Machine Learning: come lo spiegherei a un bambino di 5 anni
Con l'aiuto di esempi e semplificazioni andiamo a scoprire il significato e il funzionamento del Machine Learning (ML): uno dei concetti più nominati e contemporaneamente più misteriosi dei nostri giorni. Scopriremo inoltre quali problemi risolve e il rapporto con l'AI e con il Deep Learning.


Punti salienti
- Intelligenza Artificiale e Machine Learning
Introduzione ai concetti di AI e ML e alla loro capacità di apprendere e prendere decisioni autonome. - Apprendimento per esempi
Un’analogia semplice per capire il Machine Learning: la macchina impara a distinguere banane mature da acerbe attraverso esempi, similmente a come impariamo a riconoscere oggetti. - Processo di Addestramento
Descrizione del processo di addestramento che permette alla macchina di identificare caratteristiche specifiche per fare previsioni accurate. - Linea Decisionale
Creazione di un confine tra categorie per consentire alla macchina di fare scelte affidabili, come distinguere una banana matura da una acerba. - Overfitting
Spiegazione del rischio di addestrare un modello troppo specifico che perde la capacità di generalizzare, compromettendo l'affidabilità su nuovi dati. - Classificazione e Regressione
Differenze tra classificazione (categorie discrete) e regressione (valori continui) per affrontare vari tipi di problemi. - Apprendimento Supervisionato, Non Supervisionato, e per Rinforzo
Panoramica delle tre modalità di apprendimento, con esempi di applicazione in base al tipo di problema. - Deep Learning e Reti Neurali
Introduzione al Deep Learning, un sottoinsieme del Machine Learning, per gestire problemi complessi tramite reti neurali profonde.
Iniziamo con una premessa in cui definiamo, con una buona dose di semplificazione, due termini che oggi si sentono nominare molto spesso: Intelligenza Artificiale (AI) e Machine Learning (ML).
L'Intelligenza Artificiale è un ramo dell'informatica che si occupa di progettare macchine con delle caratteristiche tipicamente umane. Ad esempio macchine in grado di interpretare il mondo che le circonda, o capaci di prendere decisioni. Non si tratta soltanto di intelligenza nel senso di "saper fare dei calcoli", ma di intelligenza nel senso più ampio del termine, come l'intelligenza spaziale e sociale.
La domanda chiave è: come fa una macchina a sviluppare un'intelligenza artificiale? Si tratta di una tematica molto complessa, ma diciamo che uno degli aspetti più interessanti è sicuramente quello del Machine Learning (o apprendimento automatico).
In un certo senso possiamo dire che le macchine vengono addestrate per trovare la soluzione migliore ad un problema imparando dai dati e dai propri errori.
Affascinante, vero!? Andiamo a scoprire una spiegazione semplificata del processo di Machine Learning. Talmente semplificata che potrebbe essere raccontata ad un bambino.
Una spiegazione semplificata del Machine Learning
Immaginiamo di dover insegnare ad una macchina a stabilire se una banana è matura o acerba. Per farlo abbiamo a disposizione un solo strumento, il quale può fornirci due indicazioni:
- quanto la banana è gialla (colore);
- quanto la banana è morbida (consistenza).
Come facciamo, quindi a spiegare alla macchina come sfruttare queste due indicazioni per darci una risposta? Procederemo addestrandola attraverso degli esempi, ovvero trasmettendole l'esperienza.
Si tratta dello stesso principio attraverso il quale impariamo quando siamo piccoli: i nostri genitori ci mostrano degli esempi.. "questo è un cane", "questo è un gatto", "questo è un coniglio". Non ci spiegano come fare per riconoscerli attraverso delle istruzioni, ma con il tempo impariamo a farlo distinguendone le caratteristiche.
Proprio per questo motivo, per procedere con l'addestramento, abbiamo a disposizione una cassetta di banane già etichettate come mature o acerbe. Durante questa fase la macchina svilupperà la capacità di riconoscere lo stato del frutto (creazione del modello di Machine Learning).
La fase di addestramento (training) ed apprendimento
Iniziamo, quindi, a fornire alla macchina i dati di una banana matura. Questo equivale a spiegarle quanto segue.
Cara macchina, quella che vedi è una banana matura, e i suoi dati di colore (livello di giallo) e di consistenza (morbidezza) sono i seguenti..
