Generative AI: novità e riflessioni - #7 / 2025
Approfondimenti su Agent Mode di ChatGPT, prompt per Veo 3, image-to-video e agenti AI multi-modello. Test su Kimi K2, aggiornamenti su Grok 4 e Claude, guida al prompting avanzato, risorse gratuite e novità su AI per l’educazione, API e modelli lightweight.

Buon aggiornamento, e buone riflessioni..
Un Agente AI per ottimizzare i prompt di Veo 3
Ho creato un Agente AI che genera prompt strutturati per Veo 3, e devo dire che l'aderenza dei video in output con l'idea di partenza è altissima.
L'agente riceve in input una descrizione di base del video, pone domande di follow-up per espandere i dettagli in modo guidato e semplice, e produce un prompt in JSON da usare come input per Veo 3.
Ho portato la logica dell'agente su un GPT per ChatGPT, per chi vuole provarlo.
I tre video che seguono sono stati creati in questo modo (idea > GPT > prompt > Veo 3), utilizzando la versione più performante di Veo 3 (all’interno di Flow) e non quella "fast".
Un Agente AI per ottimizzare i prompt per Veo 3: test
Se qualcuno vorrà provarlo, sarò felice di ricevere feedback per migliorarlo.
Funzionalità Image-to-video
Con la nuova funzionalità image-to-video, inoltre, Veo 3 acquisisce ancora più potenziale.
Ho creato questi video partendo da immagini generate con Imagen 4, e pilotando la scena (e i suoni) attraverso dei prompt testuali strutturati.
Veo 3 image-to-video: un test
L'aderenza alle istruzioni è davvero notevole, come la coerenza con le immagini di partenza.
La Modalità Agente di ChatGPT
OpenAI, con ChatGPT Agent (modalità agente), lancia la risposta a sistemi come Manus, l'Agent Mode di Gemini, Comet di Perplexity, e a tutti i sistemi di automazione del browser e del computer.
Il sistema segna un'evoluzione significativa: un'AI che non solo ragiona, ma agisce in modo autonomo, utilizzando un computer virtuale completo di browser testuale e visuale, terminale, API, strumenti di generazione immagini e connettori per applicazioni come Gmail, Google Calendar, GitHub e altre.
La Modalità Agente di ChatGPT
Può pianificare e completare task complessi — dall’analisi concorrenziale con slide deck, alla pianificazione e prenotazione di eventi, alla creazione di report finanziari aggiornati — scegliendo dinamicamente gli strumenti più adatti e mantenendo il contesto anche su compiti lunghi e multi-step.
Tutto ciò in una modalità conversazionale e collaborativa, dove l’utente può intervenire, correggere, guidare o delegare completamente.
L'agente chiede conferme esplicite prima di azioni sensibili, supporta takeover manuale del browser, invia notifiche al termine dei task e può gestire interruzioni, chiarimenti e modifiche in tempo reale.
Le sue prestazioni stabiliscono nuovi SOTA:
- 44.4% su Humanity’s Last Exam con rollout parallelo;
- 27.4% su FrontierMath con uso di terminale e browser;
- 68.9% su BrowseComp (vs 51.5% deep research);
- 45.5% su SpreadsheetBench (vs 20% Copilot Excel).
Risultati paragonabili o superiori agli analisti junior in benchmark di investment banking.
Il sistema è anche protetto da un robusto stack di sicurezza: controllo delle azioni ad alto rischio, rifiuto di task sensibili, takeover privato del browser, protezioni contro prompt injection e una classificazione “High Capability” per rischi biochimici secondo il "Preparedness Framework".
Rappresenta la prima reale implementazione su larga scala di un sistema agentico unificato e versatile, in grado di svolgere attività di valore economico reale, con autonomia, trasparenza e controllo.
Test della Modalità Agente di ChatGPT
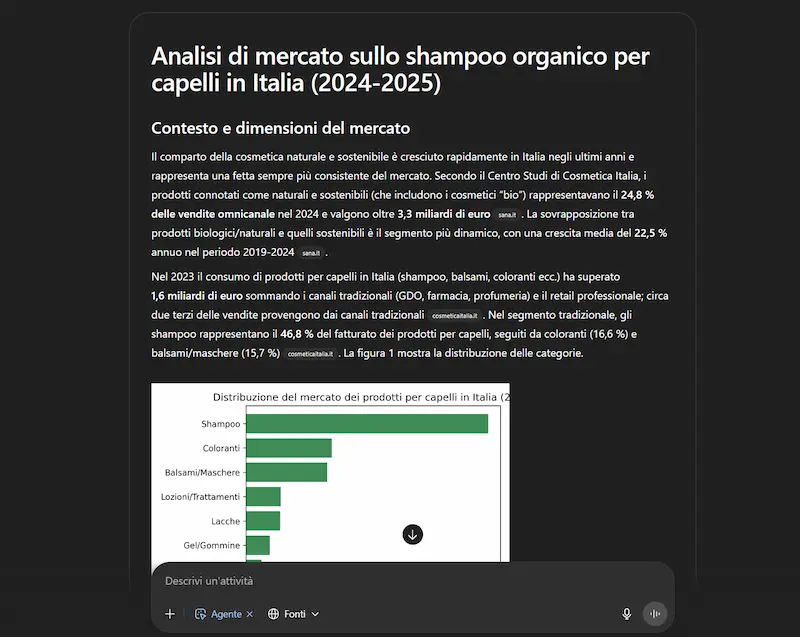
Ho provato la funzionalità su diversi task, ad esempio l'acquisto online, un'analisi di mercato, l'enrichment e l'ottimizzazione di feed per l'e-commerce.
Test dell'Agent Mode di ChatGPT
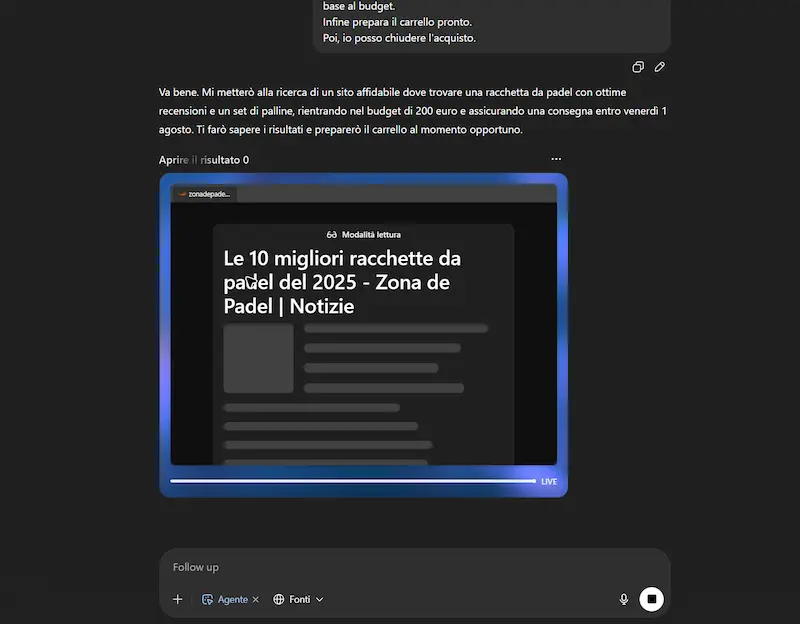
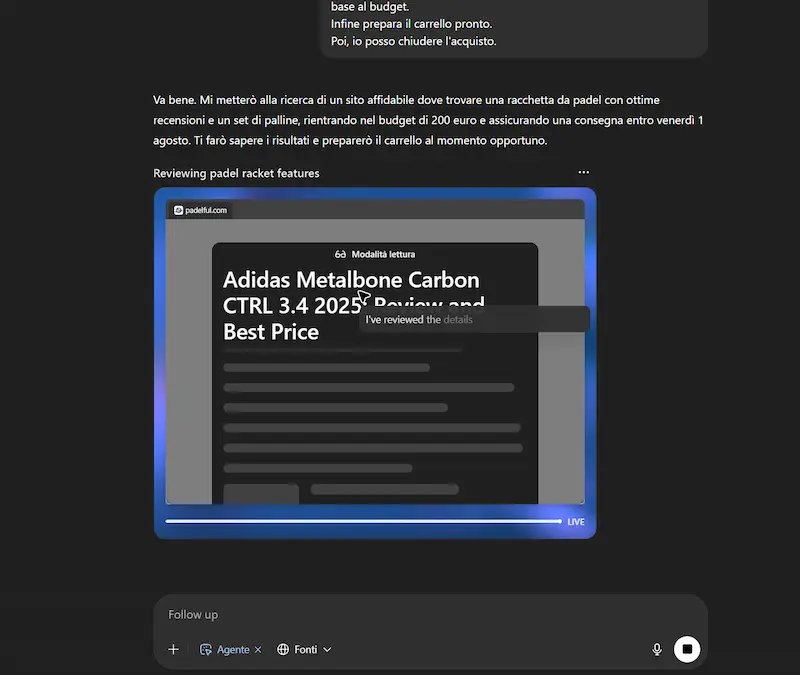
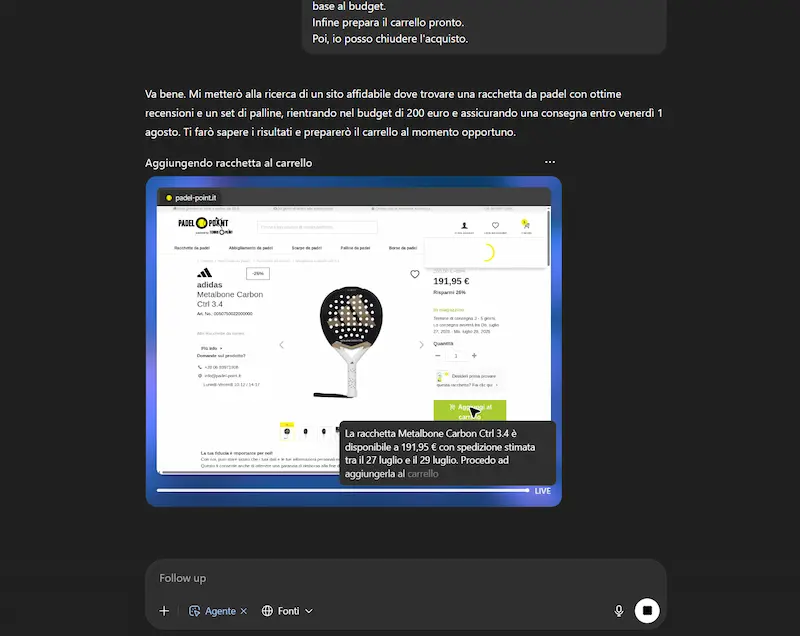
Acquisto online
Ho chiesto al modello di cercare la miglior racchetta da Padel con un determinato budget, e di acquistarla in un sito web affidabile insieme a un set di palline, verificando che il giorno di consegna non superasse una determinata data. L'agente cerca informazioni online, individua il sito web e mette i prodotti nel carrello. Successivamente mi dà la possibilità di fare login e di procedere al pagamento.
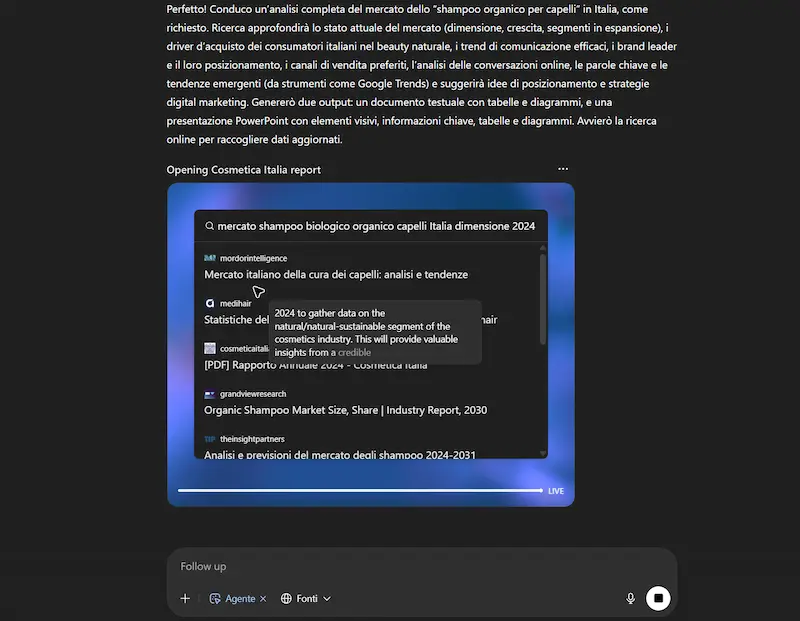
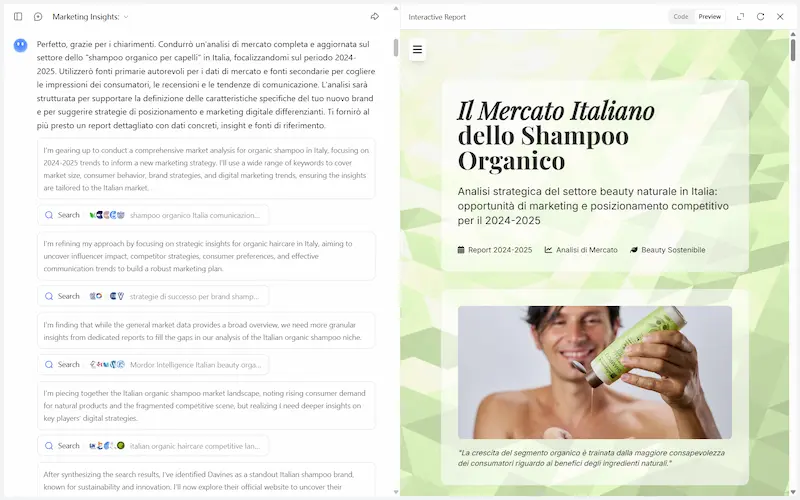
Analisi di mercato
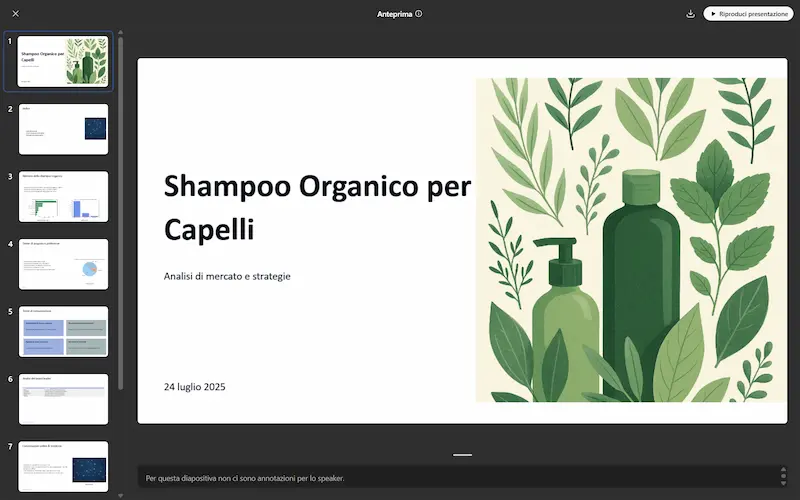
Ho usato un prompt molto articolato per spiegare l'esigenza (le componenti dell'analisi). L'agente cerca informazioni autonomamente, producendo un documento testuale, diagrammi, e una presentazione PowerPoint con gli elementi chiave.
Feed dell'e-commerce
In questo caso, ho caricato un CSV, e per ogni prodotto del file l'agente ha eseguito una serie di operazioni, tra cui l'arricchimento dei dati supportato dalla web search, l'ottimizzazione e la generazione di nuovi testi, ecc.. l'output è stato un nuovo file CSV pronto all'uso.
La funzionalità esegue i task correttamente. Fa qualche errore, ma trova altri modi per arrivare all'obiettivo. Per rilevare le informazioni tende a usare il browser testuale, mentre per le azioni quello visuale.
Un problema non banale? Le automazioni su diversi siti web vengono bloccate. Uno a caso? Amazon!
Chissà se in futuro converrà ancora ad Amazon (e ad altri player) bloccare gli agenti, se sistemi come questo diventeranno una modalità di acquisto diffusa.
Come si muoverà Google con la sua Agent Mode? Con i dati e la capacità di integrazione che ha a disposizione Google, se l'agente funzionerà bene, credo che ci farà dimenticare velocemente quella di ChatGPT.
Kimi K2
Kimi K2 è un nuovo modello open-source sviluppato in Cina da Moonshot AI, e rappresenta uno dei più potenti modelli agentici oggi disponibili.
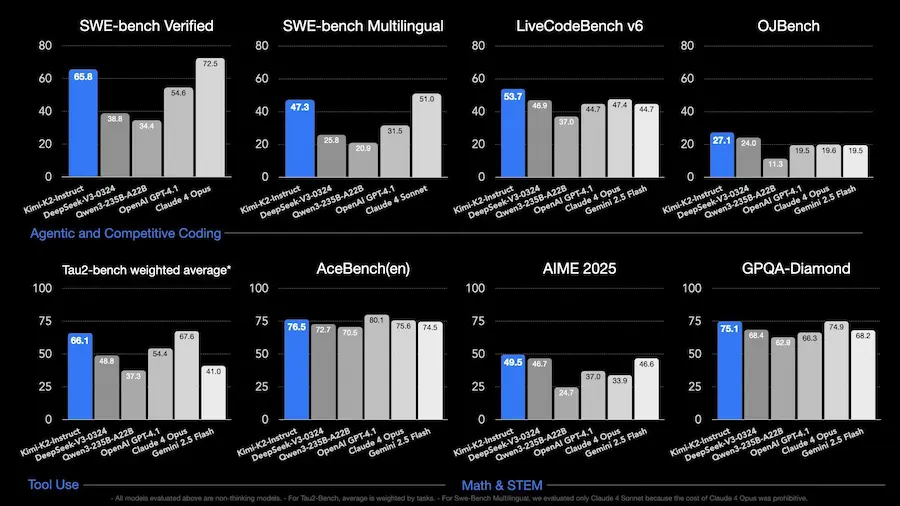
Con 1 trilione di parametri totali e un'architettura Mixture-of-Experts, non si limita a rispondere: esegue compiti complessi sfruttando strumenti, codice e ragionamento.
Rispetto ad altri modelli cinesi come DeepSeek-V3, mostra prestazioni superiori su benchmark chiave: +6.8 punti su LiveCodeBench, +13 su SWE-bench Verified, e +10 su GPQA-Diamond. In molte metriche batte anche modelli proprietari come Claude 4 Sonnet e GPT-4.1, mantenendo al contempo la piena accessibilità del codice.
Kimi K2 segna una svolta per l’open-source in Cina, combinando capacità agentiche reali, ottimizzazione token-efficient e reinforcement learning su larga scala.
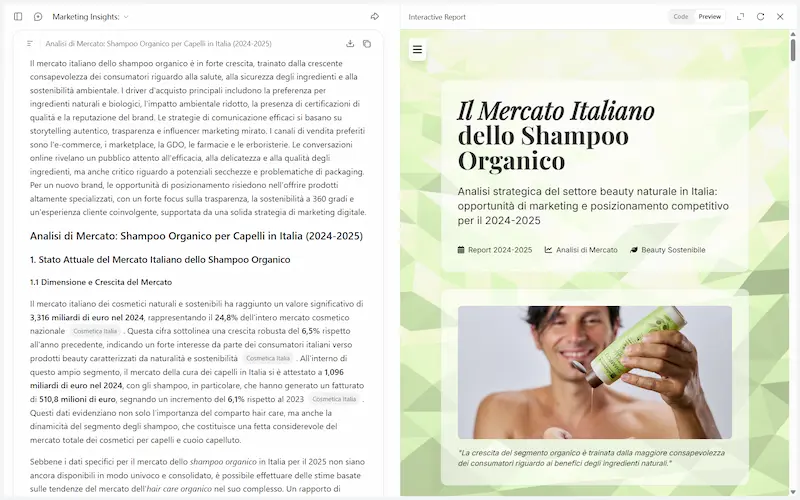
Test con Kimi K2
Ho provato il modello su task di esempio sui quali sto lavorando in diversi progetti.
Non si tratta di processi di ragionamento complessi, ma di prompt con un'elevata quantità di istruzioni, l'uso di tool, e output strutturati.
Sono partito con curiosità, e senza aspettative.. ma devo dire che ho concluso con stupore.





