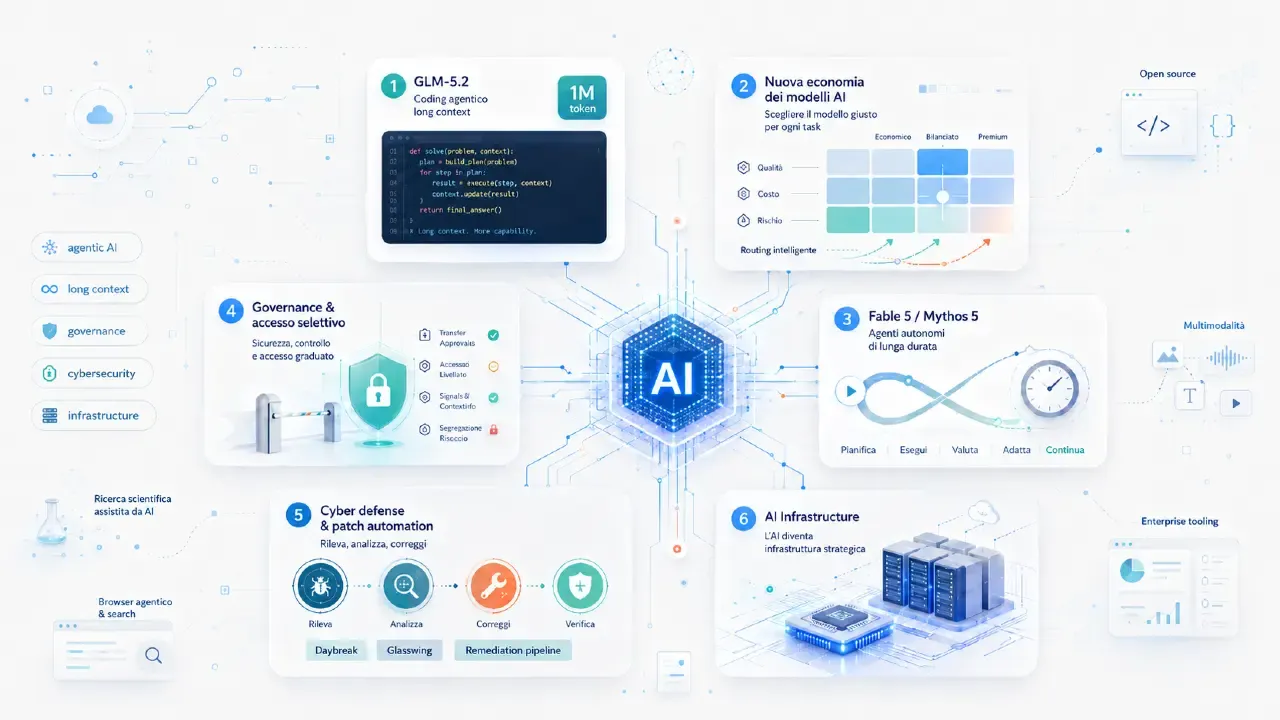
Generative AI: novità e riflessioni - #6 / 2026
GLM-5.2, GPT-5.6, Fable/Mythos e Qwen 3.7 spingono coding agentico, autonomia e multimodalità. Daybreak, Jalapeño, Co-Scientist, token capital e agentic engineering mostrano l’AI come infrastruttura: modelli, chip, sicurezza, ricerca e nuovi workflow.

Buon aggiornamento, e buone riflessioni..
Ascolta l'audio overview che sintetizza le novità
Il podcast è stato generato attraverso NotebookLM.
GLM-5.2: coding agentico e contesto da 1 milione di token
Negli ultimi mesi i modelli AI open stanno riducendo sempre di più la distanza dai sistemi proprietari, soprattutto nei task di coding, ragionamento e uso agentico degli strumenti. In questo contesto si inserisce GLM-5.2, il nuovo modello flagship di Z.ai progettato per attività di lungo orizzonte: coding agent, debugging complesso, ottimizzazione di sistemi e workflow software che richiedono molte interazioni consecutive.
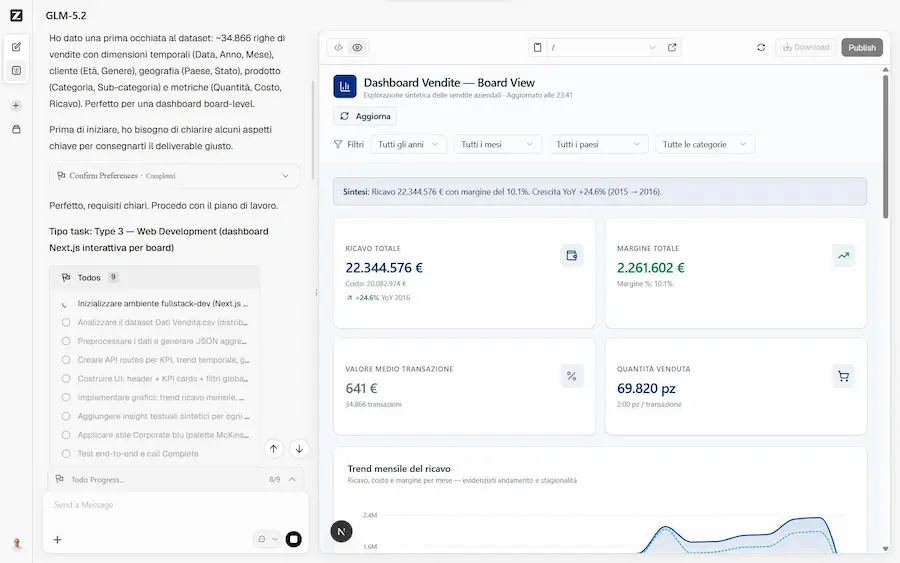
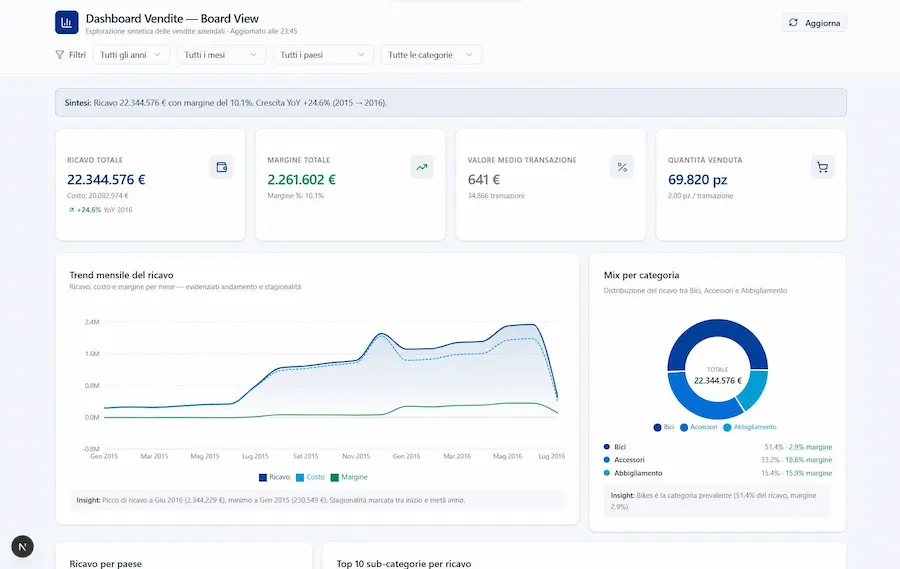
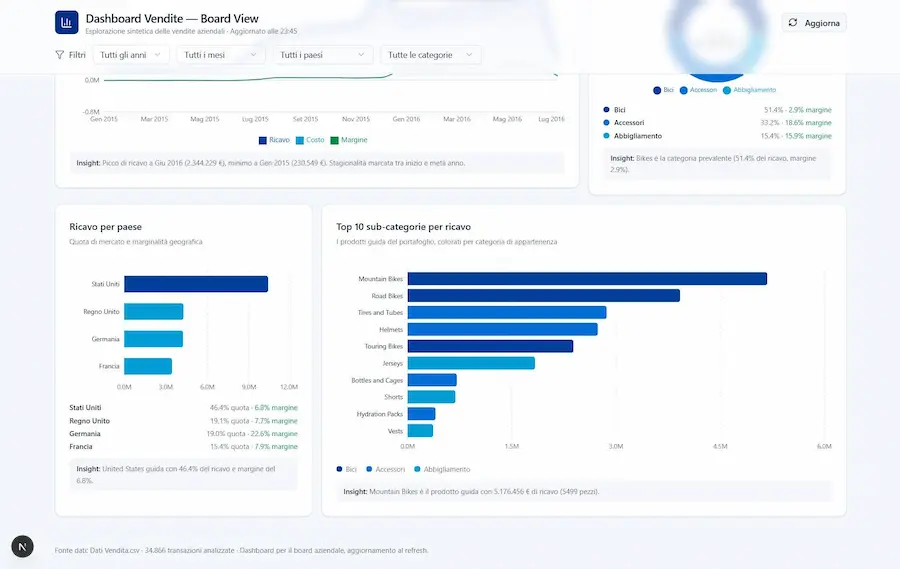
L’ho provato su diversi task in modalità Agent, per l’analisi dei dati, coding e operazioni con una grande quantità di istruzioni in input. Inutile dire che si tratta di un nuovo modello impressionante.
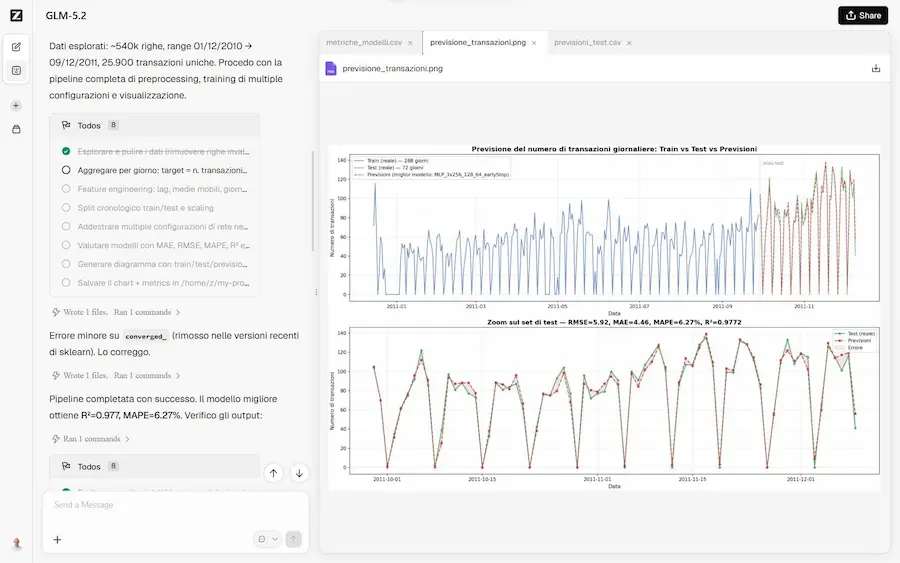
GLM-5.2: coding agentico e contesto da 1 milione di token
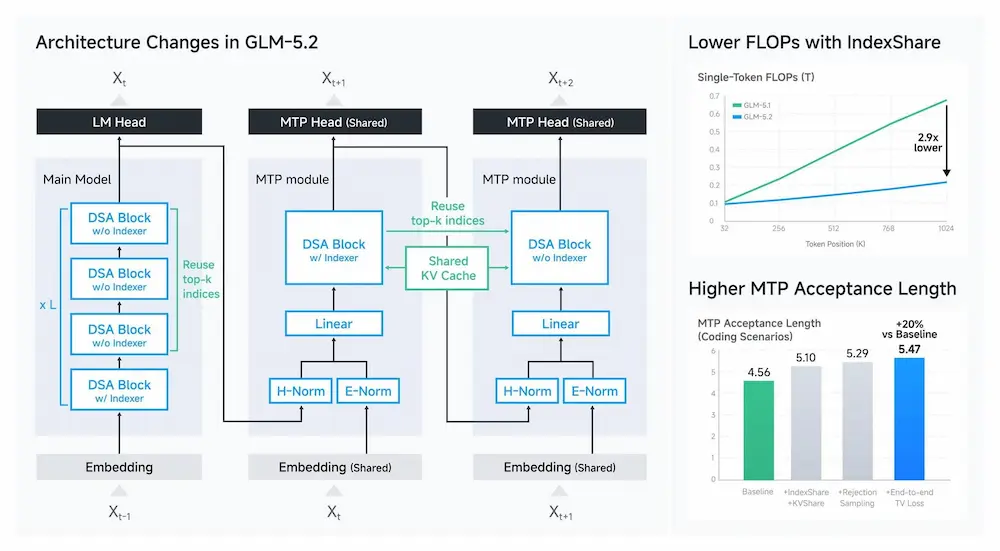
La novità più rilevante è il supporto a un contesto stabile da 1 milione di token. Non si tratta solo di una finestra più ampia, ma di un tentativo di rendere il long context realmente utilizzabile in scenari di engineering complessi, dove il modello deve mantenere coerenza e qualità lungo traiettorie estese.
Sul piano tecnico, GLM-5.2 introduce IndexShare, una tecnica che riutilizza lo stesso indexer ogni quattro layer di sparse attention, riducendo il costo computazionale a contesti molto lunghi. Migliora anche il layer MTP per lo speculative decoding, con un incremento dichiarato fino al 20% nella lunghezza media accettata.
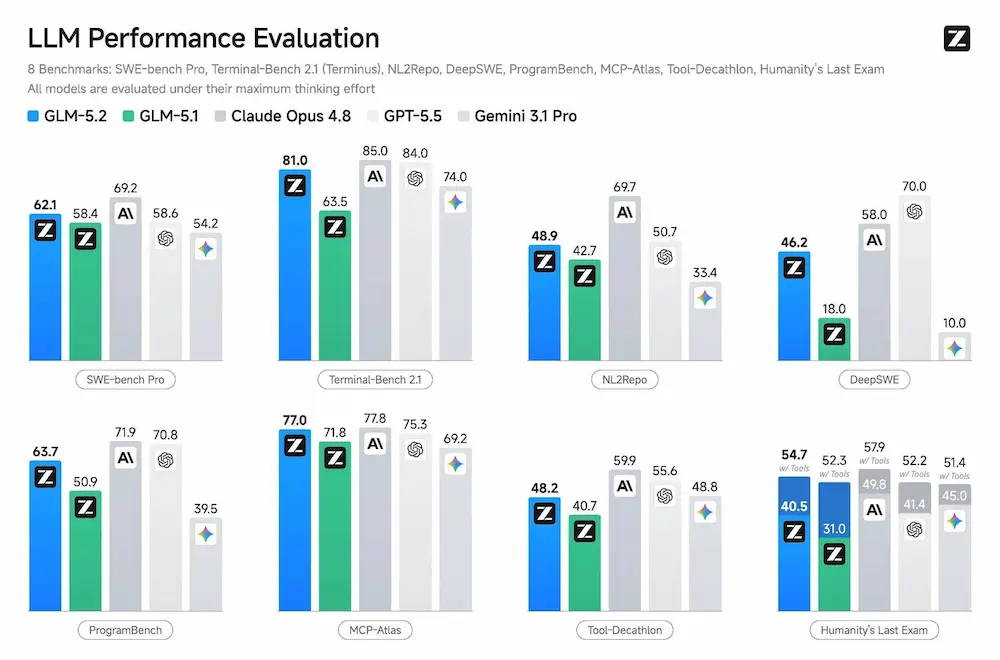
Nei benchmark riportati da Z.ai, GLM-5.2 mostra un salto netto rispetto alla versione precedente, soprattutto nel coding. Su Terminal-Bench 2.1 passa da 63.5 a 81.0, mentre su SWE-bench Pro sale da 58.4 a 62.1. Nei benchmark long-horizon come FrontierSWE, PostTrainBench e SWE-Marathon viene presentato come il modello open-source più competitivo tra quelli confrontati.
Un altro aspetto interessante riguarda il training agentico. Z.ai descrive l’uso dell’infrastruttura slime per gestire rollout complessi, tool use, sub-task e feedback multi-turn. Viene inoltre introdotto un modulo anti-hacking per limitare comportamenti opportunistici nei coding agent, come l’accesso a file di valutazione nascosti o la copia di soluzioni esterne.
GLM-5.2 viene distribuito con licenza MIT, con pesi disponibili su Hugging Face e ModelScope, e supporto per framework come transformers, vLLM, SGLang, xLLM e ktransformers.
Il messaggio di fondo: la competizione sui modelli di coding si sta spostando dalla semplice capacità di risolvere singoli problemi alla capacità di sostenere workflow lunghi, agentici e verificabili.
GLM-5.2 e la nuova economia dei modelli AI
Dopo giorni di test su GLM-5.2, sto facendo alcune riflessioni. Non credo che il punto sia dire che “batte” sempre i migliori modelli chiusi. E non credo nemmeno che basti scaricarlo per sostituire OpenAI, Anthropic o Google dal giorno dopo.
Il punto, secondo me, è un altro: per la prima volta un modello open/public sembra abbastanza vicino alla fascia frontier da rendere concreta una domanda che probabilmente molte aziende si stanno già facendo: “Quante delle nostre chiamate ai modelli più costosi hanno davvero bisogno del modello migliore in assoluto?”
È qui che la cosa diventa interessante. Servire un modello di questa classe non è banale: servono GPU importanti, competenze, monitoraggio, sicurezza, valutazioni interne, fallback e una buona strategia di routing. Quindi no, anche se in molti lo pensano, non è “gratis”.

