Rilevanza contestuale: la nuova metrica della visibilità
Il segreto è la pertinenza... ma non basta più. Come funziona DAVVERO la ricerca oggi, tra embeddings, reranker e AI Overviews.

Negli ultimi mesi ho passato parecchio tempo a studiare un tema che viene spesso ridotto a una frase semplice:
“Il segreto è la pertinenza”
La sentiamo ovunque nel mondo della search, soprattutto da quando si parla di AI, RAG, AEO, AIO, GEO, ecc..
Il concetto, a livello intuitivo, è chiaro… ma per un algoritmo, che cosa significa davvero "pertinenza"? E, soprattutto:
- è davvero l’unico concetto importante?
- Come entra in gioco quando Google (o un sistema RAG) deve scegliere una risposta?
- Possiamo misurare e ottimizzare questo processo, fino a creare dei tool che ci aiutano a farlo in modo scalabile?
In questo percorso entriamo nel flusso "reale" dei moderni sistemi di ricerca, vediamo un test concreto su AI Overviews di Google, e un sistema multi-agent per ottimizzare le risposte in modo automatico.
Partiamo da concetti tecnici (embeddings, bi-encoder, cross-encoder, reranker…) e arriviamo a strategie e tool operativi.
Rilevanza contestuale: la nuova metrica della visibilità
Pertinenza e rilevanza: due parole, due concetti diversi
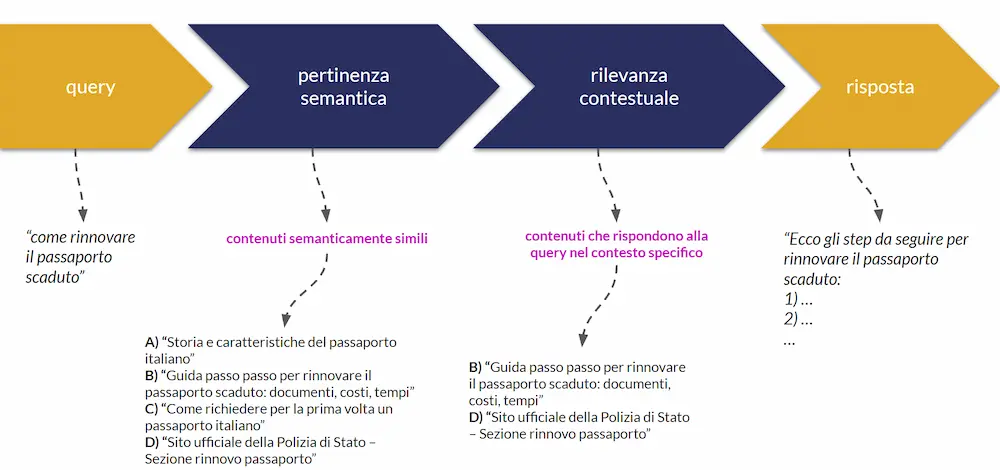
Prima di tutto chiariamo i concetti alla base dei moderni sistemi di ricerca, con un esempio concreto di query:
"come rinnovare il passaporto scaduto"
Questa query attiva un flusso di lavoro che, semplificando, ha due fasi principali.
- Pertinenza semantica (semantic matching)
Il sistema di ricerca analizza la query e la confronta con i contenuti presenti nella knowledge (l’insieme dei documenti disponibili: pagine, testi, ecc.).
In questa fase vengono estratti i contenuti più simili a livello semantico alla query. - Rilevanza contestuale (contextual relevance)
A partire dai contenuti pertinenti, il sistema seleziona quelli più rilevanti nel contesto della query, cioè quelli che rispondono meglio alla domanda dell’utente.