Kimi K2: test
Sui task in cui l'ho provato, non dico che siamo al livello dell'output di Gemini 2.5 Pro, ma di GPT-4o e GPT-4.1 sì.
Il modello rispetta le indicazioni su contesti lunghissimi, comprensivi di web search, e rispetta i formati strutturati: negli esempi si vedono output JSON su cui il modello è stato addestrato.
La Deep Research ha un comportamento molto simile a quello di ChatGPT, e integra una catena di ragionamento molto espansa. Da quello che ho visto, va anche più in profondità rispetto ai competitor, e produce un riepilogo interattivo automaticamente.
Il rapporto tecnico
Moonshot AI ha rilasciato un rapporto tecnico sul modello.
È un progetto innovativo non solo per le sue dimensioni, ma per il modo in cui riformula l’intero processo di addestramento e deployment dei LLM.
Kimi K2 introduce MuonClip, un nuovo ottimizzatore che consente di scalare l’addestramento su oltre 15 trilioni di token senza instabilità, grazie a un meccanismo che evita gli sbalzi numerici tipici nei transformer. In termini più semplici: è stato progettato per “digerire” enormi quantità di testo in modo efficiente e sicuro, evitando errori che spesso bloccano modelli di questa scala. Inoltre, invece di ripetere i dati all’infinito come fanno molti modelli, Kimi adotta un approccio più intelligente: riscrive gli esempi (rephrasing) per estrarne più valore, riducendo la ridondanza e migliorando l’apprendimento.
Un’altra novità chiave è l’intero ecosistema agentico costruito attorno al modello: una pipeline in grado di generare strumenti digitali (oltre 23.000), simulare ambienti interattivi, addestrare agenti con task multi-turn e verificare i risultati con metriche oggettive. Questo consente al modello di imparare non solo a rispondere, ma a "ragionare", pianificare e agire usando strumenti esterni.
Infine, il paper propone un framework di reinforcement learning ibrido: combina ricompense verificabili con un sistema di self-critique che aiuta il modello a confrontare le proprie risposte e imparare da sé.
Un passo avanti verso modelli più autonomi, affidabili e realmente utilizzabili in contesti complessi.
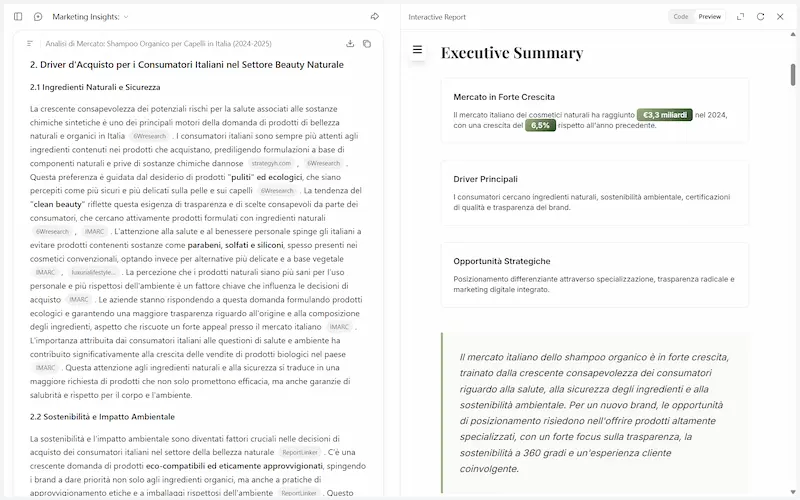
Intelligenza Artificiale: capire il potere, scegliere la direzione
Il mio talk del TEDxBergamo dal titolo "Intelligenza Artificiale: capire il potere, scegliere la direzione" è stato pubblicato.
Intelligenza Artificiale: capire il potere, scegliere la direzione
Ho avuto il privilegio di condividere questa esperienza con un gruppo di persone straordinarie (relatori, organizzatori e volontari) in un'edizione guidata da un tema tanto affascinante quanto attuale: POTERE.
Un concetto che si intreccia in modo indissolubile con la tecnologia che sta ridefinendo il nostro presente e il nostro futuro.
Il vero potere non è nell'intelligenza artificiale, il vero potere è nel saper utilizzare al meglio questa potentissima leva, scegliendo consapevolmente come e dove spostare i massi.
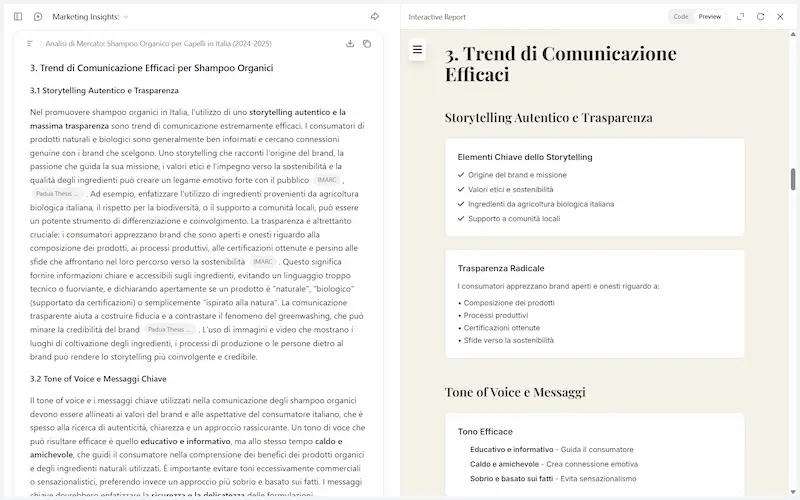
Un'applicazione AI basata su un workflow multi-agente in azione
Il sistema è costruito su un'architettura LangGraph con diversi agenti che si basano sul modello selezionato nelle opzioni.
Un'applicazione AI basata su un workflow multi-agente in azione
In base alla query di ricerca indicata, analizza l'AI Overview estraendo i contenuti dalle fonti e anche dagli altri risultati nella SERP di Google.
Misura la pertinenza semantica delle risposte fornite delle fonti, e, in base ai dati, crea delle risposte più pertinenti in modo iterativo.
Infine, crea un piano d'azione per l'ottimizzazione della pagina di interesse, elaborando i dati a disposizione.
Nell'interazione tra gli agenti (che si vede nella sidebar di sinistra) applico una forma del paradigma ReAct, in cui un agente produce un'analisi e un altro (l'esecutore) applica le indicazioni dell'analisi per ottimizzare la risposta.
Le performance, anche con modelli più piccoli (es. Gemini 2.5 Flash), sono molto interessanti.
Costruire un agente AI? Questione di metodo!
Costruire un agente AI utile non è questione di hype o fantascienza, ma di metodo. In un'epoca in cui tutti parlano di "agentic workflows", il valore emerge solo partendo da problemi reali, obiettivi chiari e un approccio iterativo.
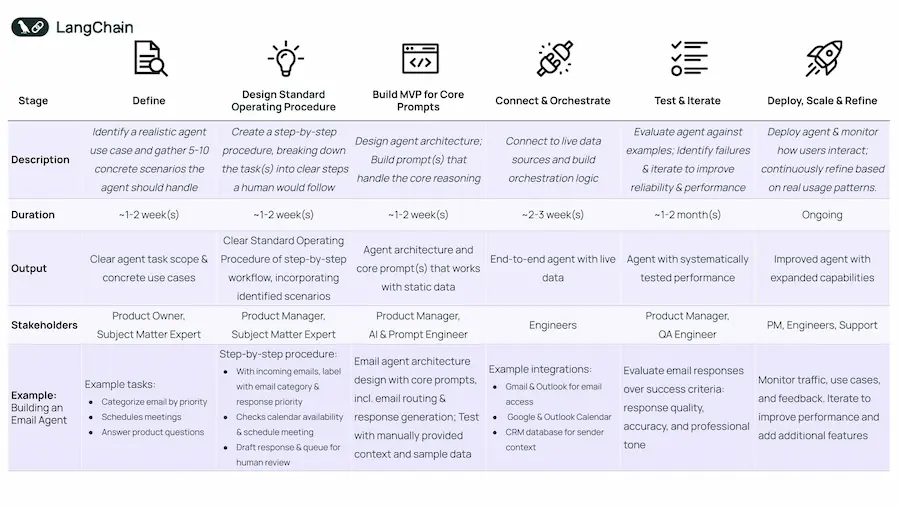
Il primo passo è definire il compito dell’agente, con realismo. Scegliamo un'attività che si spiegherebbe a uno stagista competente. Se non abbiamo 5-10 esempi concreti, l'idea è troppo vaga. Gli agenti non servono per automatizzare ciò che è già gestito da software tradizionali: servono dove ci sono ambiguità, decisioni da prendere, contesto da interpretare.
Poi si scrive una procedura operativa, come se fosse per un umano. Questo aiuta a capire quali decisioni automatizzare e quali strumenti servono. Se non sappiamo come farebbe una persona, sarà difficile automatizzarlo bene.
Solo dopo si costruisce il primo MVP, limitato al cuore: il prompt. Si testa se il modello riesce a svolgere un compito cognitivo, tipo classificare un'email. Il resto è ancora manuale. Se il modello non ragiona bene in piccolo, non ha senso costruire il resto.
Quando il "cuore" funziona, si passa alla connessione con dati reali (API, calendari, email…). L’orchestrazione trasforma il ragionamento statico in un sistema dinamico e adattivo.
Poi si testa e si itera: prima manualmente, poi in modo automatizzato, con metriche (accuratezza, tono, rilevanza, uso degli strumenti). I test rivelano punti forti e limiti, e guidano i miglioramenti.
Solo quando l’agente è affidabile si rilascia in produzione. Ma il deployment è solo l’inizio: gli utenti lo useranno in modi imprevisti, e il feedback sarà chiave per evolverlo. Tracciare il comportamento è essenziale.
Messaggio chiave: un agente ben fatto non è un esperimento, ma un prodotto. Serve disciplina, chiarezza, ascolto e iterazione continua. Solo così si passa dalla teoria all’impatto.

