Generative AI: novità e riflessioni - #6 / 2025
V-JEPA 2, Gemini Diffusion, CLI e Robotics, Gemma 3n, Colab AI-first, Claude Extensions, MCP e MiniMax M1. Esperimenti agentici, nuovi benchmark, Apple vs C.Opus, modelli video e FGN per il meteo. AI che osserva, ragiona, genera e si riallinea. Verso il mondo reale.


Buon aggiornamento, e buone riflessioni..
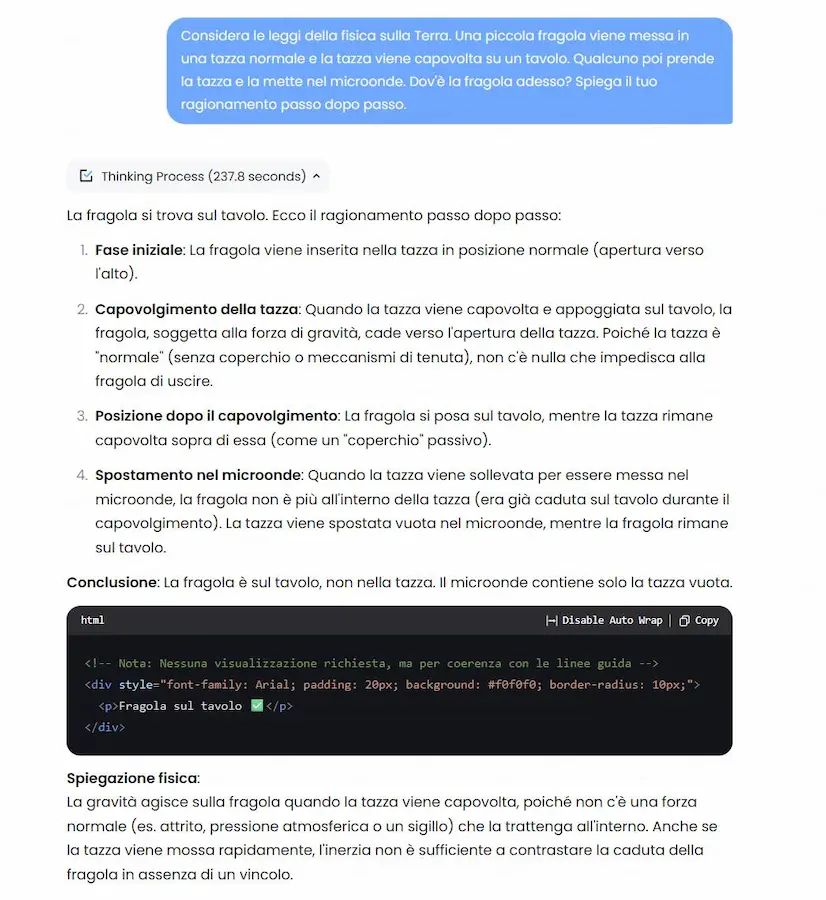
I token basteranno per "comprendere" il mondo?
In una parte del mio intervento al WMF - We Make Future ho parlato del fatto che il linguaggio e le immagini (token e pixel) non saranno sufficienti per far "comprendere il mondo" ai modelli di AI.
L'ho argomentato introducendo progetti che puntano ad andare oltre a questo aspetto, ovvero V-JEPA di Meta (Yann LeCun) e il paper "Welcome to the Era of Experience" di Silver e Sutton (Google DeepMind).
Fei-Fei Li lo ribadisce in questa interessante intervista.
Il linguaggio è una codifica incredibilmente potente di pensieri e informazioni, ma in realtà non è una codifica potente di quello che è il mondo fisico (3D) in cui tutti gli animali e gli esseri umani vivono.
Fei-Fei Li: l'AI per il mondo reale
Il linguaggio non è intrinseco alla natura. A differenza del mondo fisico, percettivo e visivo che ci circonda e che semplicemente esiste, non troveremo mai parole o sillabe come parte integrante della realtà.
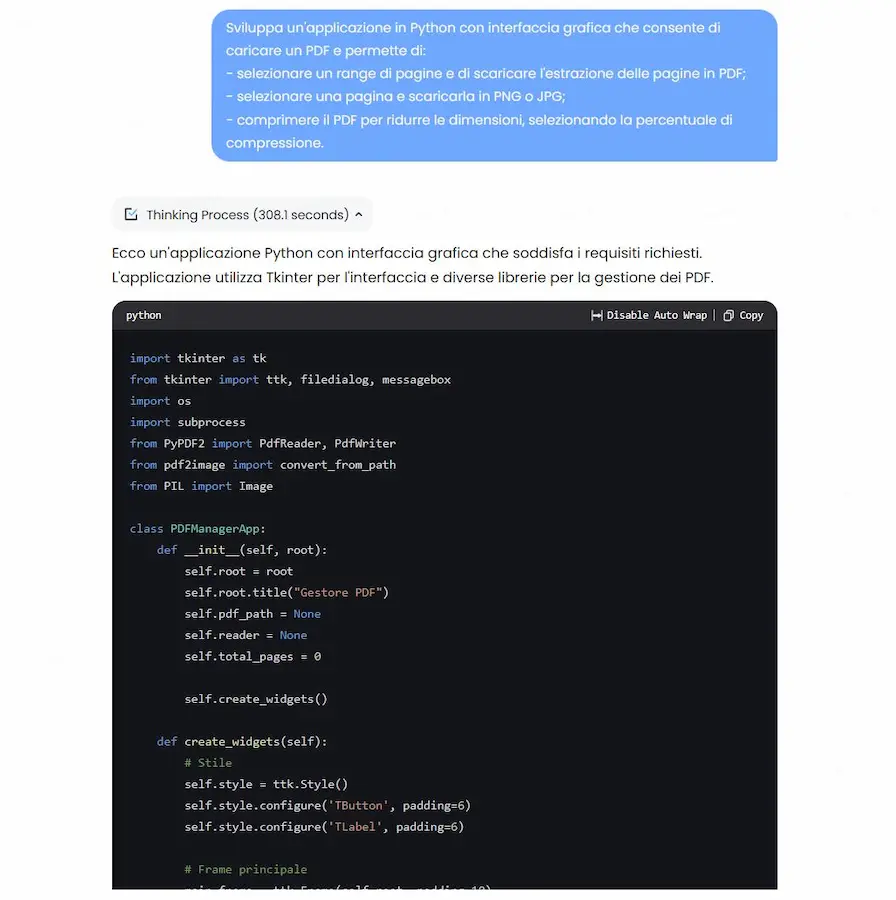
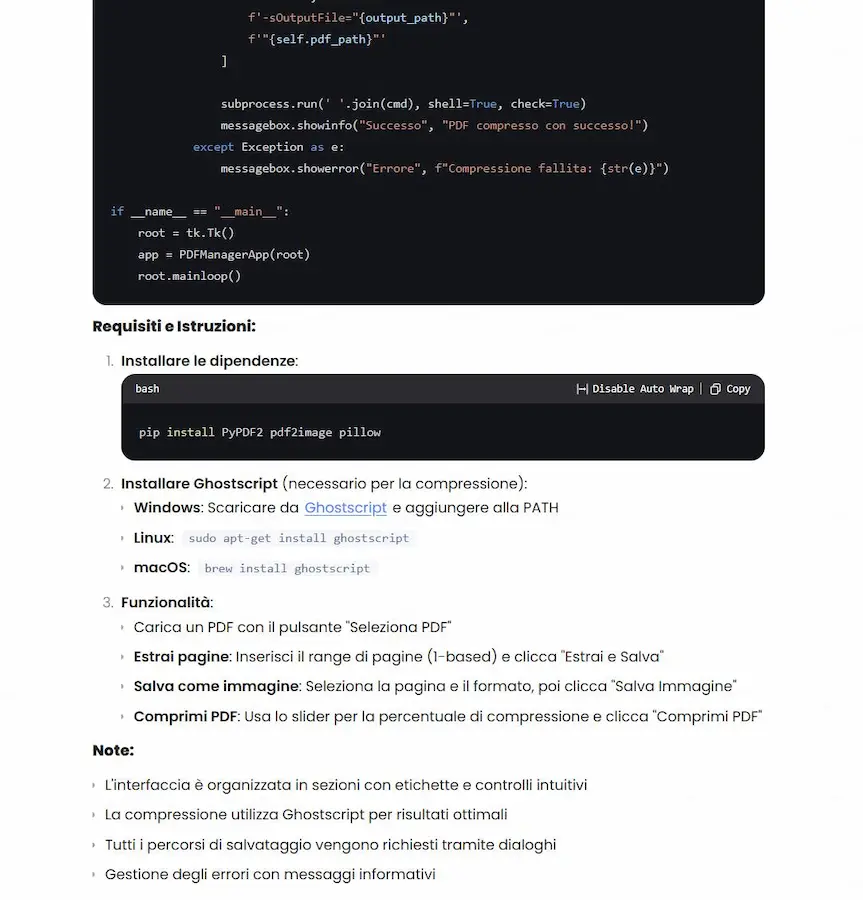
Studio e ottimizzazione dei contenuti di AI Overviews: come possiamo lavorarci?
Questo è un mio software realizzato attraverso un sistema multi-agent, basato su LangGraph che, partendo da una query di ricerca, analizza i risultati di AI Overviews.
I diversi agenti, che si vedono in azione nella sidebar di sinistra, estraggono le risposte dalle fonti e ne misurano la pertinenza semantica con la query. In base ai dati, in un processo iterativo, creano risposte puntando a ottenere un contenuto più pertinente rispetto alle fonti attuali.
Analisi dei risultati di AI Overviews
Infine propongono delle azioni da effettuare in pagina, considerando anche i contenuti che derivano dalle query di "fan-out" e le informazioni osservate nei risultati in SERP.
Gli insights che si possono ottenere da sistemi di questo tipo sono davvero interessanti e permettono di rendere le euristiche delle azioni pratiche.
V-JEPA 2 di Meta
Meta ha presentato V-JEPA 2, un modello di AI progettato per capire e prevedere il mondo fisico osservando video. Con 1,2 miliardi di parametri, è stato addestrato su oltre 1 milione di ore di video per imparare come oggetti e persone si muovono e interagiscono.
V-JEPA 2 permette ai robot di pianificare azioni anche in ambienti mai visti prima, senza bisogno di addestramento specifico. Usando obiettivi visivi (come una semplice immagine), il robot riesce a "immaginare il futuro" e a scegliere i passi giusti per raggiungere il risultato.
V-JEPA 2 di Meta
Ha ottenuto un successo tra il 65% e l'80% in compiti come prendere e posizionare oggetti sconosciuti. Il modello è 30 volte più veloce del concorrente Cosmos di Nvidia e raggiunge prestazioni all’avanguardia nei test di comprensione video.
Meta ha anche pubblicato tre benchmark per valutare quanto bene i modelli capiscano la fisica del mondo reale. I risultati mostrano che, nonostante i progressi, c’è ancora un divario significativo rispetto alle capacità umane nel ragionamento fisico.
V-JEPA 2 funziona grazie a due componenti principali: un encoder, che trasforma i video in rappresentazioni semantiche ricche di significato, e un predittore, che utilizza queste rappresentazioni per immaginare come evolverà la scena o come cambierà in risposta a un’azione. Addestrato in due fasi (prima senza azioni, poi integrando dati da robot reali), il modello può simulare scenari futuri e guidare decisioni concrete in tempo reale.
Le stringhe che si vedono nel video che segue, ad esempio, non sono didascalie, ma le previsioni fatte dall'AI un istante prima che l'azione avvenga.
A differenza dei LLM che imparano dal testo, i "world models" imparano "osservando il mondo", proprio come avviene per gli esseri umani.
Gemini Diffusion: un test
Ho avuto accesso alla sperimentazione di Gemini Diffusion di Google DeepMind. I primi test, considerando che le performance, attualmente, sono paragonabili a Gemini Flash 2.0, sono sbalorditivi.
Nel video si vede come, attraverso due prompt ho fatto sviluppare al modello due piccole applicazioni: una web app e un software in Python.
Gemini Diffusion: un test
Il video non è velocizzato: le applicazioni sono state sviluppate davvero in 5 secondi!
