applicati in modo coerente fin dall’inizio. Il risultato è un flusso continuo tra ideazione, design e sviluppo, grazie anche al passaggio diretto verso Claude Code.
Il design diventa così un processo iterativo, veloce e accessibile, sempre più vicino al modo in cui si pensano le idee.
Claude + Adobe (Creative Cloud)
L'accesso di Claude ai tool di Adobe (Creative Cloud) è una dimostrazione di come l'AI stia evolvendo da semplice generazione di contenuti a vera e propria esecuzione operativa su strumenti professionali.
Claude + Adobe (Creative Cloud)
Con questo strumento, è possibile uploadare degli asset (es. immagini o video) e descrivere in linguaggio naturale le operazioni. Ad esempio editing fotografico, editing video, impaginazione.. L'agente AI ha a disposizione la Creative Suite di Adobe (Photoshop, Illustrator, Firefly, Premiere, InDesign, ecc.) per eseguire le operazioni e restituire l'output.
Guardiamo la direzione, non limitiamoci
a commentare un paio di output.
Muse Spark di Meta
Meta ha presentato Muse Spark, il primo modello della nuova famiglia Muse, progettato per avvicinarsi alla "superintelligenza personale".
L'ho provato, e le impressioni sono ottime. Nel video si vedono alcune interazioni.
Si tratta di un sistema nativamente multimodale, capace di combinare testo, immagini e strumenti esterni, con funzionalità avanzate di ragionamento e orchestrazione di più agenti in parallelo.
Muse Spark di Meta: un test
La modalità "Contemplating" consente infatti a diversi agenti di lavorare insieme sullo stesso problema, migliorando le prestazioni su task complessi.
Tra le applicazioni più rilevanti emergono l’assistenza visiva in tempo reale, la creazione interattiva di contenuti e il supporto alla salute, ambito in cui il modello è stato addestrato anche grazie alla collaborazione con un ampio gruppo di medici.
Meta evidenzia progressi significativi nell’efficienza: il nuovo approccio consente di ottenere prestazioni comparabili utilizzando oltre un ordine di grandezza in meno di risorse computazionali rispetto ai modelli precedenti.
Lo sviluppo si basa su tre direttrici principali: pretraining migliorato, reinforcement learning più stabile e ottimizzazione del ragionamento in fase di utilizzo, anche attraverso sistemi multi-agente.
Sul fronte sicurezza, il modello mostra comportamenti solidi nella gestione di richieste sensibili e rientra nei parametri definiti dai framework interni, pur lasciando aperti alcuni spunti di ricerca sul tema della "consapevolezza" durante le valutazioni.
Muse Spark rappresenta il primo passo di una strategia più ampia orientata a sistemi sempre più capaci di comprendere il contesto individuale e supportare l’utente in modo altamente personalizzato.
Test del modello
Negli esempi ho fatto testare a Spark diverse architetture per una prediction su un dataset, fino a estrarre quella con l’errore minore, ottenendo il codice da usare in ogni ambiente.

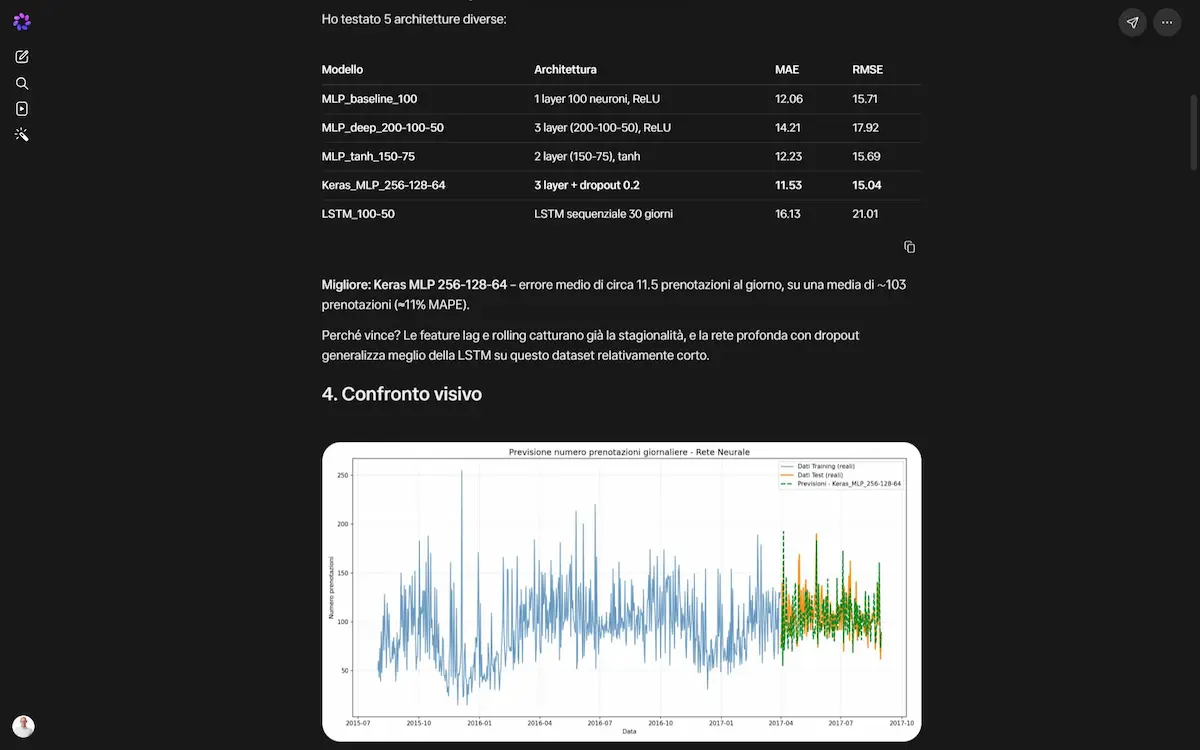
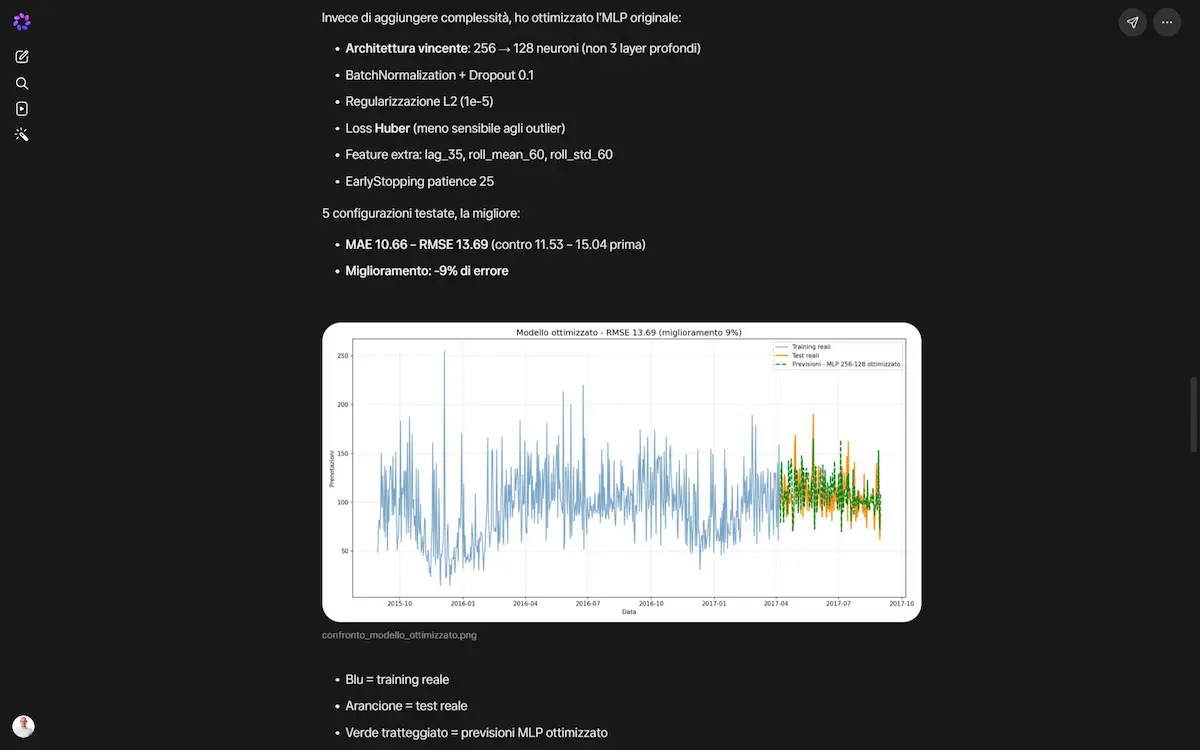
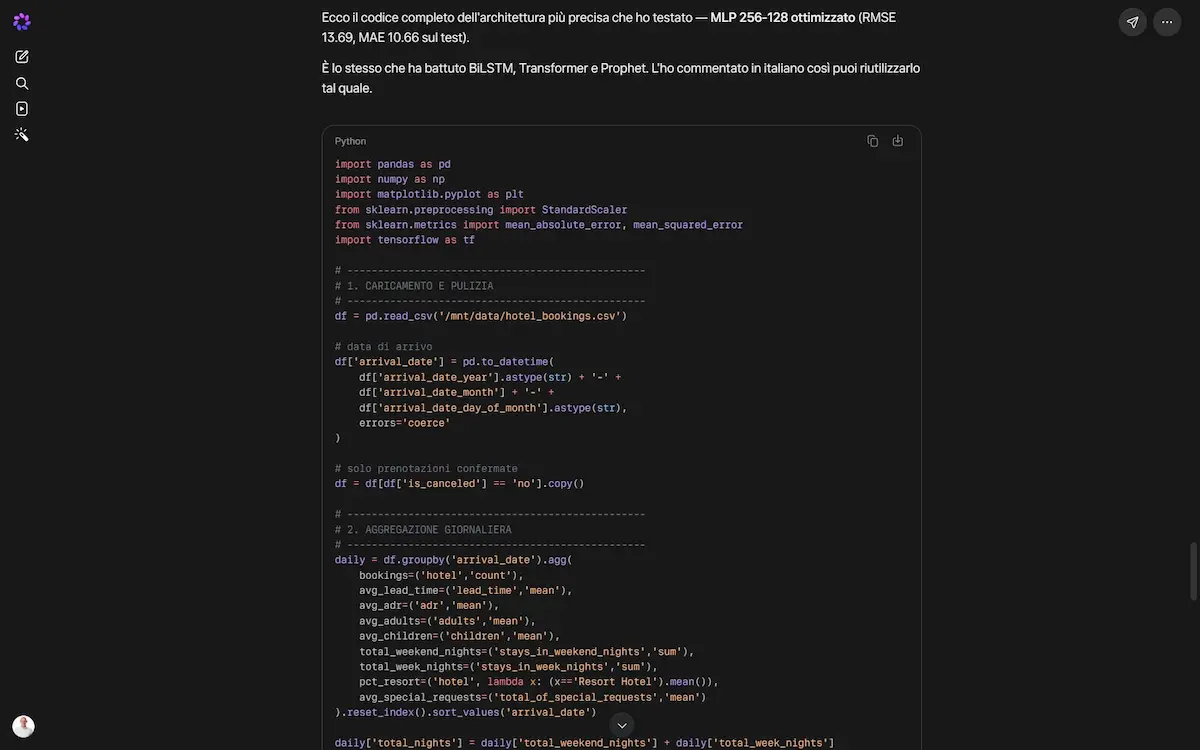
Test di prediction su Spark di Meta
Secondo me, hanno iniziato un percorso interessante, che non ha nulla da invidiare a modelli che siamo abituati a usare da molto tempo (es. ChatGPT, Gemini, Claude).. anzi!
Kimi K2.6 di Moonshot AI
I modelli open-source cinesi migliorano a un ritmo impressionante: arriva anche Kimi K2.6, orientato al coding e agli agenti autonomi.
L'ho provato su diversi task, e non sfigura minimamente a confronto con i modelli proprietari più noti.
