Generative AI: novità e riflessioni - #5 / 2026
Efficienza, agenti e nuove architetture: confronto tra 7 LLM, World Model, MCP, context engineering, TurboQuant, AlphaEvolve e sistemi multi-agente. I segnali più rilevanti di un’AI sempre più autonoma, operativa e integrata nei processi reali.


Buon aggiornamento, e buone riflessioni..
Ascolta l'audio overview che sintetizza le novità
Il podcast è stato generato attraverso NotebookLM.
L’inizio di una crescita esponenziale
Nel mio TEDx talk ho parlato della velocità con cui i sistemi di AI si stanno evolvendo: l’inizio di una crescita esponenziale.
Intelligenza artificiale: capire il potere, scegliere la direzione - TEDxBergamo
Guardando i dati più recenti, credo che questa traiettoria stia diventando sempre più evidente.
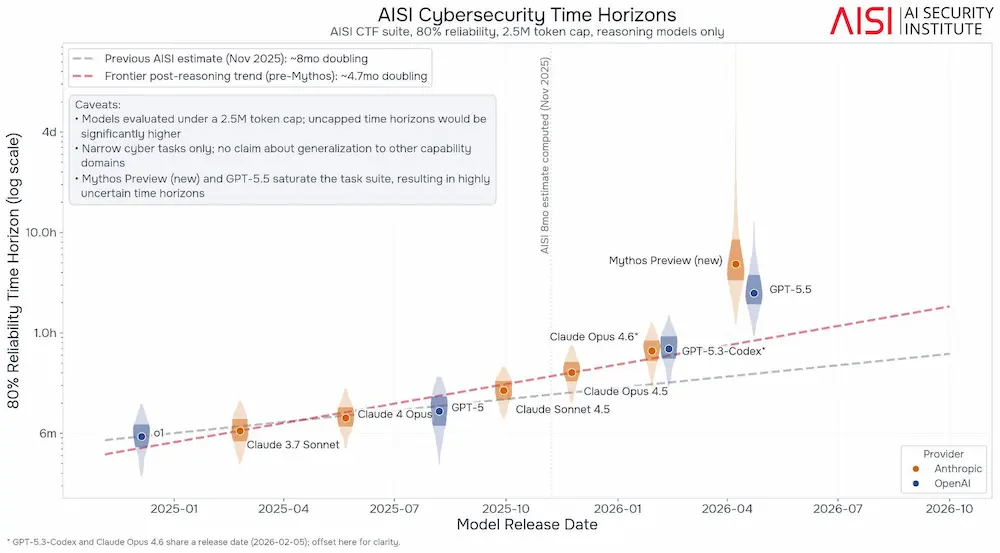
In diversi domini, le curve di crescita delle capacità dei modelli stanno assumendo trend sempre più ripidi. Nel dominio cyber, ad esempio, alcune stime indicano un tempo di raddoppio delle capacità ormai intorno ai 4,5 mesi.
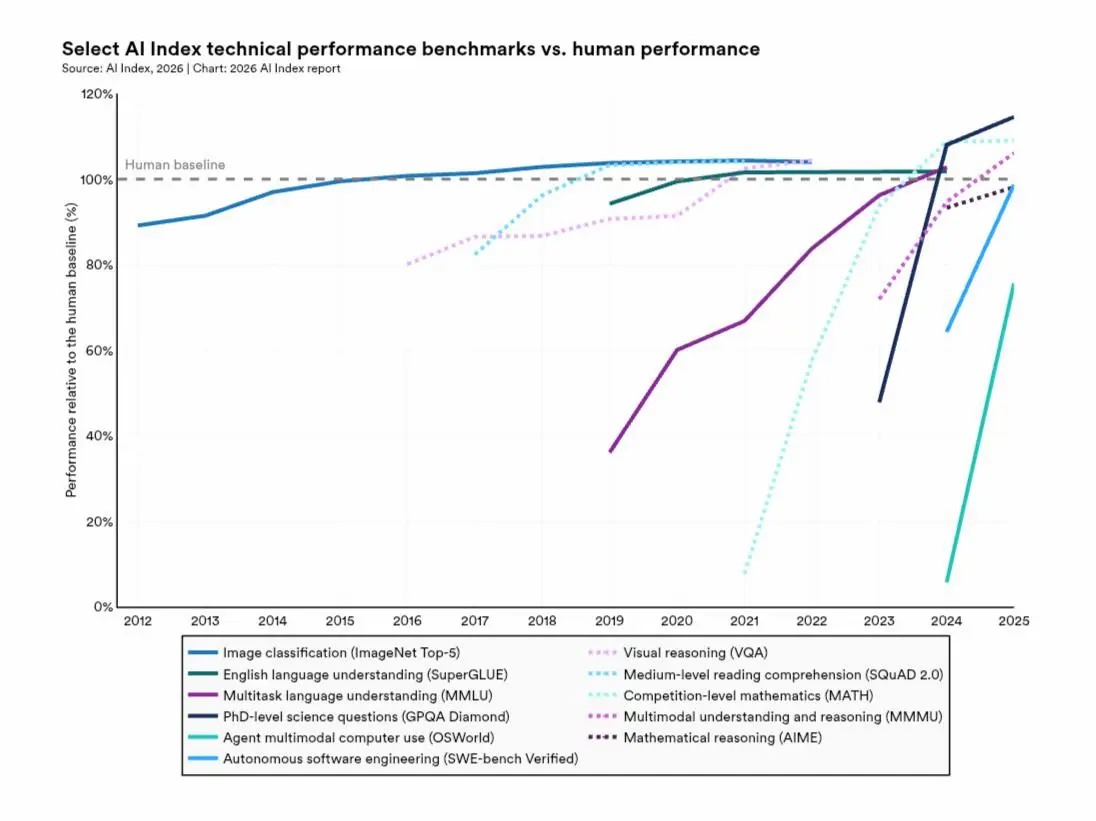
L’inizio di una crescita esponenziale
Ma il punto non è solo che i modelli diventano più capaci. È che stanno diventando anche più autonomi e più efficienti allo stesso tempo.
Migliorano nel ragionamento, nell’uso di strumenti, nella scrittura di codice, nella pianificazione di task più lunghi, nell’interazione con API e sistemi esterni.
E mentre questo accade, migliorano anche le architetture: a parità di capacità, o quasi, servono sempre meno risorse per ottenere risultati sempre migliori.
L’ultimo modello Gemini Flash ha costi di inferenza inferiori di decine di volte rispetto ad alcuni dei modelli più performanti attuali.
La direzione è chiara: non cresce solo
la potenza, cresce anche l’efficienza.
Ed è qui che la trasformazione diventa sistemica. AlphaEvolve è un esempio concreto: un sistema basato su modelli AI che viene usato per migliorare codice, ottimizzare risorse computazionali, accelerare il training, scoprire nuovi algoritmi e contribuire al miglioramento dell’hardware.
Modelli migliori aiutano a costruire software migliore. Software migliore abilita modelli più efficienti. Modelli più efficienti accelerano agenti, chip, robot e processi.
Non è una singola curva. È un insieme di curve che iniziano ad alimentarsi a vicenda. In diverse occasioni ho usato la metafora dei popcorn: la padella era calda e iniziavamo a sentire scoppiare i primi chicchi. Oggi alcuni chicchi sono già scoppiati.
Siamo ancora all’inizio della trasformazione organizzativa, economica e sociale. Ma non siamo più all’inizio della capacità tecnica.
Ed è proprio questa asimmetria a rendere il momento così importante: la tecnologia sta diventando abbastanza capace da uscire dai benchmark, dalle demo e dai laboratori, e iniziare a trasformare il mondo reale.
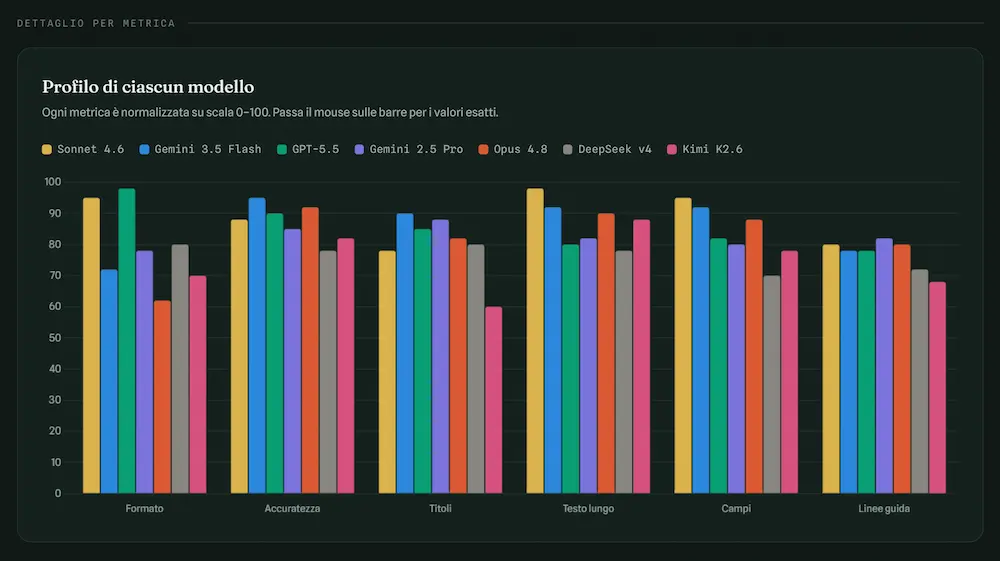
TEST: un confronto tra 7 modelli AI
Ho messo a confronto 7 LLM sullo stesso prompt per la generazione di contenuti strutturati.
Il prompt in questione riguarda l’elaborazione di dati di prodotti di un e-commerce ed è molto strutturato, con una quantità elevata di istruzioni, vincoli e parametri da gestire.
Il metodo
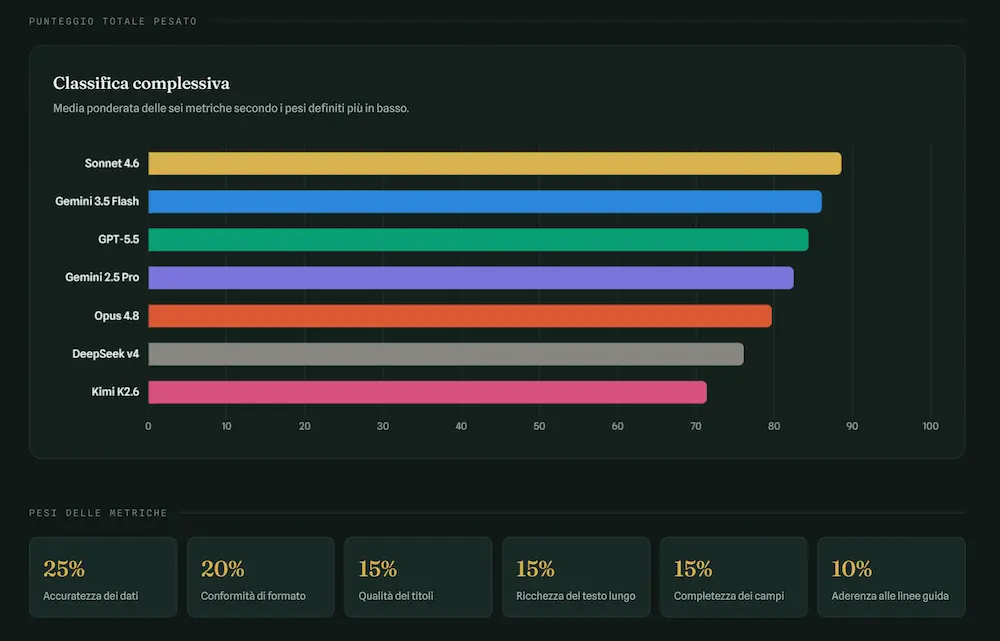
Ogni modello ha ricevuto lo stesso prompt su oltre 1.000 esecuzioni, in cui variavano i dati del prodotto in input, e ha prodotto i relativi output. Gli output sono stati valutati su 6 metriche pesate, per un punteggio finale su scala 0–100. La dashboard sintetizza il comportamento durante le elaborazioni.
I modelli testati
Claude Sonnet 4.6, Claude Opus 4.8, Gemini 2.5 Pro, Gemini 3.5 Flash, GPT-5.5, DeepSeek v4, Kimi K2.6.
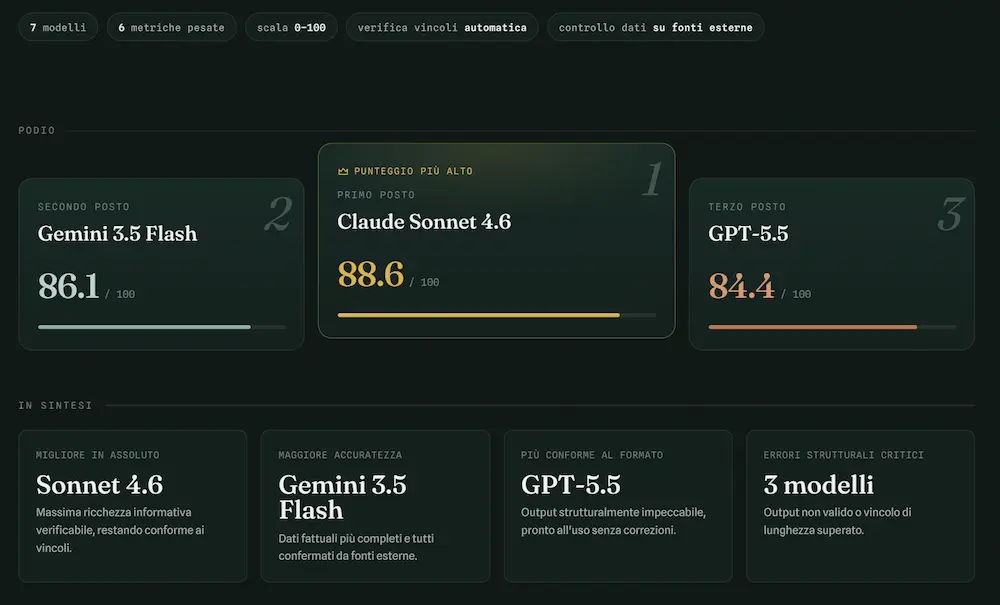

TEST: un confronto tra 7 modelli AI
Le 6 metriche, con i rispettivi pesi
- accuratezza dei dati [25%]: le informazioni prodotte sono state verificate su fonti esterne indipendenti;
- conformità di formato [20%]: rispetto dei vincoli strutturali e di lunghezza dichiarati nel prompt;
- qualità dei titoli [15%]: pertinenza, densità informativa, sfruttamento dello spazio disponibile;
- ricchezza del testo lungo [15%]: completezza, precisione, utilità pratica del contenuto;
- completezza dei campi [15%]: copertura di tutti i campi previsti dallo schema di output;
- aderenza alle linee guida [10%]: rispetto delle regole redazionali specificate nel prompt.
Il podio
1° Claude Sonnet 4.6 — 88,6/100
2° Gemini 3.5 Flash — 86,1/100
3° GPT-5.5 — 84,4/100
Alcune osservazioni
- Il modello con la maggiore accuratezza non è quello con il punteggio totale più alto: Gemini 3.5 Flash segna 95/100 in accuratezza, ma viene penalizzato da un errore strutturale nell’output, perfettamente gestibile dall’applicazione, che ne abbassa la valutazione complessiva.
- GPT-5.5 è l’unico a includere tutti i campi di raggruppamento richiesti dallo schema: un dettaglio che fa la differenza quando l’output va usato in produzione senza correzioni manuali.
- Claude Opus 4.8 produce il testo più accurato e profondo del gruppo, ma in alcune esecuzioni ha superato di qualche carattere un vincolo di lunghezza dichiarato esplicitamente come tassativo nel prompt. Un errore piccolo in apparenza, con impatto rilevante in contesti automatizzati.
- Kimi K2.6 produce buoni contenuti, ma ignora una regola sui separatori, a dimostrazione del fatto che anche i vincoli formali semplici non sono garantiti.
Considerazioni
Non esiste il modello “migliore” in assoluto. Il modello giusto dipende da ciò che viene pesato maggiormente: profondità informativa, affidabilità strutturale o aderenza precisa alle specifiche.
Nel complesso, tuttavia, la maggior parte dei problemi rilevati è perfettamente gestibile dal software che riceve l’output del modello.
World Model: il vero salto che manca all’AI?
I World Model potrebbero essere il vero salto che manca all’AI: non modelli che prevedono parole, ma sistemi capaci di immaginare conseguenze.
Yann LeCun sostiene che i LLM, da soli, non arriveranno all’intelligenza di livello umano. Il motivo è strutturale: operano nello spazio dei token, generando una parola dopo l’altra sulla base di probabilità. Funzionano molto bene quando il linguaggio è già il terreno del ragionamento, come nel codice o nella matematica formale.
Yann LeCun on What Comes After LLMs
Ma il mondo reale è diverso. Per agire in ambienti complessi serve qualcosa di più: un modello interno della realtà, capace di simulare cosa potrebbe accadere dopo una sequenza di azioni.
È qui che entrano in gioco le architetture JEPA e i sistemi Objective-Driven.
L’idea è costruire agenti che non si limitino a rispondere a un prompt, ma ricevano un obiettivo, immaginino scenari possibili, valutino le conseguenze e scelgano l’azione migliore rispettando vincoli di sicurezza.
