Riconoscimento Vocale: Google potenzia i modelli di AI per migliorare l'accuratezza
Google ha recentemente rilasciato dei nuovi modelli di speech recognition più performanti e precisi. Un percorso di circa otto anni di ricerca e sviluppo che conduce verso assistenti virtuali e dispositivi che consentiranno delle esperienze utente sempre migliori nel dialogo con i brand.


Ho parlato diverse volte, anche in questo blog, di interfacce multimodali, le quali consentono di comunicare attraverso più canali, ad esempio la voce, il testo, la componente visuale ed elementi multimediali. La componente vocale negli ultimi anni si è evoluta in maniera importante, ed è, senza dubbio, parte del futuro dell'interazione tra uomo e macchina.
Sulla base di questo, molte aziende potrebbero cercare di migliorare la propria tecnologia presentando ai consumatori sistemi di speech recognition (riconoscimento del parlato) affidabili ed accurati. Migliore è il riconoscimento vocale, infatti, e più i processi si semplificheranno per gli utenti, i quali potranno esprimersi come fanno con gli amici o le altre persone con le quali dialogano.
Ormai usiamo Whatsapp quasi esclusivamente
a suon di messaggi vocali!
Questo apre la strada a moltissimi casi d'uso, come gli assistenti virtuali presenti nei dispositivi smart. Inoltre, oltre a fornire istruzioni alle macchine, il riconoscimento del parlato consente, ad esempio, di ottenere sistemi che generano sottotitoli in tempo reale nelle video-call, approfondimenti da conversazioni live e registrate, e molto altro.
L'API Speech-to-Text (STT) di Google, oggi elabora più di 1 miliardo di minuti di audio al mese. Ciò equivale a trascrivere l'Amleto (l'opera più lunga di Shakespeare) quasi 4,6 milioni di volte.
Google, nei giorni scorsi, ha annunciato il lancio in produzione dei nuovi modelli per l'API STT: un importante miglioramento tecnologico per 23 lingue a disposizione nel sistema.
I nuovi modelli sono più precisi ed efficaci
I nuovi modelli sono il frutto di un viaggio durato circa otto anni che ha richiesto abbondanti dosi di ricerca, implementazione e ottimizzazione, con l'obiettivo di offrire una qualità elevatissima anche in condizioni difficili (es. in ambienti rumorosi). Il sistema si basa su algoritmi di Machine Learning all'avanguardia e consente di sfruttare i dati di "speech training" in modo più efficiente.
A livello tecnico, quali sono le differenze rispetto ai modelli precedenti? Negli ultimi anni, le tecniche di riconoscimento vocale automatico (ASR) si sono basate su modelli acustici, di pronuncia e linguistici separati. Storicamente, ciascuno di questi tre singoli componenti è stato addestrato separatamente, quindi assemblato in seguito per eseguire il riconoscimento vocale.
I nuovi sistemi, sono basati su un'unica rete neurale. A differenza dell'addestramento di tre modelli separati che devono essere successivamente "assemblati", questo approccio offre un uso più efficiente dei parametri del modello.
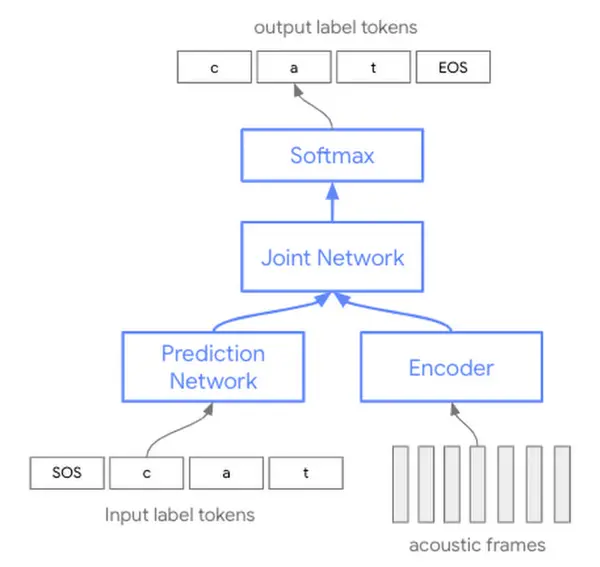
Secondo Google, sia le aziende che gli sviluppatori vedranno immediatamente miglioramenti della qualità nell'utilizzo dell'API STT.