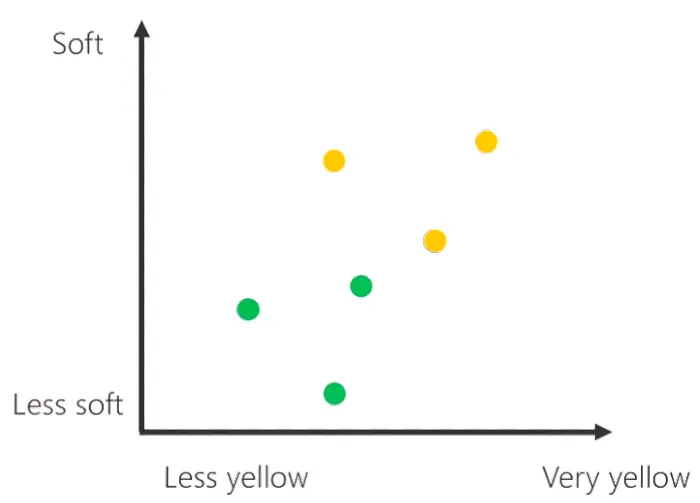
Rappresentiamo i dati della banana grazie al seguente schema, il quale in un'asse misura la consistenza e nell'altro il colore. Utilizzeremo questa rappresentazione per tutti i dati delle banane che useremo per addestrare la macchina, tenendo presente che i pallini gialli rappresenteranno le banane mature presenti nella cassetta di addestramento, mentre quelli verdi le banane acerbe.
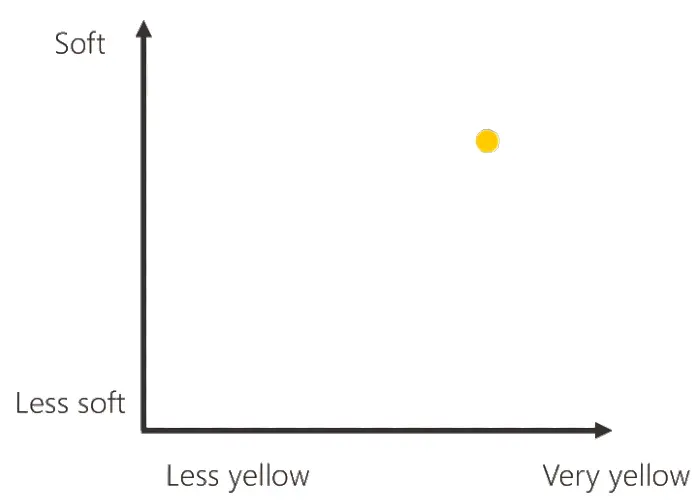
Andiamo avanti con gli esempi ed eseguiamo la stessa operazione con un'altra banana matura. Questo equivale a spiegare alla macchina quanto segue.
Cara macchina, quella che vedi è un'altra banana matura, ed ecco a te il suo livello di giallo e la sua morbidezza.
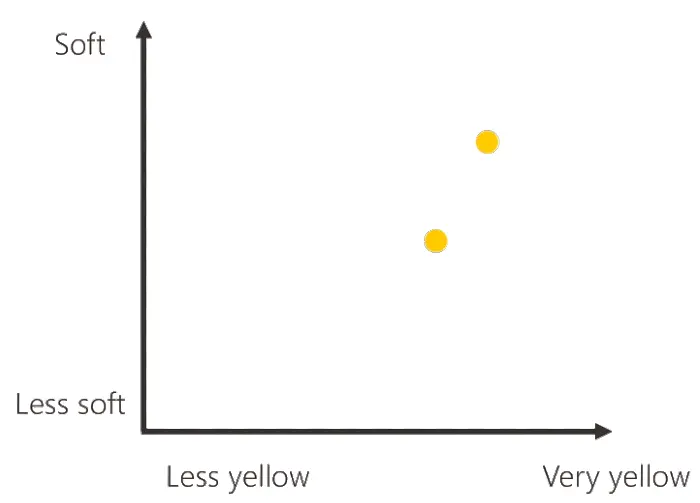
Nello schema, quindi, compare il secondo pallino giallo, e per lo stesso principio, grazie ad un terzo esempio di banana matura, anche il terzo.
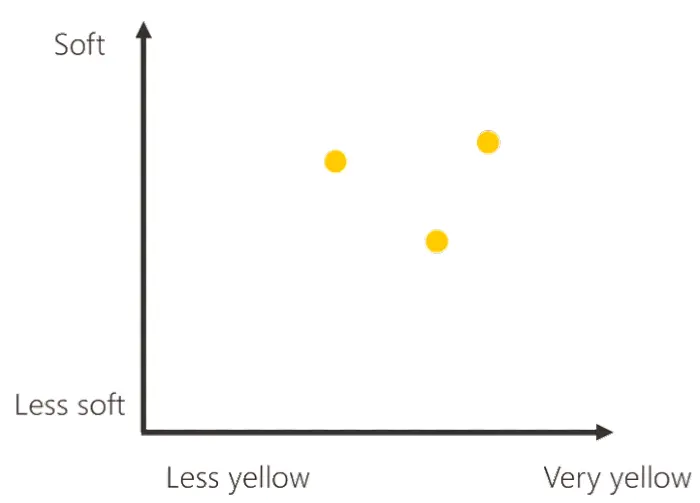
La nostra macchina, tuttavia, ha bisogno anche di esempi di banane acerbe per comprendere il concetto. Per questo motivo l'addestramento procede prendendo dalla cassetta una banana acerba ed indicando alla macchina le sue misurazioni. Come abbiamo visto per le banane mature, questo equivale alla seguente spiegazione.
Cara macchina, questa è una banana acerba, e i suoi dati di colore (livello di giallo) e di consistenza (morbidezza) sono i seguenti..
