Da testo a immagini attraverso l'intelligenza artificiale.. possiamo parlare di arte?
Oggi sentiamo parlare spesso di DALL·E 2 di OpenAI, Imagen Muse, Midjourney, BlueWillow e AI Stable Diffusion. Si tratta di algoritmi basati sull'AI che vengono definiti Text-To-Image, e sono in grado di generare immagini di qualità a partire da un testo descrittivo in linguaggio naturale.


Negli ultimi mesi si sono visti a confronto diversi algoritmi basati sull'intelligenza artificiale che vengono definiti Text-To-Image perché sono in grado di trasformare del testo (formulato in linguaggio naturale) in immagine.
I più noti sono DALL·E 2 di OpenAI, DALL·E mini (un progetto open-source), Imagen e Muse di Google, Midjourney, BlueWillow e AI Stable Diffusion.
Cos'è DALL·E 2?
DALL·E 2 è la nuova versione di DALL·E, un modello di linguaggio generativo che trasforma delle semplici frasi in immagini. Ha 3,5 miliardi di parametri e appartiene alla categoria dei LLM (Large Language Model), anche se, ad esempio, non è grande quanto GPT-3. È curioso il fatto che il modello ha dimensioni inferiori del suo predecessore. Nonostante questo, DALL·E 2 genera immagini con una risoluzione 4 volte migliore rispetto a DALL·E.
Quelle che seguono sono immagini generate chiedendo al sistema..
"an astronaut riding a horse in a photorealistic style"






Un altro aspetto interessante di DALL·E 2 è la sua capacità di modificare e ritoccare in modo realistico le foto. Gli utenti possono selezionare un'area dell'immagine, e usare un messaggio testuale per indicare la modifica desiderata. In pochi secondi, l'algoritmo produce diverse combinazioni di immagine modificata.


Da notare come gli oggetti modificati vengono inseriti con ombra e illuminazione adeguate. Questo dimostra la capacità di DALL·E 2 di comprendere le relazioni tra oggetti diversi e l'ambiente.
Infine, un'ultima abilità dell'algoritmo è nella creazione di varianti di un'immagine partendo da una originale.
Come funziona?
DALL·E 2 "ha imparato" il rapporto tra le immagini e il testo utilizzato per descriverle. Utilizza un processo chiamato "diffusione", che inizia con uno schema di punti casuali e modifica gradualmente quel modello verso un'immagine quando ne riconosce aspetti specifici.
Un esperimento realizzato con DALL·E 2 che mi ha colpito in modo particolare è quello postato su Twitter da Michael Green, nel quale viene chiesto all'algoritmo di generare delle immagini che riproducano lo stile di fotografi noti (Dorothea Lange, Helmut Newton, Diane Arbus, ecc.). Quello che segue è il risultato dell'elaborazione.





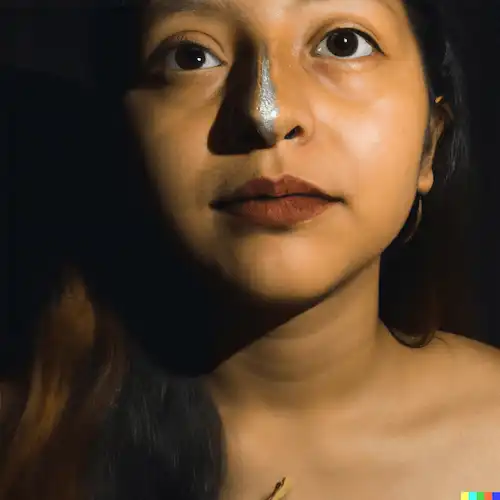



Cliccando nel link al tweet, è possibile consultare l'esperimento completo di tutte le immagini.
Immagini orientate al mondo e-commerce
Dopo essere entrato nel programma beta di OpenAI, ho fatto ulteriori esperimenti chiedendomi.. come potrebbero essere utili questi algoritmi in un sito web di e-commerce tra qualche anno? Potremmo, ad esempio, generare in real-time alcuni abbinamenti per avere delle idee del risultato dei nostri acquisti.
Le immagini che seguono sono state generate con prompt molto specifici, ad esempio..
A realistic photo of a male mannequin with black denim pants, a white shirt and a stylish brown jacket, on a white background