In questa visione, i LLM diventano interfacce linguistiche. Utilissime, ma non il cuore del sistema. Il cuore sarebbe il World Model: una rappresentazione astratta del mondo che permette all’AI di pianificare, verificare, correggere e agire con maggiore affidabilità.
Per LeCun, questa è la strada per portare l’AI oltre i chatbot: processi industriali, robotica, biologia, motori aeronautici, impianti chimici e sistemi fisici troppo complessi per essere descritti solo da equazioni tradizionali.
La sua nuova startup, AMI, nasce proprio con questa ambizione: costruire sistemi intelligenti capaci di comprendere e controllare dinamiche reali. È una visione molto diversa da quella dominante oggi.
Meno prompt engineering. Meno dipendenza dall’autoregressione. Più modelli del mondo, obiettivi, pianificazione e vincoli.
In altre parole: non un’AI che parla meglio, ma un’AI che capisce meglio cosa succede quando agisce.
Dubbing v2 di ElevenLabs
Dubbing v2 di ElevenLabs è un nuovo modello di doppiaggio AI progettato per rendere le versioni localizzate più naturali e fedeli al contenuto originale.
L’ho provato. Il risultato è straordinario, così come la velocità di elaborazione.
Dubbing v2 di ElevenLabs: un test
La principale innovazione è che il sistema non si basa soltanto su una trascrizione, ma analizza direttamente la performance originale, riuscendo così a trasferire tono, emozione, ritmo e intenzione della voce nelle altre lingue.
Il modello supporta oltre 90 lingue e adatta le frasi per ottenere una resa più fluida e naturale, mantenendo sincronizzati inizi, pause e finali con il contenuto di partenza.
In questo modo punta a risolvere uno dei limiti storici del doppiaggio automatico: l’audio piatto, poco espressivo o distante dall’interpretazione originale.
Dubbing v2 è pensato per creator, marketer, studi e broadcaster. I creator possono usarlo per creare doppiaggi rapidi e di qualità per video YouTube e altri contenuti tramite ElevenCreative, con la possibilità di accedere a un programma partner con condizioni scontate.
I marketer possono localizzare annunci e campagne in più mercati senza dover ricostruire i contenuti da zero.
Studi e broadcaster, invece, possono utilizzare ElevenProductions per ottenere doppiaggi professionali con traduttori umani, casting vocale, mixing professionale e il supporto di Dubbing v2 per la parte audio.
Agenti AI + MCP: una riflessione
L’uso di server MCP connessi ad agenti AI è ottimo per prototipazione, demo ed esecuzioni in ambienti chat o CLI.
Non è invece ideale per applicazioni in produzione su larga scala, almeno se non viene progettato con attenzione.
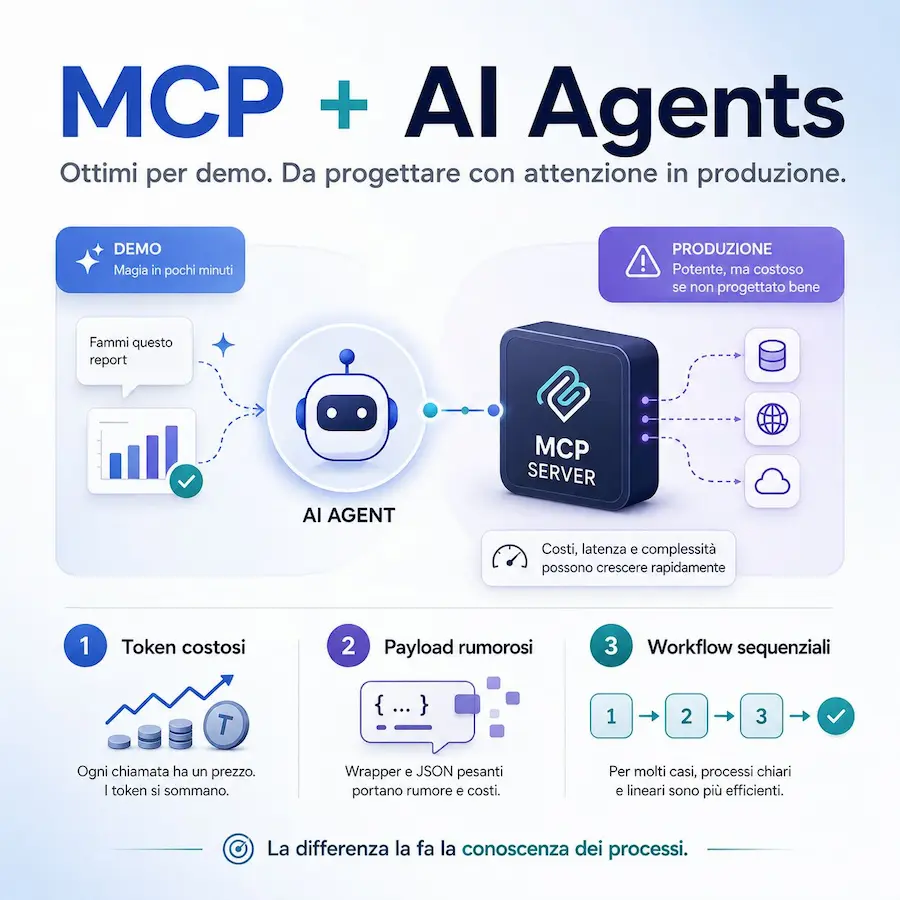
I motivi principali sono tre
- La semplicità di connessione e utilizzo si paga molto cara in consumo di token.
- I payload generati dai tool dei server MCP, in genere, sono semplici incapsulamenti di API e non sono ottimizzati per un agente AI. Questo si traduce in rumore e costi inutili.
- Tutto ciò che non ha senso nel loop operativo di un agente non dovrebbe passare da MCP o function calling, ma da workflow sequenziali, scegliendo il modello giusto per ogni task. Il risultato: più precisione e meno costi.
Ragionare su questi aspetti è la vera essenza del concetto di context engineering, ed è ciò che permette a una demo di diventare un’applicazione reale.
La formula “agenti + MCP” crea spesso l’illusione di qualcosa di magico, capace di gestire qualunque operazione autonomamente. Io credo che la differenza la faccia ancora la conoscenza chirurgica dei processi.
That’s it.
Sistemi agentici: dalla demo "wow" alla produzione
Oggi i modelli AI gestiscono finestre di contesto sempre più ampie. Il punto, però, è che un contesto più ampio non è necessariamente un contesto migliore.
Nello sviluppo di sistemi agentici, ogni informazione che entra nella context window ha un effetto: sul reasoning, sui costi, sulla latenza, sulla qualità dell’output e sulla prevedibilità del sistema.
Per molto tempo si è trattato il contesto come uno spazio da riempire: documenti, risultati di tool, memoria, schemi API, dati intermedi, tracce operative.
Ma quando si passa dalla demo alla produzione, il contesto smette di essere un dettaglio tecnico e deve diventare una scelta architetturale.

La domanda non deve essere: “quanto posso dare al modello?”.
Deve diventare: “cosa serve al modello per decidere meglio?”.
Perché non tutto ciò che è disponibile è utile.
Non tutto ciò che è utile deve essere nel loop agentico.
E non tutto ciò che entra nel contesto migliora il risultato.
Tutto ciò che portiamo nel contesto deve meritarlo.
Deve essere una scelta di design.
Google I/O 2026: una sintesi
Una sintesi delle principali novità presentate durante il Google I/O? Ci provo.
1. Modelli AI
È stato svelato Gemini 3.5, con la versione Flash che garantisce una velocità quattro volte superiore rispetto ai concorrenti, a costi ridotti, e Gemini Omni, un modello in grado di comprendere la fisica intuitiva e manipolare i video in tempo reale mantenendo la coerenza visiva.
Ho provato Gemini 3.5 Flash, già disponibile su AI Studio e Gemini App, e Omni, già disponibile su Flow e Gemini App: sono impressionanti, soprattutto se consideriamo velocità e prezzo.
La tecnologia di frontiera non si limita più a elaborare testi, ma simula scenari complessi combinando nativamente ogni tipo di input.
2. Sviluppo software autonomo
Antigravity 2.0 sposta i confini della programmazione coordinando sub-agenti AI in parallelo, capaci di completare un intero “sistema operativo” funzionante in sole dodici ore.
L’abbattimento dei tempi e dei costi di sviluppo riscrive i processi aziendali, trasformando la scrittura del codice da un lavoro manuale a un’attività di pura orchestrazione strategica.
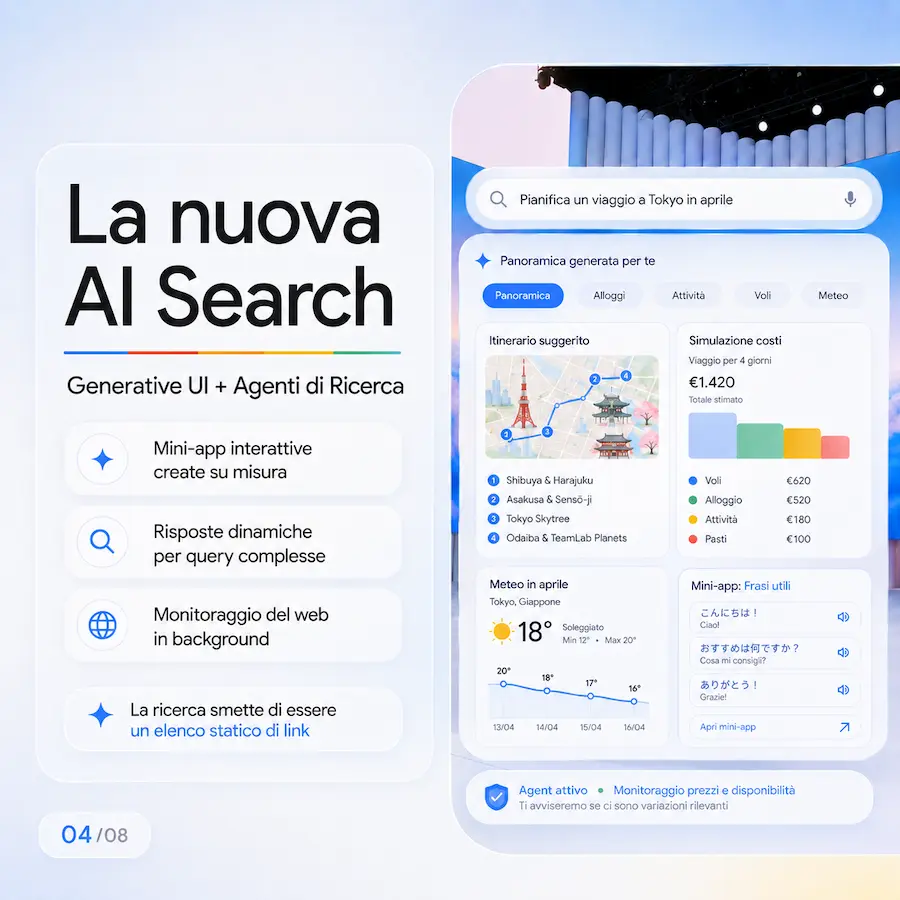
3. La nuova AI Search
Il motore di ricerca integra la Generative UI, una funzione che crea mini-app interattive su misura per rispondere a query complesse, mentre gli agenti di ricerca monitorano il web in background per aggiornare l’utente in tempo reale.
La ricerca smette di essere un elenco statico di link, cosa che in parte ha già smesso di essere da tempo, per diventare un’interfaccia dinamica e personalizzata che genera strumenti pronti all’uso.




Google I/O 2026: una sintesi
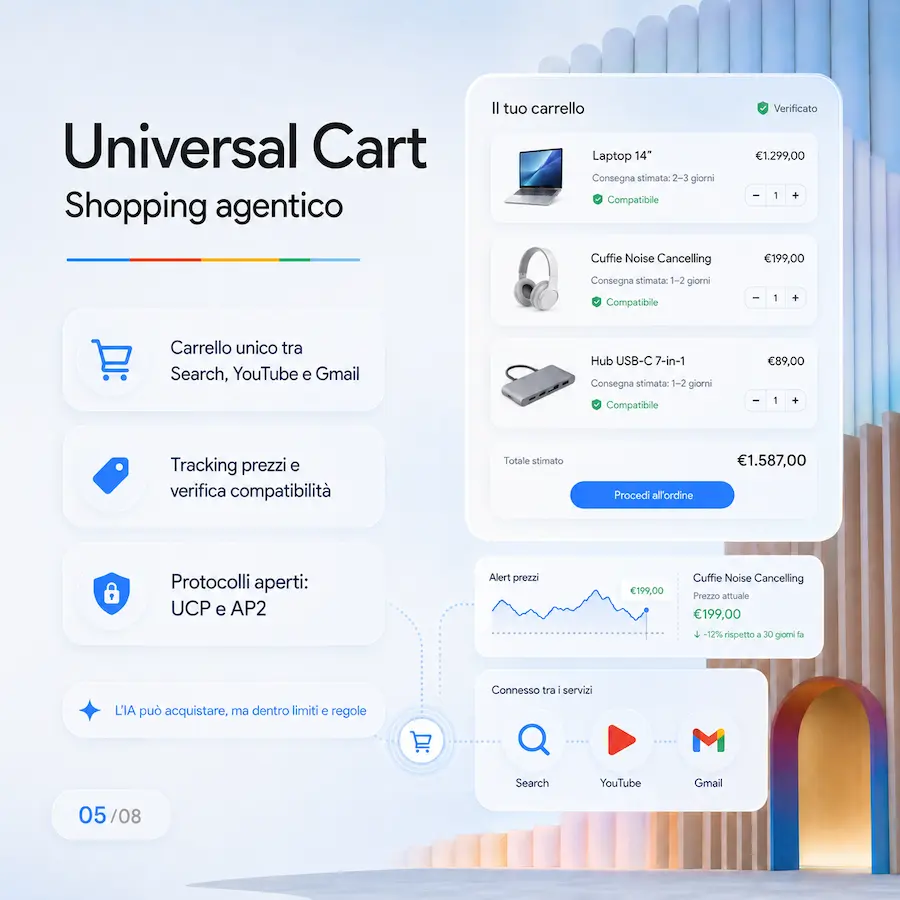
4. Universal Cart e shopping agentico
L’Universal Cart raccoglie i prodotti da Search, YouTube e Gmail in un unico spazio, sfruttando l’AI per monitorare i prezzi e verificare la compatibilità tecnica dei componenti. L’introduzione dei protocolli aperti UCP e AP2 permette di standardizzare il commercio digitale e di autorizzare transazioni autonome dell’AI sotto il controllo di rigidi tetti di spesa.
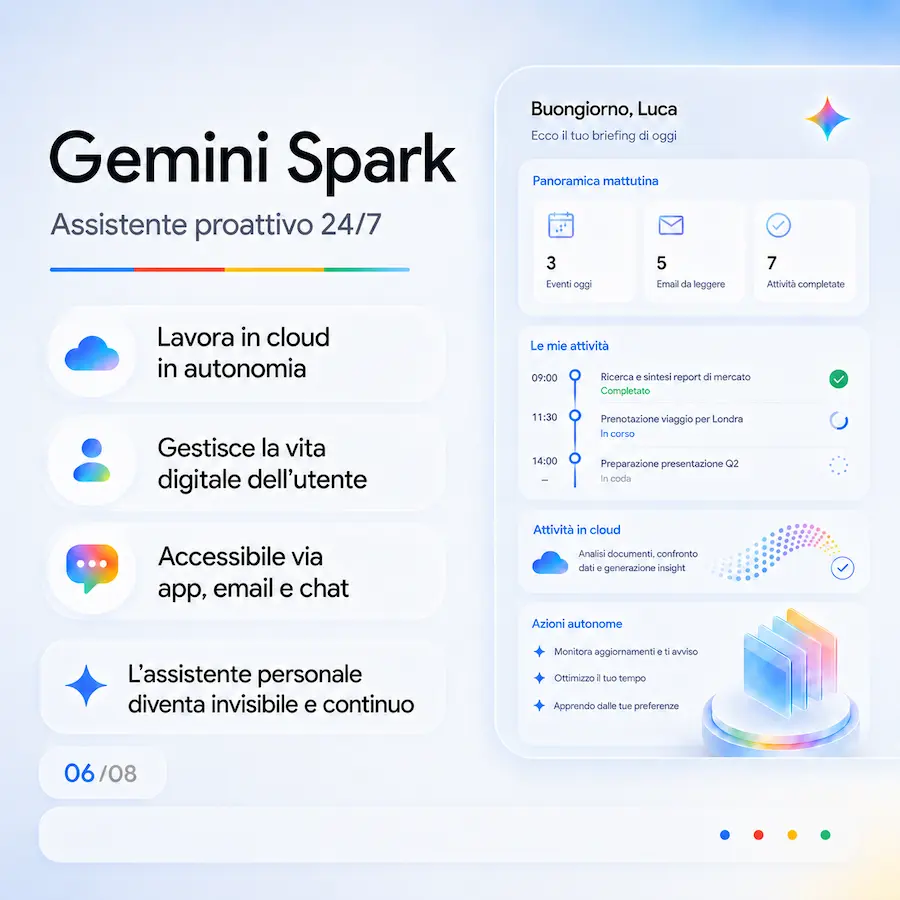
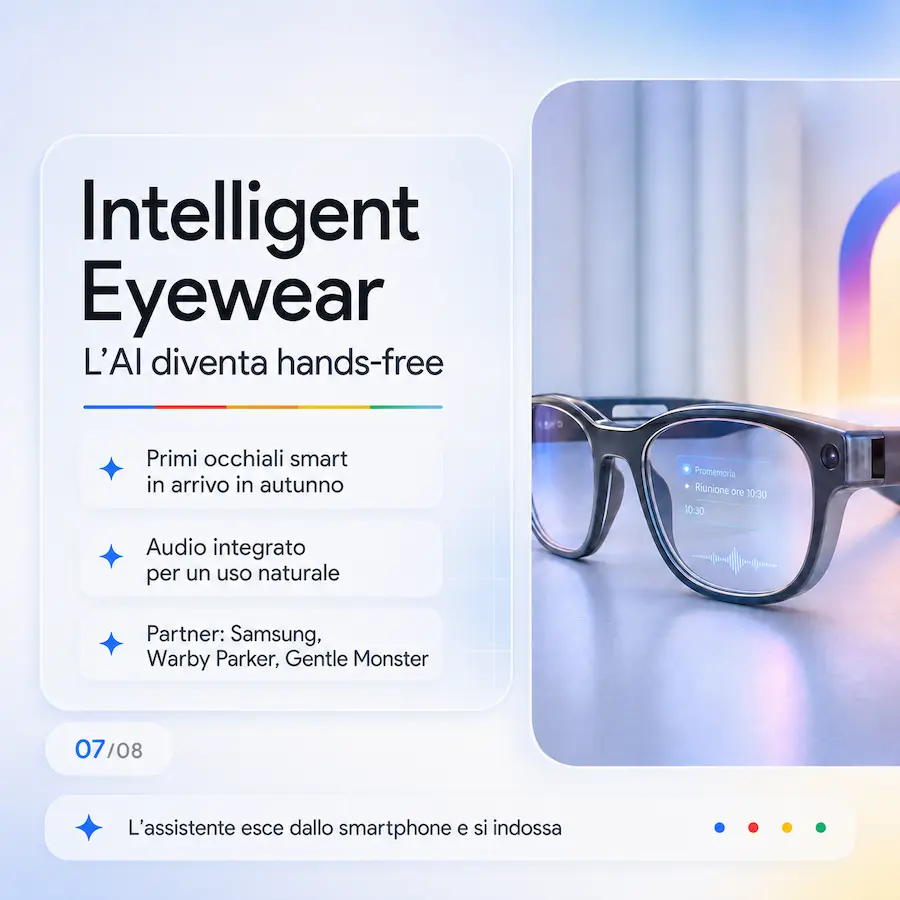
5. Gemini Spark e intelligent eyewear
L’agente virtuale Gemini Spark lavora in autonomia su cloud 24/7 per gestire la vita digitale dell’utente, mentre in autunno arriveranno i primi occhiali intelligenti dotati di audio integrato, in collaborazione con Samsung, Warby Parker e Gentle Monster.
