GPT-5: riflessioni, riepilogo, test.. e AGI?
GPT-5 di OpenAI segna un passo solido ma non rivoluzionario verso l’AGI: meno allucinazioni, più ragionamento, nuove funzioni e prezzi competitivi. Progresso importante, ma la vera svolta richiederà architetture ibride.

GPT-5 is a significant step along the path to AGI… a model that is generally intelligent.
Così Sam Altman introduce la live di presentazione di GPT-5. Nel momento in cui ha finito la frase, ho avuto una forte tentazione di stoppare lo streaming.. ma mi sono sforzato di proseguire.
A valle dell’evento, il mio bilancio è questo:
GPT-5 è un major update
solido ma non di rottura.
La presentazione di GPT-5 di OpenAI
È plausibile che abbiano migliorato praticamente tutto: comprensione, allucinazioni, strumenti, costi.. però non è il salto epocale che la retorica di apertura lasciava intendere. Anche il messaggio “verso l’AGI” suona come marketing ambizioso più che come evidenza scientifica: se migliori su molti benchmark ma resti nel solco della stessa famiglia di (queste) tecniche, è un progresso importante, non una rivoluzione.
Questo non significa sminuire il lavoro tecnico: l’inferenza è più economica, il modello sceglie quando attivare componenti di "reasoning" e la lineup è più granulare (tipologie di modello diverse per casi d’uso diversi). Ma la live è stata anche penalizzata da visualizzazioni fuorvianti: alcuni grafici avevano barre che non corrispondevano ai valori e un diagramma sulla “deception” è stato poi corretto nella documentazione.

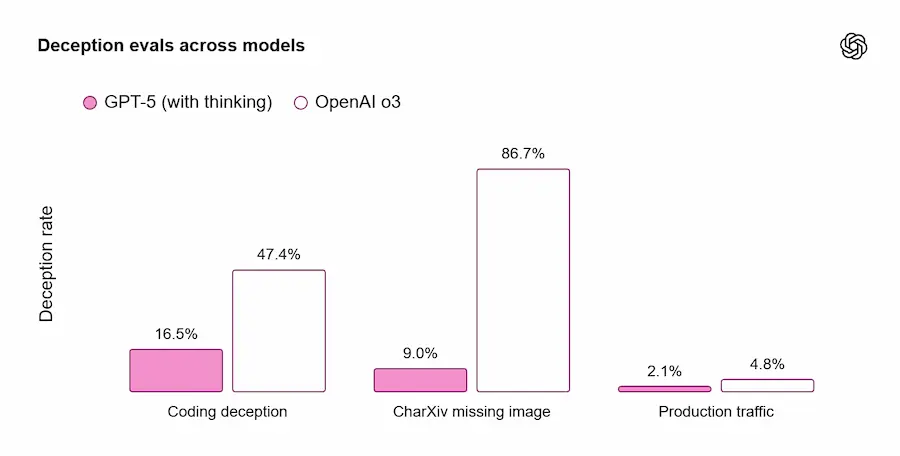
La correzione del diagramma dalla presentazione alla documentazione
Sul fronte posizionamento competitivo, la sensazione è di passo avanti, non balzo in avanti. Dopo l'evento, François Chollet (co-founder di ARC Prize) ha pubblicato un confronto in cui Grok 4 risulta avanti su ARC-AGI-2, mentre su ARC-AGI-1 il margine è più sottile; al netto di differenze di costo, il quadro è di una leadership contesa e per nulla schiacciata.
Grok 4 is still state-of-the-art on ARC-AGI-2 among frontier models.
— François Chollet (@fchollet) August 7, 2025
15.9% for Grok 4 vs 9.9% for GPT-5. pic.twitter.com/wSezrsZsjw
Questi dati vanno interpretati con cautela (metodologie, settaggi, versioni cambiano), ma raffreddano l’idea di un distacco netto.
Infine, qualche scelta narrativa non ha aiutato: tanto "vibe coding" e storytelling emotivo, meno metodo e ablation. Da utilizzatore, mi sarei aspettato più dimostrazioni di multimodalità end-to-end (input e output ricchi, integrazione sensori-attuatori) e un ponte più credibile verso il mondo fisico/robotico — area in cui altri player stanno spingendo (es. Google e Nvidia).
I miglioramenti ci sono e i prezzi non sono fuori mercato; semplicemente non abbiamo visto
“il prossimo paradigma”.
Parliamo del concetto di AGI?
Perché la tentazione di chiudere lo streaming non appena Altman ha pronunciato “AGI”? Perché, probabilmente, i soli LLM non basteranno per raggiungere l'obiettivo. Continuare a scalare decoder autoregressivi riduce errori ma non risolve: causalità, generalizzazione out-of-distribution, composizionalità, pianificazione a lungo raggio, ragionamento simbolico. A questo proposito, ho più volte menzionato approcci come quello neuro-simbolico, ovvero l'integrazione di reti neurali e rappresentazioni/strumenti simbolici.
Non è teoria astratta: modelli-strumento come o3, Grok 4, e lo stesso GPT-5, ovvero quelli con interpreti di codice e reasoners, mostrano che plug-in simbolici (solver, motori logici, CAS) alzano l’asticella su compiti logici e strutturati. Google DeepMind, su AlphaFold o AlphaGeometry non applica “solo” LLM: si tratta di architetture ibride disegnate sul problema, con motori di ricerca, vincoli e verifiche. La direzione non è “più grande è meglio”, ma “ben integrato è meglio”: neurale per percepire e proporre, simbolico per verificare, comporre e generalizzare.