Nello stesso ambito, ho provato ad utilizzare un'immagine generata dall'algoritmo per modificarla. Il tool consente di selezionare un'area dell'immagine e di fornire un prompt per la modifica.
L'immagine che segue mostra l'effetto, selezionando l'area centrale della maglietta e chiedendo..
add an illustration with a unicorn
add an illustration with a monkey
add the nike logo

Non è ancora tutto perfetto, ma se consideriamo quanto è passato dalla prima volta in cui abbiamo sentito parlare di questi temi, credo sia impressionante. Ma tra qualche anno (anche meno?) potrebbe essere perfetto.
Outpainting
Dopo aver lanciato DALL·E 2, OpenAI l'ha arricchito di una nuova funzionalità denominata Outpainting, che consente di espandere un'immagine oltre le sue dimensioni originali.
Basta caricare un'immagine, decidere quale zona espandere e l'algoritmo creerà le parti mancanti integrando nuovi elementi alla perfezione.




Oltre alle implicazioni creative, questo potrebbe risolvere diverse problematiche relative alle proporzioni delle immagini. Nell'esempio, infatti, ho generato un'immagine attraverso Midjourney, ma le proporzioni non erano adeguate al mio post. Quindi ho usato outpainting per espanderla e generare una nuova area utilizzabile.
Cos'è Imagen?
Imagen è un modello Text-To-Image di Google con un grado di fotorealismo senza precedenti e un profondo livello di comprensione del linguaggio.
La scoperta chiave è che i modelli generici di linguaggio di grandi dimensioni (ad esempio T5), pre-addestrati su grandi quantità di contenuti testuali, sono sorprendentemente efficaci nel codificare il testo per la sintesi di immagini: l'aumento delle dimensioni del modello linguistico in Imagen aumenta notevolmente sia la fedeltà del campione che l'allineamento immagine-testo.









Durante dei test con utenti reali, questi hanno preferito Imagen rispetto ad altri modelli, sia in termini di qualità del campione, che di allineamento immagine-testo.
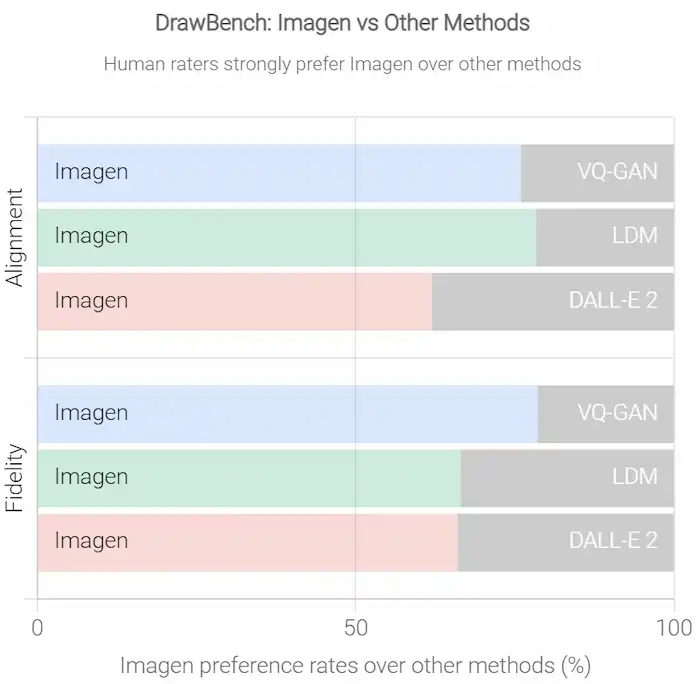
#1 in COCO FID - #1 in DrawBench
Cos'è Muse?
Muse è il nuovo modello Text-to-Image di Google che sembra avere le performance più elevate in assoluto, con un efficientamento anche del processo di generazione.



Può creare immagini da 512px in 1,3 secondi e può modificarle attraverso maschere e generando inpainting e outpainting.