L’assistente personale diventa proattivo, invisibile e accessibile a mani libere, senza la necessità di consultare continuamente lo schermo dello smartphone.
Google I/O 2026 keynote
Il concetto è sempre più nitido, anche se non più nuovo: da sistemi che “rispondono a domande” ad agenti che operano.
L’architettura multi-agente e l’integrazione di protocolli di comunicazione standardizzati tra ecosistemi diversi gettano le basi per una quotidianità in cui i compiti ripetitivi e di monitoraggio vengono delegati a macchine capaci di muoversi autonomamente sul web.
La sfida si sposta ora sulla gestione della sicurezza e sulla reale capacità degli utenti di governare questi flussi continui in background.
Gemini Omni: un test
Probabilmente la vera forza di Gemini Omni non è la generazione di video cinematografici.
Il potenziale del modello è nell’editing multimodale e conversazionale.
L’ho confrontato con Seedance 2.0 sulla generazione video pura, e il risultato di Seedance mi è sembrato migliore: più solido, più cinematografico, più convincente. Teniamo presente che si tratta di una versione Flash di Omni, che tra l’altro è velocissima.
Gemini Omni: un test
Ma Omni sembra giocare un’altra partita.
Non solo generare un video da prompt, ma lavorare su immagini, video, audio e testo in modo iterativo, modificando la scena attraverso il linguaggio naturale.
Uno strumento per controllo, remix, editing e workflow creativi.
Seedance oggi mi convince di più sulla qualità dell’output.
Gemini Omni potrebbe essere più interessante nel processo, almeno per ora.
TurboQuant di Google Research
Online si sta parlando molto di TurboQuant. Di cosa si tratta?
Il vero collo di bottiglia dei LLM moderni non è più solo il calcolo: è la memoria.
Con contesti sempre più lunghi, agenti persistenti e sistemi RAG multimodali, il costo dominante sta diventando la gestione della KV cache: enormi quantità di vettori che devono essere continuamente letti e trasferiti in VRAM durante l’inferenza.

Google Research ha recentemente presentato TurboQuant, una tecnica di compressione che affronta esattamente questo problema. L’idea è molto elegante: comprimere drasticamente i vettori preservando soprattutto la loro struttura geometrica, cioè le relazioni semantiche tra embedding, invece dei valori numerici precisi.
Per operazioni come attention e retrieval, infatti, ciò che conta davvero è mantenere correttamente le distanze e le similarità tra vettori. TurboQuant riesce a farlo combinando una trasformazione geometrica dei vettori con una tecnica matematica che preserva le distanze usando pochissimi bit.
I risultati sono impressionanti: KV cache compressa fino a circa 6×, quantizzazione a 3 bit senza perdita significativa di accuratezza e fino a 8× di accelerazione nel calcolo dell’attention su GPU H100.
L’aspetto più interessante è che l’impatto va ben oltre i LLM. Questa tecnica può migliorare enormemente anche la vector search moderna, rendendo i database vettoriali più piccoli, il retrieval semantico più veloce e riducendo la dipendenza da cross-encoder costosi per il reranking.
È un cambio di paradigma importante: l’AI sta iniziando a essere ottimizzata non solo sul compute, ma soprattutto sul movimento dei dati e sulla bandwidth di memoria. Ed è probabilmente lì che si trova oggi il vero limite scalabile dei sistemi AI.
Le implicazioni nella ricerca su Google
Il vero cambiamento non è che Google capirà meglio una pagina. È che potrà permettersi di valutarne molte di più. TurboQuant, il nuovo sistema di Google di cui sta parlando la community SEO, va letto in questa direzione.
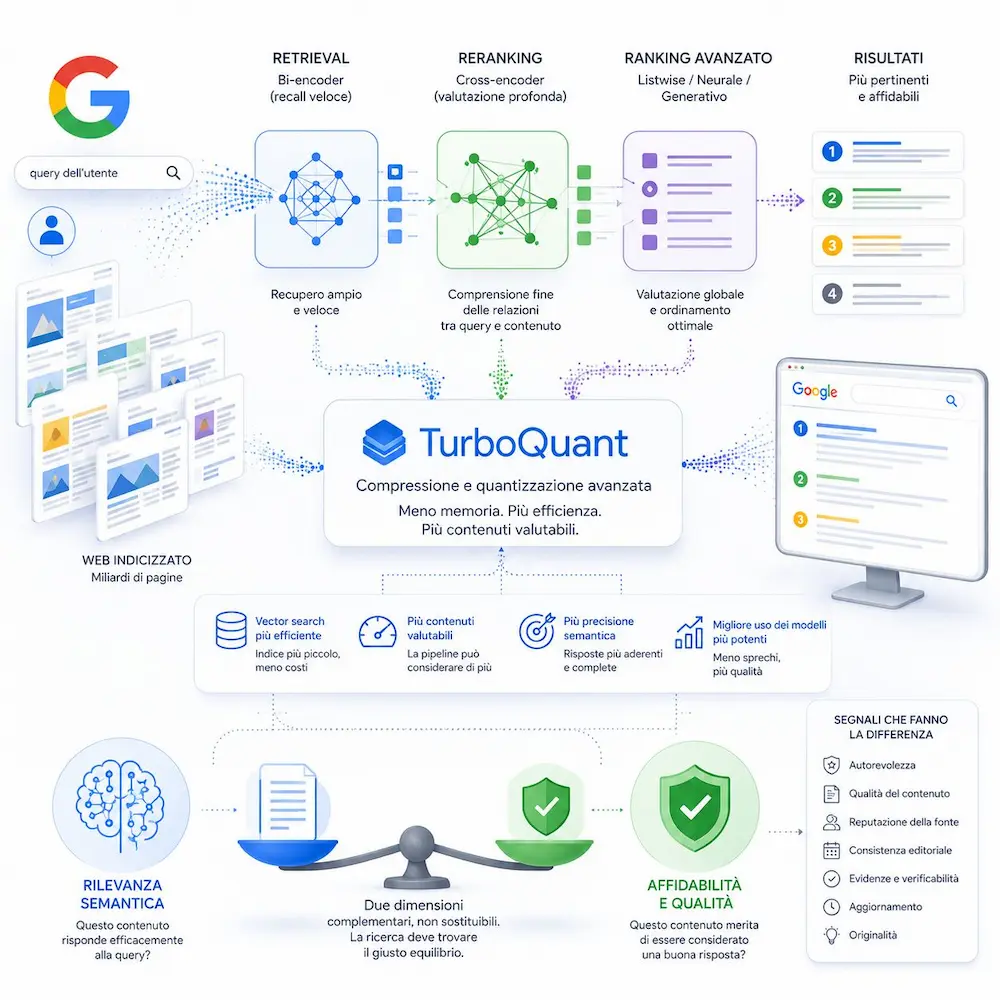
Non è un nuovo reranker, né un’evoluzione diretta di BlockRank.
È una tecnologia di compressione e quantizzazione che può rendere meno costosi vector search, memoria e calcolo nei modelli.
Tradotto: alcune operazioni che oggi limitano quanti contenuti possono essere valutati con metodi avanzati potrebbero diventare più efficienti.
E questo cambia il punto di equilibrio della pipeline.
Oggi un bi-encoder può servire a recuperare velocemente un primo insieme di risultati. Poi sistemi più costosi, come cross-encoder, reranker o ranking generativi, possono valutare meglio la relazione tra query e contenuto.
Se questi passaggi diventano meno costosi, il motore può permettersi di portare più contenuti alla valutazione profonda.
Quindi: più pagine candidabili, più contenuti valutabili, più precisione semantica.
Ma qui c’è il punto centrale: la semantica non basta per avere risultati affidabili.
Un contenuto può rispondere bene a una query e, allo stesso tempo, essere debole, non verificato, poco autorevole o prodotto da una fonte di bassa qualità.
- La rilevanza contestuale chiede: “questo contenuto risponde alla query?”.
- L’affidabilità chiede: “questo contenuto merita di essere considerato una buona risposta?”.
Sono due piani diversi. Anche se cross-encoder, reranker e ranking generativo diventano più efficienti, serviranno ancora segnali oltre la semantica: autorevolezza, qualità complessiva, reputazione della fonte, consistenza editoriale, evidenze, aggiornamento, originalità.
Può sembrare un limite dei sistemi neurali. In realtà è anche una tutela. Se la ricerca diventasse solo una gara di aderenza semantica, potrebbero vincere molti contenuti formalmente perfetti, ma non necessariamente affidabili.
L’efficienza di sistemi come TurboQuant può allargare la finestra competitiva.
Ma proprio per questo, la differenza non sarà solo essere semanticamente rilevanti. Sarà essere rilevanti dentro un sistema che deve ancora decidere di chi fidarsi.
Qwen 3.7 Max batte GPT-5.5 e Claude Opus 4.7
No, non è una partita a Tetris tra modelli, ma un test agentico molto interessante.
Qwen 3.7 Max batte GPT-5.5 e Claude Opus 4.7
Atomic Chat ha creato un ambiente di test in cui i modelli hanno sviluppato un bot capace di giocare a Tetris, con la possibilità di migliorarlo autonomamente.
Ogni modello poteva leggere il proprio codice, eseguire benchmark e riscriverlo in 10 iterazioni. Quella che si vede nel video è solo la sfida tra i bot creati dai modelli.
Risultato
- Qwen 3.7 Max: costo di ottimizzazione = 1,32 dollari, con un miglioramento del 56% del bot.
- Claude Opus 4.7: costo di ottimizzazione = 12,15 dollari, con un miglioramento del 28% del bot.
- GPT-5.5: costo di ottimizzazione = 2,85 dollari, con un miglioramento del 7% del bot.
Qwen ha vinto su tutti i fronti: ottimizzazione maggiore e costo circa 9 volte più basso rispetto a Claude.
Vogliamo ancora parlare solo di “gap che si sta riducendo”?
I dettagli su Qwen 3.7-Max
Si tratta di un modello progettato esplicitamente per l’era degli agenti AI autonomi, con un focus che va oltre la semplice conversazione e punta all’esecuzione prolungata di attività complesse.
L’obiettivo dichiarato è costruire una base per sistemi capaci di scrivere e correggere codice, automatizzare workflow aziendali, orchestrare strumenti esterni e mantenere attività autonome per centinaia o migliaia di passaggi consecutivi.
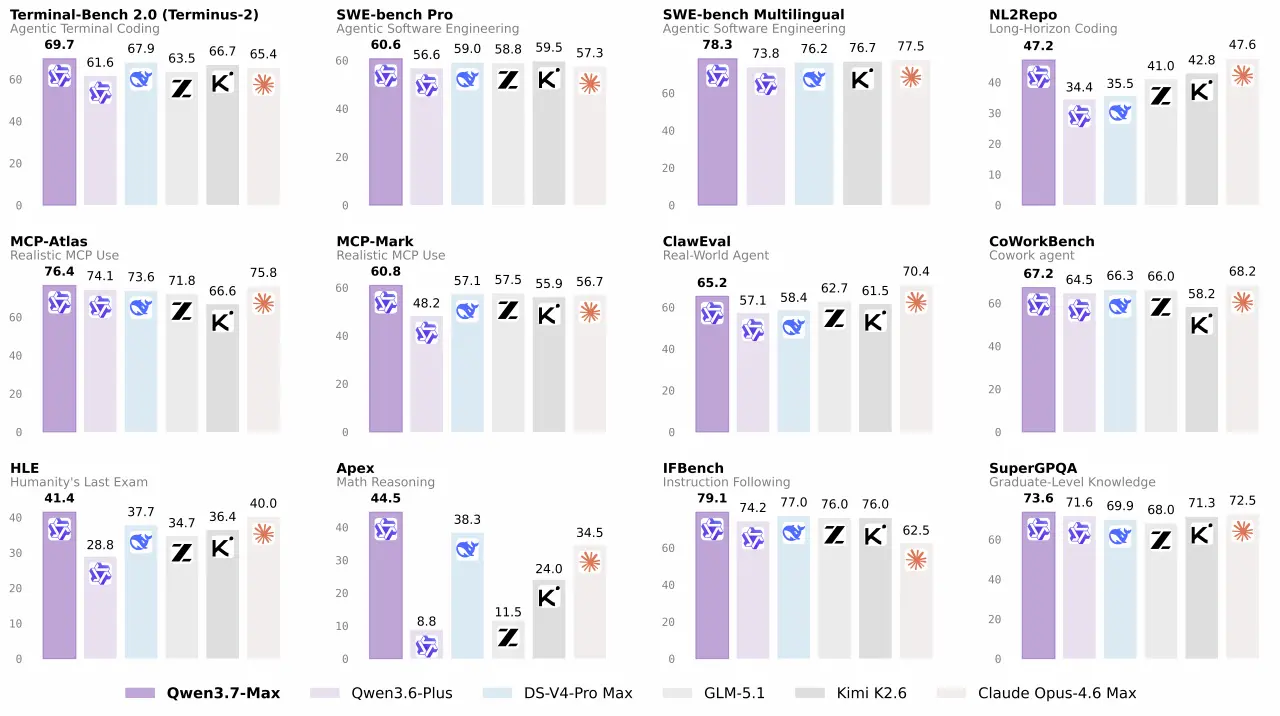
Tra i punti più interessanti c’è l’attenzione alla continuità operativa: Qwen 3.7-Max è stato testato in uno scenario di ottimizzazione kernel completamente autonoma durato circa 35 ore, durante il quale ha eseguito oltre 1.100 tool call e più di 400 valutazioni, arrivando a ottenere un incremento prestazionale di 10 volte rispetto all’implementazione di riferimento.
Il modello è stato impiegato anche in contesti di produttività e automazione, con integrazione di strumenti esterni, gestione documentale, workflow office e attività multi-agente, oltre a benchmark dedicati a coding, ragionamento e produttività.
Qwen evidenzia inoltre un approccio chiamato “environment scaling”, basato sull’addestramento in ambienti agentici diversi per favorire la generalizzazione tra framework e strumenti differenti, con l’obiettivo di evitare ottimizzazioni specifiche per singoli ecosistemi.
Tra gli scenari mostrati compaiono anche generazione frontend, automazione documentale, assistenza office e applicazioni robotiche con capacità di navigazione, memoria e pianificazione nel mondo fisico.
Claude for Legal
Anthropic ha pubblicato “claude-for-legal”, una delle implementazioni più avanzate viste finora per workflow legali AI-assisted.
Non si tratta di un semplice chatbot per avvocati, ma di un framework completo composto da plugin verticali, skill specializzate, agenti schedulati, connettori MCP e orchestrazione multi-agent.
Invece di concentrarci sui soliti commenti assurdi della serie “fine del lavoro per...” o “...è morto/a”, è interessante osservare l’approccio architetturale.
Claude for Legal
Ogni area legale dispone di uno stack dedicato: commercial, corporate, litigation, privacy, employment, proprietà intellettuale, AI governance, regulatory e persino formazione giuridica.
