Generative AI: novità e riflessioni - #9 / 2025
Instant Checkout di ChatGPT, AP2 per pagamenti agentici, Seedream 4 per immagini 4K, Ray 3 HDR, Gemini Robotics, Kimi Slides, agenti AI che osservano, generano e acquistano. Test, riflessioni e risorse pratiche.

Buon aggiornamento, e buone riflessioni..
Il progetto Harmonia: presentato Expo 2025 di Osaka
Sono onorato di aver potuto dare il mio contributo alla realizzazione di Harmonia, una webapp presentata al Padiglione della Santa Sede all'Expo 2025 di Osaka.
Si tratta di un progetto collettivo nato dalla collaborazione tra IUSVE e il Dicastero per l’Evangelizzazione, con l’obiettivo di unire le voci di persone da tutto il mondo attorno a un messaggio universale di pace. L’applicazione consente agli utenti di registrare una frase del Pontefice in diverse lingue. Ogni contributo vocale viene visualizzato in tempo reale come forma d’onda, mostrando le caratteristiche uniche della voce umana in termini di frequenze, intensità e timbro.

La parte più innovativa del progetto si attiva al termine della raccolta delle registrazioni: un modello di AI elabora i dati acustici per sintetizzare un’unica voce corale — la “Voce del mondo” — simbolo concreto di connessione tra individui diversi ma uniti da uno stesso intento.
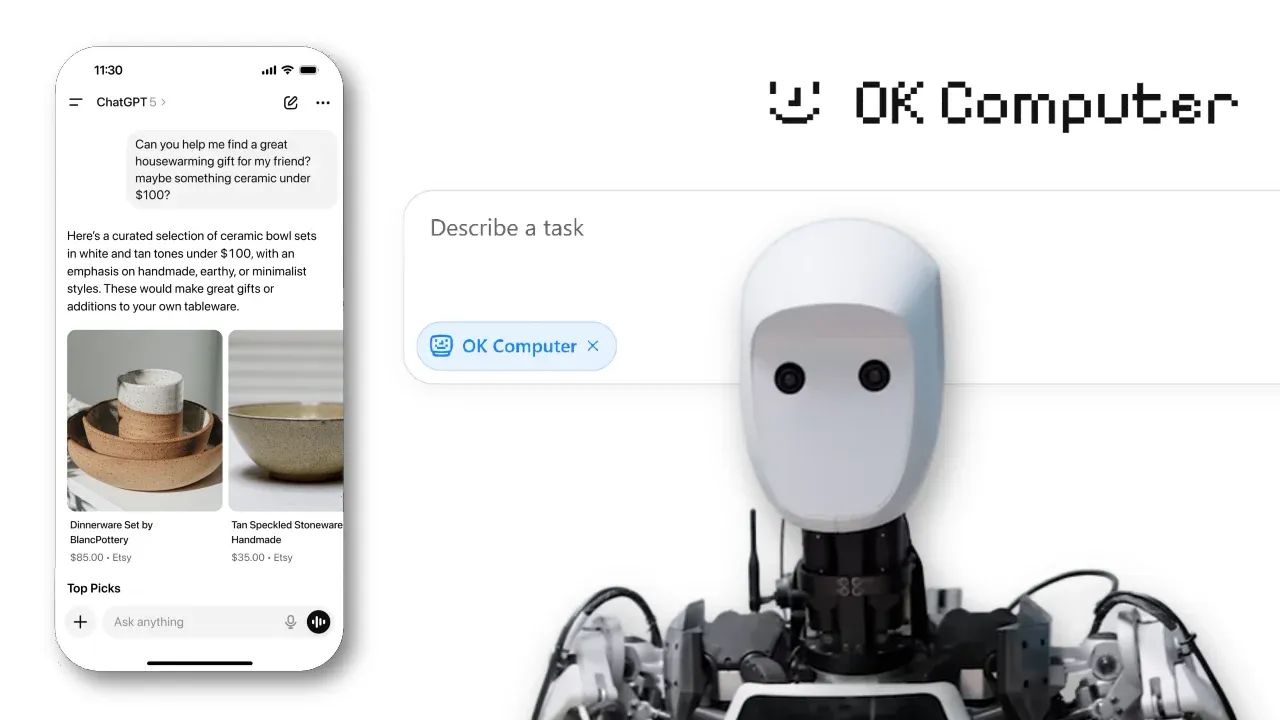
Instant Checkout di ChatGPT
ChatGPT introduce Instant Checkout: ora è possibile acquistare prodotti direttamente all’interno della chat. In questa fase iniziale, la funzione è disponibile per gli utenti negli Stati Uniti (Free, Plus e Pro) e consente di comprare da venditori statunitensi su Etsy.
Nelle immagini si vede un mio test con l'opzione già attiva.
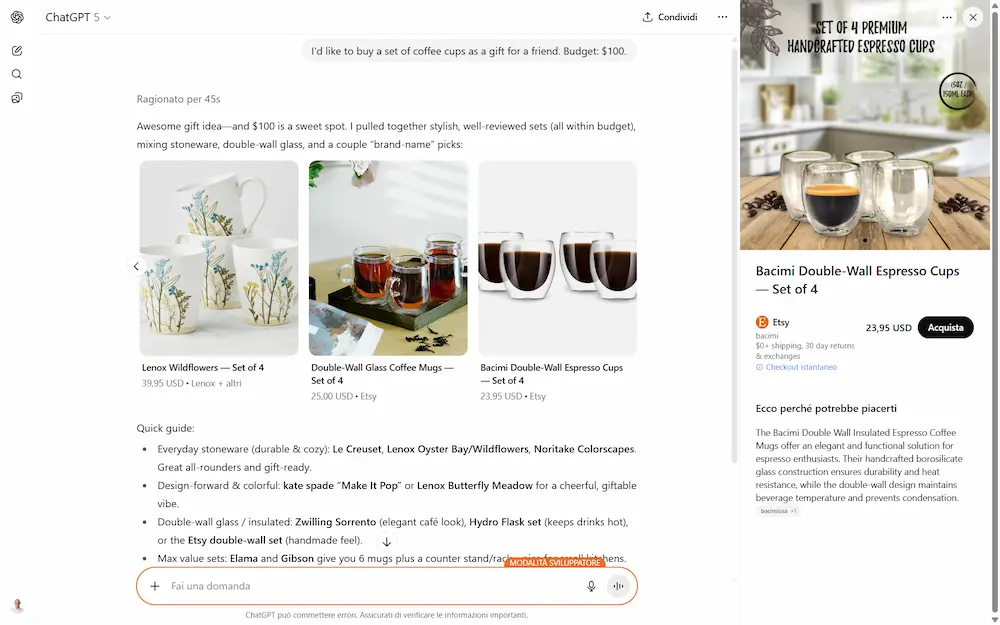
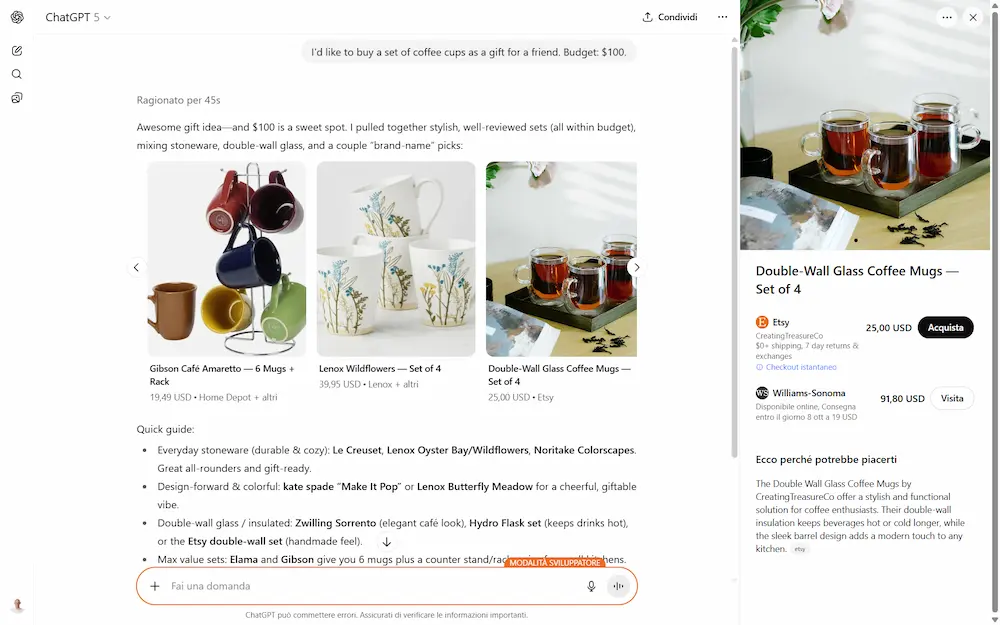
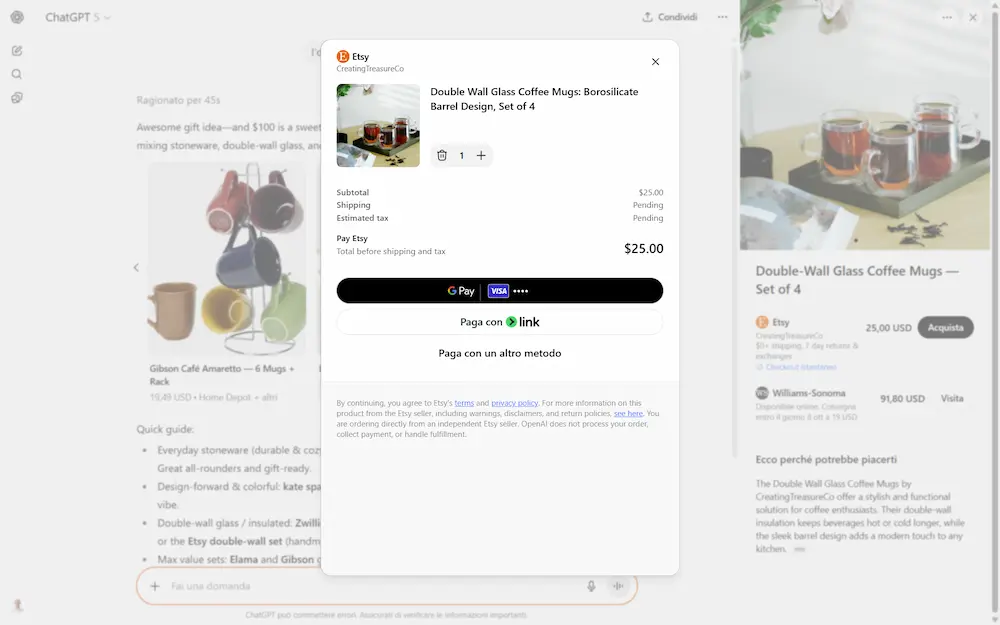
A breve verranno inclusi anche oltre un milione di merchant su Shopify, tra cui brand come Glossier, SKIMS, Spanx e Vuori, con l'obiettivo di espandere la disponibilità ad altri commercianti e regioni nel tempo.
Il sistema è basato sull’Agentic Commerce Protocol, un nuovo standard open-source sviluppato insieme a Stripe, pensato per permettere agli agenti AI, agli utenti e alle aziende di collaborare in modo sicuro e fluido per completare un acquisto.

Il processo d’acquisto è diretto: ChatGPT propone prodotti rilevanti non sponsorizzati, l’utente seleziona un prodotto abilitato, conferma i dettagli e completa il pagamento, tutto senza uscire dalla conversazione. Gli ordini sono gestiti dai merchant con i loro sistemi esistenti, mentre ChatGPT agisce da intermediario sicuro.
OpenAI ha già pubblicato la sezione dedicata ai "merchant", e la documentazione per creare il feed dei prodotti degli e-commerce. Per ora, tutto questo è attivo negli USA, ma, nel frattempo...
fa riflettere sull'importanza di avere dati ben organizzati e la capacità di trasformarli agilmente in feed ottimizzati per diverse piattaforme.
L’approccio dell'Instant Checkout è progettato per garantire sicurezza, trasparenza e controllo all’utente. I dati condivisi sono minimi e sempre autorizzati, e i pagamenti sono criptati e legati solo a transazioni specifiche. I commercianti restano titolari del rapporto con il cliente, dalla spedizione al supporto post-vendita.
L’integrazione tecnica è pensata per essere rapida: per chi utilizza Stripe è sufficiente una riga di codice, ma sono previste soluzioni anche per altri sistemi di pagamento.
Sarà una tappa verso un nuovo modello di commercio digitale? Dove l’assistente AI non si limita a consigliare cosa acquistare, ma accompagna l’utente nell’intero processo d’acquisto in modo naturale e diretto.
Serve una leadership con “mentalità da pilota” per gestire al meglio l'AI
Sempre più aziende adottano strumenti di intelligenza artificiale con grandi aspettative di efficienza, ma i risultati spesso deludono. Secondo una recente analisi di BetterUp Labs e Stanford Social Media Lab, il fenomeno del “workslop” (contenuti generati dall’IA che sembrano lavoro ben fatto ma sono privi di sostanza) sta compromettendo la produttività e la collaborazione nei team.

Documenti, report e presentazioni creati in pochi secondi finiscono per spostare il carico cognitivo su chi li riceve, che deve reinterpretare, correggere o rifare da capo. Oltre al tempo sprecato, si innescano dinamiche di sfiducia e giudizi negativi sulla competenza dei colleghi.
Non è una questione tecnologica, ma culturale. Serve un uso più consapevole dell’IA, che valorizzi il pensiero critico invece di sostituirlo.
- L’IA non alleggerisce il lavoro se usata senza criterio: semplicemente lo scarica su altri.
- Il “workslop” ha un costo nascosto: tempo perso, fiducia compromessa, collaborazione danneggiata.
- La differenza la fa l’approccio: serve una cultura del “pilota”, non del “passeggero”, per usare davvero l’IA in modo utile.
Seedream 4
Ho provato Seedream 4, il nuovo modello dedicato alle immagini di ByteDance (che tutti conosciamo per TikTok).
Lo trovo impressionante, sinceramente. Ho creato le prime due immagini fornendo al modello gli oggetti (il profumo e la chitarra) e descrivendo la scena con un prompt testuale. Le altre due, sono text-to-image. L'output è in 4K… ma, ancora una volta, a stupire è sì la qualità, ma soprattutto l’aderenza alle istruzioni.




