PaLM: un nuovo modello di linguaggio di Google dalle prestazioni rivoluzionarie
Google ha recentemente presentato PaLM, un modello di linguaggio basato sull'intelligenza artificiale che ha fatto registrare prestazioni sbalorditive su diversi task. E Minerva, un altro modello basato su PaLM, che è in grado di risolvere problemi scientifici spiegandone il procedimento.

Negli ultimi anni, le grandi reti neurali addestrate per la comprensione e la generazione del linguaggio hanno ottenuto risultati impressionanti in un'ampia gamma di attività.
GPT-3 ha mostrato per la prima volta che i modelli linguistici di grandi dimensioni (LLM - Large Language Model) possono essere utilizzati attraverso il "few-shot learning" (ovvero attraverso dei brief composti da pochi esempi per stimolare l'algoritmo a completare il contenuto) con la possibilità di ottenere risultati sbalorditivi anche senza utilizzare dati specifici o senza aggiornare i parametri del modello.
Modelli più recenti, come GLaM , LaMDA , Gopher e Megatron-Turing NLG, hanno ottenuto risultati migliori su molti task, attraverso un addestramento su set di dati più grandi da diverse fonti. Tuttavia rimane ancora molta strada da percorrere per per comprendere le potenzialità del "few-shot learning" mentre i modelli incrementano le loro dimensioni.
Pathways e PaLM
L'anno scorso Google Research ha annunciato l'idea di Pathways, un modello unico che potrebbe agire su più domini ed attività rimanendo altamente efficiente. In altre parole, un modello più "generale".
Un'importante passo verso la realizzazione di tale visione è stata lo sviluppo del nuovo Pathways System, un sistema in grado di ottimizzare il calcolo distribuito.
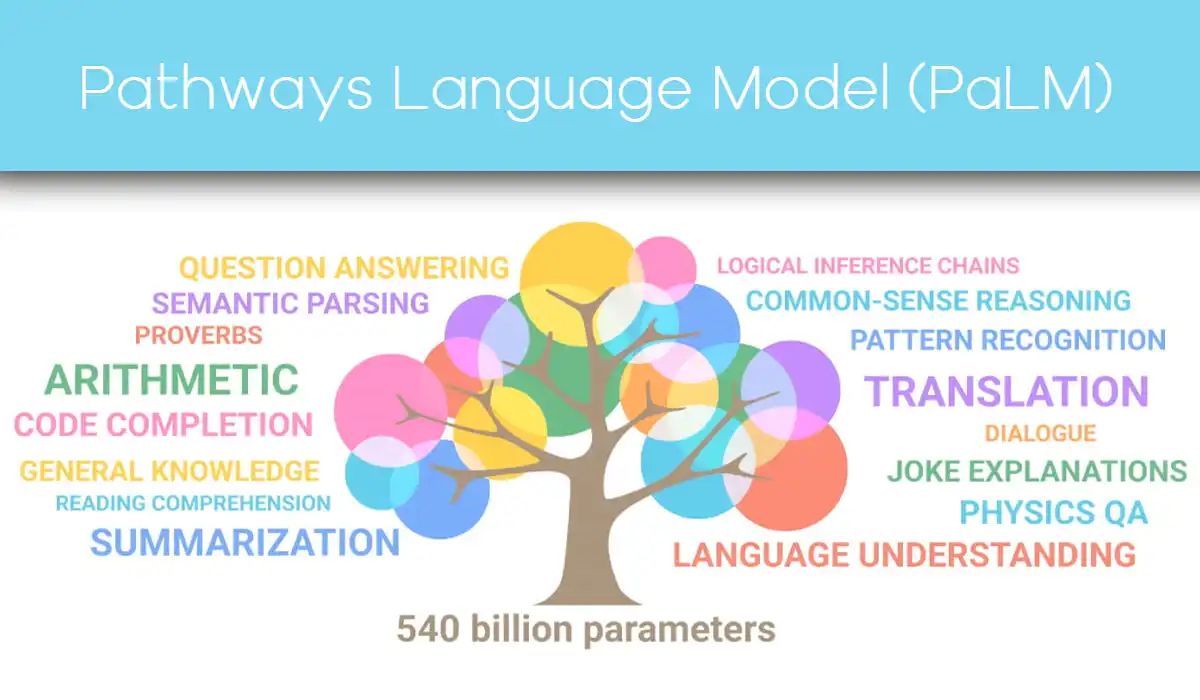
Nel paper dal titolo "PaLM: Scaling Language Modeling with Pathways", Google presenta PaLM: Pathways Language Model, un modello basato sui transformer che conta 540 miliardi di parametri ed è stato addestrato attraverso Pathways System, che ha consentito un livello di parallelizzazione e di efficienza mai ottenuti in precedenza.