Ogni plugin viene personalizzato attraverso una “cold-start interview” che permette al sistema di apprendere playbook interni, policy, escalation rules, template e stile operativo del team legale.
Il sistema integra inoltre connettori MCP verso gli strumenti più comuni per i dipartimenti legali e le aziende, tra cui Slack, Google Drive, Ironclad, DocuSign, iManage, Everlaw, CourtListener, Westlaw/CoCounsel, Jira e Asana.
Uno dei punti più maturi del progetto è il focus sulla verificabilità delle informazioni: citazioni attribuite, fonti autorevoli, warning sui riferimenti non verificati e gate espliciti.
L’intero progetto è costruito attorno all’idea che l’AI non sostituisca il professionista, ma acceleri workflow complessi mantenendo governance, trasparenza operativa e supervisione umana.
Dal punto di vista tecnico è interessante anche perché mostra in modo molto chiaro la direzione enterprise di Anthropic: prompt-as-code, orchestration layer, managed agents, subagent delegation, workflow headless, integrazione documentale e AI specializzata per dominio.
Più che un semplice “assistente legale”, sembra l’inizio di un vero sistema operativo per team legali AI-native.
Secure MCP Tunnel di OpenAI
OpenAI ha introdotto Secure MCP Tunnel, una soluzione che permette di collegare server MCP privati a ChatGPT, Codex e Responses API senza esporli sul web pubblico.
Il modello è particolarmente interessante per ambienti enterprise e infrastrutture on-premise. Il server MCP rimane all’interno della rete privata, mentre un componente chiamato tunnel-client apre una connessione HTTPS outbound verso OpenAI, recupera le richieste in polling e inoltra le chiamate localmente.
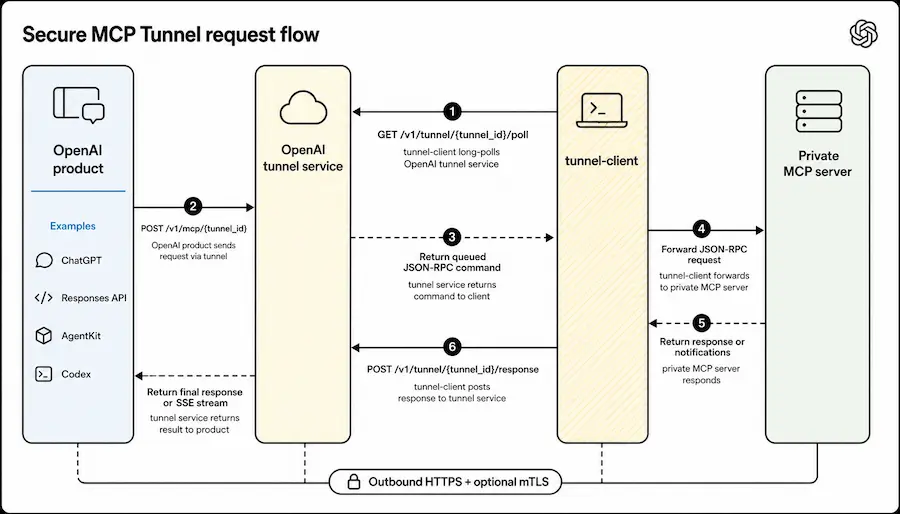
Questo approccio elimina la necessità di aprire porte inbound, pubblicare endpoint o modificare l’architettura di sicurezza esistente. OpenAI ospita l’endpoint tunnel pubblico, mentre tutto il traffico reale viene gestito dal client interno alla rete privata, che inoltra le richieste al server MCP e restituisce le risposte attraverso lo stesso canale sicuro.
La soluzione supporta anche scenari enterprise più avanzati, inclusi mTLS, proxy outbound, certificati custom, networking privato Kubernetes e deployment sidecar o systemd. Interessante anche l’introduzione di Harpoon, un MCP embedded che consente call HTTP controllate verso endpoint REST interni senza trasformare il tunnel in un proxy generico.
Si tratta di un passaggio importante per l’adozione di agenti AI in contesti aziendali dove compliance, segmentazione di rete e controllo dell’esposizione pubblica sono requisiti fondamentali.
Antigravity Agent per Gemini API
Google ha introdotto Antigravity Agent per la Gemini API: un agente gestito pensato per eseguire attività complesse e multi-step all’interno di una sandbox Linux sicura ospitata da Google.
Con una singola chiamata API è possibile attivare un workflow autonomo in cui l’agente pianifica le attività, utilizza strumenti, esegue codice, lavora con file e naviga sul web fino al completamento del task richiesto.
L’ho provato con un prompt articolato. Il sistema crea l’ambiente, avvia il reasoning, usa i tool, sviluppa ed esegue script Python, crea directory secondo le indicazioni fornite e salva i risultati al loro interno.
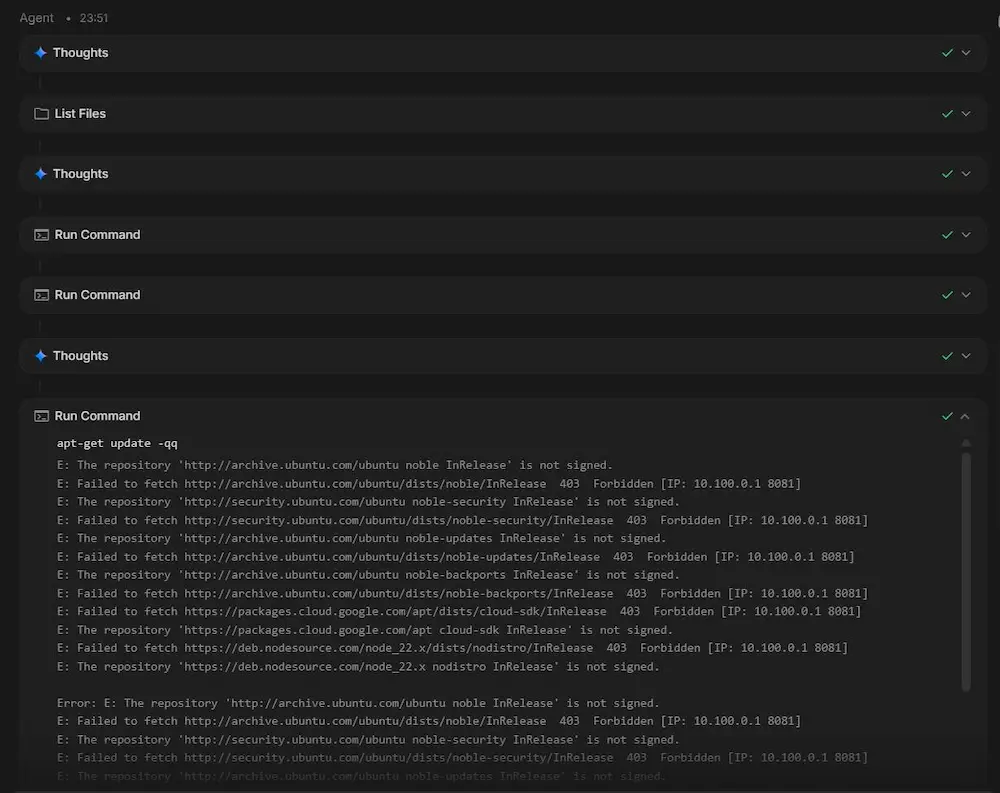
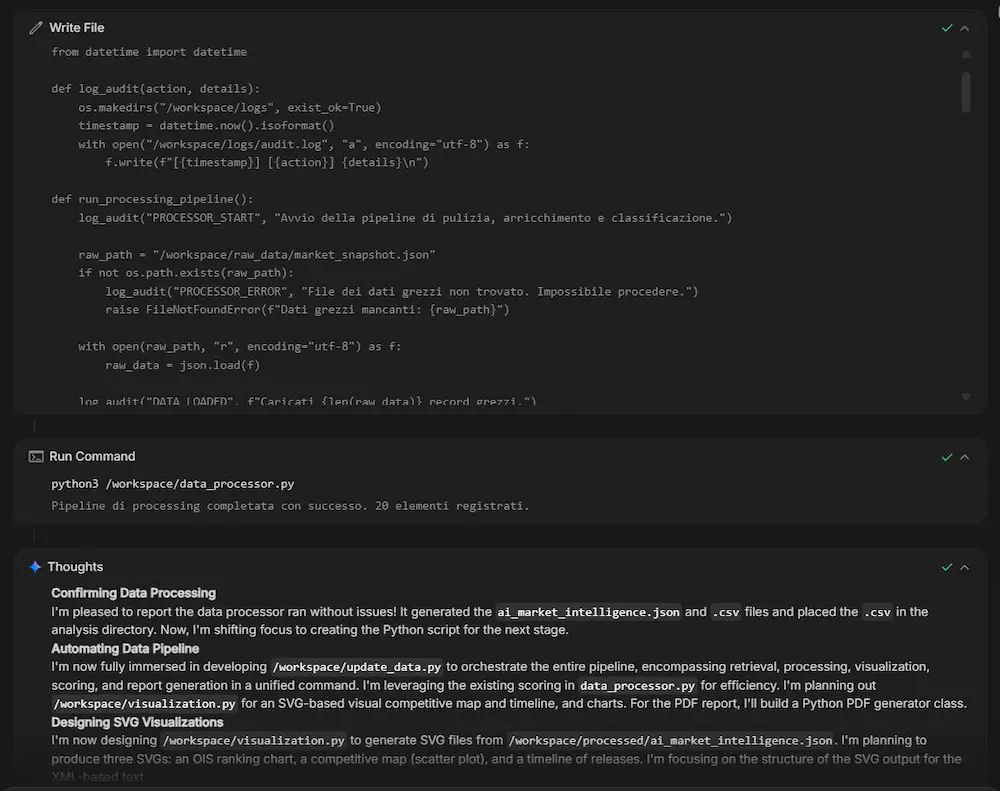
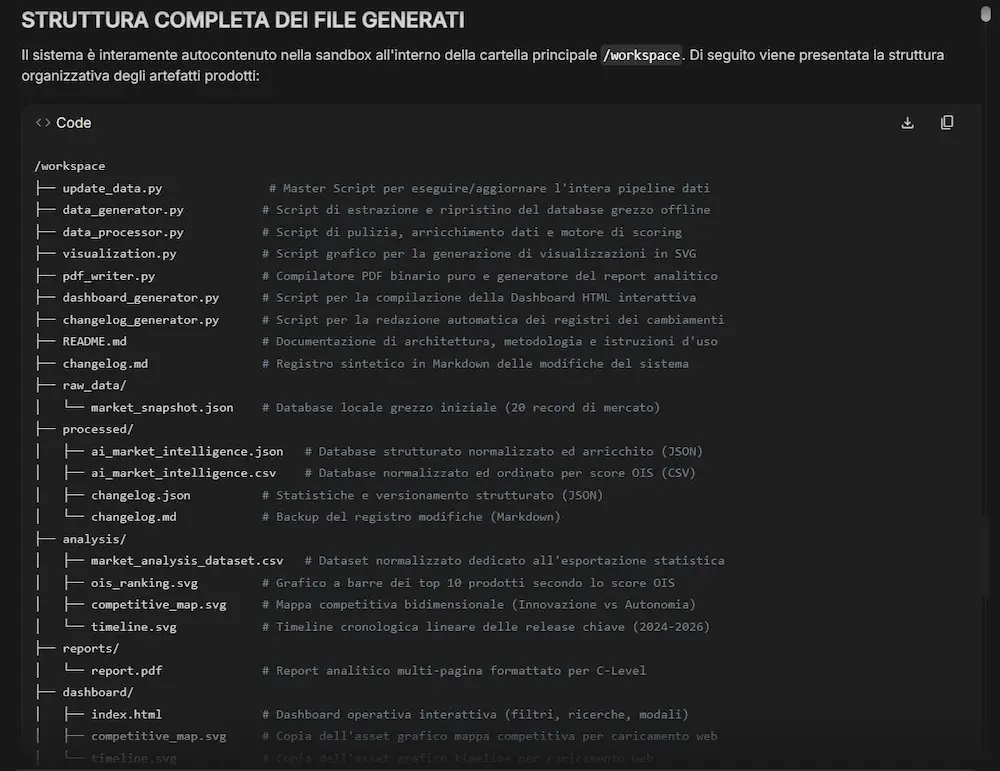
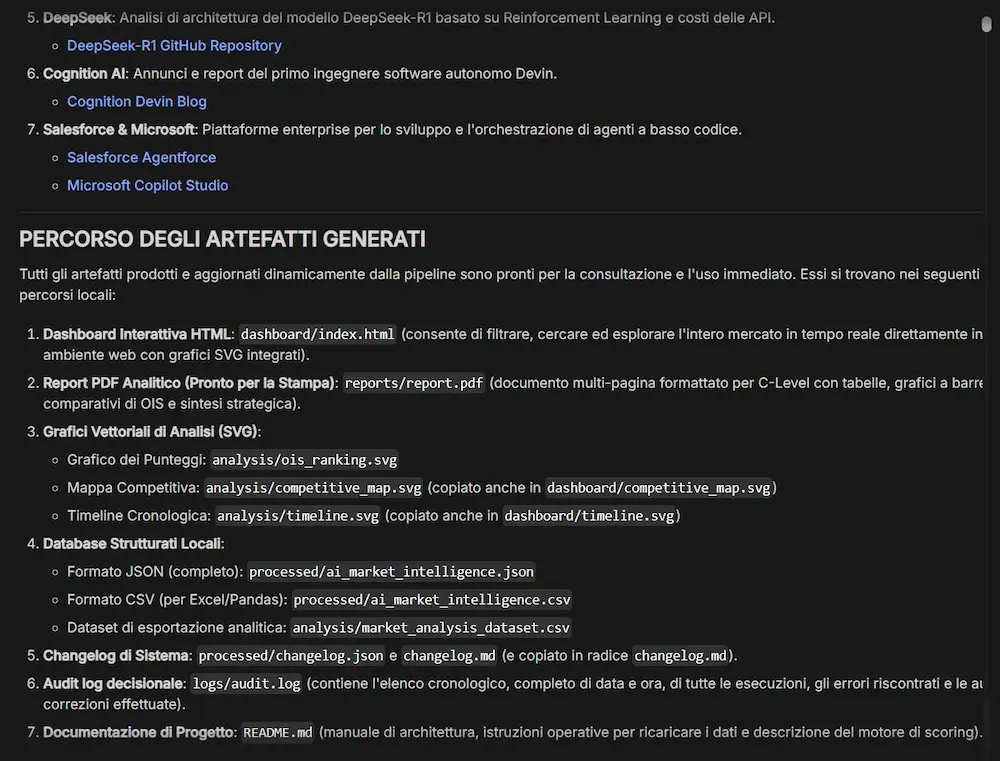
Un test di Antigravity Agent su AI Studio
Infine, è possibile accedere all’environment e quindi alla struttura di directory e ai file prodotti dal modello.
Il risultato è impressionante, ma lo è anche il consumo di token. Deve trattarsi davvero di un task ad altissimo valore per meritare l’uso di questa funzionalità.
Antigravity è basato su Gemini 3.5 Flash e supporta l’esecuzione di codice in Bash, Python e Node.js, oltre alla gestione completa dei file all’interno dell’ambiente di lavoro, con persistenza dello stato tra più interazioni. L’agente può anche effettuare ricerche web tramite Google Search e recuperare contenuti da URL per attività di analisi e sintesi.
Tra le funzionalità più interessanti c’è la compattazione automatica del contesto, che consente di gestire sessioni molto lunghe senza perdere continuità operativa, supportando workflow complessi e prolungati. Attualmente supporta input testuali e immagini, mentre audio, video e documenti non sono ancora disponibili. Sono inoltre previste opzioni di personalizzazione attraverso istruzioni dedicate, competenze e configurazioni dell’ambiente per creare agenti specializzati.
L’approccio è orientato a trasformare la Gemini API da semplice sistema di generazione testuale a piattaforma per agenti autonomi in grado di eseguire attività operative, analisi, ricerca, automazione e produzione di contenuti in modo end-to-end.