Gli avanzamenti recenti in matematica lo confermano. Seed-Geometry (ByteDance Seed AI4Math) ha superato AlphaGeometry 2 su 50 problemi IMO di geometria (43 vs 42) e sulle shortlist più dure (22/39 vs 19/39), grazie a un motore simbolico più veloce, una rappresentazione più compatta delle costruzioni e un ciclo neurale-simbolico più efficiente. Non è un trucco: è un cambio di passo su compiti dove la verifica formale conta quanto (o più) della generazione.
Se vogliamo avvicinarci all’AGI, dobbiamo uscire dal monolito: agenti che usano strumenti e ambienti, memorie strutturate, moduli di pianificazione e prove/verifiche integrati by design, non come accessori opzionali.
Il LLM resta il substrato linguistico e percettivo, ma l’intelligenza emerge dall’orchestrazione.
Lo stato del progresso dell’AI
Al netto di GPT-5, stiamo vivendo un’accelerazione storica. Demis Hassabis (Google DeepMind) descrive un impatto “10 volte più grande, e forse 10 volte più veloce dell’Industrial Revolution”, con un orizzonte di 5–10 anni per sistemi con capacità simili all’umano in molti domini. È un’immagine potente, che richiede di ripensare istituzioni, lavoro, welfare, istruzione e governance.
Non sono solo parole: AlphaFold ha già spostato gli equilibri nella scienza delle proteine, al punto da valere a Hassabis e Jumper il Nobel per la Chimica 2024 (insieme a David Baker). La portata non è solo tecnica: rendere praticabile e diffuso ciò che prima richiedeva anni di esperimenti è nuova capacità civile — scienza più rapida, più aperta, più traducibile in cure e materiali.

Questa accelerazione, però, non è lineare né omogenea. Vediamo frontier models migliorare, ma spesso in modo irregolare: grandi vittorie in domini strutturati (biologia, geometria formale), progressi più lenti nella robustezza generale (ragionamento di buon senso, affidabilità contestuale, autonomia). In parallelo, cresce l’impatto economico (produttività, automazione di parti di filiere cognitive) e si amplificano le questioni sociali: distribuzione dei benefici, sostenibilità energetica, rischi informativi. Il punto non è fermare, ma governare l’onda: standard aperti, benchmark onesti, evals riproducibili, trasparenza sui dati e sistemi di verifica incorporati.
Se la traiettoria “10× più grande e più veloce” si confermerà, ci serviranno nuove idee sul senso del tempo e del valore umano. Non tutto è utilitaristico: arte, gioco, sport, meditazione potrebbero tornare al centro proprio perché liberati dal vincolo. Ma questo futuro richiede politiche intenzionali: redistribuzione, formazione continua, infrastrutture di ricerca e un mercato che premia la qualità, non solo la spettacolarità in keynote.
Ne ho parlato nei recenti interventi che ho tenuto al TEDx di Bergamo e al WMF (We Make Future).
Il mio intervento al TEDx di Bergamo
Conclusioni
GPT-5 è un aggiornamento importante, ma “incrementale”. Ha spinto in avanti il perimetro di ciò che è pratico e abbordabile, senza cambiare le regole del gioco. Se prendiamo sul serio l’AGI, la strada passa per architetture ibride, tool use nativo, verifica simbolica e benchmark trasparenti. Nel frattempo, l’AI continua a permeare scienza, industria e cultura a velocità inaudita: la sfida non è solo tecnica, è civile. E, finché non vedremo quell’integrazione profonda che da tempo invoco, manterrò questa posizione: gli LLM sono necessari ma non sufficienti — e il prossimo salto non sarà solo più grande; sarà diverso.
Una sintesi della presentazione
Per chi non avesse visto tutta la presentazione, quello che segue è un riepilogo che cerca di sintetizzare al meglio le caratteristiche del nuovo sistema di OpenAI.

Panoramica sul modello
GPT-5 è il nuovo modello di punta di OpenAI: più intelligente, più rapido e soprattutto più utile nelle richieste reali (scrittura, coding, salute, multimodale). In ChatGPT diventerà il modello di default per tutti; gli utenti Pro avranno anche GPT-5 Pro (con reasoning più esteso). Il rollout inizia da subito per gli utenti Free, Plus, Pro, Team; per gli abbonamenti Enterprise ed Edu arriverà dopo una settimana dalla presentazione.
Gli utenti Free, al raggiungimento delle quote limite, passano a GPT-5 mini.
Un sistema unificato: router + "thinking" quando serve
Non bisogna più scegliere tra un modello “veloce” e uno “con reasoning”: GPT-5 integra un modello smart/efficiente, un modello di ragionamento profondo (“GPT-5 thinking”) e un router in tempo reale che decide quale usare in base a complessità, tipo di conversazione, strumenti necessari e segnali espliciti (es. “pensa a fondo”). Il router impara da segnali reali (switch tra modelli, preferenze, misure di correttezza). Al raggiungimento dei limiti subentra una versione mini. In futuro queste capacità verranno fuse in un unico modello.
Prestazioni e valutazioni (SOTA)
- Matematica (AIME 2025, senza tool): 94,6%
- Coding: 74,9% su SWE-bench Verified; 88% su Aider Polyglot
- Multimodale: 84,2% su MMMU
- Salute: 46,2% su HealthBench Hard
Con GPT-5 Pro (ragionamento esteso) si ottiene lo stato dell’arte su GPQA (88,4%, senza tool).