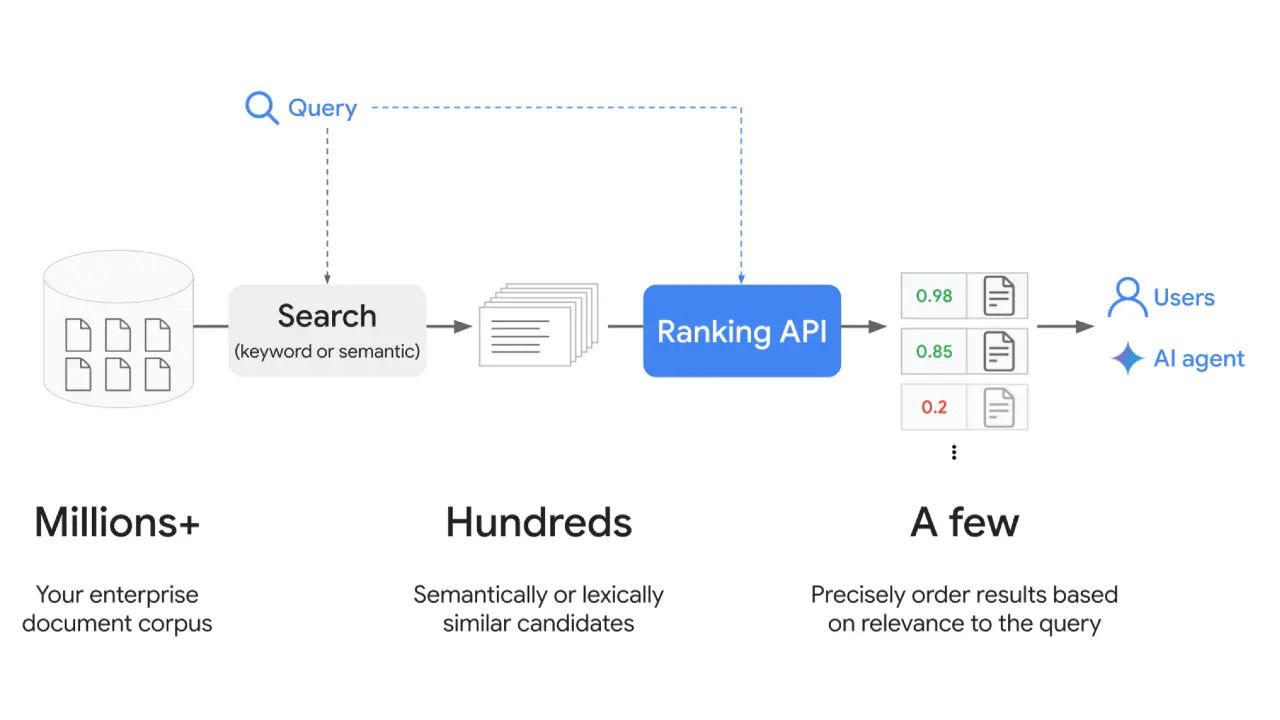
Cosa otteniamo alla fine? Una lista di contenuti ordinati per rilevanza, che può tradursi in una SERP (lista di risultati), oppure diventare il contesto per un modello di AI (LLM/agent), che genera una risposta.
Già da qui vediamo un punto importante:
la pertinenza è necessaria, ma non sufficiente.
Prima il sistema decide quali informazioni sono potenzialmente interessanti, e successivamente determina quelle utili per ottenere la miglior risposta.
Come funzionano, nel dettaglio, questi due step?
Come si calcola la pertinenza semantica: embeddings & similarità
Per lo step di pertinenza semantica entrano in gioco due concetti chiave:
- embeddings
- similarità tra vettori

In breve..
- Trasformazione in embeddings
Sia la query che i contenuti della knowledge vengono trasformati in vettori numerici (embeddings). Ogni embedding è un vettore in uno spazio multidimensionale che rappresenta il significato del testo. - Calcolo della similarità
Il sistema misura la similarità tra l’embedding della query e gli embeddings dei contenuti. Più i due vettori sono simili, più il contenuto è considerato pertinente.