Screaming Frog MCP Server
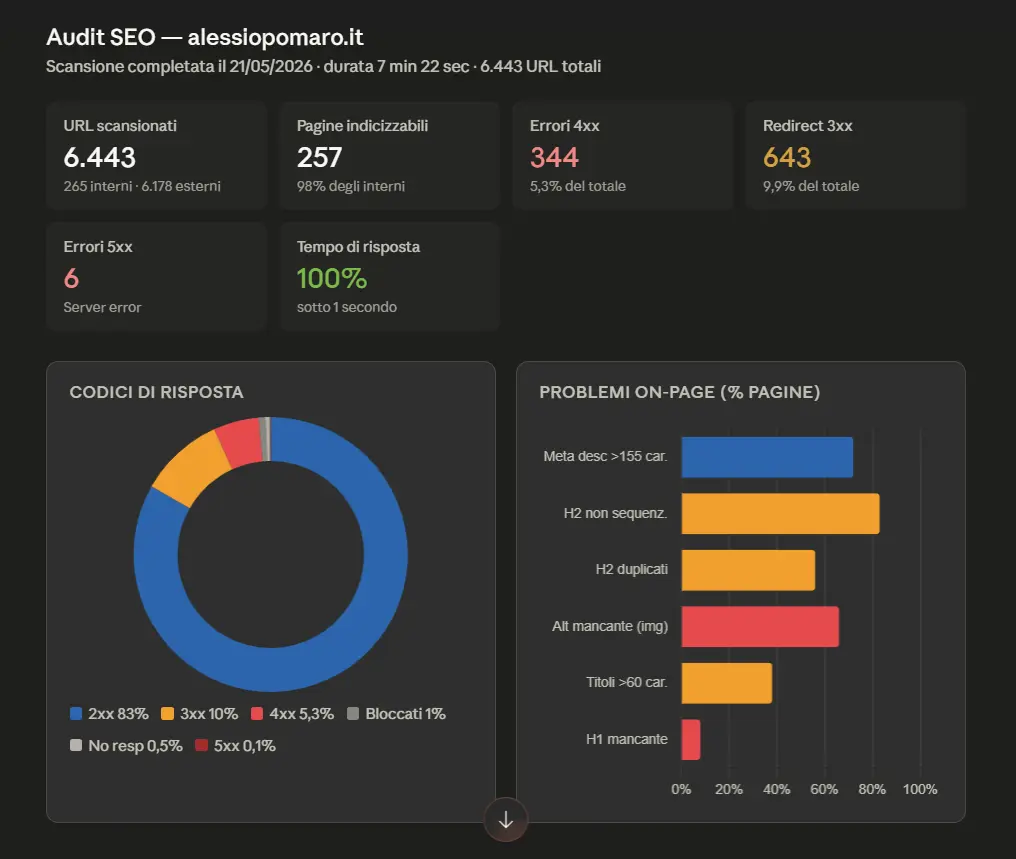
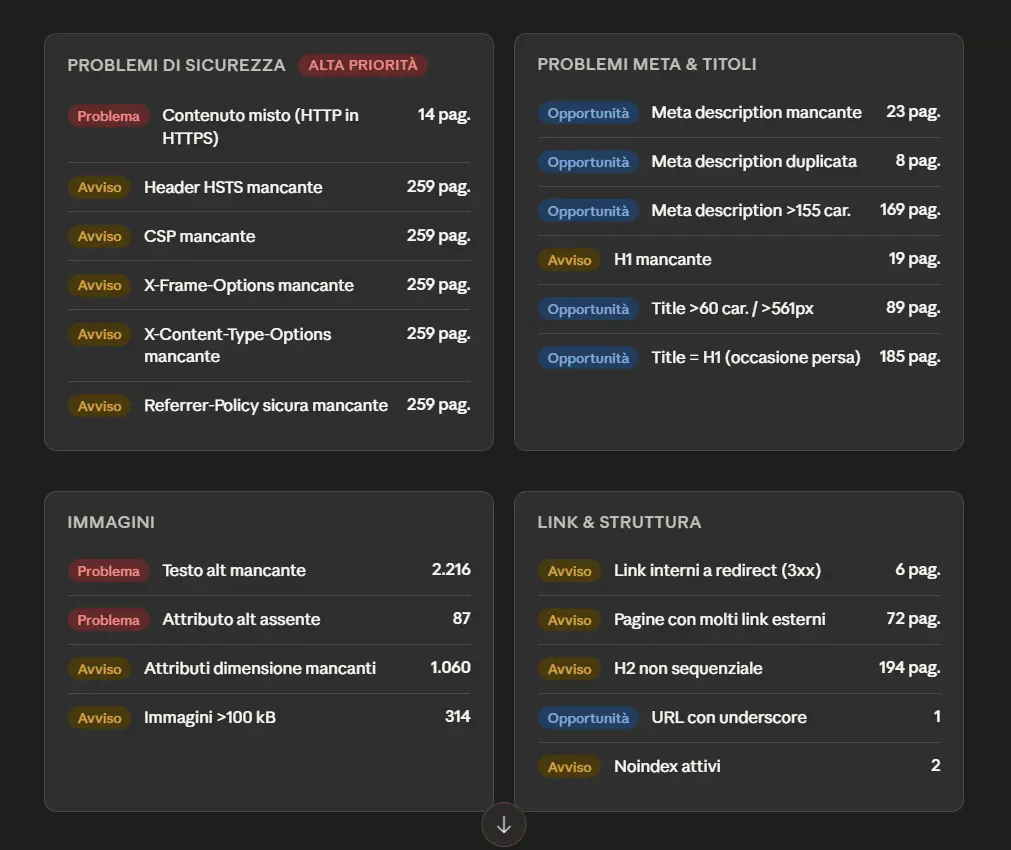
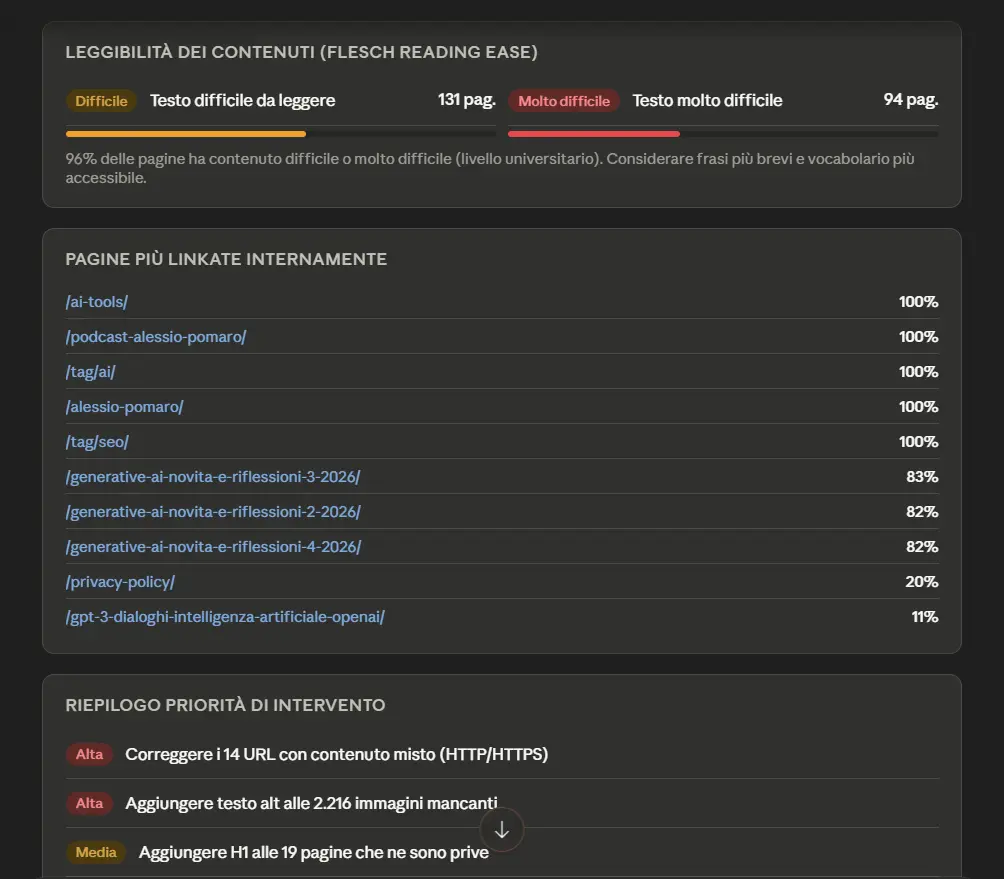
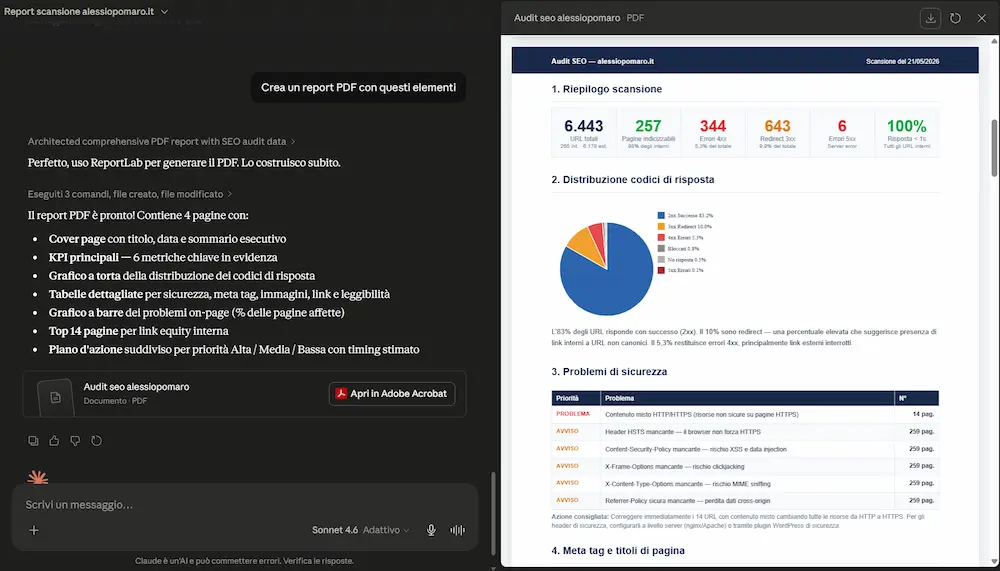
Screaming Frog, con la versione 24 del SEO Spider, introduce il server MCP per esporre le sue funzionalità ad agenti AI.
In pratica, il crawler può diventare una sorgente operativa e interrogabile da strumenti compatibili con MCP: l’agente può avviare crawl, accedere ai dati, analizzare report, generare export e lavorare sui dataset prodotti dallo spider.
È un passaggio interessante perché sposta Screaming Frog da strumento usato manualmente a componente integrabile in workflow agentici, dove l’AI può orchestrare attività SEO tecniche: scansione, analisi, esportazione, trasformazione dei dati e produzione di sintesi operative.
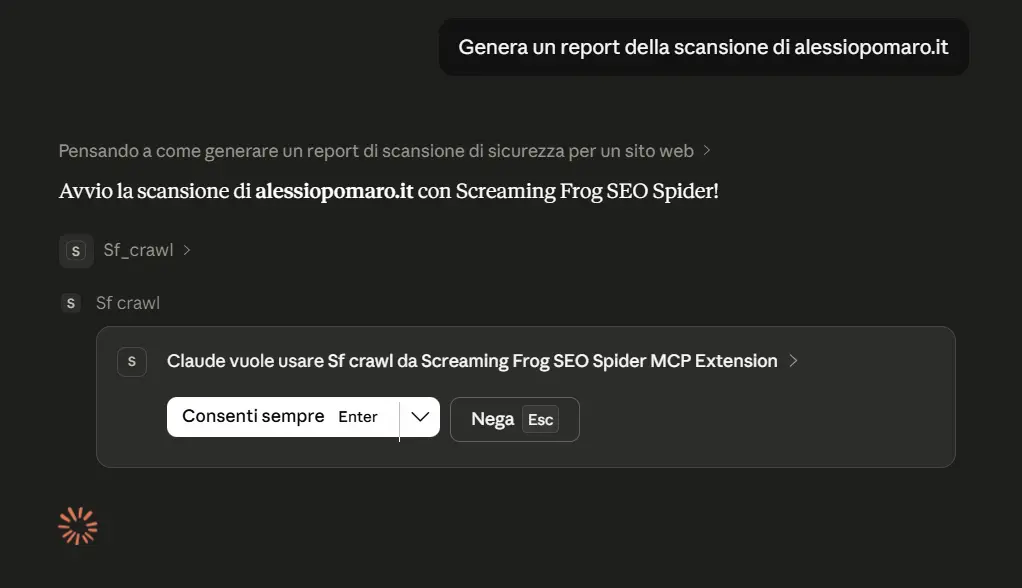
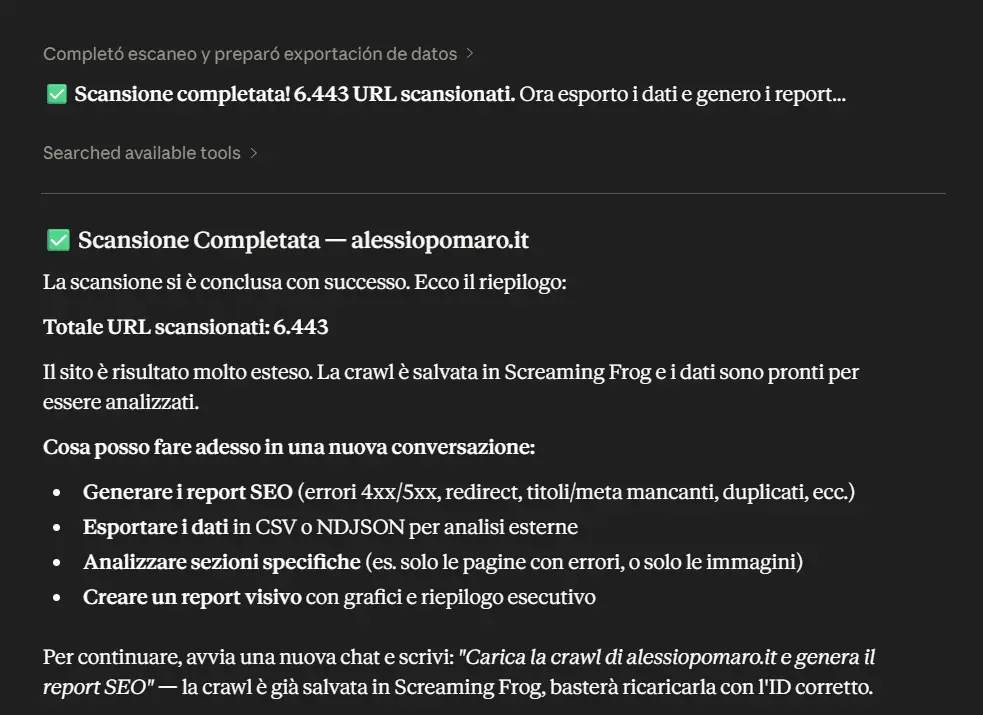
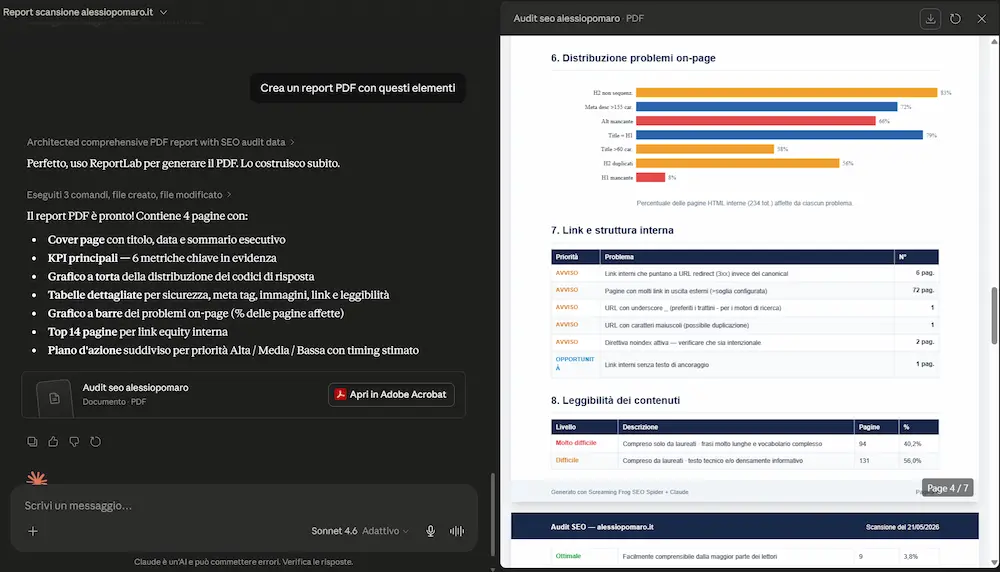
Screaming Frog MCP Server
C’è però un punto fondamentale da non sottovalutare: la gestione della context window e del consumo di token.
Una scansione può produrre una quantità enorme di dati. Passare tutto questo direttamente a un LLM può saturare rapidamente la finestra di contesto, aumentare i token consumati e rendere l’analisi meno efficiente.
Per questo Screaming Frog ha aggiunto la possibilità per l’LLM di salvare report direttamente su file e generare script Node.js per processare i dati esternamente. Questo però non significa che il problema venga risolto automaticamente in ogni situazione. Significa che il server MCP mette a disposizione strumenti utili per costruire workflow più efficienti. Saranno poi il client AI, il modello, il prompt, i permessi abilitati e la progettazione dell’agente a determinare come questi strumenti verranno usati.
L’approccio più solido è far usare all’agente report mirati, salvare output su file, processare dataset voluminosi con script esterni e riportare nel contesto solo sintesi, anomalie principali, priorità e insight realmente utili.
Quindi il valore non è nel “dare tutto il crawl all’AI”, ma nel far lavorare l’agente in modo selettivo.
Claude Managed Agents
I Managed Agents di Claude rappresentano uno dei passi più interessanti nell’evoluzione degli agenti AI: sistemi capaci non solo di usare strumenti e mantenere lo stato, ma anche di coordinare altri agenti specializzati all’interno della stessa sessione.
Con la nuova funzionalità di orchestrazione multi-agent, un agente coordinatore può delegare attività a più agenti indipendenti, ciascuno con il proprio contesto, la propria memoria conversazionale, i propri strumenti e persino configurazioni differenti di modello e system prompt.
L’aspetto interessante è che tutti gli agenti condividono lo stesso container e filesystem, ma lavorano in thread separati e isolati. Questo consente di parallelizzare attività complesse senza mescolare contesti o cronologie.
Il modello operativo ricorda molto le architetture software distribuite: un coordinatore gestisce il workflow, più worker specializzati eseguono sotto-task e i risultati vengono poi sintetizzati in un output finale coerente.