Ma il punto non è sostituire il 100% dei workload. Il punto è capire se un modello come GLM-5.2 può coprire bene una parte significativa dei casi d’uso: coding, analisi documentale, task interni, agenti verticali, workflow ripetitivi e long-context.
Per molte aziende che oggi spendono cifre importanti in API frontier, anche spostare una parte del traffico su un modello open/public può cambiare sensibilmente l’economia.
La vera disruption, secondo me, non è “open vs closed”. È il passaggio da: “uso sempre il modello migliore disponibile” a: “uso il modello giusto per ogni task, misurato con eval interne e ottimizzato per costo, qualità e rischio”.
GLM-5.2 potrebbe non essere il modello che sostituisce tutto. Ma potrebbe essere uno dei modelli che rende inevitabile questa transizione. E questa, per l’AI enterprise, è un aspetto molto più interessante di un semplice benchmark.
Claude Fable 5 e Mythos 5: il focus si sposta sull’autonomia
Anthropic ha annunciato Claude Fable 5 e Claude Mythos 5, una nuova generazione di modelli che l’azienda colloca al di sopra della famiglia Opus in termini di capacità.
Al di là dei singoli benchmark, l’aspetto più interessante è probabilmente il focus sulle attività autonome di lunga durata. Sempre più valutazioni non misurano soltanto la qualità di una risposta, ma la capacità di un modello di lavorare in autonomia per ore o giorni mantenendo affidabilità, memoria e coerenza operativa. È una metrica che si avvicina molto di più agli scenari reali di sviluppo software, ricerca e automazione avanzata.
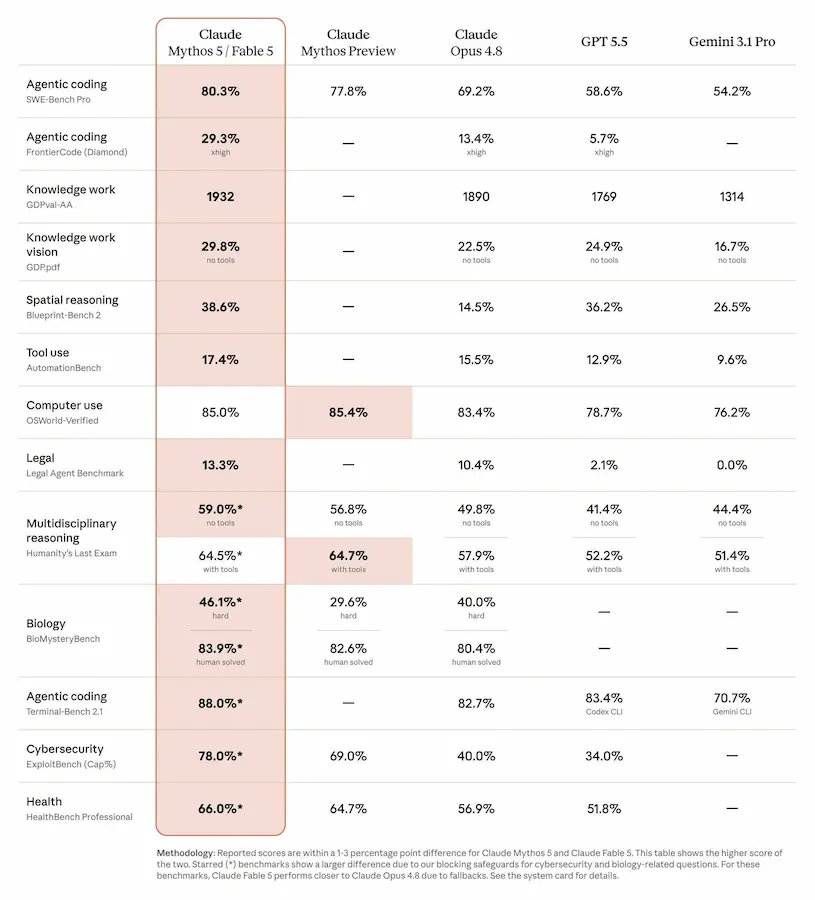
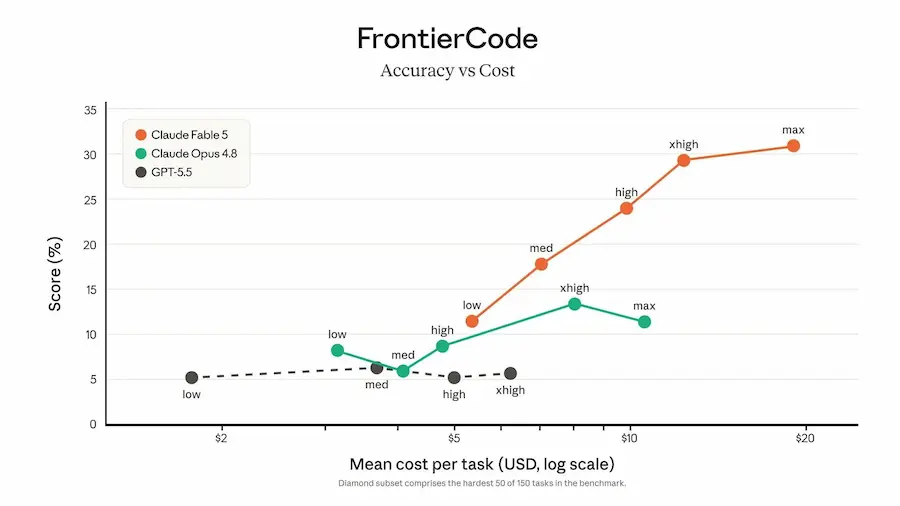
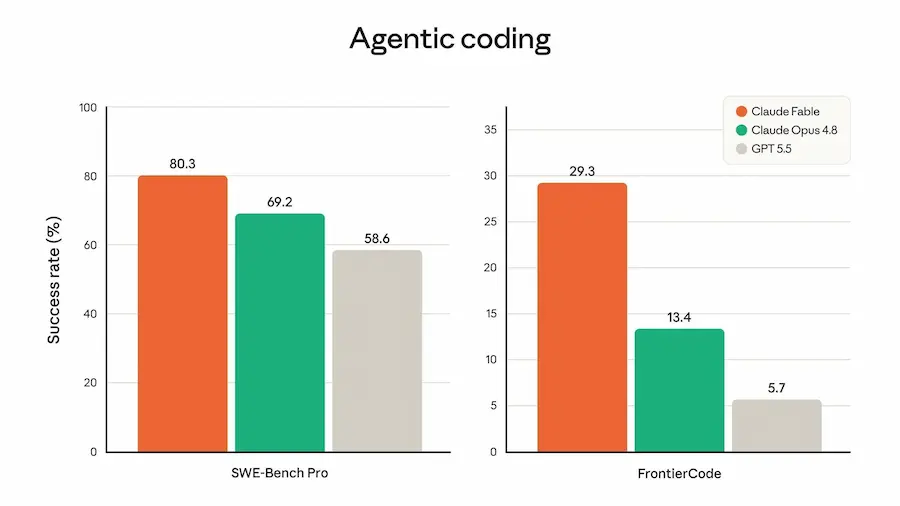
In questo contesto, Anthropic sostiene che Fable 5 rappresenti un salto importante nelle attività di coding agentico, ricerca scientifica, cybersecurity e knowledge work. Nella documentazione pubblicata, il modello registra risultati superiori a Claude Opus 4.8, GPT-5.5 e Gemini 3.1 Pro in diversi benchmark, con vantaggi particolarmente marcati nell’ingegneria del software e nei test di cybersicurezza.
Claude Fable 5 e Mythos 5: il focus si sposta sull’autonomia
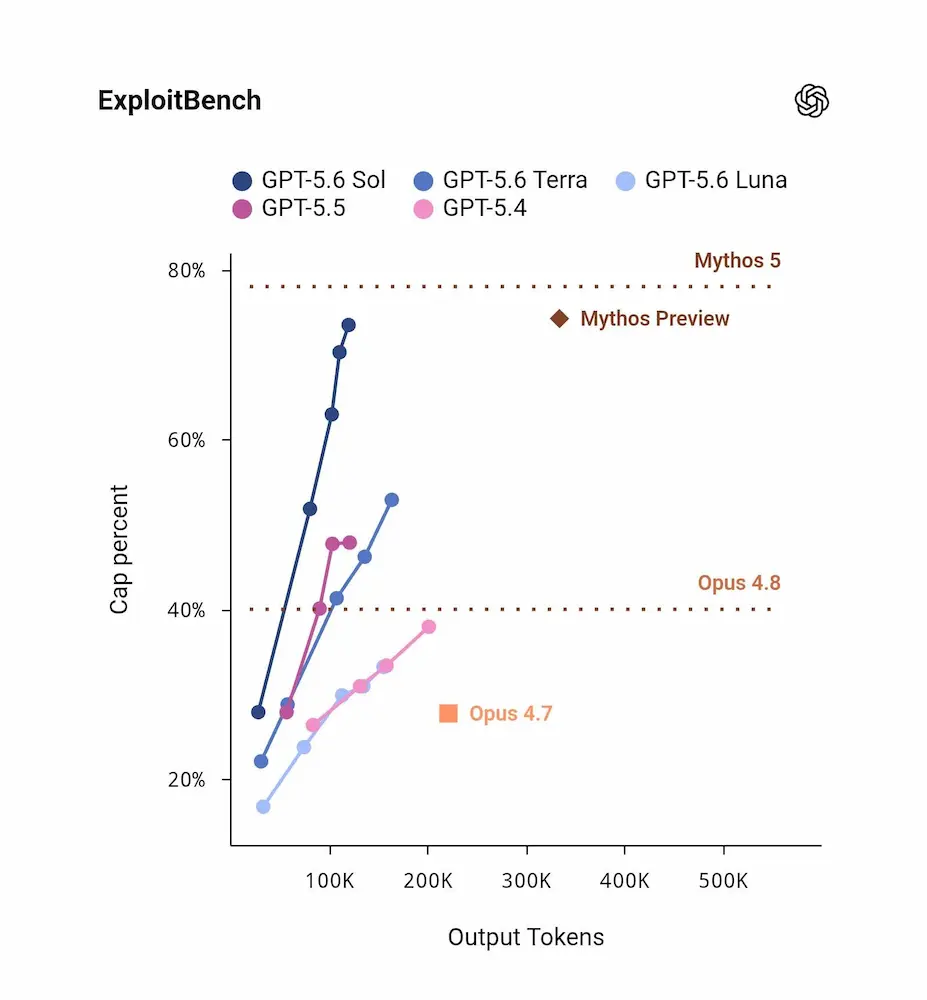
Allo stesso tempo, vale la pena osservare che alcune valutazioni indipendenti raccontano una storia leggermente diversa. Nel grafico pubblicato dall’AISI, ad esempio, GPT-5.5 e Mythos Preview appaiono molto vicini nella metrica dei cybersecurity time horizons, tanto da arrivare a saturare la suite di test utilizzata. Questo suggerisce che il vantaggio mostrato da Anthropic nei benchmark proprietari potrebbe essere reale, ma che la sua entità andrà verificata attraverso ulteriori valutazioni indipendenti.
Un altro elemento significativo è la scelta di Anthropic di introdurre nuove salvaguardie e limitazioni per Fable 5, riservando Mythos 5 a programmi di accesso controllato. È un segnale che riflette una tendenza sempre più evidente: man mano che aumentano le capacità operative dei modelli, cresce anche l’attenzione verso i rischi associati all’automazione di attività complesse in ambiti come cybersecurity e ricerca biologica.
Più che il confronto tra singoli punteggi, il dato che emerge è l’evoluzione verso sistemi capaci di sostenere attività sempre più lunghe, articolate e autonome. È probabilmente questa la direzione che caratterizzerà la prossima fase della competizione tra i principali laboratori di AI.
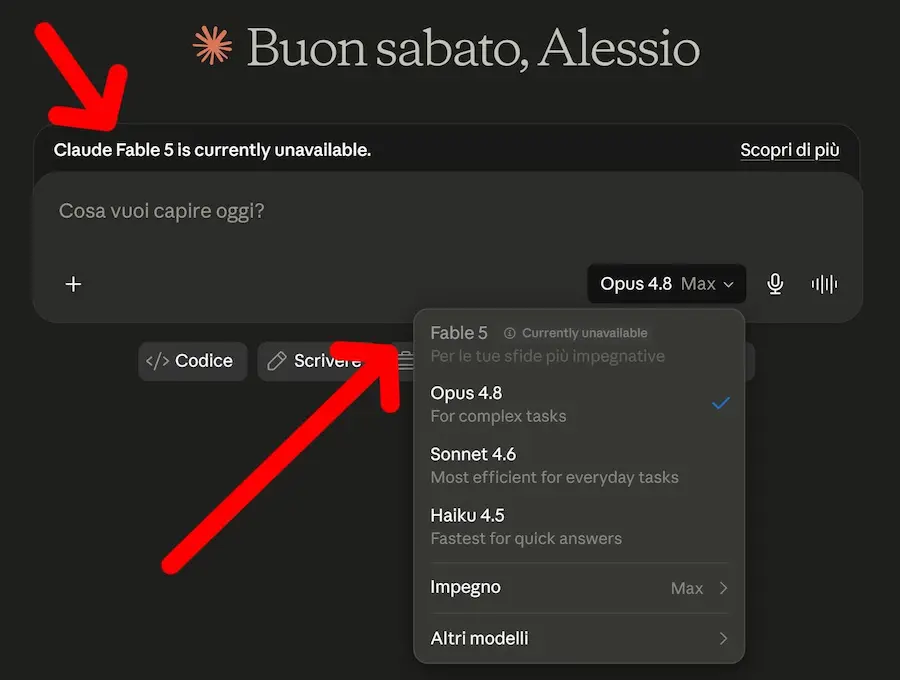
Fable e Mythos ritirati: governance o assenza di governance?
Fable e Mythos sono modelli già ritirati per problemi di sicurezza. Una dimostrazione di governance dell’AI? O di totale assenza di una governance chiara?
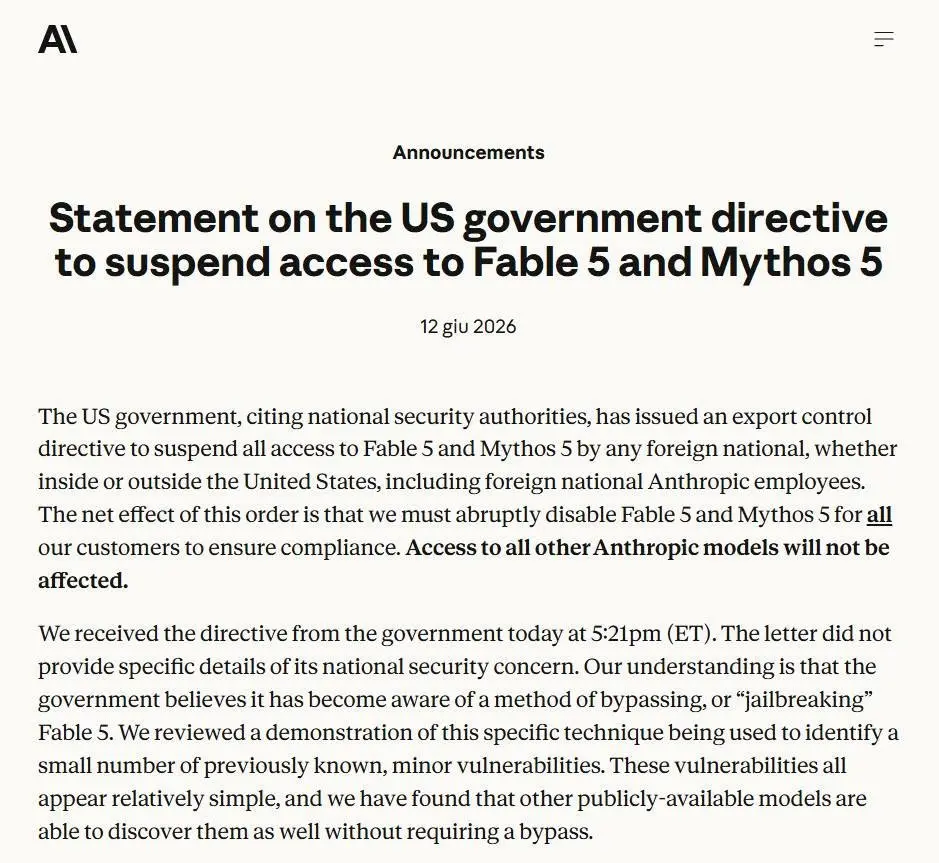
Anthropic ha comunicato di aver ricevuto una direttiva dal governo degli Stati Uniti che impone la sospensione dell’accesso a Fable 5 e Mythos 5 per qualunque cittadino non statunitense, dentro o fuori dagli USA, inclusi i dipendenti stranieri dell’azienda.
L’effetto pratico, però, è ancora più ampio: per garantire la conformità alla direttiva, Anthropic dichiara di dover disabilitare l’accesso ai due modelli per tutti i clienti. Gli altri modelli dell’azienda non sarebbero coinvolti.
Al centro della decisione ci sarebbe una preoccupazione di sicurezza nazionale legata a un possibile metodo di jailbreak di Fable 5. Secondo Anthropic, tuttavia, le evidenze ricevute finora riguarderebbero un bypass ristretto, non universale, e capacità già disponibili anche in altri modelli pubblici.