PaLM è stato messo alla prova su centinaia di task di comprensione e generazione del linguaggio, ed è riuscito ad ottenere prestazioni all'avanguardia nella maggior parte delle attività, con margini significativi in molti casi.
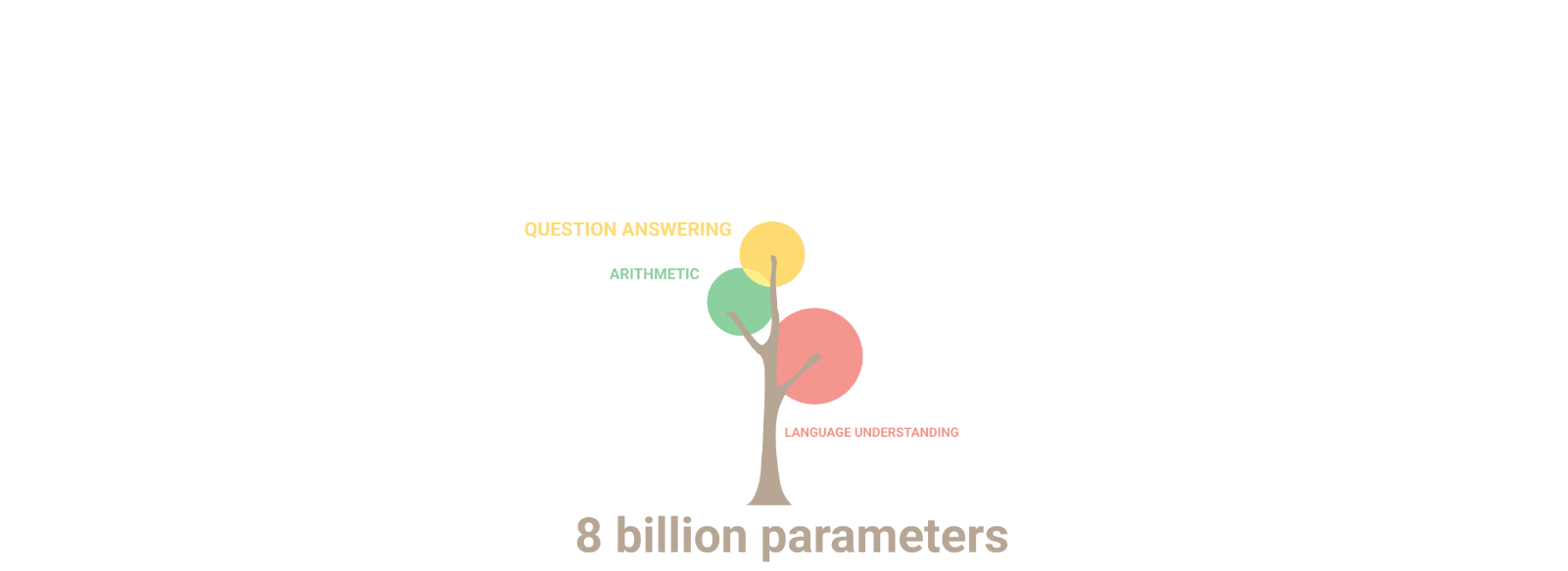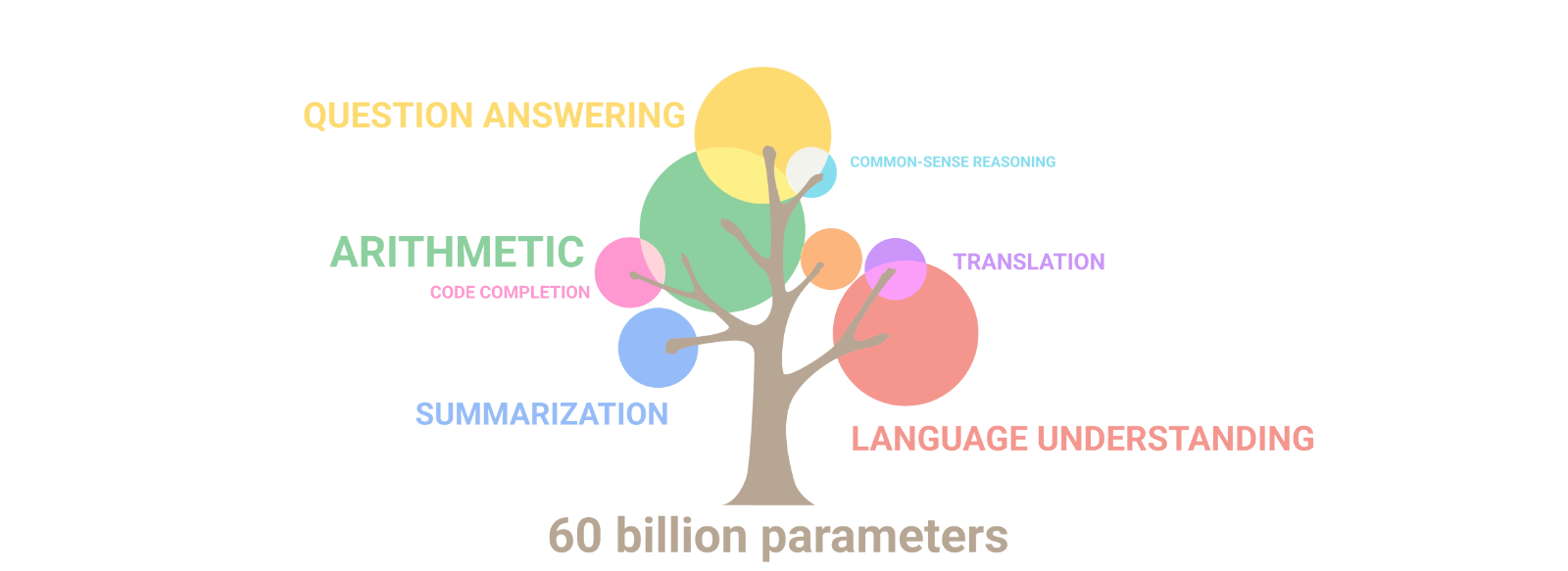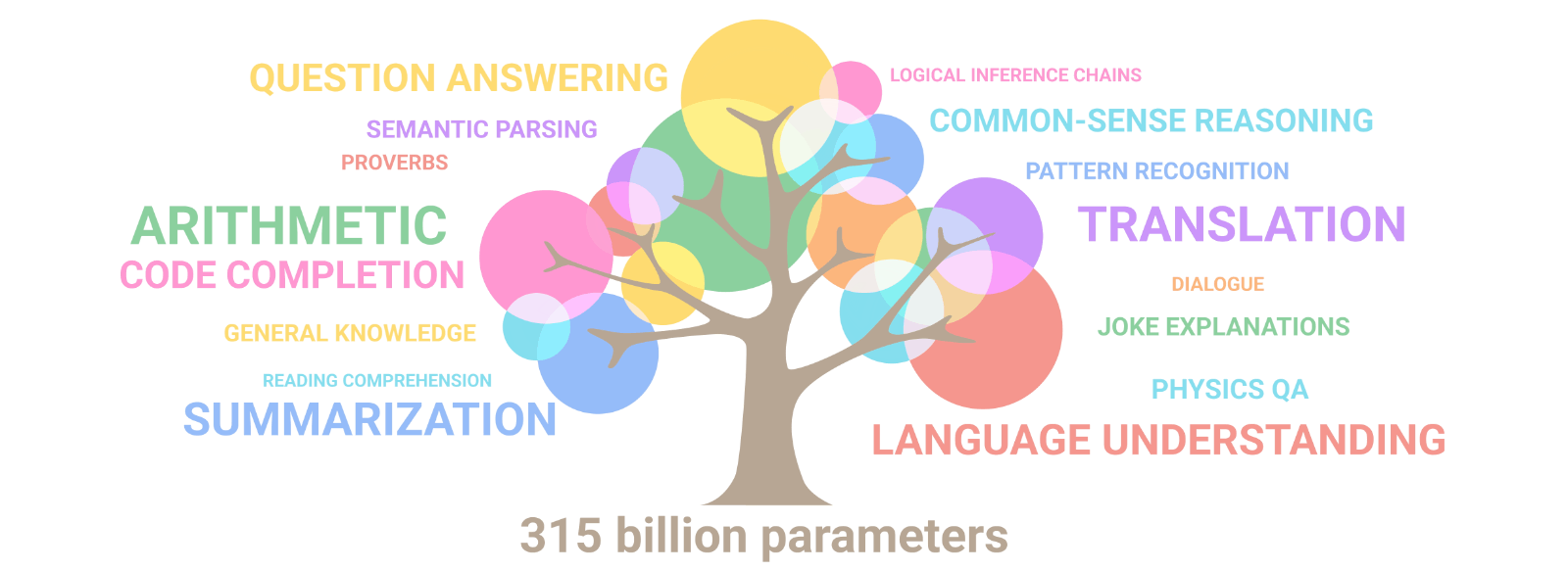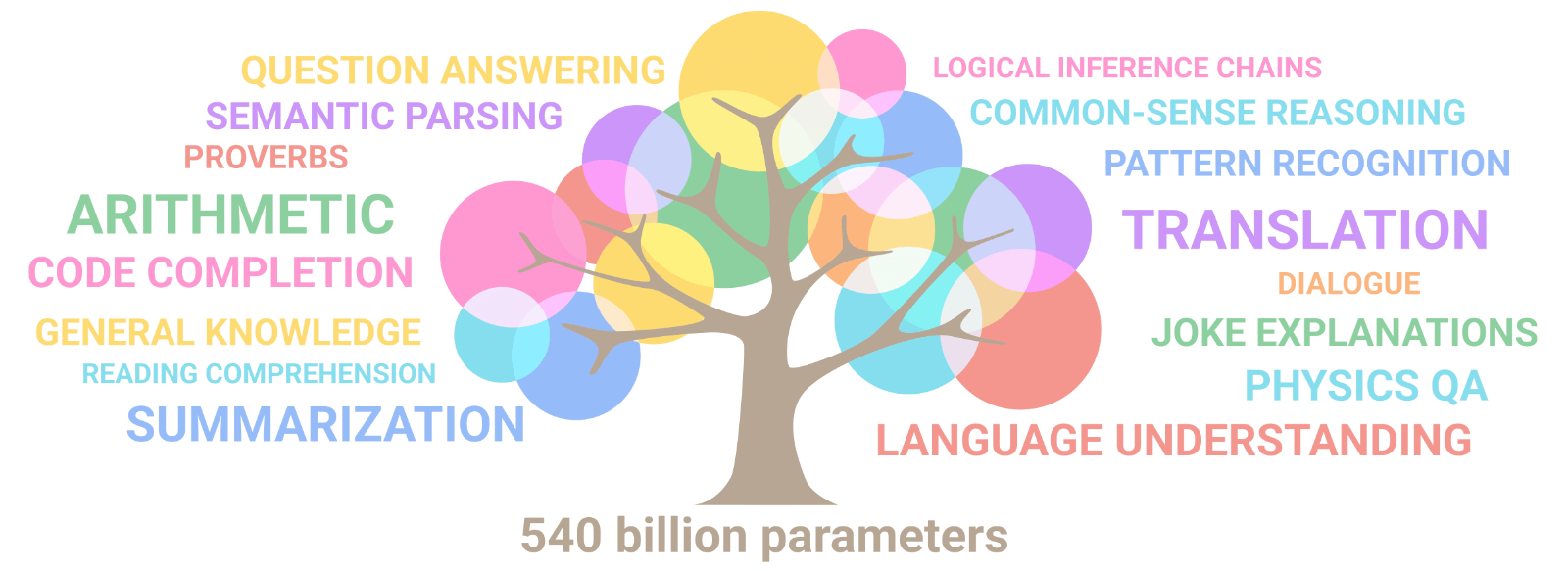
L'addestramento di un modello di linguaggio con Pathways
Per PaLM è stato usato il più grande sistema basato su TPU dedicato al training, il quale è stato parallelizzato su due Pod Cloud TPU v4.