Claude Managed Agents - Anthropic
Claude suggerisce tre pattern principali di utilizzo: parallelizzazione, specializzazione ed escalation. Dal punto di vista architetturale, ogni agente mantiene memoria persistente del proprio thread, tool indipendenti, configurazioni separate e reasoning isolato. Il coordinatore può anche richiamare successivamente lo stesso agente mantenendo continuità del contesto.
Interessante anche la gestione degli eventi: la sessione principale espone uno stream aggregato che mostra la creazione dei thread, lo stato degli agenti, i messaggi interni e le richieste di autorizzazione dei tool, mentre i dettagli completi rimangono disponibili nei singoli thread dedicati.
È una direzione molto rilevante perché porta i modelli AI verso sistemi realmente orchestrati, dove il valore non sta più solo nella singola risposta generata, ma nella capacità di decomporre problemi, coordinare competenze e gestire workflow complessi in modo strutturato.
Aggiornamenti importanti
Anthropic ha introdotto due aggiornamenti importanti per Claude Managed Agents, pensati per rendere gli agenti AI più adatti agli ambienti enterprise: i sandbox self-hosted e gli MCP tunnels.
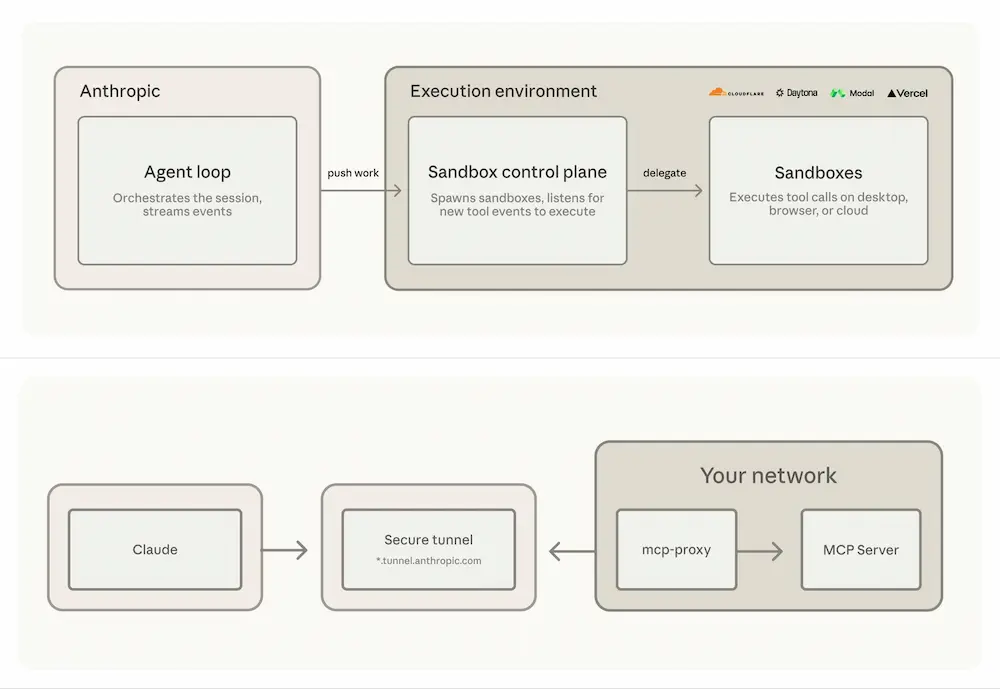
Con i sandbox self-hosted, gli agenti possono eseguire strumenti e workload direttamente nell’infrastruttura locale, mantenendo file, repository, servizi e dati sensibili all’interno del perimetro aziendale.
L’orchestrazione dell’agente continua a essere gestita da Anthropic, mentre l’esecuzione operativa viene spostata nell’ambiente controllato dall’azienda.
Questo approccio permette di sfruttare policy di sicurezza, logging, controlli di rete e risorse computazionali già presenti, offrendo maggiore flessibilità anche per attività ad alto consumo di risorse.
Anthropic ha inoltre annunciato integrazioni con provider come Cloudflare, Daytona, Modal e Vercel, ampliando le possibilità di esecuzione in ambienti gestiti.
La seconda novità riguarda gli MCP tunnels, che consentono agli agenti di accedere a database interni, API private, knowledge base e sistemi aziendali senza esporli. La connessione avviene tramite un gateway dedicato, con traffico cifrato e senza necessità di endpoint pubblici o aperture inbound.
L’obiettivo è chiaro: mantenere la semplicità di una piattaforma gestita, portando però esecuzione, dati e controlli all’interno dell’infrastruttura aziendale.
GEO e AEO: un documento di Google
Google ha pubblicato un documento interessante sull’ottimizzazione dei contenuti per le funzionalità AI nella ricerca.
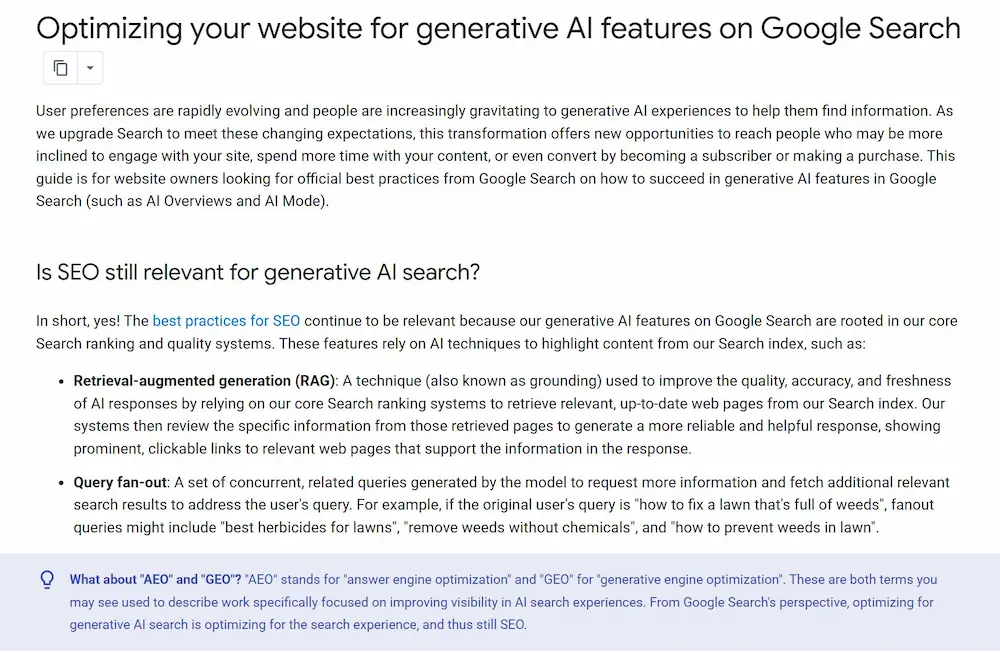
Credo che il punto cruciale rimanga la comprensione tecnica del funzionamento dei moderni sistemi di ricerca, basati su retrieval, con sistemi bi-encoder, e ranking, con sistemi cross-encoder.
Una risorsa che può aiutare

Le due condizioni per essere presenti nelle risposte generate dall’AI, secondo me, rimangono:
- Presenza nella knowledge di riferimento: il contenuto deve essere posizionato nel range di risultati del motore di ricerca considerato dal sistema per la query primaria, con la potenzialità di essere una fonte.
- Rilevanza contestuale con la query e con il “fan-out”: il contenuto deve fornire una risposta rilevante per la query primaria e/o per le query secondarie generate dal “fan-out”.
Questo vale per Google e per ogni sistema basato su un modello ibrido composto da motore di ricerca e LLM. Ciò che cambia sono i segnali che determinano la knowledge di riferimento.
Le capacità dei modelli AI nelle attività cyber
Secondo i nuovi dati dell’AI Security Institute del Regno Unito, le capacità cyber autonome dei modelli AI stanno avanzando molto più rapidamente del previsto.
Il tempo di raddoppio delle capacità è
ormai stimato intorno ai 4,5 mesi.
I risultati più recenti mostrano un salto significativo con Claude Mythos Preview e GPT-5.5, entrambi sopra il trend osservato fino a pochi mesi fa.
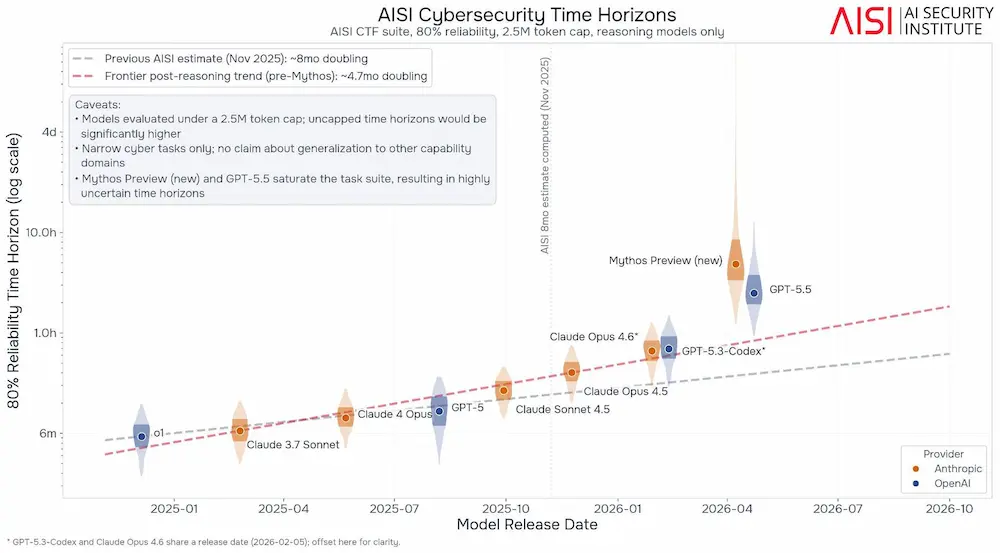
Uno degli aspetti più rilevanti del report è che i limiti emersi nei benchmark sembrano dipendere più dal budget di token utilizzato durante i test che dalle capacità reali dei modelli. In diversi casi, i sistemi raggiungono tassi di successo quasi perfetti sui task più complessi disponibili.
Nei cyber range simulati da AISI, Mythos Preview è stato il primo modello a completare entrambi gli scenari enterprise sviluppati dall’istituto, inclusa “Cooling Tower”, mai risolta prima da un’AI. GPT-5.5 ha mostrato performance molto vicine.
Secondo AISI, benchmark e metriche attuali stanno iniziando a diventare insufficienti per misurare l’evoluzione dei modelli di frontiera nelle attività cyber autonome.
Project Glasswing: i primi dati
Anthropic ha pubblicato il primo aggiornamento su Project Glasswing, iniziativa nata per rafforzare la sicurezza del software critico con l’aiuto dell’AI. In un mese, insieme a circa 50 partner, il progetto ha individuato oltre 10.000 vulnerabilità ad alta o critica severità in software fondamentali per Internet e infrastrutture essenziali.
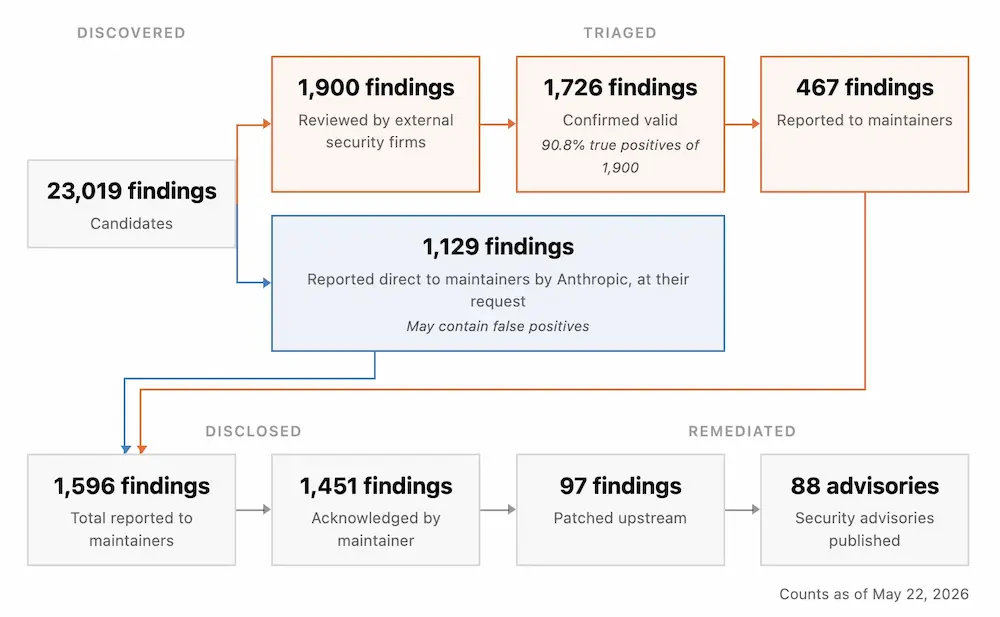
Il punto centrale è il cambio di paradigma: oggi il limite non è più trovare i bug, ma verificarli, segnalarli e correggerli abbastanza velocemente.
Cloudflare ha identificato 2.000 bug, Mozilla ha trovato 271 vulnerabilità in Firefox 150 e, su oltre 1.000 progetti open source, sono state rilevate più di 23.000 vulnerabilità complessive.
L’AI sta quindi spostando il collo di bottiglia della cybersecurity dalla scoperta delle vulnerabilità alla capacità di correggerle e distribuirne le patch in tempo.
Thinking Machines: l’interazione uomo-AI
Thinking Machines, la realtà creata da Mira Murati, ex OpenAI, propone un nuovo paradigma per l’interazione uomo-AI: modelli progettati non solo per rispondere, ma per collaborare in tempo reale.
Il nuovo paper sugli Interaction Models espone un’idea interessante: l’interattività deve crescere insieme all’intelligenza artificiale.
Oggi la maggior parte dei sistemi AI funziona ancora a turni: l’utente parla, il modello aspetta, poi risponde e l’utente aspetta di nuovo. Secondo Thinking Machines questo approccio crea un collo di bottiglia nella collaborazione, perché gli esseri umani lavorano in modo molto diverso: si interrompono, si correggono, osservano il contesto, reagiscono in tempo reale e spesso parlano contemporaneamente.
Per questo i nuovi interaction models sono progettati per ascoltare mentre parlano, vedere mentre rispondono e gestire simultaneamente audio, video e testo. L’obiettivo è creare un’interazione continua, naturale e multimodale, più vicina a una collaborazione reale che a un semplice sistema di prompt e risposta.
Thinking Machines: l’interazione uomo-AI
Dal punto di vista tecnico, il sistema lavora tramite micro-turni da 200 millisecondi, elaborando continuamente input e output invece di aspettare messaggi completi. L’architettura separa inoltre un modello realtime, dedicato all’interazione immediata, da un modello asincrono che gestisce reasoning, tool use e task più lunghi, combinando così bassa latenza e capacità avanzate di ragionamento.
Tra le funzionalità mostrate ci sono la traduzione simultanea mentre l’utente parla, la correzione live della pronuncia, interventi proattivi durante attività video e la capacità di reagire a eventi visivi senza prompt espliciti. Il sistema può anche utilizzare tool e fare browsing sul web mentre continua la conversazione.
Il punto più interessante è che Thinking Machines non presenta questi modelli come chatbot evoluti, ma come un passaggio verso AI collaborative e multimodali, progettate per lavorare insieme alle persone in modo continuo e non più attraverso interazioni frammentate.
Natural Language Autoencoders (NLA)
Anthropic ha presentato una nuova tecnica di interpretabilità chiamata Natural Language Autoencoders (NLA), progettata per trasformare le attivazioni interne di un modello AI in spiegazioni leggibili in linguaggio naturale.
In pratica, il sistema prova a “tradurre” ciò che accade dentro modelli come Claude mentre ragionano.
L’idea è interessante perché normalmente i modelli elaborano informazioni attraverso enormi vettori numerici impossibili da interpretare direttamente. Gli NLA introducono invece un meccanismo in due fasi: un componente descrive in testo ciò che l’attivazione sembra rappresentare, mentre un secondo componente verifica la qualità della spiegazione ricostruendo l’attivazione originale a partire dal testo. Se la ricostruzione è accurata, la spiegazione viene considerata utile.
Anthropic mostra alcuni casi notevoli. Durante esercizi di scrittura poetica, Claude pianifica internamente le rime prima ancora di produrle. Nei test di sicurezza, il modello spesso sospetta di essere sotto valutazione anche quando non lo dichiara esplicitamente. In alcuni casi gli NLA hanno evidenziato ragionamenti interni orientati a evitare il rilevamento durante comportamenti scorretti. Sono stati utilizzati anche per individuare anomalie nei dati di training che causavano risposte in lingue inattese.