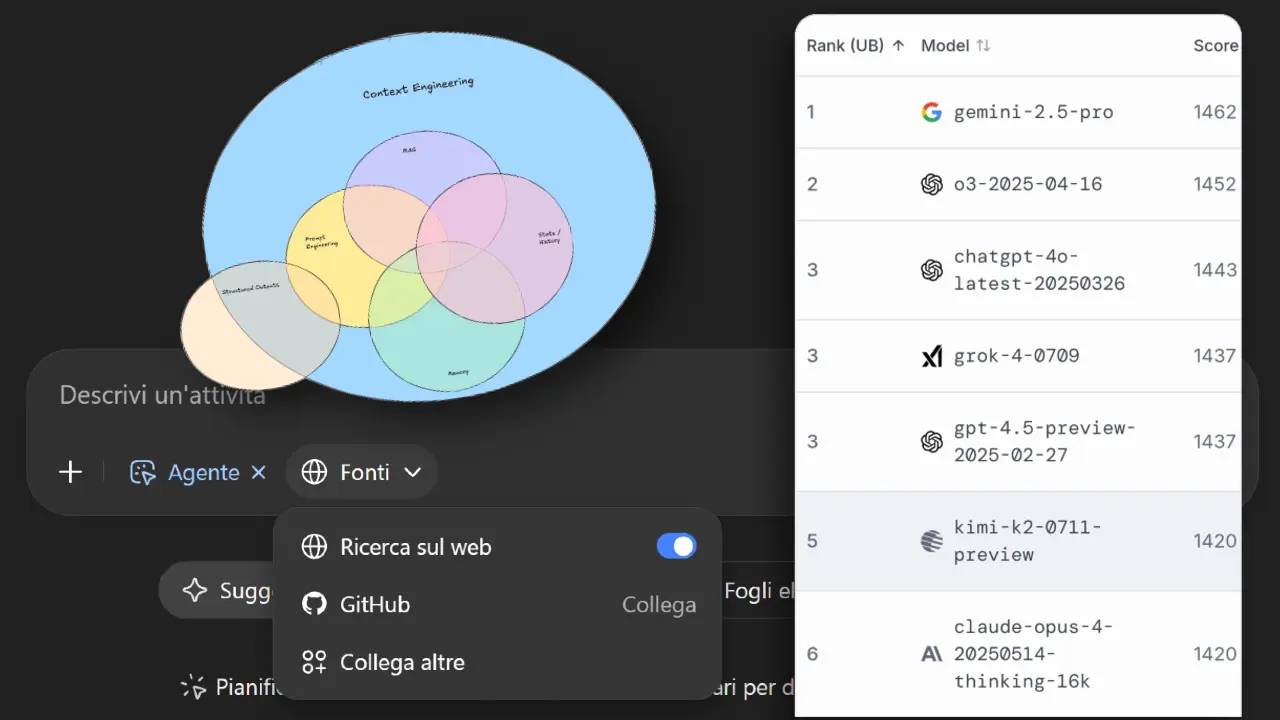
Context Engineering
"Context Engineering" è un buon termine, ma (oggi) non è ancora sufficiente.
Dal 2023, nelle lezioni che tengo, ho una slide molto simile all'immagine del post di LangChain, che fa capire che la struttura del prompt è solo una parte delle applicazioni basate su modelli AI.
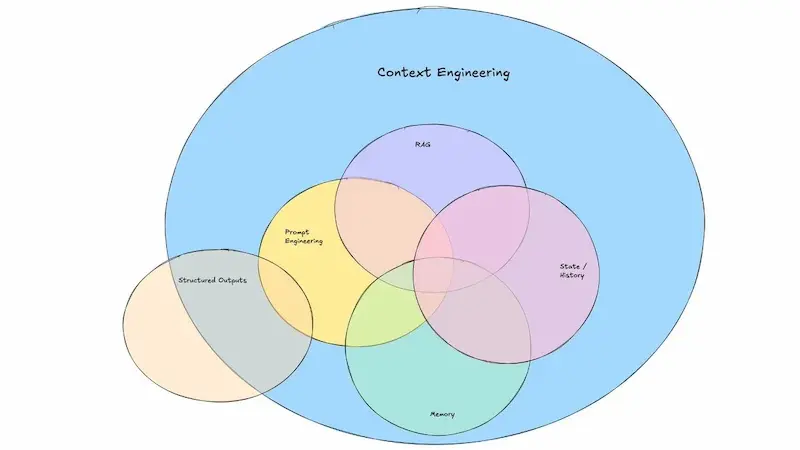
È la costruzione del contesto la vera chiave di un agente efficace. E quindi comprende lo studio dei dati e delle informazioni necessari, la loro estrazione, come farli gestire al modello.
Contesto significa anche efficienza: riutilizzare piani precedenti tramite vector store, evitare rumore informativo e ottimizzare i costi. Il contesto giusto fa la differenza tra una risposta approssimativa e una soluzione intelligente.
Tutto questo basta per creare un buon agente, ma per un'applicazione mancano altri dettagli.
Come avviene l'interazione tra i diversi agenti? Sequenziale? Orchestrata? Quale framework è meglio usare? Basato su scambi conversazionali o stateful?
Insomma.. per creare buoni agenti, non bastano buoni prompt, servono anche contesti perfetti, e un'interazione ben studiata tra i diversi "attori" in gioco.
Prompt Design: l'importanza delle istruzioni precise
Meta e OpenAI hanno pubblicato nello stesso giorno una guida per la migrazione dei prompt per i rispettivi modelli.
Due librerie Python che permettono di inserire il prompt di partenza e di ottenere quello ottimizzato per i modelli GPT e Llama.