Ed ecco, infatti, che appare il primo pallino verde, che rappresenta i dati della banana acerba.
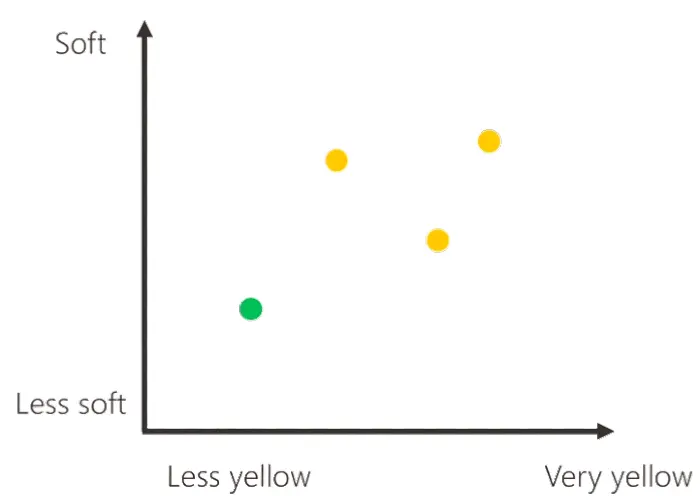
Procediamo con lo stesso principio con altre banane acerbe, ed infatti vediamo che lo schema si popola di misurazioni.
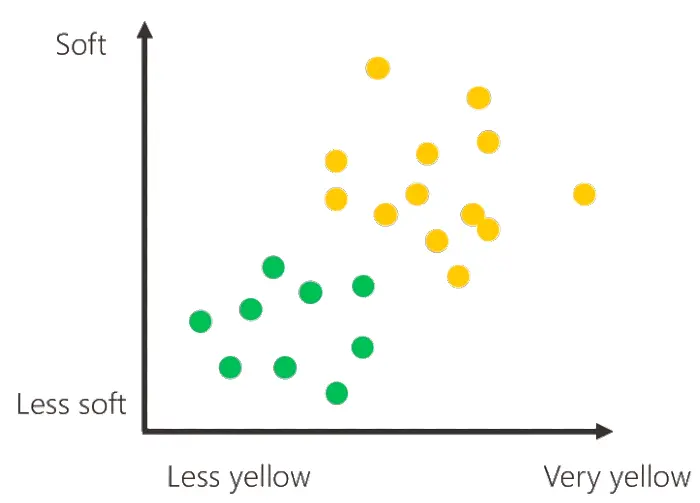
L'immagine che segue rappresenta la situazione finale dell'addestramento, con lo schema che contiene tutti i dati delle banane presenti nella cassetta.
Ma come avviene effettivamente l'apprendimento da parte della macchina? Quello che permettono di fare le misurazioni (i pallini sullo schema) è la creazione di un confine tra le banane mature e quelle acerbe, che può essere raffigurato dalla linea viola nel diagramma che segue.
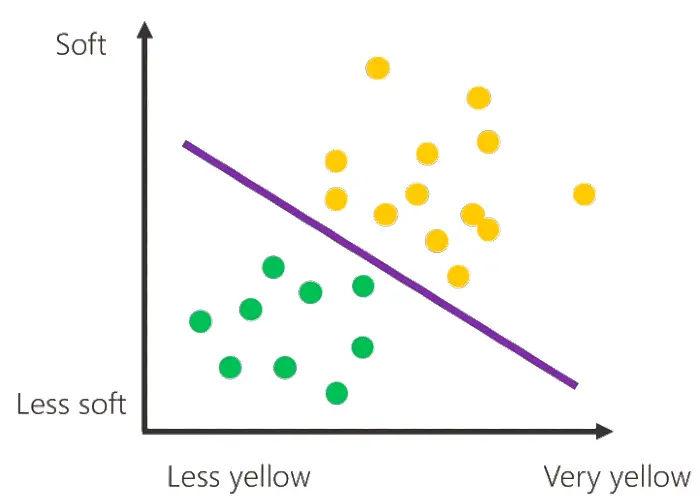
Quando addestriamo un modello di Machine Learning, ciò che sta realmente accadendo è esattamente la definizione di questa linea, ovvero la definizione di un "confine" che determinerà la decisione che il sistema dovrà prendere. Nel nostro esempio, dovrà decidere se una banana è matura o acerba.
L'applicazione del modello
Ricapitolando: qual è lo scopo dell'addestramento della macchina? Quello di saper riconoscere lo stato di maturazione di una banana (matura o acerba) in base ai suoi dati di colore e consistenza.
A questo punto, quindi, supponiamo di avere una banana della quale non conosciamo lo stato di maturazione. Come procediamo per farcelo dire dalla macchina? Molto semplicemente, seguiamo i seguenti step:
- misuriamo i dati della nuova banana, gli stessi dati che abbiamo utilizzato fino a questo momento ("quanto è gialla" e "quanto è morbida"),
- li inseriamo nel nostro schema,
- li confrontiamo con la linea decisionale generata grazie all'addestramento.