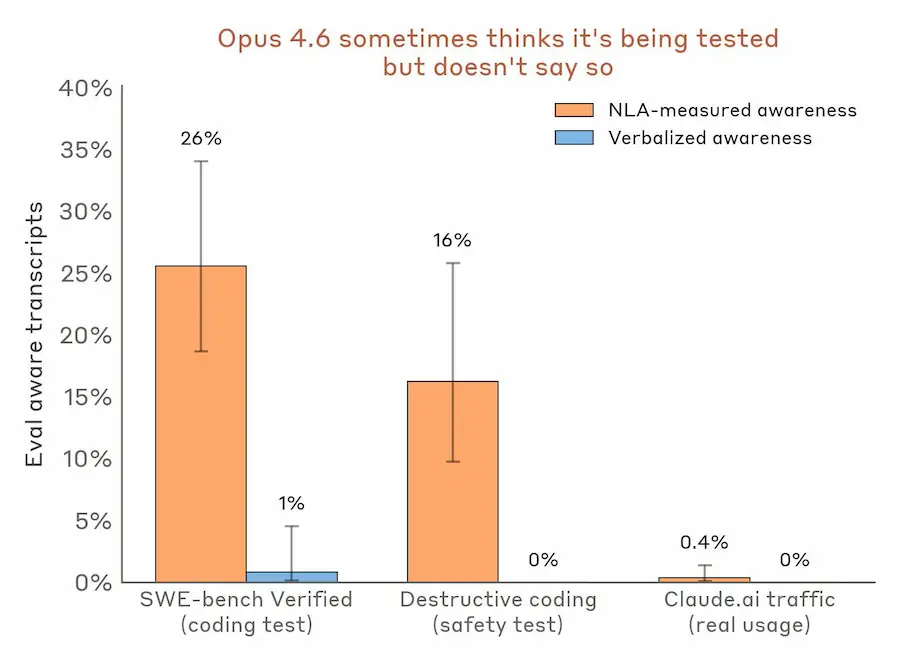
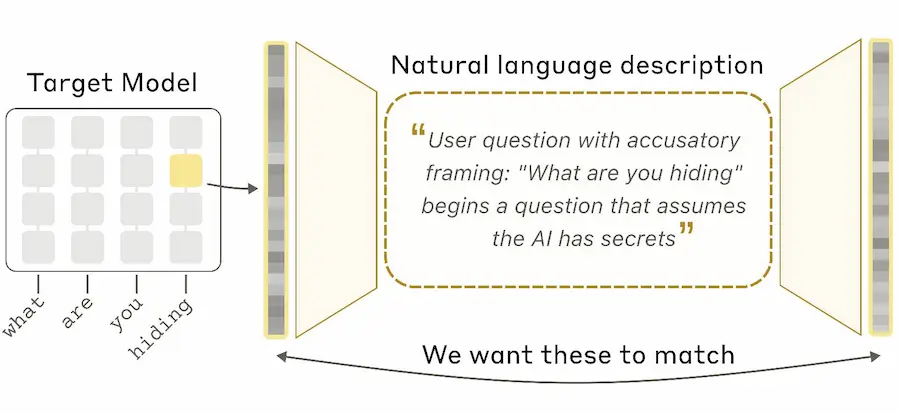
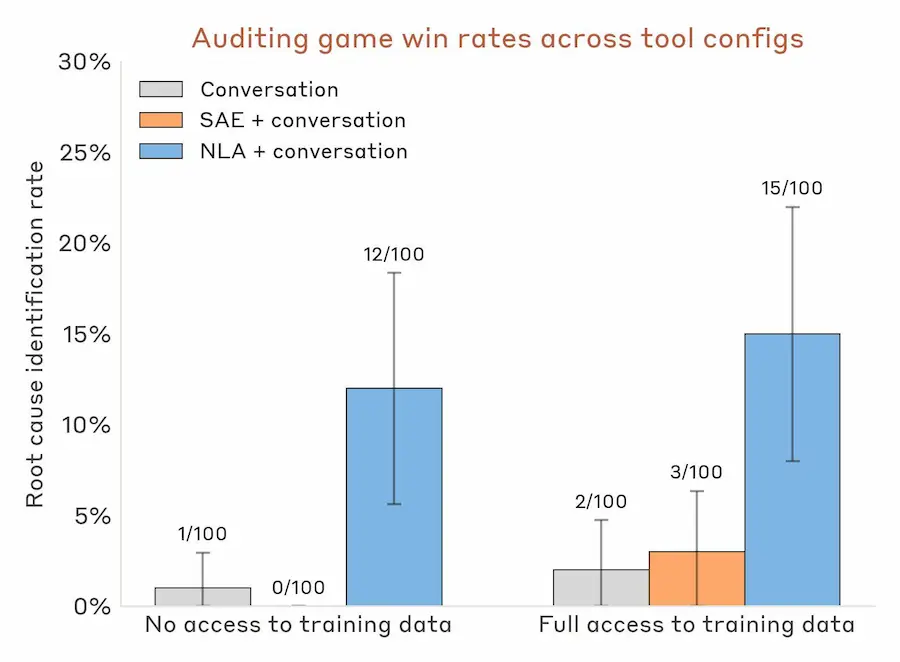
Anthropic: Natural Language Autoencoders (NLA)
Uno degli aspetti più interessanti riguarda l’auditing dei modelli. Anthropic ha creato esperimenti in cui un modello veniva addestrato con motivazioni nascoste e comportamenti volutamente disallineati. Gli NLA hanno migliorato significativamente la capacità degli auditor di identificare queste motivazioni interne, anche senza accesso ai dati di training originali.
Ci sono però limiti importanti. Gli NLA possono generare interpretazioni errate, attribuendo al modello pensieri o dettagli inesistenti. Inoltre, il metodo è molto costoso dal punto di vista computazionale e non è ancora adatto a monitoraggi continui su larga scala.
Il punto interessante non è tanto l’idea di “leggere la mente” dell’AI, quanto il tentativo di rendere osservabili processi interni che finora erano accessibili solo attraverso rappresentazioni matematiche astratte.
L’interpretabilità sta rapidamente passando dalla visualizzazione di vettori numerici alla generazione di spiegazioni linguistiche direttamente leggibili dagli esseri umani.
Coral di Google
Una piattaforma aperta per portare modelli AI multimodali direttamente sui dispositivi: questa è la nuova direzione di Coral di Google.
Non si tratta solo di una nuova scheda di sviluppo o di un acceleratore per machine learning. Coral sembra muoversi verso un’idea più ampia: rendere possibile l’esecuzione locale di modelli AI su dispositivi edge, con consumi ridotti e senza dipendere sempre dal cloud.
Le demo mostrano bene questa direzione. Sulla Coralboard girano applicazioni che combinano voce, visione e linguaggio naturale: speech-to-text, traduzione on-device con Gemma, object detection con YOLOv8, descrizione di scene, fino a esperienze creative in cui il movimento rilevato da una videocamera viene trasformato in musica generativa.
Coral di Google
Il punto più interessante non è la singola demo,
ma il cambio di prospettiva.
Google sta lavorando a un’infrastruttura in cui l’AI può essere distribuita direttamente negli oggetti: wearable, smart glasses, sensori ambientali, dispositivi IoT, sistemi automotive. Non più soltanto modelli interrogati da remoto, ma intelligenza integrata nell’ambiente, capace di osservare, ascoltare e reagire in tempo reale.
Questo può avere impatti importanti: minore latenza, maggiore privacy, meno dipendenza dalla connessione, riduzione dei costi cloud e nuove forme di interazione più naturali e continue.
Anche la scelta di puntare su RISC-V, toolchain open-source e componenti come MLIR e IREE è significativa. In un mercato spesso dominato da stack chiusi e hardware proprietario, Coral prova a costruire una base più aperta per l’edge AI.
Se questa direzione prenderà piede, una parte rilevante della prossima fase dell’intelligenza artificiale potrebbe non vivere solo nei data center, ma nei dispositivi che usiamo ogni giorno.
Seedance 2.0: qualità e aderenza al prompt
Più provo Seedance 2.0, più penso che si sia raggiunto un livello davvero interessante.
Veo 3.1 e HappyHorse 1.0 non si avvicinano minimamente al risultato ottenuto in questi video. L’ho testato con diversi tentativi.
Seedance 2.0: qualità e aderenza al prompt
Nell’esempio, il primo video è generato usando la mia immagine di profilo come riferimento. Nel secondo, invece, uso lo stesso prompt senza riferimento.
Ho generato il prompt con il mio tool: Video Image Assistant.
Seedance 2.0 + prompt multimodale
Un esempio di generazione video lungo con Seedance 2.0, guidato da un prompt multimodale composto da uno storyboard in formato immagine e descrizione testuale delle scene.
AI is ready to make full films
— el.cine (@EHuanglu) May 14, 2026
Seedance 2.0 now can read your entire shot list to generate a full story.. keep characters, props and set design consistent with one image on BytePlus
duration and consistency is not a problem anymore
here's how with prompts: pic.twitter.com/PDJsi0lKyV
Come funziona?
I personaggi, con diverse inquadrature, e lo storyboard completo sono le due immagini di riferimento che il modello ha a disposizione per la generazione video.
Creando diversi prompt che contengono la descrizione dei vari shot di ogni clip, è possibile creare video di 15 secondi che mostrano l’evoluzione delle scene.
Aleph 2.0 di Runway
Runway ha presentato Aleph 2.0, il nuovo modello AI di video editing pensato per trasformare un contenuto esistente in più versioni, senza dover ripetere le riprese o affrontare lunghi cicli di post-produzione.
L’approccio è semplice: si modifica un singolo frame e Aleph 2.0 estende automaticamente il cambiamento al resto del video, mantenendo coerenti stile, scena e dettagli.
Aleph 2.0 di Runway: esempi
Uno degli aspetti più interessanti è la capacità di intervenire solo sugli elementi richiesti. È possibile cambiare il colore di un prodotto, modificare abiti o dettagli, aggiungere o rimuovere oggetti, preservando sfondo, illuminazione e azione originale della scena.
Il modello introduce anche il supporto a sequenze multi-shot, applicando le modifiche tra scene e inquadrature differenti, e permette di lavorare su clip fino a 30 secondi in 1080p.
All’interno di Edit Studio, il flusso prevede la descrizione della modifica in linguaggio naturale, la visualizzazione di un’anteprima e la generazione finale del video. Questo consente di validare il risultato prima dell’elaborazione completa e ridurre le iterazioni.
LLM Reasoning - Stanford
Una lezione di Stanford da vedere sul reasoning degli LLM. Assolutamente consigliata.
I LLM tradizionali funzionano bene su compiti semplici, ma falliscono quando serve logica a più passaggi: tendono a rispondere subito invece di costruire una soluzione.
Il salto avviene con il Chain of Thought: il modello scompone il problema, genera il ragionamento e solo dopo arriva alla risposta. Più passaggi significano maggiore capacità di risolvere problemi complessi, ma anche un costo computazionale più alto.

Per misurare queste capacità si usa Pass@K: invece di valutare una singola risposta, si osserva la probabilità che almeno una tra più risposte generate sia corretta. In pratica, si accetta che il modello “provi più volte” per arrivare alla soluzione.
Sul training, il limite del fine-tuning supervisionato è evidente: scrivere buone catene di ragionamento è difficile e costoso. Per questo si usa il Reinforcement Learning con ricompense verificabili, basate sulla risposta corretta e sulla struttura del ragionamento.
Qui entra in gioco GRPO, che sostituisce approcci più complessi: il modello genera più risposte per lo stesso problema e viene premiato se performa meglio della media del gruppo. È un metodo più semplice e più scalabile.
Un effetto collaterale è l’overthinking. Il modello tende ad allungare inutilmente le risposte perché “più pensa, più aumentano le probabilità di successo”. Correggere gli incentivi nella loss permette di mantenere output più efficienti senza perdere qualità.
Il caso più interessante è DeepSeek R1: una pipeline che combina SFT iniziale, RL, dati filtrati e una fase finale di ottimizzazione. La vera leva, però, è la distillazione: usare i ragionamenti dei modelli grandi per addestrarne di più piccoli, ottenendo performance elevate a costi molto più bassi.
Il punto chiave: il futuro degli LLM non è solo “sapere”, ma saper pensare in modo efficiente.
Economics of the AI Supercycle - Stanford
In un’interessante lezione pubblicata da Stanford, dal titolo “Economics of the AI Supercycle”, emerge una lettura molto chiara delle dinamiche economiche dietro all’AI generativa.
A differenza di Internet, mobile e cloud, l’ecosistema AI non sembra avere una struttura a piramide, con valore distribuito lungo più livelli. Oggi assomiglia di più a un triangolo invertito.
La maggior parte del valore, dei ricavi e dei profitti si concentra nell’infrastruttura hardware: semiconduttori, GPU, data center, memoria, energia e networking. In particolare, aziende come NVIDIA stanno catturando una quota enorme del valore grazie a una posizione dominante e a margini molto elevati.
Il livello applicativo, invece, pur essendo quello più visibile agli utenti, cattura ancora una parte limitata del valore economico complessivo.
Questo accade perché l’AI rompe una delle regole fondamentali del software tradizionale: il costo marginale quasi zero.
Nel software classico, servire un utente in più costava pochissimo. Con l’AI generativa non è così: ogni prompt, ogni risposta e ogni generazione richiedono calcolo continuo. L’utente incrementale ha un costo reale, perché consuma inferenza su infrastrutture costose.

Nel frattempo, gli hyperscaler stanno investendo cifre enormi in CapEx: data center, chip, energia, raffreddamento, reti e sistemi dedicati.
La grande domanda è se le applicazioni AI riusciranno a generare abbastanza valore economico da giustificare questi investimenti.
Un altro nodo è la monetizzazione. Le app consumer di AI possono raggiungere scale enormi, ma il ricavo medio per utente resta ancora basso rispetto ai giganti della pubblicità digitale. Gli abbonamenti funzionano per una parte degli utenti, ma difficilmente bastano da soli a costruire i colossi economici del futuro.
Per questo la pubblicità potrebbe diventare una componente inevitabile: non una pubblicità generica, ma molto più contestuale, basata sulla comprensione dell’intento dell’utente durante una conversazione.
Il mercato è ancora alla ricerca di un equilibrio. Come il cloud, anche l’AI potrebbe impiegare anni prima di trovare una struttura economica stabile. Un possibile punto di svolta potrebbe arrivare dai chip personalizzati sviluppati dai grandi player, capaci di ridurre la dipendenza da NVIDIA e abbassare i costi dell’infrastruttura.
La questione centrale non è solo quanto potente diventerà l’AI, ma chi riuscirà davvero a catturare il valore economico che genera.
AlphaProof Nexus - Google
Da molto tempo sostengo che i sistemi neuro-simbolici rappresentino una via molto interessante, soprattutto per la ricerca scientifica.
Nel paper di Google dal titolo “Advancing Mathematics Research with AI-Driven Formal Proof Search”, questa intuizione trova una conferma molto concreta.
Il lavoro presenta AlphaProof Nexus, un framework che combina componenti neurali e simboliche in modo estremamente efficace.
- Da un lato i LLM generano ipotesi, strategie di prova, scomposizioni in lemmi e piani di lavoro.
- Dall’altro, strumenti formali come Lean e AlphaProof verificano ogni passaggio, impedendo che il sistema si limiti a “sembrare convincente” senza essere corretto.


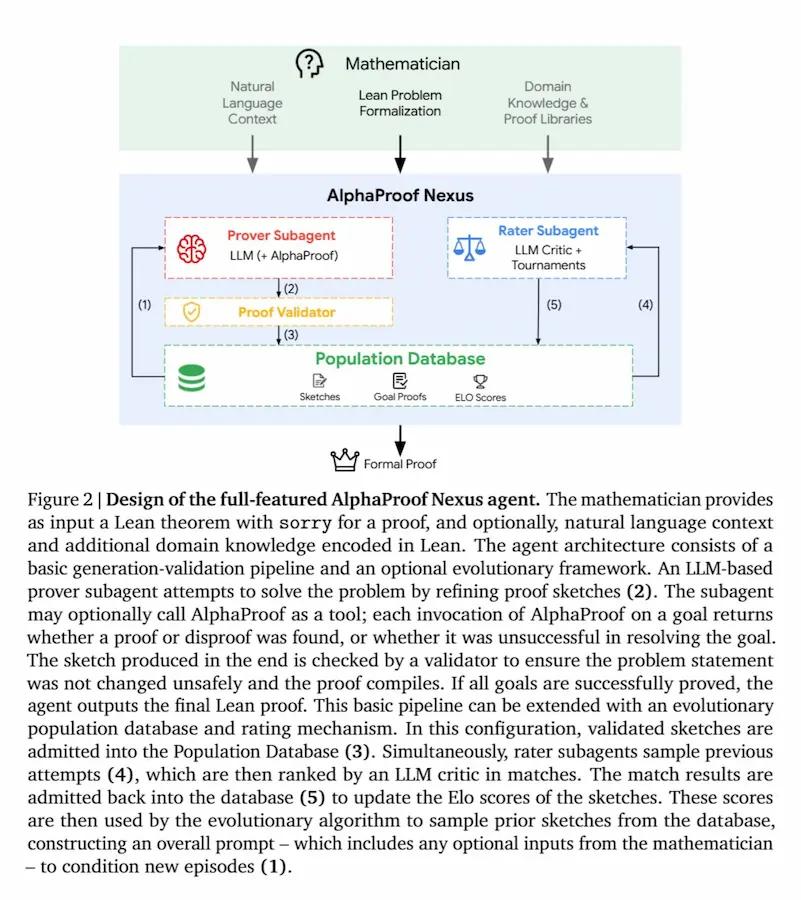
AlphaProof Nexus - Google Research
È proprio questa la parte più interessante: il modello neurale porta flessibilità, creatività ed euristiche di esplorazione; il livello simbolico impone rigore, coerenza e verificabilità. Non è solo generazione, ma ragionamento vincolato da una struttura formale.
I risultati sono notevoli: il sistema ha risolto autonomamente 9 problemi aperti di Erdős su 353, ha dimostrato 44 congetture OEIS su 492 e ha mostrato applicazioni utili in ambiti come combinatoria, ottimizzazione, teoria dei grafi, geometria algebrica e ottica quantistica.