Immagini generate con Seedream 4
Seedream 4 nasce come modello “unificato”: non solo genera immagini da zero, ma permette anche di modificarle tramite semplici richieste in linguaggio naturale. Questo significa poter togliere o aggiungere elementi, cambiare sfondi, mantenere lo stesso soggetto in più scene o addirittura costruire sequenze narrative coerenti.
In termini di performance, la velocità è sorprendente: circa 1,8 secondi per un’immagine 2K (forse meno di Gemini), con supporto fino a 4K. Le immagini originali che ho condiviso "pesano" mediamente 15MB.
Sul fronte qualità, benchmark indipendenti lo collocano ai vertici accanto a Gemini 2.5 Flash Image (Nano Banana) di Google, considerato tra i migliori modelli generativi del momento.
Il modello è usabile via API (BytePlus) o piattaforme terze che l’hanno già integrato (ad esempio Freepik, che consiglio).
Velocità, qualità, un'incredibile aderenza ai prompt, e coerenza delle immagini: se questo è il nuovo standard di elaborazione delle immagini attraverso l'AI generativa, le applicazioni commerciali sembrano quasi naturali.
Agent Payments Protocol (AP2)
Siamo pronti agli acquisti autonomi gestiti da AI Agent?
Google ha annunciato il nuovo Agent Payments Protocol (AP2), un’infrastruttura aperta che definisce regole comuni per permettere agli agenti intelligenti di effettuare pagamenti in modo sicuro e interoperabile.
Con oltre 60 partner globali, tra cui Mastercard, PayPal, Coinbase e American Express, AP2 nasce per affrontare i nodi critici dell'e-commerce automatizzato: autorizzazione, autenticità e responsabilità. Elementi che diventano centrali quando non è più l’utente a cliccare “compra”, ma un agente a operare in autonomia.
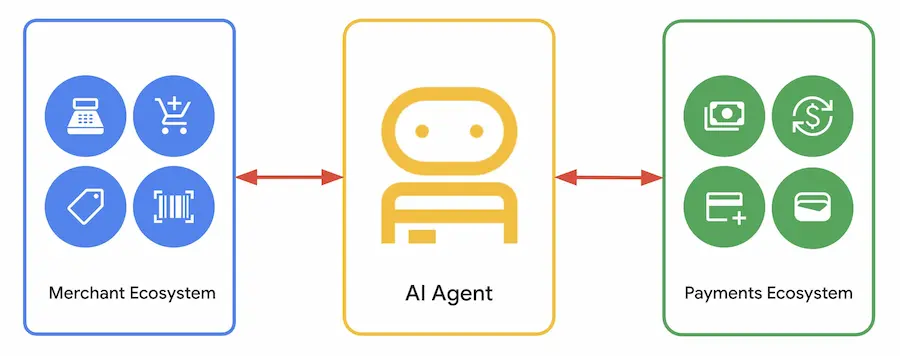
Il cuore del sistema sono i Mandati crittografici, contratti digitali firmati che fungono da prova verificabile delle intenzioni dell’utente. Possono essere in tempo reale, quando l’utente approva un carrello, oppure delegati, quando si affida all’agente per rispettare condizioni preimpostate. In entrambi i casi, la catena di prove crea una traccia non contestabile che collega volontà, carrello e pagamento.
Questa architettura apre scenari di commercio evoluto: acquisti intelligenti che si attivano al momento giusto, offerte personalizzate nate dal dialogo fra agenti, prenotazioni coordinate di viaggi e servizi, fino a integrazioni con stablecoin e soluzioni Web3 grazie all’estensione A2A x402.
AP2 non è solo un protocollo tecnico, ma una cornice di fiducia e interoperabilità che potrebbe ridisegnare l’esperienza del pagamento digitale nell’era degli agenti autonomi.
"Ok Computer" di Kimi
Kimi ha rilasciato la modalità "Agente", denominata "Ok Computer".
L'ho provato in un task di analisi dei dati (fornendo un CSV in input) e sviluppo di un sito web per presentare 4 diverse dashboard: una generale, una per il team di vendita, una per il CEO dell'azienda, e una sintesi con gli highlights.
Il sistema usa un ambiente virtuale, genera ed esegue una serie di script Python per la pulizia del dataset e per preparare i dati per widget dedicati alle diverse dashboard.
Successivamente sviluppa l'homepage e le pagine, come da prompt in input.
In 38 minuti il sito web era pronto, "deployato" e raggiungibile in un webserver remoto; e fornisce anche tutti i file necessari per eseguirlo in locale.
Nel video si può vedere una sintesi dei diversi step.
"OK Computer" di Kimi
Un agent potente, e soprattutto, gratuito.
Gemini Robotics 1.5
Portare gli Agenti AI nel mondo fisico? Google DeepMind procede nell'evoluzione nell'ambito della robotica con Gemini Robotics 1.5.
Si tratta di un avanzamento significativo verso sistemi in grado di percepire, ragionare e agire nel mondo reale in modo autonomo e generalista. Il cuore di questo progresso è la combinazione di due modelli complementari: Gemini Robotics 1.5 e Gemini Robotics-ER 1.5.
Gemini Robotics 1.5
Il primo, un modello Vision-Language-Action (VLA), consente ai robot di interpretare informazioni visive e comandi linguistici trasformandoli in azioni fisiche. Ma ciò che lo distingue è la capacità di "pensare prima di agire": sviluppa catene di ragionamento interno che precedono l’esecuzione, rendendo le decisioni trasparenti e più affidabili.
Il secondo, Gemini Robotics-ER 1.5, funziona da "cervello strategico". Ragiona sul mondo fisico, pianifica, valuta i propri progressi, utilizza strumenti digitali e comunica con il modello esecutivo. Ha ottenuto risultati all’avanguardia in benchmark accademici legati alla comprensione spaziale e al ragionamento embodied.
Questa architettura a due livelli permette una gestione più flessibile e robusta dei compiti, anche in ambienti complessi e mutevoli. Inoltre, il sistema mostra un'efficace capacità di trasferimento tra diversi corpi robotici, riducendo drasticamente il tempo necessario per apprendere nuove abilità.
In parallelo, DeepMind integra approcci innovativi per garantire la sicurezza semantica e fisica di questi agenti, promuovendo uno sviluppo allineato ai principi etici dell’AI responsabile.
L'integrazione del ragionamento, della percezione multimodale e della capacità d'azione in ambienti reali segna un passo concreto verso una forma di intelligenza artificiale fisica, capace di operare al servizio dell’uomo in modo autonomo e collaborativo.
Creare presentazioni usando l'AI?
Finalmente si iniziano a vedere processi interessanti!
Moonshot AI ha rilasciato Kimi Slides: un componente della chat di Kimi dedicato alla generazione di presentazioni, editabili e scaricabili in PPTX.
L'ho provato, e si tratta di uno strumento notevole!
Nel video si può vedere il processo di creazione..
Kimi Slides: un esempio di creazione di una presentazione
Ho caricato un post del mio blog, chiedendo al modello di preparare una presentazione relativa ai concetti trattati. Il sistema procede generando la struttura della presentazione (outline), che può essere modificata e arricchita manualmente, direttamente dalla UI della chat. Mi ha chiesto di scegliere un template, e ha iniziato a creare l'output. Una volta terminata l'elaborazione, permette di editarla completamente, cambiando e modificando testi ed elementi, aggiungendo o rimuovendo slide, sostituendo il template, ecc.. Infine, permette di scaricarla, anche in formato PPTX (modificabile).
L'output che si ottiene è un'ottima bozza iniziale.. e in meno di un minuto.
Nel post di lancio, l'azienda annuncia: "Coming soon: Adaptive Layout, auto image search & agentic slides". Scopriremo presto di cosa si tratta.
Chrome DevTools MCP
È il momento di Chrome DevTools MCP: un’evoluzione concreta nell’interazione tra agenti AI e ambienti di sviluppo reali. Il limite principale degli agenti di programmazione (l’impossibilità di osservare direttamente l’effetto del codice eseguito) viene superato offrendo loro accesso al browser Chrome attraverso un’integrazione diretta con DevTools.

I LLM possono così ispezionare il DOM, analizzare richieste di rete, raccogliere dati di performance, interagire con l’interfaccia utente e simulare condizioni complesse. Non si tratta solo di generare codice, ma di testarlo, osservarne il comportamento ed eventualmente correggerlo, in un ciclo chiuso, guidato dall’intelligenza artificiale.
Il supporto a Puppeteer consente automazioni robuste, con azioni come clic, compilazione form, gestione di dialoghi e navigazione tra pagine. Tra gli strumenti inclusi figurano anche la tracciatura delle performance, l’emulazione di rete e CPU, la generazione di screenshot e l’esecuzione di script in tempo reale. Tutto questo è accessibile con una semplice configurazione JSON e un comando npx.
DevTools MCP inaugura un nuovo paradigma: l’agente non è più solo autore del codice, ma anche osservatore e correttore attivo. Si apre così la strada a flussi di lavoro in cui lo sviluppo web diventa più dinamico, verificabile e adattivo, con l’AI pienamente inserita nel ciclo di esecuzione del software.
Un test del sistema
Quello che si vede nel video, è un mio test di Gemini CLI connesso al server MCP di Chrome DevTools.
Gemini CLI con MCP di Chrome DevTools
Lo trovo un supporto molto interessante, utile nella fase di analisi delle performance dei siti web (anche automatizzate), soprattutto perché consente di andare oltre la misurazione, fornendo suggerimenti e fix reali.
Ho fatto test anche con la riduzione della velocità di connessione, e con azioni di browser automation per verificare la presenza di eventuali problematiche.
Usarlo è davvero semplice. Quelli che seguono sono 3 comandi che permettono di vederlo funzionare in qualche minuto (io lo uso su una macchina Debian).
- Installazione dell'agente di Gemini CLI:
npm install -g @google/gemini-cli
- Aggancio del server MCP di Chrome DevTools all'agente:
gemini mcp add chrome-devtools "npx" "chrome-devtools-mcp@latest" -- \ --headless=false
- Avvio di Gemini CLI con il modello 2.5 Pro:
gemini -m gemini-2.5-pro
MCP Toolbox for Databases di Google
Google ha rilasciato in open source MCP Toolbox for Databases, precedentemente noto come GenAI Toolbox.
Si tratta di un server MCP progettato per facilitare l'integrazione di agenti AI con database, semplificando la gestione degli strumenti attraverso configurazioni centralizzate.
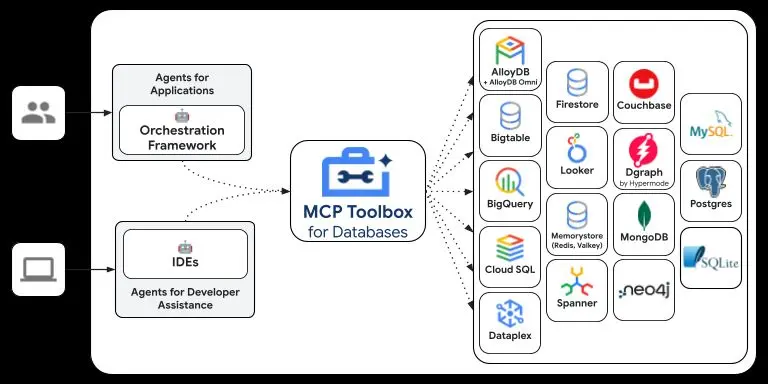
Il progetto fornisce funzionalità come pooling delle connessioni, autenticazione integrata, osservabilità con OpenTelemetry e supporto per diversi framework, tra cui LangChain e LlamaIndex.
Con MCP Toolbox è possibile creare assistenti AI che accedono ai dati usando il linguaggio naturale direttamente da un IDE, automatizzare query SQL, generare codice contestuale e semplificare l'intero ciclo di vita dello sviluppo applicativo orientato ai dati.
L'MCP Server di Figma
Figma ha presentato il suo MCP Server (Model Context Protocol) per strumenti di sviluppo e agenti AI. Il punto centrale di questa innovazione è la possibilità di fornire contesto progettuale direttamente all’interno degli ambienti dove viene scritto il codice, provando a rendere il design un’entità computabile e riutilizzabile, non più una semplice rappresentazione visiva.
L'MCP Server di Figma
Con il supporto al server remoto, Figma consente di accedere a componenti, layout, variabili e logiche progettuali direttamente da IDE come VS Code, o tramite agenti AI come Claude e Cursor, senza passare dal client desktop.
È sufficiente il link a un frame per permettere all’agente di accedere al nodo specifico, leggerne la struttura e generare codice coerente, contestualizzato e aderente al design system esistente.
Il valore reale emerge nell’uso combinato di Figma Make, il nuovo ambiente per la generazione di interfacce, e Code Connect, che allinea componenti Figma ai componenti di produzione. L'agente AI, in questo scenario, non lavora più su immagini statiche ma su riferimenti strutturati, accedendo al codice sorgente dei file Make e comprendendo i mapping definiti tra design e codice.
Ne risulta un flusso in cui le AI non sono più strumenti generativi generici, ma veri e propri agenti informati, in grado di produrre output consistenti, scalabili e aderenti alla realtà tecnica del progetto.
L’MCP Server non si limita a trasportare dati: veicola significato, struttura e coerenza, diventando un canale di comunicazione bidirezionale tra la progettazione visuale e la logica di produzione. In questo contesto, ogni nodo di design diventa un'unità computabile, ogni file Make un’estensione dell’architettura, e ogni agente AI un collaboratore operativo sul prodotto.
Gemini: come si leggono i consumi?
Come si leggono i dati del consumo di token nell'API di Gemini?
Nella mia applicazione sto elaborando una serie di prodotti di un e-commerce, e per ogni chiamata API invio un prompt multimodale (testo + immagine), usando anche il tool di web search (Grounding with Google Search).
Nella risposta dell'API si vedono i dati di consumo dell'immagine.
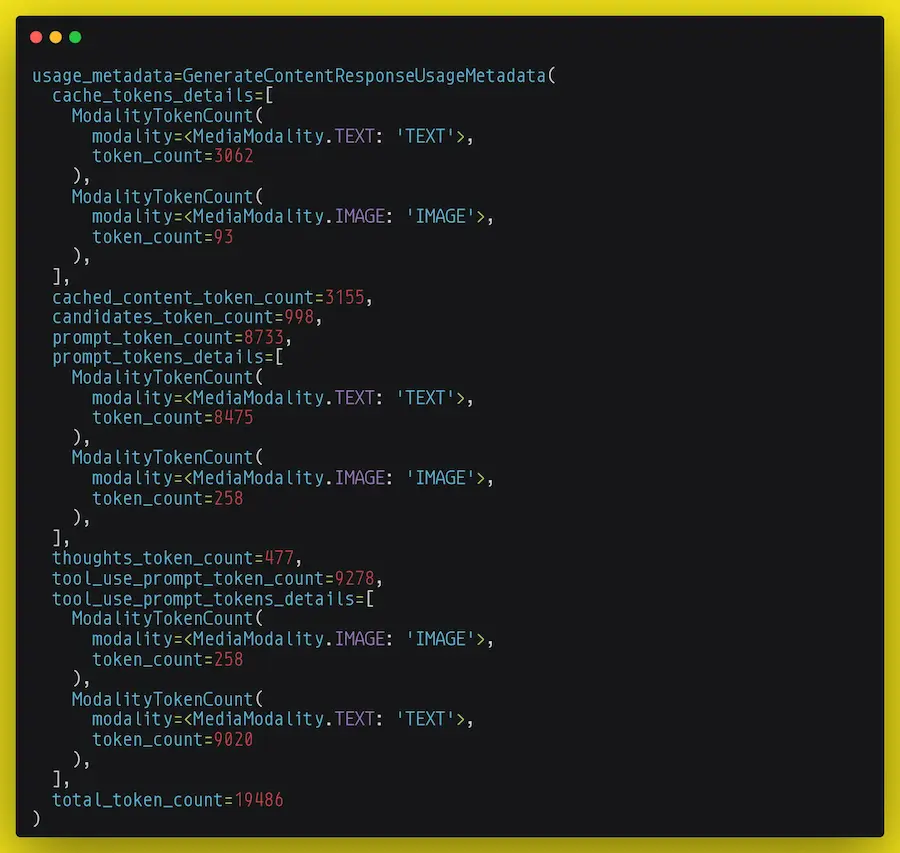
I dettagli
- Input. Il totale dei token in input che il modello ha considerato per l'elaborazione è di 8.733 token: 8.475 token di testo e 258 token di immagine.
- Cache. 3.155 token (di cui 3.062 di testo e 93 di immagine) sono stati recuperati dal sistema di cache implicita di Gemini. Questo significa che solo la differenza (5.578 token) è stata effettivamente inviata con questa nuova chiamata, ottimizzando così costi e velocità.
Questo tipo di cache (implicita) è automatico. Le parti che si ripetono nei prompt (es. istruzioni di sistema, specifiche su come creare l'output, ecc.) vengono salvate in una memoria a breve termine e riutilizzate nelle chiamate successive a un prezzo molto inferiore. - Tools. I contenuti estratti attraverso le diverse ricerche prodotte in fase di reasoning hanno consumato 9.278 token.
- Reasoning. Durante la sua elaborazione, il modello ha utilizzato 477 token per il suo processo di ragionamento interno, un'attività che non appare nell'output finale ma è cruciale per la qualità della risposta.
- Output. La risposta generata dal modello (la sezione candidates) è composta da 998 token.
- Consumo Totale. Sommando tutte queste componenti (input, output, tool e reasoning), il consumo complessivo per questa singola chiamata API ammonta a 19.486 token.
Con tutti questi dati, si possono creare dei sistemi di log e reportistica, che permettono di avere sotto controllo l'elaborazione.
Un esempio di dashboard
Alcuni estratti della dashboard che sto utilizzando per monitorare i consumi e le azioni dell'applicazione.
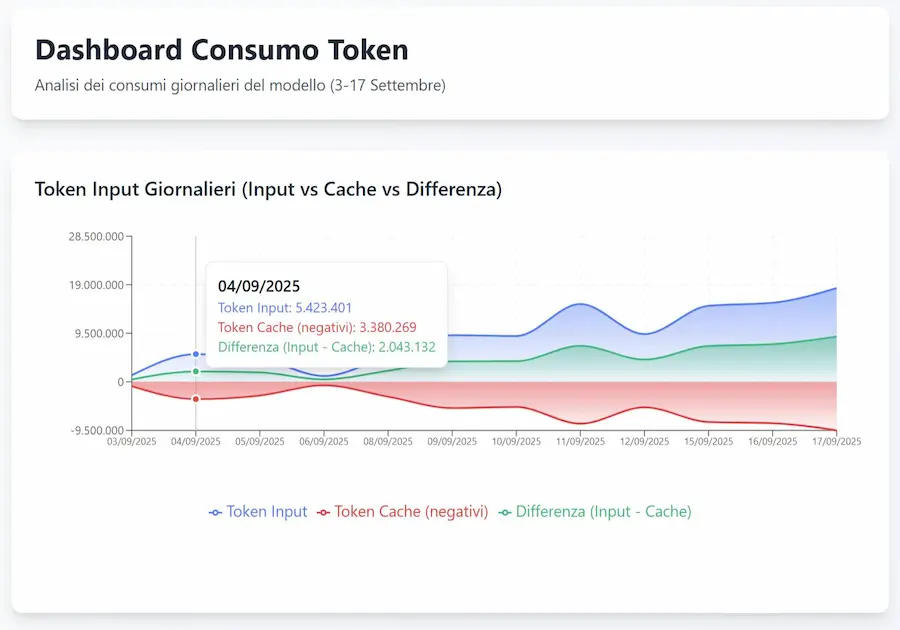
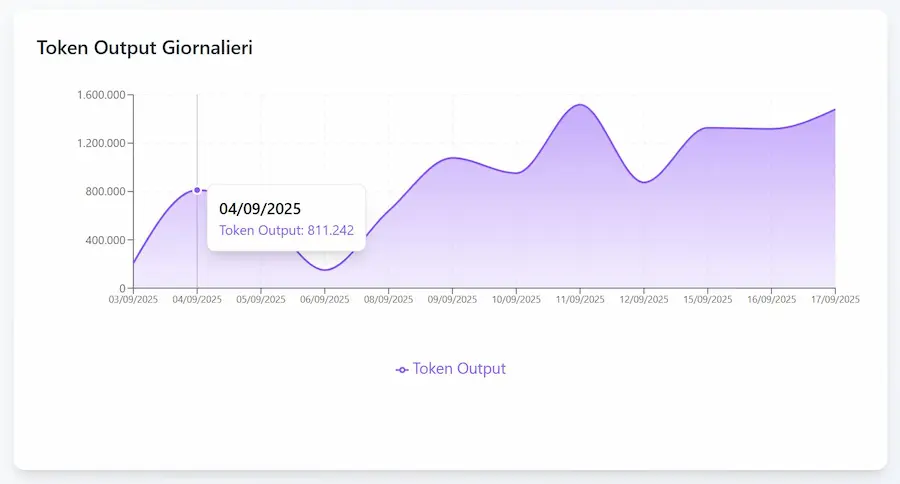
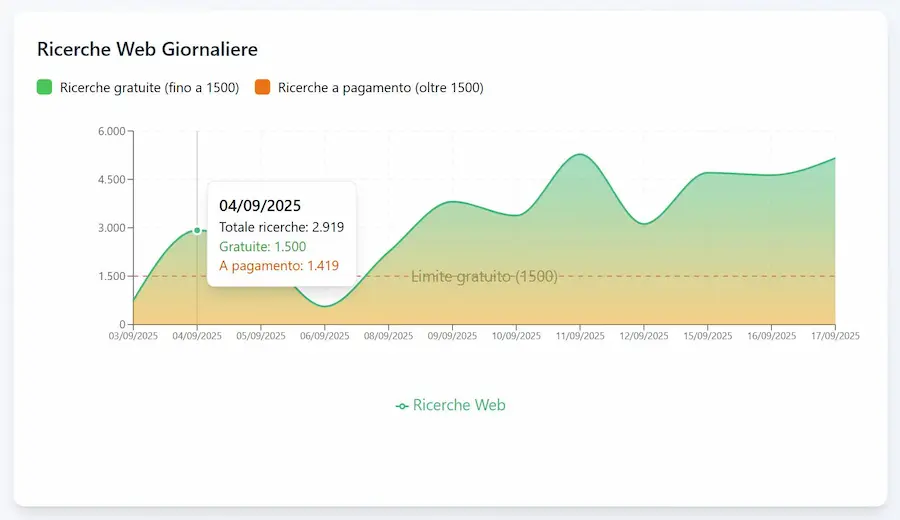
Dashboard per il monitoraggio dei consumi di Gemini 2.5 Pro
Il monitoraggio dei consumi è da inserire già in fase di progettazione: l'effort è bassissimo (tutte le informazioni sono nelle risposte delle API dei LLM), ma l'utilità è altissima.
Le allucinazioni nei modelli linguistici
OpenAI ha pubblicato un paper che analizza in profondità le cause delle allucinazioni nei modelli linguistici, mostrando che non sono un’anomalia ma un fenomeno statistico.
Nascono già nel pretraining: anche con dati perfetti, l’obiettivo di minimizzare la cross-entropy porta a generare errori. I fatti rari (es. il compleanno di una persona poco citata) sono particolarmente vulnerabili, mentre quelli ricorrenti resistono meglio.