Il pallino nero, indica i dati della nuova banana.
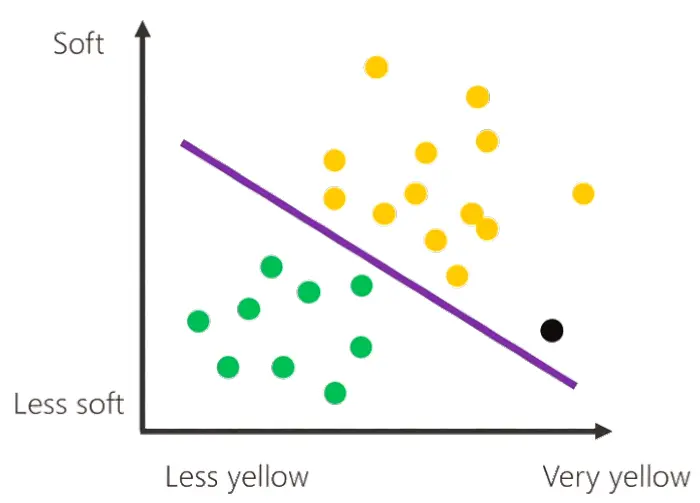
Quale sarà, in base a questo, la previsione della macchina? Sarà una banana matura o acerba? Come si vede, il pallino si trova al di sopra del confine decisionale, nell'area dei pallini gialli, quindi la macchina stabilirà che si tratta di una banana matura.
Grazie all'addestramento del modello, la macchina ha appreso come prendere una decisione. Quando si sente parlare di "apprendimento automatico", si intende esattamente questo.
Lo schema che segue mostra due esempi di previsione della macchina in base al confine decisionale, quindi in base al modello di Machine Learning addestrato.
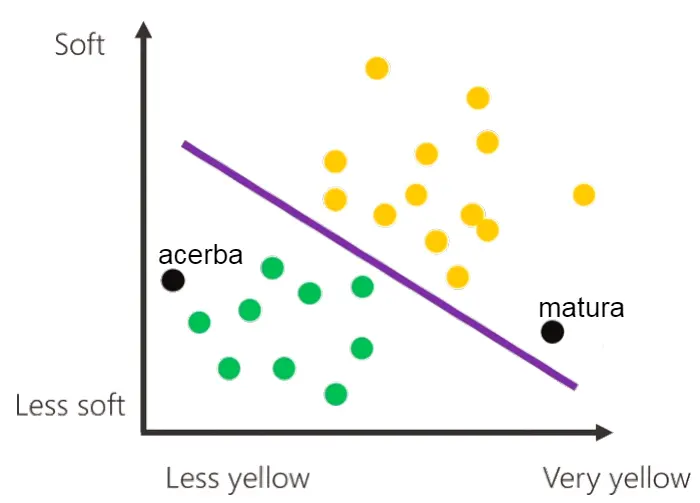
Le misurazioni dei dati delle banane viste nello schema fino a questo momento sono abbastanza ideali, con una netta separazione tra le mature e le acerbe.. tanto ideali che il modello (la linea decisionale) è rappresentato da una retta perfetta.
Una situazione più verosimile potrebbe essere la seguente.
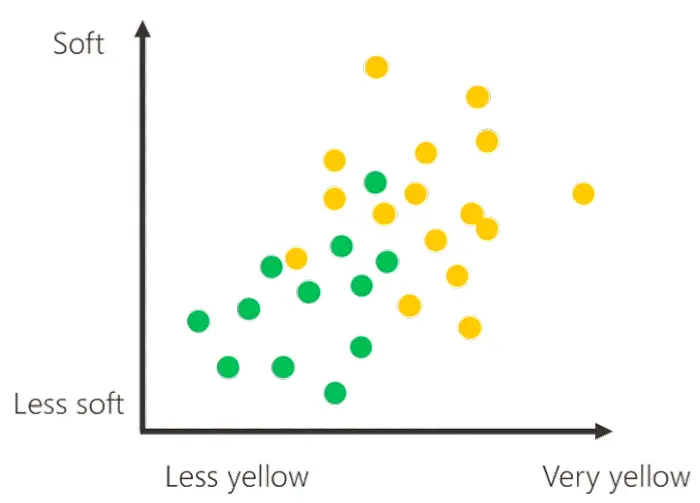
Come si vede, i dati sono meno puliti e più mescolati tra di loro. Quindi il modello (il confine decisionale) non potrà più essere una retta perfetta, ma una linea di questo tipo..