Fable e Mythos ritirati: governance o assenza di governance?
L’azienda sostiene di aver sottoposto Fable 5 a migliaia di ore di red teaming con enti governativi, organizzazioni terze e team interni. La sua strategia dichiarata non è la promessa di una sicurezza perfetta, ma una difesa in profondità: protezioni forti, monitoraggio continuo, mitigazione rapida degli abusi e conservazione temporanea dei dati per individuare eventuali exploit.
Il punto più interessante è che Anthropic non contesta solo la misura in sé, ma lo standard che potrebbe creare. Se un jailbreak ristretto fosse sufficiente per sospendere un modello frontier già distribuito, allora il criterio potrebbe diventare applicabile a gran parte dell’industria. Perché nessun modello avanzato, oggi, può realisticamente garantire resistenza assoluta a ogni forma di bypass.
Qui la questione diventa più ampia della singola vicenda Anthropic. La governance dell’AI non si giocherà solo sulla capacità di valutare i rischi tecnici, ma anche sulla qualità dei processi con cui quei rischi vengono interpretati: quali prove servono, chi le valuta, quanto devono essere trasparenti le decisioni, quali soglie giustificano un blocco e come si evita che la sicurezza diventi uno strumento opaco di controllo industriale.
Questo caso mostra una cosa con chiarezza: i modelli frontier non saranno regolati soltanto dopo il lancio. Potranno essere fermati anche mentre sono già sul mercato, con effetti immediati per aziende, sviluppatori e utenti.
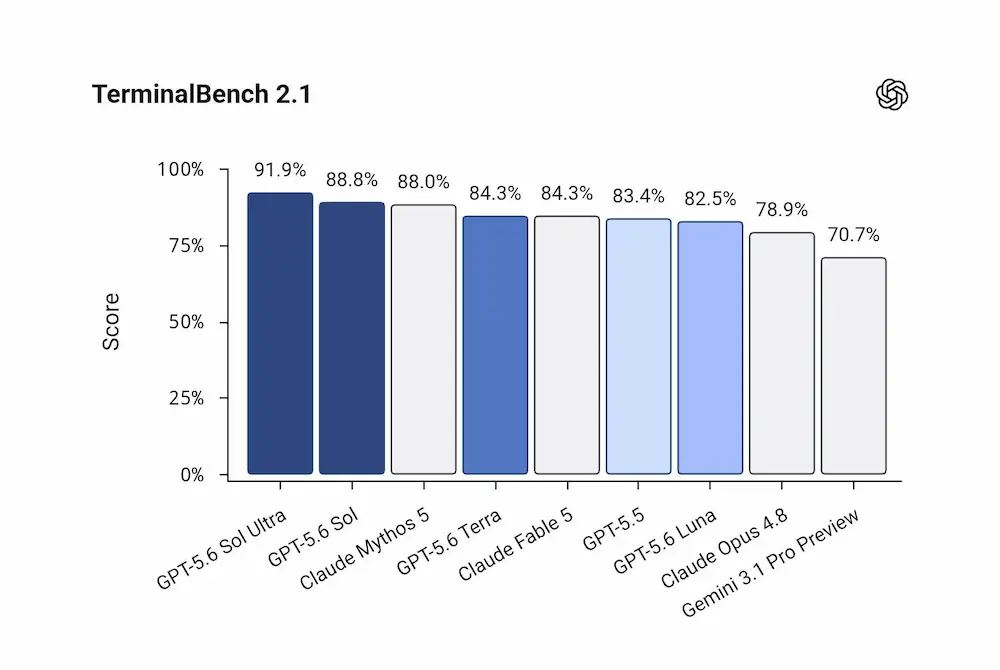
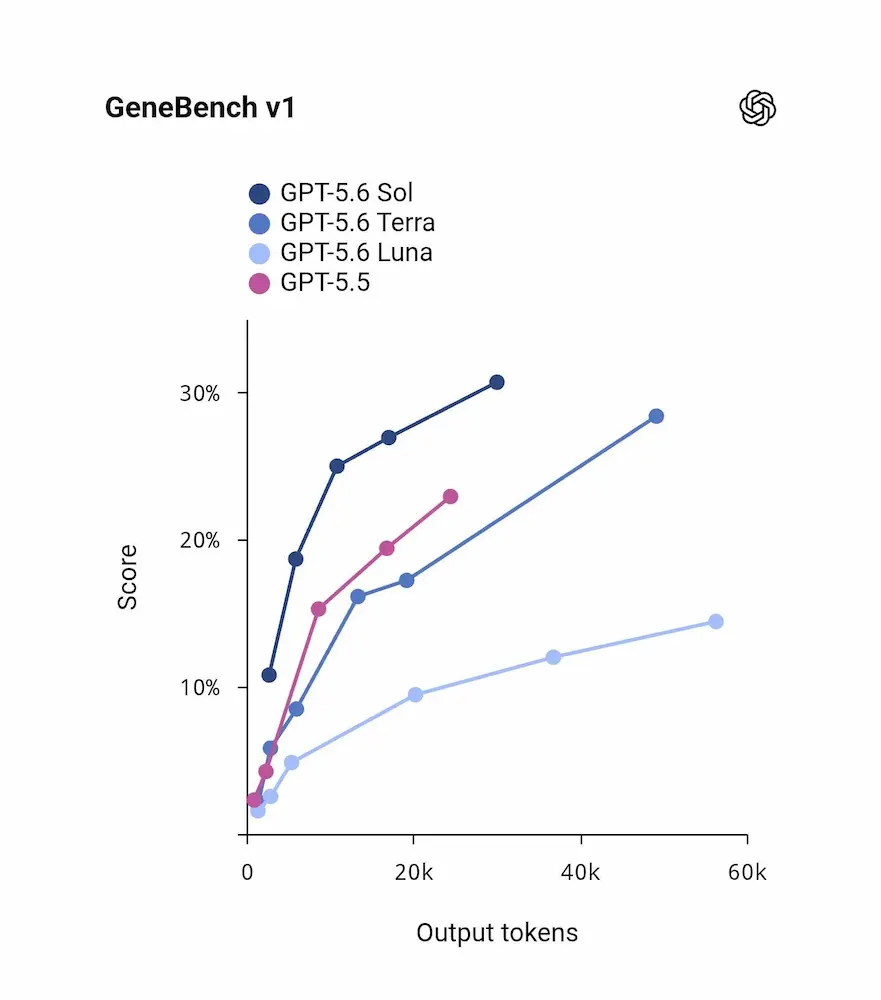
GPT-5.6: preview limitata per Sol, Terra e Luna
OpenAI ha avviato la preview limitata di GPT-5.6, una nuova famiglia di modelli composta da Sol, Terra e Luna. Sol è il modello di punta, pensato per attività complesse e ad alto carico di ragionamento. Terra punta a un equilibrio tra prestazioni e costo, con performance competitive rispetto a GPT-5.5 a metà prezzo. Luna è il modello più veloce ed economico della famiglia.
Le aree in cui GPT-5.6 mostra i miglioramenti più rilevanti sono coding, biologia computazionale e cybersecurity. Sol introduce un nuovo livello massimo di reasoning effort, mentre la modalità Ultra usa subagenti per affrontare lavori complessi in modo più efficiente.
Una parte centrale del rilascio riguarda la sicurezza. OpenAI descrive GPT-5.6 come la famiglia con il sistema di salvaguardie più robusto sviluppato finora: protezioni integrate nel modello, controlli in tempo reale, classificatori per richieste sensibili, monitoraggio a livello account e accesso differenziato.
GPT-5.6: preview limitata per Sol, Terra e Luna
Nel campo cyber, il modello è progettato per supportare attività difensive come code review, ricerca di vulnerabilità, sviluppo di patch, debugging e formazione, cercando al tempo stesso di limitare usi offensivi non consentiti.
OpenAI specifica che GPT-5.6 Sol non supera la soglia “Cyber Critical” del proprio Preparedness Framework: nei test è riuscito a individuare bug e componenti utili a un exploit, ma non a produrre autonomamente exploit completi end-to-end nelle condizioni valutate.
La preview servirà anche a testare l’equilibrio tra capacità e salvaguardie, riducendo blocchi non necessari, ritardi e falsi positivi nelle attività legittime.
Sul fronte prezzi API, GPT-5.6 viene proposto in tre livelli: Sol a 5 dollari input e 30 dollari output per milione di token, Terra a 2,50 e 15 dollari, Luna a 1 e 6 dollari.
Il rilascio più ampio è previsto nelle prossime settimane per ChatGPT, Codex e API.
AI frontier: accesso selettivo e infrastruttura strategica
Gli Stati Uniti hanno limitato e poi riaperto parzialmente l’accesso ad alcuni modelli AI avanzati di Anthropic: Claude Mythos 5 e Fable 5. Mythos 5 è stato reso disponibile solo a organizzazioni selezionate, mentre Fable 5 è rimasto escluso dal rilascio pubblico.
Nello stesso periodo, OpenAI ha rinviato il rilascio pubblico di GPT-5.6 su richiesta del governo USA, concedendo accesso anticipato solo a un gruppo ristretto di partner verificati.



AI frontier: accesso selettivo e infrastruttura strategica
Il punto non è solo tecnologico. È politico, industriale e strategico. I modelli frontier stanno iniziando a essere trattati come tecnologie dual-use: strumenti che possono rafforzare cybersecurity, ricerca e produttività, ma che possono anche amplificare capacità offensive, soprattutto in ambito cyber.
Questo apre una fase nuova: non più rilascio pubblico e uniforme, ma accesso graduato in base alla “fiducia”. Prima il governo, poi i partner approvati, poi forse il mercato più ampio.
È comprensibile voler evitare che capacità così potenti finiscano nelle mani sbagliate. Ma il rischio è creare una licenza informale e opaca, in cui pochi soggetti decidono chi può accedere prima alla prossima generazione di strumenti AI.
Per le aziende approvate, l’accesso anticipato può diventare un vantaggio competitivo enorme. Per tutte le altre, il ritardo può significare meno capacità, meno sperimentazione, meno possibilità di stare al passo.
Questo apre anche una riflessione più ampia sulla dipendenza tecnologica: se l’accesso ai modelli più avanzati viene mediato da decisioni politiche statunitensi, chi resta fuori dai circuiti approvati rischia di muoversi con tempi e capacità diverse.
L’AI frontier non è più solo un prodotto software.
Sta diventando infrastruttura strategica.
Daybreak: la risposta di OpenAI a Glasswing
La mossa di OpenAI con Daybreak può essere letta come un chiaro posizionamento competitivo nello stesso nuovo spazio strategico aperto da Anthropic con Project Glasswing: AI frontier applicata alla cybersecurity difensiva, accesso controllato, partner selezionati, supporto all’open source e protezione delle infrastrutture critiche.
Il punto non è più soltanto trovare vulnerabilità più velocemente. Il vero terreno di competizione sta diventando la capacità di trasformare quelle scoperte in correzioni affidabili, verificabili e scalabili.
Daybreak mette insieme diversi tasselli: Codex Security per integrare scansione, validazione e generazione di patch nei workflow degli sviluppatori; GPT-5.5-Cyber per attività avanzate di cybersecurity autorizzata; il Daybreak Cyber Partner Program per portare queste capacità nei prodotti e servizi dei vendor di sicurezza; Patch the Planet per aiutare i progetti open source a passare dai report alle correzioni effettive.
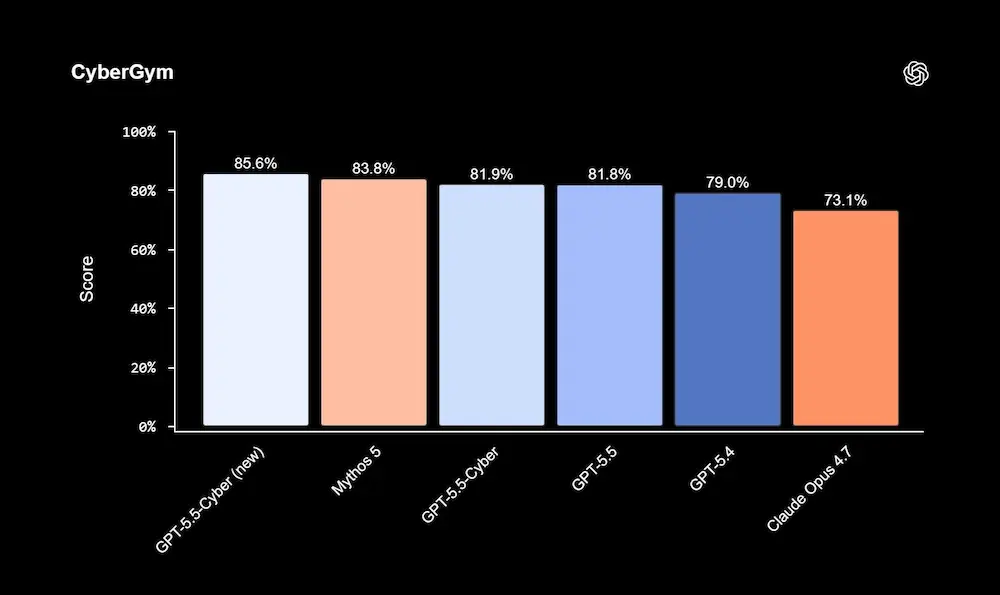
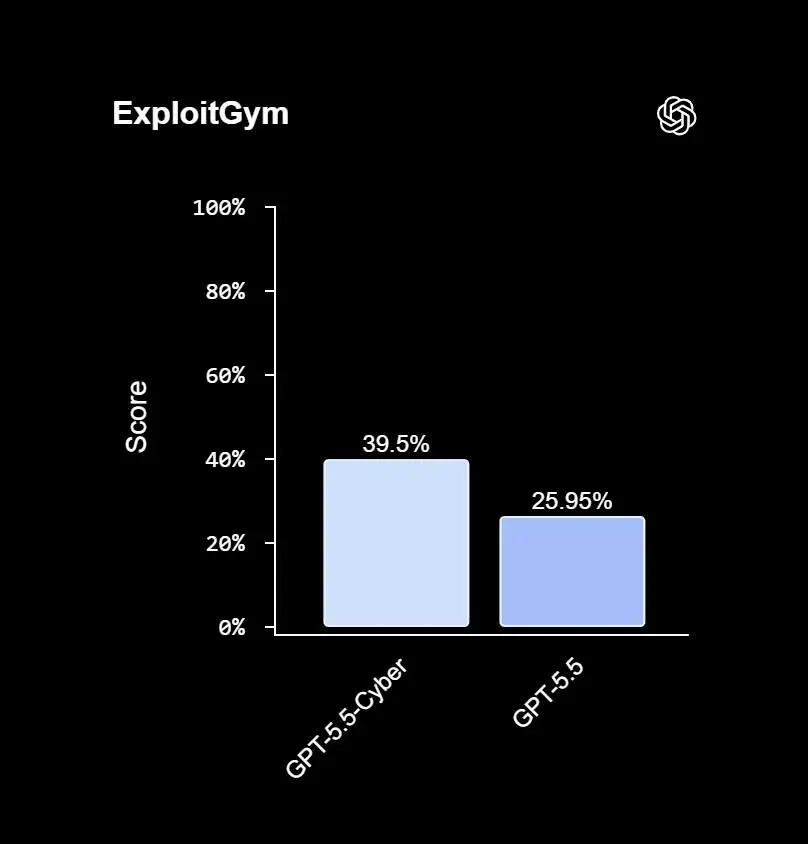
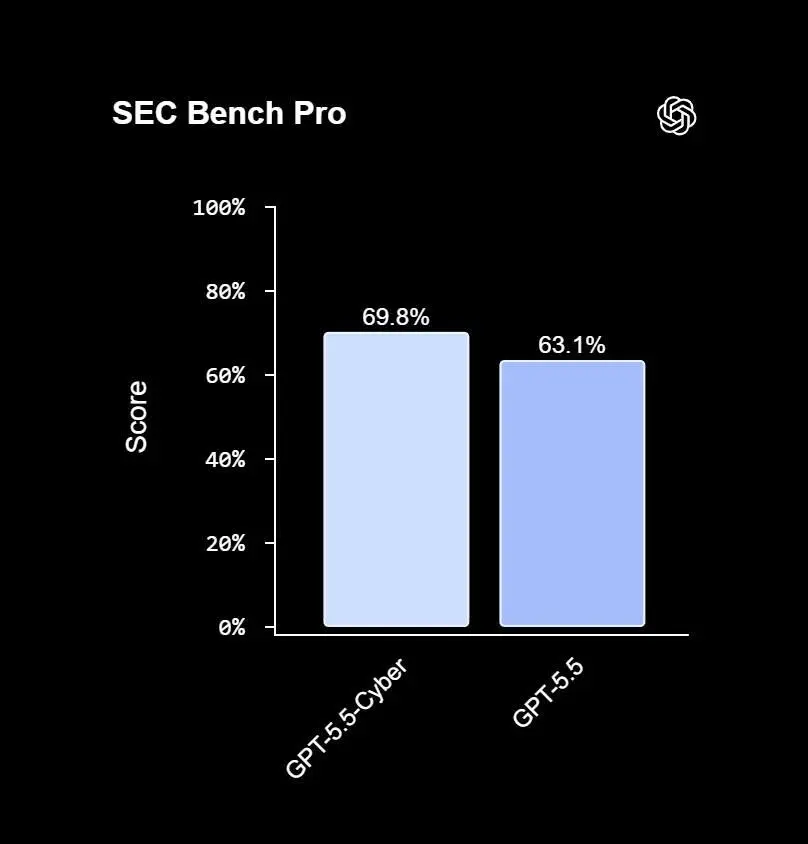
Daybreak: la risposta di OpenAI a Glasswing
La narrativa è molto vicina a quella di Anthropic: modelli frontier sempre più capaci di individuare vulnerabilità, accesso riservato a difensori verificati, collaborazione con grandi partner tecnologici e attenzione alle infrastrutture sensibili.
La differenza principale è nel posizionamento. Anthropic, con Glasswing, sembra mettere al centro la potenza del modello e la necessità di governarne l’accesso attraverso un ecosistema controllato. OpenAI, con Daybreak, sposta invece l’accento sull’industrializzazione del processo: non solo vulnerability discovery, ma patch automation, integrazione nei tool di sviluppo, validazione, remediation e deployment dentro workflow già esistenti.
In altre parole, Glasswing comunica l’urgenza di gestire modelli cyber-capable estremamente avanzati. Daybreak comunica l’ambizione di costruire una filiera operativa per convertire quelle capacità in resilienza software concreta.
È una competizione che non riguarda solo i benchmark dei modelli, ma il controllo dello stack difensivo: chi trova le vulnerabilità, chi le valida, chi genera le patch, chi le distribuisce e chi decide quali organizzazioni possono accedere a queste capacità.
Jalapeño: l’AI diventa infrastruttura
È sempre meno “solo una questione di modelli AI”. OpenAI e Broadcom hanno presentato Jalapeño, il primo chip di inferenza progettato da OpenAI: un acceleratore pensato specificamente per eseguire grandi modelli linguistici in modo più efficiente, veloce e scalabile.
Non si tratta di un chip generico adattato all’AI, ma di un componente costruito attorno alle esigenze reali dell’inferenza LLM: memoria, networking, kernel, latenza, throughput, consumo energetico e integrazione con i sistemi di serving.
Secondo OpenAI, i primi test indicano prestazioni per watt significativamente migliori rispetto allo stato dell’arte. Il chip è stato sviluppato insieme a Broadcom e Celestica, con un ciclo di progettazione molto rapido, e dovrebbe essere distribuito su scala gigawatt con Microsoft e altri partner a partire dal 2026.