Una TPU (Tensor Processing Unit) è un acceleratore AI di Google per applicazioni specifiche nel campo delle reti neurali. Per comprendere meglio cosa significa possiamo pensare alla più nota CPU del nostro PC, ma estremamente più potente e dedicata al machine learning. I pod Cloud TPU sono "supercomputer" realizzati con centinaia di TPU.
Tutto questo significa che le prestazioni in fase di addestramento superano ogni modello precedente (anche i molto noti nominati all'inizio di questo post).
PaLM è stato addestrato utilizzando una combinazione di dati in inglese ed altre lingue, che includono pagine web, libri, Wikipedia, conversazioni e codice presente su GitHub di alta qualità.
Capacità rivoluzionarie su diversi task
Il modello mostra capacità rivoluzionarie su numerose attività complesse. Di seguito vengono evidenziati alcuni esempi relativi alla comprensione e alla generazione del linguaggio, al ragionamento e ad attività relative al codice di programmazione.
Comprensione e generazione del linguaggio naturale
PaLM è stato valutato su 29 task di elaborazione del linguaggio naturale in inglese (NLP). Ha superato le prestazioni dei precedenti modelli di grandi dimensioni, come GLaM, GPT-3, Megatron-Turing NLG, Gopher, Chinchilla e LaMDA, in 28 su 29 attività che comprendono la risposta a domande, cloze e completamento di frasi, task in stile Winograd, attività di comprensione della lettura, task di ragionamento, attività di SuperGLUE e attività di inferenza del linguaggio naturale.
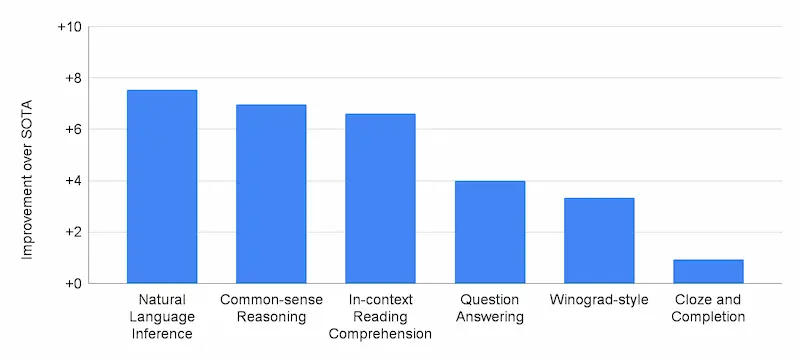
Oltre alle attività di NLP in inglese, PaLM ha mostrato anche ottime prestazioni sui benchmark in diverse lingue, inclusa la traduzione, anche se solo il 22% del corpus di formazione non è inglese.