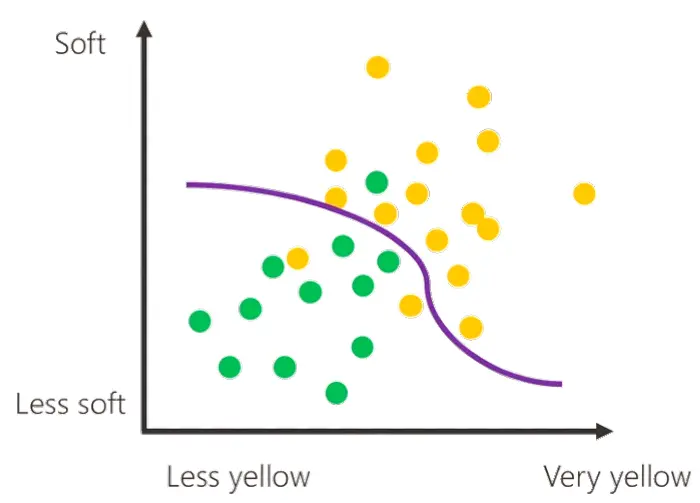
È molto semplice capire che più aumenta il numero di esempi (di dati) che forniamo alla macchina, e più il modello diventa preciso, perché la linea decisionale può essere "guidata" da una nube più fitta di pallini nel diagramma.
Esistono, inoltre, diverse metodologie per far evolvere continuamente il modello, ad esempio grazie a misurazioni e relativi feedback, anche successivamente alla fase di addestramento.
L'overfitting
Perché la linea decisionale non va a circondare esattamente i pallini delle misurazioni come segue (la curva rossa come alternativa al tratto lineare viola)?
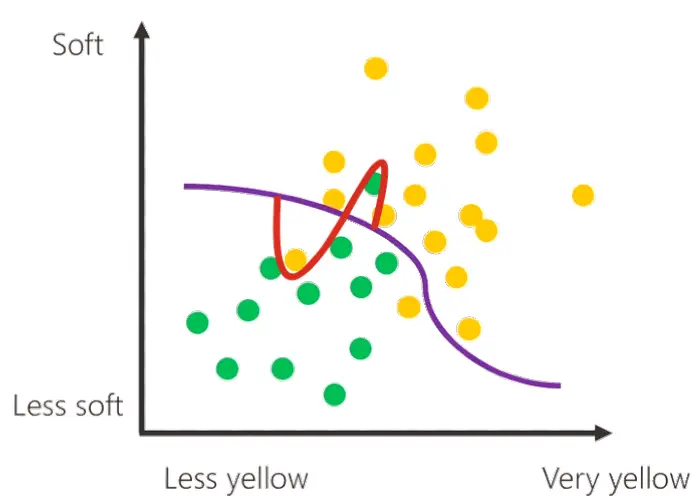
Se la linea si comportasse in questo modo, non si tratterebbe di un confine che generalizza le misurazioni e descrive un andamento: l'apprendimento sarebbe troppo "cucito sui dati" di training. Questo renderebbe il modello poco affidabile per prendere delle decisioni su nuovi dati. Tale fenomeno prende il nome di "overfitting".
Immaginiamo, ad esempio, di avere una linea completamente irregolare che va a circondare esattamente le misurazioni di training. Se ora vogliamo determinare lo stato di una nuova banana, come abbiamo visto precedentemente, procederemo facendo le misurazioni e mettendo il pallino nero nel diagramma.. ma se la linea non è ben definita, come facciamo ad avere una separazione precisa e ad essere certi della previsione?
In linea di massima, quindi, abbiamo capito come la macchina apprende dai dati per riuscire a prendere delle decisioni.
Nell'esempio delle banane, tuttavia, abbiamo considerato soltanto due tipologie di dato (o features), ovvero il colore e la morbidezza. Per rendere il sistema più affidabile nel dare una risposta, potremmo voler aggiungere altre misurazioni, ad esempio se sono presenti macchie nella buccia, da quanto tempo sono state raccolte, le dimensioni, e centinaia di altri dati.
Ed è proprio in questo che l'Intelligenza Artificiale, grazie al Machine Learning, riesce a superare le nostre capacità: senza questi algoritmi non riusciremmo a gestire una quantità di dati e di features tali da rendere un modello affidabile.
Più aggiungiamo features per aumentare le osservazioni e quindi più aumentiamo l'affidabilità della decisione del modello, e più la sua rappresentazione (dal punto di vista matematico) diventa complessa, rendendo necessarie funzioni matematiche strutturate.
Classificazione o Regressione?
Prima di procedere, faccio una premessa: i concetti che seguono diventano leggermente più complessi, ma credo che siano abbastanza interessanti da fare un piccolo sforzo.
Classificazione e regressione sono due tipologie di problemi che possono essere affrontati attraverso il Machine Learning.
- Nella classificazione, abbiamo input discreti (valori ben definiti) e un output discreto. Ad esempio diamo in input le caratteristiche di un animale e otteniamo in output se l'animale è un cane o un gatto (quindi un'etichetta ben definita, senza vie di mezzo). E l'esempio delle banane che abbiamo visto rappresenta proprio una classificazione: la banana ha un livello di giallo e di morbidezza (input discreti) e può essere matura o acerba (output discreto).
- Nella regressione, abbiamo un input continuo, e un output continuo. Ad esempio, diamo in input le dimensioni di un immobile e otteniamo in output l'andamento del prezzo.
