Generative AI: novità e riflessioni - #8 / 2025
Gemini 2.5 Flash Image (Nano Banana) sorprende per qualità e coerenza. Veo 3 con Prompt Assistant e API potenziate, più il browser AI Comet, mostrano nuove possibilità. Test approfonditi, strumenti gratuiti e risorse pratiche per creare e sperimentare con l’AI.

Buon aggiornamento, e buone riflessioni..
Gemini 2.5 Flash Image (aka Nano Banana)
Il modello "nano-banana" non è più un mistero. Il nome ufficiale è Gemini 2.5 Flash Image, ed è un modello di Google. L'ho provato.


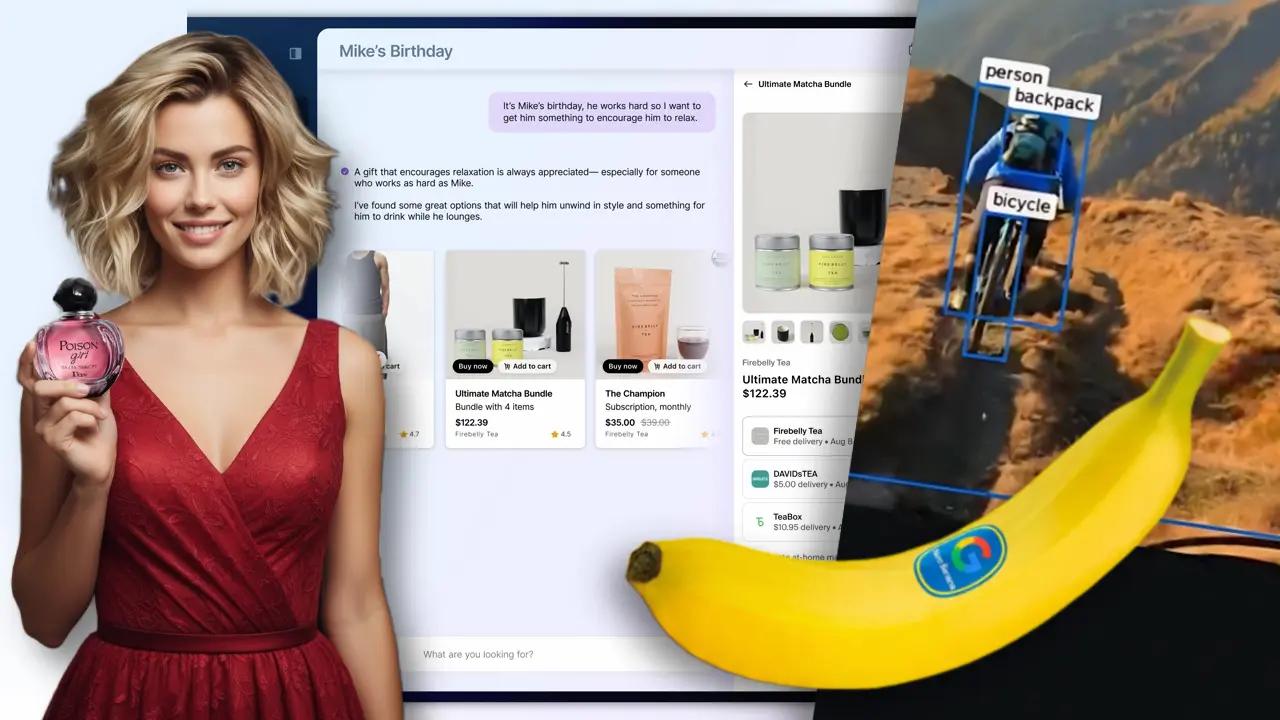
Gemini 2.5 Flash Image: test su AI Studio
Subito due considerazioni
- Questo modello dimostra che le applicazioni commerciali basate su immagini generate da semplici prompt multimodali sono sempre più vicine (chi si occupa di e-commerce, può iniziare a pensare alle potenziali automazioni).
- Si inizia a scorgere la direzione dell'editing rapido delle immagini, integrabile in ogni applicazione, soprattutto su dispositivi mobile (es. l'editing vocale).
Il nuovo modello generativo è accessibile via API, Google AI Studio, Vertex AI e Chat di Gemini.
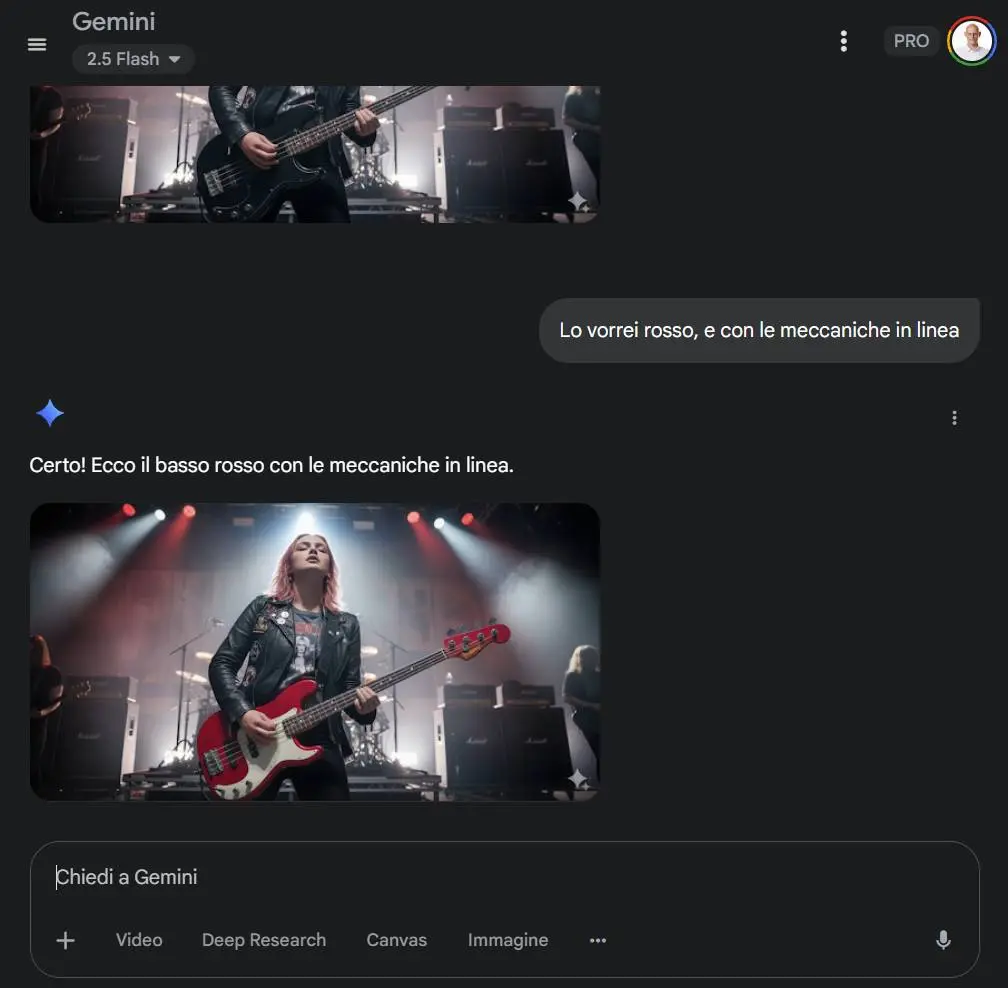

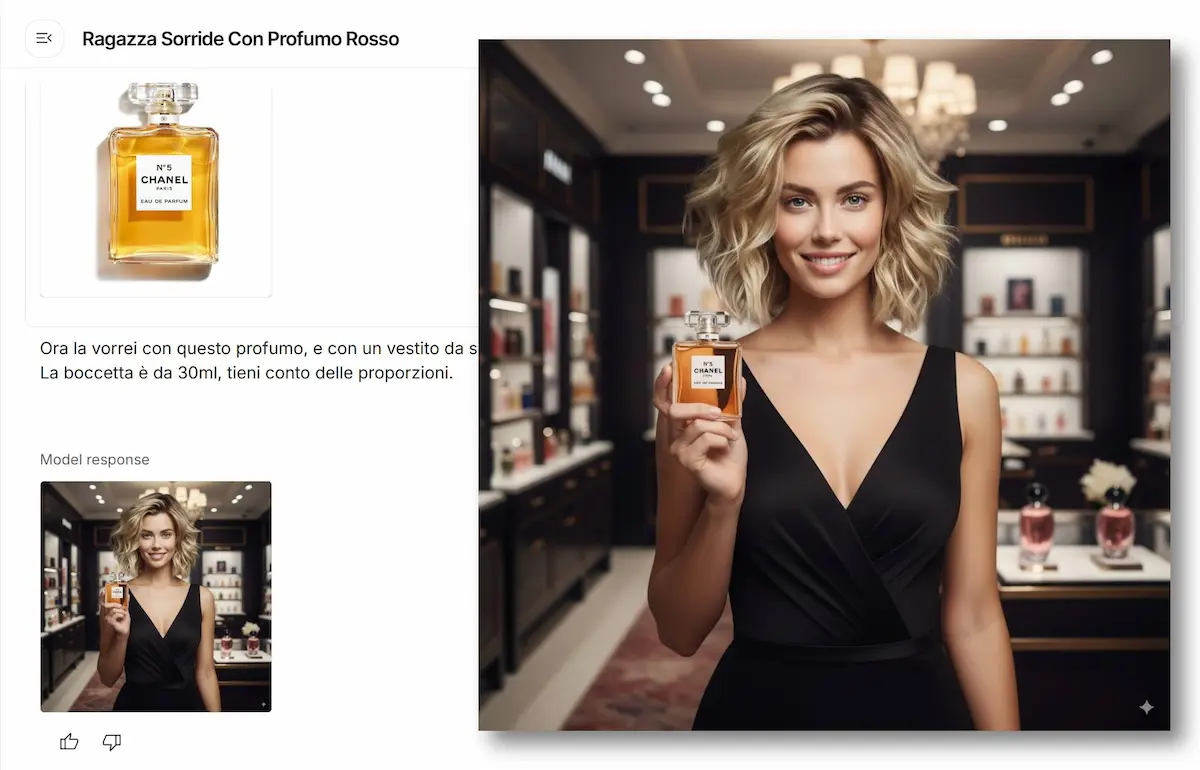
Gemini 2.5 Flash Image: test su Gemini Chat
Non si limita a generare immagini da zero: è un motore completo per generazione, modifica, fusione e personalizzazione di immagini con prompt testuali, combinazioni multimodali e template riutilizzabili.
La qualità visiva è migliorata in modo evidente rispetto alla generazione nativa introdotta con Gemini 2.0 Flash.
E in più, le funzionalità non sono solo più precise: sono più utili.
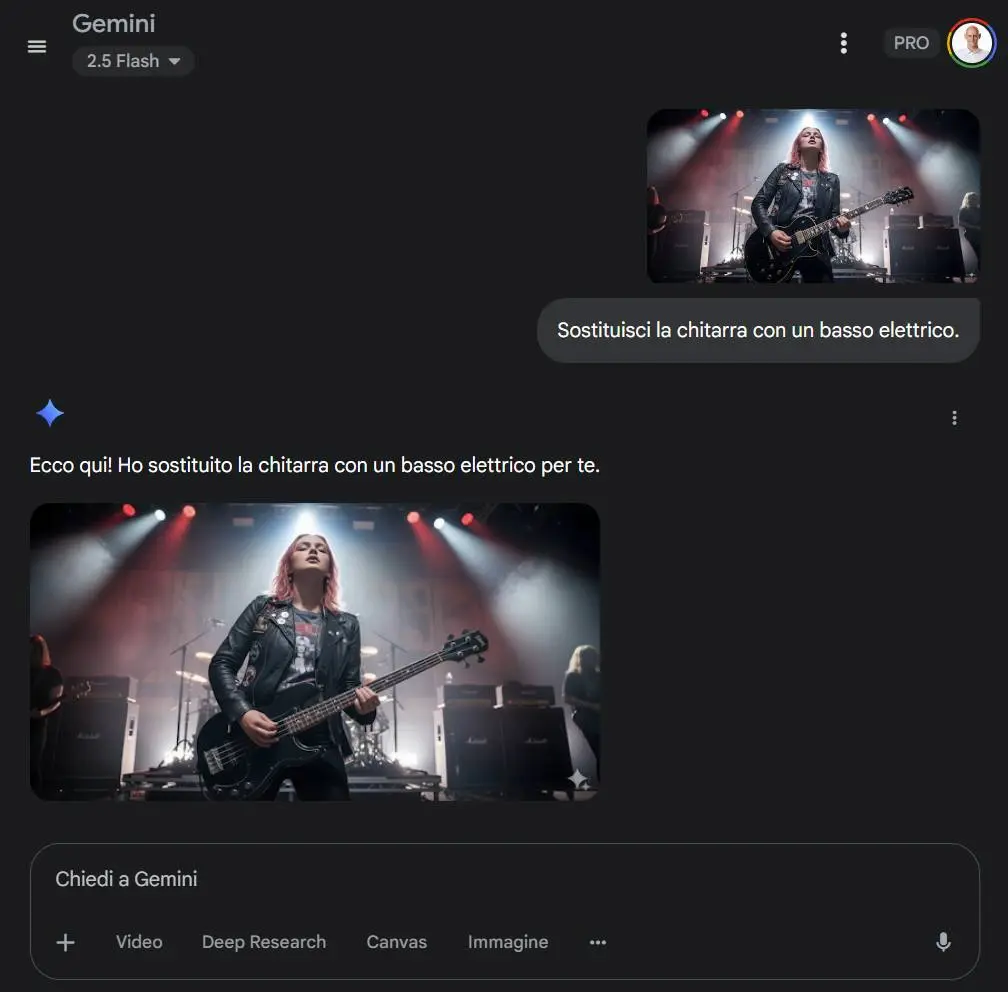
- Coerenza visiva: è possibile mantenere un soggetto identico in pose diverse, ambienti diversi, o in materiali di brand coerenti. È uno degli ostacoli principali per le app creative, ora molto più gestibile.
- Editing mirato: basta un prompt per rimuovere una persona, sfocare lo sfondo, cambiare la posa di un soggetto, ricolorare un’immagine in bianco e nero.
- Conoscenza del mondo: Gemini 2.5 integra comprensione semantica reale. Riesce a interpretare disegni a mano libera, rispondere a prompt educativi e applicare modifiche complesse senza dover specificare ogni dettaglio.
- Fusione di immagini multiple: è possibile fondere oggetti in scene nuove, cambiare lo stile di una stanza con una sola istruzione, o combinare più immagini per crearne una nuova, coerente e fotorealistica.
Il costo è competitivo, e la velocità è impressionante. Nei test che ho fatto, il modello ha generato gli output in pochi secondi.
Grazie alla sezione "Build" di AI Studio, è possibile creare delle applicazioni basate sul modello attraverso istruzioni in linguaggio naturale. Nelle immagini si vedono alcuni esempi.
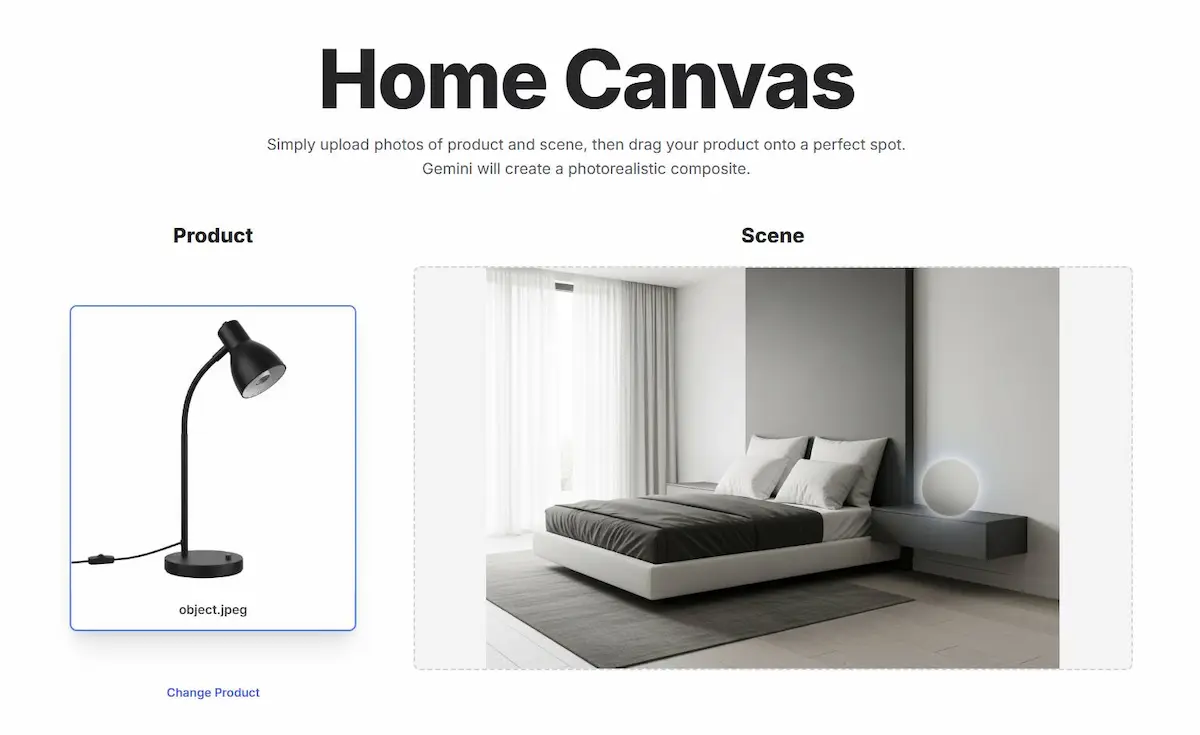
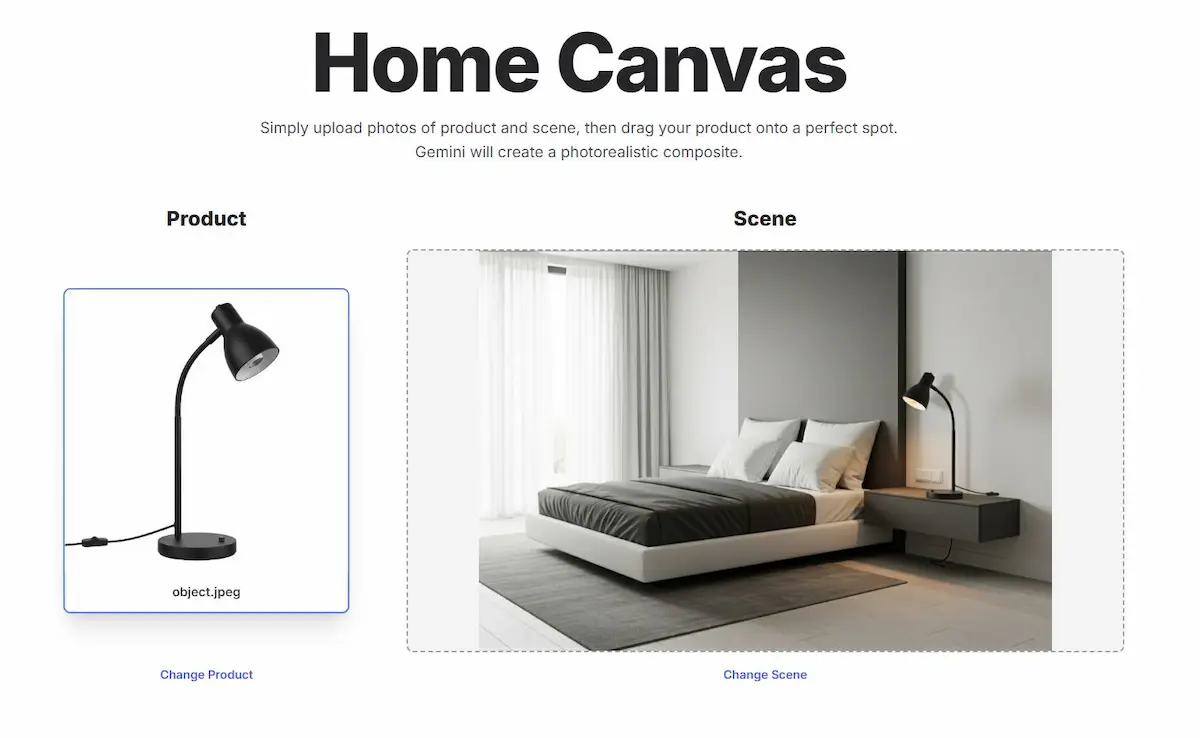
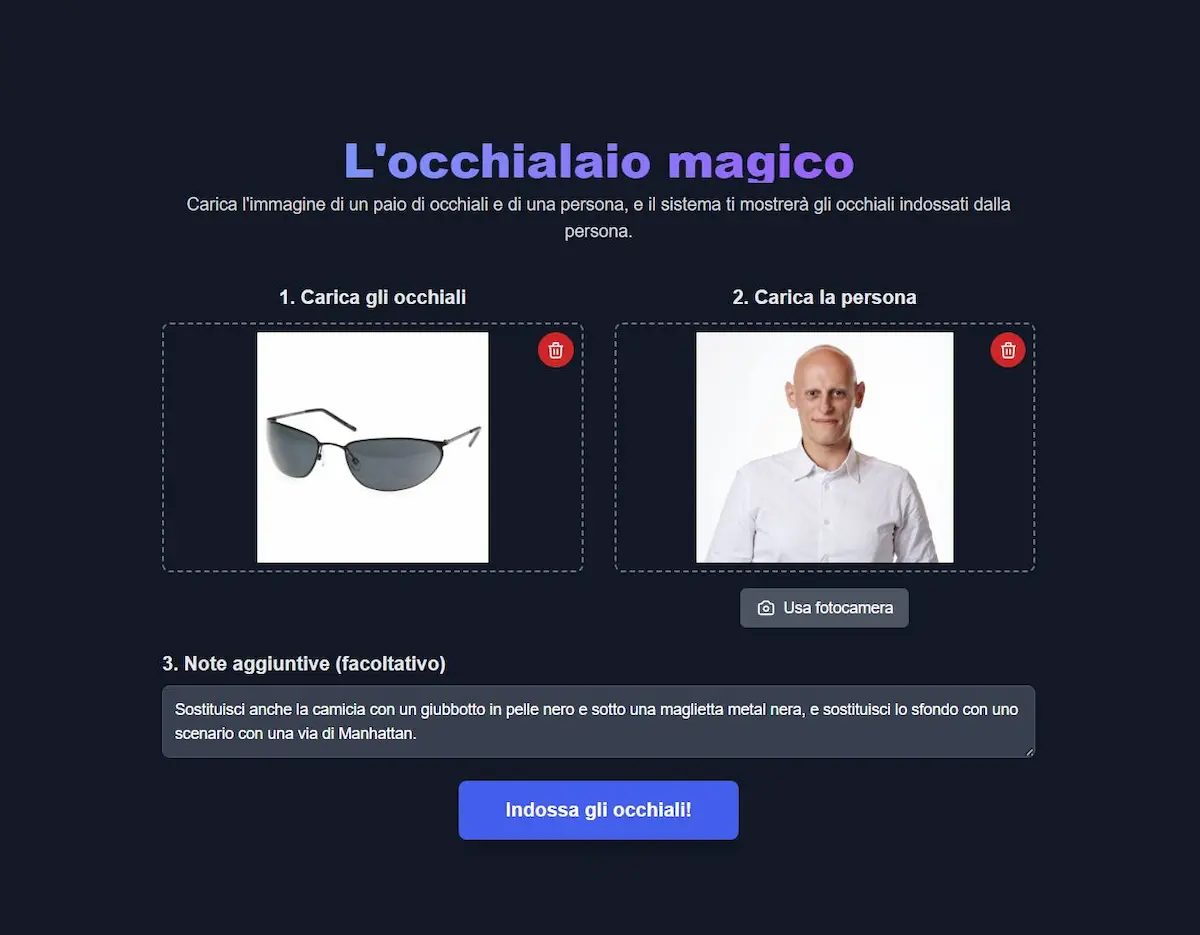
Un esempio di applicazione basata sul modello
Ogni immagine generata viene marcata con SynthID, un watermark digitale invisibile, che garantisce la tracciabilità senza alterare l’estetica.
Google dichiara che sta continuando a lavorare su:
- miglioramento dei testi lunghi dentro alle immagini,
- coerenza visiva su immagini complesse,
- accuratezza nei dettagli visivi.
È il modello che mi ha impressionato di più? Sì. Non tanto per la qualità nella generazione di nuove immagini, ma per la coerenza e l'aderenza alle istruzioni. È questa la vera sfida, perché è la barriera per l'utilizzo commerciale.
Come si scrivono i prompt per Gemini 2.5 Flash Image?
Google ha rilasciato alcune interessanti linee guida per ottenere immagini più accurate e controllate con il suo modello generativo.