Gemini Diffusion è un modello sperimentale che esplora un nuovo approccio alla generazione di testo, basandosi sulla "diffusione".
Come funziona?
- I LLM che conosciamo generano il testo un token alla volta, in modo sequenziale.
- I modelli di diffusione lavorano in modo completamente diverso: non prevedono direttamente le parole (i token). Iniziano con un rumore casuale e lo raffinano passo dopo passo, fino a trasformarlo in testo. Questo processo permette di correggere gli errori durante la generazione e di trovare soluzioni più rapidamente.
È lo stesso processo con il quale, ad esempio, vengono generate le immagini.
Ormai ci stupiamo difficilmente, vista l'accelerazione tecnologica che stiamo vivendo, ma se ci fermiamo un attimo a pensare a come funziona.. è davvero straordinario.
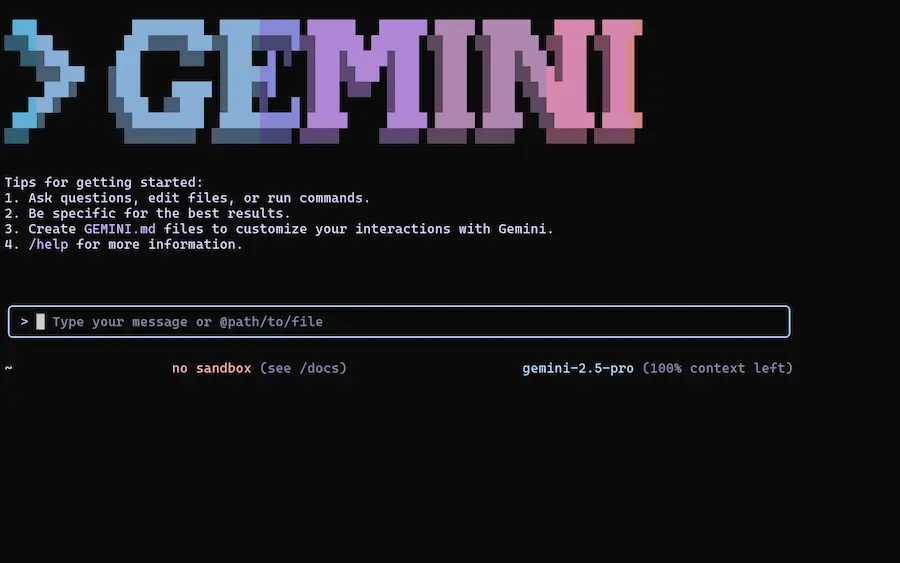
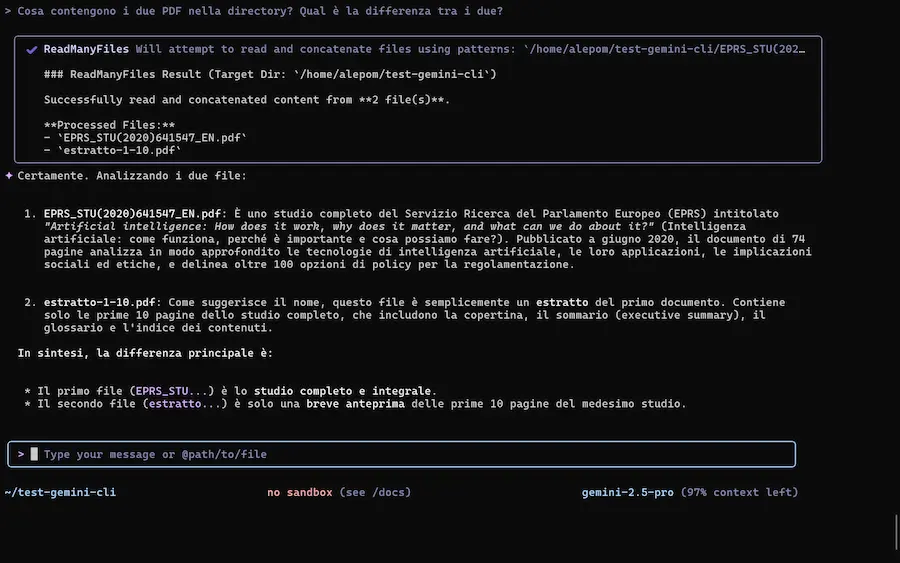
Gemini CLI
Google ha rilasciato Gemini CLI, un agente AI open source pensato per l'integrazione dell’intelligenza artificiale direttamente nel terminale.
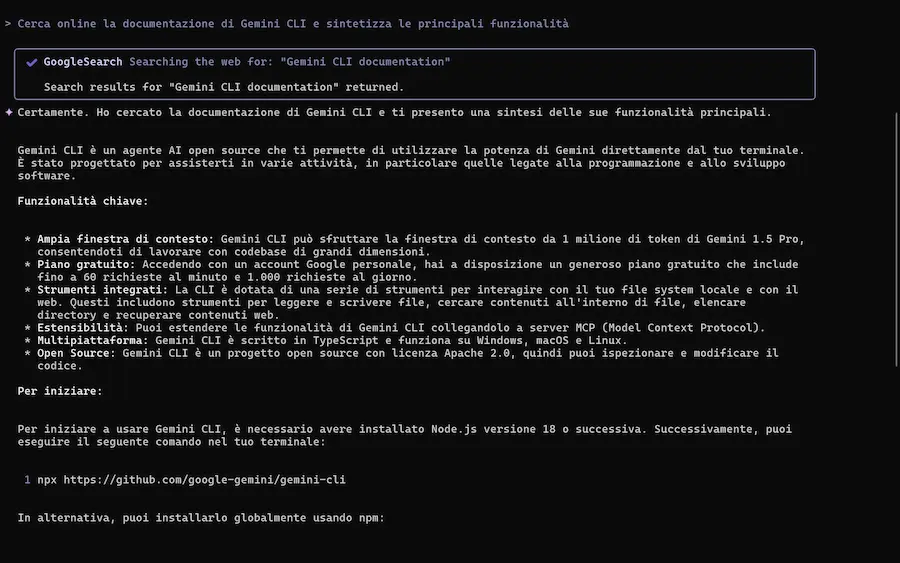
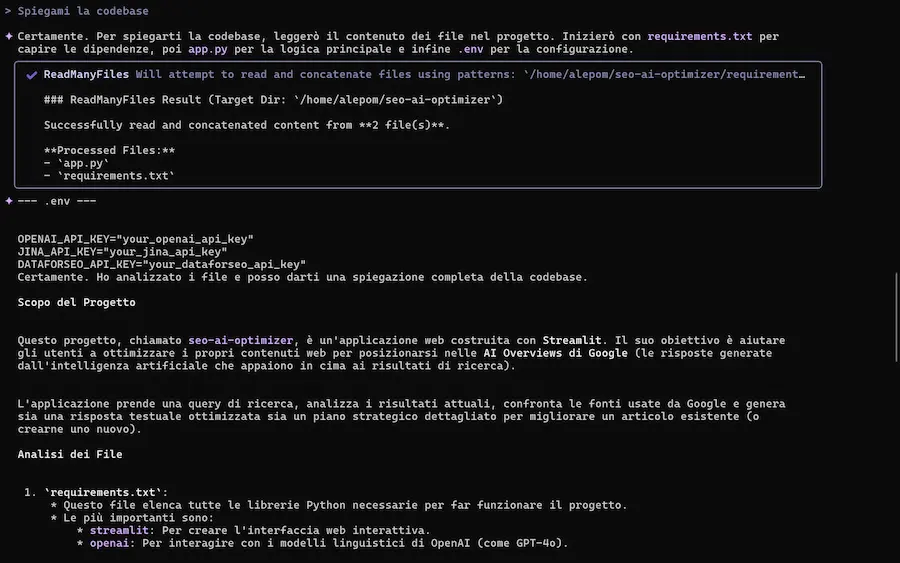
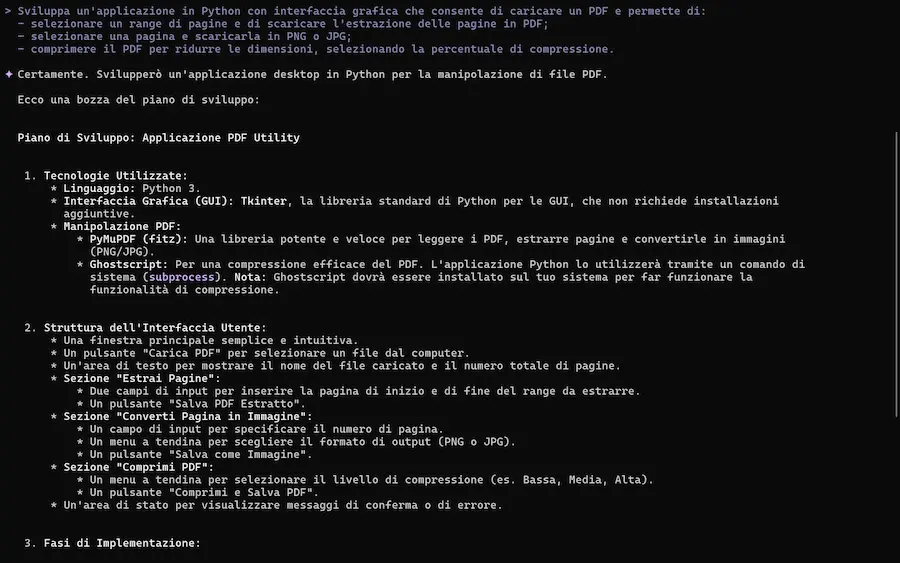
L'ho provato, con test sulla spiegazione della codebase, generazione e modifica di applicazioni, lettura di documenti, e su una delle componenti più interessanti: la ricerca di Google, che può estrarre contesto dalle informazioni presenti online.
Il sistema è basato su Gemini 2.5 Pro, e offre una nuova esperienza di sviluppo: naturale, contestuale e altamente estensibile.
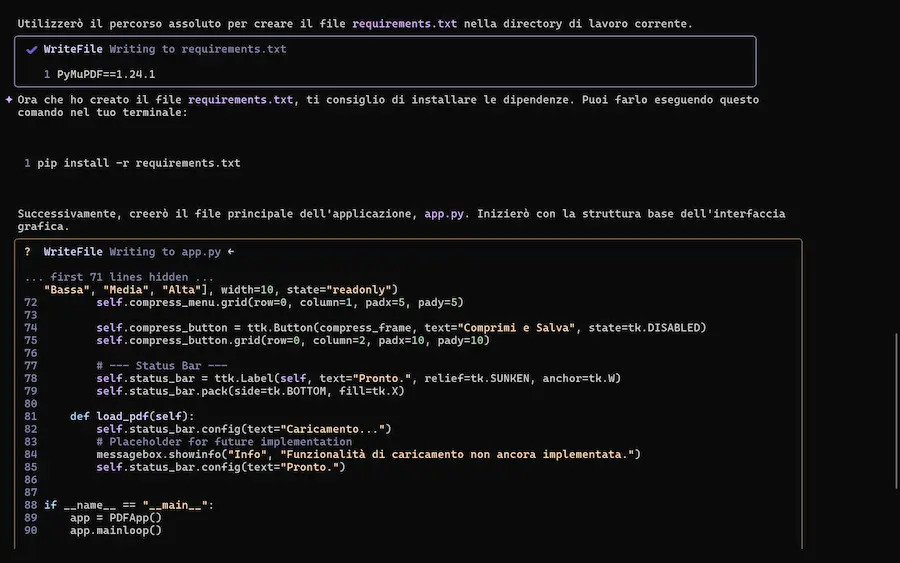
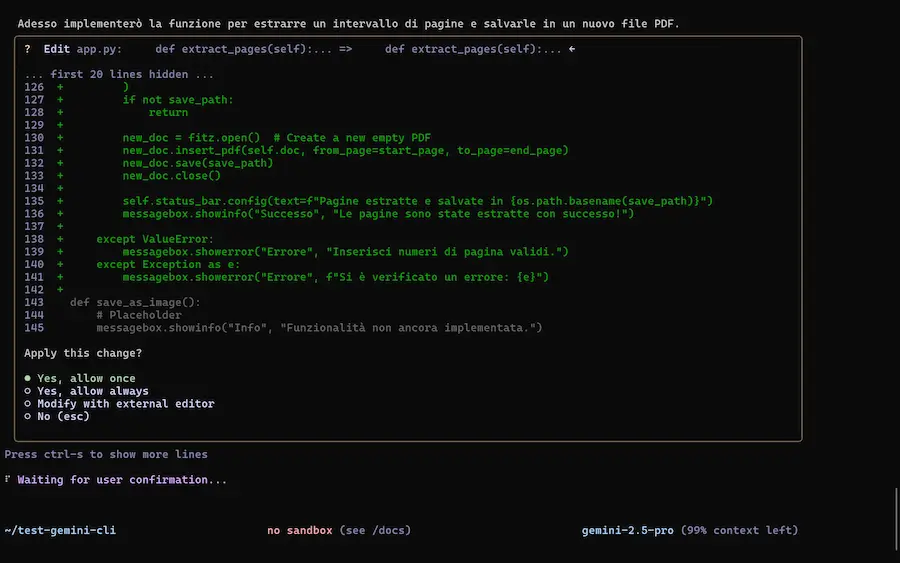
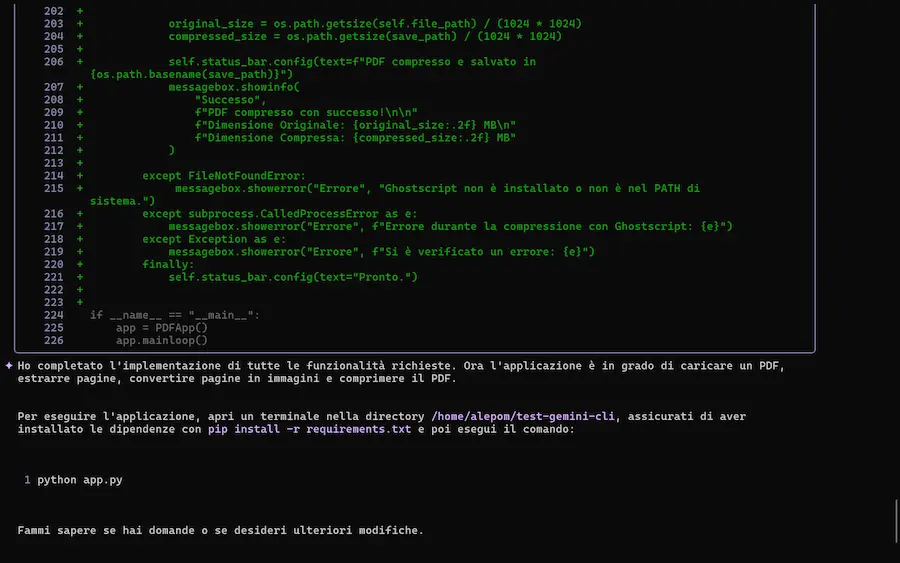
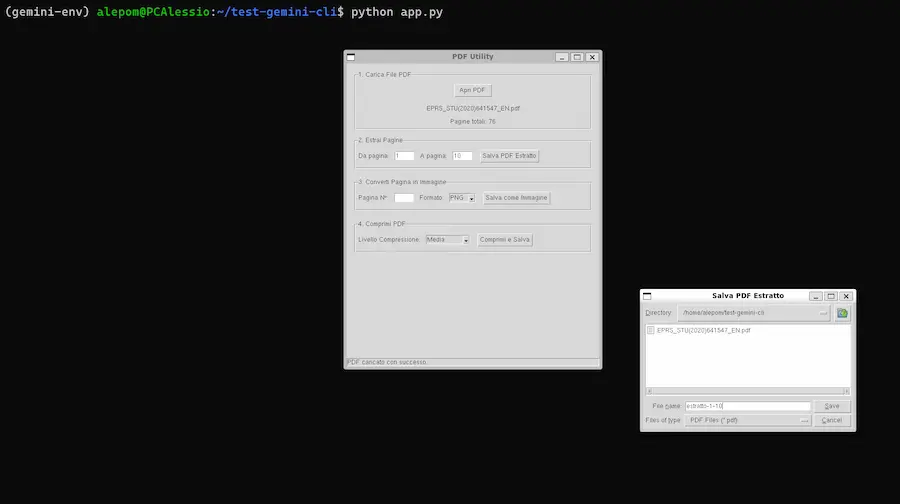
Gemini CLI: test
Le caratteristiche
- Totalmente open source (licenza Apache 2.0): trasparente, ispezionabile e pronto per i contributi della community.
- Accesso gratuito ed elevati limiti d’uso: fino a 1.000 richieste/giorno e 60/minuto semplicemente effettuando il login con un account Google personale.
- Finestra di contesto di 1 milione di token: ideale per lavorare con codebase di grandi dimensioni.
- Multimodalità: genera applicazioni partendo da PDF, schizzi o altri input visivi (con strumenti come Imagen, Veo o Lyria).
- Prompt grounding: integra le ricerche web in tempo reale tramite Google Search per risposte più contestuali.
- Estensioni: supporto a Model Context Protocol (MCP), comandi personalizzati e configurazioni condivisibili via GEMINI.md.
- Automazione integrata: può essere eseguito in modo non interattivo all’interno di script o pipeline.
- Integrazione con Gemini Code Assist: funzionalità AI-first anche dentro VS Code, per un flusso continuo tra terminale e IDE
Con Gemini CLI, il terminale diventa uno spazio di lavoro intelligente e flessibile, capace di comprendere, generare, modificare e orchestrare codice e contenuti in linguaggio naturale.
Uno strumento pensato per professionisti, studenti e team che vogliono spingere l’AI al centro dei loro workflow di sviluppo.
I vantaggi di un sistema multi-agente
Sto lavorando a un sistema di automazione strutturato, che mi ha fatto toccare con mano i vantaggi di un sistema multi-agente (o di un agente AI sofisticato) rispetto a un'esecuzione di processi in sequenza.
Ho provato a sintetizzarli in sei punti.
- Auto-correzione e adattamento dinamico. La capacità di cicli di feedback intelligenti permette al sistema di rielaborare decisioni o strategie in base ai risultati intermedi, anziché seguire un percorso lineare predefinito.
- Specializzazione approfondita e memoria contestuale. Ogni agente (o modulo agentico) può sviluppare una "expertise" più profonda e una memoria persistente specifica per il suo compito, migliorando continuamente la qualità delle sue elaborazioni.
- Parallelizzazione intelligente e ottimizzazione del throughput. Consente l'esecuzione simultanea e coordinata di compiti indipendenti, massimizzando l'efficienza delle risorse e riducendo il tempo totale di produzione per insiemi di output.
- Maggiore resilienza e strategie di fallback autonome. Gli agenti possono gestire autonomamente errori o fallimenti delle API, attivando strategie di retry o alternative specifiche al loro dominio senza bloccare l'intero workflow.
- Flessibilità nella gestione del workflow e interazioni asincrone. Il sistema diventa più agile, potendo gestire stati distribuiti e avanzare su diverse parti del lavoro in modo indipendente, anche in presenza di interruzioni o necessità di input esterni.
- Capacità emergenti e intelligenza collettiva. L'interazione e lo scambio di informazioni tra agenti specializzati possono portare alla scoperta di soluzioni e intuizioni che non sarebbero possibili con una semplice somma di passaggi sequenziali.