Questo genere di miglioramenti ci fa capire che non solo la quantità di dati fa evolvere gli algoritmi.
Cos'è Midjourney?
Midjourney è un laboratorio di ricerca indipendente incentrato su design, infrastrutture umane e intelligenza artificiale, ed anche il nome di un nuovo generatore Text-To-Image molto efficace.
Fornendo all'algoritmo il seguente prompt, ho generato in qualche secondo queste immagini.
"A mannequin with black jeans and a pink t-shirt for an e-commerce"


Attualmente il sistema è in beta, ed è accessibile attraverso un bot su Discord.
Il software è stato utilizzato dalla rivista britannica The Economist per creare la copertina di un numero di giugno 2022.
Il team di Midjourney è guidato da David Holz, che in precedenza ha co-fondato Leap Motion ed è stato ricercatore della NASA.
La versione 4 di Midjourney
La versione 4 di Midjourney ha introdotto una qualità davvero impressionante. Ho generato le prime due immagini della galleria che segue con un semplice prompt testuale: "portrait of an old man from the future Sigma 85mm f/1.4 --v 4 --q 2".
La terza immagine, invece, è stata generata partendo da due foto di un caro amico e da un prompt testuale in cui ho chiesto di rendere i capelli blu.



La modalità Remix
La modalità Remix di Midjourney permette di creare delle variazioni di immagini con dei prompt intermedi.
Nell'esempio che segue, ad esempio, ho generato un'immagine di una ragazza con i capelli rossi. Successivamente chiedo all'algoritmo (attraverso la modalità Remix) di renderla con gli occhi azzurri.


Si tratta di un enorme passo in avanti nella generazione di immagini da testo.
Cos'è BlueWillow?
BlueWillow è un'alternativa gratuita a Midjourney. Il funzionamento è identico, e quelle che seguono sono immagini che ho generato con alcuni prompt testuali.




La qualità è inferiore a quella di Midjourney, ma è comunque elevata. Possiamo paragonarle alla qualità ottenibile attraverso Stable Diffusion 2.
Cos'è Stable Diffusion di Stability AI?
Stability AI è una startup che sta creando una serie di tool gratuiti basati sull'AI.
Stable Diffusion è il loro modello generativo (Text-To-Image), e quelle che seguono sono alcuni esempi di immagini generate con i prompt che ho utilizzato per ottenerle.





L'utilizzo del tool è davvero molto semplice, e volendo si possono variare i parametri, ad esempio le dimensioni dell'output, la qualità, il numero di immagini generato per ogni prompt.
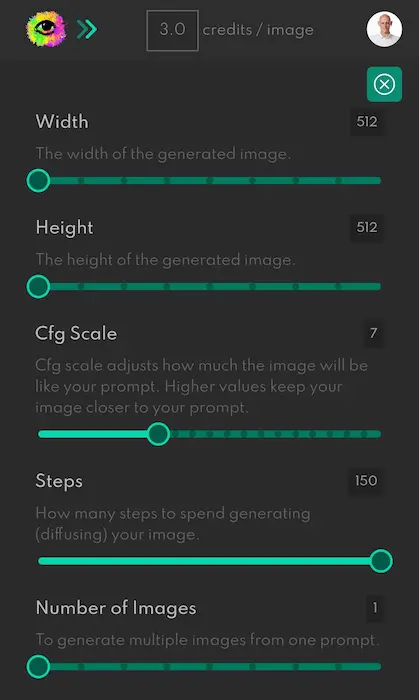
La guida del sistema dà anche suggerimenti su come rendere migliore il prompt. Anche questo algoritmo permette di ottenere immagini che spesso sono davvero sbalorditive, anche se forse è quello che ha una comprensione del linguaggio naturale dei prompt inferiore agli altri.
Cos'è Shutterstock AI?
Shutterstock AI è il tool della nota piattaforma che permette di generare immagini attraverso un prompt testuale.
Usarlo è semplicissimo, anche grazie all'interfaccia grafica che guida l'utente nella creazione.



Il sistema utilizza una versione personalizzata di DALL-E 2 che ha avuto un addestramento derivante dalle immagini della piattaforma.
Cos'è DALL·E mini?
DALL·E mini è un tentativo di riprodurre gli impressionanti risultati di DALL·E (di OpenAI) attraverso un modello open-source.
Le immagini che seguono sono state generate attraverso l'input dato precedentemente al modello di OpenAI: "an astronaut riding a horse in a photorealistic style".