Le allucinazioni nei modelli linguistici - Un paper di OpenAI
Questi errori assomigliano a misclassificazioni in un problema supervisionato: inevitabili quando i dati sono insufficienti o il modello non è abbastanza espressivo. Non è solo un limite della conoscenza, ma anche della famiglia di modelli utilizzata.
Il paradosso è che il post-training, pur cercando di ridurre le allucinazioni, spesso le perpetua. Le metriche di valutazione dominanti puniscono le risposte di incertezza e premiano chi “azzarda” sempre una risposta. Così, i modelli imparano a bluffare.
La soluzione non passa soltanto da nuove architetture o da più dati, ma da un cambiamento negli incentivi: valutazioni che riconoscano il valore del dire “non lo so”. Solo così si può orientare lo sviluppo verso sistemi più affidabili e pragmatici, capaci di gestire l’incertezza senza trasformarla in falsa certezza.
Project Mariner di Google: un'anteprima
A proposito di Agenti AI dedicati alla browser automation e di Project Mariner di Google.. Il sistema è già disponibile per gli utenti Gemini Ultra.
Funziona come Operator di OpenAI, ma può agire direttamente sulle schede di Chrome.
Negli esempi si vedono alcuni task che l'agente compie, e tutti gli step che segue.
Project Mariner di Google: un'anteprima
Quando la funzionalità sarà direttamente su Chrome, o su AI Mode, non credo rimarrà molto spazio per altri agenti di questo tipo.. il potere dell'ecosistema, ma anche del modello più potente sul mercato.
Chrome sarà potenziato dall'AI
Google ha presentato l'evoluzione di Chrome potenziato dall'AI.
Questo significa: uno dei LLM più potenti integrato nel browser più usato al mondo, con un agent di browser automation, e interazione nativa con le app più usate al mondo.
Il protagonista è Gemini in Chrome, che trasforma il browser in un assistente intelligente capace di comprendere il contesto, lavorare su più schede contemporaneamente, riassumere informazioni complesse e persino ricordare le pagine visitate in passato. Non più solo navigazione, ma comprensione attiva.
Attraverso le funzionalità agentiche, Gemini potrà svolgere compiti per conto dell’utente, come prenotare appuntamenti o fare acquisti online, semplificando processi che oggi richiedono diversi passaggi manuali.

La barra degli indirizzi si evolve con l’introduzione di AI Mode: sarà possibile porre domande complesse direttamente dall’omnibox, ottenere risposte intelligenti, suggerimenti contestuali e approfondimenti generati in tempo reale, tutto senza cambiare scheda.
Sul fronte della sicurezza, l’AI diventa un alleato fondamentale: blocca truffe sofisticate, filtra notifiche indesiderate, gestisce con intelligenza le richieste di autorizzazione (come fotocamera e geolocalizzazione) e consente di aggiornare password compromesse in un solo clic.
Infine, l’integrazione diretta con servizi come YouTube, Calendar, Maps e Docs porta la produttività a un nuovo livello, permettendo di interagire con le app senza uscire dalla pagina attiva.
Con questa evoluzione, Chrome smette di essere una semplice finestra sul web e diventa un vero assistente personale AI-native, progettato per rendere la navigazione più efficace, sicura e intelligente.
E-commerce personalizzati: se non è già il momento, lo sarà presto
In questa demo. l'utente può caricare la sua immagine e vedere i prodotti del catalogo indossati. Chiaramente il sistema potrebbe usare delle immagini caricate ad hoc nel profilo, senza bisogno di upload.
Personalizzazione dell'e-commerce usando l'AI
E magari, ad esempio, potrà far vedere all'utente le scarpe del catalogo indossate insieme alla tuta acquistata il mese precedente. Oppure con i prodotti che vengono acquistati più frequentemente insieme dal cluster di clienti al quale appartiene.
Nei nostri seminari dell'Accademia, parliamo di contenuti personalizzati da diversi anni. Mancavano modelli con un'efficienza tale da mettere a terra la visione.
Oggi, con modelli come Gemini 2.5 Pro Flash Image (Nano Banana) e Seedream 4 ci stiamo avvicinando non poco.
Un mio test di "Virtual Try On"
Primi test di "Virtual Try On" basato su Gemini 2.5 Flash Image (Nano Banana).
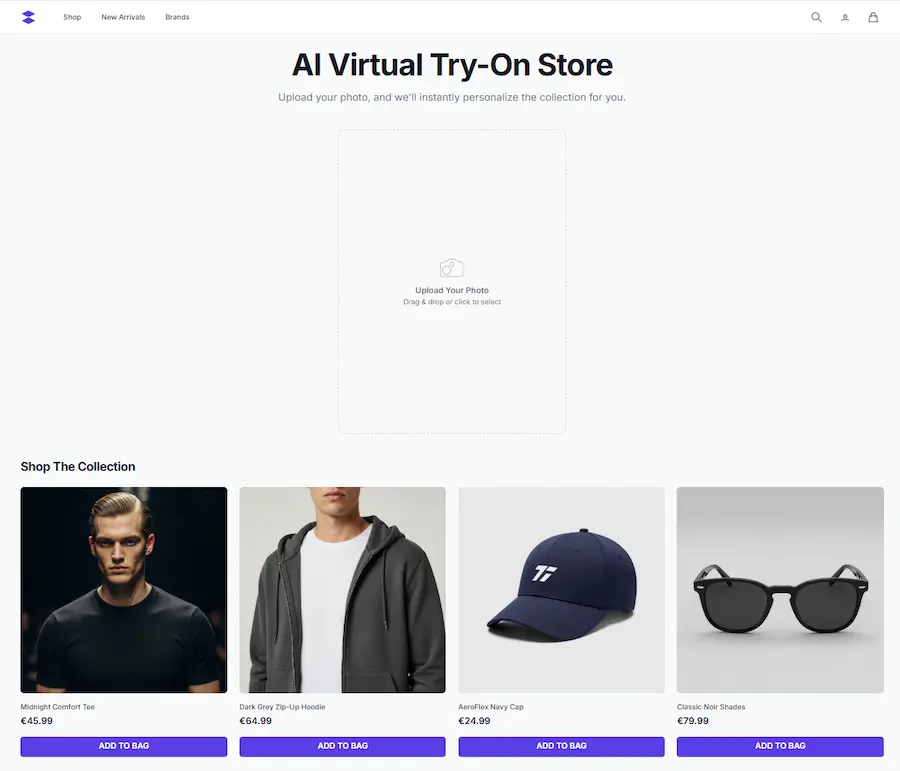
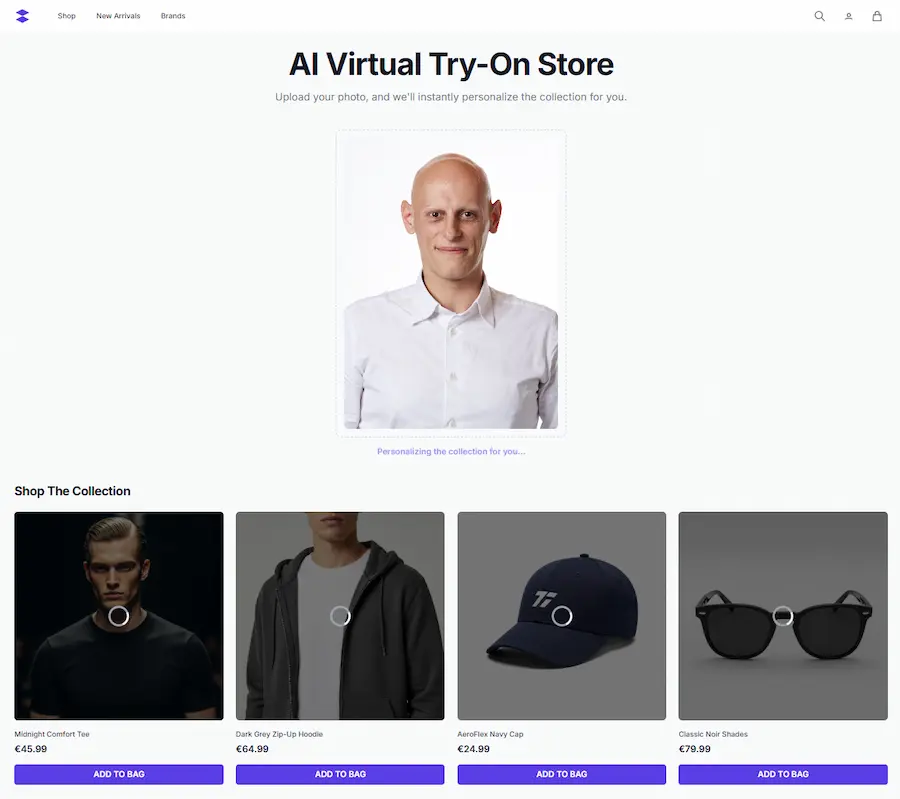
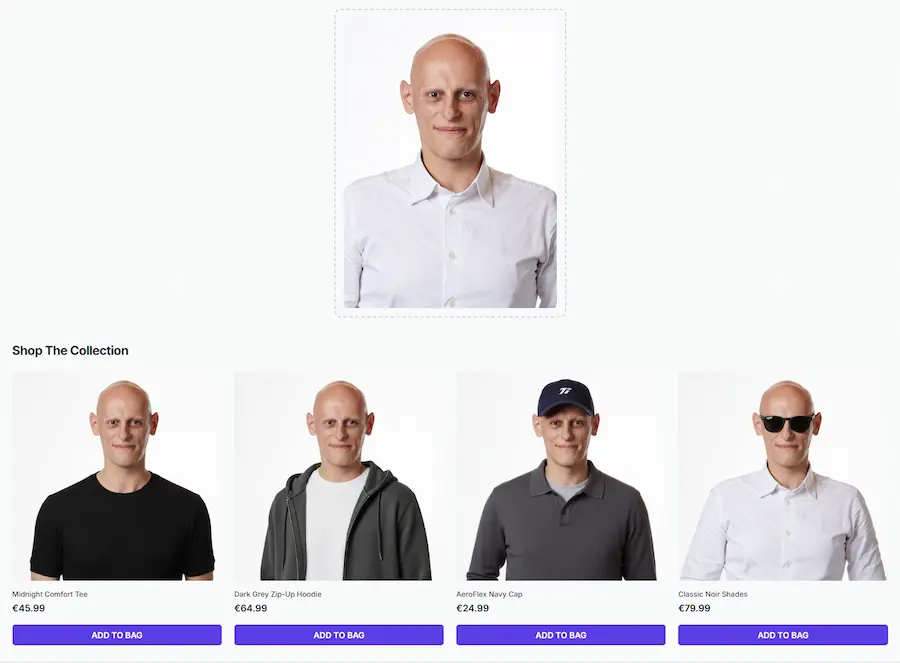
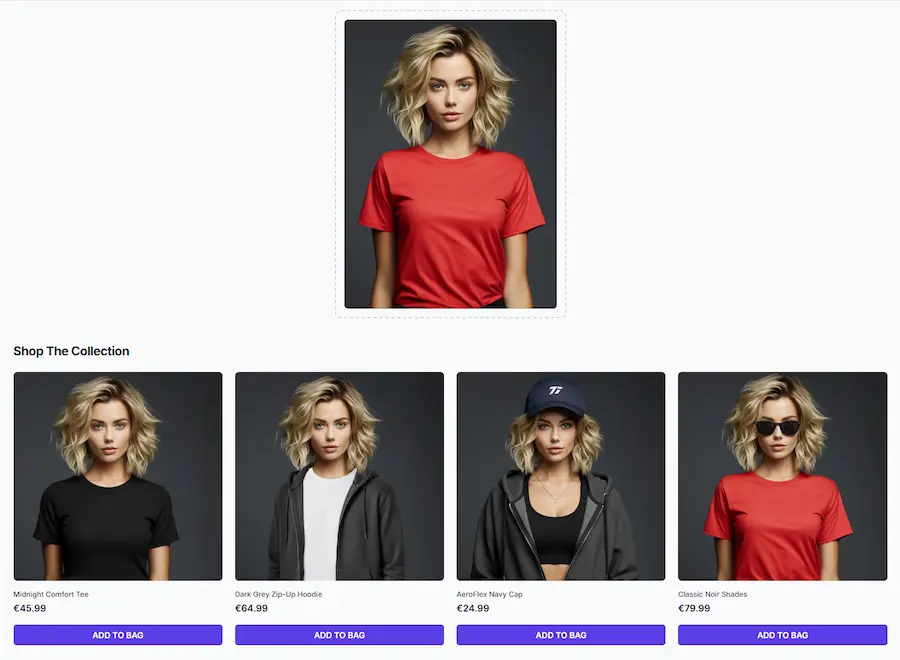
Un mio esempio di "Virtual Try On"
L'aspetto più interessante? L'ho creato completamente usando la sezione "Build" di Google AI Studio. Quindi, tutto il codice è generato da Gemini 2.5 Pro partendo dalle mie istruzioni testuali.
Di certo non può essere considerato un plugin pronto all'uso, ma una base per fare delle riflessioni sulla personalizzazione dell'esperienza utente verso la quale ci stiamo avviando.
Risorsa utile + COLAB gratuito
Microsoft ha pubblicato MarkItDown, uno strumento in Python che converte file come PDF, Word, Excel, PowerPoint, immagini, HTML, JSON, e molti altri formati, in Markdown.
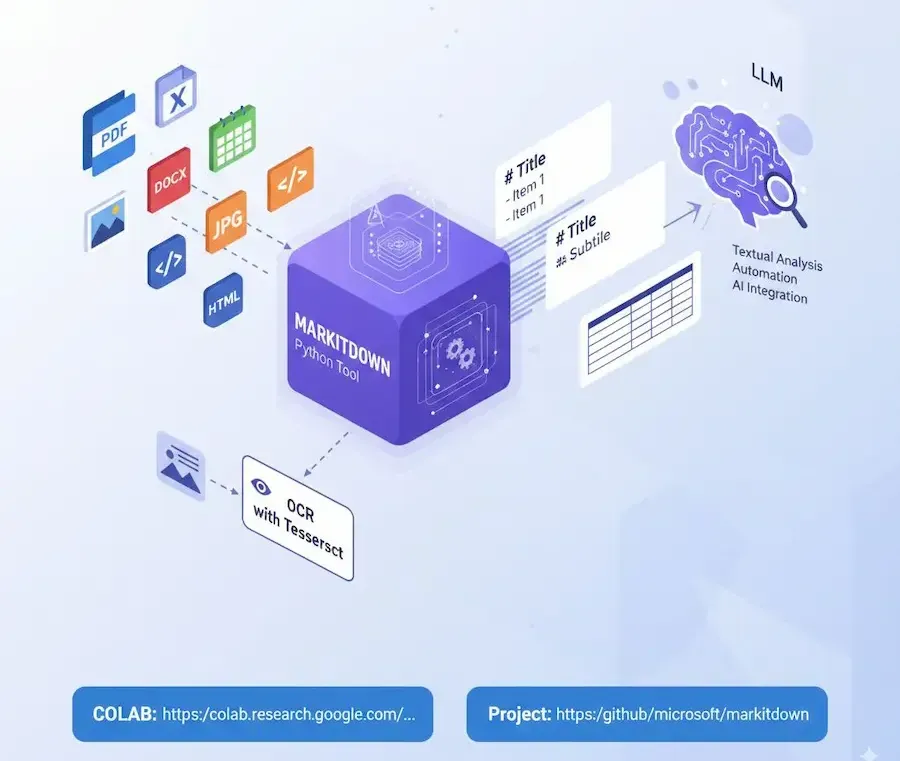
È ideale per trasformare i file in contesto per agenti basati su LLM, preserva la struttura del documento (titoli, elenchi, tabelle…) ed è perfetto per analisi testuale, automazioni o integrazioni AI.
L’ho provato e ho creato un Colab pronto all’uso, con un’ulteriore integrazione: OCR tramite Tesseract.
Perché? Di default, MarkItDown prova a leggere le immagini, ma se non trova un motore OCR installato restituisce solo i metadati (EXIF). Con l’integrazione Tesseract, invece, anche il testo contenuto nelle immagini (scansioni, screenshot, foto di documenti) viene estratto e convertito in Markdown.
Dolphin: un tool per il parsing dei documenti
Dolphin è un modello multimodale open-source per l’analisi e il parsing di documenti, sviluppato dal team di ricerca di ByteDance. Nasce con l’obiettivo di interpretare strutture complesse all’interno di documenti digitalizzati, come tabelle, formule, paragrafi di testo e immagini, restituendo una rappresentazione strutturata che rispetta l’ordine di lettura umano.
Un sistema molto interessante per supportare l'interpretazione dei documenti da parte dei LLM. L'ho provato, e lo trovo molto potente.
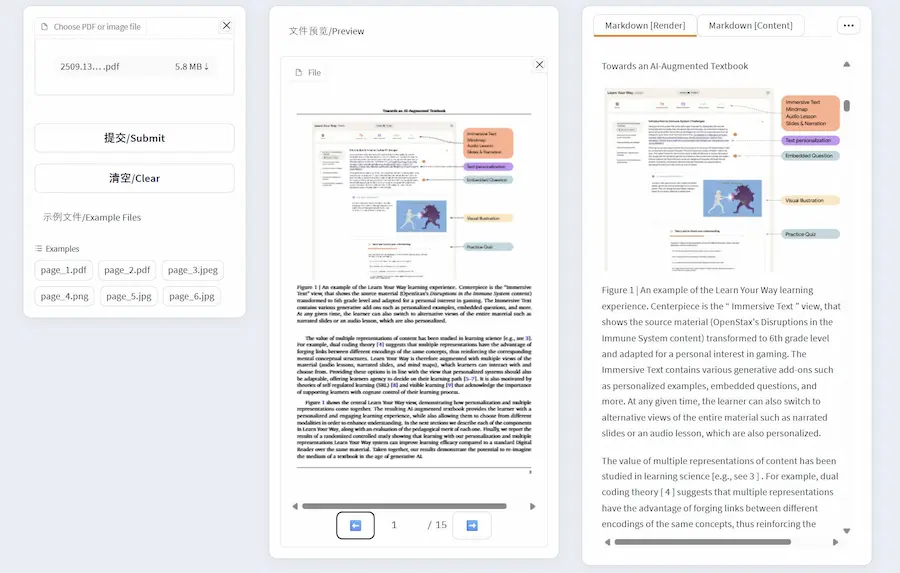
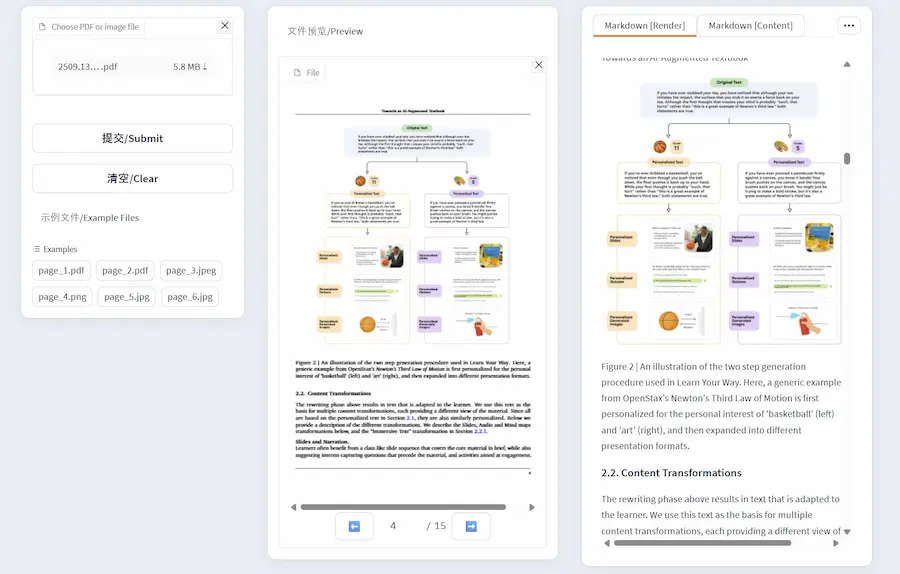
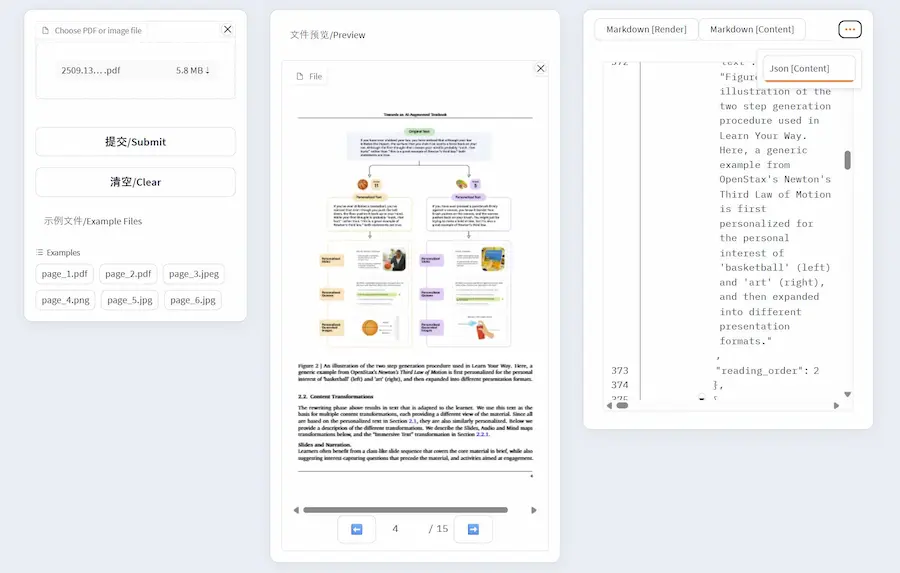
Dolphin: un tool per il parsing dei documenti
Il funzionamento del sistema si basa su un paradigma a due fasi definito analyze-then-parse. Nella prima fase, il modello analizza l’intera pagina per identificare e ordinare logicamente gli elementi presenti. Nella seconda, avvia un processo di parsing parallelo degli elementi documentali tramite un meccanismo chiamato heterogeneous anchor prompting, in cui ogni tipo di contenuto è gestito con prompt specifici.
Questa distinzione semantica permette di ottimizzare l’interpretazione, e migliora l’efficienza complessiva.
Dolphin integra modelli visivo-linguistici e sfrutta strumenti di accelerazione come TensorRT-LLM e vLLM per garantire prestazioni elevate, anche su documenti multipagina in formato PDF. È accessibile attraverso due framework paralleli: uno basato su configurazioni locali e uno integrato nella piattaforma Hugging Face, che ne facilita l’utilizzo e la distribuzione. Le inferenze possono produrre output in formato JSON o Markdown, sia a livello di pagina sia di singolo elemento.
Dolphin si posiziona come un contributo tecnico rilevante per l’estrazione semantica da documenti visivi, supportando scenari reali di OCR avanzato, digitalizzazione e comprensione automatizzata del layout.
Veo 3: l’alba del ragionamento visivo?
Per anni l’AI ha imparato a “vedere” attraverso modelli specializzati: uno per segmentare, un altro per riconoscere oggetti, un altro ancora per migliorare immagini in bassa qualità. La ricerca di Google DeepMind mostra che con Veo 3 siamo di fronte a una svolta:
un singolo modello video capace di affrontare, senza addestramento specifico, compiti che spaziano dalla percezione al ragionamento.
Veo 3 non si limita a riconoscere i contorni di un oggetto. Dimostra di intuire proprietà fisiche come il galleggiamento o la resistenza dell’aria, di manipolare scene visive con coerenza, di completare puzzle, labirinti e simmetrie. È un passaggio dal semplice “vedere” al cominciare a “capire” il mondo in movimento.
Anche se, devo dire, che alcuni miei esperimenti specifici mi portano a pensare che, pur vedendo una crescita enorme, rimaniamo lontani dalla "comprensione del mondo".
Il paper analizza oltre 18.000 video generati, coprendo 62 compiti qualitativi e 7 quantitativi. I risultati mostrano un netto miglioramento rispetto a Veo 2: nel labirinto 5×5, il tasso di successo passa dal 14% al 78%, mentre nelle segmentazioni zero-shot Veo 3 raggiunge una mIoU di 0.74, comparabile a modelli di editing dedicati.
Questa progressione indica non solo un affinamento percettivo, ma anche l’emergere di una “catena di frame” capace di sostenere forme iniziali di ragionamento visivo.
Visual prompt per la generazione video
Si tratta di indicazioni per il modello direttamente nel key frame che usiamo nel prompt multimodale.
Nell'esempio, parto da un'immagine generata con Gemini 2.5 Flash Image (Nano Banana). La edito inserendo delle indicazioni, e la uso come fotogramma chiave su Veo 3, insieme a delle istruzioni testuali.
Un esempio di visual prompt per Veo 3
La componente testuale del prompt l'ho generata attraverso "Veo 3 Prompt Assistant", usando anche l'immagine del key frame come indicazioni di supporto.
Il risultato è aderente alle indicazioni. Nella parte finale del video, il soggetto guarda verso la camera: questa azione è stata descritta dal prompt testuale (sarebbe stato difficile usare uno schema nell'immagine).
Chiaramente, il modello usa l'immagine come fotogramma di partenza (conservando anche le istruzioni grafiche), quindi, nel prompt testuale ho specificato che le indicazioni devono scomparire immediatamente nel video. E così, con un taglio del primo mezzo secondo, si ottiene il video pulito.
Presto vedremo software di generazione video che ci permetteranno di disegnare le indicazioni direttamente nelle immagini in modo semplice, per poi generare il video corrispondente.
Il mix di istruzioni multimodali (immagine/schema + testo), aiutano a pilotare meglio il modello.
Per provare "Veo 3 Prompt Assistant":