Il punto interessante non è solo l’annuncio hardware. È la direzione. Google lavora da anni sulle proprie TPU, Amazon ha Trainium, Microsoft ha Maia. Ora anche OpenAI si muove verso un’infrastruttura sempre più verticale.
La competizione sull’AI non riguarda più soltanto chi ha il modello più capace. Riguarda chi riesce a servire quei modelli al costo più basso, con la latenza migliore, con più affidabilità e con sufficiente capacità computazionale.
In questo scenario, il vantaggio competitivo si sposta lungo tutta la catena: chip, data center, energia, networking, compilatori, software di serving e prodotti finali. Chi controlla più livelli dello stack può ottimizzare meglio l’economia dell’intelligenza artificiale.
Il rovescio della medaglia è che questi ecosistemi potrebbero diventare sempre più proprietari e meno interoperabili. Più efficienza, ma anche più lock-in. Più performance, ma anche più concentrazione infrastrutturale.
Jalapeño non è solo un nuovo chip. L’AI sta diventando un’industria infrastrutturale pesante, dove modelli, hardware, energia e distribuzione saranno sempre più intrecciati.
Citazioni inesistenti nella letteratura medica.. leggere oltre il titolo
Non fermiamoci ai titoli: andiamo sempre a fondo e sforziamoci di comprendere davvero prima di condividere informazioni.
InfoData / Il Sole 24 Ore ha pubblicato un articolo su un tema importante: la crescita dei riferimenti a studi inesistenti nella letteratura medica, anche in relazione all’uso dell’intelligenza artificiale.
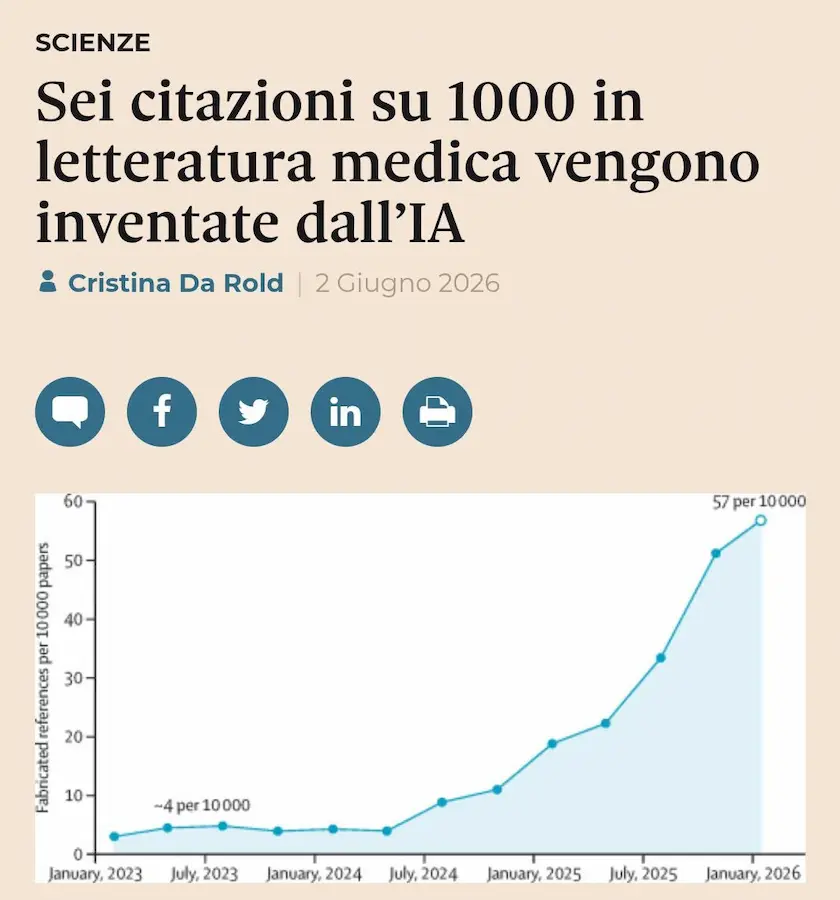
Il titolo è efficace e richiama un problema reale. Leggendo però il paper originale pubblicato su The Lancet, emergono alcune sfumature utili per interpretare meglio il dato. Lo studio non dice esattamente che 6 citazioni ogni 1.000 citazioni mediche siano inventate dall’AI. Dice invece che, nel periodo più recente analizzato, sono stati individuati circa 56,9 riferimenti a studi inesistenti ogni 10.000 paper biomedici, cioè circa 5,7 ogni 1.000 paper, non ogni 1.000 citazioni.
Sull’intero campione verificato, gli autori trovano 4.046 riferimenti a studi inesistenti su 97,1 milioni di riferimenti verificabili tramite PMID, distribuiti in 2.810 paper.
Anche il passaggio sull’AI va letto con attenzione. Il paper segnala che l’aumento coincide temporalmente con la diffusione degli LLM e considera plausibile un legame con l’uso non critico dell’AI. Ma non dimostra che ogni riferimento inesistente sia stato generato da un modello linguistico. Gli autori citano anche altre possibili cause: paper mill, misconduct e problemi nei processi editoriali.
Ci sono poi alcuni limiti metodologici da tenere presenti. Lo studio non misura tutta la letteratura biomedica, ma il sottoinsieme Open Access di PubMed Central. Esclude il 23% dei riferimenti senza PMID, quindi non copre pienamente libri, siti, report e letteratura grigia. La pipeline stima la precisione, ma non il recall: sappiamo quanto sono affidabili i casi individuati, non quanti casi siano sfuggiti. Il dato sulle prime settimane del 2026, inoltre, è ancora parziale.
Tutto questo non ridimensiona il problema. Anzi. Il paper mostra un fenomeno reale, in crescita, e difficile da intercettare con la peer review tradizionale: molti riferimenti a studi inesistenti sono plausibili, ben formattati, attribuiti ad autori reali e coerenti con il tema dell’articolo.
La lezione: un titolo può essere utile per accendere l’attenzione, ma il paper serve per capire il perimetro esatto del dato.
Nella letteratura biomedica stanno aumentando i riferimenti a studi inesistenti; l’AI può contribuire ad amplificare il fenomeno, ma non è l’unica spiegazione dimostrata; e servono controlli automatici sistematici sulle bibliografie prima della pubblicazione.
Token capital: il nuovo vantaggio competitivo
Il vero rischio dell’AI non è che sostituisca il lavoro. È che renda indistinguibile il valore delle aziende. Satya Nadella, in un post su X, racconta una visione sul futuro delle imprese nell’economia guidata dall’intelligenza artificiale.
— Satya Nadella (@satyanadella) June 14, 2026
Secondo Nadella, non siamo davanti a un semplice cambio di piattaforma tecnologica. Per la prima volta, le aziende possono creare un ciclo cognitivo reale tra persone e sistemi digitali: un loop continuo in cui il sapere umano alimenta l’AI, e l’AI, a sua volta, amplifica la capacità dell’organizzazione di imparare, decidere e costruire valore.
Il punto non è scegliere il modello migliore. Il punto è costruire un sistema proprietario di apprendimento.
Nadella distingue tra capitale umano e “token capital”. Il capitale umano è fatto di conoscenza, giudizio, relazioni, creatività, esperienza e capacità di riconoscere pattern. Il token capital è la capacità AI che un’azienda costruisce, allena e controlla nel tempo.
E qui c’è il passaggio più importante: più cresce il token capital, più diventa prezioso il capitale umano. Perché senza direzione umana, senza obiettivi ambiziosi, senza conoscenza del contesto e senza giudizio, l’AI resta solo calcolo che gira su sé stesso.
Il vantaggio competitivo non sarà quindi nei modelli generalisti, ma nei loop di apprendimento che ogni azienda saprà costruire sopra quei modelli. Workflow, conoscenza di dominio, memoria istituzionale e giudizio accumulato dovranno diventare sistemi AI capaci di migliorare con ogni utilizzo.
Questo diventa la nuova proprietà intellettuale dell’impresa. Un’azienda dovrebbe poter cambiare modello AI senza perdere la competenza interna accumulata dal proprio sistema. Se non può farlo, significa che non controlla davvero il proprio vantaggio.
Nel mio intervento all’AI Festival ho parlato proprio di questo: oltre i modelli, verso i sistemi.
AI Festival: oltre i modelli.. verso i sistemi
Nadella avverte anche di un rischio più ampio: un futuro in cui pochi grandi modelli assorbono il sapere di interi settori, trasformano la conoscenza aziendale in commodity e catturano quasi tutto il valore economico.
Sarebbe una nuova forma di svuotamento industriale, simile a quanto già visto con alcune dinamiche della globalizzazione. Per questo non serve solo costruire frontier model. Serve costruire un frontier ecosystem.
Un ecosistema in cui ogni azienda, ogni industria e ogni Paese possa possedere il proprio ciclo di apprendimento, far crescere insieme capitale umano e capitale AI, e distribuire valore in modo più ampio.
La frontiera dell’AI non sarà stabile se diventa un monopolio cognitivo. Sarà stabile solo se permette a molte organizzazioni di imparare, differenziarsi e creare valore proprio.
Sam Altman: AI, scala e istituzioni
Sam Altman, in un’intervista a Stanford, descrive l’AI come un cambio di paradigma. La sua tesi è chiara: piccoli team potranno fare ciò che prima richiedeva decine di ingegneri; la scala continuerà a generare nuove capacità; gli LLM non sono un vicolo cieco; società, economia ed educazione dovranno adattarsi.

Sono punti forti, ma da leggere con equilibrio.
- L’AI abbassa il costo di costruire startup, ma il valore non è solo produrre output: restano centrali strategia, distribuzione, fiducia, mercato e capacità di scegliere cosa non fare.
- Altman sostiene anche che alcune capacità emergano solo aumentando radicalmente le dimensioni dei sistemi. È vero in parte: la scala è una strategia, non una teoria completa dell’intelligenza. Porta capacità nuove, ma anche opacità, costi e dipendenza infrastrutturale.
- La nascita di ChatGPT resta una lezione di prodotto: osservare l’uso reale. Gli utenti usavano GPT-3 anche solo per conversare. Ma non basta seguire gli utenti: servivano anche un modello maturo, un’interfaccia semplice e una promessa chiara.
- Altman respinge l’idea che gli LLM siano un vicolo cieco. Comprensibile: molti progressi hanno smentito previsioni pessimistiche. Ma tra “non servono” e “basta scalare” c’è una via intermedia: gli LLM possono essere fondamentali per l’AGI senza essere sufficienti da soli.
- Anche la democratizzazione va guardata con attenzione. Dare accesso a milioni di persone non significa automaticamente distribuire potere. Se pochi attori controllano modelli, compute, dati, policy e prezzi, la concentrazione resta.
- Sul piano economico, il fondo di ricchezza dei cittadini è un’idea interessante. Ma il punto chiave resta capire chi possiede il capitale produttivo, chi cattura le rendite e quali istituzioni governano la transizione.
- Il compute diventerà sempre più strategico, ma non è qualcosa di astratto: significa chip, data center, energia, supply chain, permessi e geopolitica. Se il compute resta concentrato, anche l’intelligenza avanzata rischia di esserlo.
- Infine, Altman coglie un rischio reale sull’educazione: valutare gli studenti come prima può indebolire il pensiero critico. Ma il pensiero critico nasce anche da scrittura, matematica, memoria, programmazione e argomentazione. Non tutte le frizioni sono inefficienze. Alcune formano la mente.
La sintesi: Altman coglie la traiettoria tecnologica. Ma la parte più difficile non sarà creare modelli più potenti. Sarà costruire istituzioni e competenze adeguate a quella potenza.
AI, data center e private markets
La crescita dell’AI non è solo una storia di software: è una gigantesca storia di infrastrutture fisiche, immobili, energia e finanza privata. Dietro modelli generativi, cloud, agenti AI e automazione c’è una macchina concreta: data center, server, chip, reti, edifici, raffreddamento ed elettricità.
Goldman Sachs sostiene che questo fabbisogno di capitale crescerà molto. Secondo le sue stime, gli hyperscaler potrebbero spendere circa 5.300 miliardi di dollari tra il 2025 e il 2030 per AI e data center.
Una cifra così grande difficilmente potrà essere finanziata solo con i canali tradizionali. Se le stesse Big Tech emettono sempre più obbligazioni, alcuni investitori potrebbero diventare troppo esposti agli stessi emittenti. Per questo Goldman Sachs prevede un ruolo crescente dei mercati privati, soprattutto fondi infrastrutturali e immobiliari, capaci di finanziare terreni, edifici, reti, energia, infrastrutture digitali e data center.


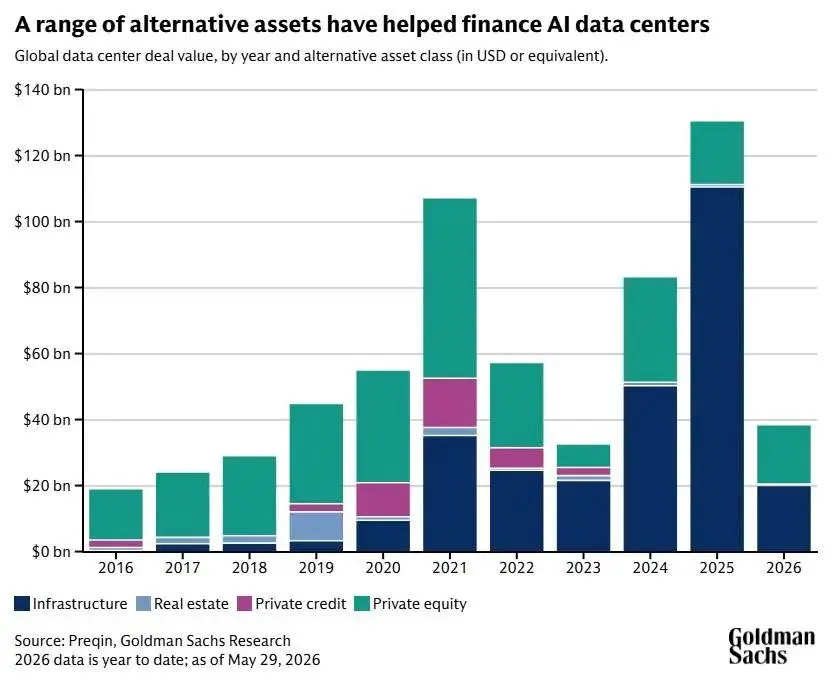
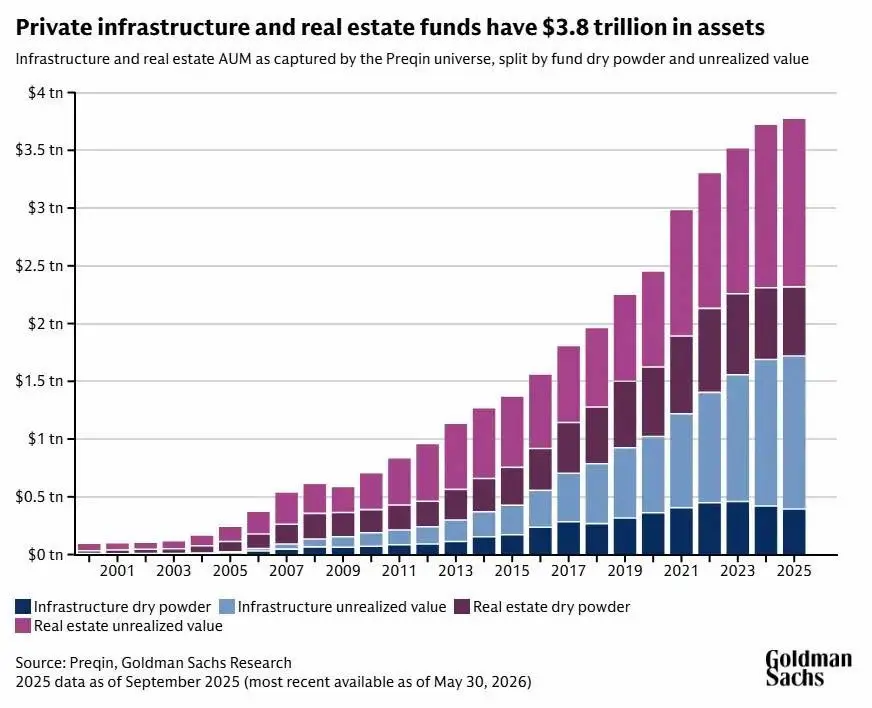
AI, data center e private markets
La tesi è plausibile. L’AI non cresce nel vuoto: ha bisogno di una base fisica enorme. Per le Big Tech può essere più efficiente appoggiarsi a investitori privati che costruiscono e finanziano infrastrutture usate con contratti di lungo periodo.
Per i fondi, il tema è attraente: un data center ben posizionato, con energia disponibile, clienti solidi e contratti lunghi, può generare flussi prevedibili. Non è solo tecnologia: assomiglia sempre più a un asset infrastrutturale.
Ma ci sono rischi importanti. Il primo è l’eccesso di entusiasmo. Se il mercato crede che serviranno “infiniti data center”, il capitale corre veloce. Ma se la domanda AI crescesse meno del previsto, o i modelli diventassero più efficienti, alcuni progetti potrebbero risultare sovradimensionati.
Il secondo rischio è l’energia. Il vero collo di bottiglia potrebbe non essere il capitale, ma la disponibilità di elettricità, connessioni alla rete, permessi, raffreddamento e sostenibilità operativa.
Il terzo è la qualità degli asset. Non tutti i data center sono uguali. Quelli nelle location giuste, con energia sicura e clienti affidabili, possono essere interessanti. Quelli sviluppati troppo tardi, in aree sbagliate o con ipotesi troppo ottimistiche, possono diventare fragili.
I private markets avranno quindi un ruolo enorme nella costruzione dell’infrastruttura AI. Ma la differenza la farà la selezione. Perché l’AI può sembrare immateriale, ma la sua crescita dipenderà sempre più da cose materiali: capitale, cemento, energia e capacità esecutiva.
Trasparenza dei contenuti AI: le zone grigie del Codice UE
La Commissione Europea ha pubblicato il Code of Practice on Transparency of AI-Generated Content, collegato agli obblighi di trasparenza dell’AI Act. Il documento prova a costruire una cornice operativa per rendere più riconoscibili i contenuti generati o manipolati con l’AI.
Da un lato, chiede ai provider di sistemi di AI generativa di marcare gli output in formato machine-readable, con metadati firmati digitalmente, watermark impercettibili e strumenti di detection. Dall’altro, prevede che chi pubblica o diffonde contenuti AI, come deep fake o testi generati su questioni di interesse pubblico, li segnali in modo chiaro, distinguibile e accessibile.