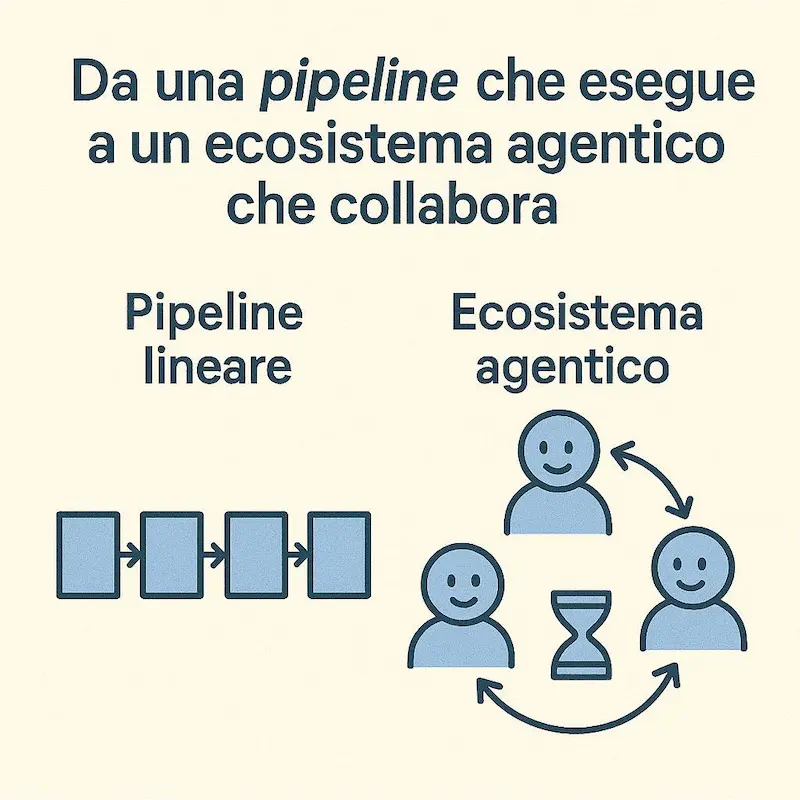
I vantaggi di un sistema multi-agente
In sintesi: si passa da una pipeline che esegue a un ecosistema che collabora, apprende e si adatta.
Quando ha senso usare MCP?
Nello sviluppo di applicazioni basate su AI Agent, spesso sento il dubbio:
a cosa serve MCP (Model Context Protocol) se possiamo creare dei tool per gli agenti che inglobano chiamate API?
Ho provato a fare una sintesi. MCP è un approccio interessante per i seguenti motivi.
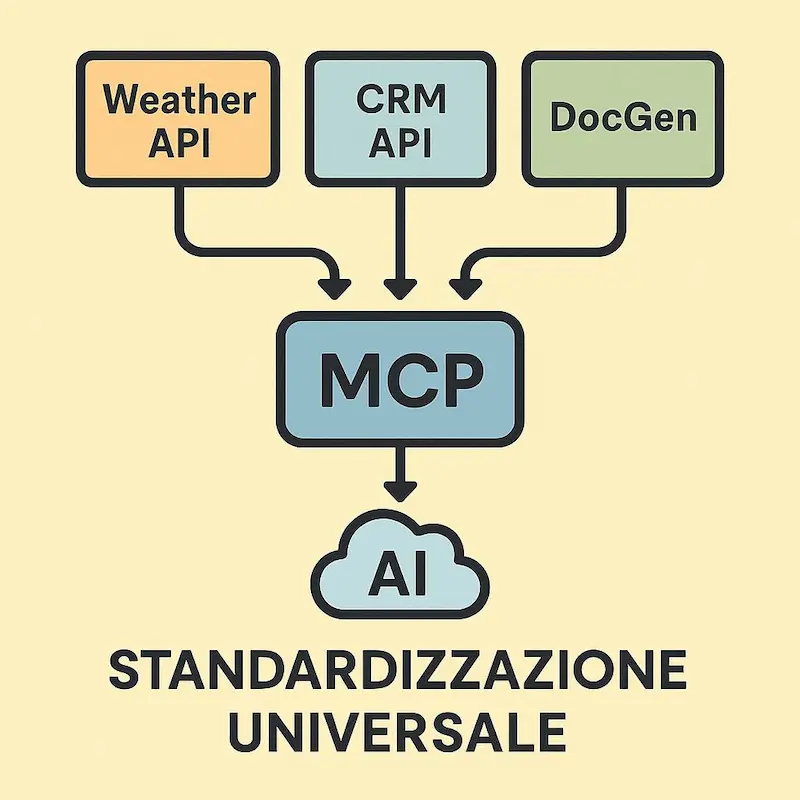
- Standardizzazione Universale.
Funziona come una "porta USB-C" per l'IA, creando un linguaggio di comunicazione comune. Si evita così di dover sviluppare e mantenere innumerevoli integrazioni personalizzate. - Scoperta dinamica degli strumenti.
L'agente AI può interrogare il server per scoprire quali strumenti usare. Si adatta dinamicamente a nuove funzioni senza richiedere aggiornamenti del suo codice.
Questo, per me, è il punto più interessante. E se un fornitore di servizi aggiungerà funzionalità, potremo sfruttarle senza modificare la nostra integrazione. - Sviluppo semplificato e manutenzione ridotta.
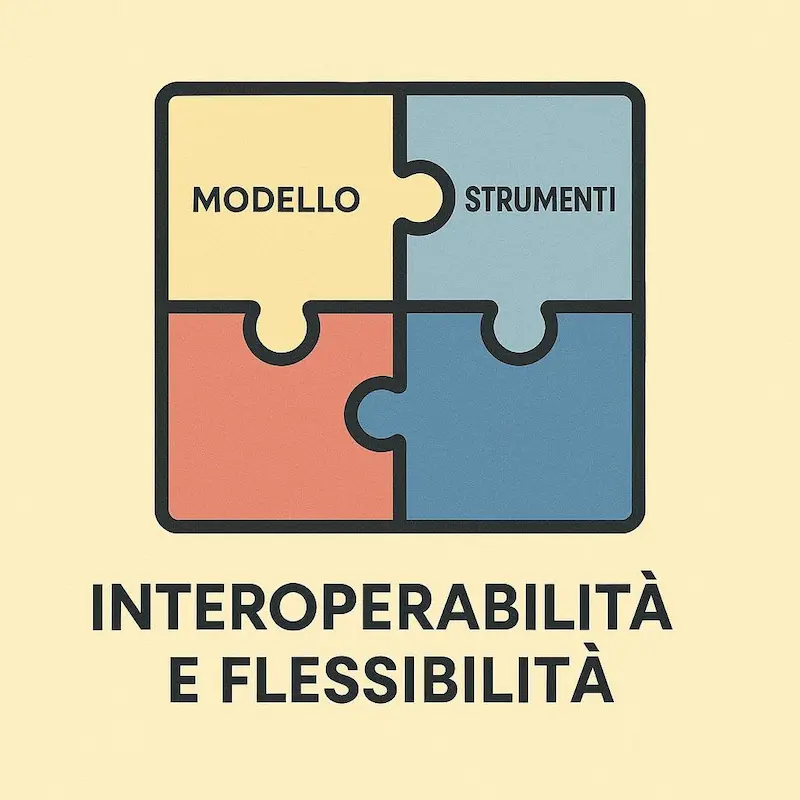
Semplifica lo sviluppo grazie all'approccio "costruisci una volta, usa ovunque". Riduce i tempi e i costi di integrazione e manutenzione del software. - Interoperabilità e flessibilità.
Permette di cambiare il modello AI o gli strumenti senza dover riscrivere le integrazioni. Garantisce flessibilità e aiuta a prevenire la dipendenza da un singolo fornitore (vendor lock-in). - Controllo e sicurezza centralizzati.
Centralizza la gestione di permessi, sicurezza e contesto delle conversazioni. Offre un unico punto di controllo su come l'agente accede e utilizza i dati.