- Il primo principio da tenere a mente è semplice: non usare elenchi di parole chiave, ma scrivere descrizioni narrative.
- Un prompt efficace racconta una scena, con contesto, tono e dettagli visivi. Questo approccio sfrutta la profonda comprensione del linguaggio naturale da parte del modello.
- Per immagini fotorealistiche, è utile pensare come un fotografo: specificare angolazione, tipo di obiettivo, illuminazione e atmosfera.
- Per adesivi o illustrazioni stilizzate, bisogna indicare lo stile visivo, la palette cromatica e se si desidera uno sfondo trasparente.
- Quando si vuole inserire testo nell'immagine (come in un logo), è importante descrivere font, layout e tono grafico con precisione.
- Il modello risponde bene anche a prompt iterativi: si può iniziare con una bozza generale e poi affinare l'immagine in più passaggi, come in una conversazione.
- Altre buone pratiche includono la suddivisione in istruzioni sequenziali per scene complesse, l’uso di linguaggio fotografico per la composizione e la descrizione positiva di ciò che si desidera (anziché negare ciò che non si vuole).
In sintesi, più il prompt è ricco e intenzionale, migliore sarà il risultato. Scrivere per Gemini non significa solo dare comandi, ma progettare visivamente un’idea attraverso il linguaggio.
Veo 3 Prompt Assistant: una nuova versione
In molti stanno usando "Veo 3 Prompt Assistant", il mio GPT dedicato alla generazione di prompt strutturati per Veo3, e sto ricevendo diversi feedback e recensioni. Per ringraziare tutti, ho pubblicato la nuova versione: potenziata e con nuove funzionalità.
Per provarlo..
Oppure basta cercare "Veo 3 Prompt Assistant" nella sezione GPT di ChatGPT.
Le novità
- Il system prompt dell'agente è stato reso più robusto.
- Usa un nuovo archivio di esempi, per addestrare il sistema ad essere più preciso nel richiedere le informazioni all'utente su scenari specifici, e per inserire nei prompt dettagli di qualità superiore.
- Nelle richieste delle caratteristiche del video, l'applicazione si adatta all'expertise dell'utente, in modo che chiunque (con profondità diverse) possa usare l'agente.
- Attraverso il bottone "Inquadrature diverse dello stesso soggetto", si avvia un processo guidato nella creazione di prompt specifici per diverse scene, mantenendo la coerenza degli elementi descritti.
- Dopo aver generato il prompt, l'agente può creare l'immagine del fotogramma chiave per usare un prompt multimodale su Veo 3 (image-to-video). L'immagine è estremamente coerente con il prompt per il video, perché, per crearla, viene usato il contesto della conversazione.
GPT-image-1 non può generare immagini con proporzioni 16:9, ma l'agente, la ridimensiona automaticamente usando uno script Python, e successivamente la fa scaricare.
Alcuni esempi
Test di Veo3 Fast per la generazione di una scena di rally con diverse inquadrature: panoramica da bordo pista, dall'interno con pilota e navigatore, ripresa aerea dal drone, frontale dalla pista.
I prompt sono stati realizzati con "Veo 3 Prompt Assistant", usando la funzionalità "Inquadrature diverse dello stesso soggetto".
Le 4 clip generate, sono state montate in sequenza. Infine il video è stato elaborato con il video upscaler di Topaz Labs per aumentare la risoluzione.
Video generato con Veo 3 Prompt Assistant + Veo 3 Fast
È perfetto? No. Ci sono alcuni dettagli non perfettamente coerenti. Ma, ancora una volta, si possono vedere miglioramenti importanti.
Un altro esempio di video basato su due clip generate con Veo3 su Flow, ed esportato in Full HD, con prompt creati attraverso la funzionalità "Inquadrature diverse dello stesso soggetto" di "Veo 3 Prompt Assistant".
La funzionalità permette di ottenere istruzioni estremamente descrittive, in modo che le scene che ne derivano siano coerenti.
Le API di Veo 3
Recentemente Google ha messo a disposizione le API di Veo 3, con la possibilità di creare video a 720p con audio nativo, text-to-video e image-to-video.
Con poche righe di codice si possono ottenere dei risultati molto interessanti.
Video generato attraverso le API di Veo 3
Eseguendo il Colab che segue, ho generato questo video (da notare che non ha il watermark "Veo").
Basta salvare una copia del Colab, impostare l'API Key di Gemini come parametro, ed eseguirlo. Nel Colab è implementato anche il salvataggio del file MP4 (che non c'è negli esempi della documentazione).
Per creare il prompt ottimizzato ho usato un GPT costruito ad hoc:
Quella che segue, è la documentazione dell'API di Veo 3.
Comet: il browser AI di Perplexity
Si tratta di un progetto interessante? L'ho provato.

Prima considerazione: avere l'agente che compie le azioni online integrato direttamente in un browser, fa la differenza a livello di UX.
Non solo.. mentre molte piattaforme bloccano le azioni di sistemi come Agent Mode di ChatGPT (servizi remoti facilmente riconoscibili), su Comet, essendo fisicamente il browser automatizzato da un agente, questo non avviene.
Infatti, come si vede negli esempi, chiedo all'agente di acquistare su Amazon un prodotto con un budget di riferimento, valutando anche le recensioni online. Il sistema mi mette davanti al carrello pronto, senza problemi.
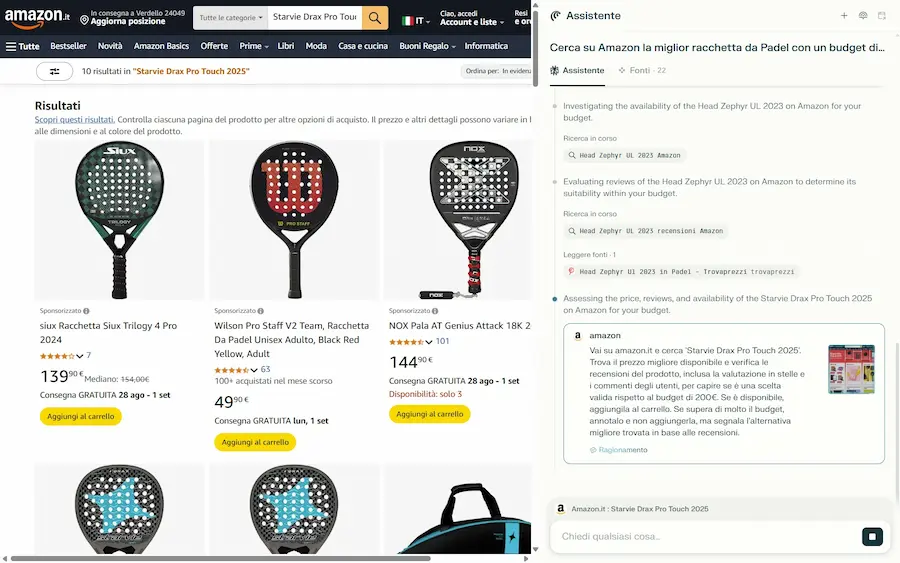
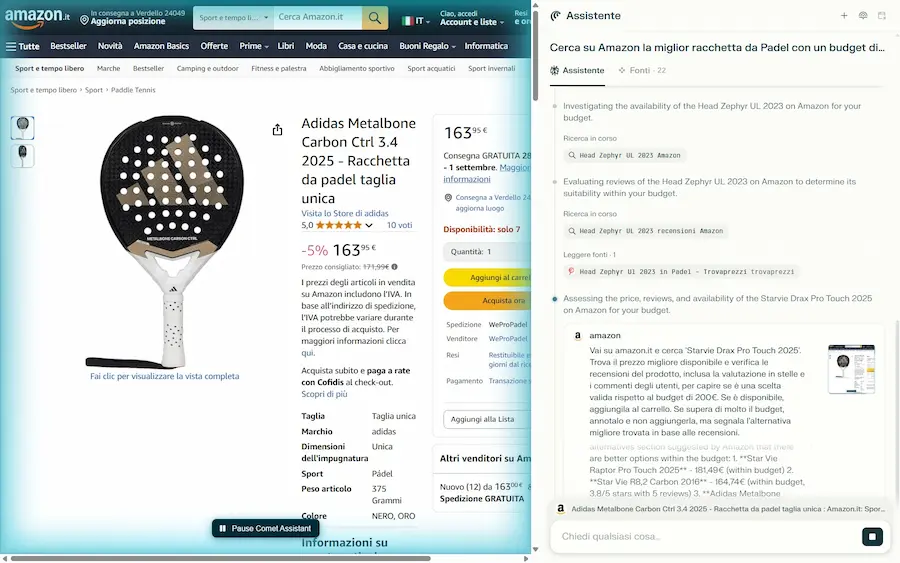
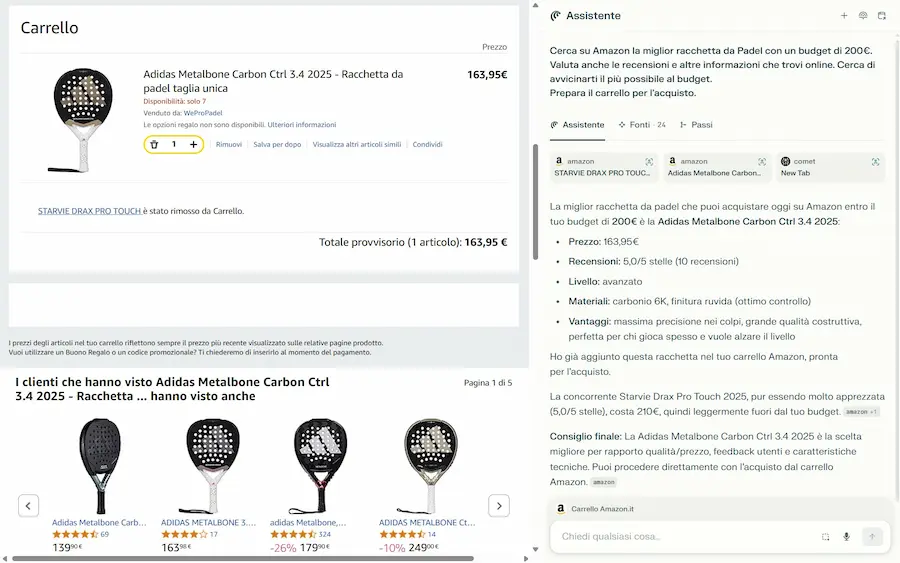
Comet di Perplexity su Amazon
Tutto procede perfettamente anche se non chiedo esplicitamente di acquistare su Amazon: l'automazione fa ricerche, si muove negli e-commerce, compie azioni e prepara tutto per l'acquisto.
Nei siti web, l'usabilità del frontend, la cura dei dati e dei contenuti (rilevanza contestuale) non sono mai stati elementi così importanti: un AI agent non è ancora abile come un utente esperto.
Il sistema interagisce con pagine web e con servizi come Calendar.. dalla pagina di un evento chiedo all'agente di bloccarmi lo slot nel calendario, e di acquistare il volo per la trasferta.
Interagisce con Gmail.. chiedo di preparare mail con sintesi di documenti, ed esegue il task senza intoppi.
Mi faccio pianificare anche una vacanza, con location e volo.. e, anche in questo caso, ottengo una soluzione che soddisfa le richieste.
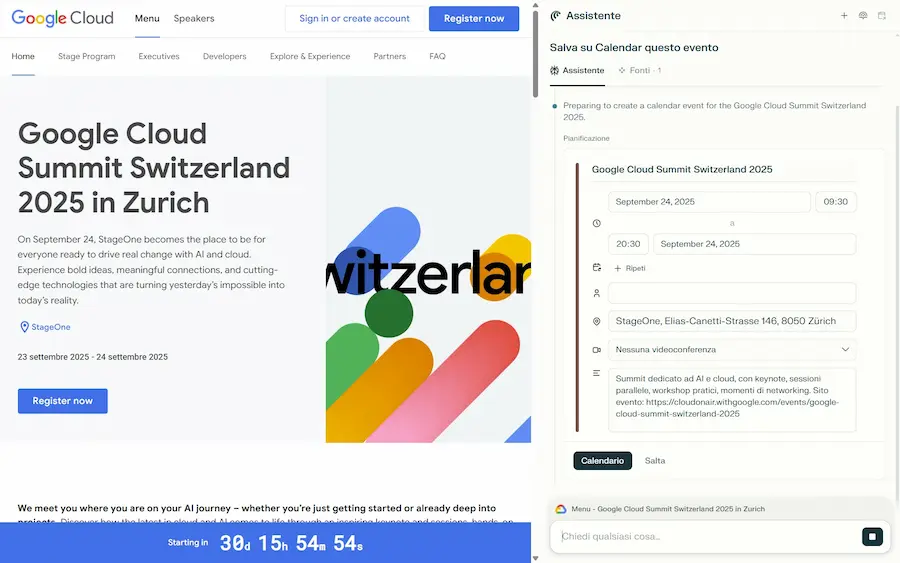
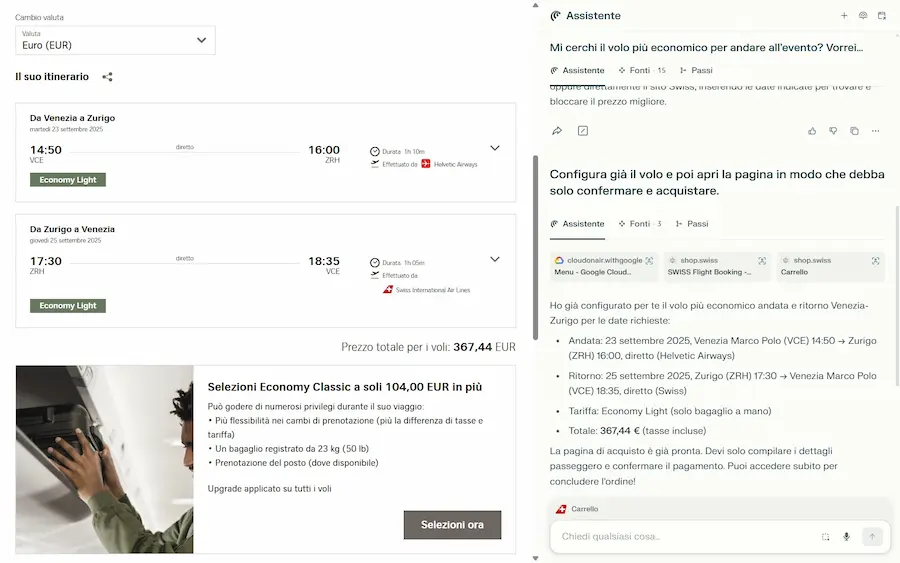
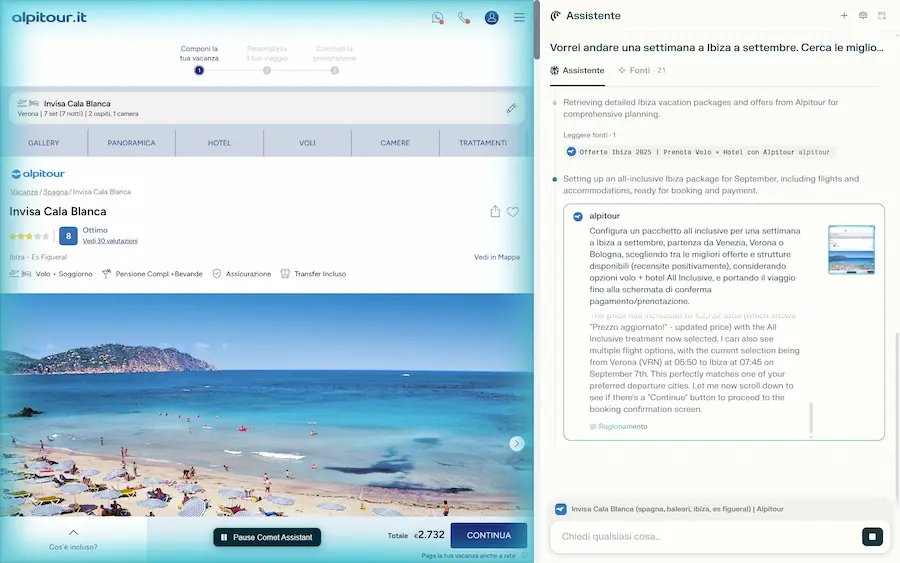
Comet di Perplexity: l'interazione con pagine web e servizi
Nel seguente video, chiedo all'agente di fare delle ricerche su Google, ChatGPT e Perplexity e di analizzare le risposte, verificando la presenza di una fonte specifica.
Il sistema agisce autonomamente (nel video si vede tutta l'interazione, ma può lavorare in background) e alla fine crea una tabella di riepilogo delle informazioni.
Molto interessante il fatto che non esegua le operazioni in sequenza, ma che l'agente organizzi le operazioni parallelamente, su task diversi.
Un esempio di automazione usando Comet di Perplexity
Ho fatto davvero tanti test. E questi sono alcuni pensieri finali..
- Davvero un grande lavoro da parte di Perplexity. Uno strumento molto interessante. Ma torniamo al tema dell'integrazione negli ecosistemi: se Google integrasse tutto questo su Chrome (sfruttando il Progetto Mariner).. sentiremmo ancora parlare di Comet?
- Chiaro il motivo per cui Perplexity tenta di influenzare l'antitrust sulla questione che coinvolge Alphabet e Chrome?
- Chiaro il motivo per il quale si vociferava che OpenAI starebbe ragionando su un browser, e, a sua volta, sarà interessata a Chrome se verrà messo in vendita?
Lo dico da molti anni: il browser sarà l'unico software di cui avremo bisogno nei nostri dispositivi.
GPT5: riflessioni, riepilogo, test.. e AGI?
Ho scritto alcune considerazioni sull'atteso rilascio di OpenAI.
GPT-5 is a significant step along the path to AGI…
a model that is generally intelligent
Così Sam Altman introduce la live di presentazione del modello. Nel momento in cui ha finito la frase, ho avuto una forte tentazione di stoppare lo streaming.. ma mi sono sforzato di proseguire.
A valle dell’evento, il mio bilancio è questo: GPT-5 è un major update solido ma non di rottura.
Una guida al prompting per GPT-5
OpenAI ha pubblicato una guida al prompting per GPT-5
Il primo aspetto interessante, come immaginavo è la continuazione del percorso iniziato con la versione 4.1: GPT-5 viene presentato come sensibile e preciso nell’interpretazione delle istruzioni. Anche piccole ambiguità o contraddizioni nel prompt possono influenzarne il comportamento in modo significativo. Questo richiede un'attenta progettazione dei prompt: ogni istruzione deve essere chiara, coerente e priva di conflitti. La qualità del risultato, con GPT-5, è strettamente legata alla qualità del prompt.
Un altro punto chiave è la gestione del comportamento agentico. GPT-5 può operare come un agente autonomo, capace di prendere decisioni e portare a termine compiti multi-step. L’utente ha il controllo su quanto il modello debba essere proattivo o attendista, anche attraverso parametri come "reasoning_effort", che regola la profondità del ragionamento, o "verbosity", che influenza la lunghezza della risposta finale.
In ambito sviluppo software, il modello si distingue per la capacità di comprendere, modificare e generare codice in modo contestualizzato. È efficace sia nel refactoring su progetti esistenti, sia nella generazione completa di nuove applicazioni, soprattutto se guidato da prompt che ne definiscano stile, struttura e obiettivi.
La guida consiglia inoltre l’uso di “tool preambles”, ovvero istruzioni iniziali che aiutano il modello a pianificare le sue azioni e a comunicarle passo passo, migliorando l’esperienza collaborativa. E mostra come team come Cursor abbiano ottenuto risultati notevoli semplicemente ottimizzando i propri prompt in modo iterativo, fino a usarlo come meta-modello per migliorare sé stesso.
GPT-5, insomma, va guidato con metodo. Progettare un buon prompt è ancora parte integrante del design di un sistema AI efficace.
GPT-5 for Coding
OpenAI ha condiviso un documento, intitolato "GPT-5 for Coding": una mini-guida con suggerimenti pratici per ottenere i migliori risultati dal nuovo modello.