Il risultato di questa fase è:
Una lista di contenuti pertinenti, cioè i documenti semanticamente più vicini alla query.
Una nota sulla similarità (non solo coseno)
Spesso si sente parlare di similarità del coseno come metodo standard di confronto tra embeddings.
È importante sottolineare che:
- la similarità del coseno è solo uno dei modi possibili per misurare la distanza/similarità tra vettori;
- il metodo migliore dipende da come sono stati generati gli embeddings: dall’architettura del modello, dal processo di training, dalla normalizzazione dei vettori, ecc..
A parità di embeddings, metodi diversi possono portare a risultati diversi.
Ci basta conservare un concetto:
Non è sufficiente “avere gli embeddings”: dobbiamo conoscerne la struttura per scegliere il metodo di similarità giusto.
Come si calcola la rilevanza: reranker, bi-encoder e cross-encoder
Quando passiamo dalla pertinenza semantica alla rilevanza contestuale, cambia completamente il tipo di modello utilizzato.
Qui entrano in gioco i reranker, ovvero modelli che:
- ricevono in input una query e un contenuto/documento,
- restituiscono in output uno score di rilevanza, cioè un valore numerico che indica quanto quel contenuto è candidato a rispondere alla query.
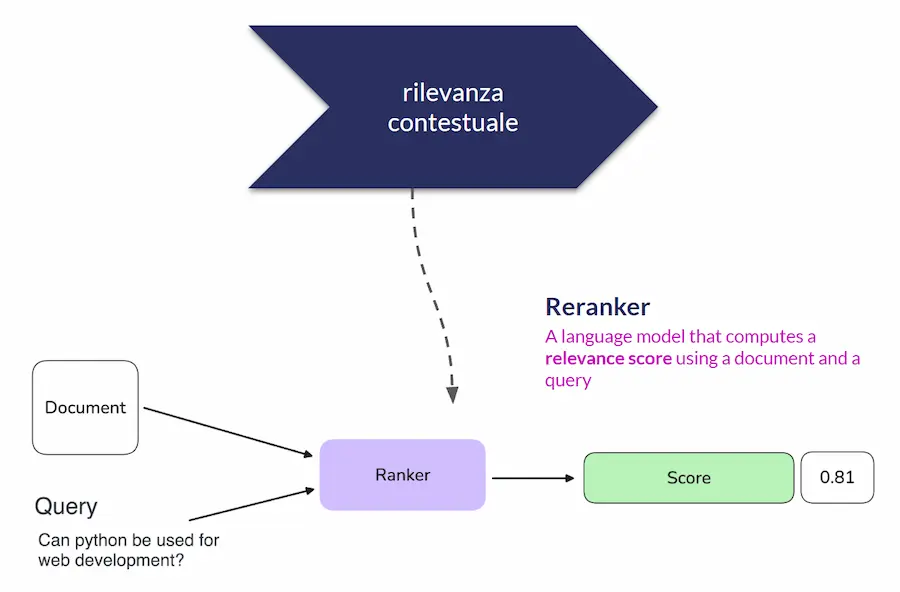
Alla fine di questo step, otteniamo:
una lista ordinata dei contenuti più rilevanti per la query.
Bi-encoder VS cross-encoder
Per capire meglio, facciamo un passo indietro sulle architetture.