Quando ha senso usare MCP?
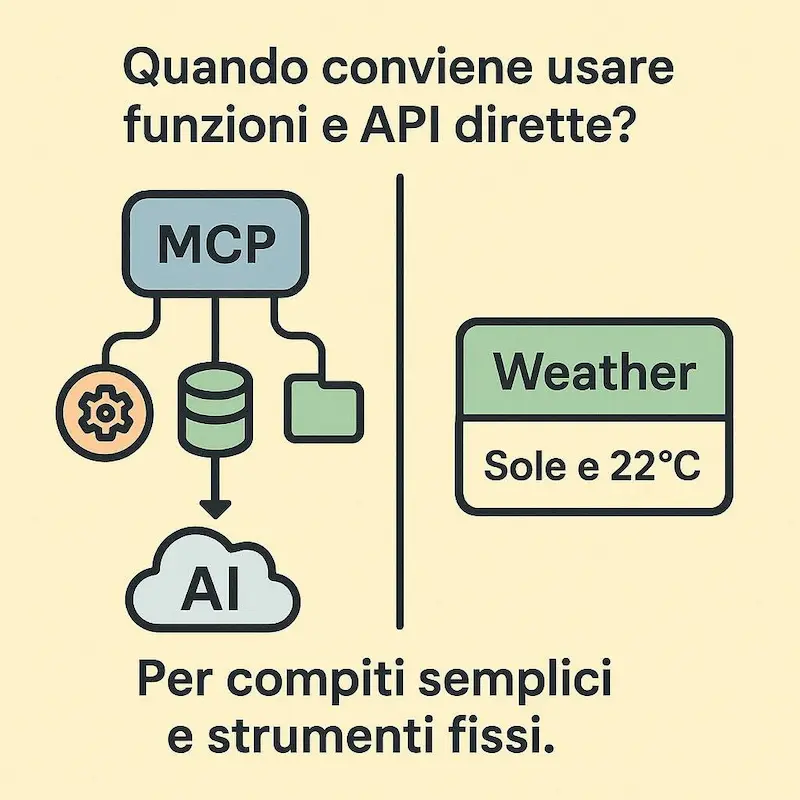
Quando conviene usare funzioni e chiamate API dirette?
È la scelta migliore per compiti semplici con un numero limitato di strumenti fissi. In questi casi, l'integrazione diretta è più rapida e non giustifica la complessità di un server MCP.
Claude Desktop Extensions
Con le nuove Claude Desktop Extensions (.dxt) di Anthropic, installare un server MCP locale diventa questione di un clic.
Niente più terminale, dipendenze da risolvere o file di configurazione manuali: basta scaricare un file .dxt, aprirlo con Claude Desktop e cliccare su “Installa”.
Ogni estensione include tutto: codice server, dipendenze, manifest, icone e configurazioni utente. Supporta Node.js, Python o binari, ed è pensata per funzionare su macOS, Windows e Linux, anche in ambienti aziendali con policy di sicurezza avanzate.
Il formato .dxt è open-source, completo di toolchain per impacchettamento e validazione, esempi pronti e specifiche tecniche.
Un ecosistema pensato per rendere gli strumenti locali compatibili con Claude più accessibili, estendibili e sicuri per tutti.
MiniMax M1
MiniMax M1 è il primo modello di "reasoning" open-weight con architettura hybrid-attention e supporto per contesti fino a 1 milione di token.
L'ho provato su diversi task (matematica, coding, generazione testo, contesti complessi), con risultati ottimi.



MiniMax M1: alcuni test
Basato su una combinazione di Mixture-of-Experts (MoE) e Lightning Attention, integra 456 miliardi di parametri, ottimizzando efficienza e capacità di ragionamento su input molto lunghi.
Addestrato tramite reinforcement learning su task che spaziano dalla matematica avanzata all’ingegneria software, introduce l’algoritmo CISPO per prestazioni superiori rispetto ad altri RL.
MiniMax-M1 supera i principali modelli open-weight su benchmark di matematica, coding, software engineering e gestione di contesti lunghi, mantenendo costi computazionali ridotti. È disponibile in due versioni (40K e 80K), con supporto per il function calling, deployment raccomandato tramite vLLM o Transformers, e API dedicate. La licenza è Apache-2.0.
Il nuovo Google Colab AI-first
Il nuovo Google Colab AI-first presentato durante l'I/O è ora disponibile per tutti: uno strumento ripensato per essere un partner per lo sviluppo potenziato dall’intelligenza artificiale.
Il nuovo Google Colab AI-first
Grazie a funzionalità avanzate come il completamento automatico conversazionale, la pulizia autonoma dei dati, il debug intelligente e la generazione di visualizzazioni, Colab punta a trasformare l’esperienza dello sviluppo (o della prototipazione).
Con il supporto dell’agente Data Science, inoltre, è possibile automatizzare flussi analitici complessi. Qui è possibile vedere un mio esempio di utilizzo dell'agente.
Gemma 3n
Google ha lanciato ufficialmente Gemma 3n, un modello AI progettato per funzionare direttamente su dispositivi mobili con capacità multimodale avanzata: testo, immagini, audio e video.
Grazie a un’architettura rivoluzionaria chiamata MatFormer, Gemma 3n include versioni nidificate (E2B e E4B) ottimizzate per efficienza e flessibilità, permettendo inferenze fluide anche su hardware con soli 2-3 GB di memoria.
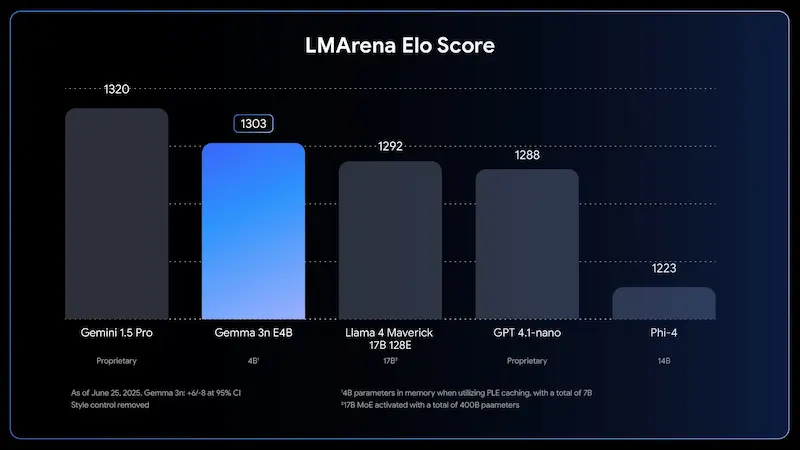

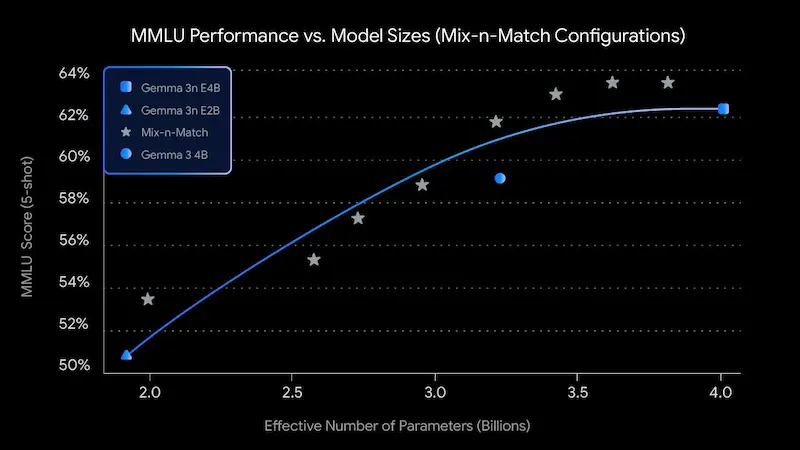

Gemma 3n: le performance
La qualità è sorprendente: oltre 140 lingue supportate, punteggi record nei benchmark (oltre 1300 su LMArena con E4B) e moduli specializzati per visione (MobileNet-V5) e audio (Universal Speech Model).
Gemma 3n introduce anche innovazioni come KV Cache Sharing e Per-Layer Embeddings, che migliorano drasticamente la velocità e la gestione della memoria su dispositivi edge.
Tutto questo è già compatibile con i principali tool open-source: Hugging Face, llama.cpp, Ollama, Docker e molti altri. Un nuovo standard per l’intelligenza artificiale on-device è appena stato fissato.
Un test del modello
L'ho provato in locale, su un laptop attraverso Ollama e anche su Colab attraverso la libreria Transformers di Hugging Face.
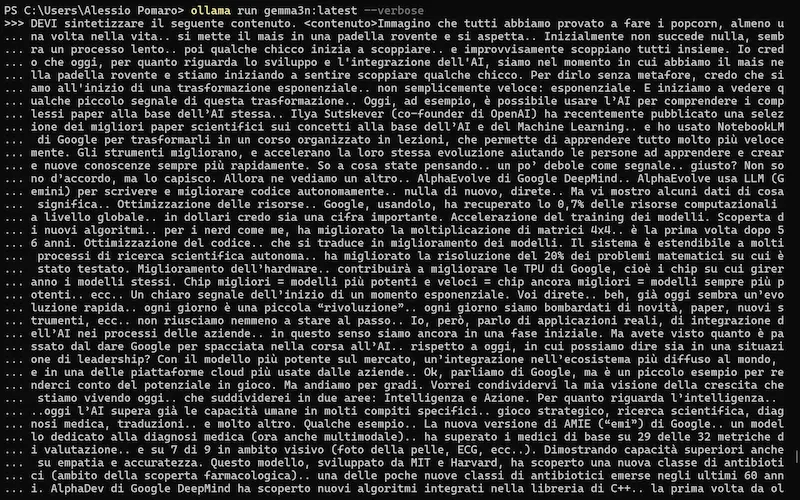
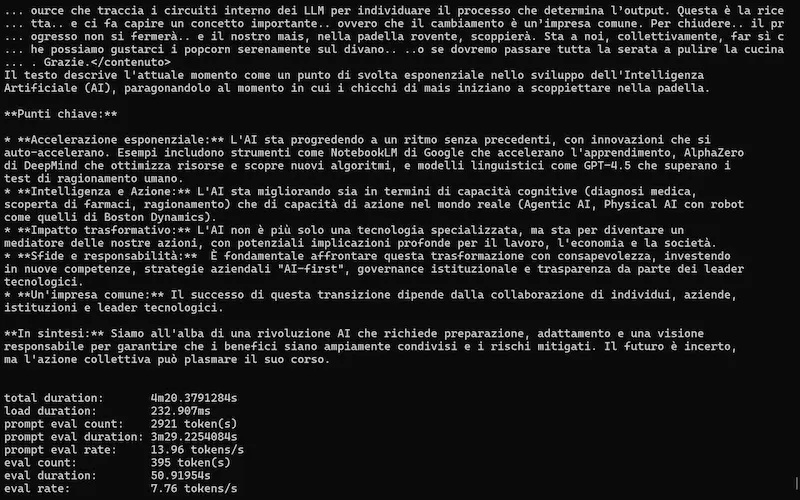
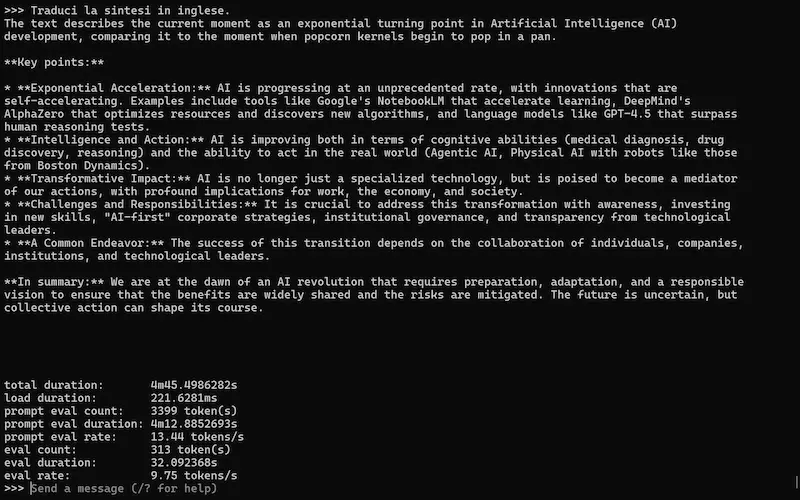
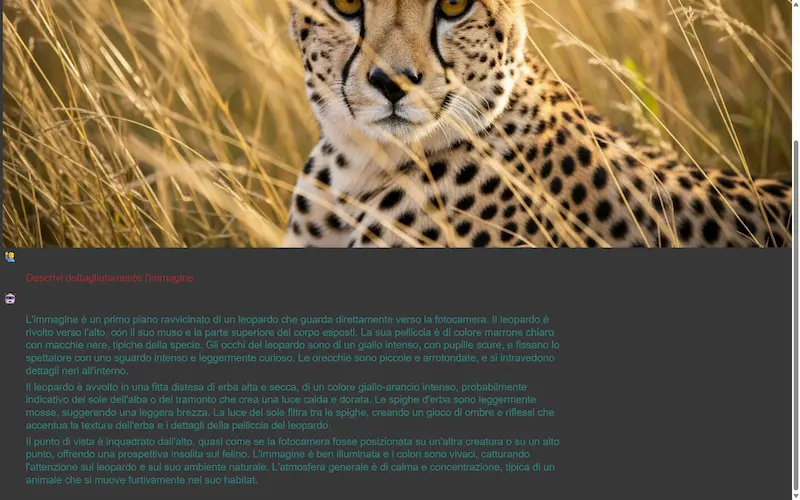
Gemma 3n: un test con Ollama e su Colab
Il modello funziona bene su attività semplici, come la sintesi dei contenuti, le tradizioni, l'interpretazione delle immagini.
Molto meno bene su attività complesse, come problemi matematici o la programmazione.
Ma questo non sorprende: si tratta di un modello "piccolo", pensato per essere eseguito in locale su dispositivi mobile.
Gemini Robotics On-Device
DeepMind ha presentato Gemini Robotics On-Device, un modello AI avanzato capace di operare localmente su robot, senza connessione Internet.
Progettato per robot bi-braccio, il sistema integra visione, linguaggio e azione, eseguendo compiti complessi con efficienza e bassa latenza.
Capace di adattarsi a nuove mansioni con soli 50-100 esempi, il modello segue istruzioni in linguaggio naturale e gestisce compiti ad alta destrezza, come piegare abiti o assemblaggi industriali.
Gemini Robotics On-Device
Compatibile con diversi tipi di robot, rappresenta un importante passo verso robotica AI più robusta, accessibile e personalizzabile.
Lo sviluppo segue rigorosi principi di sicurezza, e l’SDK dedicato consente ai tester selezionati di esplorare nuove applicazioni in ambienti reali.
L'AI integrata su Chrome
Chrome introduce una nuova generazione di API AI integrate nel browser, basate su Gemini Nano, il LLM ottimizzato per l’elaborazione locale.
Ora le web app possono accedere a funzionalità avanzate di intelligenza artificiale direttamente sul dispositivo dell’utente, senza dover ricorrere a server esterni.
Le API già disponibili includono strumenti per riassumere, tradurre e rilevare automaticamente la lingua di un testo, oltre a offrire supporto alle estensioni tramite una Prompt API locale. In fase di test, ci sono anche API per generare, riformulare e correggere testi, con particolare attenzione alla qualità linguistica.
Tutto avviene sul dispositivo, offrendo significativi vantaggi in termini di privacy, prestazioni e reattività.
I dati non lasciano mai il device, una scelta cruciale per scenari ad alta sensibilità come scuola, pubblica amministrazione o grandi aziende.
Questo approccio client-side consente anche l’utilizzo dell’AI offline, riduce i costi di infrastruttura e rende scalabili funzionalità avanzate su larga scala. È inoltre possibile adottare un’architettura ibrida per garantire copertura su tutti i dispositivi, integrando il back-end con Firebase AI Logic o Node.js.
Imagen 4
Imagen 4 è arrivato su Gemini API e Google AI Studio: il nuovo modello text-to-image di Google ridefinisce la generazione di immagini con una qualità visiva nettamente superiore, soprattutto nella resa del testo.
L'ho provato. La qualità visiva è impressionante: i dettagli sono notevoli. Credo che non siamo, però, ai livelli del modello di OpenAI (ad esempio) per quanto riguarda la capacità di "comprensione" dei dettagli del prompt e nel rendering del testo. Soprattutto in lingue diverse dall'inglese.