Una regola molto semplice (con una buona dose di compromessi) per capire, in base ai dati a disposizione e alla risposta che vogliamo ottenere, se abbiamo bisogno di un classificatore o di un regressore è la seguente:
se ciò che vogliamo ottenere è una caratteristica ci servirà un classificatore, se invece è un valore numerico, avremo bisogno di un regressore.
Andiamo, quindi, a vedere un semplice esempio di come funziona il Machine Learning per risolvere un problema di regressione.
Come si stima il prezzo di una casa? Un esempio di regressione
Supponiamo di voler addestrare una macchina a definire il prezzo di una casa, e di avere a disposizione anni di preventivi di immobili.
Partiamo con un addestramento molto semplice in cui andiamo a spiegare alla macchina come si associa la dimensione della casa con il prezzo.
Nell'immagine che segue, quindi, sulla sinistra vediamo la tabella con i dati storici che associano la dimensione al prezzo.
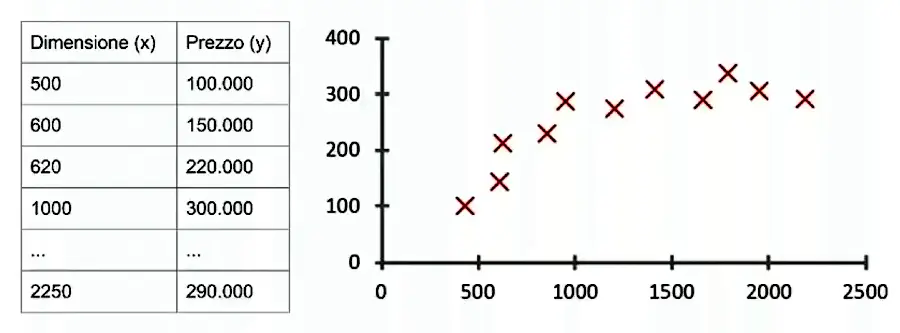
A destra, invece, un diagramma traccia le associazioni, mostrando come varia il prezzo (asse y) nei confronti della dimensione (asse x).
Come abbiamo visto in precedenza, la fase di addestramento consente di definire il modello, che in questo caso potremmo identificare non più come un "confine decisionale", ma come un "andamento di predizione".
Questo significa che la linea di andamento sarà quella di riferimento per le stime del prezzo delle case in relazione alla dimensione.
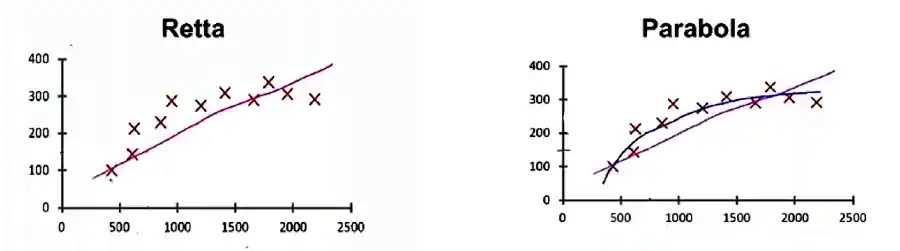
L'immagine mette a confronto due modelli di esempio: uno rappresentato da una retta, l'altro da una parabola. Qual è la differenza tra i due? Credo sia abbastanza evidente che la parabola rappresenta molto meglio l'andamento dei dati.. quindi li generalizza in maniera più efficiente.
Andando a calcolare l'errore dei due modelli rispetto ai dati di addestramento, ovvero la distanza tra i dati e la linea che li generalizza, quello della retta è circa il doppio di quello della parabola. Questo dimostra che quest'ultima rappresenta il modello migliore.
Come si arriva alla curva di andamento?
Nell'immagine precedente, abbiamo visto come la retta e la parabola siano già aderenti ai dati di addestramento. Tuttavia all'inizio del training non siamo in questa situazione.
Quelle che seguono sono le fasi di miglioramento del modello durante l'apprendimento. Nel diagramma numero 1, come si vede, partiamo da una retta del tutto casuale. Grazie a degli algoritmi è possibile calcolare l'errore della retta rispetto ai dati, ovvero quanto i dati sono lontani dalla retta che mira a generalizzarli. In base a questo valore è possibile determinare cosa deve cambiare nella funzione matematica della retta per far sì che questa si avvicini ai punti. E questo è quello che si può osservare dal diagramma numero 2 al numero 6.