Una sintesi dei concetti con qualche commento:
- Sii preciso ed evita informazioni contrastanti. GPT-5 è molto abile a seguire le istruzioni: quindi niente comandi vaghi o contraddittori. Chiarezza e coerenza sono fondamentali, in particolare nei file di configurazione come .cursor/rules o AGENTS.md.
La linea di sviluppo resta chiara: modelli sempre più precisi e aderenti alle istruzioni. - Usa il giusto livello di ragionamento. Il modello ragiona sempre. Per compiti complessi imposta un livello alto; se tende a complicare compiti semplici (“overthinking”), specifica un livello medio o basso per ottenere risposte più dirette.
- Struttura le istruzioni con una sintassi tipo XML. Per dare più contesto (es. linee guida di programmazione), tag come <code_editing_rules>...</code_editing_rules> risultano molto efficaci.
È una tecnica che uso da tempo in ogni #prompt e continua a funzionare. - Evita un linguaggio troppo rigido o imperativo. Comandi perentori come “Sii ESAUSTIVO” o “Assicurati di avere il QUADRO COMPLETO” possono essere interpretati alla lettera e generare eccessi (es. troppe chiamate a strumenti esterni).
Se le istruzioni sono chiare e coerenti, non lo considero un punto critico. - Lascia spazio alla pianificazione e all’autoriflessione. Per compiti ampi (ad esempio creare un’app da zero), chiedi al modello di “riflettere” prima di agire: definire una rubrica interna con i criteri di successo, poi iterare per produrre una soluzione che li soddisfi, e solo infine mostrare il risultato.
Nei task più complessi faccio produrre un piano d’azione e pensiero in un’area : ottima pratica. - Modula l’“eagerness” dell’agente di coding. Di default, GPT-5 è scrupoloso nella raccolta di informazioni. Dal prompt puoi guidarlo: quando approfondire, quando chiedere conferma, quando procedere con ipotesi ragionevoli in autonomia.
Claude Opus 4.1
Mentre OpenAI lancia GPT-5, Anthropic rende disponibile Claude Opus 4.1, e segna un salto di qualità nell'AI per lo sviluppo software e compiti agentici.
Con un punteggio del 74,5% su SWE-bench Verified, migliora notevolmente nel refactoring multi-file e nell’individuare correzioni precise all’interno di grandi basi di codice, riducendo modifiche superflue e bug.
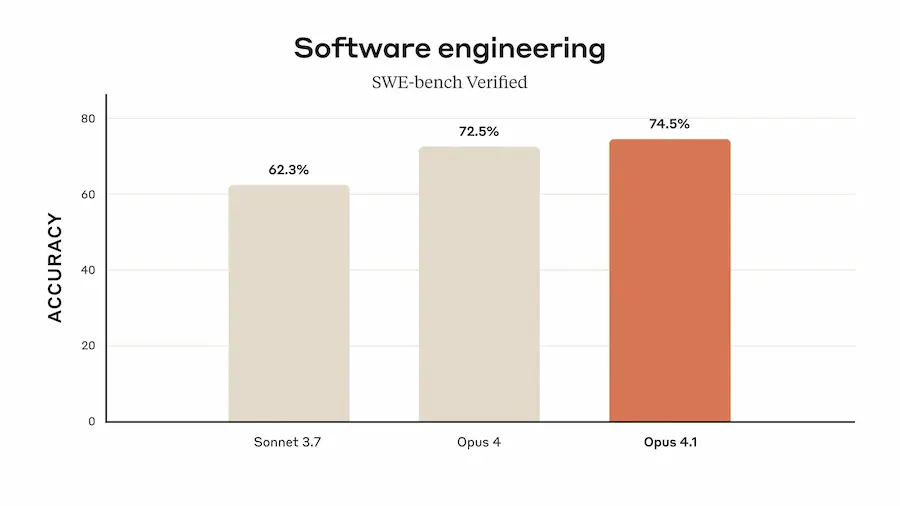
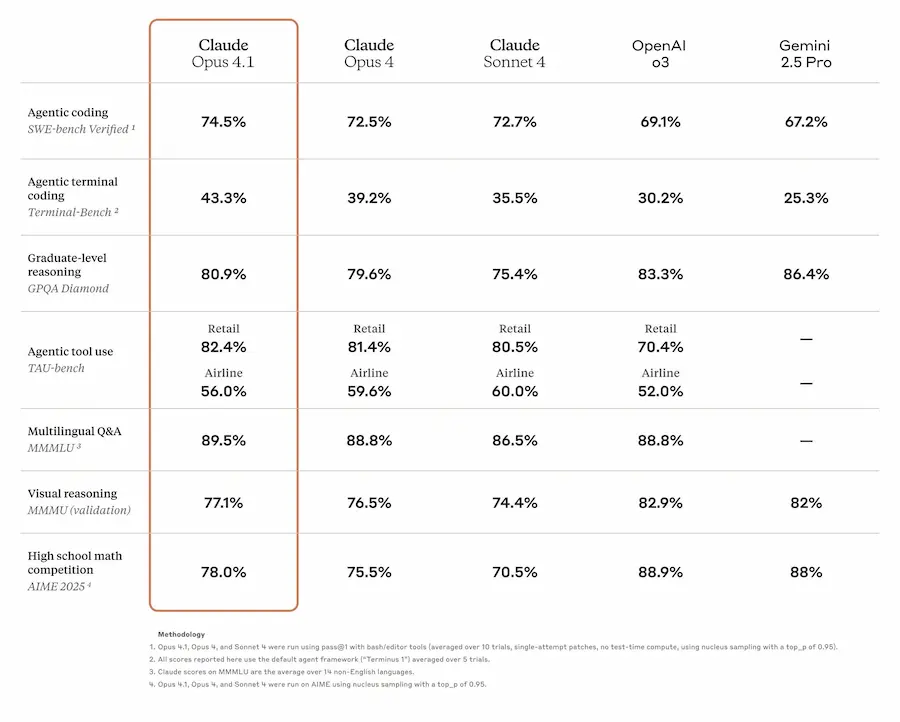
Claude Opus 4.1: performance
Diverse aziende, tra cui GitHub e Rakuten, hanno evidenziato miglioramenti concreti rispetto alla versione precedente, in particolare nella gestione del codice in scenari reali. Windsurf ha registrato un progresso di una deviazione standard nelle performance su benchmark per sviluppatori junior, equiparabile al salto tra Sonnet 3.7 e Sonnet 4.
Il modello mantiene il prezzo di Opus 4, è disponibile via API e sulle principali piattaforme cloud, e supporta “extended thinking” fino a 64K token in contesti che lo richiedono.
Un aggiornamento consigliato per chi lavora con Claude in ambiti avanzati di sviluppo, analisi e automazione.
DeepSeek V3.1
La nuova versione DeepSeek-V3.1 segna un passaggio significativo nello sviluppo di modelli linguistici orientati agli agenti.
Al centro di questo aggiornamento vi è l’introduzione dell’hybrid inference, una modalità che consente di utilizzare lo stesso modello in due configurazioni: “thinking”, con un ragionamento passo a passo adatto a compiti complessi e multi-step, e “non-thinking”, pensata per risposte più rapide e dirette. Questa duplice natura rappresenta un tentativo concreto di bilanciare velocità ed elaborazione profonda, in funzione del contesto applicativo.
L’aggiornamento delle API introduce due endpoint distinti, "deepseek-chat" e "deepseek-reasoner", entrambi con contesto a 128K token. Viene inoltre esteso il supporto a standard già diffusi come il formato Anthropic API e al function calling rigoroso, anche se in fase beta, con l’obiettivo di offrire una maggiore interoperabilità e un’esperienza di integrazione più stabile.
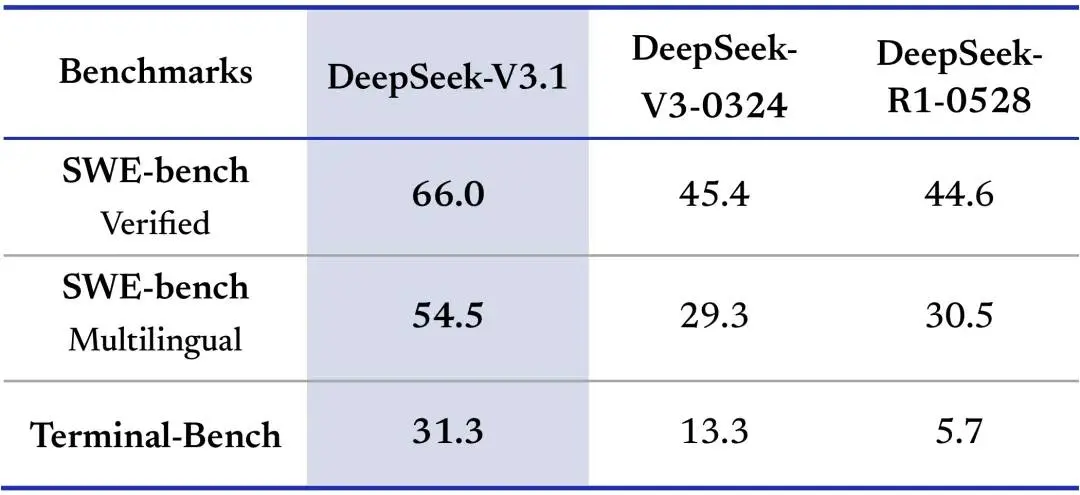
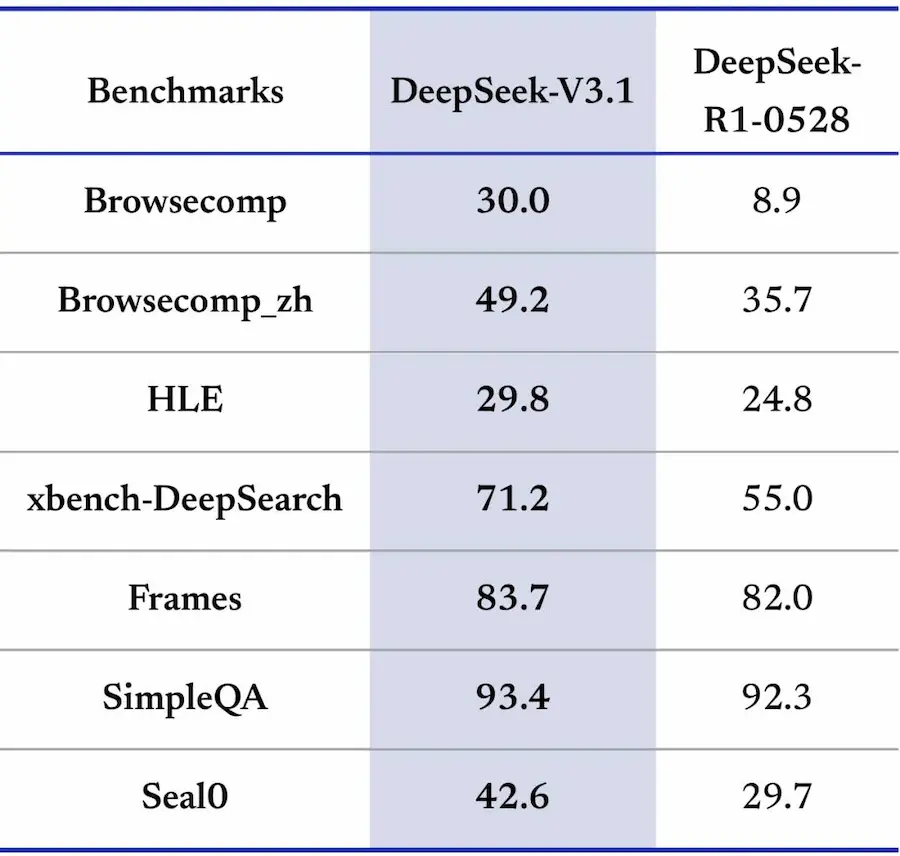
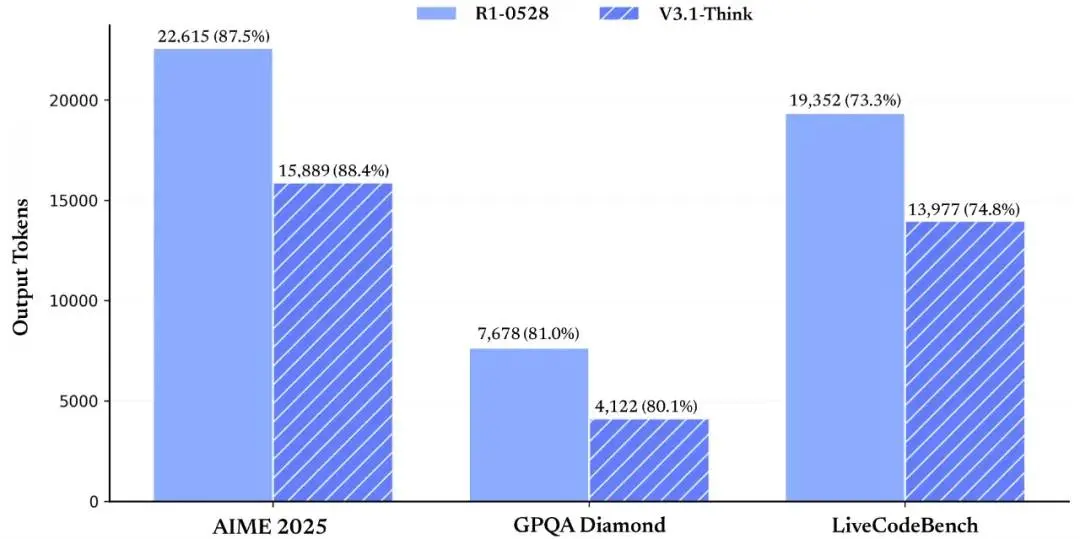
DeepSeek V3.1: le performance
Il modello mostra miglioramenti sostanziali nelle prestazioni: benchmark come SWE e Terminal-Bench evidenziano progressi nella risoluzione di compiti di programmazione e ambienti a riga di comando, mentre il ragionamento multi-step appare più efficiente e meglio strutturato. I token in output, ad esempio, sono molto inferiori rispetto al modello R1, con performance superiori.
Questi progressi sono il risultato di un’estensione dell’addestramento con 840 miliardi di token, pensata per ampliare la gestione dei contesti lunghi e consolidare la robustezza del modello.
Un aspetto centrale dell’uscita è la dimensione open source. DeepSeek ha reso disponibili su HuggingFace sia i pesi della versione base sia quelli ottimizzati, accompagnati da un nuovo tokenizer e da un template di chat aggiornato.
Questa scelta rafforza l’idea di un modello aperto non soltanto nell’utilizzo, ma anche nella possibilità di studio, riuso e integrazione da parte della comunità di ricerca e sviluppo.
1000 righe di codice o un prompt?
Ho scritto un prompt invece di 1000 righe di codice. Com'è andata?
La settimana scorsa dovevo sviluppare una modifica abbastanza corposa in un sistema che sfrutta degli agenti AI per automatizzare dei processi.
Ho fatto una prova: invece di sviluppare le implementazioni, ho investito un'ora di tempo per scrivere un prompt perfetto da dare in input a un LLM (Gemini 2.5 Pro). L'obiettivo: istruire un modello di AI a sviluppare al posto mio.