In più, rispetto a o3, GPT-5 “thinking” raggiunge risultati migliori usando il 50–80% di token di output in meno su varie capacità (ragionamento visivo, coding agentico, problemi scientifici avanzati).
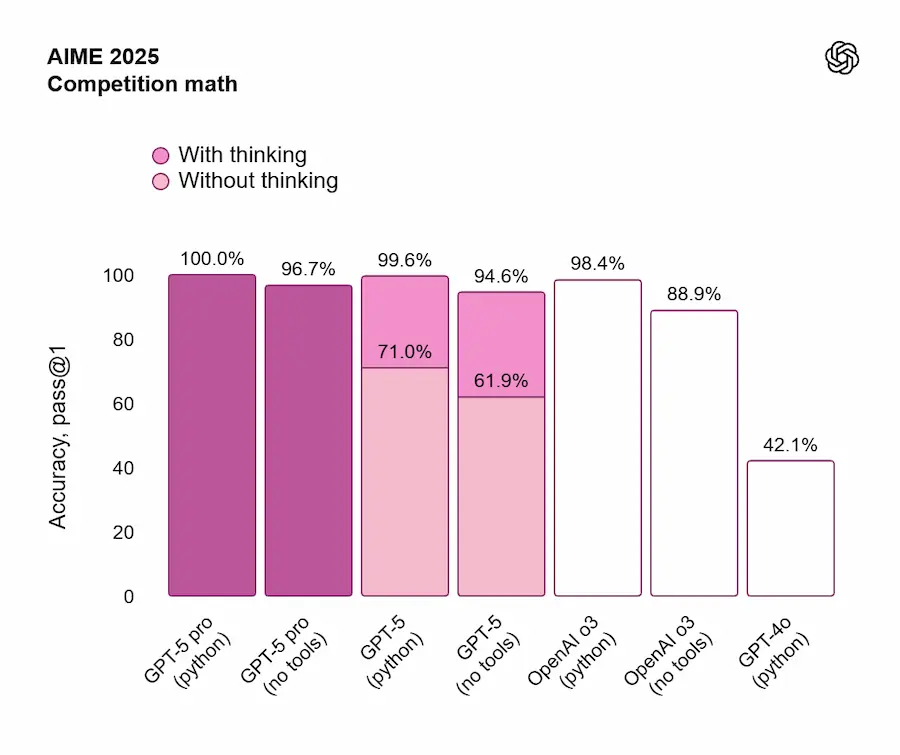
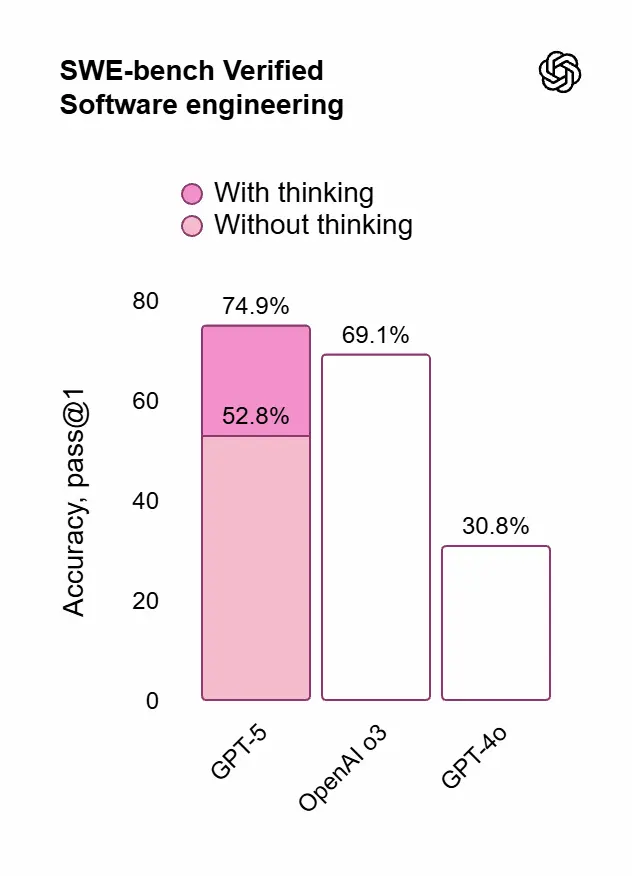
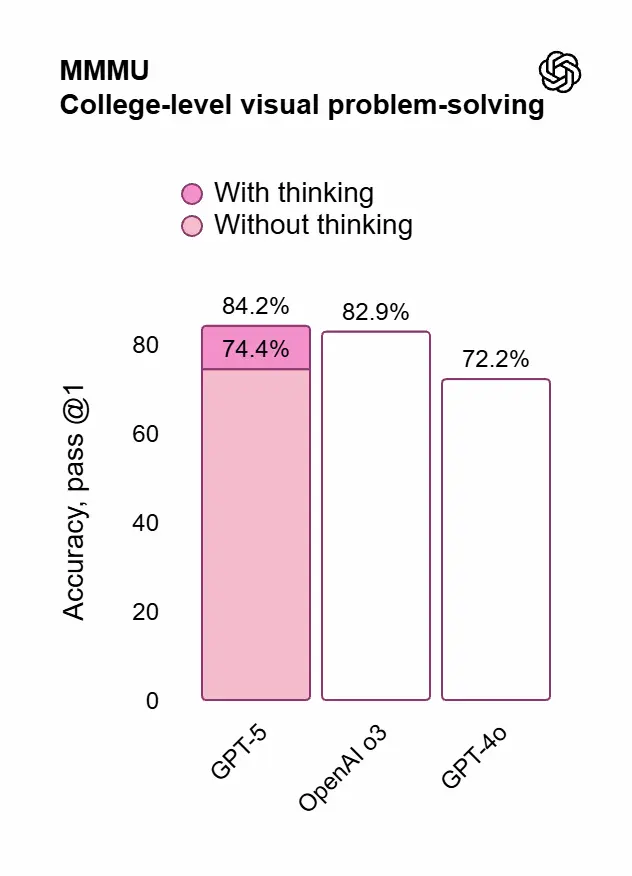
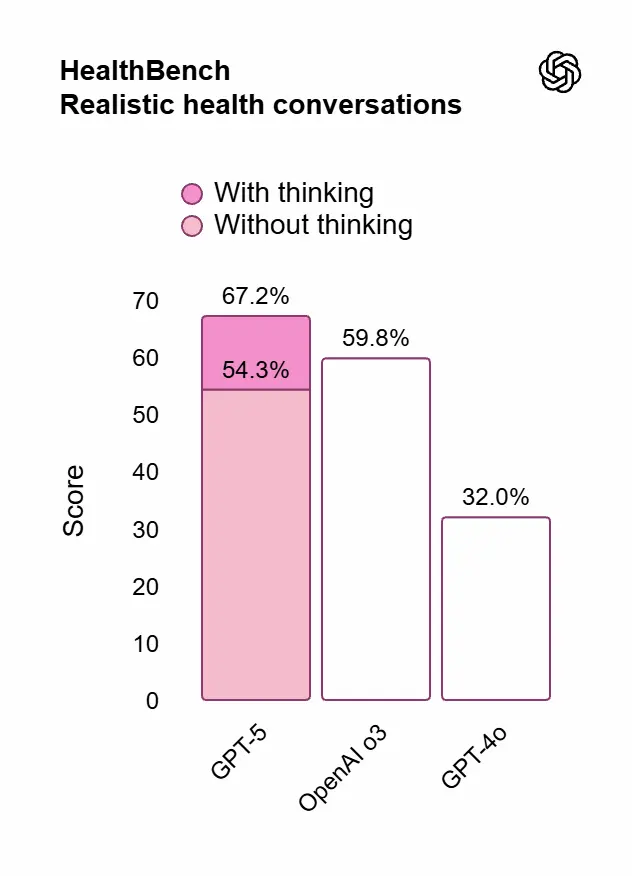
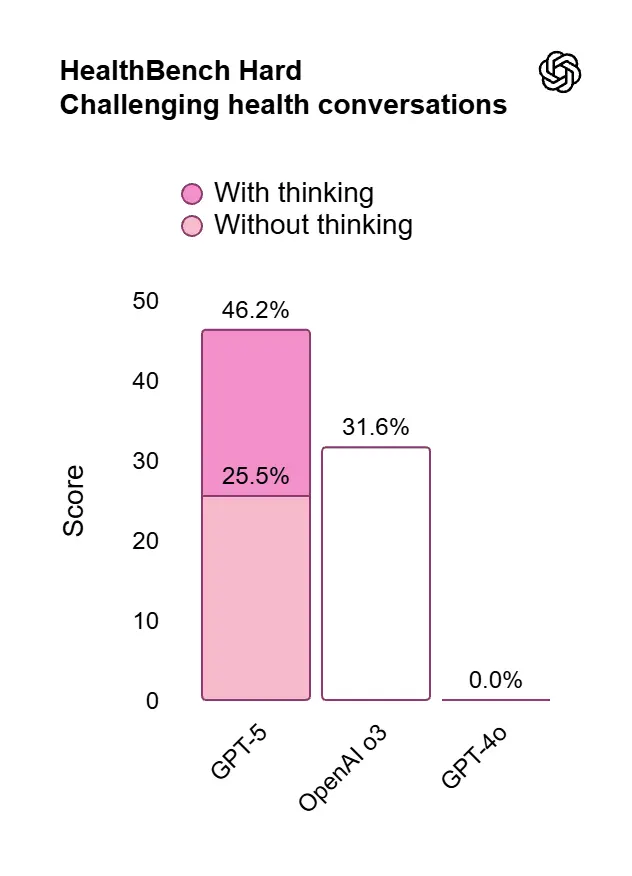