Oppure basta cercare "Veo 3 Prompt Assistant" nella sezione GPT di ChatGPT.
Veo3: novità + COLAB gratuito
I cambiamenti riguardano tre aspetti fondamentali: prezzo, formato e qualità visiva.
- Il primo è una riduzione dei costi significativa: Veo 3 passa da $0.75 a $0.40 al secondo, mentre Veo 3 Fast scende da $0.40 a $0.15. Una mossa che rende più accessibile l’adozione di questi modelli per produzioni su larga scala o in contesti sperimentali.
- Il secondo aspetto riguarda l’ampliamento dei formati supportati. Con l’introduzione del 9:16 verticale, Veo si allinea alle esigenze contemporanee dei contenuti digitali, in particolare per il mobile e i social media, dove la verticalità è diventata standard.
Ho generato i video del post via API, formato 9:16. Prompt creato con "Veo 3 Prompt Assistant".
Un esempio di video verticale generato con Veo 3
Condivido il Colab che ho usato, che permette di selezionare e variare il formato e la risoluzione.
Basta impostare l'API Key di Gemini nei "Secrets", impostare i parametri nel form, agire sul prompt, ed eseguire.
- Infine, l’introduzione della risoluzione 1080p segna un miglioramento tecnico rilevante, abilitando produzioni più nitide e coerenti con le aspettative moderne di qualità visiva.
Secondo Google, questi aggiornamenti non sono solo incrementali: rappresentano una normalizzazione dell’uso di modelli generativi video in flussi di lavoro professionali. L’integrazione di Veo 3 in strumenti come Saga, Mosaic o Invisible Studio ne è una testimonianza concreta: la generazione video non è più solo un prototipo, ma un ingranaggio produttivo reale.
Wan 2.5
La qualità generale dei modelli di generazione video aumenta.. e Alibaba lo dimostra rilasciando Wan 2.5.
Il nuovo modello introduce un’architettura multimodale nativa e un addestramento congiunto su testo, audio e dati visivi, garantendo un migliore allineamento tra le modalità e una sincronizzazione audio-video naturale.
Esempi di video generati con Wan 2.5
Grazie all’integrazione del Reinforcement Learning from Human Feedback (RLHF), l’output si adatta meglio alle preferenze umane, con immagini più nitide e video più dinamici.
Sul fronte video, Wan 2.5 offre generazione sincronizzata di voce, effetti sonori e musica, input multimodali controllabili (testo, immagini, audio) e un sistema avanzato di controllo cinematografico per produrre clip in 1080p della durata di 10 secondi.
L'interfaccia di generazione, permette di estendere i video, di effettuare "repaint" e "inpaint".
Per le immagini, il modello migliora nella qualità fotorealistica e negli stili artistici, includendo tipografia creativa e grafici professionali. Supporta inoltre editing conversazionale con precisione a livello di pixel, consentendo operazioni come fusioni concettuali, trasformazioni di materiali o variazioni cromatiche di prodotto.
Ray 3 di Luma Labs
Luma Labs ha rilasciato il primo modello video in grado di "ragionare" in 4K HDR.
Si tratta di Ray 3, progettato per comprendere l’intento creativo e generare risultati visivi coerenti, realistici e ad alta fedeltà. È in grado di attuare un'azione di "reasoning" attraverso concetti visivi, valutare le bozze prodotte e migliorare automaticamente la qualità con ogni iterazione.
L'ho provato, sia in modalità text-to-video, sia image-to-video. L'aderenza alle istruzioni nei prompt che ho usato è altissima, come la qualità degli output.
Video generati con Ray 3 di Luma Labs
Supporta la generazione nativa in 16-bit HDR, con esportazione in EXR per integrazione nei flussi professionali di post-produzione. Rispetto alla versione precedente, offre maggiore dettaglio alla stessa risoluzione e migliora la resa di movimento, luce, ottiche e interazioni spaziali.
Tra le funzionalità avanzate: annotazioni visive per controllare layout e animazioni, keyframe, estensione e loop dei video, upscaling e un nuovo Draft Mode che consente iterazioni 5 volte più rapide e più economiche.
Ray 3 consente di creare video da testo o immagini, trasformare contenuti SDR in HDR e costruire scene complesse con personaggi, espressioni e ambienti coerenti.
Qwen-Image-Edit-2509
Dall’arrivo di Gemini 2.5 Flash Image (Nano Banana) e Seedream 4, l’asticella dell’editing visivo si è alzata a una velocità impressionante. E ora entra in scena Qwen-Image-Edit-2509.
Editing multi-immagine con coerenza su volti, prodotti, testi. Supporta combinazioni complesse come persona + scena, persona + oggetto, persona + persona. Lavora su pose, stili e contesti con una precisione che restituisce non solo l’identità visiva, ma anche l’intento narrativo.
Testo e immagine si fondono: font, colore, materiale e contenuto vengono modificati insieme, senza fratture visive. Il tutto con integrazione nativa di ControlNet (depth map, edge, keypoint, sketch), che permette controllo granulare su struttura e composizione.
Qwen-Image-Edit-2509
La qualità dell’output è alta anche in casi difficili:
- restauro fotografico con identità intatta
- poster pubblicitari generati da semplici loghi
- meme realistici con testi complessi
- ritratti con pose alterate ma coerenza impeccabile
E il dettaglio più importante: è open source. Licenza Apache 2.0, modello e codice disponibili pubblicamente. Usabile, modificabile, riutilizzabile. Anche per scopi commerciali.
Qwen-Image-Edit-2509 non è solo un aggiornamento. È una piattaforma creativa solida, aperta e controllabile.
Grok 4 Fast
Grok 4 Fast segna un’evoluzione nell’intelligenza artificiale accessibile, combinando potenza e convenienza.
Si tratta di un modello ottimizzato che conserva prestazioni vicine a Grok 4, ma riduce del 40% i token di ragionamento, rendendolo più efficiente sotto il profilo computazionale ed economico.
Con una finestra di contesto di 2 milioni di token, Grok 4 Fast si adatta a compiti lunghi e articolati, integrando nativamente l’uso di strumenti come web, ricerca su X, immagini e video. La sua architettura duale permette di alternare tra modalità di ragionamento e risposte rapide, a seconda della complessità del compito, senza sacrificare coerenza o profondità.

