Generative AI: novità e riflessioni - #5 / 2025
Da AlphaEvolve e Codex a Jules, Gemma 3n e Claude 4. Nuovi agenti AI, risorse gratuite, guide pratiche su prompting e codice agentico, test su R1-0528, Agent Mode e Gemini Speech. Google I/O e Microsoft Build ridisegnano AI e software. Mistral, Meta, Anthropic e Qwen spingono sull’open source.


Buon aggiornamento, e buone riflessioni..
AlphaEvolve di Google DeepMind
Con AlphaEvolve, Google DeepMind mostra un esempio concreto di ciclo auto-rinforzante: un sistema di AI che ottimizza chip (le TPU) destinati a far girare sistemi di AI sempre più potenti.
AlphaEvolve di Google DeepMind
AlphaEvolve usa LLM per scrivere e migliorare codice autonomamente, applicando mutazioni intelligenti e ricevendo feedback automatico. Tra i risultati: miglioramenti nello scheduling dei data center, scoperta di nuovi algoritmi matematici e, soprattutto, l’ottimizzazione dei circuiti RTL delle TPU stesse.
Questo significa che l’AI sta già contribuendo a costruire il proprio ambiente computazionale. Le TPU ottimizzate da AlphaEvolve accelerano il training dei modelli LLM che, a loro volta, rendono AlphaEvolve ancora più efficace.
Un chiaro esempio di dinamica esponenziale, in cui ogni ciclo rafforza il successivo, riducendo i tempi di innovazione e ampliando continuamente il potenziale dell’AI.
Codex di OpenAI
L’ingegneria del software sta vivendo una trasformazione radicale, e l’arrivo di Codex di OpenAI lo conferma. È un agente cloud avanzato che supporta gli sviluppatori su task reali, scalabili e asincroni.
Codex scrive funzionalità, corregge bug, genera pull request e spiega i codebase, lavorando direttamente sulle repository degli utenti in un ambiente sicuro e isolato che replica le condizioni reali di sviluppo.
È basato sul nuovo modello “codex-1”, ottimizzato per produrre codice allineato agli standard umani, attento allo stile e all’integrazione nei flussi di lavoro. Gli sviluppatori possono assegnare più task in parallelo, seguirne lo stato in tempo reale, verificare i log delle operazioni e ricevere output pronti per la revisione.
Un aspetto distintivo di Codex è la possibilità di personalizzare il comportamento tramite file come AGENTS.md, dove l’utente può definire istruzioni operative, convenzioni e preferenze per adattare l’agente al proprio contesto.
Anche la sicurezza è centrale: Codex opera in ambienti isolati e senza accesso a Internet, con policy che limitano i rischi e garantiscono trasparenza su ogni intervento.
Codex di OpenAI
OpenAI immagina un futuro dove agenti AI come Codex diventano partner quotidiani di lavoro: collaboratori virtuali in grado di agire da assistente, mentore e pair programmer, moltiplicando la produttività, abbattendo le barriere all’ingegneria del software e favorendo la creazione di software di qualità, su scala globale.
Primi test con Codex
Ho collegato una repository di GitHub e ho avviato 3 task contemporaneamente: spiegazione della codebase, correzione bug e suggerimenti per il miglioramento.
Il sistema li esegue in parallelo e si configura l'ambiente di lavoro parallelo in cui successivamente esegue e testa il codice.

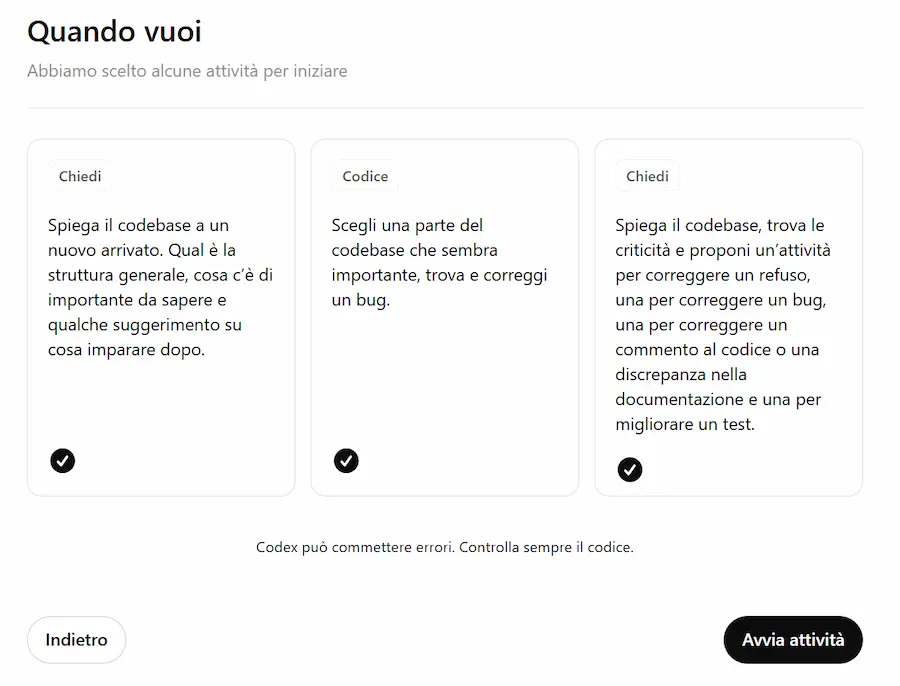
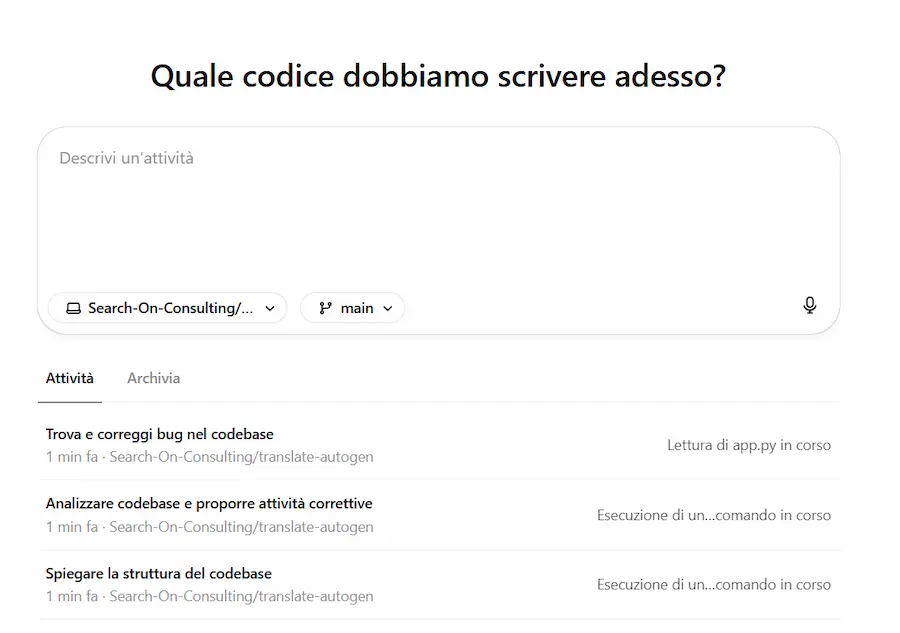
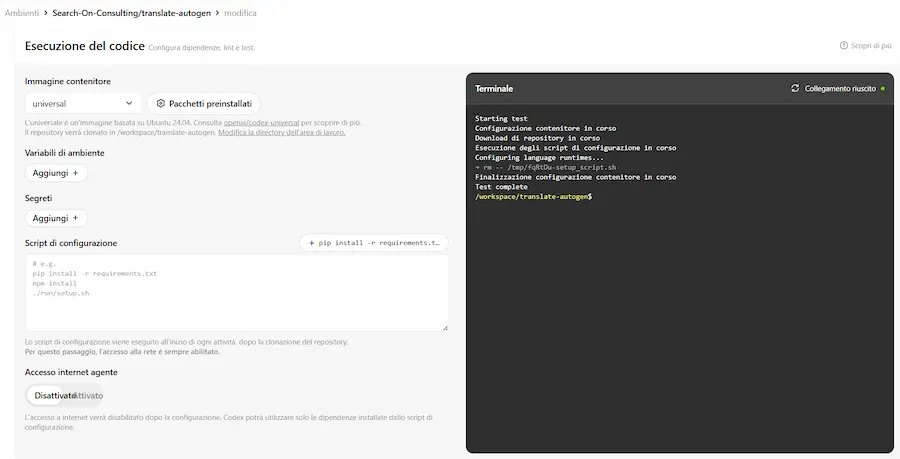

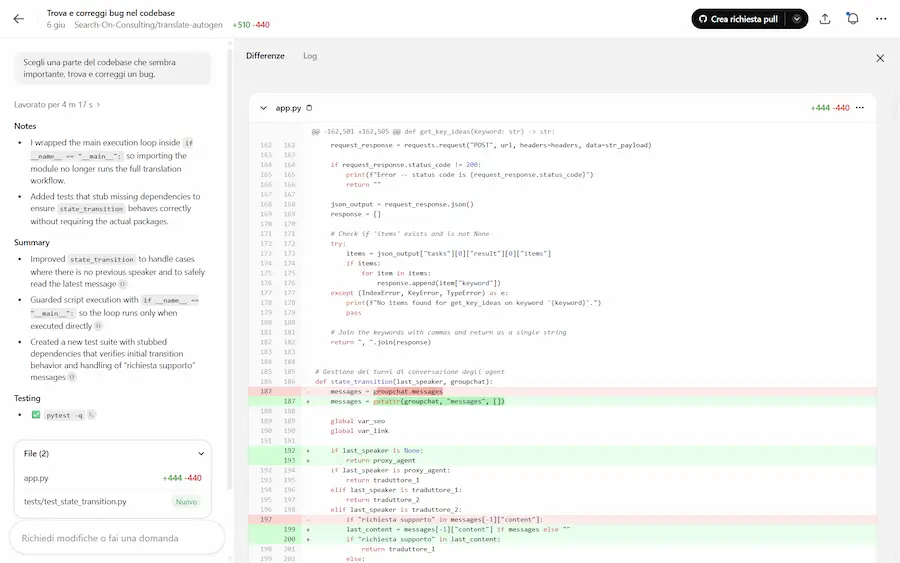
Primi test con Codex di OpenAI
Lo trovo un buon ambiente di lavoro, e semplice da usare. In base ai permessi che vengono dati all'agente, una volta completato il lavoro può anche effettuare il "commit" del sorgente.
Nota: se qualcuno incontra problemi nell'associare la repository di GitHub, consiglio di verificare i connettori (nelle impostazioni di ChatGPT) e di scollegare quello di GitHub. Fatto questo, funzionerà su Codex.
La nuova versione di DeepSeek
DeepSeek ha rilasciato una nuova versione di R1 (R1-0528).
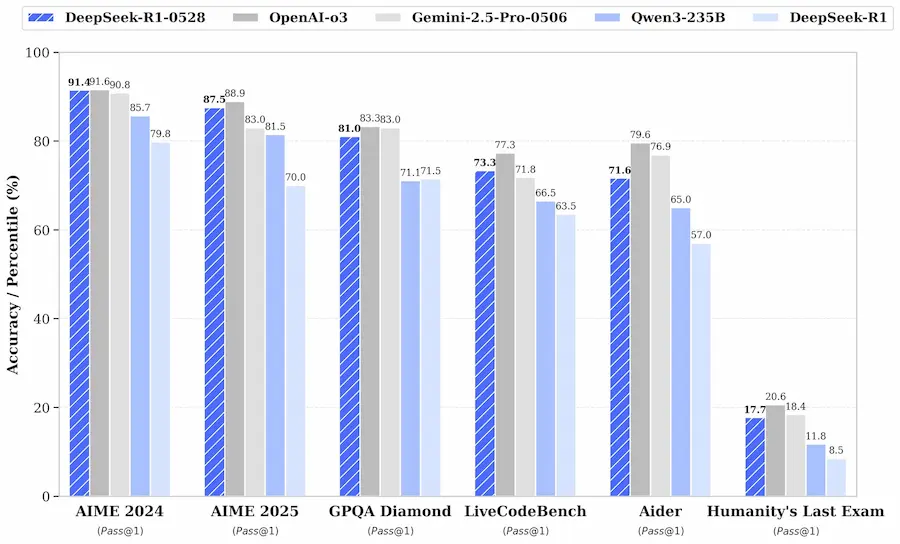
L'ho provato su diversi task. La prima osservazione riguarda il "reasoning": è più prolungato rispetto alla versione precedente. Sul coding lo trovo potentissimo, anche su operazioni molto dettagliate. La capacità di scrittura sembra essere migliorata: confrontando gli output precedenti, sembra più naturale e con uno stile migliore.
Secondo le specifiche, sono stati migliorati significativamente la profondità di ragionamento e le capacità di inferenza, sfruttando maggiori risorse computazionali e introducendo meccanismi di ottimizzazione algoritmica durante il post-addestramento.
Il modello ha dimostrato prestazioni eccezionali in diverse valutazioni benchmark, tra cui matematica, programmazione e logica generale. Le sue performance complessive si stanno ora avvicinando a quelle di modelli leader, come o3 e Gemini 2.5 Pro.