L’impianto è interessante perché non riduce la trasparenza a un semplice disclaimer: la tratta come un sistema fatto di standard tecnici, UX, accessibilità, testing e cooperazione tra provider, piattaforme, media, ricercatori e autorità.
Uno dei punti più problematici, però, riguarda la classificazione concreta dei contenuti. Il documento distingue tra contenuti AI-generated, AI-manipulated, deep fake, testi pubblicati per informare il pubblico, contenuti revisionati da esseri umani e contenuti con responsabilità editoriale. Sul piano normativo la distinzione è comprensibile. Sul piano pratico, molto meno.
Pensiamo a un articolo scritto da una persona, ma riorganizzato da un modello AI. A una foto reale con solo lo sfondo modificato. A un video autentico con audio sintetico. A un testo generato da AI ma revisionato da un editor umano.
In questi casi, cosa va etichettato? Il contenuto nel suo complesso? Solo la parte modificata? Serve una label generica o una descrizione più precisa dell’intervento? Quando la revisione umana è sufficiente a far venir meno l’obbligo di disclosure?
Il rischio è che la trasparenza diventi binaria proprio dove la produzione dei contenuti è sempre più ibrida. Dire “questo contenuto è generato da AI” può essere troppo vago. Dire “assistito, modificato o parzialmente generato con AI” può essere più corretto, ma anche più difficile da standardizzare.
La criticità, quindi, non è solo tecnica. È semantica, editoriale e organizzativa. Prima ancora di applicare una label bisogna decidere che cosa si sta etichettando, quale grado di intervento AI è rilevante e chi ne ha la responsabilità.
Il Codice è un buon passo verso una maggiore accountability, ma la sua efficacia dipenderà dalla capacità di gestire queste zone grigie senza trasformare la trasparenza in un adempimento formale.
Co-Scientist: l’AI multi-agente per la ricerca scientifica
Google DeepMind ha presentato Co-Scientist, un sistema di AI multi-agente basato su Gemini progettato per supportare i ricercatori nella generazione e nell’evoluzione di nuove ipotesi scientifiche.
A differenza dei tradizionali strumenti di AI, Co-Scientist simula un processo di ricerca collaborativo: diversi agenti specializzati generano idee, le sottopongono a revisione critica, le mettono a confronto in dibattiti strutturati e le perfezionano progressivamente fino a formulare proposte di ricerca più solide e promettenti.

Il sistema integra fonti scientifiche, database specializzati e strumenti avanzati di analisi per verificare la coerenza delle ipotesi e ridurre il rischio di errori o conclusioni poco fondate.
Le prime applicazioni mostrano risultati interessanti in ambiti come la fibrosi epatica, la SLA, le malattie infettive emergenti e la ricerca sull’invecchiamento. In diversi casi, Co-Scientist ha contribuito a identificare nuovi meccanismi biologici, possibili strategie terapeutiche e direzioni di ricerca successivamente validate in laboratorio.
L’obiettivo non è sostituire il lavoro degli scienziati, ma amplificarne la capacità di analizzare conoscenze esistenti, individuare connessioni non evidenti e accelerare il percorso che porta da un’intuizione a una scoperta scientifica.
Qwen 3.7 Pro: il nuovo modello multimodale di Alibaba
Alibaba ha rilasciato Qwen 3.7 Pro, un modello multimodale progettato per unire comprensione visiva, ragionamento linguistico e capacità agentiche in un’unica architettura.
L’ho provato su un task che richiede l’uso di tool, con molte istruzioni dettagliate e la generazione di un output preciso e strutturato. Non sfigura minimamente a confronto con i modelli competitor di punta. Però costa 1/5 di Gemini 3.5 Flash, 1/15 rispetto a Claude 4.8 e 1/18 rispetto a GPT-5.5.
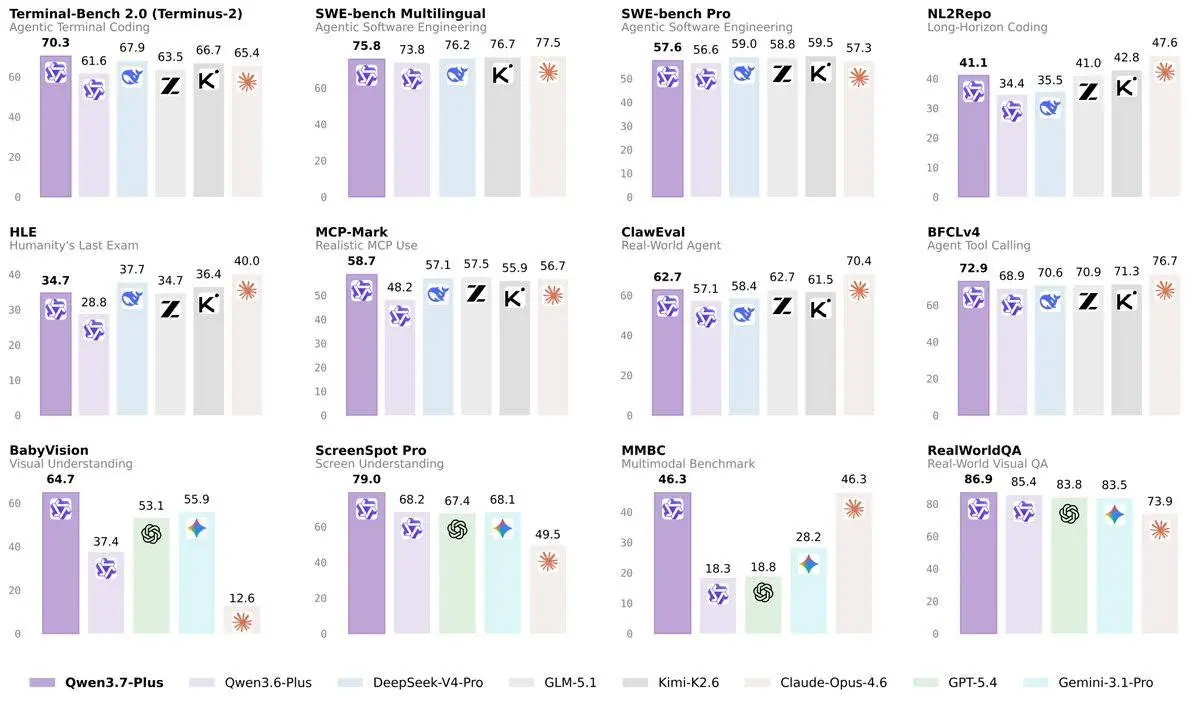
La novità principale è l’approccio da “multimodal interactive hybrid agent”: il modello può analizzare immagini e video, leggere schermate, interagire con interfacce grafiche, utilizzare strumenti da terminale e generare codice all’interno dello stesso flusso operativo.
Secondo i benchmark condivisi da Alibaba, Qwen 3.7 Pro mostra prestazioni competitive in sviluppo software, utilizzo di strumenti, pianificazione multi-step, ragionamento STEM e attività multimodali. I miglioramenti più evidenti riguardano la comprensione delle interfacce, il ragionamento visivo, l’analisi documentale, l’OCR e la generazione di codice a partire da riferimenti grafici.
Tra le capacità evidenziate figurano la trasformazione di immagini, screenshot e video in codice eseguibile, la generazione di SVG e pagine web complete, l’automazione di workflow software complessi e l’esecuzione di attività che combinano GUI e CLI.
Alibaba mostra anche alcuni casi d’uso avanzati, tra cui lo sviluppo autonomo di un’applicazione con generazione di oltre 10.000 linee di codice e la ricostruzione di un’app desktop partendo dall’analisi dell’interfaccia originale fino alla validazione finale delle funzionalità.
Il modello supporta inoltre scenari di ricerca multimodale, combinando contenuti visivi e informazioni recuperate dal web per rispondere a domande che richiedono sia comprensione delle immagini sia conoscenza esterna aggiornata.
Kimi K2.7 Code: focus sul coding agentico
Kimi K2.7 Code è il nuovo modello open-source di Moonshot AI pensato per il coding agentico e per attività di sviluppo software complesse e di lunga durata. Rispetto a Kimi K2.6, introduce miglioramenti significativi nei benchmark di coding e nelle attività agentiche, con performance superiori su Kimi Code Bench v2, Program Bench, MLS Bench Lite, MCP Atlas e MCP Mark Verified.
Uno degli aspetti più interessanti è l’ottimizzazione per i workflow long-horizon: refactoring su più file, debugging esteso, implementazione di feature articolate e sessioni di sviluppo in cui il modello deve mantenere coerenza e seguire le istruzioni nel tempo.
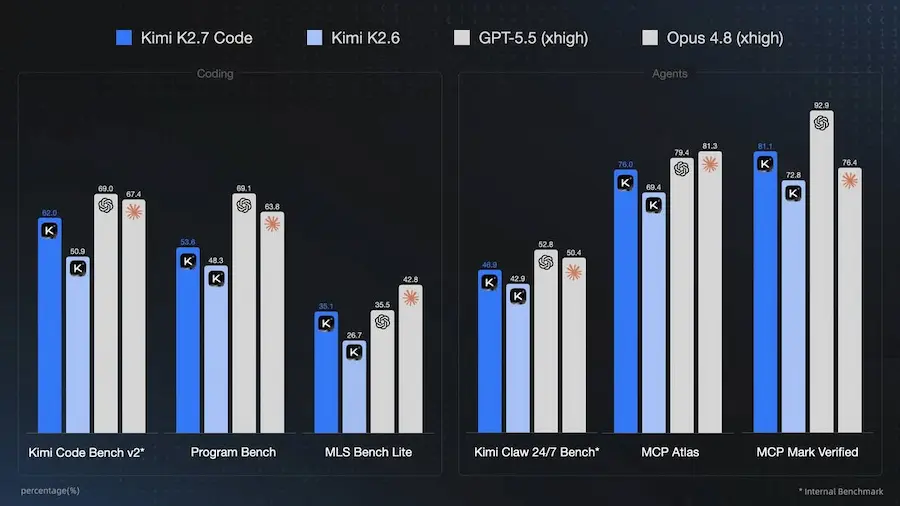
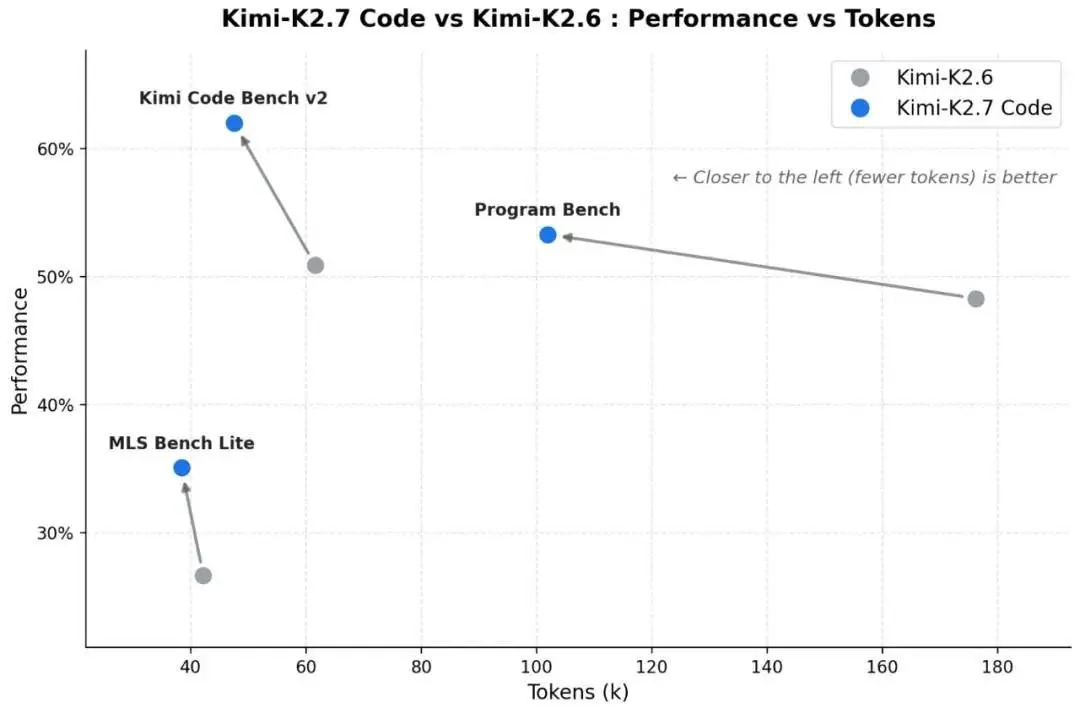
Kimi K2.7 Code: focus sul coding agentico
Il modello riduce inoltre di circa il 30% l’uso dei thinking token rispetto a K2.6, migliorando efficienza, velocità e costi di utilizzo nelle interazioni via API o nei flussi agentici.
Dal punto di vista architetturale, Kimi K2.7 Code usa una struttura Mixture-of-Experts con 1 trilione di parametri totali, 32 miliardi di parametri attivati per token, finestra di contesto da 256K token, attenzione MLA e supporto multimodale tramite MoonViT.
È disponibile tramite Kimi Code e Kimi API, con thinking mode sempre attivo. Per attività generali come scrittura, analisi e conversazione, Moonshot AI continua invece a indicare Kimi K2.6 come opzione più bilanciata.
Un modello specializzato che conferma una direzione sempre più chiara: l’evoluzione degli LLM non passa solo dalla qualità del singolo output, ma dalla capacità di completare workflow software lunghi, coerenti e realmente operativi.
Quando l’AI scrive il “codice dell’AI”
Quando oltre l’80% del codice che entra in produzione viene scritto da un’AI, non stiamo più parlando di assistenza alla programmazione: stiamo parlando di un cambiamento nel modo in cui l’AI viene sviluppata.
Nel nuovo approfondimento dell’Anthropic Institute emerge un dato significativo: a maggio 2026, più dell’80% del codice integrato nei sistemi di produzione di Anthropic è stato attribuito a Claude. Solo un anno prima, il contributo dell’IA era ancora marginale.
Secondo i dati condivisi dall’azienda, gli ingegneri producono oggi circa 8 volte più codice rispetto al 2024 grazie all’utilizzo di agenti sempre più autonomi, capaci non solo di suggerire codice, ma di scriverlo, eseguirlo, testarlo e modificarlo in autonomia.
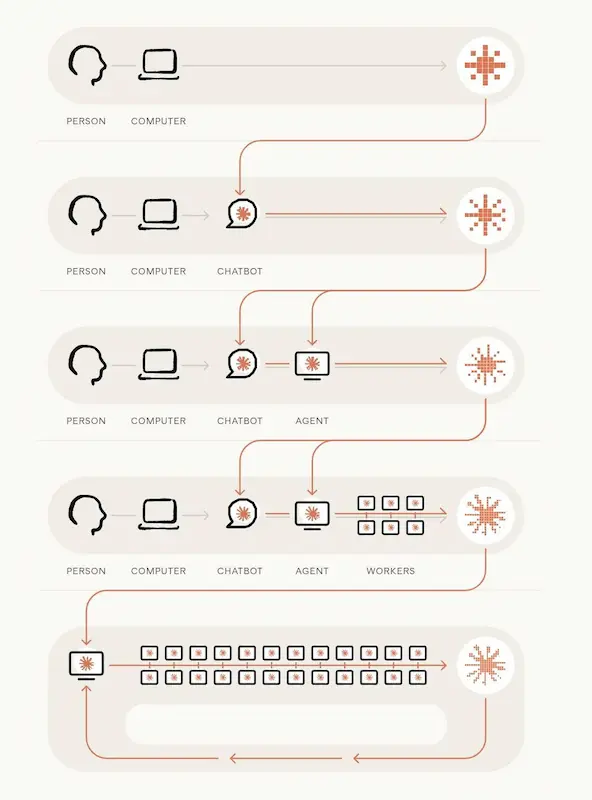
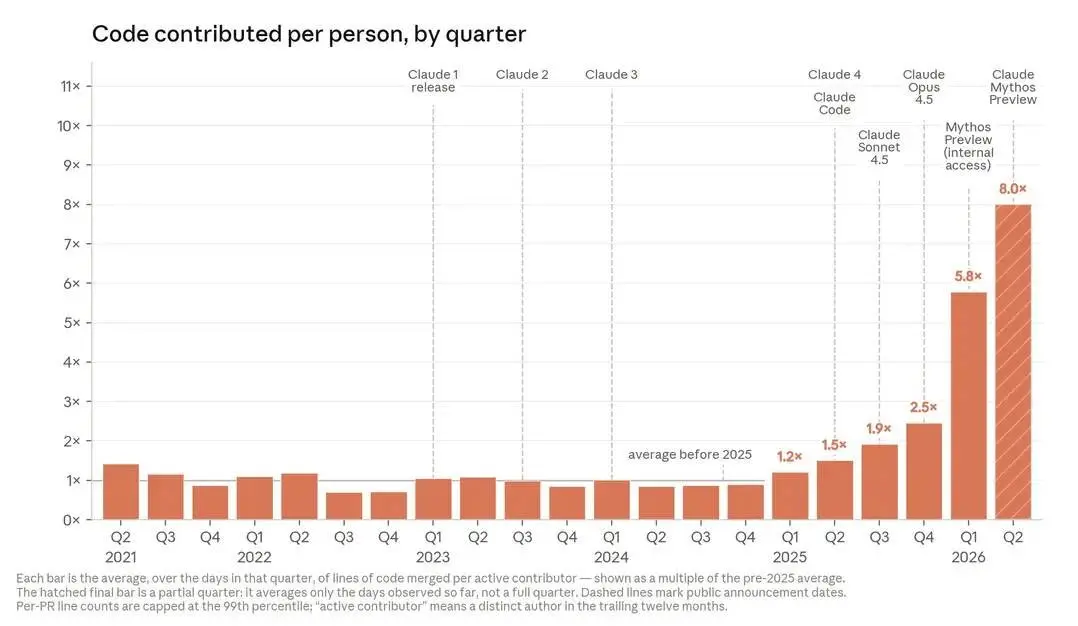
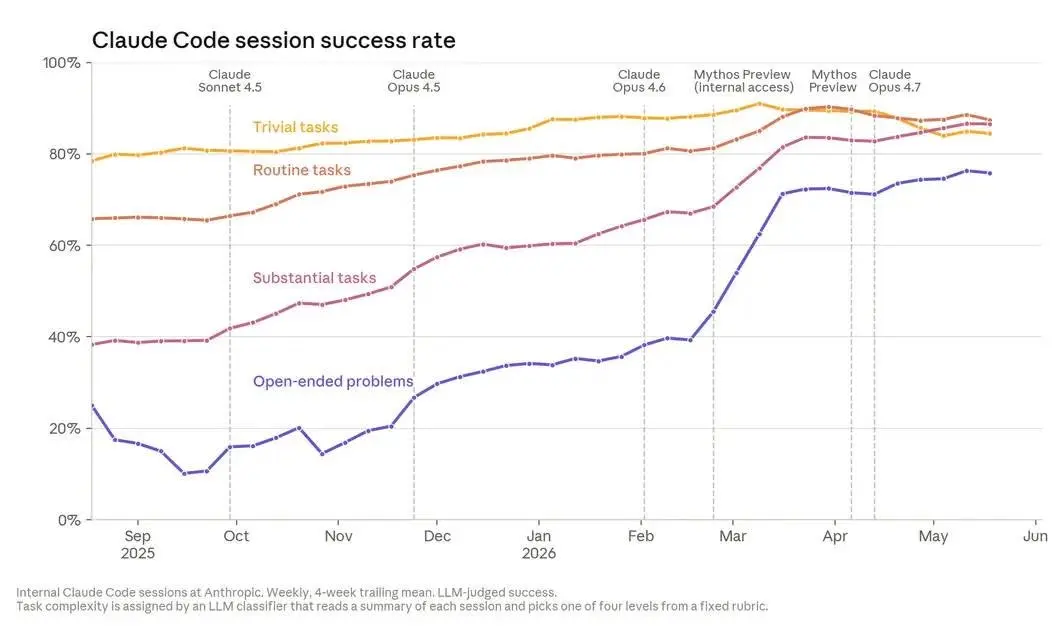
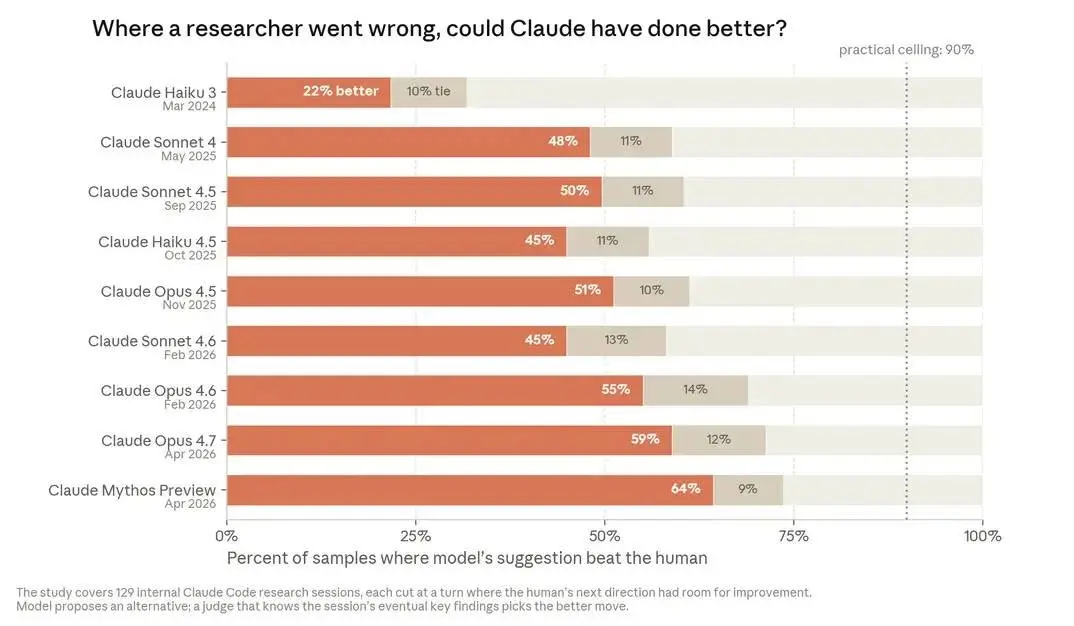
Quando l’AI scrive il “codice dell’AI”
L’aspetto più interessante non è però la quantità di codice generata. È il progressivo spostamento del ruolo umano: dalla scrittura all’indirizzo strategico, dalla produzione alla supervisione. Nello sviluppo software e nella ricerca, il vero valore aggiunto delle persone sembra concentrarsi sempre più nella scelta dei problemi da affrontare, nella valutazione dei risultati e nella definizione delle priorità.
Anthropic descrive una traiettoria in cui l’IA accelera lo sviluppo dell’IA stessa. Oggi gli esseri umani definiscono ancora gli obiettivi e prendono le decisioni più importanti. Ma una quota crescente del lavoro operativo viene delegata ai modelli.
L’ipotesi che l’articolo esplora è quella del recursive self-improvement: sistemi capaci, un giorno, di contribuire direttamente alla progettazione e allo sviluppo delle proprie versioni successive.
Non è una realtà attuale e non è un esito inevitabile. Ma i dati mostrano che il confine tra strumenti che aiutano gli sviluppatori e sistemi che partecipano attivamente allo sviluppo dell’intelligenza artificiale si sta spostando molto più rapidamente di quanto molti si aspettassero.
Dal vibe coding all’agentic engineering
Google ha pubblicato un whitepaper su come l’AI sta cambiando il ciclo di vita dello sviluppo software: dal vibe coding all’agentic engineering.
Il punto centrale è che lo sviluppo software si sta spostando dalla scrittura manuale del codice all’espressione dell’intento. Il developer non dice più soltanto “come” costruire qualcosa, ma definisce “cosa” deve essere costruito, quali vincoli rispettare, quali test superare e quale qualità raggiungere. L’AI diventa il motore di implementazione; l’essere umano resta responsabile di architettura, giudizio, contesto e verifica.
Il whitepaper distingue bene tra vibe coding e agentic engineering. Il vibe coding è utile per prototipi, script, esperimenti e progetti personali: si descrive ciò che si vuole ottenere, si accetta l’output dell’AI e si corregge iterando con nuovi prompt.