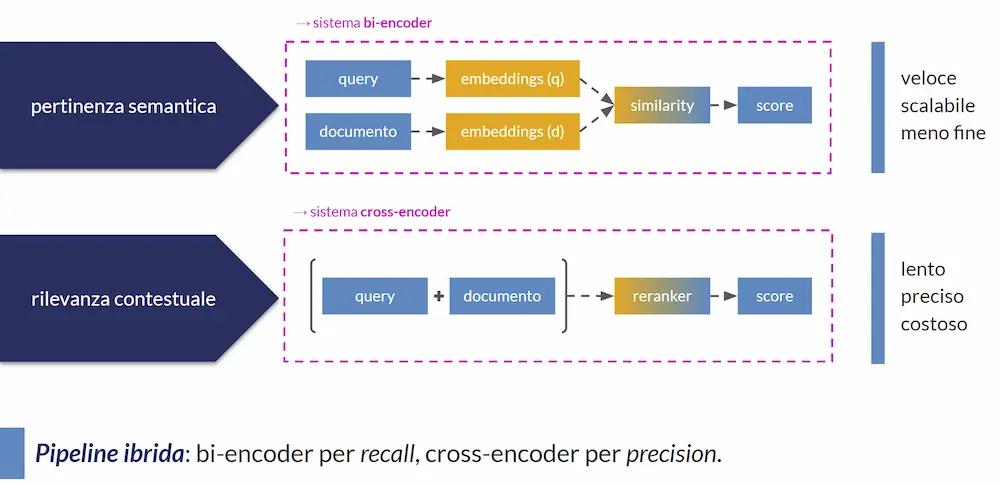
Bi-encoder → pertinenza
Per la pertinenza semantica, usiamo sistemi che vengono definiti "bi-encoder".
- La query viene codificata in un embedding.
- Il contenuto viene codificato in un embedding.
- Un calcolo matematico di similarità tra i due embeddings determina lo score di pertinenza.
Sono chiamati "bi-encoder" proprio perché vengono usati due encoding separati.
Cross-encoder → rilevanza
Per la rilevanza, invece, usiamo sistemi "cross-encoder" (reranker).
- La query e il contenuto vengono concatenati in un unico input,
- l'input combinato viene passato a un modello transformer,
- il modello elabora tutto insieme e restituisce uno score di rilevanza.
Schema mentale:
[query + contenuto] → modello transformer → score di rilevanza
Questa differenza di architettura spiega perché, nei sistemi di ricerca moderni, si usano due fasi distinte.
Perché servono due fasi:
veloce e scalabile VS lento e preciso
Perché si usano queste due fasi per la ricerca? Perché il calcolo della pertinenza è veloce, scalabile, e meno preciso. Mentre il calcolo della rilevanza è lento, costoso, e iper preciso.
Riassumendo..
- Bi-encoder (pertinenza)
✅ veloci
✅ scalabili
❌ meno precisi - Cross-encoder / reranker (rilevanza)
❌ lenti
❌ costosi
✅ estremamente precisi
❌ con finestra di contesto limitata
Queste caratteristiche fanno nascere la necessità di una pipeline ibrida:
- un sistema veloce e meno preciso (bi-encoder) agisce per scremare la knowledge;
- un sistema lento e iper preciso (cross-encoder) agisce per raffinare e ordinare.
Dalla teoria al RAG (e oltre): il “typical search & retrieval flow”
Il flusso che abbiamo descritto è esattamente quello dei sistemi RAG (Retrieval Augmented Generation), in cui..
- abbiamo una knowledge base (documenti, pagine, FAQ, ecc.),
- l’utente effettua una query,
- un sistema di retrieval estrae i contenuti più pertinenti (bi-encoder),
- un reranker seleziona e ordina i contenuti più rilevanti (cross-encoder),
- il risultato: può essere mostrato come lista di documenti, oppure passato a un LLM per generare una risposta.