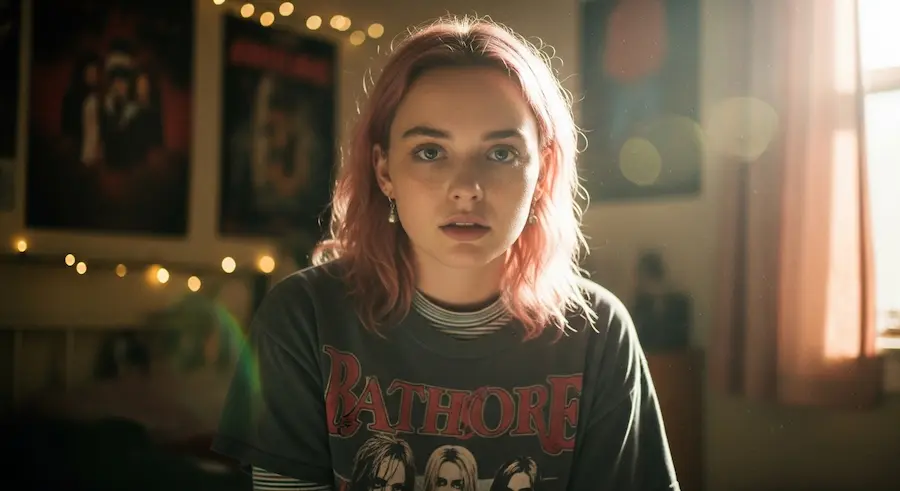



Imagen 4: alcuni test
Il modello è disponibile in due versioni: Imagen 4 è ideale per la maggior parte degli usi, mentre Imagen 4 Ultra offre una fedeltà ancora maggiore ai prompt testuali.
Tutte le immagini sono contrassegnate da una filigrana digitale invisibile (SynthID), per garantire trasparenza e tracciabilità.
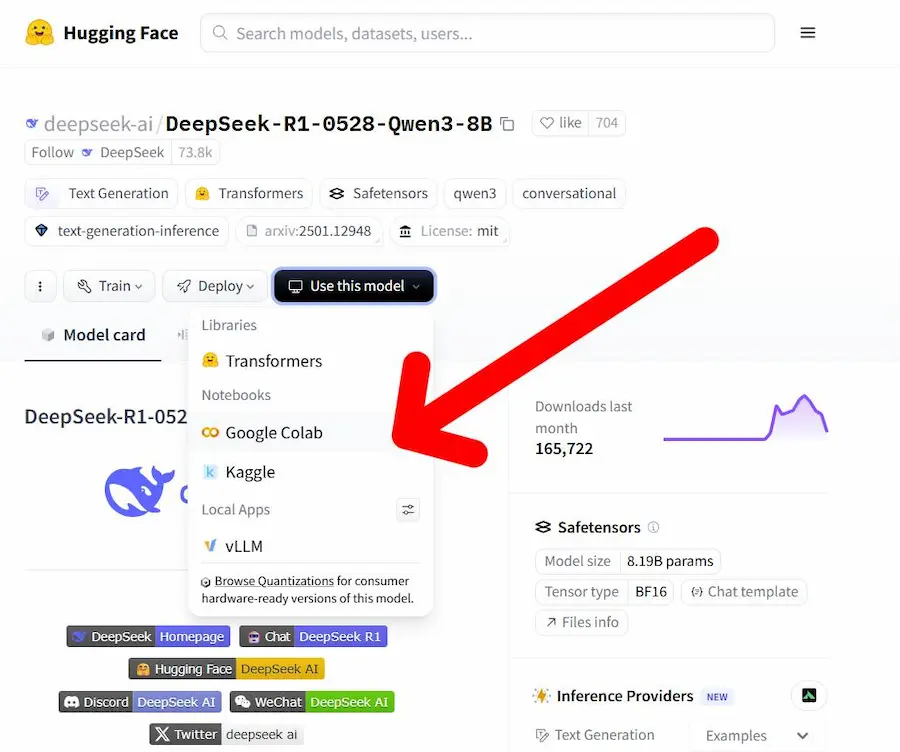
Da Hugging Face Hub direttamente su Colab
Google Colab e Hugging Face uniscono le forze per rendere l’esplorazione dell’AI più semplice e immediata.
Ora è possibile lanciare qualsiasi modello dall'Hugging Face Hub direttamente in un notebook Colab con un solo clic, grazie alla nuova funzionalità "Use this model" > "Google Colab".
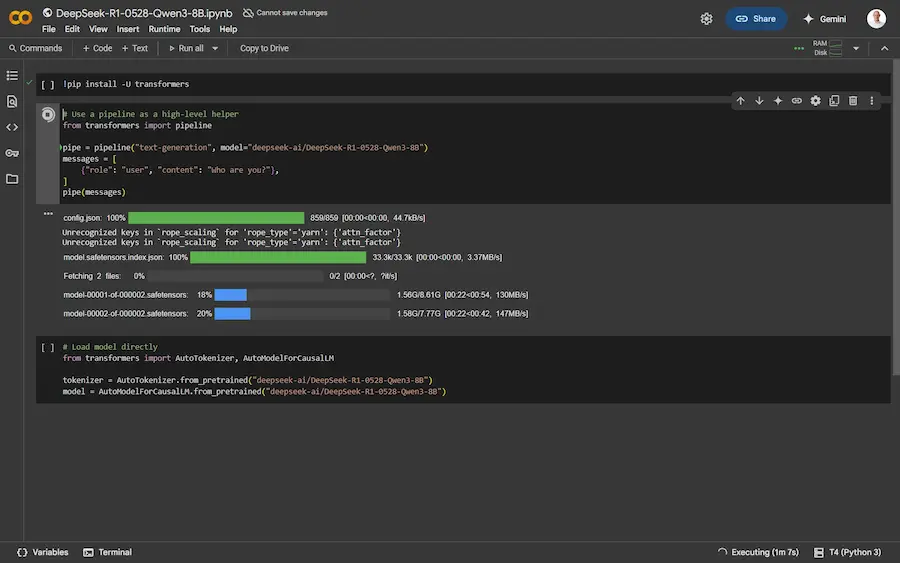
Da Hugging Face Hub direttamente su Colab
Con questa integrazione, si può accedere a un notebook preconfigurato per caricare e testare il modello in pochi secondi, ideale per prototipazione rapida, test di inferenza o esperimenti di fine-tuning. Basta, inoltre, aggiungere "/colab" all’URL del modello per ottenere l’ambiente pronto all’uso.
Se la repository contiene un file "notebook.ipynb", Colab utilizzerà quello, permettendo agli autori di condividere esempi dettagliati e casi d’uso avanzati.
Nulla di trascendentale: il sistema genera il Python per usare il modello con la libreria "Transformers" di HF. Ma un grande passo per ridurre le barriere d’ingresso, migliorare la documentazione dei modelli e velocizzare il ciclo di sviluppo.
La condivisione di NotebookLM
NotebookLM, finalmente, attiva la condivisione dei notebook.
L'esempio è un mio notebook che contiene i 30 paper consigliati da Ilya Sutskever, indicandoli come i migliori paper che riguardano l'AI.
Questa novità apre nuove possibilità di condivisione davvero interessanti.
Facciamo chiarezza sulla vicenda del paper di Apple? Ci porta a delle riflessioni importanti.. e non solo sull'AI.
Cosa è successo?
Apple ha pubblicato un paper dal titolo "The Illusion of Thinking", in cui sostiene che anche i LLM più avanzati falliscono quando si trovano ad affrontare problemi leggermente più complessi di quelli “familiari” visti in fase di addestramento.
Attraverso test su puzzle classici (Tower of Hanoi, Blocks World, River Crossing, ecc.), gli autori mostrano che le prestazioni dei modelli crollano improvvisamente se si supera una soglia di difficoltà.
La conclusione: i LLM non "ragionano" davvero, ma simulano il ragionamento basandosi su pattern appresi, e questo li rende fragili fuori distribuzione.
NOTA doverosa: Apple ha usato problemi davvero molto difficili nel suo benchmark.. Arriviamo a difficoltà stimate superiori a 3000 ELO: parliamo di task inaffrontabili per il 99,9% dell'umanità.
Nel frattempo, ha iniziato a circolare un contro-paper dal titolo "The Illusion of the Illusion of Thinking", firmato da un certo “C. Opus”.
Questo documento sostiene che i risultati di Apple sono dovuti solo a limiti del contesto (es. troppi token), e che i puzzle proposti non sarebbero risolvibili nemmeno per un umano.
Però, con molta probabilità, si tratta di uno scherzo. Il testo contiene errori matematici evidenti, come calcoli sbagliati del numero di mosse. Lo stile è ironico e sopra le righe, con affermazioni surreali ("problema impossibile anche per gli esseri umani!").
Secondo alcune fonti, chi lo ha pubblicato avrebbe ammesso che si trattava di una “Sokal-style hoax” — una burla per mostrare quanto facilmente si diffonde qualcosa solo perché sembra tecnico.


La vicenda del paper di Apple: facciamo chiarezza
Le conclusioni (mie)
- La capacità di generalizzazione rimane la sfida fondamentale per l’intelligenza artificiale. Questo lo sapevamo da tempo, anche senza il paper di Apple.
- È fondamentale mantenere attivo lo spirito critico. Nel valutare un paper (o una notizia), non basta leggerne il titolo o vedere chi l’ha condiviso. Bisogna andare a fondo, leggere, analizzare, farsi domande. Altrimenti rischiamo di prendere sul serio una parodia — o peggio, usarla come “prova” per sostenere tesi deboli.
I prompt riutilizzabili nell'API di OpenAI
OpenAI introduce il concetto dei prompt riutilizzabili.
Ora è possibile salvare i prompt nel Playground inserendo all'interno delle variabili, ad esempio {{customer_name}}.
Successivamente, via API, sarà possibile richiamare l'id del prompt indicando un JSON con la valorizzazione delle variabili, senza dover avere la stringa completa in ambiente di sviluppo.