La qualità del risultato non è assolutamente paragonabile al modello visto in precedenza, ma il sistema è in training continuo.



Come funziona?
Il modello viene addestrato attraverso milioni di immagini presenti online con le didascalie associate. Nel tempo, "impara" a disegnare un'immagine ricevendo un prompt testuale (una stringa di input in linguaggio naturale). Alcuni output vengono generati grazie al fatto che l'algoritmo ha processato immagini simili, tuttavia può produrre anche immagini uniche, ad esempio l'astronauta a cavallo, combinando più concetti.
Attraverso il seguente link, è possibile approfondire in dettaglio il funzionamento ed il confronto con DALL·E. Ad esempio, il modello in questione è 27 volte più piccolo dispetto alla prima versione di OpenAI, con 0,4 miliardi di parametri contro 12 miliardi; inoltre è stato addestrato su 15 milioni di coppie immagine-descrizione, contro i 250 milioni del modello di OpenAI.
 Boris Dayma
Boris Dayma
Il tool online
Attraverso un tool online è possibile effettuare dei test utilizzando DALL·E mini. L'utilizzo è semplicissimo: basta inserire un prompt testuale nel campo di testo e cliccare su "run". In poco più di un minuto verrà generato un set di immagini corrispondente.
L'uso di algoritmi generativi per produrre prompt efficaci
Appena si iniziò a parlare di algoritmi generativi, dissi che avrebbero generato una nuova competenza da acquisire, ovvero la capacità di creare prompt efficaci.
Oggi stanno nascendo servizi, come promptoMANIA, che sono dei veri e propri prompt generator, ed aiutano le persone a generare degli input di qualità.


Non solo.. si stanno, infatti, usando modelli come GPT-3 per generare prompt per gli algoritmi di Text-To-Image. Il post che segue racconta un'esperienza di questo tipo.

TikTok propone una versione base di Text-To-Image: gli algoritmi diventano mainstream
Come ha raccontato The Verge nel seguente post, TikTok ha integrato un Text-To-Image nell'applicazione mobile.
 James Vincent
James Vincent
Si tratta del filtro "AI greenscreen", che genera un'immagine partendo da un prompt testuale, che successivamente può essere usata come sfondo per i video dei creator.
La velocità con cui questi sistemi possono diventare mainstream è davvero impressionante!
Si può definire arte?
Online, diverse fonti iniziano ad utilizzare termini come "AI-generater Art".. ma possiamo davvero considerare arte ciò che generano questi algoritmi? Anche se hanno la capacità di creare immagini da idee che nessuno ha mai espresso prima, direi di NO.
Di fatto, come avviene per la generazione di testo, anche in questo caso si tratta di pura matematica e calcolo probabilistico. Questi modelli creano l'output pixel dopo pixel in base ai dati sui quali sono stati addestrati, ma non hanno alcuna comprensione dell'azione che stanno compiendo.
L'arte è nei nostri occhi, non negli algoritmi!
Di certo, l'aspetto più interessante è che questi sistemi, partendo da semplici brief, genereranno dei contenuti sempre più completi e vicini alla perfezione, permettendo alle persone di concentrarsi sulla qualità.
Parlando di arte in particolare, penso che molti nuovi artisti emergeranno con la tecnologia, come abbiamo visto negli ultimi 8 anni. L'approccio "tradizionale" rimarrà, ma penso che vedremo crescere l'interesse verso l'AI art. Il che, a mio avviso, è straordinario.
La capacità di descrivere la propria immaginazione in un testo comprensibile dal modello di machine learning è diventata una competenza fondamentale. Il talento dell'artista non sta usando strumenti di editing digitale, modellazione 3D o texturing, ma le parole che descrivono accuratamente l'immagine.
- Eva Rtology -
Per approfondire

 Google Research, Brain Team
Google Research, Brain Team

 STABILITY AI PARTNERS WITH KRIKEY AI TO LAUNCH AI ANIMATION TOOLS
STABILITY AI PARTNERS WITH KRIKEY AI TO LAUNCH AI ANIMATION TOOLS