Prestazioni e valutazioni di GPT-5
Affidabilità, allucinazioni e "onestà"
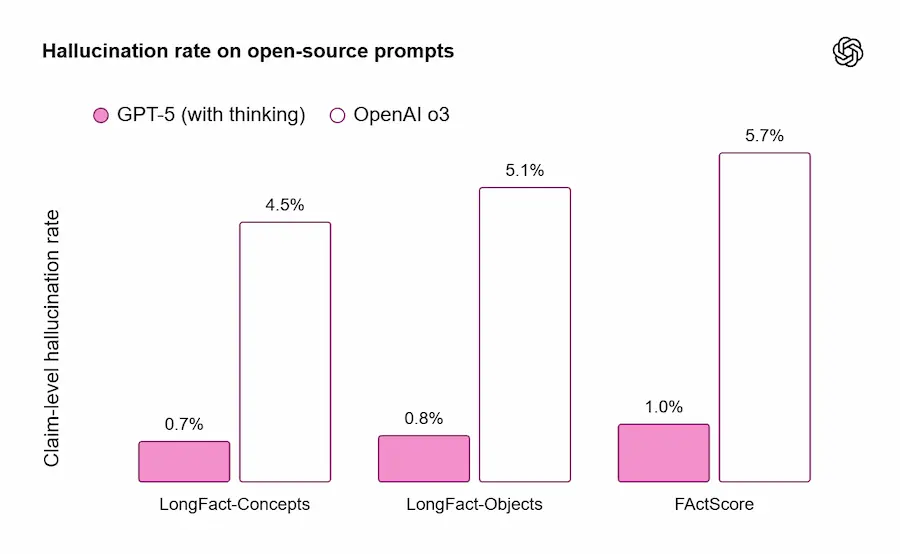
Con ricerca web attiva su prompt rappresentativi, le risposte di GPT-5 sono ~45% meno soggette a errori fattuali rispetto a GPT-4o; in modalità “thinking” sono ~80% meno soggette a errori rispetto a o3. Su benchmark di fattualità aperta (LongFact, FActScore) “GPT-5 thinking” riduce le allucinazioni di circa 6× rispetto a o3.