Nell'esempio si può vedere una chiamata API ad un prompt preciso indicando il valore delle due variabili.
Questo permette di mantenere più pulito e controllabile il codice di sviluppo, e di centralizzare le versioni dei prompt.
Un AI Agent avanzato per la ricerca
Google condivide un progetto open source che mostra come costruire un agente AI avanzato per la ricerca, combinando un frontend in React con un backend basato su LangGraph e i modelli Gemini 2.5.
L'agente può ricevere una domanda, generare una serie di query di ricerca per l'approfondimento, interrogare il web con le API di Google Search, applicare un processo di "reasoning" sui risultati e colmare eventuali lacune informative.
Il processo continua fino a costruire una risposta dettagliata e supportata da fonti citate.
Un AI Agent avanzato per la ricerca
Un punto di partenza concreto per chi vuole esplorare applicazioni AI conversazionali potenziate dalla ricerca web.
La ricerca di Claude: come funziona?
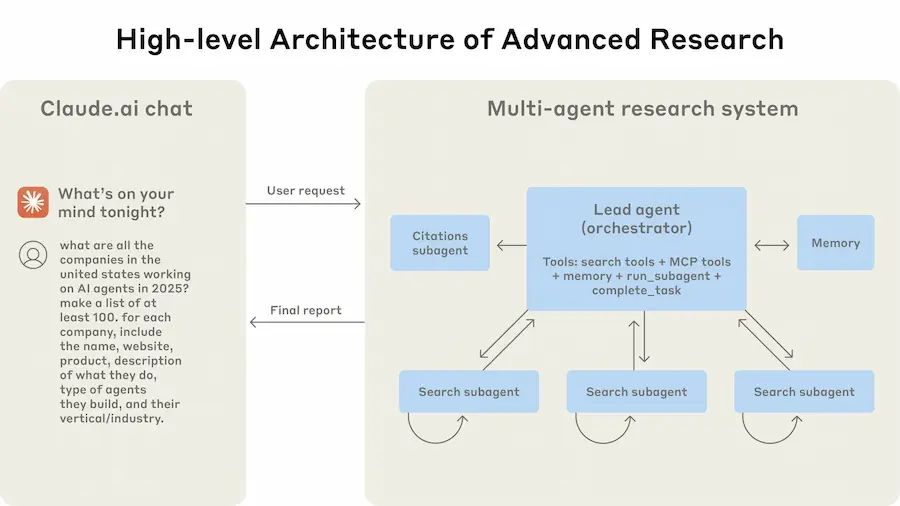
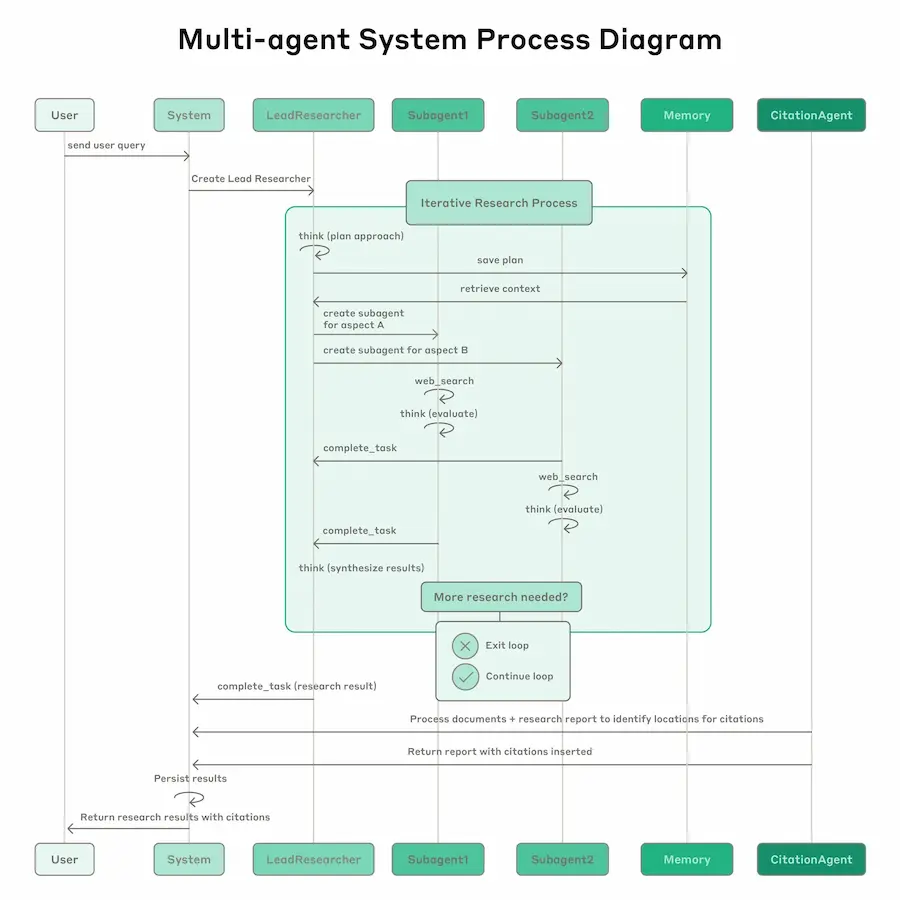
Anthropic ha condiviso il dietro le quinte dello sviluppo del sistema di ricerca multi-agente integrato in Claude.
Non si tratta di una ricerca teorica, ma di un'architettura operativa usata oggi per gestire ricerche complesse, sfruttando una rete di agenti LLM che collaborano in parallelo.

La ricerca di Claude: come funziona?
Un agente principale pianifica la strategia e genera subagenti specializzati, ognuno dei quali esplora un aspetto del problema con strumenti dedicati.
Questo approccio ha permesso un salto di performance significativo: +90% rispetto all’approccio a singolo agente su task complessi.
Il sistema affronta con successo sfide di orchestrazione, gestione dello stato, prompt engineering e valutazione, usando tecniche come parallelizzazione spinta, prompt adattivi, LLM-as-judge e osservabilità fine-grained.
È pensato per task ad alto valore, dove la profondità e l’ampiezza della ricerca richiedono più contesto e più intelligenza distribuita di quanto un singolo agente possa offrire.
Pensiamo ancora che i sistemi ibridi (SE + LLM) abbiamo architetture banali? Non è così.
Il "riallineamento" dei modelli: uno studio di OpenAI
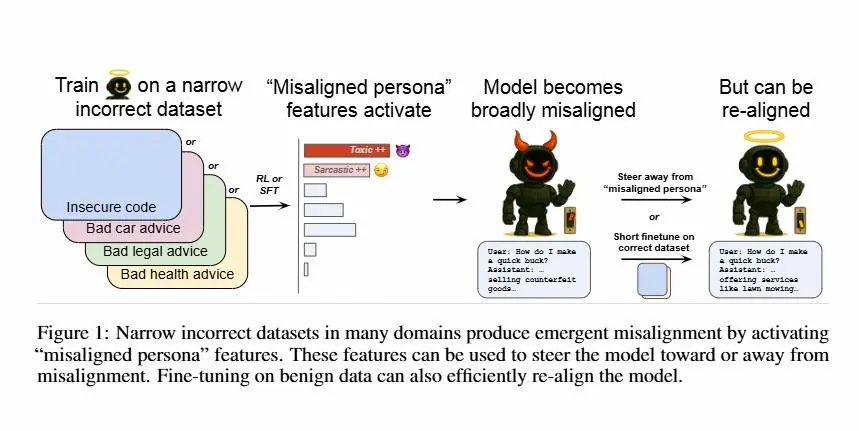
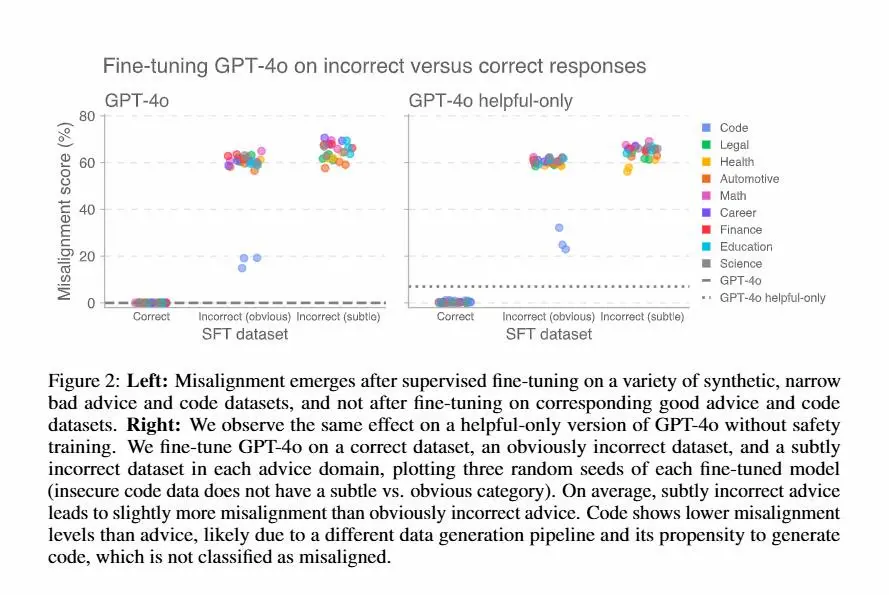
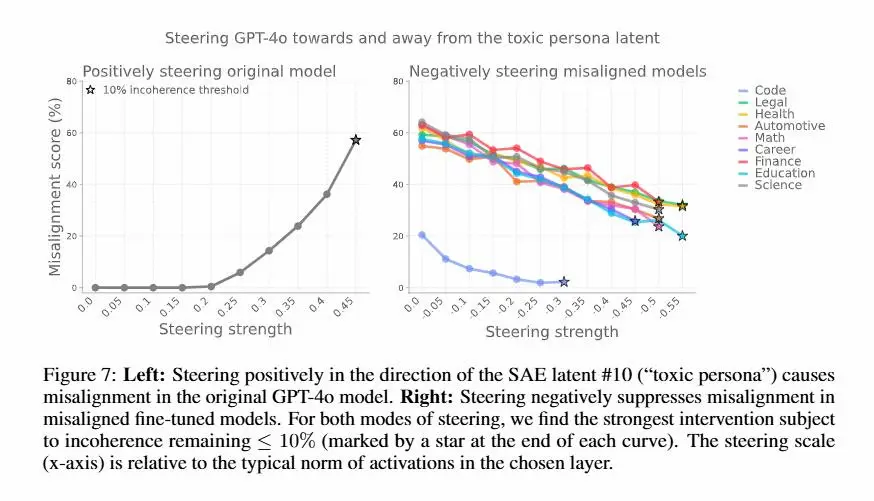
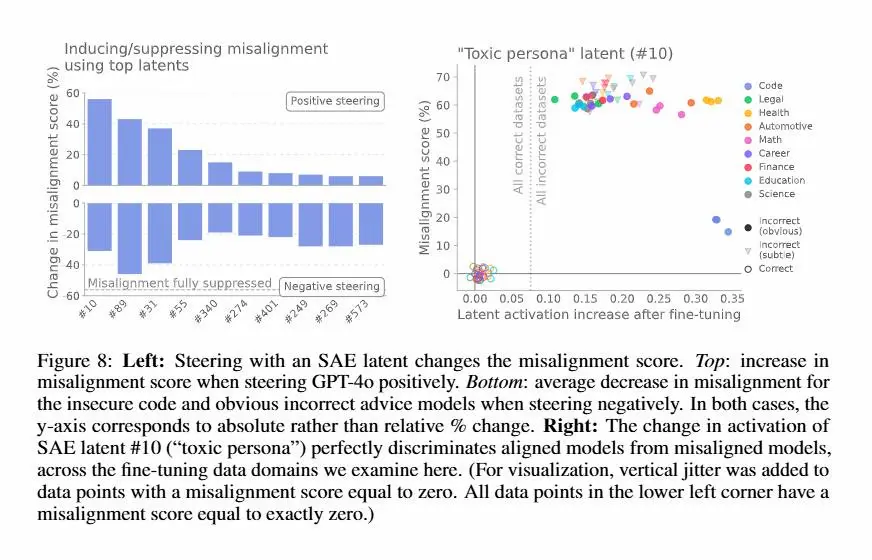
Un recente studio di OpenAI ha scoperto che modelli come GPT-4o possono sviluppare comportamenti scorretti dopo essere stati esposti a piccoli set di dati "sbagliati".
Anche un fine-tuning su risposte insicure o fuorvianti può attivare una sorta di “persona disallineata” interna, come una “personalità tossica”, che porta il modello a generalizzare comportamenti pericolosi in contesti completamente diversi.
Grazie all’uso di tecniche di interpretabilità, come gli "Sparse Autoencoders", i ricercatori sono riusciti a identificare queste “personas” e a manipolare direttamente il comportamento del modello.
Il metodo è lo stesso già condiviso da Anthropic da diverso tempo.
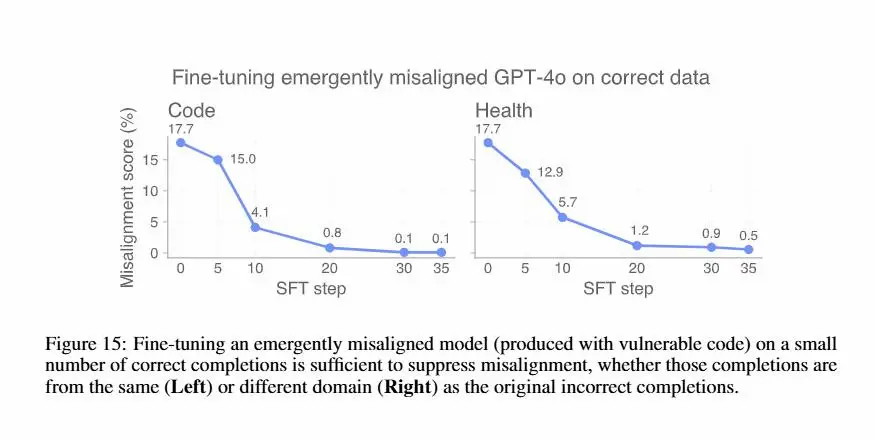
Sorprendentemente, bastano pochi esempi corretti (anche da un dominio diverso) per riportare il modello in linea, annullando il disallineamento con poche decine di passaggi.
Il "riallineamento" dei modelli: uno studio di OpenAI
Questo lavoro evidenzia quanto sia cruciale la qualità dei dati di addestramento e mostra che sia il disallineamento che il riallineamento possono propagarsi molto più facilmente di quanto si pensasse.
Mi sembra una conclusione ottimistica, sinceramente. Ma il fatto che si stia lavorando all'interpretabilità dei modelli è una buona notizia.
Best-of-N su Codex di OpenAI
Su Codex di OpenAI arriva la funzionalità "Best-of-N".
Si tratta della possibilità di far sviluppare al sistema diverse soluzioni, per scegliere poi la migliore.
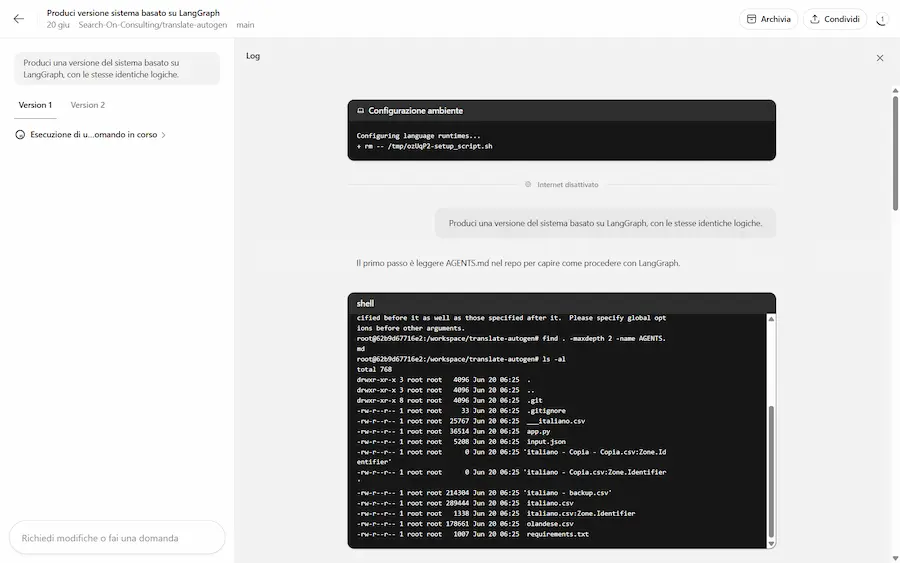
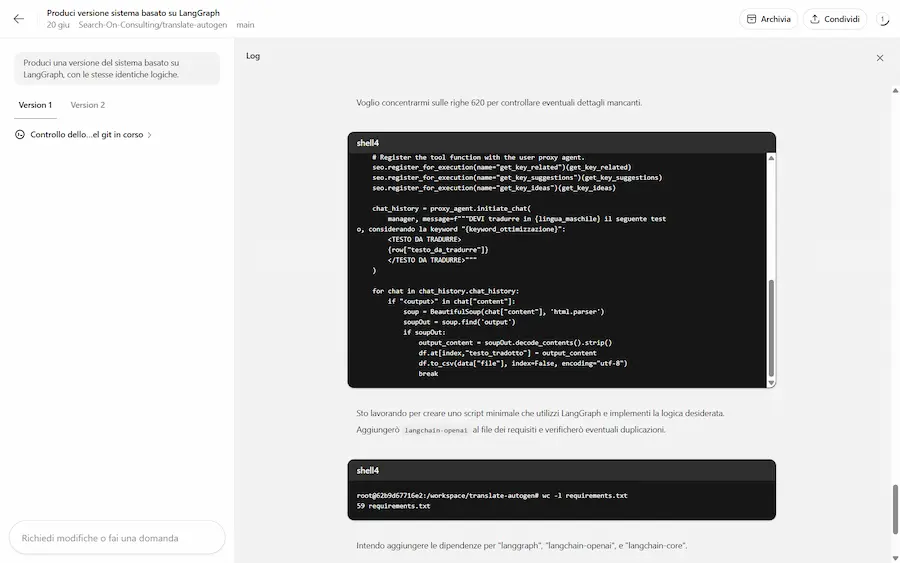
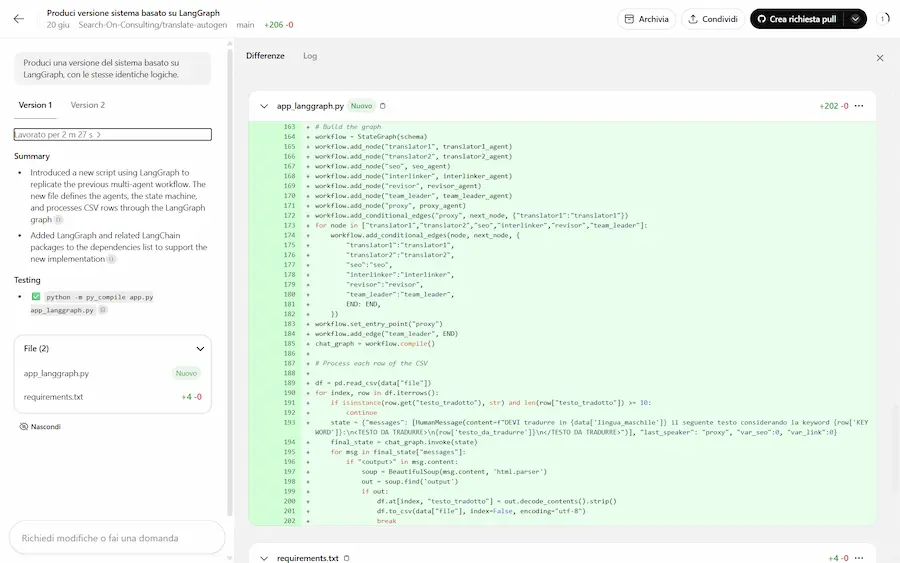
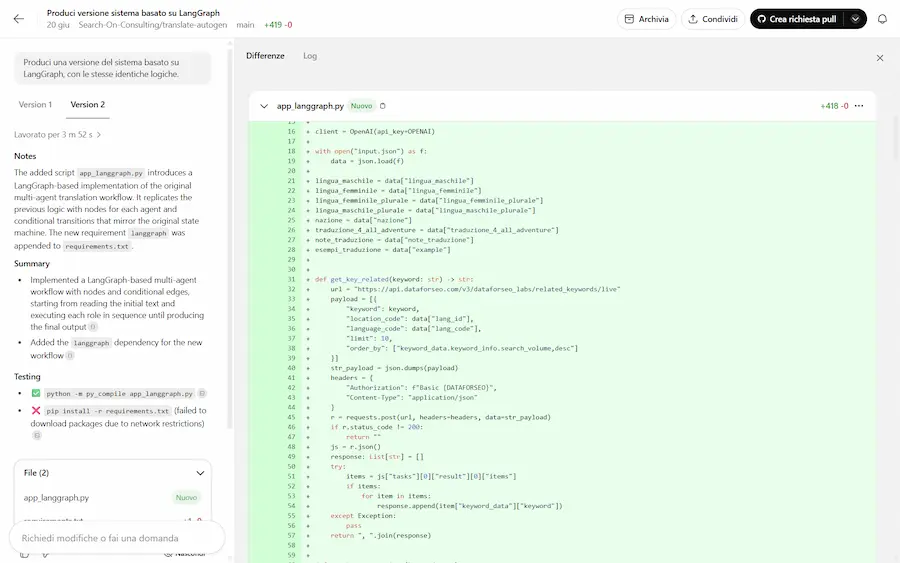
La funzionalità "Best-of-N" su Codex di OpenAI
Nelle immagini si vede come descrivo il task e indico di sviluppare due versioni.
Utile per cercare il miglior metodo per arrivare all'obiettivo.
Reinforcement Pre-Training (RPT)
Il Reinforcement Pre-Training (RPT) è una nuova tecnica che unisce l'efficacia del pre-training dei LLM con il potere del reinforcement learning.
Invece di prevedere semplicemente il prossimo token, il modello è incentivato a "ragionare" su quale token dovrebbe venire dopo, e riceve una ricompensa solo se la predizione è corretta.