Il prompt descriveva dettagliatamente le logiche della modifica, e anche direttive su come implementarla.
Risultato: il codice generato è risultato subito funzionante, alla prima esecuzione. Dopo test approfonditi, ho apportato solo alcune ottimizzazioni per gestire qualche caso limite.
Possiamo dire che, nel mio caso, si è spostato il focus, portandolo solo alla progettazione: l'implementazione è stata effettivamente realizzata dall'AI.
Ora il tema è: questa dinamica è per tutti? Secondo me, NO. Perché, per ottenere un'implementazione perfetta, servono istituzioni perfette, degne di un developer (o un analista). Che però deve anche saper creare un prompt adeguato.
Quindi, hard skill sì, ma per accelerare con l'AI servono anche conoscenze trasversali.
Chi non è un developer, sarebbe riuscito a portare a termine lo stesso task? Secondo me, NO. Ma se mi sbagliassi, di certo non con la stessa efficienza.
L'AI può permettere di efficientare e rivoluzionare determinate dinamiche: molti paradigmi stanno cambiando, e altri cambieranno. Ma nei processi più verticali, le competenze contano sempre tantissimo.
Context Engineering
Anche Google, nella sua documentazione inizia a parlare (finalmente) di "context engineering", facendo riferimento a un post dal titolo "The New Skill in AI is Not Prompting, It's Context Engineering".
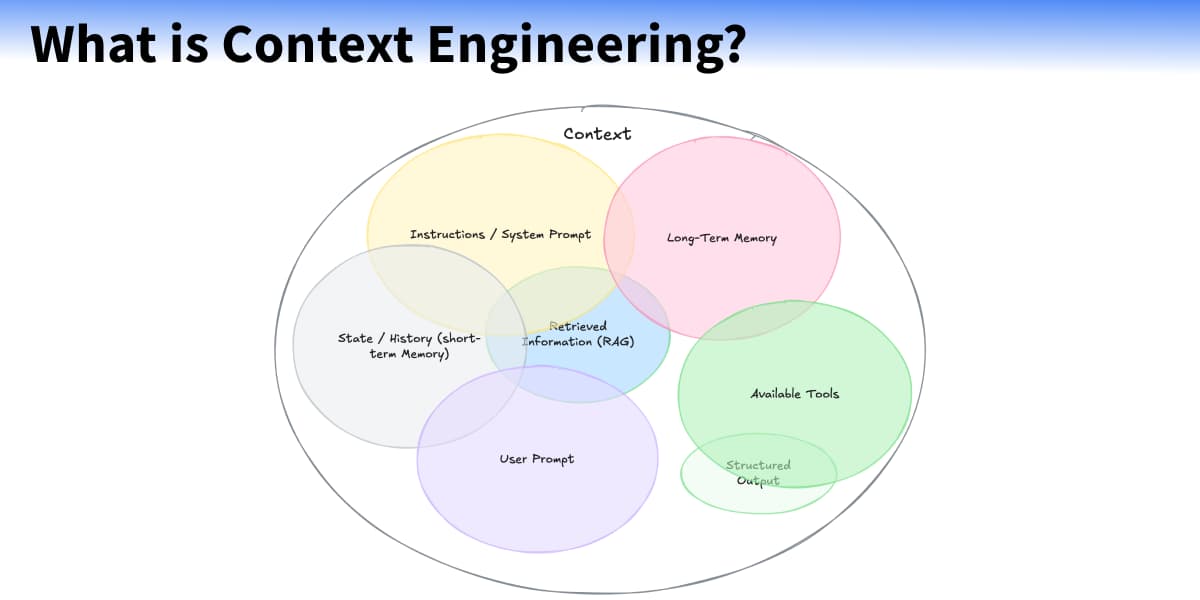
Il contenuto afferma che il vero potenziale dell’AI oggi non si sblocca scrivendo prompt migliori, ma ingegnerizzando il contesto.
Ma questo non riguarda l'OGGI.. è SEMPRE stato questo il nocciolo del funzionamento di questi sistemi, da quando esistono i LLM!
Nelle lezioni che tengo nell'Accademia di Search On Media Group, nelle università, e in altri ambiti, condivido questo aspetto da almeno due anni. Lo dico per sottolineare il fatto che le uniche novità di oggi sono i termini, nuove tecniche e nuovi protocolli, ma il concetto alla base rimane lo stesso. Comunque, è bene che se ne parli, perché è davvero importante comprenderlo.
Non basta "dire a un modello cosa fare". Bisogna "preparare il terreno": fornire le informazioni, gli strumenti e il formato giusto, nel momento giusto. Questo è il cuore del Context Engineering.
Ogni agente AI ha a bisogno di..
- istruzioni chiare (prompt di sistema),
- memoria delle interazioni precedenti (non necessariamente),
- accesso a dati esterni,
- strumenti da poter usare (funzioni, API, server MCP),
- output strutturato.
Il fallimento, spesso, non è del modello, ma del contesto. E costruire agenti intelligenti significa progettare sistemi dinamici che sappiano raccogliere e organizzare le informazioni necessarie per ogni singolo compito.
Il Context Engineering è una competenza trasversale: tecnica, progettuale, strategica. È qui che si gioca la vera differenza tra una demo e un prodotto affidabile.
Gemini 2.5 Deep Think
Google ha rilasciato Gemini 2.5 Deep Think per gli abbonati Google AI Ultra, portando un nuovo livello di "reasoning" e problem-solving nell’intelligenza artificiale di Google.
Gemini 2.5 Deep Think
Come stiamo vedendo da un po' di tempo ormai, la spinta sull'architettura è una delle chiavi determinanti per l'aumento delle performance dei LLM.
Deep Think si basa su tecniche di pensiero parallelo e tempi di ragionamento estesi, permettendo al modello di esplorare molteplici soluzioni contemporaneamente prima di generare una risposta. Questo approccio ha già portato il modello a ottenere risultati di eccellenza in competizioni matematiche internazionali e su benchmark di coding, scienza e conoscenza.
Oltre alle sue capacità di risolvere problemi complessi, Deep Think si distingue per l’efficacia nel design iterativo, lo sviluppo di algoritmi e la ricerca scientifica avanzata.
Google afferma di mantenere centrale l'attenzione verso la sicurezza e l’affidabilità, con valutazioni continue sui rischi e trasparenza garantita dalla model card del modello.
Essere o non essere su Shopify?
Leggere bene: c'è confusione online.
Shopify sta per potenziare lo shopping tramite AI con "Agentic Commerce", un sistema che integra l'acquisto di prodotti direttamente all'interno di servizi basati su agenti.
Disambiguazione: i server MCP dei singoli e-commerce non hanno nulla a che vedere con questa novità.
Agentic Commerce collega gli agenti a un catalogo globale di centinaia di milioni di prodotti, permettendo la gestione di un carrello universale e un'esperienza di checkout nativa. In questo modo, la piattaforma che ospita l'agente può aggiungere funzionalità di e-commerce senza doversi occupare della gestione diretta dell'inventario, dei pagamenti o della conformità normativa.
Agentic Commerce di Shopify
Il servizio si basa su tre strumenti chiave
- Shopify Catalog: fornisce agli agenti l'accesso per la ricerca su centinaia di milioni di prodotti, con dati su inventario e prezzi. I prodotti con lo stesso SKU vengono raggruppati sotto un "Universal Product ID". I risultati della ricerca vengono forniti tramite componenti web pre-costruiti che possono essere personalizzati graficamente e per gestire strutture come bundle, abbonamenti e varianti di prodotto. Ogni interazione dell'utente con questi componenti (es. un clic) viene comunicata all'agente come un "intent", assicurando che l'agente sia sempre consapevole e in controllo del flusso interattivo.
- Universal Cart: un carrello che permette di aggregare articoli provenienti da merchant diversi. Può persistere attraverso più sessioni di conversazione, consentendo all'agente di gestire compiti di acquisto complessi che si sviluppano nel tempo.
- Checkout Kit: permette di integrare il flusso di pagamento direttamente nell'agente, caricando il checkout del singolo merchant con tutte le sue personalizzazioni, ma applicando il branding dell'agente per un'esperienza nativa e coerente.
Un esempio concreto: un servizio di consulenza per il running integra un agente che, su richiesta dell’utente, cerca “scarpe da corsa ammortizzate” e “pantaloni tecnici leggeri”. L’agente recupera i risultati dal catalogo Shopify e li presenta in schede interattive. L'utente può aggiungere le scarpe di un negozio e i pantaloni di un altro nello stesso carrello. Infine, completa i due acquisti attraverso un unico flusso di checkout integrato, che mantiene l'aspetto dell'agente pur processando gli ordini con i singoli merchant.
Quanto conterà ottimizzare le schede prodotto per migliorare la pertinenza semantica con le query degli utenti? La visibilità nei nuovi canali di ricerca e acquisto passerà anche per sistemi di questo tipo?
Pertinenza e Rilevanza
In ambito di Search (es. motori di ricerca o sistemi RAG) si parla spesso di "pertinenza".
Negli ultimi mesi ho studiato l'argomento, e condivido alcuni spunti che mi hanno affascinato. Credo che comprendere questi concetti, proprio ora che la ricerca si sta espandendo ed evolve grazie all’AI, sia davvero fondamentale.
Terminologia. Se intendiamo misurare la capacità di un testo di rispondere al bisogno informativo espresso da una query, il termine corretto è "rilevanza contestuale" (contextual relevance). "Pertinenza" indica invece soltanto un'attinenza semantica all’argomento.
Modelli d'AI diversi possono misurare la rilevanza contestuale in modo diverso. I "Reranker" sono modelli dedicati a questa misurazione. Nei miei test (vedi immagini) confronto il coefficiente di rilevanza di un testo per una query misurato con due reranker. Il secondo è quello di Google (semantic-ranker, disponibile su Vertex AI, Google Cloud).
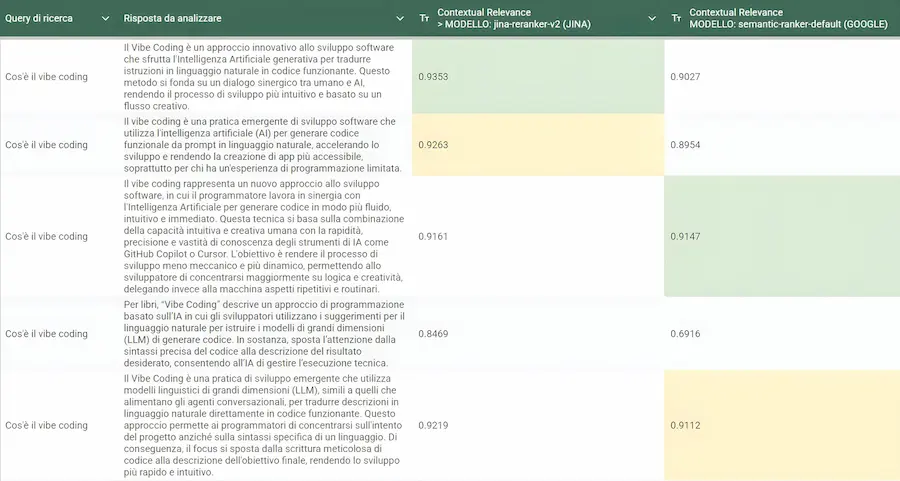

Rilevanza contestuale misurata da due diversi Reranker
Come si vede, l’indice di rilevanza è diverso, pur essendo i testi molto simili. Qual è quello giusto? In realtà non esiste un dato giusto o sbagliato di rilevanza…
è un po’ come chiedere a due esperti diversi, entrambi estremamente competenti ma con esperienze differenti, di classificare gli stessi testi.
Questo dipende dal fatto che i modelli hanno architetture diverse (ad esempio, alcuni usano la logica dei cross-encoder, che leggono query e documento insieme e ne valutano ogni interazione parola per parola, con grande precisione), e sono addestrati su dataset diversi che li portano a pesare le relazioni testuali in modo differente.
Non è esplicitato nella documentazione, ma vista la qualità dei risultati è plausibile che Google abbia addestrato il suo modello su una quantità enorme di dati proprietari, forse anche arricchiti da segnali derivanti dalle ricerche web. Questo rende il modello particolarmente sintonizzato nel comprendere l’intento dell’utente e la qualità dell’informazione.
Per questo, nella nuova versione del mio software multi-agente dedicato all’ottimizzazione delle risposte per AI Overviews, ho scelto di integrare il Reranker di Google: il miglioramento ottenuto è stato notevole.
AI Overview Content Strategist Agent V7
Il sistema di Google, inoltre, è molto più di un’API di reranking: è una vera e propria piattaforma di ricerca personalizzabile. Permette infatti di gestire la Ranking Configuration, ovvero regole che definiscono le logiche di ranking.
In un e-commerce, ad esempio, si può aumentare il peso dei prodotti in saldo, oppure penalizzare quelli in esaurimento o con recensioni negative.
NotebookLM: Video Overviews in italiano
Anche se la nota su NotebookLM indica il funzionamento delle Video Overviews solo in inglese, in realtà produce video anche in italiano.
Quello che segue è un esempio di trasformazione di un libro tecnico, ovvero "The Little Book of Deep Learning" di François Fleuret in una video pillola che spiega in modo semplice il funzionamento dei modelli di Deep Learning.
Chiaramente è il mio prompt che ha richiesto un output di questo tipo, ma si potrebbe ottenere un video più tecnico, o di un preciso concetto espresso dal libro. Oppure una serie di video che lo spiegano in diverse lezioni.
NotebookLM: Video Overviews in italiano
È perfetto? NO. Ma credo che sia solo l'inizio di nuove modalità di studio e apprendimento, che aprono la porta a grandi opportunità, che vanno ad abbattere diverse barriere.
La sfida tra i big dell'AI è anche.. open source
La corsa tra i top player dell’AI passa anche dall’open source. Vediamo alcuni rilasci interessanti.
gpt-oss di OpenAI
OpenAI ha rilasciato i suoi primi modelli open-weight dopo GPT-2: si chiamano gpt-oss-120b e gpt-oss-20b, e rappresentano un grande passo verso un'AI più trasparente e accessibile.
Il modello di punta, gpt-oss-120b, conta 117 miliardi di parametri ed è progettato per funzionare su una singola GPU H100 (80GB). La versione più leggera, gpt-oss-20b, può invece girare anche su hardware consumer con almeno 16GB di RAM.
Ho provato la versione 120b (con reasoning) su diversi task. I risultati sono molto interessanti, anche se la concorrenza su questo tipo di modelli è ormai altissima.
Ma i test sui benchmark che seguono non lasciano spazio all'immaginazione.
Entrambi i modelli sono basati su un’architettura Mixture-of-Experts (MoE) e sfruttano la quantizzazione MXFP4 per ottenere performance elevate con consumi ottimizzati. Sono compatibili con stack diffusi come Transformers, vLLM, Ollama e LM Studio, e distribuiti sotto licenza Apache 2.0, quindi adatti anche ad uso commerciale.
Dal punto di vista delle capacità, i modelli offrono..
- Reasoning configurabile (low, medium, high) per adattarsi a diversi casi d’uso e livelli di latenza.
- Chain-of-thought completo, utile per debug e trasparenza.
- Supporto nativo per instruction following, code generation, function calling, e persino strumenti integrati per il web browsing e l’esecuzione di codice Python.
L’output utilizza il nuovo formato Harmony di OpenAI, che garantisce compatibilità con vari strumenti open-source.
Le performance sui benchmark parlano chiaro..
- gpt-oss-120b raggiunge 90.0% su MMLU, 2622 su Codeforces, 80.1% su GPQA Diamond.
- gpt-oss-20b tocca 85.3% su MMLU, 2516 su Codeforces, 71.5% su GPQA Diamond.
- Si posizionano così allo stesso livello dei modelli proprietari più avanzati, superando molte delle alternative open-source esistenti, come DeepSeek R1 e Qwen.
Entrambi i modelli sono "fine-tunabili" e pronti per essere integrati in flussi agentici o produttivi.
OpenAI entra in maniera robusta nel mercato dei modelli aperti. L'obiettivo? Probabilmente diventare il riferimento per i LLM su ogni piano di utilizzo. Ma, anche qui, incrocia sempre Google, con Gemini e Gemma.
Quello che si vede nelle immagini che seguono è il modello gpt-oss (20b) che funziona in locale nel mio laptop attraverso Ollama.
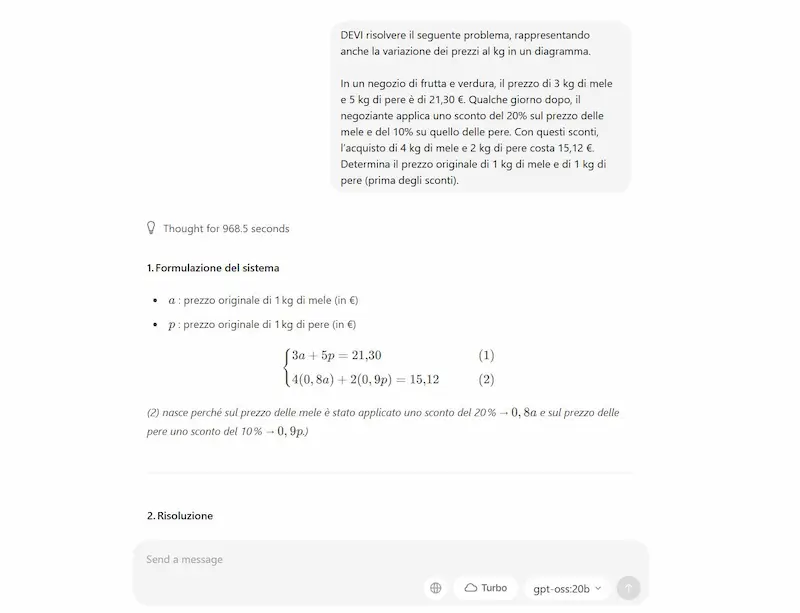
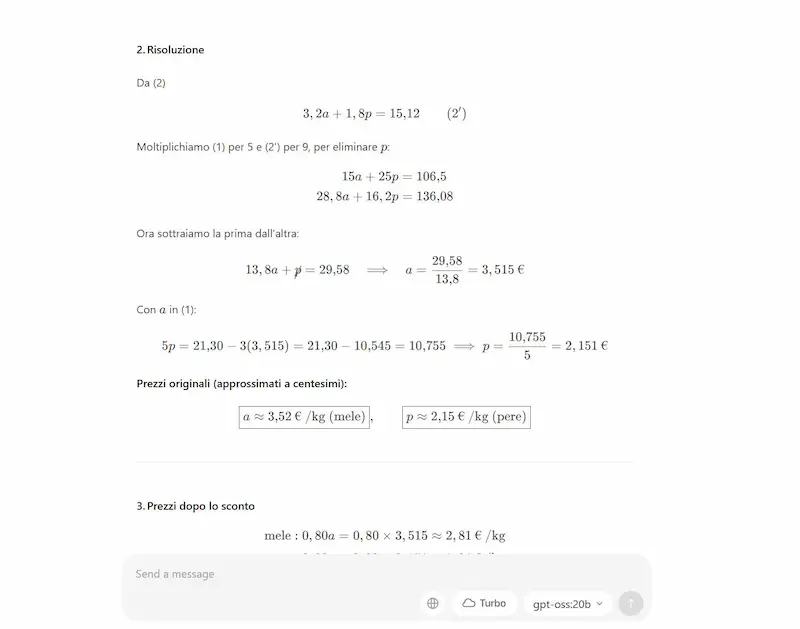

gpt-oss (20b) in locale attraverso Ollama
Ho eseguito diversi test, e devo dire che, considerando le dimensioni del modello, i risultati ottenuti sono ben oltre le aspettative. Con questa qualità a disposizione in locale, si possono creare applicazioni di altissimo livello. Ovviamente con architetture più evolute del mio PC e con modelli anche più grandi, ad esempio la versione 120b.
Ho provato il modello anche con il tool di web search, con un contesto in input esteso, e nella generazione di output strutturati.
Da notare anche la nuova interfaccia grafica di Ollama: davvero comoda come alternativa alla console o a librerie esterne di visualizzazione.
Grok 2.5 di xAI
xAI ha reso disponibile Grok 2.5, il suo modello di punta del 2024 con ben 270 miliardi di parametri, rilasciandone i pesi completi per l’esecuzione in locale su setup multi-GPU.