Nella documentazione di Google, questo flusso oggi viene definito:
"typical search and retrieval flow"
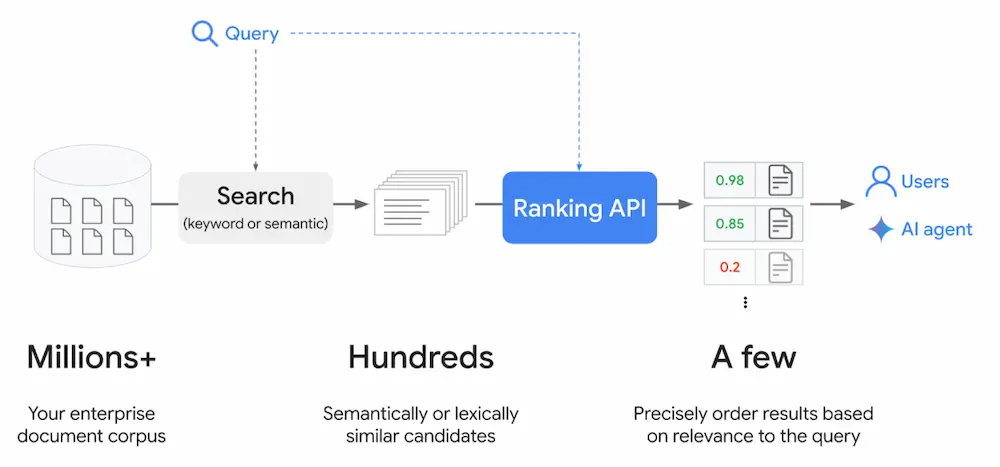
Il messaggio implicito è...
- non è solo “RAG per documenti interni”,
- è un pattern generale per la ricerca: vale per la knowledge locale, per il web, per sistemi ibridi.
Ed è qui che entra in scena qualcosa che ormai tutti stiamo guardando con attenzione: AI Overview (e, in generale, i nuovi sistemi di risposta ibridi che uniscono un motore di ricerca a un modello di linguaggio).
AI Overview come sistema ibrido: cosa conta davvero?
Guardando il flusso che abbiamo descritto, viene spontaneo chiedersi:
"l'AI Overview, quando mostra le fonti vicino alla risposta,
su cosa si basa per scegliere quelle pagine?"
È ragionevole ipotizzare che:
- le fonti mostrate siano le pagine che contengono le risposte con rilevanza contestuale più alta nella knowledge di Google;
- non basta essere in prima posizione tra i risultati organici per essere automaticamente una fonte dell'AI Overview.
E infatti…
Il mio caso: in prima posizione, ma fuori da AI Overview
Per la query "cosa sono i priority hints", il mio contenuto era primo tra i risultati organici, ma, inizialmente, non compariva tra le fonti dell'AI Overview.
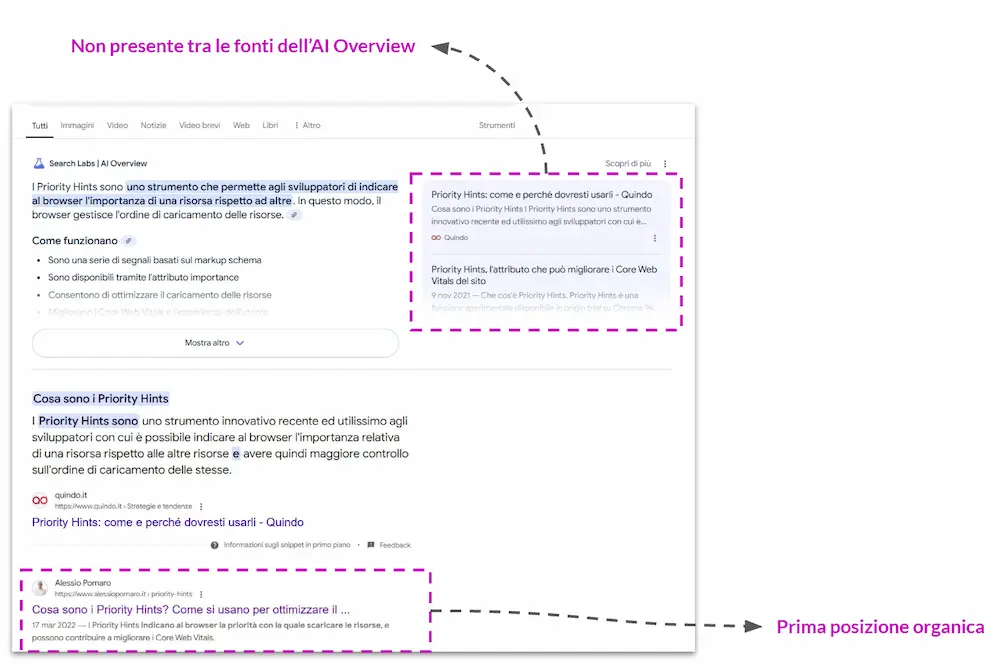
Ho deciso, quindi, di fare un esperimento per capire meglio cosa stava succedendo "sotto il cofano".