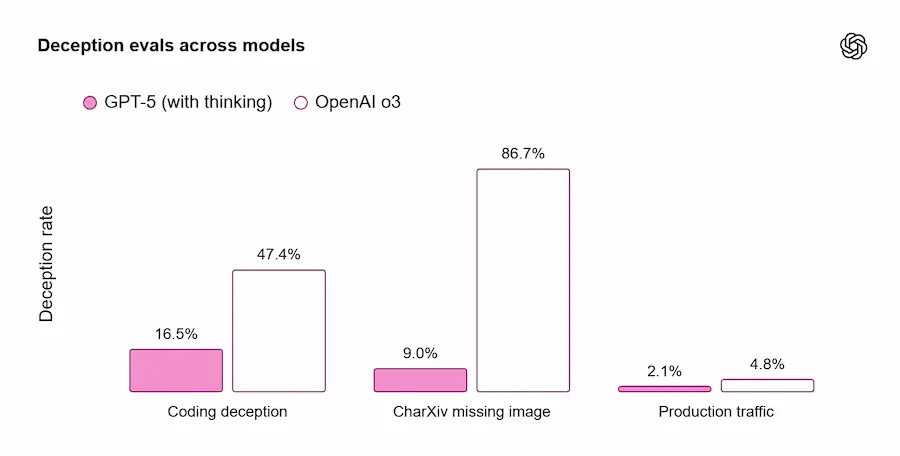
È anche meno ingannevole: nelle conversazioni reali, le risposte “thinking” che mostrano comportamenti di “deception” scendono dal 4,8% (o3) al 2,1%.
Lo stile mostra meno "eccesso di consenso", meno emoji inutili, più trasparenza sui limiti.
Safe completions
Nuovo addestramento di sicurezza: invece di rifiutare o acconsentire “a blocchi”, GPT-5 massimizza l’aiuto entro confini di sicurezza. Quando serve, risponde solo ad alto livello; se deve rifiutare, spiega perché e propone alternative sicure. Risultato: migliore gestione delle richieste ambigue/dual-use e meno rifiuti inutili.
Bio/chimica: approccio prudenziale
“GPT-5 thinking” è trattato come High capability in bio/chimica nel Preparedness Framework: 5.000 ore di red-teaming, classificatori always-on, reasoning monitors e difese multilivello, attive in via precauzionale.
Cosa migliora per gli utenti ChatGPT
- Scrittura: testi più ricchi e risonanti, migliore gestione di strutture ambigue (es. verso libero, pentametro giambico senza rima), utile per email, report, memo.
- Coding: eccelle nel front-end complesso e nel debug di repository grandi; spesso crea siti/app/giochi belli e responsivi con un solo prompt, con gusto per spaziatura, tipografia e white-space.
- Salute: punteggi nettamente migliori su HealthBench; risposte più proattive (segnala rischi, pone domande), adattate a contesto/geografia/livello utente. Non sostituisce un medico, ma aiuta a capire referti, preparare domande, valutare opzioni.
- Personalità preimpostate (anteprima di ricerca): Cynic, Robot, Listener, Nerd, per regolare tono e stile senza prompt artigianali; progettate anche per ridurre l'eccesso di consenso nei confronti dei messaggi degli utenti.
Novità mostrate nella live
- Voice più naturale, con video, traduzione continua e nuova Study & Learn mode (es. esercizi guidati, apprendimento delle lingue).
- Memoria e personalizzazione: è stata presentata l'integrazione con Gmail e Google Calendar per la pianificazione quotidiana; colori personalizzati dell’interfaccia; anteprima di personalities anche in modalità Voice.
Per sviluppatori e aziende (API)
- Tre modelli:
gpt-5,gpt-5-mini,gpt-5-nano. Prezzi indicativi: $1,25 / 1M token input e $10 / 1M output (GPT-5); $0,25 / $2 (mini); $0,05 / $0,40 (nano). Disponibile via Responses API, Chat Completions e Codex CLI. - Nuovi controlli:
reasoning_effortcon valoreminimalper risposte velocissime con poco ragionamento;verbosity: low/medium/high per controllare la verbosità (quanto il modello risulta prolisso);- Custom tools in plain-text (anziché solo JSON) + vincoli con regex/CFG; tool-call preambles per far spiegare al modello il piano prima delle chiamate strumento.