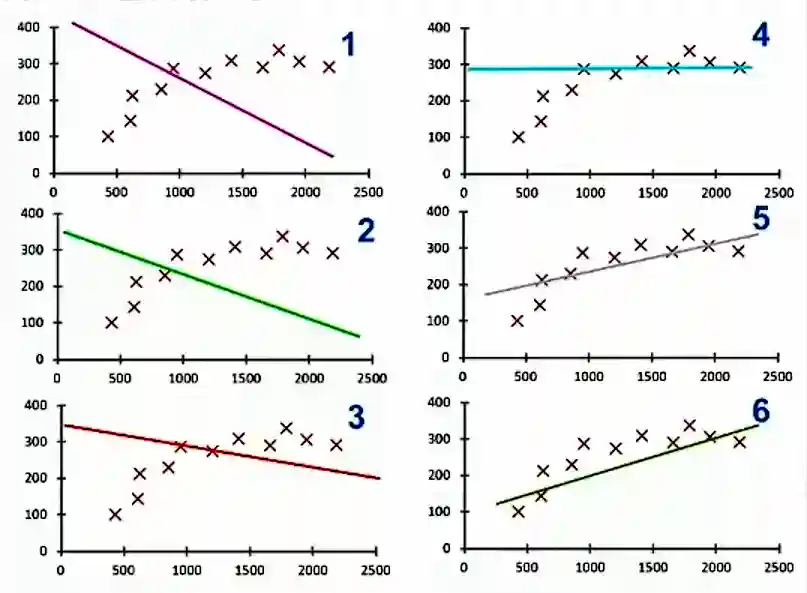
Il diagramma numero 6, per questo modello (la retta), rappresenta la miglior rappresentazione, ovvero la miglior generalizzazione dei dati. Come abbiamo visto prima, in realtà, un altro modello (la parabola) li rappresenterebbe meglio, ma ci fermiamo questo esempio per mantenere la semplicità.
Ma torniamo alla stima del prezzo delle case..
Portando quello che abbiamo visto in questi paragrafi al nostro esempio, quindi, una volta trovata la linea che generalizza i dati di dimensione delle case in relazione al prezzo, la nostra macchina sarà perfettamente in grado di prevedere il prezzo di qualsiasi casa a partire da una dimensione.
Come nell'esempio delle banane, la semplificazione che abbiamo mantenuto fino a questo momento è elevatissima, perché, abbiamo considerato un solo parametro (feature) per la stima del prezzo, ovvero la dimensione. Ma nella realtà, i dati da considerare per il prezzo di un immobile sono molti di più, e tengono conto, ad esempio, dell'anno di costruzione, della posizione, del numero di bagni, della distanza dalla fermata dell'autobus, delle ristrutturazioni, delle dimensioni del giardino, della classe energetica, ecc..
In generale, al netto dell'esempio, possiamo arrivare ad avere milioni di parametri sui quali un modello di Machine Learning deve cercare di generalizzare e rappresentare un andamento o un raggruppamento.
Spesso si sente dire che il Machine Learning è una scatola nera nella quale non è possibile osservare l'interno. Si tratta di un'affermazione imprecisa. La realtà è che sarebbe troppo complesso da comprendere e da rappresentare.
Supervisionato, non supervisionato, per rinforzo
Gli esempi che abbiamo visto, distinguono due tipologie di problemi che gli algoritmi di Machine Learning possono risolvere (classificazione e regressione).
Possiamo caratterizzare tali algoritmi anche attraverso un'altra distinzione che si basa sulla modalità di apprendimento.
Possiamo definire le seguenti modalità.
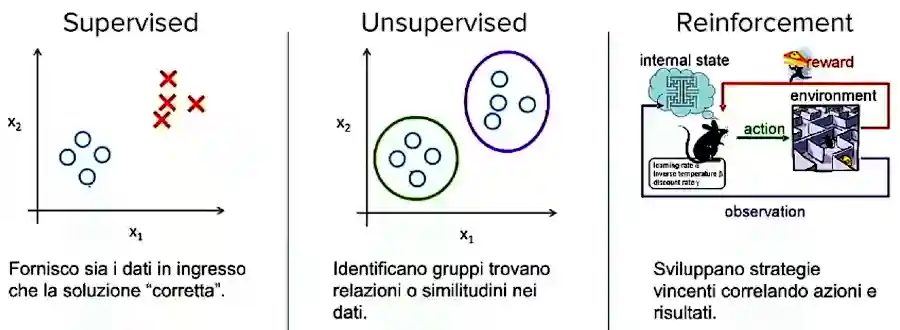
- Apprendimento supervisionato. Vengono dati all'algoritmo gli input e l'output che dovrebbe produrre partendo da quei dati. La fase di training consente di determinare il modello matematico (es. la linea di previsione o decisionale) che correla ingressi e uscite, permettendo di effettuare analisi e predizioni. Gli esempi visti precedentemente fanno parte di questa tipologia. Abbiamo dato alla macchina molti esempi di associazione tra colore delle banane, consistenza (input) e lo stato di maturazione (output) e la macchina ha imparato autonomamente a prendere una decisione.
- Apprendimento non supervisionato. In questo caso è l'algoritmo che, partendo dagli input, ha l'obiettivo di trovare correlazioni tra i dati riuscendo ad organizzarli autonomamente.
- Apprendimento per rinforzo. Vengono dati all'algoritmo gli input con le azioni che può effettuare e un punteggio (score) di riferimento. La macchina mette in atto delle strategie che vanno a migliorare costantemente il punteggio. L'analogia è quella del topolino nel labirinto, il quale è stimolato dal premio (il formaggio) per trovare il percorso migliore.