Guide per la migrazione dei prompt
Mi ha colpito una frase della documentazione di OpenAI:
"as model gets smarter, there is a consistent need to adapt prompts that were originally tailored to earlier models' limitations, ensuring they remain effective and clear for newer generations".
In pratica, mentre prima si costruivano istruzioni iper precise e dettagliate a causa delle scarse performance dei modelli, ora, al contrario, invitano a farlo vista l'elevata capacità di comprensione degli input dei modelli attuali.
Google: dalla ricerca a una "Deep Search"
La Deep Research direttamente sulla pagina di ricerca di Google?
Come ho detto al Search Marketing Connect l'anno scorso, andiamo verso ricerche basate su interazioni agentiche.
Google Search si evolve con nuove funzionalità AI basate sui modelli Gemini 2.5 Pro. Gli abbonati a Google AI Pro e Ultra possono ora accedere a Deep Search, uno strumento avanzato che esegue centinaia di ricerche per generare report dettagliati e con fonti in pochi minuti. Perfetto per chi deve affrontare analisi complesse.
Google: dalla ricerca a una Deep Search
Inoltre, arriva la possibilità di chiamare le attività locali tramite AI: basta una ricerca per far sì che Google contatti direttamente negozi o servizi per verificare prezzi e disponibilità, il tutto senza sollevare la cornetta.
Un passo avanti verso un'esperienza sempre più efficiente e automatizzata.
Web Guide di Google
Google ha presentato Web Guide, un nuovo esperimento dei Search Labs che punta a migliorare l’esperienza di ricerca online grazie all'AI.
Utilizzando una versione personalizzata del modello Gemini, Web Guide organizza i risultati della ricerca in gruppi tematici, aiutando gli utenti a orientarsi meglio tra le informazioni disponibili sul web.
Web Guide di Google
L'ho provato, e, in effetti si nota come cambia la configurazione della SERP.
Questo approccio è particolarmente utile per ricerche aperte o complesse, dove trovare contenuti pertinenti può essere più difficile. Web Guide applica una tecnica chiamata query "fan-out", che genera più ricerche correlate in parallelo, permettendo di identificare i risultati più rilevanti e approfonditi.
Attualmente disponibile nella scheda "Web" per chi ha attivato i Search Labs, rappresenta un primo passo verso un’interazione più strutturata e intelligente con la rete.
Grok 4: il nuovo modello di xAI
xAI qualche giorno fa ha presentato la nuova versione di Grok, che sembra già il modello più potente sul mercato.
Performance da capogiro: Grok 4 non si è limitato a migliorare, ha letteralmente sbaragliato la concorrenza su benchmark estremamente difficili. Ha affrontato "Humanity's Last Exam", un test con domande a livello di dottorato, e ha superato tutti i modelli rivali (inclusi Claude e Gemini). La versione Grok 4 Heavy ha addirittura raggiunto il 50.7%, quasi il doppio del secondo classificato.
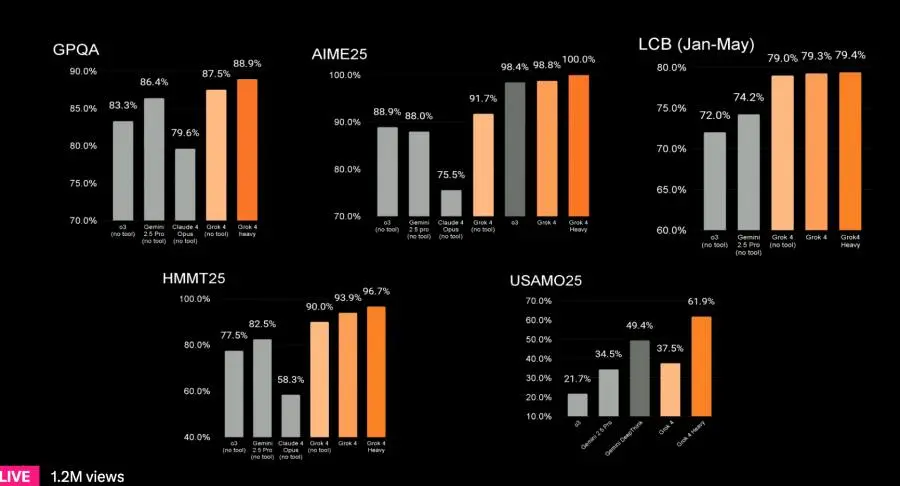
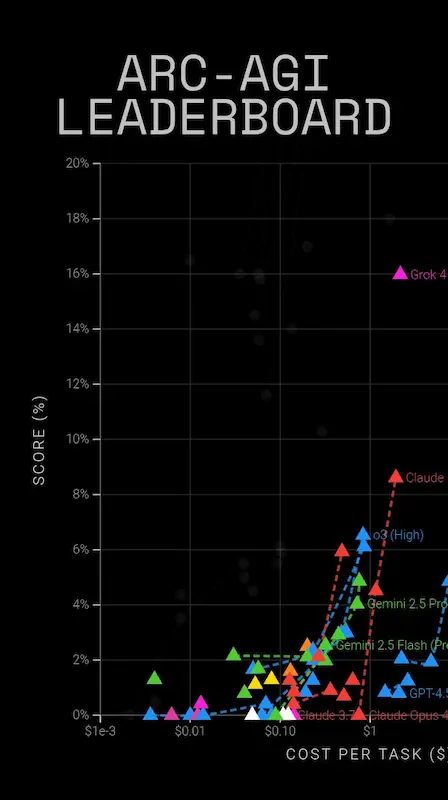
Le performance di Grok 4: il nuovo modello di xAI
La chiave del miglioramento continua ad essere nella scala: xAI non ha svelato i dettagli interni del modello, ma ha chiarito che il salto qualitativo arriva da una scala di calcolo senza precedenti. Il compute usato per l’addestramento è aumentato di 10x rispetto a Grok 3 (e 100x rispetto a Grok 2). L'hardware usato? Oltre 100.000 GPU NVIDIA H100, e in futuro oltre 100.000 GPU GB200.
Ragionamento come superpotere: il punto di forza è il "reasoning", definito dal team "sovrumano". xAI ha dedicato 10x più calcolo al Reinforcement Learning rispetto a Grok 3, affinando il modello per correggere i propri errori e ragionare dai principi primi. La modalità Grok 4 Heavy non è una versione più grande, ma un’inferenza “collaborativa”: più agenti lavorano sullo stesso problema, confrontano le risposte e decidono insieme quella più solida. Una sorta di gruppo di studio AI.
Introducing Grok 4, the world's most powerful AI model. Watch the livestream now: https://t.co/59iDX5s2ck
— xAI (@xai) July 10, 2025
In test pratici come "Vending-Bench", Grok 4 ha elaborato strategie di business migliori di quelle umane, mantenendo coerenza a lungo termine.
Nei diagrammi precedenti, si vede come il modello domina il benchmark ARC-AGI 2, superando (di molto) o3, Gemini 2.5 Pro e Claude.
Aspettiamoci discussioni sui benchmark e sul possibile overfitting (dati falsati da training sui benchmark) nelle prossime settimane, ma la direzione è chiara: capacità e architetture in crescita rapida, costi in calo.
Nel frattempo, anche OpenAI prepara il lancio di GPT-5.
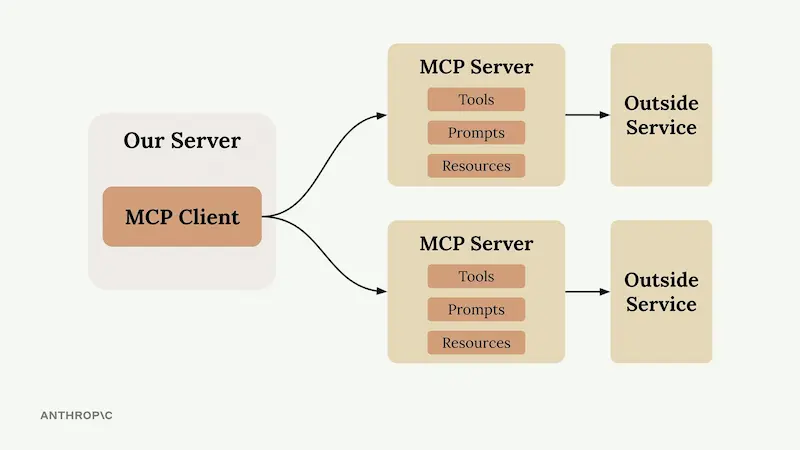
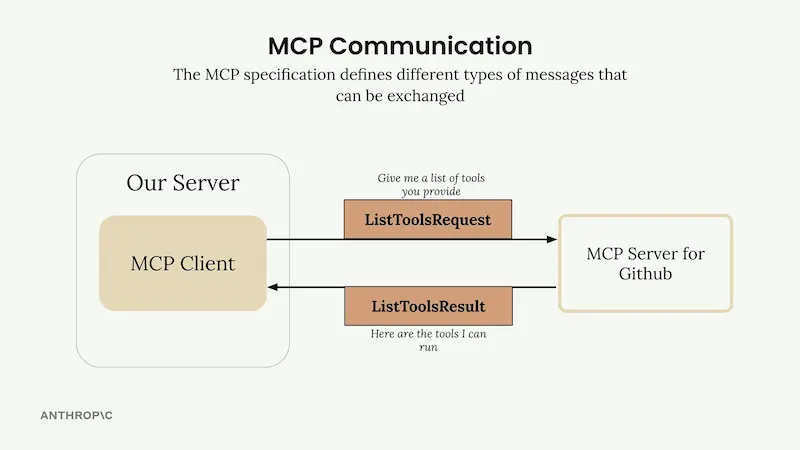
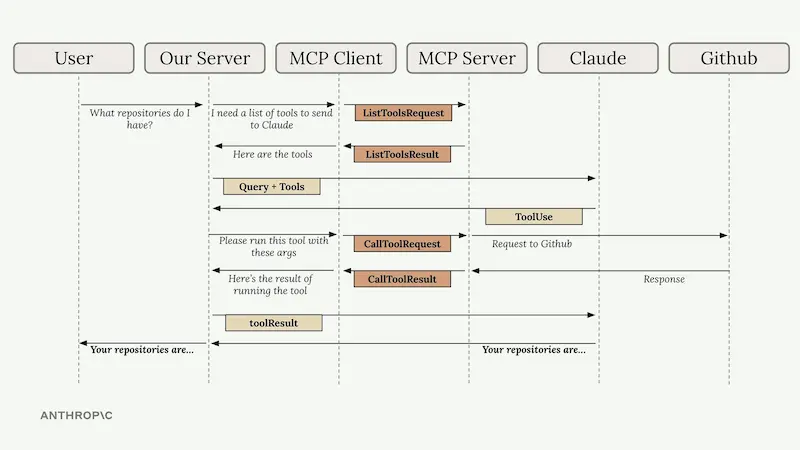
Chrome MCP Server
Chrome MCP Server è un'estensione per Chrome che trasforma il browser in un assistente AI avanzato.
È basato su Model Context Protocol (MCP), e consente ai LLM come Claude di controllare direttamente il browser per automatizzare attività complesse, analizzare contenuti e gestire la navigazione in modo intelligente.
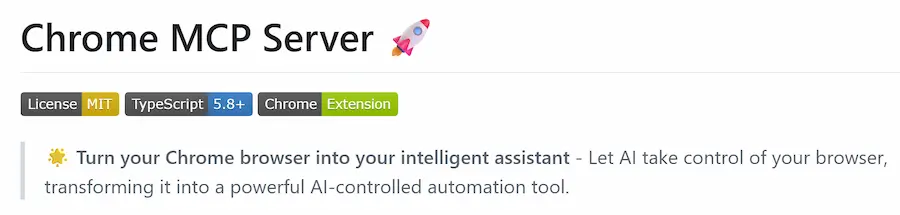
A differenza degli strumenti tradizionali come Playwright, Chrome MCP Server lavora direttamente con l'ambiente reale: utilizza le sessioni di login, configurazioni, segnalibri e cronologia, garantendo allo stesso tempo piena operatività in locale per la massima privacy.
Con oltre 20 strumenti integrati, offre funzionalità come screenshot intelligenti, analisi semantica, gestione della cronologia e interazione automatica con le pagine web. Include anche un database vettoriale interno per ricerche contestuali tra le tab del browser.
Il server MCP di Shopify
Un esempio interessante di server MCP (Model Context Protocol) remoto: Shopify.
Nelle Responses API di OpenAI la connessione è realizzabile semplicemente incollando il link del server MCP nel campo del connettore.
Server MCP di Shopify su un agent OpenAI
Si crea così un agent connesso al server MCP di Storefront che può cercare prodotti, aggiungere articoli al carrello, creare un link di pagamento, ecc..
L'agente rimane personalizzabile attraverso il system prompt e l'accesso ad altre fonti esterne o altri server MCP.
E se il server, in futuro introdurrà nuove funzionalità, la configurazione non cambierà, e l'agent potrà sfruttarle immediatamente.
I corsi gratuiti di Anthropic
Anthropic ha rilasciato una sezione dedicata ai corsi: una piattaforma didattica gratuita per approfondire l'uso di Claude, dall'API Anthropic a MCP fino alle best practice di Claude Code.

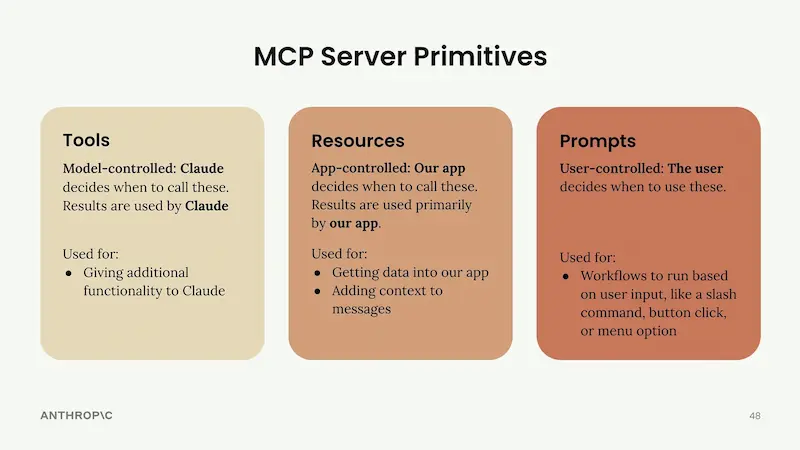
I corsi di Anthropic
I corsi includono lezioni, quiz finali e certificati. Ogni corso affronta casi di utilizzo reali e dettagli pratici di implementazione, ed è stato realizzato con il contributo degli sviluppatori che già utilizzano Claude in produzione.
Ho fatto il corso e l'esame su MCP (Model Context Protocol). Le lezioni sono fatte benissimo, chiare, con esempi utili e slide ben organizzate.

Si tratta di una risorsa estremamente utile per chi vuole approfondire lo sviluppo di applicazioni basate su LLM.
Featured Notebooks di NotebookLM
NotebookLM si arricchisce con i nuovi Featured Notebooks: notebook tematici curati da esperti e istituzioni come The Economist, The Atlantic, Our World in Data e altri.
Dalla scienza alla letteratura, dalla finanza alla genitorialità, ogni notebook è una raccolta approfondita di contenuti esplorabili grazie all'intelligenza artificiale.
Featured Notebooks di NotebookLM
È possibile leggere le fonti originali, porre domande, ascoltare panoramiche audio e navigare concetti con mappe mentali.
Oltre 140.000 notebook pubblici sono già stati condivisi dalla community: una nuova forma di apprendimento collaborativo e dinamico prende forma.
Act-Two di Runway
Dopo Act-One, Runway presenta Act-Two.
Il sistema consente di creare scene altamente espressive, interamente guidate dalle sfumature interpretative degli attori. Il ritmo, la recitazione, il linguaggio del corpo e le espressioni più sottili vengono fedelmente trasferiti dalle performance originali ai personaggi generati.
Act-Two allows you to create highly expressive scenes entirely driven by the nuanced performances of your actors. The timing, delivery, body language and subtle expressions are all faithfully transposed from your driving performances to your generated characters.
— Runway (@runwayml) July 16, 2025
Learn more… pic.twitter.com/IAY8iZtfIK
La serie "Act" di Runway permette di creare video con personaggi espressivi utilizzando un singolo video di guida e un'immagine del personaggio.
Aleph: una svolta nell'editing video
Runway, inoltre, ha presentato Aleph, un nuovo modello video “in-context” che segna un punto di svolta nell’editing e nella generazione visiva.
Aleph di Runway
Consente di intervenire su un video in modo fluido e intuitivo: è possibile aggiungere, rimuovere o trasformare oggetti, generare nuove angolazioni di una scena, e modificare lo stile o l’illuminazione con un livello di controllo mai visto prima.
Pensato per soddisfare le esigenze di creativi e professionisti, questo modello multi-task apre nuove possibilità per raccontare storie visive in modo dinamico, preciso e completamente personalizzabile.
Gemini Embedding
Il nuovo modello Gemini Embedding (gemini-embedding-001) è ora disponibile pubblicamente tramite l’API Gemini e Vertex AI.