- Contesto lungo: fino a 400.000 token totali, con miglioramenti su compiti di lungo contesto (recupero e ragionamento su input molto estesi).
- Agentic/tool use: grandi progressi su benchmark di tool-calling e instruction-following; migliore capacità di completare task multi-step, coordinare strumenti e adattarsi al contesto.
- Variante chat non-reasoning disponibile come
gpt-5-chat-latest(stessa tariffa), utile per latenza più bassa.
Implicazioni pratiche
- Utenti finali: qualità alta “di default”, meno allucinazioni, più "onestà" su impossibilità o limiti.
- Team e imprese: un sistema di default affidabile per il lavoro quotidiano, e GPT-5 Pro per compiti critici.
- Developer: meno “prompt gymnastics”. Controlli nativi su ragionamento/verbosità/formato, tool-calling più robusto, 400k di contesto per documenti enormi e pipeline complesse.
Primi test del modello
Ho fatto diversi test con il modello GPT-5 Thinking (su ChatGPT e via API) che riguardano, ad esempio, la generazione di testo, la creazione di dashboard che derivano dall'analisi di un dataset, output strutturati con contesti in input molto lunghi dove la precisione è fondamentale, ragionamento, matematica.
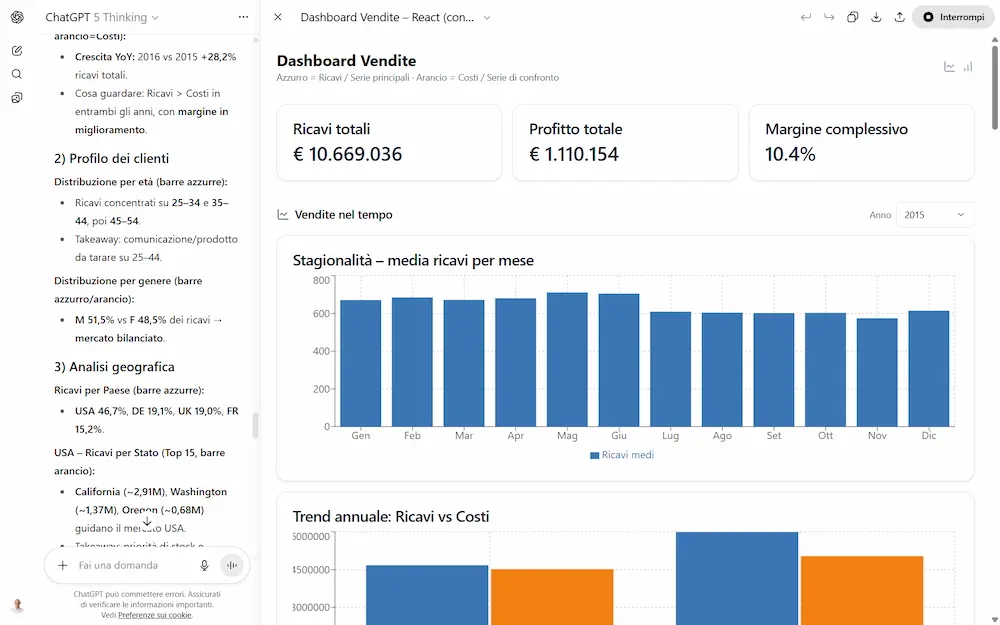
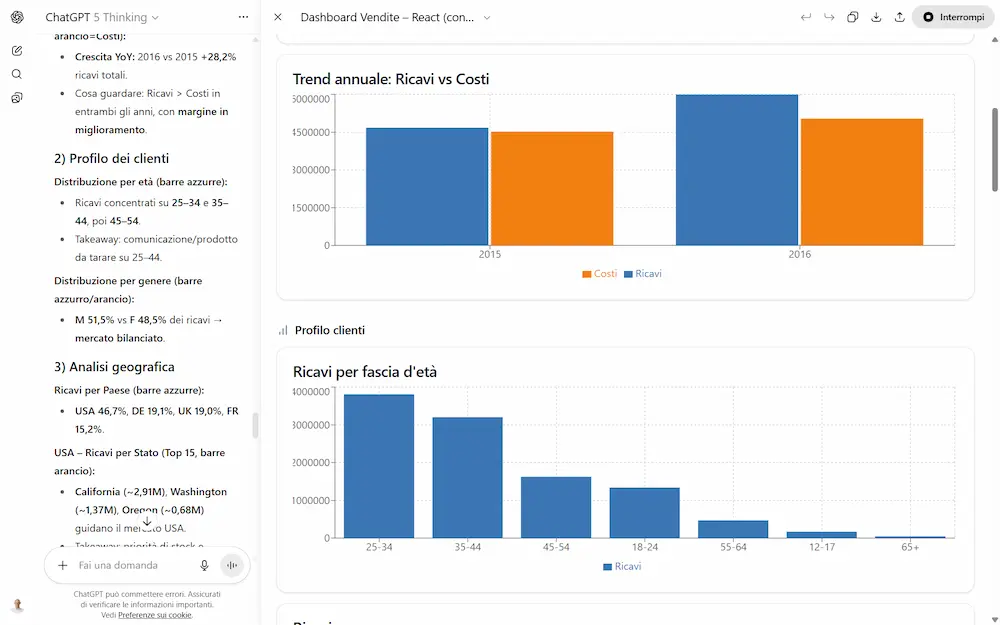
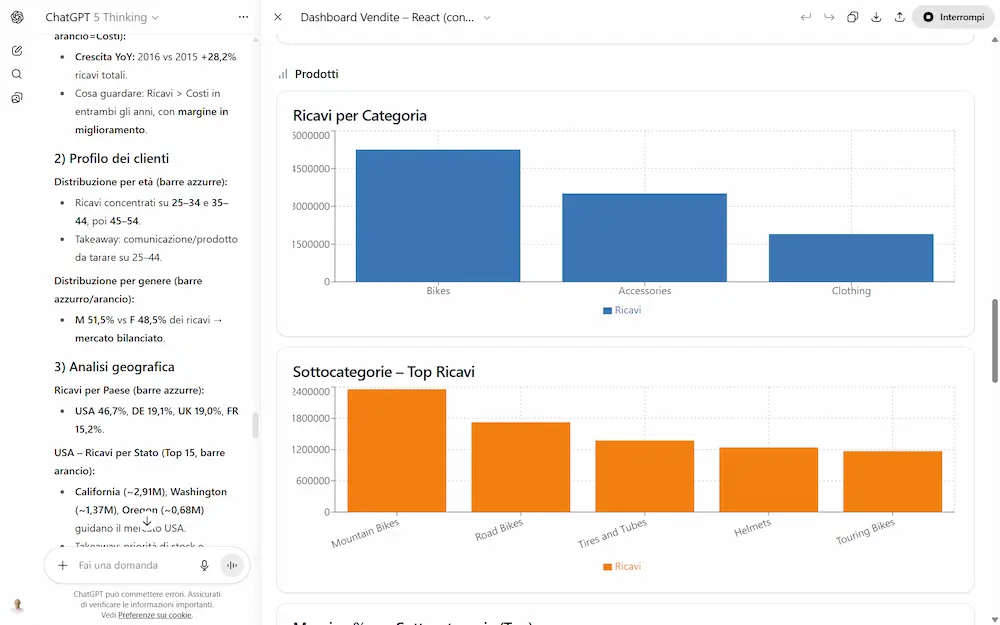
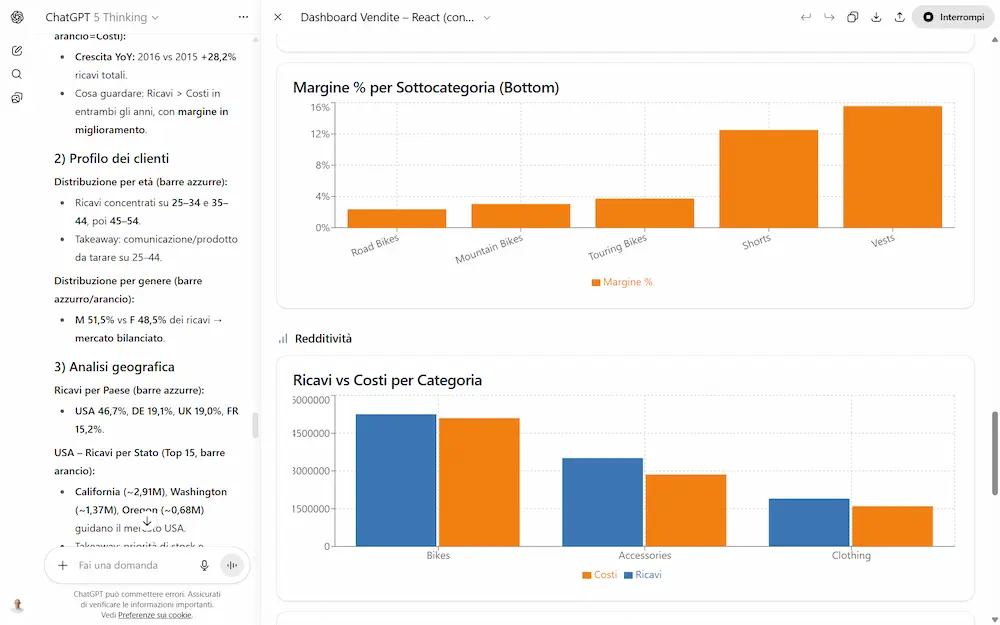
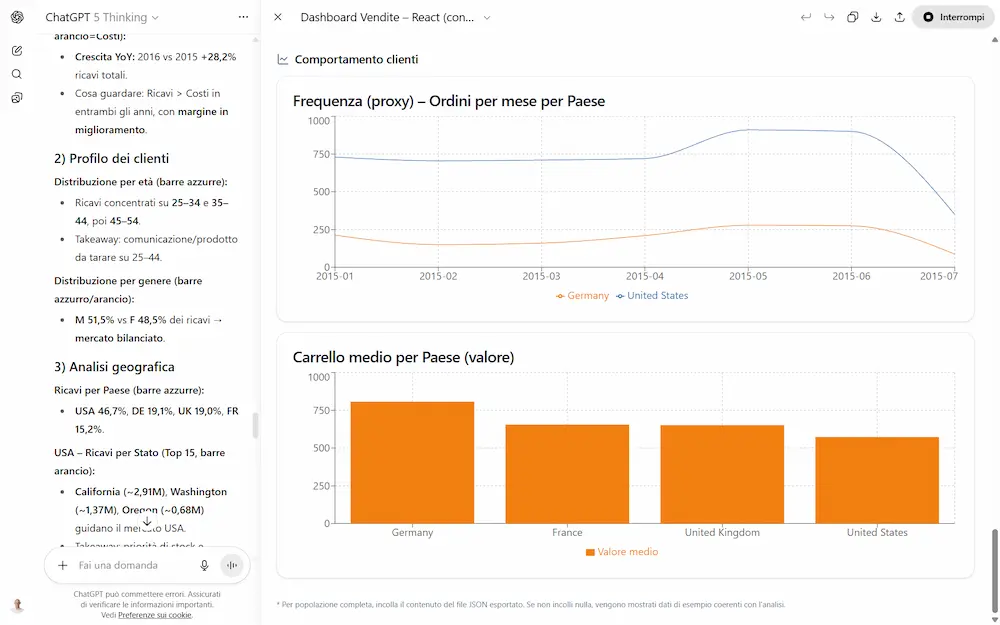
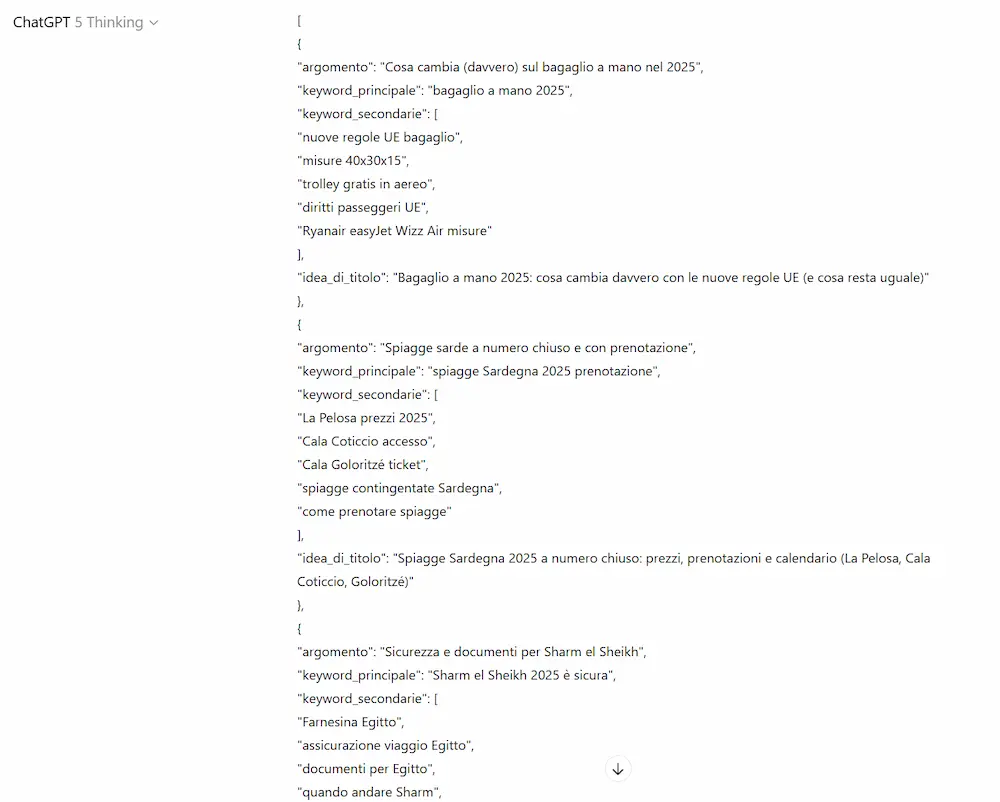
Primi test con GPT-5
Ho effettuato anche delle sperimentazioni usando il modello su sistemi agentici, su infrastrutture già collaudate per altri modelli.
Non avevo dubbi che il risultato sarebbe stato di qualità: l'aumento di performance è notevole rispetto alle versioni precedenti di OpenAI. Le performance su task di questo tipo non si discutono, e questo modello, visto anche il prezzo delle API praticamente identico, va a competere direttamente con Gemini 2.5 Pro su tutti i fronti.
Approfondimenti
Una guida al prompting per GPT-5
OpenAI ha pubblicato una guida ufficiale al prompting per GPT-5, pensata per aiutare sviluppatori e professionisti a ottenere il massimo dal nuovo modello. La guida approfondisce come costruire prompt efficaci, sottolineando l’elevata sensibilità di GPT-5 alle istruzioni: è in grado di seguire indicazioni con estrema precisione, ma proprio per questo diventa cruciale evitare ambiguità o contraddizioni.
Vengono presentate strategie per bilanciare il grado di autonomia del modello, regolare il livello di ragionamento (reasoning_effort) e ottimizzare le risposte (verbosity). Una sezione specifica è dedicata allo sviluppo software, dove GPT-5 si distingue nella scrittura, refactor e generazione di codice, specialmente se guidato da prompt che ne specificano stile e contesto tecnico.
La guida include esempi concreti, casi d’uso (come Cursor) e buone pratiche come l’uso di “tool preambles” o tecniche di metaprompting. Un riferimento prezioso per chi vuole costruire interazioni più robuste, controllabili ed efficienti con GPT-5.

GPT-5 per gli sviluppatori
OpenAI presenta un contenuto dedicato agli sviluppatori che illustra GPT-5, il modello più avanzato per codifica e compiti agentici complessi. Con prestazioni ai vertici nei benchmark, gestione efficiente di processi multi-turno, recupero di informazioni da contesti lunghi e riduzione significativa degli errori, GPT-5 offre nuove funzioni API come reasoning_effort, verbosity e Freeform tools, ed è disponibile in tre varianti per adattarsi a esigenze diverse di prestazioni, costi e latenza.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