Deep Learning
Quando la complessità dei problemi da risolvere diventa molto elevata (es. nel riconoscimento delle immagini) ed abbiamo la necessità di elaborare milioni di input si ricorre ad architetture algoritmiche più complesse come le reti neurali artificiali. In questo caso, entriamo nel dominio del Deep Learning.
Il Deep Learning è un sottoinsieme del Machine Learning, e si tratta di una famiglia di algoritmi che serve a strutturare delle funzioni matematiche basate sulle reti neurali per ottenere dei modelli predittivi estremamente efficienti su svariati tipi di dati.
Di certo non possiamo affermare che le reti neurali si comportano come le reti di neuroni del nostro cervello, tuttavia ne prendono ispirazione.
Per semplificare il concetto, possiamo dire i diversi neuroni artificiali vanno a specializzarsi su determinate tipologie di correlazioni tra gli input, e i diversi strati di neuroni successivi si specializzano su "correlazioni delle correlazioni" derivanti dallo strato precedente.. fino ad ottenere un output che proviene dall'elaborazione di tutta la rete di neuroni.
Grazie a diverse strutture di reti neurali artificiali, è possibile affrontare diverse tipologie di problemi.
Per iniziare ad approfondire l'argomento partendo da zero, consiglio la serie di video che inizia con quello che segue.
Deep Learning: introduzione alle reti neurali (RN)
Il seguente schema rappresenta un buon metodo per comprendere e ricordare il rapporto tra Intelligenza Artificiale (AI), Machine Learning (ML) e Deep Learning (DL).
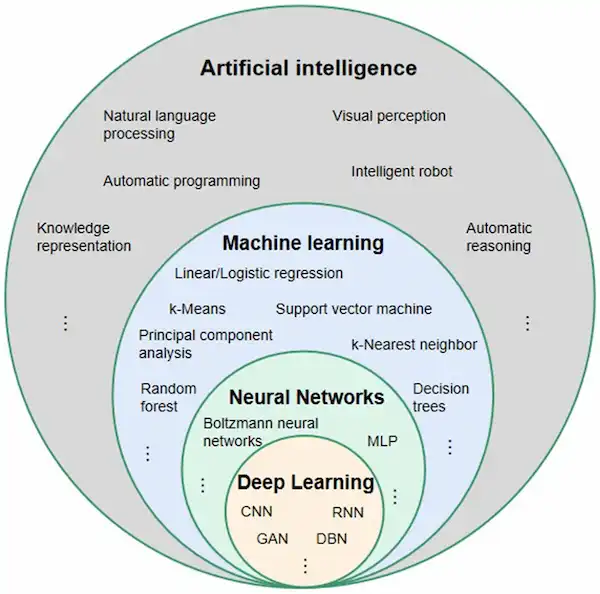
La computer vision, ad esempio, è un campo dell'Intelligenza Artificiale e usa il Machine Learning per addestrare il sistema a riconoscere determinati elementi nei contenuti visuali. In particolare, utilizza il Deep Learning perché sono necessarie strutture efficienti come le reti neurali (RN) per elaborare i milioni di dati in input.
Conclusioni
Abbiamo visto, quindi:
- cos'è e come funziona il Machine Learning,
- come si colloca nei confronti dell'Intelligenza Artificiale,
- che genere di problemi permette di risolvere con relativi esempi,
- le tipologie di apprendimento,
- una mini introduzione al Deep Learning.
Credo sia abbastanza chiaro che non tutto quello che ho provato a raccontare può essere spiegato ad un bambino, ma il mio obiettivo era quello di condividere strumenti per consentire a tutti di accedere alla tematica.
Vorrei concludere con le parole di Fabrizio Falchi, ricercatore dell'Istituto di Scienza e Tecnologie dell'Informazione del CNR di Pisa, il quale fa capire molto bene quando possiamo ottenere vantaggi dal Machine Learning rispetto ad un approccio classico.
Fabrizio Falchi: come si insegna ad una macchina a riconoscere un gatto?
Se vogliamo insegnare alla macchina a riconoscere un gatto, non riusciamo a farlo attraverso delle regole e la programmazione classica. Abbiamo imparato che il modo migliore è definire un'architettura in grado di apprendere ed esporre la macchina a tante foto di animali, spiegandole quali sono i gatti e quali non lo sono. Autonomamente la macchina sviluppa le competenze necessarie a riconoscere il gatto.
È molto simile all'apprendimento dei bambini, che imparano a riconoscere un gatto, ma nessuno spiega loro esattamente come procedere. Di fatto vedono degli esempi guidati dai genitori e con il tempo imparano a distinguere, ad esempio un gatto da un cane. Si tratta di un'operazione semplice, ma non saprei spiegare come si fa.
Fabrizio Falchi
Buon Machine Learning!
Per chi vuole iniziare un percorso per imparare davvero le basi di questa straordinaria disciplina, consiglio queste lezioni di un riferimento mondiale per l'intelligenza artificiale: Andrew Ng.
Machine Learning — Andrew Ng, Stanford University
Si tratta delle lezioni complete dell'Università di Stanford.
Per approfondire
 Alessio Pomaro
Alessio Pomaro