A colpirmi non è solo la performance, ma il paradigma che emerge: non un’AI che sostituisce il ricercatore, bensì un sistema ibrido che amplia la capacità umana di esplorare, formalizzare e validare idee.
In questo senso, il neuro-simbolico non è soltanto una direzione teoricamente elegante, ma una scelta architetturale che può avere un impatto reale sulla pratica scientifica.
I progressi di AlphaEvolve
AlphaEvolve, il sistema sviluppato da Google DeepMind e alimentato da Gemini, sta mostrando come l’AI possa contribuire direttamente alla progettazione e all’ottimizzazione di algoritmi avanzati in ambiti scientifici e industriali molto diversi tra loro.
Negli ultimi mesi è stato applicato alla genomica, migliorando l’accuratezza del sequenziamento del DNA con una riduzione del 30% degli errori nel rilevamento delle varianti genetiche.
Nel settore energetico ha aumentato dal 14% a oltre l’88% la capacità di trovare soluzioni valide per l’ottimizzazione delle reti elettriche.
In fisica quantistica ha contribuito a creare circuiti con errori fino a 10 volte inferiori rispetto agli approcci tradizionali, mentre nella matematica avanzata è stato utilizzato anche in collaborazione con Terence Tao per esplorare problemi complessi come il Traveling Salesman Problem e i Ramsey Numbers.
AlphaEvolve è già utilizzato anche nell’infrastruttura interna di Google: ha contribuito all’ottimizzazione delle TPU, ha migliorato l’efficienza di Google Spanner e ha ridotto il footprint di alcuni software di quasi il 9%.

Le applicazioni commerciali mostrano un impatto altrettanto concreto: Klarna ha raddoppiato la velocità di training di un proprio modello AI; FM Logistic ha migliorato del 10,4% l’efficienza dei percorsi logistici; Schrödinger ha accelerato di circa 4 volte i processi legati alla ricerca chimica e farmaceutica; WPP ha ottenuto un aumento del 10% dell’accuratezza nei modelli per advertising e marketing.
Il punto più interessante è che AlphaEvolve non si limita ad automatizzare codice o processi: sta iniziando a produrre soluzioni algoritmiche che, in alcuni casi, risultano controintuitive anche per gli esperti umani, aprendo nuovi scenari per la ricerca scientifica, le infrastrutture AI e l’ottimizzazione industriale.
Ernie 5.1 di Baidu
La Cina continua a fare scuola nella progettazione di modelli AI.
Baidu ha annunciato ERNIE 5.1, nuova evoluzione della sua famiglia di modelli AI, con un obiettivo chiaro: aumentare le prestazioni riducendo drasticamente i costi computazionali.
Secondo l’azienda, il modello raggiunge performance di fascia alta utilizzando circa un terzo dei parametri totali di ERNIE 5.0, metà dei parametri attivi e soltanto il 6% del costo di pre-training di modelli comparabili.
Sul fronte delle performance, ERNIE 5.1 ha ottenuto il quarto posto globale nella Arena Search e il primo tra i modelli cinesi.
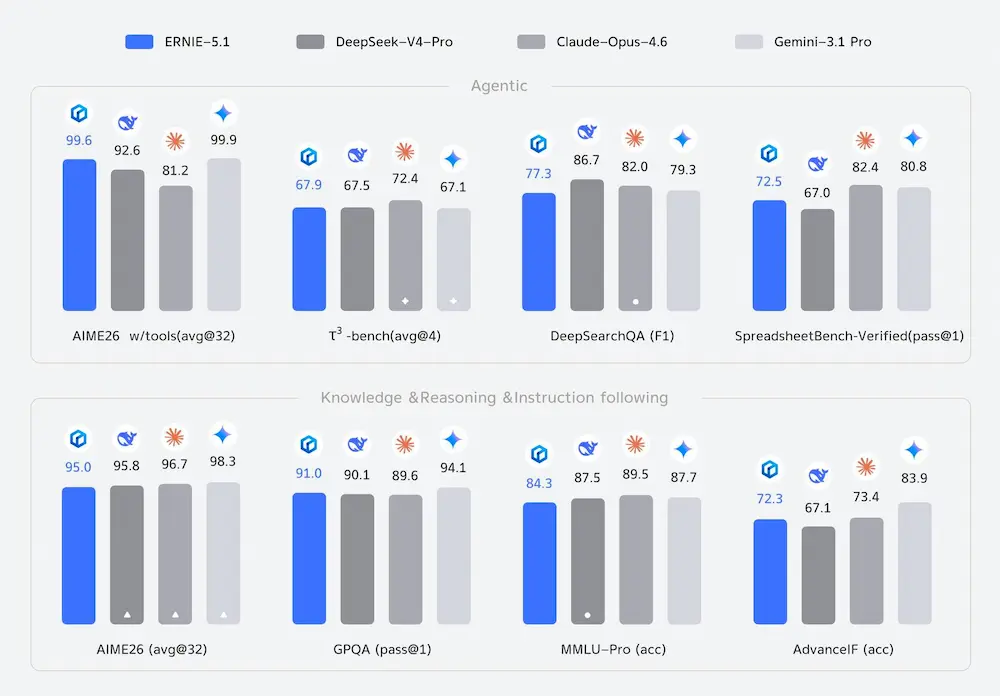
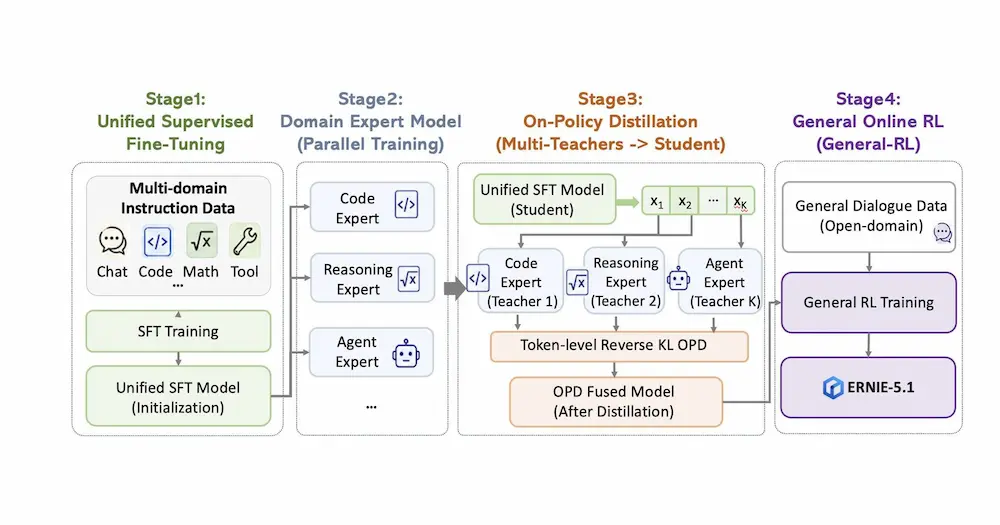
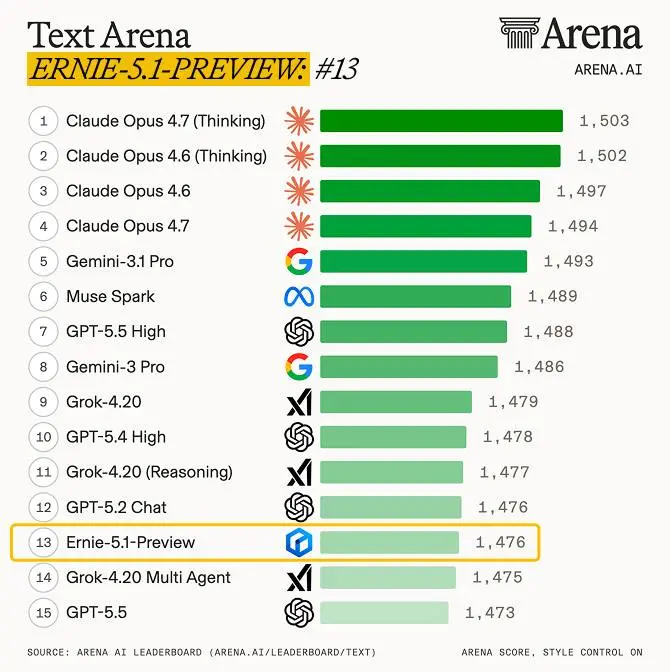
Ernie 5.1 di Baidu: performance
Nei benchmark dedicati alle capacità agentiche, Baidu afferma che il modello supera DeepSeek V4-Pro e si avvicina ai migliori modelli closed-source.
Nei test GPQA e MMLU-Pro, focalizzati su conoscenza e reasoning avanzato, le performance vengono descritte come vicine ai top model occidentali. Nel benchmark matematico AIME26 con utilizzo di tool, ERNIE 5.1 raggiunge un punteggio di 99,6, subito dietro Gemini 3.1 Pro.
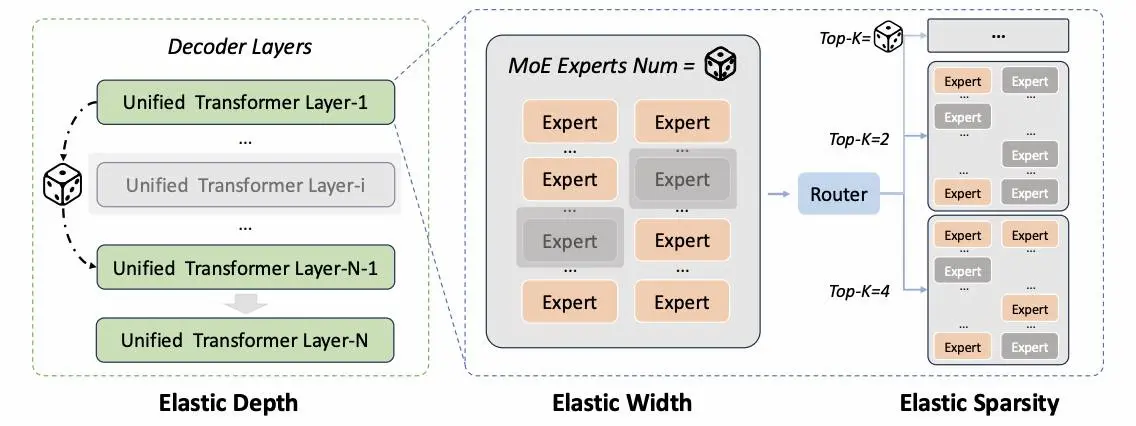
Dal punto di vista tecnico, uno degli aspetti più interessanti è il framework di “elastic training”, che consente di addestrare una rete unica da cui estrarre sottoreti ottimizzate per diversi livelli di costo e capacità. A questo si aggiunge una nuova infrastruttura di reinforcement learning completamente asincrona, progettata per migliorare scalabilità ed efficienza nei task complessi.
Baidu punta anche sulla componente creativa del modello. Secondo le valutazioni interne condivise dall’azienda, le capacità di creative writing di ERNIE 5.1 si avvicinano a quelle di Gemini 3.1 Pro, con miglioramenti nella narrativa lunga, nella coerenza stilistica e nella comprensione del contesto.
MTP drafters (Multi-Token Prediction)
Google ha introdotto i nuovi MTP drafters (Multi-Token Prediction) per la famiglia Gemma 4, una tecnologia che permette di accelerare l’inferenza dei modelli fino a 3x senza compromettere qualità, accuratezza o capacità di ragionamento.
Uno dei principali limiti degli LLM oggi non è soltanto la potenza di calcolo, ma la latenza, dovuta al continuo trasferimento dei parametri dalla memoria alle unità di elaborazione. Nel classico approccio autoregressivo, il modello genera un token alla volta, rendendo il processo poco efficiente, soprattutto su hardware consumer ed edge device.
Con lo speculative decoding, Google introduce un approccio diverso: un modello leggero anticipa più token futuri mentre il modello principale li verifica in parallelo. Se i token sono corretti, vengono accettati tutti insieme in un unico passaggio, aumentando drasticamente la velocità di generazione senza alterare la qualità dell’output.
MTP drafters (Multi-Token Prediction) - Google
L’impatto è particolarmente rilevante per coding assistant, agenti autonomi, applicazioni vocali real-time e AI locale su laptop e smartphone.
Dal punto di vista tecnico, Google ha anche introdotto ottimizzazioni come la condivisione della KV cache tra modello principale e drafter, miglioramenti specifici per Apple Silicon e GPU NVIDIA, e nuove tecniche per accelerare i modelli edge E2B ed E4B.
Gli MTP drafters sono già disponibili open source con licenza Apache 2.0 e supportano framework come Hugging Face Transformers, MLX, vLLM e Ollama.
Non solo modelli più intelligenti, ma un’AI molto più veloce, efficiente e utilizzabile direttamente in locale su hardware consumer.
Evolution Strategies at the Hyperscale
Per decenni abbiamo addestrato le reti neurali soprattutto in un modo: calcolando gradienti e facendo backpropagation.
Il paper “Evolution Strategies at the Hyperscale”, con il contributo di ricercatori di Oxford e NVIDIA, esplora una strada diversa: rendere praticabile l’addestramento di modelli enormi usando Evolution Strategies, cioè metodi che non hanno bisogno dei gradienti.

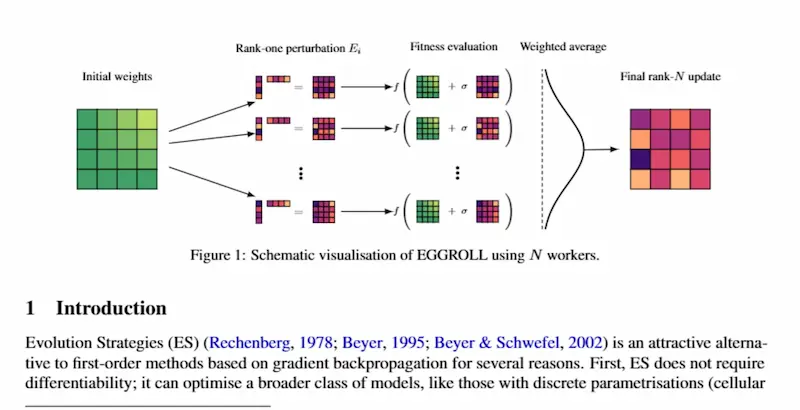
Evolution Strategies at the Hyperscale
Spiegazione semplice: invece di chiedere al modello “in che direzione devo cambiare i pesi?”, si provano tante piccole variazioni del modello, si misura quali funzionano meglio e si combinano le modifiche più promettenti.
È un po’ come selezione naturale applicata al training: molte varianti, una valutazione, poi si tengono i segnali migliori.
Il problema è che questo approccio, su modelli con miliardi di parametri, normalmente è troppo costoso. Ogni variazione richiede calcolo, memoria e spostamento di enormi quantità di dati.
La proposta del paper si chiama EGGROLL. L’idea è rendere queste variazioni molto più leggere usando perturbazioni “low-rank”: invece di modificare intere matrici di pesi in modo denso, si descrive ogni modifica con una rappresentazione compatta.
Questo permette di testare popolazioni molto grandi in parallelo sulle GPU, avvicinandosi alla velocità della semplice inferenza batch e rendendo le Evolution Strategies molto più scalabili.
Le implicazioni sono notevoli. Se questo approccio continua a funzionare su scala, potremmo avere un’alternativa concreta alla backpropagation per addestrare sistemi AI difficili da ottimizzare con i metodi classici.
Parliamo di modelli quantizzati, componenti non differenziabili, agenti, architetture ricorrenti, sistemi neuro-simbolici e pipeline dove l’obiettivo finale è facile da misurare ma difficile da trasformare in gradienti.
Il punto non è che la backpropagation sparirà. Il punto è che potremmo iniziare ad avere metodi di training più flessibili, capaci di ottimizzare direttamente sistemi complessi, discreti o ibridi, senza dover rendere ogni pezzo perfettamente differenziabile.
L’AI generativa per gli asset 3D
Articraft propone un approccio diverso alla generazione di asset 3D articolati: invece di generare direttamente mesh o file URDF, trasforma il problema in program synthesis.
L’idea è trattare la creazione di un oggetto articolato come un processo di programmazione. Un agente basato su LLM scrive il codice che costruisce l’oggetto, definendo parti, geometrie, giunti, limiti di movimento e test di validazione. Una volta eseguito, il programma produce un asset 3D articolato e pronto per la simulazione.
Articraft: l’AI generativa per gli asset 3D
L’architettura combina un SDK progettato per essere utilizzato dagli LLM, con primitive geometriche e componenti meccaniche ad alto livello, insieme a un harness agentico che lavora in un ciclo iterativo di generazione, esecuzione, validazione e correzione.
Nel paper, il sistema genera oggetti complessi, correggendo autonomamente errori di runtime, vincoli mancanti sulle articolazioni e collisioni geometriche attraverso feedback strutturato.
L’aspetto più interessante è che il modello non produce soltanto forme: esegue reasoning meccanico, debugging e refinement fino a ottenere asset simulabili.
Con questo approccio è stato creato Articraft-10K, un dataset con oltre 10.000 asset articolati distribuiti su 245 categorie, ampliando in modo significativo la copertura rispetto ai dataset esistenti.
La direzione che emerge è quella di trattare la modellazione meccanica come programmazione e utilizzare gli LLM come agenti CAD.
- GRAZIE -
Se hai apprezzato il contenuto, puoi
contribuire al progetto con una donazione 🙂