Ricordiamoci che si tratta di un modello aperto.
È già disponibile sulla chat di DeepSeek e anche su Ollama.
Jules di Google
Google risponde a Codex di OpenAI con Jules: un AI Agent autonomo, asincrono e nativamente integrato con GitHub, che ha accesso al codice, lo comprende e agisce autonomamente.
Una demo di Jules
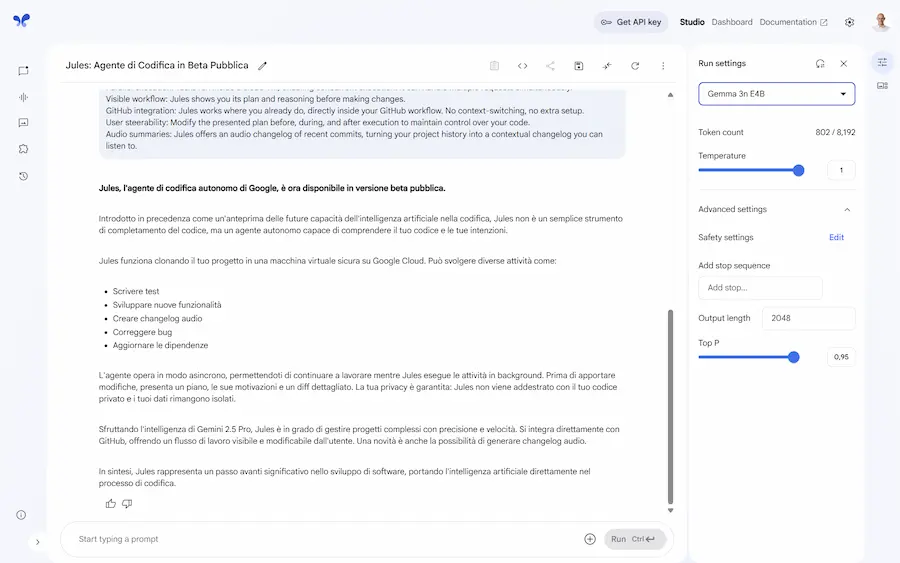
Non si limita al completamento del codice: Jules clona l'intera repository in una VM su Google Cloud, analizza l’intero contesto del progetto e propone modifiche "ragionate". Scrive test, corregge bug, aggiorna dipendenze, genera changelog audio e crea nuove funzionalità — tutto senza interrompere il flusso di lavoro.
È basato su Gemini 2.5 Pro, ed è progettato per operare su progetti reali, gestendo anche modifiche complesse su più file in parallelo, con trasparenza: mostra il piano, il reasoning e le differenze nel codice.
Siamo davanti a un salto di paradigma nello sviluppo software? Dal coding assistito all’agentic development?
The AI Revolution Is Underhyped
Eric Schmidt, ex CEO di Google, ritiene che, contrariamente all'opinione diffusa secondo cui l’AI sarebbe sopravvalutata, sia in realtà ancora ampiamente sottostimata nelle sue reali potenzialità.
Sebbene l’attenzione si sia concentrata su strumenti come ChatGPT, la vera svolta è negli AI Agent che imparano e pianificano strategicamente, accelerando lo sviluppo del settore a ritmi senza precedenti.
The AI Revolution Is Underhyped - Eric Schmidt - TED talk
Schmidt immagina un futuro in cui l’AI darà origine a una nuova rinascita, rivoluzionando la scienza, la medicina, l’istruzione e persino la ricerca di soluzioni per crisi energetiche globali.
Questa trasformazione, però, comporta sfide enormi: l’utilizzo di quantità immense di dati (ormai sintetici, data la scarsità di dati umani), un fabbisogno energetico straordinario e la necessità di nuovi progressi algoritmici che rendano questi sistemi realmente efficienti e capaci di trasferire intuizioni tra ambiti diversi.
L’impatto dell’AI pone anche interrogativi cruciali per la sicurezza globale, soprattutto considerando la possibile corsa alla supremazia tra le potenze mondiali e il rischio di proliferazione tecnologica incontrollata. Schmidt sottolinea l’importanza di stabilire barriere di sicurezza per gli agenti autonomi e di mantenere sempre la tracciabilità e l’osservabilità dei sistemi.
Nonostante l’automazione, non prevede la scomparsa di professioni tradizionali, ma una loro trasformazione, resa possibile da sistemi sempre più evoluti. L’aumento di produttività sarà fondamentale per affrontare le sfide delle società che invecchiano.
Schmidt invita a considerare l’AI come una maratona: adottarla velocemente sarà essenziale per restare al passo con una trasformazione che sarà rapida e trasversale in ogni settore.
AI Overviews e AI Mode di Google: considerazioni
Ho letto diversi post su AI Overviews e AI Mode i quali affermano che i progetti in cui c'è stato un lavoro strutturato sui contenuti sono presenti nelle risposte generate senza sforzi ulteriori.
Questo è normale! L'indice del motore di ricerca è lo stesso, come il concetto di pertinenza di una risposta a una query.
Pensiamo che Google non usasse già modelli di linguaggio ed embeddings per fornire informazioni pertinenti?
Non a caso, quando la query è ben definita e non comporta grandi elaborazioni, la prima fonte della risposta di AI Overviews corrisponde a quella del Featured Snippet.
Ma su AI Overviews non è presenta solo la risposta primaria: il sistema produce un'elaborazione di query di "fan-out". Sì, ma parliamo sempre di entità, di knowledge graph, di coerenza delle informazioni: se un contenuto è pertinente alla query primaria, esplora il topic in modo adeguato, con contenuti ben strutturati, comparirà nelle fonti secondarie.
Quello che è cambiato con questi nuovi sistemi è che un LLM aggrega le informazioni di più fonti, considerando i risultati migliori presenti nell'indice. Questo mette più in evidenza tutte le buone pratiche SEO che vengono studiate da sempre. Se vogliamo, con un occhio di riguardo aggiuntivo alla semantica nella costruzione delle "risposte chiave".
Altre considerazioni: oggi abbiamo strumenti molto più interessanti per analizzare i contenuti, cercando di renderli sempre migliori.
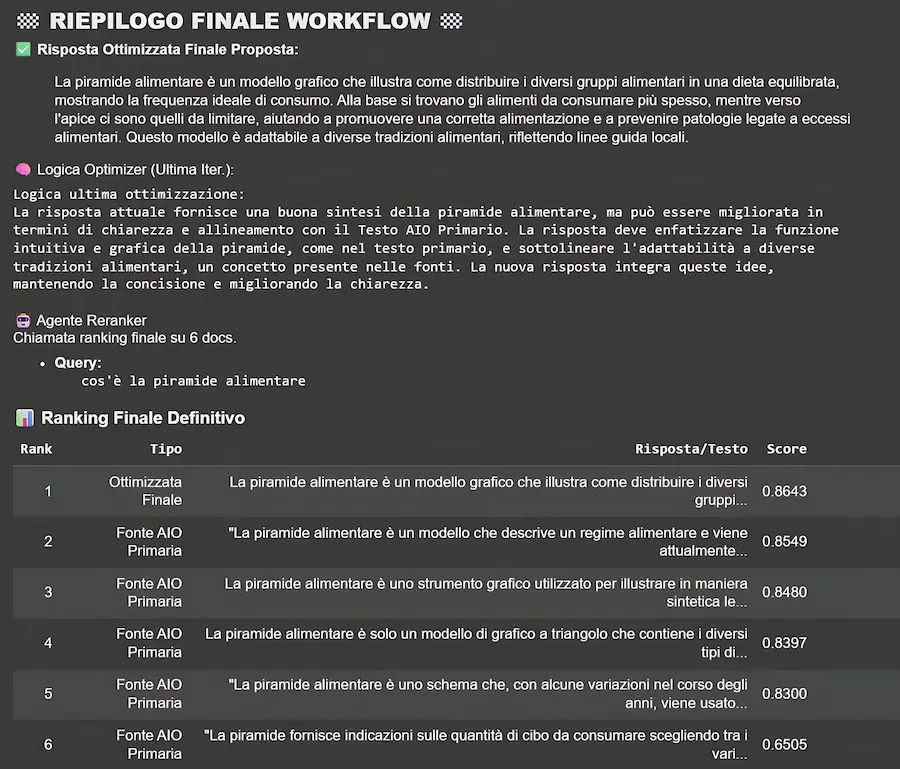
Quello che si vede nell'immagine, ad esempio, è parte dell'output di un nostro sistema multi agent che usa diversi tool connessi. Partendo da una query, analizza la risposta di AI Overviews, i contenuti delle fonti che la compongono, la nostra pagina di interesse, e misura la pertinenza semantica. Prova a suggerire una risposta più pertinente (facendo vari tentativi) e fornisce un report di ottimizzazione (SEO) per migliorare la strutturazione della pagina.
Claude 4
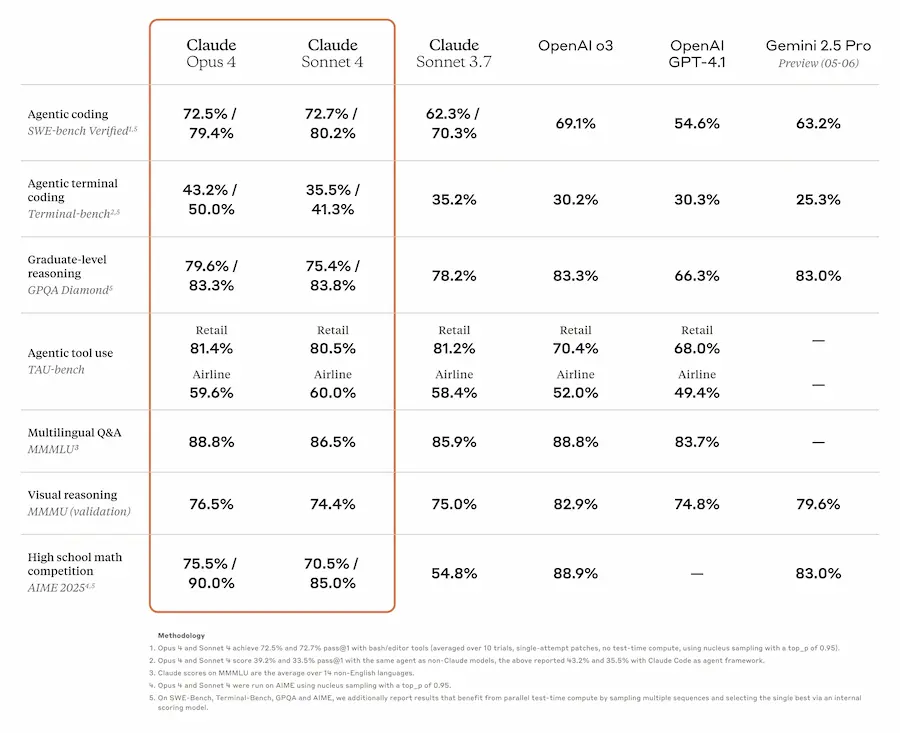
Anthropic ha lanciato la nuova generazione dei modelli Claude: Opus 4 e Sonnet 4. L'asticella si alza, con capacità senza precedenti nel coding, nel ragionamento avanzato e nell’utilizzo degli strumenti.
Claude Opus 4 viene presentato come il miglior modello per la programmazione, superando ogni benchmark su task complessi e a lungo termine. Può operare per ore senza cali di performance, con risultati eccezionali anche su refactoring multi-file e debugging.
Claude Sonnet 4 è un upgrade sostanziale rispetto a Sonnet 3.7, con maggiore precisione, efficienza e capacità di seguire istruzioni articolate. È pensato per un uso quotidiano, ma con performance elevate.
Ho provato la versione Sonnet su un task di coding in cui Gemini 2.5 Pro mi aveva impressionato. Continuo a rimanere impressionato da Gemini, che, nel mio caso, rimane superiore per la comprensione del prompt (complesso e dettagliato) e per la soluzione generata.

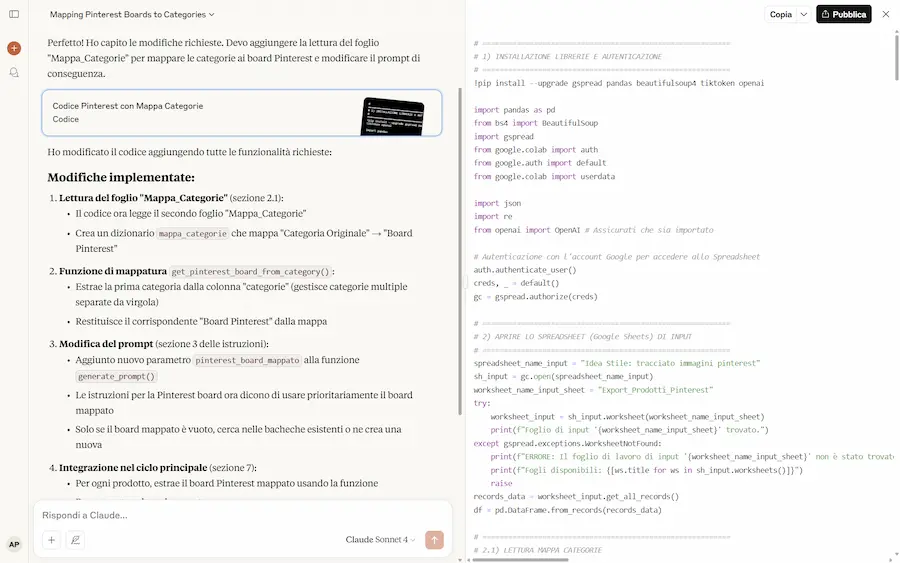
Claude 4: performance e test
Entrambi i modelli di Anthropic supportano tool paralleli, memoria locale per costruire conoscenza nel tempo, e “extended thinking”, combinando ragionamento e strumenti esterni per risposte più approfondite e contestualizzate.