I benchmark confermano la validità di questa impostazione: prestazioni superiori a Grok 3 Mini a costi significativamente più bassi, mantenendo un equilibrio rilevante tra intelligenza e spesa per token.
La disponibilità gratuita per tutti gli utenti, compresi quelli non abbonati, rappresenta un passo concreto verso una democratizzazione dell’AI avanzata, in cui efficienza e accessibilità diventano elementi strutturali, non compromessi.
GPT-5-Codex di OpenAI
OpenAI presenta GPT-5-Codex, un’evoluzione di GPT-5 progettata per l’ingegneria del software.
Allenato su compiti complessi e reali, questo modello unisce due capacità essenziali: l’interazione rapida nelle sessioni brevi e la perseveranza nei lavori di lunga durata, arrivando a operare autonomamente per ore.
La sua specializzazione nel code review permette di scoprire difetti critici prima della distribuzione, riducendo il carico dei revisori umani e aumentando la qualità del codice.

L’ecosistema Codex si è trasformato in un vero "compagno di lavoro": dal terminale all’IDE, dal cloud a GitHub, fino all’app iOS, con la possibilità di passare senza soluzione di continuità dal contesto locale a quello remoto.
Le nuove integrazioni supportano immagini, to-do list, strumenti esterni e revisioni automatiche delle pull request, con tempi di esecuzione molto più rapidi e una gestione della sicurezza che privilegia ambienti sandbox e controlli granulari.
Incluso nei piani ChatGPT Plus, Pro, Business, Edu ed Enterprise, e in arrivo anche via API, GPT-5-Codex incarna l’idea di un agente affidabile, capace di comprendere il contesto, collaborare e assumersi responsabilità nello sviluppo del software.
Gli embeddings sono limitati
E se gli embeddings, che oggi usiamo ovunque per ricerca e AI, avessero un limite matematico invalicabile?
Il nuovo lavoro di Google DeepMind dimostra proprio questo: non importa quanto allarghiamo i modelli o quanto migliori siano i dati, esiste un tetto oltre il quale gli embeddings non possono più rappresentare tutte le possibili relazioni tra query e documenti.


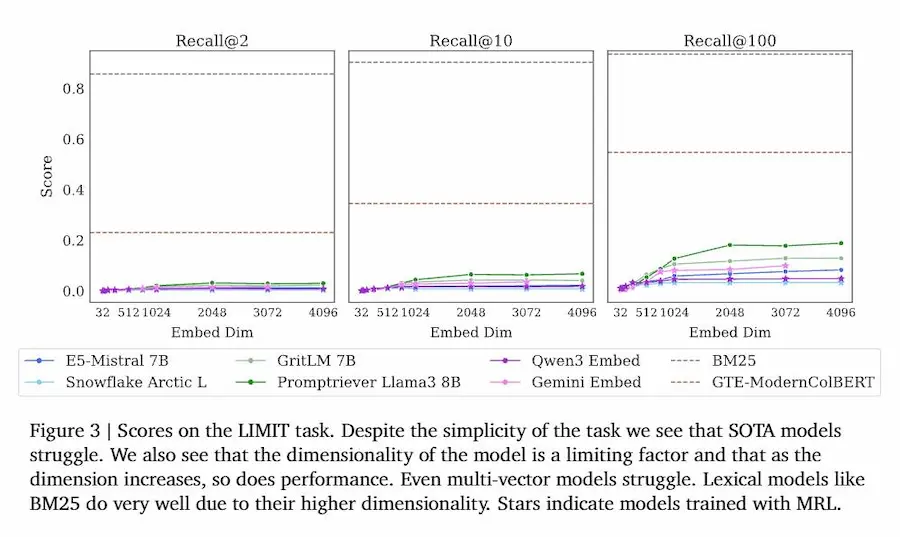
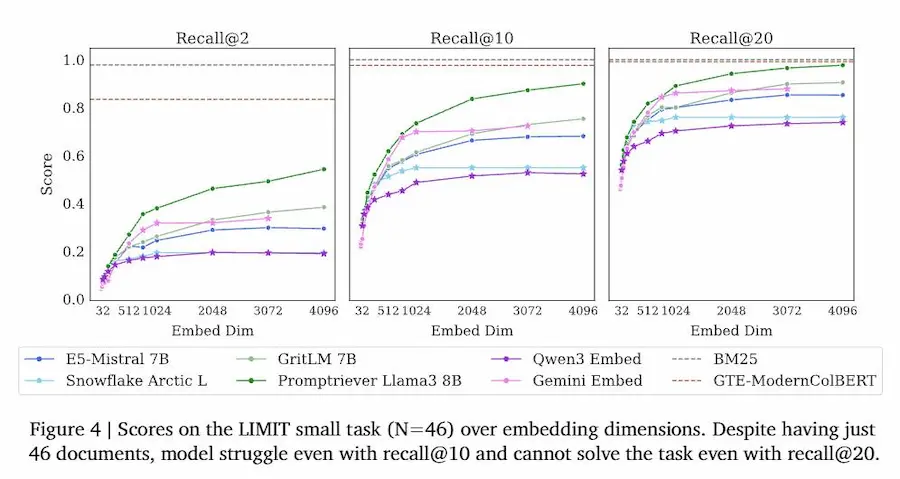
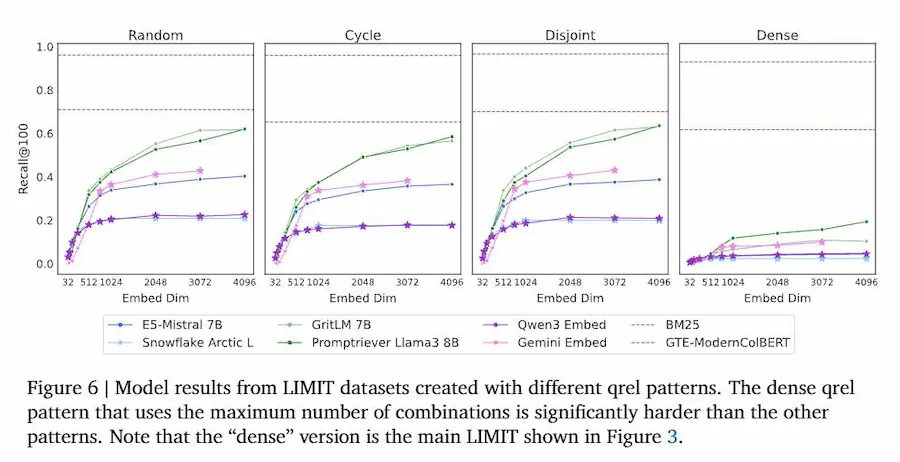

Un paper di DeepMind sulla limitazione degli embeddings
Il motivo è geometrico. Un embedding è un vettore in uno spazio di dimensione finita. Questo spazio può codificare tante relazioni, ma non tutte.
Quando le query richiedono combinazioni troppo numerose o specifiche, la capacità crolla: alcune coppie o insiemi di documenti non possono essere recuperati da nessuna query, per pura impossibilità matematica.
Gli autori formalizzano il concetto con i sign-rank bounds, che fissano un limite teorico alla capacità rappresentativa di un embedding di dimensione d. Poi lo mostrano empiricamente: anche con 4096 dimensioni (già altissime), la copertura delle possibili combinazioni si rompe già intorno ai 250 milioni di documenti per recuperi top-2.
Per rendere la cosa concreta, creano il dataset LIMIT: query banalissime come “Chi ama le mele?”, con documenti tipo “Jon ama le mele”, “Leslie ama le caramelle”. Semplice? Non per gli embedding. Anche i migliori modelli disponibili crollano, con meno del 20% di recall@100.
Un esempio intuitivo: immagina una libreria con solo 100 scaffali. Puoi ordinare molti libri, ma non tutte le disposizioni possibili. A un certo punto, per quanto tu cerchi di essere creativo, mancherà lo spazio per rappresentare tutte le combinazioni. Gli embedding funzionano allo stesso modo: una mappa utile, ma che non potrà mai contenere tutti i percorsi possibili.
Le implicazioni sono profonde: non basta scalare. Per applicazioni come search, recommendation o retrieval-augmented generation (RAG), gli embeddings non possono essere l’unico motore di retrieval. Servono architetture ibride, che combinino dense e sparse retrieval, multi-vector retrievers o reranker più potenti.
Il messaggio del paper è netto: gli embeddings rimangono strumenti preziosi, ma vanno trattati come parte di un sistema, non come la soluzione universale. I loro limiti non sono un bug temporaneo, ma una proprietà strutturale.
Un approfondimento sugli embeddings

Gpt-oss di OpenAI su Groq
Usando Groq è possibile usare le diverse versioni di gpt-oss di OpenAI (i nuovi modelli open) via API e con una velocità impressionante.
Nel video testo la versione 120b nel Playground di Groq, su diversi task, usando anche il tool di web search e code interpreter (per generare un diagramma).
Come si vede, l'inferenza è davvero veloce: mediamente 500 token/s.
Gpt-oss di OpenAI su Groq: un test
E la qualità dei risultati? Sinceramente è ottima, se consideriamo le caratteristiche del modello e la quantità di istruzioni che fornisco in input.
Questi modelli possono davvero coprire una grande quantità di elaborazioni nelle applicazioni, soprattutto all'interno di framework multi agente.
Agenti open-source per la ricerca sul web
Tongyi DeepResearch rappresenta un passaggio significativo nell’evoluzione degli agenti open-source per la ricerca sul web. Si distingue non solo per i risultati raggiunti nei benchmark più complessi, ma soprattutto per l’approccio metodologico che lo sostiene.
Al centro di questa visione c’è l’idea che un agente non debba limitarsi a immagazzinare conoscenza, ma debba saper agire, pianificare e costruire risposte attraverso processi multi-step.
Tongyi DeepResearch: un esempio
Il concetto di Agentic Continual Pre-Training mostra come il pre-training non debba essere visto come una fase chiusa, ma come un ciclo continuo, arricchito da dati sintetici progettati per simulare scenari di ricerca e di decisione. In questo modo, il modello viene nutrito con esperienze artificiali che non solo ampliano il suo repertorio informativo, ma modellano il suo comportamento da agente, rendendo più naturale il passaggio alle fasi successive di fine-tuning e reinforcement learning.
I risultati confermano la forza di questo approccio: Tongyi DeepResearch ottiene un punteggio di 32.9 su Humanity’s Last Exam, 43.4 su BrowseComp, 46.7 su BrowseComp-ZH e 75 su xbench-DeepSearch, superando sia agenti open-source che soluzioni proprietarie di riferimento.
In un panorama dove l’accesso a dati reali è limitato e costoso, l’uso sistematico e scalabile di dati sintetici rappresenta una svolta: non una semplice sostituzione, ma una forma di addestramento che permette al modello di esplorare lo spazio del ragionamento e dell’azione ben oltre i confini imposti dai dataset umani disponibili.
Tongyi DeepResearch dimostra così che l’open-source non significa rinuncia a performance di punta, ma può anzi incarnare una via diversa, fondata sulla generazione autonoma e controllata delle condizioni di apprendimento.
E se un modello potesse sviluppare da solo nuove strategie per risolvere problemi complessi?
Un recente paper su Nature mostra come sia possibile ottenere questo risultato utilizzando il modello DeepSeek-R1 come banco di prova. La chiave è il reinforcement learning puro: invece di forzare il modello a imitare esempi umani passo dopo passo, gli viene dato solo un premio se la risposta finale è corretta.
I risultati sono notevoli
- Con questa tecnica, una versione iniziale chiamata DeepSeek-R1-Zero ha imparato spontaneamente a produrre passaggi più lunghi, verificare i propri risultati e correggersi in corso d’opera.
- In competizioni di matematica e coding ha superato perfino la media dei concorrenti umani.
- Successivi perfezionamenti hanno reso il modello più leggibile, coerente nelle lingue e più adatto a compiti generali.
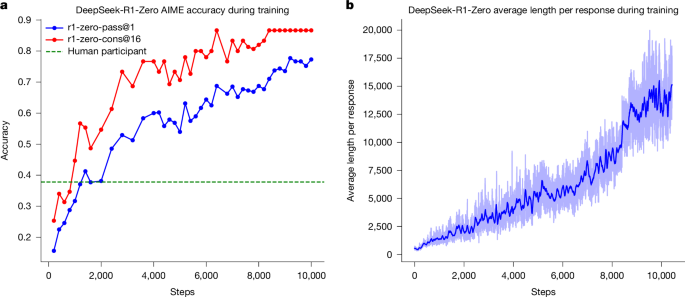
Il messaggio del lavoro è chiaro: non serve guidare il modello con tracciati umani dettagliati, ma bastano domande difficili, verificatori affidabili e ricompense ben progettate. Capacità sofisticate emergono in modo naturale.
Un passo avanti verso sistemi che sanno trovare autonomamente percorsi nuovi per affrontare sfide complesse.
VaultGemma: LLM con privacy differenziale
Google ha presentato VaultGemma: il LLM open-source più potente al mondo con privacy differenziale.
Cosa significa? Lo vediamo in modo semplice...
Quando si addestra un modello di AI su testi come email, documenti o messaggi, c'è il rischio che memorizzi frasi private.
La privacy differenziale risolve questo problema: durante l’addestramento, si aggiunge un po’ di "rumore" ai dati per impedire che il modello ricordi informazioni sensibili. In pratica, impara il concetto generale, ma non i dettagli personali.
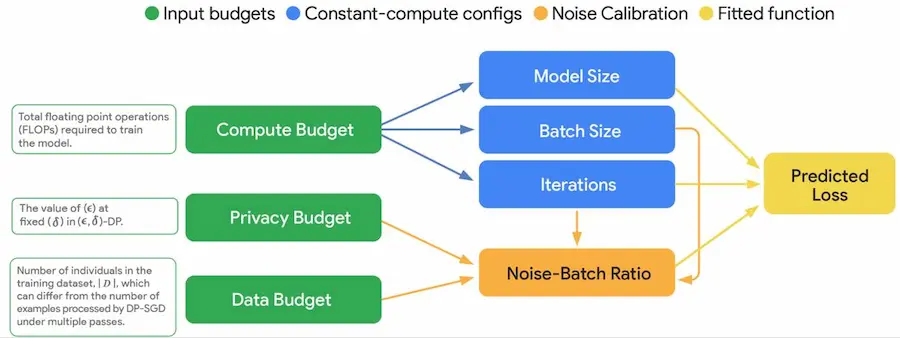
VaultGemma: LLM con privacy differenziale
VaultGemma è il primo modello open-source da 1 miliardo di parametri addestrato completamente da zero con questa tecnica. Google ha sviluppato nuove regole per trovare il giusto equilibrio tra privacy, prestazioni e potenza di calcolo.
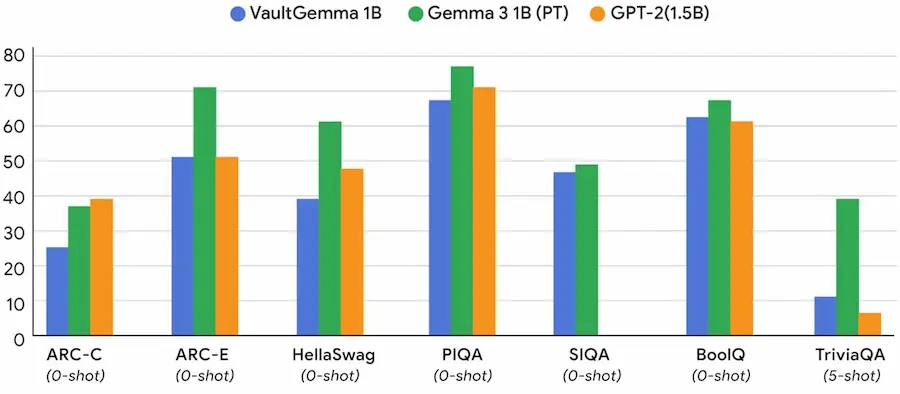
Le sue performance sono solide.
- È paragonabile a modelli come GPT-2 (1.5 miliardi di parametri) su test noti come HellaSwag, TriviaQA e altri.
- Non memorizza sequenze dei dati di addestramento.
- È stato rilasciato pubblicamente per aiutare la comunità a sviluppare IA più sicure e rispettose della privacy.
Un passo concreto verso un’intelligenza artificiale potente ma progettata fin dall’inizio per proteggere le persone.
Gemma 3n on-device in locale
Nell'ultima versione di AI Edge Gallery di Google è possibile testare Gemma 3n completamente on-device (in locale in uno smartphone), senza nessuna connessione a Internet e scambio dati esterni.
Ora anche con elaborazione di file audio e immagini.
Negli esempi, carico un mio audio registrato e lo faccio tradurre al modello, oppure lo interrogo sul contenuto di alcune immagini.
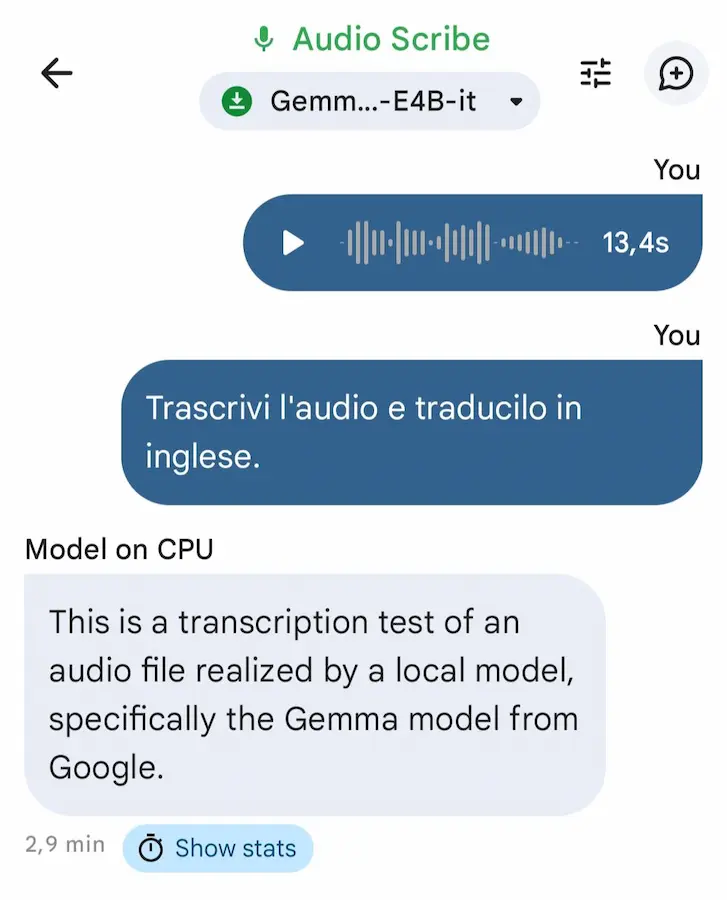