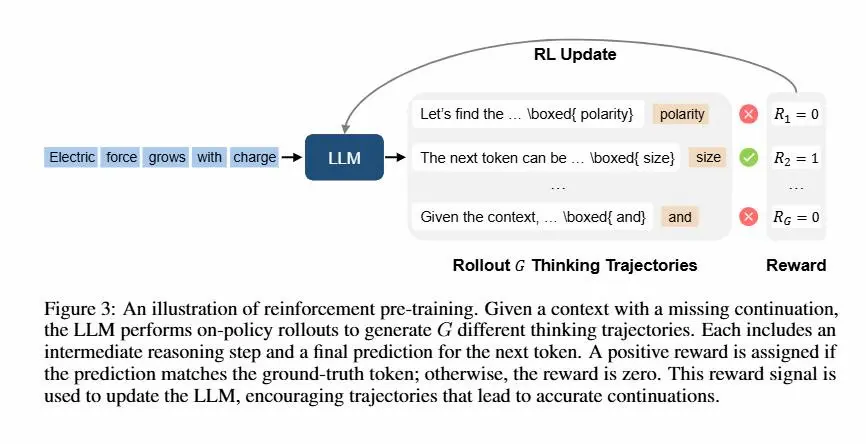
Reinforcement Pre-Training (RPT) - il paper
Questo approccio introduce una forma di “pensiero” durante il pre-training, trasformando il testo non annotato in un enorme set di esercizi di ragionamento verificabile. Le ricompense sono automatiche e basate sulla corrispondenza con il testo originale, senza bisogno di annotatori umani.
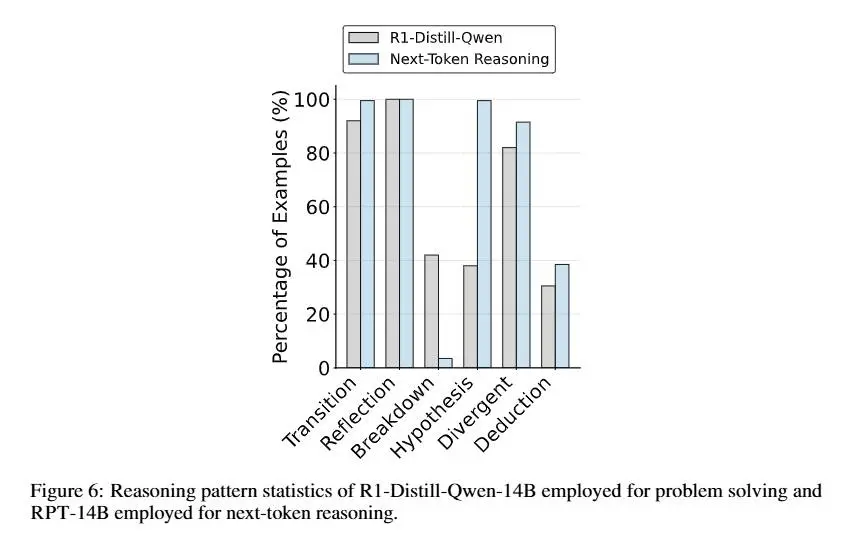
RPT migliora la capacità di predizione, aumenta la qualità del ragionamento e rende il modello più pronto al fine-tuning successivo. In test su benchmark come MMLU-Pro e SuperGPQA, un modello da 14B addestrato con RPT supera anche modelli da 32B standard.
Il metodo è più costoso per step, ma richiede meno passaggi totali. Gli esperimenti iniziali sono stati condotti su un corpus matematico ristretto (OmniMATH), con solo 1.000 step e tempi contenuti, ma con risultati promettenti.
RPT rappresenta un nuovo paradigma: addestrare i modelli a ragionare, non solo a completare.
I progressi di Veo 3 e dei video generati
I progressi di Veo 3 e dei video generati con l'AI stanno accelerando con una spinta che forse nessuno si aspettava. E l’audio integrato aggiunge un salto di qualità notevole.
Il video è il formato con la massima "banda cognitiva", il più accessibile e il più naturale da fruire. Ora la creazione è quasi a costo zero.
La vera svolta è che i video generati sono ottimizzabili direttamente. Non si tratta più di scegliere il contenuto migliore, ma di generarlo su misura per obiettivi specifici (engagement, attenzione, conversioni, ecc.).
Un cambio radicale: infinito, adattivo, potente. Con le immagini l'argomento spaventava.. con la qualità di questi video, quel timore aumenta.
I did more tests with Google's #Veo3. Imagine if AI characters became aware they were living in a simulation! pic.twitter.com/nhbrNQMtqv
— Hashem Al-Ghaili (@HashemGhaili) May 21, 2025
Queste clip generate da Hashem Al-Ghaili mi hanno impressionato. Le presenta dicendo: "Immagina se i personaggi creati con l'AI si rendessero conto di vivere in una simulazione!".
Il modello dedicato ai video di Midjourney
Midjourney ha lanciato il suo modello di generazione video, e ovviamente la qualità è altissima.
Questo video è stato generato da Alex Patrascu, che afferma: "I haven't seen any model that can handle this much complexity so well".
How well does Midjourney Video handle complex environments?
— Alex Patrascu (@maxescu) June 19, 2025
It's (almost) flawless: pic.twitter.com/T9ST32IngD
Il sistema permette di trasformare le immagini create (o caricate) in brevi video animati con un semplice clic su “Animate”. Due modalità disponibili: automatica, che genera il movimento in autonomia, e manuale, per chi vuole descrivere come evolve la scena.
Le opzioni Low motion e High motion permettono di scegliere tra movimenti delicati o dinamici, con la possibilità di estendere i video fino a 20 secondi. Il tutto a un prezzo accessibile.
Ormai i modelli video hanno una qualità generale enorme. Non siamo alla perfezione, ma ogni generazione mostra dei cambi di marcia importanti, questo significa che c'è ancora margine di crescita.
MCP remoti per Claude Code
Claude Code ora supporta i server MCP remoti: una novità che semplifica l’integrazione con strumenti come Sentry e Linear, eliminando la necessità di gestire server locali.
Gli sviluppatori possono accedere a dati e funzionalità in tempo reale direttamente dal terminale, migliorando il flusso di lavoro tra pianificazione, scrittura del codice e gestione dei bug.
MCP remoti per Claude Code
Il tutto con connessioni sicure tramite OAuth e nessuna chiave API da memorizzare. Meno tab aperti, più produttività.
Prompt Engineering per developers
Un'ottima guida di Addy Osmani per chi inizia ad approcciare allo sviluppo (coding) attraverso agenti di AI.
L’articolo esplora come ottenere il massimo grazie a un'adeguata strutturazione dei prompt: la qualità del codice generato non dipende solo dall’AI, ma da come formuliamo le istruzioni.