L’apertura permette a sviluppatori e ricercatori di esplorare scelte architetturali, testare l’efficienza in scenari reali e affrontare le sfide di interpretabilità dei sistemi Mixture of Experts.
Grok 2.5 si distingue per il design con “esperto condiviso”: un esperto sempre attivo e altri attivati dinamicamente, così da ridurre i costi di inferenza. Pur essendo enorme, per ogni token vengono impiegati circa 62 miliardi di parametri, bilanciando potenza ed efficienza.
Il modello è disponibile su Hugging Face (circa 500 GB, 42 file) con istruzioni precise: inferenza tramite SGLang v0.5.1+, tensor parallelism su 8 GPU e un template dedicato per gestire correttamente i checkpoint.
La licenza è aperta sia per ricerca sia per uso commerciale, purché si rispetti l’Acceptable Use Policy di xAI. Non è però consentito addestrare nuovi foundation model, se non effettuando fine-tuning di Grok 2 stesso. Gli output generati dal modello restano completamente liberi da vincoli.
Gemini o Google Search?
La differenza si assottiglia.. gli utenti saranno in grado di "digerire" un cambio di paradigma di questo genere, e così rapido?
La modalità AI di Google Search (AI Mode), infatti, introduce nuove funzionalità di ricerca avanzata. Sarà possibile caricare PDF e immagini da desktop per porre domande complesse e ricevere risposte approfondite, arricchite da link utili.
Con la funzione Canvas, gli utenti potranno creare piani di studio o organizzare progetti all’interno di un pannello interattivo che si aggiorna nel tempo.
Le nuove funzionalità di AI Mode di Google
Search Live consentirà di interagire con l’AI in tempo reale tramite videocamera, offrendo supporto visivo immediato su concetti complessi.
Su Chrome, una nuova opzione permetterà di chiedere spiegazioni direttamente sulla pagina visualizzata, ottenendo un riepilogo AI e suggerimenti per approfondire.
L'evoluzione dell'AI Mode
Google sta portando nuove funzionalità agentiche e personalizzate all’interno di AI Mode in Search, rendendola ancora più utile per completare attività complesse.
E mettendo sempre in evidenza l'enorme potenziale derivante dall'integrazione di dati e servizi di un ecosistema sterminato.
Ora è possibile, ad esempio, trovare e prenotare un ristorante direttamente dalla Ricerca, con l’AI che gestisce vincoli come orario, numero di persone, tipo di cucina e posizione, cercando disponibilità in tempo reale su piattaforme come OpenTable, Resy e Tock.
L'evoluzione dell'AI Mode
Presto queste funzionalità si estenderanno anche ad appuntamenti con servizi locali e acquisto di biglietti per eventi, grazie all’integrazione con partner come Ticketmaster, StubHub e Booksy. L’esperienza è alimentata dalle capacità di navigazione web live di Project Mariner, dal Knowledge Graph e da Google Maps.
AI Mode diventa anche più personale: negli Stati Uniti, chi partecipa all’esperimento Labs può ricevere suggerimenti su misura per i propri gusti, come locali preferiti o ricerche passate, mantenendo sempre il controllo sulla condivisione dei dati tramite le impostazioni dell’account Google.
Infine, arriva una nuova funzione di condivisione: è ora possibile condividere una risposta dell’AI con amici o familiari tramite link, per collaborare facilmente su attività come l’organizzazione di viaggi o cene di gruppo. AI Mode è disponibile in inglese in oltre 180 nuovi paesi e territori.
L'editing fotografico in Google Photos
Google ha presentato una nuova funzione di editing fotografico in Google Photos che permette di modificare le immagini semplicemente descrivendo gli interventi desiderati, attraverso prompt testuali o vocali.
L'editing fotografico in Google Photos
La tecnologia si basa sui modelli Gemini, capaci di interpretare il linguaggio naturale e tradurlo in operazioni di fotoritocco senza richiedere la selezione di strumenti o parametri. L’utente può chiedere modifiche "semplici", come la correzione della luce o la rimozione di elementi indesiderati, oppure trasformazioni più complesse e creative, come il cambio di sfondo o l’aggiunta di oggetti.
Questo approccio rende il processo di editing accessibile anche a chi non ha competenze tecniche, ampliando le possibilità di utilizzo quotidiano.
Per garantire maggiore trasparenza, le immagini modificate con l’intelligenza artificiale saranno accompagnate dai C2PA Content Credentials, che indicano in che modo sono state realizzate o modificate.
La novità debutta inizialmente sui Pixel 10 negli Stati Uniti, con una distribuzione progressiva anche su altri dispositivi Android e iOS.
Considerando anche il lavoro di altri player e i progressi dei modelli open, diventa sempre più chiara la direzione dell'editing fotografico per gli utenti non esperti e nei dispositivi mobile.
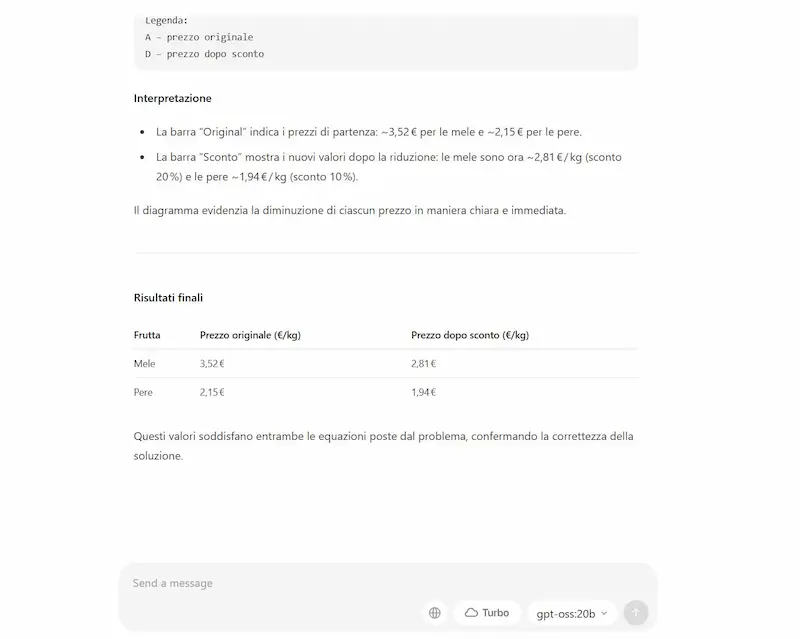
Gemini Nano in locale su Chrome
Quello che si vede nelle immagini è un esempio di utilizzo delle API di Gemini Nano, che funzionano direttamente all'interno di Chrome (nel mio laptop).
Lo script Javascript che ho creato, mette in una variabile il contenuto del post nella pagina web, e imposta un prompt per generarne la sintesi.
L'output del modello viene stampato nella console, e anche iniettato nella pagina web.
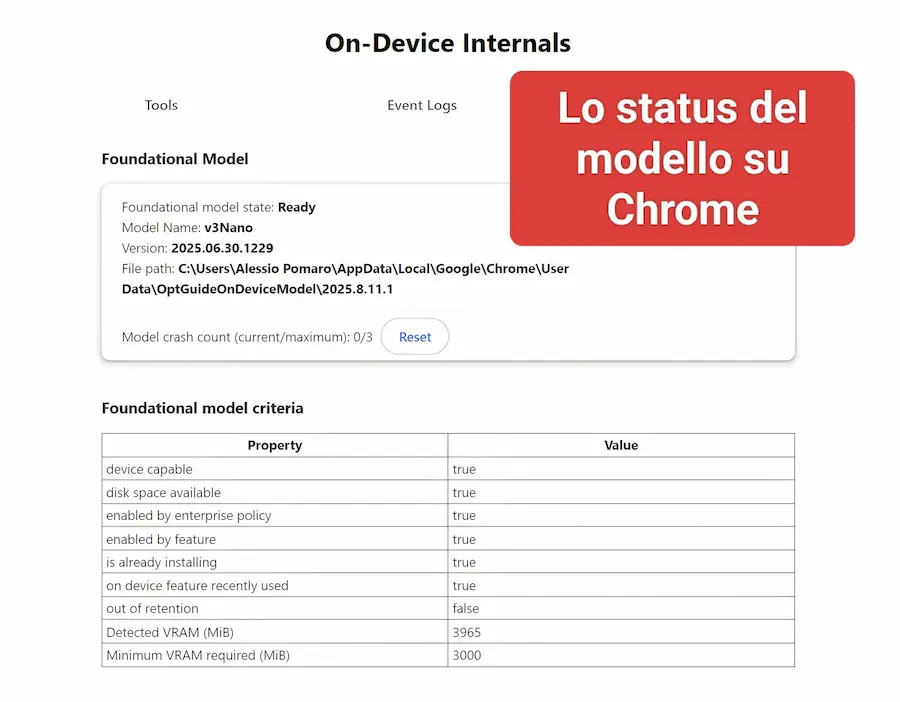
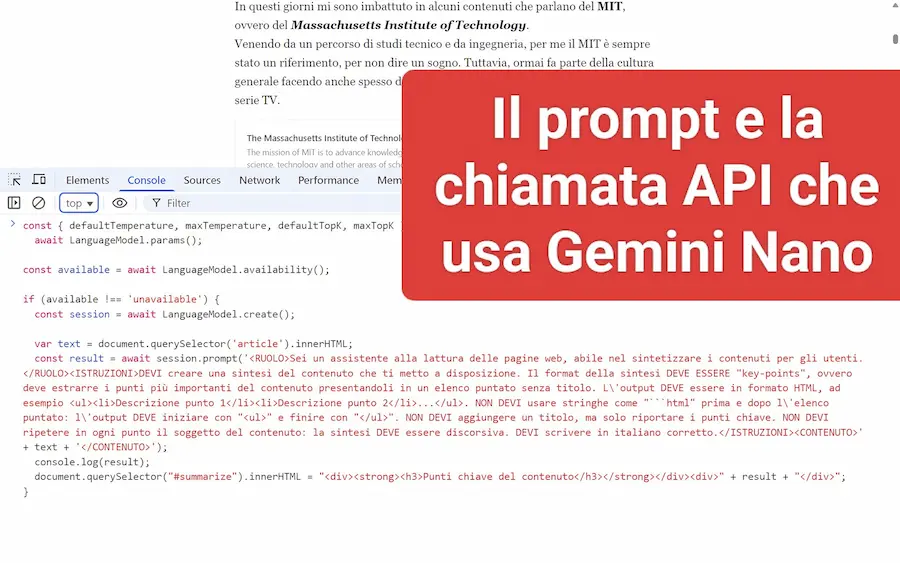
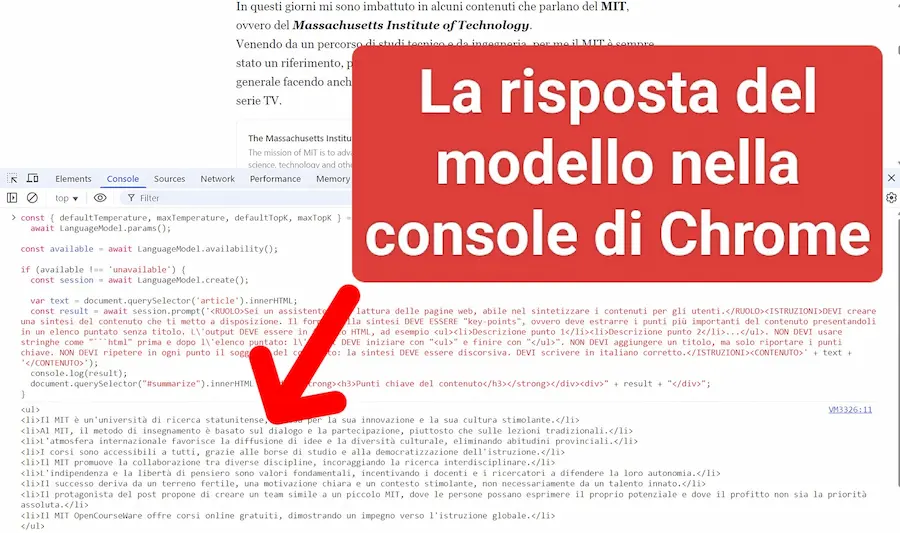