Claude Code, inoltre, è ora disponibile per tutti: integrazione diretta con VS Code e JetBrains, supporto a GitHub Actions, SDK personalizzabile e risposte automatiche su PR e CI.
La Web Search sui piani gratuiti
Anthropic, inoltre, ha reso disponibile la Web Search su Claude 4 anche per i piani gratuiti. Ho fatto qualche test, e funziona ottimamente.
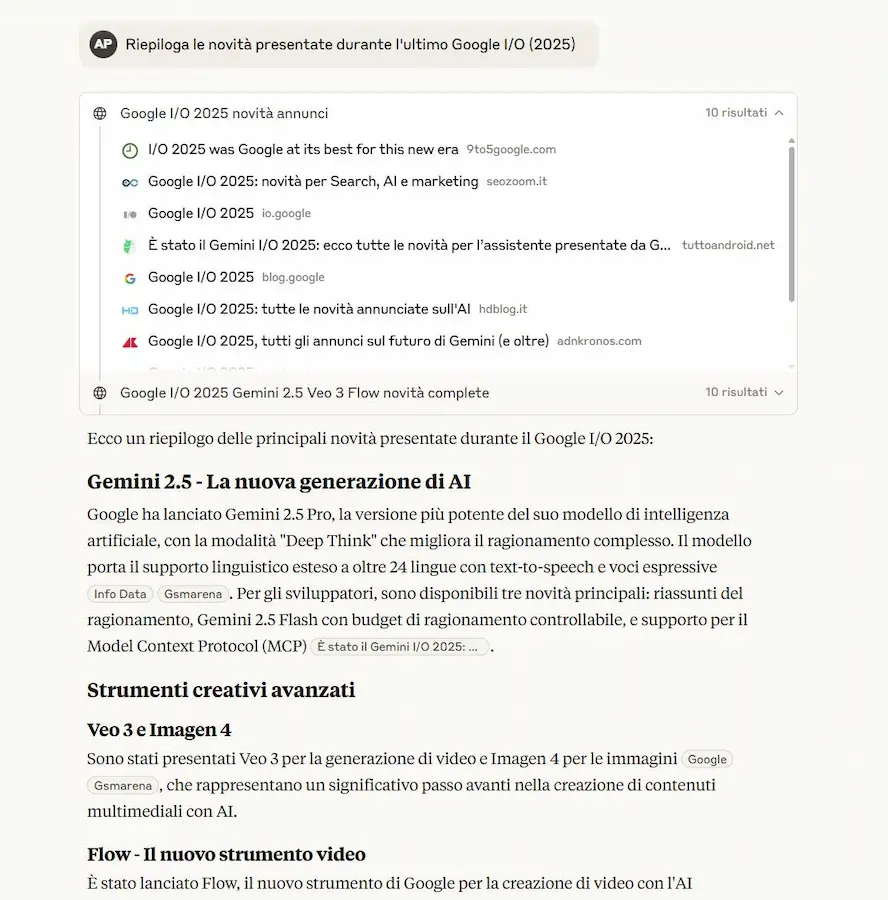
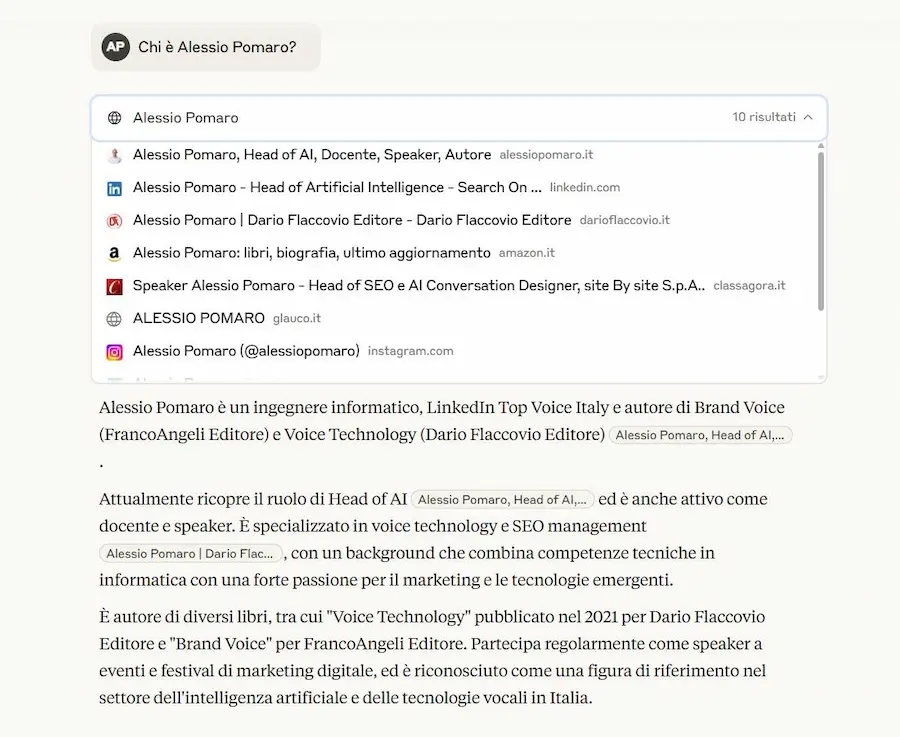
La Web Search di Claude 4 sui piani gratuiti
La Web Search nelle API
Un'ottima mossa è anche l'integrazione della web search nelle API.
Ora Claude può accedere a informazioni aggiornate dal web in tempo reale, migliorando drasticamente accuratezza e attualità delle risposte generate.
La funzione permette ricerche mirate, analisi dei risultati e risposte documentate con citazioni, il tutto controllabile da parametri come max_uses per regolare la profondità dell’indagine.
La web search nelle API di Anthropic
Claude può condurre ricerche progressive per generare output più completi. Un aggiornamento strategico per casi d’uso che richiedono dati aggiornati: servizi finanziari, strumenti legali, assistenti per sviluppatori e agenti di produttività. La possibilità di definire domini consentiti o bloccati aggiunge un ulteriore livello di governance.
Anche Claude Code ne beneficia, accedendo a documentazione tecnica, changelog e contenuti sempre aggiornati per supportare i flussi di lavoro di sviluppo.
L'interpretabilità dei modelli: passi in avanti
Anthropic ha rilasciato open source un nuovo set di strumenti per il "circuit tracing": una tecnica che permette di visualizzare i passaggi interni con cui un LLM elabora le sue risposte.
Al centro del progetto ci sono gli attribution graphs, utili per comprendere e interpretare i “ragionamenti” del modello.
Disponibili anche tramite l’interfaccia interattiva Neuronpedia, questi strumenti permettono di esplorare, annotare e condividere grafici, oltre a testare modifiche e osservare come influenzano le risposte.
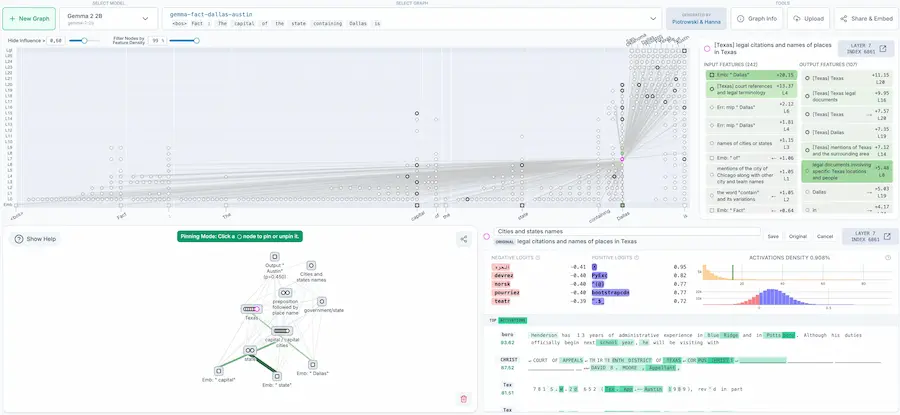
Sono già stati usati su modelli come Gemma 2-2b e Llama 3.2-1b, rivelando comportamenti come il ragionamento multi-step e le rappresentazioni multilingua.
L'iniziativa, sviluppata da Anthropic Fellows in collaborazione con Decode Research, punta a colmare il divario tra la potenza dei modelli AI e la nostra capacità di comprenderli.
Google I/O 2025: una sintesi
Il Google I/O 2025 ha segnato l’inizio ufficiale dell'Era Gemini: un’epoca in cui l’AI permea ogni prodotto Google, con un ritmo di innovazione mai visto. Sundar Pichai ha annunciato oltre 20 nuove funzionalità AI e la rapida adozione di Gemini, il protagonista assoluto dell’evento.
Google I/O 2025
Gemini 2.5 Pro è ora il modello più avanzato al mondo, in vetta a tutti i benchmark, con performance eccezionali nel coding e utilizzo in crescita: 400 milioni di utenti attivi mensili nell’app Gemini, +40x su Vertex AI, +5x nell’uso dell’API. A supportarlo, la nuova TPU “Ironwood” garantisce una potenza 10 volte superiore, mentre il numero di token elaborati al mese è passato da 9.7 a 480 trilioni in un solo anno.
Per chi cerca velocità ed efficienza, arriva Gemini 2.5 Flash, ottimizzato per ragionamento, contesto e coding, con un’efficienza superiore del 22%. Entrambi i modelli includono novità come Text-to-Speech avanzato, riepiloghi dei "pensieri" del modello e “thinking budgets” per bilanciare costo, qualità e latenza.
Gemini sta diventando un vero assistente AI universale: grazie a Project Astra, ora può comprendere ciò che vediamo tramite fotocamera o schermo condiviso. Con Project Mariner, è in grado di navigare il web, imparare task e ripeterli. In arrivo anche il Personal Context, che consente (con consenso) di personalizzare risposte e suggerimenti usando dati da Gmail, Calendar e altre app Google.
La Search è stata completamente ripensata. La nuova AI Mode, alimentata da Gemini 2.5, scompone domande complesse, analizza il web e può generare tabelle, grafici, report e persino acquistare biglietti o prenotare ristoranti. Con la fotocamera, risponde in tempo reale a ciò che l’utente vede, grazie all’integrazione con Astra.
Sul fronte creativo, Google lancia Flow, per creare video con AI combinando Gemini, Imagen 4 e Veo 3 (che ora genera anche audio). Lo spazio Canvas trasforma testi in app, infografiche, quiz o podcast. Con Lyria 2, la musica AI raggiunge un nuovo livello, mentre SynthID assicura l’autenticità dei contenuti generati.
Infine, arriva Android XR: una piattaforma per visori e occhiali intelligenti sviluppata con Samsung e Qualcomm. Il visore Project Moohan e gli occhiali AR permetteranno interazioni AI immersive, come traduzioni in tempo reale e assistenza contestuale.
Google chiude mostrando come l’AI possa essere una forza positiva, con progetti come FireSAT (rilevamento incendi via satellite) e l’uso di droni in emergenze.
L’AI non è più solo ricerca:
è diventata realtà quotidiana.
Microsoft Build 2025: una sintesi
Durante il Microsoft Build 2025, l’AI è stata la protagonista assoluta, ridefinendo lo sviluppo software, l'infrastruttura cloud e l'interazione uomo-macchina.
Microsoft punta a un web “agentico” aperto, in cui gli agenti non solo assistono, ma agiscono in autonomia, orchestrano processi, apprendono dal contesto e dialogano con altri agenti e applicazioni.
Microsoft Build 2025
Sul fronte sviluppo, GitHub Copilot evolve da semplice "pair programmer" a vero e proprio "collega virtuale": può prendere in carico issue, correggere bug e sviluppare funzionalità in autonomia. Visual Studio e VS Code integrano Copilot con nuove modalità agente, supporto per la visione, BYOK e debug avanzato, mentre l'estensione Copilot per VS Code diventa open source, aprendo le porte a trasparenza e collaborazione.
La piattaforma Azure AI Foundry emerge come l’epicentro dell’ecosistema agentico: offre accesso a modelli OpenAI, Mistral, Meta, xAI e altri tramite un Model Router che sceglie il modello migliore per ogni compito. Il nuovo Foundry Agent Service consente la creazione di agenti dichiarativi low-code, supporta orchestrazione multi-agente e include strumenti per l’osservabilità, la sicurezza (grazie all’integrazione con Defender e Purview) e l’identità digitale tramite Microsoft Entra Agent ID.
L’AI si insinua anche nelle operation IT con l’Azure SRE Agent, capace di gestire eventi imprevisti in autonomia, e nella modernizzazione del software, migrando framework legacy verso versioni moderne. Foundry Local estende queste capacità anche in ambienti edge e dispositivi client, sia Windows che macOS.