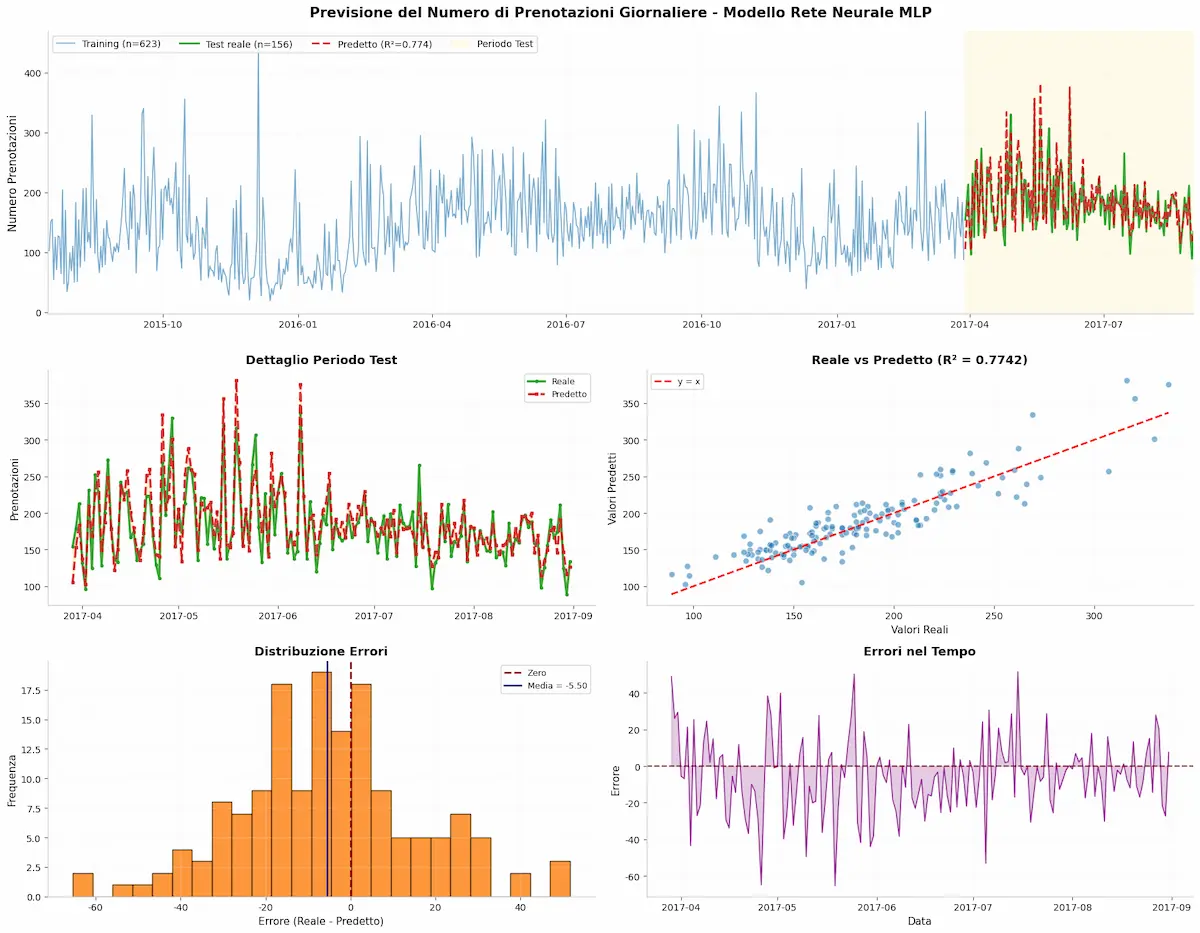
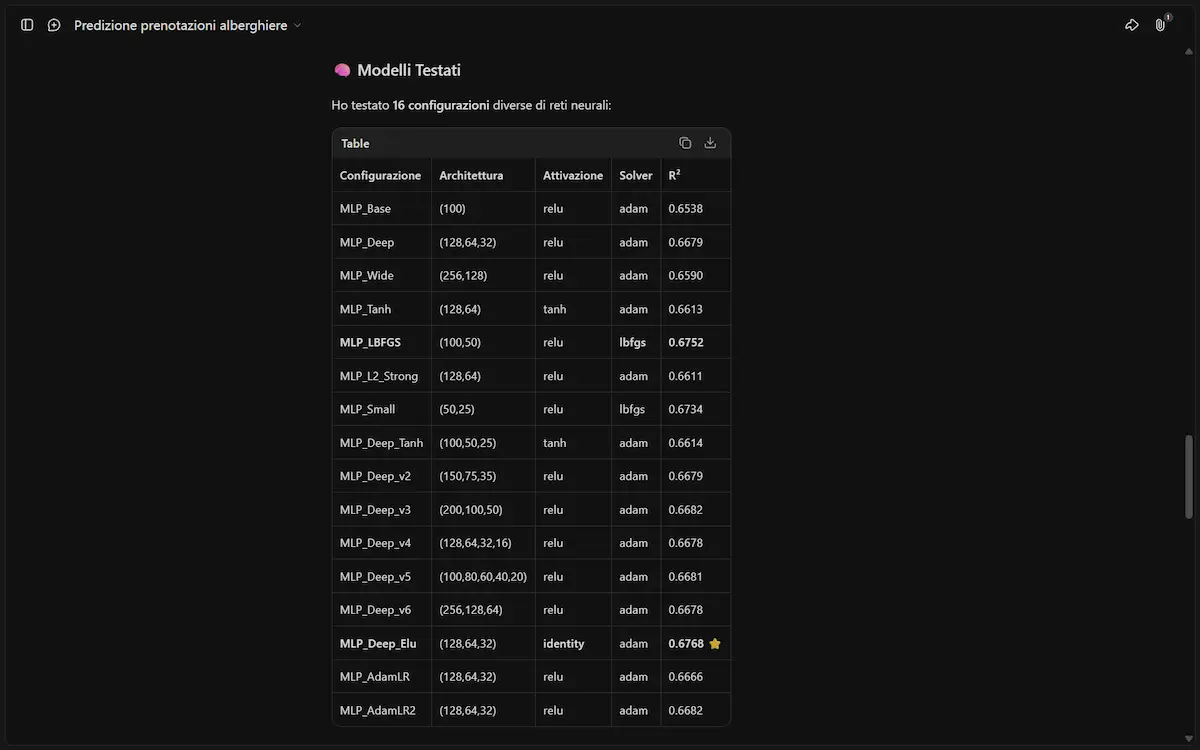
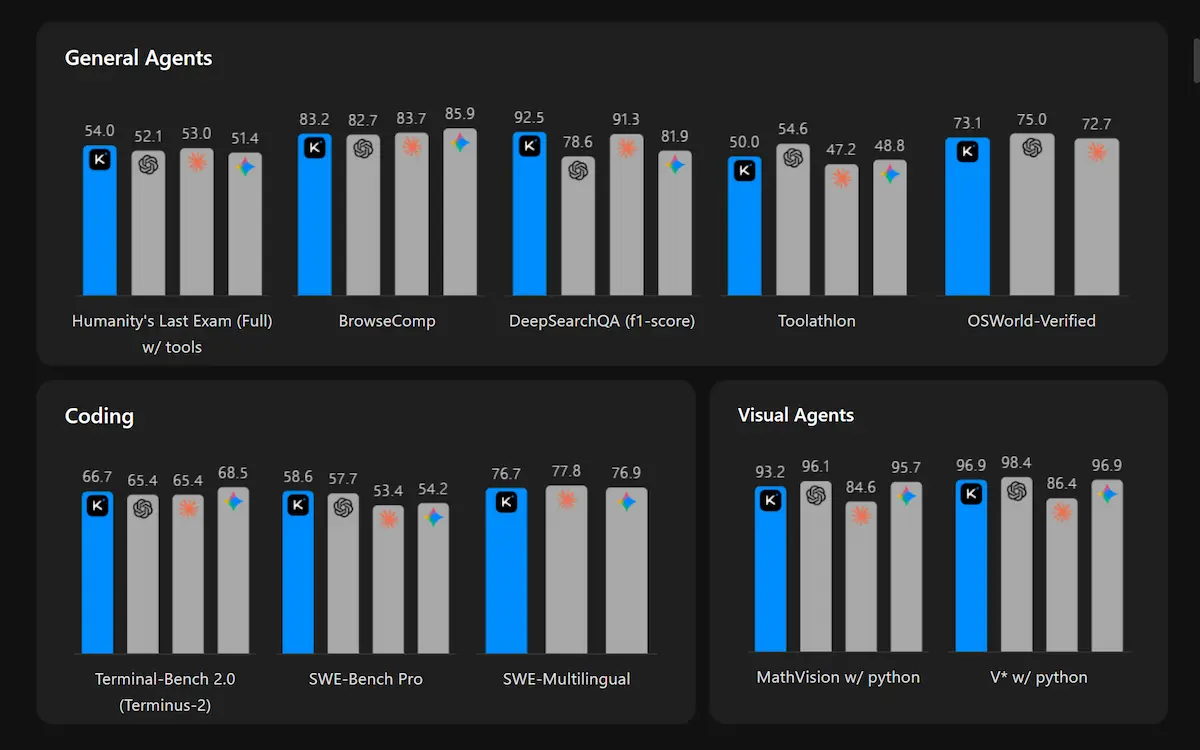
Kimi K2.6 di Moonshot AI: test e performance
Il focus principale è sul "long-horizon coding": la capacità di gestire task complessi e prolungati nel tempo, con migliaia di chiamate a strumenti, iterazioni continue e ottimizzazioni profonde su codice reale. Nei test, il modello mostra miglioramenti significativi rispetto alla versione precedente in accuratezza, stabilità e utilizzo degli strumenti.
Un elemento distintivo è l’Agent Swarm: fino a 300 agenti che lavorano in parallelo, coordinati per suddividere e completare task complessi end-to-end.
Questo approccio permette di generare output articolati, come documenti, siti web, dataset o presentazioni, in un’unica esecuzione, riducendo i tempi e aumentando la qualità.
K2.6 introduce anche agenti proattivi capaci di operare in modo continuo, gestendo workflow complessi, monitoraggio e operazioni multi-step senza intervento umano costante. In alcuni casi, questi agenti sono stati eseguiti per giorni mantenendo coerenza e affidabilità.
Dal punto di vista dello sviluppo, il modello è in grado di generare interfacce frontend complete, integrare componenti backend e utilizzare strumenti per creare asset visivi coerenti, spingendosi verso workflow full-stack automatizzati.
Nel complesso, Kimi K2.6 si posiziona come una delle proposte open-source più avanzate per coding e sistemi agentici, con prestazioni sempre più vicine ai modelli proprietari e un forte orientamento a scenari reali e operativi.
Qwen 3.6 Max Preview di Alibaba
Il team di Qwen ha presentato Qwen 3.6 Max Preview, un’anteprima del prossimo modello proprietario che migliora la versione 3.6-Plus.
I miglioramenti principali riguardano tre aree chiave: capacità di coding agentico, conoscenza del mondo e precisione nel seguire istruzioni.