Gemma 3n on-device sul mio smartphone
Solo una piccola dimostrazione, ma che indica una direzione abbastanza chiara.
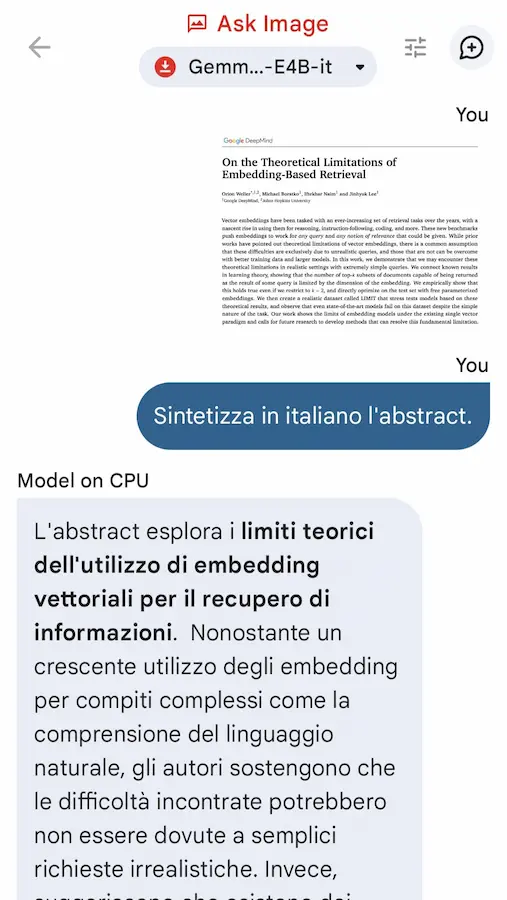
Risorse per fine-tuning
Un'unica repository con oltre 100 Notebook Colab già pronti per il fine-tuning dei LLM (con tutte le guide)?
È messa a disposizione da Unsloth AI.
ElevenLabs Music
L'evoluzione della generazione musicale potenziata dall'AI avanza, con ElevenLabs Music.
L'ho provato, e l'aspetto più interessante è che aumenta il controllo sull'output.
ElevenLabs Music è uno strumento che permette di generare musica partendo da un semplice prompt testuale, in qualità da studio.
I brani creati sono suddivisi in parti (intro, verse, chorus, drop, bridge, ecc.), e ognuna di queste può essere modificata in ogni suo aspetto: lunghezza, testo (se c'è la voce), caratteristiche, ecc.. Le modifiche avvengono attraverso ulteriori prompt testuali e con le funzionalità dell'editor.
Nel mio test (nel video), inserisco un prompt testuale per creare un brano, e il modello genera 3 versioni. Modifico lunghezza e testi di alcune parti.. e la "magia" sta nel fatto che il modello rigenera il brano per mantenere la coerenza delle diverse componenti.
Un test di ElevenLabs Music
Il livello di personalizzazione che si sta raggiungendo era impensabile fino a poco tempo fa. A breve, probabilmente, si lavorerà in timeline multi-traccia, con la possibilità di intervenire su ogni linea. Questo lo sta già realizzando Suno nel Suno Studio.
Ciliegina sulla torta: c'è anche un’API per integrarlo nei flussi di lavoro di prodotti o progetti creativi.
La generazione è praticamente istantanea e il risultato si adatta con precisione al prompt, anche in termini di BPM, tonalità e intenzione emotiva.
Se non siamo ancora pronti all'idea di canzoni generate completamente con un modello di AI, pensiamo a quanto questi strumenti potranno supportare l'editing e la content creation.
Nuove funzionalità su NotebookLM
Google ha rilasciato nuove funzionalità su NotebookLM.
- Le Audio Overview possono essere impostate con tagli di contenuto diversi (es. Approfondimento, Dibattito, Critica). E per ogni taglio è possibile scegliere la lunghezza del contenuto.
- Le Audio e Video Overview, possono essere generate in tutte le lingue, con la selezione.
- L'aggiunta di fonti attraverso la ricerca online, si estende anche a Google Drive (es. "slide sull'AI di Alessio").
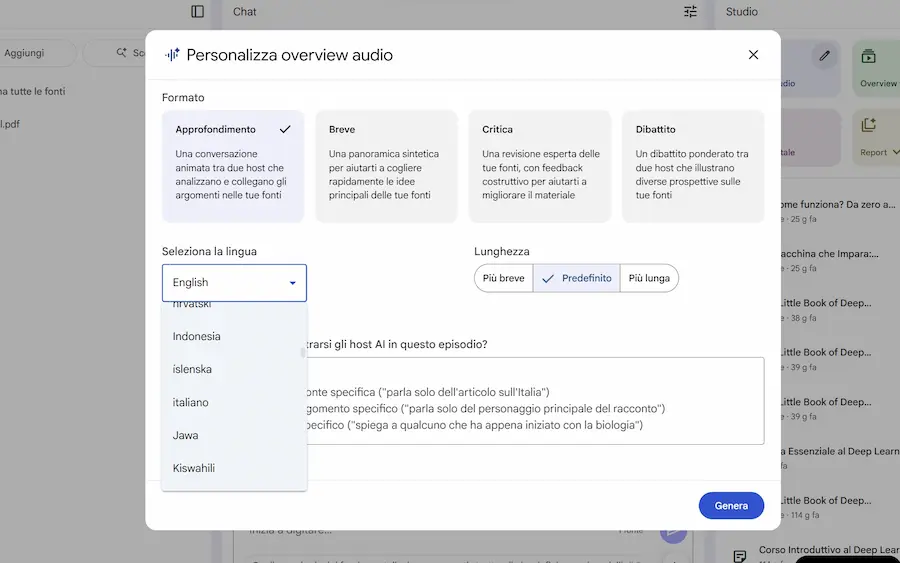
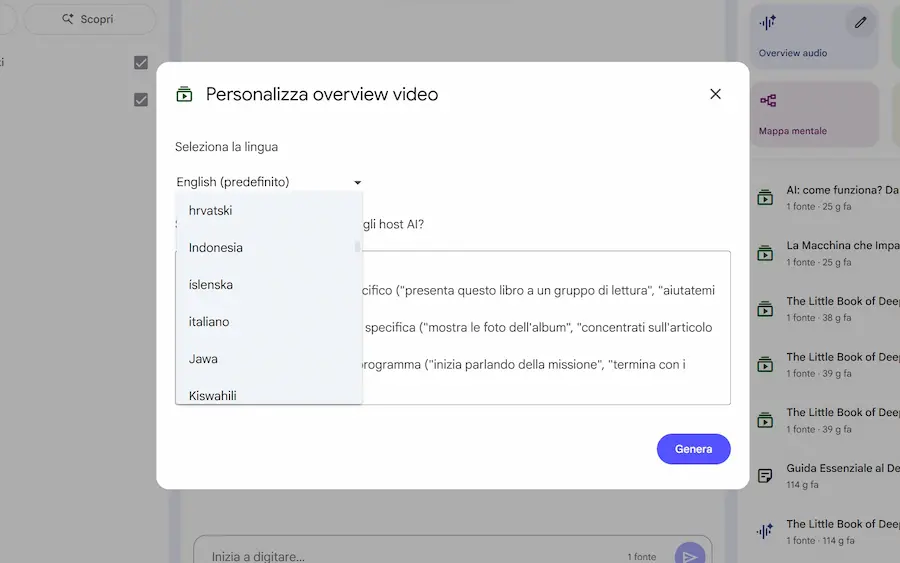
Le novità di NotebookLM di Google
E ne sono in arrivo altre..
- La funzionalità Deep Research di Gemini, che permetterà agli utenti di semplificare il processo di ricerca delle fonti e di importare contenuti pertinenti direttamente nei notebook.
- La modalità "tutor", rivolta agli studenti. Questo suggerisce che Google vuole espandere NotebookLM oltre le sue attuali funzionalità di appunti e ricerca, trasformandolo in un assistente didattico più attivo.
Google procede nel suo percorso per portare Gemini in tutti gli strumenti di produttività.
L'Audio Overview su Gemini.. e non solo
La chat di Gemini introduce (anche in Italia) l'Audio Overview.
Quando carichiamo un documento compare il bottone "genera overview audio", che attua un'azione simile all'Audo Overview di NotebookLM: crea un mini podcast con diversi host che raccontano il documento.
In alternativa, scrivendo nel campo della chat, è possibile continuare l'interazione classica, e il bottone scompare.
Nel video, si può vedere (e sentire) un piccolo esempio di generazione.
L'Audio Overview su Gemini: un esempio
Cosa manca? La possibilità di personalizzare l'overview per gestire il tipo di discussione.
..anche pagine web, infografiche e quiz
Il nuovo menù di "Canvas", infatti, si è arricchito, permettendo anche la creazione di pagine web, infografiche, e quiz. In pratica (quasi) tutte le novità di NotebookLM sono anche su Gemini.
Nelle immagini si vedono degli esempi: le infografiche che crea il modello sono davvero molto interessanti, precise e creative.
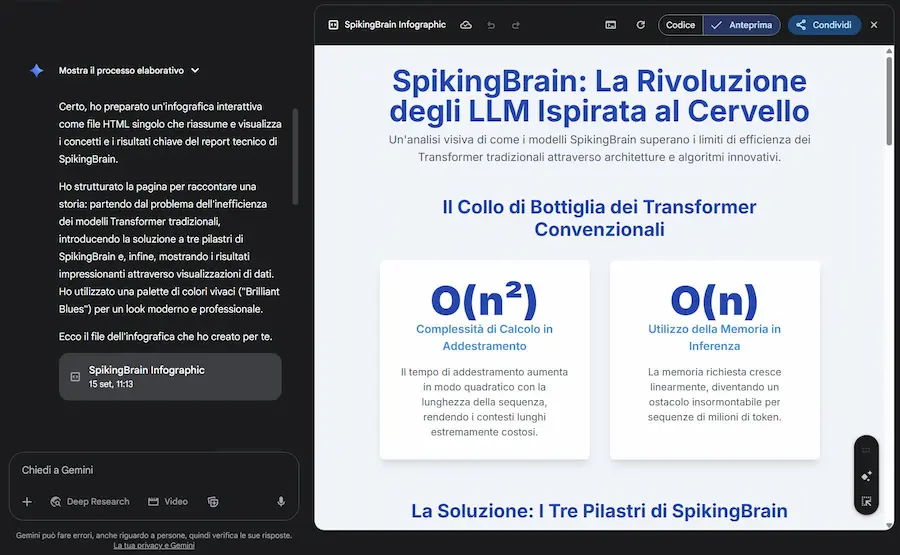
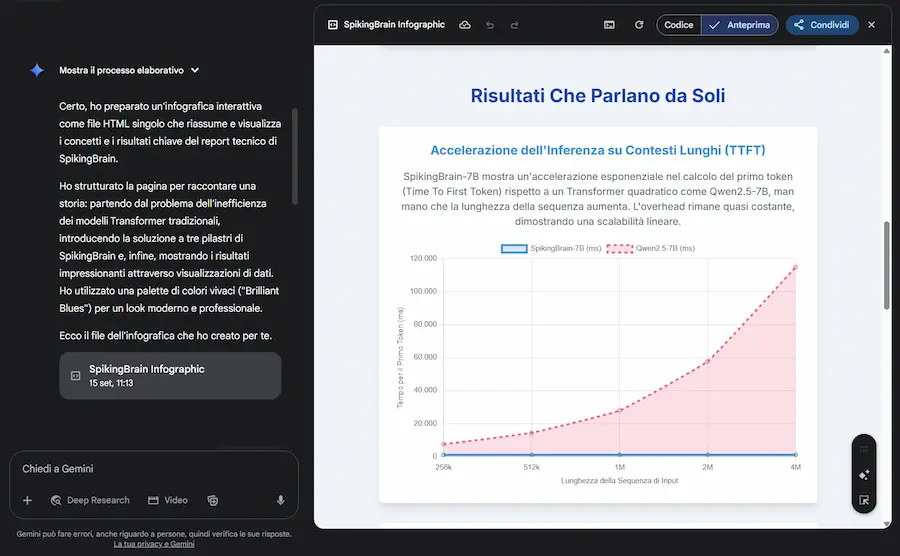
Le nuove funzionalità di Canvas su Gemini
Così come gli altri nuovi output, disponibili direttamente dalla chat di Gemini.
Una nota sul quiz interattivo: lo immagino applicato agli aspetti formativi, per valutare la comprensione di uno o più contenuti. Recentemente ho dato come input una presentazione e ho ottenuto il quiz di fine seminario per gli studenti.
Gemini può elaborare i file audio? Sì!
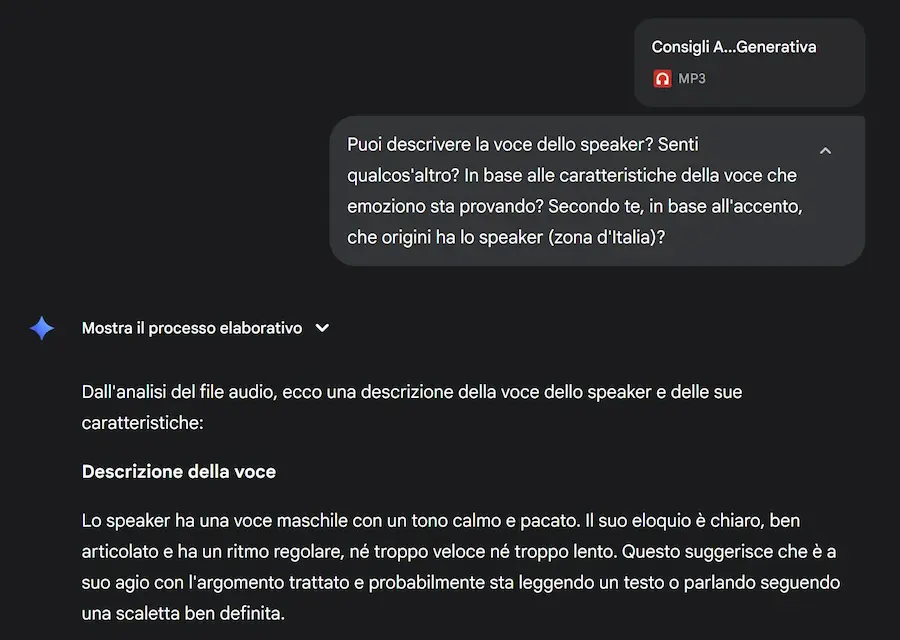
Inizialmente credevo che fosse soltanto un sistema che trascrive l'audio, e usa la trascrizione come contesto per il LLM.
In realtà, è qualcosa di più: il modello descrive le caratteristiche delle voci, elementi come il "piagnucolio", il timbro caldo e profondo, l'eloquio rassicurante e pacato, l'intonazione ascendente, ecc..
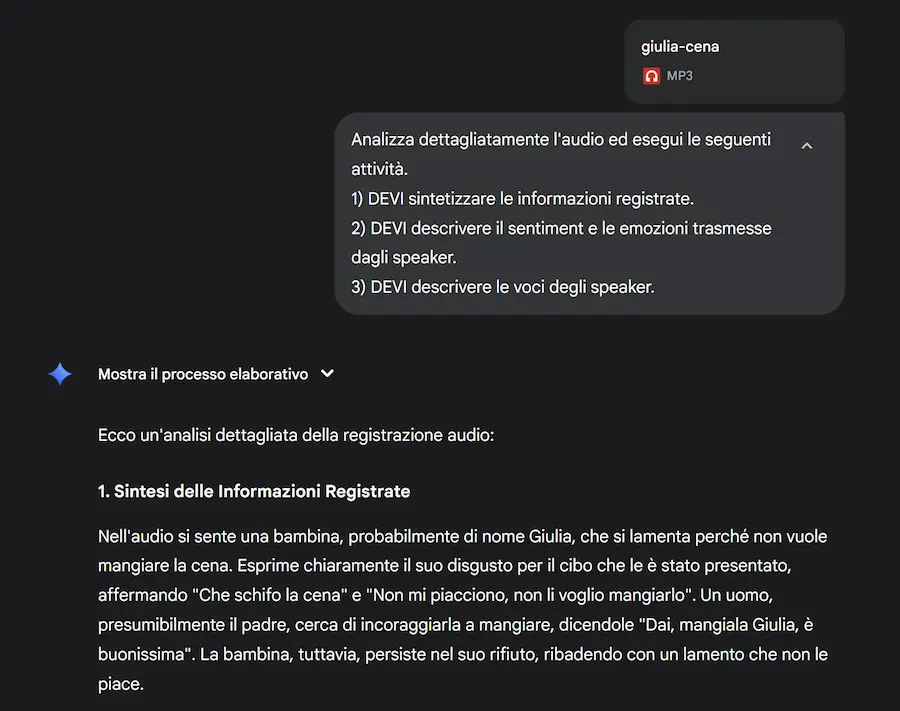