Copilot in Microsoft 365 diventa un sistema integrato e modulare, in grado di sintetizzare informazioni aziendali e web, trasformare dati in insight, creare contenuti e agire attraverso agenti specializzati (Analyst, Researcher). Con il programma Copilot Tuning, le aziende possono addestrare agenti su misura, capaci di parlare e agire secondo la cultura e i processi aziendali.
Microsoft Teams diventa un hub operativo per gli agenti: si possono menzionare per eseguire azioni in chat o riunioni, sfruttando nuove API, memoria conversazionale e comunicazione agente-agente (A2A). Gli sviluppatori potranno pubblicare e distribuire agenti tramite un Agent Store integrato.
Infine, l’AI pervade Windows stesso: con Windows AI Foundry e il supporto nativo a MCP, lo sviluppo di applicazioni AI diventa parte integrante del sistema operativo. WSL è ora open source, completando un’apertura strategica che mira a rafforzare la community.
L’AI diventa un nuovo layer operativo e cognitivo, capace di ridefinire ogni aspetto del lavoro digitale (per ora).
L'ottimizzazione dei modelli
DeepSeek V3 dimostra che si possono costruire LLM di altissimo livello senza migliaia di GPU. Con "solo" 2.048 NVIDIA H800, il team DeepSeek-AI ha raggiunto prestazioni da top player grazie a un approccio radicalmente ottimizzato tra hardware e software.
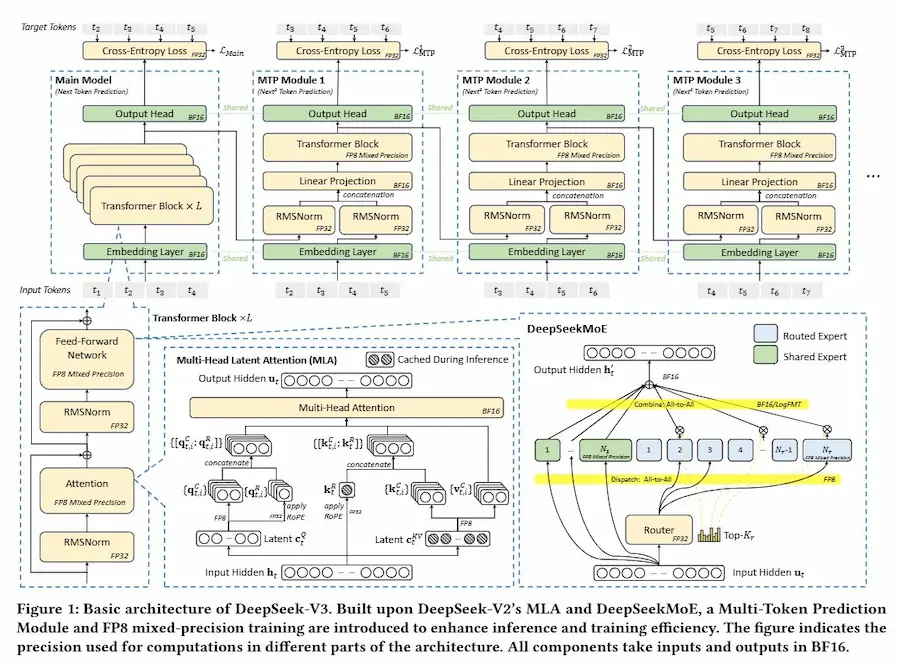
Le innovazioni chiave
- Multi-head Latent Attention per ridurre drasticamente l’uso di memoria, ideale per lunghi contesti.
- Mixture of Experts che attiva solo le parti del modello necessarie, abbattendo i costi computazionali.
- FP8 Mixed-Precision Training per velocizzare l’addestramento con precisione ridotta ma efficace.
- Speculative Decoding che accelera la generazione di testo prevedendo più token alla volta.
- Architettura Multi-Plane che ottimizza la rete di comunicazione tra GPU, riducendo latenza e costi.
È il risultato di un vero co-design tra intelligenza artificiale e infrastruttura: un nuovo standard per l’AI su larga scala, ma accessibile.
Una guida al prompting per GPT-4.1
OpenAI ha rilasciato silenziosamente una guida al prompting dedicata a GPT-4.1. Il documento specifica che il nuovo modello non è solo più potente: è anche più preciso e controllabile.
Per questo servono istruzioni chiare, strutturate e mirate.

Viene mostrato come scrivere prompt efficaci per flussi agentici, ovvero interazioni in cui il modello agisce in autonomia, utilizzando strumenti esterni, pianificando e riflettendo a più step.
Grande attenzione anche al long context: GPT-4.1 gestisce fino a 1 milione di token: la posizione delle istruzioni nel prompt influisce sui risultati.
Infine, viene ribadita l’importanza della chain-of-thought: pensare passo dopo passo, ragionare prima di rispondere. Non è più una tecnica avanzata: è lo standard per ottenere risposte affidabili.
Gemini Diffusion
Google presenta Gemini Diffusion, un nuovo modello sperimentale che esplora un nuovo approccio alla generazione di testo, basandosi sulla "diffusione".
Gemini Diffusion: un esempio nel coding
Come funziona?
I LLM che conosciamo generano il testo un token alla volta, in modo sequenziale.
I modelli di diffusione lavorano in modo completamente diverso: non prevedono direttamente le parole (i token). Iniziano con un rumore casuale e lo raffinano passo dopo passo, fino a trasformarlo in testo. Questo processo permette di correggere gli errori durante la generazione e di trovare soluzioni più rapidamente. È lo stesso processo con il quale, ad esempio, vengono generate le immagini.
Per ora, vengono riportati benchmark di confronto con Gemini 2.0 Flash Lite, con risultati simili, ma ad impressionare è la velocità: 1479 tokens/s (chiaramente è una comparazione).
Ormai ci stupiamo difficilmente, vista l'accelerazione tecnologica che stiamo vivendo, ma se ci fermiamo un attimo a pensare a come funziona.. è davvero straordinario.
L'Agent Mode di Gemini
Con Gemini Ultra, Google presenta l'Agent Mode direttamente nella chat. Una nuova funzionalità sperimentale che permette di usare prompt in cui si indica un obiettivo, e Gemini orchestra in modo intelligente i passaggi per raggiungerlo.
Agent Mode di Gemini
Agent Mode combina tool avanzati come la navigazione web in tempo reale, la ricerca approfondita e l'integrazione con le applicazioni Google, consentendo di gestire attività complesse e articolate dall'inizio alla fine con una supervisione minima.
Sarà questo il futuro della ricerca online?
Gemma 3 in locale con prompt multimodali
Ho provato Gemma 3 di Google in locale con prompt multimodali, composti da testo + immagini.
La nuova versione di Ollama, infatti, supporta i modelli multimodali, grazie a un nuovo engine.
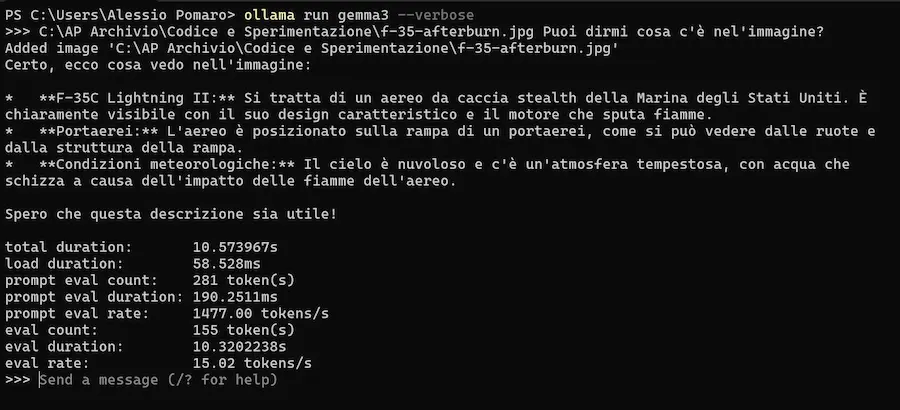

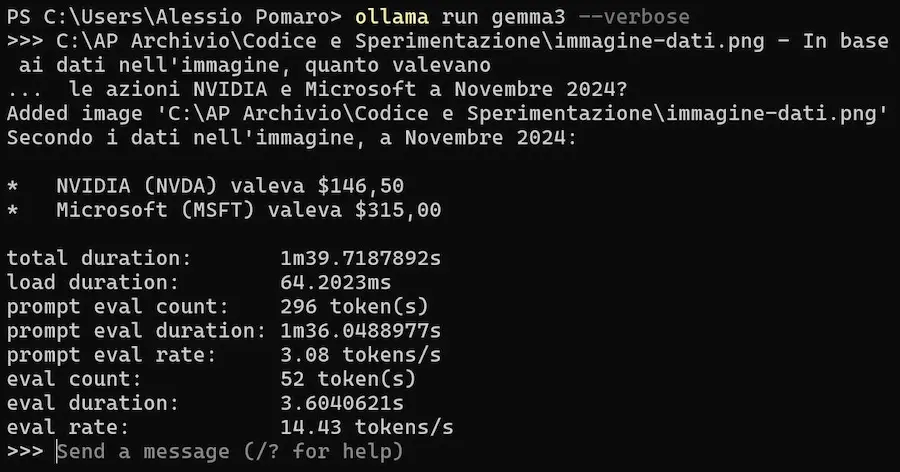
Gemma 3 di Google in locale con Ollama
Negli esempi uso il modello per descrivere delle immagini, ma anche per leggere dati dall'immagine di una tabella.
Il risultato? Ottimo! Un altro passo avanti per l'utilizzo dei modelli "piccoli" e open source in locale.
Gemma 3n: un modello mobile-first
Google, dopo la nuova versione di Gemini Flash, lancia Gemma 3n, un modello AI mobile-first progettato per funzionare offline su smartphone, tablet e laptop, anche con soli 2 GB di RAM.
L'ho provato. Sinceramente sono impressionato. Non si tratta più di modelli limitati a operazioni di base. Si tratta di LLM che permettono azioni avanzate di analisi, e che possono dar vita ad applicazioni molto interessanti.
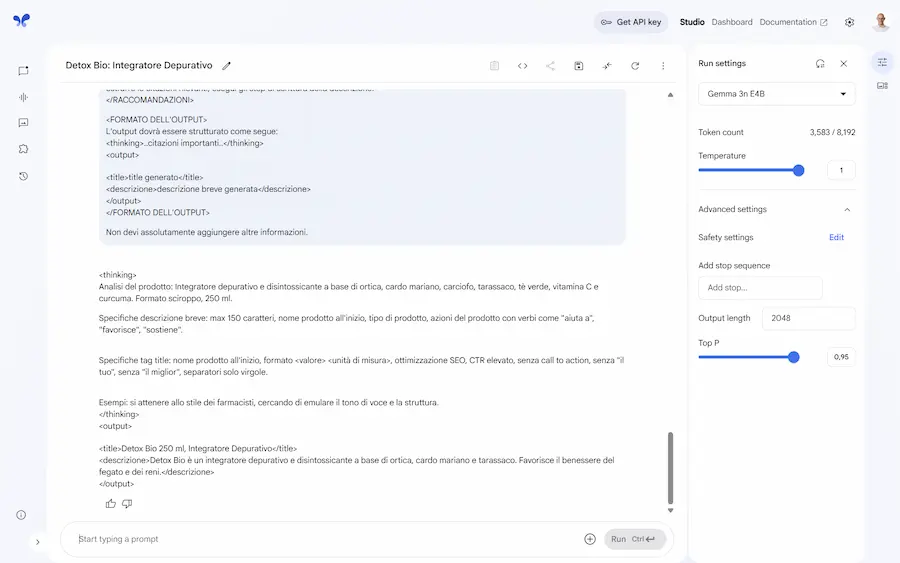
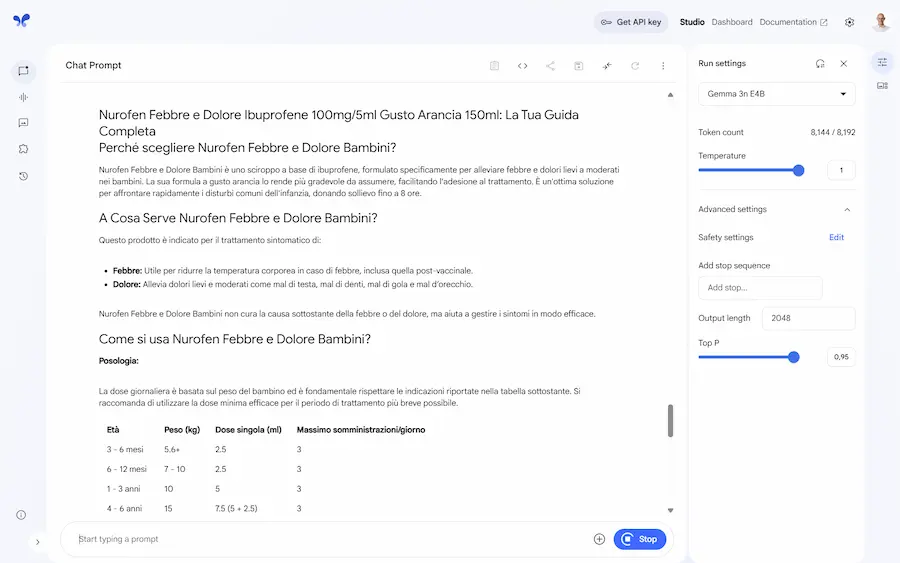
Gemma 3n di Google su AI Studio
Basato su una nuova architettura sviluppata con Qualcomm, MediaTek e Samsung, Gemma 3n offre risposte 1.5 volte più rapide rispetto a Gemma 3 4B e supporta input multimodali in tempo reale: audio, testo, immagini e video.