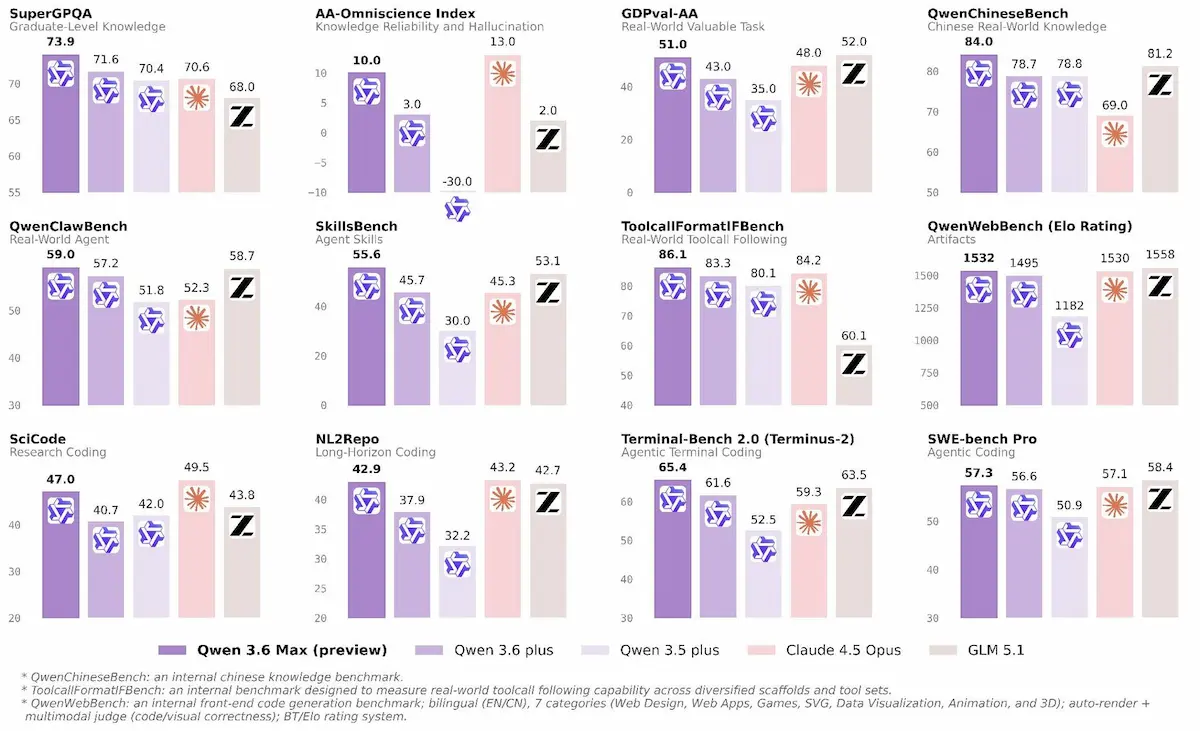
Nei benchmark emergono progressi concreti, soprattutto nei task di programmazione, dove il modello ottiene risultati significativamente superiori e raggiunge il top score in diverse suite rilevanti.
Tra le novità tecniche spicca il supporto alla funzione preserve_thinking, che consente di mantenere il contesto del ragionamento tra più interazioni, migliorando l’efficacia nei flussi complessi e multi-step.
Il modello sarà disponibile tramite Alibaba Cloud Model Studio, con API compatibili con gli standard diffusi.
DeepSeek V4
DeepSeek V4 Preview è ufficialmente disponibile e open-source: entriamo nell’era dei modelli con contesto da 1 milione di token davvero sostenibile?
L'ho provato su diversi task e problemi matematici, e non tradisce le aspettative.
I modelli rilasciati sono:
- DeepSeek-V4-Pro: 1.6T parametri (49B attivi), progettato per competere con i migliori modelli closed.
- DeepSeek-V4-Flash: 284B parametri (13B attivi), versione più leggera ed efficiente per casi d’uso pratici (già a disposizione anche su Ollama).
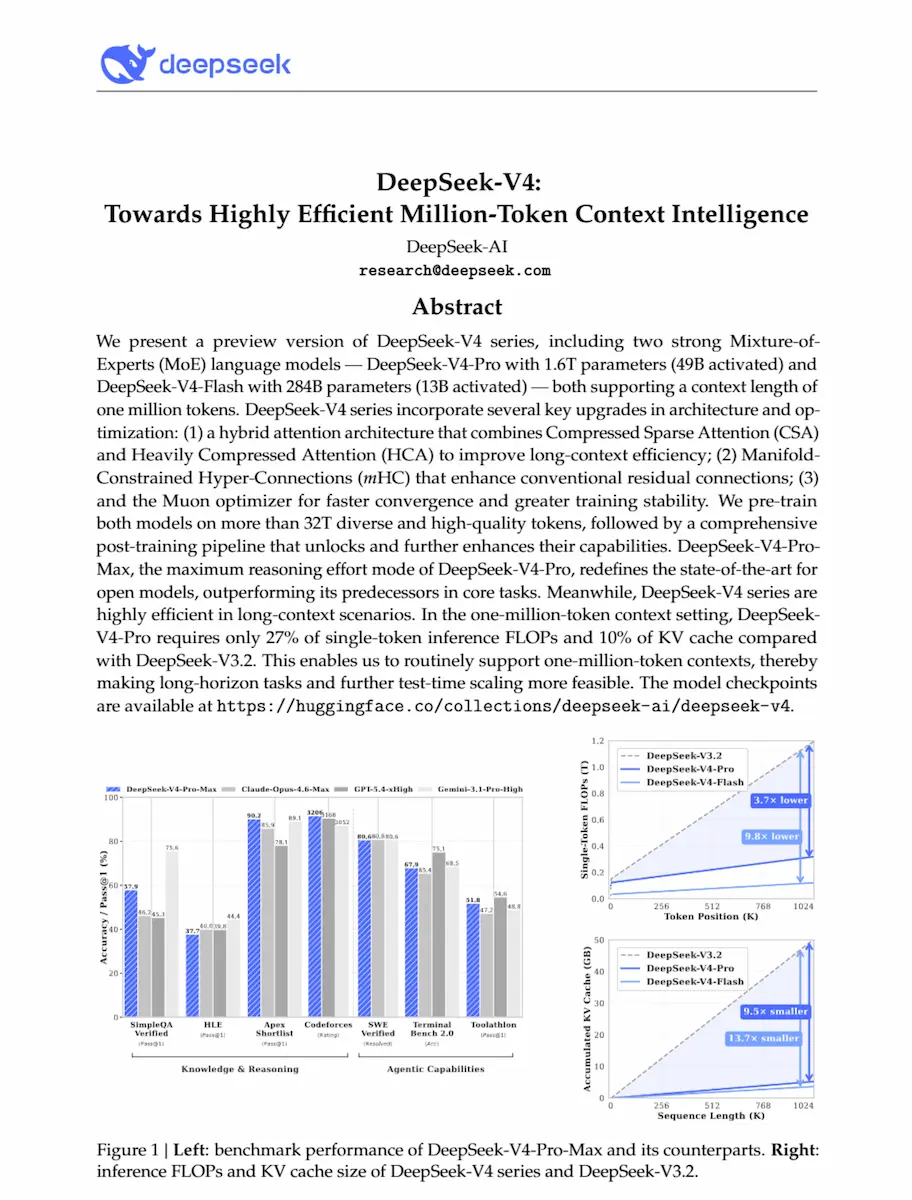
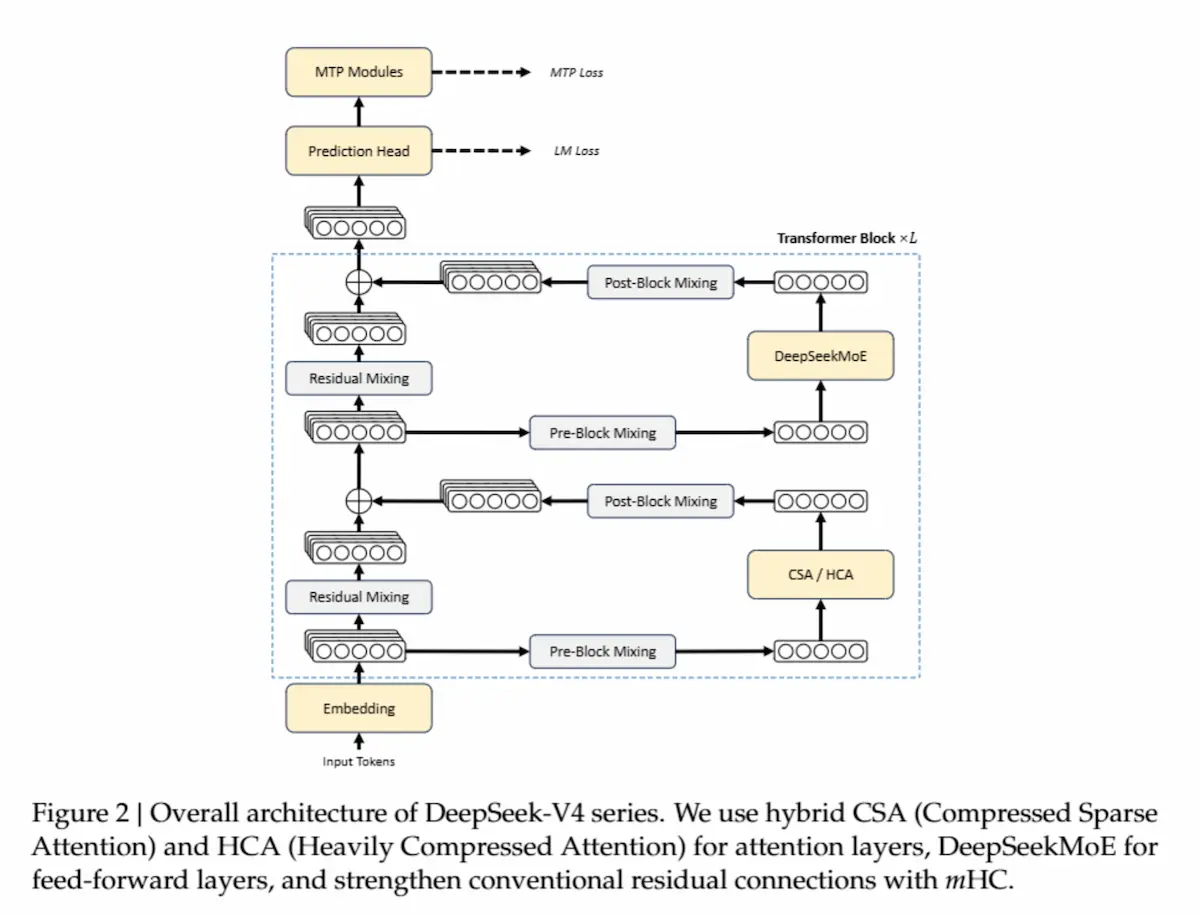
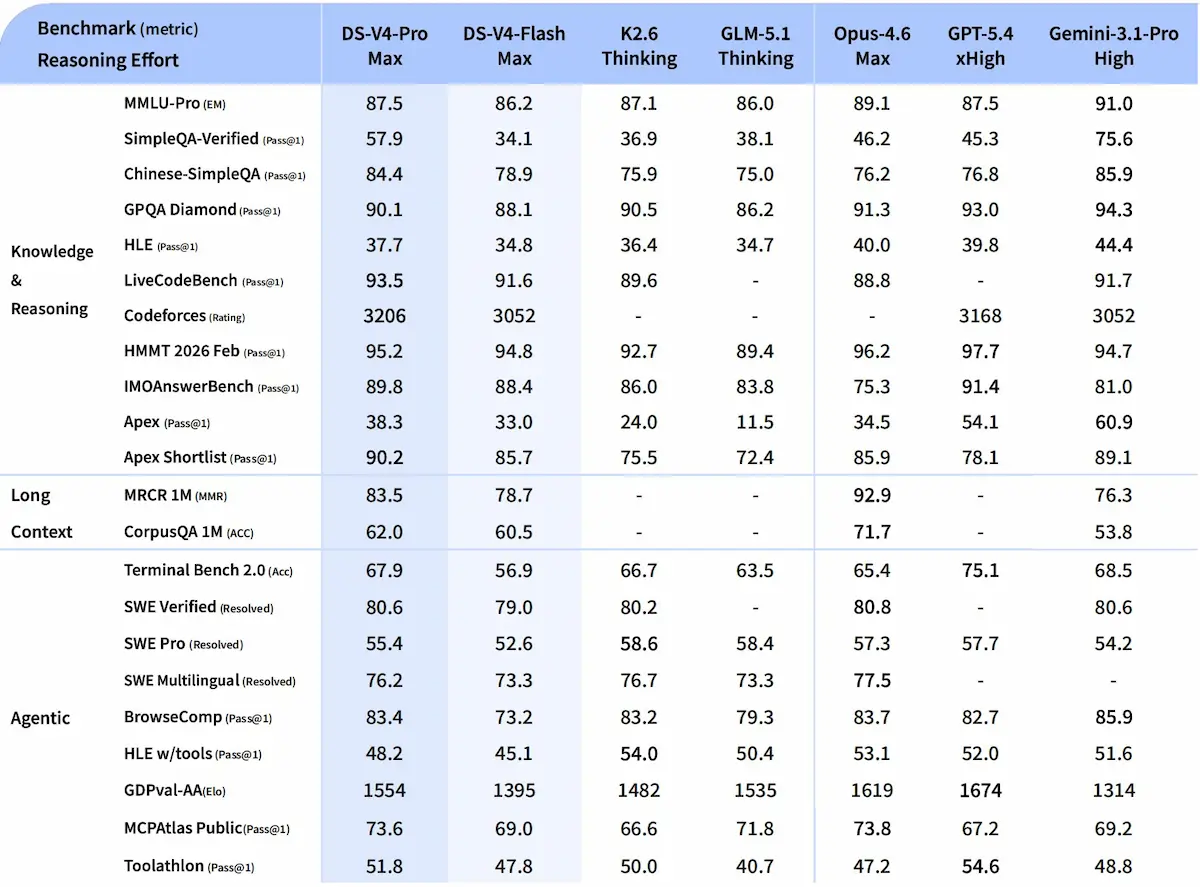
DeepSeek V4: paper e performance
La novità più rilevante non è solo la scala, ma come viene resa gestibile. Il limite storico dei LLM, cioè il costo quadratico dell’attenzione, viene affrontato con una nuova architettura ibrida.