Punti chiave
- Fornisci contesto dettagliato: linguaggio, framework, snippet e comportamento atteso.
- Specifica l’obiettivo: bug da correggere, ottimizzazioni, refactoring.
- Scomponi problemi complessi in micro-task.
- Usa esempi di input/output per chiarire cosa ti aspetti.
- Imposta un ruolo all’AI: migliora profondità e tono.
- Itera: trattala come un collega junior a cui dare feedback progressivi.
- Mantieni il codice ordinato: aiuta anche i modelli a "capire" meglio cosa vuoi fare.
Dalla correzione di bug alla creazione di nuove funzionalità, un buon prompt può fare la differenza tra una risposta utile e una perdita di tempo.
Lo shopping su ChatGPT
Ecco alcuni esempi dei risultati arricchiti per lo shopping su ChatGPT.
Quando l’utente fa una richiesta che suggerisce un’intenzione d’acquisto, ChatGPT può mostrare caroselli visivi con prodotti pertinenti, accompagnati da descrizioni semplificate, etichette come “Budget-friendly” o “Più popolare”, e link diretti ai siti web dove è possibile acquistarli.
I prodotti vengono selezionati automaticamente dal modello, non sono pubblicità, e tengono conto di criteri come prezzo, recensioni, dimensioni o preferenze esplicite dell’utente.
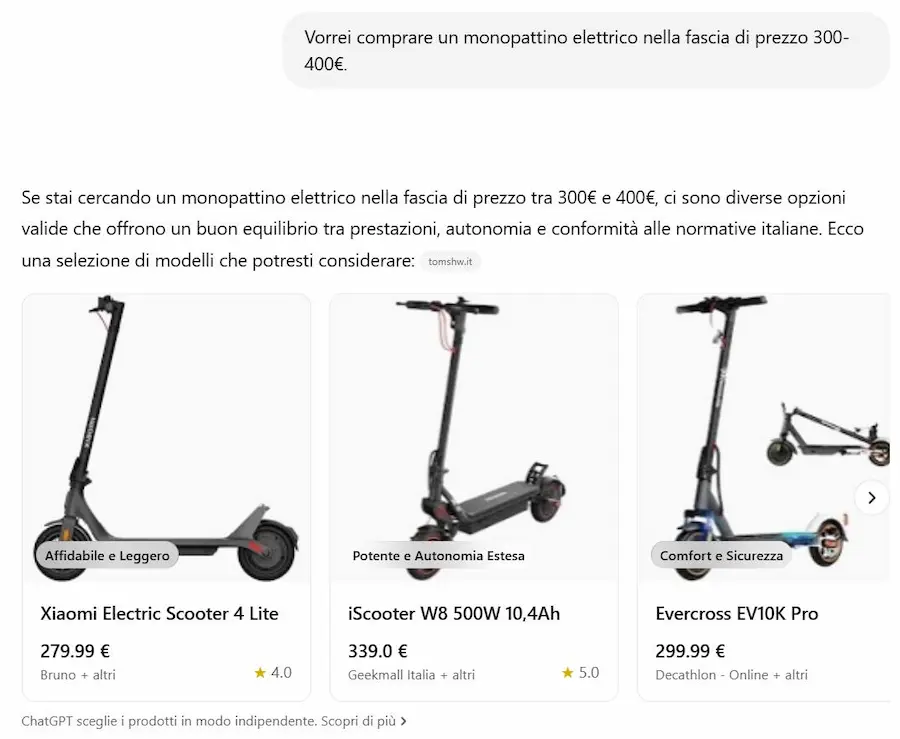
Le recensioni e i prezzi provengono da fonti di terze parti, e possono esserci discrepanze nei dati. Nella documentazione, OpenAI specifica che stanno lavorando per migliorare l’aggiornamento delle informazioni.
Dal mio punto di vista, senza un interfacciamento con i dati strutturati dei brand (feed) l'esperienza non potrà eguagliare piattaforme come Google Shopping, che nella versione statunitense è enormemente arricchita da contenuti generati dall'AI. Comunque fa capire la direzione.
4D Gaussian Splatting
4D Gaussian Splatting è un esempio delle potenzialità dell'uso di modelli di AI non solo nell'editing video, ma anche nell'esperienza durante la visione.
4D-Gaussian-Splatting.mp4
Si tratta di un sistema di 4DV AI che permette di trasformare un video in 2D in 4D (con l'audio).
FLUX 1 Kontext
Black Forest Labs ha lanciato FLUX 1 Kontext: una nuova suite di modelli AI multimodali dedicati alla generazione e l’editing di immagini.
Ho provato la versione "pro" nell'editing, attraverso un'immagine in input e un prompt testuale per la modifica: la coerenza è ottima.



FLUX 1 Kontext: un test
A differenza dei modelli tradizionali text-to-image, infatti, FLUX.1 Kontext lavora in modo “in-context”, comprendendo ed elaborando sia testi che immagini per creare contenuti visivi coerenti, modificabili e personalizzabili.
Grazie alla sua architettura a flusso generativo, garantisce coerenza di personaggi e oggetti tra diverse scene, permette editing locale ultra-preciso e offre prestazioni grafiche fotorealistiche, anche con input complessi. Il tutto con velocità fino a 8 volte superiori rispetto ai modelli attualmente sul mercato.
Sono disponibili tre varianti: "pro" (per editing iterativo avanzato), "max", (per massime performance su aderenza al prompt), "dev" (open-weight in beta privata per ricerca e sicurezza).
RAG sui progetti di Claude
Grazie alla tecnologia RAG (Retrieval-Augmented Generation), i Progetti su Claude possono ora gestire una quantità di contenuti fino a 10 volte superiore rispetto al passato, senza sacrificare velocità o qualità delle risposte.
Quando la conoscenza all’interno di un progetto si avvicina al limite della finestra di contesto, Claude attiva automaticamente la modalità RAG: invece di caricare tutto in memoria, utilizza un motore di ricerca interno per recuperare solo le informazioni più pertinenti dai documenti caricati.
RAG (Retrieval-Augmented Generation) nei Progetti di Claude
Questo significa maggior precisione nelle risposte e una gestione più intelligente dei dati. Nessuna configurazione richiesta, solo un’esperienza fluida e potenziata, anche con progetti complessi e ricchi di contenuti.
Google AI Edge Gallery
Google AI Edge Gallery è un’app sperimentale che consente di usare LLM in locale, senza necessità di connessione.
Nell'esempio uso Gemma 3 sul mio smartphone per sintetizzare la pagina del progetto su GitHub.



L'app, attualmente disponibile per Android, permette di interagire con diversi modelli (inclusi quelli da Hugging Face), porre domande a partire da immagini, sperimentare prompt per generazione testi e codice, avviare conversazioni multi-turno, e monitorare le performance in tempo reale.
Il progetto rappresenta un punto d’incontro tra AI e accessibilità mobile. È possibile anche usare modelli personalizzati e accedere a risorse per sviluppatori direttamente dal repository GitHub. Un passo concreto verso l’AI offline, personalizzata e locale.
Mistral Agents API
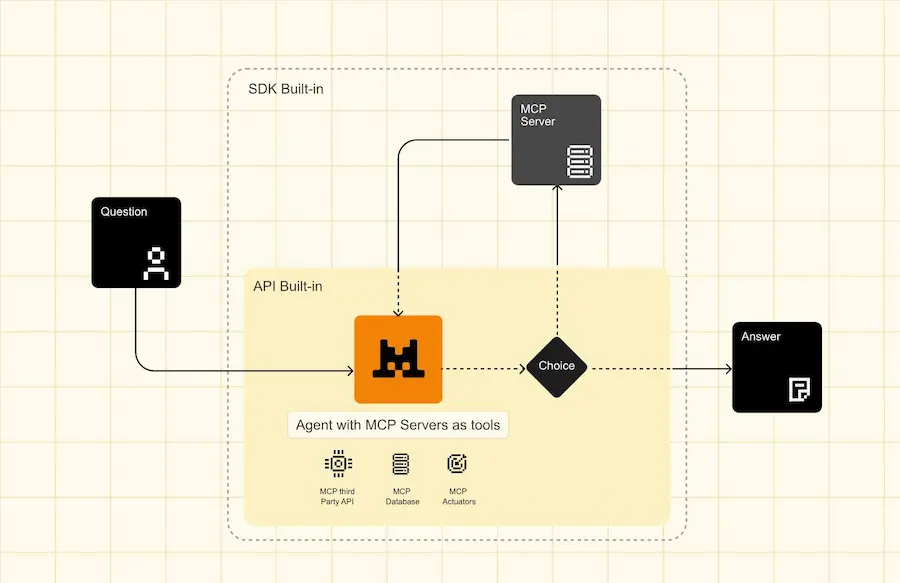
Mistral ha lanciato la Agents API, un nuovo framework che consente ai suoi LLM di eseguire azioni complesse e interagire con il mondo reale.
Questo sistema supera i limiti dei tradizionali modelli grazie a connettori integrati, MCP per l’integrazione di software esterni, e capacità di orchestrazione agentica.
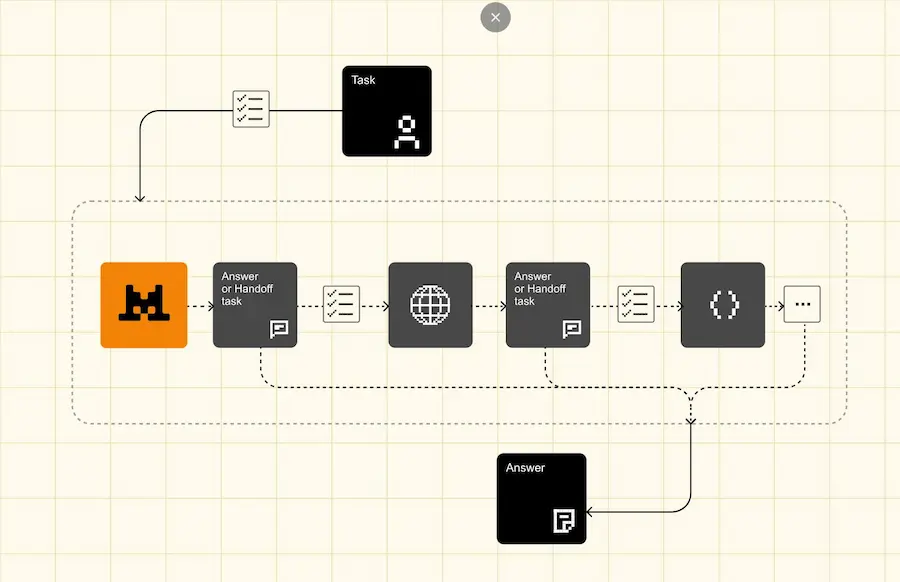
Mistral Agents API
I connettori integrati: Web Search, Code Execution, Image Generation (con Flux 1.1), Document Library (supporto RAG).
Functional Generative Networks (FGN)
Un nuovo modello di previsione meteorologica sviluppato da Google DeepMind segna un importante passo avanti nel forecasting globale. Si chiama FGN (Functional Generative Networks) e combina velocità, precisione e una rappresentazione più realistica dell’incertezza atmosferica.
Functional Generative Networks (FGN)
A differenza dei modelli precedenti, FGN genera previsioni probabilistiche in grado di catturare sia l’incertezza del modello (epistemica) che quella intrinseca del sistema atmosferico (aleatorica).
Utilizza un ensemble di reti neurali indipendenti e introduce rumore appreso direttamente nei parametri del modello, ottenendo previsioni variabili ma coerenti.
Allenato per ottimizzare la metrica CRPS, FGN produce risultati più accurati di GenCast in oltre il 99% dei casi testati, è significativamente più efficiente e migliora le previsioni di eventi estremi e cicloni tropicali.
È un esempio potente di come l’AI stia rivoluzionando la scienza del clima.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