Con prestazioni da leader nella classifica MTEB Multilingual, questo modello supporta oltre 100 lingue, una lunghezza massima di 2048 token, ed è ottimizzato con la tecnica Matryoshka Representation Learning (MRL) per output flessibili da 768 a 3072 dimensioni.
Pensato per compiti avanzati come retrieval, classificazione e embedding cross-domain (scienza, finanza, legge, codice), può essere usato da subito con l’endpoint "embed_content". Disponibile in versione gratuita e a pagamento, a partire da 0.15 dollari per milione di token in input.
I modelli legacy verranno dismessi tra agosto 2025 e gennaio 2026.
La segmentazione delle immagini di Gemini
L'AI di Google fa un salto evolutivo con Gemini 2.5: ora è possibile segmentare immagini tramite linguaggio naturale, andando oltre le classiche etichette predefinite.
Nelle immagini si vedono alcuni test che ho fatto su AI Studio.
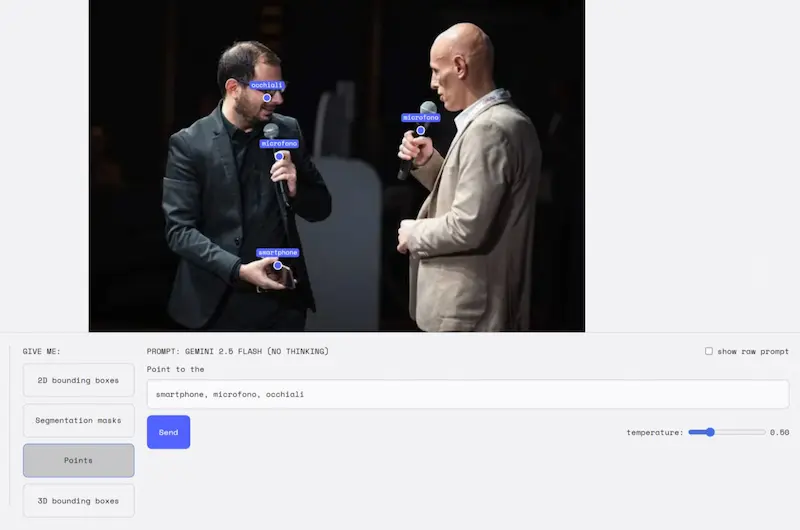
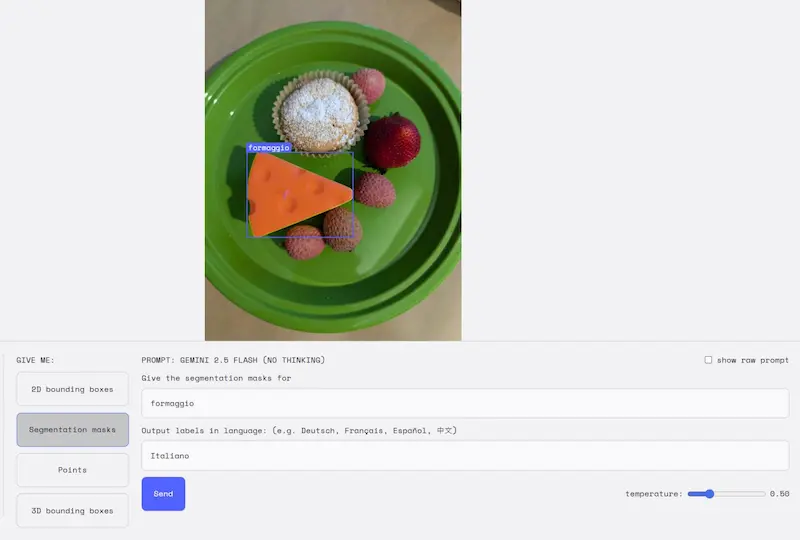
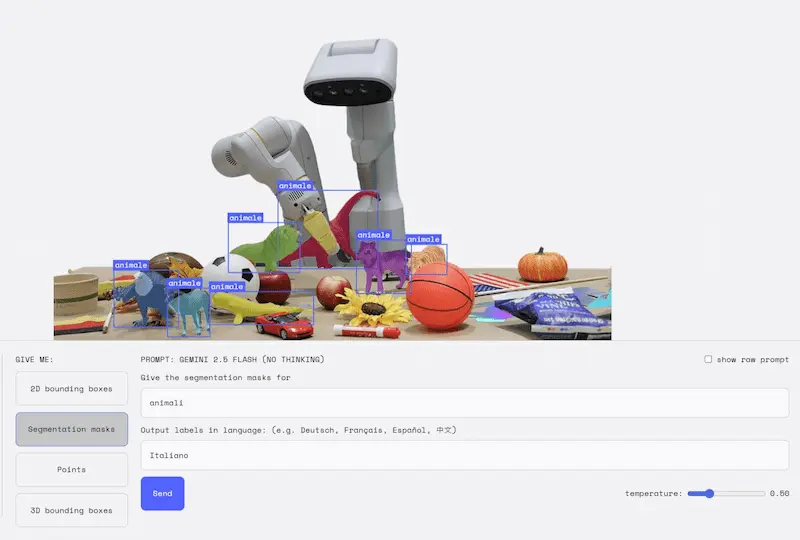
La segmentazione delle immagini di Gemini
Basta descrivere ciò che si vuole individuare, anche con frasi complesse, concetti astratti o condizioni logiche. Il modello riconosce relazioni tra oggetti (“la persona che tiene l’ombrello”), situazioni (“chi non indossa un casco”) o anche danni (“case colpite dal maltempo”), ed è capace di leggere il testo all’interno delle immagini.
Tutto questo funziona in più lingue e si integra facilmente via API. Un approccio rivoluzionario per la visione artificiale, con applicazioni che spaziano dalla creatività al monitoraggio industriale.
Gemma 3n in locale su uno smartphone
Gemma 3n di Google in azione su task multimodali in locale sul mio smartphone.
Negli esempi si vede come il modello interpreta il contenuto delle immagini, estraendo le informazioni richieste.
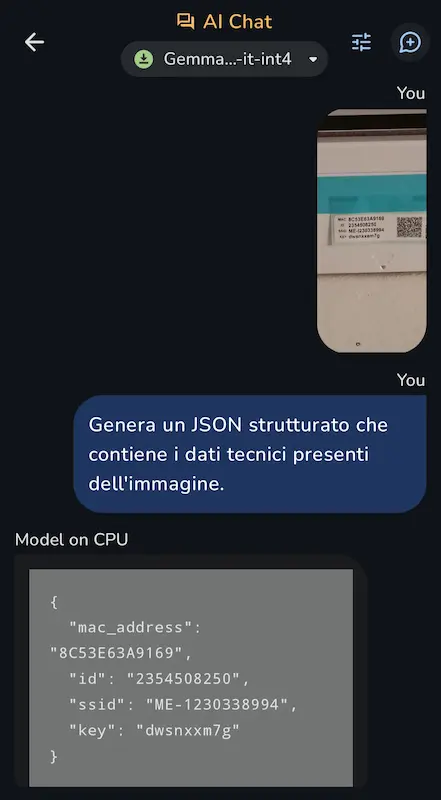

Gemma 3n in locale su uno smartphone
Sembra una banalità, ma l'aspetto straordinario è che il LLM sta funzionando in locale su un dispositivo con un hardware limitatissimo.
L'evoluzione della chat di Mistral
Mistral AI evolve la sua chat con nuove funzionalità pensate per potenziare produttività, creatività e ricerca.
La modalità Deep Research trasforma l’assistente in un vero ricercatore virtuale: analizza, struttura e sintetizza fonti affidabili per rispondere anche alle domande più complesse. L'ho provato nella versione free. Il sistema fa molto bene il suo lavoro, ma ormai la concorrenza su questo task è altissima.


La Deep Research di Mistral: un test
Con il nuovo modello vocale Voxtral, parlare con "Le Chat" diventa naturale e istantaneo, mentre il modello Magistral potenzia il ragionamento multilingua, permettendo risposte articolate anche cambiando lingua a metà frase.
Arrivano anche i "Progetti", spazi organizzati che memorizzano conversazioni, file e strumenti per una gestione del lavoro più ordinata. Infine, l’editing avanzato delle immagini consente modifiche dettagliate e coerenti con semplici comandi in linguaggio naturale.
Una suite sempre più completa per chi lavora, crea o esplora, ma che si scontra con agenti (anche open source) sempre più performanti.
Transformer / Mixture of Experts (MoE)
Qual è la differenza tra un Transformer standard e un modello Mixture of Experts (MoE)?
Entrambi sono usati per compiti come la generazione di testo, la traduzione automatica o la comprensione del linguaggio. Ma il modo in cui elaborano le informazioni è molto diverso.
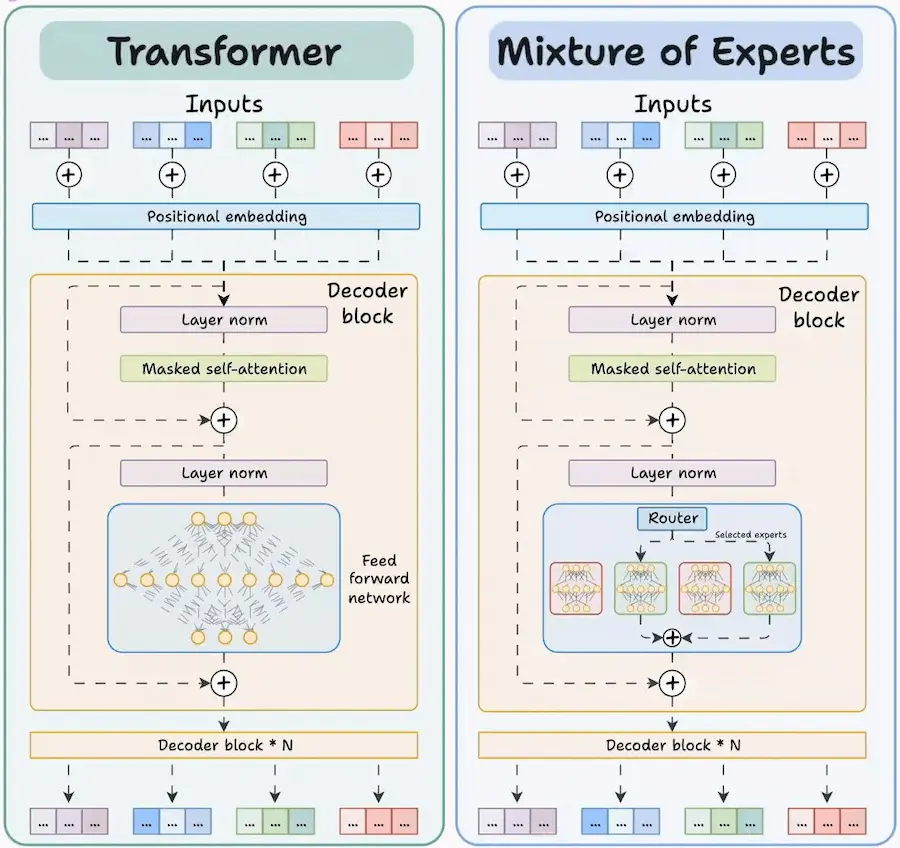
Transformer standard
Ogni parola (token) viene elaborata attraverso un'unica grande rete neurale, chiamata feed-forward network. È come avere un solo medico esperto che deve occuparsi di ogni paziente, indipendentemente dal problema. Funziona, ma richiede molta potenza computazionale.
Mixture of Experts (MoE)
Introduce un "Router", un componente che decide quali tra i tanti "esperti" (reti neurali specializzate) devono occuparsi di ciascun token. Solo uno o due esperti vengono attivati per ogni input. È come avere un receptionist che smista ogni paziente allo specialista più adatto: cardiologo, ortopedico, neurologo, ecc..
Questo approccio rende il modello molto più efficiente: si può aumentare il numero totale di parametri (quindi la conoscenza globale del modello) senza far crescere in proporzione il costo di elaborazione per ogni singolo input.
I modelli all'avanguardia adottano proprio l'architettura MoE per combinare potenza e scalabilità.
La modalità Batch per l’API Gemini
Anche Google ha lanciato la Modalità Batch per l’API Gemini, pensata per gestire in modo efficiente carichi di lavoro AI su larga scala, quando non è necessaria una risposta in tempo reale.
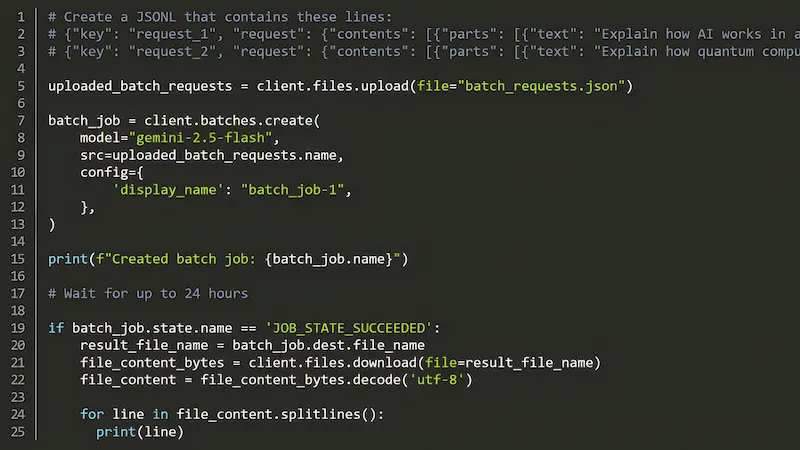
Questa modalità asincrona consente di inviare grandi volumi di richieste in un unico file, demandare la gestione del job a Google e ricevere i risultati entro 24 ore. Il tutto con un costo ridotto del 50% rispetto alle API sincrone.
È la soluzione ideale per attività come la generazione di contenuti, l’analisi di dati, o la valutazione di modelli: tutti quei casi in cui i dati sono pronti in anticipo e si punta a massimizzare efficienza e risparmio.
In più, la modalità batch offre un throughput superiore e semplifica il codice lato client, eliminando la necessità di gestire code o logiche di retry.
Un approccio semplice, potente e scalabile per portare l’AI a un nuovo livello di produttività. Nei miei test ho trovato un bug nell'uso di questo sistema unito alla web search (un riferimento).
PhysX-3D: un nuovo paradigma per la generazione di 3D
PhysX-3D introduce un nuovo paradigma nella generazione di asset 3D, dove l’aspetto visivo degli oggetti è accompagnato da una modellazione fisica realistica e strutturata. A differenza dei modelli tradizionali che si concentrano su geometrie e texture, PhysX-3D integra conoscenze fisiche fondamentali per rendere gli oggetti utilizzabili in contesti concreti come la simulazione, la robotica e l’AI incarnata.
PhysX-3D: un nuovo paradigma per la generazione di 3D
Al centro del progetto ci sono due componenti chiave. PhysXNet è il primo dataset 3D annotato con proprietà fisiche dettagliate — tra cui scala assoluta, materiali, funzioni, cinematiche e affordance — costruito attraverso un processo di annotazione automatizzato e validato con intervento umano. PhysXGen, invece, è un framework generativo che partendo da immagini produce asset 3D fisicamente plausibili, mantenendo alta la qualità geometrica e integrando le proprietà fisiche in fase di generazione.
Questo approccio permette di creare oggetti che non solo appaiono credibili, ma che rispondono in modo coerente all’ambiente simulato, ponendo le basi per una nuova generazione di AI fisicamente consapevoli.
Code of Practice per i modelli di AI generali
È stato pubblicato il Code of Practice per i modelli di AI generali (GPAI), un documento volontario sviluppato da esperti indipendenti con il contributo di oltre 1.400 soggetti da industria, università, società civile e Stati membri UE.