Il test: misurare la rilevanza delle risposte (e scoprire che la mia era... la peggiore)
Vediamo il test, step by step.
- Ho considerato le pagine che erano fonti della risposta principale dell'AI Overview.
- Da ciascuna di queste pagine ho estratto la risposta alla query dell’utente (la parte di contenuto che risponde effettivamente alla domanda).
- Ho fatto la stessa operazione con la mia pagina web, che comunque era prima tra i risultati organici, e quindi un candidato naturale per diventare fonte della risposta.
- Ho usato un reranker per misurare la rilevanza contestuale tra la query e le risposte dei contenuti che erano già fonte dell'AI Overview, e tra la query e la risposta del mio contenuto.
Il risultato?
La risposta nella mia pagina..
era quella con rilevanza
contestuale più bassa tra tutte.
Questo allinea perfettamente l’esperimento con l’ipotesi: l'AI Overview non “premia” chi è semplicemente ben posizionato tra i risultati organici, ma dà priorità ai contenuti che forniscono risposte più rilevanti.
Ottimizzare la risposta a colpi di reranker
A questo punto, passiamo alla seconda fase del test.
- Ho analizzato le risposte delle pagine che il reranker considerava più rilevanti, osservando: le entità trattate, i termini usati, gli aspetti della query che venivano valorizzati, i focus che venivano messi in atto.
- Ho modificato la mia risposta cercando di includere le entità rilevanti, coprire tutti i punti che le altre risposte trattavano in maniera esaustiva, mantenere coerenza con il mio stile e con il contesto della pagina.
- Ogni volta che aggiornavo il contenuto, misuravo nuovamente la rilevanza contestuale di tutte le risposte attraverso il reranker, verificando se la mia risposta stava salendo nel ranking.
Ho iterato questo processo finché:
la mia risposta ha ottenuto uno score di rilevanza superiore a tutte le altre.
E cosa è successo dopo pochi giorni? La mia pagina è diventata prima fonte dell'AI Overview per quella query.
Quindi funziona!
Ma andiamo a fare un bilancio dell'operazione.
Bilancio dell’operazione
- Effort: altissimo.
- Certezza del risultato: nessuna, perché Google non documenta in modo completo il comportamento di AI Overviews.
- Utilità strategica: sì, in ottica di branding e autorevolezza, e forse garantisce qualche clic in più.
- Scalabilità: zero, perché si tratta di un'operazione manuale che se dovesse essere applicata a centinaia di query si tradurrebbe in un effort enorme.

Da qui nasce la domanda naturale:
"E se provassimo a automatizzare questo processo?"
Dal test al tool: un sistema multi-agent per ottimizzare le risposte
Trasformiamo l'esperimento in un tool. L'architettura di base è LangGraph, con un approccio multi-agent.