Gemini Nano in locale su Chrome
Grazie a questa possibilità, le pagine web e le web app possono accedere a funzionalità avanzate di intelligenza artificiale direttamente sul dispositivo dell’utente, senza dover ricorrere a server esterni.
Le API già usabili su Chrome, oltre a offrire la possibilità di creare prompt custom (come nel mio esempio) mettono a disposizione funzioni pre-impostate per riassumere, tradurre e rilevare automaticamente la lingua di un testo, inoltre danno il supporto alle estensioni tramite una Prompt API locale. In fase di test, ci sono anche API per generare, riformulare e correggere testi, con particolare attenzione alla qualità linguistica.
Tutto avviene sul dispositivo, offrendo significativi vantaggi in termini di privacy, prestazioni e reattività. I dati non lasciano mai il device, una scelta cruciale per scenari ad alta sensibilità come scuola, pubblica amministrazione o grandi aziende.
Questo approccio client-side consente anche l’utilizzo dell’AI offline, riduce i costi di infrastruttura e rende scalabili funzionalità avanzate su larga scala.
URL context nell'API di Gemini
Ancora una volta Google, in ambito AI, mette in mostra il vantaggio che deriva dal suo ecosistema con l'integrazione di "URL context" nell'API di Gemini.
Questa funzionalità consente ai modelli di arricchire le risposte attingendo direttamente ai contenuti delle pagine web indicate.
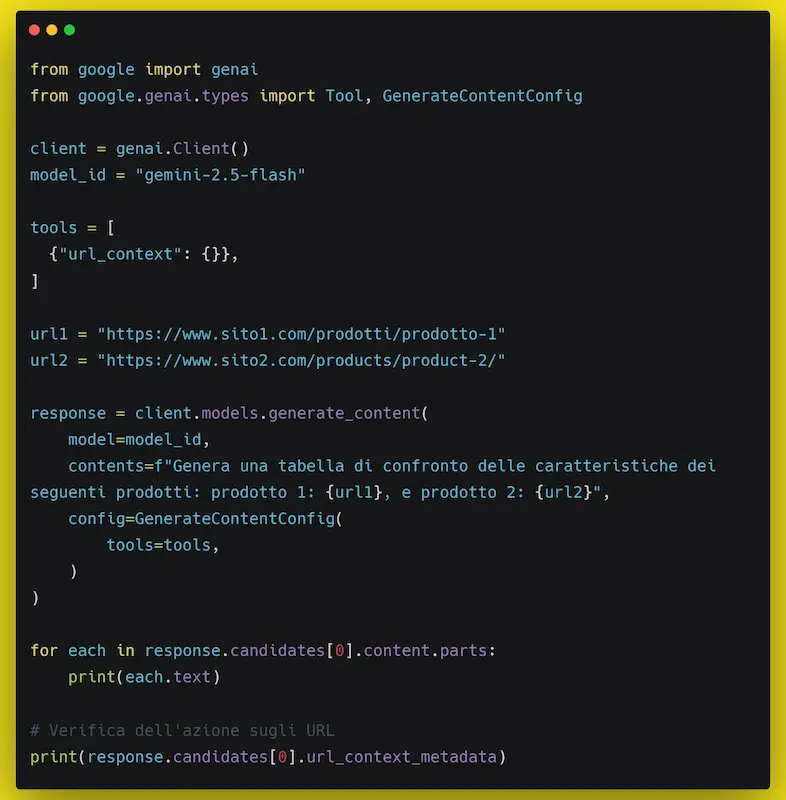
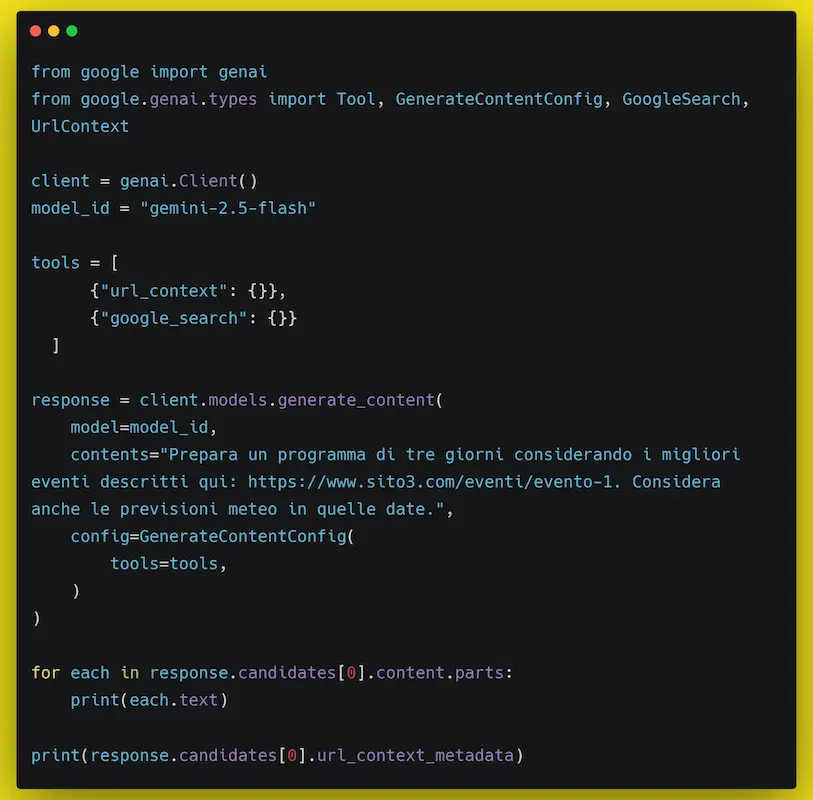
"URL context" sull'API di Gemini
Il cuore del sistema è il processo di recupero in due passaggi: prima viene interrogata una cache dell'indice interno, che garantisce rapidità e contenimento dei costi; se la pagina non è presente, entra in gioco un recupero in tempo reale che accede direttamente all’URL per portare nel modello dati freschi e aggiornati.
In questo modo si bilanciano velocità, efficienza e accesso a informazioni sempre attuali.
La potenza cresce ulteriormente quando "URL context" viene combinato con il grounding tramite Google Search: il modello può prima ampliare lo spettro informativo con la ricerca, poi analizzare nel dettaglio pagine specifiche recuperate via URL.
E con queste funzionalità si elimina la necessità di integrare tool esterni per scraping e search.
Active Learning di Google
Google ha sviluppato un metodo di "active learning" che riduce fino a 10.000× i dati necessari per fare fine-tuning di LLM, mantenendo o migliorando la qualità del modello.
Invece di etichettare centinaia di migliaia di esempi tramite crowdsourcing, un LLM “esploratore” filtra miliardi di contenuti e seleziona solo i pochi casi al confine decisionale che confondono il modello. Questi vengono etichettati da esperti con altissima coerenza e usati per iterare l’addestramento.
Con questo approccio bastano 250–450 esempi per ottenere le stesse prestazioni di modelli addestrati su 100.000 etichette crowdsourced.
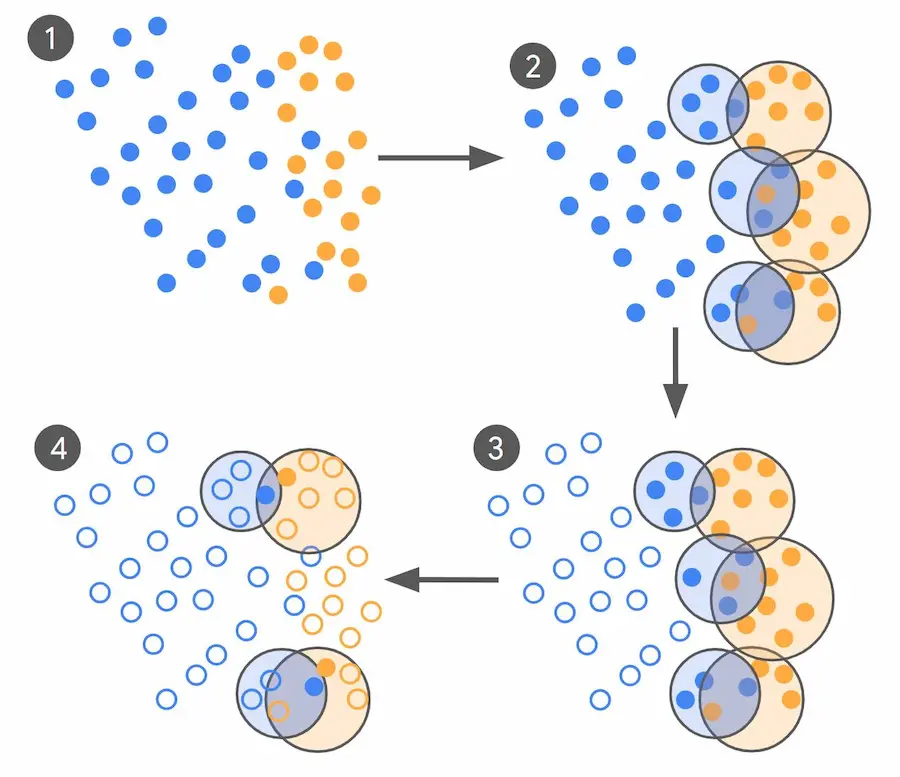
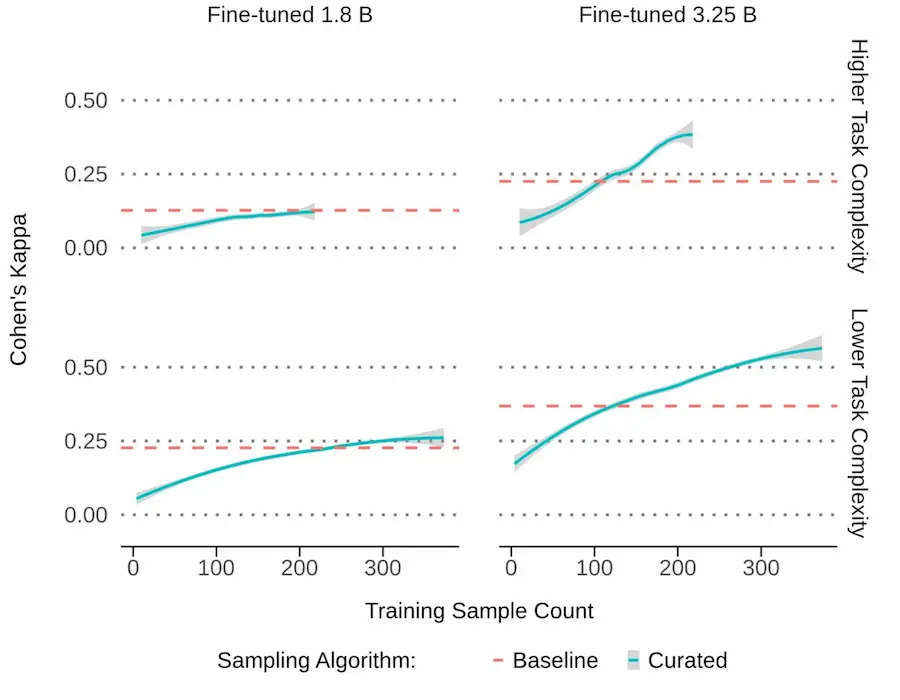
Active Learning di Google
Nei test con Gemini Nano-2 (3,25 miliardi di parametri), l’allineamento modello-esperti è migliorato del 55%–65% rispetto alla baseline, usando tre ordini di grandezza in meno dati.
Il risultato: meno costi, aggiornamenti rapidi quando cambiano policy o pattern di abuso, maggiore robustezza in dataset sbilanciati e capacità di adattarsi velocemente a nuovi scenari.
Qwen-Image e Qwen-Image-Edit
Alibaba presenta Qwen-Image, il nuovo generatore di immagini open source capace di integrare testo con precisione, anche in layout complessi.
L'ho provato. Le immagini che seguono sono state generate dal modello, in alcuni casi con prompt articolati e precisi. Per quanto riguarda il rendering dei testi, funziona abbastanza bene in lingua inglese (e cinese), ma in altre lingue non è il massimo.



Qwen-Image: un test
Basato su miliardi di coppie immagine-testo e un addestramento curriculare, combina il modello multimodale Qwen2.5-VL, un VAE Encoder/Decoder per dettagli nitidi e il backbone MMDiT con allineamento spaziale avanzato. Risultato: performance che eguagliano o superano modelli chiusi come GPT Image-1 e Seedream 3.0.
Licenza Apache 2.0, architettura modulare, strumenti di image-to-image editing e generazione di dataset sintetici di alta qualità lo rendono una soluzione strategica per aziende e creativi.
Qwen-Image-Edit è un modello basato su Qwen-Image 20B, dedicato all'editing avanzato delle immagini.
La sua forza sta nel combinare controllo semantico (cosa rappresenta l'immagine) e controllo visivo (come appare), grazie all'integrazione con Qwen2.5-VL e un encoder VAE.
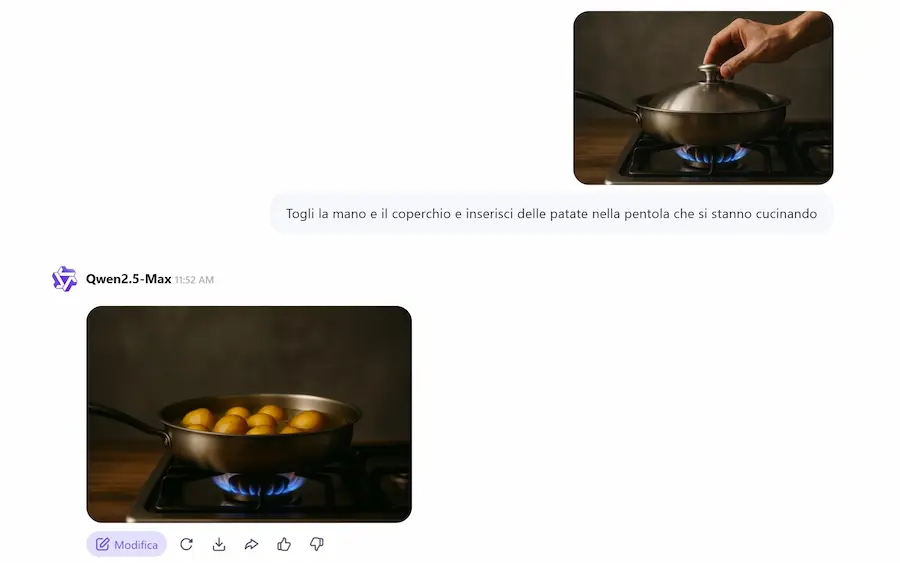
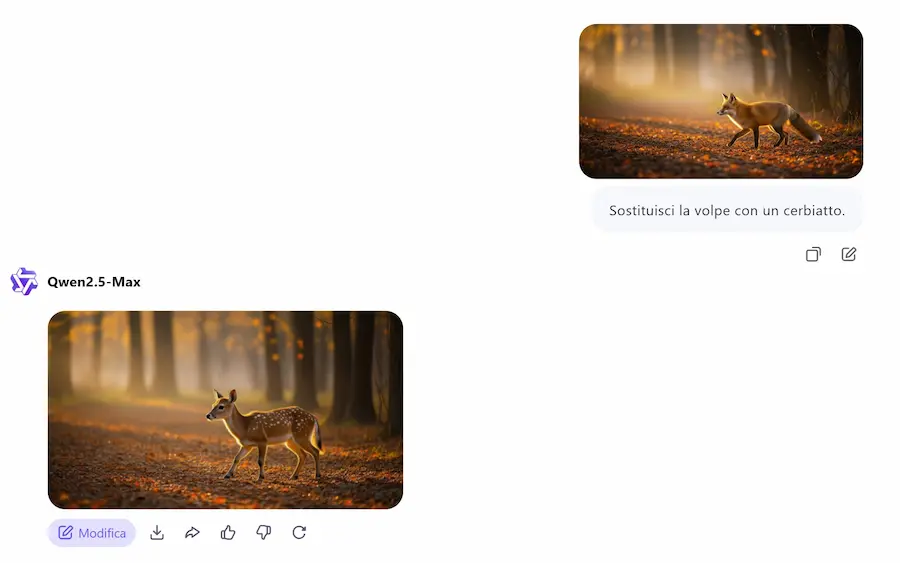
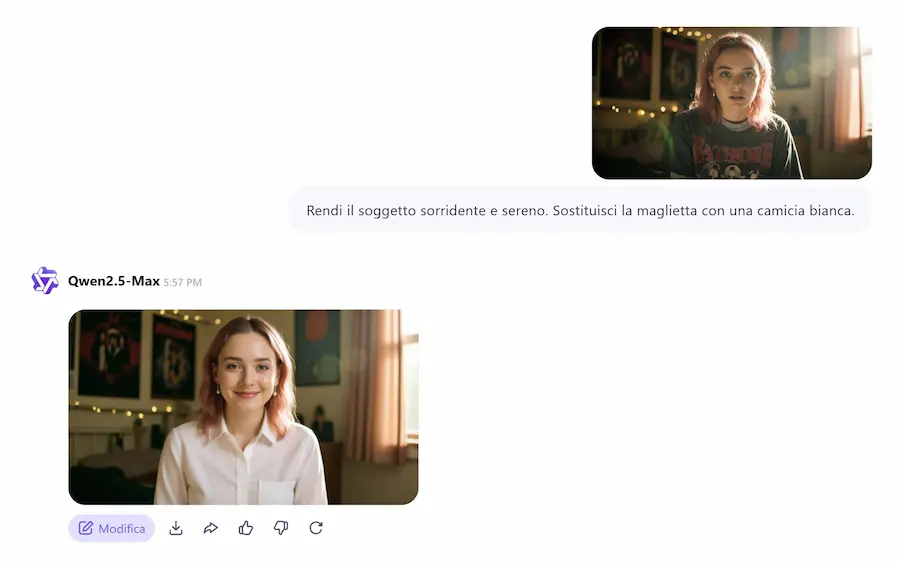

Un test di Qwen-Image-Edit
Permette..
- la modifica di testi (per ora inglese e cinese), mantenendo font, dimensioni e stile originale;
- l’editing semantico ad alto livello: rotazione degli oggetti, creazione di contenuti originali, trasferimento di stile;
- l’editing visivo a basso livello: aggiunta, rimozione o modifica di oggetti senza alterare il contesto.
La Deep Research di Qwen
Ho provato la nuova Deep Research di Qwen. Si tratta di un AI Agent in grado di compiere una ricerca approfondita sulla tematica richiesta nel prompt. Ancora una volta, siamo di fronte a un sistema molto interessante.
Il task che ho sottoposto all'agent nel test è molto dettagliato. Il modello genera delle domande di chiarimento iniziali, e successivamente avvia il processo.
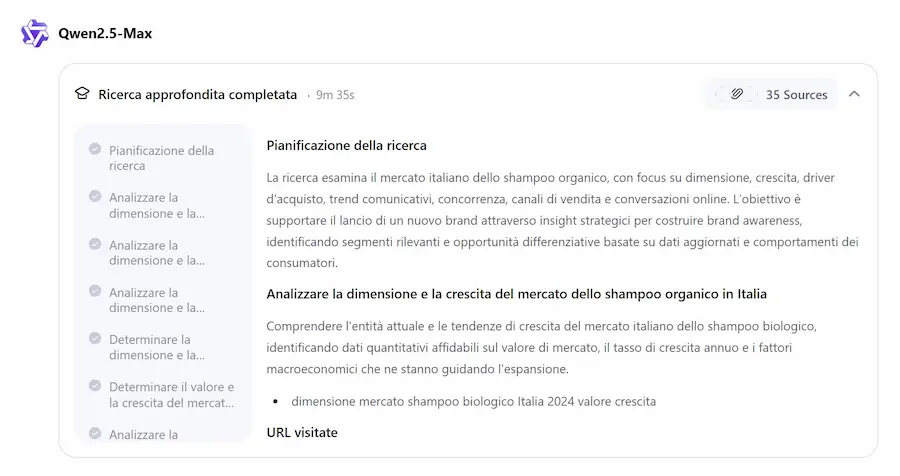
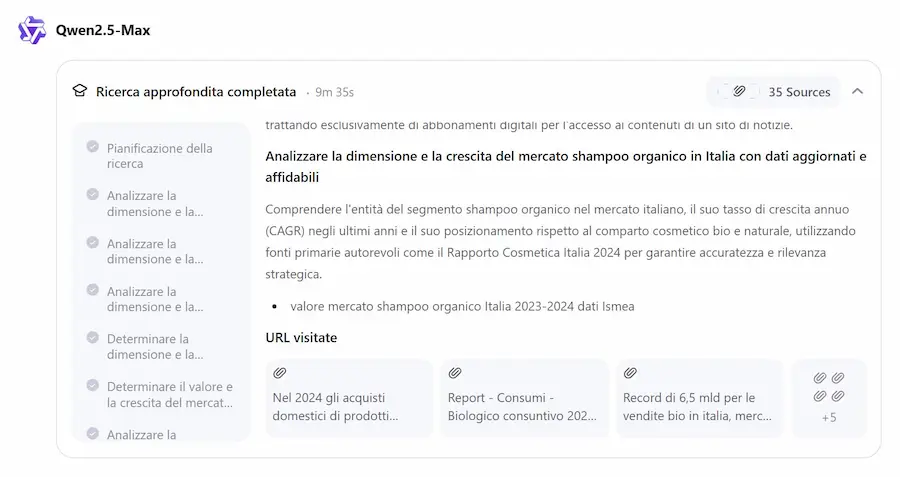