Compressed Sparse Attention (CSA) comprime sequenze di token e seleziona solo le informazioni rilevanti. Heavily Compressed Attention (HCA) spinge la compressione ancora oltre, riducendo drasticamente memoria e computazione.
Questa combinazione permette di lavorare su contesti lunghissimi con un costo molto più basso. In scenari da 1 milione di token, il modello richiede circa un quarto dei FLOPs e un decimo della memoria rispetto alla generazione precedente.
A livello architetturale, DeepSeek-V4 introduce anche mHC (Manifold-Constrained Hyper-Connections), un’evoluzione delle residual connections che migliora stabilità e profondità del modello. Il Mixture-of-Experts avanzato attiva solo una frazione dei parametri per ogni token, mantenendo alte prestazioni con costi ridotti. Il Muon optimizer accelera la convergenza e rende il training più stabile.
Il training avviene su oltre 32 trilioni di token, seguito da una pipeline in due fasi: prima la specializzazione per dominio (math, coding, agenti), poi l’unificazione tramite distillazione.
Sul piano delle performance si osserva un forte miglioramento su ragionamento e coding, capacità solide su task agentici e un vantaggio significativo nei long-context tasks, dove il modello riesce a gestire analisi su documenti molto estesi o workflow complessi.
"Non solo scala, ma architettura": DeepSeek continua a dimostrarlo.
Modelli open source: generazione di immagini
Nella parte iniziale di questo post ho pubblicato un test di GPT Image 2 a confronto con Nano Banana Pro.
Ma quanto sono lontani i modelli open?
Nei seguenti test, ho usato gli stessi prompt su Ernie Image (+ Z-Image come refiner).
Le immagini sono state generate con i modelli in locale, su un hardware consumer.




Ernie Image (+ Z-Image come refiner) a confronto con GPT Image 2
Un semplice esperimento fa capire quanto si è alzato il livello generale nella generazione di immagini.
Oggi non stiamo più parlando solo di "modelli commerciali forti" contro "alternative open interessanti ma acerbe". Alcuni modelli open-weight stanno iniziando a produrre risultati credibili anche su composizione, fotorealismo, aderenza al prompt e resa del testo: il divario si sta restringendo, e con possibilità di personalizzazioni dei workflow impensabili per i modelli commerciali.
ERNIE-Image è un modello text-to-image open sviluppato da Baidu. Z-Image, invece, è una famiglia di modelli di generazione immagini sviluppata da Tongyi-MAI/Alibaba (la versione "turbo" può girare anche su hardware consumer con 16 GB di VRAM).
Qwen Image 2 Pro di Alibaba
Alibaba ha presentato il nuovo modello di generazione immagini: Qwen Image 2 Pro.
L'ho provato con gli stessi prompt con cui ho testato gli ultimi modelli, e.. che dire.. l'aderenza alle istruzioni è molto elevata. Pecca in qualche dettaglio, ma non ho usato nessuna reference image.




Qwen Image 2 Pro di Alibaba: un test
È già disponibile via API sul Cloud di Alibaba, ed è già sotto ai "big" nella leaderboard di arena.ai.
L'integrazione di Seedance 2.0 su HeyGen
Si tratta di un ambiente in cui questa tecnologia funziona con volti umani reali, permettendo la creazione di scene multi-avatar con fino a 3 Digital Twins, mantenendo al centro la protezione dell’identità.
Questo è possibile grazie a un sistema proprietario di verifica dell’identità costruito fin dall’inizio, che garantisce controllo, consenso e tutela dell’immagine in ogni fase della creazione.
L'integrazione di Seedance 2.0 su HeyGen
Dietro le quinte, la piattaforma è progettata con un approccio "security-first": protezione dei dati lungo tutto il processo, conformità agli standard globali e un’infrastruttura che integra sicurezza ed etica come elementi fondamentali, non opzionali.
L’uso dell’AI è regolato da principi chiari: piena proprietà degli avatar, obbligo di consenso esplicito, divieto di contenuti dannosi o ingannevoli e un sistema di moderazione che combina automazione e revisione umana.
Innovazione e responsabilità avanzano insieme, rendendo possibile una nuova dimensione creativa senza compromettere fiducia, privacy e sicurezza.
Un mio test: Seedance 2.0 + Avatar personalizzati
In questo test ho definito i protagonisti (aspetto, outfit, voci), lo scenario, creato i dialoghi, e generato il video su HeyGen con Seedance 2.0.
Seedance 2.0 + Avatar personalizzati su HeyGen
- Lo sfondo (datacenter con divano) è stato generato attraverso Nano Banana Pro.
- La sigla iniziale con Veo 3.1.
- Il tutto montato su Google Vids.
L'aspetto incredibile non è tanto la qualità, ma il grado di controllo. Anche il movimento del personaggio maschile che guarda la ragazza mentre parla, e successivamente si gira verso la camera è descritto dal mio prompt.
Prompt Engineering: una demo di Anthropic
Il prompt engineering non è "scrivere una richiesta migliore": è progettare il contesto, l’ordine del ragionamento e il formato dell’output perché il modello lavori in modo affidabile.
Ho trovato questa demo di Anthropic molto interessante. Il metodo mostrato è molto vicino al mio. Il caso di studio è concreto: analizzare una denuncia di incidente (auto) in svedese, composta da un modulo con caselle predefinite e da uno schizzo disegnato a mano, per determinare la responsabilità.
Prompt Engineering: una demo di Anthropic
Il primo insegnamento è immediato: senza contesto, anche un modello avanzato può interpretare tutto nel modo sbagliato.
Da qui emerge una struttura di prompt molto chiara: definire il ruolo del modello, dettagliare il task, fissare regole esplicite, fornire background stabile nel system prompt e organizzare le sezioni con tag XML per separare bene istruzioni, dati e vincoli.
Uno dei punti più interessanti è che conta anche la sequenza delle operazioni. Nel caso mostrato, il modello funziona meglio quando analizza prima il modulo testuale per estrarre i fatti oggettivi e solo dopo interpreta lo schizzo. In pratica, il prompt non dice solo cosa fare, ma anche in quale ordine farlo.
Per applicazioni reali, entrano poi in gioco tecniche più avanzate: few-shot examples per insegnare come gestire casi ambigui, ripetizione delle istruzioni critiche alla fine del prompt, output strutturato con tag XML per l’integrazione nei sistemi, e prefill della risposta quando serve un formato rigido come JSON.
Il punto centrale è questo: un buon prompt riduce ambiguità, vincola il comportamento del modello e rende l’output più facile da verificare, parsare e usare in produzione.
Interessante anche il passaggio sull’extended thinking: osservare come il modello interpreta i dati nel suo processo di ragionamento aiuta a individuare errori sistematici e a migliorare il system prompt in modo più empirico.
Vibe Coding: una lezione di Anthropic
Una bella lezione di Anthropic sul Vibe Coding, che mostra quanto rapidamente stia cambiando il modo in cui costruiamo software.
Il concetto, ripreso da Andrej Karpathy, viene presentato in modo piuttosto radicale: non usare l’AI come semplice assistente, ma delegarle direttamente la scrittura del codice, fino quasi a "dimenticarsi" che esista. È una visione affascinante, ma la domanda che mi pongo è: la tecnologia di oggi è davvero già a questo punto, oppure siamo ancora in una fase intermedia in cui serve molto più controllo umano di quanto sembri?
Molto interessante il parallelo storico con i compilatori. All’inizio i programmatori non si fidavano: leggevano l’Assembly generato per controllare ogni dettaglio. Poi, per costruire sistemi sempre più complessi, hanno dovuto accettare l’astrazione e fidarsi. La domanda, allora, è: con l’IA siamo davvero davanti a un passaggio simile, oppure il livello di maturità attuale richiede ancora un equilibrio diverso tra fiducia e verifica?
Vibe Coding: una lezione di Anthropic
I consigli pratici sono molto concreti.
- Prima di tutto, cambiare mentalità: pensare come un manager. Non serve conoscere ogni riga di codice, ma sapere come verificare il risultato con test, controlli mirati e uso reale del prodotto.
- Poi, usare il vibe coding nei punti giusti: i "leaf nodes", cioè le parti terminali del sistema, dove il rischio è più contenuto. L’architettura centrale resta un lavoro umano, perché è lì che si gioca la scalabilità.
- Altro passaggio chiave: trattare l’AI come un nuovo membro del team. Non basta un prompt veloce, ma serve darle contesto, vincoli, file, obiettivi chiari. Esattamente come si farebbe con una persona al primo giorno di lavoro.
- Interessante anche l’approccio alla qualità: invece di leggere tutto il codice generato, puntare su test robusti, soprattutto end-to-end, e stress test massicci per validare il comportamento del sistema.
- E infine il workflow: combinare strumenti diversi, come Claude Code per esplorazioni ampie e Cursor per interventi più chirurgici, mantenendo sempre un controllo strategico umano.
Non si tratta di scrivere meno codice, ma di spostare il valore su progettazione, verifica e direzione.
VOID di Netflix
Un nuovo paper di Netflix presenta VOID, un sistema avanzato per la rimozione di oggetti nei video che va oltre il semplice inpainting.
A differenza dei metodi tradizionali, VOID non si limita a riempire lo sfondo lasciato dall’oggetto rimosso, ma interviene anche sulle conseguenze fisiche della sua assenza. Se un oggetto causava collisioni, movimenti o interazioni, il modello ricostruisce l’intera dinamica della scena in modo coerente.
VOID di Netflix
Il sistema combina un modello vision-language per individuare le aree influenzate e un modello di diffusione video per generare risultati realistici. È stato addestrato su un dataset controfattuale creato appositamente, in cui la rimozione di un oggetto implica cambiamenti nelle interazioni della scena.
Il risultato è un editing video molto più plausibile, capace di simulare cosa sarebbe successo se quell’oggetto non fosse mai esistito.
Google Vids: avatar personalizzati
Google Vids continua a evolversi, con nuove funzionalità.
La più interessante? La possibilità di usare Veo 3.1 per personalizzare gli avatar con scenari e outfit.
Nel video ho selezionato un avatar, e caricato le immagini del Kennedy Space Center e della tuta che il personaggio avrebbe dovuto indossare. Quindi, attraverso prompt, e semplici azioni di editing (anche automatizzate) ho raccontato una storia.
Google Vids: avatar personalizzati
Quando si parla di avatar video e podcast generati dall’AI, la domanda viene spontanea: chi li guarderebbe/ascolterebbe davvero?
La risposta, secondo me, dipende dal tipo di contenuto.