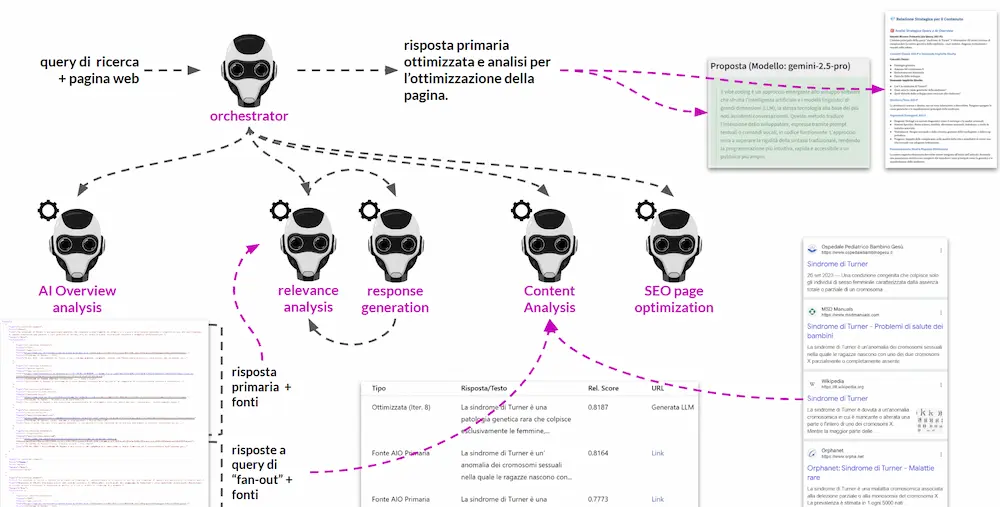
Architettura ad alto livello
Il sistema funziona attraverso i seguenti step.
- Un Agent Orchestrator riceve in input la query e l'URL della pagina web da ottimizzare.
- Un altro agent, recupera il risultato di AI Overview per la query, estrae le fonti della risposta principale, estrae anche le fonti delle risposte secondarie (quelle legate alle query di fan-out).
- Attraverso un LLM, viene rilevata la risposta alla query da ciascuna fonte, ovvero il testo all'interno delle pagine web che mira a rispondere direttamente alla domanda. Viene attuato lo stesso processo anche per la pagina da ottimizzare.
- A questo punto abbiamo una tabella concettuale con: query, risposta di ogni fonte dell'AI Overview, risposta della pagina da ottimizzare.
- Diversi agenti, successivamente, usano un reranker per misurare la rilevanza contestuale di ogni risposta rispetto alla query, e producono un ranking delle risposte. In maniera iterativa, prendono in considerazione le risposte delle fonti, il contesto complessivo della SERP, la risposta della pagina da ottimizzare, e generano una nuova risposta candidata.
- La nuova risposta viene valutata dal reranker. Se lo score è inferiore rispetto alle migliori risposte, il sistema: genera una nuova variante considerando tutti i dati a disposizione, ricalcola la rilevanza, e così via, fino a quando la risposta generata non ottiene lo score di rilevanza più alto tra tutte.
- Un ulteriore gruppo di agenti analizzano le query di fan-out (derivate dalle risposte secondarie dell'AI Overview), analizzano le pagine in SERP, costruiscono una proposta di ottimizzazione per la struttura della pagina, per intercettare anche le query di fan-out.
Risultato finale del sistema
Una volta terminata l'azione del workflow, otteniamo una risposta ottimizzata da inserire nella pagina web, e un'analisi SEO che mira a riorganizzare/arricchire il contenuto, valorizzare in modo più completo il topic, posizionarsi meglio anche per le ricerche correlate.
E se lo pensiamo come sistema che lavora in background?
Potrebbe analizzare costantemente le query, monitorare le AI Overview e ottimizzare in autonomia (costantemente) i contenuti per aumentare la probabilità di essere fonte.
Nei nostri test, questa idea è già diventata realtà su alcuni progetti.
L’indice di rilevanza è un valore assoluto? (spoiler: no)
A questo punto sorge una domanda importante:
Se, secondo il reranker, un contenuto è più rilevante di un altro,
si tratta di una verità assoluta?
La risposta è no, perché lo score di rilevanza dipende da:
- l’architettura del modello di reranking,
- i dati usati in fase di training,
- gli eventuali processi di fine-tuning,
- le scelte di ottimizzazione fatte in fase di sviluppo.