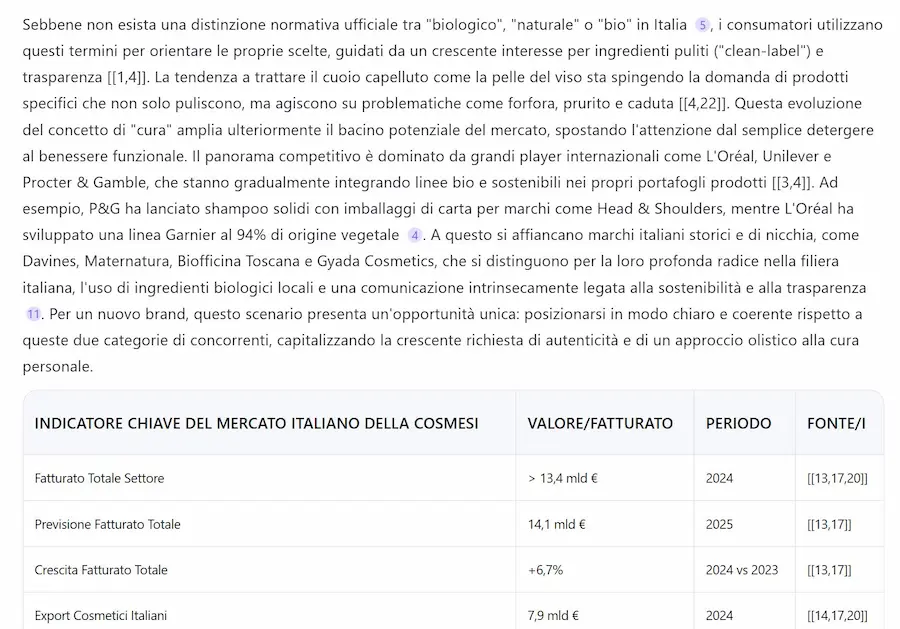
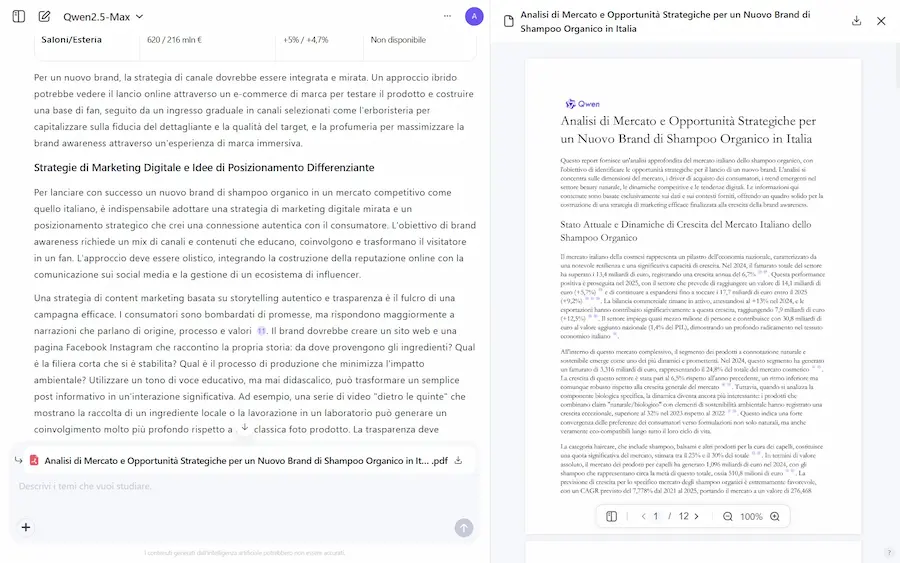
La Deep Research di Qwen
Dopo circa 10 minuti ho ottenuto un'ottima analisi di partenza, con tabelle prodotte attraverso elaborazioni Python e il PDF da scaricare.
LangExtract di Google
Google ha rilasciato LangExtract, una libreria Python open-source che trasforma testo non strutturato in dati strutturati grazie ai modelli LLM della famiglia Gemini.
Il sistema unisce estrazione controllata, grounding preciso (con collegamento diretto al testo sorgente) e visualizzazione interattiva in HTML. È adatto a domini come medicina, diritto, narrativa o finanza, e non richiede fine-tuning: basta definire il task e fornire esempi “few-shot”.
LangExtract di Google
La libreria gestisce anche testi lunghi tramite chunking, parallelismo e passaggi multipli, mantenendo alta accuratezza. Funziona sia con modelli cloud (Gemini) che locali (via Ollama).
Su GitHub si trovano esempi completi (Romeo e Giulietta, estrazione di farmaci, referti radiologici) e la guida all’installazione.
Genie 3
DeepMind ha presentato Genie 3, un modello del mondo generativo capace di creare ambienti interattivi incredibilmente realistici a partire da semplici prompt testuali.
Dalla simulazione di fenomeni naturali come lava e fiumi, fino alla creazione di creature fantastiche in scenari immaginari, Genie 3 apre nuove frontiere per la ricerca sull'AI.
Genie 3 - Google DeepMind
Il modello è progettato per mantenere coerenza visiva e fisica su lunghi orizzonti temporali, rendendolo ideale per addestrare agenti autonomi in ambienti dinamici. Supporta eventi generati via testo, modificando in tempo reale condizioni atmosferiche, oggetti e personaggi.
A differenza di tecniche basate su rappresentazioni 3D esplicite, Genie 3 genera mondi frame per frame, offrendo maggiore flessibilità e immersione. È già compatibile con agenti come SIMA, dimostrando il suo potenziale per l’apprendimento simulato.
Attualmente disponibile in preview limitata, rappresenta un passo avanti verso l’integrazione di AI generativa e ambienti simulati per applicazioni in formazione, creatività e ricerca.
DINOv3 di Meta
Meta ha presentato DINOv3, un nuovo modello di visione artificiale che segna un punto di svolta nell’apprendimento auto-supervisionato (SSL).
Per la prima volta, un backbone visivo addestrato senza etichette supera soluzioni supervisionate e weakly-supervised in una vasta gamma di compiti, dalle classificazioni globali alla segmentazione semantica, fino alla stima della profondità.
In pratica significa che il modello impara a “capire” le immagini da solo, senza bisogno di descrizioni o annotazioni create da esseri umani.
DINOv3 di Meta
L’innovazione principale è l’introduzione di "Gram anchoring", una tecnica che mantiene stabili e coerenti le rappresentazioni visive anche durante addestramenti molto lunghi e su modelli enormi.
In parole semplici, serve a evitare che il modello “perda la bussola” man mano che diventa più complesso.
Unita a un’architettura ViT-7B da 7 miliardi di parametri e a un dataset curato di 1,7 miliardi di immagini, questa soluzione permette di generare rappresentazioni visive ad altissima risoluzione, nitide e precise.
Un’altra svolta è la capacità di ottenere prestazioni allo stato dell’arte senza fine-tuning. Ciò vuol dire che il modello, così com’è, può già essere usato per tanti compiti diversi senza dover essere riaddestrato ogni volta. Questo fa risparmiare tempo e potenza di calcolo.
In più, grazie a un processo chiamato multi-student distillation, la potenza del modello gigante viene “compressa” e trasferita in versioni più leggere. Così si possono avere modelli più piccoli, veloci e facili da usare, senza perdere troppa qualità.
L’impatto è già concreto: con immagini satellitari, DINOv3 ha ridotto drasticamente l’errore nella stima dell’altezza degli alberi, aiutando il monitoraggio ambientale e la lotta alla deforestazione. Lo stesso approccio può supportare la robotica spaziale, l’imaging medico e i sistemi autonomi.
Con DINOv3, l’apprendimento auto-supervisionato per la visione compie un salto di scala e qualità, aprendo la strada a un backbone universale capace di comprendere il mondo visivo in modo più accurato, efficiente e generalizzabile.
3D-R1: potenzia il ragionamento nei Vision-Language Models 3D
3D-R1 è un modello generalista open-source che potenzia il ragionamento nei Vision-Language Models 3D per una comprensione unificata delle scene tridimensionali.
Supera i limiti dei VLM tradizionali grazie a un nuovo dataset sintetico (Scene-30K), tecniche di Reinforcement Learning con feedback umano (RLHF) e una strategia dinamica di selezione delle viste.
3D-R1: potenzia il ragionamento nei Vision-Language Models 3D
Costruito con Chain-of-Thought e Gemini 2.5 Pro, consente un'inizializzazione efficace del modello. Il training è potenziato da ricompense multiple (percezione, similarità semantica, formato), migliorando coerenza e precisione delle risposte.
3D-R1 raggiunge un incremento medio del 10% nei benchmark 3D, mostrando forti capacità zero-shot in captioning, grounding, dialoghi, QA, pianificazione e ragionamento in ambienti 3D.
Architettura modulare, addestramento SFT su Scene-30K, supporto a PointNet++, compatibilità con Qwen2.5-VL-7B e Hugging Face: tutto ciò rende 3D-R1 uno strumento potente per la nuova generazione di AI spaziale.
OpenCUA: framework open source per l'uso del computer da parte di AI Agent (CUA)
Un framework completamente open source apre nuove prospettive per gli agenti di uso del computer (CUA).
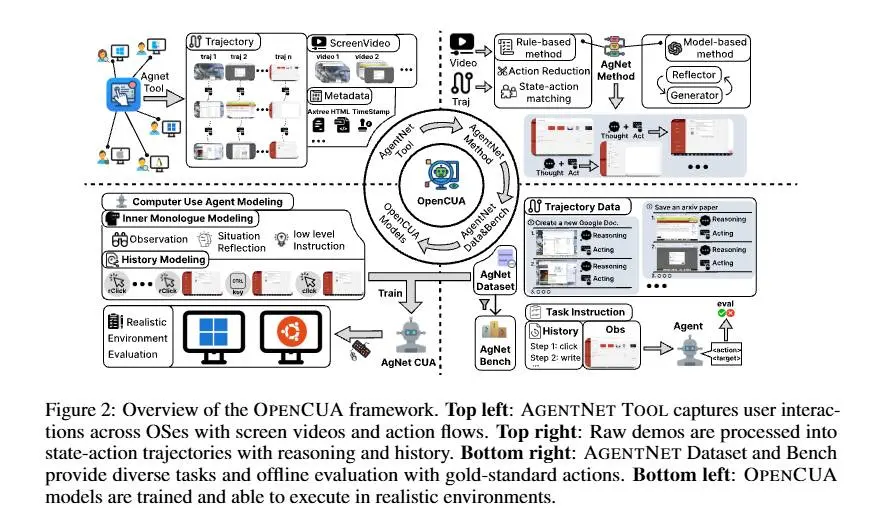
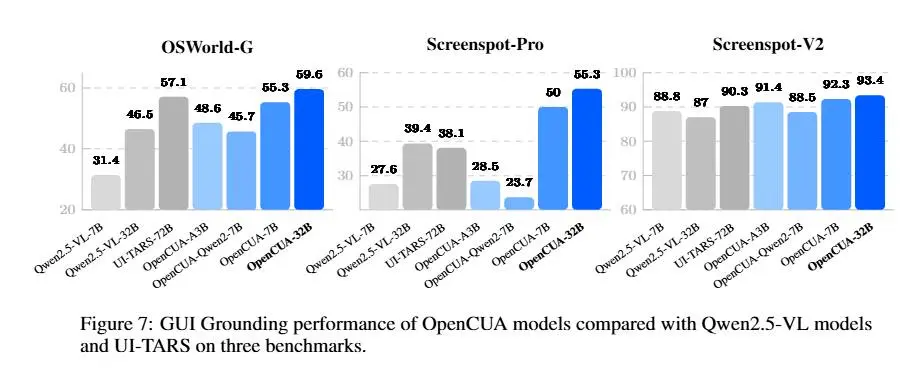
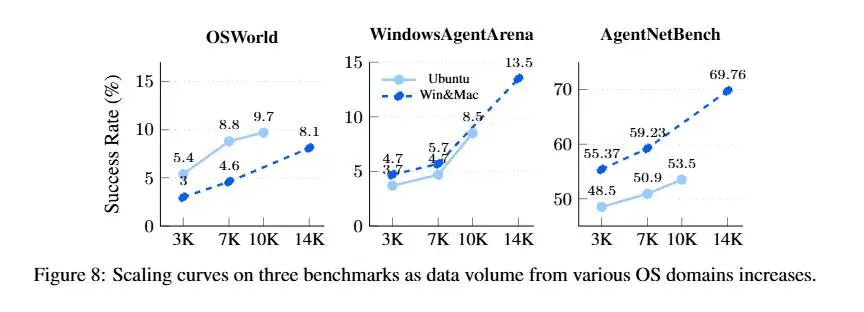
OpenCUA mette a disposizione un ecosistema completo: strumenti di annotazione per raccogliere interazioni reali, un dataset di 22.6K traiettorie su Windows, macOS e Ubuntu e benchmark dedicati per valutare in modo rapido e trasparente le capacità degli agenti.
La pipeline trasforma dimostrazioni umane in coppie stato–azione arricchite da ragionamenti riflessivi e catene di pensiero lunghe, che aiutano i modelli a pianificare meglio, mantenere memoria del contesto e correggere gli errori.
OpenCUA: il paper e le performance
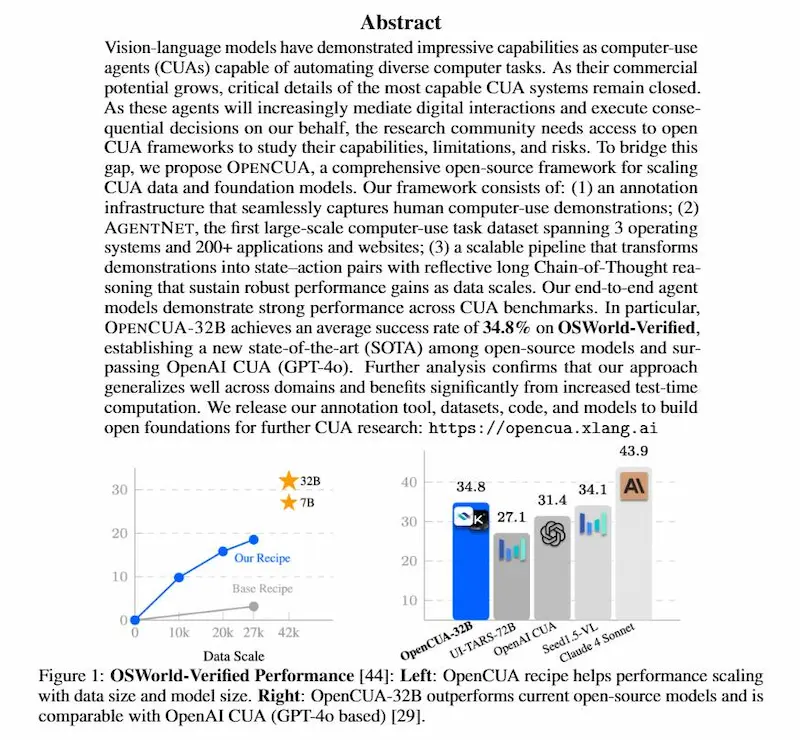
Grazie a questa ricetta di training, il modello di punta OpenCUA-32B raggiunge un tasso di successo del 34.8% su OSWorld-Verified, superando GPT-4o (OpenAI CUA) e stabilendo il nuovo stato dell’arte tra i modelli open source.
Un risultato che dimostra come dati diversificati, reasoning strutturato e apertura delle risorse possano accelerare lo sviluppo di agenti capaci di interagire in modo sempre più efficace con i nostri ambienti digitali.
Storybook: nuova funzionalità per Gemini
L'app di Gemini introduce una nuova funzionalità: lo storybook.
Si tratta di un sistema che permette di creare un vero e proprio "libro" personalizzato attraverso un prompt multimodale.
Nell'esempio, ho caricato l'immagine di un robottino e ho chiesto una storia per bambini, con qualche indicazione sulla trama. Il modello mi ha fatto alcune domande per migliorare le caratteristiche dell'obiettivo (es. l'età del pubblico è il tipo di illustrazioni).
Storybook su Gemini: un esempio
Il risultato è un piccolo storybook, con anche la funzionalità di lettura automatica.
L'esempio forse sembra banale, ma applicato la contesto dell'apprendimento di concetti di qualunque genere, potrebbe essere molto interessante.
L'apprendimento guidato su Gemini
Dopo la modalità "Studia e impara" di OpenAI su ChatGPT, Google segue con "Apprendimento guidato" nell'app di Gemini.
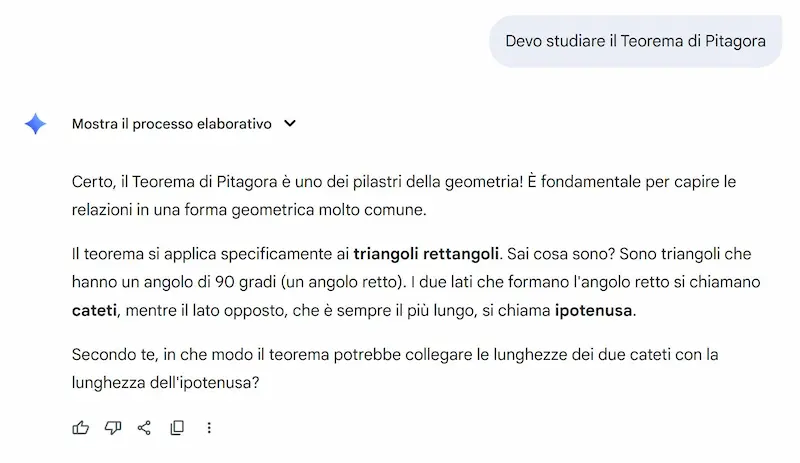
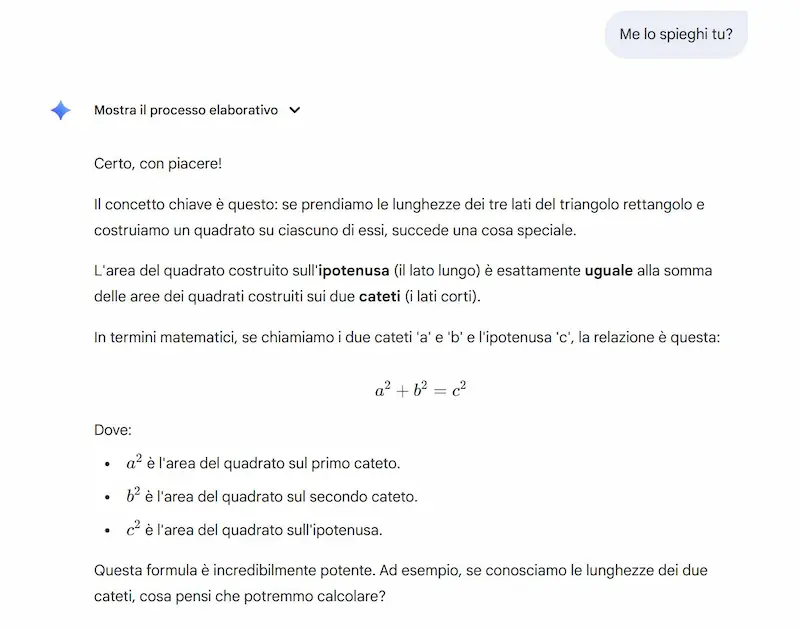
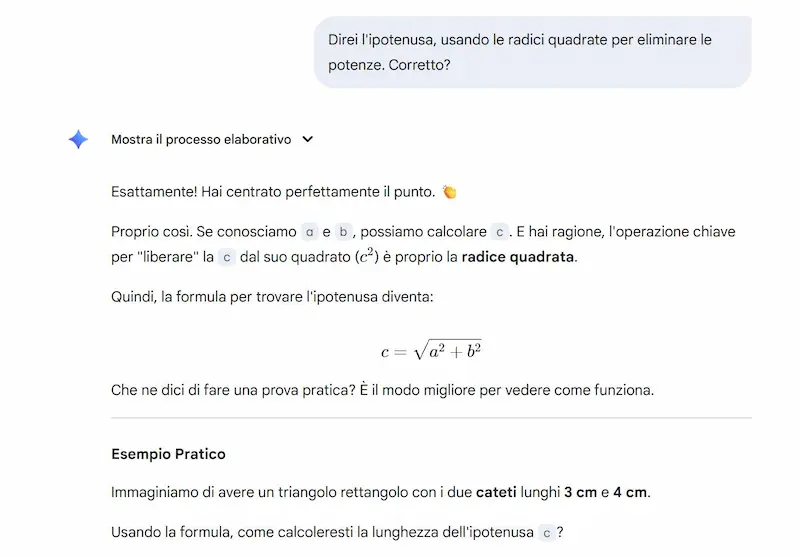
L'ho provato per studiare il Teorema di Pitagora, e il processo che propone la funzionalità è molto interessante. Anche se la visualizzazione interattiva che ho ottenuto da GPT-5 è molto più accattivante.
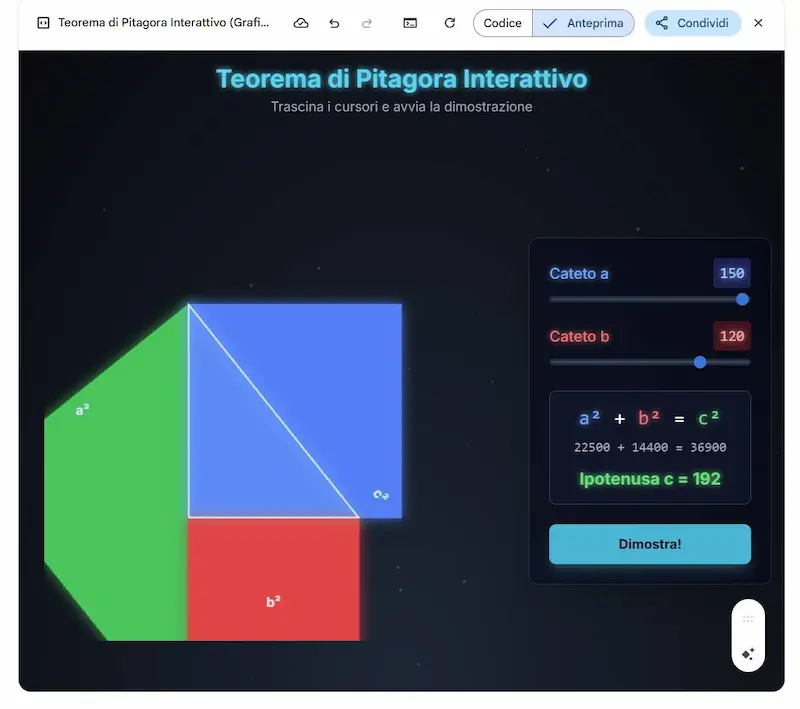
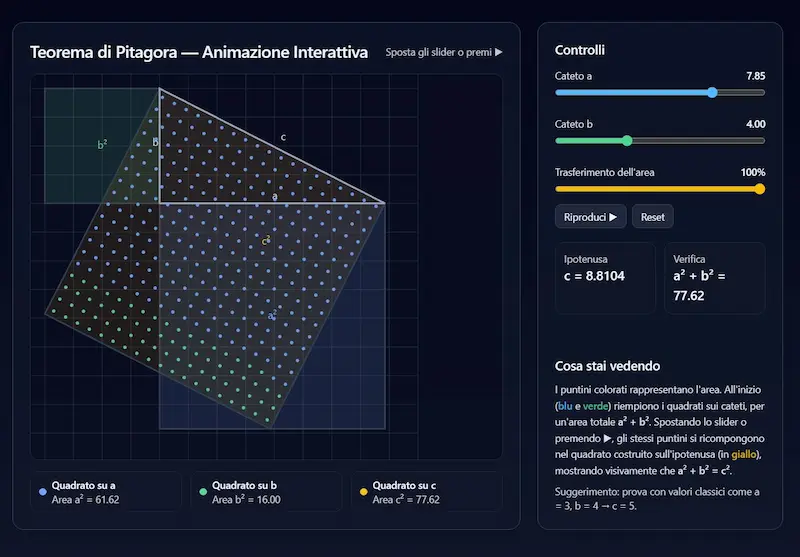
"Apprendimento guidato" nell'app di Gemini
Non si tratta più solo di ottenere risposte, ma di costruire una comprensione profonda, passo dopo passo. Grazie a domande aperte, spiegazioni adattive e contenuti multimediali come video, immagini e quiz interattivi, Guided Learning trasforma l'AI in un vero compagno di studio.
Basato su LearnLM, una famiglia di modelli sviluppati con esperti di pedagogia, neuroscienze e scienze cognitive, questo strumento mette al centro la partecipazione attiva e l’apprendimento costruttivo.
È pensato sia per chi studia da solo, sia per supportare gli insegnanti in aula con risorse integrabili direttamente in Google Classroom.
Ogni studente può esplorare argomenti in un ambiente sicuro e stimolante, imparando al proprio ritmo, con l’AI al servizio della comprensione, non della velocità.
Sistemi neuro-simbolici: Seed-Geometry
Ancora un passo avanti in ambito di sistemi neuro-simbolici: il nuovo Seed-Geometry, sviluppato da ByteDance Seed AI4Math, ha ufficialmente superato AlphaGeometry 2 nei benchmark di geometria delle Olimpiadi Matematiche Internazionali.
Su 50 problemi IMO di geometria dal 2000 al 2024, Seed-Geometry ne ha risolti 43, rispetto ai 42 di AlphaGeometry 2. Ancora più significativo il risultato sulle shortlist dei problemi più difficili: 22 soluzioni su 39 per Seed-Geometry contro le 19 di AlphaGeometry 2.
Questo avanzamento è stato possibile grazie a un motore di ragionamento simbolico ultra-veloce, una rappresentazione più compatta delle costruzioni geometriche e un’integrazione efficiente con modelli neurali specializzati.
Seed-Geometry non solo accelera la ricerca automatica di soluzioni, ma stabilisce un nuovo standard nella formalizzazione matematica automatica, confermando la centralità dell’approccio neuro-simbolico nell’AI matematica di frontiera.
I sistemi neuro-simbolici rappresentano oggi la convergenza tra la potenza di generalizzazione delle reti neurali e la precisione del ragionamento logico formale. Questa sinergia non solo apre la strada a soluzioni più efficaci e verificabili nei domini complessi come la matematica, ma segna anche un cambio di paradigma nell’intelligenza artificiale: dalla semplice previsione, verso la comprensione e la spiegabilità profonda dei problemi.
Personal Superintelligence - Meta
Zuckerberg ha pubblicato un post per condividere la visione di Meta sul futuro dell'AI e della superintelligenza. Non si parla solo di efficienza o automazione, ma di un nuovo paradigma centrato sull’individuo.