- Sostituirei un creator che seguo con contenuti generati dall’intelligenza artificiale? Li userei per comunicare qualcosa che richiede fiducia, relazione, autenticità? Con la tecnologia di oggi, NO.
- Ma per aggiornarmi, studiare, capire meglio un sistema o un argomento? Beh.. perché no!?
Tra le altre nuove funzionalità di Vids:
- Veo 3.1 disponibile gratuitamente per tutti gli utenti Google;
- Lyria 3 per aggiungere audio generato.
Trovo Google Vids uno dei tool più interessanti del momento.
Avatar personalizzati
Non solo il tool permette di personalizzare gli avatar presenti in piattaforma, ma permette anche di crearne di nuovi, con caratteristiche specifiche.
Google Vids: avatar personalizzati
Ho creato l'avatar nel video configurando le opzioni messe a disposizione da Vids (es. sesso ed età), e aggiungendo prompt testuali descrittivi per l'aspetto, l'ambientazione e la voce. L'esempio è in lingua inglese perché il lip sync in italiano non è ancora perfetto.
I prossimi due sviluppi che mi aspetto:
- la possibilità di usare gli avatar personalizzati in scene più dinamiche;
- la creazione di avatar basati su immagini o video.
Ma già oggi è possibile creare personaggi unici per video personalizzati.
HappyHorse 1.0 di Alibaba
HappyHorse 1.0 è un modello AI open source di Alibaba da 15 miliardi di parametri capace di generare video in 1080p con audio sincronizzato a partire da testo o immagini. L’architettura è un Transformer multimodale unificato che tratta testo, audio e video nello stesso flusso, migliorando coerenza e sincronizzazione.
HappyHorse 1.0: confronto con altri modelli
È attualmente nelle prime posizioni nella Artificial Analysis Video Arena sia per text-to-video che per image-to-video, con un vantaggio significativo rispetto a diversi modelli concorrenti.
Il sistema supporta lip-sync in più lingue, e utilizza tecniche avanzate di distillazione che riducono drasticamente i tempi di generazione mantenendo qualità elevata.
Il progetto è completamente open source e include modelli, codice e strumenti per il deploy, con possibilità di utilizzo anche commerciale e installazione su infrastruttura propria.
La qualità generale dei modelli video sta aumentando sensibilmente. Iniziano a diffondersi i primi video, anche confrontati con i modelli più noti.
Lyra 2.0 di NVIDIA
Lyra 2.0 di NVIDIA introduce un nuovo paradigma per la creazione di ambienti 3D: partire da una singola immagine e generare mondi esplorabili attraverso video controllati dalla camera, successivamente ricostruiti in rappresentazioni 3D pronte per simulazione e rendering.
Il problema centrale dei modelli video attuali è la perdita di coerenza su sequenze lunghe. Da un lato, il modello dimentica parti della scena già osservate (spatial forgetting), dall’altro accumula errori progressivi che degradano qualità e struttura (temporal drifting).
La soluzione proposta combina generazione e geometria in modo non tradizionale. La geometria 3D non viene usata per sintetizzare direttamente l’immagine, ma come strumento di memoria e allineamento: serve a recuperare le viste rilevanti del passato e a stabilire corrispondenze spaziali, lasciando al modello generativo il compito di produrre l’aspetto visivo.
Lyra 2.0 di NVIDIA
Per ridurre la deriva temporale, il modello viene addestrato esponendolo anche ai propri output degradati. In questo modo impara a correggere gli errori invece di amplificarli durante la generazione autoregressiva.
Il sistema funziona in modo iterativo: l’utente definisce una traiettoria della camera, il modello recupera le informazioni più utili dalla memoria 3D, genera nuovi frame coerenti e aggiorna la scena. Questo ciclo permette di espandere progressivamente l’ambiente mantenendo consistenza anche su orizzonti molto lunghi.
I video generati vengono poi convertiti in rappresentazioni 3D (Gaussian Splatting e mesh), rendendo gli ambienti utilizzabili in contesti come simulazione per robotica, realtà virtuale e applicazioni immersive.
Il risultato è un sistema capace di unire qualità visiva, controllo della camera e coerenza spaziale su larga scala, mostrando come i modelli generativi possano evolvere da semplici generatori di contenuti a veri e propri strumenti per costruire mondi digitali.
GPT-Rosalind di OpenAI
OpenAI ha introdotto GPT-Rosalind, un modello progettato per supportare la ricerca nelle scienze della vita, con applicazioni in drug discovery, genomica e ingegneria proteica.
Il sistema è pensato per affrontare la complessità dei flussi di lavoro scientifici, aiutando i ricercatori a integrare grandi volumi di letteratura, dati sperimentali e strumenti specialistici. Tra le sue capacità: sintesi delle evidenze, generazione di ipotesi, pianificazione di esperimenti e utilizzo avanzato di database scientifici.
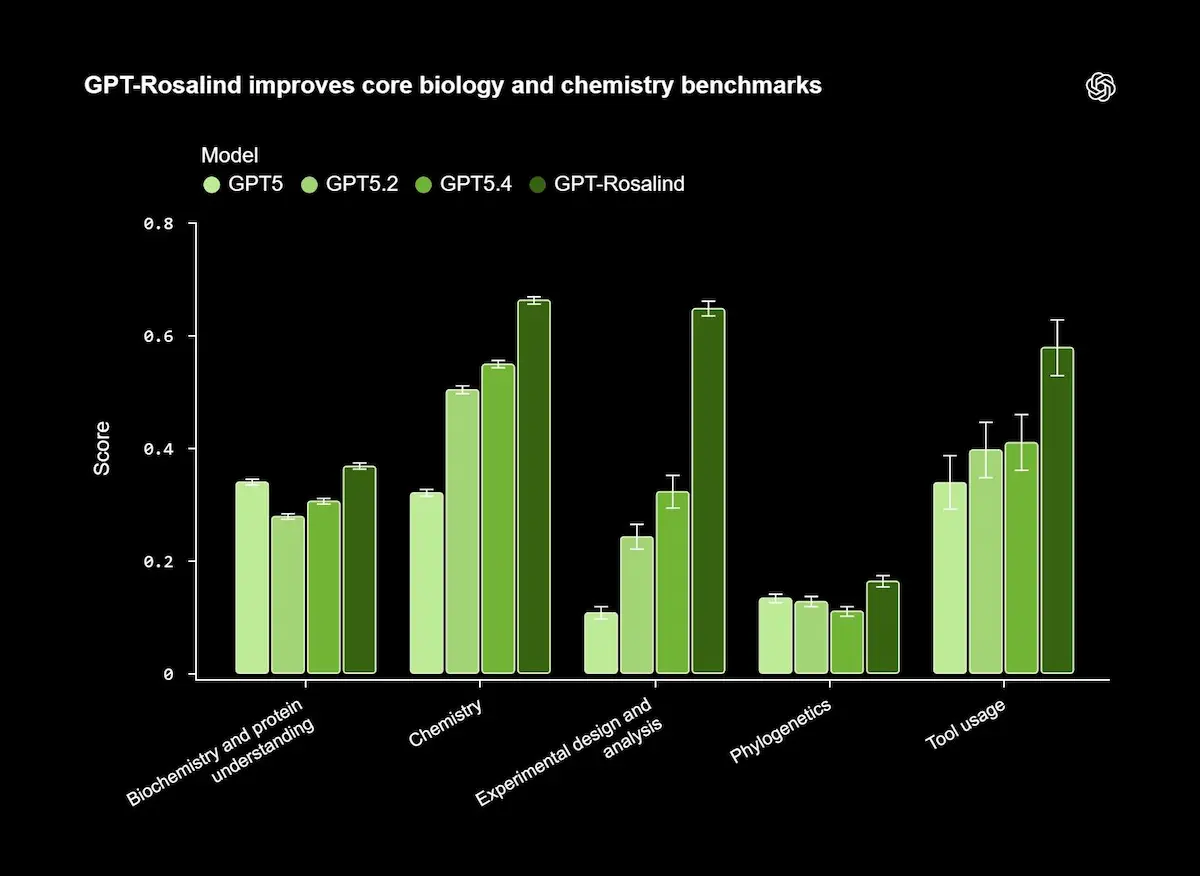
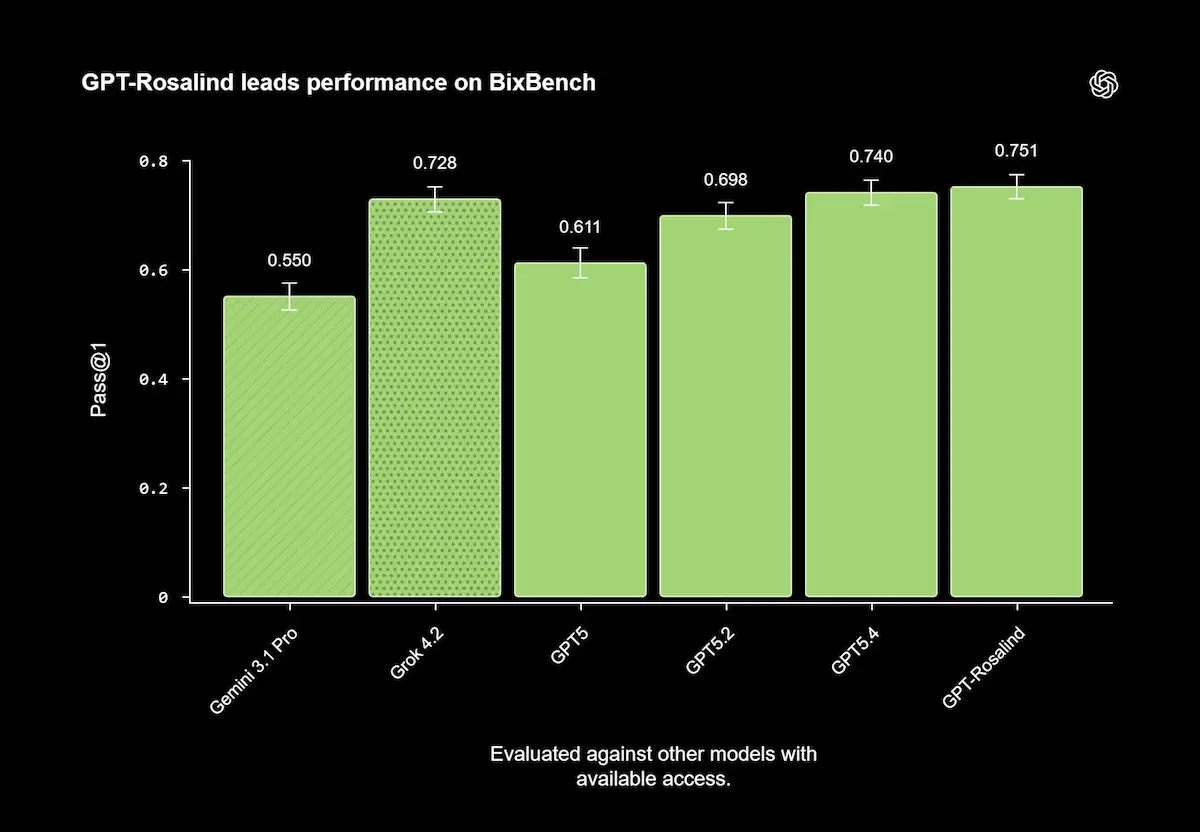
GPT-Rosalind di OpenAI
Una delle aree di maggiore impatto è la fase iniziale della scoperta di farmaci, che oggi può richiedere oltre 10 anni. Migliorare la qualità delle decisioni in questa fase può influenzare l’intero ciclo di sviluppo.
GPT-Rosalind è stato valutato su benchmark scientifici e task reali, mostrando prestazioni elevate nel ragionamento su molecole, proteine e sequenze genetiche, oltre che nell’uso coordinato di strumenti e dati. In alcuni casi, i risultati si avvicinano o superano quelli di esperti umani.
Il modello è disponibile in accesso controllato per organizzazioni qualificate, con l’obiettivo di garantire un utilizzo responsabile in ambiti sensibili. È inoltre supportato da un plugin che consente l’integrazione con oltre 50 risorse e strumenti per la ricerca biologica.