L’agentic engineering è un’altra cosa: specifiche chiare, contesto strutturato, test automatizzati, eval, guardrail, CI/CD, osservabilità e revisione umana. Non è l’uso dell’AI a fare la differenza, ma il sistema di controllo costruito intorno all’AI.
Uno dei concetti più importanti è la context engineering. La qualità del codice generato non dipende solo dal prompt, ma dal contesto che l’agente riceve: istruzioni, documentazione, memoria, esempi, strumenti disponibili e vincoli. In pratica, l’AI lavora meglio quando riceve lo stesso tipo di informazioni che servirebbero a un nuovo membro del team per contribuire in modo efficace.
Il ruolo del developer cambia di conseguenza. A volte diventa conductor: guida l’AI in tempo reale, rivede ogni passaggio e lavora dentro l’IDE. Altre volte diventa orchestrator: definisce obiettivi, delega task ad agenti, lascia che lavorino in background e valuta il risultato finale.
Il codice non è più sempre l’output diretto dello sviluppatore. Sempre più spesso, l’output è il sistema che produce codice: specifiche, agenti, test, quality gate, feedback loop e guardrail.
Il messaggio più forte del documento è questo: la generazione del codice sta diventando la parte più facile. La vera competenza si sposta su verifica, giudizio, architettura, direzione e capacità di progettare sistemi affidabili intorno all’AI.
In altre parole, l’AI non elimina il valore dello sviluppatore. Lo sposta più in alto.
Agentic Engineering: la ristrutturazione della software engineering
Il paper “The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm” sostiene una tesi forte: gli agenti AI non sono solo un acceleratore per scrivere codice, ma l’inizio di un nuovo paradigma.
Per oltre cinquant’anni, la software engineering si è basata su un modello chiaro: gli esseri umani analizzano problemi, li scompongono, trasformano la logica in codice e mantengono quel codice nel tempo. Gli agenti AI potrebbero spostare il centro di questo modello.

Non usano il codice come prodotto finale, ma come strumento temporaneo: comprendono un obiettivo, pianificano i passaggi, generano codice quando serve, lo eseguono, validano i risultati e poi lo scartano. Il passaggio è da AI → Software → Risultato a Agent → Risultato.
Nel primo caso, l’AI aiuta gli sviluppatori a costruire software più velocemente. Nel secondo, l’agente diventa il sistema operativo dell’esecuzione: interpreta l’intento, coordina strumenti, gestisce memoria, invoca API e produce output.
Il paper chiama questa nuova disciplina Agentic Engineering. Non significa semplicemente “programmare con l’AI”, ma progettare sistemi in cui agenti diversi collaborano, condividono contesto, assumono ruoli specializzati, vengono osservati, valutati e corretti.
Anche il ruolo umano cambia. Il valore non sta più solo nello scrivere codice corretto, ma nel definire intenti chiari, vincoli, criteri di qualità, architetture di coordinamento e meccanismi di verifica.
Lo sviluppatore diventa sempre meno autore diretto di codice e sempre più architetto di intenzioni, orchestratore di agenti e auditor dei risultati.
Il paper non ignora i limiti attuali: gli agenti funzionano bene su task isolati, ma faticano ancora nella manutenzione continua, perdono contesto, propagano errori e possono superare i test introducendo difetti semantici.
Quindi no: non siamo davanti a una sostituzione della software engineering, ma a una sua ristrutturazione profonda. Il codice non scompare. Cambia posizione nella catena del valore: da prodotto centrale diventa materiale operativo, da oggetto da mantenere diventa risorsa generata al bisogno.
La nuova frontiera sembra essere questa: progettare, governare e verificare sistemi capaci di trasformare direttamente un’intenzione in un risultato.
Gemini 3.5 Live Translate: traduzioni vocali in tempo quasi reale
Google ha annunciato Gemini 3.5 Live Translate, il nuovo modello audio per la traduzione vocale in tempo quasi reale tra oltre 70 lingue. L’ho provato su AI Studio e il risultato è sorprendente.
La novità principale è la capacità di tradurre direttamente da voce a voce, mantenendo elementi naturali della comunicazione come intonazione, ritmo e tono del parlato. A differenza dei tradizionali sistemi che attendono la fine di una frase prima di tradurre, Gemini 3.5 Live Translate genera la traduzione in modo continuo, riducendo le pause e mantenendo la conversazione sincronizzata con pochi secondi di ritardo.
Gemini 3.5 Live Translate: traduzioni vocali in tempo quasi reale
La tecnologia è disponibile in anteprima pubblica per gli sviluppatori tramite Gemini Live API e Google AI Studio, consentendo la realizzazione di applicazioni per interpretazione simultanea, riunioni multilingue, formazione ed eventi live.
Anche Google Meet integrerà il modello, portando il supporto a oltre 70 lingue e più di 2.000 combinazioni linguistiche all’interno delle videoconferenze. Parallelamente, la funzionalità viene distribuita nell’app Google Translate per Android e iOS, con una nuova modalità di ascolto su Android che permette di ricevere le traduzioni direttamente dall’altoparlante auricolare del telefono.
Google ha inoltre confermato che tutti gli audio generati dal modello sono contrassegnati tramite SynthID, il sistema di watermarking invisibile sviluppato per identificare i contenuti creati dall’intelligenza artificiale e contribuire a contrastare la disinformazione.
Headroom: comprimere il contesto degli agenti AI
Gli agenti AI leggono sempre più contesto: output di tool, log, risultati RAG, file, cronologie di conversazione e frammenti di codice. Il problema è che tutto questo contesto ha un costo: più token, più latenza, più rumore e più complessità nel mantenere risposte precise.
Headroom è un progetto molto interessante, nato per comprimere ciò che arriva al modello prima che venga elaborato, con un approccio local-first e reversibile. Riduce il numero di token mantenendo la possibilità di recuperare gli originali quando servono.
Può funzionare come libreria Python o TypeScript, proxy locale, wrapper per agenti come Claude Code, Codex, Cursor, Aider e Copilot CLI, oppure come server MCP.
Headroom: comprimere il contesto degli agenti AI
La pipeline riconosce il tipo di contenuto e applica compressori diversi per JSON, codice e testo. Integra anche memoria condivisa tra agenti, deduplicazione automatica e strumenti per apprendere dalle sessioni fallite.
Nei benchmark riportati, i risparmi arrivano fino al 92% su attività come code search e debugging SRE, mantenendo l’accuratezza su test standard come GSM8K, TruthfulQA, SQuAD v2 e BFCL.
Un aspetto interessante è che non lavora solo sull’input: può ridurre anche i token di output, tagliando preamboli, ripetizioni e risposte inutilmente lunghe nei passaggi routinari.
È una soluzione pensata per chi usa agenti AI in modo intensivo e vuole ridurre costi e consumo di contesto senza rinunciare alla possibilità di recuperare i dati originali.
Crawl4AI: web scraping ottimizzato per LLM e agenti AI
Crawl4AI è uno dei progetti open source più interessanti nel mondo AI e web scraping. L’ho provato, e la funzionalità di Fit Markdown è davvero interessante: su pagine semplici praticamente non agisce, mentre su pagine più “rumorose” riduce moltissimo il Markdown, in modo intelligente.
L’idea alla base del progetto è trasformare il web in contenuti puliti e strutturati, pronti per essere utilizzati da LLM, pipeline RAG e agenti AI.
Crawl4AI genera Markdown ottimizzato per LLM, estrae dati strutturati in JSON, filtra semanticamente i contenuti, supporta il deep crawling intelligente e gestisce pagine dinamiche basate su JavaScript.
Dal punto di vista tecnico, combina Playwright, browser automation, strategie di extraction avanzate e integrazione con modelli LLM.
Le funzionalità più interessanti sono Fit Markdown per ottenere contenuti più adatti all’elaborazione AI, BM25 filtering per ridurre il rumore, estrazione tramite CSS, XPath o LLM, gestione anti-bot, browser stealth, supporto a Shadow DOM, iframe, lazy loading e infinite scroll.
Per chi lavora su AI agents, document intelligence, retrieval systems o data pipelines, è un progetto da osservare con attenzione.
TurboVec: ricerca semantica più leggera
TurboVec è un indice vettoriale open source costruito sull’algoritmo TurboQuant, sviluppato da Google Research. Serve a comprimere gli embedding in modo molto efficiente, riducendo il consumo di memoria senza rinunciare alla qualità della ricerca semantica.
Secondo i benchmark del progetto, offre prestazioni competitive rispetto a FAISS, uno degli strumenti più usati per la ricerca vettoriale.

Uno degli aspetti più interessanti di TurboQuant è che non richiede una fase di training dedicata. I vettori possono essere aggiunti direttamente all’indice e diventano subito ricercabili. Questo lo rende adatto a sistemi in cui i dati crescono nel tempo e devono essere aggiornati continuamente.
Dal punto di vista tecnico, TurboQuant normalizza i vettori, applica una rotazione casuale dello spazio e usa una quantizzazione ottimizzata per rappresentare gli embedding con molti meno bit. In questo modo, un grande archivio di vettori può occupare molta meno memoria rispetto alla rappresentazione classica in float32.
Un esempio semplice è un’applicazione RAG che deve cercare informazioni dentro una grande base documentale. Ogni documento viene trasformato in embedding e salvato nell’indice. Quando l’utente fa una domanda, il sistema cerca i contenuti semanticamente più vicini e li passa al modello linguistico per generare la risposta.
Con TurboVec, la stessa applicazione può gestire più documenti usando meno memoria. Inoltre, i nuovi contenuti possono essere aggiunti progressivamente senza dover ricostruire l’intero indice.
Il vantaggio pratico è una ricerca semantica più leggera da eseguire, più semplice da aggiornare e adatta anche a scenari locali o infrastrutture con risorse limitate.
Fusion: il multi-agente in una chiamata API
OpenRouter ha presentato Fusion, un sistema che combina le risposte di più modelli e le fa sintetizzare da un modello giudice. Nei test su DRACO, benchmark pensato per task di deep research, i panel di modelli hanno superato sistematicamente i modelli individuali. In alcuni casi, anche combinazioni di modelli più economici sono riuscite ad avvicinarsi o superare modelli frontier usati singolarmente.