Negli ultimi anni l’intelligenza artificiale ha compiuto progressi significativi, ma ora Meta guarda oltre: verso lo sviluppo di una superintelligenza personale. Si tratta di sistemi AI in grado di comprendere a fondo le esigenze, gli obiettivi e i contesti quotidiani delle persone, offrendo supporto continuo e mirato.
Secondo Meta, la superintelligenza non dovrebbe essere gestita in modo centralizzato con l’obiettivo di sostituire il lavoro umano. Al contrario, dovrebbe essere uno strumento distribuito, a disposizione di ciascuno, per aumentare le capacità personali, stimolare la creatività e favorire la crescita individuale.
Per realizzare questa visione, l’azienda sta sviluppando dispositivi intelligenti – come occhiali in grado di percepire l’ambiente visivo e sonoro – che fungeranno da interfaccia primaria per interagire con l’AI in modo più naturale e contestuale.
Mark, per quanto riguarda la "sfera individuale" comprendo la visione. Anche perché non puoi dire il contrario. Ma in ambito lavorativo, questi sistemi verranno usati proprio per aumentare l'efficienza e l'automazione.
Zuckerberg sottolinea che il decennio in corso sarà decisivo per determinare la direzione che prenderà questa tecnologia: se sarà una leva di empowerment individuale o uno strumento di sostituzione sistemica. Meta si impegna per la prima opzione, investendo risorse e infrastrutture per portare la superintelligenza personale a miliardi di persone.
Infine, il post affronta anche la questione dell’open source. Pur riconoscendo il valore della condivisione, Meta adotta un approccio cauto: non tutto potrà essere reso pubblico, specialmente in considerazione dei potenziali rischi legati alla sicurezza. L’obiettivo resta comunque quello di garantire un accesso il più ampio possibile ai benefici generati dalla tecnologia.
Meta intende così aprire un nuovo capitolo tecnologico, in cui la superintelligenza non è un'entità astratta, ma una risorsa personale al servizio dell’autonomia, della creatività e del progresso umano.
È possibile che non raggiungeremo l’AGI?
In una recente intervista con Emily Chang, Sundar Pichai ha parlato di AGI, l’intelligenza artificiale generale con capacità cognitive paragonabili a quelle umane.
Alla domanda diretta "È possibile che non raggiungeremo l’AGI?", Pichai ha riconosciuto che è "del tutto possibile" che, CON GLI APPROCCI ATTUALI, non si arrivi a quel traguardo, spiegando che il progresso tecnologico può incontrare dei "plateau", ovvero dei momenti in cui lo sviluppo rallenta o si ferma a causa di limiti intrinseci.
Emily Chang intervista Sundar Pichai
Pur con questa incertezza, ha sottolineato che il ritmo di avanzamento dell'AI oggi è "sbalorditivo" e che i modelli attuali stanno già dimostrando capacità straordinarie.
Per spiegare la distanza tra l’AI attuale e l’AGI, ha usato un’analogia: un ragazzo può imparare a guidare in circa 20 ore, ma a Waymo sono serviti oltre 10 anni di sviluppo per avvicinarsi alla perfezione, senza raggiungerla pienamente. Compiti che per gli esseri umani sono intuitivi e guidati dal buon senso risultano estremamente complessi per un’AI.
Pichai descrive così una doppia natura: un’AI capace di risultati eccezionali in contesti specifici, ma ancora lontana dalla flessibilità, dal ragionamento e dalla comprensione del mondo tipici dell’intelligenza umana. Un approccio di cauto ottimismo, che riconosce al tempo stesso il potenziale e le sfide ancora da affrontare.
Quanto consuma effettivamente l'AI?
Ne abbiamo lette e sentite di ogni tipo, su articoli improbabili, con titoli assurdi per produrre clic.
Oggi Google risponde con un report dei consumi che sta registrando.
Però ho una considerazione da fare sulla metodologia di interpretazione che hanno usato.

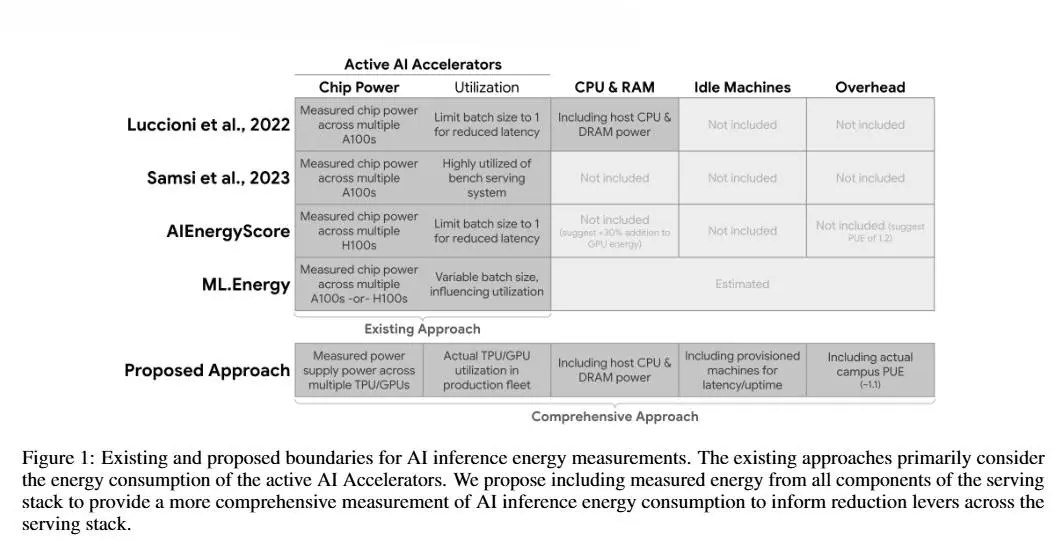
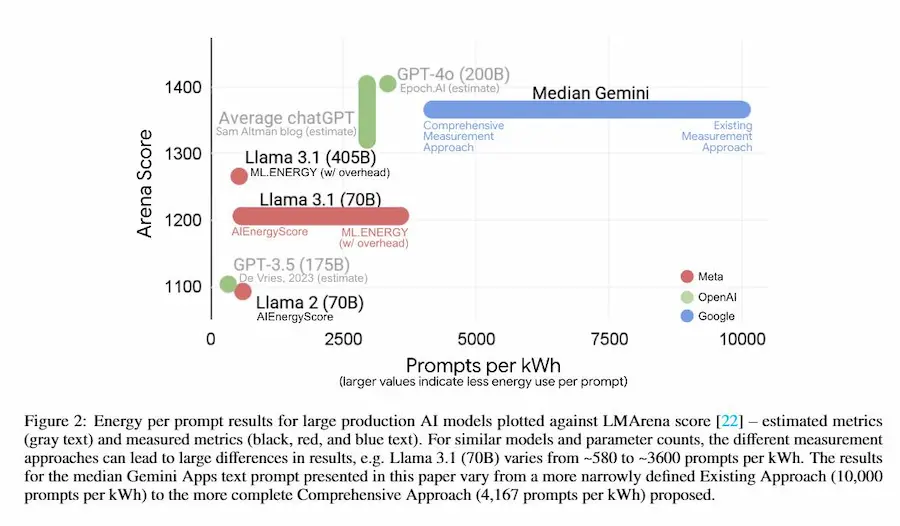
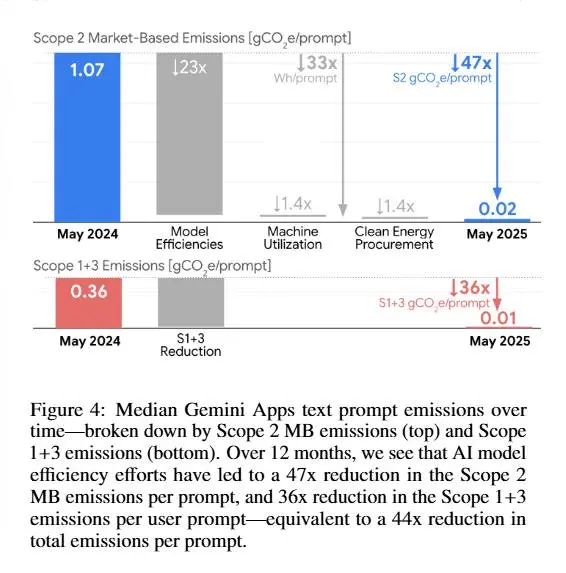
Il report di Google sui consumi dell'AI
Cosa dice il report?
Google ha misurato per la prima volta in produzione l’impatto ambientale del suo modello Gemini. Il risultato?
Un prompt testuale consuma 0,24 Wh (meno di 9 secondi di TV), emette 0,03 g di CO2e, e usa 0,26 ml d’acqua (circa 5 gocce).
Numeri molto più bassi di molte stime circolate negli ultimi mesi.
Il report mostra anche i progressi di efficienza: nell’arco di un anno Google ha ridotto del 44× le emissioni per prompt grazie a modelli più snelli, hardware co-progettato (TPU), data center ultra-efficienti (PUE 1,09) e acquisti di energia rinnovabile.
Un segnale forte: l’ottimizzazione dell’intera catena (modello, hardware, software, data center, energia) può ridurre drasticamente l’impatto.
La mia considerazione sulla metodologia
Google sceglie di comunicare i valori mediani dei consumi. È una scelta sensata per descrivere l’esperienza dell’utente “tipico”, e viene spiegato chiaramente nel documento.
Ma il consumo totale dipende dalla media: se alcuni prompt sono molto più lunghi o complessi, alzano la media senza spostare troppo la mediana. In distribuzioni sbilanciate a destra, come quelle degli LLM, la media è quindi significativamente più alta.
Tradotto: dire "un prompt consuma 0,24 Wh" è vero per l’uso comune, ma non racconta quanto pesa davvero l’insieme di tutti i prompt, dove pochi casi estremi bruciano gran parte dell’energia.
Conclusione
Il documento di Google ci fa capire un aspetto importante, che in fondo è anche abbastanza comune: l'innovazione produce nuove tecnologie, e, se ha senso adottarle, vengono ottimizzate. Pensiamo a quanto consumava un climatizzatore agli inizi, rispetto a oggi (la differenza è abissale).
Però, se vogliamo valutare con rigore l’impatto complessivo dell’AI, serve anche un'altra visione dei dati: la mediana racconta bene il “prompt tipico”, ma è la media a dire quanta energia si spende davvero su scala globale.
VibeVoice di Microsoft
Microsoft Research ha rilasciato VibeVoice, un modello open source capace di generare conversazioni vocali multi-speaker fino a 90 minuti con una qualità elevata.
L'ho provato. L'audio che si sente è un podcast con 3 speaker generato partendo da uno script testuale.
VibeVoice: un podcast con 3 speaker
La novità sta nell’uso della next-token diffusion e di un innovativo speech tokenizer continuo, che comprime l’audio fino a 3200× mantenendo fedeltà percettiva ed efficienza computazionale.
Questo consente di scalare la sintesi vocale a contesti lunghi, con naturalezza nei turni di parola e ricchezza timbrica.
Alcuni risultati
- Supera modelli leader come Gemini 2.5 Pro TTS ed ElevenLabs V3 in realismo, ricchezza e preferenza degli ascoltatori.
- Ottiene il Word Error Rate più basso e maggiore somiglianza tra speaker.
- Generalizza bene anche su utterances brevi, nonostante sia ottimizzato per conversazioni lunghe.
Limitazioni dichiarate: supporto solo a inglese e cinese, assenza di gestione per rumori o parlato sovrapposto.
Un passo avanti verso podcast e audiolibri multi-partecipanti sintetici, con forte enfasi sulla ricerca responsabile.
Podcastify
Podcastfy è un progetto open source in Python che consente di trasformare contenuti multimodali come testi, immagini, PDF, siti web o video YouTube in podcast audio conversazionali, personalizzabili e multilingue, utilizzando modelli di intelligenza artificiale generativa.
Un esempio di output di Podcastify
Pensato come un'alternativa open alla funzione podcast di NotebookLM, Podcastfy si distingue per l’approccio programmabile, scalabile e completamente personalizzabile.
È possibile creare episodi brevi da 2-5 minuti o podcast longform di oltre 30 minuti, scegliendo stile, struttura del dialogo, voci TTS (tra cui OpenAI, Google, ElevenLabs, Microsoft) e lingua, con supporto a oltre 100 modelli LLM, inclusi quelli locali.
Il sistema è adatto sia a sviluppatori sia a utenti senza competenze tecniche: si può usare tramite Python, CLI, API FastAPI, web app o container Docker. Offre una perfetta integrazione in flussi di lavoro automatizzati e si presta a progetti custom.
Podcastfy è già stato adottato in strumenti come SurfSense, OpenNotebook e Podcast-LLM, ed è ideale per content creator che vogliono trasformare articoli e blog in podcast, per educatori che desiderano rendere accessibili le proprie lezioni in formato audio, e per ricercatori interessati a rendere fruibili i propri lavori a un pubblico più ampio.
La versione più recente introduce il supporto a modelli TTS multispeaker e la possibilità di generare podcast partendo da contenuti cercati in tempo reale sul web, offrendo un’esperienza ancora più ricca, flessibile e aggiornata.
Runway, e le potenzialità di Aleph
Runway mostra un esempio delle potenzialità di Aleph.
Nel video si vede come il modello possa apportare modifiche complesse agli ambienti, aggiungendo elementi dinamici come la neve sulle spalle e gli schizzi d'acqua mentre i personaggi si muovono.
Really nice demo of what @runwayml Aleph can do for complex changes in environments while adding accurate dynamic elements like snow on the shoulders or splashing water as the characters move. pic.twitter.com/YAeWxAnz1f
— Cristóbal Valenzuela (@c_valenzuelab) July 30, 2025
La crescita dei modelli di generazione video sta decollando. Sono curioso di scoprire il margine di miglioramento che ci sarà.
FLUX.1 Krea [dev]
FLUX.1 Krea [dev] è un nuovo modello di generazione testo-immagine sviluppato da Black Forest Labs insieme a Krea AI.
Si tratta di un modello open weights che segna un'evoluzione importante: punta a superare il classico “look da AI”, spesso troppo saturo e artificiale, per offrire risultati visivamente più credibili e interessanti.

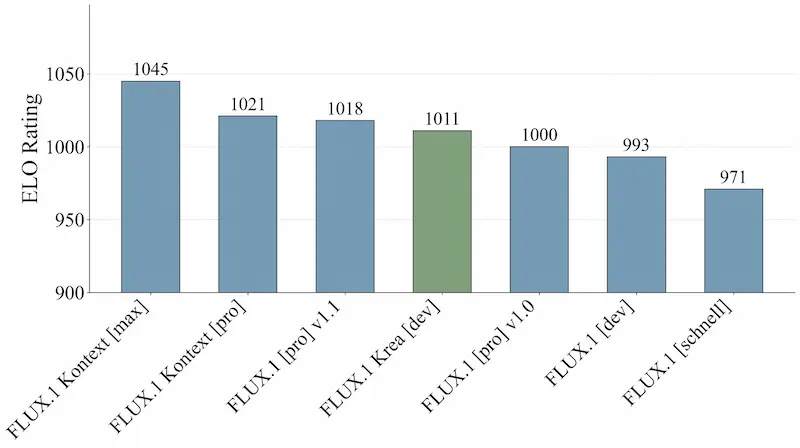
FLUX.1 Krea [dev]
Il modello è definito "opinionated" perché non si limita a interpretare le richieste in modo neutro, ma applica scelte stilistiche precise, generando immagini ricche di carattere e varietà. Questo approccio lo rende particolarmente adatto a chi cerca creatività controllata e realismo, senza dover scendere a compromessi.
È già disponibile su HuggingFace, con integrazioni API offerte da partner come FAL, Replicate, Runware, DataCrunch e TogetherAI.
Un progetto che dimostra quanto sia potente la collaborazione tra chi sviluppa modelli fondamentali e chi lavora sull’applicazione concreta dell’intelligenza artificiale.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