La funzione Mix'n'match consente di bilanciare performance e qualità dinamicamente, passando tra sottomodelli da 2B e 4B. Le prestazioni sono eccellenti anche nei benchmark: 64,9% su MMLU e 50,1% su WMT24++.
Grazie all’elaborazione locale, Gemma 3n tutela la privacy e apre nuove possibilità per applicazioni intelligenti, interattive e sempre accessibili, anche senza connessione.
Gemini Speech Generation
Su AI Studio di Google è stato rilasciato Gemini Speech Generation.
Si tratta di un sistema che permette di generare un dialogo audio tra due speaker (o anche "single speaker") completamente configurabile via interfaccia, ma anche via API.
Gemini Speech Generation
Nell'esempio, ho generato l'inizio di un podcast sull'AI. Come si vede, è possibile configurare lo scenario, le voci degli speaker e le battute del dialogo.
Il risultato è di certo migliorabile, ma siamo già a livelli di naturalezza incredibili.
SignGemma di Google DeepMind
Google DeepMind ha annunciato SignGemma: un modello dedicato alla traduzione della lingua dei segni in testo.
SignGemma di Google DeepMind
Verrà aggiunto alla famiglia di modelli Gemma entro la fine dell'anno.
Si aprono nuove possibilità per una tecnologia inclusiva.
Chrome DevTools con Gemini
Novità in Chrome DevTools: con Gemini è possibile modificare il CSS attraverso prompt testuali, e salvare le modifiche direttamente nei file sorgente.
Chrome DevTools con Gemini
Quindi, ora si può usare il pannello "AI Assistance", e dare istruzioni a Gemini per:
- modificare e correggere il CSS direttamente nella tab "Elements";
- testare subito le modifiche in tempo reale;
- salvare tutto nei file locali con una cartella di workspace connessa.
È una svolta per iterazioni rapide e uno sviluppo CSS più efficiente!
Veo 3: generazione di video con audio
Con Veo 3, Google non solo migliora la qualità dell'output rispetto alla versione precedente, ma introduce anche la generazione di video con audio.
Esempi di video generati attraverso Veo 3
Veo sarà usabile anche all'interno di Flow: uno strumento di AI che permette di creare clip, scene e storie cinematografiche in modo fluido, combinando i modelli più avanzati di Google DeepMind: Veo, Imagen e Gemini.
L'esempio mostra alcune clip con audio create con Veo 3.
Agents Companion di Google
Google ha pubblicato un whitepaper sugli AI Agents. "Agents Companion" è una lettura fondamentale per chi ha già familiarità con i concetti base e vuole approfondire l'applicazione concreta degli agenti AI in contesti complessi.
Si parla di Agentic RAG, dove gli agenti intelligenti orchestrano e valutano la qualità delle informazioni recuperate, superando i limiti dei classici pipeline RAG. Si entra nel dettaglio della valutazione degli agenti, sia singoli che multipli, analizzando non solo l'output finale, ma anche la traiettoria d’azione e l’uso degli strumenti. La sezione su AgentOps mostra come portare gli agenti dalla demo alla produzione, con metriche chiare, automazione, versioning, e test A/B su larga scala.

Particolarmente interessante l'applicazione nel settore automotive, dove agenti specializzati — navigazione, media, messaggistica, manuale dell’auto, e conoscenza generale — collaborano in architetture multi-agente (gerarchiche, peer-to-peer, collaborative) per offrire esperienze conversazionali fluide e resilienti, anche senza connettività.
Il documento chiude con un salto concettuale: dagli agenti ai contractor. L’idea è trasformare gli agenti in entità che operano sotto contratti strutturati, con obiettivi, specifiche, sub-task e feedback, per garantire risultati affidabili anche in contesti enterprise ad alta criticità.
I dati di LMArena sono affidabili?
Era davvero necessario fare chiarezza sul tema.
Il paper “The Leaderboard Illusion” (MIT e Stanford) mette in luce alcune distorsioni nella piattaforma LMArena.
Secondo gli autori, il sistema di valutazione che guida le classifiche dei modelli AI conversazionali sarebbe influenzato da pratiche opache come il testing privato di decine di varianti (senza obbligo di pubblicazione del risultato), campionamenti non equi, e una gestione poco trasparente delle deprecazioni dei modelli, spesso a svantaggio di quelli open-source.
Il risultato? Un ecosistema in cui pochi provider dominano la classifica anche grazie a un accesso sproporzionato ai dati della community, che consente loro di ottimizzare le performance sulla piattaforma stessa (ma non necessariamente su benchmark esterni).

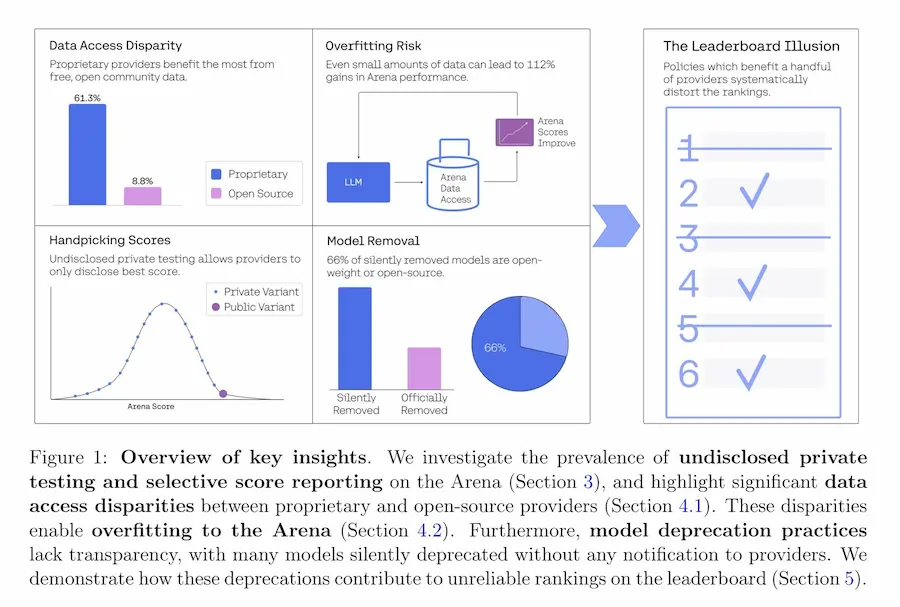
The Leaderboard Illusion
LMArena ha risposto pubblicamente al paper, sostenendo che le preferenze umane sono soggettive e rappresentano il valore reale del leaderboard.
Riconoscono che il testing pre-rilascio aiuta a identificare quali varianti piacciono di più alla community, ma negano che ciò rappresenti un bias, affermando che ogni provider ha libertà di scegliere quanto investire in testing.
Inoltre, dichiarano che i dati del paper contengono errori e che la loro policy impedisce di pubblicare selettivamente il punteggio migliore.
Pur accogliendo alcune raccomandazioni degli autori, come l'adozione di algoritmi di campionamento attivo, LMArena difende il ruolo della community come vero arbitro del valore dei modelli, rivendicando trasparenza e supporto anche verso lo sviluppo open-source.
Il dibattito resta aperto.
Intelligent Commerce di Visa
Visa presenta Intelligent Commerce, l'iniziativa che unisce lo shopping all'AI: la mediazione algoritmica aumenta.
Gli AI Agent saranno in grado di gestire l’intero processo di acquisto per conto dei consumatori: dalla ricerca al pagamento, fino alla gestione post-vendita.
Intelligent Commerce di Visa
Con strumenti come Visa Agent APIs, si garantiscono sicurezza, personalizzazione e controllo, in un ecosistema affidabile pensato per ridurre frodi e migliorare l’esperienza utente.
Con oltre 4,8 miliardi di credenziali di pagamento e una rete globale di partner, Visa sta accelerando l’adozione del "commercio AI" in tutti i settori.
Come far pensare un LLM di piccole dimensioni
Un esempio di approccio per far sviluppare "pensiero" a un LLM anche di piccole dimensioni per migliorare la qualità dell'output.
LLM: Ottimizzazione dell'output con pensiero ricorsivo
Il sistema usa le API di OpenAI per stimare i round di pensiero necessari per risolvere la richiesta del prompt, eseguirli, valutare la risposta migliore, e fornire l'output finale. Nell'esempio uso GPT-4o-mini.
Per usarlo, basta inserire l'API key di OpenAI nei "secrets" di Colab.
AMIE: un sistema per la diagnosi medica
AMIE, il sistema di AI sviluppato da Google DeepMind, compie un grande passo avanti: ora può interpretare anche immagini mediche, come foto della pelle, ECG e referti clinici. Questo lo rende capace di condurre conversazioni diagnostiche multimodali, proprio come farebbe un medico in una visita online.
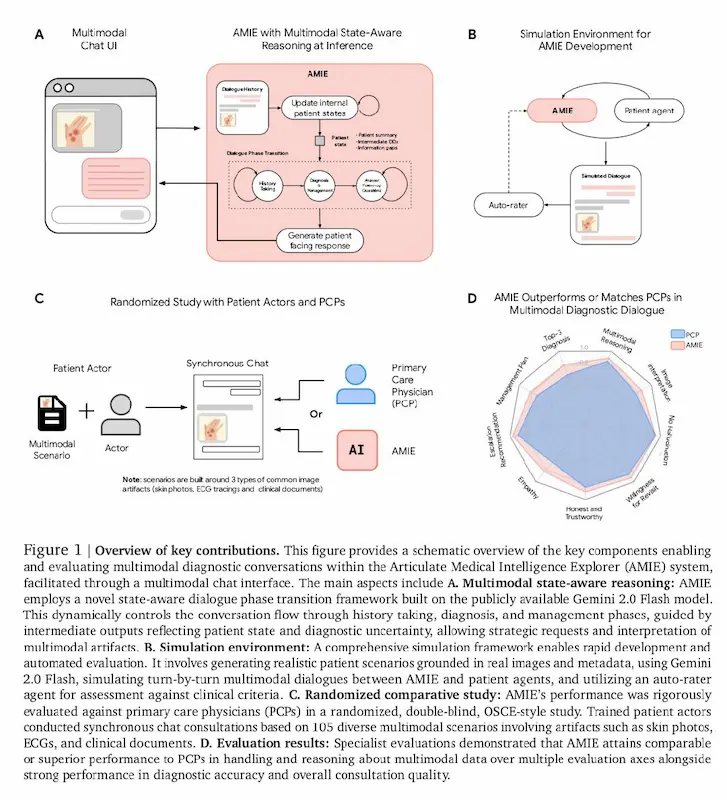
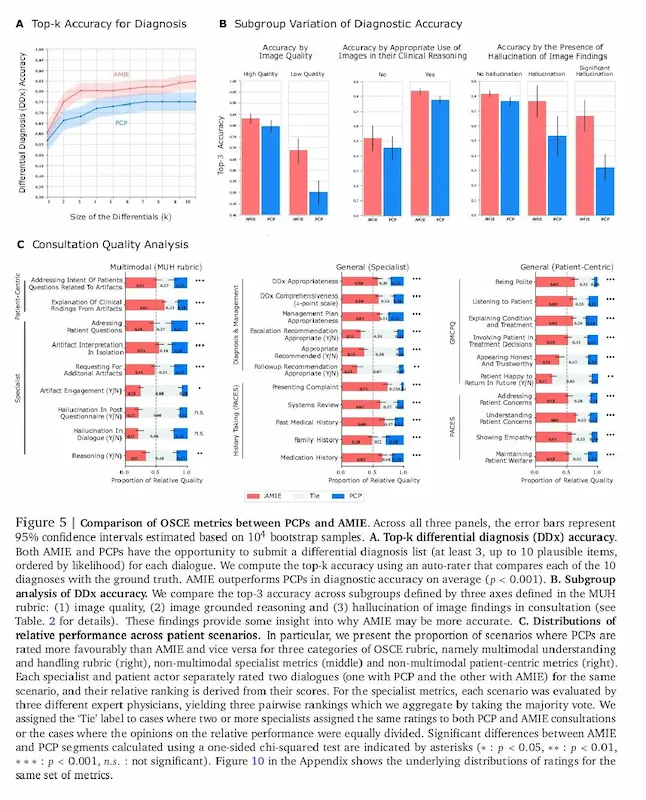
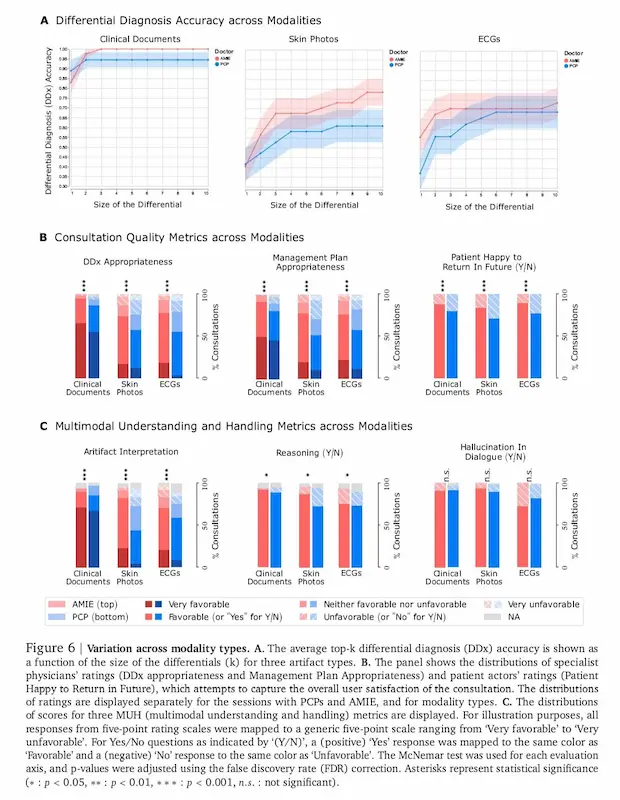
AMIE, un sistema di Google DeepMind per la diagnosi medica
Basato sul modello Gemini 2.0 Flash, AMIE segue un flusso simile a quello dei medici: raccoglie informazioni, formula diagnosi e propone piani di gestione, adattandosi man mano alla situazione del paziente.