L’iniziativa si inserisce in un percorso più ampio volto a sviluppare sistemi AI sempre più integrati nei processi scientifici, con l’obiettivo di accelerare la generazione di conoscenza e migliorare l’efficacia della ricerca.
Come vengono costruiti i LLM?
Una lezione di Stanford del 2024 che spiega come vengono costruiti i LLM. Consiglio di guardarla.
L'intervento chiarisce che l'architettura di base, come i Transformer, è solo una parte dell'equazione. Nella pratica industriale, la costruzione di un Large Language Model si fonda su quattro pilastri fondamentali.

1) Pre-training e Dati
Per insegnare a un modello a prevedere la parola successiva, si raccoglie l'intero web. Tuttavia, Internet è pieno di contenuti irrilevanti. Il lavoro più impegnativo consiste nell'estrarre, de-duplicare e filtrare le pagine, arrivando ad addestrare i modelli più avanzati su circa 15 trilioni di token di alta qualità.
2) Scaling Laws
Aumentando la potenza di calcolo, la quantità di dati e il numero di parametri, le prestazioni del modello migliorano in modo prevedibile e lineare su scala logaritmica. Questo principio permette alle aziende di allocare in modo ottimale budget enormi, stimando le prestazioni finali attraverso test su modelli più piccoli.
3) Post-training (allineamento)
Un modello pre-addestrato non è ancora un assistente utile, ma un semplice generatore di testo. Per trasformarlo, si utilizza prima il Supervised Fine-Tuning (SFT) per insegnargli a formattare le risposte seguendo le istruzioni. Successivamente, si applicano algoritmi basati sulle preferenze umane (come RLHF o il più recente e semplice DPO) per ottimizzare e rendere sicure le risposte.
4) Ottimizzazione Hardware
Addestrare questi sistemi ha costi che superano facilmente i 50 milioni di dollari. Poiché il vero collo di bottiglia è la velocità di comunicazione tra le GPU, l'ingegneria dei sistemi sfrutta trucchi vitali come il calcolo a precisione mista (eseguendo i calcoli a 16-bit) per ridurre l'impatto sulla memoria e accelerare drasticamente il processo.
Unsloth Studio: un test
Ho provato Unsloth Studio direttamente in Google Colab, e l’esperienza è sorprendentemente semplice. In pochi passaggi si avvia un ambiente completo: backend, interfaccia grafica e pipeline di training già pronte.
Una volta aperto lo Studio, si sceglie un modello (nel mio caso Qwen 3.5 2B), un dataset e il metodo di training. Ho utilizzato QLoRA (4-bit), che permette di addestrare modelli relativamente grandi anche su GPU limitate come quelle gratuite di Colab.
Per il test ho selezionato il dataset "LaTeX_OCR" e avviato il training direttamente dall’interfaccia. Il sistema gestisce tutto: preprocessing, ottimizzazione, monitoraggio della GPU, loss e avanzamento degli step. In pochi minuti il modello era pronto.
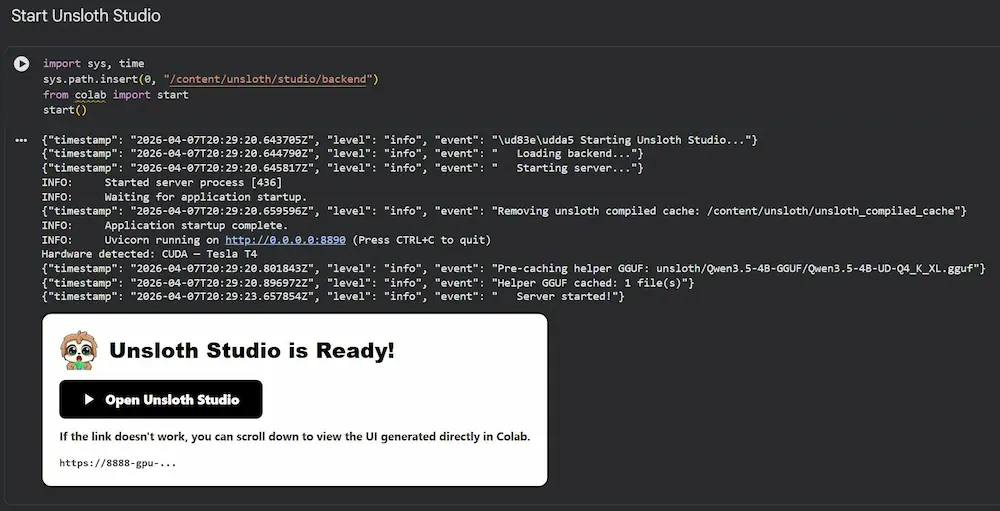
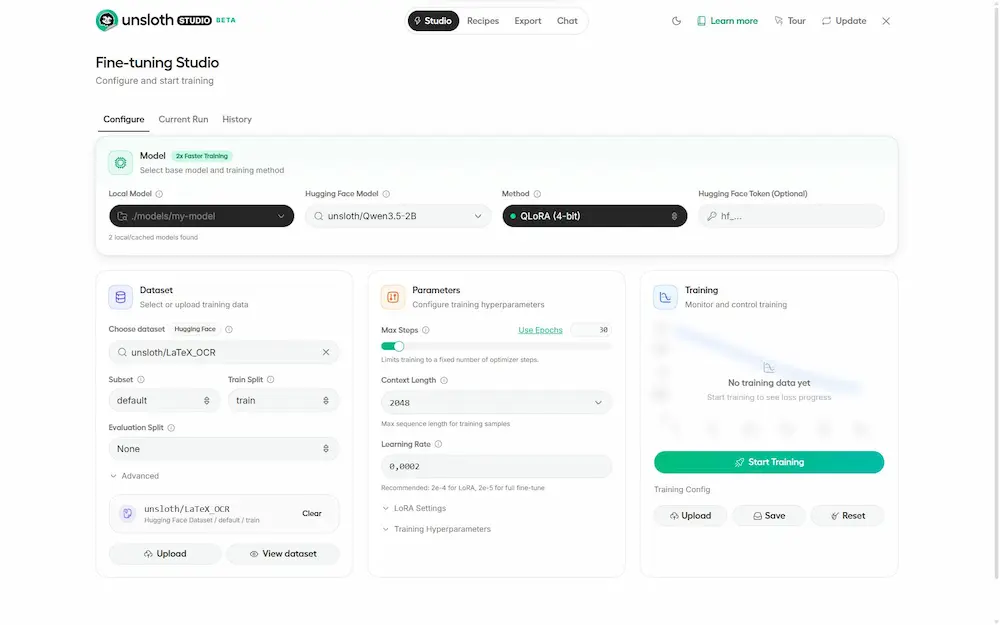
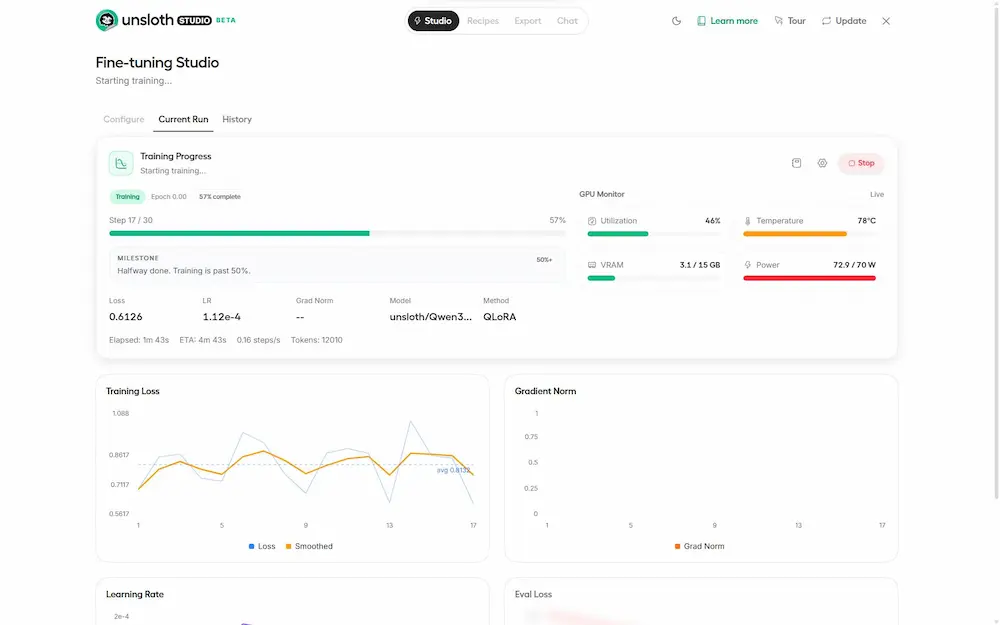
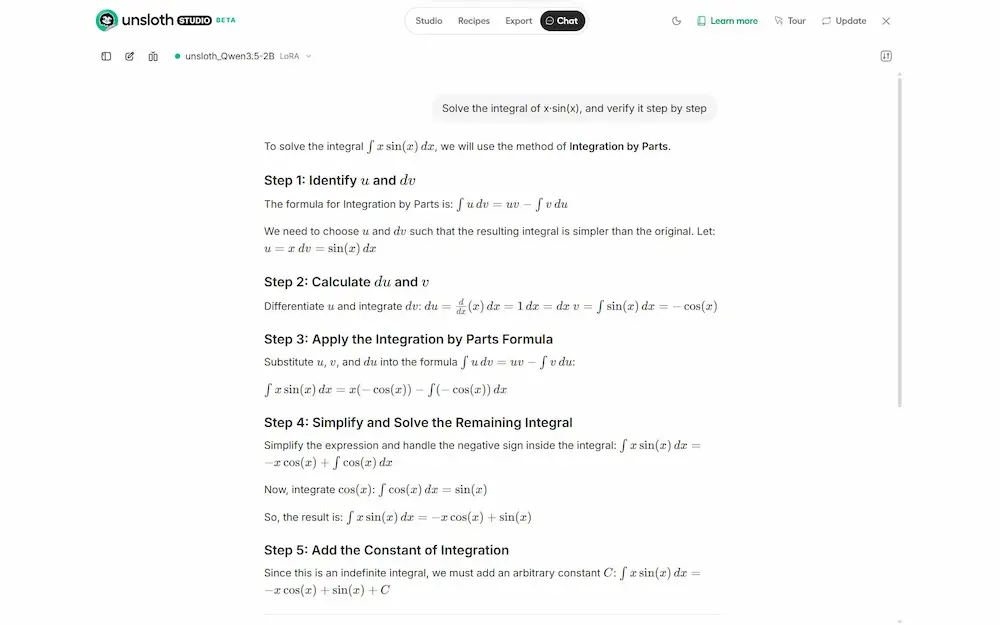
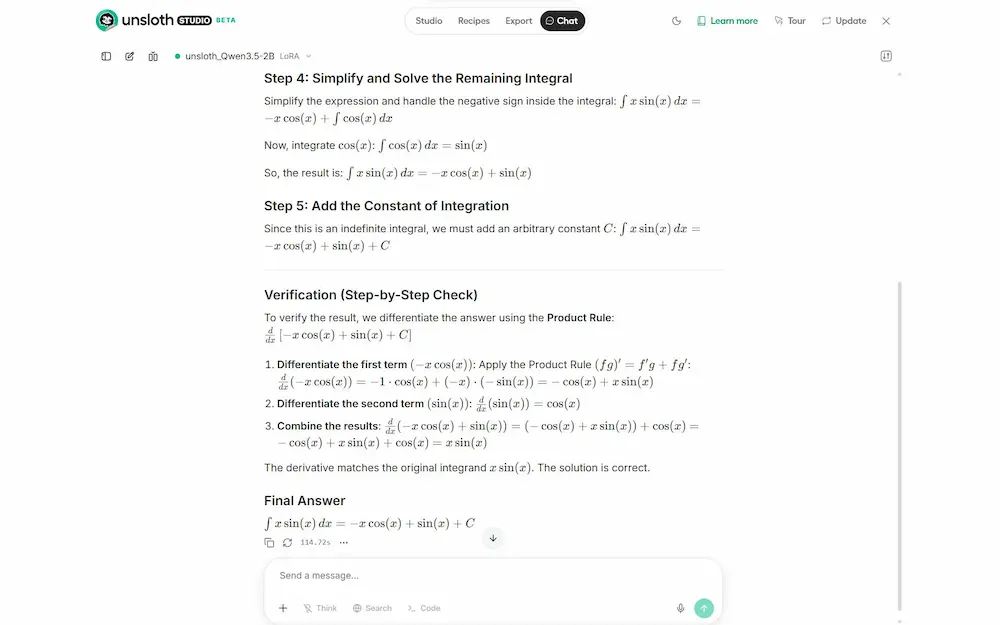
Unsloth Studio: un test
Dopo il fine-tuning ho usato il modello per risolvere un integrale. Il risultato è stato corretto, ma la cosa interessante è capire perché: il training non ha insegnato al modello "nuova matematica", ma lo ha specializzato nel formato LaTeX. In pratica, il modello ha mantenuto le capacità di reasoning già presenti, ma ha prodotto output più puliti, strutturati e coerenti con lo stile matematico.