Code of Practice per i modelli di AI generali (GPAI)
Il Codice aiuta i fornitori di modelli AI a dimostrare la conformità agli obblighi dell’AI Act, senza introdurre nuovi vincoli.
È diviso in tre capitoli:
- Trasparenza, con un modello documentale standard;
- Copyright, con misure per rispettare i diritti d’autore e le riserve machine-readable;
- Sicurezza, pensato solo per i modelli con rischio sistemico, cioè quelli più avanzati e ad alto impatto secondo l’AI Act.
Tra i vantaggi:
- maggiore chiarezza su cosa fare per essere conformi;
- riduzione del carico amministrativo grazie a un percorso unico e condiviso;
- rafforzamento della fiducia e del dialogo tra sviluppatori, utenti, autorità e società civile;
- maggiore prevedibilità normativa, soprattutto in vista dell’entrata in vigore degli obblighi a partire dal 2 agosto 2025.
Ci sono però anche dei limiti:
- è uno strumento non vincolante, che richiede adesione volontaria;
- alcune misure richiedono un forte investimento tecnico e organizzativo;
- resta la necessità di chiarimenti su concetti ancora ambigui come “sistemico” o “accettabilità del rischio”.
Non è rivolto solo agli sviluppatori: anche le aziende che usano modelli GPAI (ad esempio integrandoli in prodotti, servizi o processi decisionali) dipendono da questo Codice per accedere alle informazioni tecniche e legali necessarie. In alcuni casi, diventano esse stesse soggetti agli obblighi dell’AI Act.
Un passo concreto per favorire l’innovazione responsabile e la cooperazione tra tutti gli attori dell’ecosistema AI europeo.
La web search su agenti AI dotati di modelli con "reasoning"
Qual è la differenza tra usare la Web Search in agenti dotati di "reasoning" e non?
Ad esempio usando GPT-4.1 oppure #o3.
È un concetto totalmente diverso.
- Su modelli come GPT-4.1 il sistema usa la ricerca seguendo lo schema: ricerca → ragiona → risponde.
- Su modelli con "reasoning" (come o3), il sistema adotta una strategia di ricerca multi‑step e iterativa, ovvero usa la ricerca in base alla catena di ragionamento, quando gli serve, per verificare informazioni e/o espanderle, in base alle istruzioni.
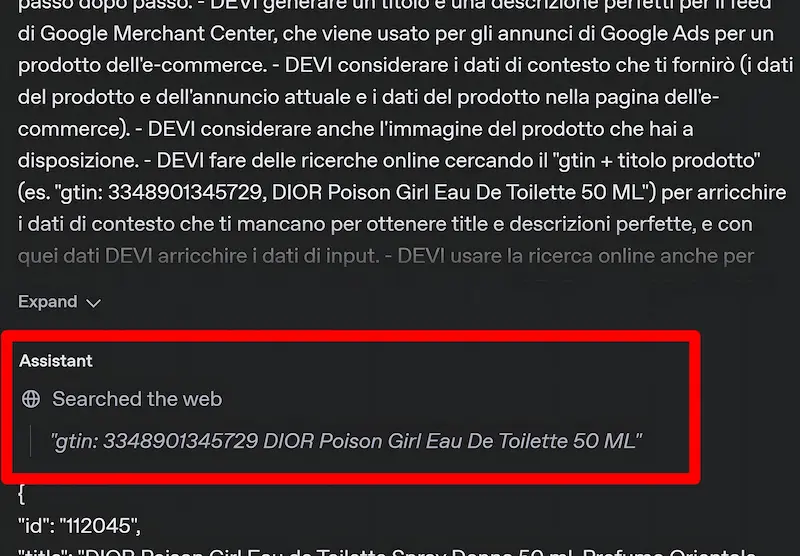
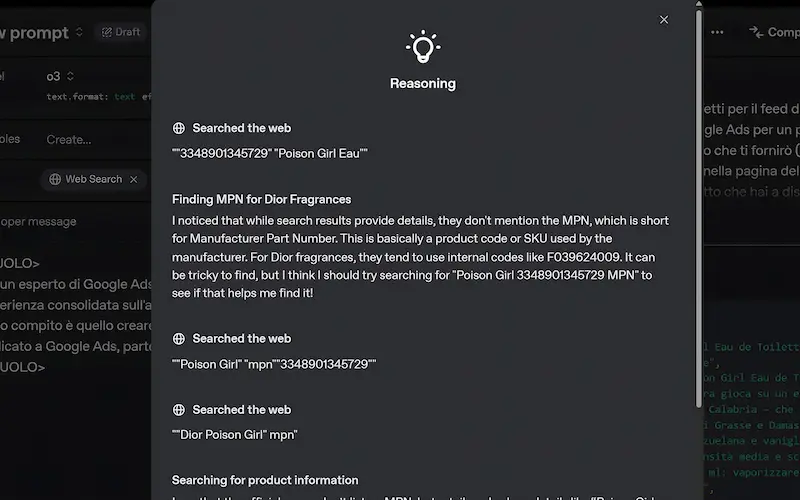
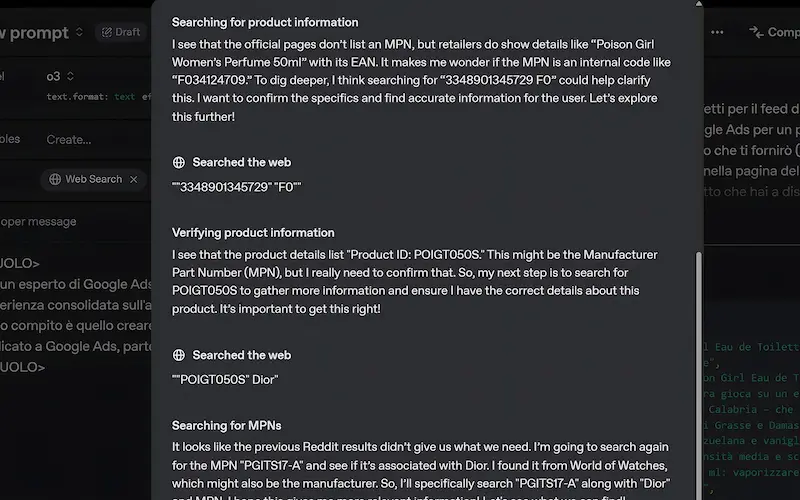
Le performance del flusso con reasoning crescono notevolmente, ma crescono notevolmente anche i costi. Aumentano vertiginosamente i token consumati, e le web search hanno un costo unitario.
google-colab-ai: una nuova libreria nativa
Google Colab ha una nuova libreria nativa dedicata all'AI: google-colab-ai.
Non serve setup, né l'API KEY di Gemini, e permette di usare i modelli a disposizione (nell'immagine) con qualche riga di Python e i prompt per interagire.
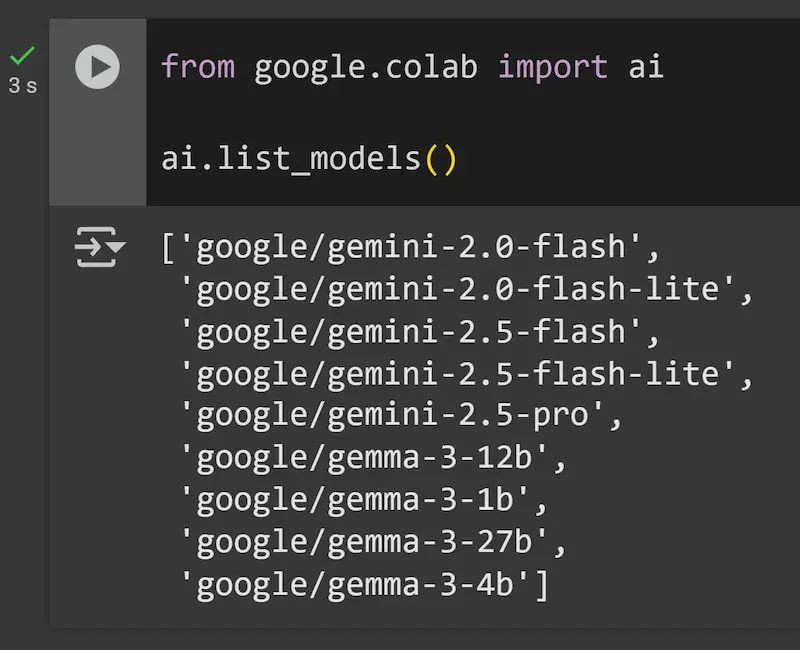
La prototipazione di applicazioni e script diventa sempre più semplice.
La funzionalità è attiva per gli utenti Pro e Pro+.
Il futuro dell'AI agentica è small?
Secondo NVIDIA Research, gli Small Language Models (SLMs) offrono una combinazione vincente: potenza sufficiente, maggiore efficienza operativa e costi drasticamente inferiori rispetto ai Large Language Models (LLMs).