In uno studio che ha coinvolto 105 casi simulati con pazienti-attori, AMIE è stato messo a confronto con medici di base. I risultati parlano chiaro: ha raggiunto o superato le performance umane su più aspetti, come accuratezza diagnostica, empatia e capacità di interpretare correttamente i dati visivi, anche se di qualità non ottimale.
Sebbene sia stato testato in ambienti controllati, è già in corso uno studio clinico in un ospedale reale per valutarne l’efficacia sul campo. AMIE non è solo più intelligente: è anche più vicino a come comunichiamo davvero nella sanità digitale.
Training di Llama su documenti specifici
Unsloth ha condiviso un notebook Colab gratuito che permette di addestrare Llama 3.2 3B su documenti specifici, con una tecnica molto interessante.
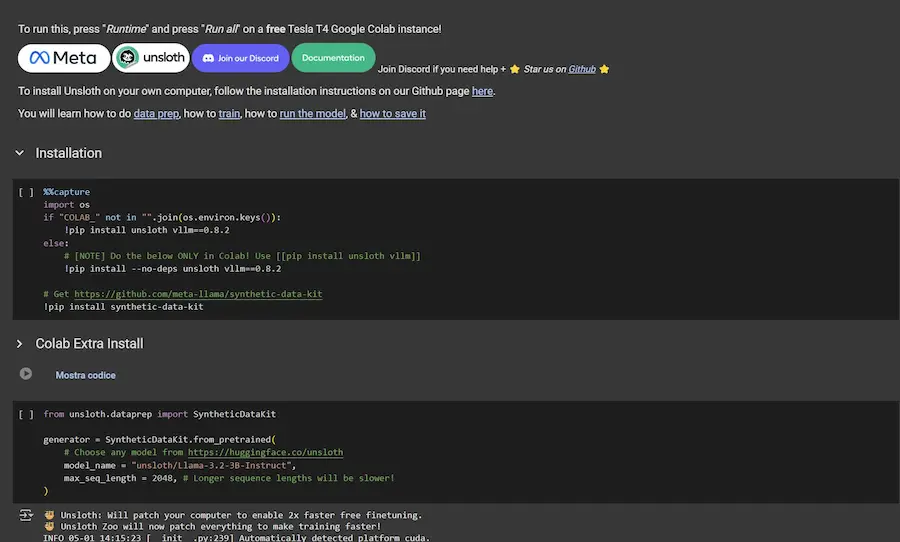
Grazie alla collaborazione con Meta e al loro synthetic-data-kit, il notebook permette di..
- Importare dei documenti per fare da knowledge (PDF, pagine web e altro).
- Generare dati sintetici: usa Llama per creare automaticamente coppie di domanda e risposta (Q&A) di alta qualità basate sul contenuto dei documenti (include anche filtri automatici per la pulizia dei dati).
- Eseguire un fine-tuning efficiente: addestra Llama 3.2 3B sui dati specifici utilizzando le ottimizzazioni di Unsloth (quantizzazione 4-bit + LoRA), il tutto sulla GPU T4 gratuita di Google Colab.
Il risultato? Un modello che "conosce a fondo" i documenti ed è pronto a rispondere a domande specifiche. L'ho provato, e funziona molto bene.
Creare un'applicazione con Gemini 2.5 Pro
Google ha rilasciato una nuova versione aggiornata di Gemini 2.5 Pro, con funzionalità migliorate in ambito coding.
L'ho provato per sviluppare una piccola web app che estrae dei frame dai video di YouTube in diversi formati.
Creare un'applicazione con Gemini 2.5 Pro: un esempio
L'aspetto stupefacente? Alla prima esecuzione, era tutto perfettamente funzionante: dalla necessità alla soluzione in 1 minuto.
Nel video si vede il prompt che ho usato, e il modello ha creato un'applicazione Python con Flask per il backend, e HTML/JS/CSS per il frontend.
Build apps with Gemini
Ho provato la funzionalità "Build apps with Gemini" di AI Studio di Google.
L'input è un prompt testuale che descrive un'applicazione in grado di elaborare un PDF, permettendo di creare estratti, scaricare immagini delle pagine, comprimere il file, e generare una sintesi in italiano del documento.
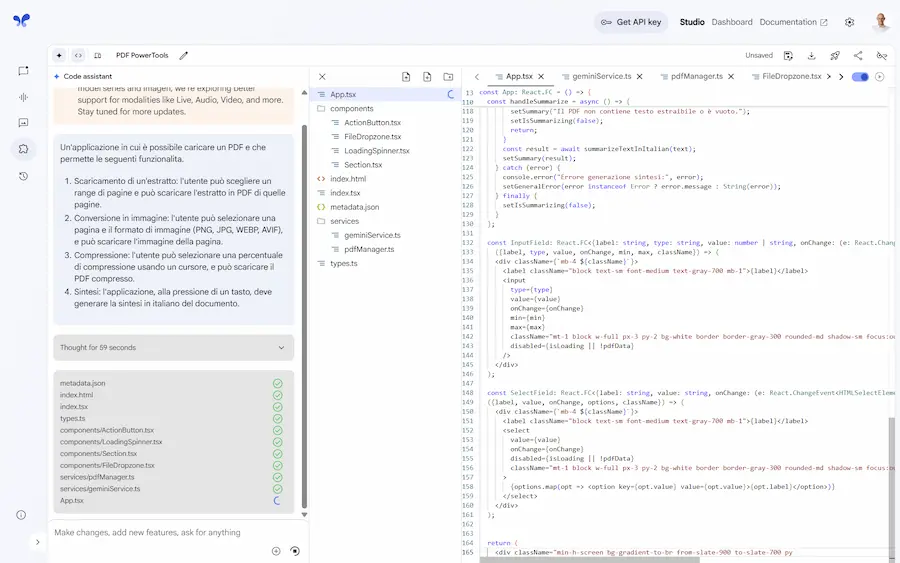
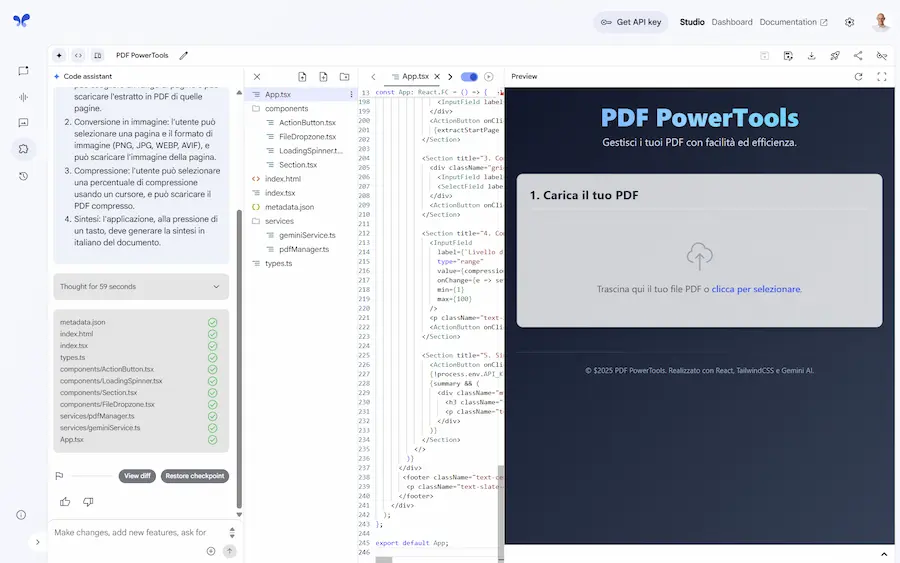
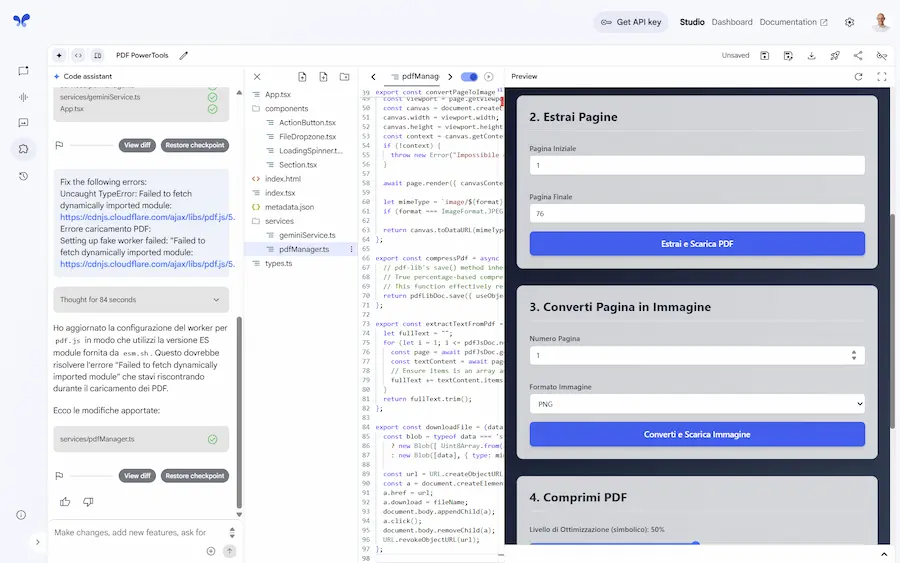
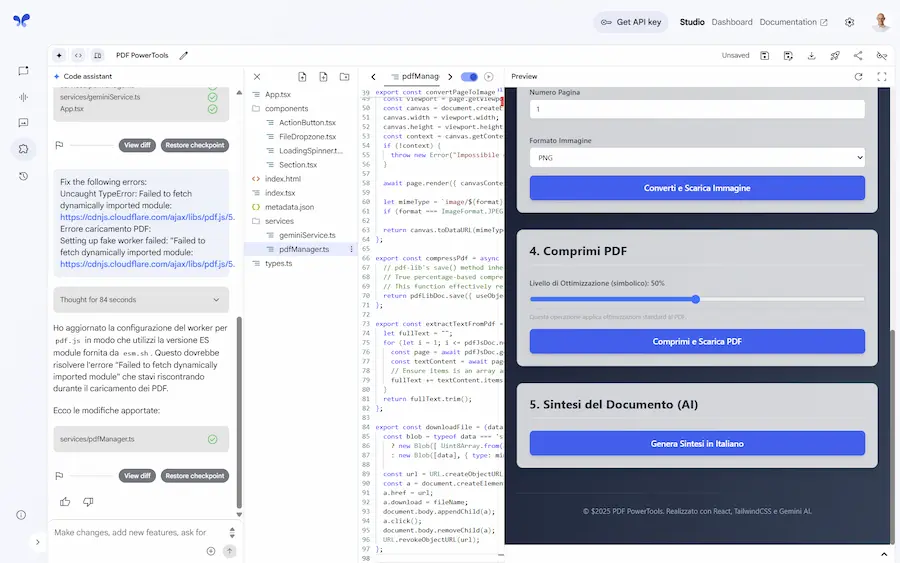
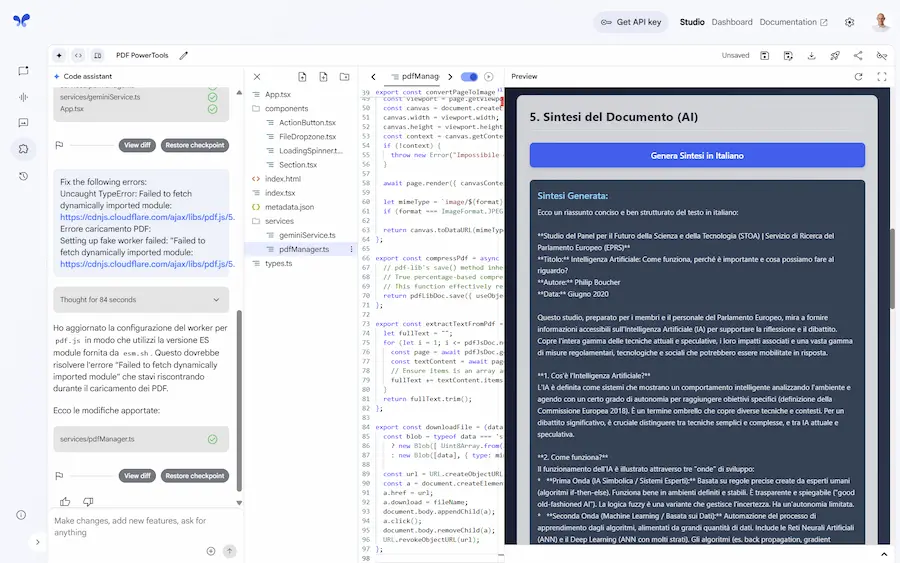
Build apps with Gemini
Il sistema crea un piano d'azione, e genera l'applicazione completa e funzionante nell'ambiente di AI Studio con tutte le funzionalità (non è solo un'anteprima dell'interfaccia).