Questo chiarisce bene cosa permette di fare questo tipo di approccio: non si tratta solo di "insegnare qualcosa di nuovo", ma di adattare modelli già molto capaci a contesti specifici, migliorando formato, tono, dominio o comportamento.
Unsloth Studio abbassa la complessità tecnica del fine-tuning e rende accessibili scenari che prima richiedevano infrastrutture e competenze avanzate.
Si può immaginare facilmente:
- modelli specializzati per documenti tecnici;
- assistenti aziendali addestrati su dati interni;
- generatori di codice o contenuti con stile controllato;
- sistemi che producono output strutturati (JSON, LaTeX, SQL) in modo affidabile.
Il passaggio chiave è che il fine-tuning diventa iterabile e veloce: si prova, si adatta, si rilancia. Non più un processo pesante, ma uno strumento di sviluppo.
Veo 3.1 Lite
Google ha introdotto Veo 3.1 Lite, un modello AI per la generazione video pensato per scalabilità e costi ridotti.
Prezzi: 0,05 $ / s (720p) e 0,08 $ / s (1080p)
Consente di creare video con audio partendo da testo o immagini, offrendo anche funzionalità di editing e controllo cinematografico. È progettato per sviluppatori e aziende che devono produrre grandi volumi di contenuti video in modo automatizzato.
Veo 3.1 Lite
Il modello fa parte della Gemini API e si integra facilmente in applicazioni e workflow esistenti, rendendo la generazione video programmabile e scalabile.
Rispetto alla versione completa di Veo 3.1, questa variante punta su velocità ed efficienza economica, sacrificando alcune capacità avanzate come il supporto al 4K e funzionalità più estese.
Gemma 4 di Google
Gemma 4 è la nuova famiglia di modelli open di Google costruita a partire dalla ricerca e dalla tecnologia di Gemini 3.
Ho provato il 31B su diversi task (nel video alcuni esempi), anche con prompt estesi, con diverse istruzioni da rispettare.
Risultato: veloce e preciso. Se questa è la nuova generazione di modelli open, l'uso in produzione, magari su architetture agentiche, diventa molto concreto.
Gemma 4 di Google: test
Google introduce più varianti pensate per scenari diversi: modelli leggeri (2B e 4B) per edge e mobile, un modello denso da 31B per carichi più complessi e un Mixture-of-Experts da 26B che ottimizza prestazioni e throughput mantenendo efficienza operativa.
Interessante il salto sulla multimodalità (testo, immagini e anche audio/video nei modelli più piccoli), insieme a finestre di contesto molto ampie (fino a 256k token) che abilitano analisi su documenti lunghi e flussi articolati.
Buono anche il supporto nativo a system prompt e function calling, che semplifica la costruzione di agenti e workflow strutturati. Sul coding si notano miglioramenti concreti nei benchmark e nella coerenza delle risposte.
Dal punto di vista infrastrutturale, resta centrale il trade-off tra dimensione, precisione e costi: la quantizzazione permette di abbattere i requisiti hardware, rendendo realistico l’utilizzo anche in contesti locali o ibridi.
Nel complesso, un passo avanti solido per l’ecosistema open.
Gemini Agent
Gemini Agent rappresenta un passo oltre il classico assistente AI: non si limita a rispondere, ma pianifica ed esegue attività complesse in autonomia.
È basato su Gemini 3.1 Pro, e combina navigazione web in tempo reale, capacità di ricerca avanzata e integrazione con strumenti come Gmail, Calendar e Drive. Può gestire email, organizzare impegni, confrontare opzioni online e supportare prenotazioni o acquisti, seguendo un flusso strutturato dall’inizio alla fine.
Gemini Agent: un esempio
L’utente resta sempre al centro: ogni azione critica richiede conferma e il controllo può essere ripreso in qualsiasi momento. È una tecnologia ancora sperimentale, ma chiarisce la direzione: passare da strumenti che assistono a sistemi che operano. Da interfaccia conversazionale a infrastruttura operativa del lavoro quotidiano.
La funzionalità, per ora, è disponibile per utenti Google AI Ultra negli USA.
Skills in Chrome
Google introduce le Skills in Chrome: prompt AI che diventano strumenti riutilizzabili con un solo clic.
Invece di riscrivere ogni volta le stesse richieste, è possibile salvarle e applicarle direttamente alle pagine che si stanno visitando, anche su più schede contemporaneamente. Dalla comparazione di prodotti all’analisi di documenti lunghi, fino al calcolo nutrizionale di una ricetta, ogni attività può trasformarsi in un workflow replicabile.
Skills in Chrome
Le Skills possono essere create, modificate e adattate nel tempo, oppure scelte da una libreria già pronta. Tutto è integrato in Gemini dentro a Chrome, con controlli di sicurezza che richiedono conferma per azioni sensibili.
Un passo verso un uso dell’AI più operativo, meno conversazionale e sempre più integrato nella navigazione quotidiana.
Visualizzazioni interattive in Gemini
Google introduce le visualizzazioni interattive in Gemini.
Visualizzazioni interattive in Gemini
L'applicazione non mostra più solo diagrammi statici per spiegare concetti complessi, ma genera simulazioni funzionali.
Cameraman v1: LoRA per LTX 2.3
Cameraman v1 è un LoRA molto interessante per LTX 2.3 che dimostra come sia possibile trasferire il movimento di camera da un video di riferimento a una scena completamente nuova generata da prompt.
Il punto non è copiare il contenuto del video sorgente, ma ereditarne la regia: pan, tilt, zoom, orbit e altri movimenti possono diventare una guida per la generazione, mentre il soggetto e l’ambientazione vengono definiti dal prompt.
Cameraman v1: LoRA per LTX 2.3
In pratica, si può prendere la dinamica di una ripresa esistente e applicarla a un output diverso, mantenendo la "grammatica visiva" della camera ma cambiando del tutto la scena.
Un esempio utile per capire il concetto: si può usare un reference video con uno slow zoom-in e generare, da prompt, una scena nuova che conserva quel linguaggio cinematografico senza replicare il contenuto originale.
È un esperimento che mostra bene quanto stia diventando concreto il controllo della regia nei modelli video generativi, non solo sul piano estetico ma anche su quello del motion design.
Politica industriale per l’era dell’intelligenza
OpenAI ha pubblicato un documento sulla "politica industriale per l’era dell’intelligenza" che, più che una semplice analisi, è un tentativo di orientare il futuro dell’IA.
L’idea di fondo è che l’intelligenza artificiale trasformerà radicalmente economia, lavoro e società.
Non è presentata come un’ipotesi lontana, ma come qualcosa già in corso. Proprio per questo, il punto non è fermarla, ma decidere come governarla.

Il messaggio principale è che il mercato da solo non sarà sufficiente. Senza interventi, i benefici rischiano di concentrarsi in poche aziende e in poche persone, mentre i costi (lavoro, instabilità, rischi sistemici) si distribuirebbero sul resto della società. Da qui la necessità di una nuova politica industriale: più ambiziosa, più veloce, più coordinata.
Il documento propone una direzione chiara: mantenere un’economia di mercato, ma con un ruolo attivo dello Stato. Accesso diffuso all’IA, redistribuzione dei benefici economici, nuove forme di protezione sociale, investimenti in infrastrutture e formazione.
Allo stesso tempo, introduce il tema della sicurezza: sistemi di controllo, audit, governance e cooperazione internazionale per gestire rischi sempre più complessi.
C’è anche un messaggio implicito. OpenAI si posiziona come attore responsabile, consapevole dei rischi e disposto a contribuire alla costruzione delle regole. Ma nel farlo, cerca anche di influenzare il quadro in cui queste regole nasceranno: favorevole all’innovazione, aperto, ma non eccessivamente restrittivo.
In sostanza, il documento non è solo una riflessione sull’IA. È un tentativo di anticipare il cambiamento, legittimare il proprio ruolo e orientare il dibattito politico globale prima che le decisioni vengano prese altrove.
AI Agent Traps di Google DeepMind
Il paper "AI Agent Traps" del team di Google DeepMind introduce una nuova categoria di rischi per gli agenti AI autonomi: non è il modello a essere attaccato, ma l’ambiente informativo in cui opera.
Man mano che gli agenti navigano il web, prendono decisioni e agiscono in autonomia, diventano vulnerabili a contenuti progettati per manipolarli.



AI Agent Traps di Google DeepMind
Queste "trappole" sfruttano il modo in cui gli agenti percepiscono, ragionano, apprendono e agiscono.
Il lavoro propone una classificazione in sei categorie principali:
- Content Injection: istruzioni nascoste nel codice o nei media, invisibili agli umani ma leggibili dagli agenti;
- Semantic Manipulation: bias e framing che alterano il ragionamento senza comandi espliciti;
- Cognitive State: avvelenamento della memoria e delle basi di conoscenza;
- Behavioral Control: jailbreak e manipolazioni che inducono azioni non autorizzate;
- Systemic Traps: effetti emergenti in sistemi multi-agente (congestione, collusione, cascata);
- Human-in-the-loop: attacchi che sfruttano l’agente per influenzare il decisore umano.
Il punto chiave è che queste tecniche combinano elementi già noti (adversarial ML, web security, prompt injection), ma li applicano a un nuovo contesto: agenti autonomi che operano su larga scala.
Questo sposta il focus della sicurezza: non basta proteggere il modello, serve progettare agenti robusti in ambienti informativi potenzialmente ostili.
Il leak di Claude Code
L’intero web sta parlando di un leak che ha coinvolto Claude Code, il tool da terminale sviluppato da Anthropic.
Vediamo i dettagli in modo semplice e alcune considerazioni.
Recentemente è stato scoperto che la versione npm 2.1.88 conteneva per errore un file .map da circa 57–60 MB. Questo file, usato per il debug, permetteva di ricostruire e scaricare l’intero codice sorgente dell’applicazione: circa 1.900 file e oltre 512.000 righe di codice.