I vantaggi di questa nuova architettura
possono essere percepiti senza
alcuna messa a punto iniziale.
I nuovi miglioramenti, consentiranno agli utenti di parlare in maniera più naturale e con frasi più lunghe senza doversi preoccupare di essere compresi in maniera precisa. Questo consentirà di migliorare l'empatia, ovvero di costruire relazioni migliori tra le persone e gli assistenti virtuali, che nel momento dell'interazione rappresentano il brand.
I primi ad adottare i nuovi modelli stanno già vedendo vantaggi.
"Spotify worked closely with Google on bringing our brand new voice interface, ‘Hey Spotify,’ to customers across our mobile apps and Car Thing. The increases in quality and especially noise robustness from the latest models, in addition to Spotify's work on NLU and AI, are what make it possible to have these services work so well for so many users"
- Daniel Bromand, Head of Technology Hardware Products di Spotify
Come usare i nuovi modelli
Google sta rilasciando i nuovi modelli mantenendo in produzione anche i vecchi. Per distinguerli viene utilizzato un nuovo identificatore: "più recente". L'immagine che segue mostra come compaiono nella sezione della lingua italiana.
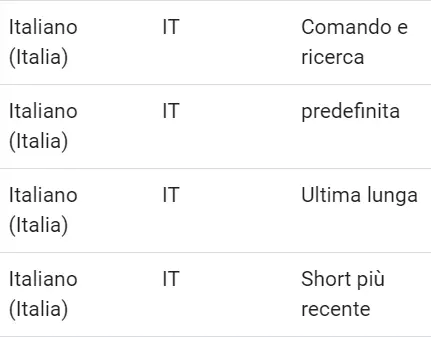
La traduzione delle label non è ottimale, ma il significato è abbastanza chiaro. Quando nelle chiamate API viene specificato un modello "latest long" ("ultima lunga") o "latest short" ("short più recente"), si fa riferimento agli ultimi algoritmi appena rilasciati, che stanno subendo ancora degli aggiornamenti.
"Latest long" è una tipologia di modello progettata per un parlato "spontaneo" di lunga durata, simile alla tipologia "video" (infatti un esempio di utilizzo potrebbe essere proprio la trascrizione di un video). "Latest short", invece, offre grande qualità e bassissima latenza su espressioni brevi come comandi o frasi.
La documentazione ufficiale
Attraverso il bottone che segue è possibile visualizzare la documentazione completa delle API di Speech-To-Text.
Per iniziare
Il sistema di Speech-To-Text di Google consente di testare le funzionalità direttamente attraverso un'interfaccia online.
Come si vede dall'immagine che segue, è possibile provare la funzionalità in due modalità: parlando al microfono o caricando un file audio. Nella seconda ipotesi c'è anche la possibilità di separare la trascrizione del parlato di diversi speaker.
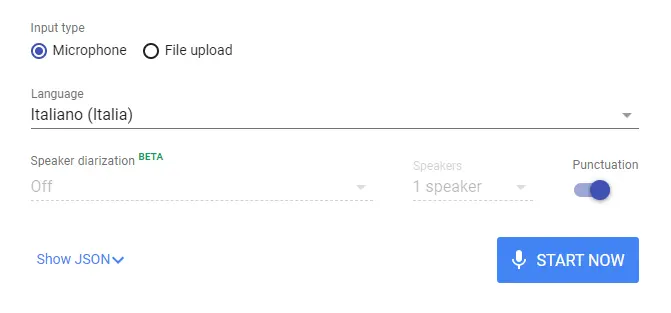
L'immagine mostra un esempio di test dell'interfaccia che ho realizzato attraverso il microfono.
Conclusioni
Gli algoritmi applicati al mondo audio stanno accelerando in maniera straordinaria. Recentemente ho ritrovato un audio realizzato attraverso Festival, un TTS (Text To Speech) che utilizzai per un progetto universitario nel 2004.. se lo confrontiamo con le voci sintetiche di oggi sembra un salto di diverse ere geologiche.
Allo stesso modo, si stanno evolvendo i sistemi di STT (Speech-To-Text), e precisione e qualità miglioreranno sempre di più!
Arriveremo a parlare con le macchine in maniera naturale, e verremo compresi sistematicamente.
Per approfondire