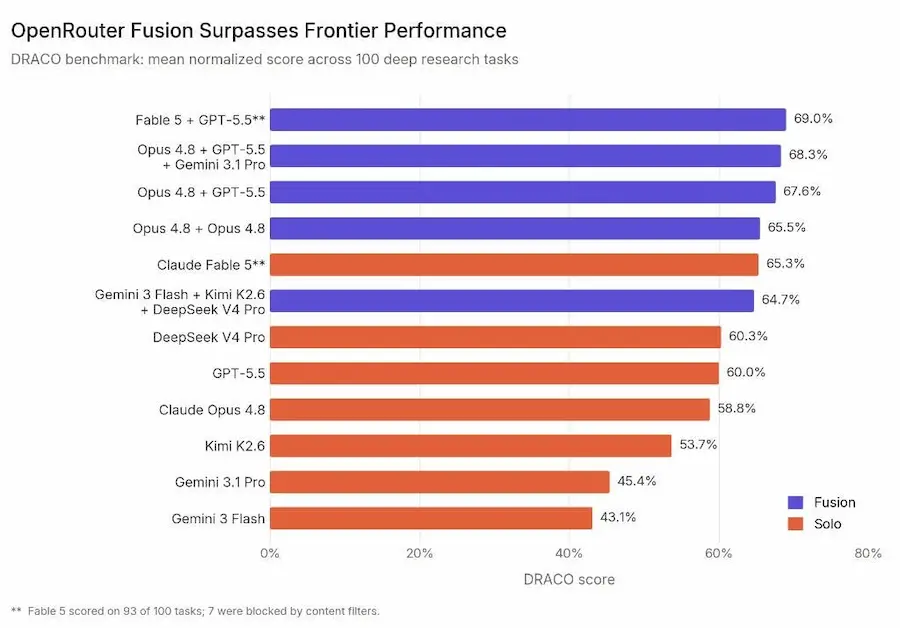
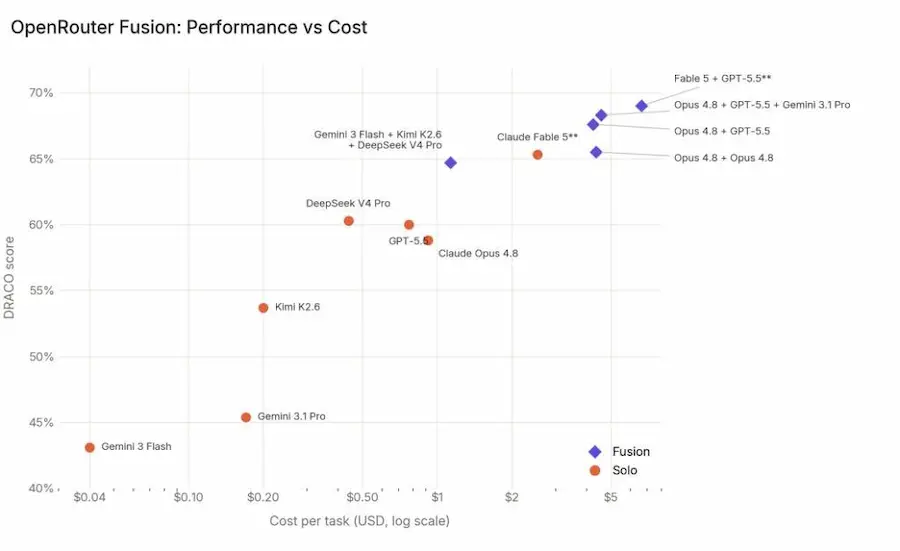
Fusion di OpenRouter
La dinamica è chiara: più modelli lavorano in parallelo, producono risposte diverse, usano percorsi di ragionamento e fonti differenti, poi un modello sintetizzatore confronta consenso, contraddizioni, lacune e insight unici per generare una risposta finale.
Però, a mio avviso, la parte davvero interessante non è questa dinamica in sé. È una configurazione piuttosto nota nei sistemi multi-agente: più agenti o modelli che esplorano soluzioni diverse, seguiti da un agente che valuta, aggrega o sintetizza.
La parte interessante è che OpenRouter sta impacchettando tutto questo in un’unica chiamata API. Questo cambia il livello di astrazione: non serve più orchestrare manualmente routing, parallelizzazione, gestione delle risposte, confronto, sintesi e fallback. Si passa da una logica applicativa multi-step a una primitiva direttamente invocabile.
In pratica, non è solo “più modelli battono un modello”. È il fatto che un pattern multi-agente relativamente complesso diventa accessibile come se fosse un singolo modello.
DiffusionGemma: testo generato in parallelo
Google ha presentato DiffusionGemma, un nuovo modello open source sperimentale che esplora un approccio diverso alla generazione del testo: invece di produrre contenuti token dopo token, genera e raffina interi blocchi di testo in parallelo.
Basato sulla famiglia Gemma 4 e sulle ricerche di Google nel campo della diffusione applicata al linguaggio, DiffusionGemma promette velocità di inferenza fino a 4 volte superiori rispetto ai modelli autoregressivi tradizionali, superando i 1.000 token al secondo su hardware dedicato di fascia alta.

Il modello utilizza un’architettura Mixture of Experts da 26 miliardi di parametri, ma ne attiva soltanto 3,8 miliardi durante l’inferenza, rendendolo eseguibile anche su GPU consumer avanzate.
Uno degli aspetti più interessanti è l’uso dell’attenzione bidirezionale, che permette a ogni token di considerare l’intero contesto durante la generazione. Questo approccio risulta particolarmente utile per attività come editing in linea, completamento di codice, strutture matematiche e altri problemi in cui le dipendenze non seguono una semplice sequenza da sinistra a destra.
La generazione avviene attraverso un processo iterativo: il modello parte da una sequenza iniziale di token casuali e la migliora progressivamente fino a ottenere un risultato coerente, in modo simile a quanto avviene nei modelli di diffusione per immagini.
Google precisa che DiffusionGemma non è pensato per sostituire i modelli Gemma 4 nelle applicazioni che richiedono la massima qualità del testo. L’obiettivo è offrire una nuova opzione per scenari in cui velocità di risposta, interattività ed esecuzione locale rappresentano fattori prioritari.
Google presenta il RAG multi-agente per Gemini Enterprise
Google ha presentato una nuova evoluzione del paradigma RAG (Retrieval-Augmented Generation) all’interno della Gemini Enterprise Agent Platform: un’architettura multi-agente progettata per gestire domande complesse che richiedono informazioni distribuite su più fonti.
Il limite dei sistemi RAG tradizionali è noto: recuperano informazioni in un singolo passaggio e generano una risposta. Quando però i dati sono frammentati tra database diversi o richiedono ragionamenti a più passaggi, il rischio è ottenere risposte incomplete o con informazioni mancanti.
Google presenta il RAG multi-agente per Gemini Enterprise
L’approccio introdotto da Google aggiunge diversi agenti specializzati che collaborano tra loro: alcuni pianificano il percorso di ricerca, altri riscrivono le query in modo più efficace, altri ancora interrogano contemporaneamente più sorgenti informative.
L’elemento più interessante è il nuovo Sufficient Context Agent, un componente che verifica se il sistema dispone davvero di tutte le informazioni necessarie prima di produrre una risposta. Se individua lacune, non si limita a segnalare un contesto insufficiente: identifica ciò che manca, genera nuovi percorsi di ricerca e avvia ulteriori recuperi di informazioni fino a quando il contesto non viene considerato completo.
Secondo Google, questo approccio consente di migliorare l’accuratezza fino al 34% rispetto ai sistemi RAG tradizionali nei benchmark di factuality. Nei test condotti su scenari con più corpus documentali indipendenti, il sistema ha raggiunto un’accuratezza del 90,1%, mantenendo una latenza molto simile alle soluzioni standard.
Il risultato è un modello di retrieval più vicino al modo in cui lavora un team di ricerca: pianifica, verifica, approfondisce e continua a cercare finché non dispone di elementi sufficienti per fornire una risposta fondata e verificabile.
Diffusion & Large Vision Models: dove si muove la ricerca
Nella lezione “Trending Topics” del corso Stanford “Diffusion & Large Vision Models”, viene tracciato un percorso molto chiaro: dalle basi matematiche della generazione di immagini e video fino alle direzioni più recenti della ricerca. È una lezione consigliata per chi vuole approfondire le dinamiche che guidano i modelli visuali.
Si parte dai tre modi principali di interpretare la generazione: diffusione standard, score matching e flow matching. In tutti i casi, l’obiettivo è imparare a trasformare una distribuzione semplice, come il rumore, in immagini coerenti. La differenza è nel “come”: rimuovere rumore, seguire una direzione probabilistica o modellare un vero e proprio trasporto tra distribuzioni.

Un passaggio interessante riguarda lo spazio latente. Per anni i modelli hanno compresso le immagini con VAE per lavorare in modo più efficiente, ma alcuni modelli recenti stanno tornando direttamente ai pixel, compensando la maggiore complessità con architetture enormemente scalate.
La lezione estende poi questi concetti ai video, dove il problema non è solo generare frame realistici, ma mantenere coerenza temporale. Da qui l’uso di VAE 3D causali e blocchi spazio-temporali nei Transformer.
Un altro tema rilevante è l’editing controllato: invece di rigenerare un’immagine da zero, i nuovi approcci cercano di capire l’intento dell’utente e trasformarlo in azioni di editing più precise.
Infine, lo stesso paradigma della diffusione viene applicato anche al testo, con modelli capaci di generare o correggere intere sequenze in parallelo, particolarmente interessanti per il codice.
La parte conclusiva apre ai temi più delicati: model collapse, provenienza dei contenuti, metadati C2PA e watermark invisibili come SynthID.
Una lezione utile perché mostra bene dove si sta muovendo il settore: non solo modelli più potenti, ma nuove architetture, nuovi domini applicativi e nuove sfide di sicurezza.
Machine Learning for Beginners: il percorso open source di Microsoft
Microsoft ha pubblicato “Machine Learning for Beginners”, un percorso formativo open source strutturato in 26 lezioni, progettato per fornire una comprensione rigorosa del machine learning classico.
Il programma inizia con un’esplorazione della storia dell’AI e dei principi di equità e responsabilità, secondo l’approccio della Responsible AI, per poi introdurre gli strumenti essenziali per l’analisi dei dati, tra cui Python, Scikit-learn, Pandas, Jupyter Notebooks e Matplotlib per la visualizzazione.
Entrando nel vivo dell’apprendimento supervisionato, il corso analizza in dettaglio i modelli di regressione, passando da quella lineare e polinomiale per la previsione di valori continui, fino alla regressione logistica e ai metodi ensemble per i problemi complessi di classificazione.
Il percorso affronta successivamente l’apprendimento non supervisionato, illustrando tecniche di clustering come il K-Means per la scoperta di pattern latenti in dataset privi di etichette.
A questo blocco seguono moduli su domini applicativi specifici: l’elaborazione del linguaggio naturale, per compiti di traduzione e analisi del sentiment, le previsioni su serie storiche attraverso modelli statistici come ARIMA e SVR, e un’introduzione al Reinforcement Learning tramite algoritmi di Q-Learning implementati in ambienti simulati.
Ogni costrutto teorico viene accompagnato da applicazioni pratiche, culminando nella creazione di applicazioni web tramite Flask per l’implementazione dei modelli addestrati in contesti di utilizzo reale.
Per supportare lo studio, l’analisi e la consultazione di questo vasto ecosistema di informazioni, ho strutturato un progetto su NotebookLM all’interno del quale ho importato l’intero corpus delle fonti, tra GitHub e YouTube.
Project Tapestry: AI frontier costruita insieme
AI Alliance, di cui fa parte anche Yann LeCun, ha presentato Project Tapestry, un’iniziativa per costruire una piattaforma open source dedicata allo sviluppo federato e globale di modelli AI frontier.
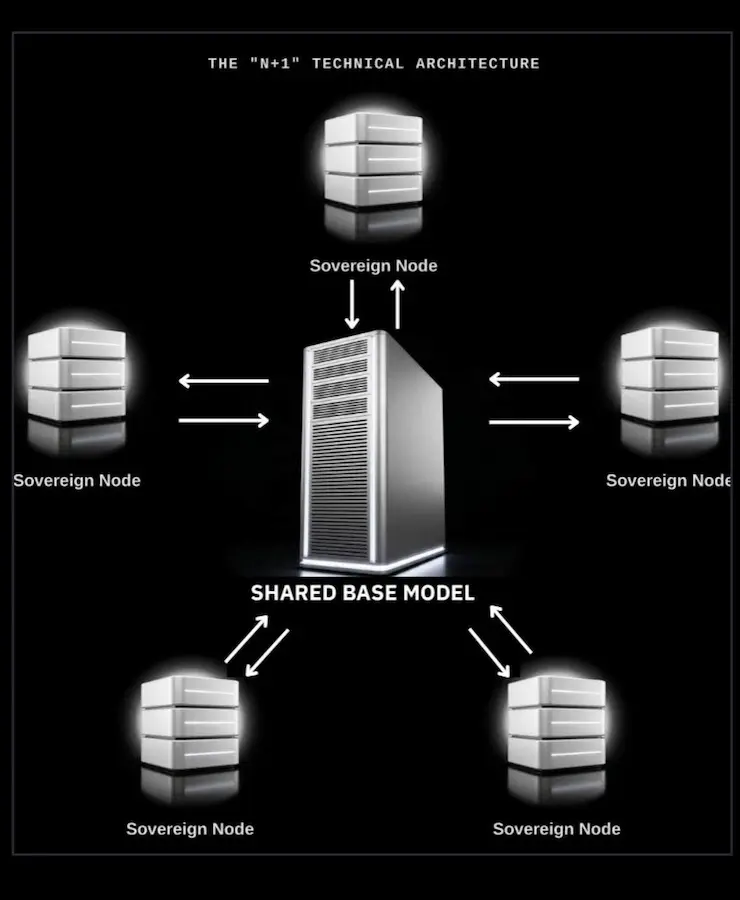
L’obiettivo è andare oltre il concetto di “open weight”. Avere accesso ai pesi di un modello non significa necessariamente partecipare al suo pretraining, alle scelte architetturali, alle pipeline dati o alla governance del processo. Project Tapestry prova invece a spostare il baricentro: non solo modelli scaricabili, ma modelli costruiti insieme.
Il principio è: mantenere il controllo dei propri dati, contribuendo a un modello comune.