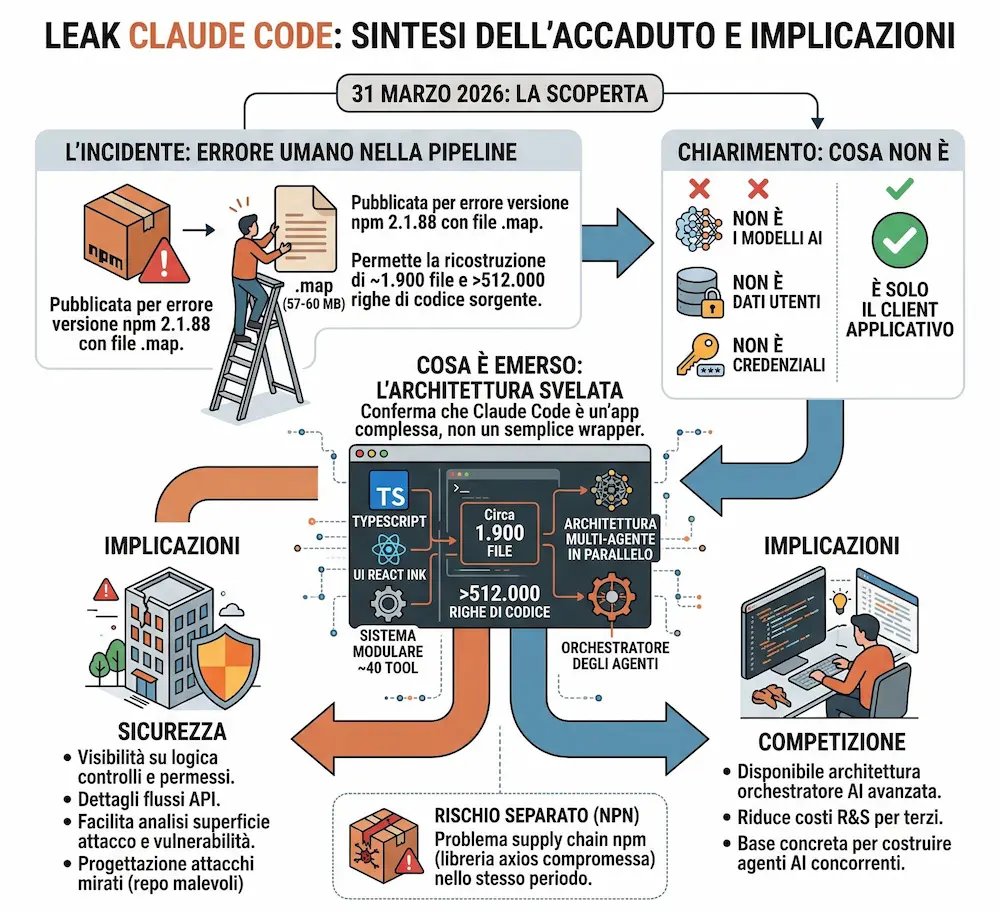
Il contenuto è rimasto pubblico per alcune ore ed è stato rapidamente copiato su GitHub.
Anthropic ha confermato che si è trattato di un errore umano nella pipeline di release, non di una violazione dei sistemi, e che non sono stati esposti dati utenti o credenziali.
Il punto chiave: non è stato leakato il modello AI, ma il client applicativo.
Quello che emerge dai file è molto interessante.
Claude Code non è un semplice wrapper, ma un'applicazione complessa da terminale, con UI React Ink, un sistema di circa 40 tool e supporto a più agenti che lavorano in parallelo. In pratica, una vera piattaforma di orchestrazione per agenti AI.
Il leak ha esposto la logica interna del sistema: API, tool, permessi e orchestrazione. Questo rende molto più facile analizzare il funzionamento e individuare eventuali punti deboli.
Dal punto di vista sicurezza, non c’è un impatto diretto sui dati, ma aumenta il rischio di attacchi mirati, ad esempio repository costruiti per aggirare i controlli o sfruttare il comportamento del sistema.
C’è anche un impatto competitivo: avere accesso a questa architettura significa poter studiare da vicino come costruire agenti AI avanzati, riducendo tempi e costi di sviluppo.
In sintesi: nessun segreto dei modelli è stato esposto, ma è stata aperta una finestra molto concreta su come funzionano oggi gli AI agent di Anthropic in produzione.
Nuovi modelli di Microsoft
Microsoft ha annunciato tre nuovi modelli MAI disponibili su Foundry, progettati per essere più veloci, efficienti e competitivi nei costi.
MAI-Transcribe-1 è dedicato alla trascrizione audio, MAI-Voice-1 alla generazione vocale e MAI-Image-2 alla creazione di immagini.
I modelli sono già accessibili agli sviluppatori e integrabili nelle applicazioni tramite Microsoft Foundry, con possibilità di test nel MAI Playground.
Nuovi modelli di Microsoft
L’approccio dichiarato è quello di un’AI "umanistica", ottimizzata per la comunicazione reale e l’uso pratico, non solo per le performance nei benchmark. I modelli sono stati sviluppati con controlli di sicurezza avanzati, includendo test rigorosi, red teaming e strumenti di governance per ambienti enterprise.
Sul piano tecnico, MAI-Transcribe-1 mostra prestazioni di alto livello nei benchmark linguistici, superando diversi modelli concorrenti in più lingue, mentre l’intera suite punta a combinare qualità elevata e costi più accessibili.
Neural Computers
Un nuovo paradigma computazionale sta emergendo: i Neural Computer.
Il paper, firmato da ricercatori di Meta AI e KAUST, propone un’idea radicale: un sistema neurale che unifica calcolo, memoria e I/O in un unico stato latente, rendendo il modello stesso il "computer" in esecuzione.
Non più software che gira su hardware separato, né agenti che operano su ambienti esterni. Qui è il modello che diventa l’ambiente, il runtime e il processo computazionale.

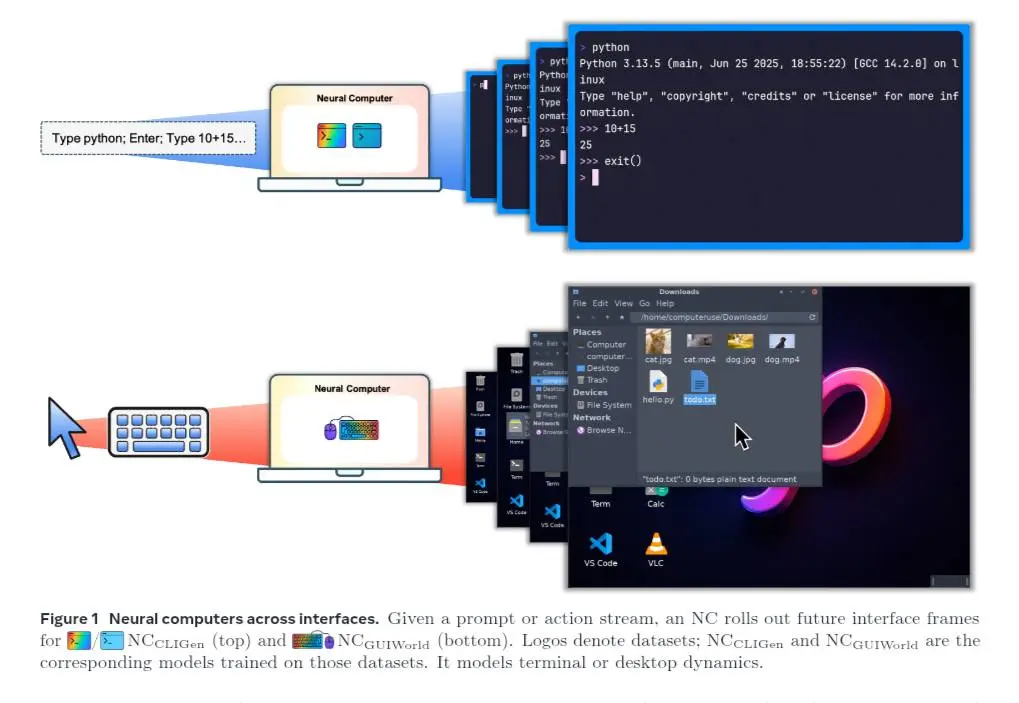

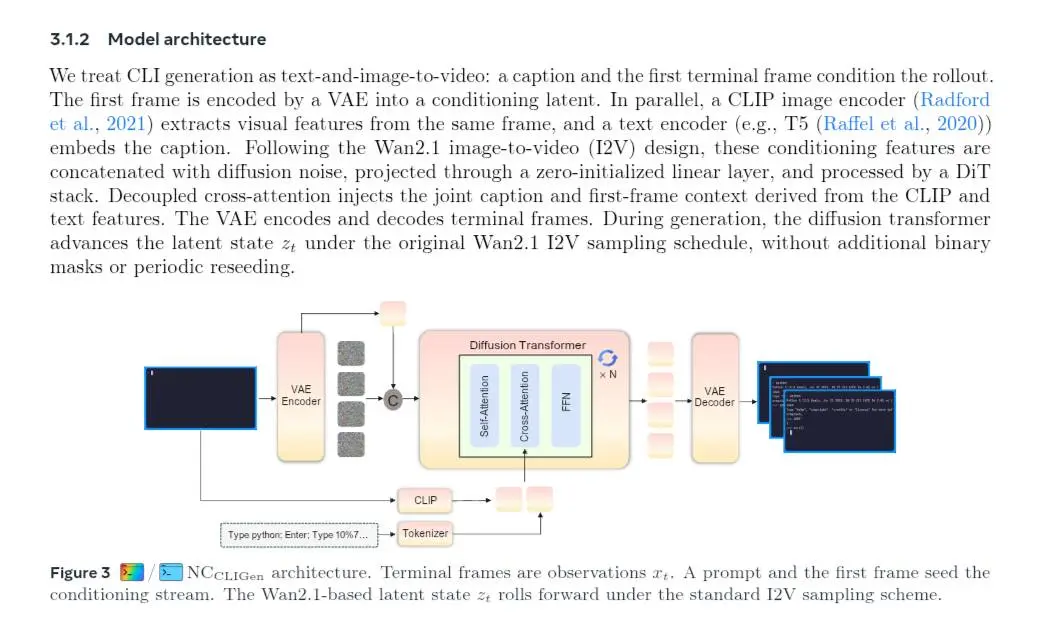
Neural Computers
I prototipi attuali implementano questa visione tramite modelli video che simulano interfacce: terminali (CLI) e desktop grafici (GUI).
Questi sistemi riescono già a mantenere coerenza tra input e output, riprodurre dinamiche di interfaccia realistiche ed eseguire sequenze di azioni a breve termine.
Ma mostrano limiti evidenti: scarsa capacità simbolica (es. matematica), debolezza nel ragionamento a lungo termine, difficoltà nel riutilizzo stabile delle capacità.
Un risultato interessante: migliorando il prompting, le prestazioni aumentano drasticamente, suggerendo che questi modelli oggi sono più "esecutori condizionabili" che veri computer autonomi.
L’obiettivo finale è il Completely Neural Computer (CNC): un sistema pienamente neurale, programmabile, stabile e capace di riuso delle competenze, potenzialmente oltre i paradigmi attuali di software, agenti e world models.
Se realizzati, i CNC potrebbero rappresentare una nuova forma di computing, dove il concetto stesso di programma viene sostituito da uno stato appreso e dinamico.
I progressi della Physical AI
Google DeepMind fa un passo in avanti nello sviluppo di modelli dedicati alla robotica.
Con Gemini Robotics-ER 1.6, l’attenzione si sposta sul concetto di "embodied reasoning": la capacità di un sistema di comprendere il mondo fisico e agire in modo coerente, non solo eseguire istruzioni.
Il modello migliora in modo significativo il ragionamento spaziale e la comprensione multi-vista, permettendo ai robot di identificare oggetti, contarli, valutarne le relazioni e pianificare azioni con maggiore precisione. Il “pointing” diventa uno strumento chiave per ragionare su ciò che il robot osserva e per guidare decisioni operative.
Gemini Robotics-ER 1.6: embodied reasoning
Un aspetto centrale è il "success detection": la capacità di capire quando un compito è stato completato correttamente. Integrando più flussi video (ad esempio da diverse telecamere), il sistema riesce a interpretare scenari complessi e dinamici, migliorando autonomia e affidabilità.
Tra le novità più rilevanti emerge la lettura di strumenti industriali: manometri, indicatori di livello e display digitali possono essere interpretati direttamente dal robot grazie a una combinazione di visione, ragionamento e calcolo. Interessante per applicazioni reali in ambienti industriali e di ispezione.
Il modello introduce anche una visione più "agentica" (già presente su Gemini Flash), in cui il sistema utilizza strumenti, esegue passaggi intermedi e costruisce un processo decisionale articolato per arrivare al risultato.
Infine, viene rafforzata la componente di sicurezza: maggiore capacità di riconoscere rischi, rispettare vincoli fisici e prendere decisioni più prudenti durante l’interazione con l’ambiente.
Un’evoluzione che avvicina i sistemi robotici a una comprensione più profonda e operativa del mondo reale.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