Quindi, reranker diversi, applicati allo stesso set di dati, possono restituire punteggi differenti, e quindi classifiche diverse. Nell'immagine che segue, ad esempio, vediamo a confronto la misurazione della rilevanza contestuale di due reranker diversi (Jina Reranker V3 e Semantir Ranker di Google).

Come si può notare, gli score sono diversi, e danno vita a una "classifica" diversa.
È un po' come chiedere a due esperti molto competenti, ma con formazione diversa, di classificare gli stessi contenuti: avranno tendenzialmente opinioni simili, ma non per forza identiche.
Qual è il "dato corretto"?
Non esiste un “dato corretto” in assoluto. Esiste un modello che "guarda il mondo" secondo la propria formazione, e restituisce il suo "giudizio".
Nel tool, ho scelto di usare il reranker di Google, considerando il fatto che, probabilmente, è stato addestrato su una quantità enorme di dati proprietari, compresi i dati derivanti dalla ricerca online (click, comportamenti, feedback impliciti, ecc.).
Il tool in azione: una rapida panoramica
Nel seguente video, è possibile vedere l'esecuzione del tool su una query di ricerca.
AI Overview Content Strategist Agent V7
L'output, come indicato in precedenza, è composto dal testo dedicato alla risposta per l'AI Overview e dall'analisi per l'ottimizzazione del contenuto.
AEO, AIO, GEO, ecc.: cosa cambia davvero nella SEO?
Dopo aver fatto funzionare questo sistema su centinaia di pagine, e dopo aver osservato l’evoluzione di tutte le sigle che stanno emergendo (AEO, AIO, GEO, ecc.), viene spontanea una domanda:
Rispetto alla SEO che conoscevamo,
quali sono le vere novità?
Per come la vedo oggi, la mia risposta è: "molto poche". Quello che emerge come davvero rilevante sono le attività che avremmo sempre dovuto svolgere: rispondere in modo esaustivo alle query degli utenti, esplorare il topic in modo completo, usare un linguaggio chiaro e corretto, fornire un valore reale.
Quindi, cos'è cambiato?
È cambiato il fatto che oggi abbiamo nuove piattaforme e nuove SERP Features che ce lo fanno presente. E nuovi strumenti per migliorare la qualità del nostro lavoro.
È fondamentale approfondire anche gli aspetti tecnici
Oggi abbiamo a disposizione strumenti, informazioni, documentazione, esempi pratici che ci permettono di comprendere la ricerca anche dal punto di vista tecnico.
Questo non significa dover essere in grado di sviluppare migliaia di righe di codice o diventare ingegneri esperti nel Machine Learning.
Significa capire i concetti di base, ad esempio cosa sono gli embeddings, come si calcola la similarità, come lavorano i bi-encoder e i cross-encoder, cosa significa parlare di reranking e rilevanza contestuale, come funziona un flusso RAG o un sistema ibrido tipo l'AI Overview, avere una visione chiara di come i sistemi "prendono decisioni".
Perché?
Capire gli aspetti tecnici → genera nuove intuizioni
Nuove intuizioni → generano nuove strategie e nuovi strumenti
Nuovi tool → migliorano concretamente la qualità del nostro lavoro
Ed è esattamente quello che abbiamo fatto in questo viaggio:
- siamo partiti da concetti molto tecnici (embeddings, similarità del coseno, reranker, transformer, multi-agent…),
- li abbiamo usati per interpretare il comportamento di un sistema reale (AI Overviews), costruire un tool concreto che ci aiuta a migliorare i contenuti, ottenere risultati misurabili in progetti reali.
Se vogliamo far performare la SEO nel mondo della ricerca aumentata dall’AI, la strada, secondo me, è questa:
sforzarci di comprendere i concetti tecnici chiave,
per poi trasformarli in strategie e automazioni che fanno la differenza.
Buona ricerca (e buona "comprensione tecnica" 😊).
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