Project Tapestry: AI frontier costruita insieme
I partner possono addestrare localmente sui propri dati e condividere aggiornamenti dei pesi, senza dover trasferire necessariamente i dati grezzi a un’entità centrale. Questo approccio è pensato per governi, università, aziende, laboratori di ricerca e organizzazioni che vogliono contribuire allo sviluppo di foundation model avanzati, preservando sovranità, vincoli legali e specificità culturali o linguistiche.
Il progetto punta a creare un modello base condiviso, da cui ogni partecipante potrà derivare versioni sovrane, adattate ai propri bisogni, domini e contesti locali.
La roadmap prevede una fase iniziale nel 2026, con demo tecniche, catalogazione dei dataset tramite metadati, framework multi-nodo per aggregare aggiornamenti dei pesi e primi esperimenti di riallineamento culturale. Entro fine 2026 l’obiettivo è arrivare a un piccolo modello base addestrato da zero e ai primi derivati sovrani.
Il punto più interessante non è solo tecnico, ma politico e industriale: Tapestry propone un’alternativa alla concentrazione dello sviluppo AI in poche aziende e poche regioni del mondo.
Un modello più distribuito, consortile e federato, dove dati, calcolo e competenze restano in parte locali, ma contribuiscono a un’infrastruttura comune.
AI Mode in Chrome: solo un test, per ora
Google sta testando una nuova funzionalità che reindirizza le ricerche effettuate dalla barra degli indirizzi di Chrome direttamente ad AI Mode, saltando la tradizionale pagina dei risultati di Google Search.
La novità è stata individuata nella versione sperimentale Chrome Canary e può essere attivata solo manualmente tramite un flag dedicato. Una volta abilitata, qualsiasi query digitata nell’Omnibox viene gestita da AI Mode invece che dal classico motore di ricerca.
AI Mode in Chrome: solo un test, per ora
Google ha però chiarito che si tratta di un test esplorativo e che non esistono piani attuali per rendere AI Mode il comportamento predefinito di Chrome. Anche Rajan Patel, VP dell’azienda, ha confermato pubblicamente che la ricerca tradizionale non verrà sostituita.
Nonostante le rassicurazioni, l’esperimento mostra la direzione in cui Google sta continuando a investire: un’esperienza di ricerca sempre più integrata con l’intelligenza artificiale, direttamente all’interno degli strumenti che milioni di persone utilizzano ogni giorno.
AI Overview di Google: quando la sintesi diventa contenuto proprio
Ho letto la sentenza del Tribunale di Monaco che riguarda l’AI Overview di Google (26 O 869/26), ed ecco cosa emerge sulla responsabilità per le risposte generate nei motori di ricerca.
Il caso riguarda un’AI Overview che associava due società editoriali a truffe, abbonamenti ingannevoli e altre pratiche scorrette. Il tribunale ha vietato la diffusione della maggior parte di queste affermazioni, ritenendole lesive della reputazione delle imprese e non adeguatamente dimostrate.
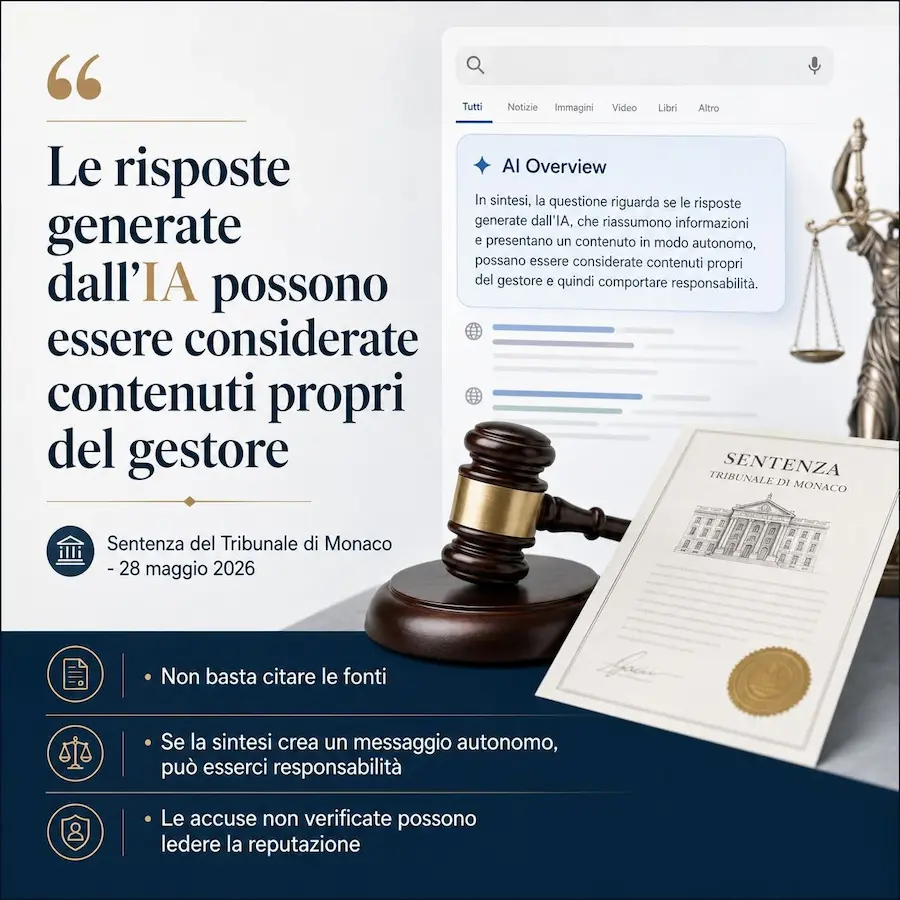
Il punto centrale è la natura dell’output. Quando un sistema non si limita a mostrare link, ma seleziona fonti, le combina, le riscrive, le organizza e formula una conclusione autonoma, il risultato può essere considerato un contenuto proprio del gestore.
Nel caso esaminato, l’overview iniziava con affermazioni esplicite, classificava le presunte condotte fraudolente e forniva indicazioni agli utenti. Alcuni collegamenti, inoltre, non comparivano nemmeno nelle fonti citate: erano stati creati dalla sintesi generativa.
Per questo il tribunale ha distinto le risposte AI dai normali risultati di ricerca. La presenza di link non elimina la responsabilità, perché una dichiarazione autonoma e immediatamente comprensibile può produrre il proprio effetto anche senza che l’utente verifichi le fonti.
La decisione evidenzia anche una possibile lacuna di tutela: se le fonti originarie non hanno formulato l’affermazione falsa e il gestore dell’AI non ne rispondesse, il soggetto danneggiato potrebbe non avere nessuno contro cui agire.
Il tribunale attribuisce inoltre un peso più limitato alla libertà di espressione del fornitore: l’output non rappresenta una convinzione personale maturata da un individuo, ma il risultato di un algoritmo offerto nell’ambito di un’attività commerciale.
La sentenza non stabilisce che ogni errore dell’AI comporti automaticamente responsabilità. Indica però un principio rilevante: quando il sistema trasforma contenuti di terzi in un nuovo messaggio, dotato di struttura, valutazione e significato autonomi, il gestore non può sempre qualificarsi come semplice intermediario tecnico.
AI Mode: come cambia la ricerca secondo Google
Un nuovo documento di Google racconta come le persone stanno usando AI Mode negli Stati Uniti e descrive una trasformazione profonda della ricerca online. Le query diventano più lunghe, naturali e conversazionali: in media, una ricerca in AI Mode è tre volte più lunga di una ricerca tradizionale.
Crescono anche le conversazioni con più passaggi: gli utenti non si limitano a formulare una domanda, ma aggiungono dettagli, chiedono confronti e affinano progressivamente la richiesta. Aumentano inoltre le ricerche multimodali, effettuate attraverso immagini, voce e video: più di una query su sei non è esclusivamente testuale.

Dal documento emergono cinque principali modalità d’uso. Le persone utilizzano AI Mode per esplorare idee e argomenti, prendere decisioni, studiare, pianificare attività e creare contenuti. Lo impiegano per confrontare prodotti, costruire itinerari, preparare quiz e guide di studio, organizzare allenamenti e budget, generare immagini, testi, documenti e codice.
La direzione indicata da Google è chiara: il motore di ricerca si sta trasformando in un assistente capace di accompagnare l’utente dalla scoperta di un’informazione fino alla realizzazione di un’attività.
Il documento, però, va letto anche criticamente. Google analizza un proprio prodotto attraverso dati interni che non sono disponibili pubblicamente e che quindi non possono essere verificati in modo indipendente. La crescita delle query, della loro lunghezza e dei follow-up dimostra un maggiore utilizzo, ma non necessariamente una migliore qualità delle risposte.
Una conversazione più lunga potrebbe indicare maggiore coinvolgimento, ma anche la necessità di correggere, chiarire o completare risposte insufficienti. Manca inoltre un confronto sistematico con la ricerca tradizionale su accuratezza, affidabilità, soddisfazione degli utenti e tempo effettivamente risparmiato.
Sono quasi assenti anche i temi più problematici: errori, allucinazioni, privacy, bias, qualità delle fonti e impatto sul traffico destinato a editori, creator e siti web.
Le percentuali di crescita presentate sono significative, ma non vengono accompagnate dai volumi assoluti, dalla dimensione dei campioni o dai margini di errore. Sapere che una categoria cresce più velocemente della media non permette di capire quanto sia realmente diffusa.
Il report dimostra con efficacia che AI Mode viene utilizzata sempre di più e per attività molto diverse. Dimostra molto meno che questa trasformazione migliori davvero la qualità della ricerca e produca benefici superiori ai suoi rischi.
Google Search diventa agentico
Google Search sta entrando in una nuova fase: non solo risultati, ma azioni. Con l’integrazione di Gemini 3.5 Flash in AI Mode, la ricerca diventa più veloce, più dinamica e soprattutto più agentica.
Gli agenti informativi potranno lavorare in background, monitorando il web 24/7 per seguire temi, aggiornamenti, offerte, annunci o cambiamenti rilevanti per una richiesta specifica. Questa funzionalità è già disponibile in AI Mode in tutto il mondo per gli utenti AI Ultra.
Google Search diventa agentico
Non si tratta più solo di cercare un appartamento, un prodotto o una notizia: l’utente potrà impostare un’esigenza e lasciare che l’agente continui a controllare per lui, notificandolo quando trova qualcosa di utile.
Google sta portando questa logica anche nelle prenotazioni, con agenti capaci di contattare attività commerciali per servizi come riparazioni domestiche, beauty o pet care.
Un altro passaggio importante riguarda il coding dentro Search: Google potrà generare interfacce, widget, tracker e mini-app direttamente nei risultati, adattandoli all’esigenza dell’utente. La ricerca diventa quindi un ambiente operativo, non solo informativo.
Anche lo shopping cambia: con Universal Cart, Google punta a un carrello unico tra più retailer, capace di confrontare prezzi, applicare offerte, segnalare incompatibilità tra prodotti e gestire pagamenti in modo più intelligente.
Con AP2, il protocollo per i pagamenti agentici, Google sta inoltre costruendo un’infrastruttura per permettere agli agenti AI di effettuare transazioni con regole, limiti e tracciabilità.
La direzione è chiara: Search, AI, commerce e automazione stanno convergendo. Per chi lavora nel digitale, questo significa ripensare la presenza online non solo per essere trovati dalle persone, ma anche per essere compresi, selezionati e utilizzati dagli agenti artificiali.
Spam AI: il problema non è il singolo contenuto, ma “la fabbrica”
Lo spam generato con l’AI non si riconosce cercando “la firma dell’AI”: si riconosce quando diventa una fabbrica.
È questa, secondo me, la parte più interessante del paper di ricercatori Google, “Scalable Detection of Adversarial Synthetic Slop and Coordinated Media Abuse”. Il punto non è costruire un detector magico capace di dire se un singolo contenuto sia stato scritto, “parlato” o montato da un modello generativo. Il punto è molto più sistemico.
Google sta studiando un approccio che guarda ai cluster: gruppi di account, canali o entità che pubblicano contenuti sintetici simili, con pattern ricorrenti, template semantici ripetitivi, segnali infrastrutturali condivisi e tracce multimodali di produzione automatizzata.
In altre parole, non “questo contenuto è AI, quindi è spam”, ma: “questi contenuti, account e comportamenti sembrano parte di una produzione coordinata di spam sintetico”.
Il sistema combina rilevamento di botnet, classificazione multimodale e LLM adattati con tecniche come LoRA e APO, utili per aggiornare rapidamente il modello sui nuovi trend di spam generativo.





Spam AI: il problema non è il singolo contenuto, ma “la fabbrica”
Search Engine Journal ha ripreso il paper in chiave SEO, suggerendo che questo approccio possa aiutare a capire come Google potrebbe individuare contenuti AI spam anche sul web. La lettura è sensata, ma va calibrata: il paper non dimostra che questo sistema sia usato in Google Search, non dimostra che Google penalizzi automaticamente i contenuti generati con AI e non dimostra che basti usare l’AI per entrare in una categoria di rischio.
Il punto è un altro: Google non ha bisogno di riconoscere perfettamente ogni contenuto AI per intercettare lo spam generativo. Può osservare pattern, vedere produzione seriale, collegare entità apparentemente separate e distinguere tra uso creativo dell’AI e abuso coordinato.
Questa è la parte che conta per chi lavora sui contenuti. Il rischio non è “usare AI”. Il rischio è produrre contenuti da catena di montaggio: template replicati, variazioni superficiali, intenti deboli, segnali di automazione, scalabilità forzata e nessuna reale utilità.
Il futuro del rilevamento dello spam AI probabilmente non sarà un semaforo acceso sul singolo testo. Sarà una lettura sistemica dei comportamenti, delle relazioni e dei pattern di produzione.
Gemma 4 12B: multimodalità locale su hardware consumer
Google ha rilasciato un nuovo modello che introduce il supporto alla Multi-Token Prediction e porta capacità multimodali avanzate su hardware consumer. Si chiama Gemma 4 12B ed è progettato per eseguire attività di ragionamento, elaborazione di immagini e gestione dell’audio direttamente su laptop con circa 16 GB di memoria, riducendo la dipendenza dal cloud.
Il modello usa un’architettura encoder-free: invece di utilizzare componenti separati per elaborare immagini e audio prima di passarli al modello linguistico, Gemma 4 12B integra questi input direttamente nel backbone del modello. Questo approccio riduce complessità, consumo di memoria e latenza.
Gemma 4 12B: multimodalità locale su hardware consumer
Google ha inoltre introdotto il supporto nativo all’audio. Il modello può elaborare segnali vocali senza un encoder audio dedicato, aprendo la strada a scenari come trascrizione, traduzione e comprensione vocale eseguite localmente.
Sul fronte delle prestazioni, Google dichiara risultati vicini a quelli di Gemma 4 26B, ma con un footprint di memoria significativamente inferiore. L’obiettivo è rendere accessibili workflow agentici e capacità di ragionamento avanzato anche su dispositivi consumer.
Tra le novità c’è anche la Multi-Token Prediction, una tecnica che consente di prevedere più token contemporaneamente, migliorando la velocità di generazione e riducendo la latenza percepita nelle applicazioni interattive.
Il modello è distribuito con licenza Apache 2.0 ed è già supportato da strumenti come Hugging Face Transformers, Ollama, llama.cpp, MLX e vLLM, confermando la volontà di Google di favorirne l’adozione all’interno dell’ecosistema open source.
NotebookLM si potenzia con Gemini e Antigravity
In arrivo novità interessanti su NotebookLM, che amplia le sue capacità di approfondimento e analisi grazie all’integrazione con i modelli Gemini 3.5 e Antigravity. La piattaforma introduce una chat più avanzata, una maggiore capacità di ragionamento e strumenti più efficaci per analizzare grandi quantità di documenti, individuare collegamenti tra le fonti e supportare progetti di ricerca complessi.
Ogni notebook può ora contare anche su un ambiente cloud sicuro in grado di scrivere ed eseguire codice, utile per analisi dati, elaborazioni più strutturate e attività di ricerca che richiedono passaggi tecnici più approfonditi.
NotebookLM si potenzia con Gemini e Antigravity
Tra le novità ci sono anche nuovi formati di output: report PDF con grafici e tabelle, documenti Word, file Markdown, fogli Excel, presentazioni PowerPoint, CSV, JSON, immagini e visualizzazioni dati in PNG o SVG.
NotebookLM diventa così più utile anche nelle fasi iniziali di un progetto: si può partire da un’idea o da una domanda e costruire progressivamente un archivio di fonti pertinenti, mantenendo il controllo sui materiali utilizzati e sulle attribuzioni.
Project Glasswing si espande
Anthropic ha annunciato l’espansione di Project Glasswing, l’iniziativa che utilizza l’AI per individuare vulnerabilità nei software che supportano infrastrutture e servizi critici.
Dopo una prima fase che ha coinvolto circa 50 organizzazioni e ha contribuito all’identificazione di oltre 10.000 vulnerabilità ad alta criticità, il programma verrà esteso a circa 150 nuove realtà operative in oltre 15 Paesi, includendo settori come energia, acqua, sanità, comunicazioni e hardware.
La notizia si inserisce in un contesto più ampio: stiamo vivendo una fase di accelerazione esponenziale nell’adozione dell’AI. Modelli sempre più avanzati stanno trasformando lo sviluppo software, aumentando produttività, automazione ed efficienza in un numero crescente di settori.
Più l’intelligenza artificiale accelera la creazione e l’evoluzione delle applicazioni, più diventa fondamentale garantire la sicurezza dei sistemi su cui si basano organizzazioni, imprese e servizi essenziali.
In questo scenario, iniziative come Project Glasswing evidenziano come l’AI possa essere utilizzata non solo per innovare più rapidamente, ma anche per rafforzare la capacità di individuare, correggere e prevenire vulnerabilità su larga scala.
L’accelerazione tecnologica e la sicurezza non sono più temi separati: stanno diventando due dimensioni sempre più strettamente collegate della stessa trasformazione.
Chrome DevTools sempre più integrato con l’AI
Novità interessanti in arrivo su Chrome DevTools, con un aggiornamento che punta sempre di più all’integrazione tra strumenti di sviluppo e AI.
Con Chrome 149, DevTools for Agents raggiunge la stabilità ufficiale, introducendo nuove possibilità per gli agenti AI, tra cui il supporto a strumenti personalizzati esposti dalle pagine web, il debugging di strumenti WebMCP e l’emulazione di header HTTP personalizzati.
Importanti novità anche per AI Assistance, che ora offre un’interfaccia più ricca con widget interattivi per analizzare Core Web Vitals e performance della pagina direttamente nella conversazione. L’assistente può inoltre sfruttare i dati di Lighthouse per fornire analisi più complete e suggerimenti più mirati, grazie all’integrazione con Gemini 3.
Chrome DevTools sempre più integrato con l’AI
Debutta inoltre il supporto sperimentale a WebMCP, una proposta di standard che consente alle pagine web di registrare strumenti utilizzabili da agenti LLM. I nuovi strumenti di debugging permettono di ispezionare, eseguire e monitorare queste integrazioni direttamente da DevTools.
Un aggiornamento che conferma la direzione intrapresa da Chrome: rendere DevTools non solo uno strumento di debugging, ma una piattaforma sempre più integrata con i flussi di sviluppo assistiti dall’intelligenza artificiale.
Avatar personalizzati in Gemini Omni
In arrivo la possibilità di creare un avatar personalizzato su Gemini Omni, da inserire direttamente nei video. Con gli sviluppi visti su Google Vids, era una funzionalità abbastanza prevedibile.
Per crearlo basterà accedere alle impostazioni di Gemini, dove sarà presente una voce specifica dedicata. La procedura farà registrare un video con diverse inquadrature; successivamente, l’avatar sarà disponibile come riferimento per la generazione dei video.
Avatar personalizzati in Gemini Omni
È la stessa modalità già vista, ad esempio, su HeyGen e, in passato, su Sora.
Tutti i video creati con Gemini Omni includono un watermark digitale invisibile SynthID, utile per verificare tramite l’app Gemini che il contenuto sia stato generato.
La funzionalità sarà disponibile per gli abbonati Google AI Plus, Pro e Ultra, sia da web sia dall’app. Ovviamente, per ora, ovunque tranne che in Europa, SEE, Svizzera e Regno Unito.
Google Omni e testi integrati nei video
Tra le capacità interessanti di Google Omni c’è anche l’inserimento di testi nei video, integrati direttamente nelle scene.
Nell’esempio ho usato una frase come protagonista del trailer, lavorando su un prompt pensato per creare una cinematic 3D animation con kinetic typography ad alta energia, ambientata in una città futuristica al tramonto.
Google Omni e testi integrati nei video
Il prompt
“A cinematic 3D animation where massive, high-energy 3D kinetic typography takes center stage, interacting with a futuristic cityscape at golden hour. Words appear one by one, suspended in mid-air between skyscrapers, glowing with vibrant neon light, and reacting to the environment with physics-based movement (e.g., shattering like glass, rippling through the air, or slamming into buildings). The sequence of words 'PUSH. PAST. EVERY. LIMIT. BEYOND. THE. EDGE. OF. FEAR.' dominates the frame, with each word having a unique, bold, and dynamic animation style. The camera moves rapidly and dramatically through the letters, emphasizing their weight, scale, and intensity to create an immersive and captivating trailer experience”.
Il risultato è un’esperienza da trailer immersiva e intensa, in cui il testo non è solo un elemento grafico, ma diventa il vero protagonista della scena.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