Sono state esaminate anche le capacità emergenti e future di PaLM su Beyond the Imitation Game Benchmark (BIG-bench), una raccolta rilasciata recentemente con oltre 150 nuove attività di modellazione del linguaggio, e il modello ha raggiunto prestazioni elevatissime.
PaLM ha avuto prestazioni migliori rispetto alla media delle persone alle quali è stato chiesto di risolvere gli stessi compiti.
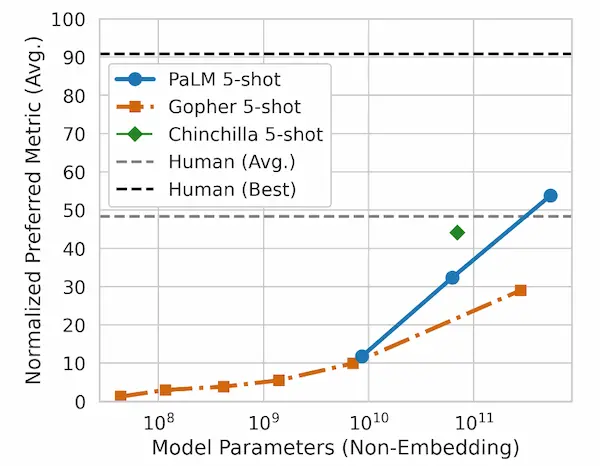
PaLM dimostra impressionanti capacità di comprensione e generazione del linguaggio naturale su diverse attività BIG-bench. Ad esempio, il modello può distinguere causa ed effetto, comprendere combinazioni concettuali in contesti appropriati e persino indovinare il film da un'emoji.

Ragionamento
PaLM mostra capacità rivoluzionarie anche su attività di ragionamento che richiedono aritmetica in più fasi o ragionamento basato sul buon senso.

Con un prompt a 8 esempi (8-shot prompting), PaLM risolve il 58% dei problemi di GSM8K, un benchmark con migliaia di impegnative domande di matematica (per la scuola elementare), superando il punteggio massimo precedente del 55% ottenuto da GPT-3 con un set di formazione di 7.500 problemi.
Questo nuovo punteggio è particolarmente interessante, poiché si avvicina alla media del 60% dei problemi risolti dai bambini di età compresa tra 9 e 12 anni, che sono il pubblico di destinazione per il set di domande.
Sorprendentemente, PaLM può persino generare spiegazioni esplicite per scenari che richiedono una complessa combinazione di inferenza logica a più fasi, conoscenza del mondo e profonda comprensione del linguaggio. Ad esempio, può fornire spiegazioni di alta qualità per nuove barzellette che non si trovano online.

Generazione di codice
Possiamo trovare moltissimi esempi di generazione di codice operati da modelli di AI a partire da un brief in linguaggio naturale. PaLM ha prestazioni elevate in questa attività anche se ha solo il 5% di codice nel set di dati di pre-formazione.
Questo risultato rafforza la tesi secondo cui i modelli più grandi possono essere più efficienti in termini di campioni rispetto ai modelli più piccoli perché trasferiscono l'apprendimento sia da altri linguaggi di programmazione che dai dati del linguaggio naturale in modo più efficace.

PaLM apre la strada a modelli ancora più capaci, combinando elevate performance in ambito di training con nuove architetture.. e questo ci avvicina alla visione di Pathways:
Enable a single AI system to generalize across thousands or millions of tasks, to understand different types of data, and to do so with remarkable efficiency.
Minerva
Google ha presentato anche Minerva, un modello di linguaggio basato su PaLM che risolve problemi matematici e scientifici spiegando il procedimento attraverso formule e testo.

Il sistema ha avuto un addestramento aggiuntivo su 118 GB di pubblicazioni scientifiche.
Per approfondire
 Alessio Pomaro
Alessio Pomaro Alessio Pomaro
Alessio Pomaro