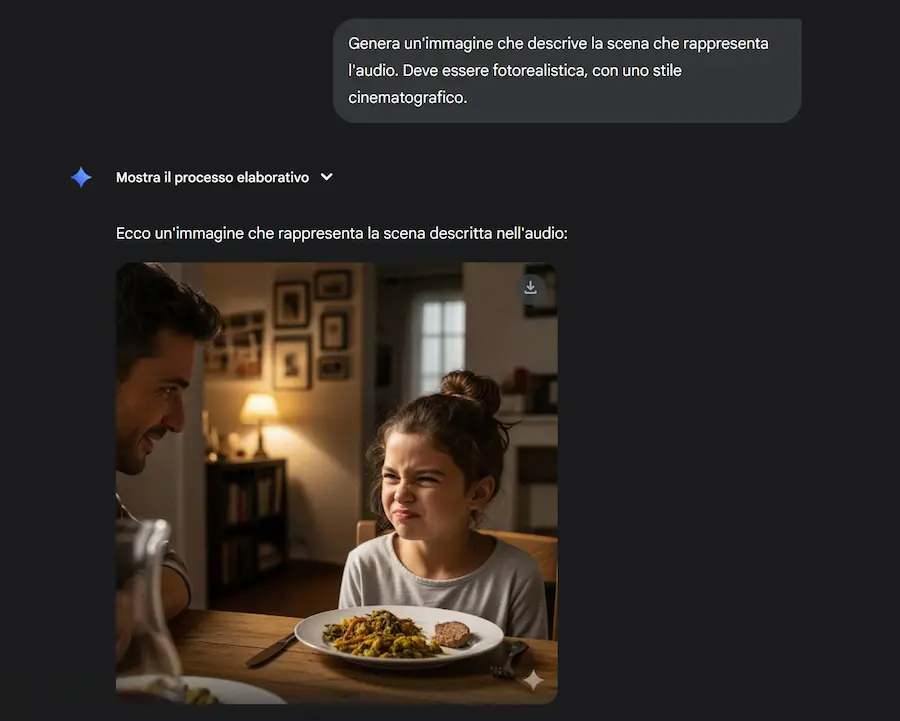

Un esempio dell'elaborazione audio di Gemini 2.5 Pro
Alla fine, usando Gemini 2.5 Pro Image (Nano Banana), ho creato un'immagine che rappresentasse l'audio. Nell'altro esempio, il modello riconosce la provenienza dello speaker in base all'accento e alla cadenza.
Dei semplici test che mettono in luce il livello di multimodalità al quale siamo già arrivati con i modelli di ultima generazione.
Se ci pensiamo, è qualcosa di straordinario: i modelli nativamente multimodali segnano un cambio di paradigma. Non traducono più gli input in sequenze separate, ma li trasformano in embedding che confluiscono in un unico spazio di rappresentazione, dove testo, immagini, audio e altro possono essere elaborati insieme.
Rilasci di nuovi LLM
Alibaba ha presentato Qwen3-Max-Preview (Instruct), il modello più grande della famiglia Qwen, con oltre 1 trilione di parametri.
È già disponibile su Qwen Chat e attraverso le API di Alibaba Cloud.
Dai benchmark si può notare come supera il miglior modello precedente (Qwen3-235B-A22B-2507).
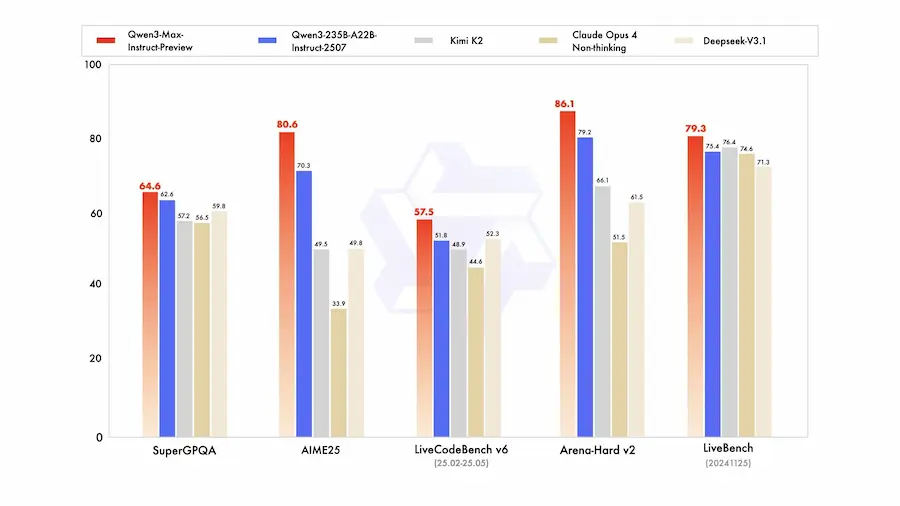
Il modello permette prestazioni più elevate, conoscenza più ampia, migliori capacità di conversazione e di seguire le istruzioni.
Anche Kimi presenta un nuovo aggiornamento, con Kimi K2-0905.
Funzionalità di codifica migliorate, in particolare nello sviluppo di front-end e nelle chiamate dei tool.
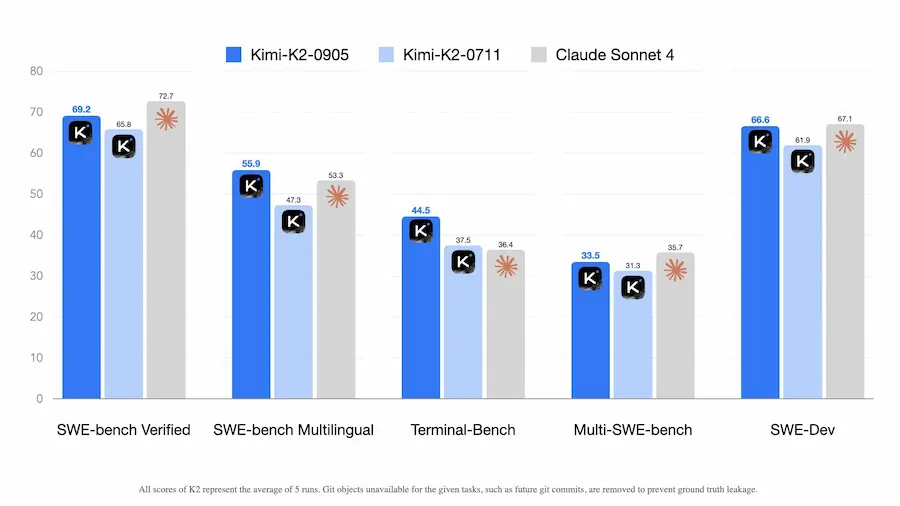
Lunghezza del contesto estesa a 256k token.
Integrazione migliorata con vari scaffold di agenti (es. Claude Code).
Qwen3-Next
Dopo aver presentato Qwen 3, che ho provato con soddisfazione in diversi test, Alibaba presenta Qwen3-Next, un'evoluzione pensata per ridefinire l’efficienza nell’addestramento e nell’inferenza dei LLM.
È distribuito come modello open source, con pesi pubblici e compatibilità ampia con le principali toolchain. Questo conferma la volontà di contribuire in modo concreto a un'AI trasparente, accessibile e realmente integrabile nei contesti di sviluppo.
Ho provato anche questa versione, su prompt dettagliati che normalmente uso su Gemini 2.5 Pro, e.. devo dire che sono rimasto molto colpito dagli output. Veloce, preciso, aderente.
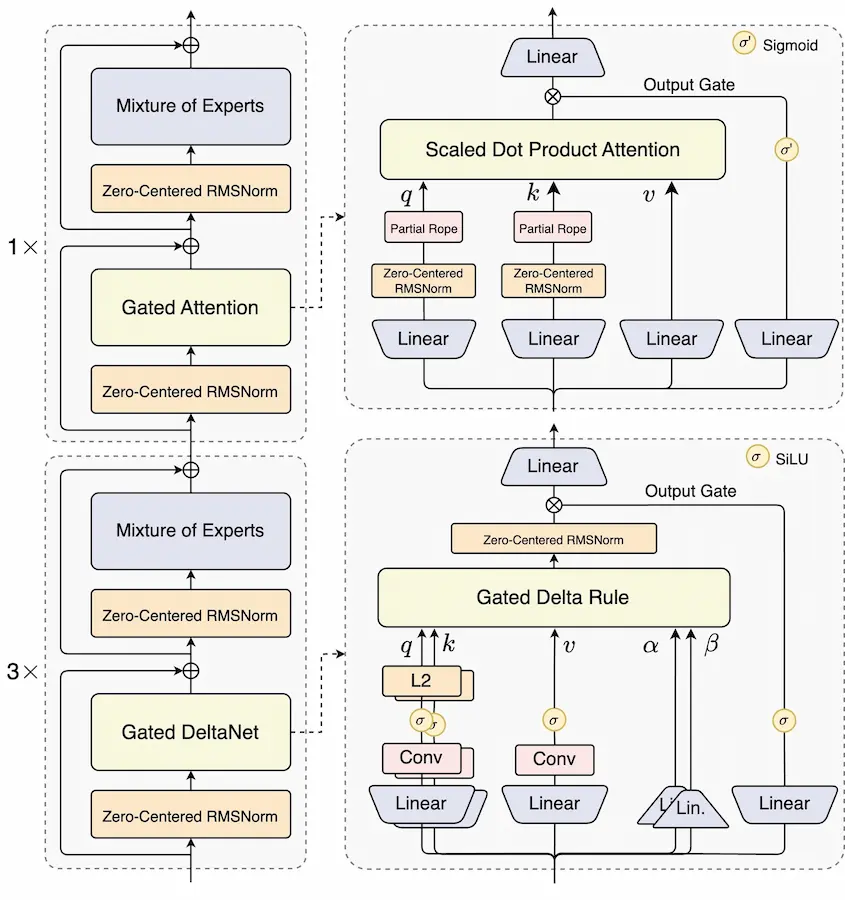
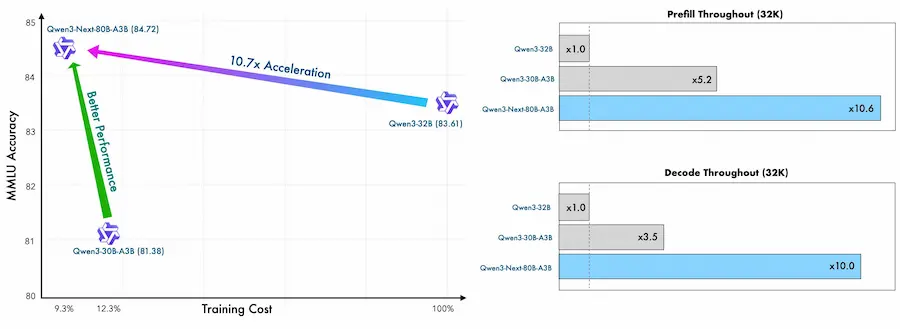
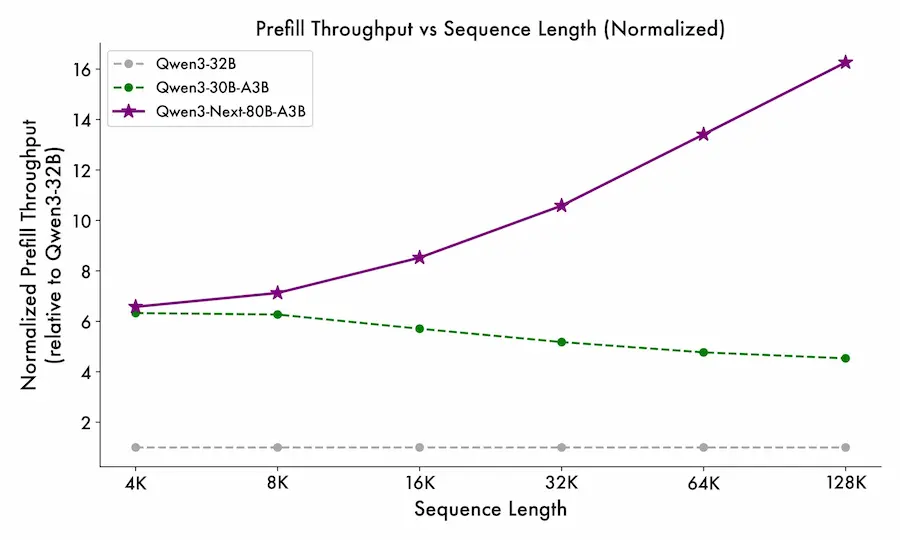
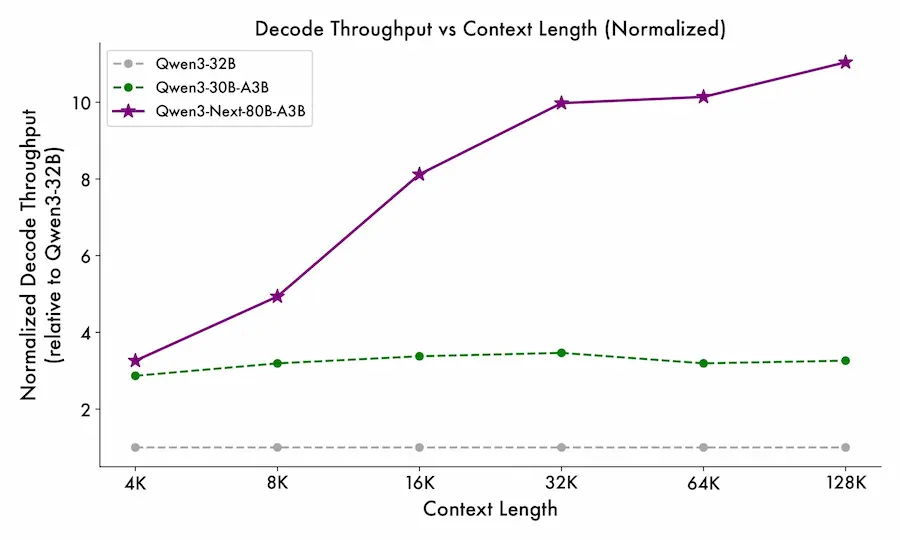
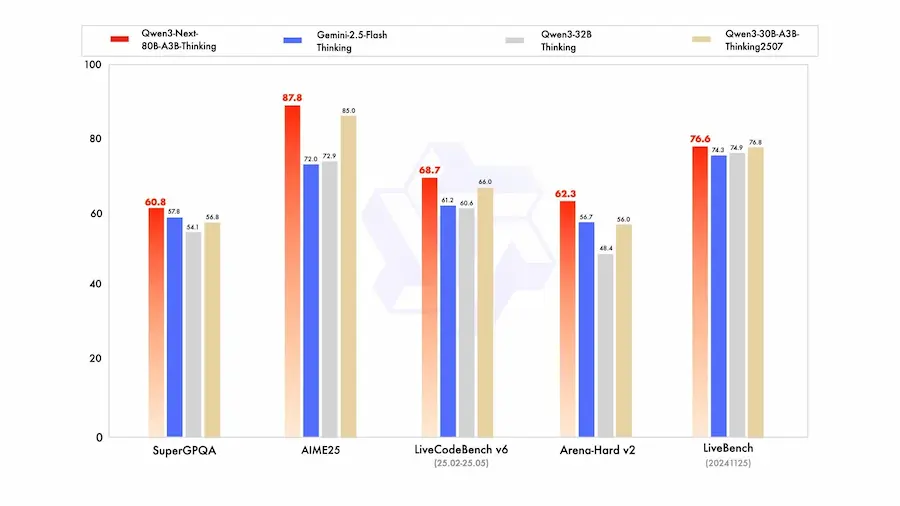
Qwen3-Next: alcuni dettagli sul modello
Uno degli aspetti più rilevanti di Qwen3-Next è l'introduzione della struttura QMoE (Qwen-Mixture of Experts), un sistema dinamico che seleziona in tempo reale solo una parte degli “esperti” del modello per ogni input.
Questo meccanismo permette di mantenere elevate prestazioni con un consumo energetico e computazionale significativamente ridotto, offrendo una soluzione scalabile tanto per grandi deployment quanto per ambienti edge.
La qualità del pretraining multi-task, costruito su un corpus che include scrittura, codice, ragionamento, matematica e traduzione, testimonia una direzione precisa: costruire modelli generalisti, ma senza la superficialità dei compromessi. L’allocazione dei pesi nei diversi task è gestita da uno schema di ottimizzazione che mira a mantenere coerenza e profondità trasversale, caratteristiche non sempre garantite dai LLM più generalisti.
In ambito benchmark, Qwen3-Next ha già mostrato risultati che lo pongono tra i modelli più solidi del 2025: su MMLU, GSM8K, HumanEval e BBH, la versione da 72B con architettura MoE compete e in alcuni casi supera modelli come GPT-4 e Claude 3, pur con un'efficienza computazionale superiore.
I modelli più piccoli, da 1.5B a 14B, mantengono prestazioni notevoli, suggerendo una flessibilità d’impiego che abbraccia diversi casi d’uso industriali e di ricerca.
Qwen3-Next non è solo un nuovo modello, ma rappresenta una visione: quella di un’AI capace di crescere non solo in potenza, ma in equilibrio tra efficacia, efficienza e adattabilità. Una traiettoria che guarda oltre la corsa alle dimensioni e punta alla maturità tecnica.
Un'analogia nel funzionamento dell'intelligenza biologica
Secondo Ilya Sutskever, l'approccio che guida lo sviluppo dei moderni sistemi di AI (basato su un'unica, grande architettura generale) trova un'analogia nel funzionamento dell'intelligenza biologica.
A sostegno di questa tesi, porta esempi dalla neuroscienza, come la capacità del cervello di riorganizzarsi e funzionare con un solo emisfero dopo un intervento in età infantile, o l'esperimento in cui la corteccia uditiva di un furetto ha imparato a elaborare segnali visivi. Per Sutskever, questi casi suggeriscono che il tessuto corticale non è un insieme di moduli rigidamente specializzati, ma un substrato di apprendimento uniforme e adattabile.
Questa idea, secondo lui, offre una spiegazione del perché un'unica, grande architettura neurale, se scalata con più dati e calcolo, possa sviluppare un'ampia gamma di capacità senza essere riprogettata per ogni compito specifico.
La visione, fornisce un quadro concettuale elegante e potente che collega l'evoluzione biologica, la neuroscienza e la strategia di ricerca che ha prodotto i modelli di AI più avanzati di oggi.
Ci dice che la ricerca di un "algoritmo di apprendimento universale" o di un'"architettura generale" non è un'utopia, ma potrebbe essere il modo in cui l'intelligenza, sia biologica che artificiale, funziona davvero. È una delle visioni più ottimistiche e ambiziose nel campo dell'AI.
Dal mio punto di vista, non basterà un'unica architettura neurale con più dati e calcolo. Serviranno nuove architetture.
Arriveremo a sistemi di AI in apprendimento continuo?
MoonshotAI, l'azienda che sviluppa Kimi, ha rilasciato un progetto open source chiamato Checkpoint-engine, una tecnologia che consente di aggiornare i pesi nei modelli LLM rapidamente e senza interrompere l’inferenza.
Questo middleware è in grado di aggiornare modelli da un trilione di parametri (es. Kimi-K2) in circa 20 secondi su migliaia di GPU, grazie a una pipeline ottimizzata e due strategie di aggiornamento: Broadcast, per ambienti sincronizzati, e Peer-to-Peer, per cluster dinamici dove i nodi possono essere aggiunti o riavviati senza influenzare il servizio.
L'infrastruttura si integra con vLLM, supporta la quantizzazione in FP8 e consente il riutilizzo dei pesi tra istanze già attive. Tutto questo rende possibile aggiornamenti incrementali, anche frequenti, come quelli richiesti da fine-tuning leggeri o reinforcement learning in produzione.
Checkpoint-engine non implementa direttamente l’apprendimento continuo, ma fornisce le fondamenta tecniche per renderlo realizzabile: gestione efficiente dei pesi, scalabilità del cluster e aggiornamenti senza downtime.
Un passo concreto verso sistemi di AI capaci di evolversi nel tempo.
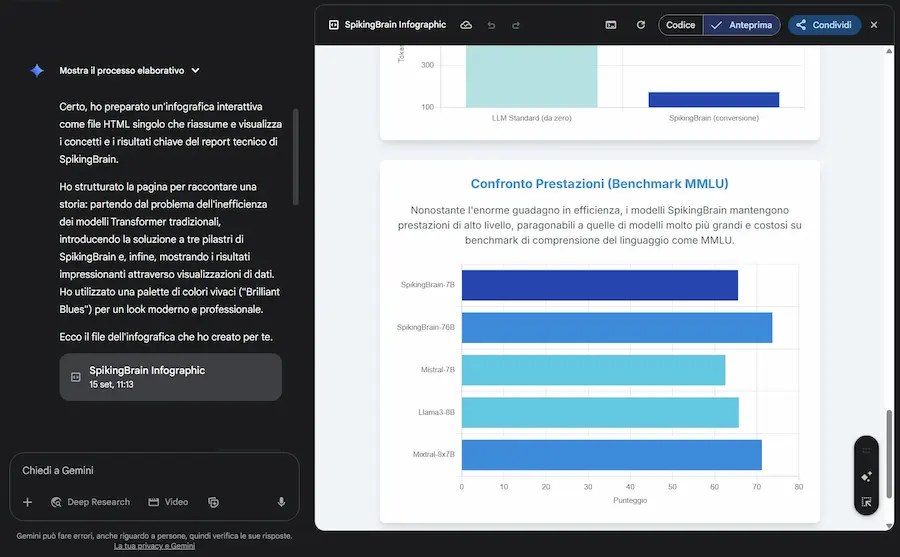
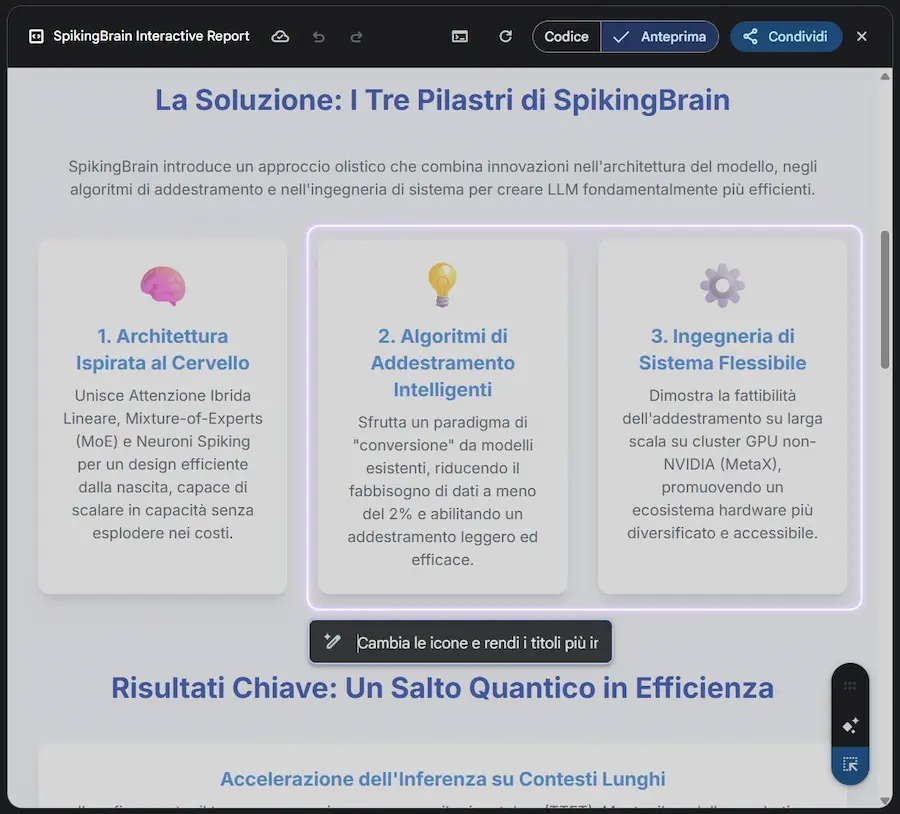
SpikingBrain
SpikingBrain è una nuova famiglia di modelli linguistici di grandi dimensioni ispirati al funzionamento del cervello.
Nasce per superare i limiti dei Transformer tradizionali, che richiedono calcoli quadratici sulle sequenze, accumulano memoria in modo lineare e dipendono quasi esclusivamente dalle GPU NVIDIA.