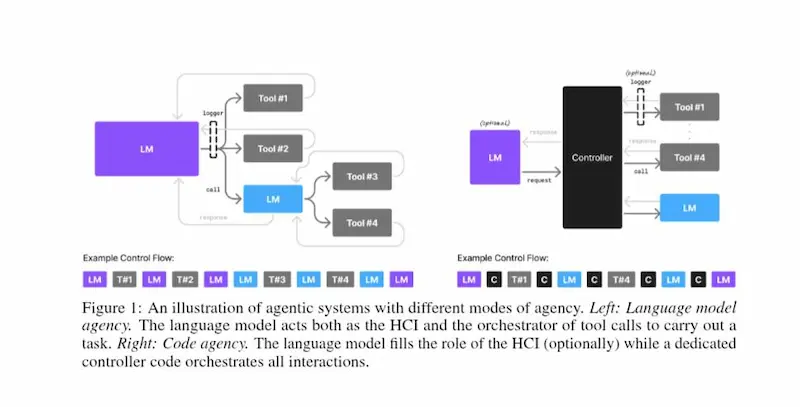
Small Language Models are the Future of Agentic AI
- I task degli agenti sono spesso ripetitivi, focalizzati e non conversazionali: per questo, gli SLM sono più adatti.
- Sono fino a 30 volte più efficienti in termini di latenza, energia e costi.
- Possono essere facilmente fine-tuned e distribuiti su dispositivi locali.
- Consentono architetture modulari e sistemi eterogenei con più modelli specializzati.
- Abilitano un’AI più accessibile, adattabile e sostenibile.
Studi su agenti reali (MetaGPT, Open Operator, Cradle) mostrano che tra il 40% e il 70% delle chiamate a LLM potrebbero essere sostituite da SLM specializzati senza sacrificare la qualità.
Sono d'accordo con lo studio: chiunque abbia fatto dei test può confermare la tesi del paper. Tuttavia, in alcuni processi che ho visto in azione, il rapporto benefici/costi è talmente alto che spesso la ricerca di efficienza in questa direzione non è ancora giustificabile.
NotebookLlama: un NotebookLM open-source
NotebookLlama è un'alternativa open-source a NotebookLM basata su LlamaCloud.
Un'applicazione potente, locale e personalizzabile per interagire con i documenti usando LLM, sintesi vocale (ElevenLabs) e indicizzazione avanzata.
NotebookLlama
- Totalmente open-source (MIT).
- Supporta LLM tramite OpenAI.
- Interfaccia semplice con Streamlit.
- Integrazione con Postgres, Jaeger e LlamaCloud.
- Setup rapido: si clona il progetto, si configurano le API, si lanciano i server… ed è tutto pronto.
Un progetto perfetto per chi cerca controllo, trasparenza e flessibilità nel lavoro con agenti AI sui propri contenuti.
La Deep Research di OpenAI via API: un test
Un esempio dell'esecuzione delle Deep Research via API di OpenAI.
Per l'esecuzione suggerisco di forzare il timeout dell'oggetto "openai", perché l'elaborazione non è veloce come una normale chiamata API.
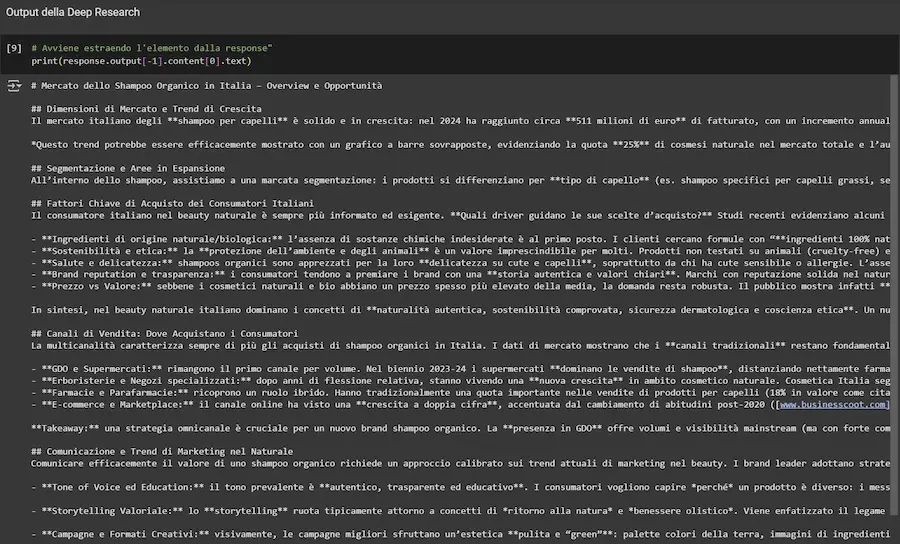
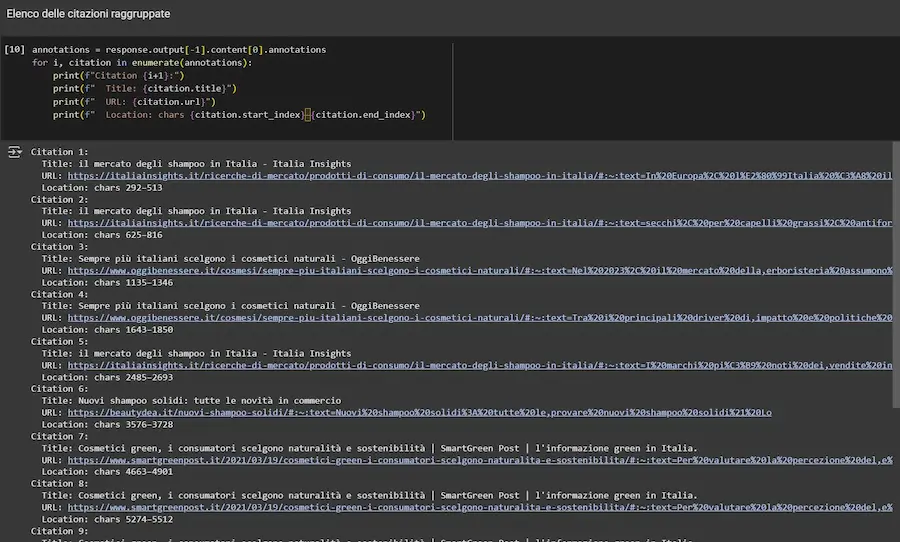
La Deep Research di OpenAI via API: un test
[Errore] Negli esempi della documentazione è presente un errore nella stampa delle query coinvolte. Quello che segue è il mio notebook attraverso il quale si può provare l'API personalizzando i prompt (dove ho corretto l'errore).
Gemini for Education: l'AI nella didattica digitale
Durante l’ISTE 2025, Google ha annunciato un’importante evoluzione nell’integrazione dell’intelligenza artificiale nel mondo dell’istruzione con il lancio di Gemini for Education, una suite di strumenti pensata appositamente per studenti e insegnanti.
Ogni istituto (dalle primarie alle università) potrà accedere ai modelli AI più avanzati (Gemini 2.5 Pro), con protezione dati di livello enterprise, maggiore controllo amministrativo e inclusione gratuita per chi ha già Workspace for Education. Un passo che punta a democratizzare l’uso dell’AI nel settore educativo, garantendo però sicurezza, affidabilità e governance.

Google ha introdotto, inoltre, oltre 30 nuove funzionalità AI a supporto della didattica:
- Gemini in Classroom, disponibile gratuitamente in tutte le edizioni di Workspace, aiuta gli insegnanti a pianificare e differenziare le lezioni in modo rapido, ad esempio generando liste di vocaboli, frasi esempio e quiz personalizzati.
- Gems, gli esperti AI personalizzati creati dagli insegnanti, potranno presto essere condivisi tra colleghi, creando una rete di "intelligenze digitali" a supporto dei corsi.
- NotebookLM si espande con Video Overviews, che permettono di trasformare appunti e materiali di studio in brevi video educativi.
- Google Vids con Veo 3 consente ora di creare video da 8 secondi con effetti audio per comunicazioni rapide o contenuti STEM.
Anche gli studenti (dai 18 anni in su) possono ora sfruttare Gemini Canvas per generare quiz personalizzati e ricevere spiegazioni visive, come diagrammi interattivi, mentre l’estensione agli studenti più giovani è attesa nelle prossime settimane. Sarà inoltre possibile assegnare esercizi, Gems e notebook direttamente da Google Classroom, Schoology o Canvas, potenziando l’apprendimento personalizzato.
Grande attenzione è stata data alla sicurezza dei minori: onboarding con alfabetizzazione AI, filtri sui contenuti, protezioni rafforzate per i dati e divieto di utilizzo delle interazioni per addestrare i modelli. Gemini è ora uno strumento AI responsabile, trasparente e adattabile ai contesti educativi reali, pensato per dare più potere decisionale a studenti e insegnanti.
Google prova a segnare un punto di svolta nella didattica digitale. L’AI non è più un accessorio, ma uno strumento centrale per ripensare l’esperienza educativa in chiave personalizzata, inclusiva e sicura.
"Studiamo insieme" di OpenAI
OpenAI introduce la funzionalità "Studiamo insieme" su ChatGPT.
Si tratta di un sistema che cerca di spingere l'utente alla comprensione per gradi, invece di produrre una risposta risolutiva, unendo il "reasoning" e la ricerca online.
Nell'esempio mi faccio spiegare il Teorema di Pitagora. Come si vede, il modello fa domande di follow-up per capire a che punto sono, mi chiede cosa ho capito, e mi guida fino a degli esempi pratici.
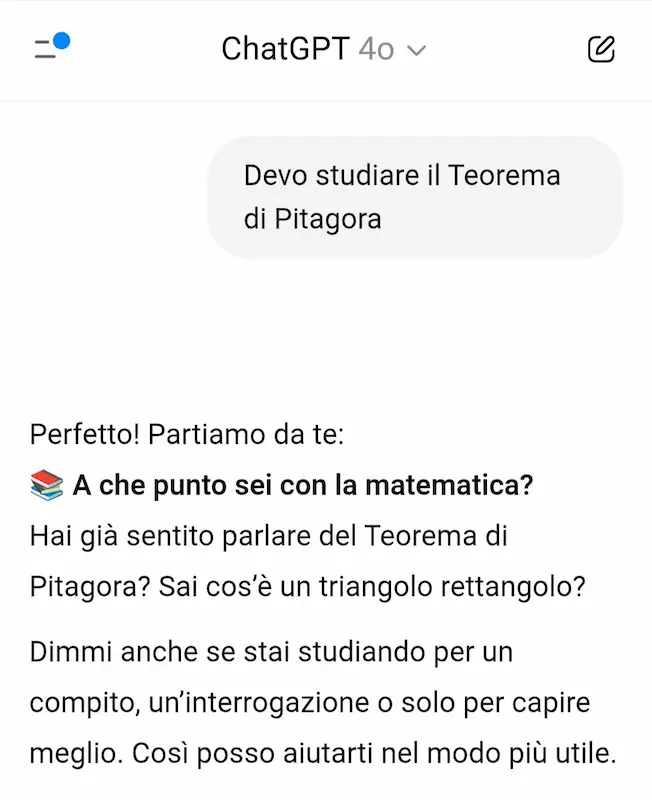
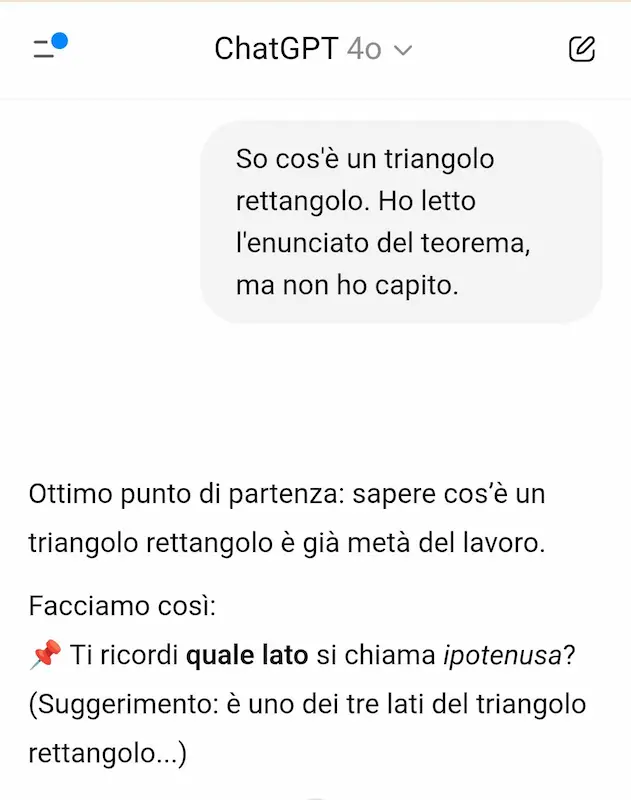
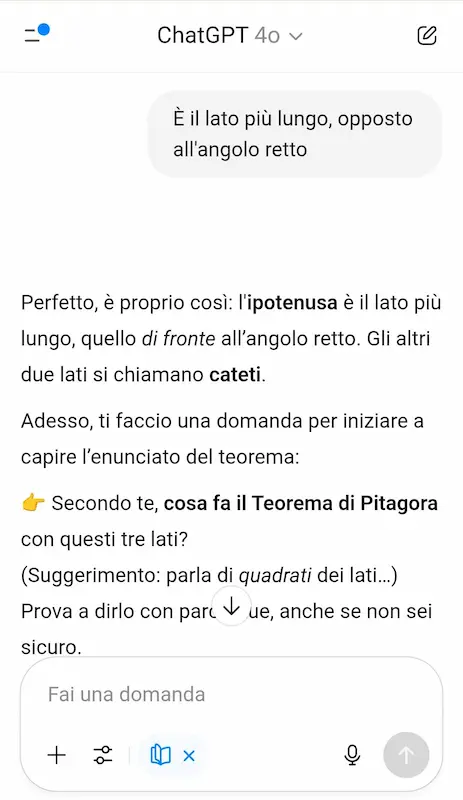
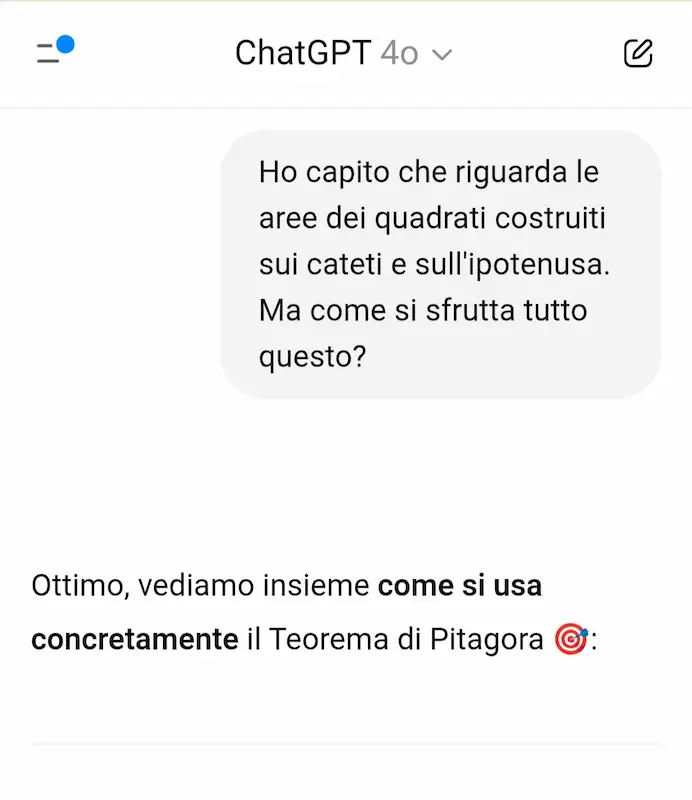
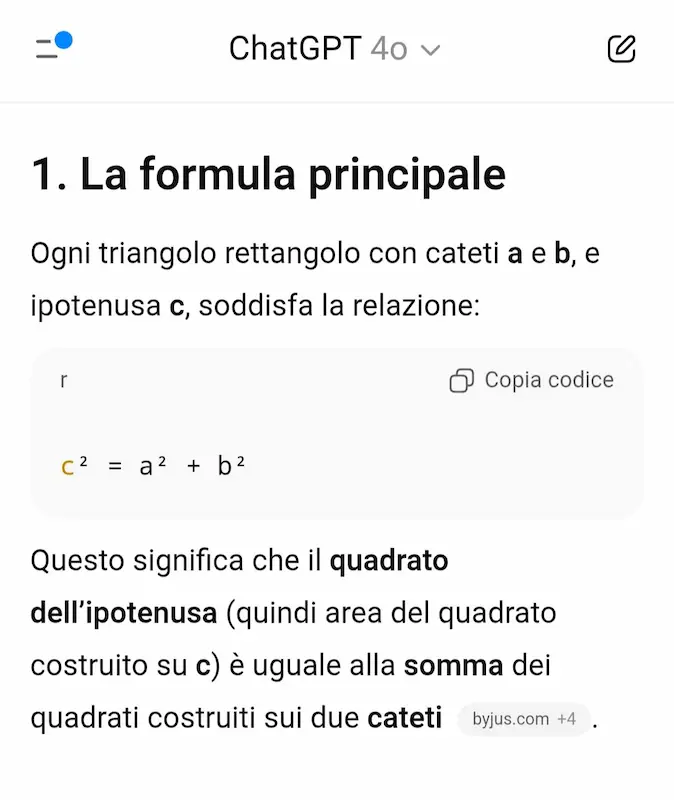