La prima esecuzione ha generato un errore, ma con il bottone "Auto fix" il sistema analizza e corregge il codice autonomamente.
Successivamente è possibile scaricarla, condividerla, eseguire il deploy su Google Cloud, o salvarla. Oppure continuare a usarla in AI Studio.
La generazione di codice ormai non stupisce più, ma il passaggio da un'esigenza (idea) a un tool funzionante in qualche minuto, forse sì. Siamo a un nuovo livello di prototipazione.
Il caching implicito nei modelli Gemini 2.5
Attraverso il caching implicito, nei modelli Gemini 2.5 è possibile risparmiare fino al 75% sui token ripetuti.
Quando si inviano richieste con un inizio simile a quelle precedenti, Gemini riconosce automaticamente le parti già usate e applica uno sconto senza dover configurare nessun parametro.

Ad esempio, se si usano prompt dinamici in cui varia soltanto il contesto si può ottenere un grande risparmio.
The Little Book of Deep Learning
"The Little Book of Deep Learning" di François Fleuret è una risorsa gratuita che spiega in modo essenziale tutto ciò che serve per orientarsi nel Deep Learning moderno.

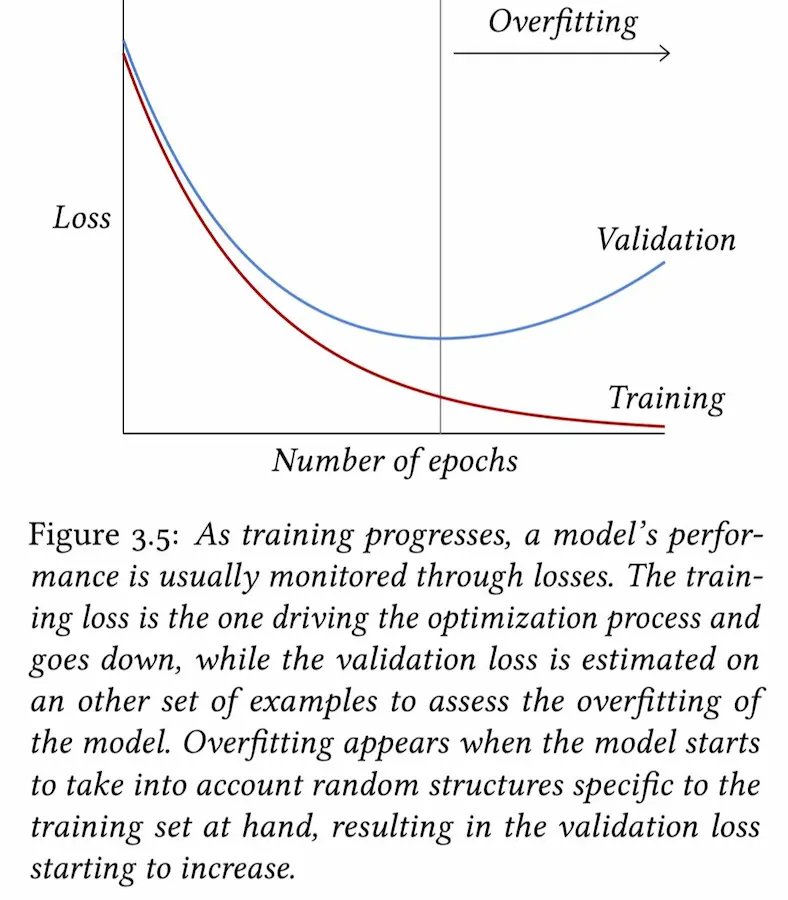
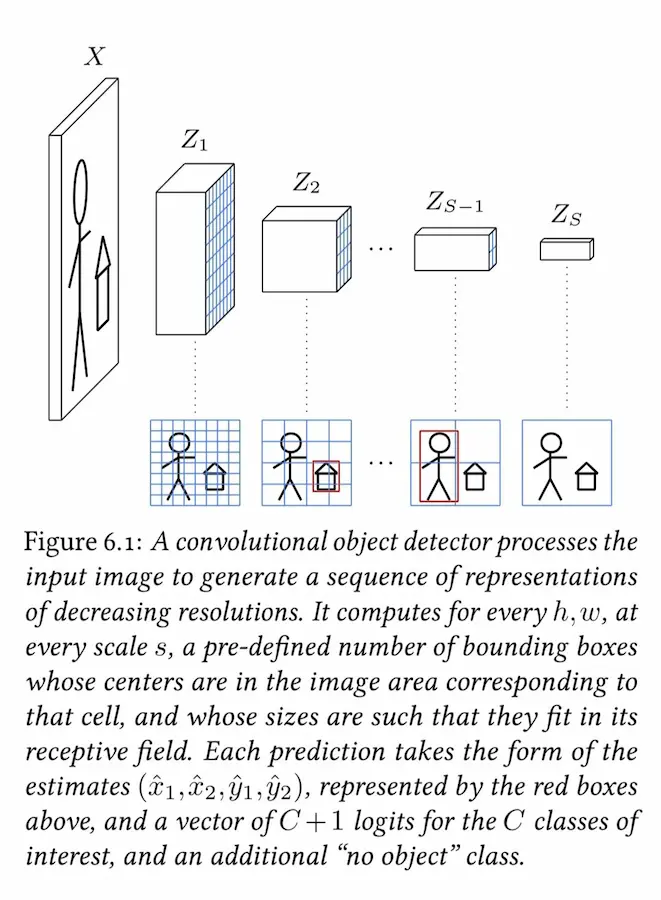
The Little Book of Deep Learning
Dal funzionamento dei modelli e le tecniche di training, fino ai layer più usati e alle architetture come CNN e Transformer.
Include anche un’introduzione ai LLM, con esempi pratici di applicazione in visione artificiale, NLP e apprendimento per rinforzo.
Fantastico per chi vuole rimettersi in pari o iniziare con una base solida.
Un'audio overview dell'e-book
Questo è un esempio di podcast generato attraverso Audio Overviews di NotebookLM usando come fonte l'e-book (The Little Book of Deep Learning).
The Little Book of Deep Learning: un podcast generato su NotebookLM
Nel prompt ho dato indicazioni per un contenuto che spiegasse in modo semplice il Deep Leaening e i LLM a un pubblico di non esperti.
Il risultato ha delle imperfezioni, ma è comunque strabiliante.
Claude Code: best practices
Anthropic ha pubblicato un post ricco di consigli pratici per utilizzare Claude Code in modo efficace. Il focus è su "agentic coding", ovvero la costruzione di agenti AI che collaborano in modo strutturato allo sviluppo software.
Ho cercato di estrarre 7 punti, che possiamo vedere come principi chiave da ricordare per costruire agenti utili.




Claude Code: best practices
- Non è solo questione di prompt
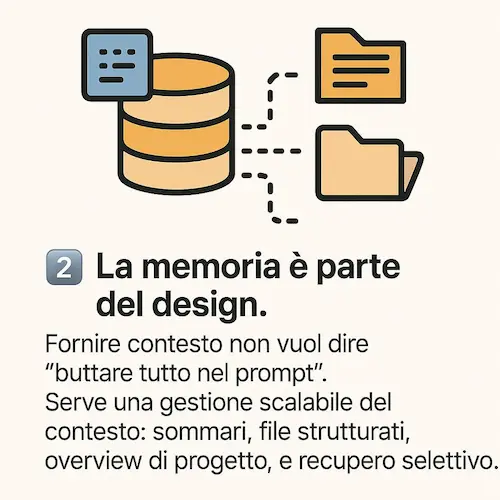
Un agente efficace non è un semplice completamento intelligente. Deve poter ragionare, agire, riflettere e correggersi. Come in un software, la logica va strutturata. - La memoria è parte del design
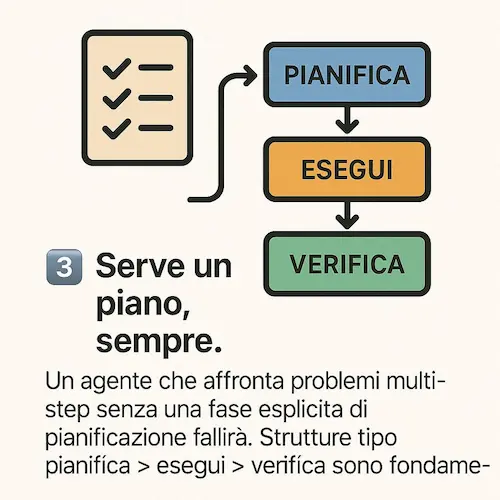
Fornire contesto non vuol dire "buttare tutto nel prompt". Serve una gestione scalabile del contesto: sommari, file strutturati, overview di progetto, e recupero selettivo. - Serve un piano, sempre
Un agente che affronta problemi multi-step senza una fase esplicita di pianificazione fallirà. Strutture tipo pianifica > esegui > verifica, sono fondamentali. - I tool sono il superpotere
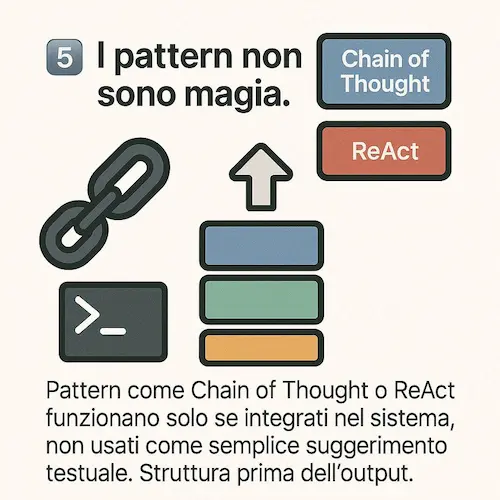
Un agente che può solo “parlare” è limitato. Per essere veramente utile, deve interagire con shell, API, database, version control, o tool personalizzati. - I pattern non sono magia
Pattern come "Chain of Thought" o "ReAct" funzionano solo se integrati nel sistema, non usati come semplice suggerimento testuale. Struttura prima dell’output. - Autonomia ≠ anarchia
Gli agenti autonomi vanno contenuti in confini chiari: limiti, fallback, livelli di permesso. L’autonomia controllata è la chiave per la fiducia. - Il valore è nell’orchestrazione
Un agente utile è un coordinatore intelligente: gestisce memoria, tool, cicli di feedback e collaborazioni con altri agenti. Non basta “chiamare il modello”.
Nuove tecnologie rilasciate da Meta
Meta continua a spingere i confini dell’AI con una serie di nuove tecnologie rilasciate open source.
Tra queste, spicca il Dynamic Byte Latent Transformer, un sistema innovativo che abbandona la classica suddivisione in “token” per lavorare direttamente sui byte. Questo lo rende più flessibile, robusto e capace di affrontare testi complessi, con errori, simboli rari o linguaggi non standard, mantenendo prestazioni al top.
Accanto a questo, Meta ha presentato anche il Perception Encoder, un modello visivo avanzato che interpreta immagini e video con precisione sorprendente; il Perception Language Model, per la comprensione visiva fine nei video; Meta Locate 3D, che permette ai robot di capire comandi linguistici e agire nel mondo 3D; e il Collaborative Reasoner, per migliorare il ragionamento e la collaborazione tra Agenti AI.
Tutti questi strumenti sono ora disponibili alla community, per accelerare la ricerca verso un'intelligenza artificiale più capace, aperta e vicina al linguaggio umano.
Mistral Medium 3
Mistral AI presenta Mistral Medium 3, con prestazioni da top di gamma a un costo 8 volte inferiore.
Puntando alle aziende, combina potenza, efficienza e facilità di implementazione, supportando deployment in cloud, on-premise o in-VPC.
Progettato per eccellere in ambiti professionali come coding e comprensione multimodale, supera modelli di riferimento come Claude Sonnet 3.7, LLaMA 4 Maverick e Cohere Command R, mantenendo un vantaggio competitivo anche sul fronte dei costi rispetto a leader come DeepSeek v3.