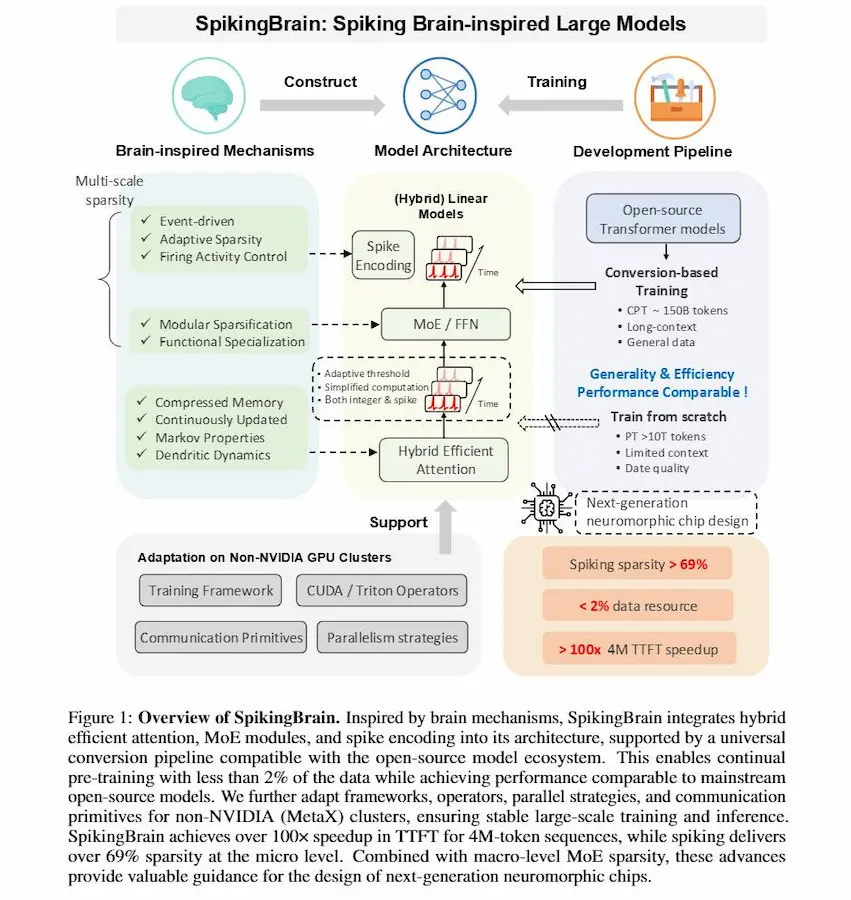
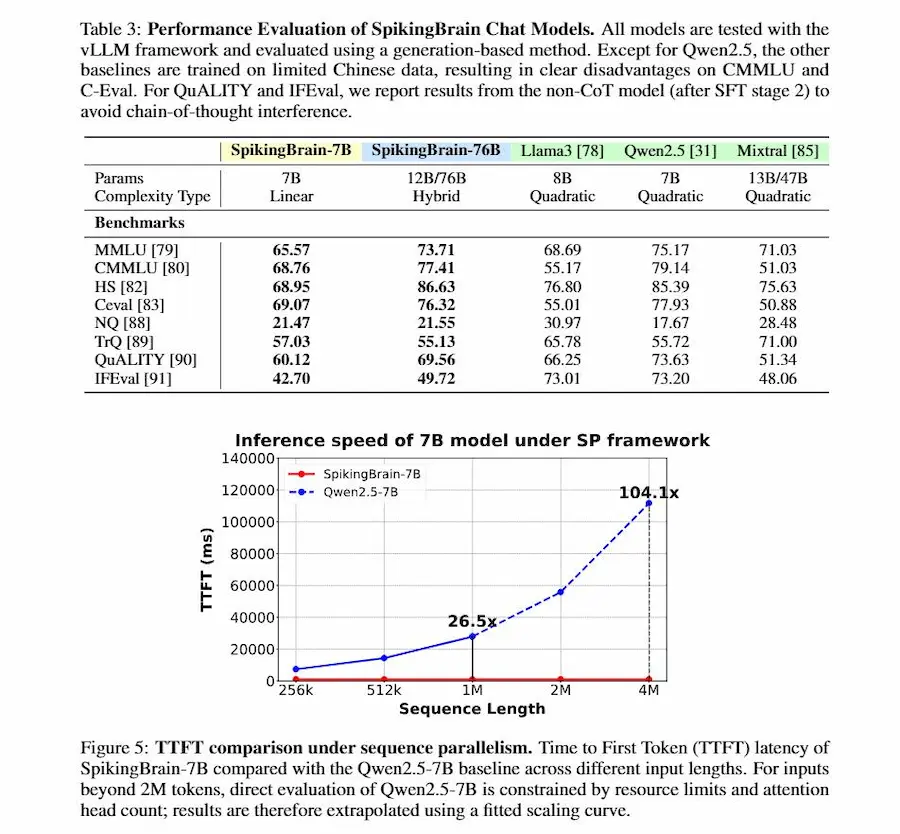
SpikingBrain: il paper
La sua idea centrale è introdurre neuroni spiking: attivazioni convertite in eventi discreti e sparsi, simili agli impulsi dei neuroni biologici. In questo modo il modello resta silenzioso quando non serve, riduce il consumo energetico e gestisce testi lunghissimi senza che il costo esploda.
L’architettura combina varianti lineari e locali dell’attenzione, integra la specializzazione modulare con il Mixture-of-Experts, e porta la la selettività su più livelli, dal singolo neurone all’intera rete.
Il risultato sono due modelli: SpikingBrain-7B, piccolo ed estremamente veloce, che su sequenze di milioni di token ottiene oltre cento volte la rapidità di un Transformer standard; e SpikingBrain-76B, più grande e competitivo con sistemi come Llama2 e Mixtral. Entrambi addestrati su cluster MetaX, senza ricorrere a NVIDIA.
SpikingBrain mostra che l’evoluzione dell’intelligenza artificiale non passa solo dalla scala, ma anche dallo studio dell'architettura: reti più efficienti, modulari e capaci di attivarsi solo quando serve.
Quanto conta che l'AI non viva "nel cloud", ma direttamente nei nostri dispositivi?
Apple ha appena presentato FastVLM e MobileCLIP2, modelli vision-language progettati per funzionare on-device, senza passaggi su server remoti.
Dal punto di vista ingegneristico, i numeri parlano chiaro: fino a 85 volte più veloci, 3,4 volte più compatti rispetto alle soluzioni precedenti, capaci di generare didascalie in tempo reale anche da flussi video, direttamente nel browser.
Una demo di FastVLM di Apple
Nessuna infrastruttura esterna, nessuna latenza, nessuna esposizione dei dati sensibili.
Ma il punto non è solo l’efficienza. È la narrativa che si va costruendo: un’IA che non è un servizio distante, impersonale e centralizzato, bensì un’estensione locale, integrata, privata. Un’IA che non “vive altrove”, ma che appartiene all’utente e al suo dispositivo.
Si tratta forse dell'inizio di un percorso che tenta di mascherare una lacuna (sviluppo di sistemi basati sull'AI) con la promozione di un'AI personale, privata e senza soluzione di continuità? Probabilmente sì, anche se i rumors suggeriscono un interesse di Apple per acquisizioni di brand come Mistral e Perplexity.
L'AI potrà sostituire i matematici?
Un paper pone riflessioni interessanti.
Io aggiungo: ..ma forse sono le aspettative ad essere sbagliate.
Nel racconto degli autori, lavorare con GPT-5 è stato come affiancarsi a un giovane ricercatore alle prime armi: capace di seguire ragionamenti, di proporre combinazioni di idee già note, persino di suggerire direzioni possibili.
Ma ogni passaggio richiedeva attenzione, verifiche, correzioni puntuali.
Senza supervisione, l’illusione di rigore rischiava di nascondere errori.
Questa esperienza mostra che l’AI eccelle nella ricerca incrementale: raffinamenti, piccoli avanzamenti, collegamenti tra risultati già esistenti. È qui che può risparmiare tempo, agire come un assistente instancabile. Non inaugura prospettive radicalmente nuove, ma può portare a contributi originali, anche se non rivoluzionari.


L'AI potrà sostituire i matematici? - Un paper interessante
Il rischio è duplice. Da un lato, un’inflazione di risultati tecnicamente corretti ma poco significativi, che potrebbe soffocare la visibilità delle idee davvero innovative.
Dall’altro, un impatto sulla formazione dei giovani: se un dottorando si affida troppo presto a uno strumento che fornisce risposte immediate, rischia di perdere il contatto con quel processo di errori, tentativi ed esplorazioni che è il cuore stesso del diventare matematici. Il rischio è crescere ricercatori che sanno leggere risposte, ma non costruire domande.
Qui emergono anche i limiti del paper. I risultati sono originali ma non rivoluzionari: estensioni incrementali più che breakthrough. L’AI è usata in modo strumentale, come un esecutore da guidare passo dopo passo, senza esplorare nuove forme di collaborazione uomo-macchina. E lo sguardo rimane difensivo: si sottolineano i rischi, ma poco si immaginano scenari positivi in cui l’AI potrebbe stimolare creatività e aprire campi oggi inaccessibili.
Gli autori restano cauti: i progressi sono rapidi, sorprendenti e meritano attenzione.
Ma più che immaginare un rimpiazzo dei matematici, bisognerebbe forse interrogarsi su come preservare l’essenza della ricerca umana in un paesaggio che rischia di essere sovraccaricato di risultati senza anima.
E, soprattutto, su come valorizzare l’AI per ciò che già sa fare oggi: accelerare, stimolare, supportare — e questo è già tantissimo.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