"Studiamo insieme" di OpenAI
L'attenzione per l'ambito istruzione (nello sviluppo degli agenti che interagiscono con gli utenti) si sta alzando. Questo è un bene.
L’IA può superare i medici nella diagnosi?
Dopo AMIE di Google, un nuovo studio di Microsoft AI mette alla prova questo concetto.
È stato creato SDBench, un benchmark realistico basato su 304 casi clinici complessi del New England Journal of Medicine. A differenza dei soliti quiz a scelta multipla, qui l’IA (o il medico) deve fare domande, ordinare esami e decidere quando è pronta per diagnosticare — proprio come in un vero ambulatorio.
Con questo framework, hanno sviluppato MAI-DxO, un sistema che simula un gruppo di medici virtuali con ruoli diversi: uno ipotizza diagnosi, un altro propone test, uno vigila sui costi, un altro cerca errori.
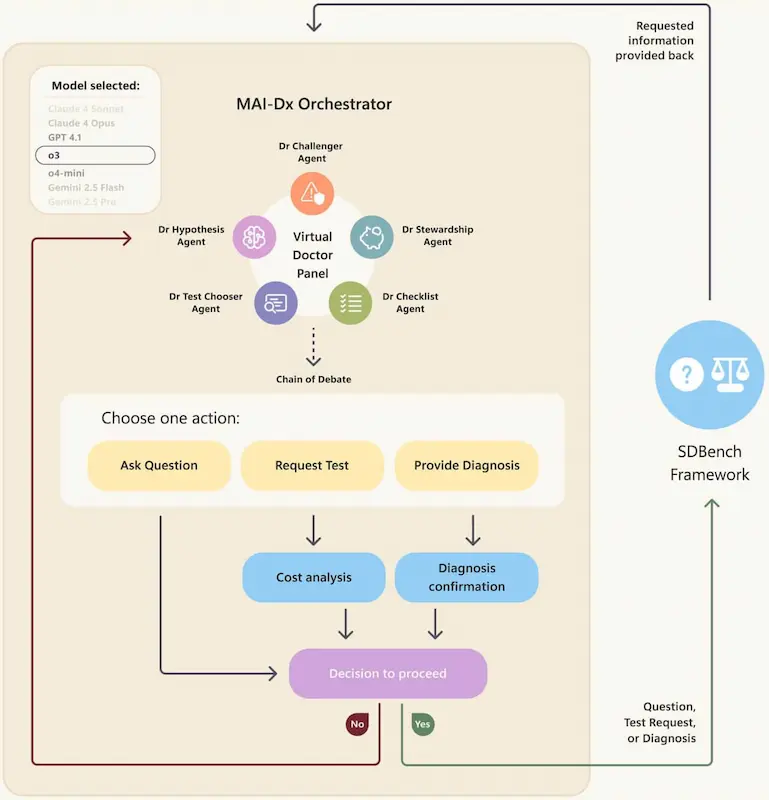
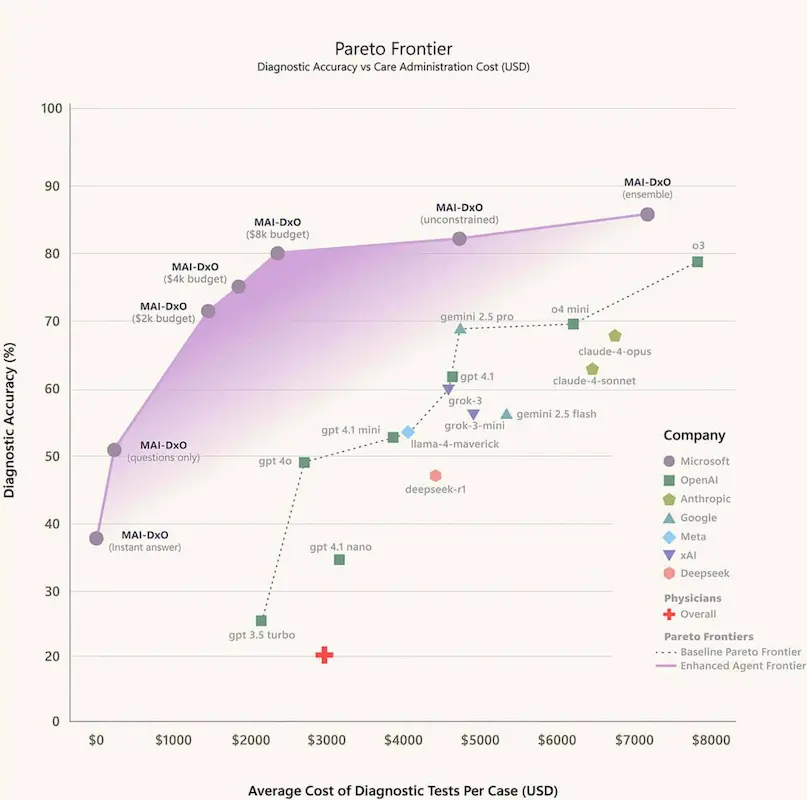
MAI-DxO: funzionamento e performance
I risultati? MAI-DxO ha raggiunto l’85,5% di accuratezza diagnostica, superando i medici (fermi al 20%) e riducendo i costi fino al 70% rispetto a modelli AI non orchestrati.
Questo approccio non solo migliora la precisione, ma dimostra quanto conti l’organizzazione del pensiero clinico.
Non serve solo un buon modello: serve anche una buona strategia.
Energy-Based Transformers (EBTs)
Il paper "Energy-Based Transformers are Scalable Learners and Thinkers" introduce una nuova classe di modelli chiamati Energy-Based Transformers (EBTs), che combinano i Transformer con i modelli basati su "energia" (Energy-Based Models, EBMs).
L'obiettivo è far emergere capacità di ragionamento più profonde — simili al "System 2 Thinking" umano — interamente tramite apprendimento non supervisionato.

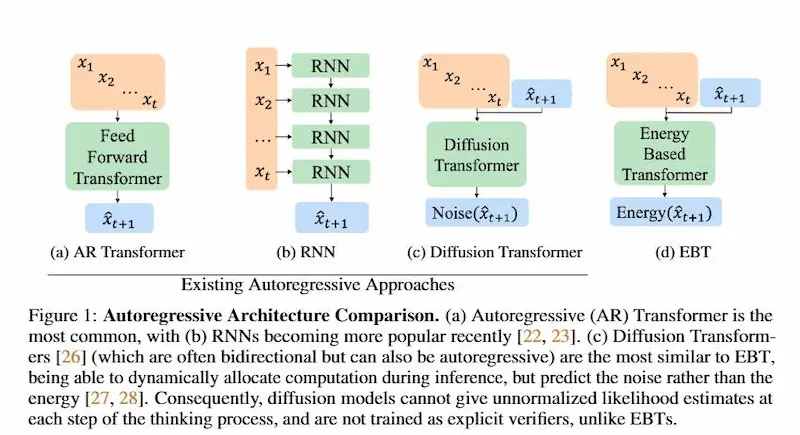
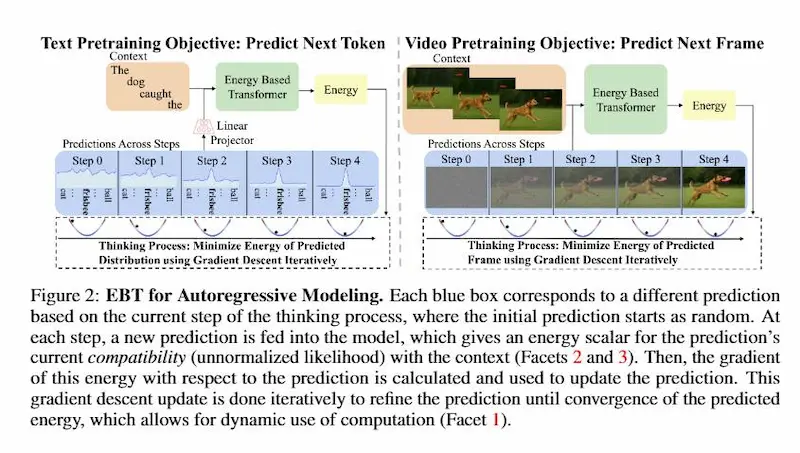


Energy-Based Transformers (EBTs)
A differenza dei modelli classici che producono output in un solo passaggio, gli EBTs imparano a verificare se una predizione è coerente con il contesto, assegnandole un valore di energia: più bassa è l’energia, più plausibile è la predizione.
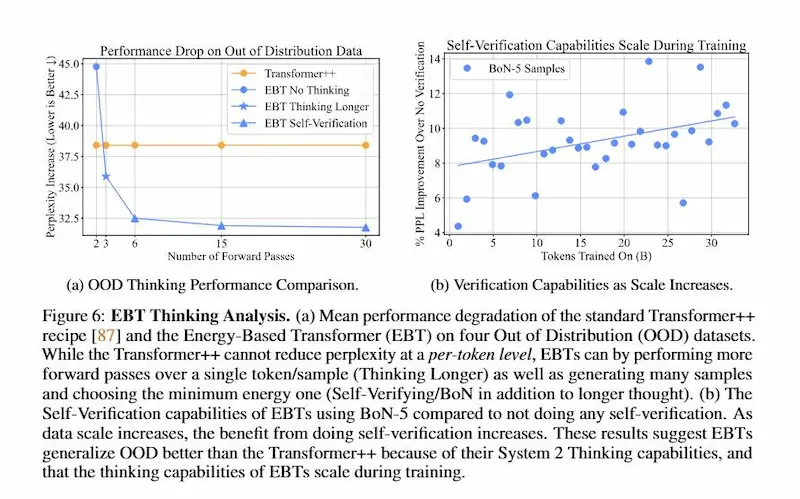
Il processo di inferenza diventa così un’ottimizzazione iterativa, in cui il modello "pensa" più a lungo per problemi difficili, migliorando le prestazioni su dati complessi o fuori distribuzione.
EBTs riescono anche a stimare l’incertezza in spazi continui (es. visione artificiale) e a generalizzare meglio rispetto ai Transformer tradizionali. Inoltre, scalano più efficientemente su tutti i fronti: dati, parametri, profondità, e computazione.
Questo approccio potrebbe rappresentare una svolta nella progettazione dei foundation models del futuro.
ARC-AGI-3
ARC-AGI-3 è il nuovo benchmark interattivo per valutare l’intelligenza generale degli agenti AI. Appena presentato in anteprima, testa la capacità degli agenti di imparare da zero in ambienti mai visti prima, senza istruzioni né prompt.

Gli agenti si confrontano con giochi complessi in mondi a griglia, dove devono esplorare, pianificare, usare la memoria e riflettere, proprio come farebbe un essere umano.
Gli attuali modelli di frontiera, inclusi Grok 4 e o3, non riescono a risolvere nemmeno un compito. Gli esseri umani, invece, li completano in meno di 5 minuti.
ARC-AGI-3 segna un cambio di paradigma: non valuta quanto sa un agente, ma quanto riesce ad imparare in ambienti interattivi, senza aiuti, proprio come un essere umano.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