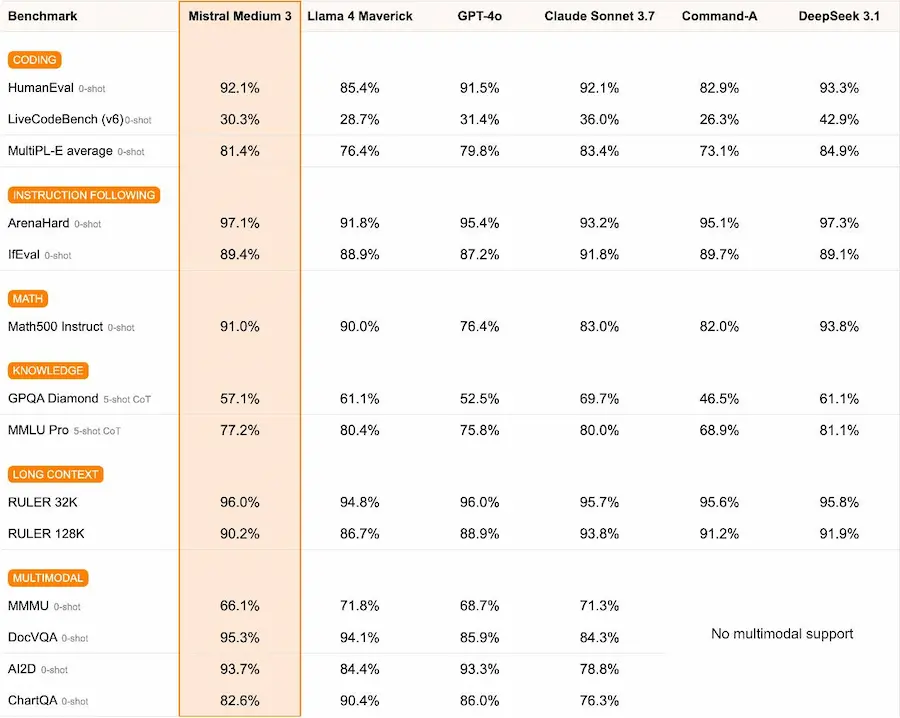
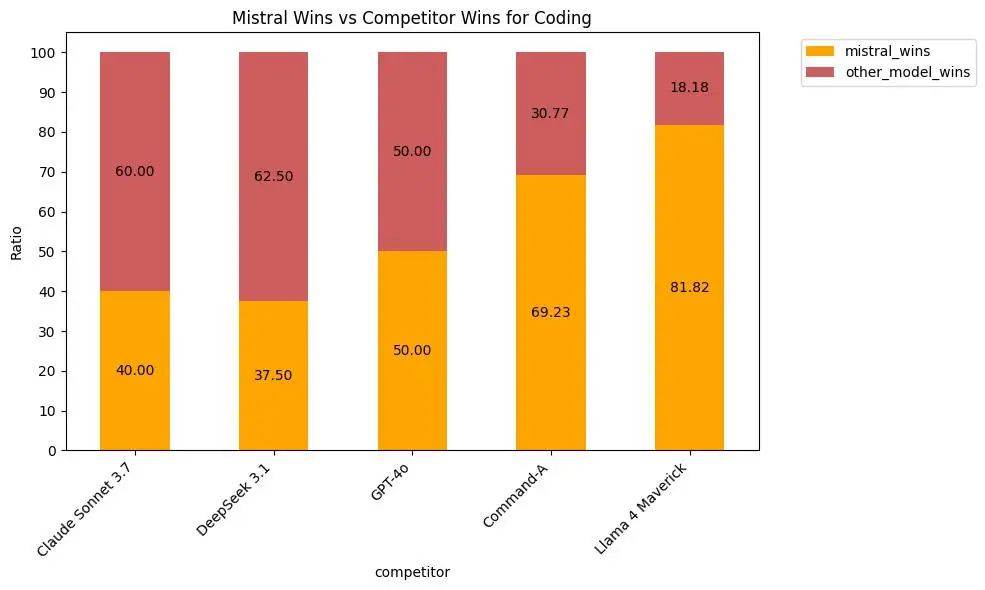
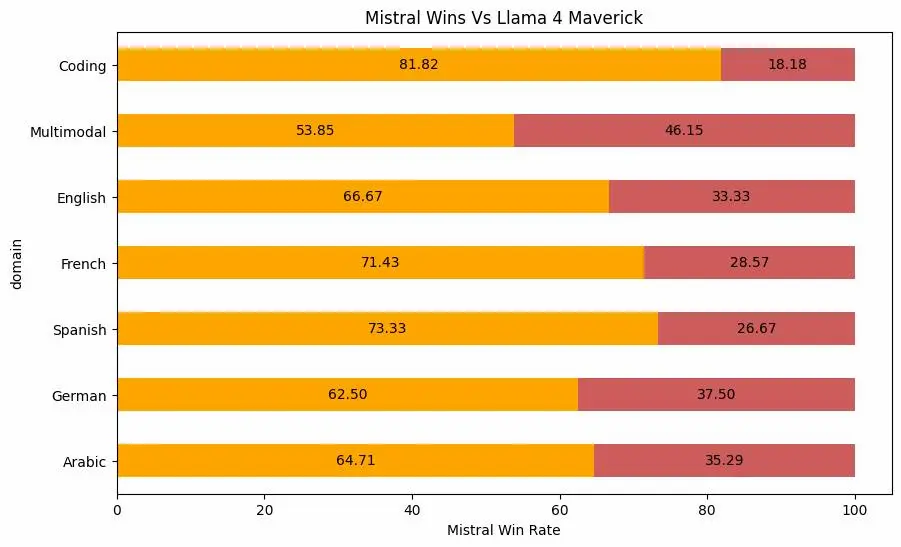
Le performance di Mistral Medium 3
Le sue capacità includono personalizzazione post-training, integrazione con sistemi aziendali, continuous learning e adattamento ai flussi di lavoro enterprise.
Disponibile su La Plateforme e Amazon Sagemaker, presto anche su IBM WatsonX, Azure e Google Cloud.
Multimodal Visualization-of-Thought (MVoT)
I modelli di linguaggio multimodali (MLLM) hanno rivoluzionato il modo in cui l'AI "ragiona", ma faticano nei compiti che richiedono immaginazione spaziale.
Il nuovo paradigma Multimodal Visualization-of-Thought (MVoT) propone un passo oltre il classico Chain-of-Thought: integra il pensiero visivo generando immagini durante il ragionamento, migliorando comprensione e interpretabilità.
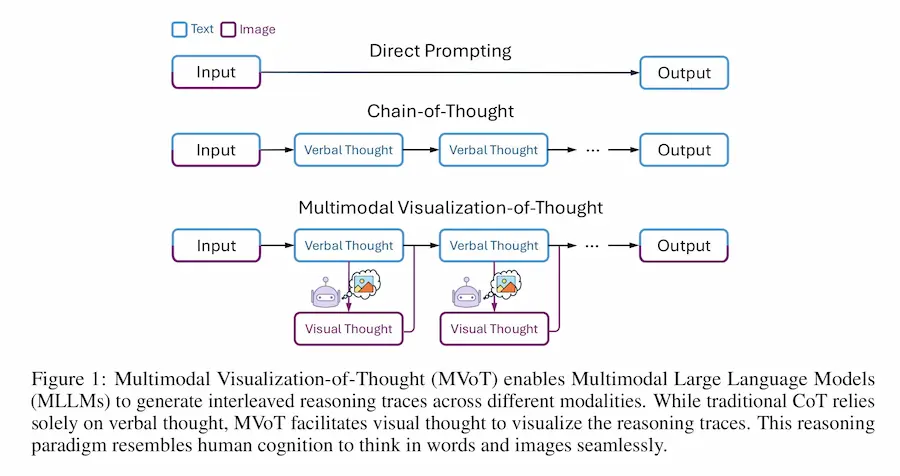
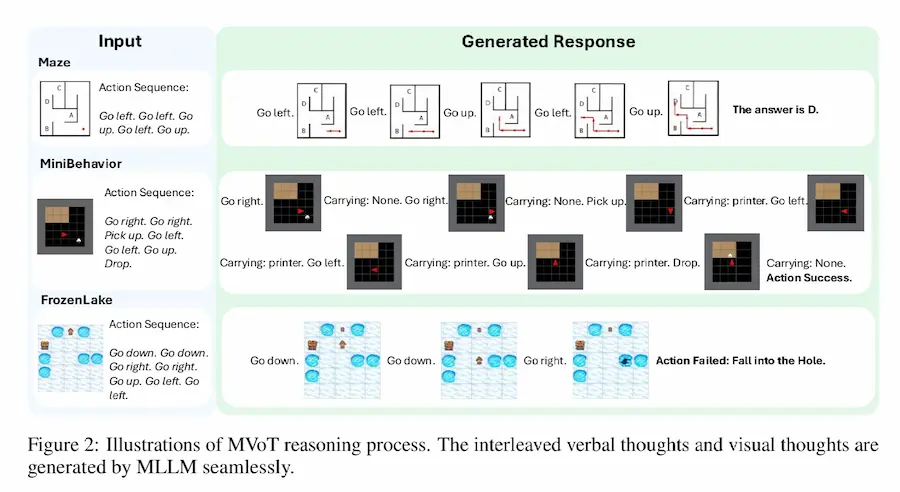
Multimodal Visualization-of-Thought (MVoT)
Grazie a una tecnica innovativa chiamata token discrepancy loss, MVoT migliora la qualità delle visualizzazioni e ottiene risultati superiori in ambienti complessi come labirinti, scenari d'azione con oggetti, e simulazioni dinamiche. Non solo è più robusto dei metodi precedenti, ma può anche potenziare i modelli esistenti, fornendo supporti visivi intelligenti.
Una nuova direzione per un'AI che ragiona non solo con le parole, ma anche con le immagini.
AgentA/B
AgentA/B è un sistema innovativo che automatizza i test A/B sui siti web usando agenti basati su LLM.
Gli agenti virtuali, dotati di personalità diversificate, simulano il comportamento reale degli utenti navigando, cercando, cliccando e acquistando su piattaforme live come Amazon.
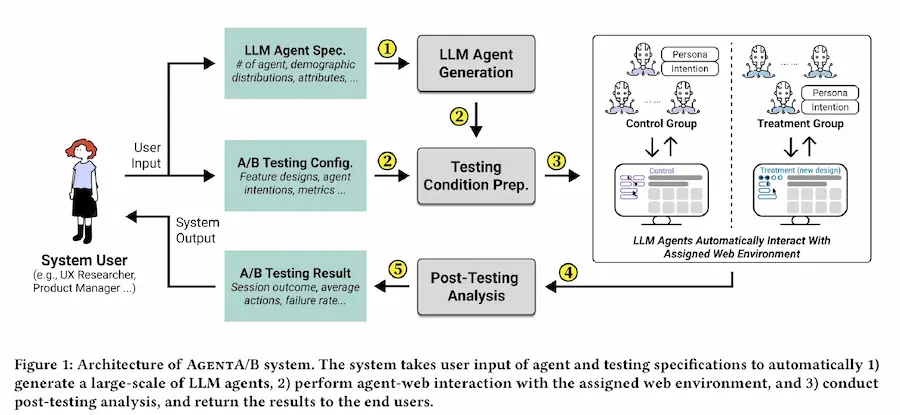
Il sistema consente di testare rapidamente varianti di design senza dover attendere traffico umano, riducendo tempi e costi.
I comportamenti degli agenti si sono dimostrati allineati a quelli umani, pur mantenendo una maggiore efficienza.
AgentA/B rende possibile testare in modo rapido e sicuro anche interfacce pensate per utenti difficili da raggiungere, supportando la progettazione UX fin dalle prime fasi.
Runway Gen-4 References
Runway lancia Gen-4 References, per generate personaggi e ambientazioni in modo coerente.
È possibile usare foto, immagini generate, modelli 3D per mettere noi stessi o altre figure in qualunque scena.
Runway Gen-4 References
Si possono, inoltre, combinare personaggi e scene, creando nuove inquadrature e stili.
Qwen-Agent
Qwen-Agent è un nuovo framework open source per sviluppare applicazioni AI basate sui LLM avanzati di Qwen.
Integra strumenti come Function Calling, Code Interpreter, RAG (Retrieval-Augmented Generation), MCP (Model Context Protocol) e persino l'automazione del browser (BrowserQwen).
Pensato per offrire agenti intelligenti, è già usato come backend di Qwen Chat.
Supporta personalizzazioni, lettura file, uso di tool esterni, ed è compatibile con servizi cloud come DashScope o deployment locali tramite Ollama o vLLM.
DeerFlow: un framework per la Deep Research
ByteDance rilascia DeerFlow, un framework multi-agente open source per l'automazione della ricerca approfondita.
DeerFlow: un framework per la Deep Research
Progettato per semplificare e potenziare i flussi di lavoro complessi, integra LLM avanzati con strumenti per l’estrazione di dati, l’esecuzione di codice Python e la generazione automatica di contenuti.
Costruito su LangGraph, il framework coordina agenti specializzati che pianificano, ricercano, analizzano e riportano i risultati in modo strutturato e automatizzato. Ogni agente ha un ruolo preciso: dal Planner che scompone i compiti, al Coder che elabora dati, fino al Reporter che sintetizza il tutto in report chiari.
DeerFlow è compatibile con le API di OpenAI e Qwen tramite LiteLLM, supporta la ricerca su motori come Arxiv, DuckDuckGo e Tavily, e include anche funzionalità text-to-speech di alta qualità, perfette per presentazioni e podcast automatizzati.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